What's New in DataGrip 2022.3
DataGrip 2022.3 is here! This major update is packed with various enhancements. Let’s take a look at what’s inside!
General
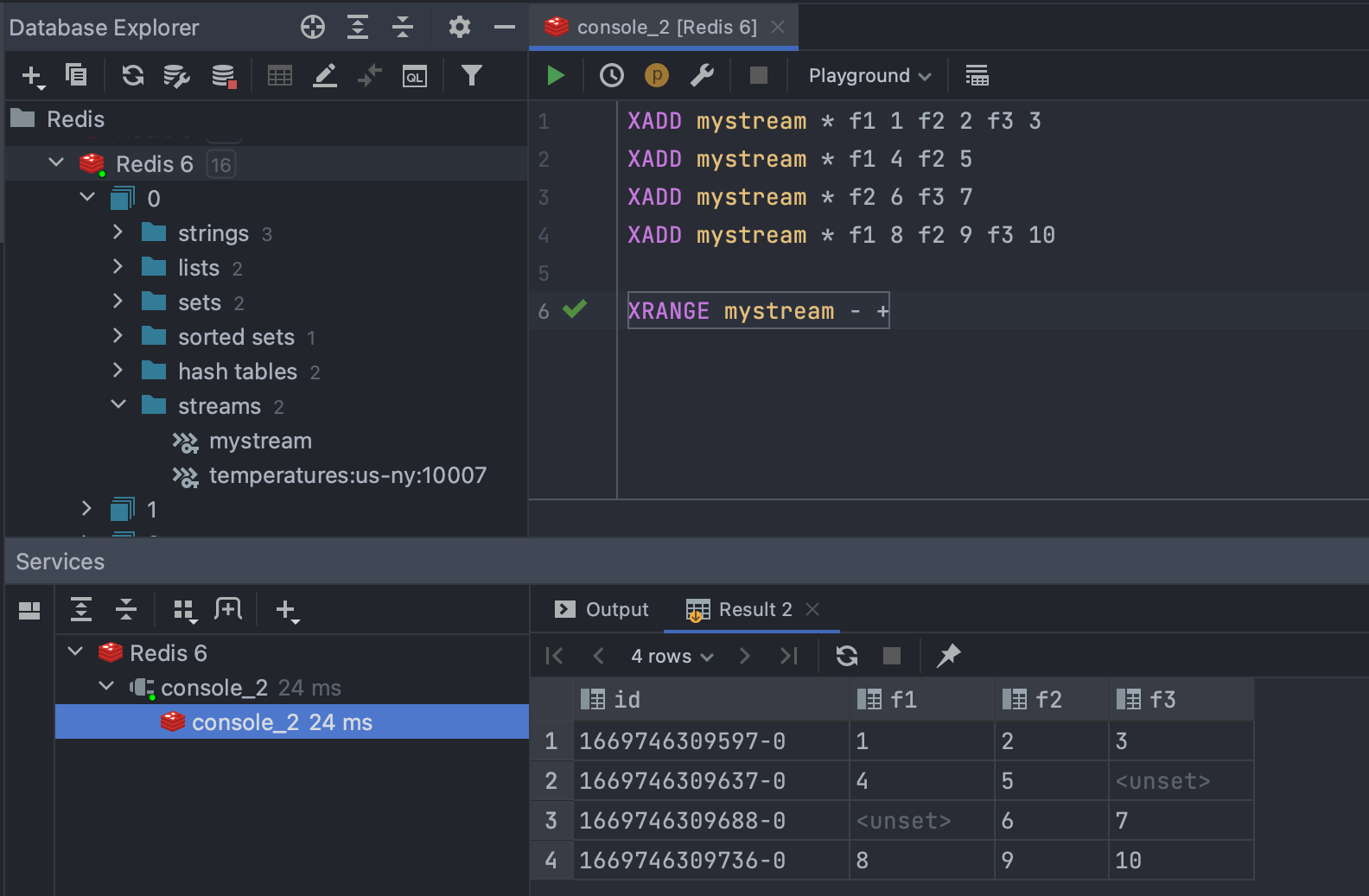
Redis Support
We’ve implemented long-awaited support for Redis. You can now connect to Redis Single Instance, explore key values in the Data Viewer, write and execute Redis queries with the help of our smart coding assistance, and more.
Here’s a quick overview of what it is included:
- Connectivity: Redis Single Instance.
- Introspection: Introspection of databases and keys, including the ability to set a default key filter for the introspector.
- Database Explorer: Separate folders for keys of different types for Redis v6.0+, and one folder with all keys for older versions.
- Query Execution: The JDBC driver supports the execution of the majority of queries.
- Coding assistance: Code highlighting, keyword completion, and resolution for databases and keys.
- Object Editor: Renaming and deleting keys.
- Data Viewer: Filtering and JSON highlighting.
For more details please read our blog post.
New UI available via settings
This May, we announced a closed preview program for the new UI for IntelliJ-based IDEs. DataGrip is no exception!
With this first step, we aimed to introduce the reworked look and feel of our products to a limited number of users. The preview program helped us accumulate and process a lot of insightful feedback, and now we’re ready to invite everyone to try out the new UI.
You can switch to the new UI in Settings / Preferences | Appearance & Behavior | New UI Preview, take it for a test drive, and share your thoughts with us.
We are still in the process of making the new UI more useful for DataGrip. For instance, creating a Run Configuration, which is crucial for other IDEs, may not be the number one action to use a bright blue button for. If you have any ideas about customizing the top toolbar, please share them with us.
New Settings Sync solution
In this release, we’ve introduced a reworked solution to synchronize your IDE settings. It is implemented via a plugin that is bundled by default. The new Settings Sync option will appear in the settings:
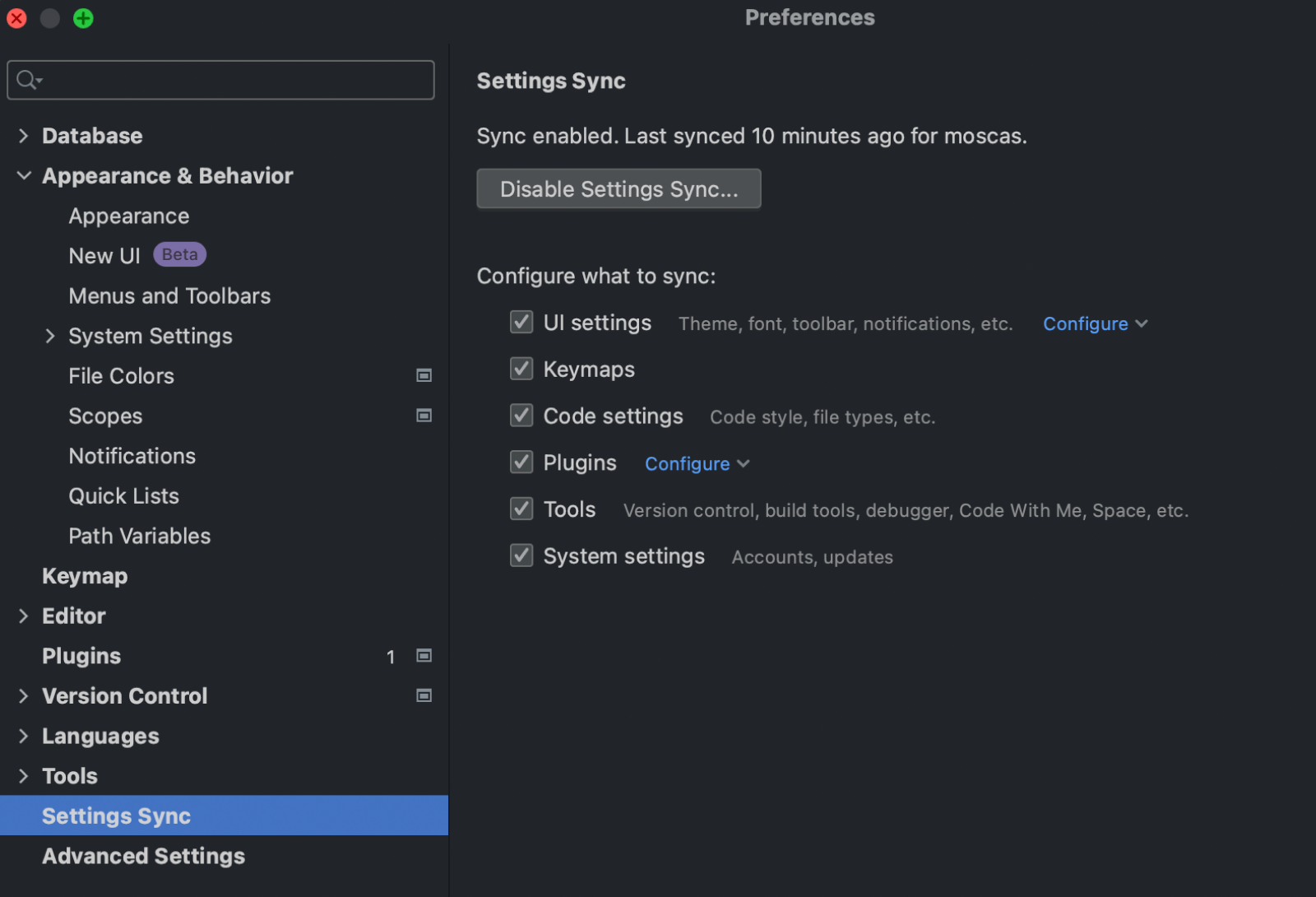
Before, we had two independent plugins for settings synchronization: IDE Settings Sync and Settings Repository.
If you have been using IDE Settings Sync, your data will be automatically migrated to the new plugin, so you won’t need to take any action.
If you are a Settings Repository user, we advise you to continue using your current setup, as the migration is still a work in progress. You’ll get an in-IDE notification when the functionality is ready.
The settings are stored in the cloud attached to your JetBrains Account. If you use different IntelliJ-based IDEs with the same JetBrains Account, your settings will automatically sync.
Known issue: The Database section of the Settings cannot currently be synchronized. This functionality will be made available soon in one of the minor updates to 2022.3.
Please note that the data sources are not part of the settings. If you want to share the data sources, please follow this tutorial.
