What's New in DataGrip 2023.3
Data visualization
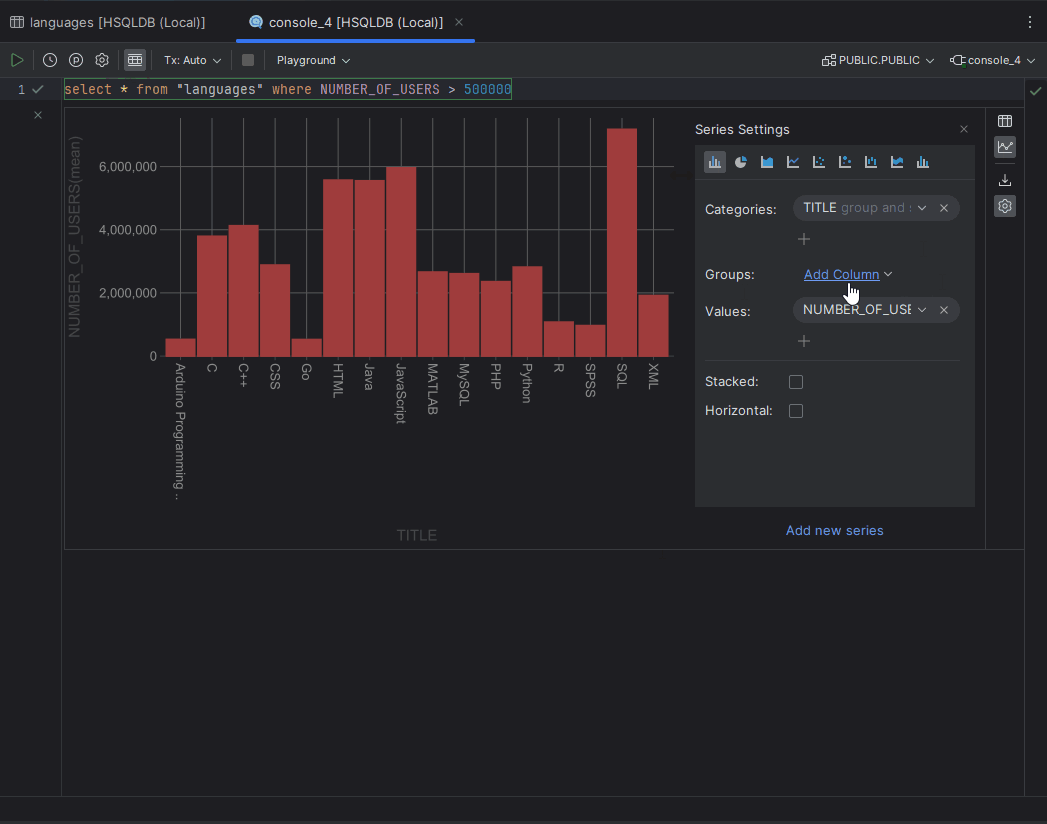
Since the release of DataGrip 2023.3, it's been possible to visualize data following our integration of the Lets-Plot library, with its basic no-code data visualization possibilities. The visualization is available on all three types of grids:
- Main tab: When you open the table, view, or CSV file, the plot is displayed in split mode.
- Result tab: When you observe the result of a query in the Services tool window, the plot can be displayed instead of the grid.
- In-editor results: You can display the plot instead of the grid.
Note there is a known issue: The settings for the visualization are not saved, which means that if you reopen the grid, the plot will be in its default state. For more information on data visualizations, please refer to our documentation. This feature is still under development, and we would like to hear your feedback! You can provide it by using the feedback form, creating an issue in our tracker, or writing directly to datagrip@jetbrains.com.
New import functionality
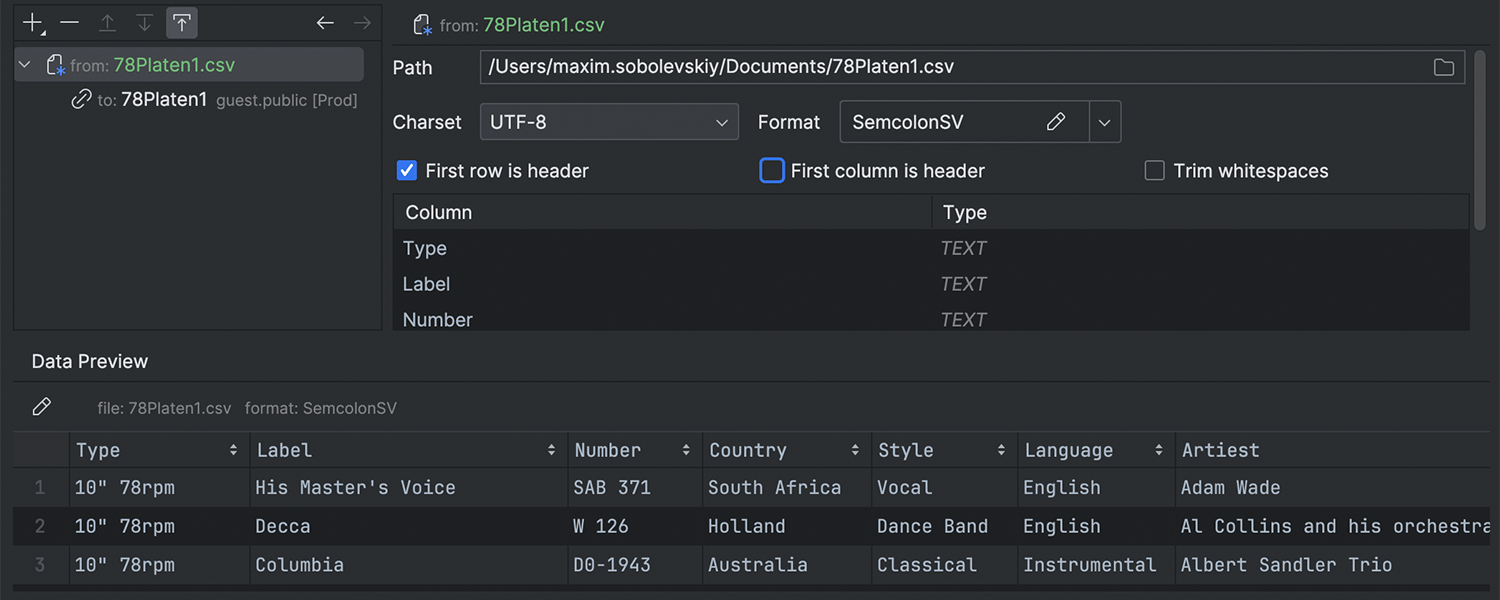
We have spent a significant amount of time reworking our import functionality, but we believe it was worth it for the following reasons:
- It was the last chapter in the big transition to our generated Modify Object UI, which is described in detail here.
- The feature now lets you import to several targets.
- It is now possible to edit multiple things at the same time. For example, you can change formats or encode for several files, changing the schema for several targets.
