What's New in DataGrip 2024.1
DataGrip 2024.1 is out! This first major upgrade of 2024 is filled with numerous improvements. Let's unpack all the new features and updates!
AI Assistant: option to attach schemas DataGrip only
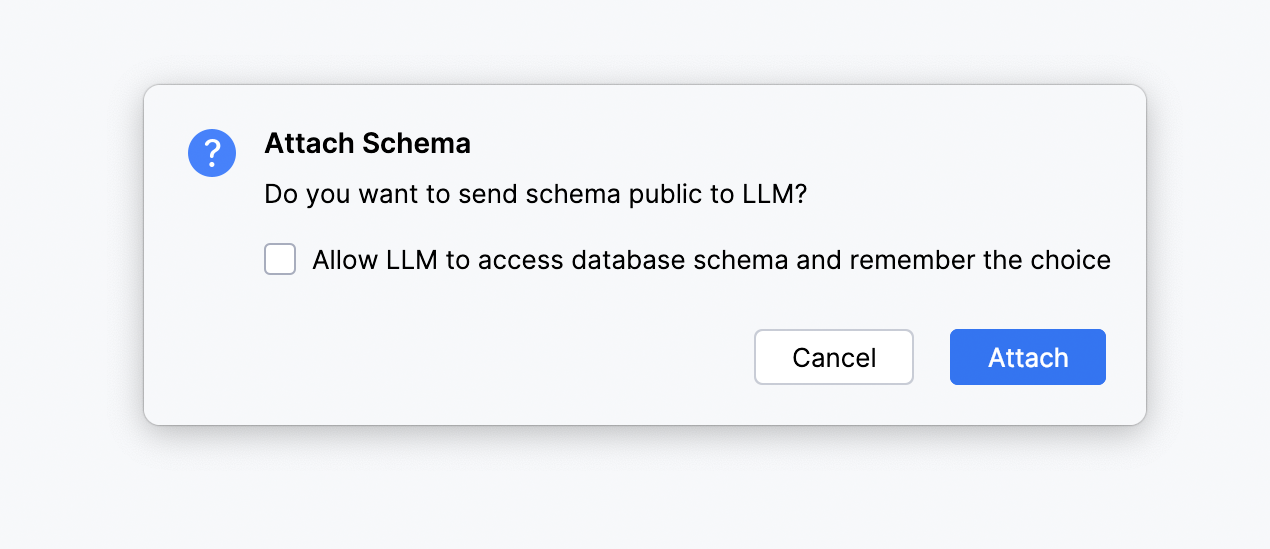
AI Assistant now allows you to improve the quality of generated SQL queries by attaching a database schema for context in the chat. For now, only table and column names are attached and there is a maximum limit of 50 tables.
To use this feature, you need to grant AI Assistant consent to search for database objects in your project.
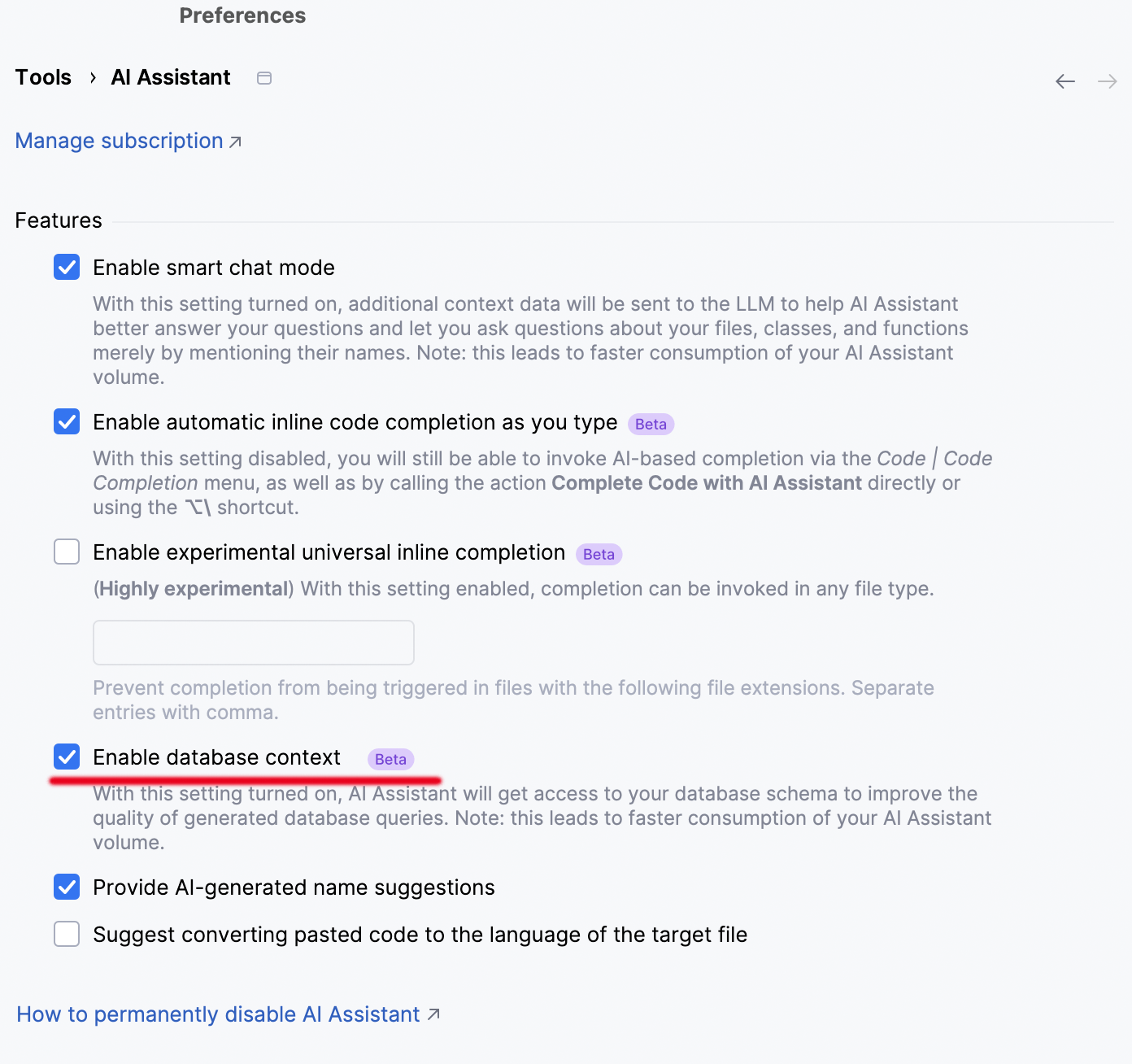
You can do this each time you attach a new schema, or you can simply tick the option in the Attach Schema popup that allows AI Assistant to remember your choice. In that case, the Enable database context setting will automatically be turned on:
Important: If the Enable database context setting is ticked, AI Assistant will have access to all object names from all data sources.
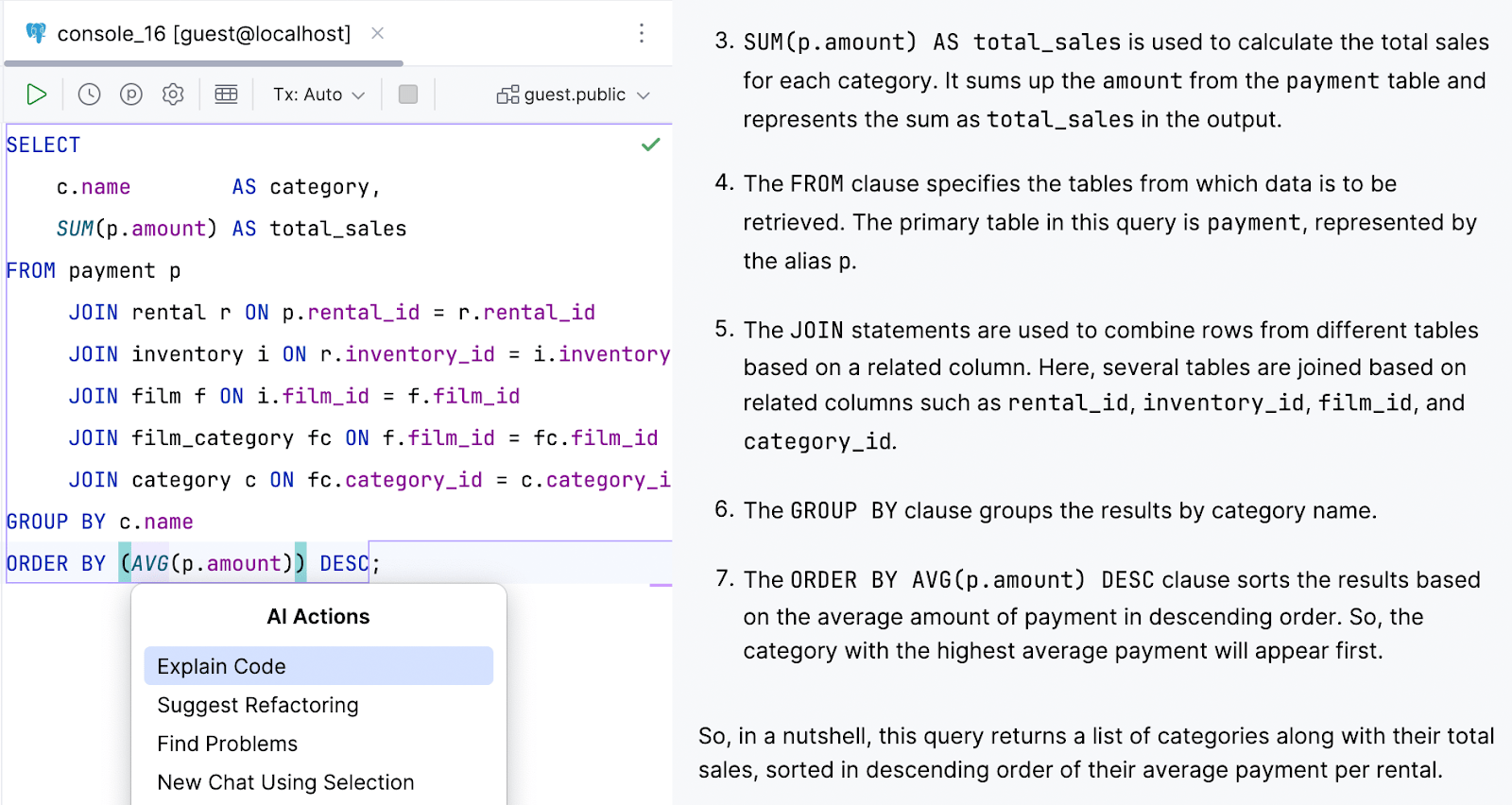
Context menu features in the editor, such as Explain Code, now understand the current schema when invoked from database consoles.