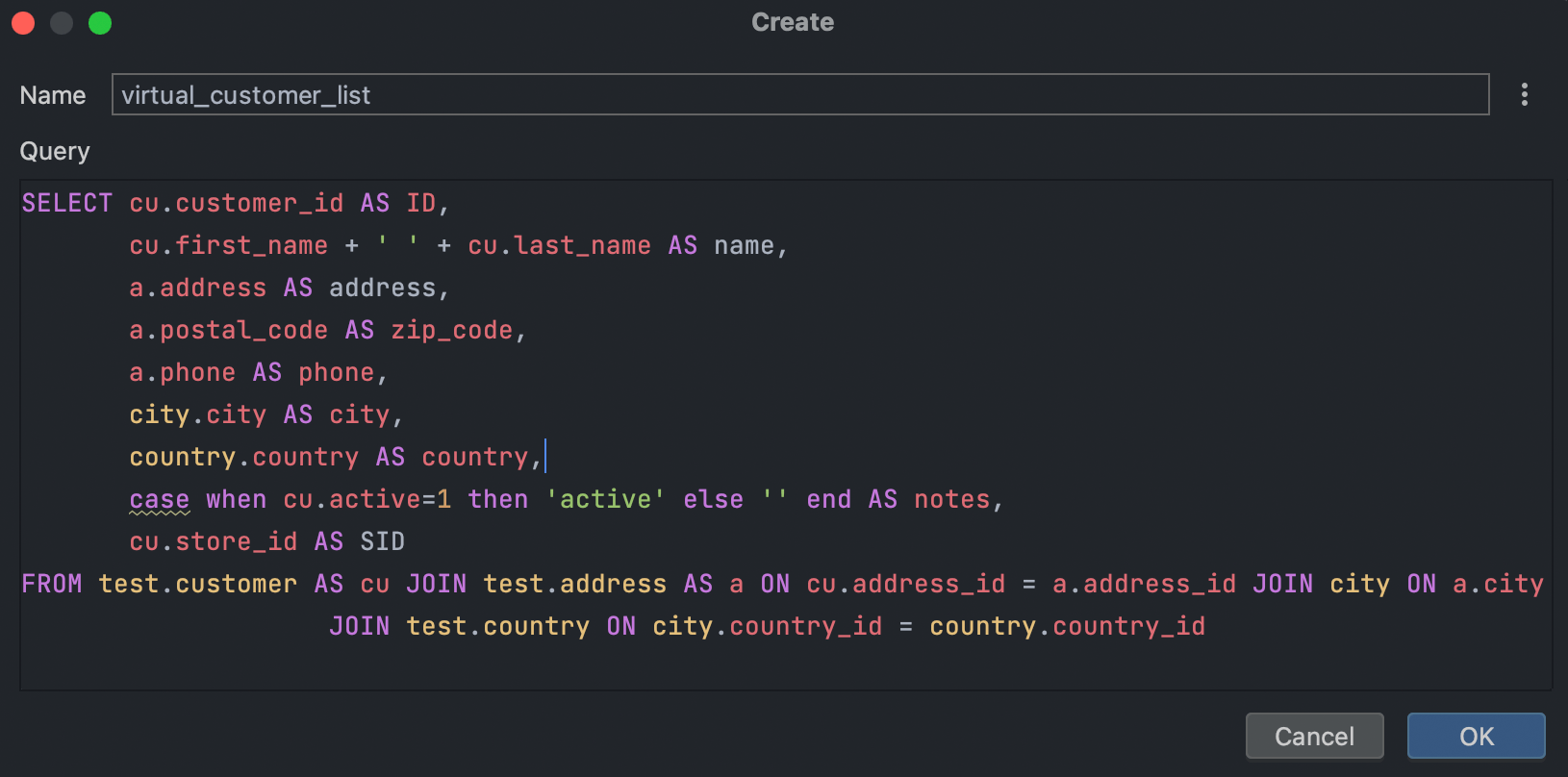
Virtual views
This new concept is virtual and lets you use views without actually creating them in your database. Basically, it’s just a query that retrieves the result and is stored inside DataGrip.
Virtual views are visible in the database explorer and can be run with a double-click.
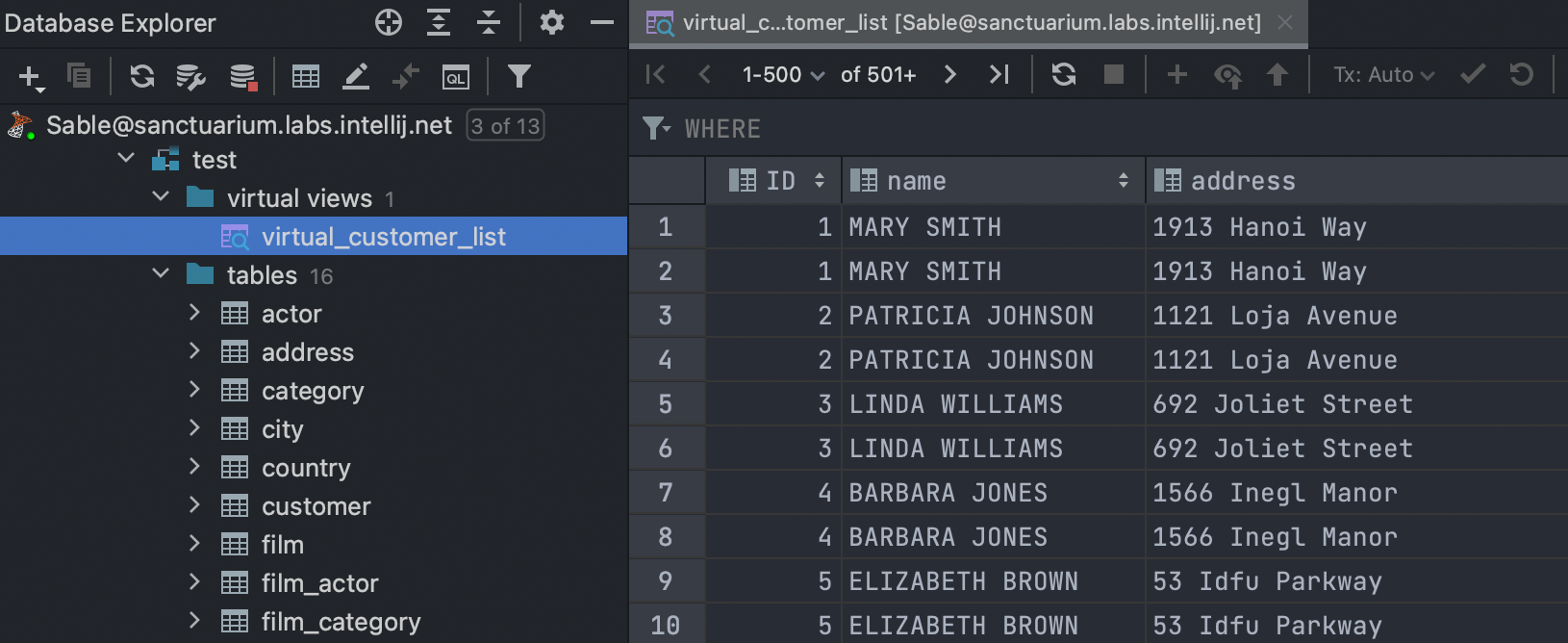
Please note that using virtual views in your SQL code is not currently possible.
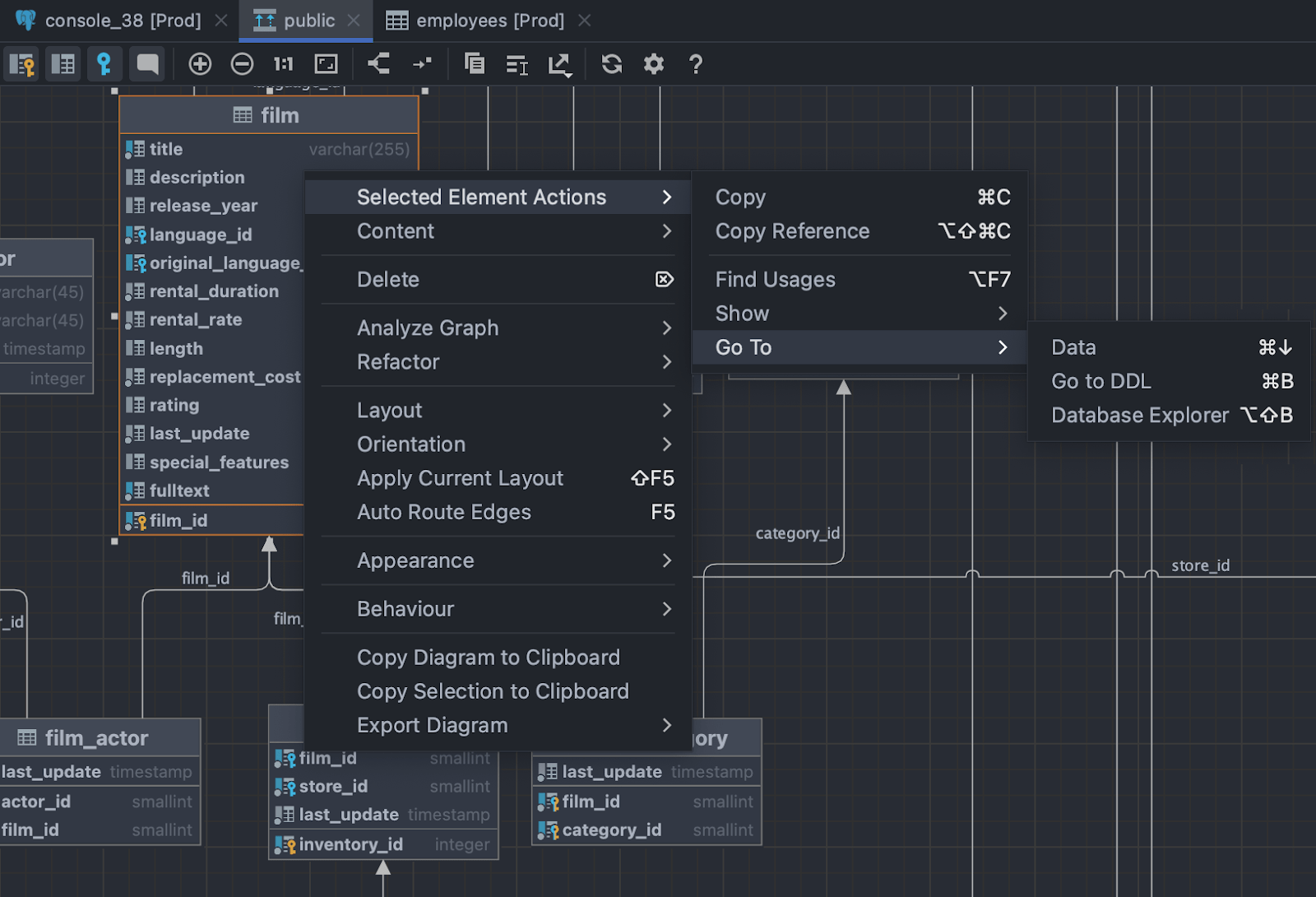
Navigation in diagrams
Diagram elements are now fully navigable. All major navigation actions can be performed there:
- Open DDL: Ctrl/Cmd+B
- Open data: F4
- Select in the database explorer: Alt/Opt+Shift+B
- Modify: Cmd/Ctrl+F6
Database explorer
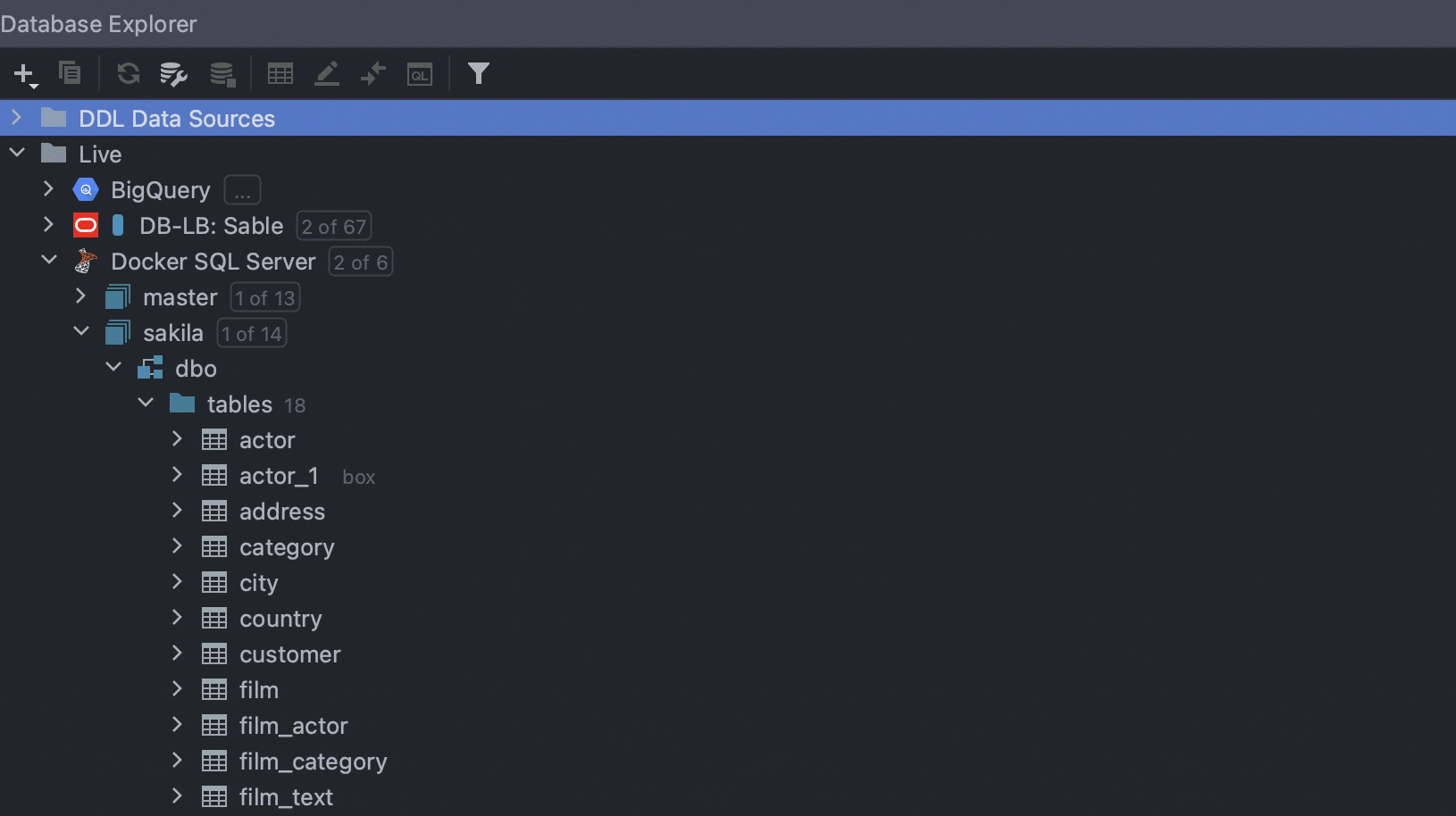
Quick filter
One more long-awaited feature is finally available! Now when using quick search, you also have the ability to filter objects. All non-matching objects will be hidden.
