Das ist neu in DataGrip 2025.2
Abgestufte Introspektion für MS SQL Server und PostgreSQL, Datenbankobjekte als KI-Kontext, editierbare SELECT-Abfrageergebnisse und mehr.
Funktionen des AI Assistant
Um die in diesem Abschnitt beschriebenen Funktionen nutzen zu können, müssen Sie möglicherweise das AI-Assistant-Plugin installieren. Sobald das Plugin installiert ist, werden die Funktionen in Ihrer IDE standardmäßig aktiviert.
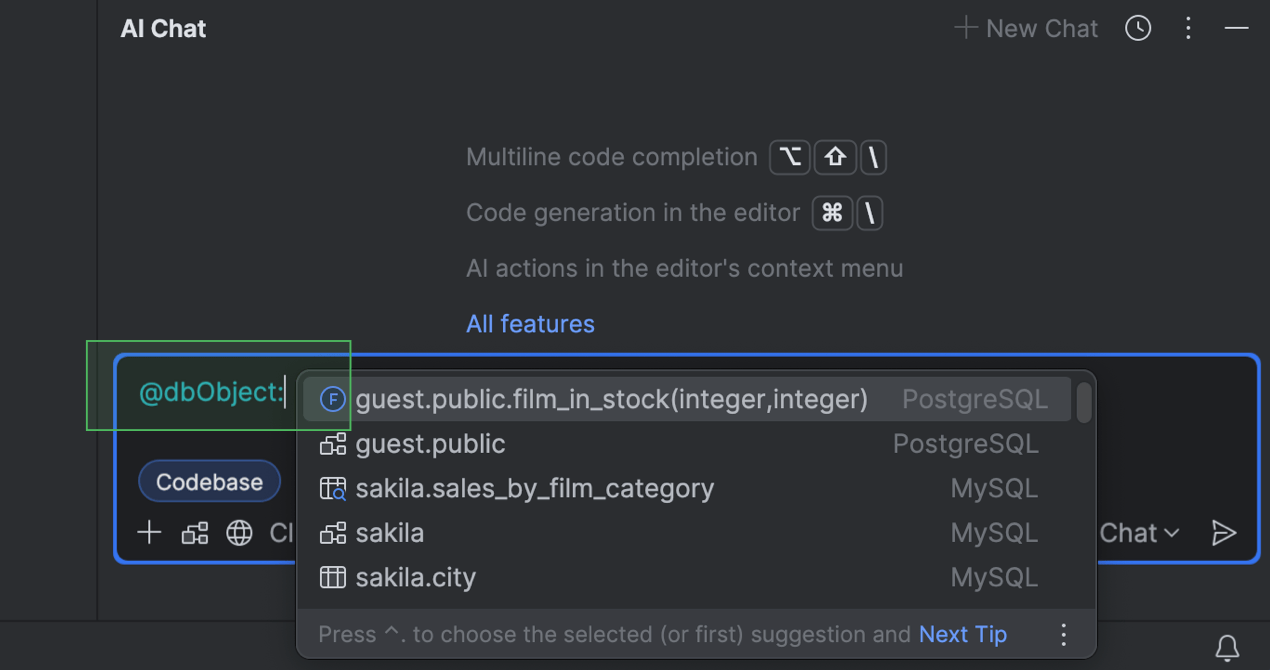
Datenbankobjekte an den KI-Chat anhängen
Bei Verwendung des KI-Chats können Sie jetzt noch spezifischeren Datenbankkontext bereitstellen. Bisher konnte nur das komplette Schema angehängt werden. Jetzt können Sie das Datenbankobjekt anhängen, mit dem Sie arbeiten möchten – zum Beispiel eine Tabelle oder View. Besonders nützlich ist dies, wenn Sie mit größeren Schemata arbeiten.
Um ein Datenbankobjekt anzuhängen, geben Sie @ oder # in das Eingabefeld ein, wählen Sie dbObject: aus oder tippen Sie es ein und wählen Sie dann in der Liste das Objekt aus, das Sie anhängen möchten.
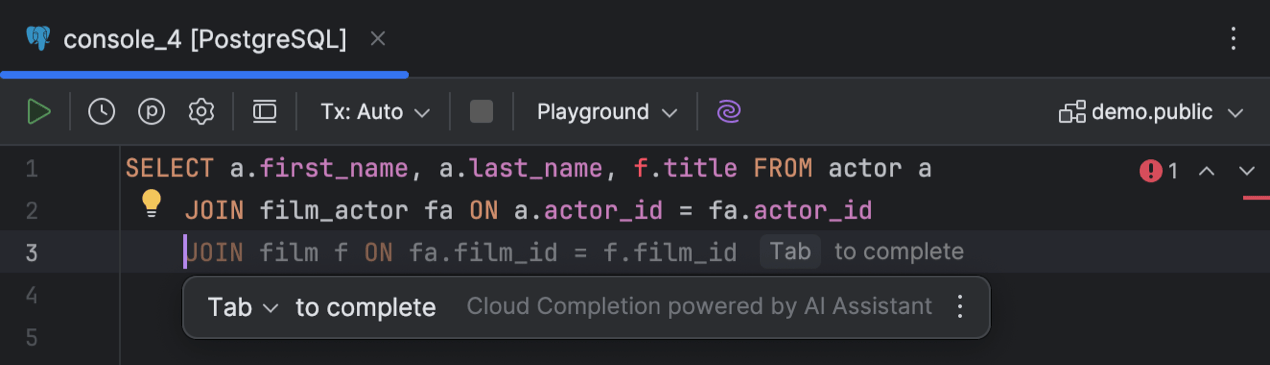
Cloud-basierte Code-Completion
DataGrip unterstützt jetzt die cloudbasierte Code-Completion. Durch die Nutzung von Cloud-Ressourcen, die eine größere Rechenleistung als das lokale System bereitstellen, wird eine präzisere Code-Completion ermöglicht. Dadurch kann die IDE einzelne Zeilen, Codeblöcke oder sogar ganze Skripte anhand des verfügbaren Kontexts in Echtzeit vervollständigen. Der generierte SQL-Code entspricht Ihrem Stil und Ihren Namenskonventionen und ist dadurch den Anweisungen, die Sie selbst schreiben würden, weitgehend ähnlich.
Bei der cloudbasierten Code-Completion zeigt DataGrip während der Eingabe Vorschläge im Editor an, und mit Alt+Umschalt+\ können Sie sie auch manuell aufrufen. Um diese Funktion abzuschalten, deaktivieren Sie unter Settings | Editor | General | Inline Completion das Kontrollkästchen Enable cloud completion suggestions.
