Datenverbindungen
Ganz gleich, ob Sie mit CSV-Dateien, S3-Buckets oder SQL-Datenbanken arbeiten – Datalore bietet Ihnen einfache Möglichkeiten, in Ihrem Notebook auf mehrere Datenquellen zuzugreifen und Informationen abzufragen.
Im nachfolgenden Video finden Sie eine Übersicht zu Datenverbindungen:
Interner Speicher
Datalore verfügt über einen persistenten internen Speicher für den schnellen Zugriff auf Notebooks und andere Arbeitsartefakte.

Notebook-Dateien
Ganz gleich, ob Sie lokale Dateien oder Ordner hochladen, Daten per Link importieren oder Dateien mittels Code herunterladen: Alle Daten werden in Notebook-Dateien gespeichert. Wenn Sie ein Notebook für Mitwirkende freigeben, werden die Notebook-Dateien ebenfalls automatisch freigegeben.
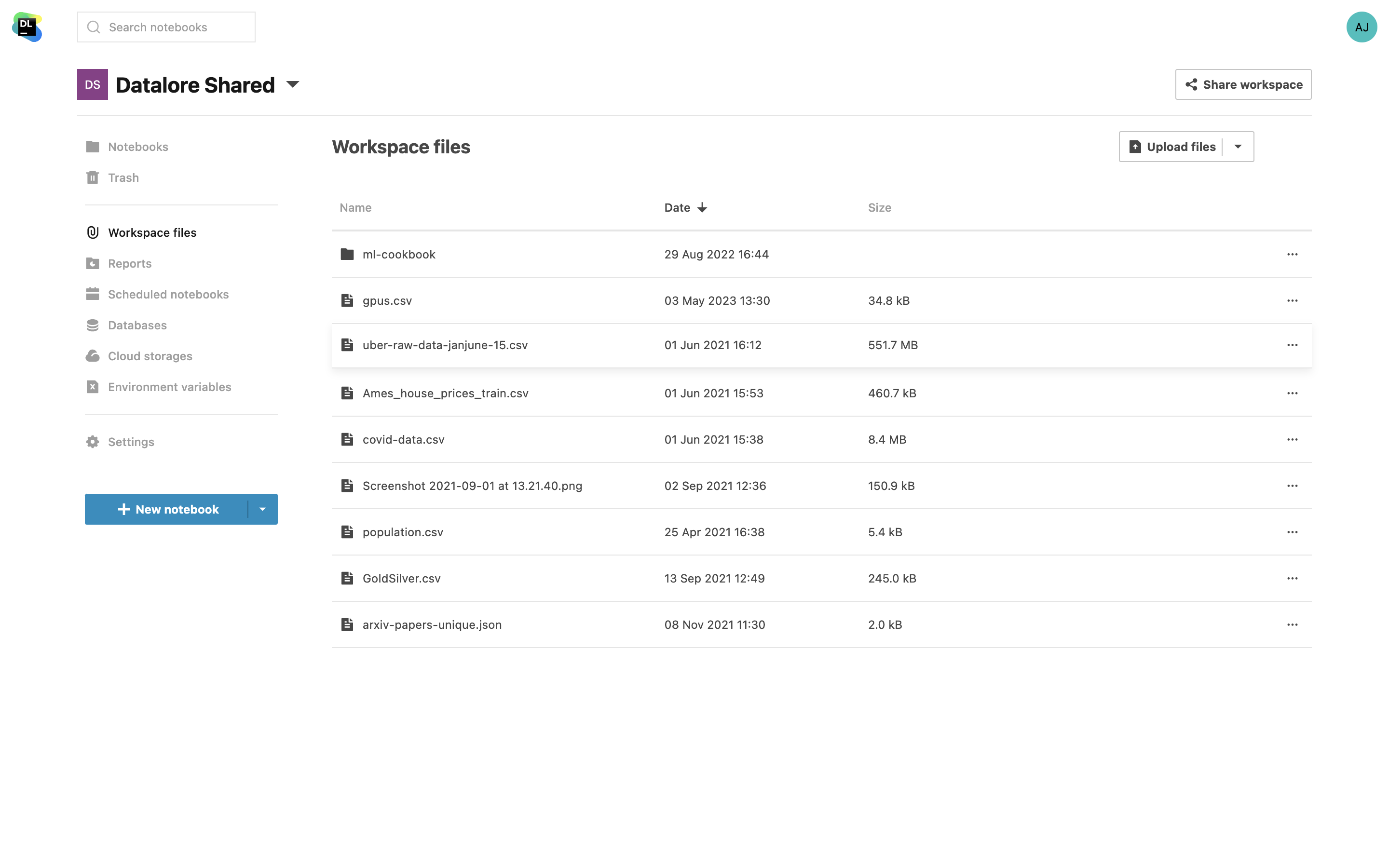
Workspace-Dateien
Über Workspace-Dateien können Sie Datensammlungen mit mehreren Notebooks teilen. Wenn Sie in einem gemeinsamen Workspace arbeiten, genügt es, eine Datensammlung einmal hochzuladen, um sie für jeden Editor im Workspace zugänglich zu machen.