Some features to highlight:
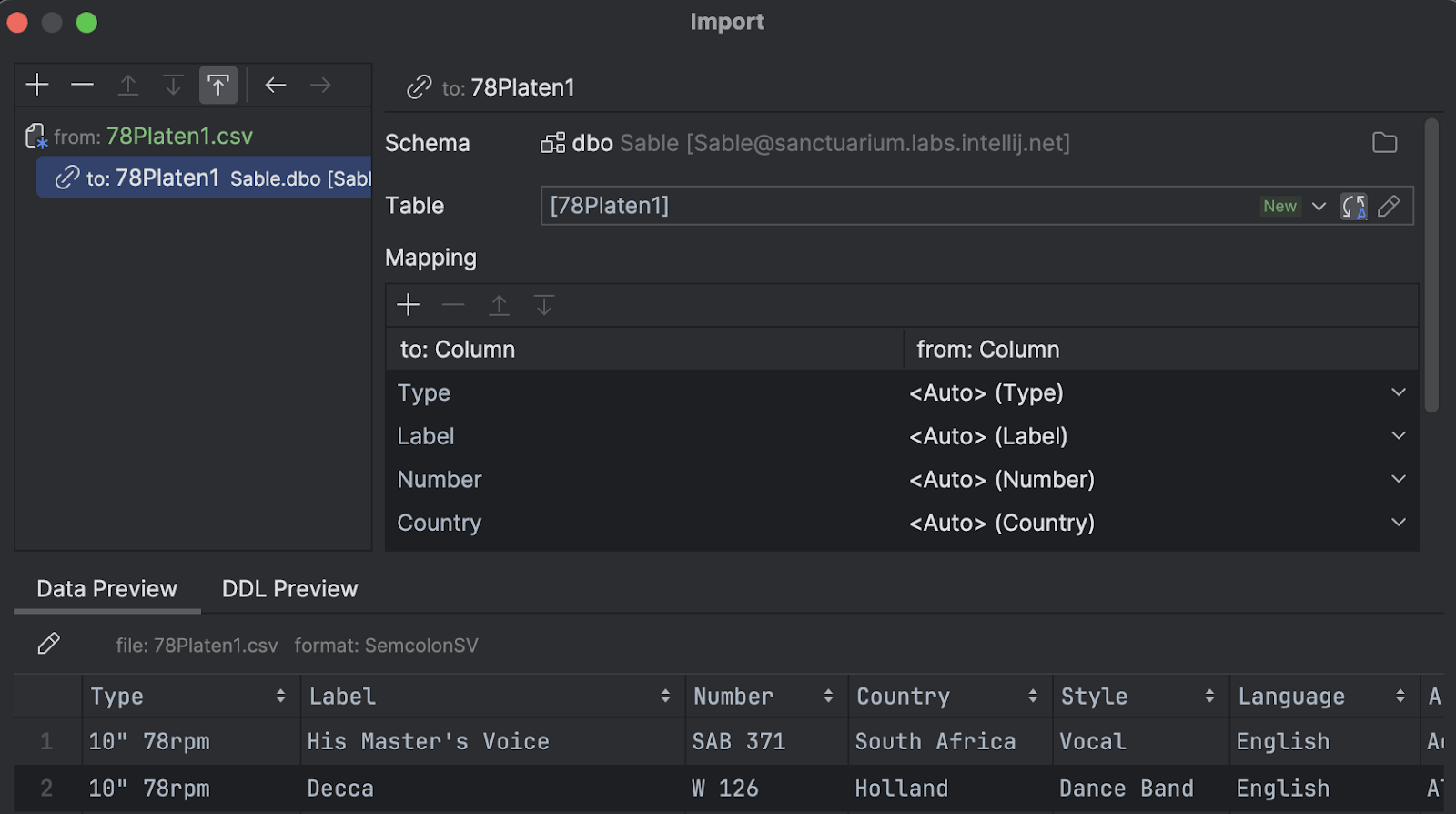
Mapping
The default target entity is called mapping. Here, you can define the target table and map the file columns with the columns of the target table. If you need to edit the table itself, click the Edit button:
The table will appear in the tree UI on the right. This UI completely repeats the Modify Object UI, letting you manipulate the table and its objects in various ways.
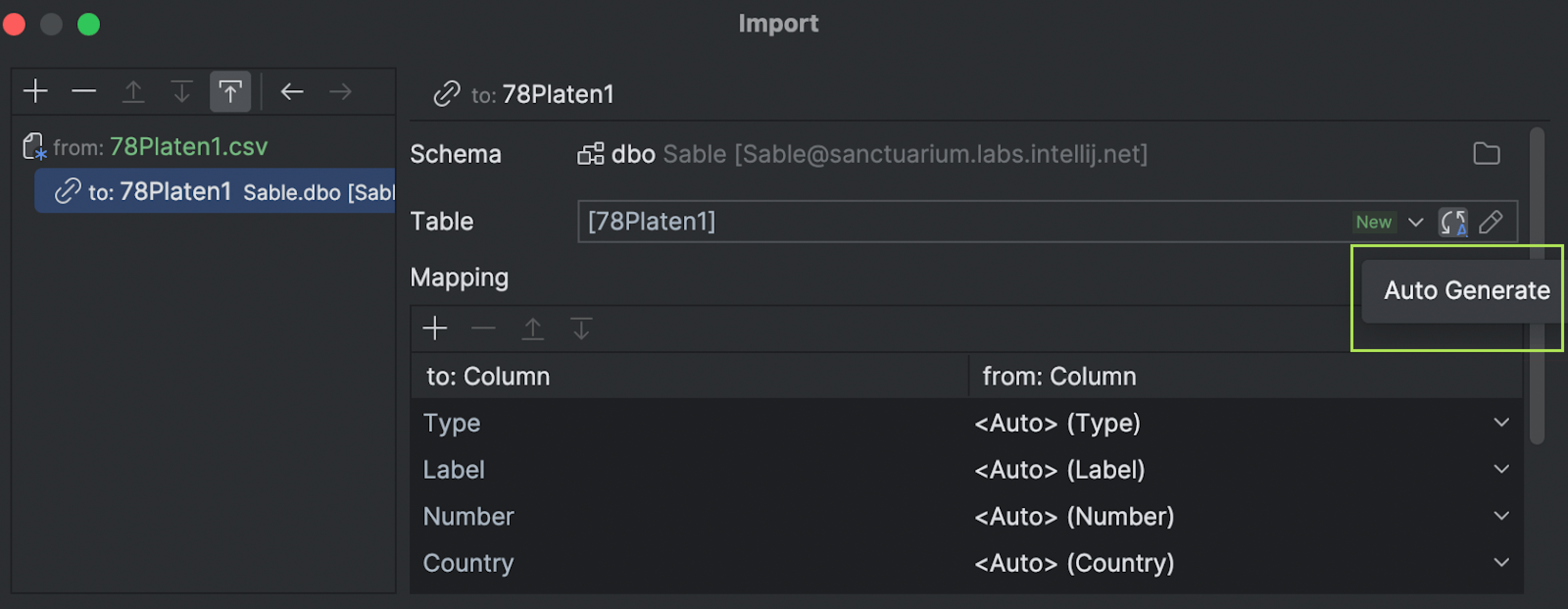
Auto-generate table names
This button automatically generates the table name from the source file. It can be useful if you rename a table but then want to revert to its default name.