Konnektivität
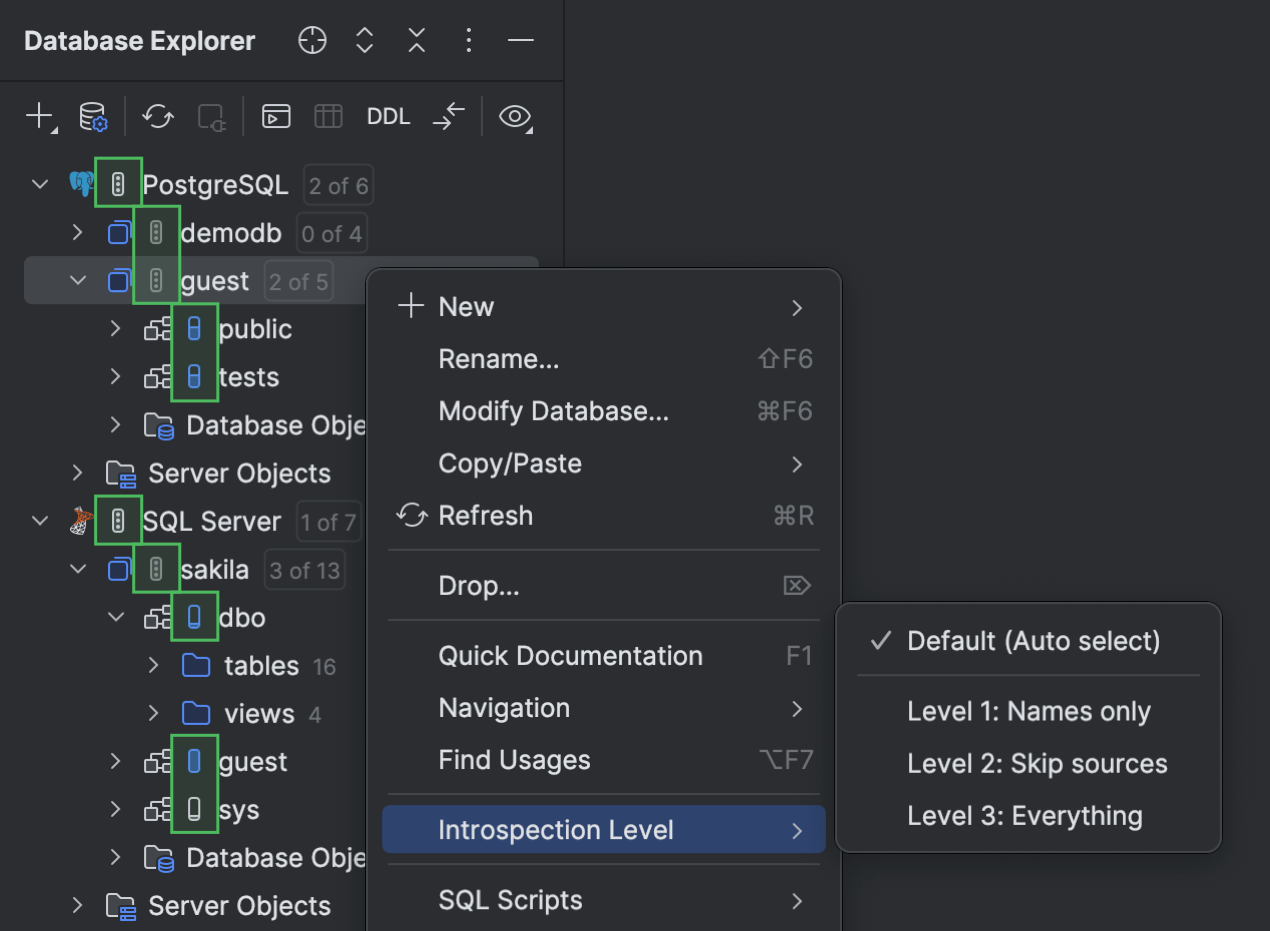
Abgestufte Introspektion PostgreSQL Microsoft SQL Server
Wir erweitern die stufenweise Introspektion auf weitere Datenbanken – aktuell auf PostgreSQL und Microsoft SQL Server! DataGrip passt bei diesen Datenbanken jetzt die Menge der geladenen Metadaten automatisch der Größe Ihrer Datenbank an. Dadurch können Sie auch bei größeren Datenbanken direkt mit der Arbeit loslegen, ohne auf das Laden aller Metadaten warten zu müssen.
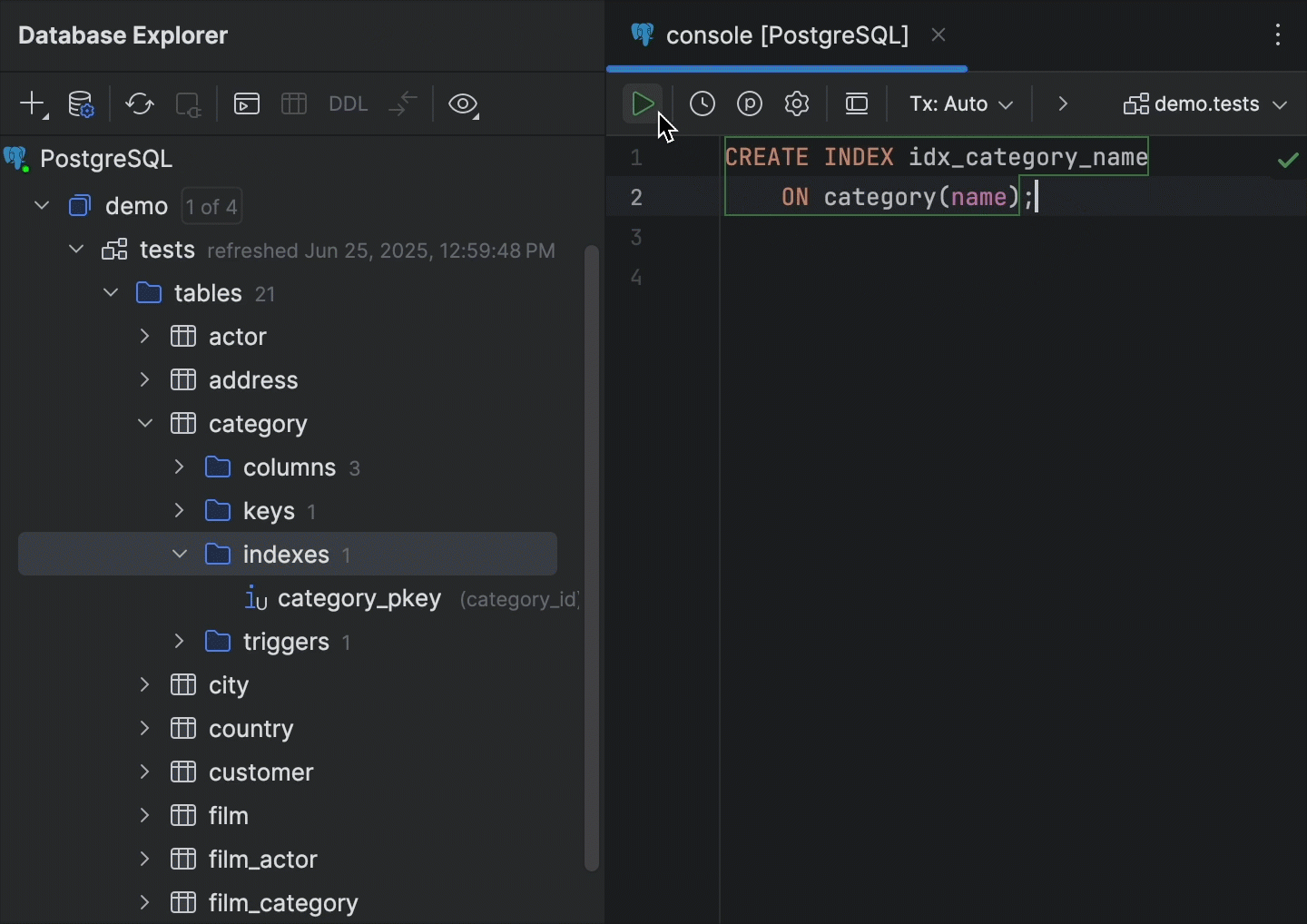
Smart-Refresh PostgreSQL
DataGrip unterstützt jetzt die Smart-Refresh-Funktion bei PostgreSQL-Datenbanken. Früher hat die IDE nach jedem Ausführen einer DDL-Anweisung das gesamte Schema im Datenbank-Explorer automatisch aktualisiert. Dank Smart-Refresh analysiert DataGrip jetzt, welche Objekte möglicherweise durch die Abfrage geändert wurden, und aktualisiert nur diese Gruppe von Objekten.