Because AI Assistant is aware of your schema, you can:
- Generate queries from natural language requests:
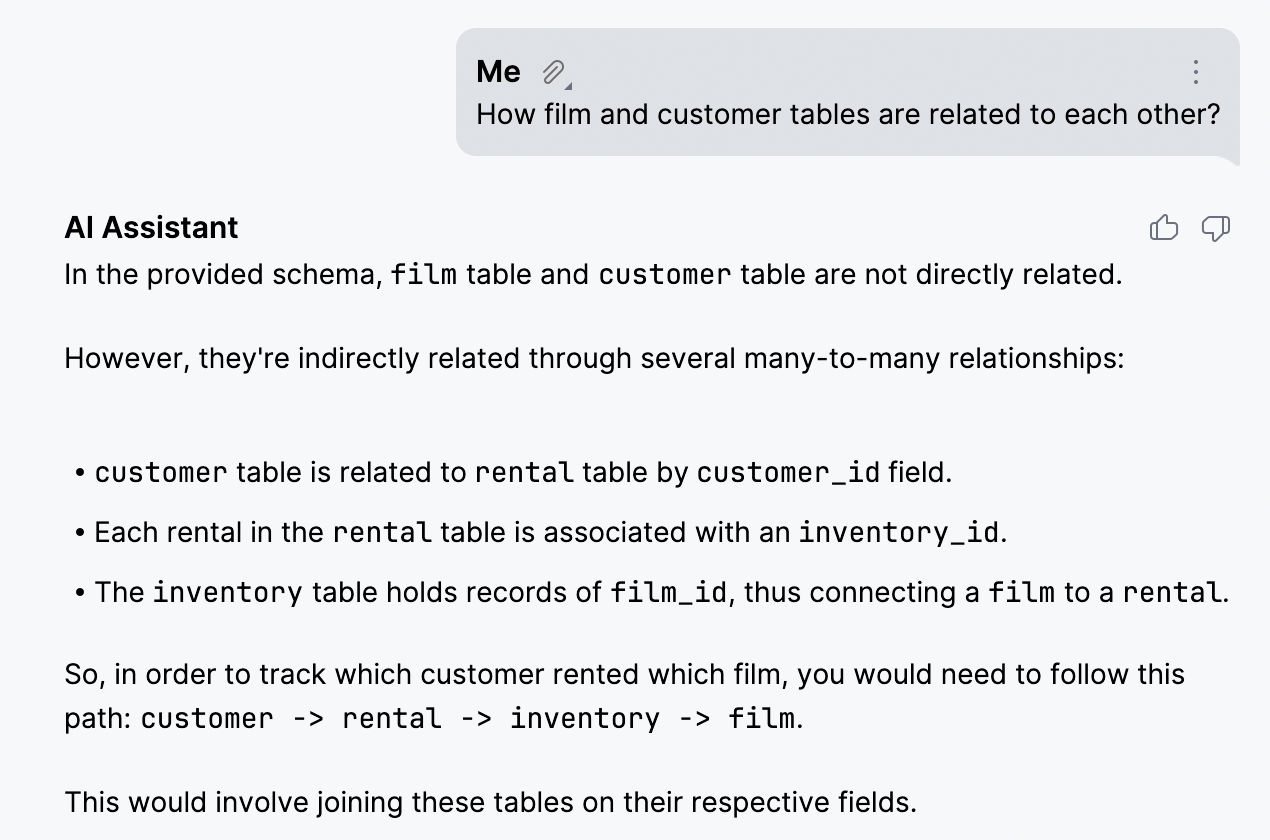
- Get insights about your schemas:
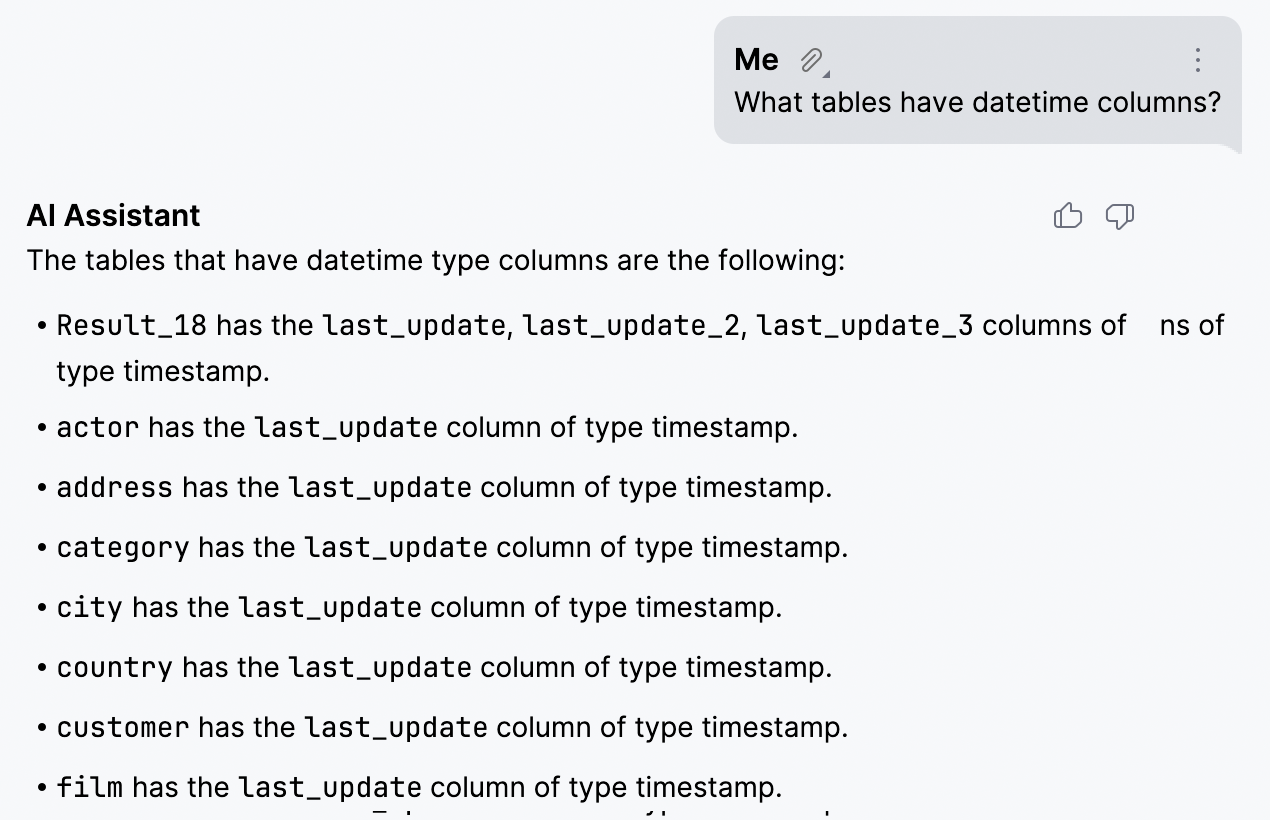
- Perform non-trivial searches:
And that’s just a small sample of what you can do. The possibilities are endless!
Working with data
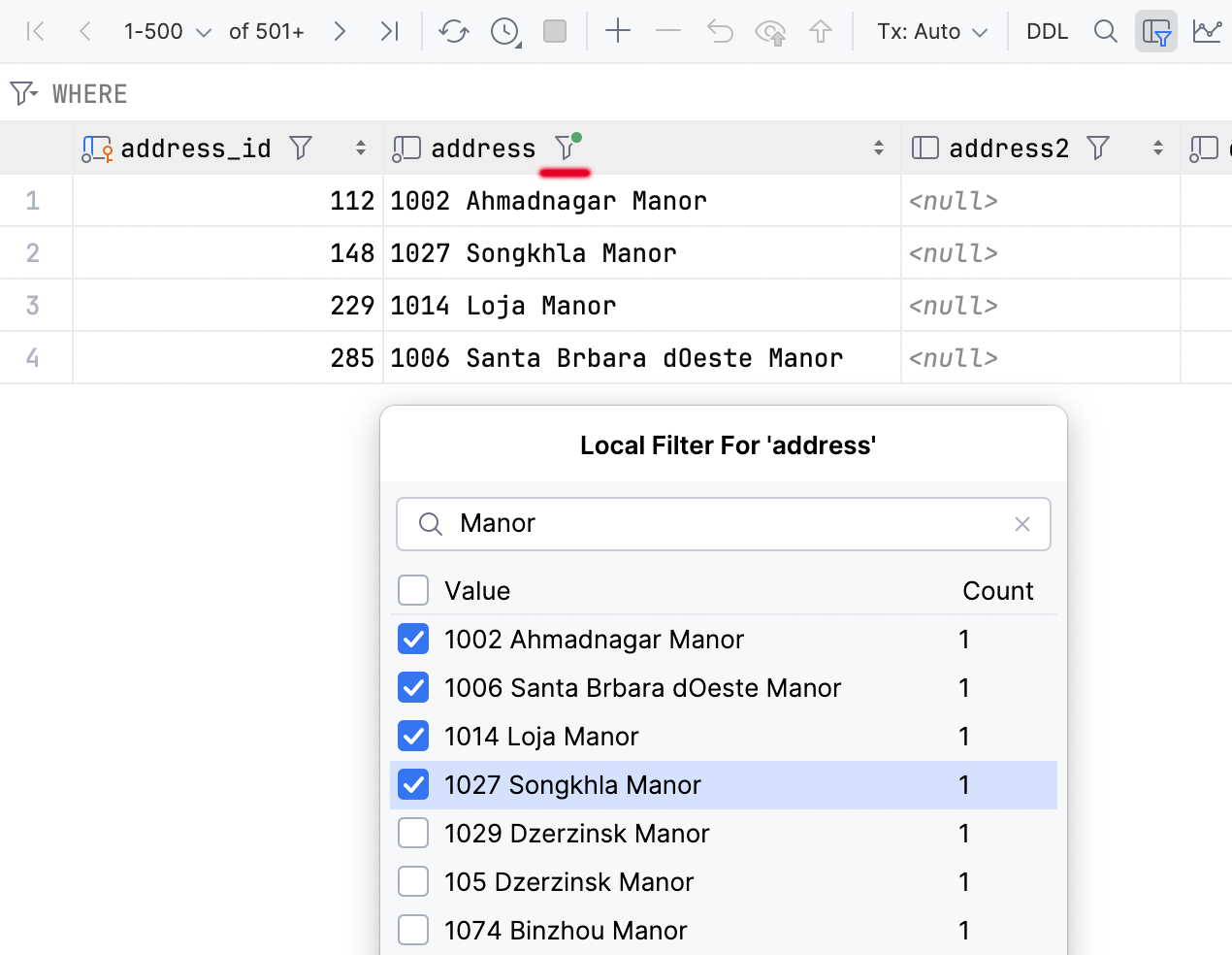
Local filter in the data editor
A long-awaited feature is finally here: You can now filter rows by values in columns.
This method is fast since it doesn’t involve sending a query to the database. However, it’s worth noting that the filter will only affect the current page. Therefore, if you want to filter more information, you can simply change the page size or fetch all the data.
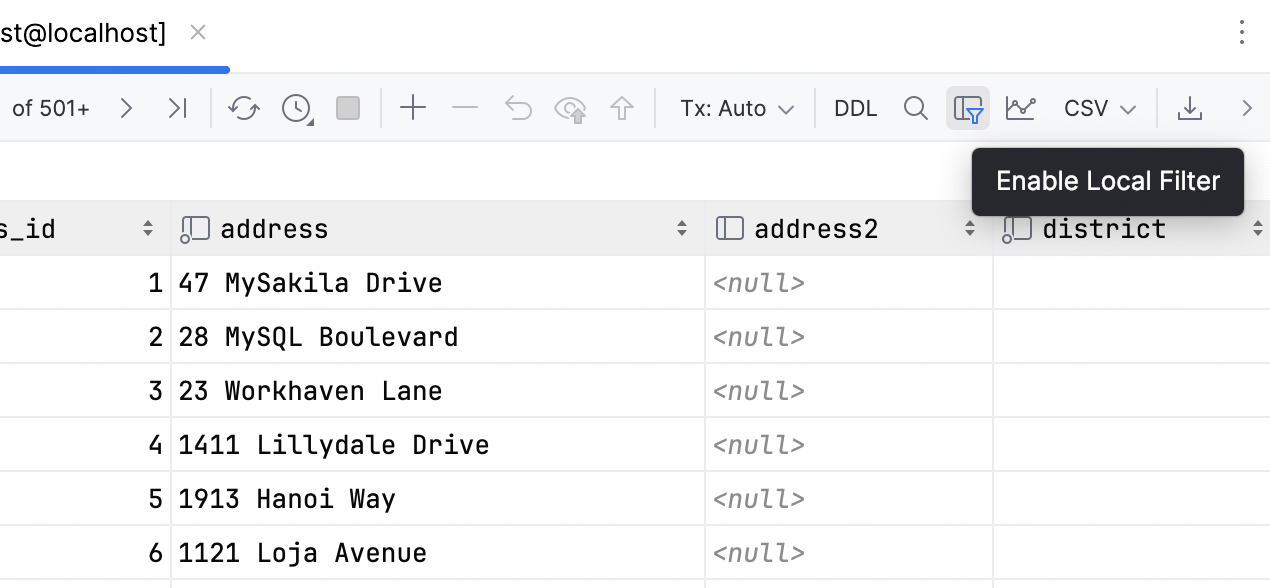
If you want to turn off all the local filters for the current data editor, deselect the Enable Local Filter button  .
.
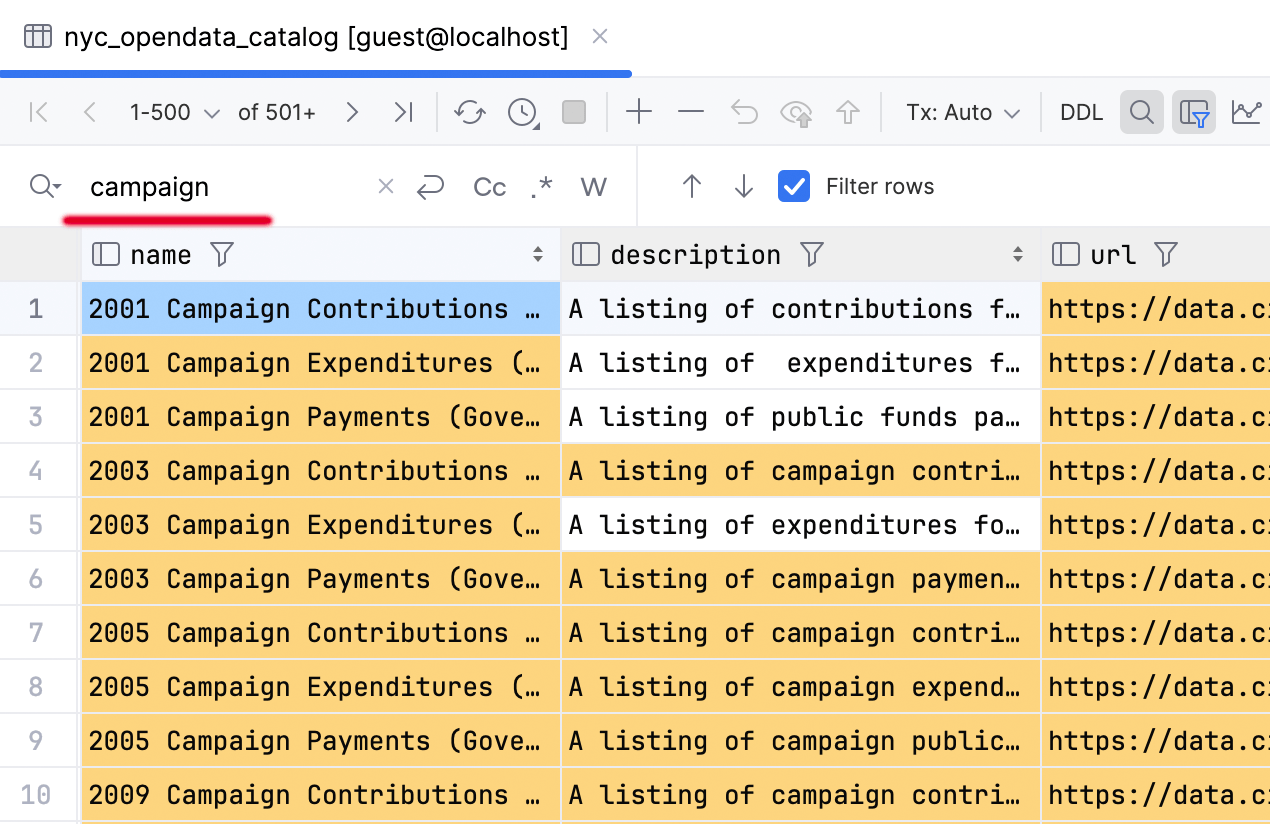
And don't forget about the local text search function (Ctrl/Cmd+F)! It has been around for decades and can still be useful, especially if you only have a rough idea of the location of
the data you’re searching for.
