Das ist neu in DataGrip 2021.3
DataGrip 2021.3 ist da! Dies ist das dritte große Update des Jahres 2021, und es ist vollgepackt mit den verschiedensten Verbesserungen. Sehen wir uns an, was es zu bieten hat!
Dateneditor
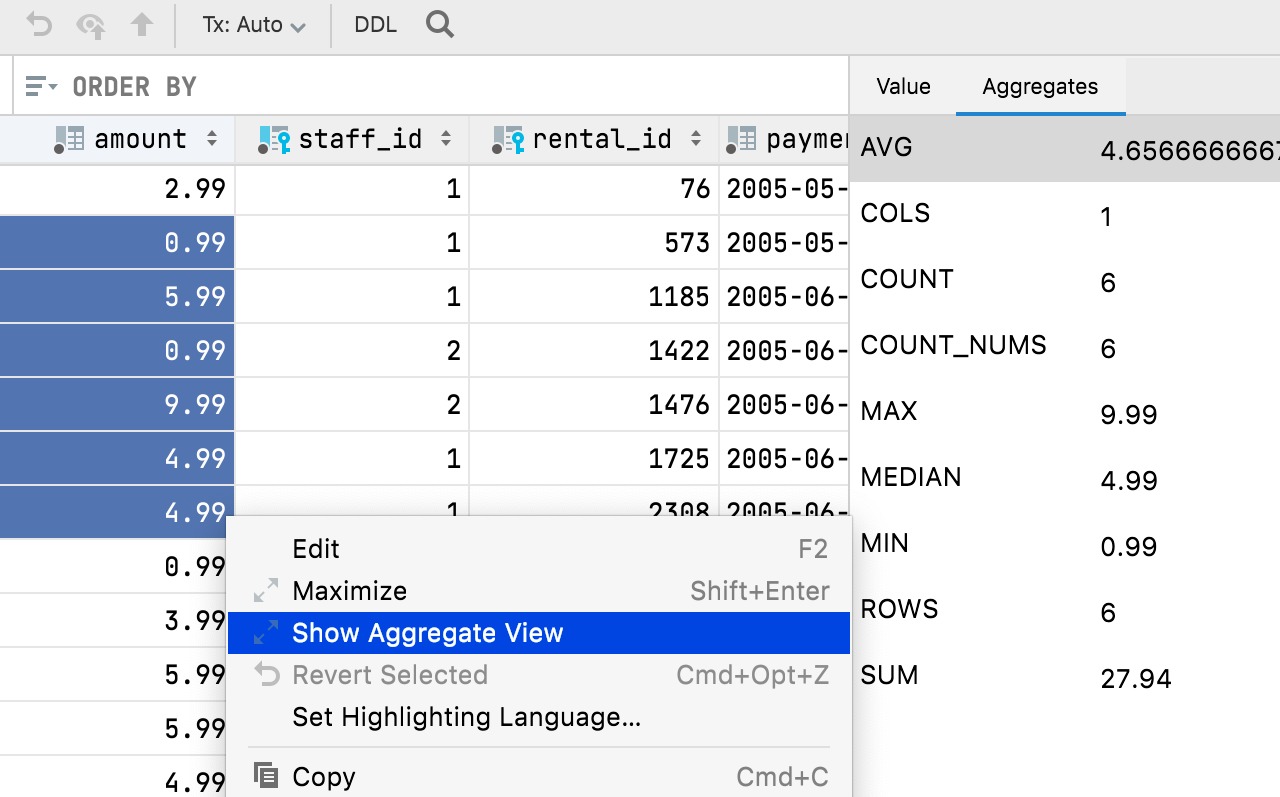
Aggregate
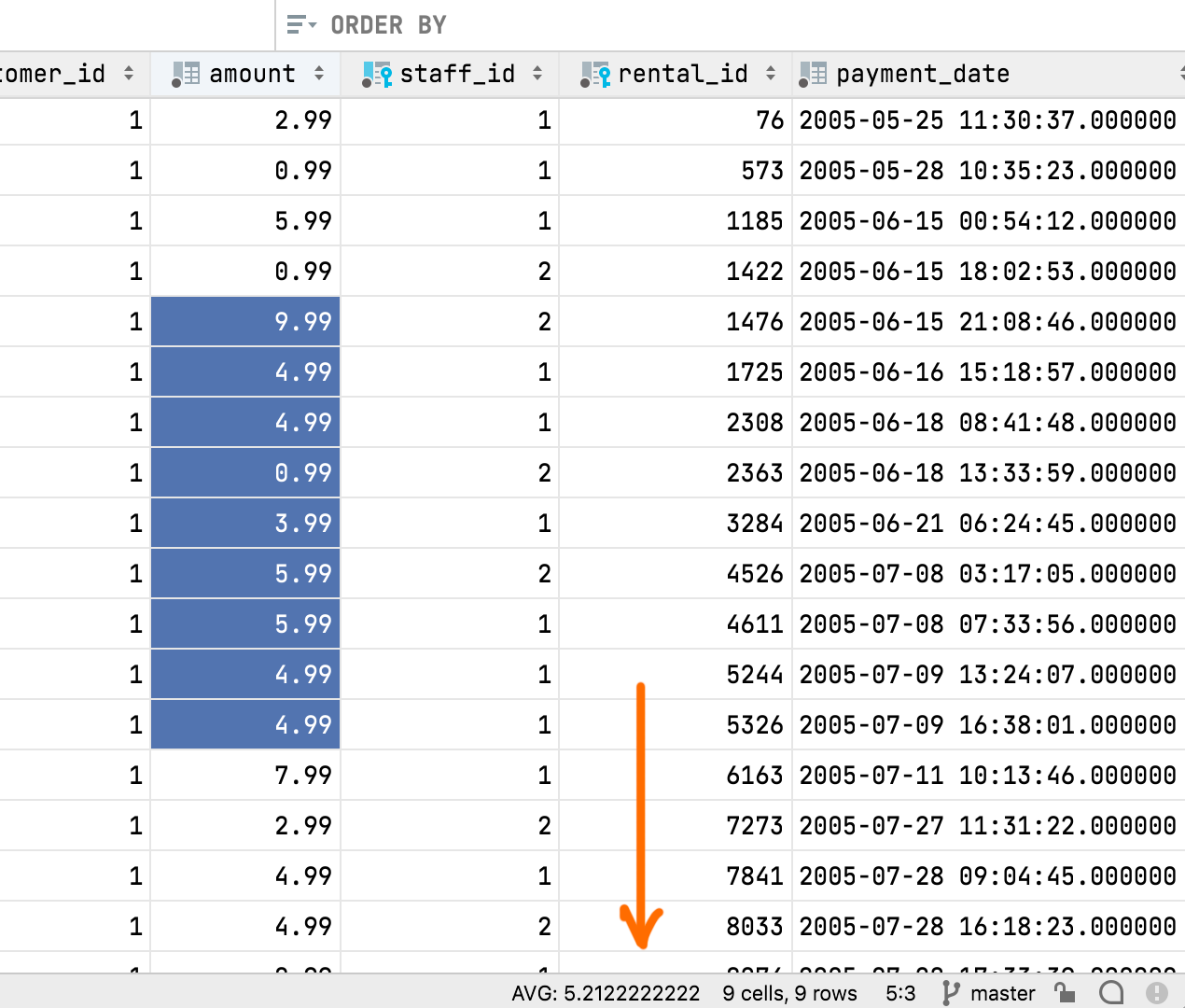
Wir haben die Möglichkeit hinzugefügt, eine aggregierte Ansicht für einen Zellenbereich anzuzeigen. Diese lang erwartete Funktion hilft Ihnen bei der Verwaltung Ihrer Daten und dürfte Ihnen so manche zusätzliche Abfrage ersparen! Der Dateneditor wird dadurch noch leistungsfähiger und benutzerfreundlicher und kommt Excel und Google Tabellen einen Schritt näher.
Wählen Sie einfach den gewünschten Zellenbereich aus, klicken Sie mit der rechten Maustaste und wählen Sie Show Aggregate View.
Das Wichtigste in Kürze:
- Die Aggregate-Ansicht teilt sich einen Fensterbereich mit der Value-Ansicht – beide haben jetzt ihren jeweils eigenen Tab. Sie können diesen Bereich an den unteren Rand des Dateneditors verschieben.
- Mit dem Zahnradsymbol können Sie beliebige Aggregate in dieser Ansicht ein- oder ausblenden.
- Wie Extraktoren sind auch Aggregate Skripte. Zusätzlich zu den neun standardmäßig mitgelieferten Skripten können Sie Ihre eigenen Skripte erstellen und mit anderen teilen.
- Aggregatskripte und Extraktoren sind austauschbar. Wenn Sie zuvor einen Extraktor verwendet haben, um einen Einzelwert zu erhalten, können Sie ihn jetzt in den Ordner Aggregators kopieren und für Aggregate verwenden. Diesen Ordner finden Sie wie auch den Ordner Extractors unter Scratches and consoles / Extensions / Database Tools and SQL.
In der Statusleiste wird ein Aggregat angezeigt, und Sie können auswählen, welcher Wert (Summe, Mittelwert, Median, Minimum, Maximum usw.) das sein soll.
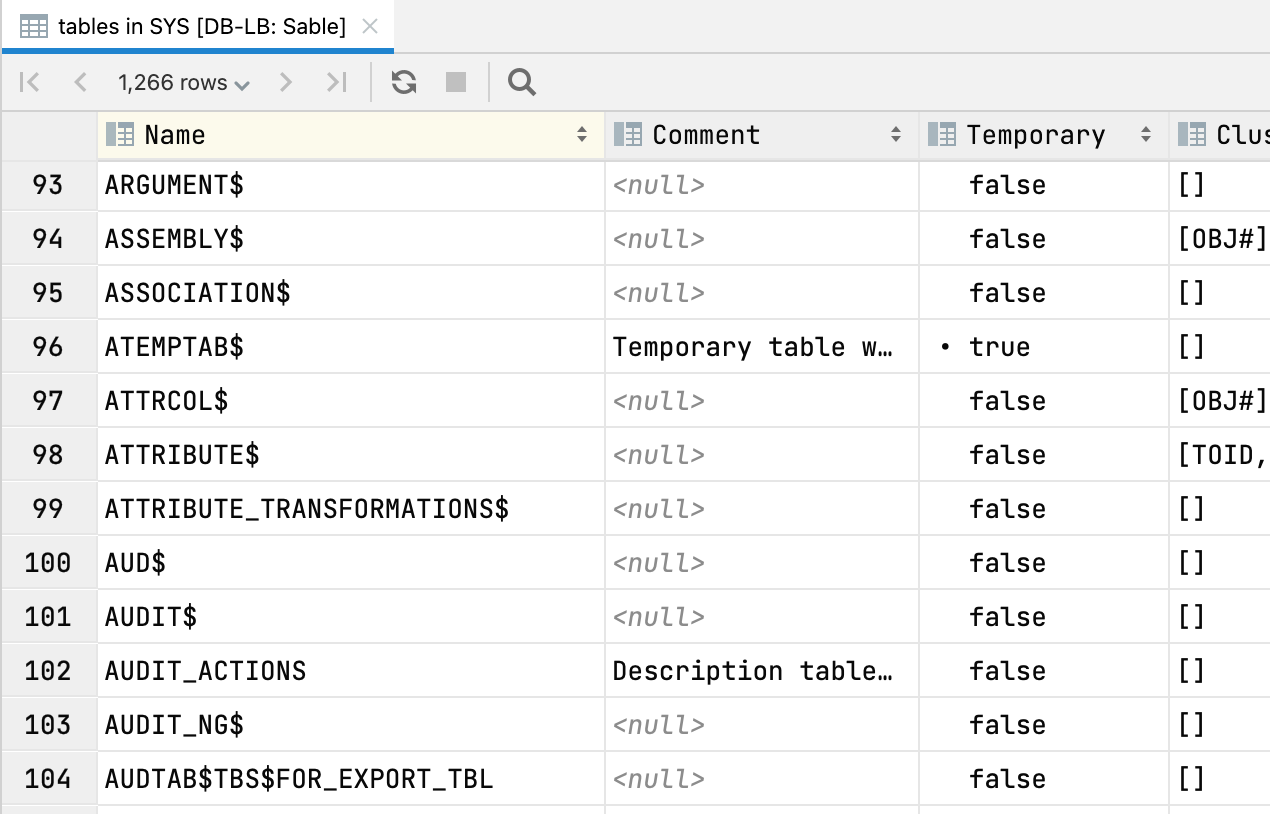
Tabellenansicht für Baumknoten
Durch Drücken von F4 auf einem Schemaknoten wird der Inhalt in einer Tabellenansicht angezeigt. Sie können sich beispielsweise eine Tabellenansicht aller Tabellen in Ihrem Schema anzeigen lassen:
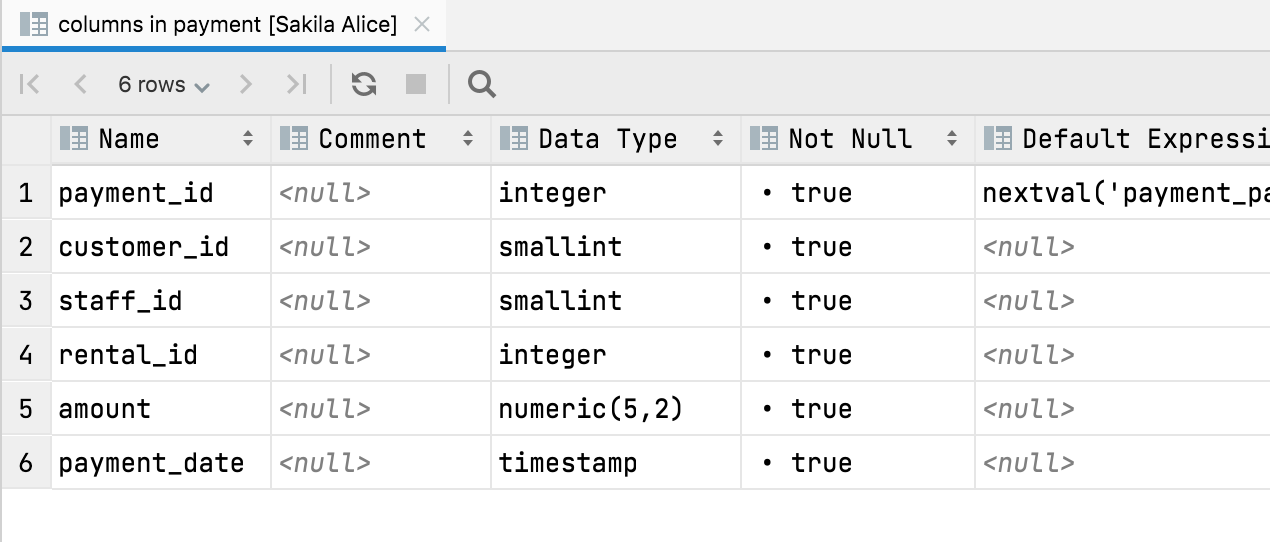
Oder Sie können eine Tabellenansicht der Spalten einer Tabelle abrufen:
In dieser Ansicht können Sie Spalten aus- und einblenden, die Daten in zahlreiche Formate exportieren und die Textsuche verwenden. Noch wichtiger dürfte sein, dass die folgenden Navigationsaktionen ebenfalls funktionieren:
- Strg+B zeigt die DDL.
- F4 zeigt die Daten.
- Alt+Umschalt+B hebt das Objekt in der Datenbankstruktur hervor.
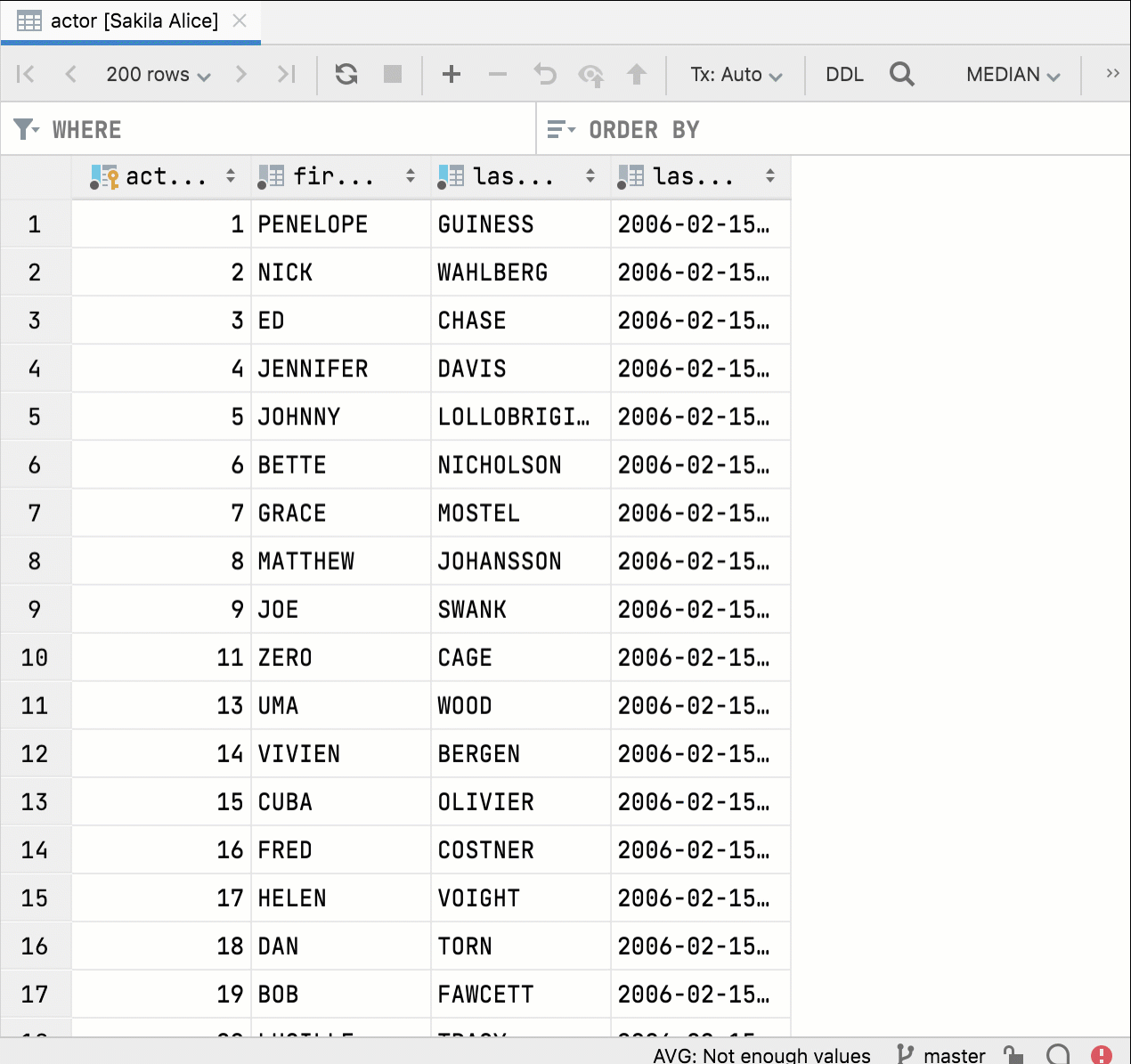
Aufteilung in unabhängige Fenster
Wenn Sie den Editor teilen und dieselbe Tabelle erneut öffnen, sind jetzt die beiden Dateneditor-Fenster völlig unabhängig voneinander. Sie können dann unterschiedliche Filter- und Sortieroptionen festlegen, um die Daten zu vergleichen und zu bearbeiten. In früheren Versionen wurden Filter- und Sortieroptionen synchronisiert, was nicht ideal war.
