Features
This section will give you a brief overview of the features available in DataGrip. It is also relevant for the database plugin used in IntelliJ IDEA Ultimate, PyCharm Professional, PhpStorm, RubyMine, CLion, GoLand, Rider, and WebStorm. For more details, visit the documentation page.
Exploring your databases
DataGrip is a multi-engine database environment. If the DBMS has a JDBC driver, you can connect to it via DataGrip. It provides database introspection and various instruments for creating and modifying objects for the supported engines:
Navigation
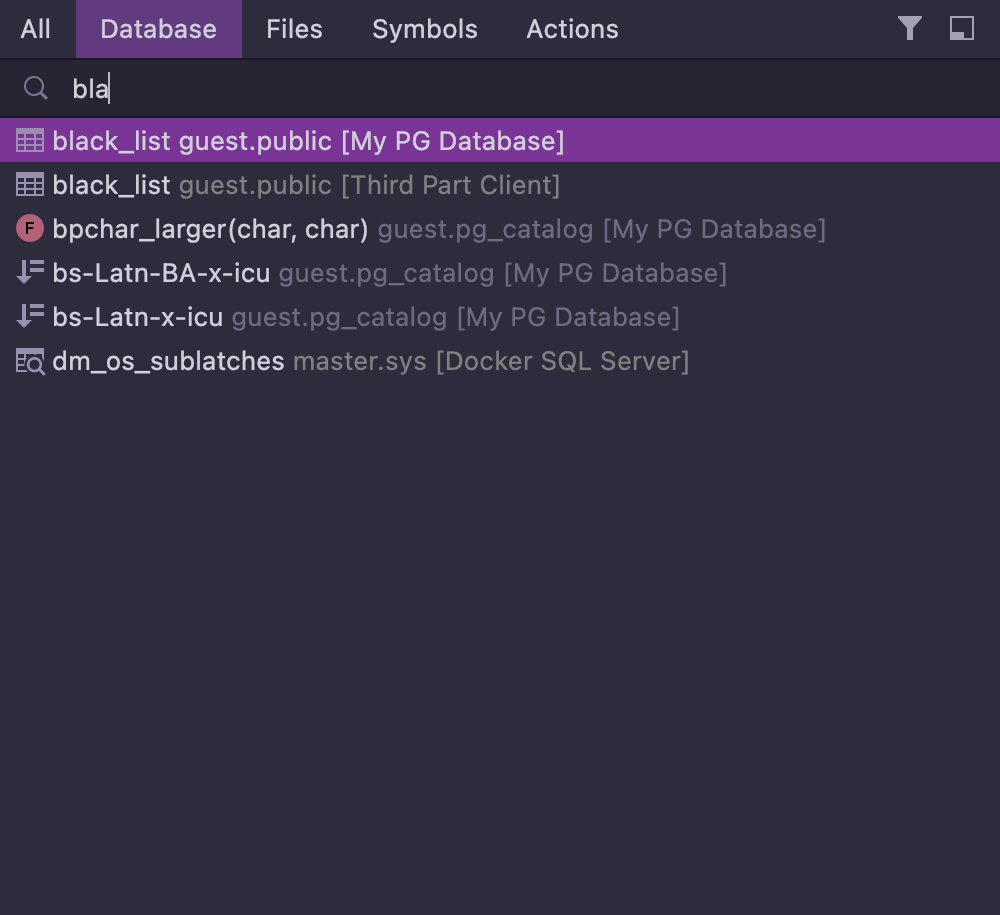
Quick navigation takes you to an object independently of whether it has just been created in your code or previously read from a database.
Diagrams
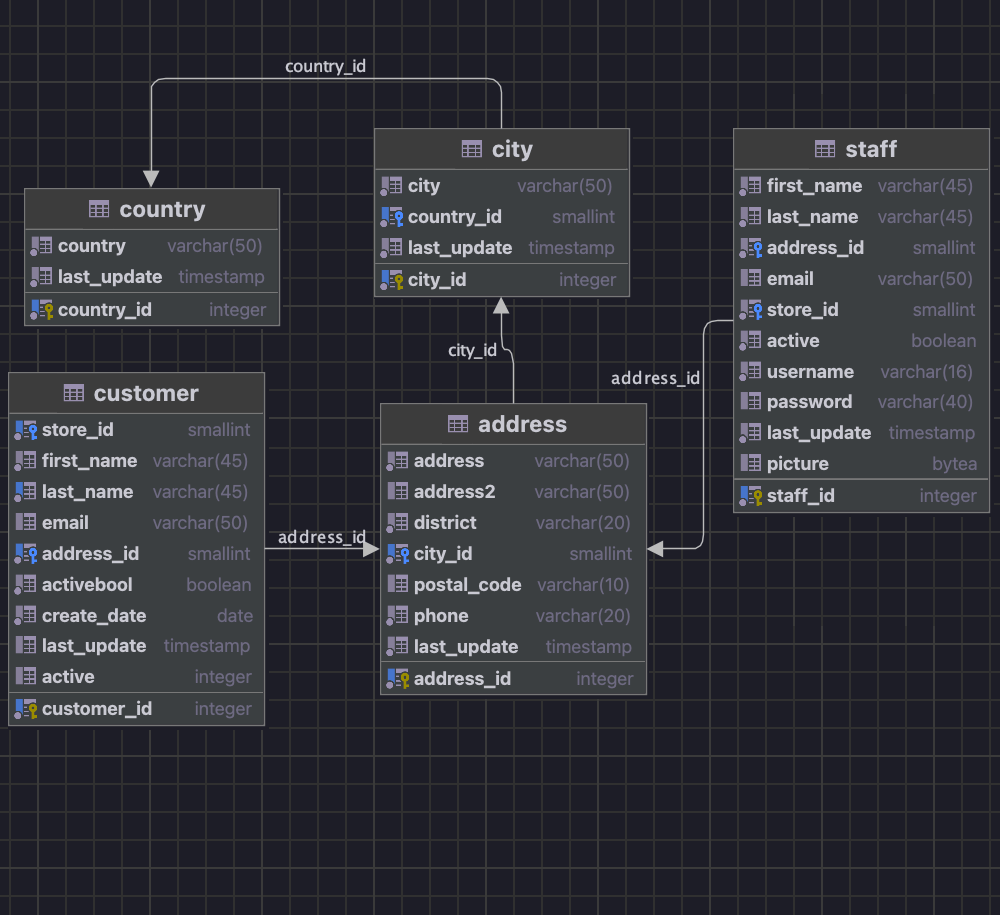
Explore your tables and their relationships using an insightful diagram.