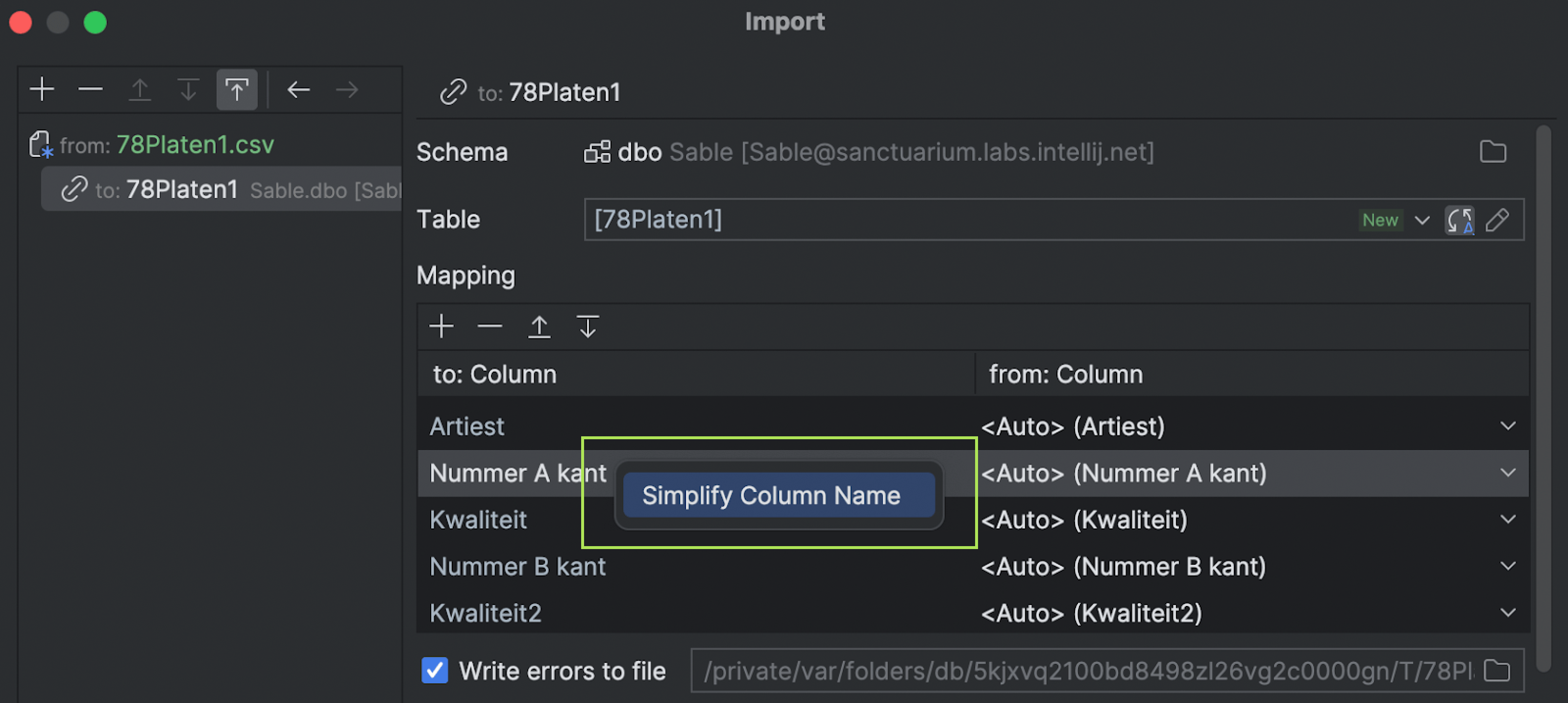
Simplify column name
This action can come in handy when the original column names contain spaces.
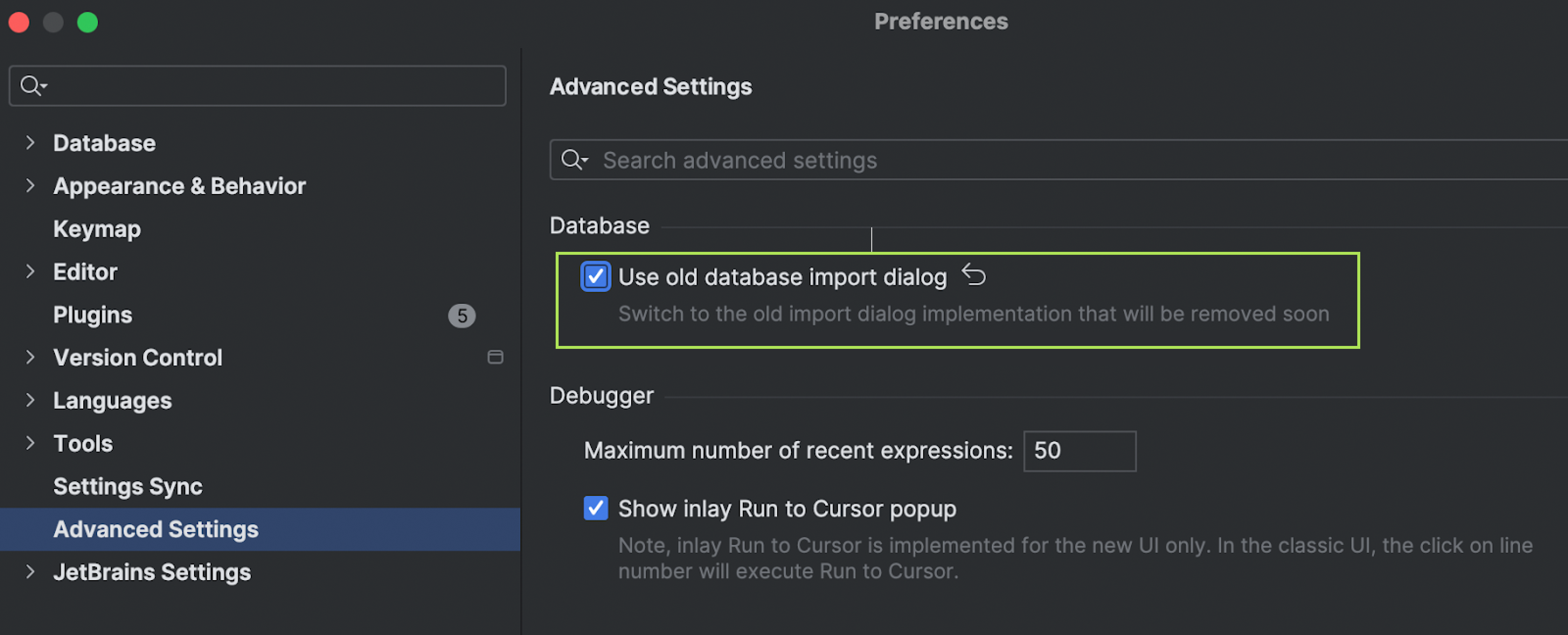
Ability to revert to the old UI
We understand that this rework is a huge change that may be inconvenient for some of our users. We would appreciate any feedback you can share with us to help us understand how we can improve the new UI, making it both more powerful and clearer for all use cases.
If, for any reason, you wish to revert to the old UI, you can use this option.
This option will be available until we process all the feedback we have received about the new UI.