Benutzerdefinierte Schriftart
Sie können unter Database | Data views | Use custom font eine separate Schriftart für die Datenanzeige auswählen.
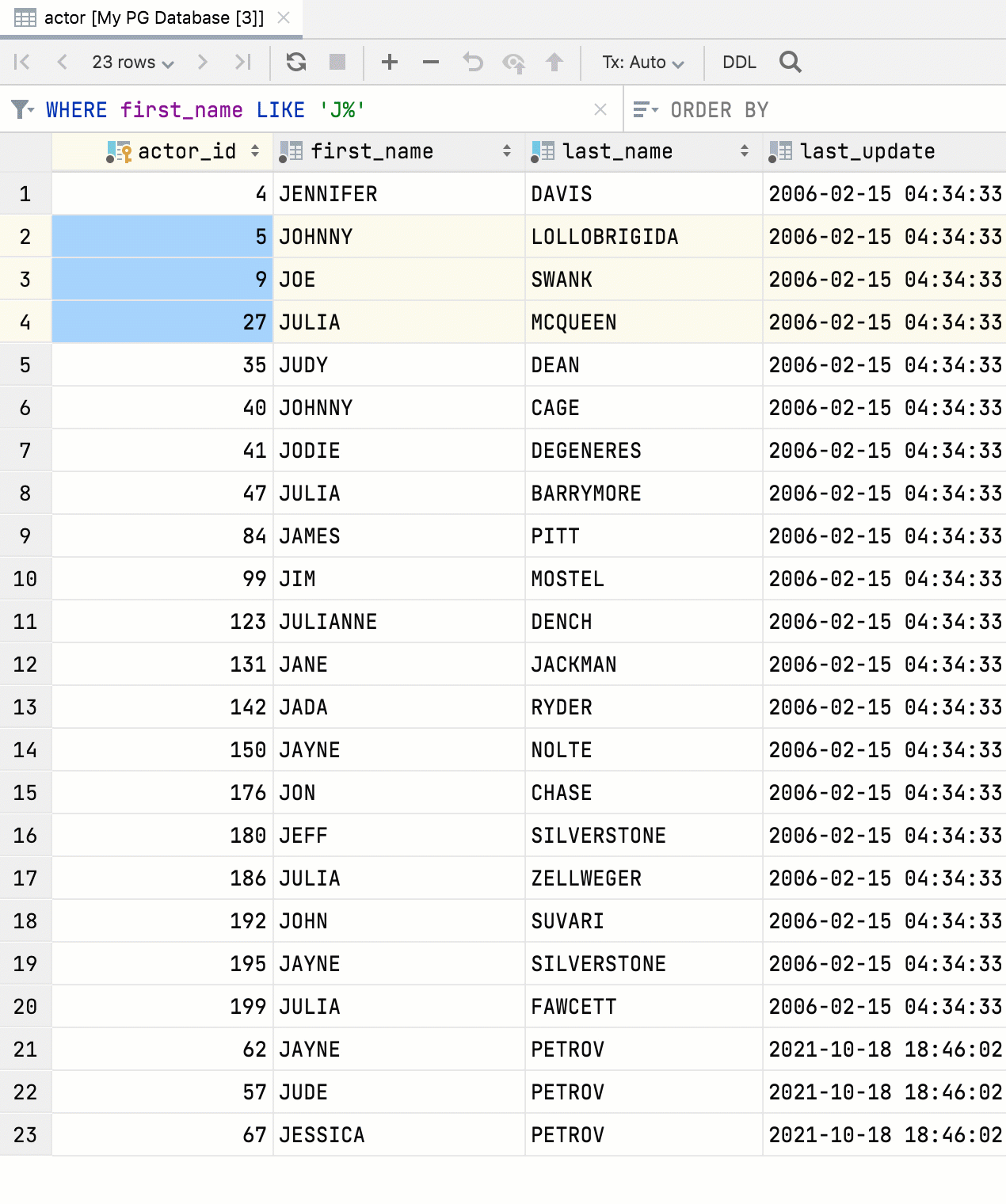
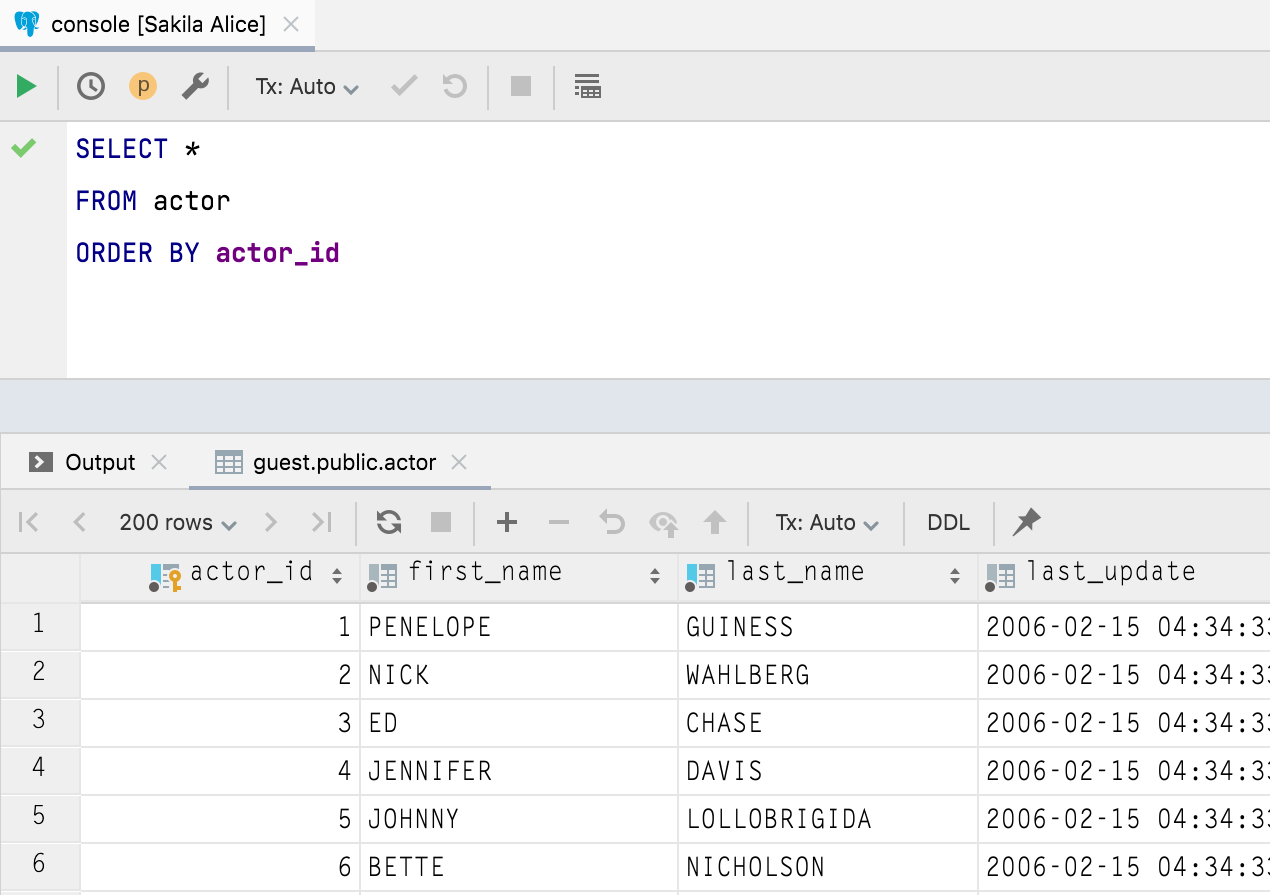
Fremdschlüssel-Navigation anhand mehrerer Werte
Im Dateneditor können Sie nun mehrere Werte auswählen und zu den zugehörigen Daten navigieren.
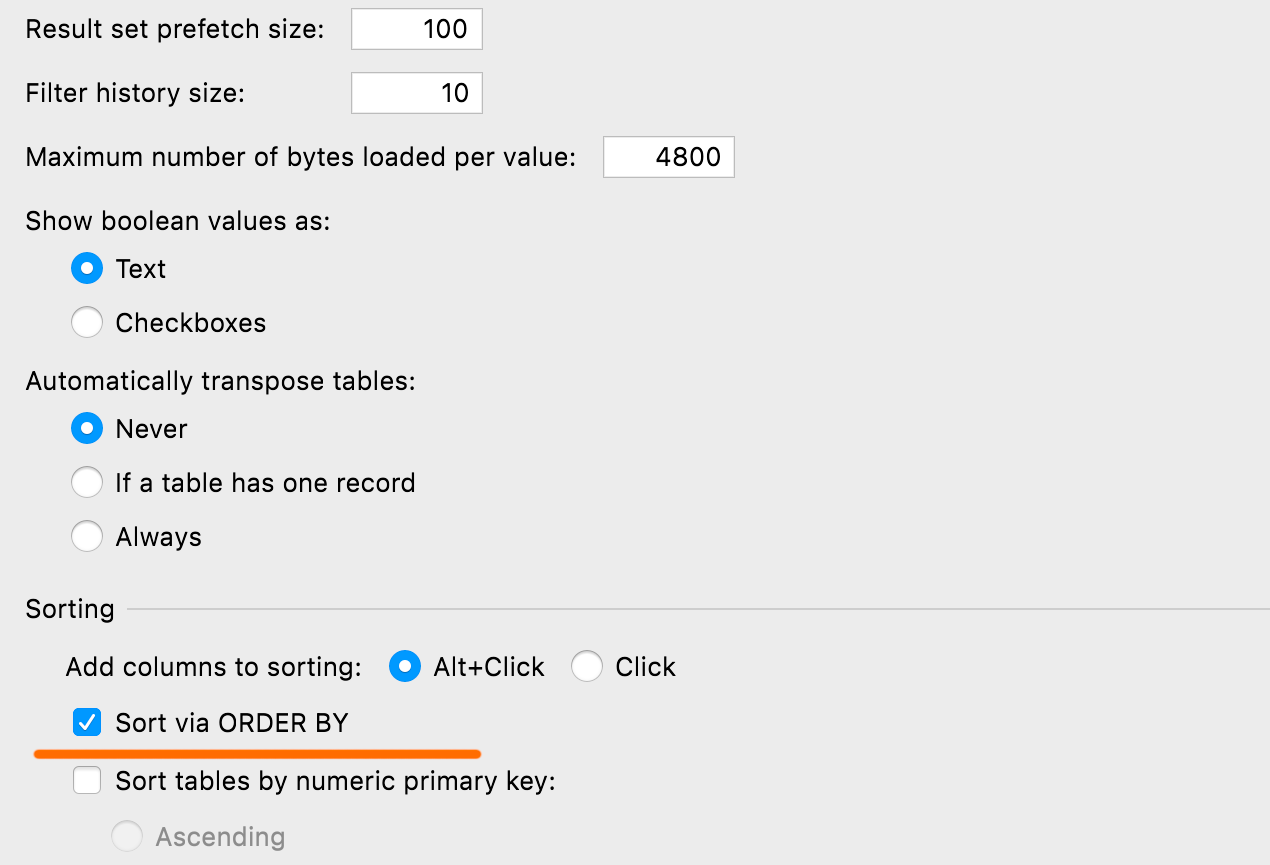
Einstellbare Standardsortierung
Sie können die Standardmethode zum Sortieren von Tabellen definieren – über ORDER BY oder auf der Clientseite. Die letztere Methode führt keine neuen Abfragen aus und sortiert nur die aktuelle Seite. Die Einstellung finden Sie unter Database | Data views | Sorting | Sort via ORDER BY.
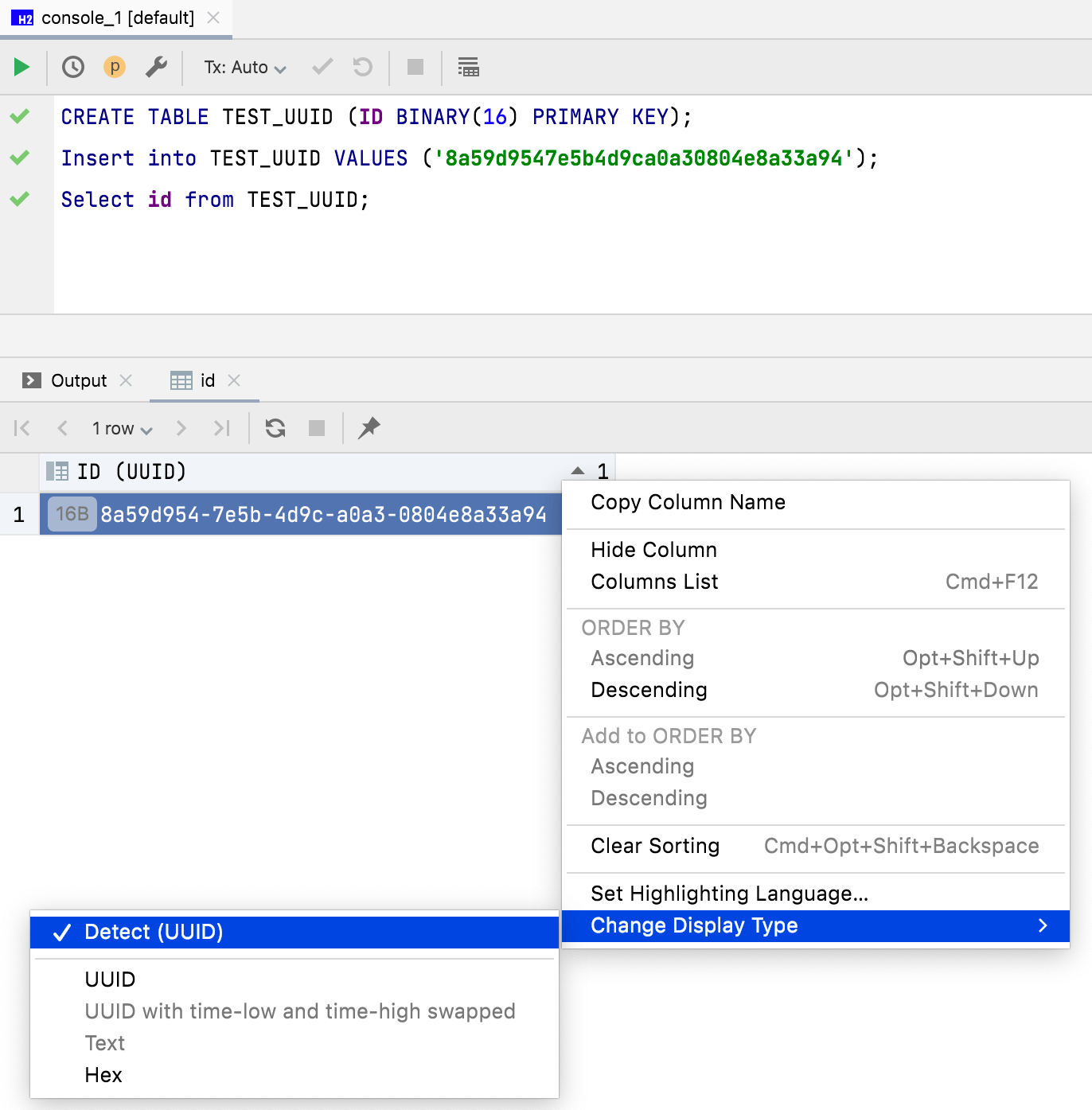
Anzeigemodus für Binärdaten
16-Byte-Daten werden jetzt standardmäßig als UUID angezeigt. Sie haben auch die Möglichkeit, die Anzeige von Binärdaten in der Dateneditor-Spalte anzupassen.
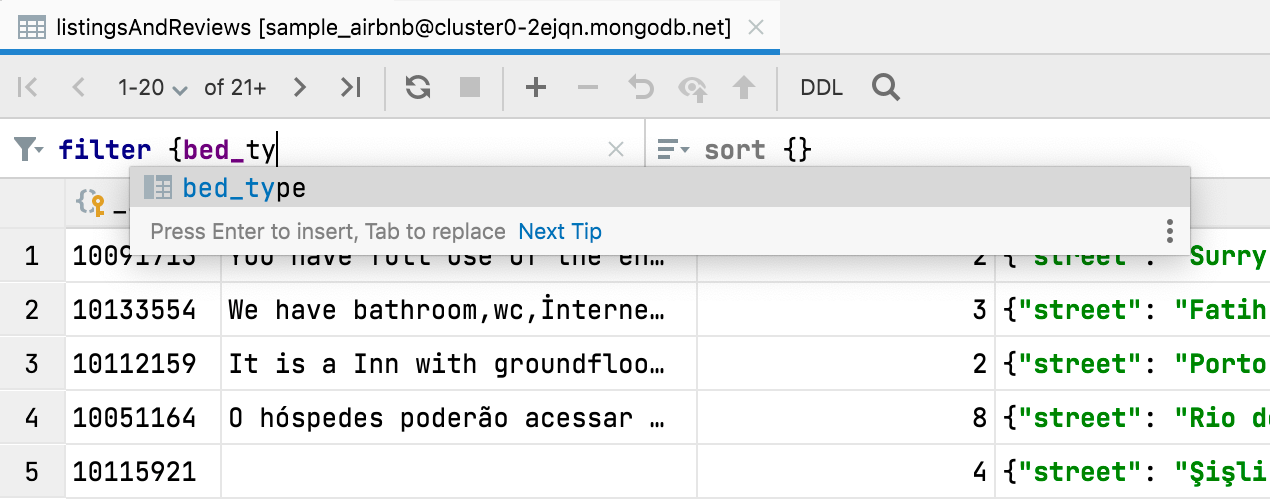
Completion für filter {} und sort {} MongoDB
Beim Filtern von Daten in MongoDB-Collections steht Ihnen jetzt die Code-Completion zur Verfügung.