Dadurch müssen Sie, auch wenn Ihre Datenbank viele Objekte enthält, nicht bei jedem Ausführen einer DDL-Anweisung längere Zeit warten, bis das gesamte Schema aktualisiert wurde. Da nur eine Untergruppe der Objekte synchronisiert wird, können Sie viel schneller weiterarbeiten, als wenn jedes Objekt aktualisiert werden müsste – und im Datenbank-Explorer stehen Ihnen trotzdem alle benötigten Informationen zur Verfügung.
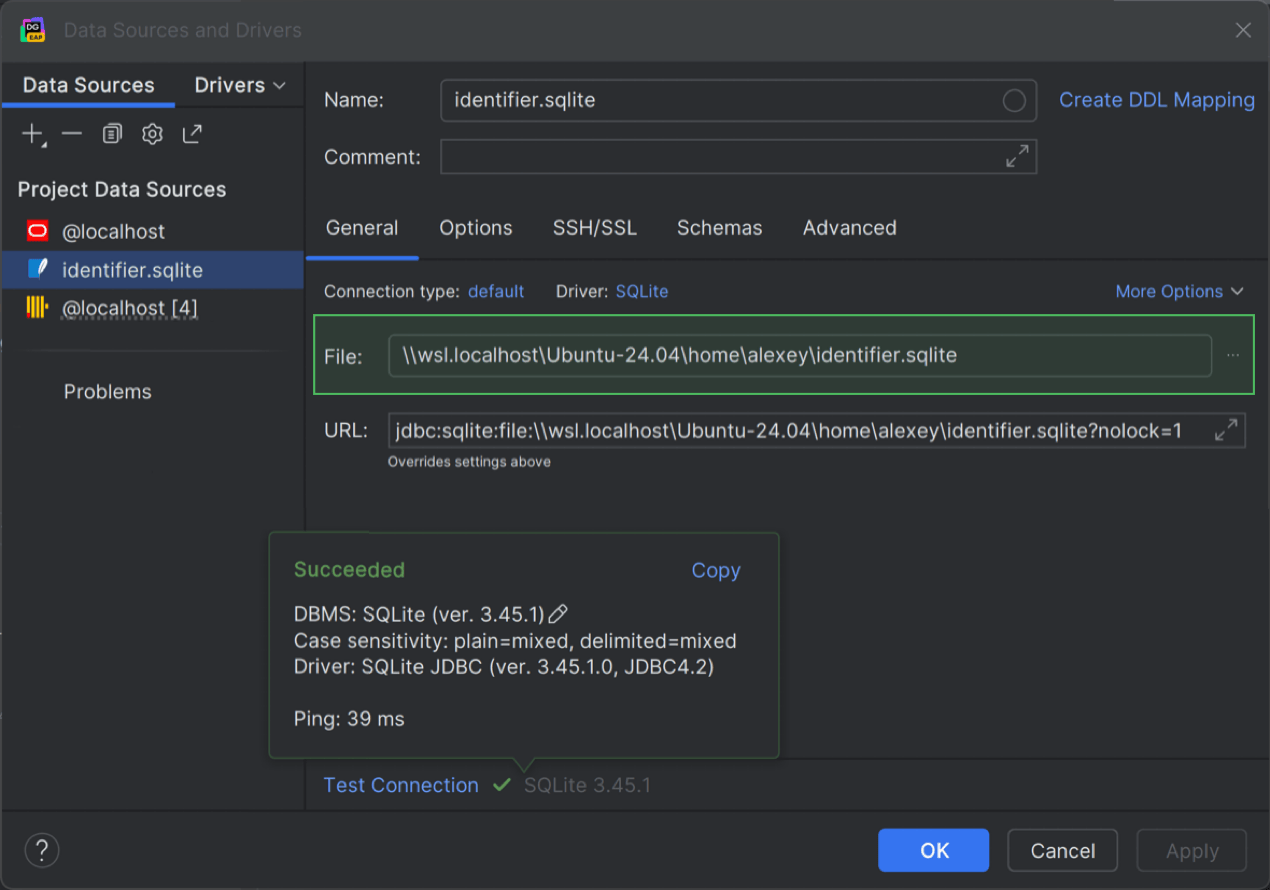
WSL-Pfad zu Datenbank-Dateien SQLite
DataGrip bietet jetzt die lang erwartete Unterstützung für WSL-Dateipfade bei SQLite-Datenbanken. Wir haben dafür unsere eigene Lösung für das Problem der Schreibsperre in WSL implementiert.
Dies bedeutet, dass Sie jetzt im WSL auf Ihre SQLite-Datenbank zugreifen und mit ihr arbeiten können, ohne dass die Datenbankdatei für Sie gesperrt ist. Öffnen Sie dazu den Dialog Data Sources and Drivers und geben Sie den Dateipfad im folgenden Format ein: \\wsl$\<Betriebssystem>\home\<Benutzername>\<Datenbank-Dateiname>.sqlite. Zum Beispiel: \\wsl.localhost\Ubuntu-24.04\\home\alexey\identifier.sqlite.
