What’s new in Big Data Tools 1.6 EAP
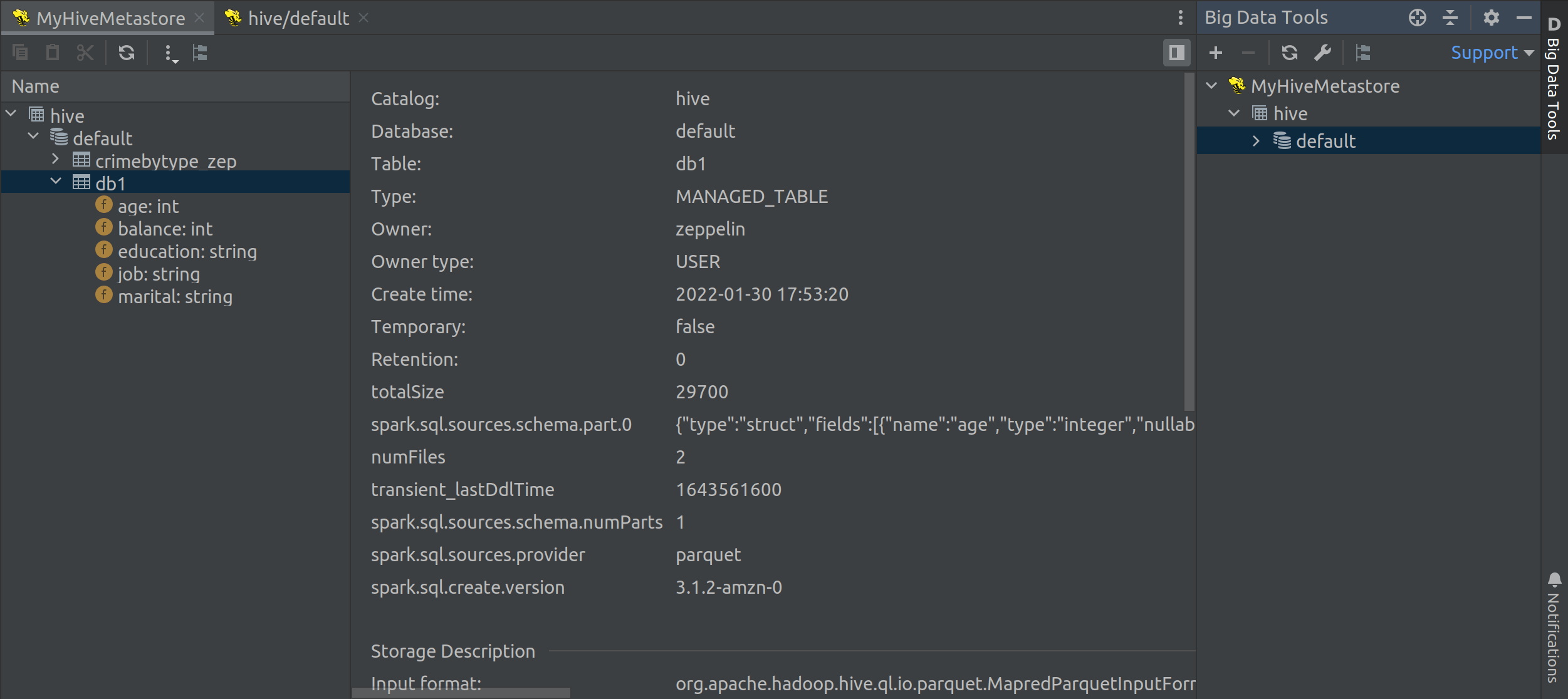
Hive Metastore support
Added basic support for Hive Metastore: ability to create a Hive Metastore connection right from the IDE and browse Hive catalogs, tables, and columns.