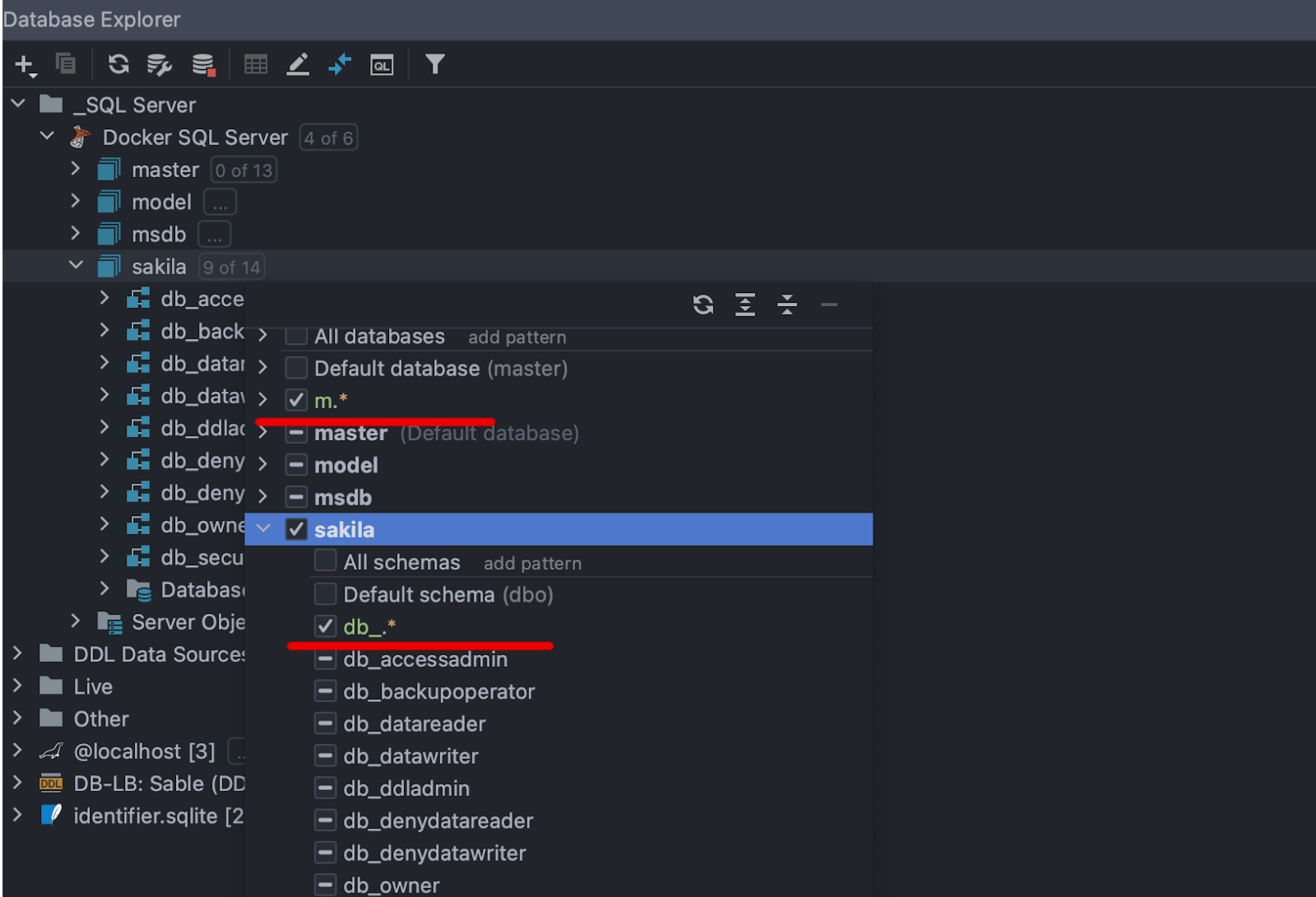
Pattern-based schema filtering
If you have lots of different schemas, you’ll appreciate this enhancement. It’s now possible to choose databases or schemas for introspection based on regular expression patterns. To do so, click on Add Pattern and define a regular expression pattern in the new node. The databases/schemas will be chosen according to that pattern.
Adding multiple patterns will combine multiplicities, not create an intersection of them.
The All node now behaves differently from previous versions: It doesn’t select the default schema automatically. You now need to choose between All schemas, Default schema, or applying a regexp filter.
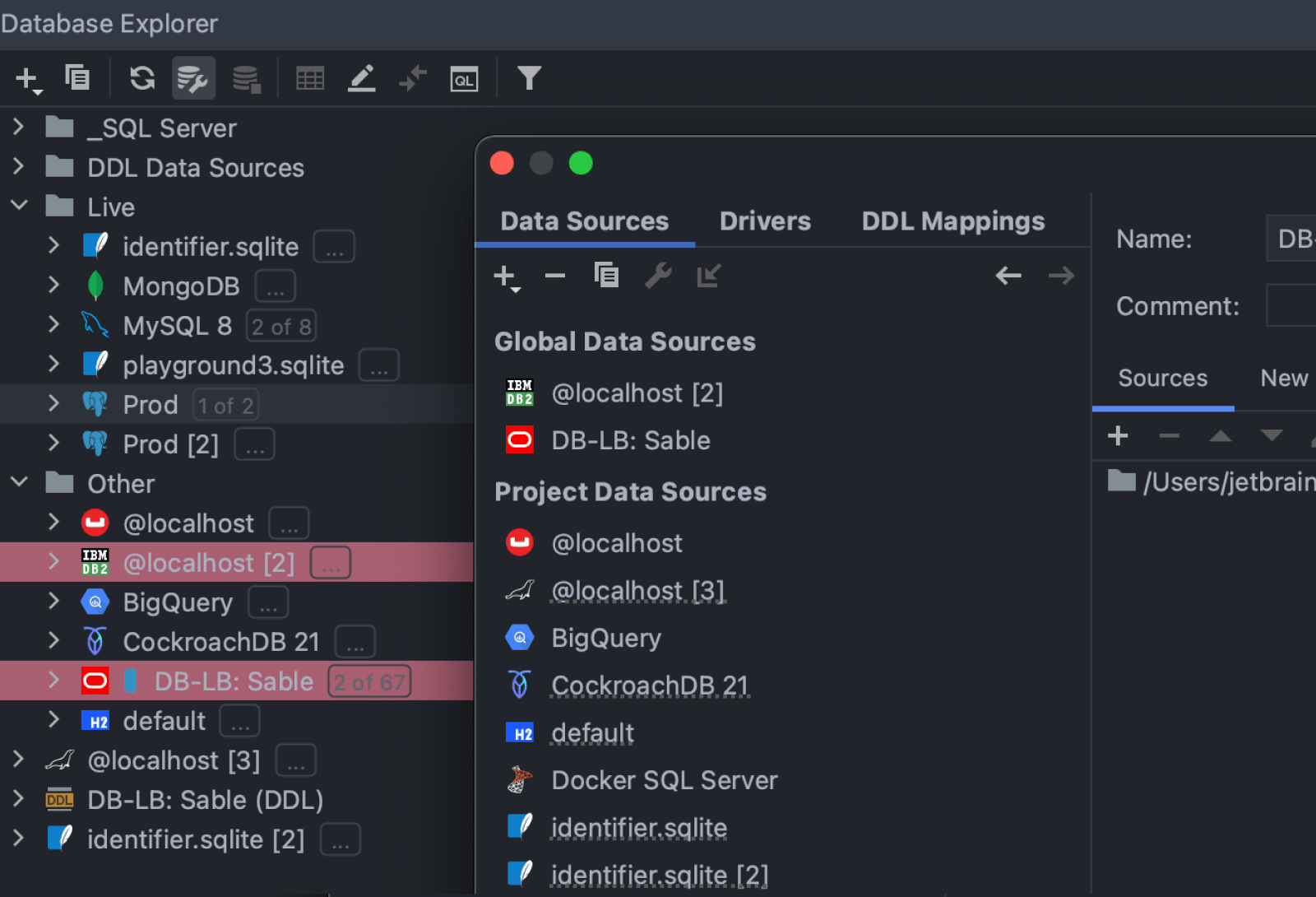
Colors for global data sources
Now when you set the color for the global data source, it is shared along with its data source.