Schema diff
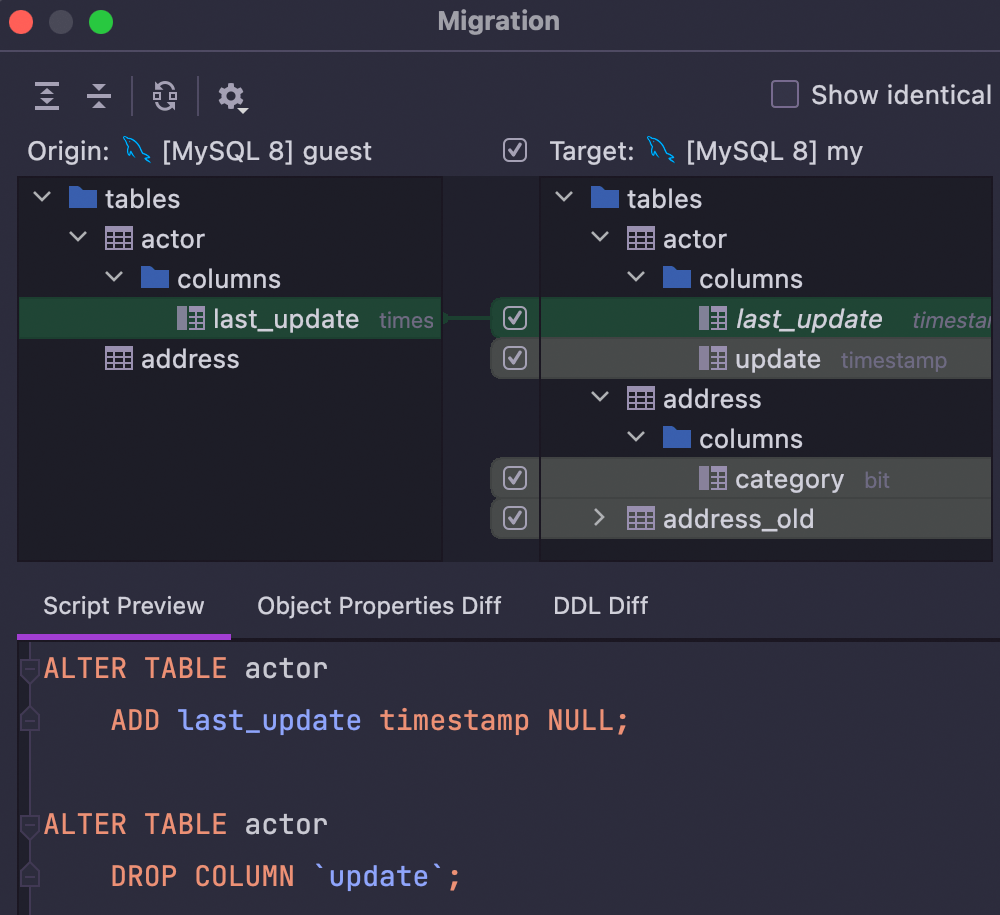
Compare schemas to see the difference and generate migration scripts for them.
Working with data
Databases are all about data. Use DataGrip to handle all the data manipulations: edit, search, import and export.
Data editor
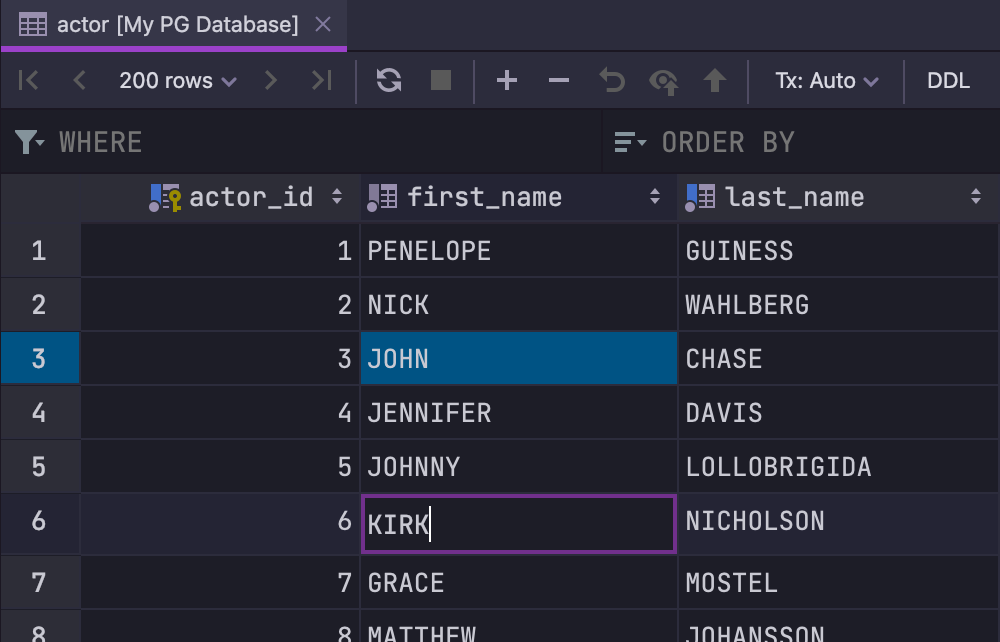
The powerful data editor lets you add, remove, edit, and clone data rows. Navigate through the data by foreign keys and use the text search to find anything in the data displayed in the data editor.