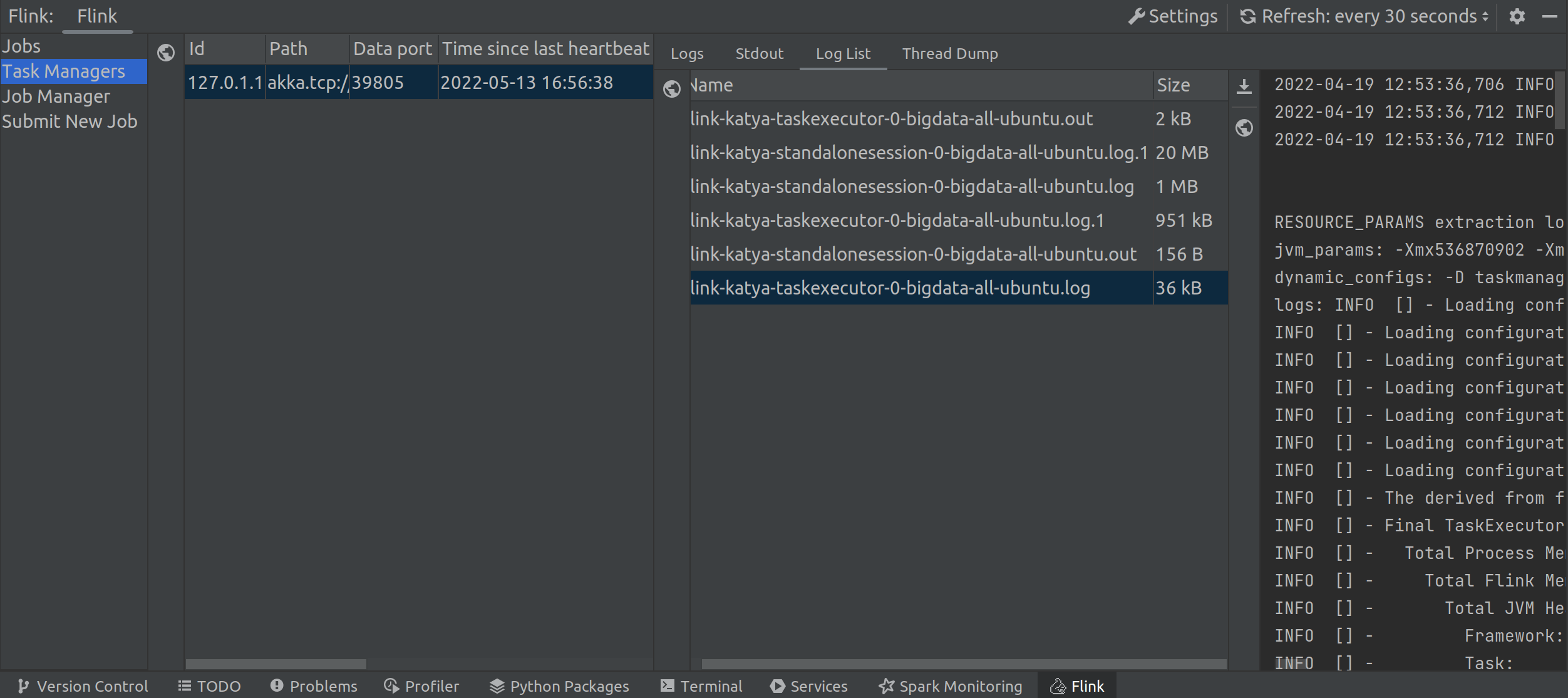
Apache Flink Monitoring in the IDE
You can now monitor Flink applications right in your IDE. Just like in the Flink Dashboard, you can launch and stop jobs.
In the dedicated Flink tool window, you can preview:
- a list of jobs with their details: exceptions, checkpoints, configurations
- Task Managers with the ability to view logs, stdout, log list, and thread dump
- Job manager with information on configuration, logs, stdout, and log list
From each of these tabs, you can quickly open the Flink web interface by clicking the ‘Open in Browser’ icon.