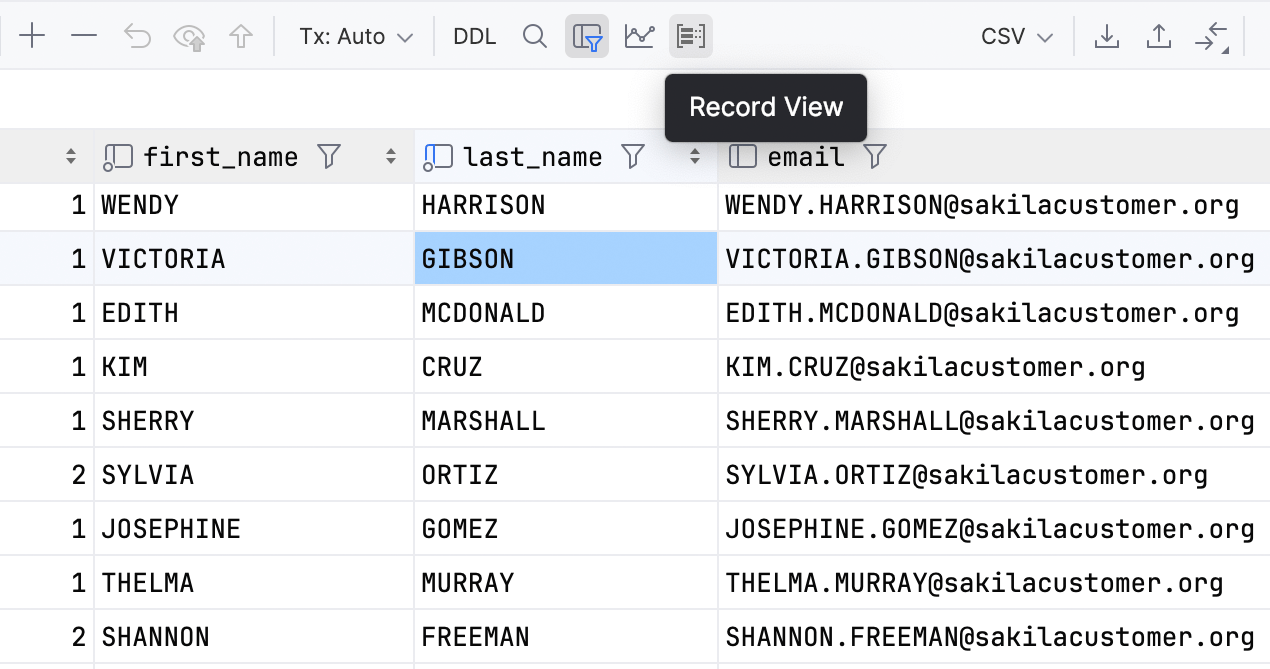
Single record view
You can now focus on a single record in the data editor. To open a record view, use the Ctrl/Cmd+Shift+Enter shortcut or the Record View button  on the toolbar.
on the toolbar.
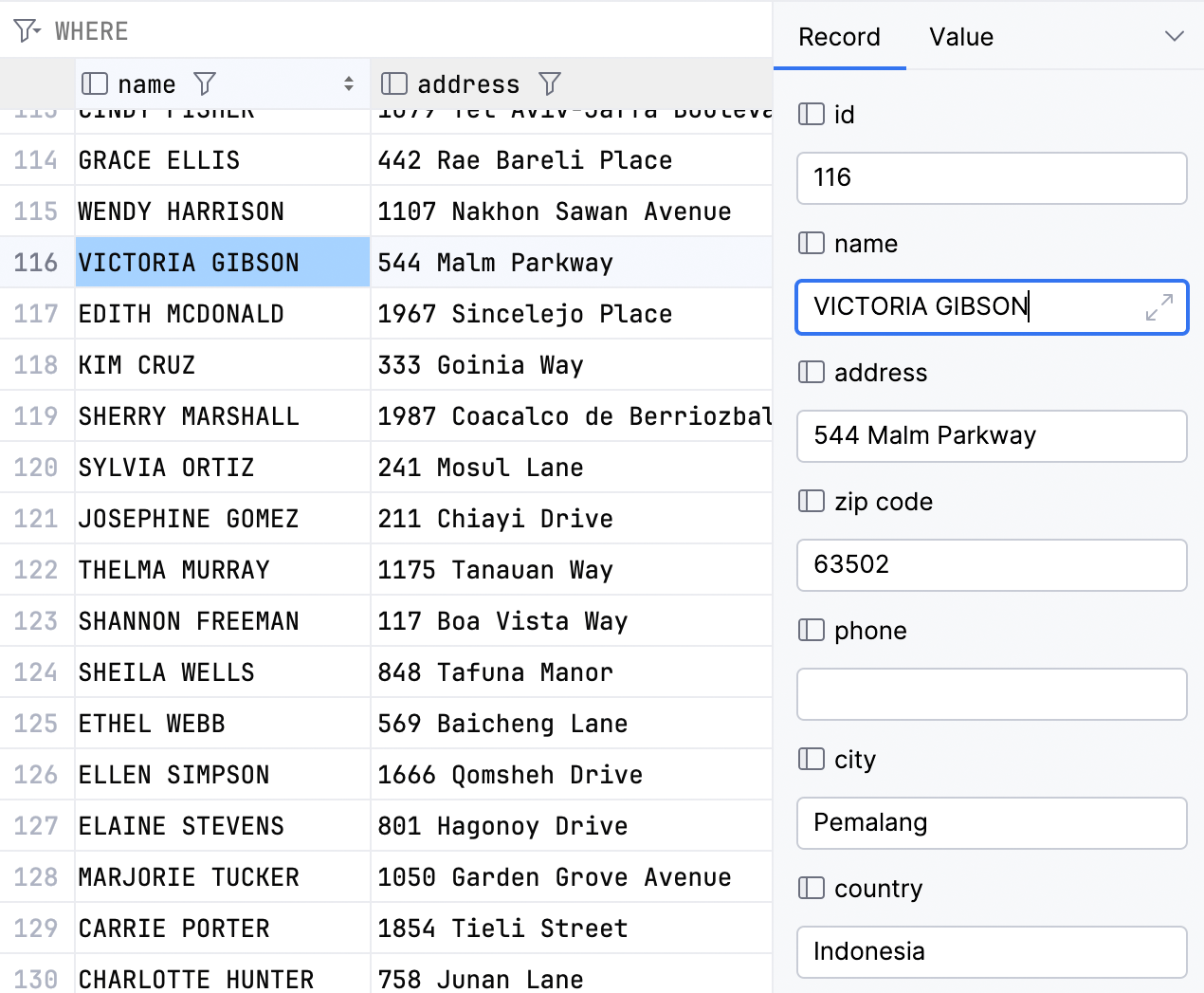
The cells in the record view will be editable if they are editable in the main grid.
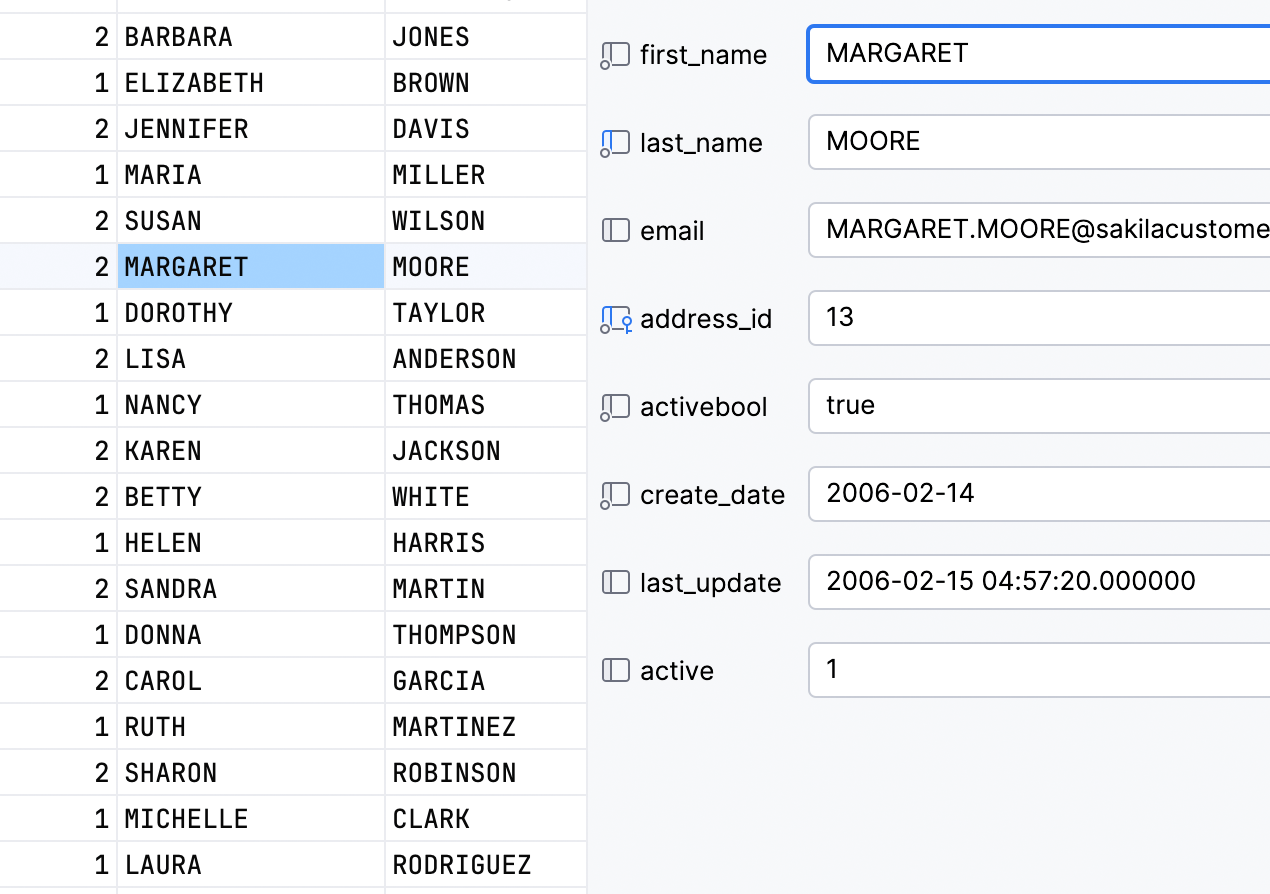
You can also change the layout to two columns if that fits your use cases:
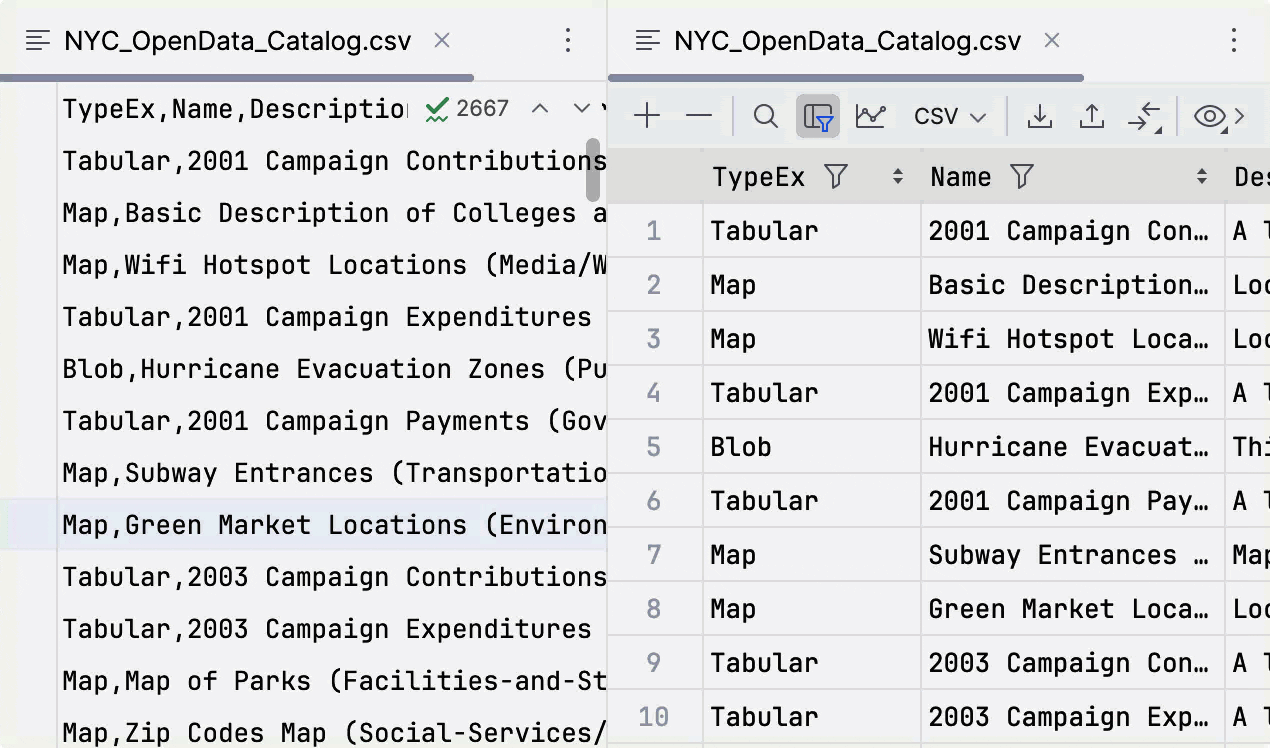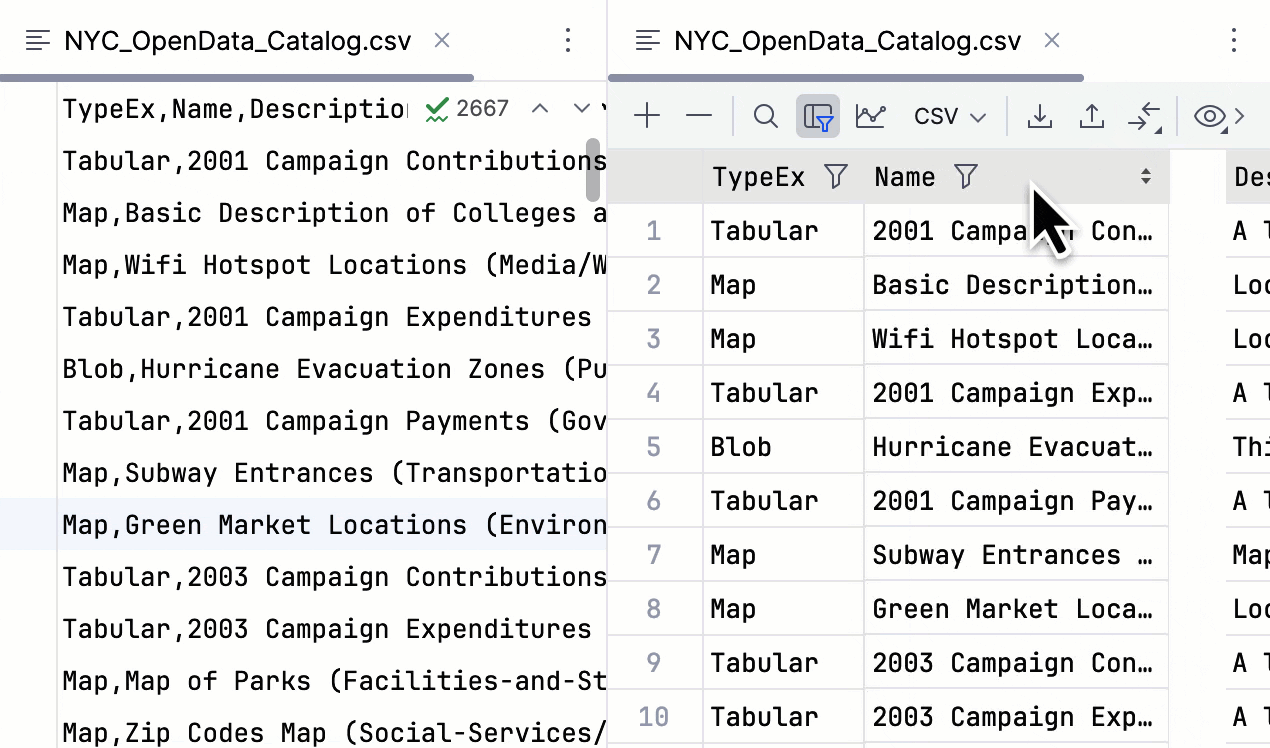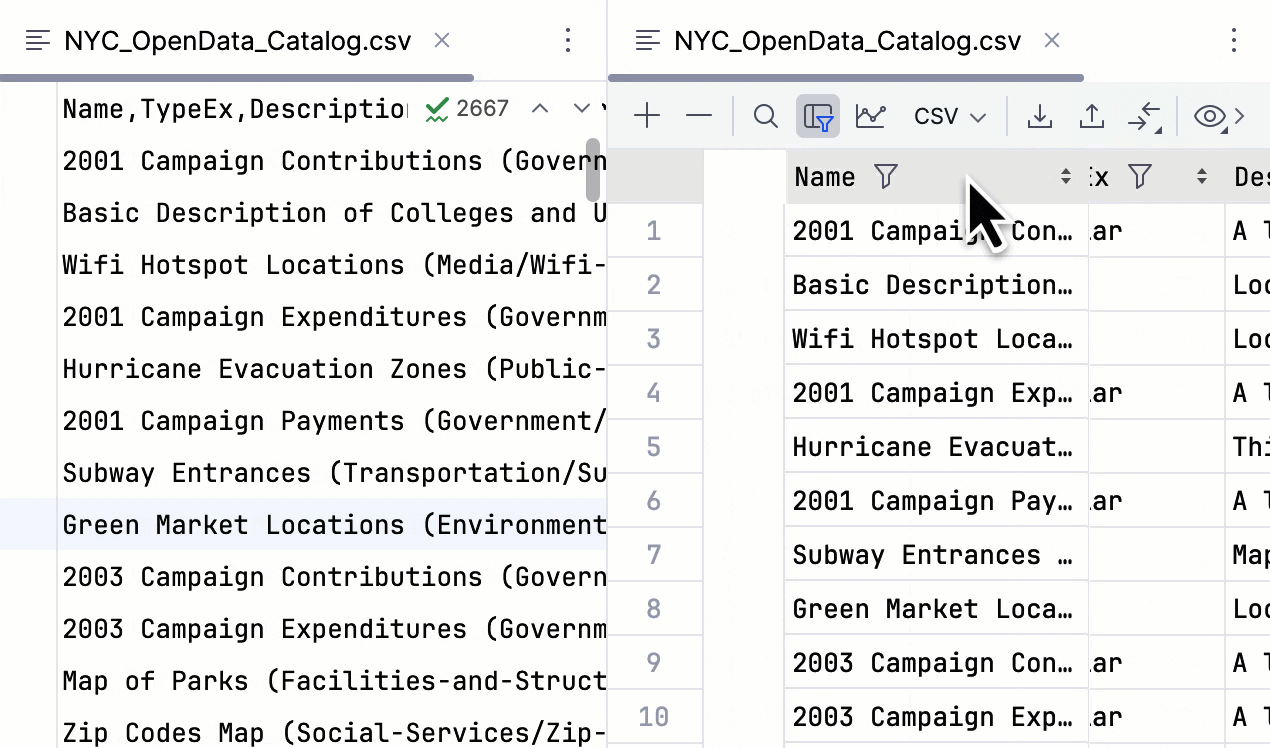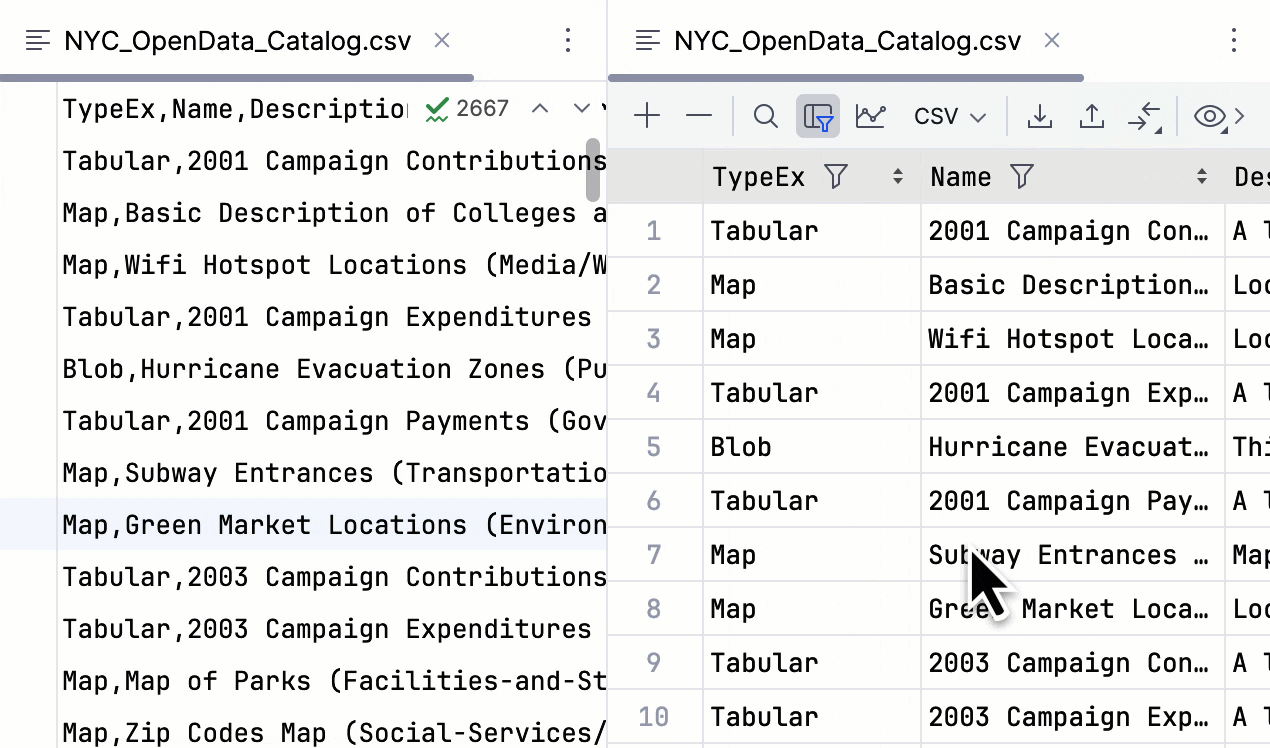
Ability to move columns in CSV files
Starting from 2024.1, you can move columns in the data editor for a CSV file and the changes will be applied to the file itself.
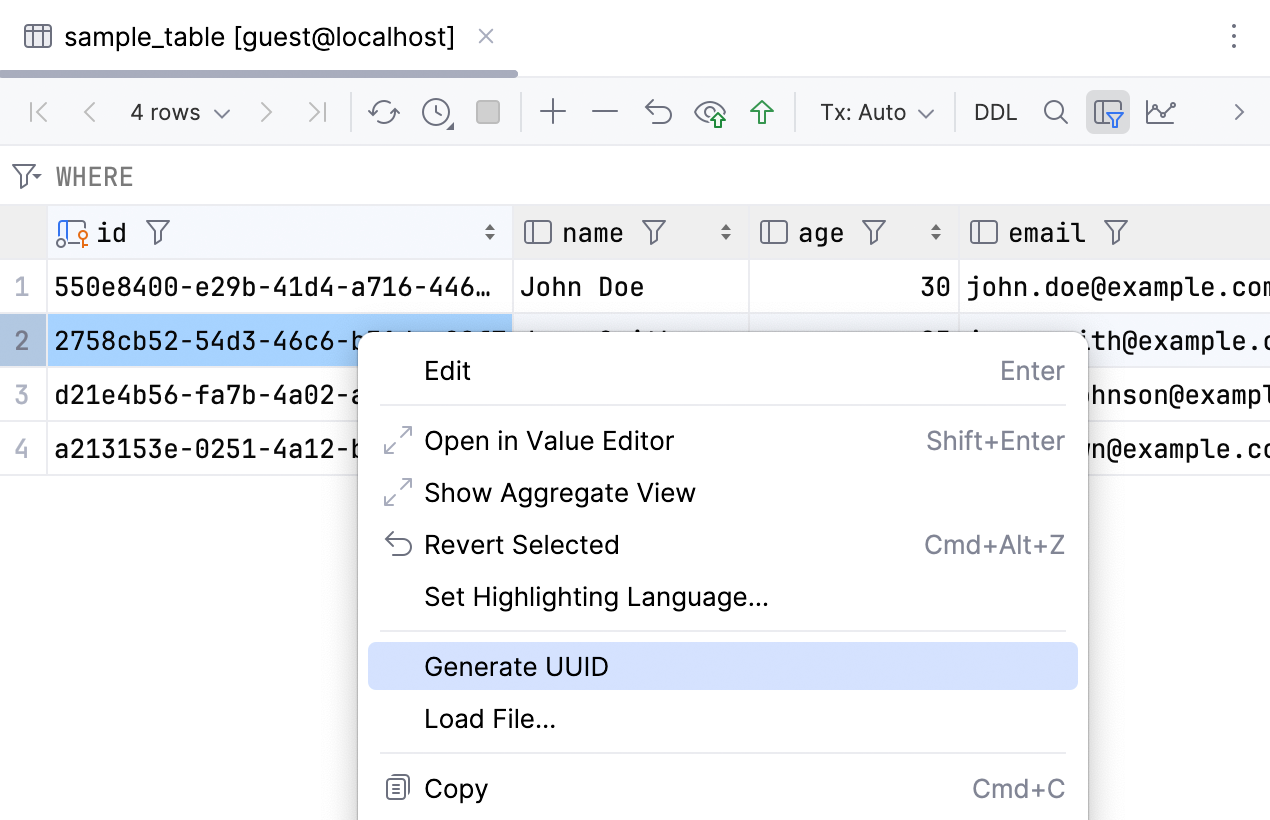
More features for UUIDs
In response to a variety of requests we’ve received in our issue tracker, we’ve made it easier to work with UUIDs:
- We’ve added a new action: Generate UUID.
- It is now possible to edit any column with UUIDs, including those represented by
binary(16),blob(16), and similar types. - Values in UUID columns can now be validated while editing. PostgreSQL
Simplification of sessions
Over the last few years, we've received tons of feedback from users who say that they don't understand the concept of sessions and that this functionality has contributed significantly to DataGrip's learning curve. Here are several examples:
The project-first and separate-console-session model is way over the top overkill. This model makes opening and executing a simple SQL file a real chore. If I just want to open and execute a script I have to first create a project, then add the file to the project, then open a console, then open a session, and then attach the file to the session. What a gigantic PAIN.
Coming from SQL Server Management Studio, DataGrip's UI is a lot more complex. In SSMS you basically just have servers, queries and results. In DataGrip there's sessions and consoles and scratch files, etc., etc., making the tool much less intuitive for new users.
Some of the way the UI works is clunky and non-obvious. When I have to select a console to run a script on, it's not entirely clear to me why I have to do this or what the ramifications of the selection are. This shouldn't really be the default behavior.
In DataGrip, "session" is a technical term that refers to the container for a connection. In other words, connections can be established, stopped, and re-established within one session. For each connection, there is one session.
The ability to attach sessions is a powerful mechanism, but in the majority of cases, users just need to set the context (data source and database or schema) for the queries to be run.
Starting from version 2024.1, users will no longer need to manually choose which session to run queries in, and this will be the case for all types of queries. Sessions are still there under the hood, but you won't need to worry about them. Let's take a deep dive into how this change affects DataGrip's main use cases.
