What’s New in DataSpell 2023.2
DataSpell 2023.2: Polars Support, Faster Table Data Exploration, and New UI Improvements
Polars Support
Interactive tables
DataSpell has introduced interactive tables for Polars DataFrames, allowing you to sort, export, and view data effortlessly. These tables are supported both in Jupyter notebooks and in Python consoles. You can conveniently access the tables using the Python and Jupyter debuggers, variable viewers, and Data Vision.
Column-name completion
We’ve introduced column-name completion for supported Polars functions. This feature simplifies your interactions with the library and facilitates data manipulation within DataSpell.
Faster Table Data Exploration
Faster table data exploration
We have streamlined the data exploration process, which is crucial and often time-consuming for data professionals. By simply hovering over a column’s header, you can now access valuable information about it, such as the value distribution, mean, and standard deviation, as well as missing values. This feature is currently available for pandas and Polars DataFrames.
New UI Improvements
Colored project headers in the new UI
DataSpell 2023.2 introduces colored headers to simplify navigation between multiple open projects. You can now assign a unique color and icon to each of your projects, making them easier to distinguish in your workspace. Headers now come with predefined colors by default, but you can customize them. To set a new color for your project, first right-click on a header to access the context menu. Then select the Change Toolbar Color option and choose your desired color. To disable this feature, deselect the Use Project Colors in Toolbar option in the context menu.
Single-click navigation between project directories
In the Project view, there’s a new Open Directories with a Single Click option that makes expanding and collapsing the project folders quicker and more responsive. The option is available from the drop-down menu once you click on the kebab (three vertical dots) menu.
Jupyter-managed server configuration support
Jupyter-managed server configuration support
DataSpell 2023.2 allows configuring Jupyter-managed servers, providing you with, among other things, the ability to:
- Specify environment variables for managed servers.
- Configure managed servers to launch from any directory, not just the project root.
- Specify additional parameters for Jupyter or the JupyterLab servers.
Improved Synchronization of Jupyter Notebooks With External Applications