EMR Support

User-friendly and simple UI interface to work with clusters.
You can create a connection just with one click to
- HDFS
- Hadoop and Spark Monitoring
- Zeppelin
- AWS S3
- Main and data nodes SFTP
and also open internal cluster service web pages (like ganglia) through an automatically created SSH tunnel.
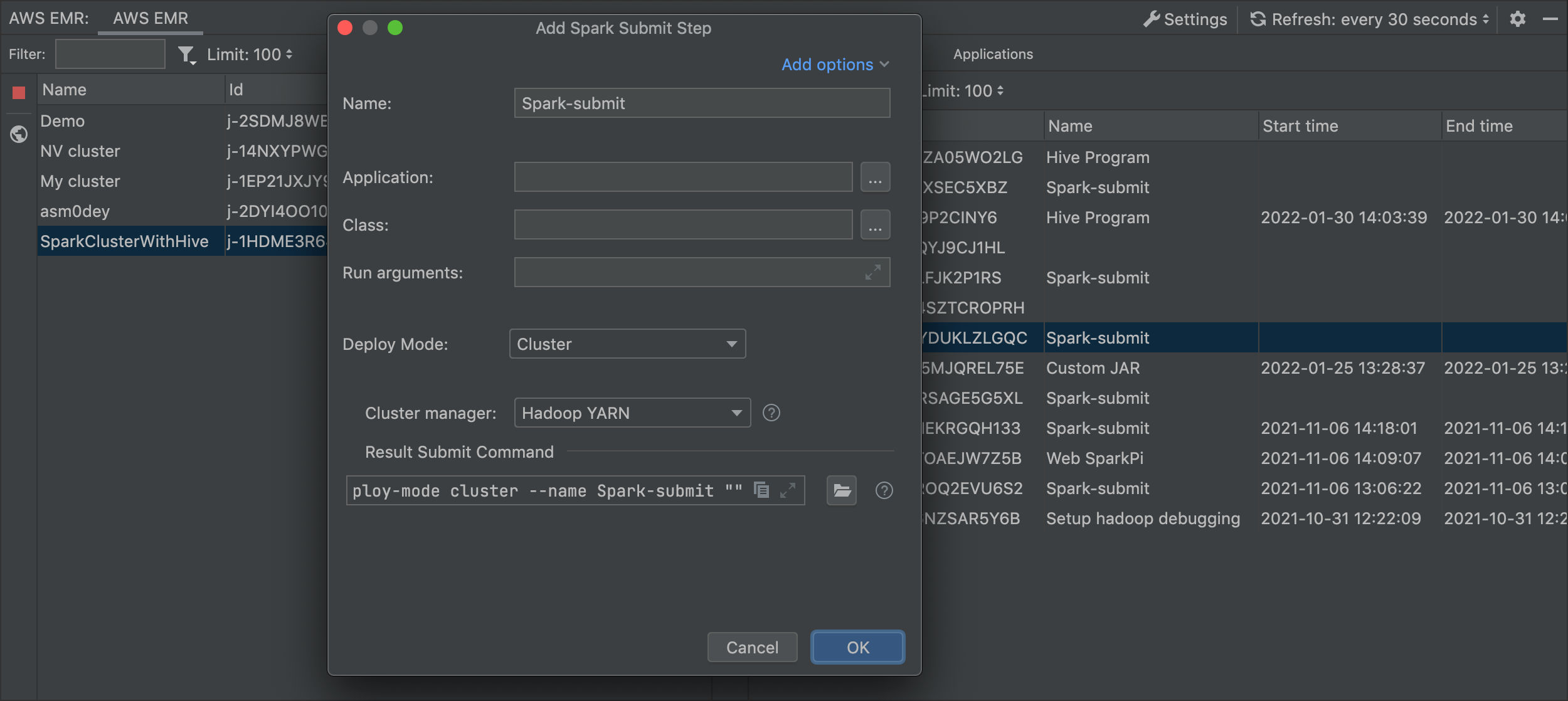
AWS EMR Spark Submit
You can configure all parameters of spark-submit. Also, there is the ability to upload jars from a local machine to s3 or some other cluster.