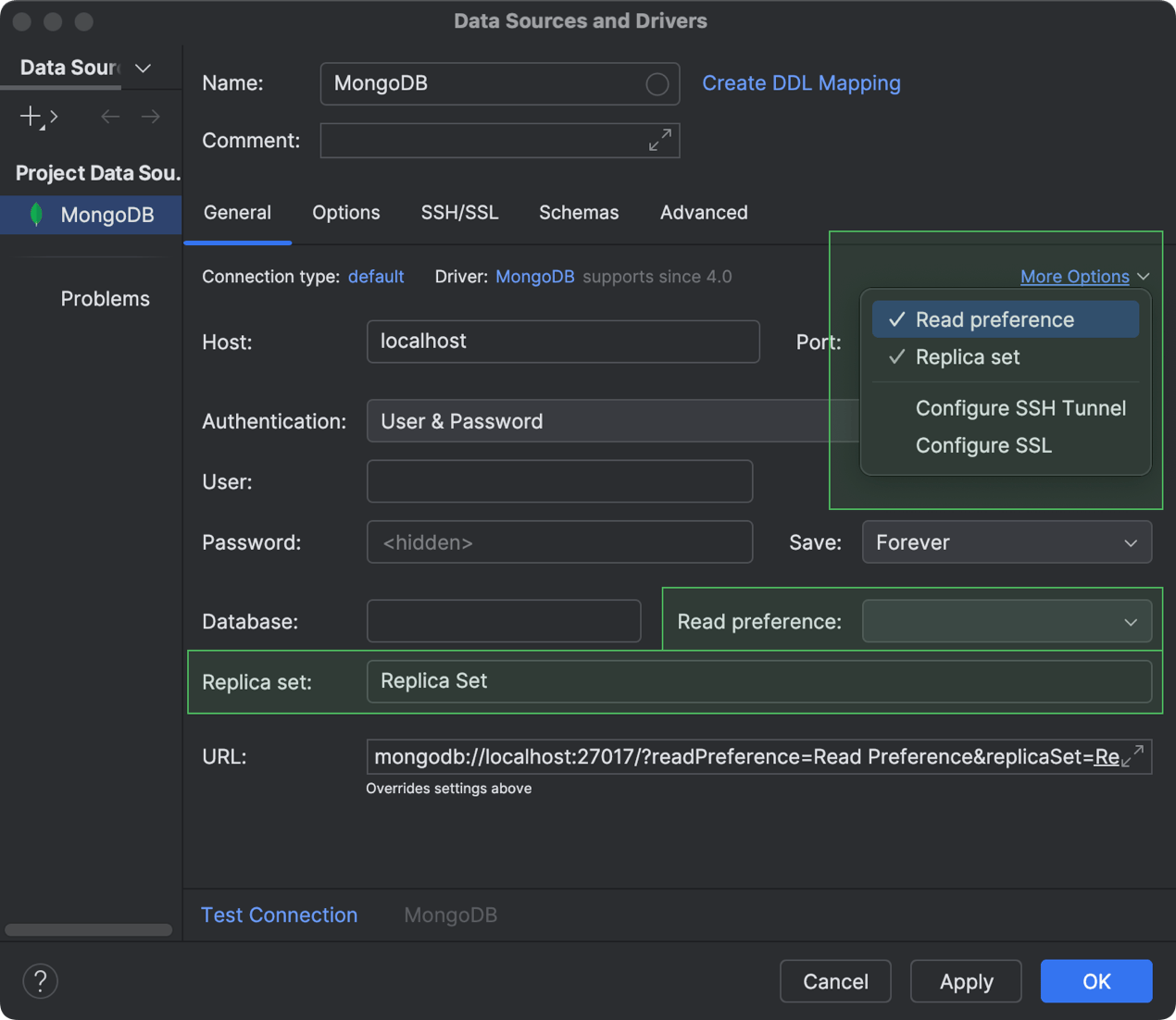
Unterstützung für die Verbindungseinstellungen Read preference und Replica set MongoDB
Sie können jetzt konfigurieren, wie Leseoperationen an die Elemente eines MongoDB-Replikatsets weitergeleitet werden, und sogar festlegen, welches Replikatset verwendet werden soll. Gehen Sie dazu beim Konfigurieren der Verbindung zu Ihrer MongoDB-Datenbank zu More Options und aktivieren Sie die entsprechende Option im Dialog Data Sources and Drivers. Sobald Sie eine der Optionen aus der Liste auswählen, erscheint ein neues Feld, in dem Sie die Einstellung festlegen können. Ihre Lesepräferenz können Sie im Feld Read preference angeben. Um Ihr Replikatset zu definieren, geben Sie einfach den Namen des Sets im Feld Replica set ein.
Mit Daten arbeiten
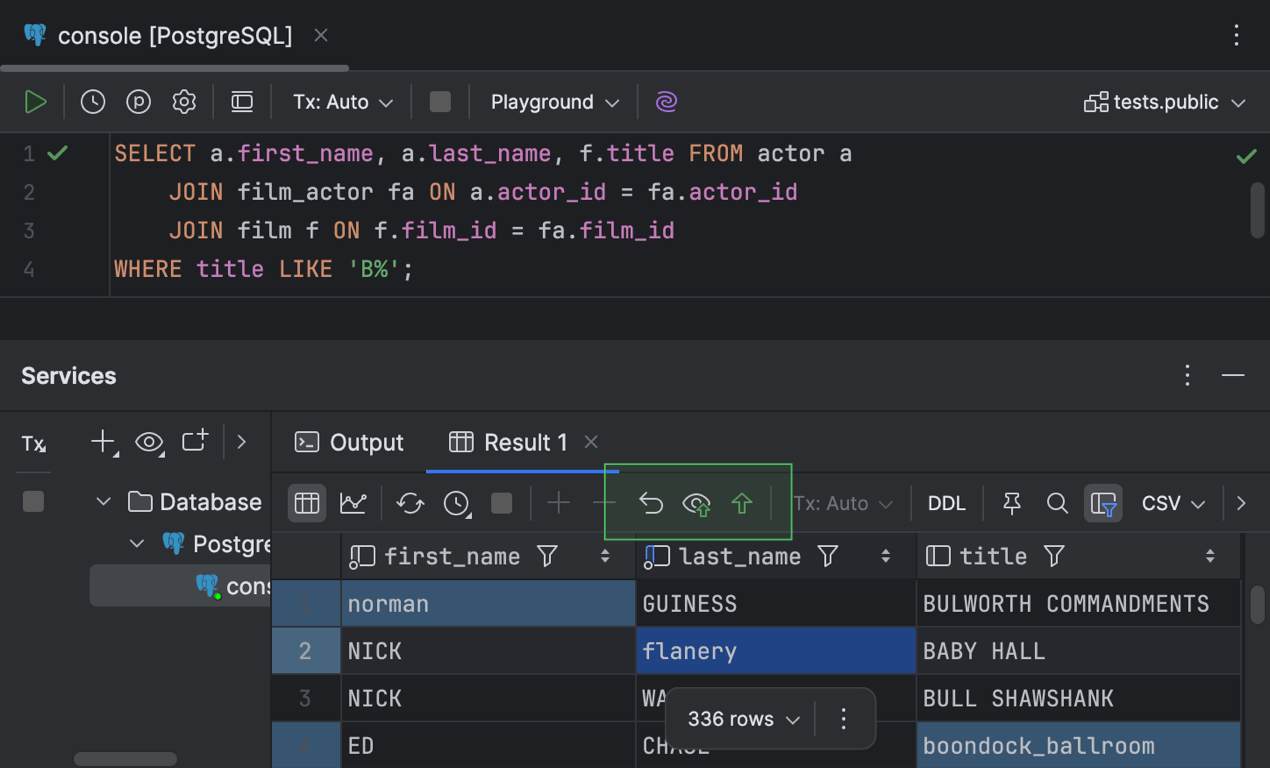
Editierbare Ergebnisse bei SELECT-Abfragen mit JOIN-Klauseln
Nach einem Jahrzehnt Arbeit ist diese lang erwartete Funktion endlich Realität! Zuvor war die Ergebnistabelle bei SELECT-Abfragen mit JOIN-Klauseln schreibgeschützt. Jetzt können Sie nach dem Ausführen einer solchen Abfrage die Zellenwerte direkt in der Ergebnistabelle bearbeiten. Doppelklicken Sie dazu einfach auf eine Zelle oder markieren Sie sie und drücken Sie Enter. Außerdem können Sie wie in jeder anderen Tabellenanzeige mit der rechten Maustaste auf die Zelle klicken und Open in Value Editor auswählen, um den Wert in einem separaten Fenster auf der rechten Seite zu bearbeiten.