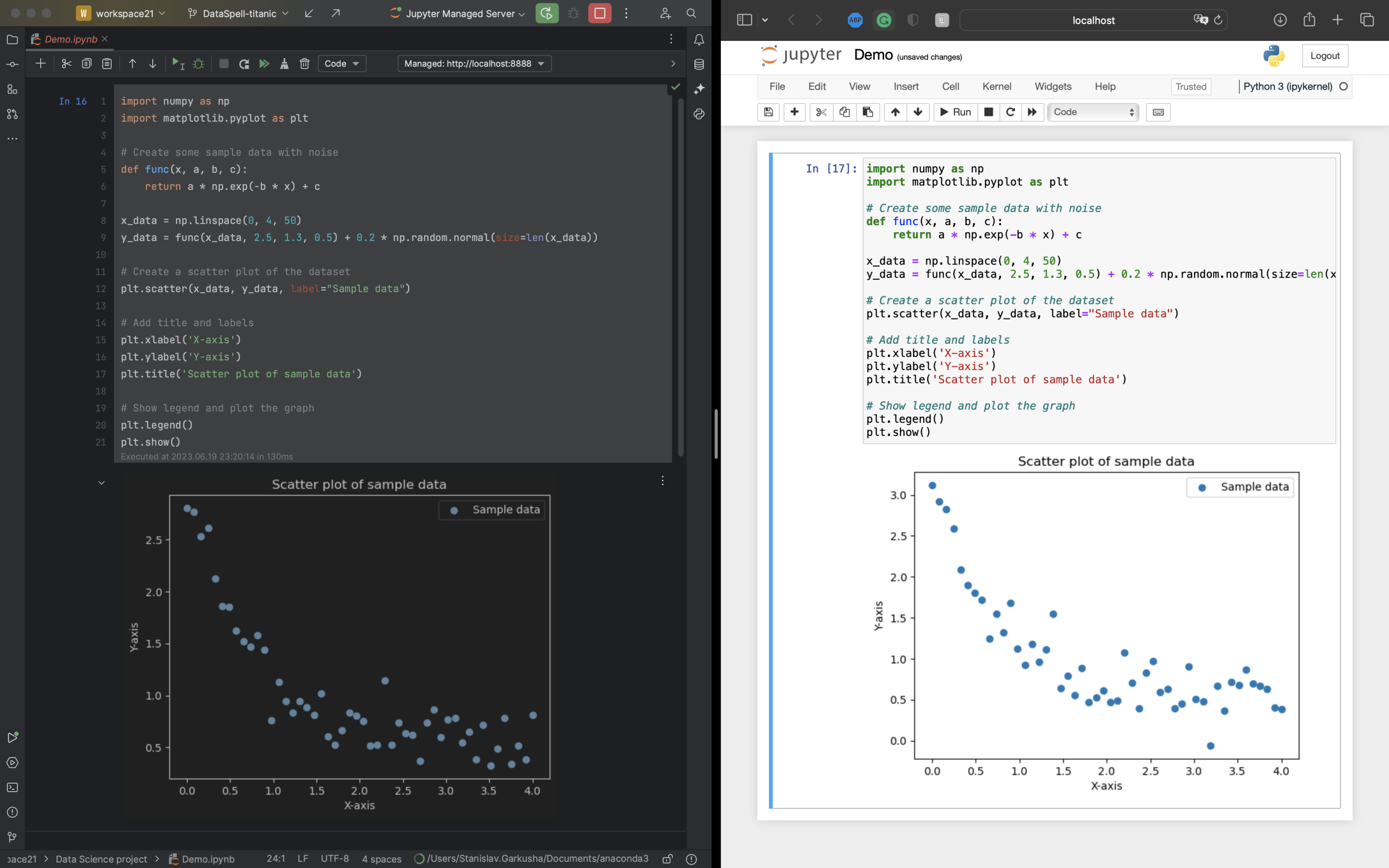
Improved synchronization of Jupyter notebooks with external applications
In this release, we have significantly improved how Jupyter notebook changes are synchronized between DataSpell and external applications such as Git or the browser version of Jupyter. You can effortlessly switch between DataSpell and external applications, and any changes you make in either place will be perfectly synchronized.
Data Management
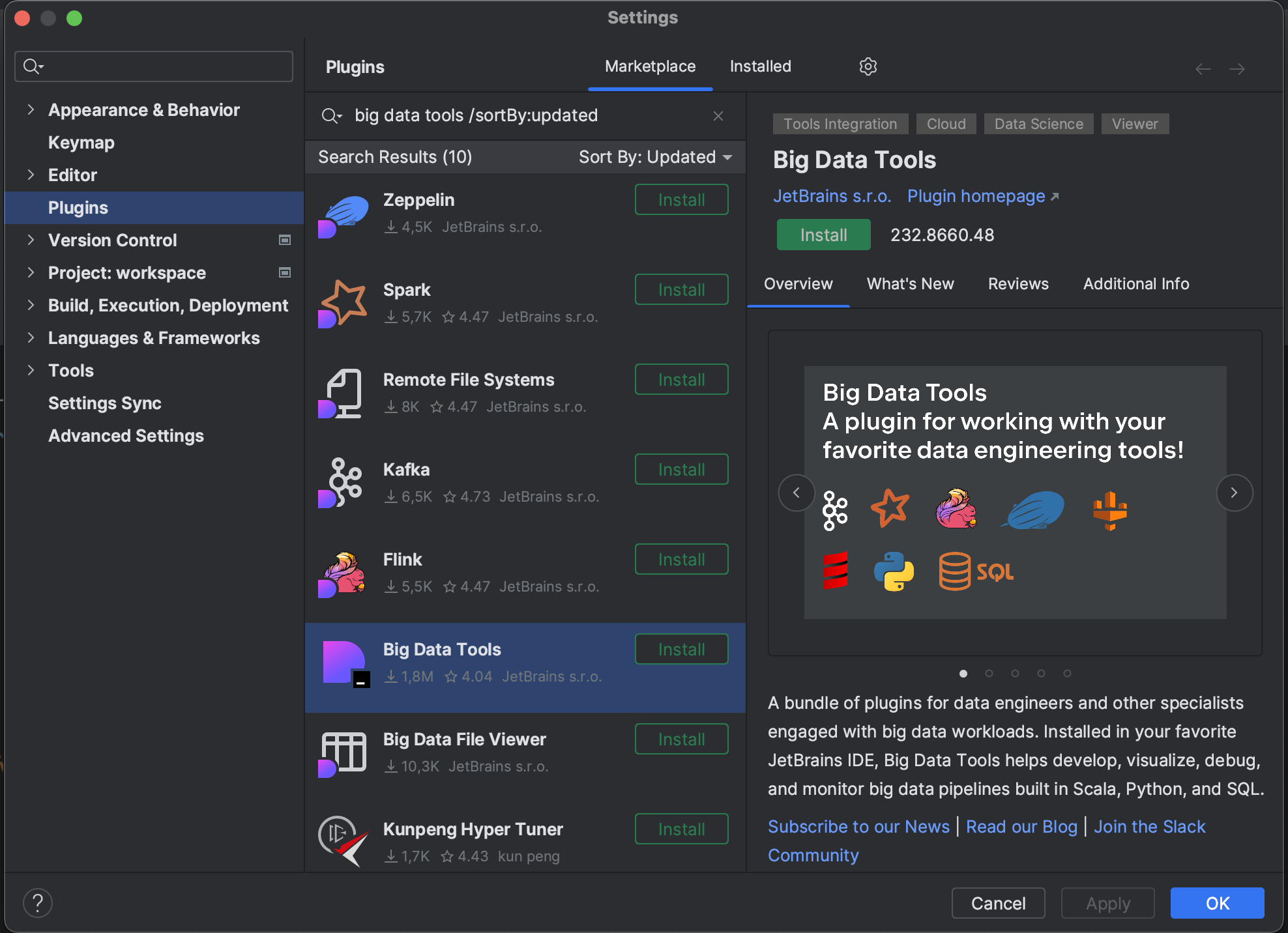
Big Data Tools plugin
We have decomposed the Big Data Tools plugin, allowing you to use its parts separately. This means six new plugins are available for DataSpell: Kafka, Spark, Flink, Remote File Systems, Big Data File Viewer, and Zeppelin. If you need all six, installing the umbrella Big Data Tools plugin is still possible and a convenient way to get them all in one click.
Support for Redis Cluster Databases plugin
With the latest update, you can now connect to Redis Cluster and enjoy the same comprehensive feature set as with standalone Redis.
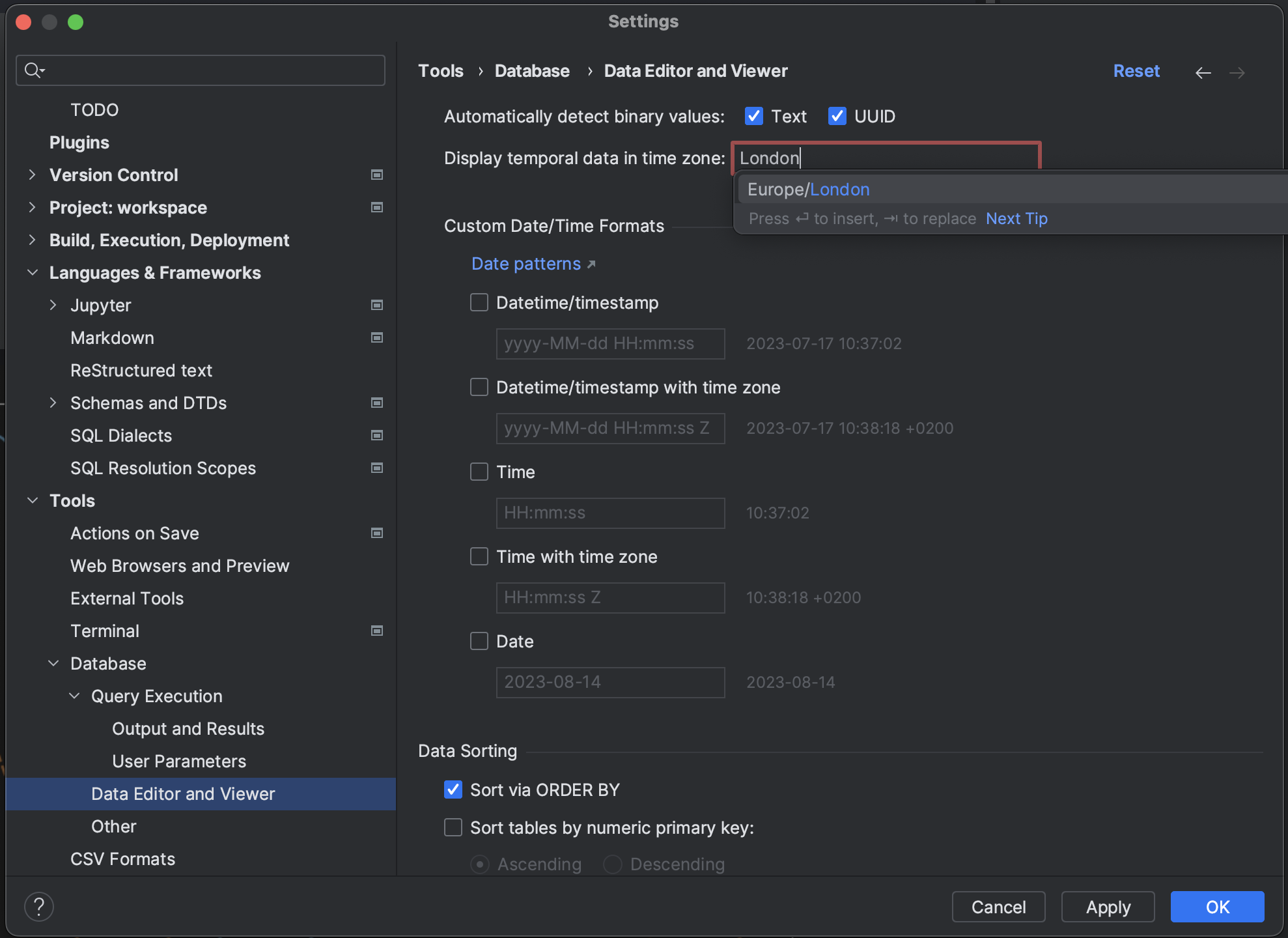
Time zone setting for the data editor Databases plugin
DataSpell offers a new Time zone setting, allowing you to specify which
time zone should be used for displaying datetime values.