Working with data
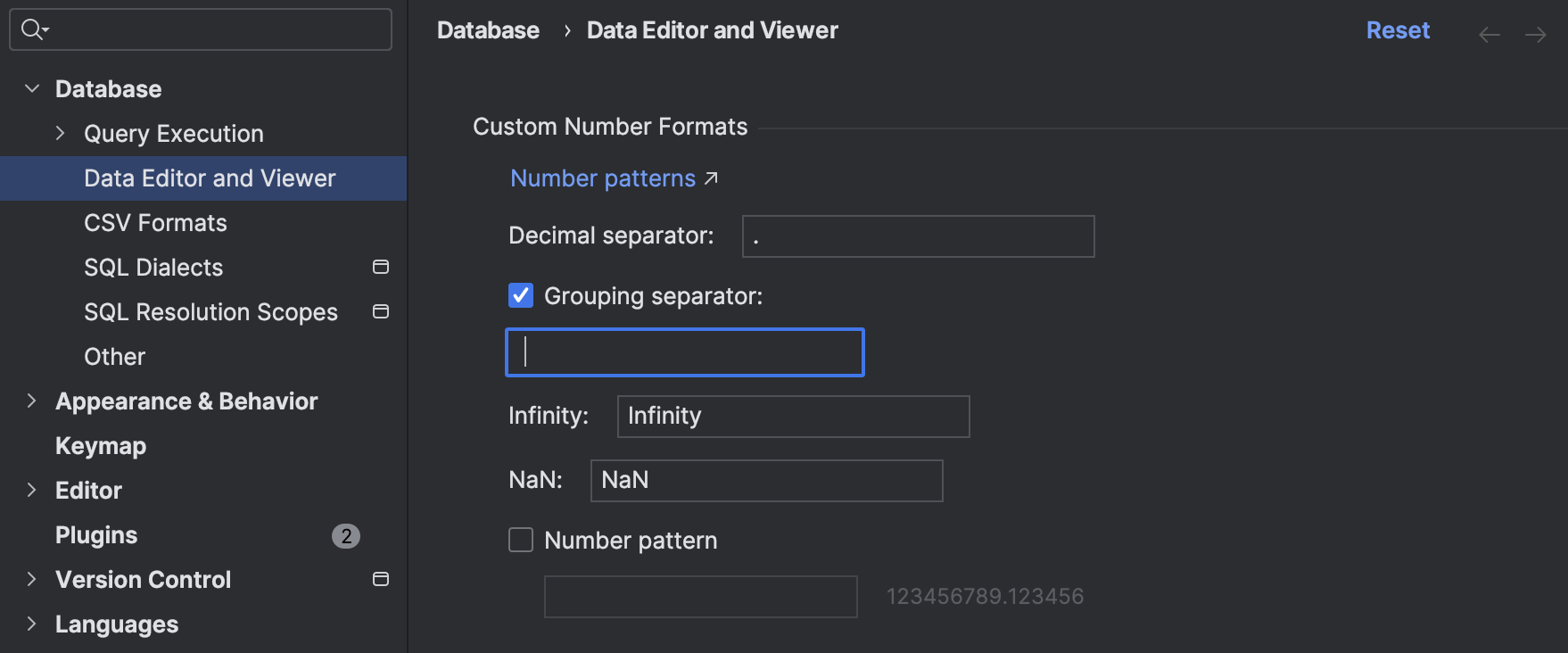
Customizable number formats in the data editor
There is now much greater flexibility in how you can see numbers in the data editor. Most significantly, you can specify decimal and grouping separators. Other options include the ability to define how infinity and NaN will be rendered.
Ability to render numbers as UNIX timestamps
In the UNIX timestamp format, timestamps are stored as numbers, expressing how many milliseconds have elapsed since January 1, 1970 (UTC). This format is now supported in DataGrip.
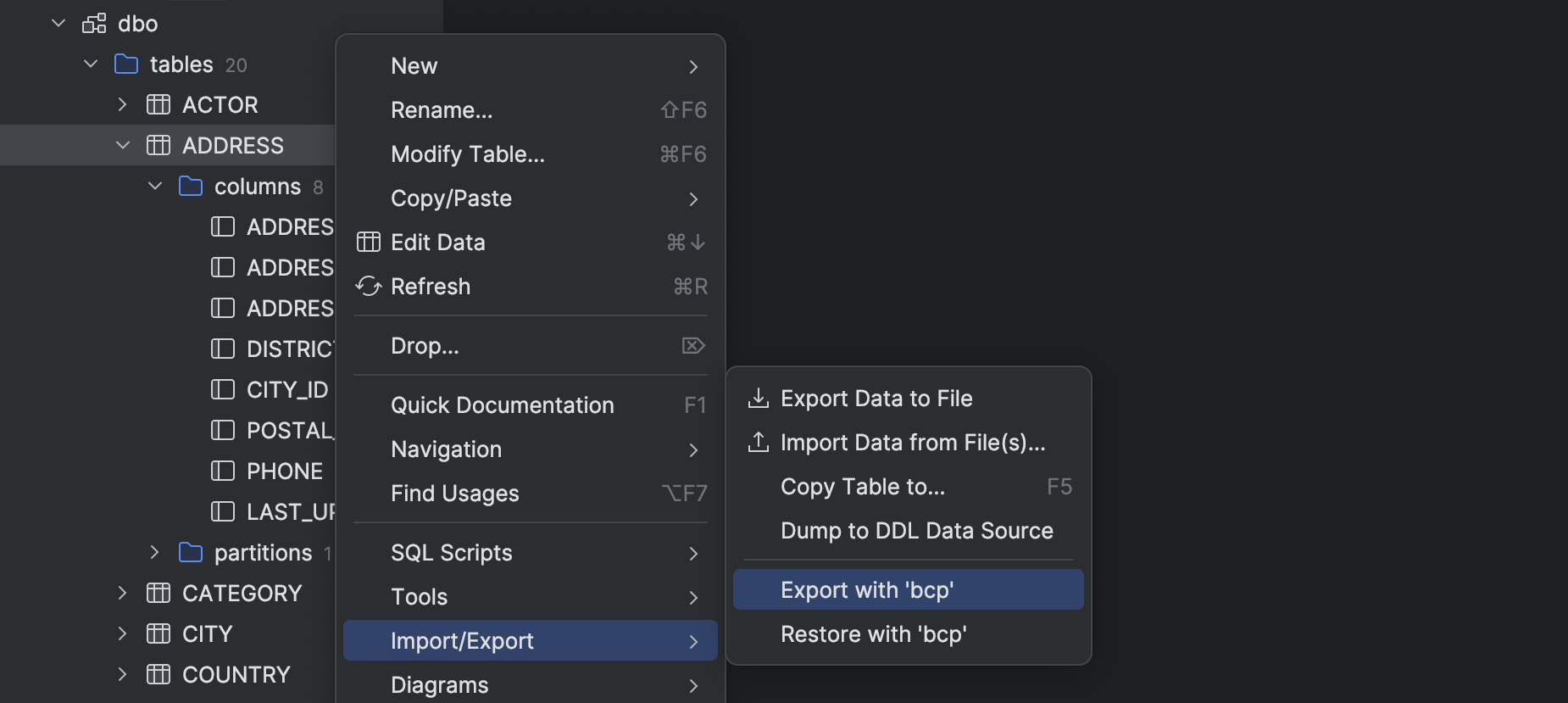
SQL Server Support for import/export tables via BCP
We've added support for the BCP tool, which lets you export and import tables in SQL Server.