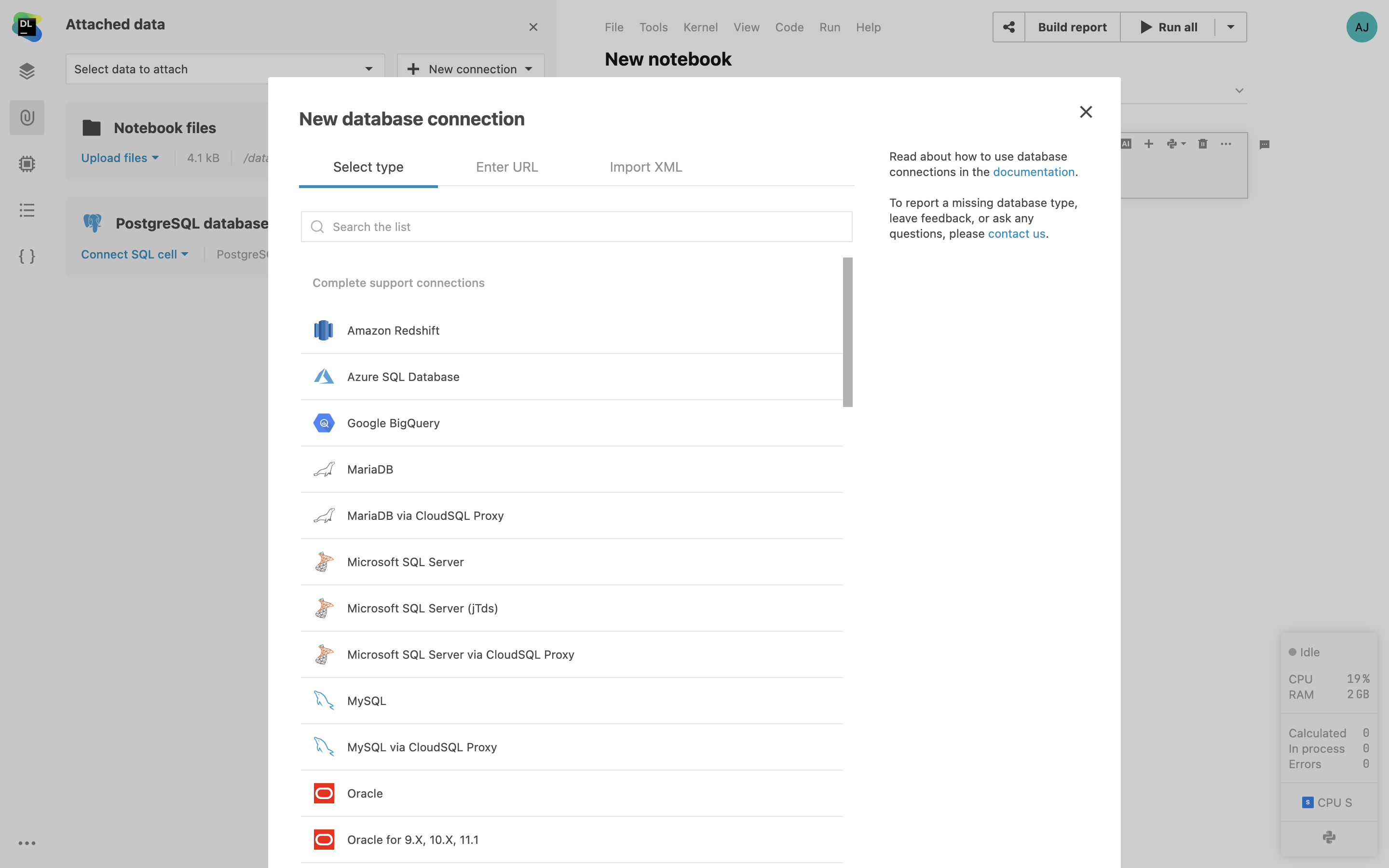
Datenbankverbindungen über die Bedienoberfläche
Wenige Klicks genügen, um Ihre Notebooks direkt im Editor mit Datenbanken zu verbinden. Sie können Ihre Daten in nativen SQL-Zellen abfragen, ohne Ihre Anmeldeinformationen mit der Umgebung zu teilen.