Speichern von Datenbanken im VCS
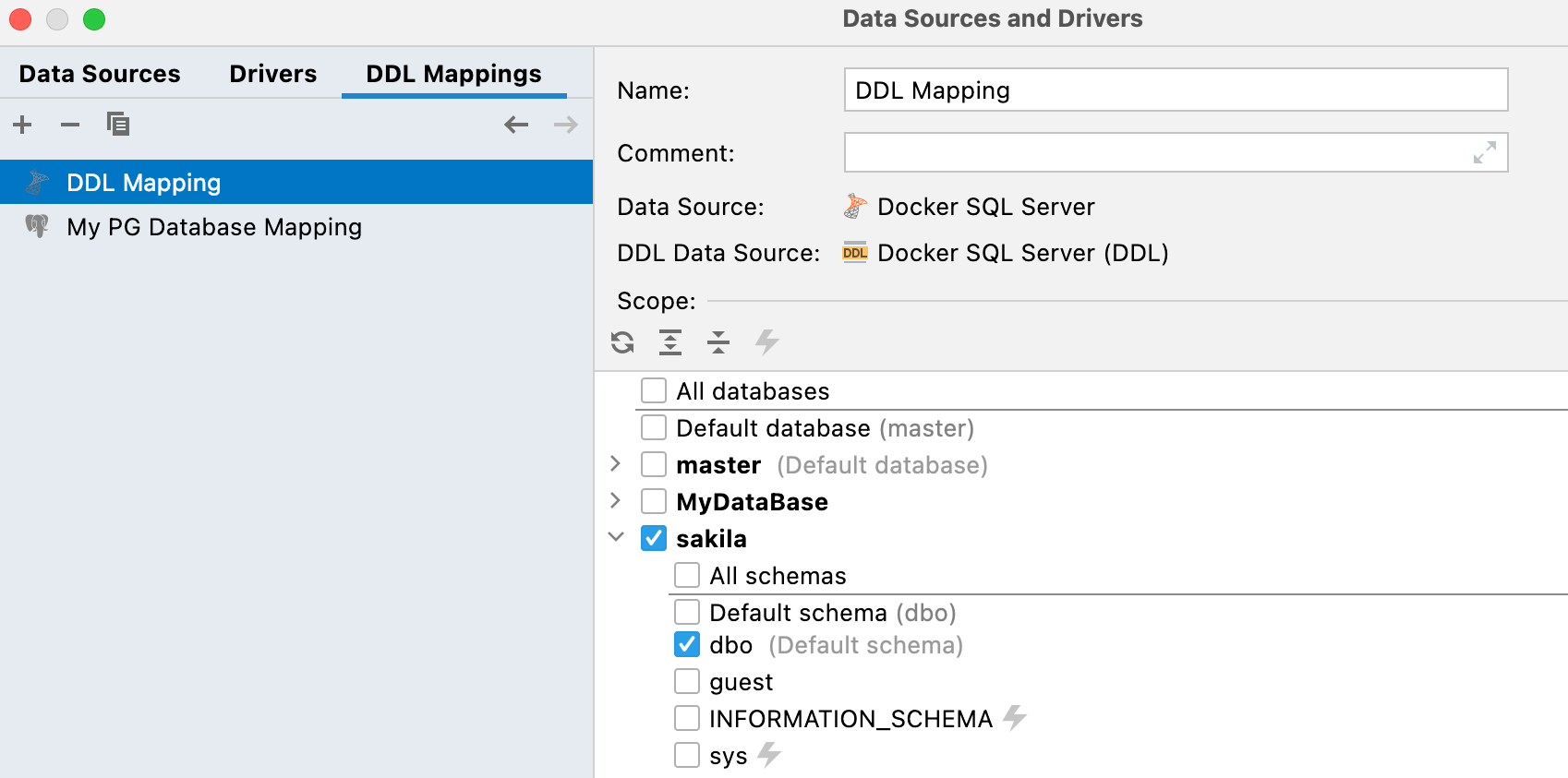
Zuordnungen zwischen DDL- und echten Datenquellen
Dieses Release ist eine logische Fortsetzung des letzten, das die Möglichkeit einführte, eine DDL-Datenquelle anhand einer echten Datenquelle zu generieren. Dieser Workflow wird jetzt vollständig unterstützt. Sie haben folgende Möglichkeiten:
- Generieren Sie eine DDL-Datenquelle aus einer echten Datenquelle: siehe Ankündigung zur Version 2021.2.
- Ordnen Sie eine DDL-Datenquelle einer echten Datenquelle zu.
- Vergleichen Sie beide und synchronisieren Sie sie in beiden Richtungen.
Zur Erinnerung: Eine DDL-Datenquelle ist eine virtuelle Datenquelle, deren Schema auf einer Reihe von SQL-Skripten basiert. Das Speichern dieser Dateien in Ihrer Versionsverwaltung bietet Ihnen die Möglichkeit, Ihre Datenbanken zu versionieren.
Auf dem neuen Tab DDL mappings in den Datenkonfigurationseigenschaften können Sie vorgeben, welche reale Datenquelle welcher DDL-Datenquelle zugeordnet ist.
Wenn Sie mehr darüber erfahren möchten, wie diese neuen Funktionen Ihre täglichen VCS-Workflows unterstützen, lesen Sie bitte diesen Artikel.
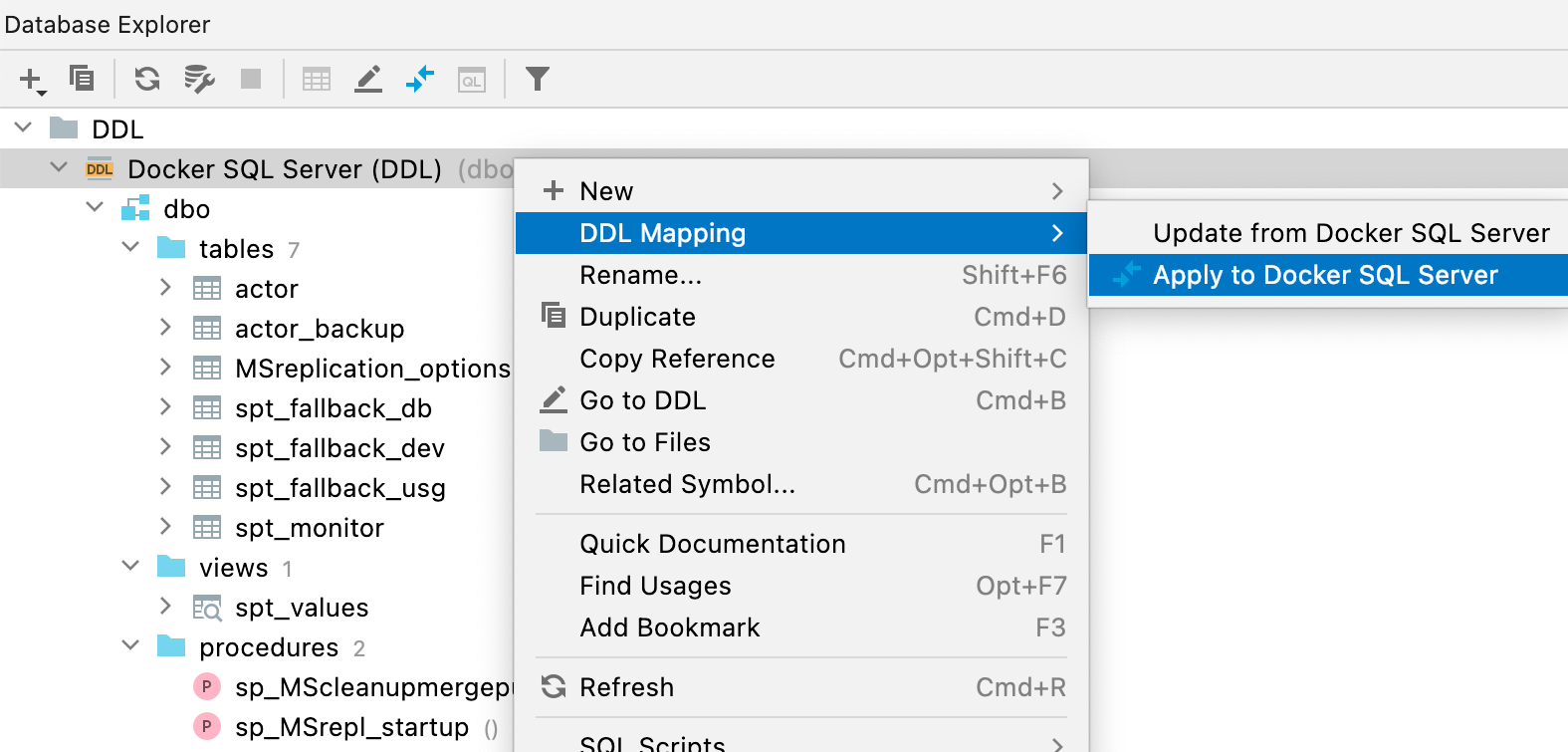
Neues Diff-Fenster für Datenbanken
Um Ihre DDL-Datenquelle mit der dazugehörigen echten Datenquelle zu vergleichen und zu synchronisieren, öffnen Sie das Kontextmenü und wählen Sie im Untermenü DDL Mappings den Eintrag Apply from... oder Dump to... aus.
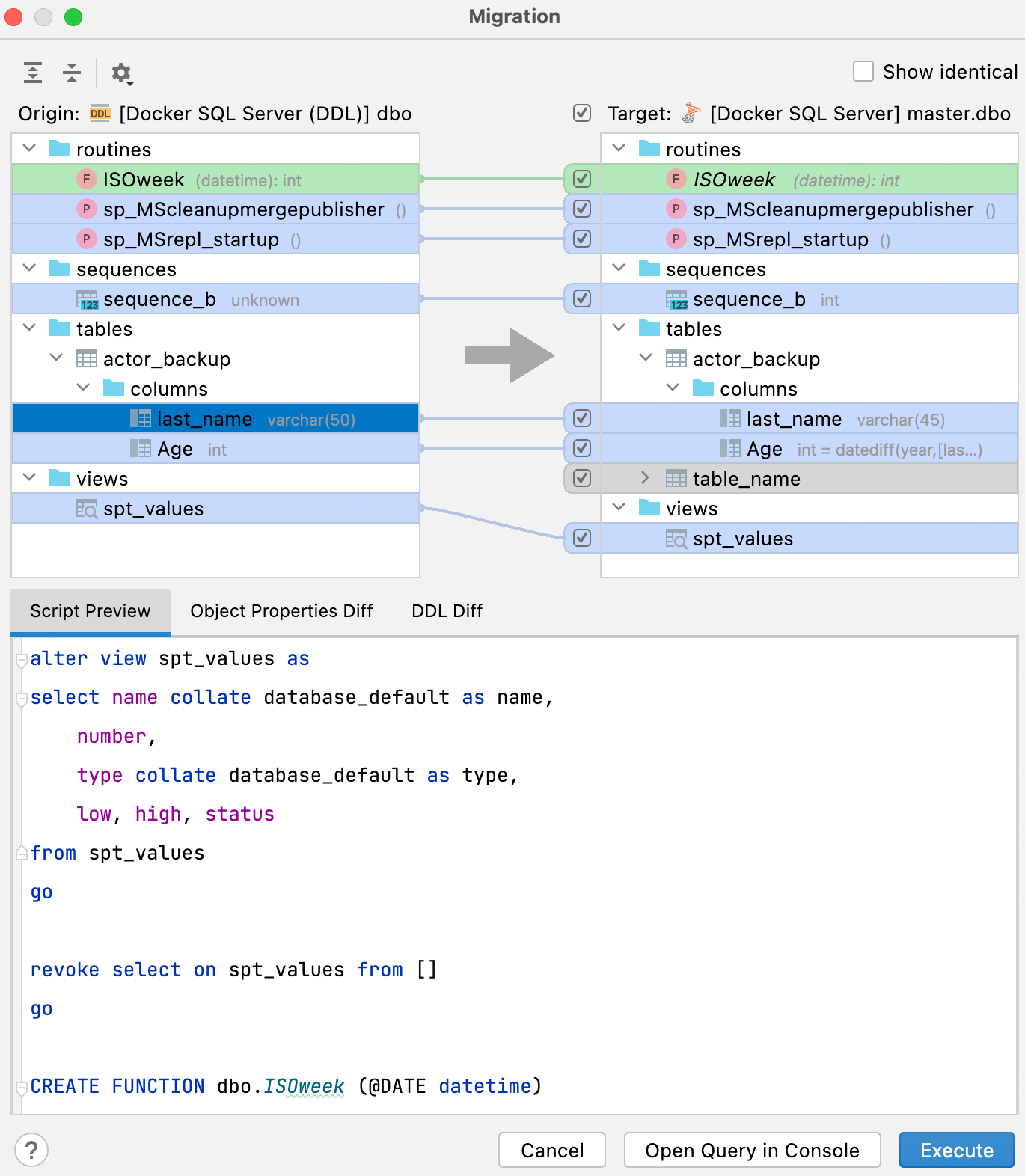
Dieses neue Fenster bietet eine bessere Benutzerführung und zeigt auf der rechten Seite genau an, welches Ergebnis Sie bei einer Synchronisierung erhalten.
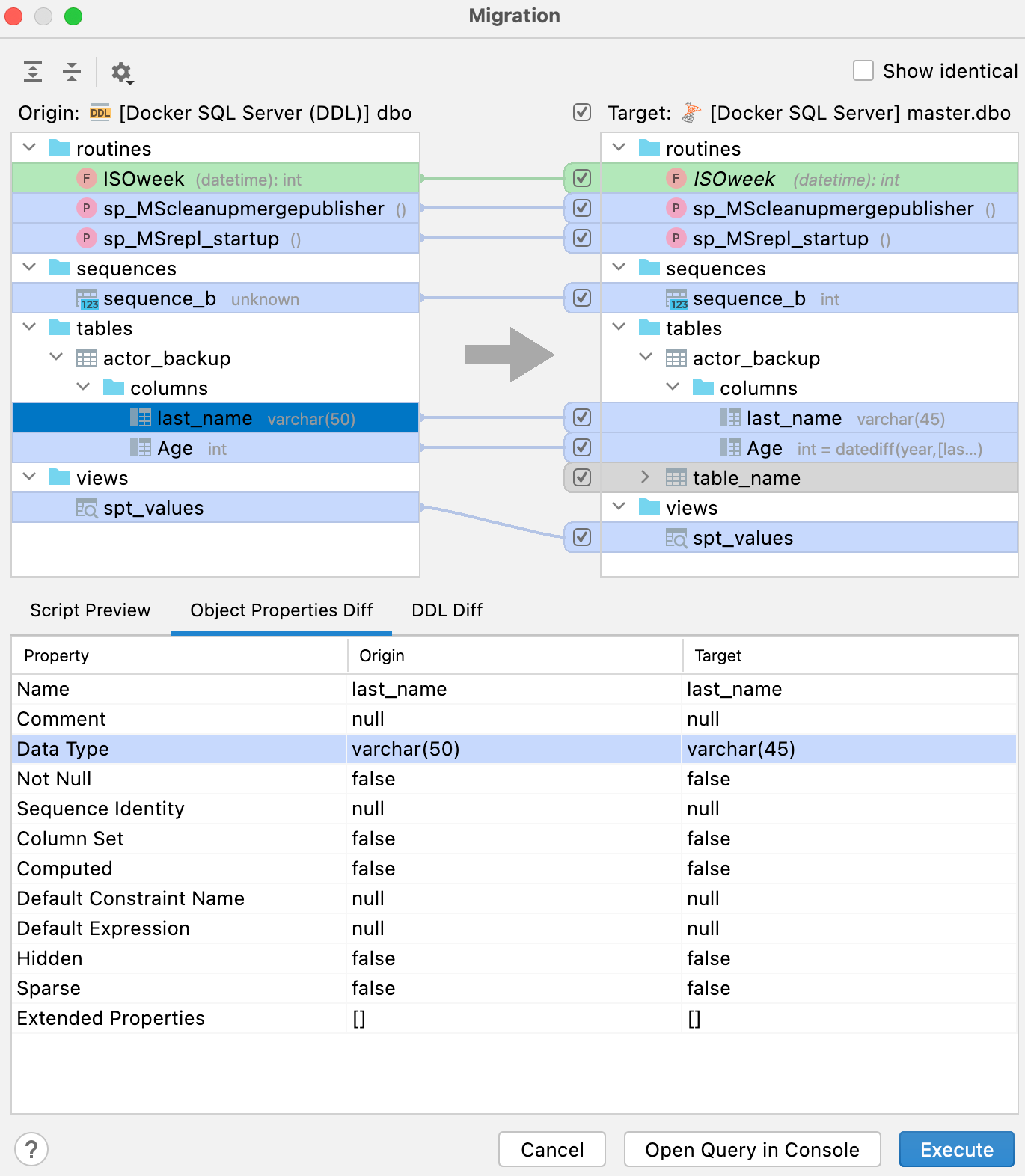
Die Legende im rechten Fensterbereich zeigt an, was die Farben für das potenzielle Ergebnis bedeuten:
- Grün und kursiv: Ein Objekt wird erstellt.
- Grau: Ein Objekt wird gelöscht.
- Blau: Ein Objekt wird geändert.
Im Tab Script preview sehen Sie das Ergebnisskript, das entweder in einer neuen Konsole geöffnet oder in diesem Dialog ausgeführt werden kann. Die Änderungen, die durch dieses Skript vorgenommen werden, führen dazu, dass die Datenbank rechts (Ziel) zu einer Kopie der Datenbank links (Quelle) wird.