DynamoDB support
We are pleased to announce that the 419 people who voted for this ticket didn't do so in vain. Support for DynamoDB is now coming to JetBrains IDEs!
Here’s what we have implemented so far:
- DynamoDB data can be viewed via DataGrip's data viewer.
- PartiQL for DynamoDB support in the code editor.
- Tables with keys and indexes are now introspected.
If there's anything else that you think needs to be supported as a priority, please comment on this YouTrack issue.
Introspection
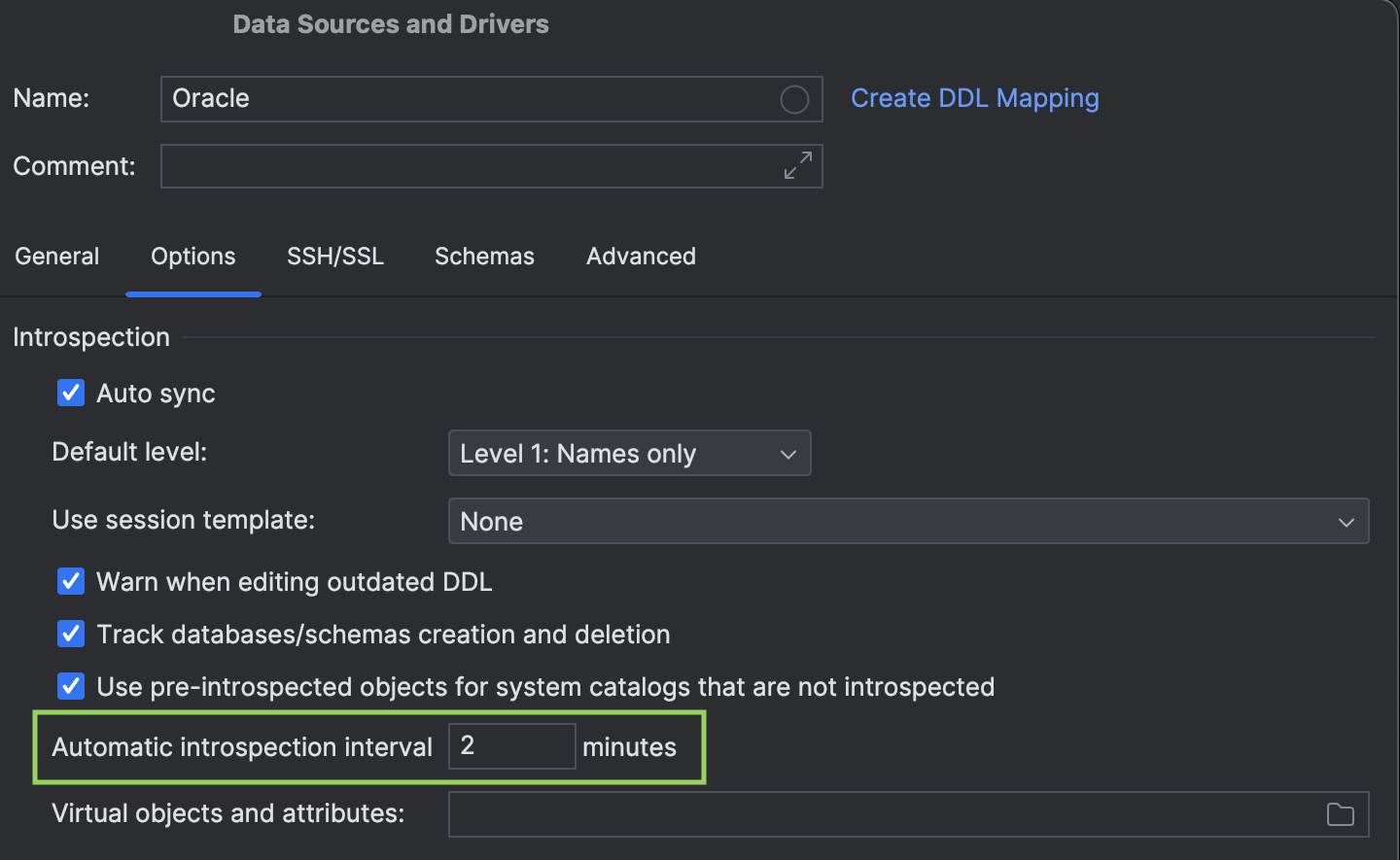
Introspection scheduler
You can now set an introspection interval for each data source.
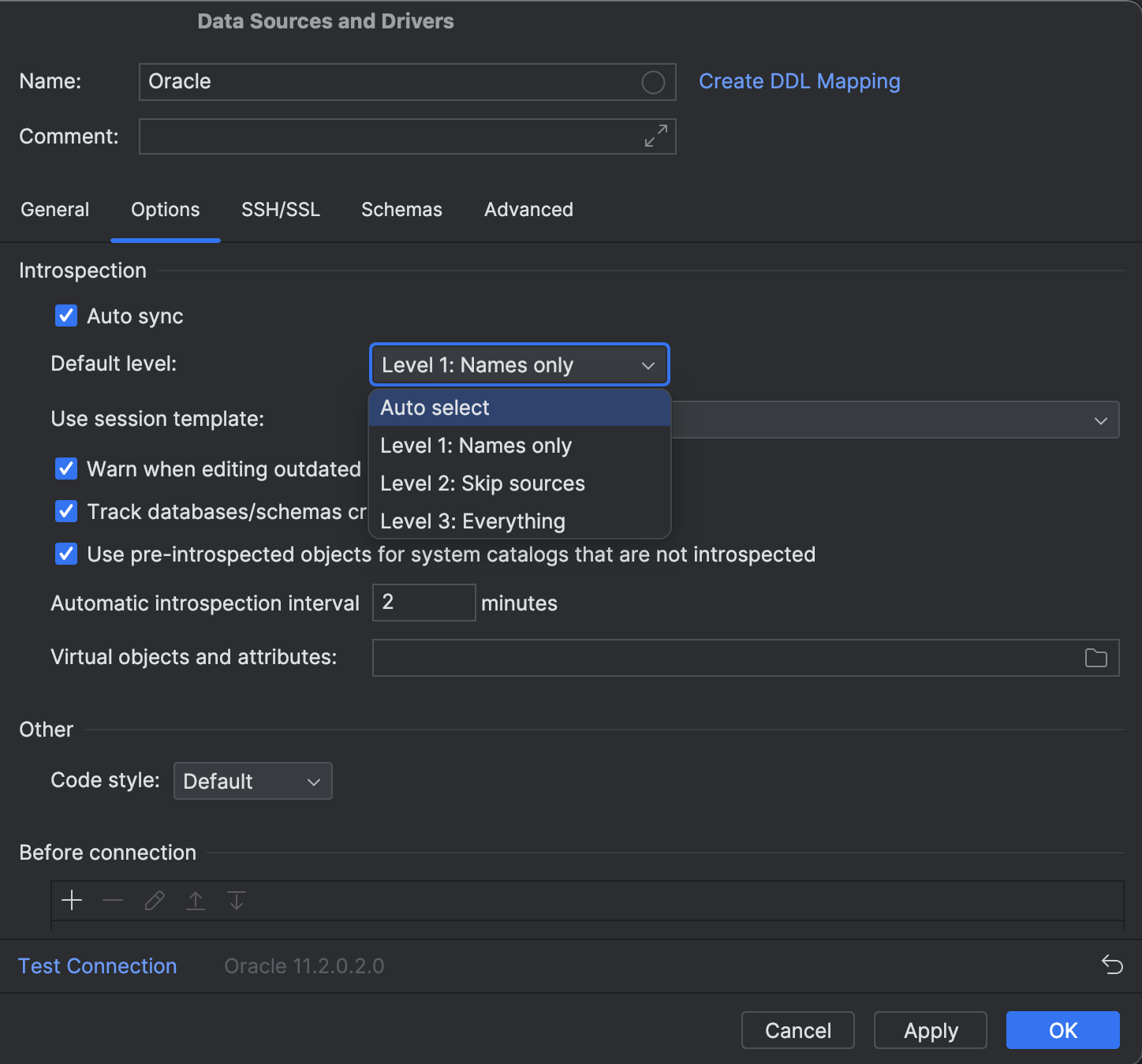
Oracle Introspection level defaults
DataGrip takes a long time to introspect schemas in Oracle because Oracle catalogs are generally pretty slow. To address this problem, introspection levels were introduced.