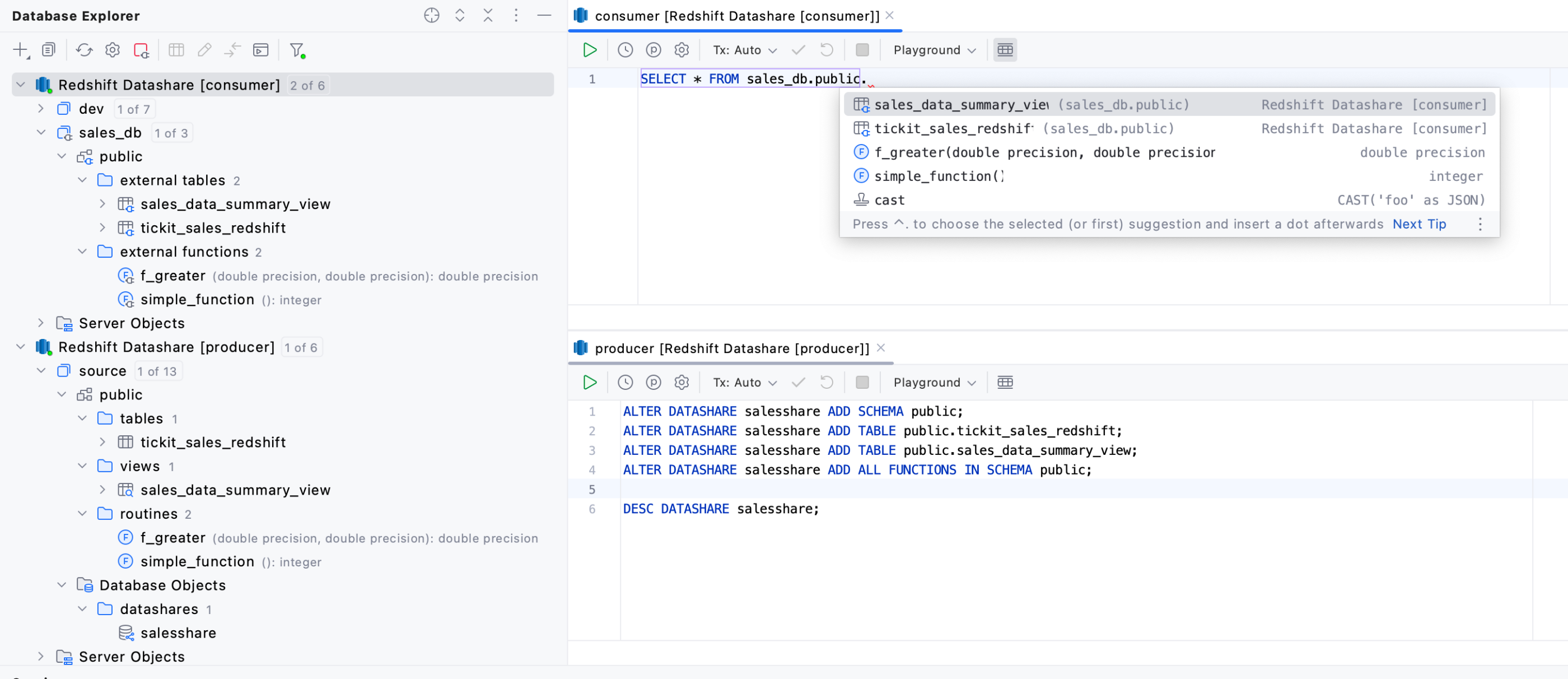
Support for external databases and datashares Databases plugin Redshift
Shared databases and their contents are now introspected. The datashares that these databases are created on are also introspected. You can modify shared databases and datashares using the Ctrl/Cmd + F6 shortcut. Furthermore, all related statements are now supported in the SQL editor.