Datalore unterstützt die Benutzer-/Passwortauthentifizierung für Amazon Redshift, Azure SQL Database, MariaDB, MySQL, Oracle, PostgreSQL, Snowflake und weitere Datenbanksysteme. Bitte kontaktieren Sie uns unter datalore-support@jetbrains.com, wenn Sie spezielle Fragen zur Datenbankkonnektivität haben.
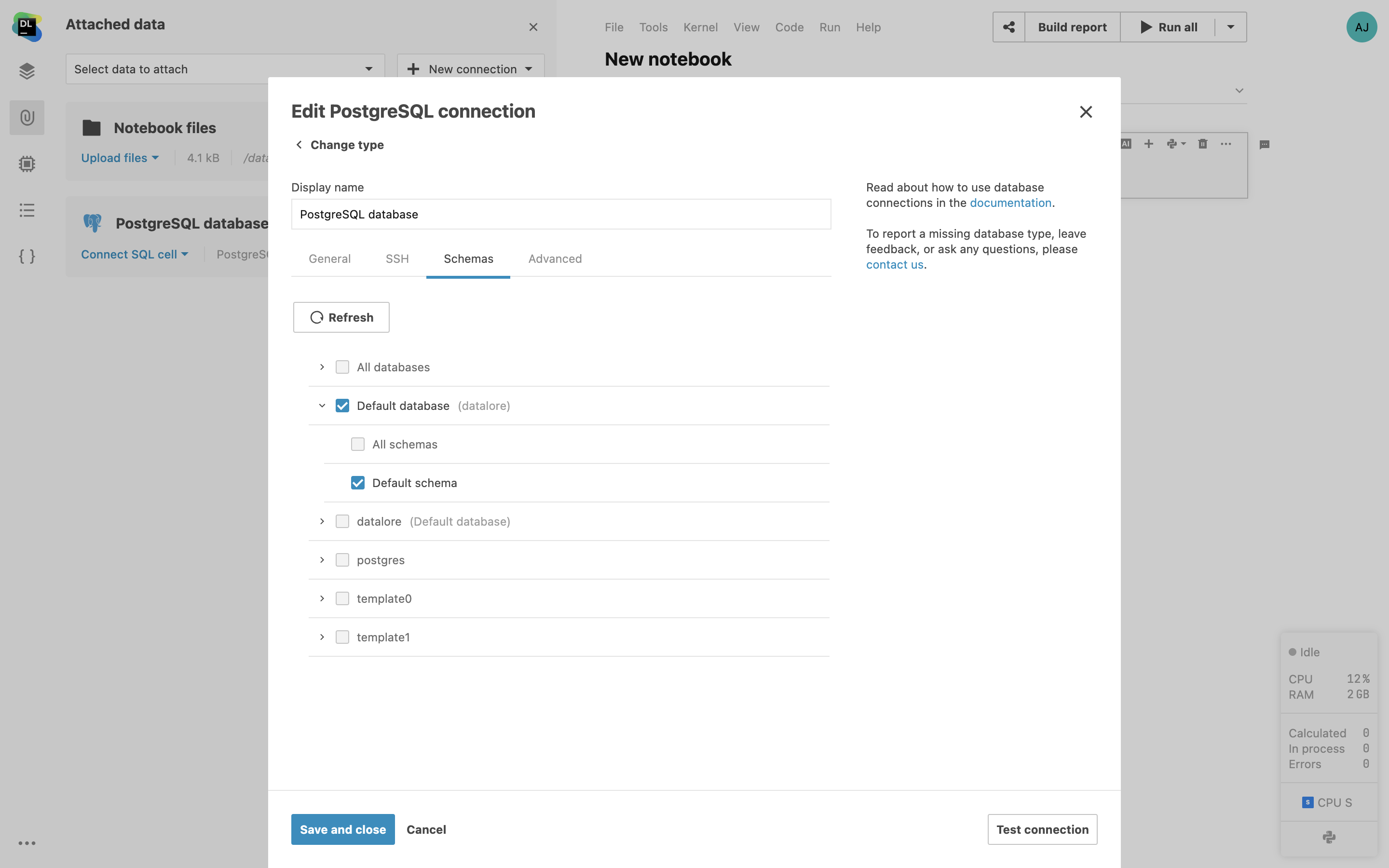
Schemata für Datenbank-Introspektion einschränken
Wenn Sie eine Datenbankverbindung in Datalore erstellen, können Sie bestimmte Datenbankschemata und Tabellen für die Introspektion auswählen. Dadurch erhalten Sie schneller die ersten Introspektionsergebnisse, und auch die Schemanavigation wird vereinfacht.