Import/Export
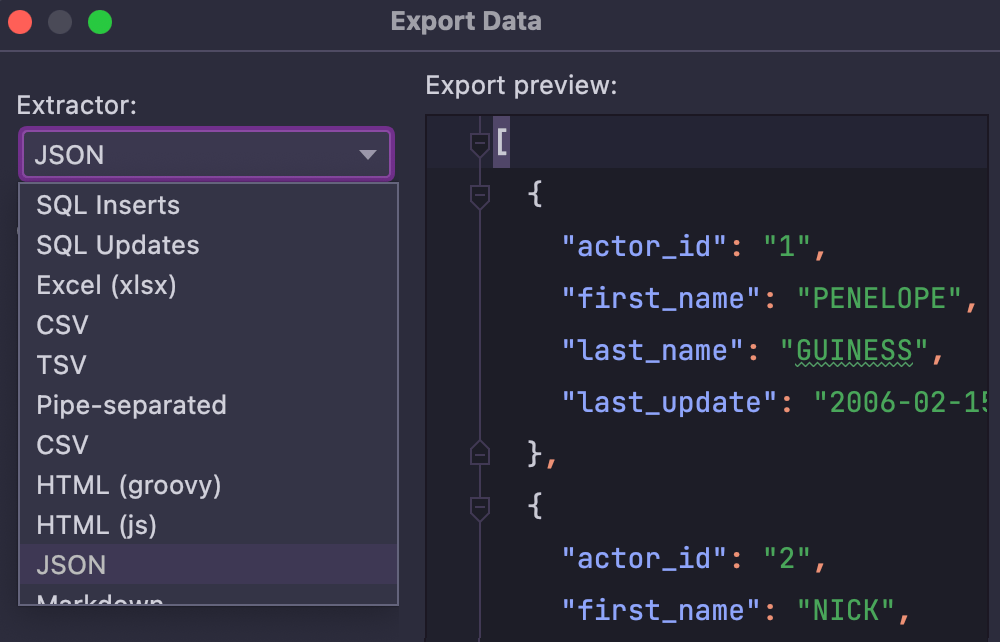
In addition to the trivial ability to import from CSV files, DataGrip provides a powerful scripting mechanism for export which lets you create any text format you like. CSV, JSON, HTML, Markdown and many others are already bundled – export to Excel is also included.
Data compare
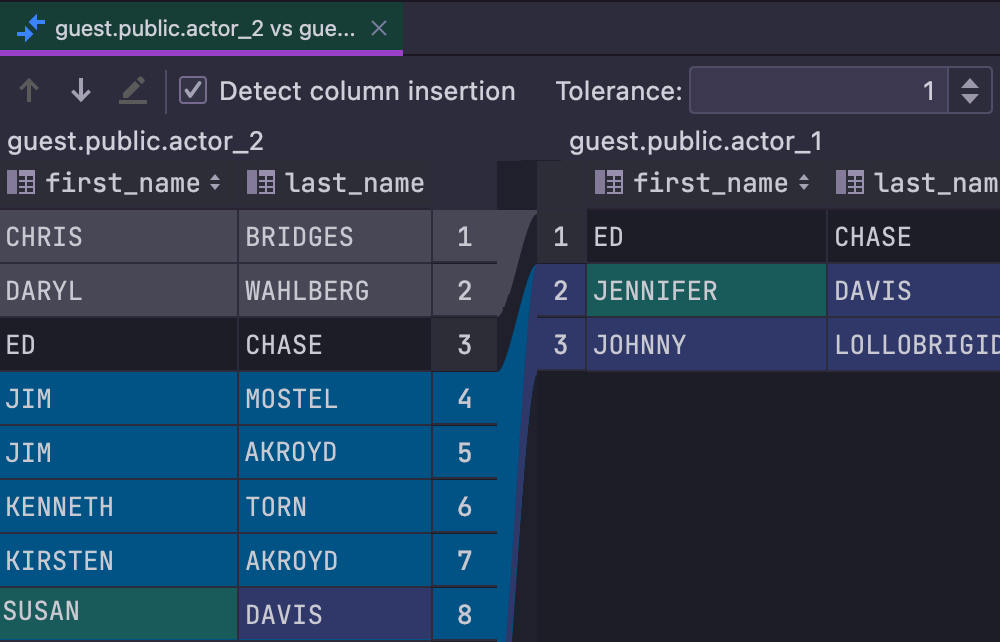
Use the diff viewer to compare tables or query results. DataGrip highlights the differences between the two and lets you manage the level of the comparison criteria via a tolerance parameter.
Writing SQL
Just as any decent IDE should do, DataGrip provides smart code completion, code inspections, on-the-fly error highlighting, quick-fixes, and refactoring capabilities. It saves you time by making the process of writing SQL code more efficient.
Smart text editor

Just as with any IntelliJ platform IDE, DataGrip includes a code editor that helps you be more productive. Transform and move blocks of code, use multi-cursors to manage selections, and much more.