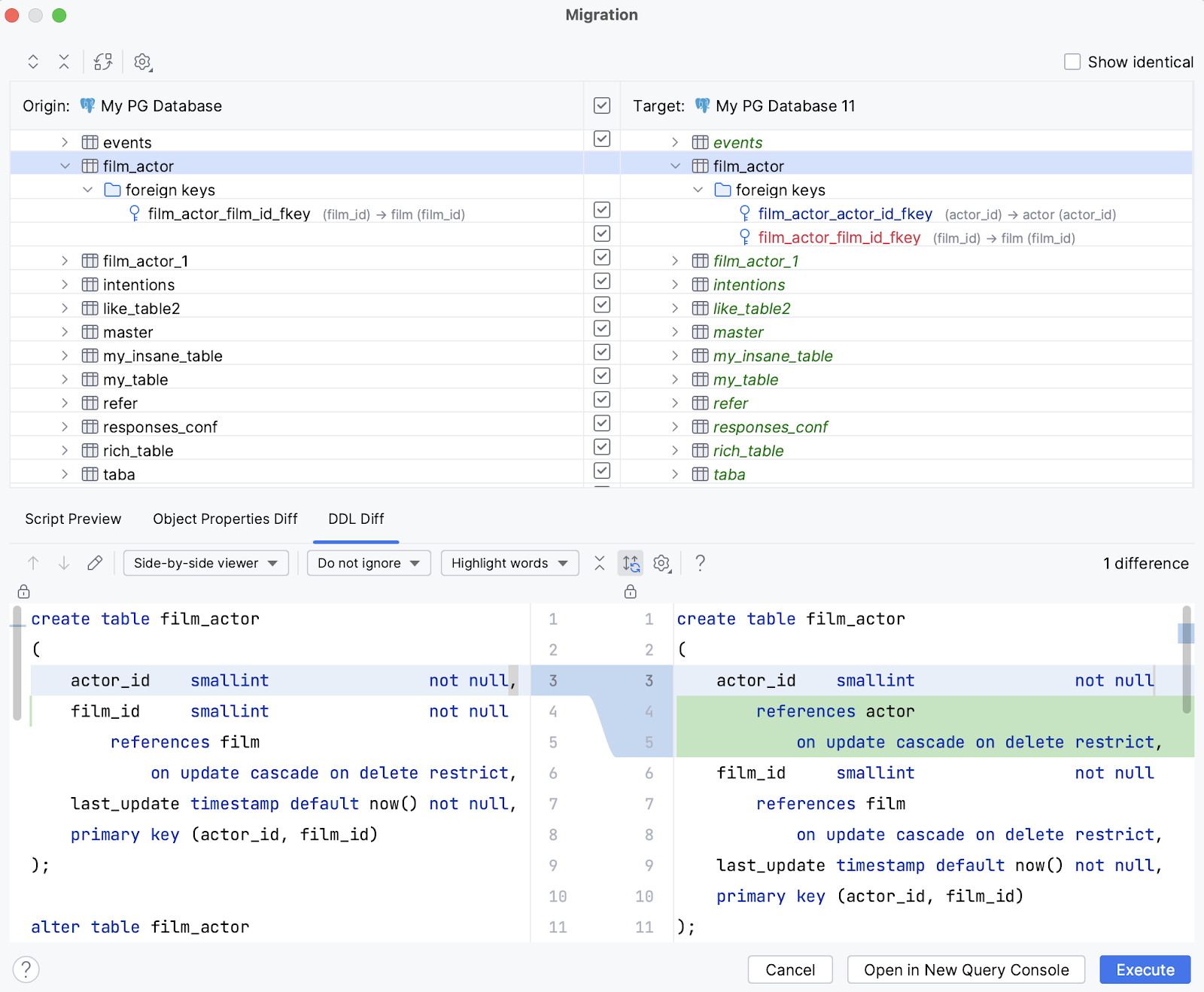
New UI for the schema migration dialog Databases plugin
To enhance usability, we have significantly improved the schema migration functionality in this release of DataSpell.
The major change is that the same object is now placed on the same line in both parts of the dialog, making it easier to understand which objects will be added, removed, or modified in the target schema.