New file viewer
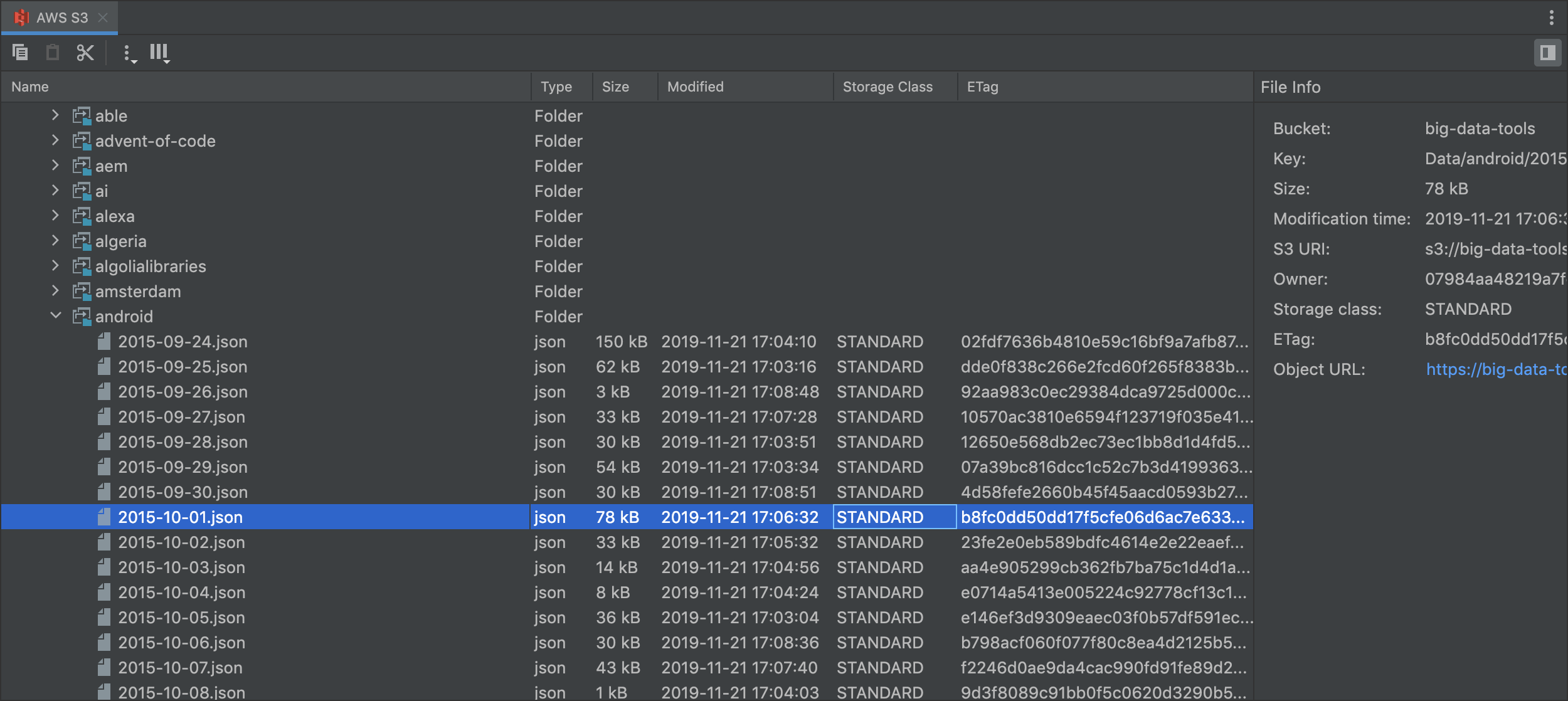
Full-size viewer for remote file system
You can use a full-size viewer for any remote file system. The viewer can be opened separately in the editor tab from the BDT connections tree. In the file viewer, you can find more metainfo about folders and files.