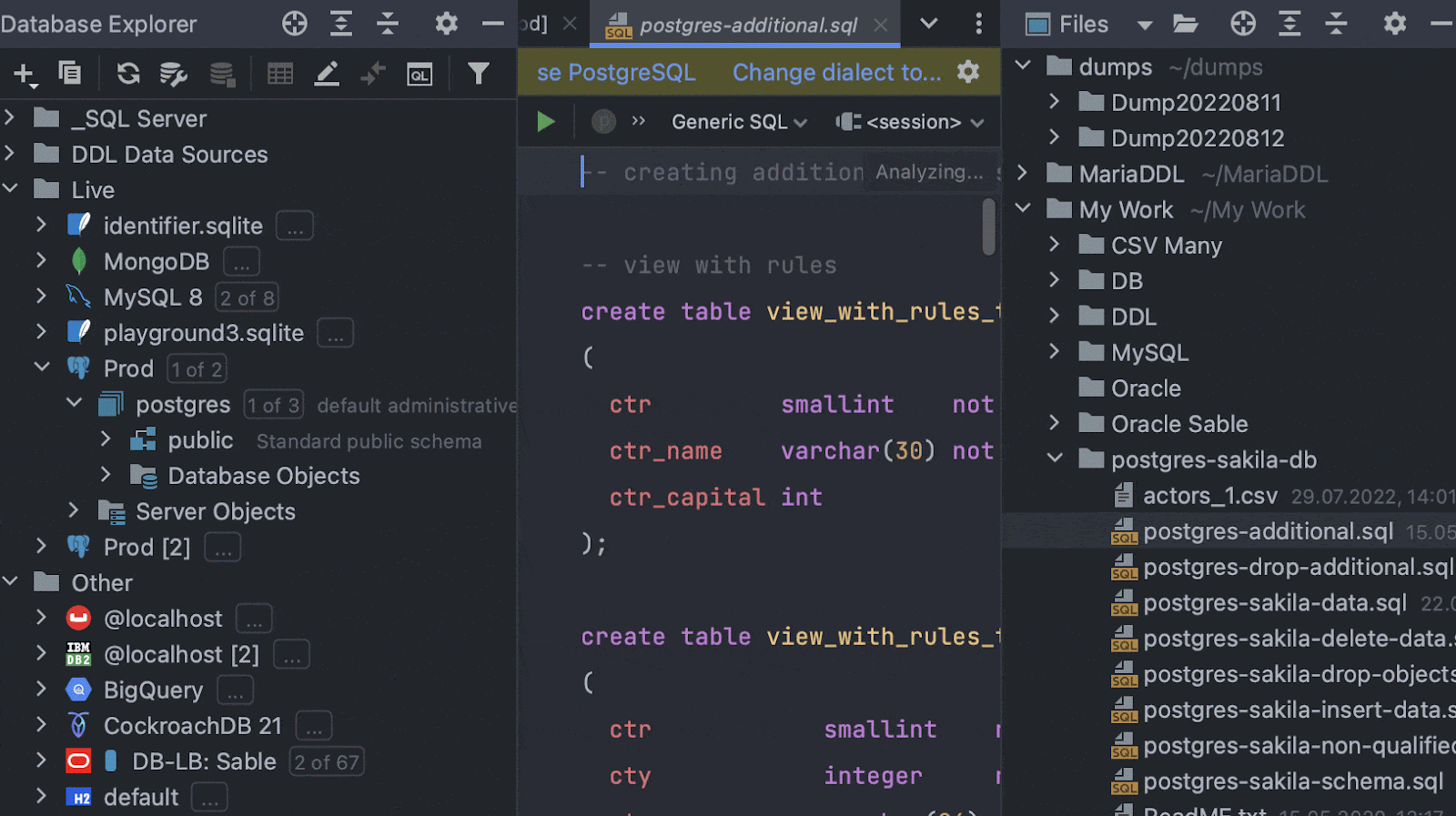
Drag and drop for script files
To run a script against any schema, you can now just drag and drop your script file from the Files tool window.
Data editor
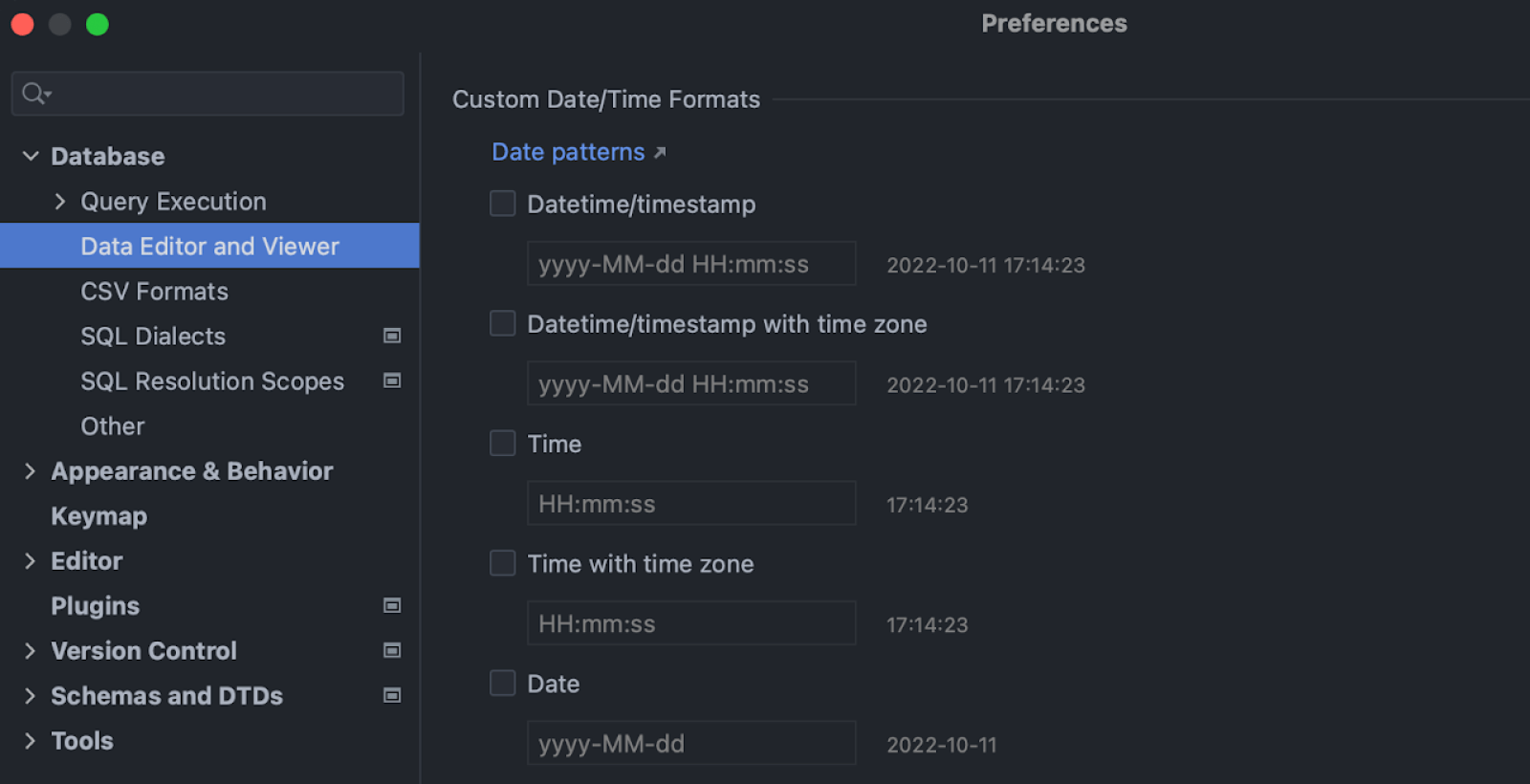
Formats for date and time data types
It’s now possible to customize how fields of date and time types will be displayed in the data editor. The settings are located in Database | Data Editor and Viewer.
This is now available for three types of fields:
Datetime/timestamp (with or without timezone), Time (with or without
timezone), and Date.
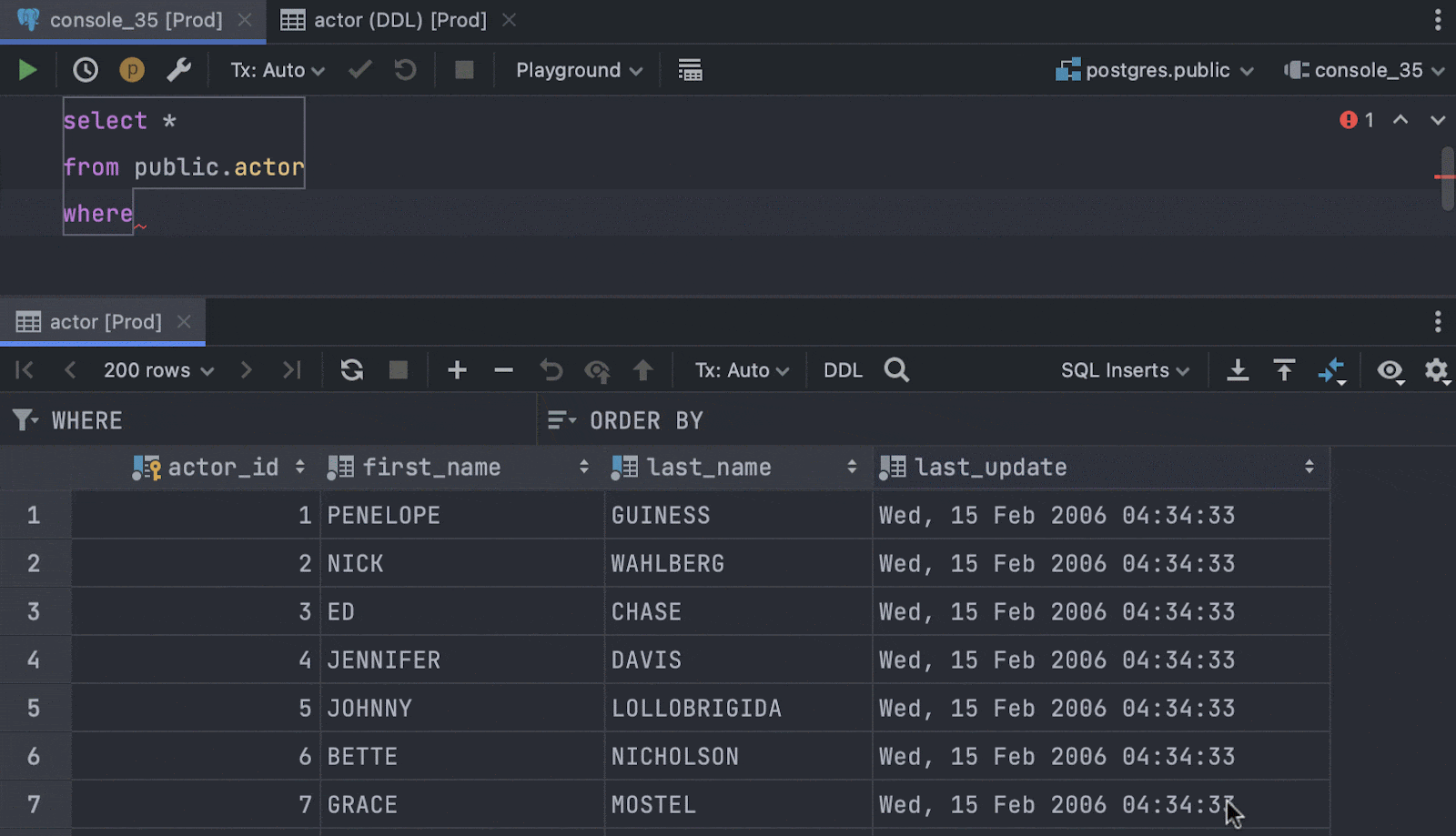
New extractor: WHERE clause
A selected range of values can be now extracted as part of the WHERE clause:
-
Values within one column are combined with the
ORoperator. -
Values within one row are combined with the
ANDoperator. -
If values of only one column are extracted, they are combined into an
INoperator.