Code completion
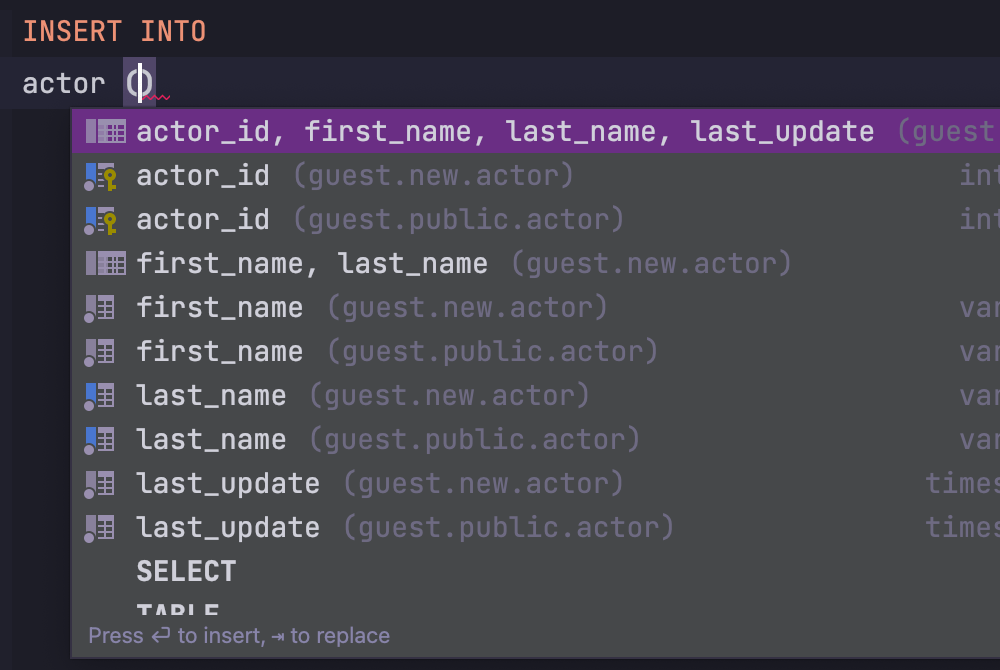
DataGrip provides context-sensitive, schema-aware code completion, helping you write code faster. Completion is aware of the tables structure, foreign keys, and even database objects created in the code you're editing.
Code generation
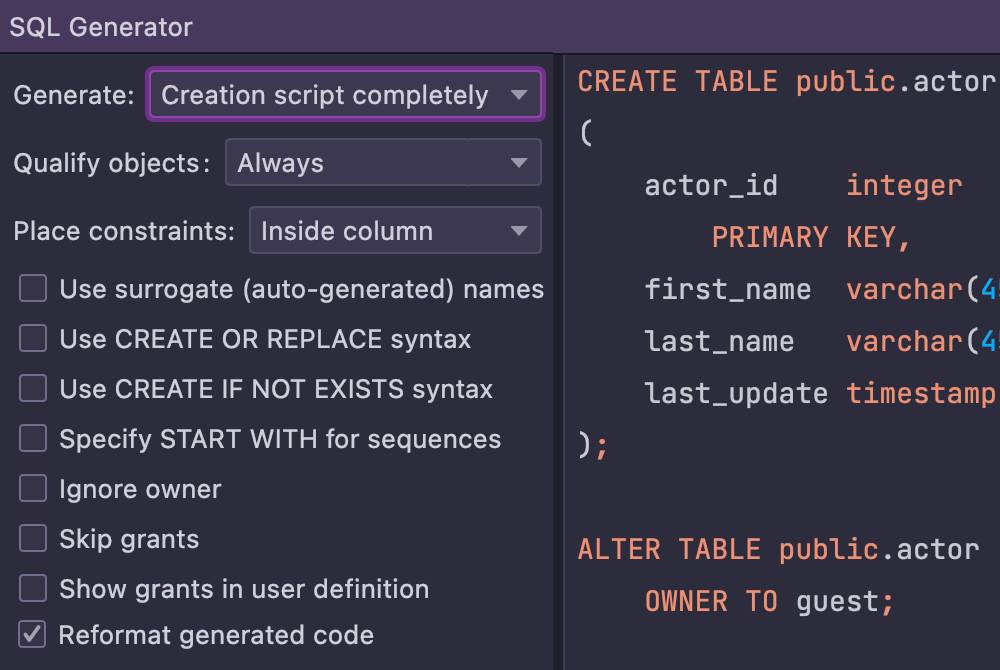
Forget about writing typical code manually: DataGrip will do that for you. It generates code for changing objects like tables, columns, etc., based on the UI. Moreover, it helps you to get a DDL for any object and provides DML queries from result-sets and updates.
Code analysis and quick-fixes
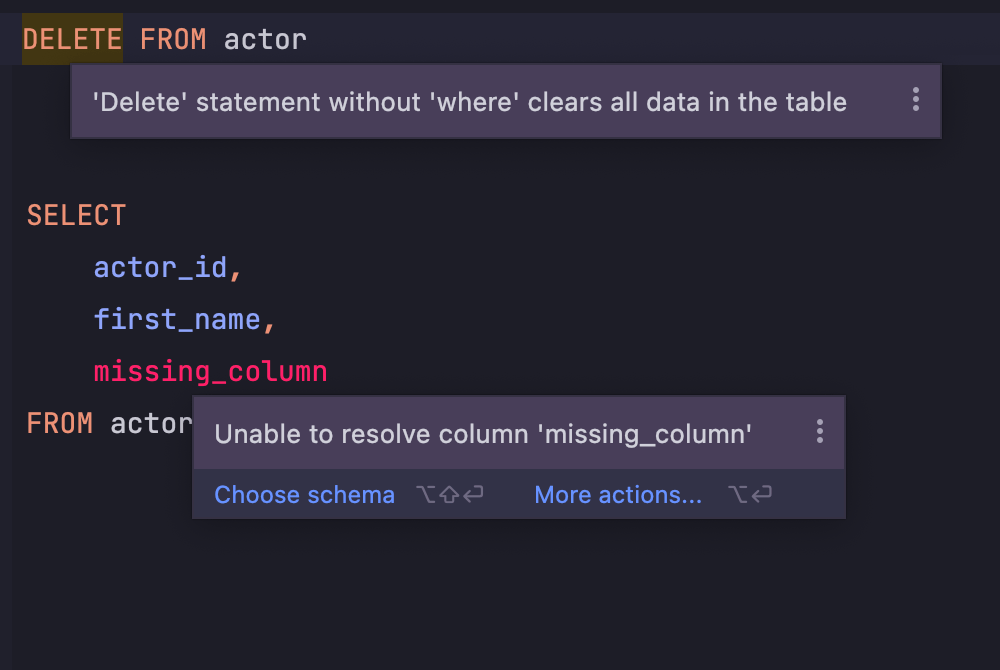
DataGrip detects where bugs are likely to occur in your SQL code and suggests the best options to fix them on-the-fly. It will immediately let you know about unresolved objects, the use of keywords as identifiers, and always offers you a way to fix the problem.