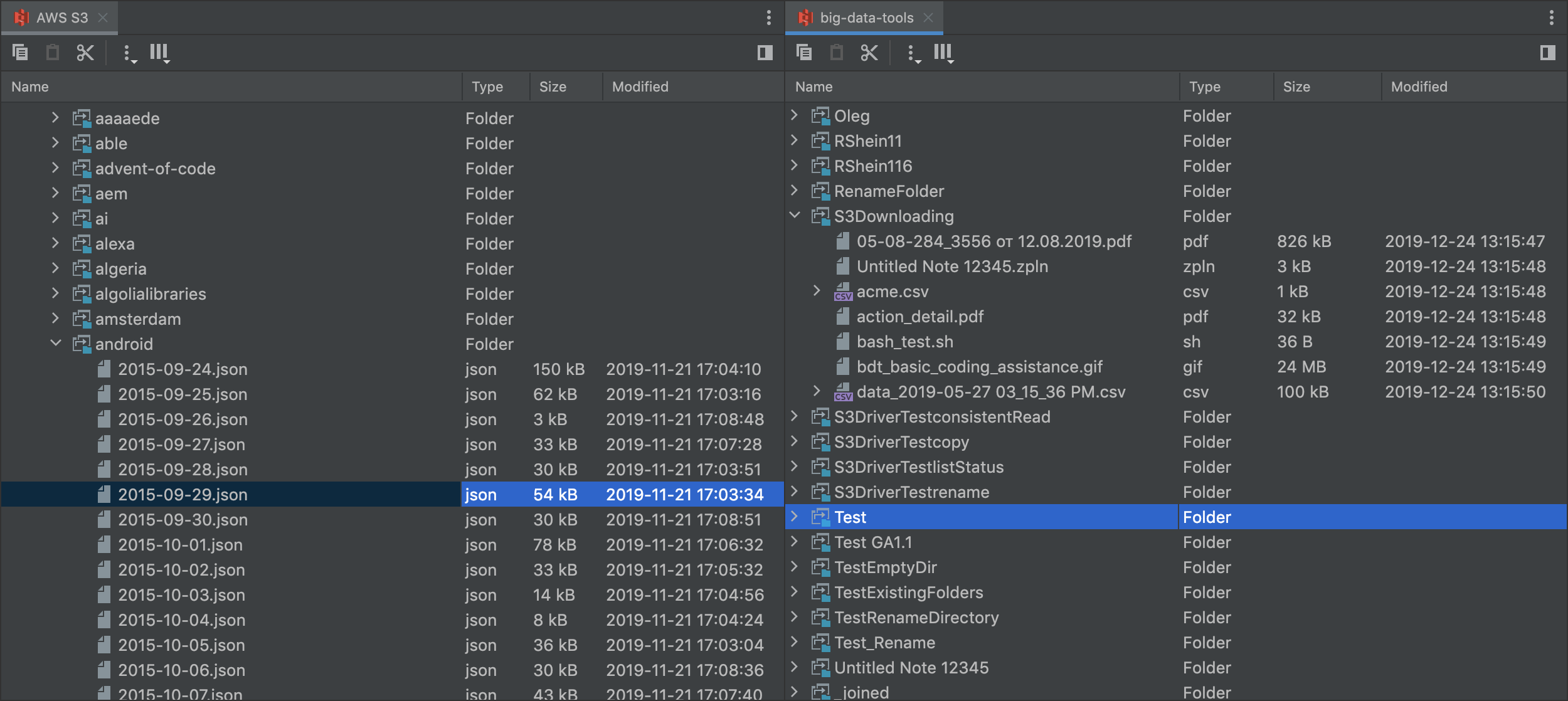
Panels in file viewer
You can create, for example,a two-panel file viewer by using different layouts for the IDE components.