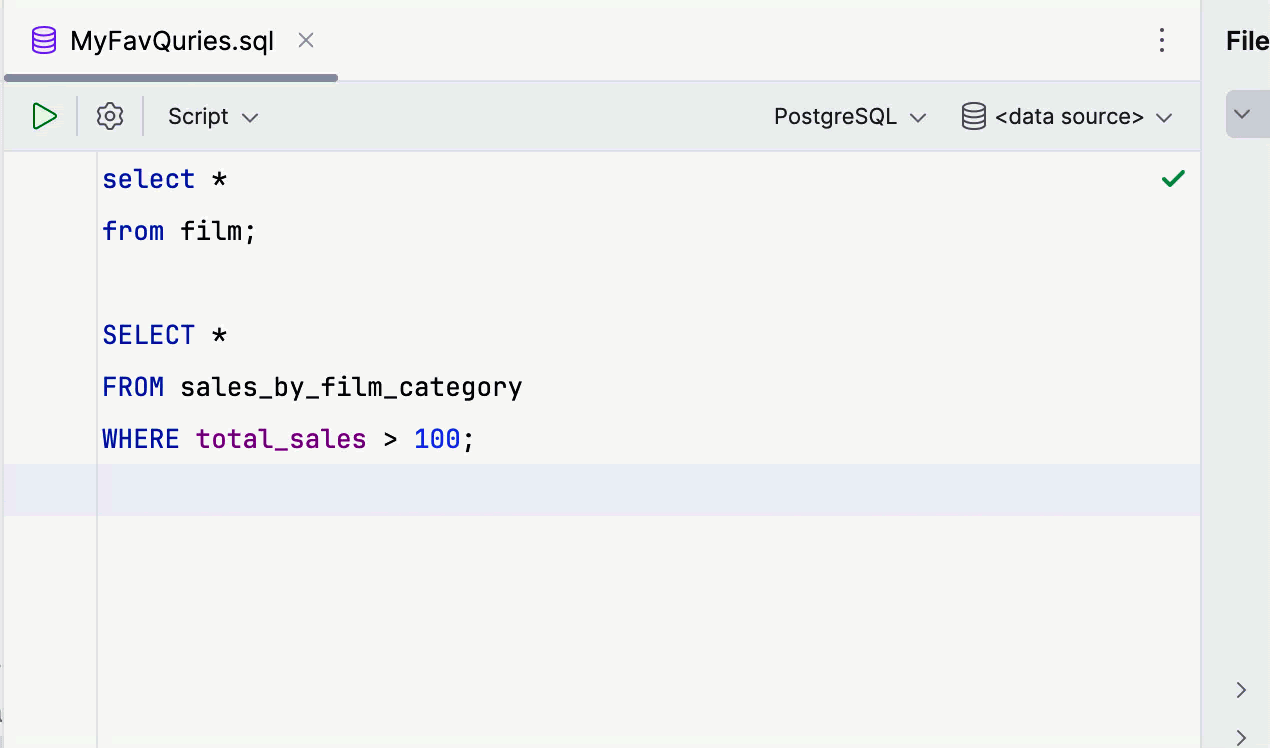
Attaching and switching data sources
To attach a file, you now simply need to select the data source, rather than the session. After selecting the data source, you choose the schema.
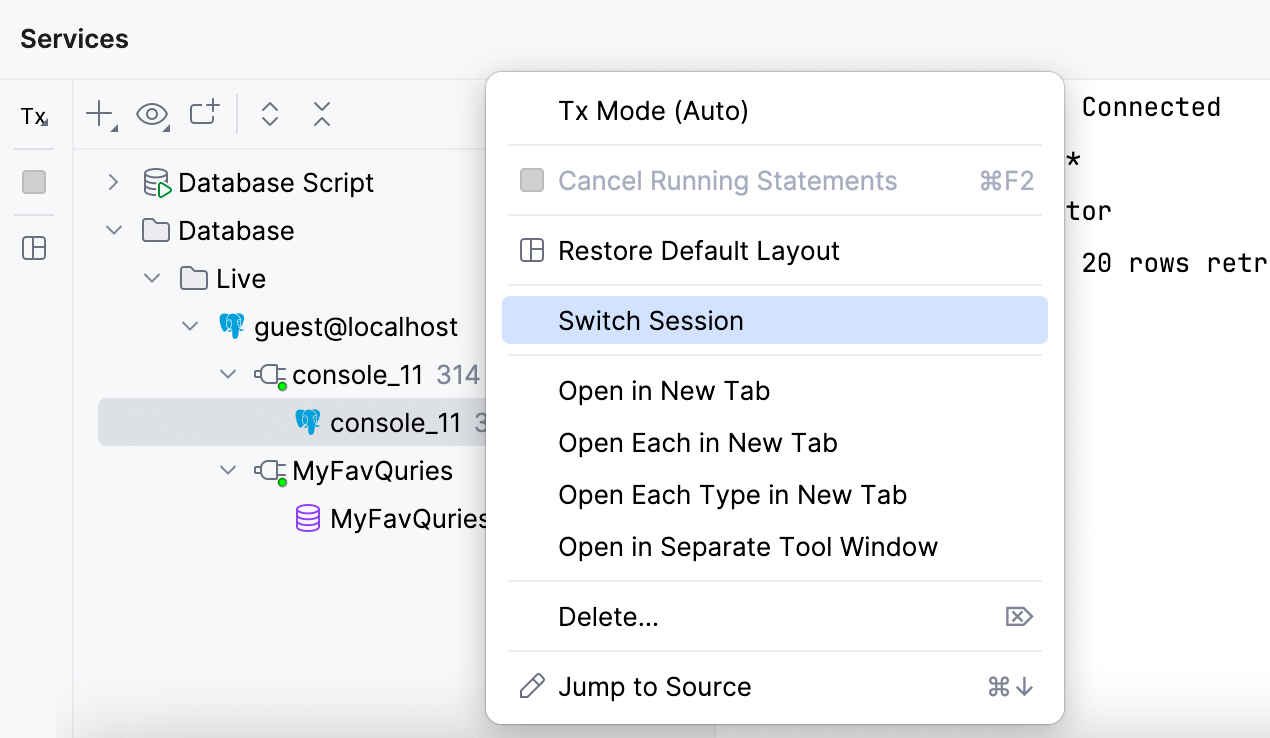
Switching sessions
The Switch Session action now only appears in the client's context menu in the Services tool window. It allows you to switch the session only within the current data source.
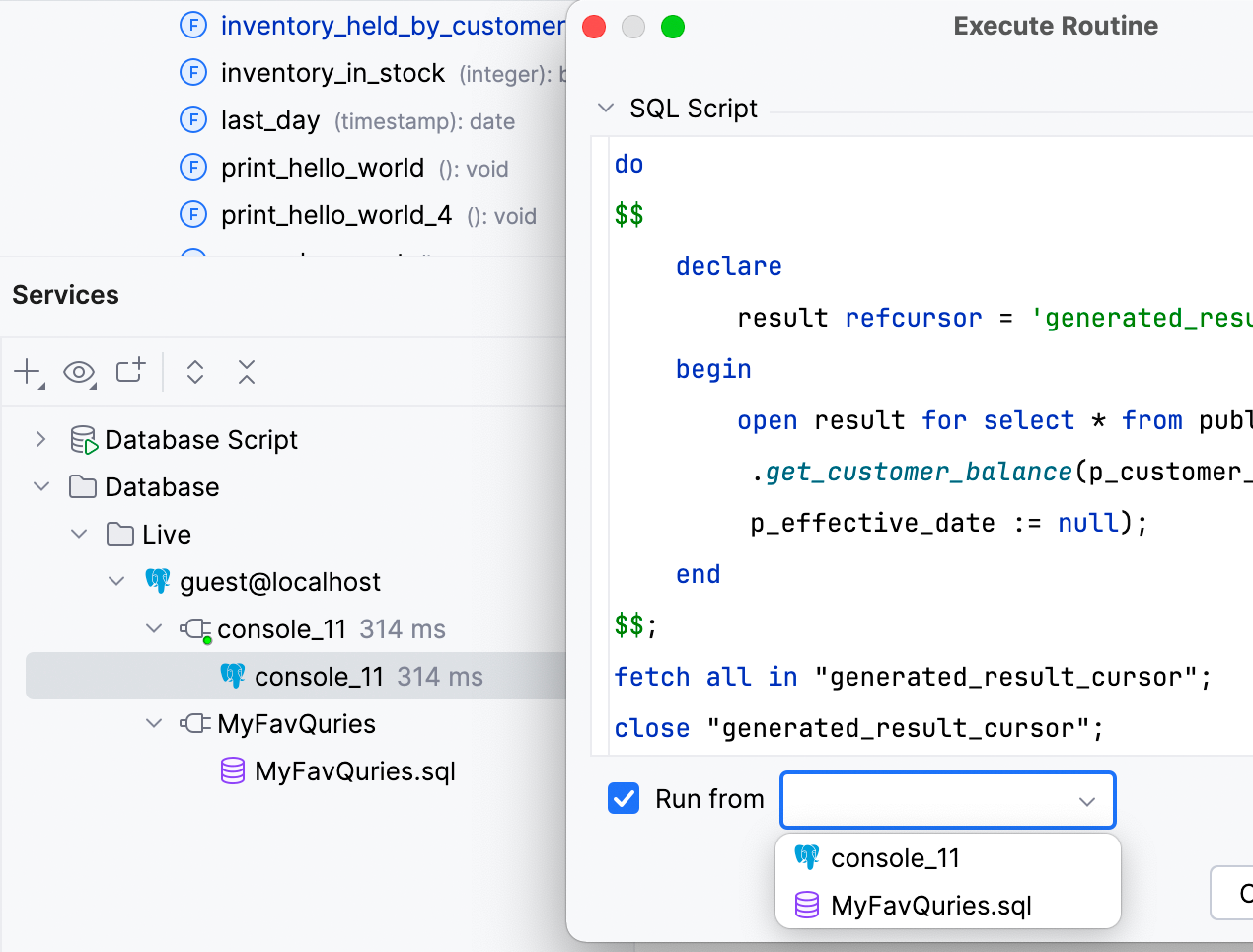
Running functions
You no longer need to select a session before launching a function. In the Execute Routine window, a Run from option allows you to select the console or file from which the function will be launched.
Working with code
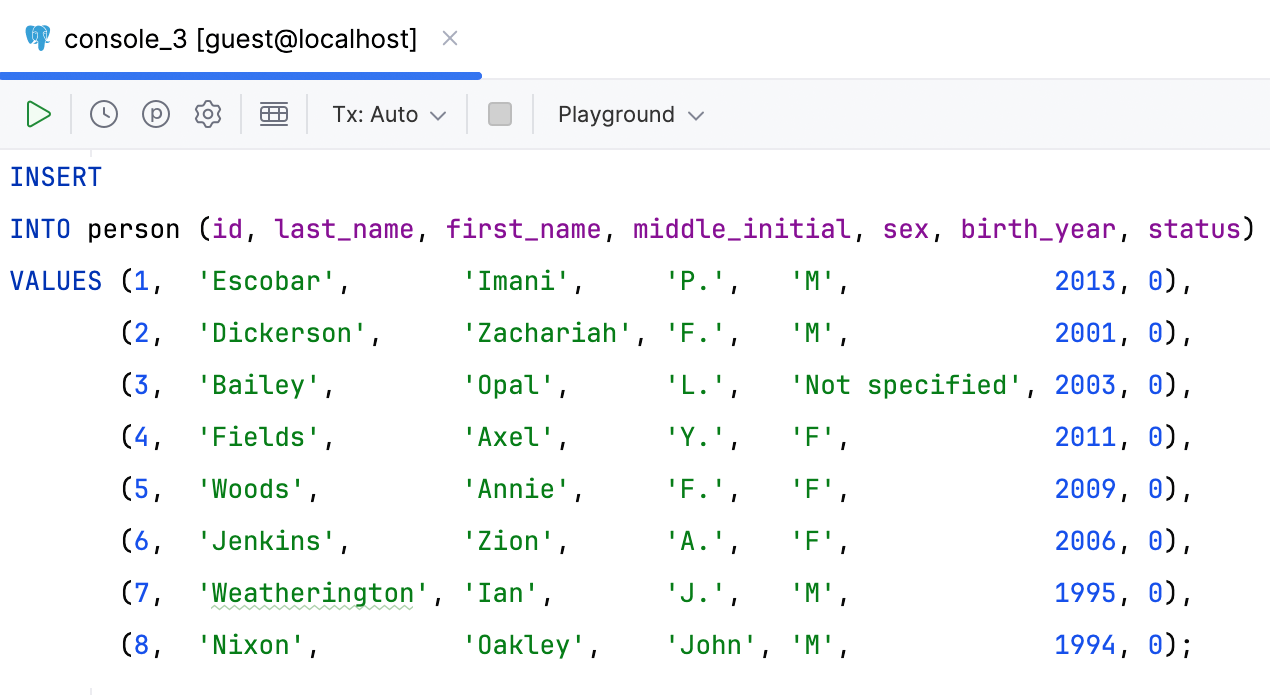
Aligned code style for multi-row INSERT statements
You can now format multi-row INSERT statements so their values are aligned. The formatter will analyze the width of the values in each column and apply the most suitable widths.