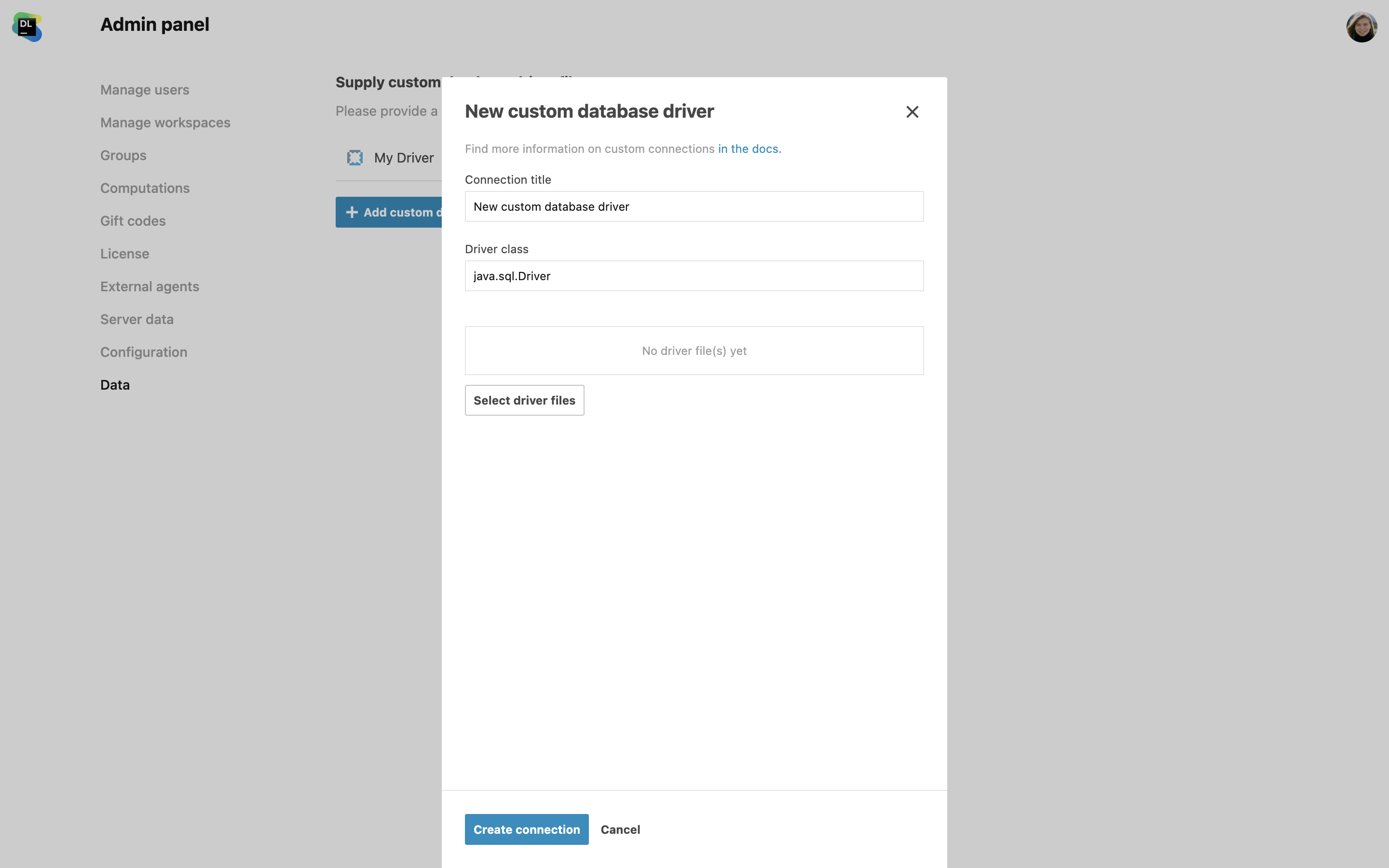
Unterstützung für benutzerdefinierte JDBC-Treiber
Administratoren können jetzt benutzerdefinierte JDBC-Treiber hinzufügen, um Datenbanken zu verbinden, die Datalore On-Premises nicht nativ unterstützt. Auf dem Admin panel können Sie unter Miscellaneous | New custom database driver Treiberdateien von Ihrem lokalen System auswählen und hochladen.