Refactoring and finding usages
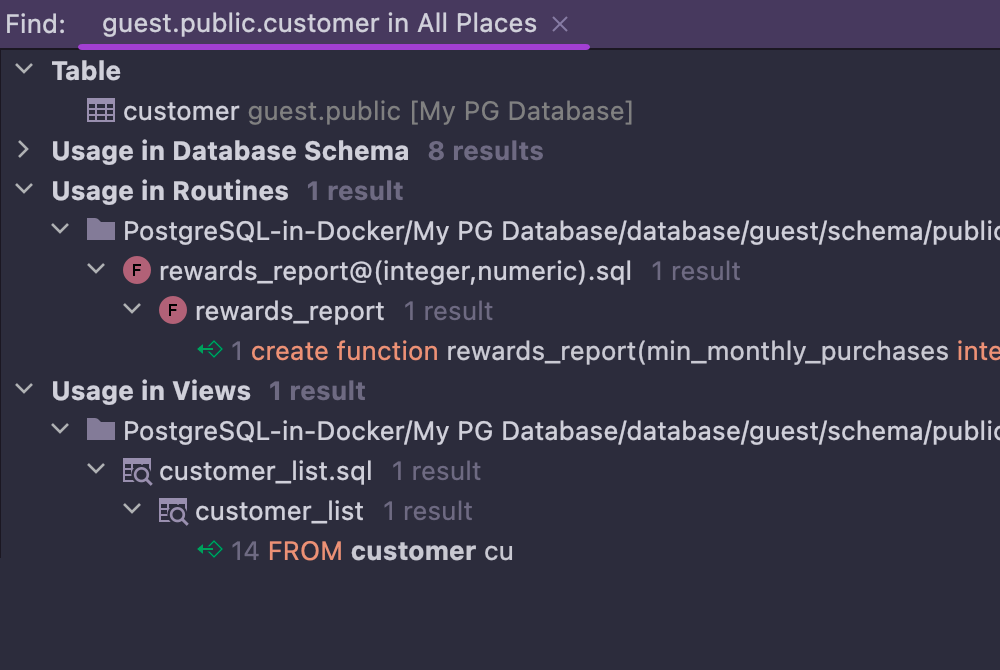
DataGrip correctly resolves all references in your SQL files. When you're renaming database objects from SQL, they will also be renamed in the database. You can quickly find out in which stored procedures, functions and views your tables are used.
Code formatter
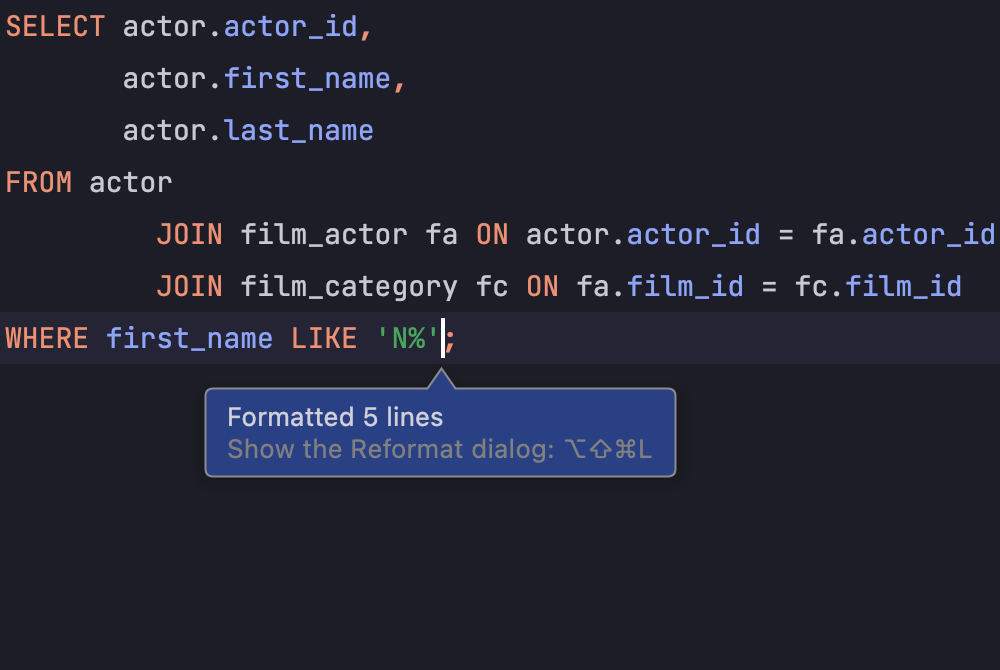
Since each database developer has their own slightly unique style, the ability to configure each individual option in the code formatter helps ensure that all their individual needs are met.
Running queries
The query console in DataGrip is a basic necessity for any SQL developer. You can use it to create multiple consoles, each with its own schema context and query options.