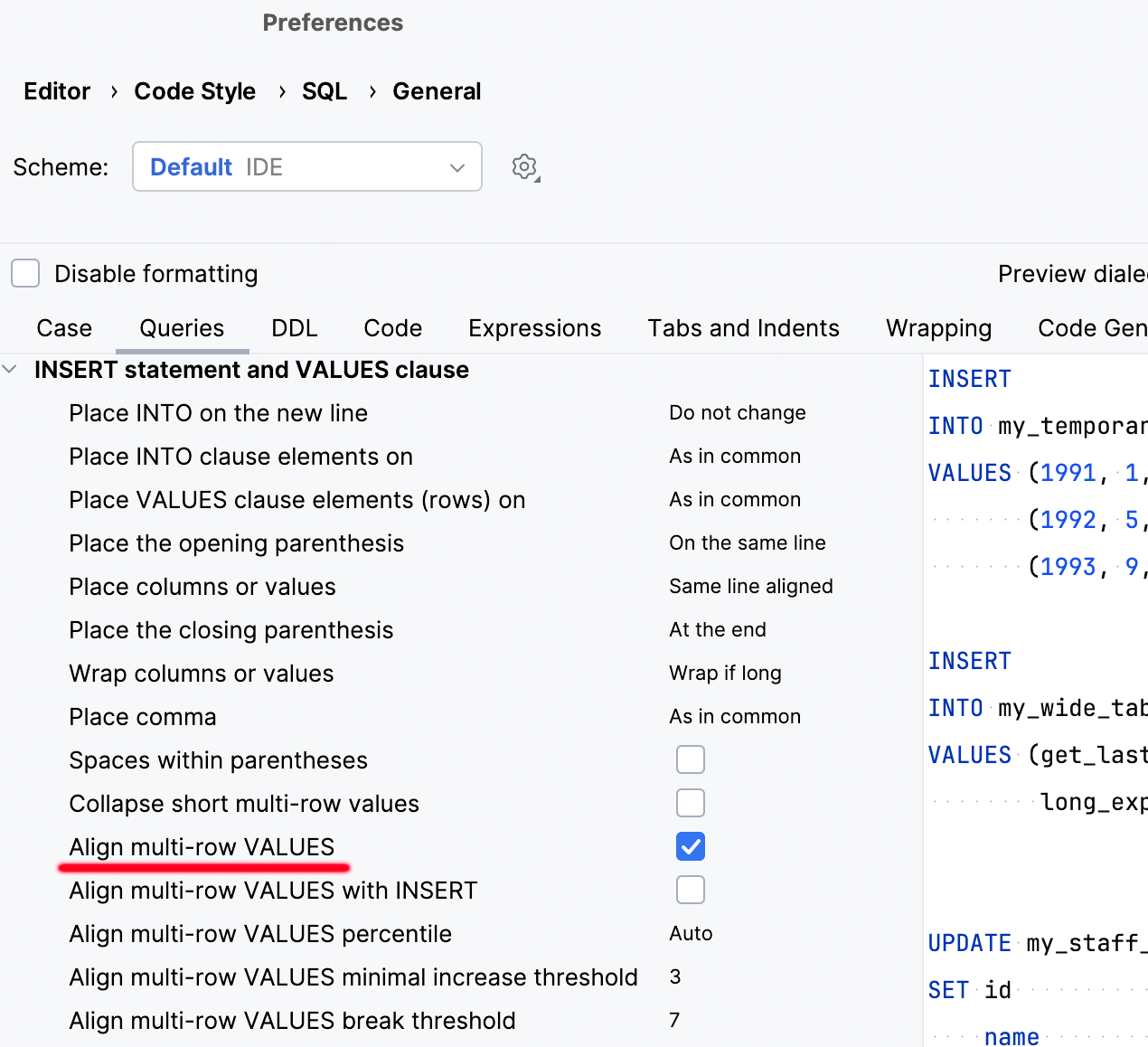
To turn this feature on, enable the Align multi-row VALUES option:
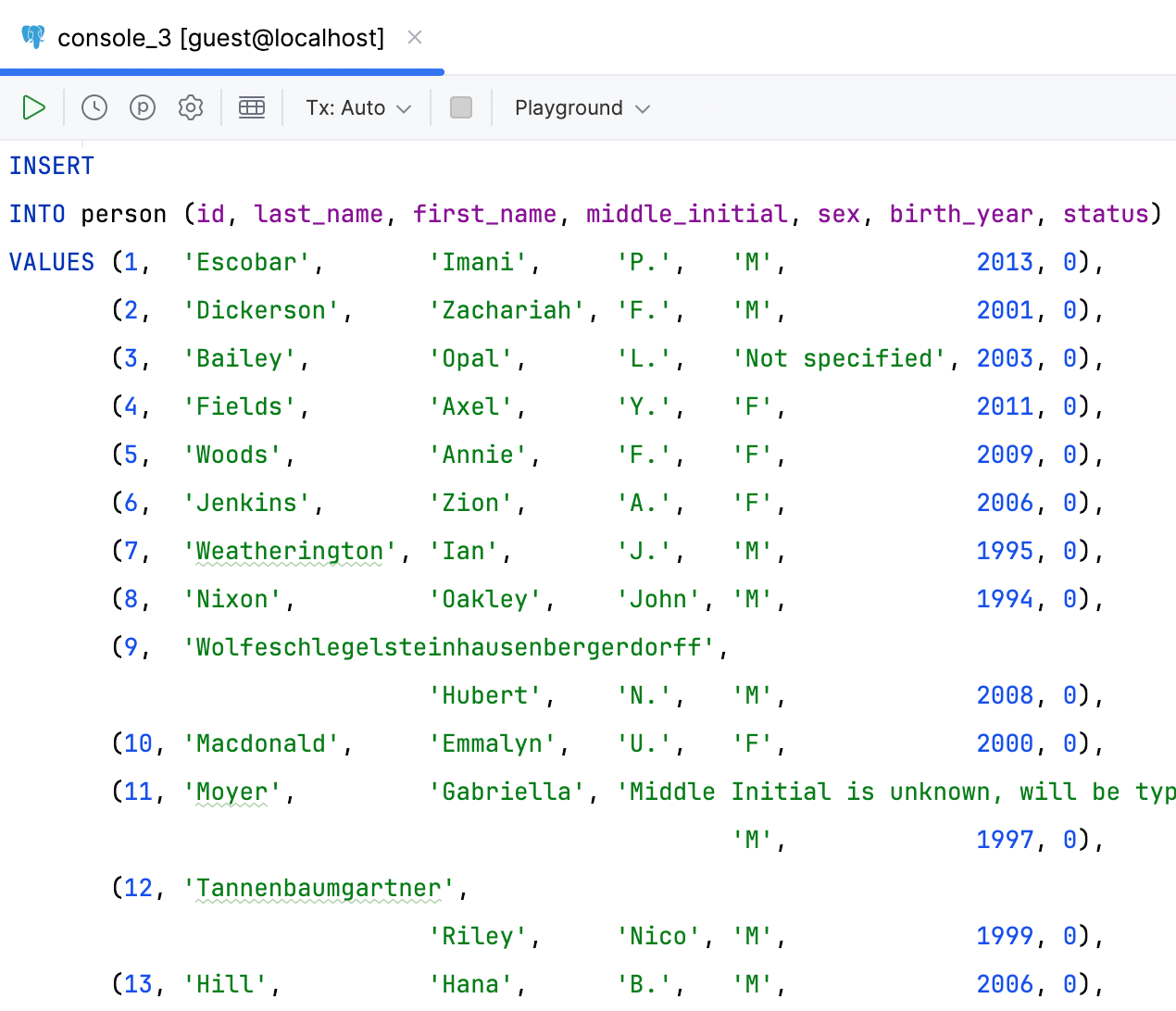
DataGrip is even able to handle situations where some values are much longer than others. The formatter will detect such values and make exceptions for them, moving the remaining fields to the next row.
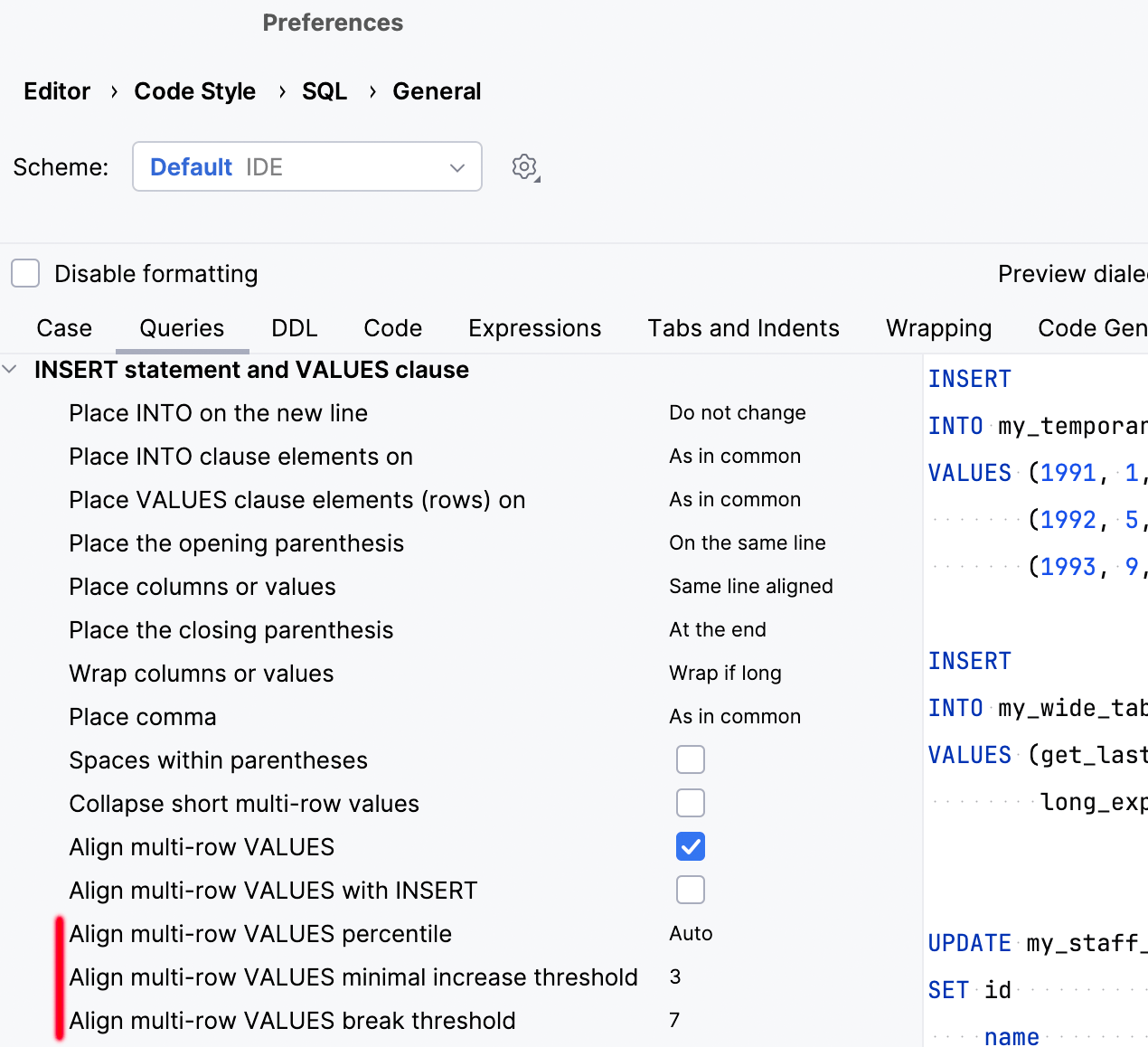
This behavior is managed by these three options:
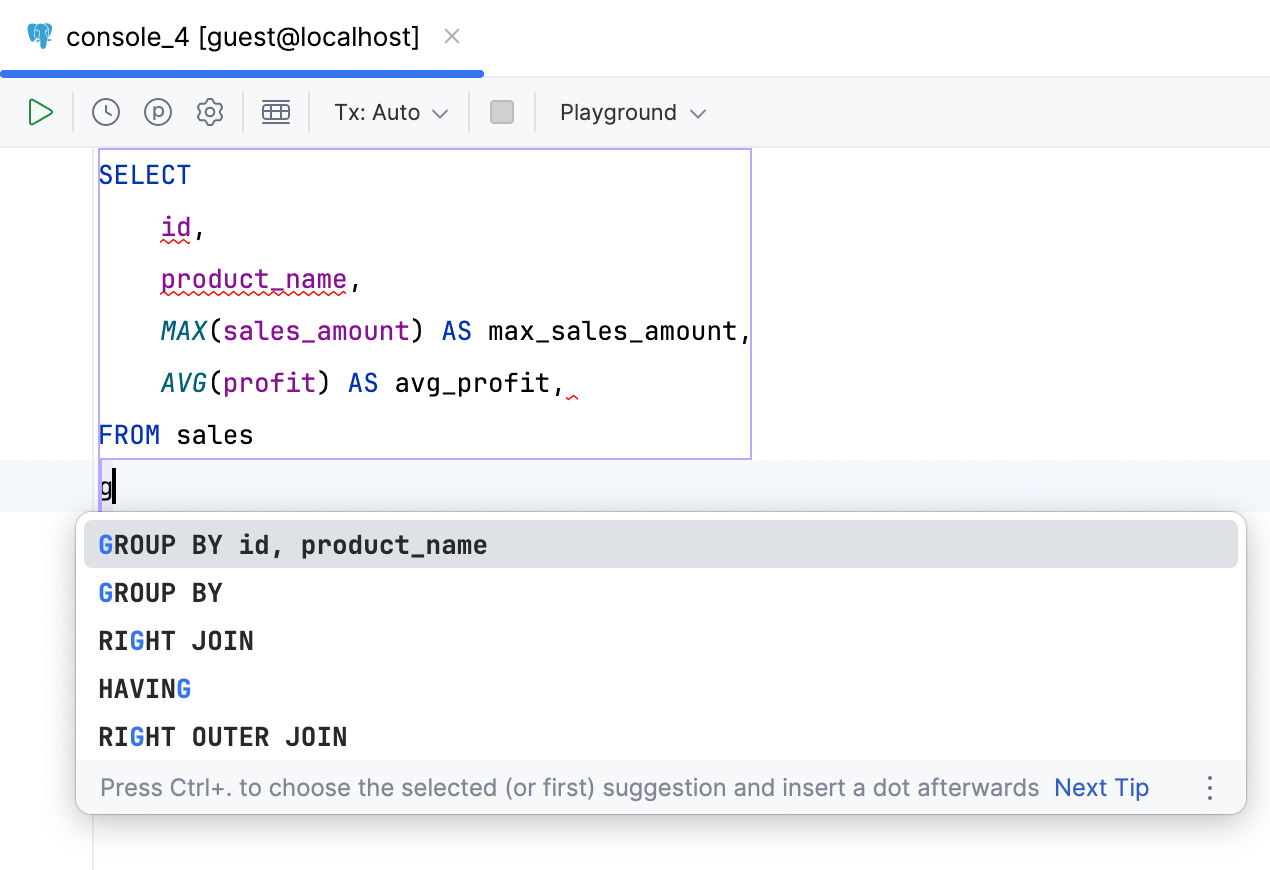
Column completion for GROUP BY clauses
DataGrip now analyzes the aggregates used in SELECT clauses and includes the appropriate column lists in GROUP BY clause suggestions.