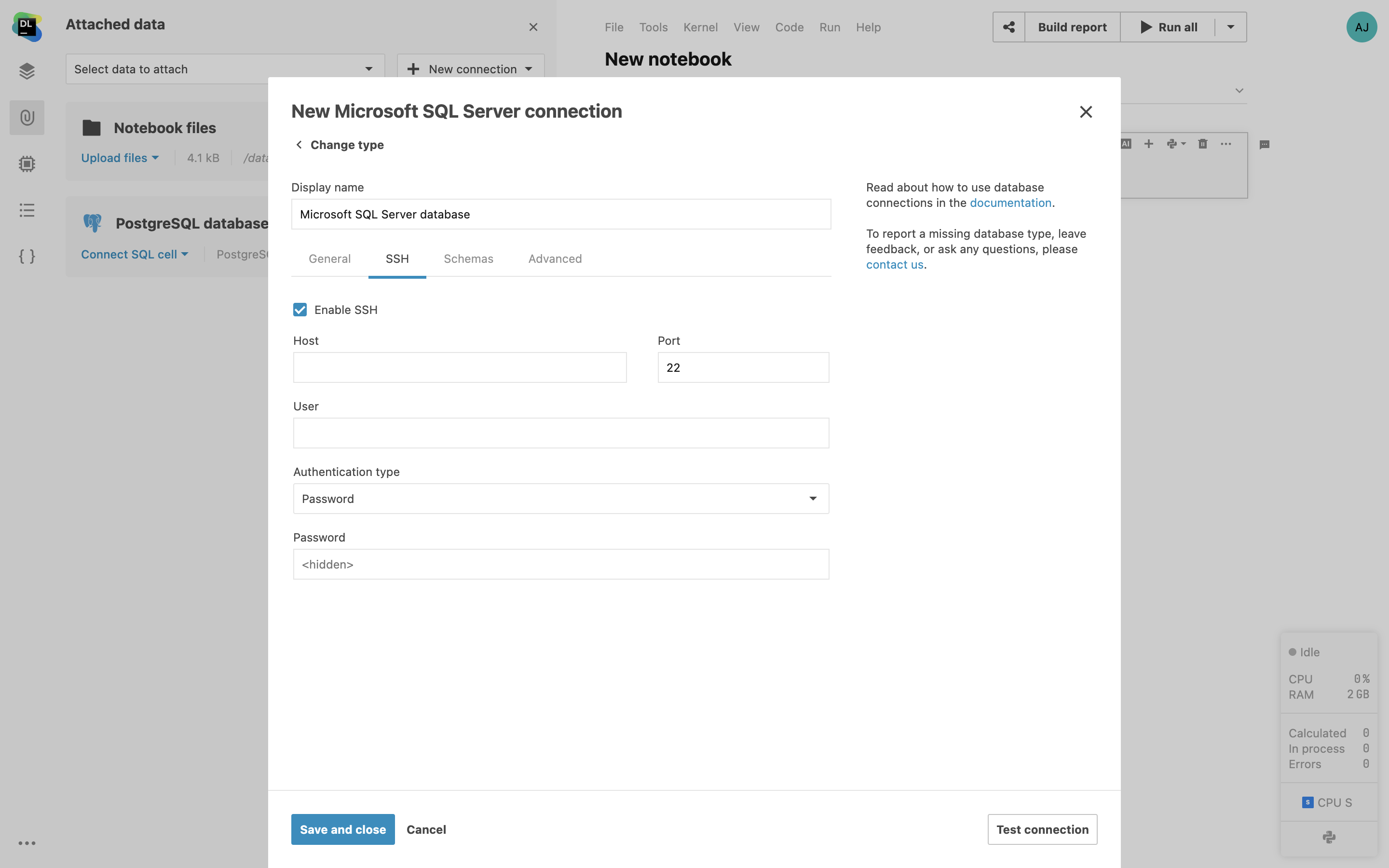
Unterstützung von SSH-Tunneling
Verbindungen zu Remote-Datenbanken können in Datalore über SSH-Tunneling hergestellt werden. Dadurch wird eine verschlüsselte SSH-Verbindung zwischen Datalore und Ihrem Gateway-Server aufgebaut. Über SSH-Tunnel können Sie sich mit Datenbanken verbinden, die nicht in einem öffentlichen Netzwerk zugänglich sind.