Neben dem Tab Script preview enthält der untere Fensterbereich zwei weitere Tabs: Object Properties Diff und DDL Diff. Sie zeigen die Unterschiede zwischen den jeweiligen Versionen des Objekts in Ursprungs- und Zieldatenbank an.
Zur Erinnerung: Wenn Sie lediglich zwei Schemata oder Objekte vergleichen möchten, wählen Sie diese einfach aus und drücken Sie Strg+D.
Wichtig! Der Diff-Betrachter wird noch intensiv weiterentwickelt. Da jede Datenbank spezielle Eigenschaften hat, können zwei Objekte als unterschiedlich angezeigt werden, auch wenn sie in Wirklichkeit identisch sind. Dies kann zum Beispiel aufgrund von Typ-Aliasnamen oder beim Weglassen von Standardeigenschaften bei der Generierung geschehen. Wenn Sie auf diesen Fehler stoßen, melden Sie ihn bitte in unserem Tracker.
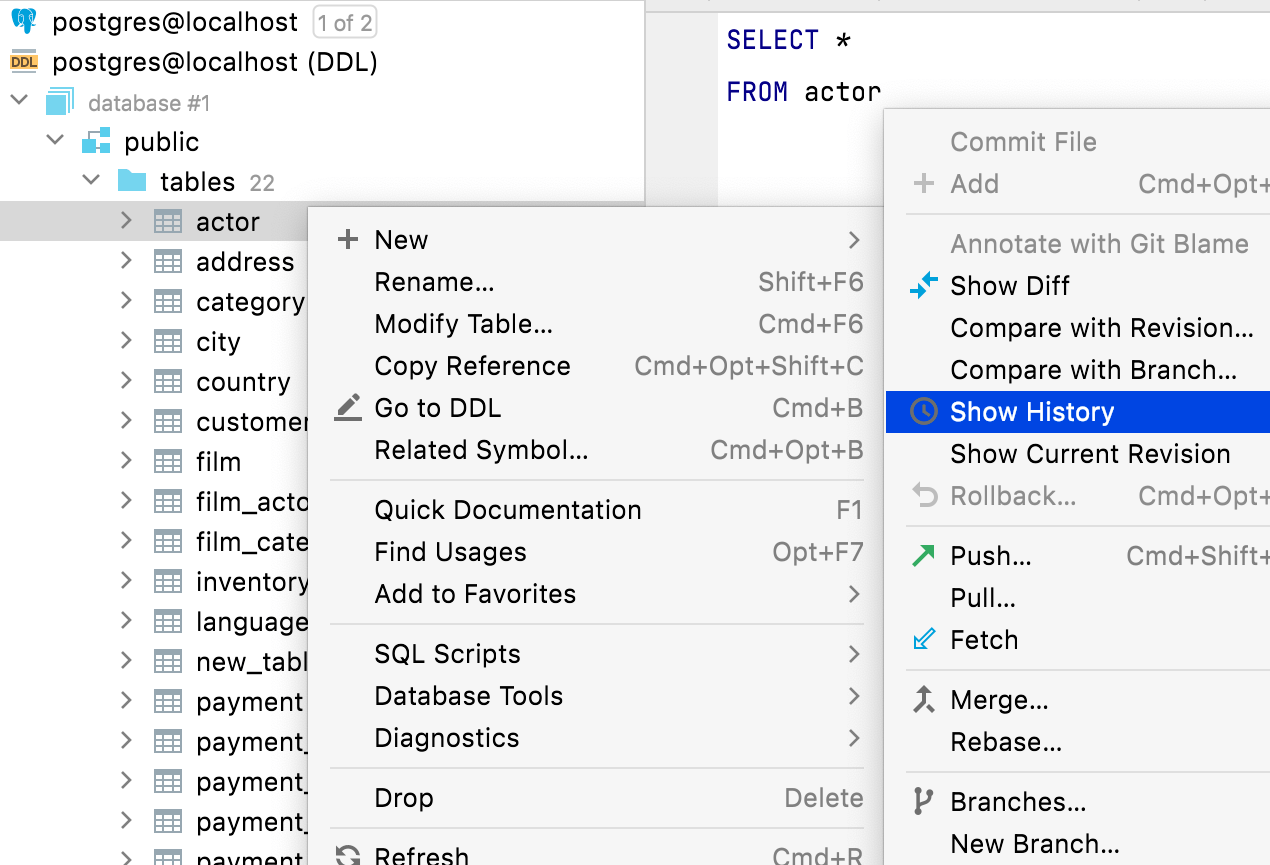
Dateiaktionen
Alle Dateiaktionen sind auch für DDL-Datenquellen verfügbar. Sie können beispielsweise Dateien, die sich auf Schemaelemente beziehen, im Datenbank-Explorer löschen, kopieren oder committen.
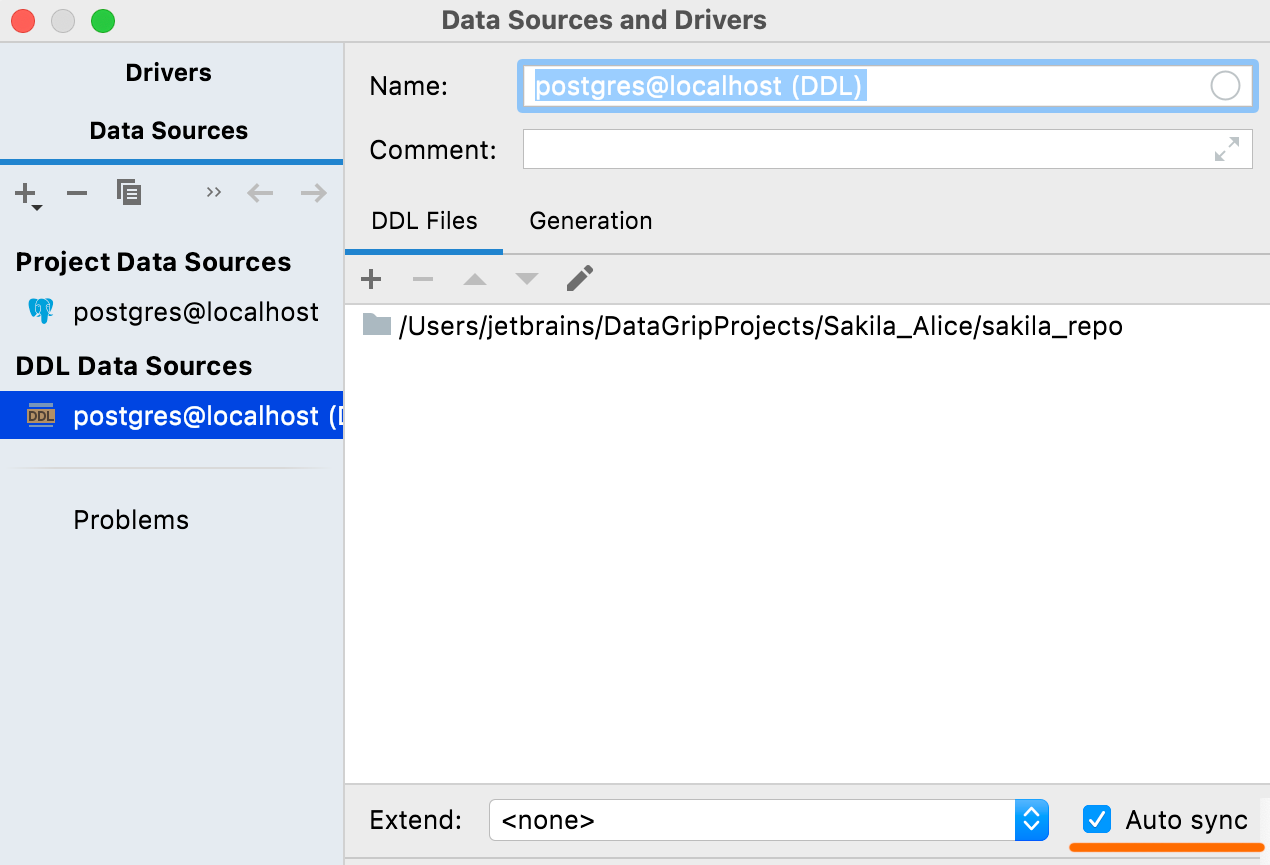
Auto-sync
Wenn diese Option aktiviert ist, wird Ihre DDL-Datenquelle automatisch aktualisiert, wenn die entsprechenden Dateien geändert wurden. Dies war bisher das Standardverhalten. Jetzt haben Sie die Möglichkeit, es zu deaktivieren.
Wenn Sie die Option deaktivieren, werden Änderungen in den Quelldateien nicht automatisch in die DDL-Datenquelle übernommen, sodass Sie auf Refresh klicken müssen, um die Änderungen anzuwenden.
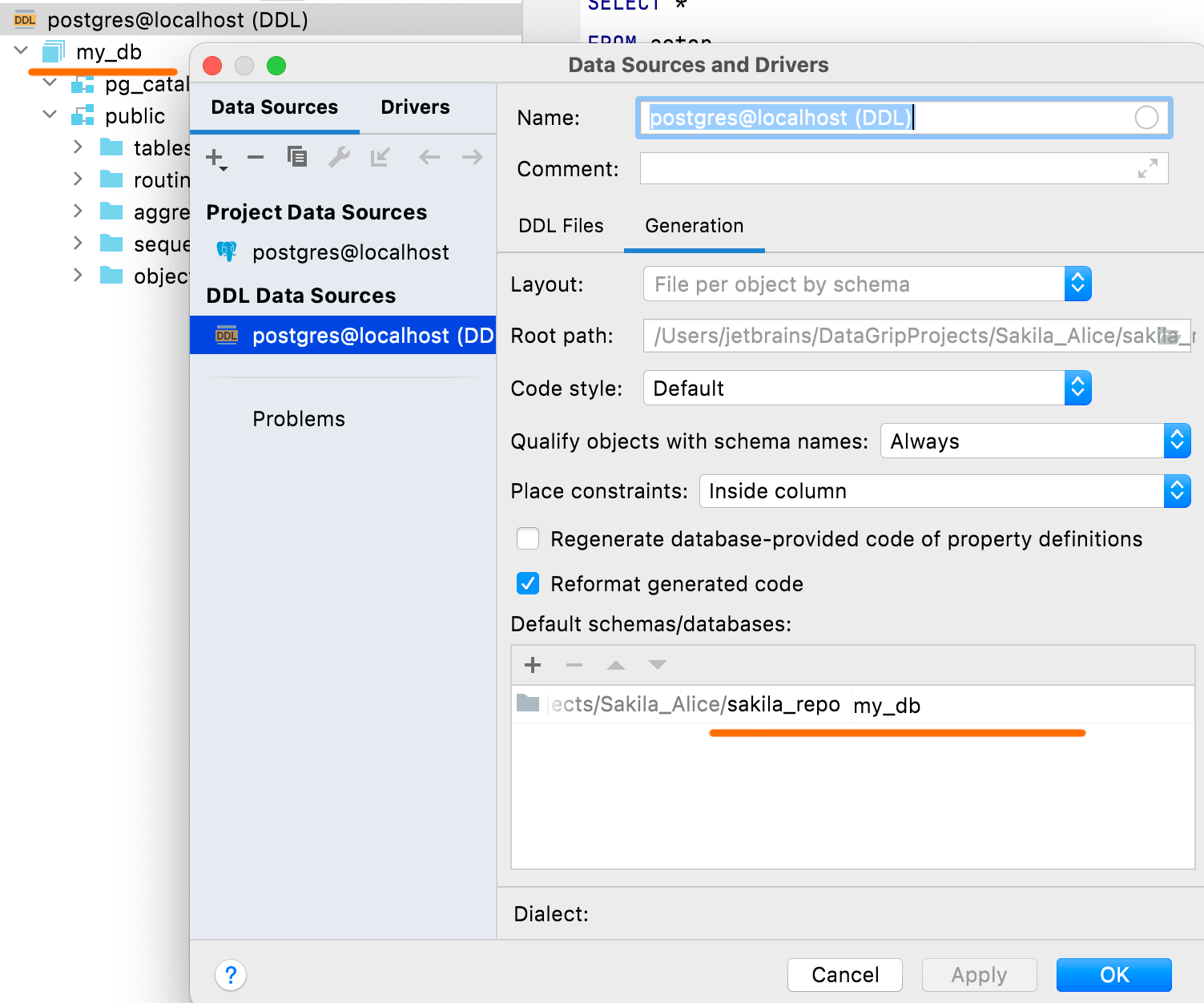
Standardschemata und -datenbanken
Im Bereich Default schemas/databases können Sie Datenbank- und Schema-Namen definieren, die in der DDL-Datenquelle angezeigt werden. DDL-Skripte enthalten normalerweise keine Namen, und in solchen Fällen werden standardmäßig Dummy-Namen für Datenbanken und Schemata verwendet.
Konnektivität
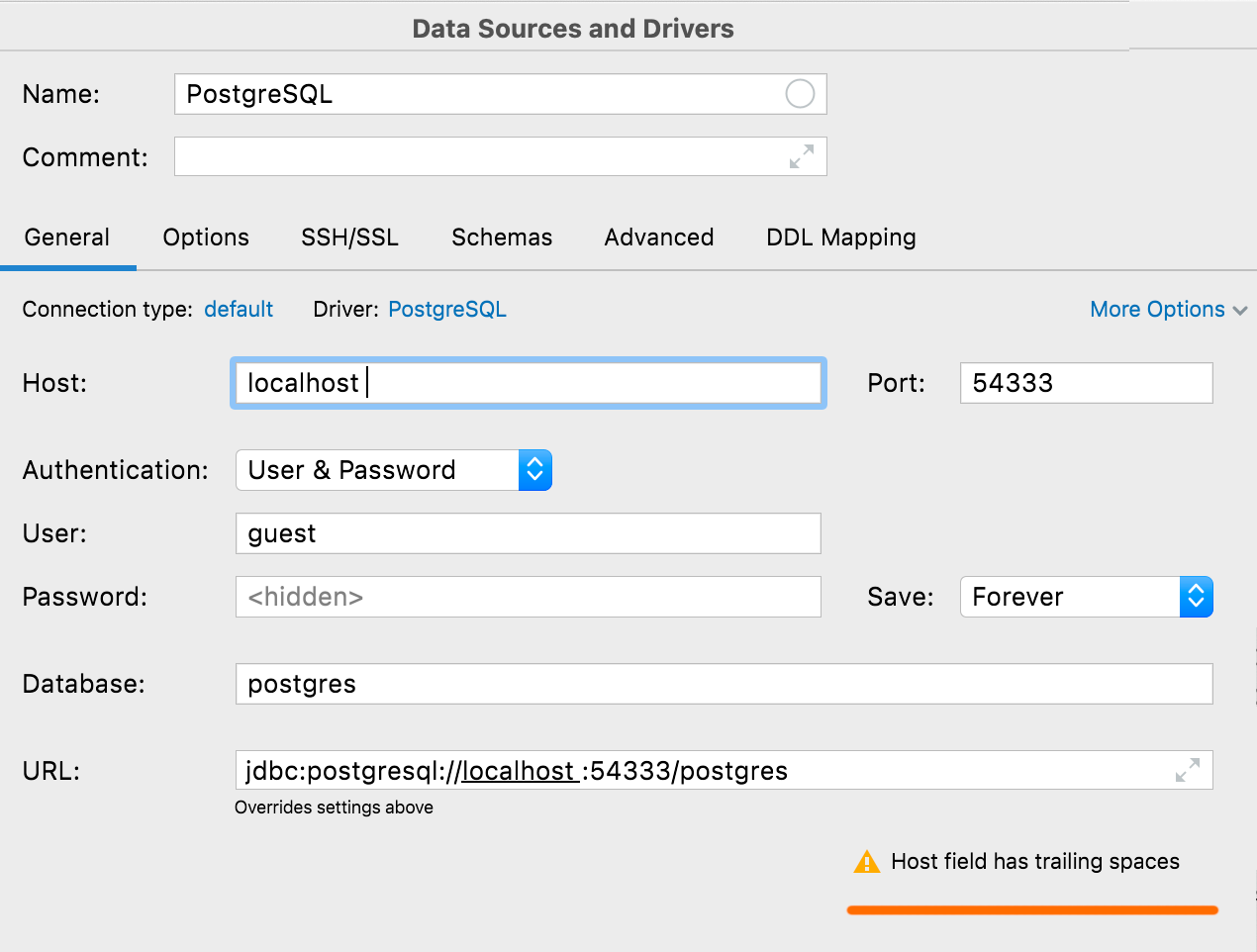
Warnung vor versehentlichen Leerzeichen
Wenn ein Wert außer User oder Password führende oder abschließende Leerzeichen enthält, warnt DataGrip Sie, wenn Sie auf Test Connection klicken.