By default, the highest level was selected. This meant that introspection only began at the third level for selected schemas, which was slow. What’s more, some users were unaware that the introspection level setting existed at all.
DataGrip 2023.3 prioritizes user experience and performance over fullness of functionality. The default introspection level value is now set to Auto Select.
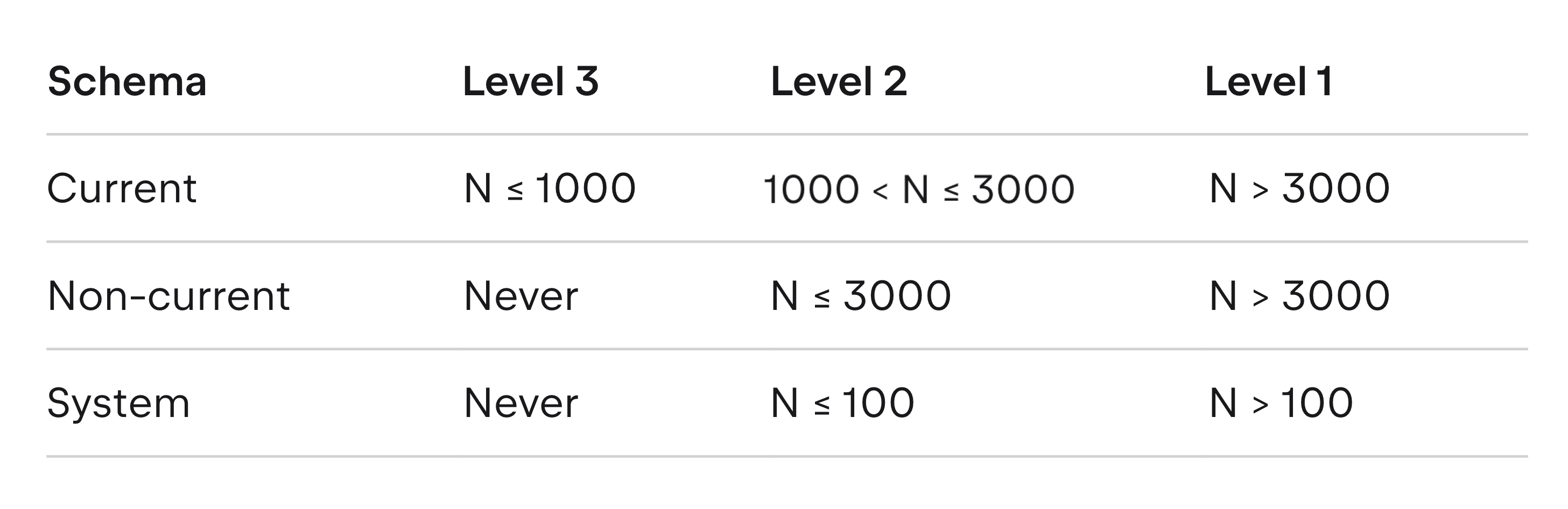
Our new approach is to set the default introspection level for each schema based on the schema type and number of objects. We assumed that users most often work with the current schema (the one the Oracle session is connected to), less often with non-current ones, and very rarely with system schemas.
For each schema, the introspector counts the objects and selects the introspection level using the following thresholds (where N is the number of objects).
We’ve also implemented fragmental introspection – the ability to retrieve metadata for one single object. This helps in situations where the metadata (usually, the source code) is explicitly requested by the user. For example, if you double-click on a view but the introspection level is low, DataGrip requests the source code at the same moment. This is more similar to how all other database tools work.
The automatic level detection is enabled by default. If you want DataGrip to work as before, go to Data Source properties | Options | Introspection | Default level and select Level 3. To learn more about how this feature works, please read this article.