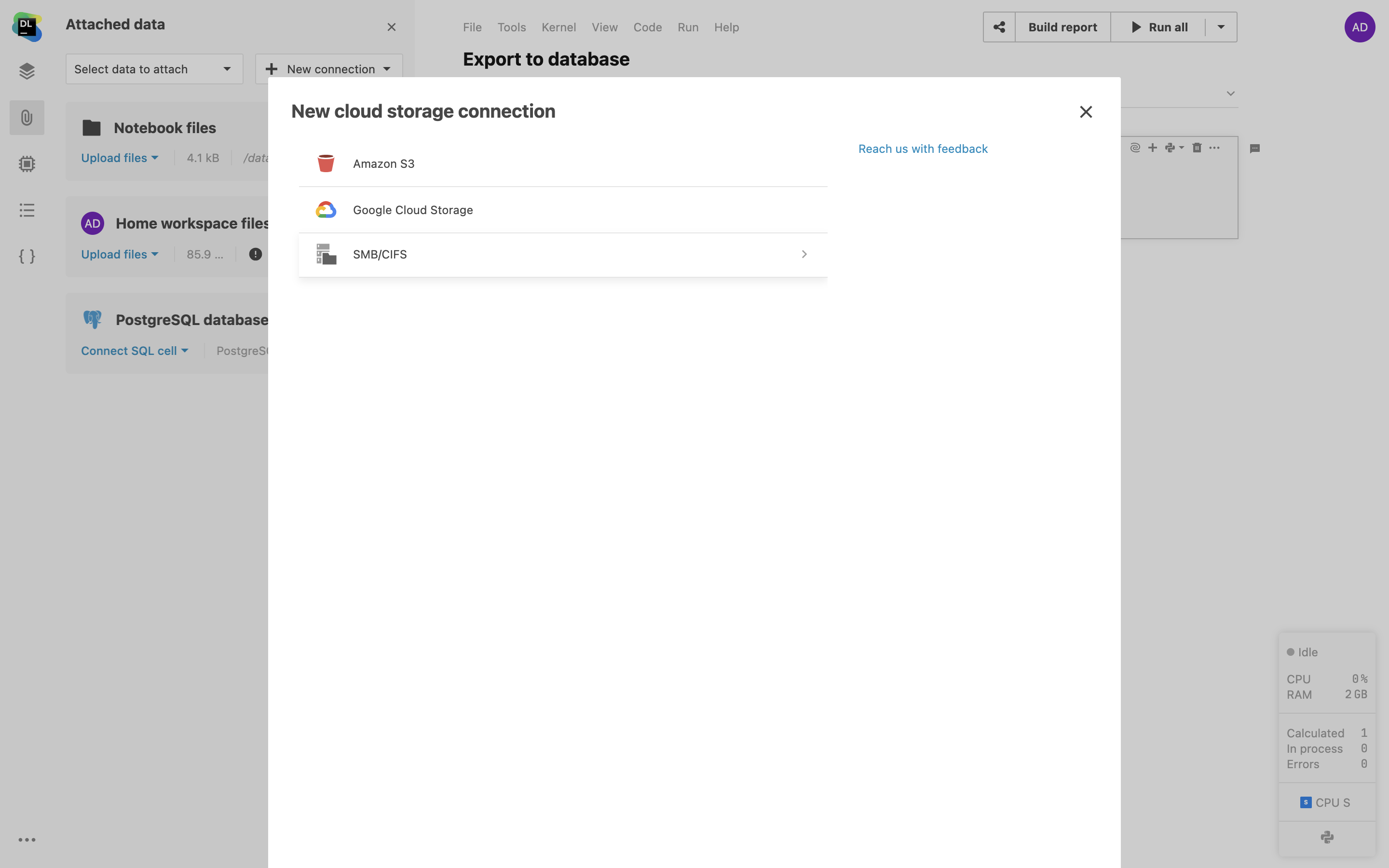
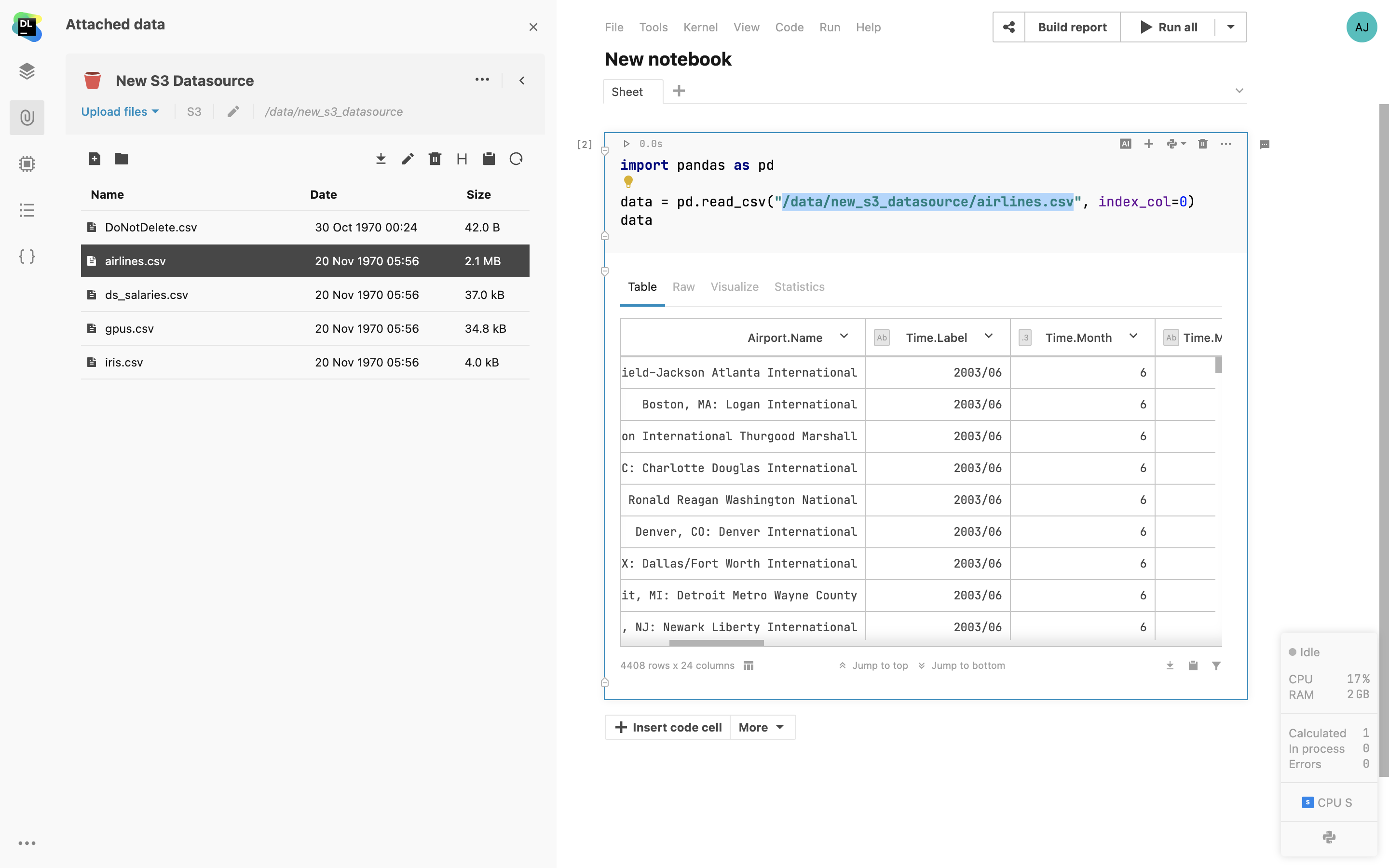
Mounten von S3-Buckets
Stellen Sie AWS-S3- und GCS-Buckets direkt im Notebook als Ordner bereit, ohne Ihre Anmeldeinformationen mit der Umgebung zu teilen.
Datenverbindungen über Code
Unabhängig von den Datenverbindungen, die über die Bedienoberfläche hergestellt werden können, lassen sich beliebige Buckets, Datenbanken oder Datenspeicher wie in Jupyter-Notebooks üblich per Code verbinden.