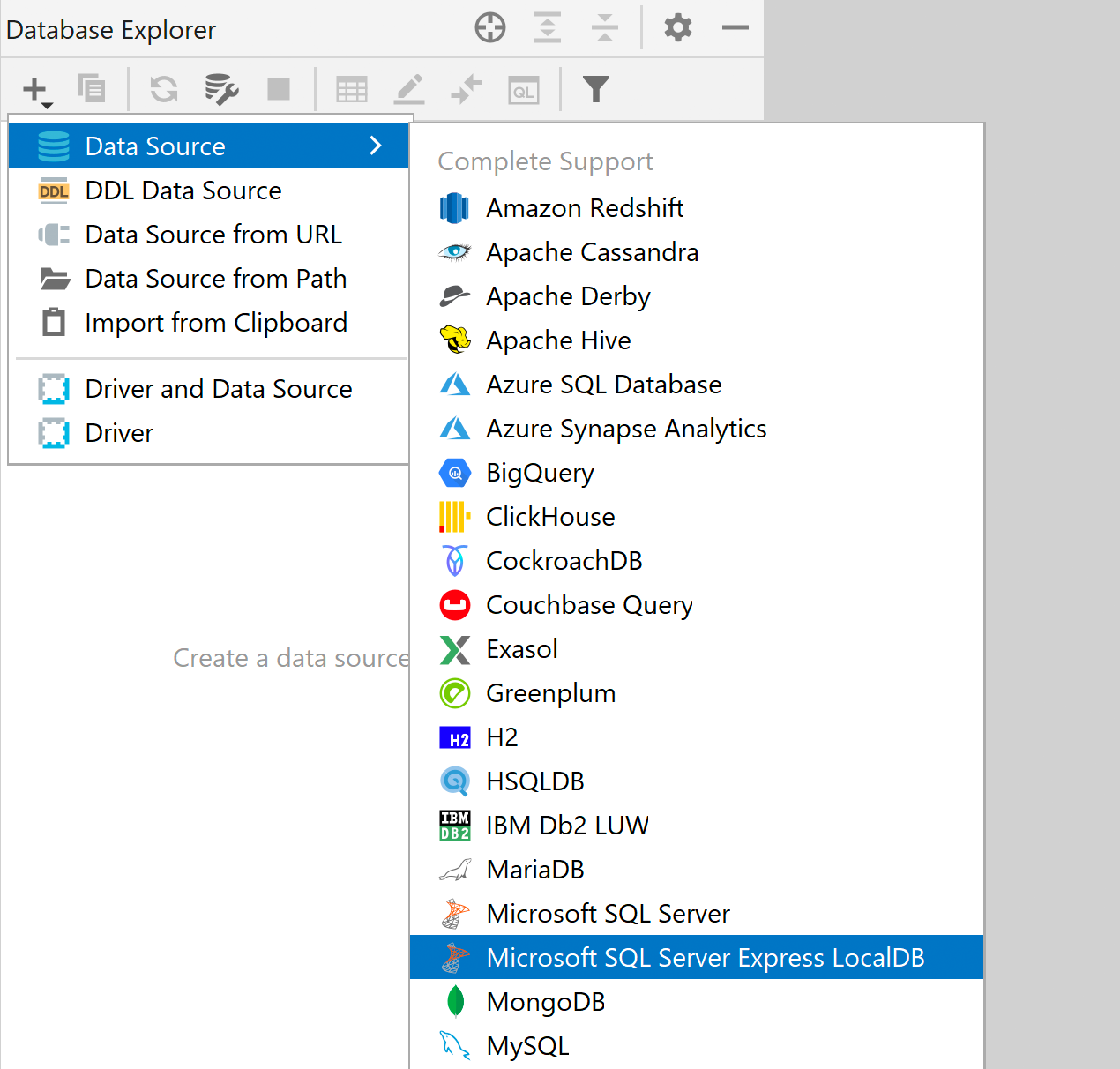
LocalDB als dedizierte Datenquelle SQL Server
SQL Server LocalDB verfügt über einen eigenen Treiber in der Treiberliste. Dies bedeutet, dass es einen separaten Datenquellentyp gibt, der für LocalDB verwendet werden sollte. Daraus ergeben sich folgende Vorteile:
- Die LocalDB-Verbindung lässt sich besser untersuchen.
- Sie müssen den Pfad zur ausführbaren Datei nur einmal in den Treiberoptionen angeben, und er wird in alle Datenquellen übernommen.
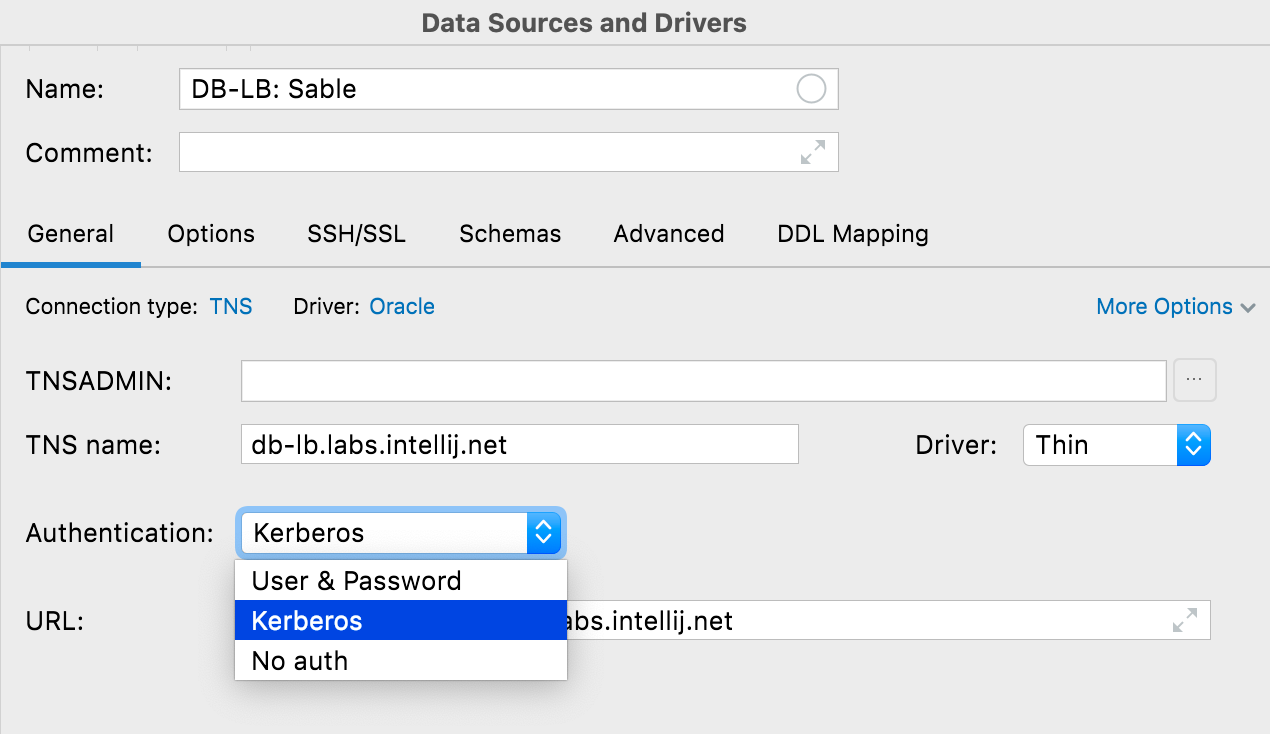
Kerberos-Authentifizierung Oracle, SQL Server
Die Kerberos-Authentifizierung kann jetzt in Oracle und SQL Server verwendet werden. Sie müssen mit dem Befehl kinit ein TGT (ticket-granting ticket) für den Prinzipal erstellen, das DataGrip verwendet, wenn Sie die Kerberos-Option wählen.
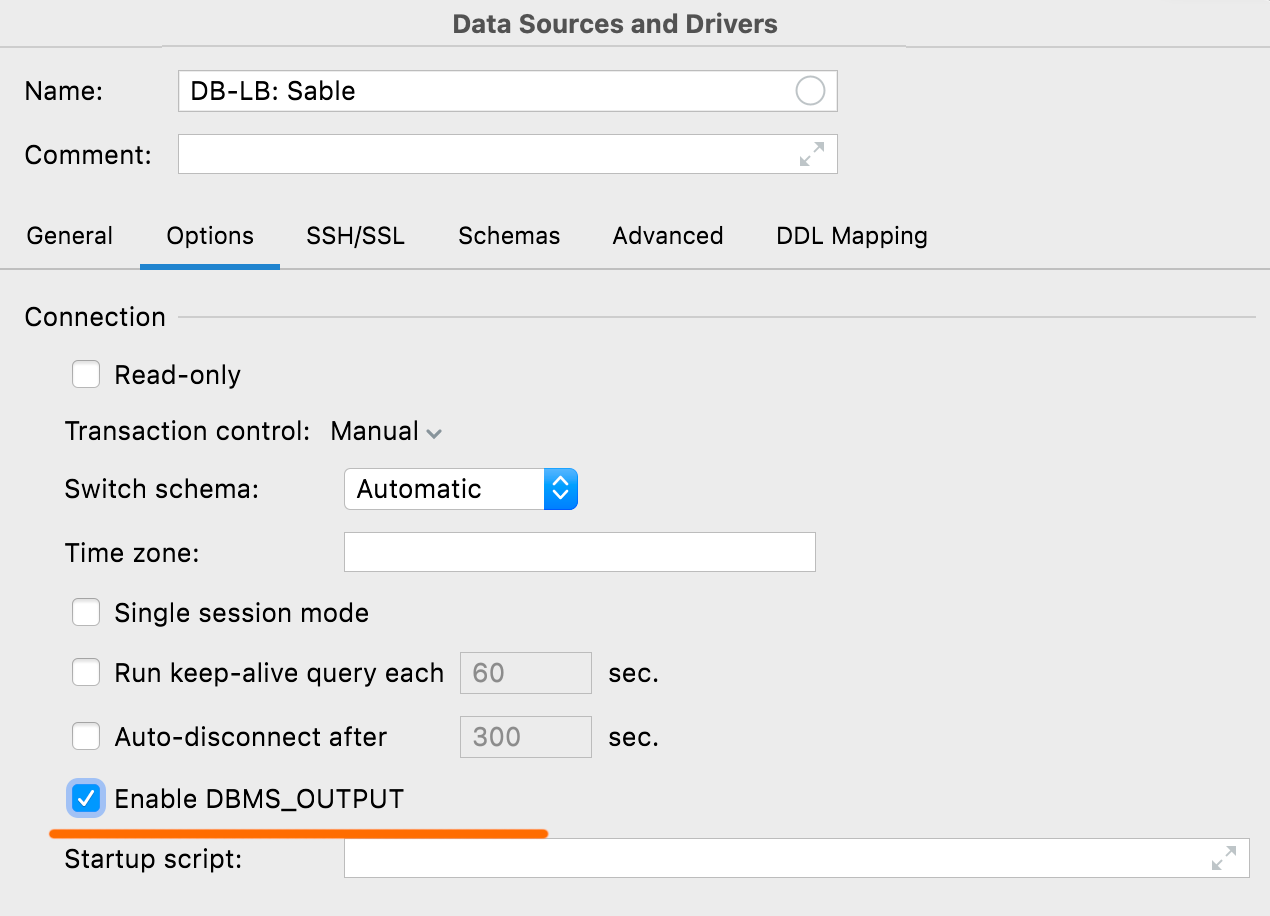
Aktivierung von DBMS_OUTPUT Oracle, IBM Db2
Mit dieser neuen Option auf dem Options-Tab können Sie DBMS_OUTPUT standardmäßig für neue Sitzungen aktivieren.
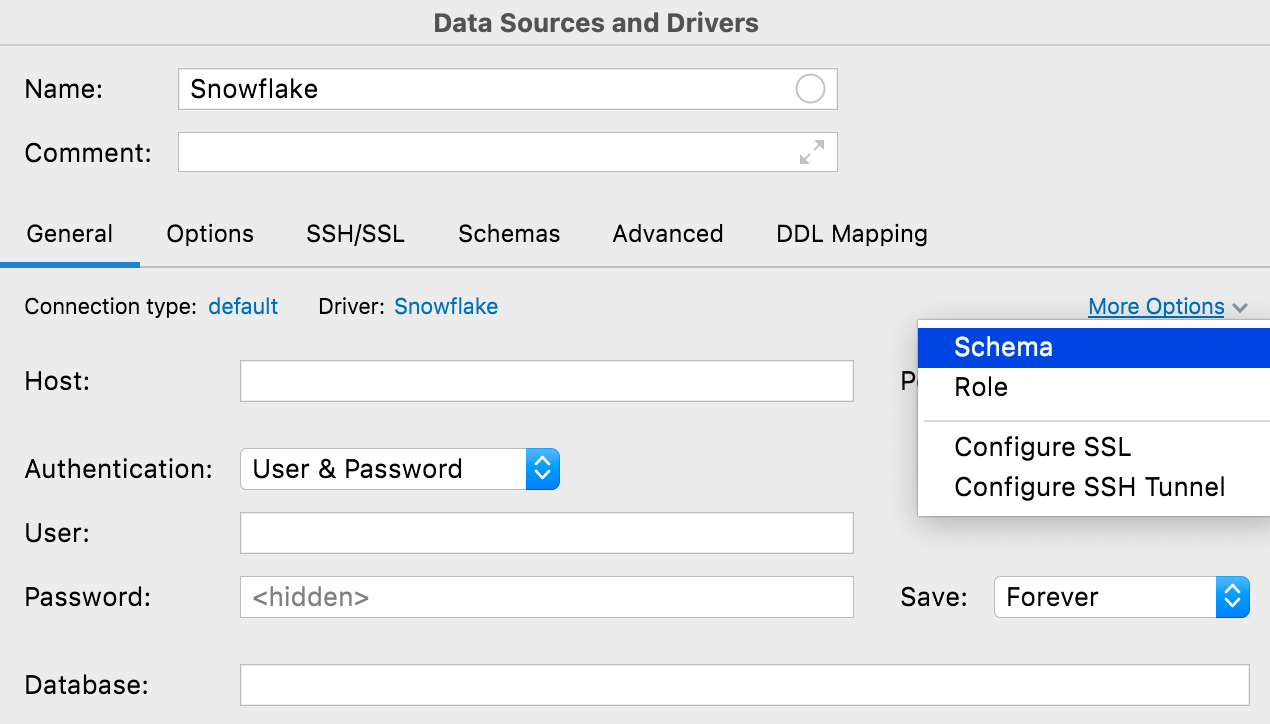
Schaltfläche More Options
Für Fälle, in denen Sie eine selten verwendete Einstellung einer Verbindung bearbeiten müssen, haben wir die Schaltfläche More Options hinzugefügt. Die derzeit verfügbaren Optionen umfassen das Hinzufügen der Felder Schema und Role für Snowflake-Verbindungen und zwei Menüeinträge für die SSH- und SSL-Konfiguration, um die Auffindbarkeit zu verbessern.
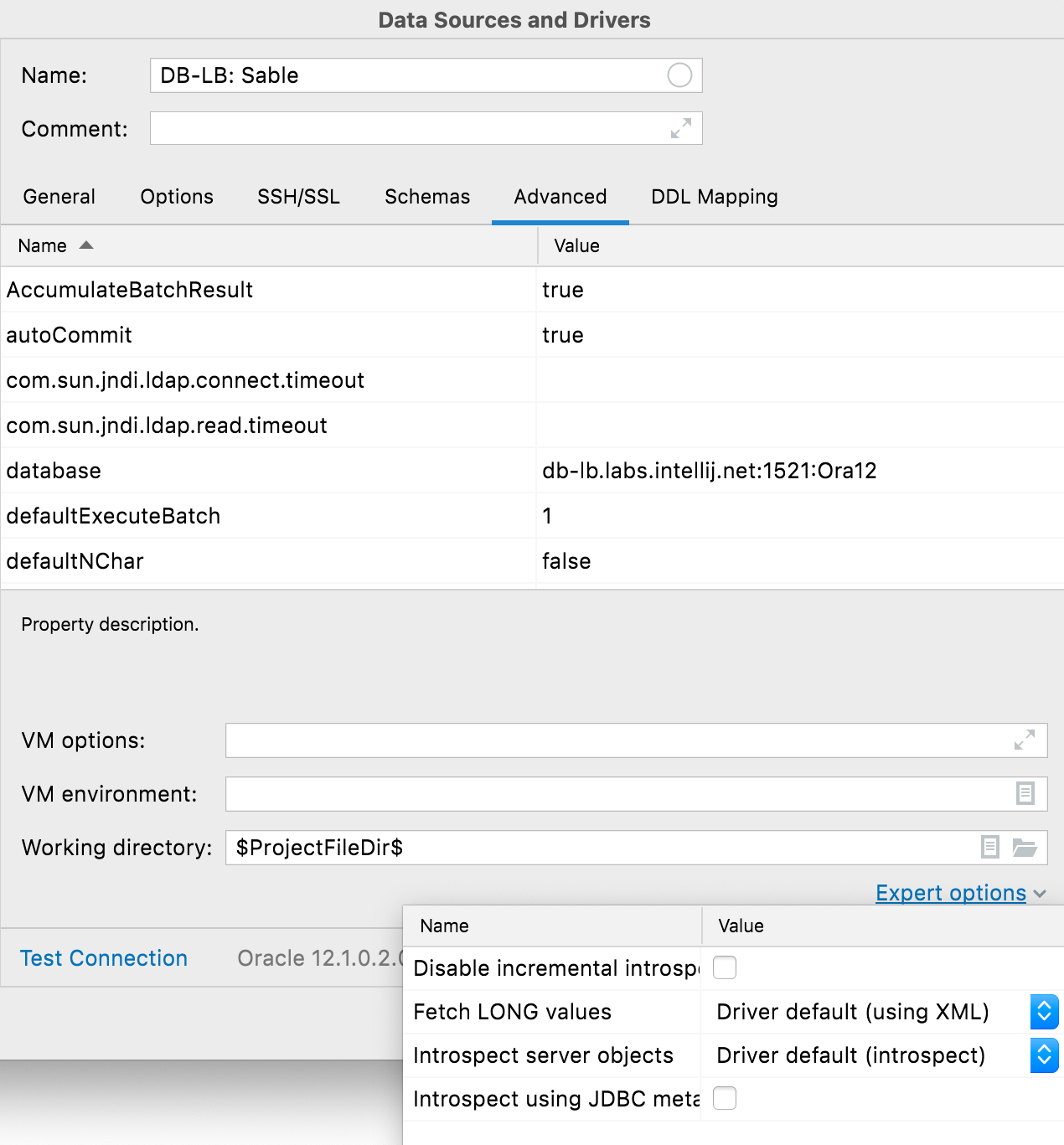
Expertenoptionen
Der Tab Advanced enthält jetzt eine Liste der Expert options (Expertenoptionen). Neben dem Aktivieren des JDBC-Introspectors (bitte diese Option nur nach Rücksprache mit unserem Support verwenden!) stehen folgende datenbankspezifische Optionen zur Verfügung:
- Oracle: Disable incremental introspection, Fetch LONG values und Introspect server objects
- SQL Server: Disable incremental introspection
- PostgreSQL (and similar): Disable incremental introspection und Do not use xmin in queries to pgdatabase
- SQLite: Register REGEXP function
- MYSQL: Use SHOW/CREATE for source code
- ClickHouse: Automatically assign sessionid
Introspektion
Introspektionsstufen Oracle
Bei Oracle-Systemen trat das Problem auf, dass die Introspektion mit DataGrip lange dauerte, wenn viele Datenbanken und Schemata vorhanden waren. Introspektion bezeichnet das Abrufen von Metadaten aus der Datenbank – z. B. Objektnamen und Quellcode. DataGrip benötigt diese Daten, um eine schnelle Programmierunterstützung sowie Navigations- und Suchfunktionen bereitzustellen.