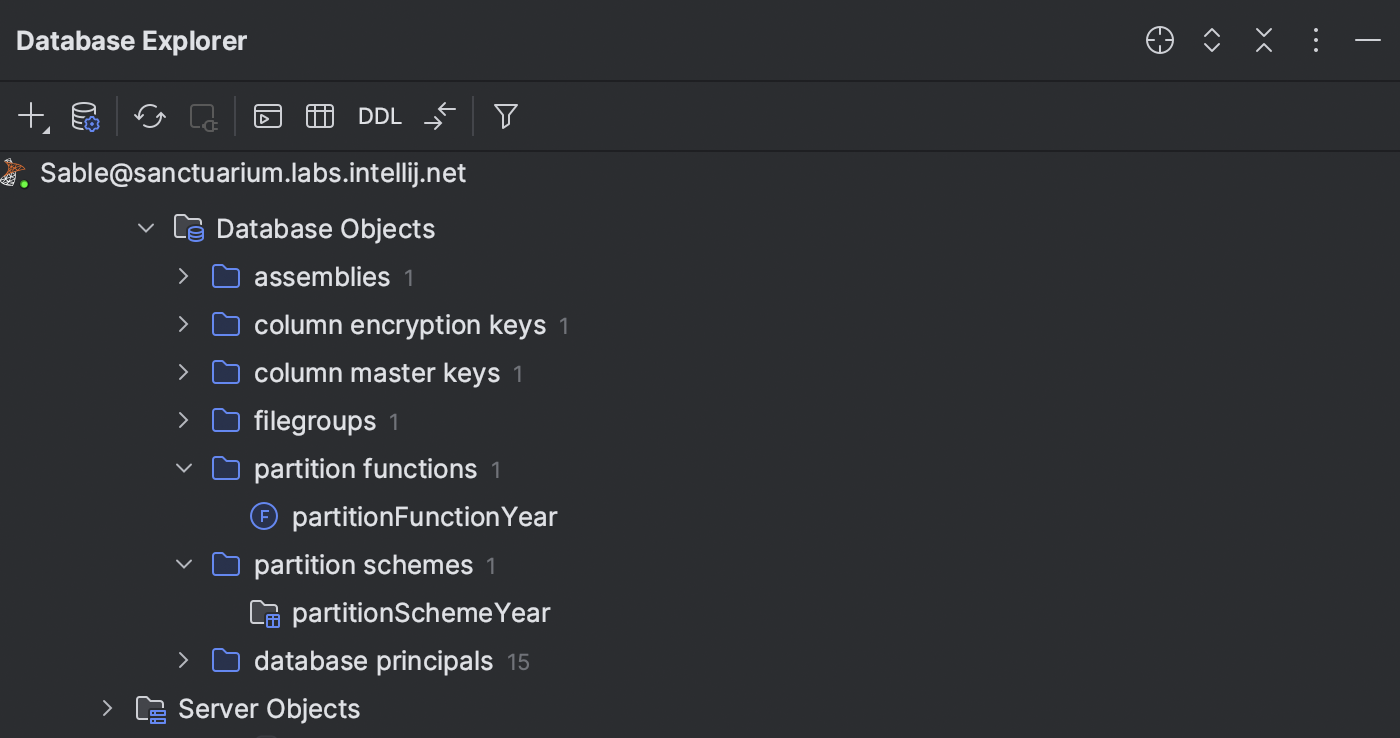
SQL Server Support for new objects
New objects are supported in SQL Server:
- Partition functions and partition schemes
- Partitions and related table/index properties
- Ledger tables
- Filegroups
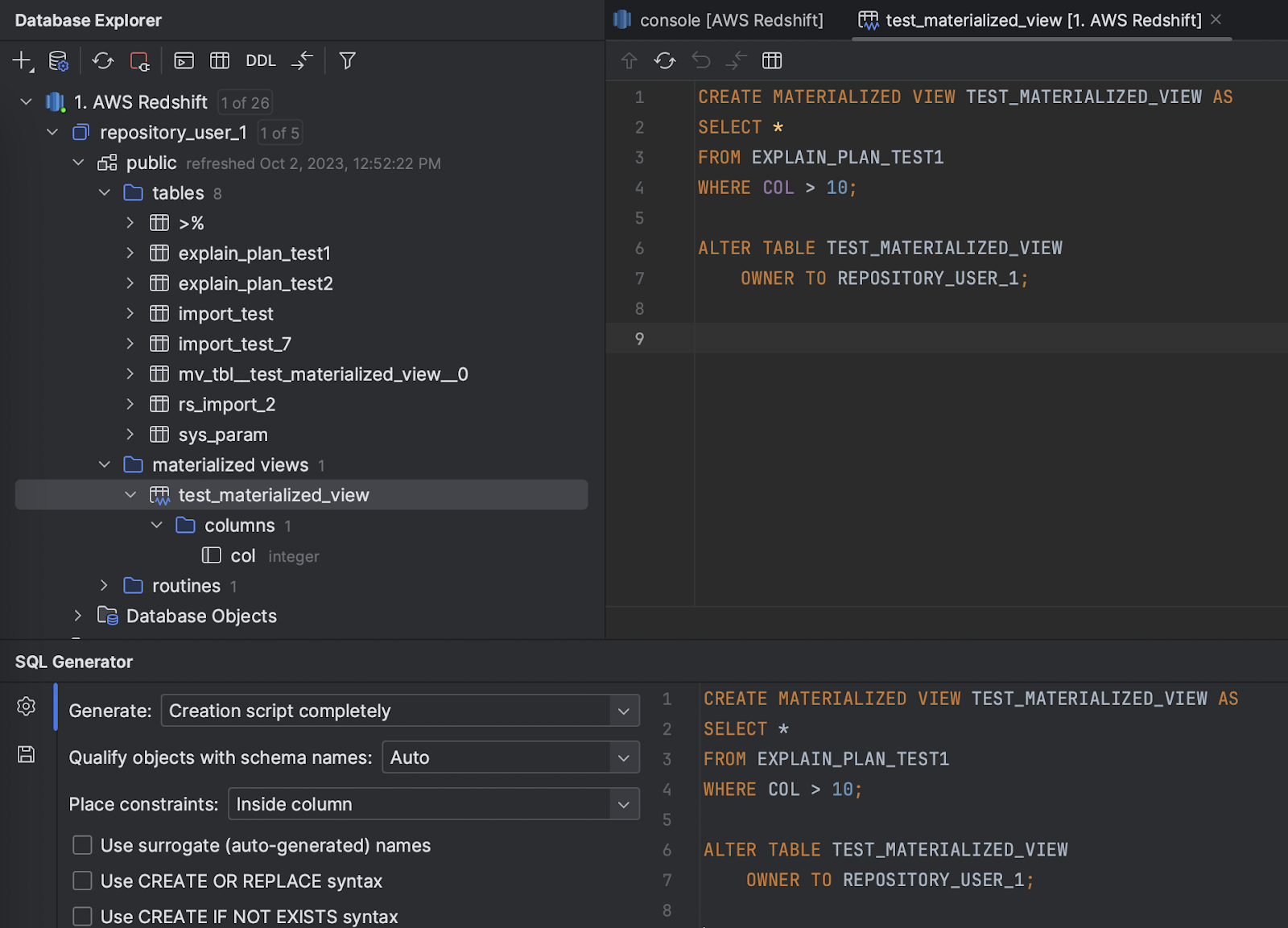
Redshift Support for materialized views
Materialized views in Redshift are now introspected and displayed in a dedicated node in the Database Explorer.
Running queries
Oracle Support for ref cursors in the query console
You can now get the result from ref cursors if you run the query in the console or in the SQL file.
- If the function you run returns a result containing only one ref cursor, DataGrip immediately navigates to the result from the ref cursor.
- In more complex cases where the result contains several ref cursors or something other than a ref cursor, DataGrip shows the main result and gives you the opportunity to view results from other ref cursors. From the cell with the ref cursor, you can go to the corresponding result set (Enter/Double-click) and vice versa (Ctrl+B).