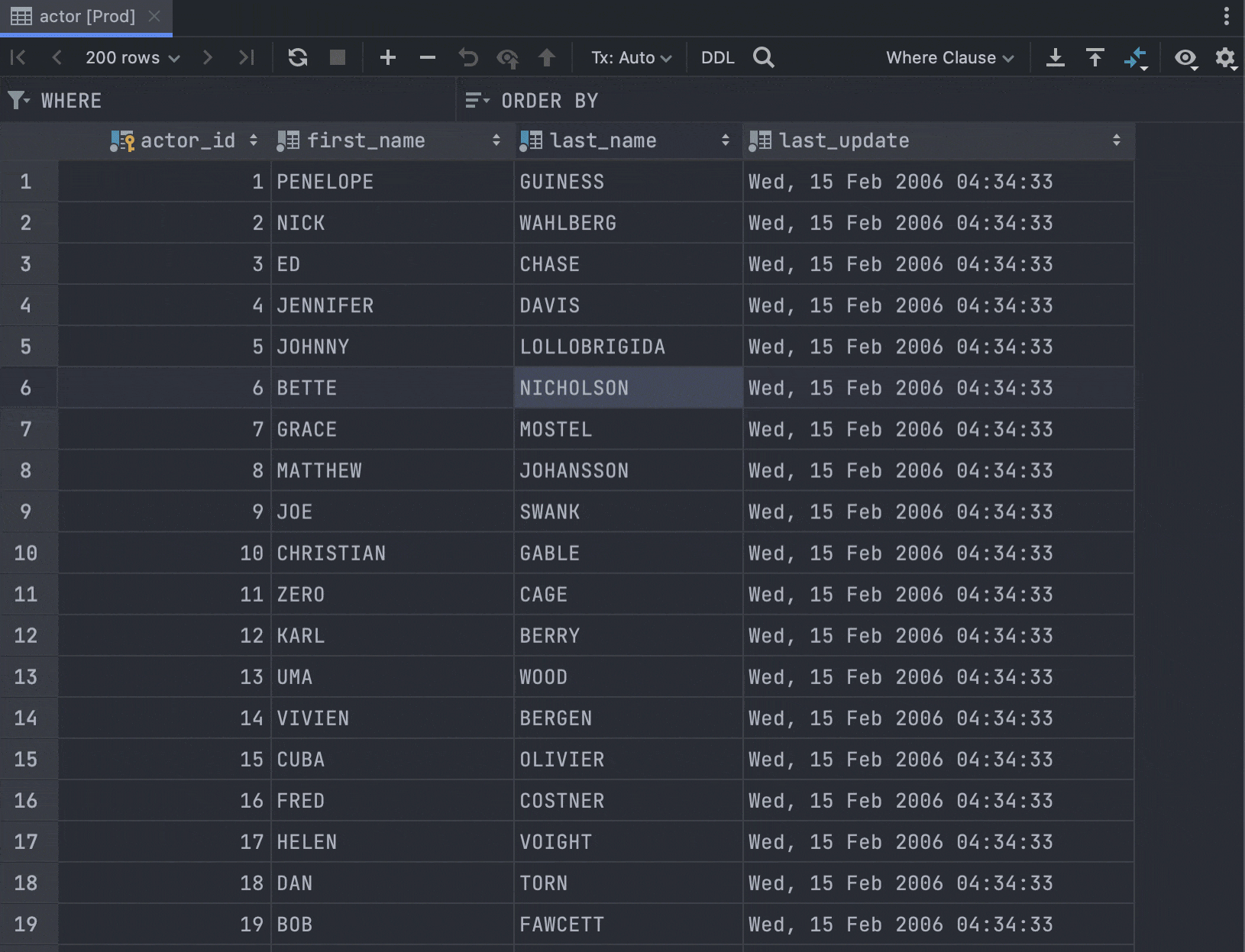
SQL filtering by multiple values
The Filter by action now generates a condition if you select several values.
Text search field: populate with selection
If you press Ctrl/Cmd+F for text search, the search fields will be automatically populated with the value under the cursor. This is similar to the well-known logic of the text editor.
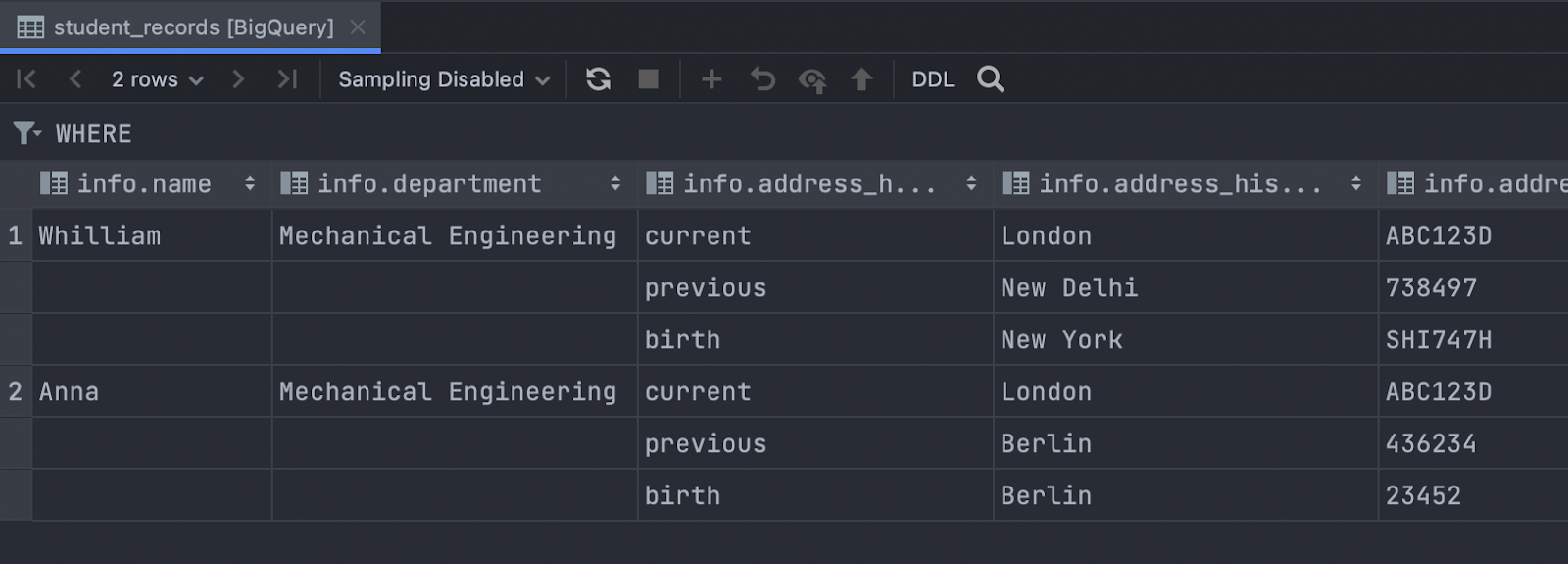
Struct values are displayed correctly Big Query
Struct values are now displayed in a readable way: Each nested value is displayed as a separate column.
Working with code
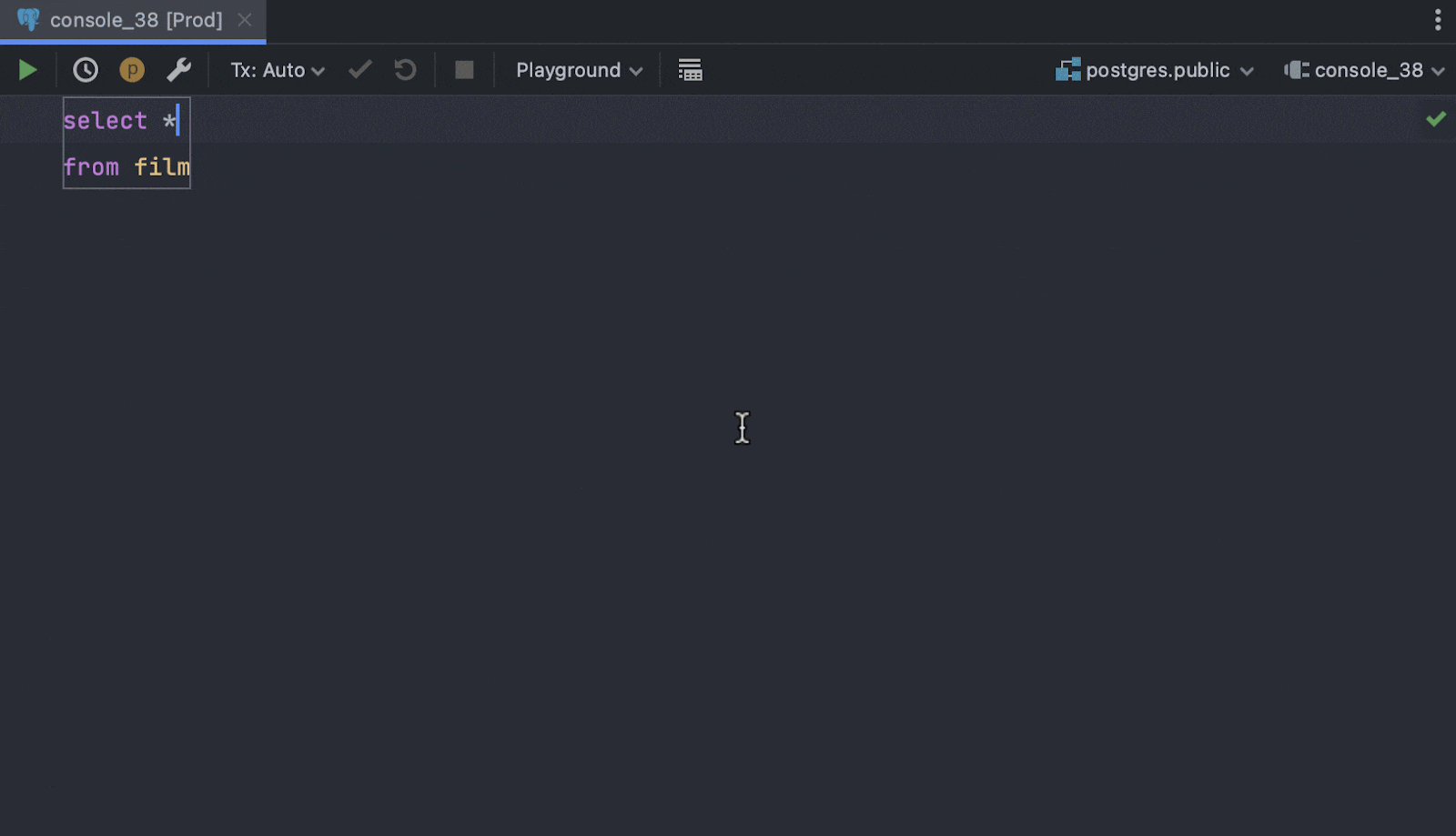
Intention action preview
Now you can instantly see how your query will be altered once you apply the IDE’s
suggestions. The preview appears when you open the list of available intention
actions and hover over an option.
You can disable the preview feature by pressing
F1/Ctrl+Q while the list of intention actions is open.