Der Dateneditor bietet Ihnen die Möglichkeit, die Werte entweder in der Ergebnisanzeige im Editor oder im Services-Toolfenster zu bearbeiten. Nachdem Sie einen Zellenwert bearbeitet haben, werden in der Symbolleiste des Result-Tabs im Services-Toolfenster die folgenden Schaltflächen aktiviert: Revert Selected, Preview Pending Changes, Submit.
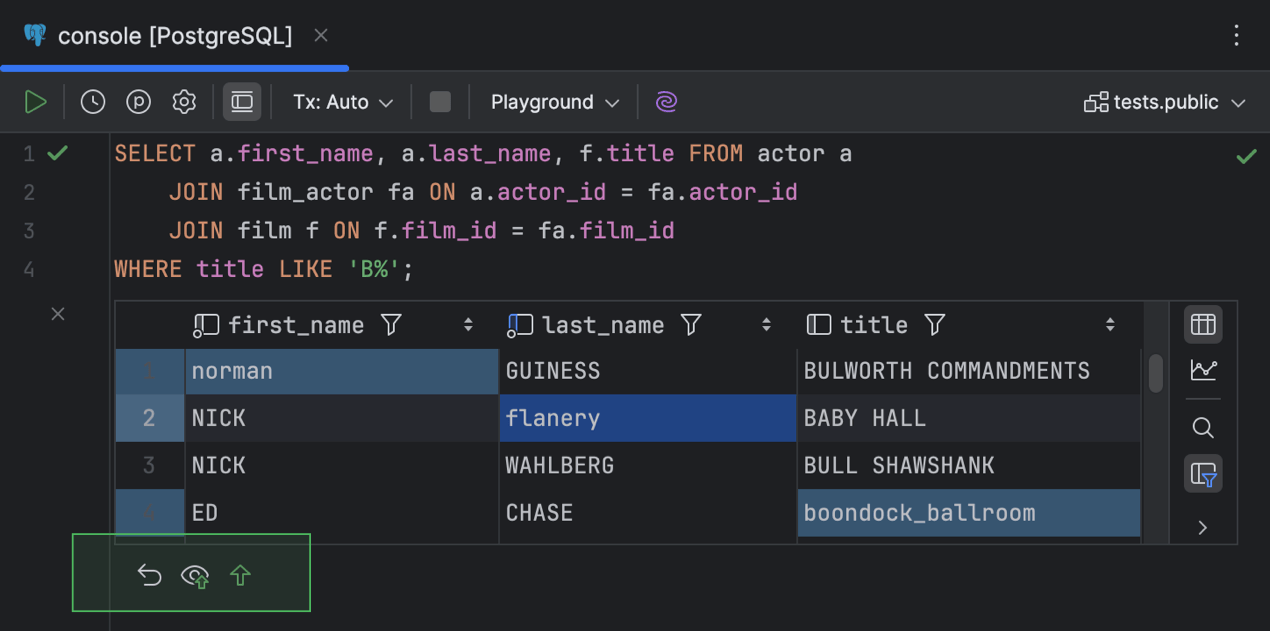
Außerdem erscheint eine weitere Symbolleiste mit diesen Schaltflächen am unteren Rand des Ergebnisfensters im Editor.
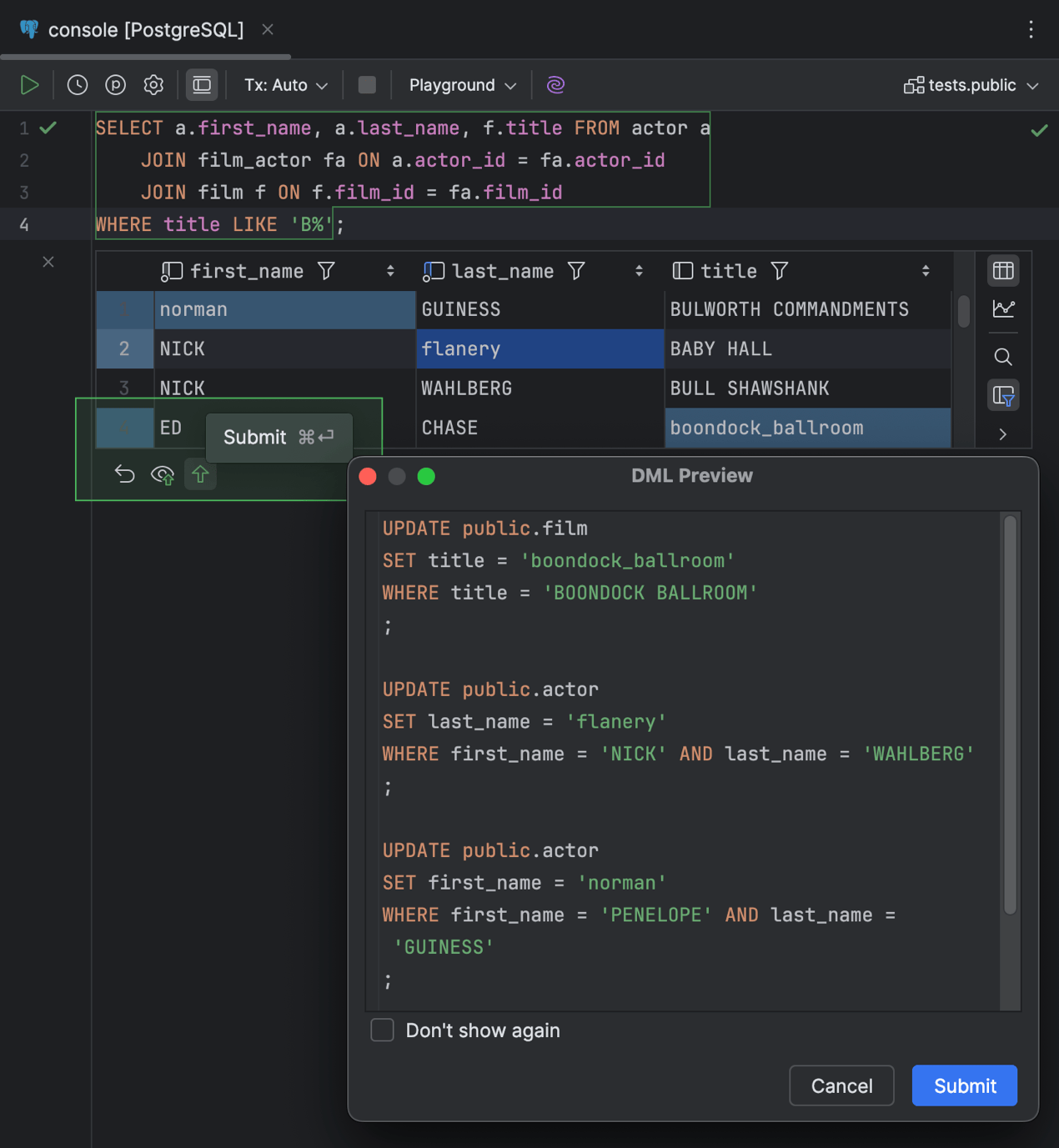
Wenn Sie Ihre Änderungen an die Datenbank übermitteln, zeigt DataGrip den Dialog DML Preview an, damit Sie die generierten Anweisungen vorab prüfen können. Wenn Sie Ihre Änderungen bearbeiten möchten, klicken Sie auf Cancel und fahren Sie mit der Bearbeitung fort. Um die Änderungen zu übermitteln, klicken Sie auf Submit.