Remote file system
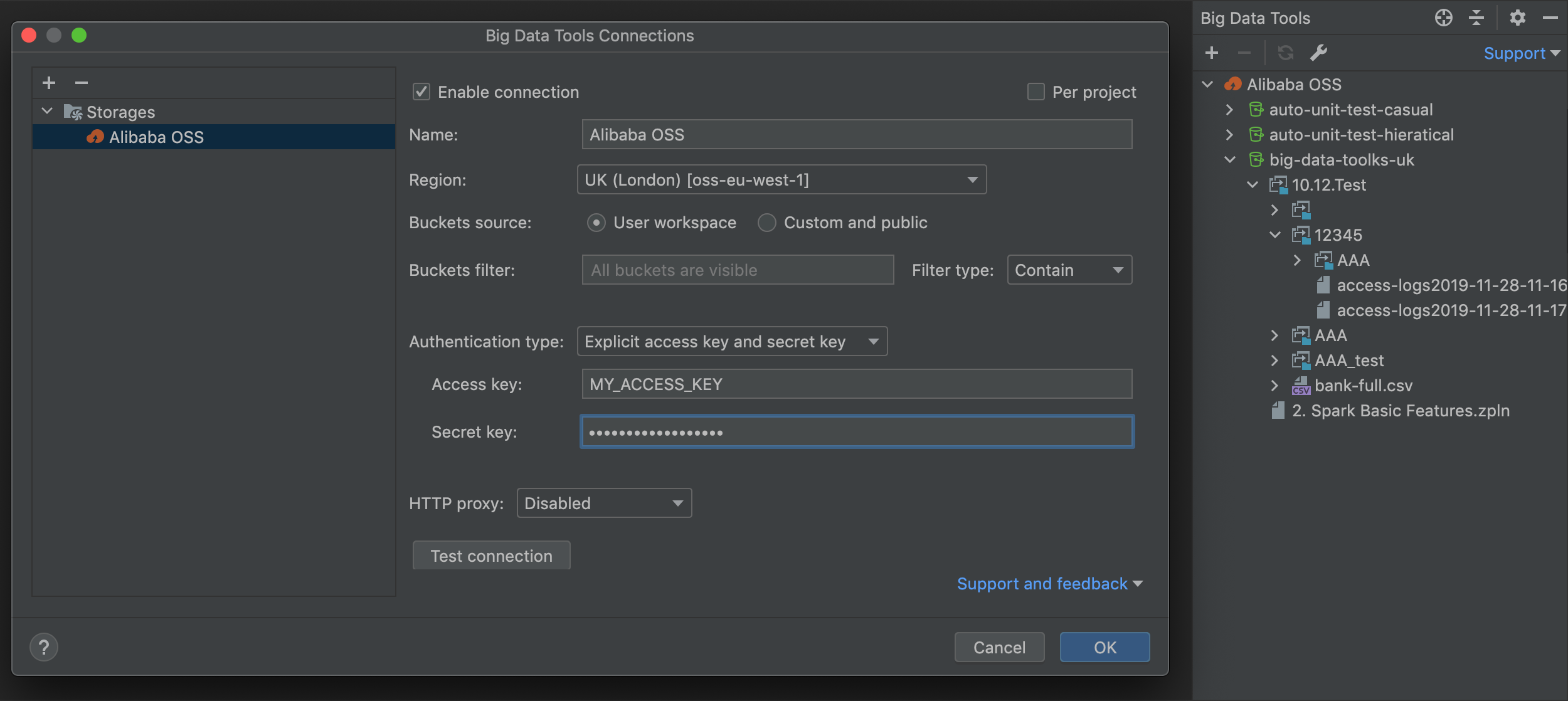
Alibaba OSS support
You can access data in the Alibaba Cloud Object Storage Service directly from IDE.
