What's New in DataGrip 2024.3
Text-to-SQL In-Editor Diff, AI Assistant Actions for Handling SQL Errors, Grid UI Improvements, and More!
AI Assistant features

SQL error handling by AI Assistant
We have implemented a couple of useful actions for handling SQL query execution errors with AI Assistant. Now, for each error message, DataGrip shows two actions on the far right-hand side of the error message: Explain with AI and Fix with AI.

Explain with AI opens the AI chat, sends an automatic prompt, and gives you AI Assistant’s explanation of the error.

Fix with AI generates a fix for the query execution error in the editor.

Text-to-SQL: In-editor diff for generated results
We have improved the experience of working with AI Assistant in the editor.

Now, when you ask AI Assistant to do something with a chunk of code, the editor contains a diff with both the original and the generated code. AI Assistant’s suggestions are highlighted with a different color and marked with the Revert button in the gutter.
You can also edit the resulting query yourself in the diff. Your changes are highlighted the same way.
For example, you can ask AI Assistant to retrieve more data with a query and then add an ORDER BY clause to the generated result.
These two new actions work similarly to the Fix SQL Problem Under Caret and Explain SQL Problem Under Caret intention actions.
This feature requires attaching the database schema to suggest proper explanations and fixes.
Working with data
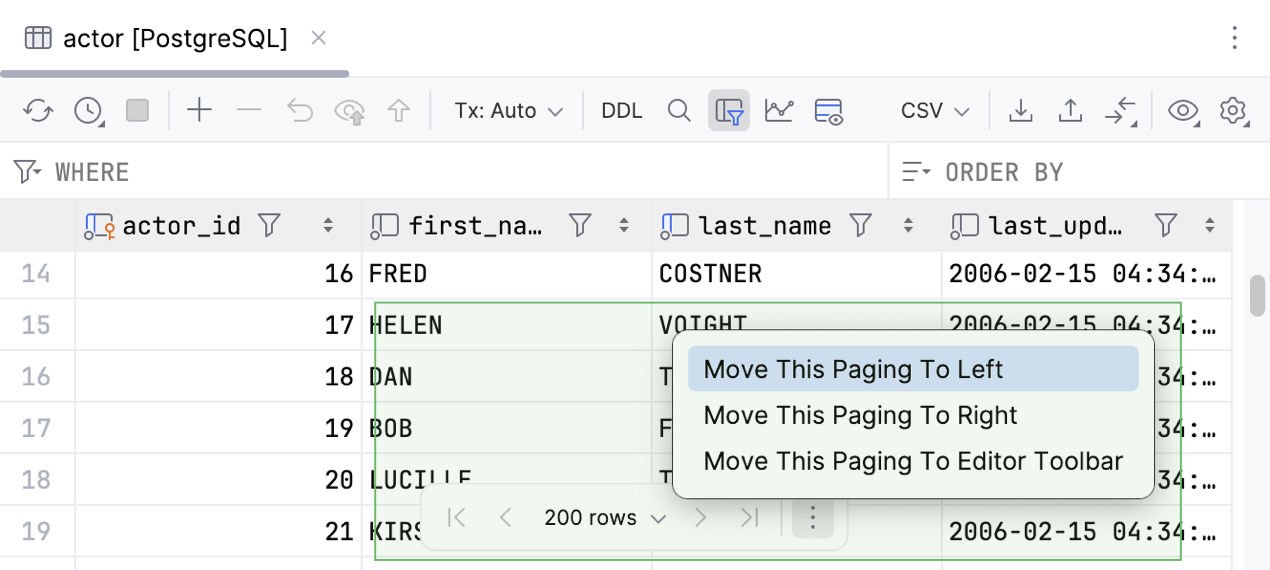
Floating pagination toolbar
To make grid paging more noticeable in the data editor, we have moved the control from the toolbar to the bottom center of the data editor.
To move this control back to the toolbar, open the IDE settings, go to Database | Data Editor and Viewer, scroll to Position of the grid pagination control, and select Data editor toolbar.

Wider in-editor results grid
Previously, the width of the in-editor results grid was limited. Now the grid automatically adjusts to the full width of your editor, allowing you to view more data.

Non-modal Create and Modify dialogs
For some time, a highly requested feature has been the ability to interact with other parts of the IDE interface while modifying an object in the Create and Modify dialogs. DataGrip 2024.3 introduces non-modal dialog behavior. Now, you can easily browse through your databases, data sources, files, and any other parts of your project without having to interrupt your work creating or modifying an object in the dialog.
Code editor

Highlight occurrences of selected text
By default, DataGrip will now automatically highlight all instances of the text you select within a file. This makes it easier to track where your selected text appears throughout your code.

Inspection for an excessive number of JOIN clauses
In certain cases, running a query that contains an excessive number of
JOIN clauses is not recommended due to performance degradation.
The editor can now identify and highlight such queries.
You can enable this inspection in the IDE settings. To do so, navigate to Editor | Inspections, expand the SQL section, and select Excessive JOIN count.

Table-valued functions support BigQuery
We have improved support for BigQuery table-valued functions (TVFs). Now DataGrip properly detects both the TVFs and their return columns.
Connectivity
Fragment introspection and smart refresh MySQL MariaDB
DataGrip now supports fragment introspection.
Previously, the introspector could perform only a full introspection of schemas in the MySQL or MariaDB databases but not refresh the metadata of a single object. Every time a DDL statement was executed in the console and that execution could modify an object in the database schema, the IDE would start a full introspection of the entire schema. This was time-consuming and often disrupted the workflow.
Now, DataGrip can analyze a DDL statement, determine which objects could have been affected by it, and refresh only those objects.
If you select a single item in the database explorer and call the Refresh action, only that specific object will be refreshed, instead of the entire schema as before.
Bug fixes
- DBE-21843: The first rows no longer disappear for large tables.
- DBE-20350: The Qualify object with: Database code completion feature works as intended.
- DBE-21526: There is no longer an issue with the availability of context live templates in the context menu of database objects.
-
DBE-18445:
MySQL
The
ST_SRIDfunction is now supported. -
DBE-19042:
MySQL
Multiple roles in
GRANTstatements are now supported. -
DBE-19984:
MySQL
The
block_encryption_modesystem variable is now supported. - DBE-16521: MariaDB Support of temporal tables in query consoles has been improved.
-
DBE-19041:
MySQL
MariaDB
SET ROLEandSET DEFAULT ROLEstatements are now supported. - DBE-14986: SQL Server Synonym resolve in function calls works as expected.
- DBE-15201: SQL Server Schema qualification for function completion works as expected.
-
DBE-21204:
SQL Server
The
OPTIONkeyword inCURSORdeclarations is now supported. -
DBE-3771:
Oracle
An inspection for qualified columns in
USINGhas been added. -
DBE-3772:
Oracle
An inspection for qualified columns in
NATURAL JOINhas been added. -
DBE-5657:
Oracle
Autocompletion for
PARTITIONclauses works as expected. -
DBE-10459:
Oracle
Autocompletion for
BEGINis now supported. -
DBE-17022:
Oracle
ON COMMIT PRESERVE DEFINITIONis now supported. -
DBE-21014:
Oracle
The resolve of
CURSORdeclared in package headers works as intended. - DBE-20309: Oracle Column resolve against function calls works as intended.
- DBE-21006: Oracle Column resolve against record types works as intended.