Diese Funktion wird in den folgenden Fällen nicht unterstützt: bei Verwendung des SQL-Operators UNION, wenn dieselbe Tabelle auf beiden Seiten eines JOIN-Vorgangs verwendet wird (Self-Joins), wenn die Ergebnis-Datensätze berechnete Werte enthalten (zum Beispiel CONCAT) sowie bei NoSQL-Datenbanken. Für eine korrekte Funktion muss jede Zeile über ein oder mehrere Felder eindeutig identifiziert werden können.
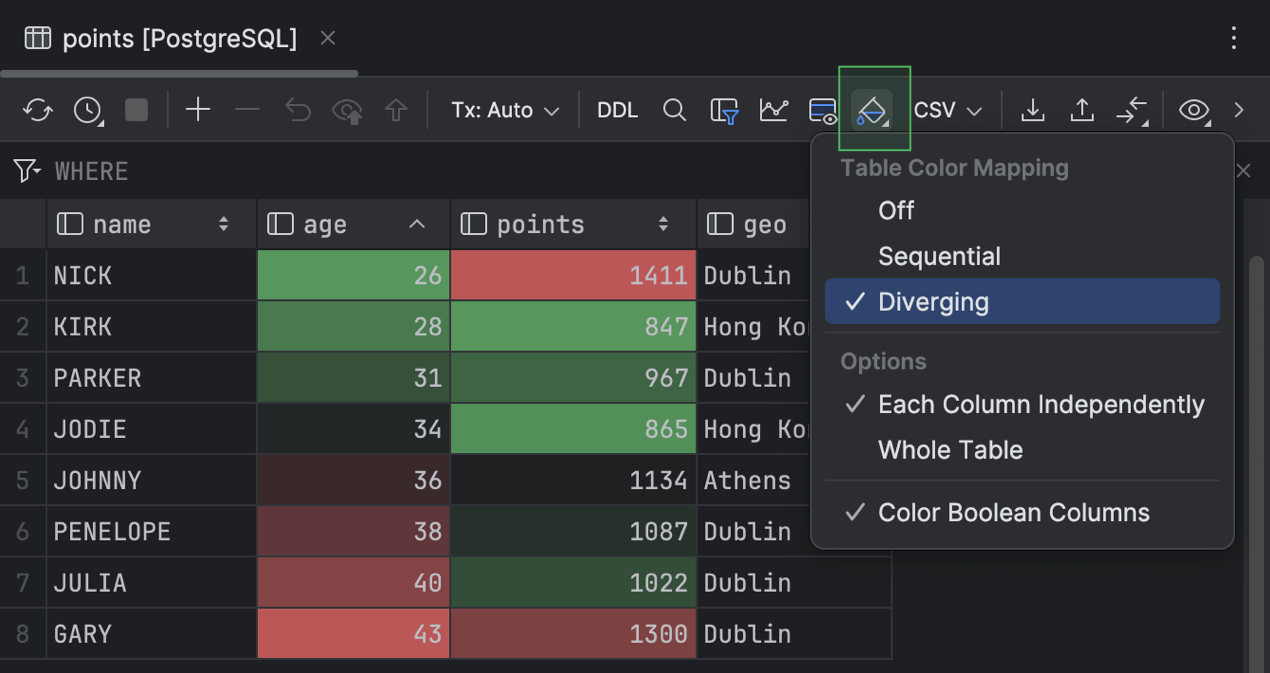
Heatmap im Tabellenraster
Im Dateneditor stellt DataGrip jetzt Raster-Heatmaps mit zwei Farbschema-Optionen bereit: Diverging und Sequential. Um die Heatmap für Ihr Tabellenraster zu aktivieren, klicken Sie in der Symbolleiste auf Table Coloring Options und wählen Sie ein Schema aus.
Das Farbschema Diverging betont Abweichungen von einem Normwert. Es besteht aus zwei kontrastierenden Farben, die von einem zentralen Wert in entgegengesetzte Richtungen abweichen.
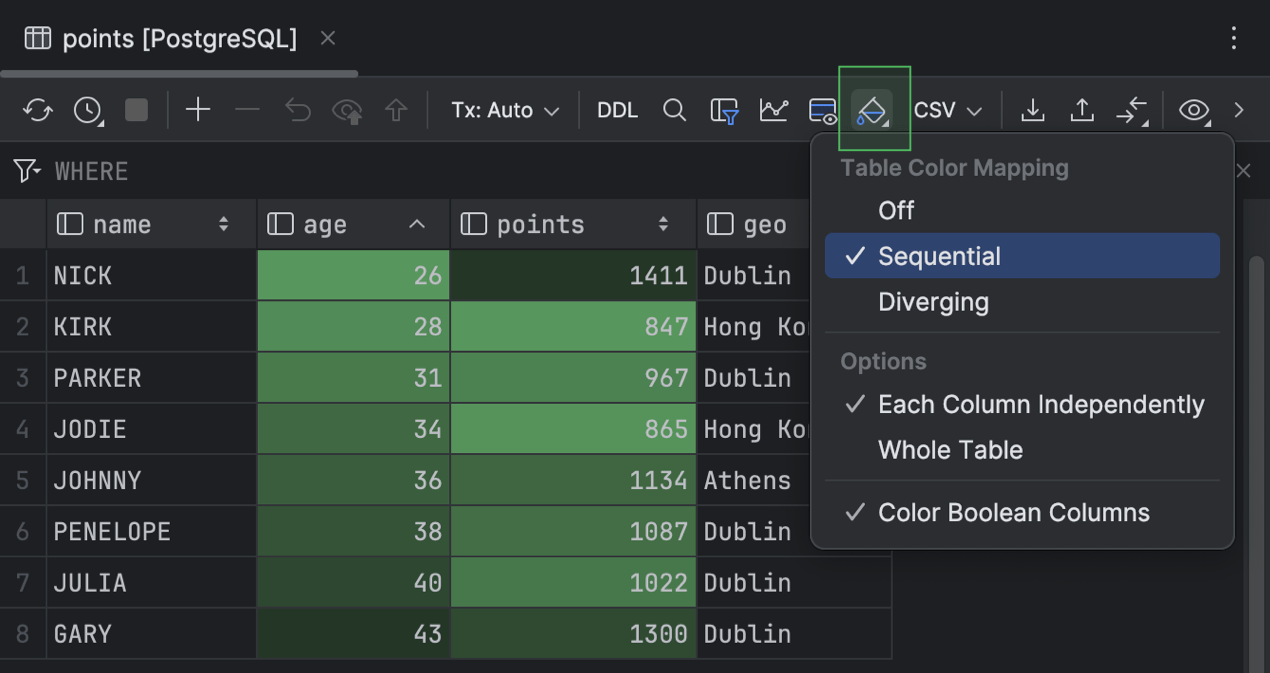
Das Farbschema Sequential besteht aus einer einzigen Farbe oder einer Reihe von ähnlichen Farben, die in ihrer Intensität variieren.
Sie können die Heatmap-Farbschemata auf die gesamte Tabelle oder auf einzelne Spalten anwenden oder nur boolesche Werte einfärben.