Single line copy-paste
If there is no selection, pressing Ctrl/Cmd+C automatically selects and copies the entire line in the text editor. It worked like this before, but now we have completely rounded out this action by making it easier to paste the line as well. This copied line will be pasted as a new line with a carriage return if there is no selection, as shown in this video:
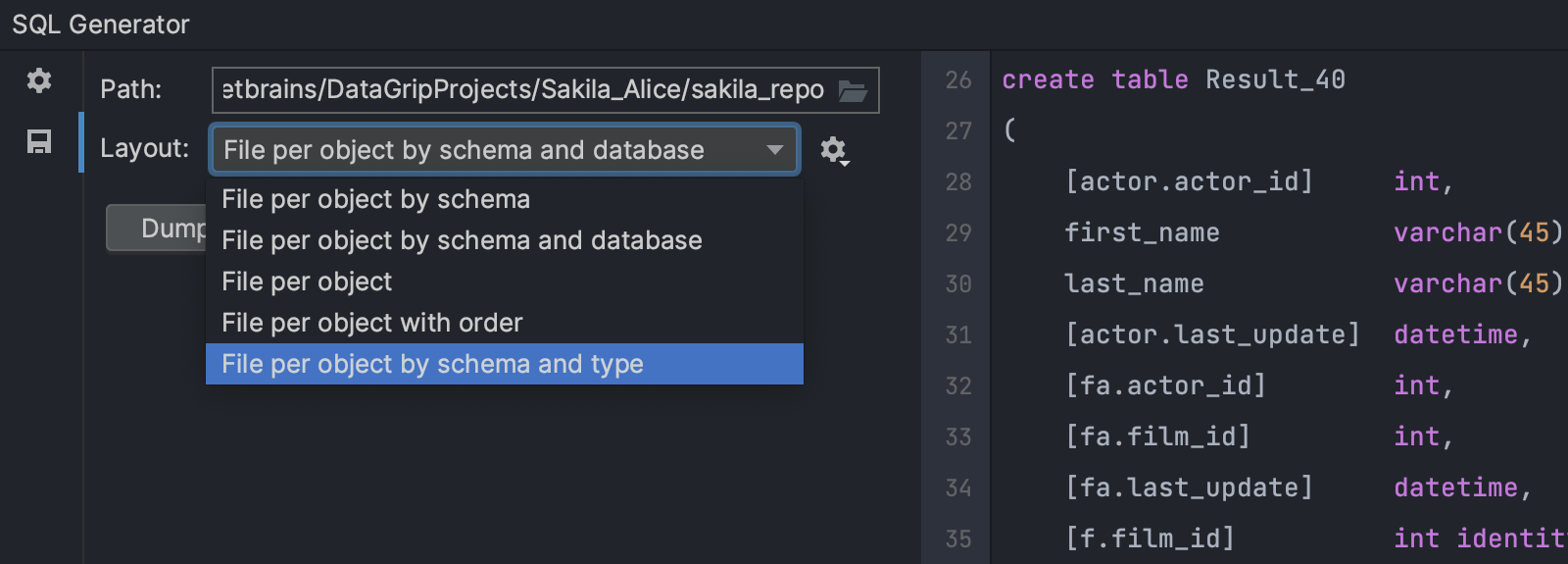
New layout for the SQL schema generator: Per Object By Schema and Type
The new layout is called Per Object By Schema and Type. If it’s used for generating SQL for the whole schema, the resulting files will be placed in folders according to the object’s type: tables, views, etc.
Working with tables
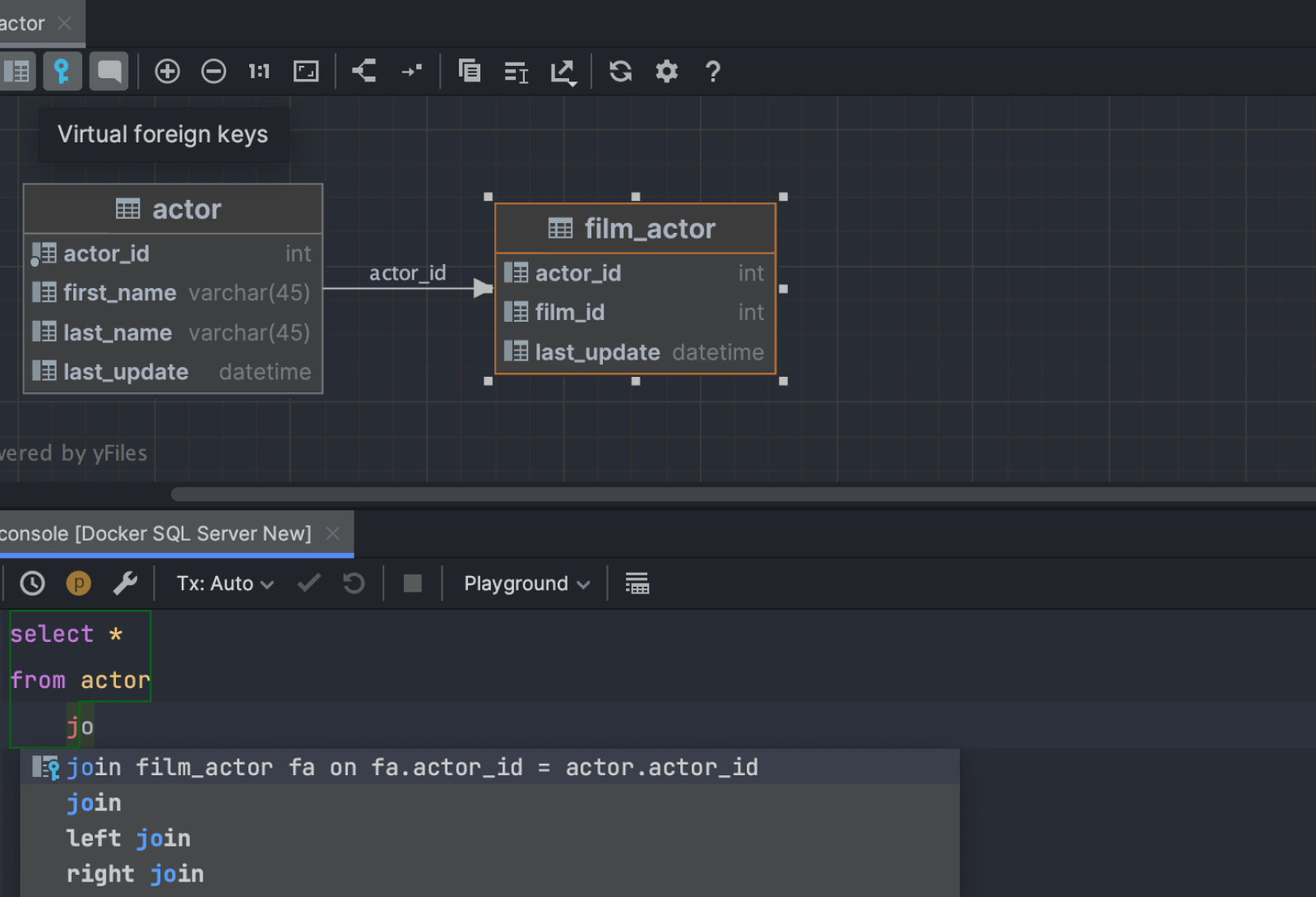
UI for virtual foreign keys
The ability to create virtual foreign keys was introduced a while ago. They are mainly used for:
-
JOINclause code completion. - Showing virtual relationships in the diagrams.
- Navigation by data relationships in the data editor.
The main way to create them was by using the Store Relation intention action
at the JOIN clause in your query. This was a little tricky to find, and
the whole functionality lacked an intuitive way to use it. Here’s what we’ve changed.
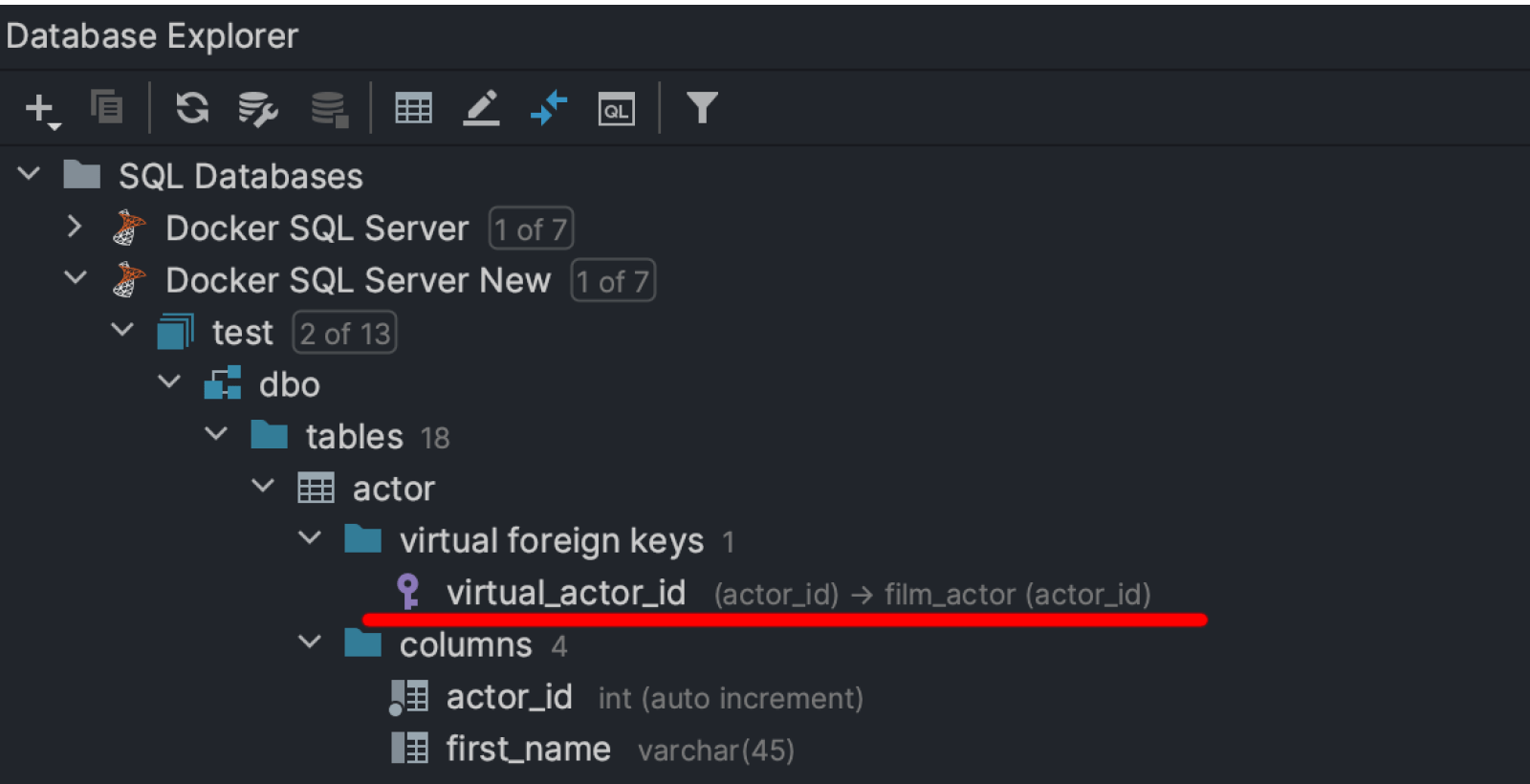
Virtual foreign keys are now visible in the database explorer:
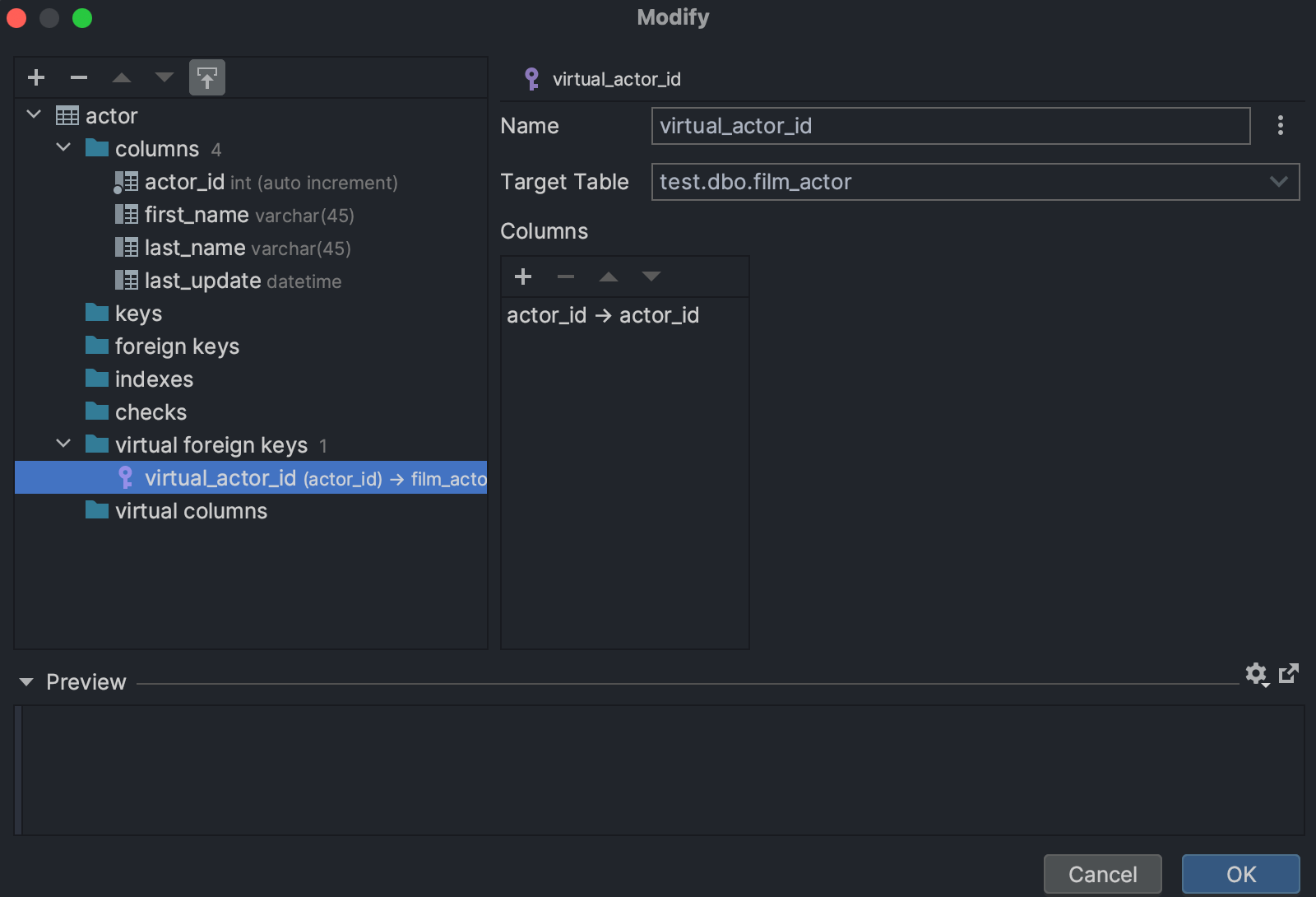
You can create and drop them here, in the database explorer, and in the Modify Table dialog.