Code generation
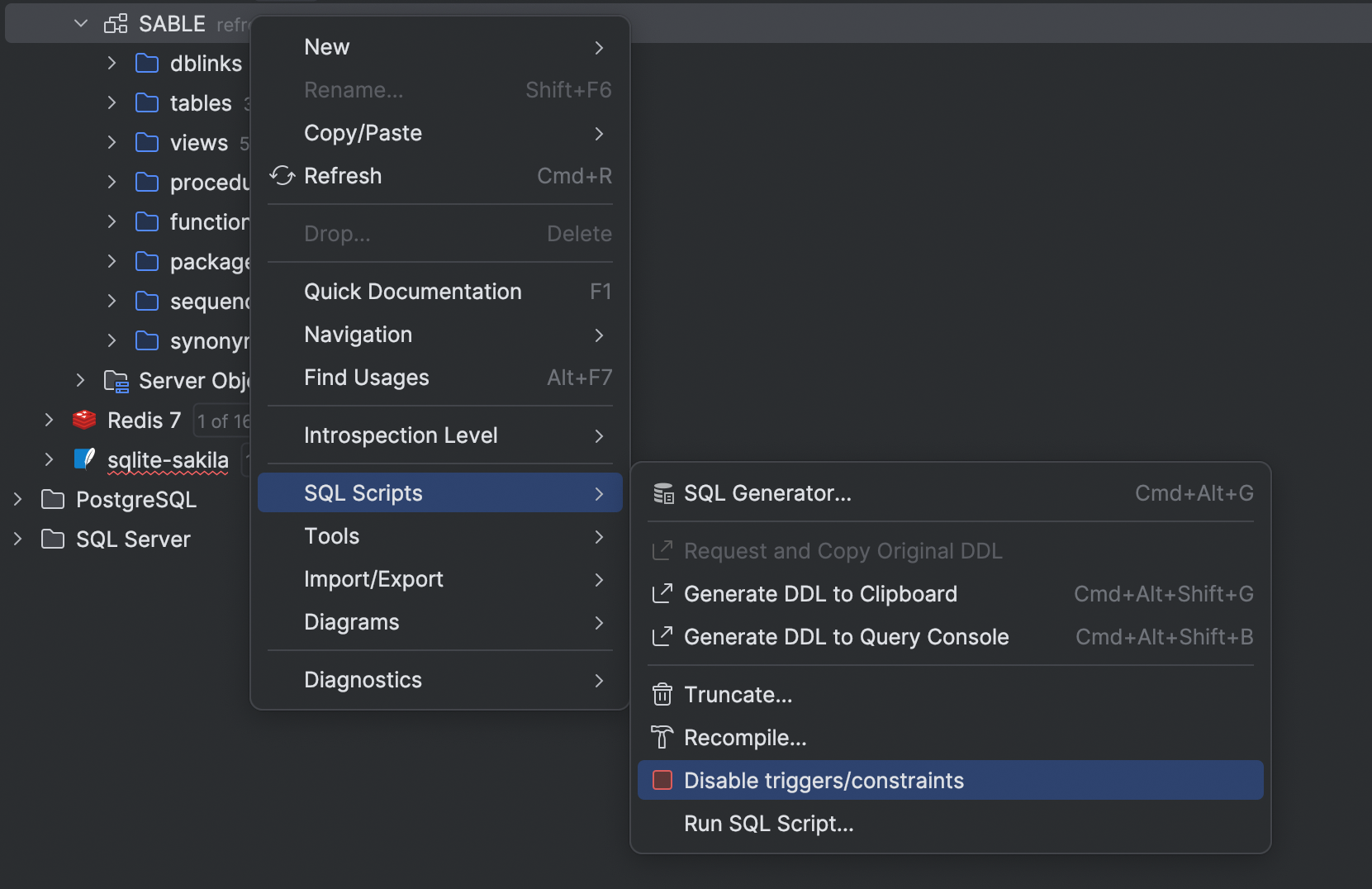
Enable/disable database objects
Some types of objects can be enabled and disabled. From now, DataGrip supports performing this via the UI, letting you generate and run the corresponding code pieces.
This feature is applicable for:
- MySQL Events.
- PostgreSQL Rules, triggers, and event triggers.
- MS SQL Indexes, Foreign keys, check constraints, and triggers.
- Oracle Keys, uniques, foreign keys, check constraints, triggers, tablespaces, and user accounts.
Miscellaneous
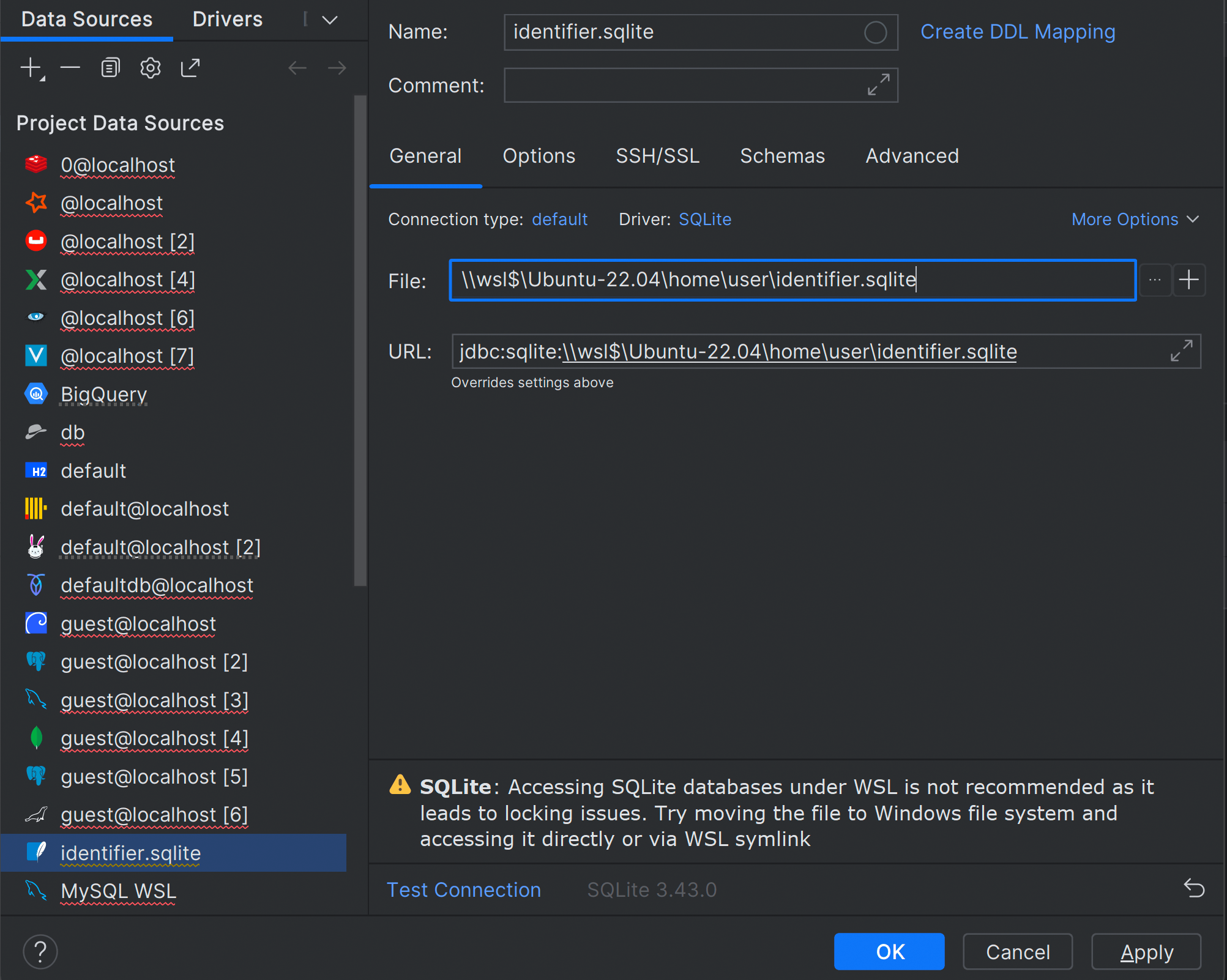
SQLite Warning if using WSL path
Unfortunately, it is impossible to work with the SQLite database located under a WSL path. The reason is that WSL doesn’t respect the SQLite file locking mechanism. For now, the only available solution for DataGrip is to show a warning in that particular case.
Please vote for the original WSL issue if this is critical for you.