Aktion zum Löschen aller lokalen Tabellenraster-Filter
Jetzt können Sie die lokalen Filter aller Spalten in Ihrem Tabellenraster mit einer einzigen Aktion löschen. Öffnen Sie dazu mit Strg+Umschalt+A das Popup Find Action, beginnen Sie mit der Eingabe von Clear Local Filter For All Columns und wählen Sie dann die Aktion in der Liste aus.
Code-Editor
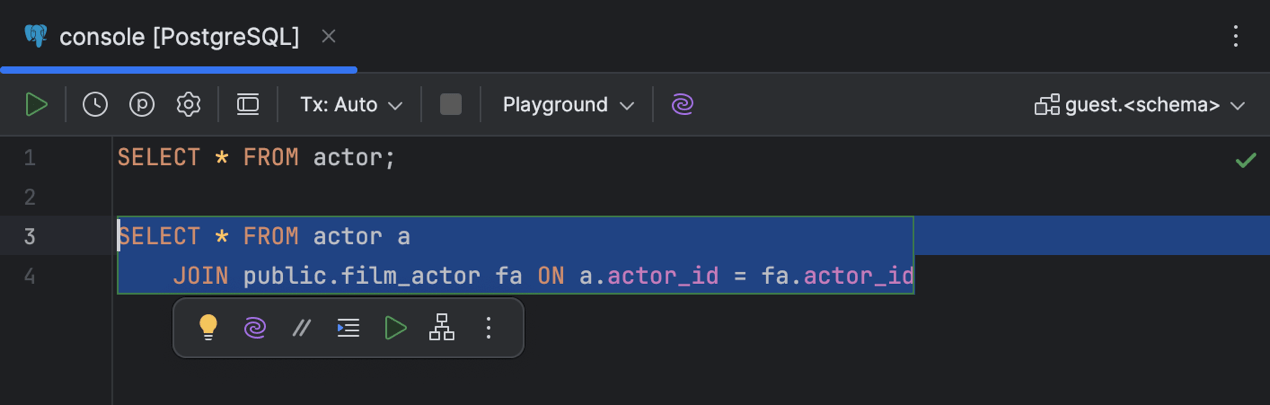
Schwebende Symbolleiste
DataGrip zeigt jetzt kontextbasierte und KI-gestützte Aktionen, die für einen bestimmten Codeabschnitt verfügbar sind, in einer schwebenden Symbolleiste an. Wählen Sie einen beliebigen Codeabschnitt in Ihrem Editor aus, um die Symbolleiste zu aktivieren.
Sie können die schwebende Symbolleiste über das vertikale Dreipunktmenü anpassen. Zum Ausblenden können Sie entweder dasselbe Menü verwenden oder unter Settings | Advanced Settings | Editor die Option Hide floating toolbar for code editing aktivieren.
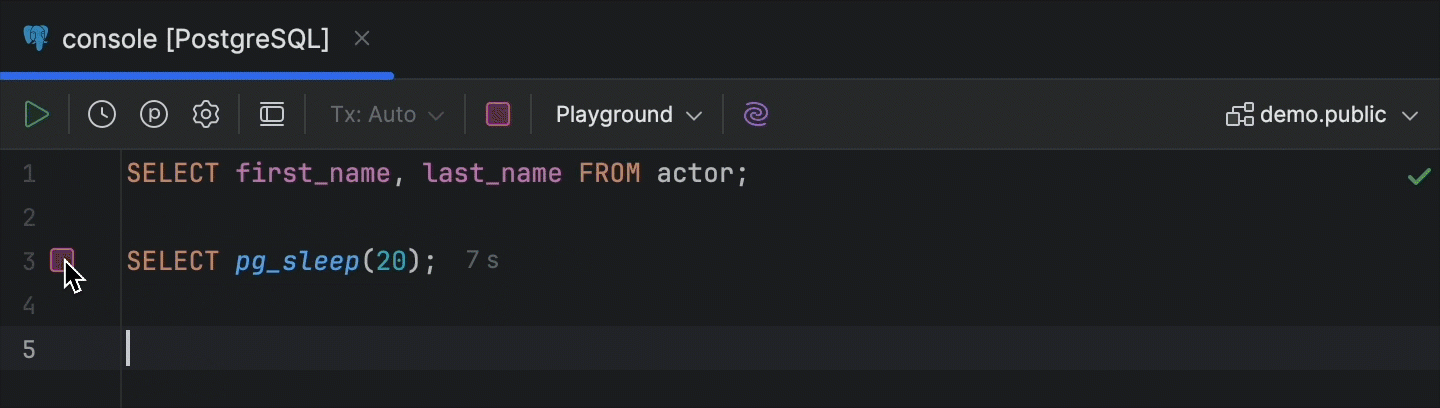
Schaltfläche Cancel Running Statements in der Randleiste
Wenn eine Anweisung gerade ausgeführt wird, verwandelt sich das Fortschrittssymbol in der Randleiste jetzt in die Schaltfläche Cancel Running Statements, wenn Sie mit dem Mauszeiger darüber fahren.
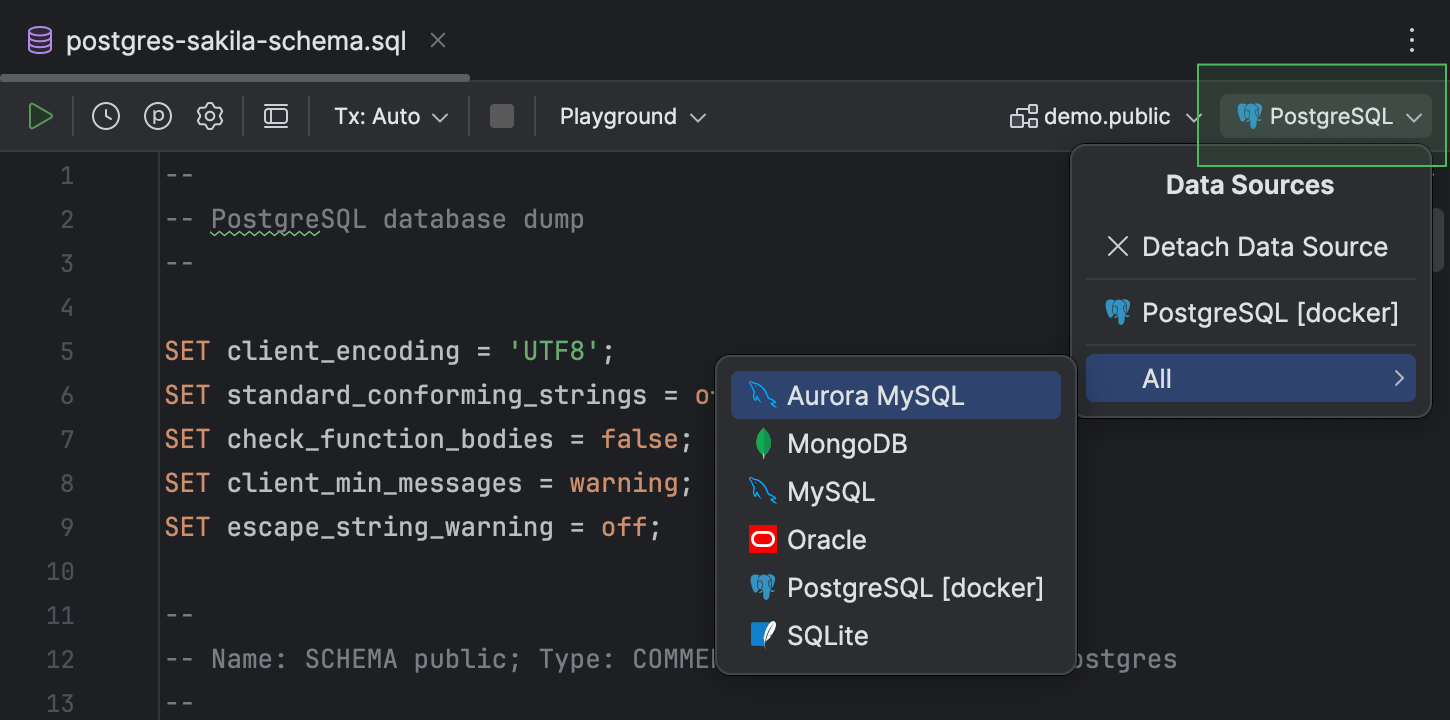
Angehängte Datenquellen überstehen Neustarts
Bisher mussten bei jedem Neustart der IDE Datenquellen an die Dateien angehängt werden. Wir haben diese lästige Einschränkung jetzt behoben!