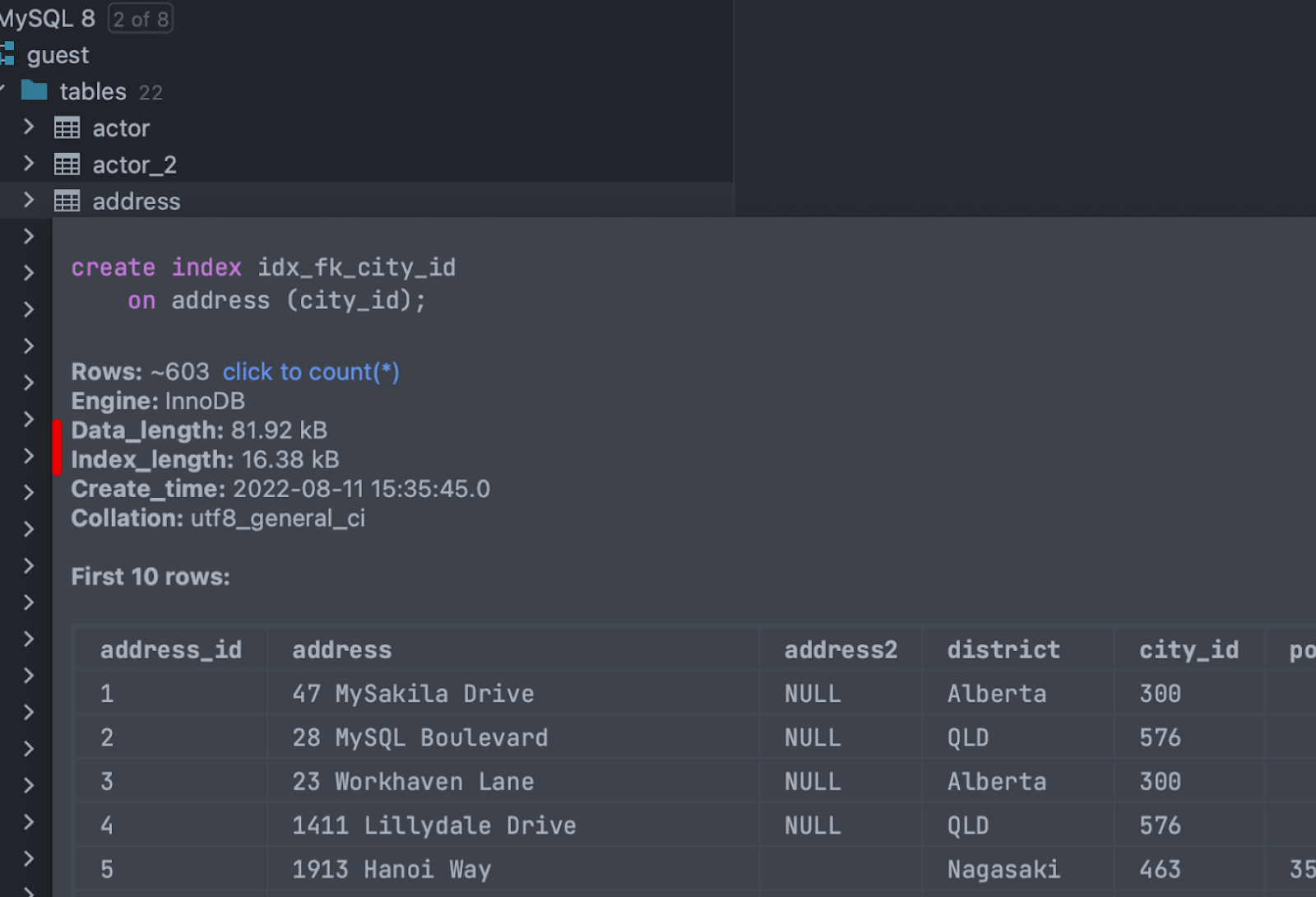
Table size in quick documentation MySQL PostgreSQL
The size of the table is now displayed in the quick documentation popup for MySQL and PostgreSQL. To see it, click on Show table preview.
Connectivity
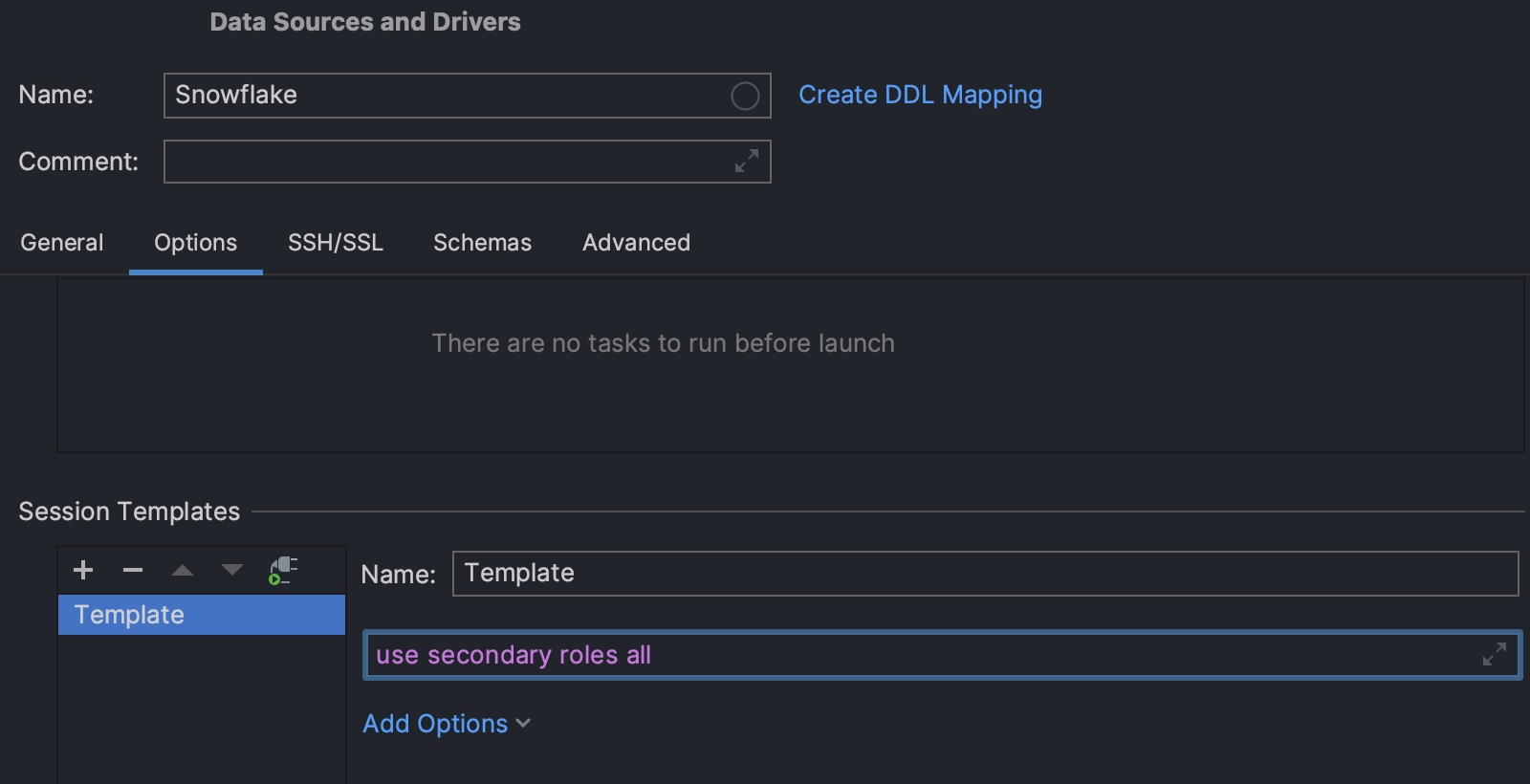
Startup script for session templates
It’s now possible to set the startup script for the session templates. This means
that the script will be run each time a new session is created based on the
corresponding template.
For example, it lets DataGrip run the
use secondary roles all statement for introspection in Snowflake.