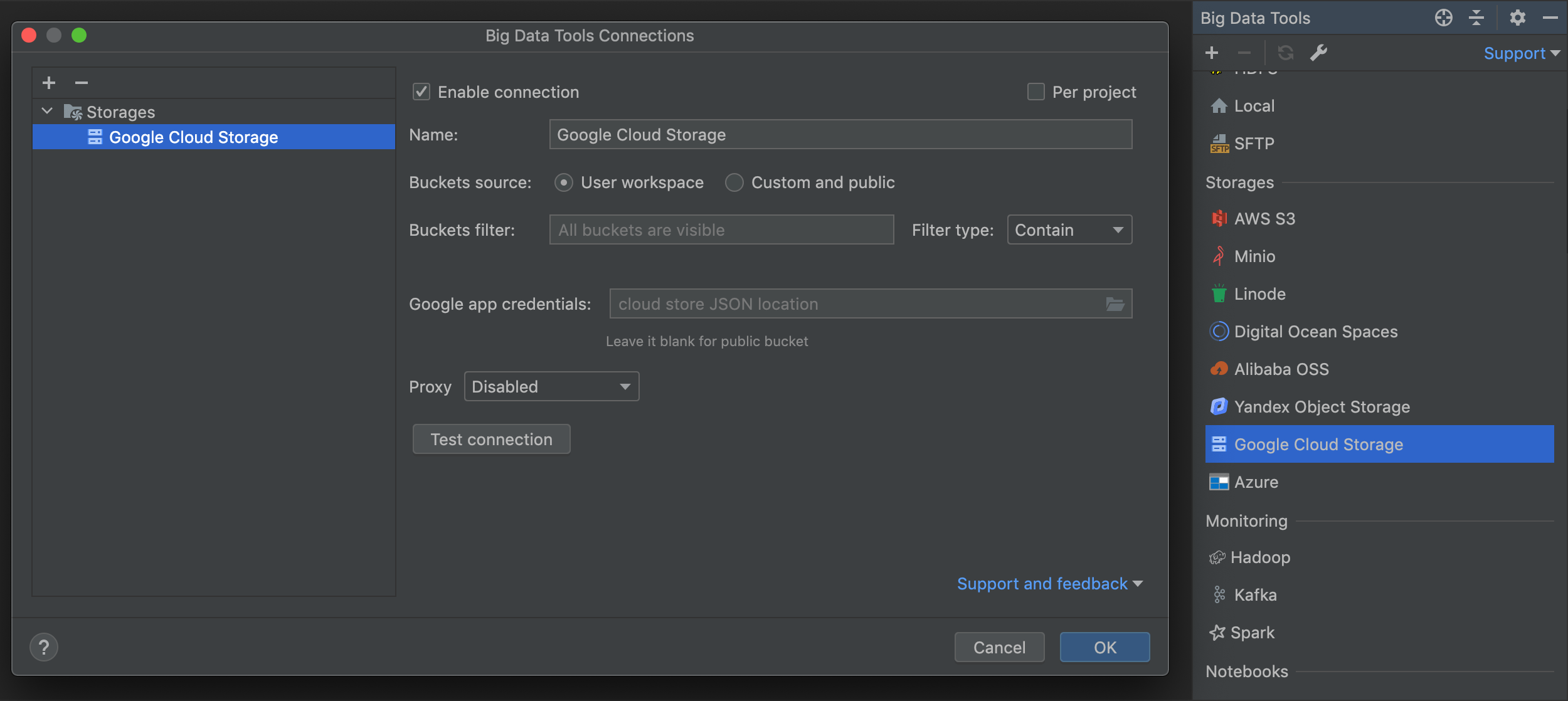
Remote file systems improvement
Multiple buckets are supported for Google Cloud Storage You can establish connections to custom paths like bucket/folder/folder for OSS, S3, and GCS.