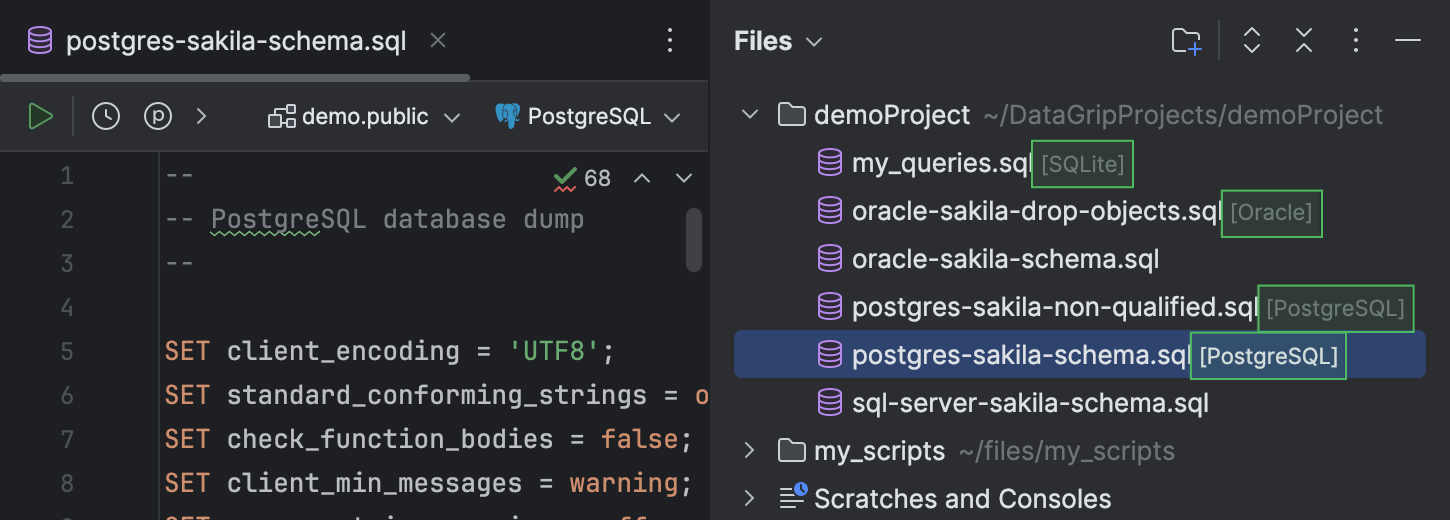
Außerdem wird die angehängte Datenquelle jeder Datei im Files-Toolfenster angezeigt.
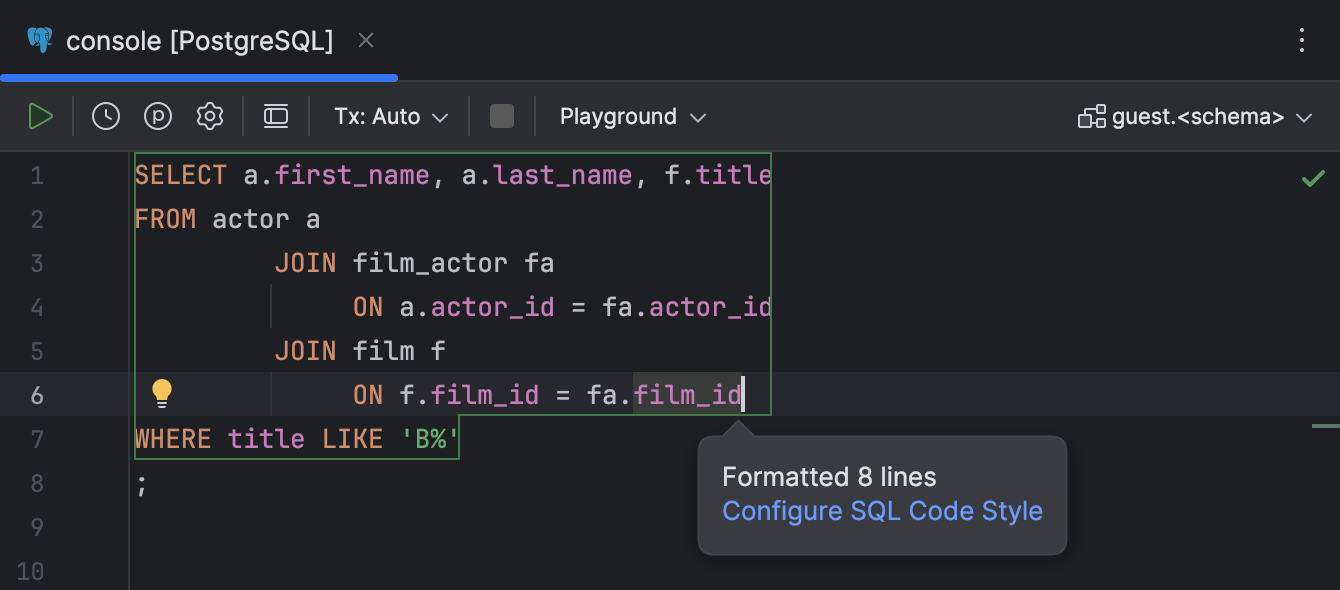
Schnellzugriff auf Codestil-Einstellungen
Sie können jetzt die Codestil-Einstellungen direkt aus dem Popup heraus aufrufen, das bei jedem Neuformatieren des Codes angezeigt wird.
Wir hoffen, dass diese Updates nach Ihrem Geschmack sind! Wenn Sie auf einen Fehler stoßen oder eine Funktion vorschlagen möchten, erstellen Sie bitte ein Ticket in unserem Issue-Tracker.
Sie möchten über die neuesten Funktionen informiert werden und Tipps für ein produktiveres Arbeiten mit Datenbanken erhalten? Abonnieren Sie unser Blog und folgen Sie uns auf X!