Die Oracle-Systemkataloge sind ziemlich langsam, und die Introspektion war noch langsamer, wenn der Account keine Administratorrechte hatte. Wir haben unser Bestes getan, um das Abfragen der Metadaten zu optimieren, aber unsere Möglichkeiten waren begrenzt.
Wir haben erkannt, dass es für die meisten Alltagsvorgänge und sogar für eine effektive Programmierunterstützung das Laden des Quellcodes der Objekte nicht erforderlich ist. In vielen Fällen reichen die Objektnamen aus, um eine ordnungsgemäße Code-Completion und Navigation zu ermöglichen. Aus diesem Grund haben wir drei Introspektionsstufen für Oracle-Datenbanken eingeführt:
- Stufe 1: Namen und Signaturen aller unterstützten Objekte, ausgenommen Namen von Indexspalten und privaten Paketvariablen
- Stufe 2: Alles außer dem Quellcode
- Stufe 3: Alle Daten
Die Introspektion ist auf Stufe 1 am schnellsten und auf Stufe 3 am langsamsten.
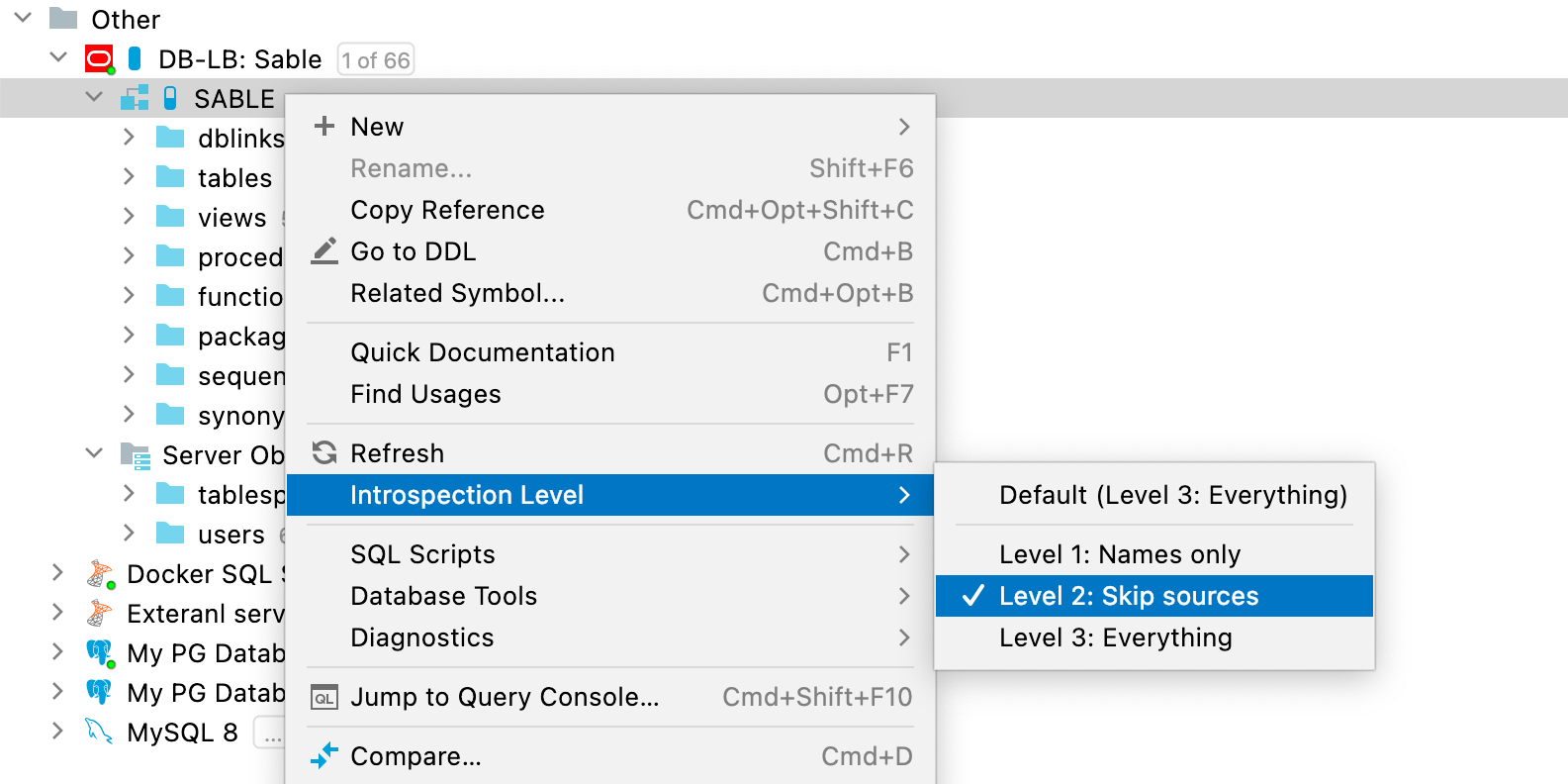
Über das Kontextmenü können Sie die Introspektionsstufe nach Bedarf ändern:

Die Introspektionsstufe kann entweder für ein Schema oder für die gesamte Datenbank festgelegt werden. Die Schemata erben ihre Introspektionsstufe von der Datenbank, Sie können für sie aber auch eine abweichende Stufe festlegen.
Die Introspektionsstufe wird durch die pillenähnlichen Symbole neben dem Datenquellensymbol angezeigt. Je höher der Füllgrad der Pille ist, desto höher ist die Introspektionsstufe. Ein blaues Symbol bedeutet, dass die Introspektionsstufe direkt festgelegt ist, während ein graues Symbol eine geerbte Stufe darstellt.
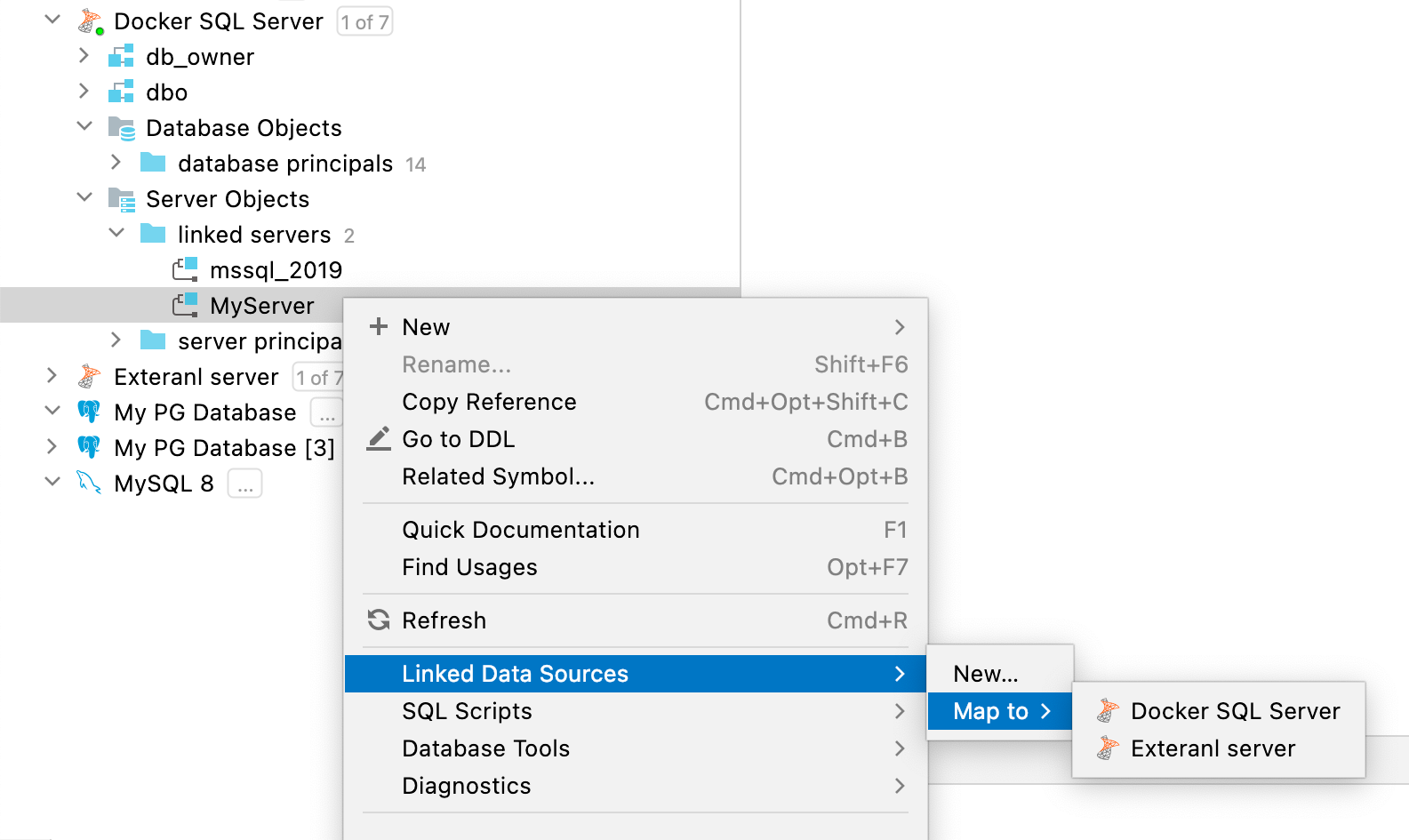
Zuordnen von verknüpften Servern und Datenbanklinks zu Datenquellen SQL Server, Oracle
Sie können Ihren verknüpften Server in SQL Server oder Ihren Datenbanklink in Oracle einer beliebigen vorhandenen Datenquelle zuordnen.
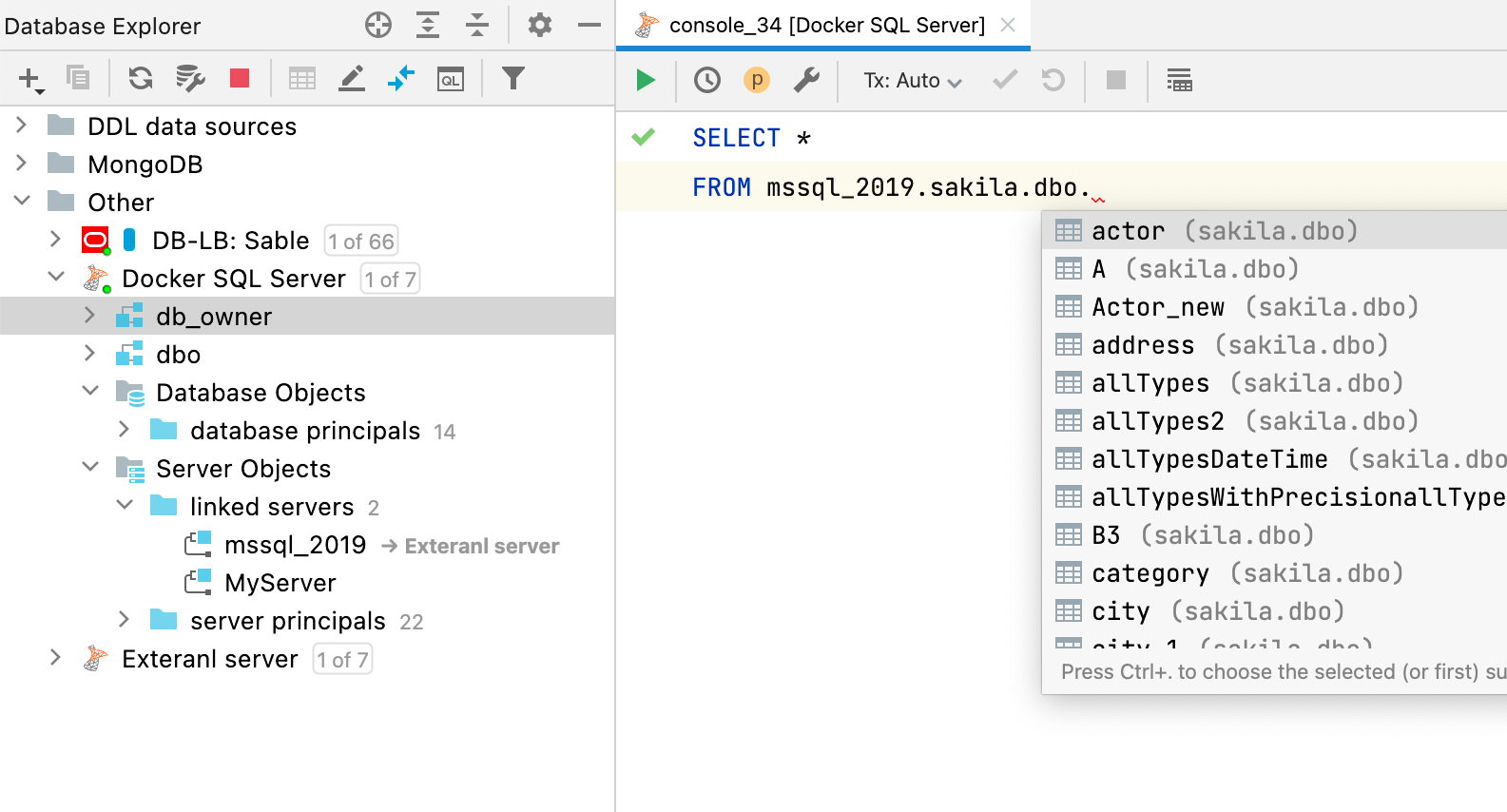
Wenn der Datenquelle externe Objekte zugeordnet sind, werden in Abfragen bei der Code-Completion und der Auflösung diese externen Objekte verwendet.
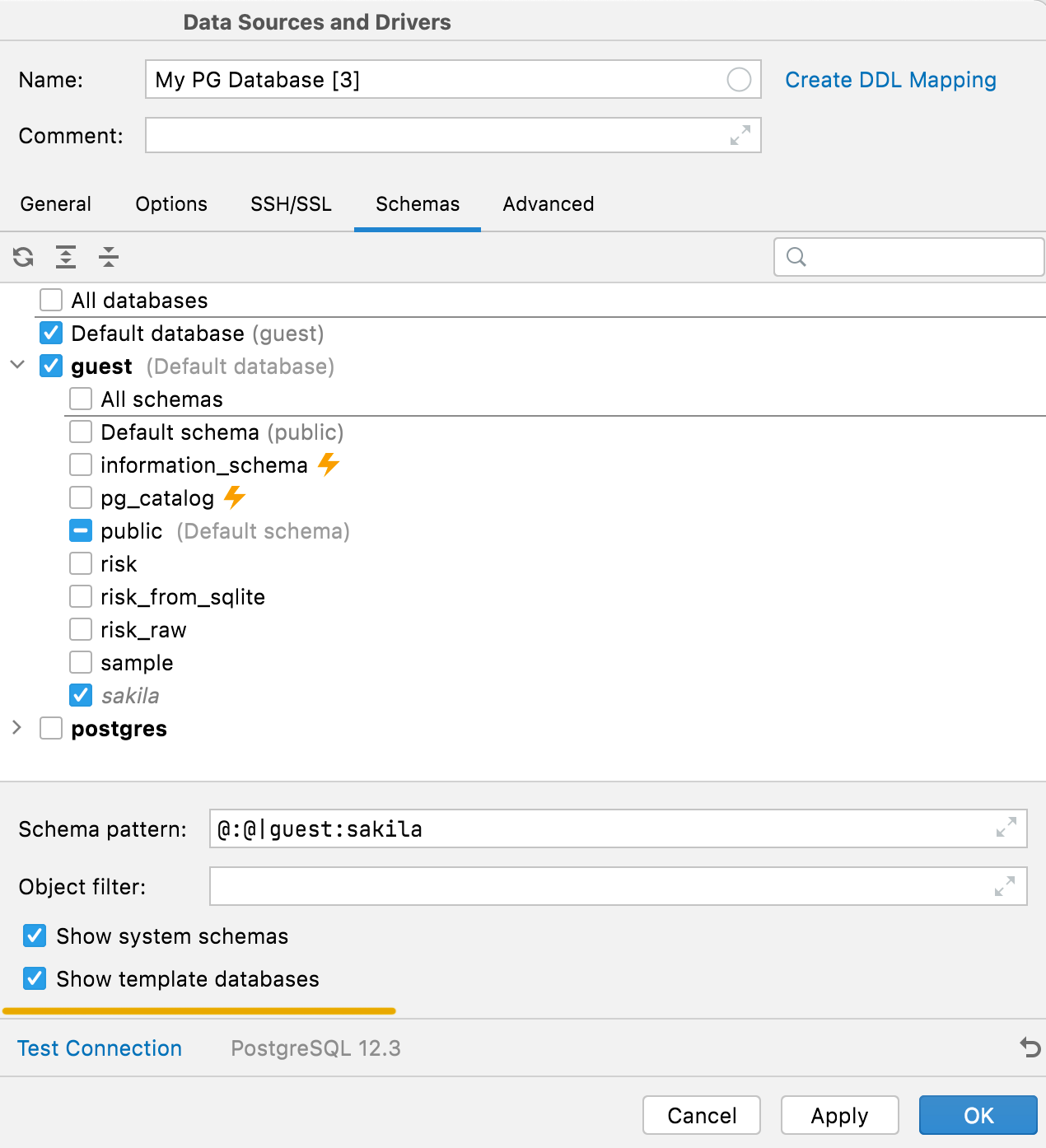
Ausblenden von Systemschemata und Vorlagendatenbanken PostgreSQL
Interne Systemschemata (wie pg_toast oder pg_temp) sowie Vorlagendatenbanken wurden früher nicht in der Schemaliste angezeigt. Mithilfe der entsprechenden Optionen auf dem Schemas-Tab können sie jetzt angezeigt werden.