Query console
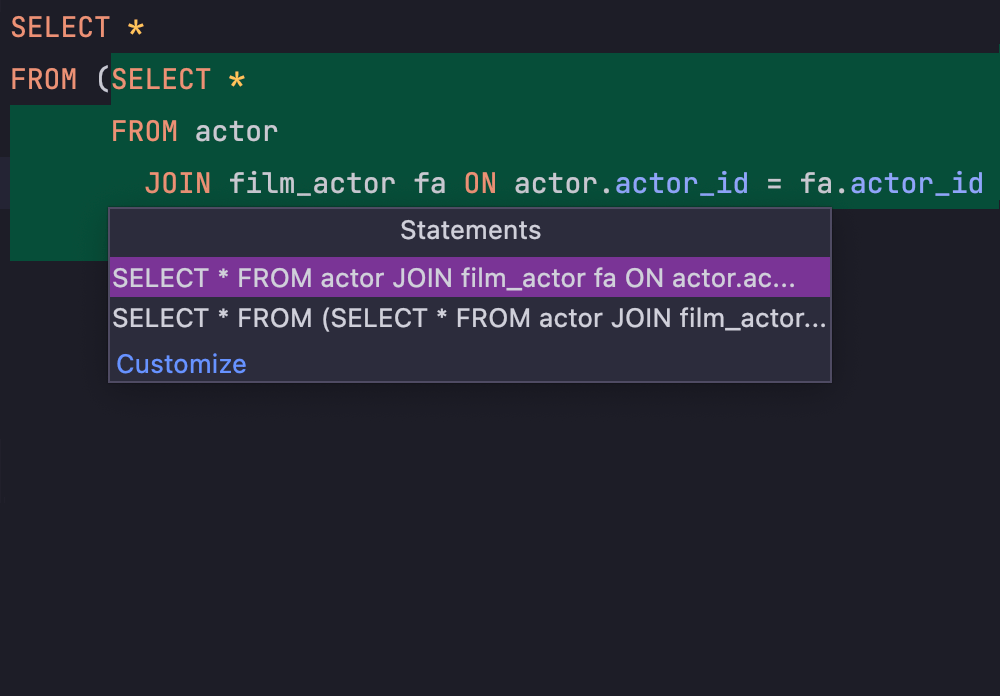
Specify the console’s behavior for running queries by choosing what you want to execute – from the smallest statement to the largest one. Available modes include read-only, results-in-editor, and manual transaction committing.
Query history
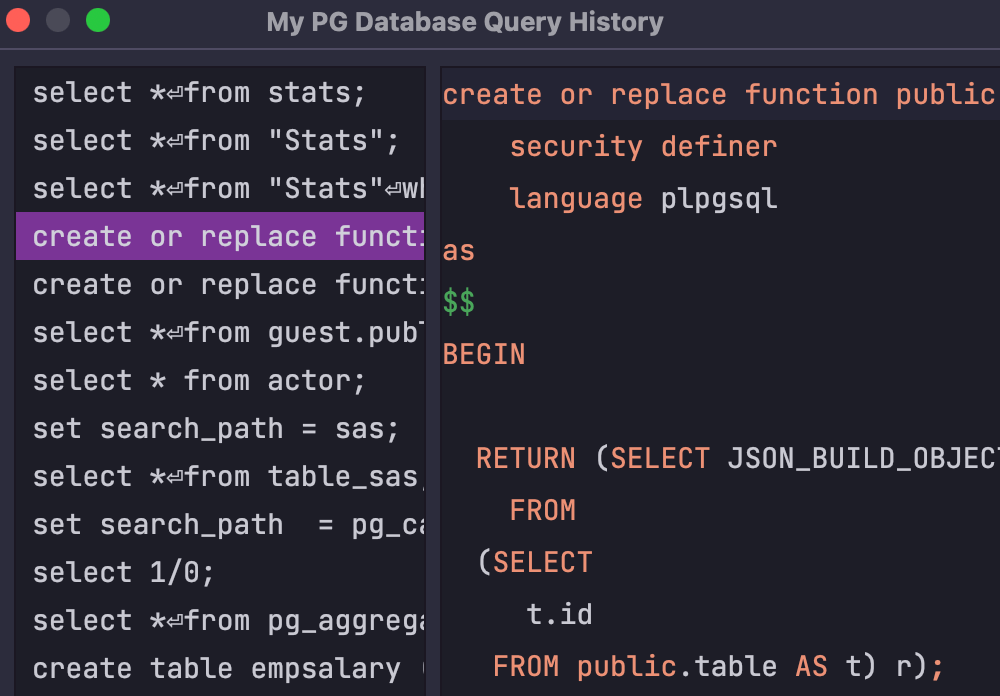
Each query you run is saved in the log file. There is also a local history of each file, which means everything you type is saved as soon as you type it so that you don’t lose any work.
User parameters
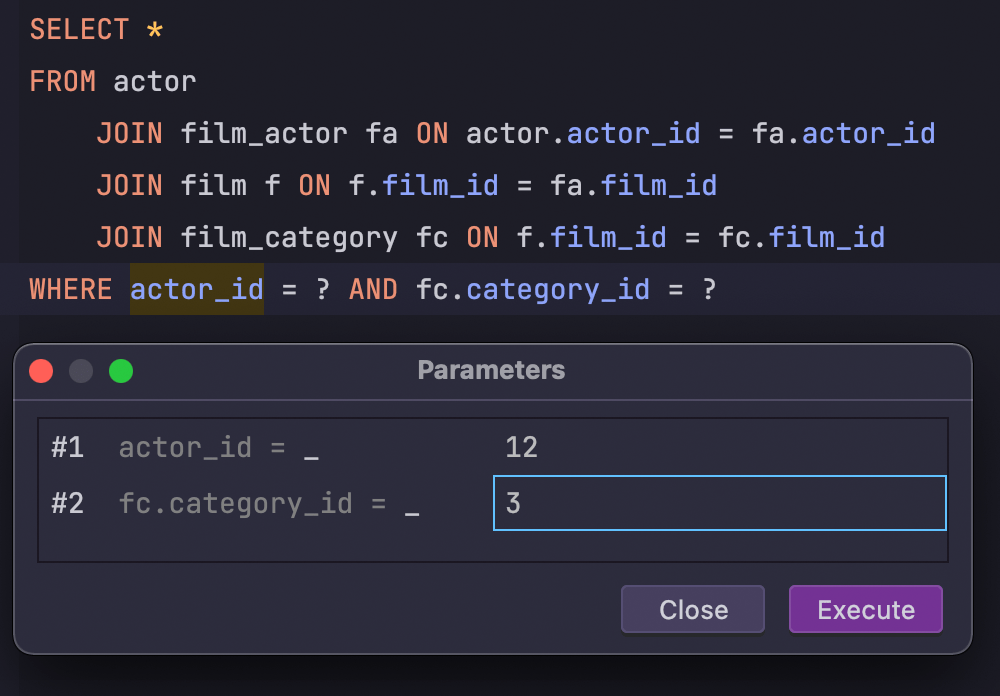
DataGrip supports running parameterized SQL queries. Add your own parameter patterns using regular expressions and choose the SQL dialects that these patterns will be applied to.