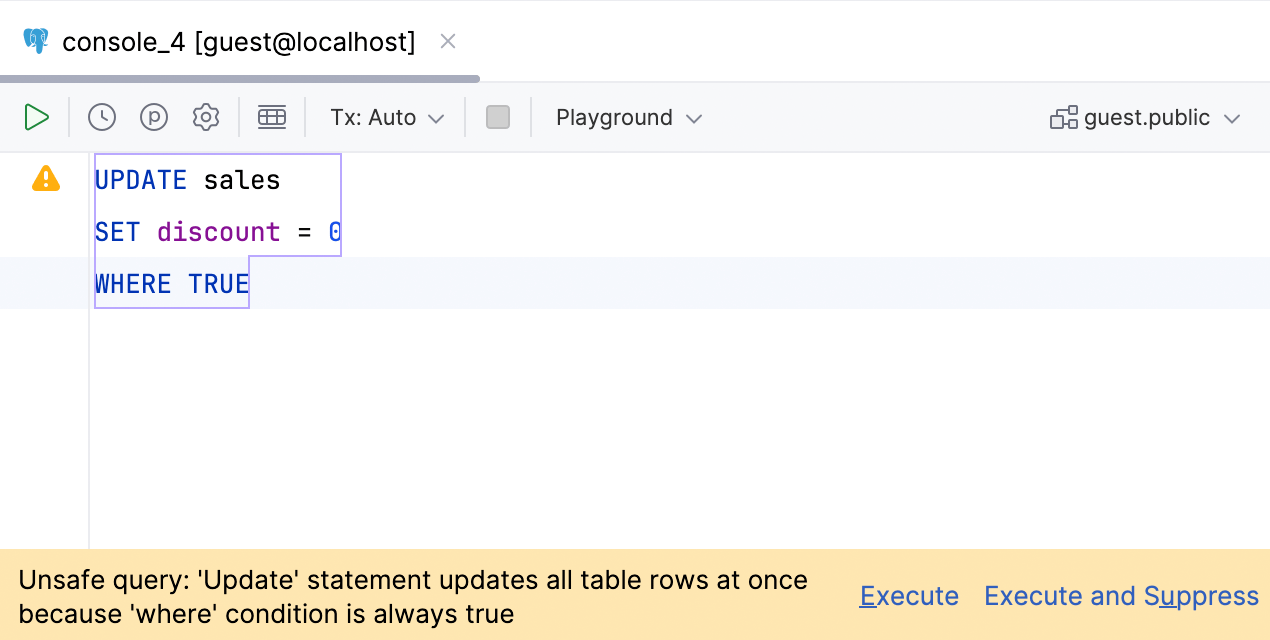
Warning for WHERE TRUE clauses
We’ve expanded our Unsafe query warning. It now warns you if you run a query with the WHERE TRUE condition or one of its variations. This can be a lifesaver if
you’re someone who likes having this clause for debugging purposes but occasionally forgets to change it!

Custom symbols to accept suggestions
We've added the ability to specify which symbols you will use to accept code completion suggestions, allowing you to write SQL even faster. To make this work, you need to enable two options. This one:
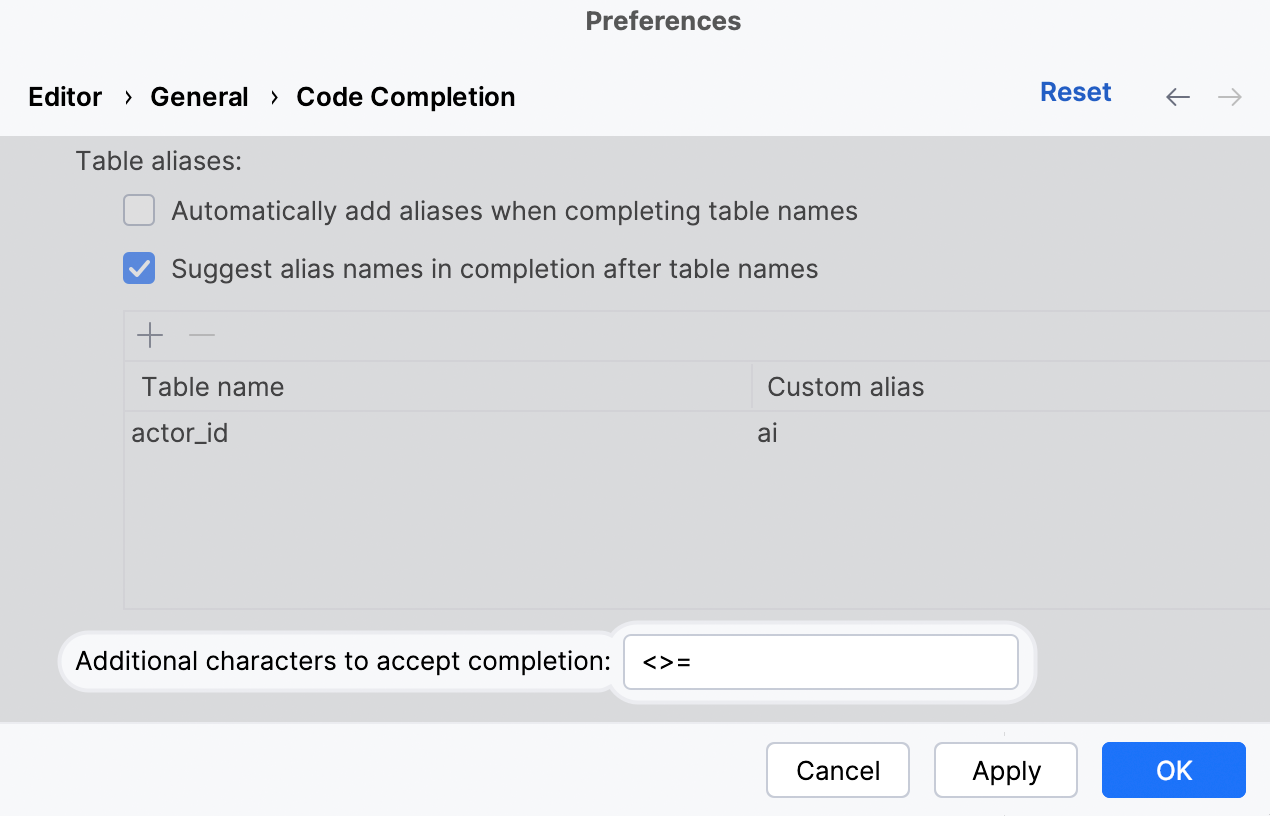
And this one:
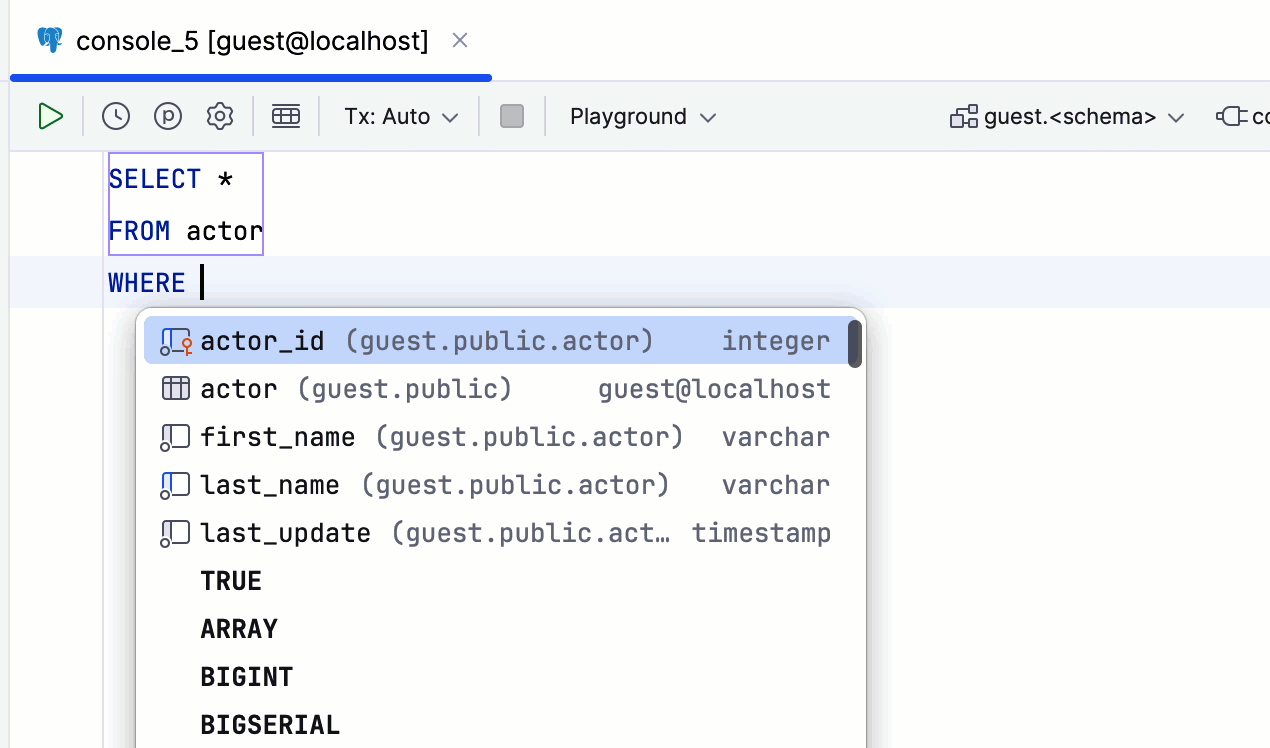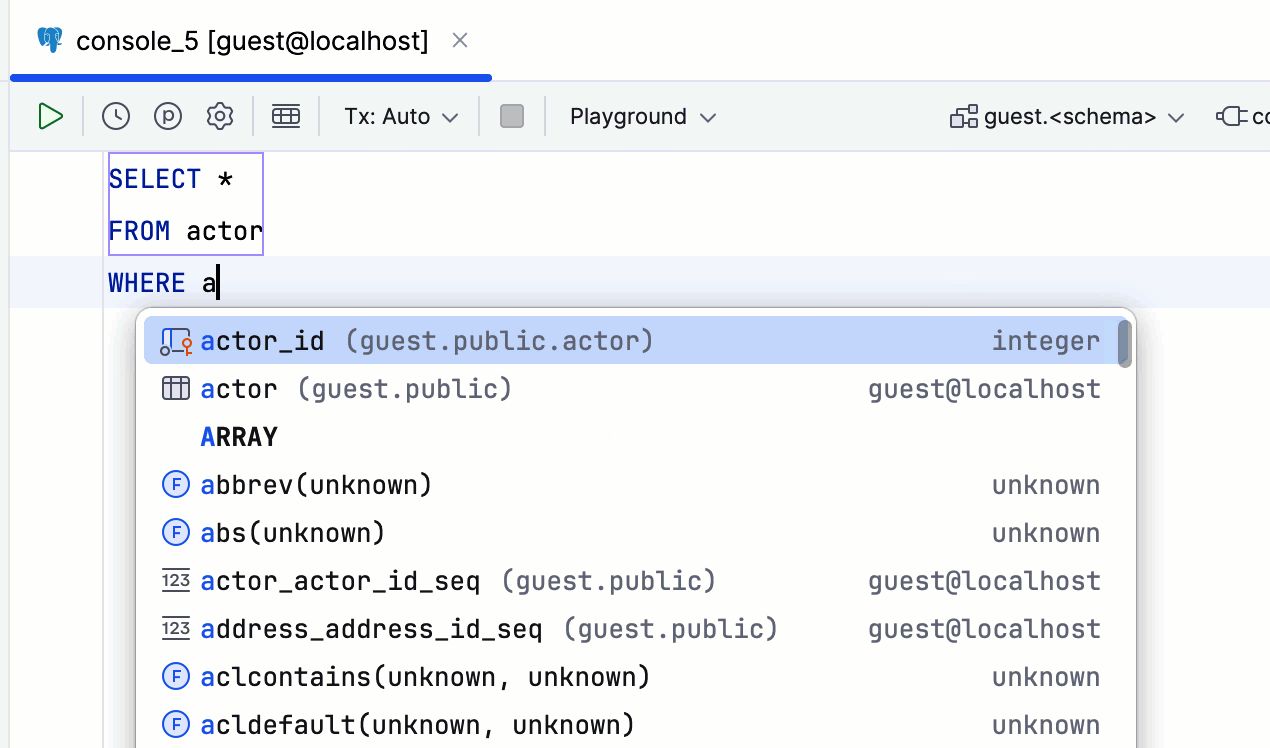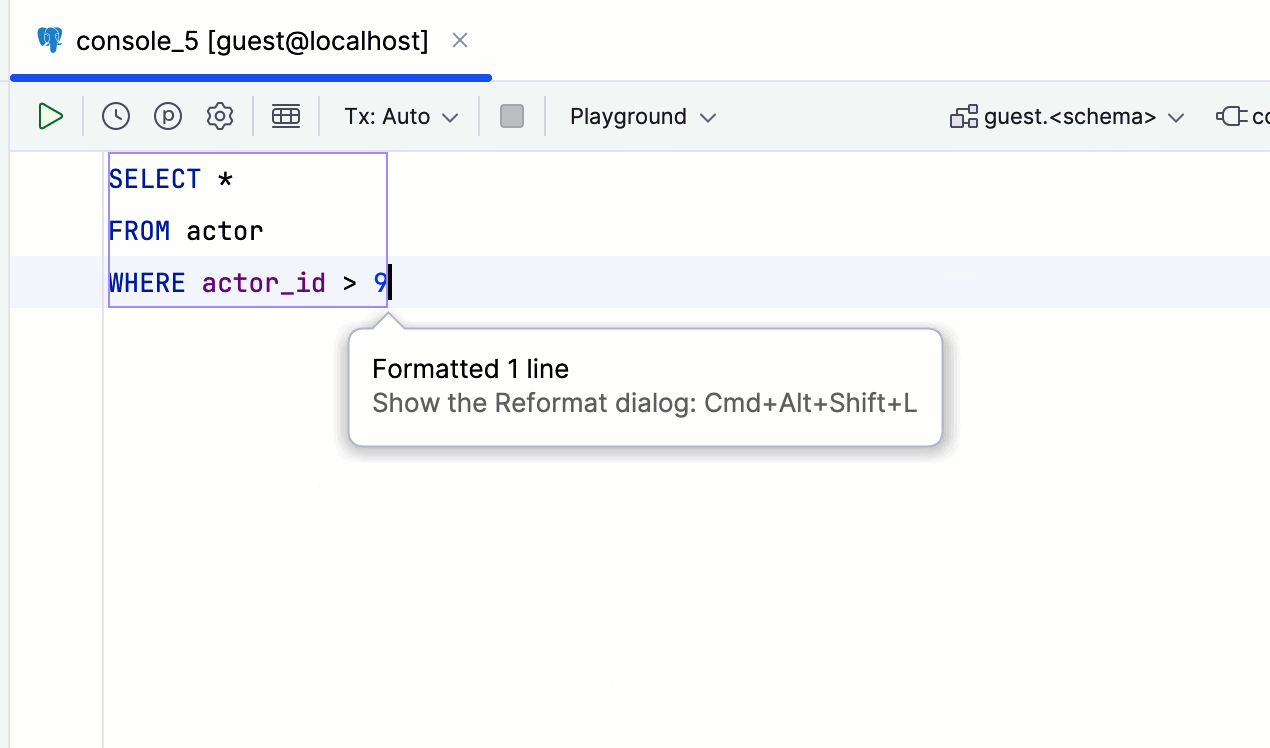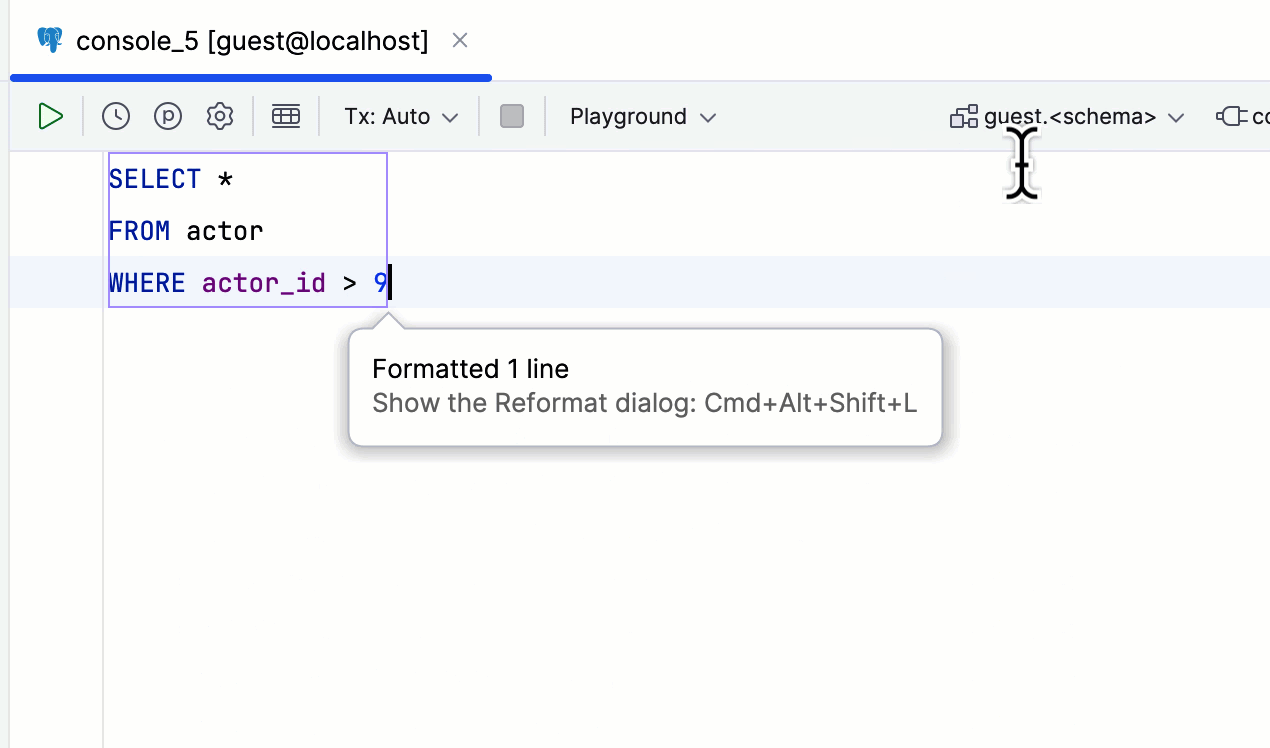
This feature can be especially useful when using operators:
Sticky lines in the editor
To simplify working with large files, we’ve introduced sticky lines in the editor. This feature keeps key structural elements, like CREATE statements, pinned to the top
of the editor as you scroll. This way, the context always remains in view, and you can promptly navigate through the code by clicking on a pinned line.