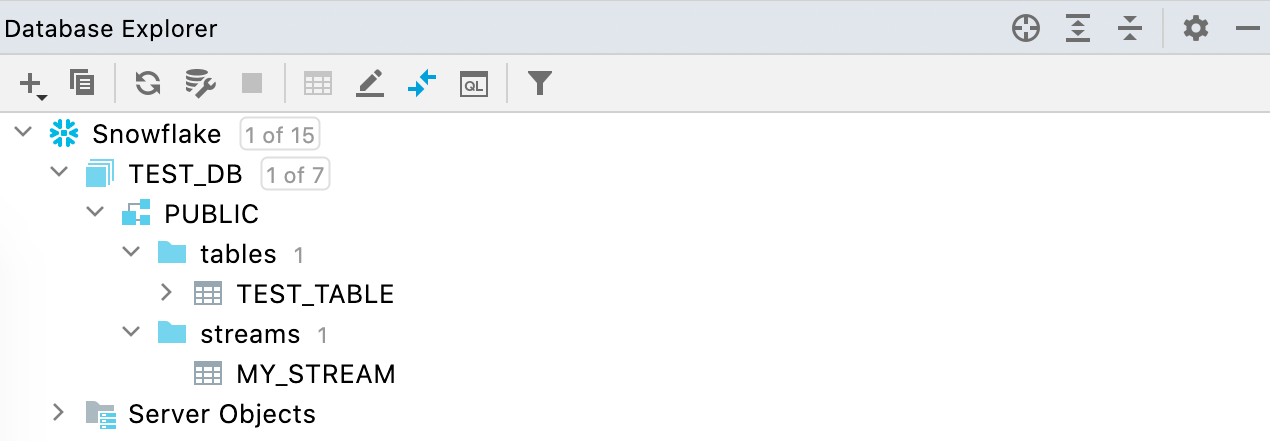
Unterstützung für Streams Snowflake
In der Datenbankansicht werden jetzt neben Tabellen und Views auch Streams angezeigt.
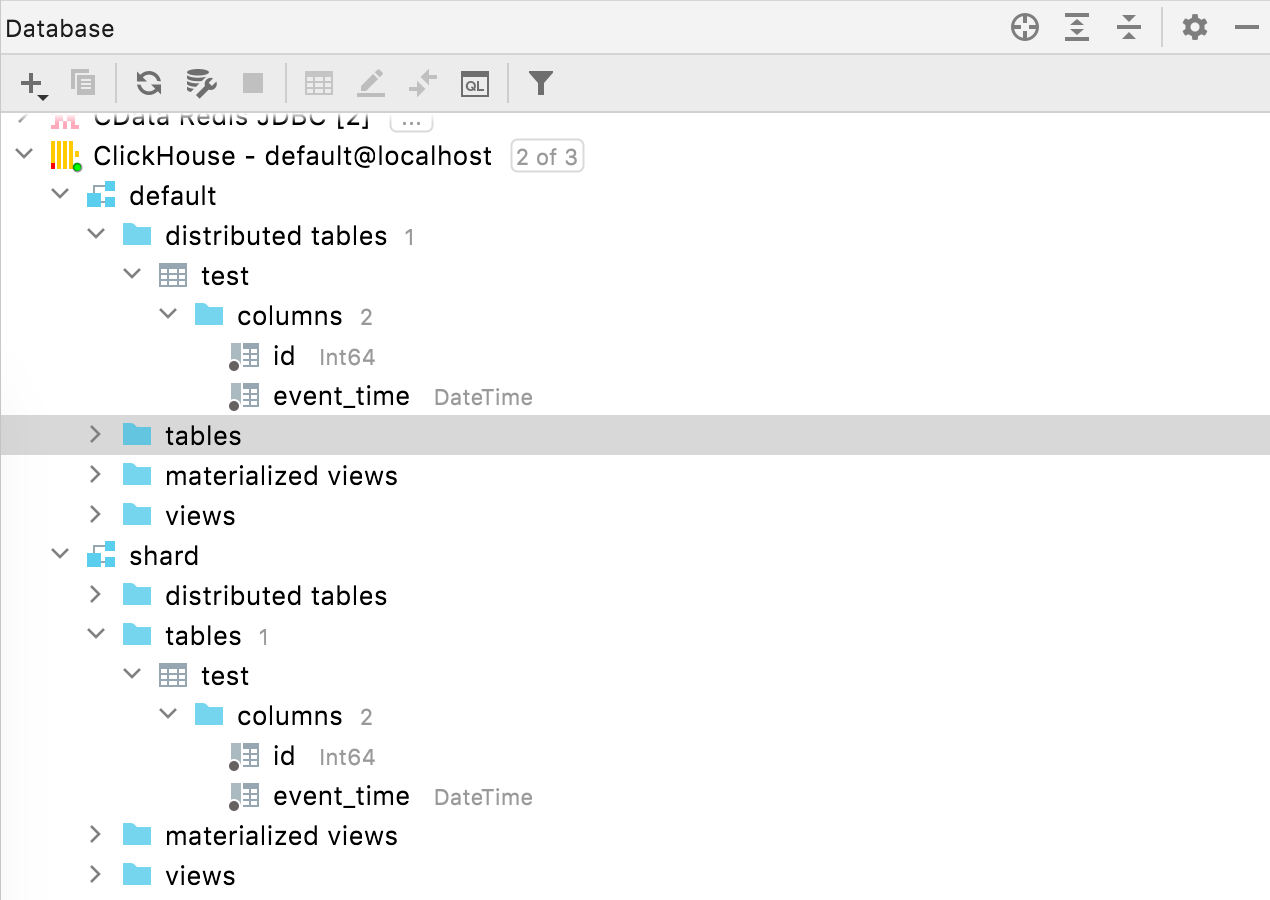
Verteilte Tabellen ClickHouse
Verteilte Tabellen sind jetzt im Datenbank-Explorer unter einem speziellen Knoten zu finden.
Abfragekonsole
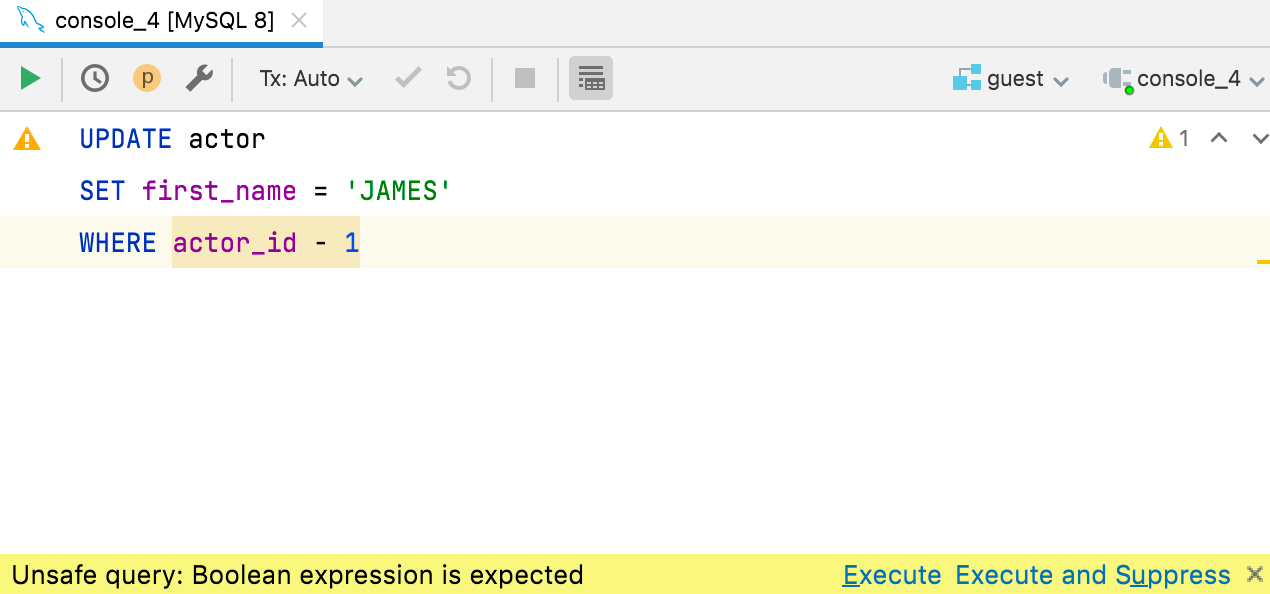
Prüfung auf boolesche Ausdrücke
One of our users posted about an unfortunate situation: he executed the UPDATE query on a production database with the condition WHERE id - 3727 (instead of =) and had millions of records updated!
Wir waren auch überrascht, dass MySQL so etwas zulässt, aber so ist das Leben. Aber wir wären nicht das DataGrip-Team, wenn uns dafür keine Inspektion einfallen würde. Wir bitten um Applaus für die Inspektion auf boolesche Ausdrücke in WHERE- und HAVING-Klauseln!
Wenn der Ausdruck kein expliziter boolescher Wert zu sein scheint, hinterlegt DataGrip ihn gelb und warnt Sie, bevor Sie eine solche Abfrage ausführen. Die Inspektion funktioniert mit ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite und Vertica. In allen anderen Datenbanken wird dies als Fehler gekennzeichnet.
Abfragen als Funktion extrahieren
Sie können jetzt Abfragen als Tabellenfunktion extrahieren. Wählen Sie dazu die Abfrage aus, öffnen Sie das Menü Refactor und klicken Sie auf Extract Routine.
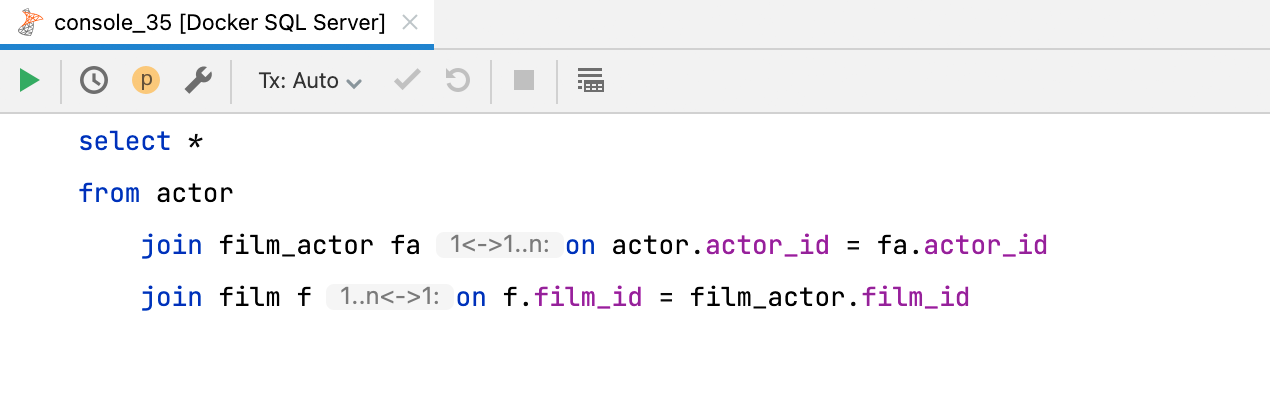
Inlay-Hint für JOIN-Kardinalität
Ein neuer Inlay-Hint zeigt Ihnen die Kardinalität von JOIN-Klauseln an. Es gibt drei Möglichkeiten: eins-zu-eins, eins-zu-viele und viele-zu-viele. Zum Deaktivieren ändern Sie die Einstellung Preferences | Editor | Inlay Hints | Join cardinality.
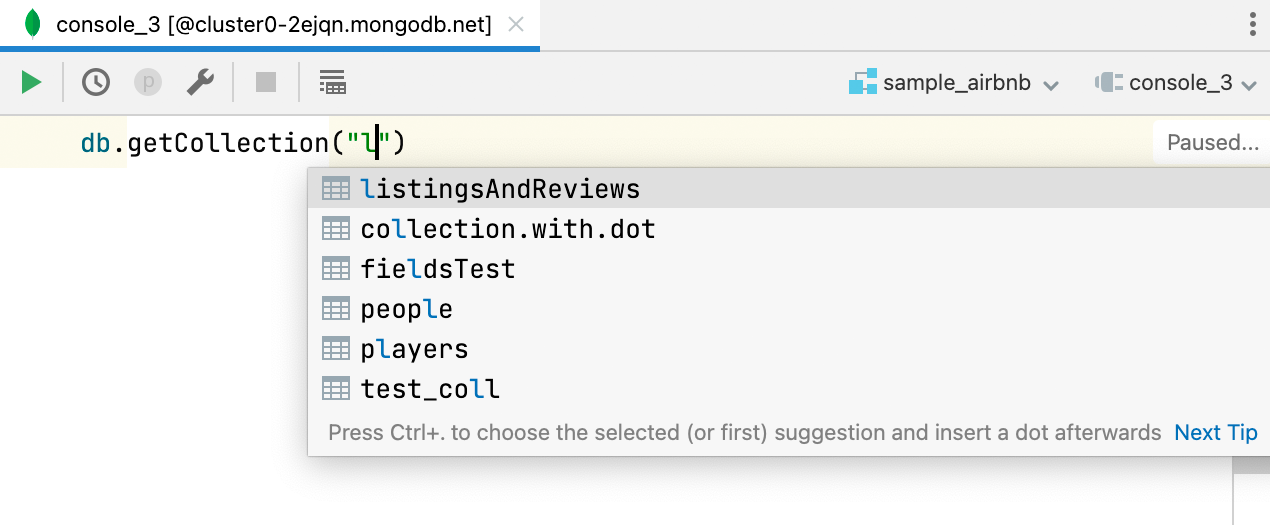
Code-Completion für Datenbanknamen MongoDB
Datenbanknamen werden bei der Verwendung von getSiblingDB vervollständigt, und bei getCollection erhalten Sie Vorschläge für Collection-Namen.
Darüber hinaus werden Feldnamen vervollständigt und aufgelöst, wenn sie aus einer Collection verwendet werden, die mit getCollection definiert wurde.
Services-Toolfenster
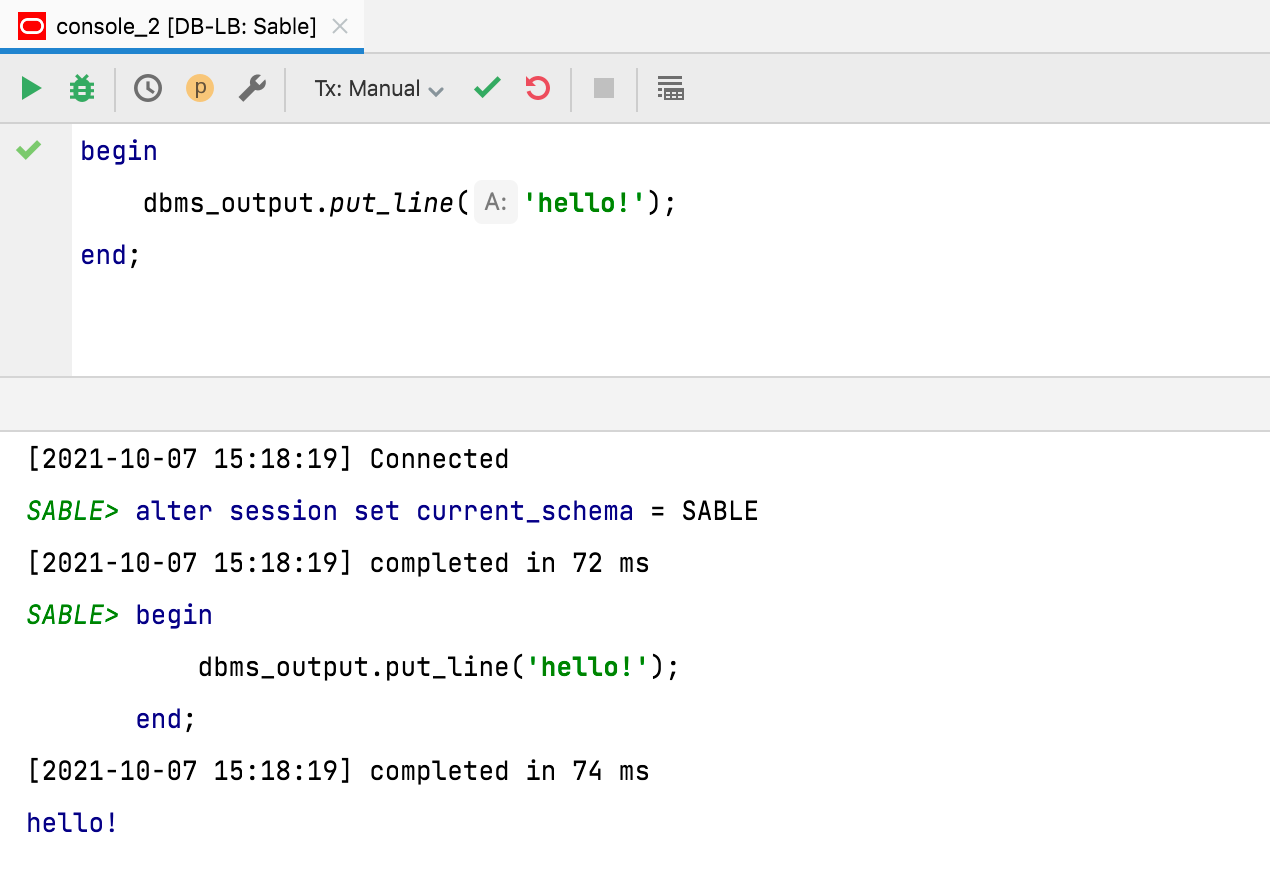
Ausgabe standardmäßig ohne Zeitstempel
Wie in diesem Ticket gefordert wird die Abfrageausgabe standardmäßig ohne Zeitstempel angezeigt. Um zum bisherigen Verhalten zurückzukehren, können Sie die Einstellung Database | General | Show timestamp for query output ändern.