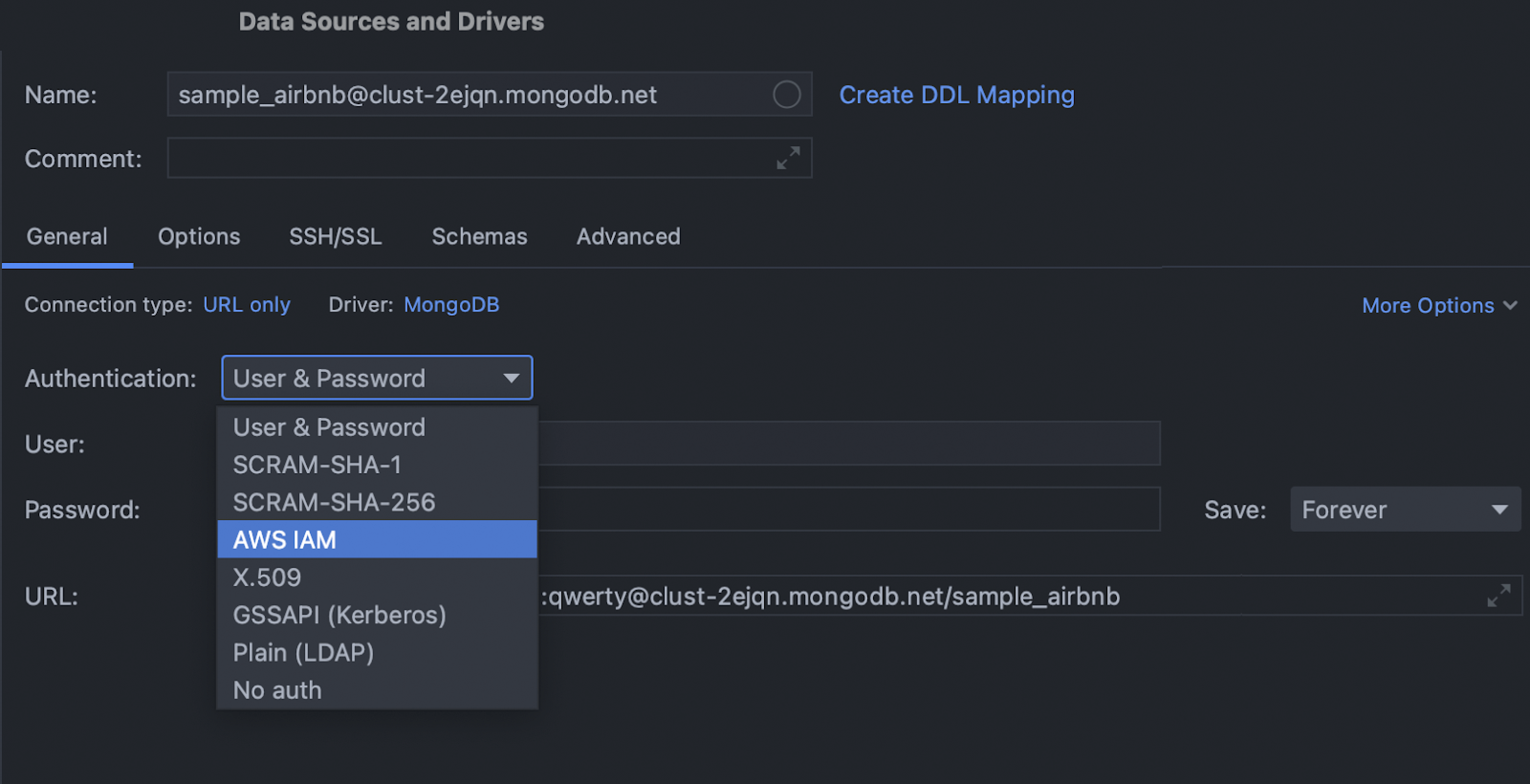
Authentication options MongoDB
We added many authentication mechanisms to the connection dialog for MongoDB. To use them, update your driver to version 1.16.
Schema diff viewer
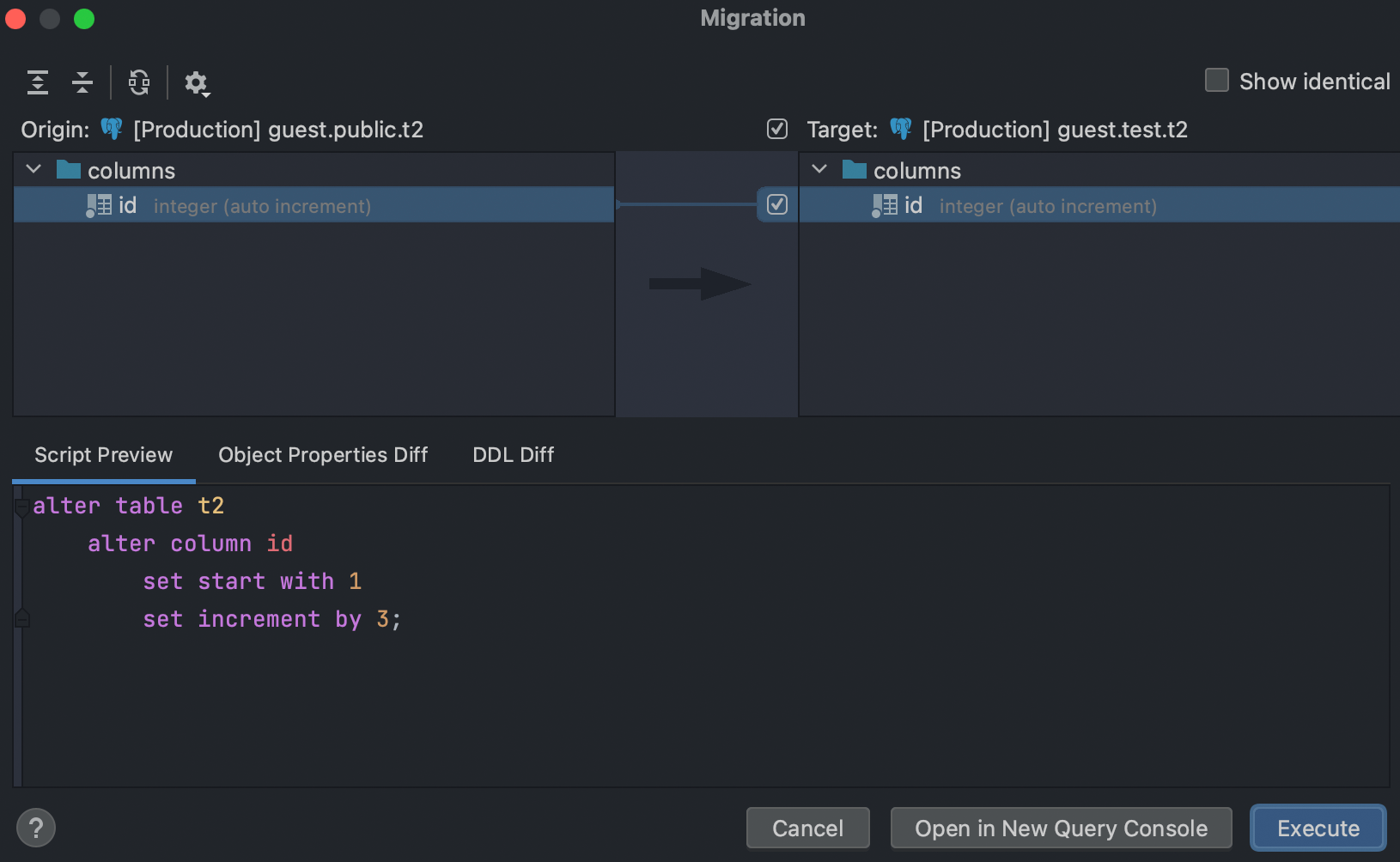
Support for object dependencies
The schema diff viewer now takes into account dependent objects. The most important such object is PostgreSQL identity columns. If the related sequences are different for two otherwise identical identity columns, then this difference will be displayed when these two columns are compared.
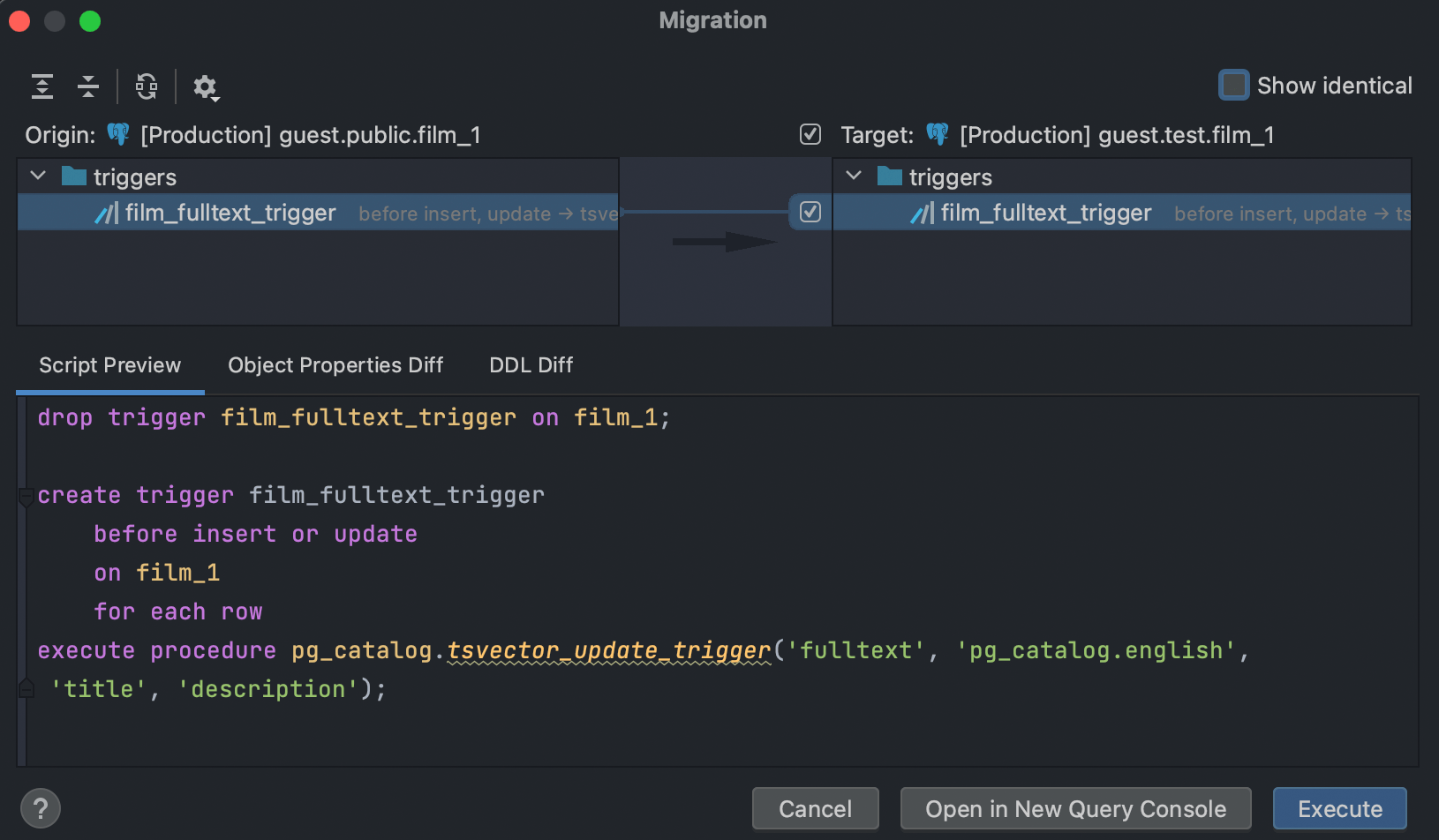
Another example would be a trigger calling a procedure from another schema. Now the difference between such triggers will be displayed if the routine names are different:
There are still two major known limitations we want to highlight about the schema diff viewer:
- DBE-16814: If a routine/view references some object from its body, the correct script order is not guaranteed. For instance, if a routine calls another routine, it is not guaranteed that the latter will be created before the first one.
- DBE-15598: In some cases, object qualification is not correct inside source object bodies, default expressions, etc.