Working with files
Many developers store their queries scripts in files. DataGrip provides many features to handle them.
DDL data source
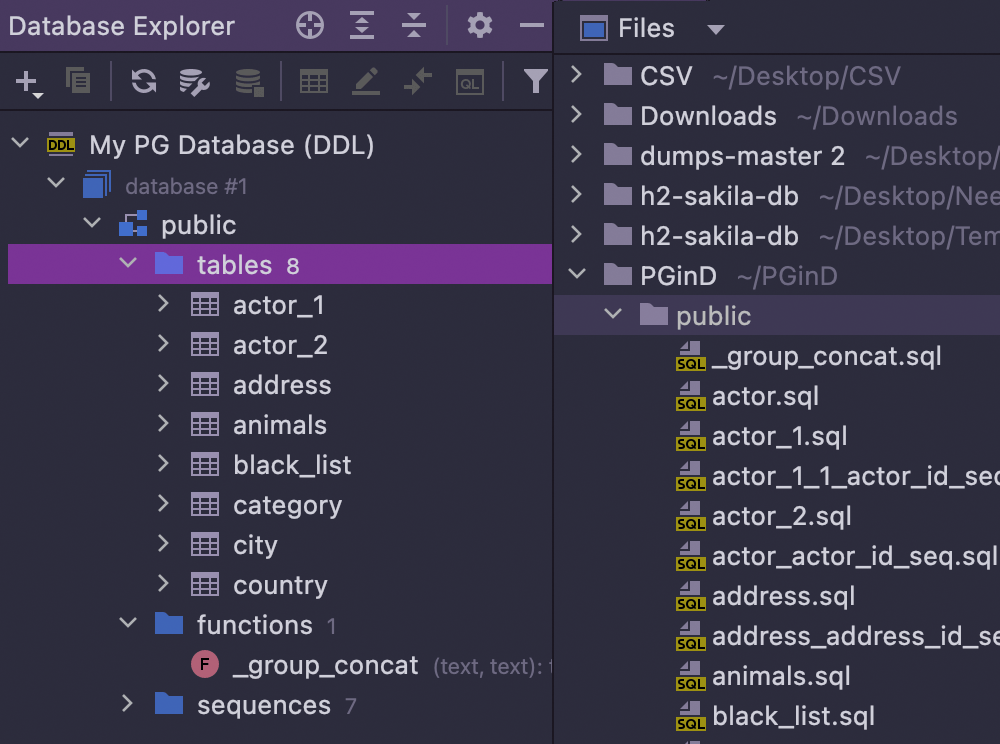
SQL files that contain DDL statements of the schema can be used as data sources. As a result, you can reference all tables, columns, and other objects defined in such files. You can also map a DDL data source to a real one and migrate both sides.
VCS support
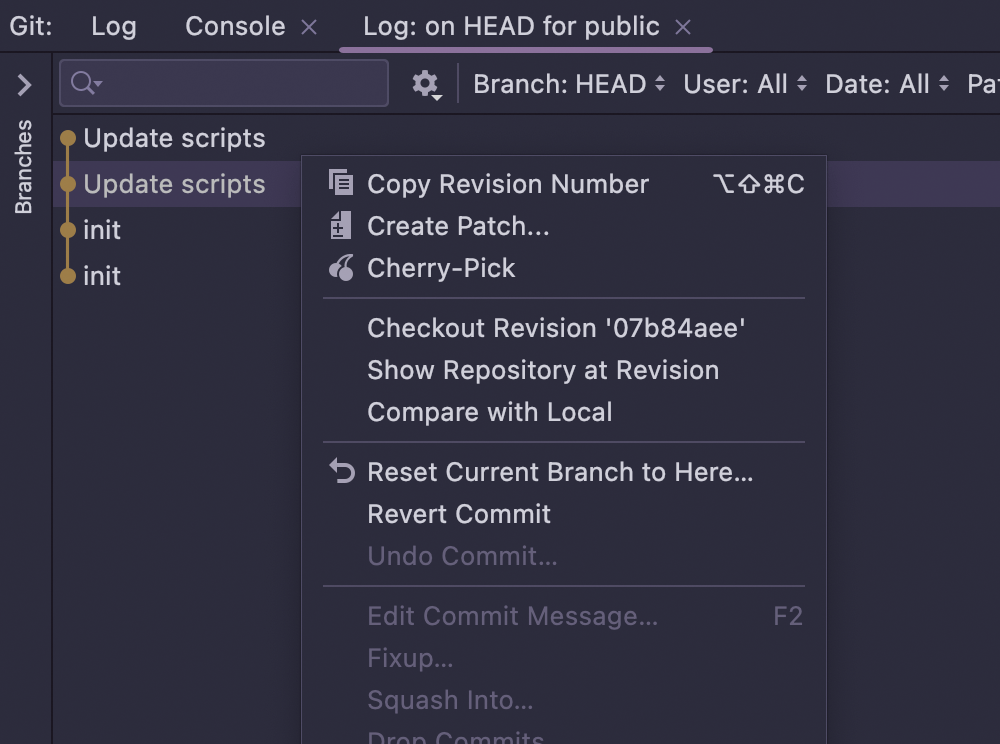
DataGrip provides a unified interface for most of the popular version control systems, ensuring a consistent user experience with Git and other systems. GitHub integration is also available.