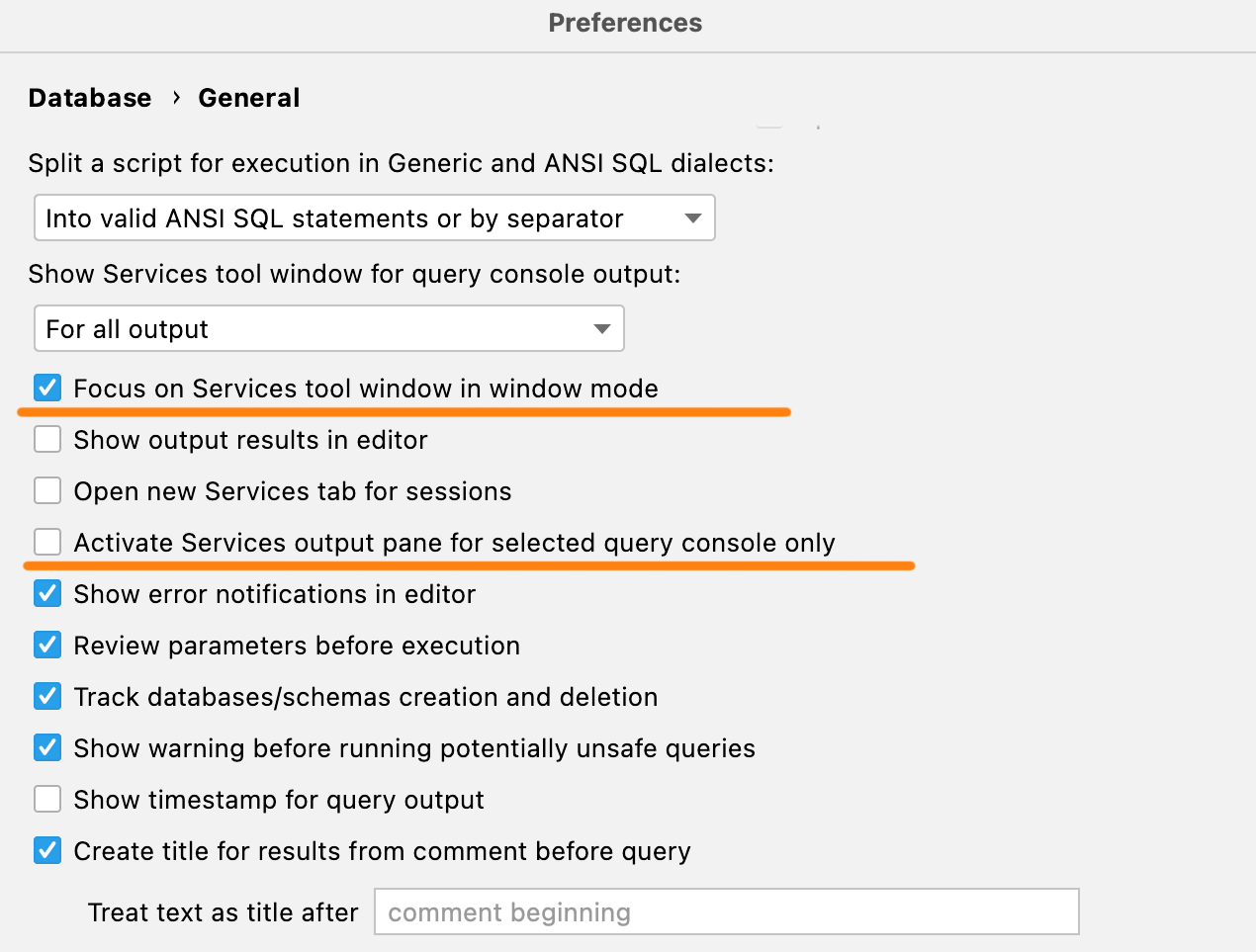
Neue Aktivierungseinstellungen
Wenn Sie das Services-Toolfenster im Fenstermodus verwenden, ist er standardmäßig hinter der IDE versteckt. Mit der neuen Einstellung wird der Fokus bei Ausführung einer Abfrage an das Fenster übergeben, damit es nach Abschluss der Abfrage angezeigt wird.
Sollte es Sie stören, wenn nach Abschluss einer langen Abfrage in einer anderen Konsole der entsprechende Tab im Services-Toolfenster aktiviert wird, aktivieren Sie das Kontrollkästchen Activate Services output pane for selected query console only.
Import/Export
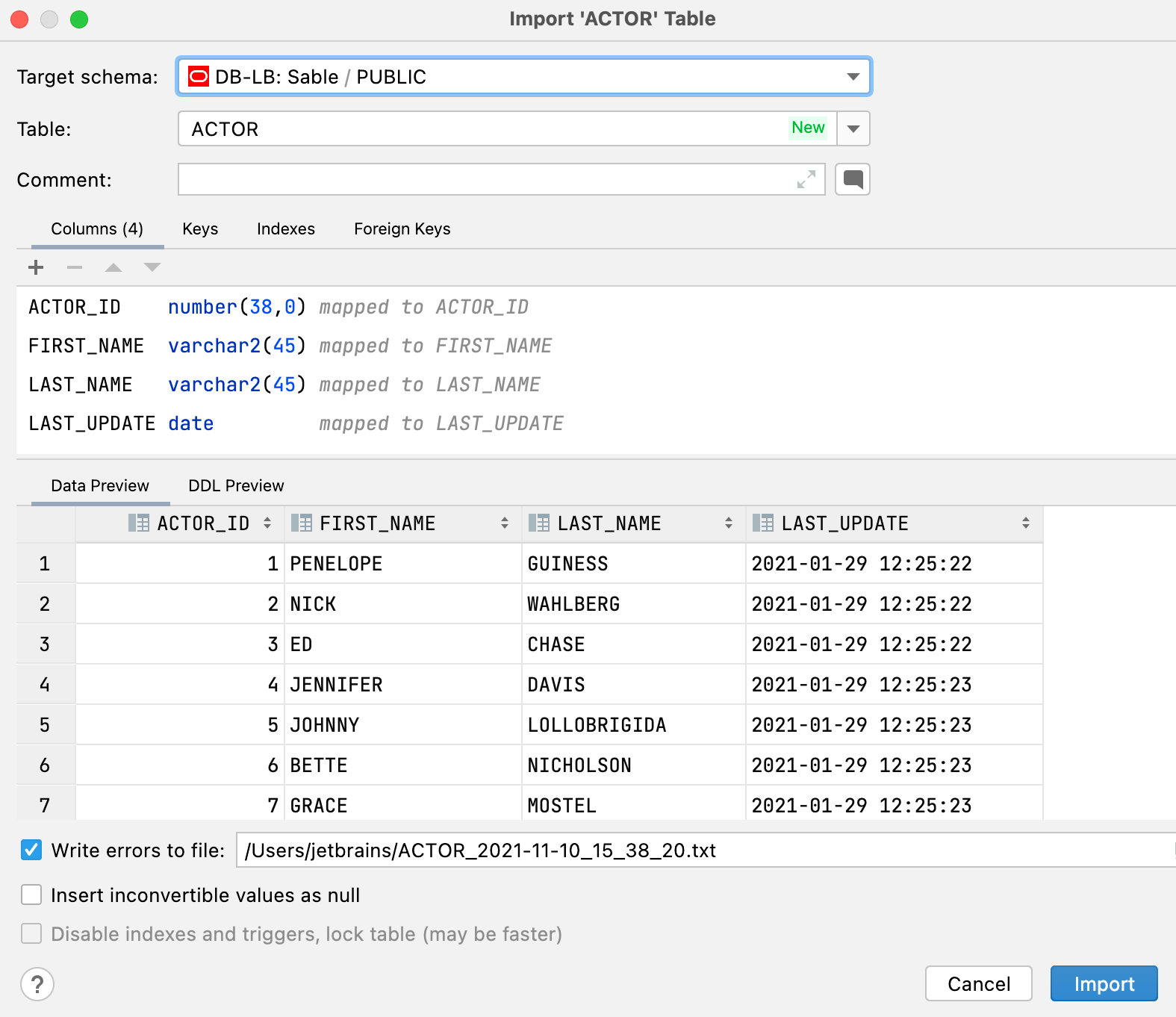
Datenimport mit neuer Benutzerführung
Beim Importieren von .csv-Dateien oder beim Kopieren von Tabellen/Ergebnissen werden Sie folgende Verbesserungen feststellen:
- Sie können eine vorhandene Tabelle auswählen oder eine neue erstellen.
- Sie können das Zielschema im Importdialog ändern. Der Dialog für das Ziel wird nicht angezeigt, wenn Sie eine Tabelle oder eine Ergebnismenge kopieren.
- Für jedes Schema wird das Ziel als Standardeinstellung gespeichert. Wenn Sie also ständig von einem bestimmten Schema in ein anderes kopieren, müssen Sie nicht jedes Mal das Ziel auswählen.
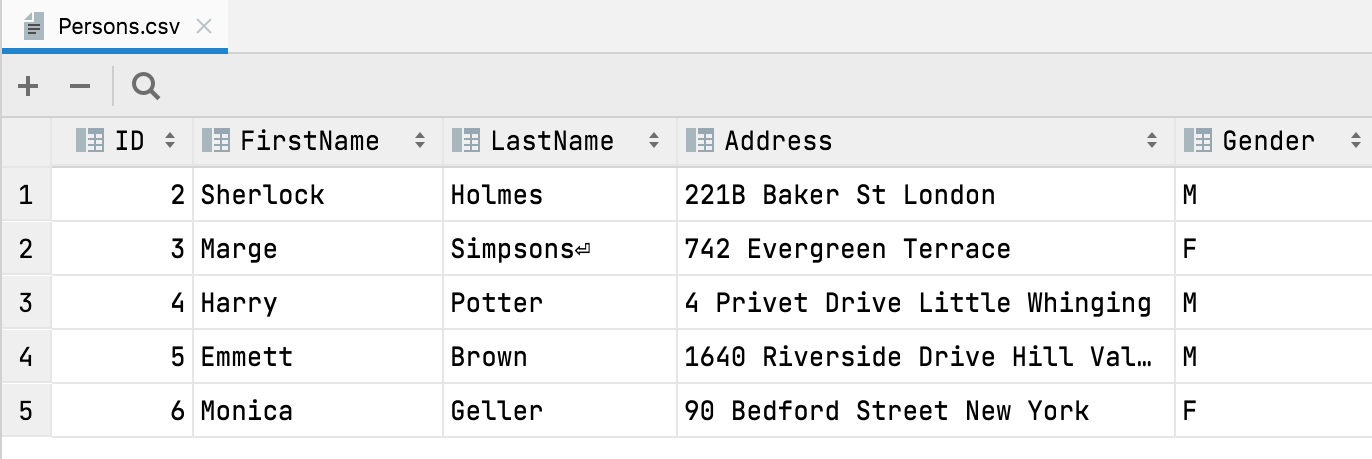
Automatische Kopfzeilenerkennung
Beim Öffnen oder Importieren einer CSV-Datei erkennt DataGrip ab sofort automatisch, wenn die erste Zeile eine Kopfzeile mit Spaltennamen ist.
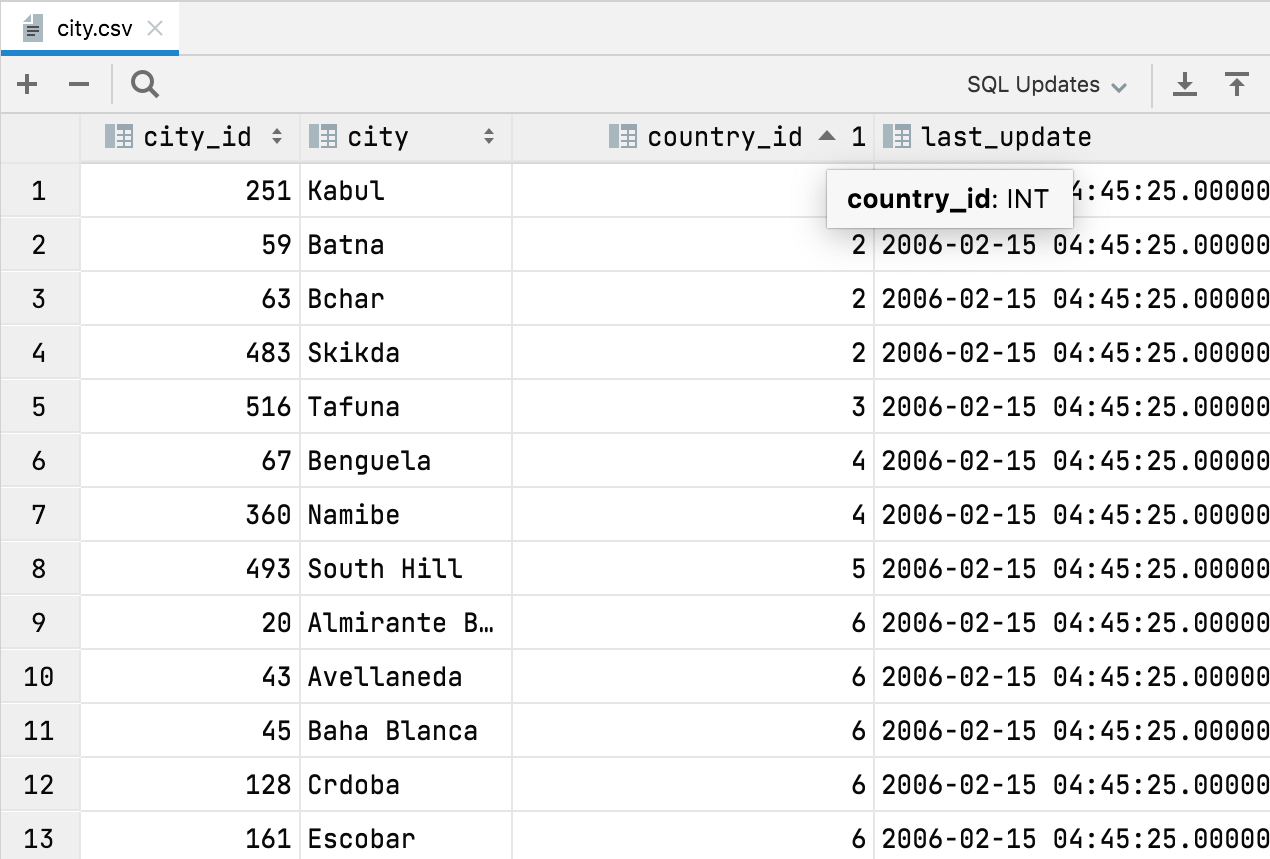
Automatische Spaltentypen in CSV-Dateien
DataGrip kann jetzt Spaltentypen in CSV-Dateien erkennen. Der Hauptvorteil besteht darin, dass Sie Daten nach Zahlenwerten sortieren können. Vorher wurden sie als Text behandelt und die Sortierung entsprach nicht immer den Erwartungen.
Verschiedenes
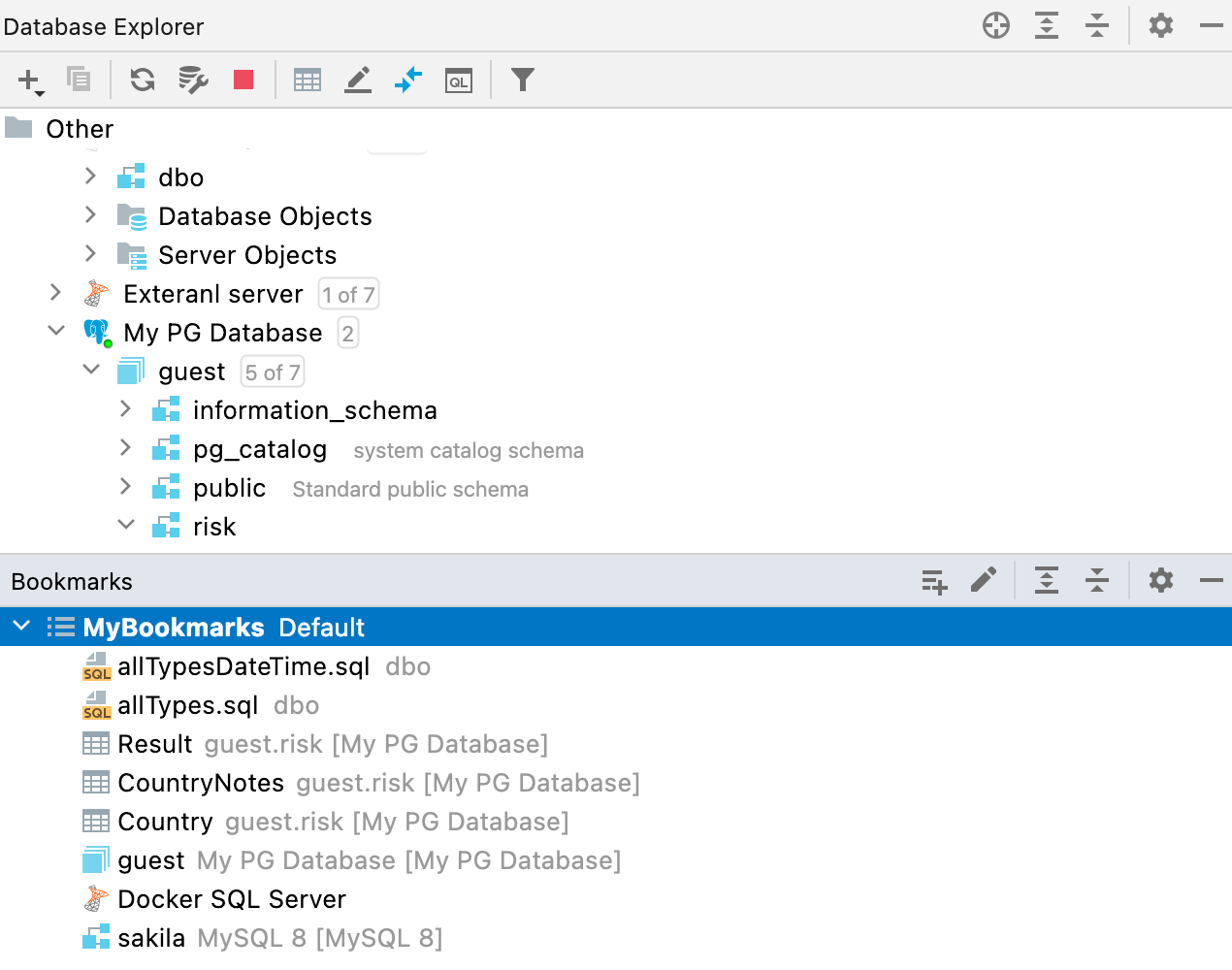
Neues Bookmarks-Toolfenster
Bisher hatten wir zwei sehr ähnliche Fenster – Favorites und Bookmarks. Da der Unterschied zwischen den beiden manchmal nicht ganz klar war, haben wir uns entschieden, nur eines zu behalten – Bookmarks. Wir haben den Workflow für diese Funktionalität überarbeitet und ein neues Toolfenster dafür erstellt.
Von nun an werden alle Objekte oder Dateien, die Sie mit F3 (macOS) oder F11 (Windows/Linux) als wichtig markieren, im neuen Bookmarks-Toolfenster angezeigt.