This feature is enabled by default. You can turn it off via a checkbox in Settings/Preferences | Editor | General | Appearance, where you can also set the maximum number of pinned lines.
Miscellaneous
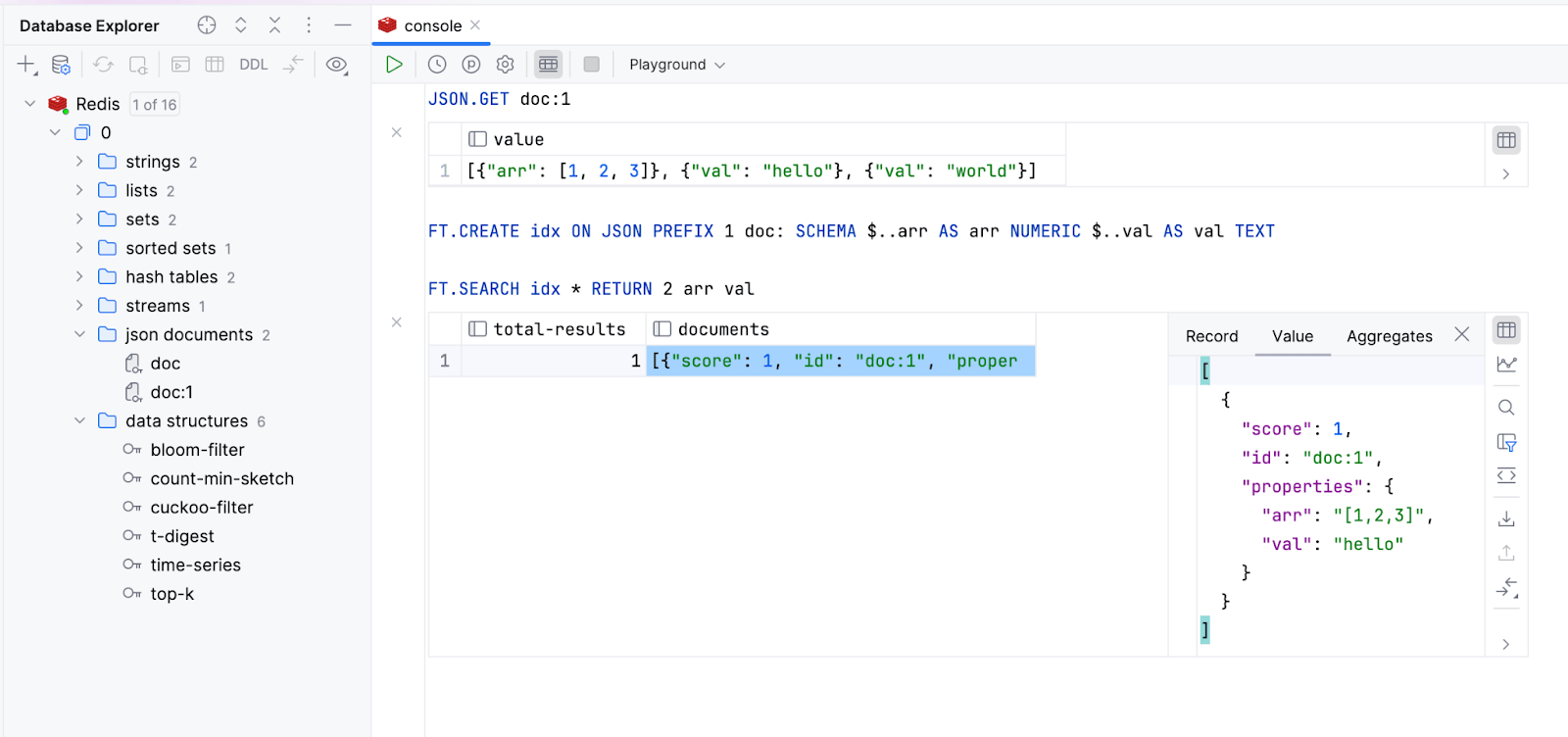
Support for Redis Stack module commands Redis
DataGrip now supports commands from the four main Redis Stack modules: RedisJSON, RediSearch, RedisBloom, and RedisTimeSeries. This support also requires the new version of the driver: v1.5. The RedisGraph module is obsolete and will no longer be supported. With this module support:
- You can send commands from these modules and see the results.
- Commands from these modules are properly highlighted.
- The keys of types provided by these modules are displayed in the database explorer.
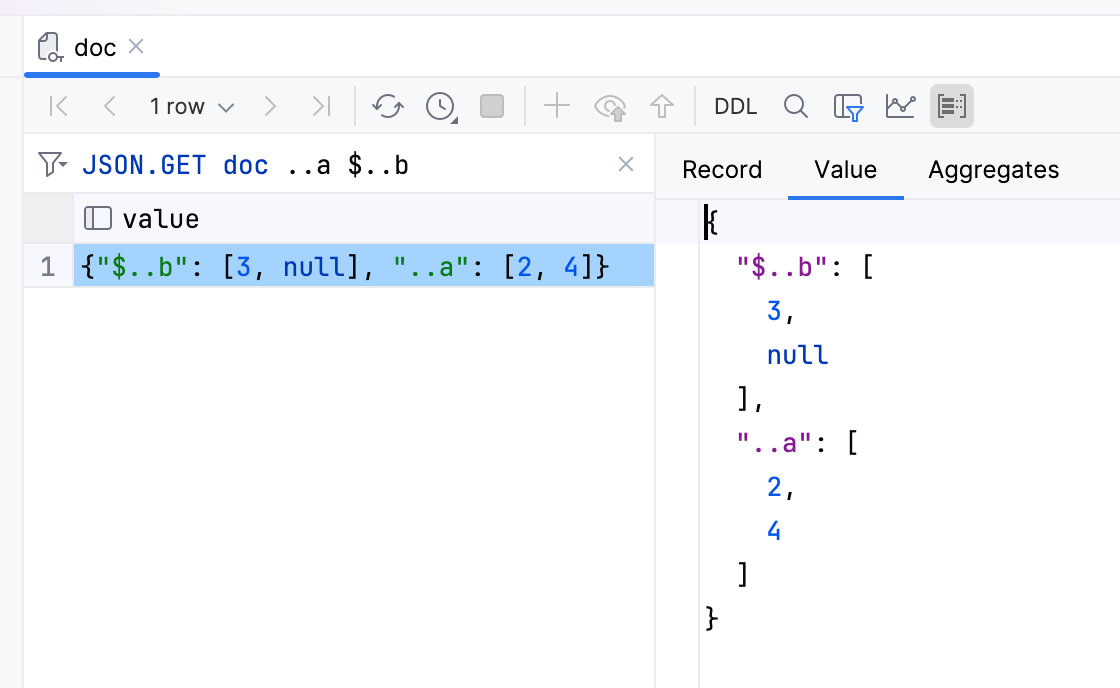
JSON documents
JSON documents are now displayed in a dedicated folder. You can view their values in the data viewer, and you can specify the JSON path.

Other data types
Keys of types provided by the RedisTimeSeries and RedisBloom modules are displayed under the data structures folder.
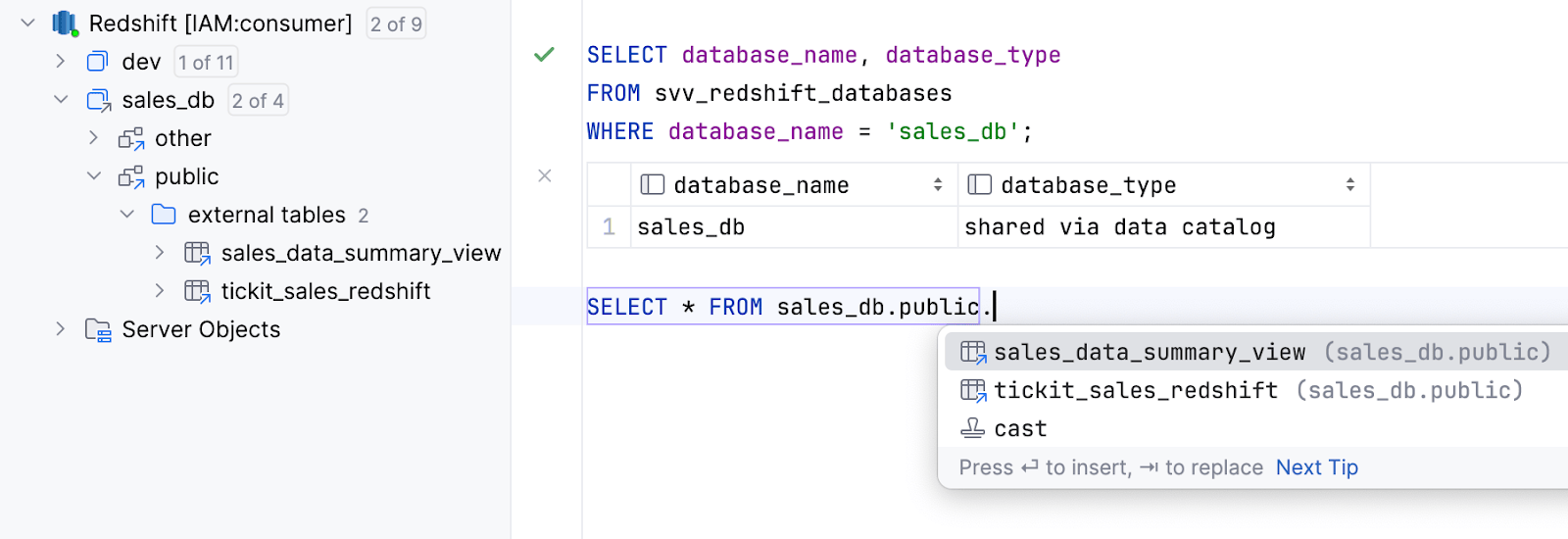
Support for external databases shared via data catalogs Amazon Redshift
External databases shared via data catalogs are now supported. Their content is now introspected and completion is available for them.