Run Configurations
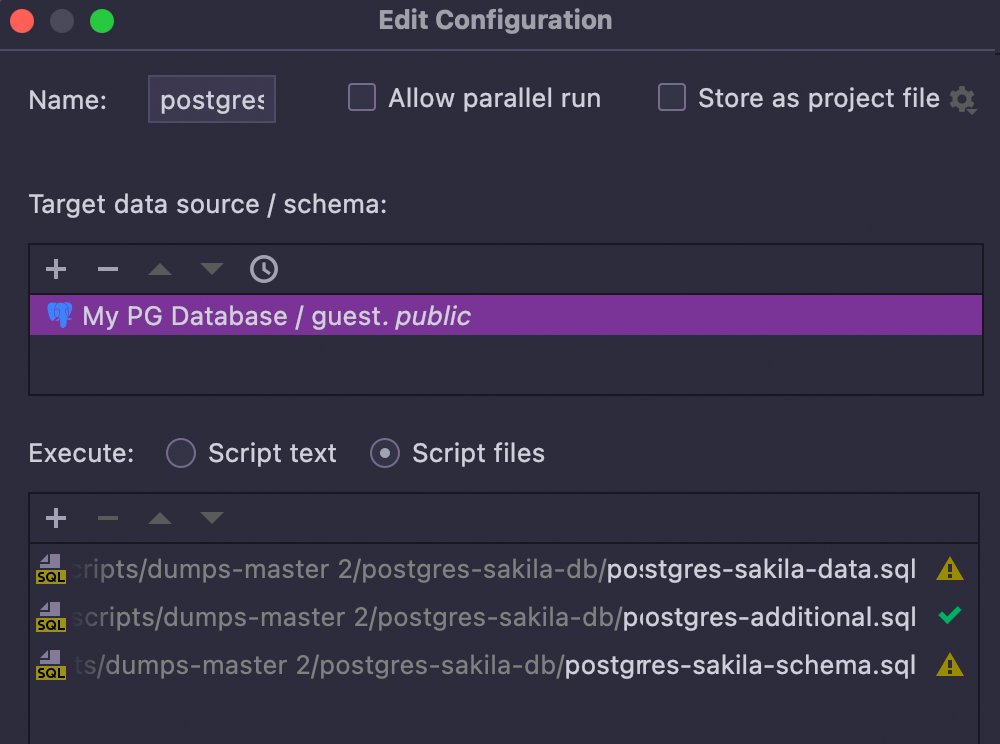
You can run scripts without opening them with the help of run configurations. Each configuration can contain several script files in the required order, several target schemas, and the list of tasks to complete before the actual run.
User Interface
Localized UI
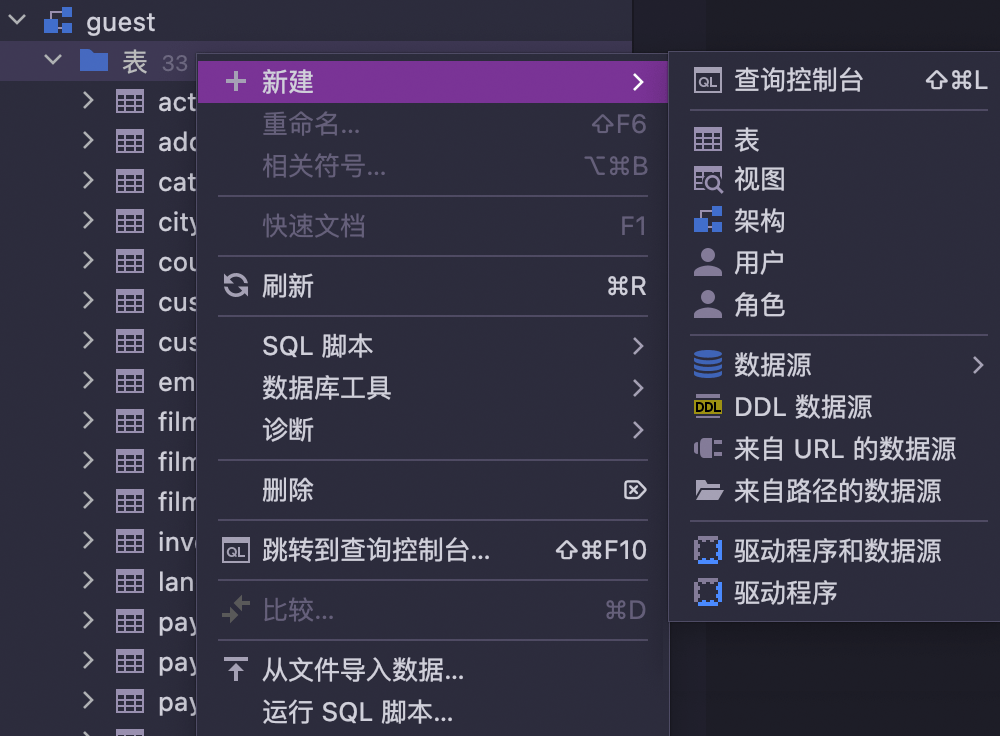
The user interface can be displayed to any of the following languages: Chinese, Japanese, and Korean.
Customizable appearance
DataGrip comes with light and dark themes. Each of them can be fully customized and any color can be changed. The user can even create their own color themes, and our plugin repository provides countless options.
Customizable keymap

The power of DataGrip lies in shortcuts. You can change the ones that are not convenient for you and assign your own to any action within the IDE.