SQL-Zellen
Mit nativen SQL-Zellen können Sie Ihre Datenbankverbindungen abfragen. Außer der SQL-Syntaxhervorhebung steht Ihnen auch eine Code-Completion basierend auf der Introspektion der Datenbanktabellen zur Verfügung. Das Abfrageergebnis wird automatisch in einen Pandas-DataFrame übertragen und kann in Python weiterbearbeitet werden.
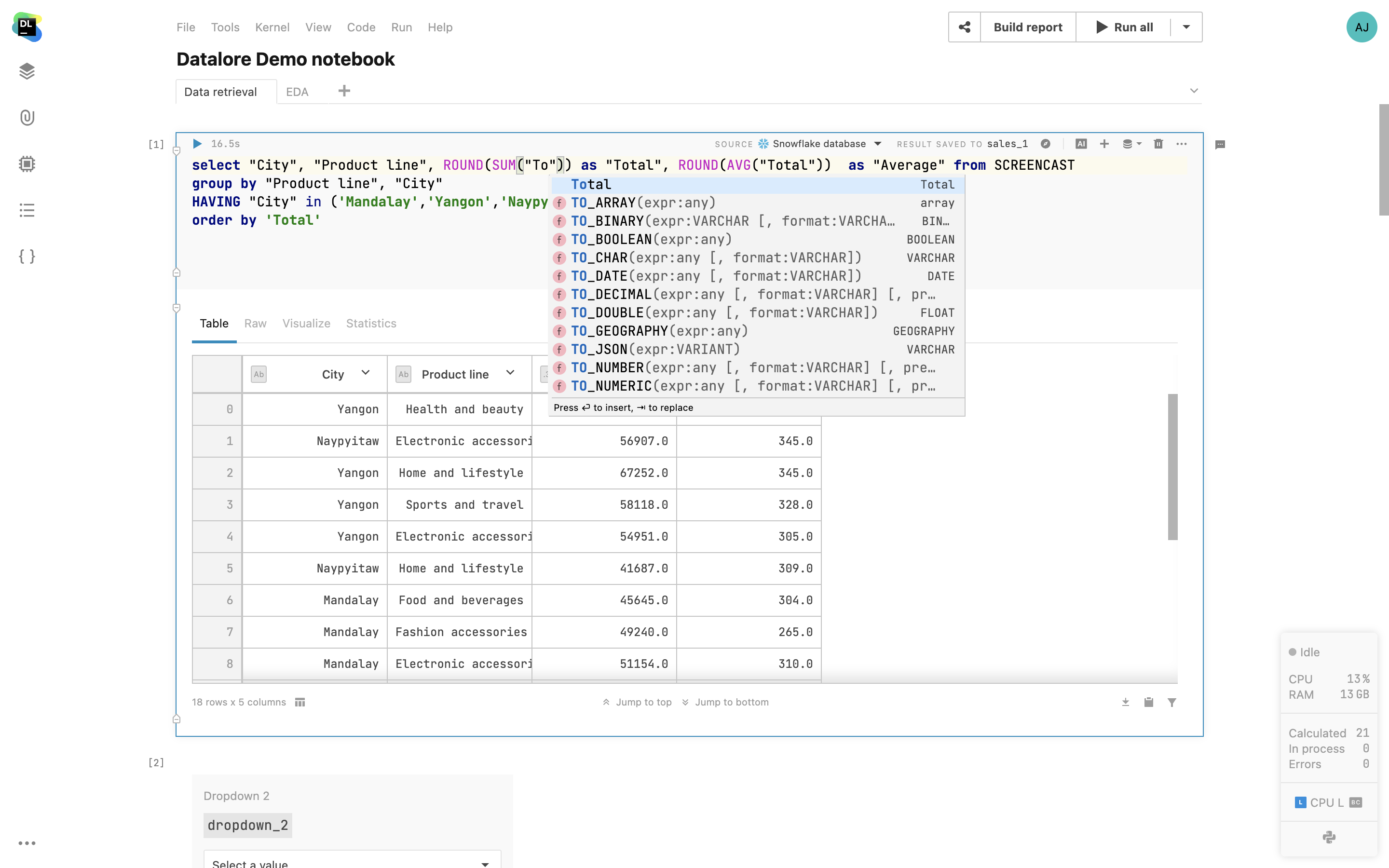
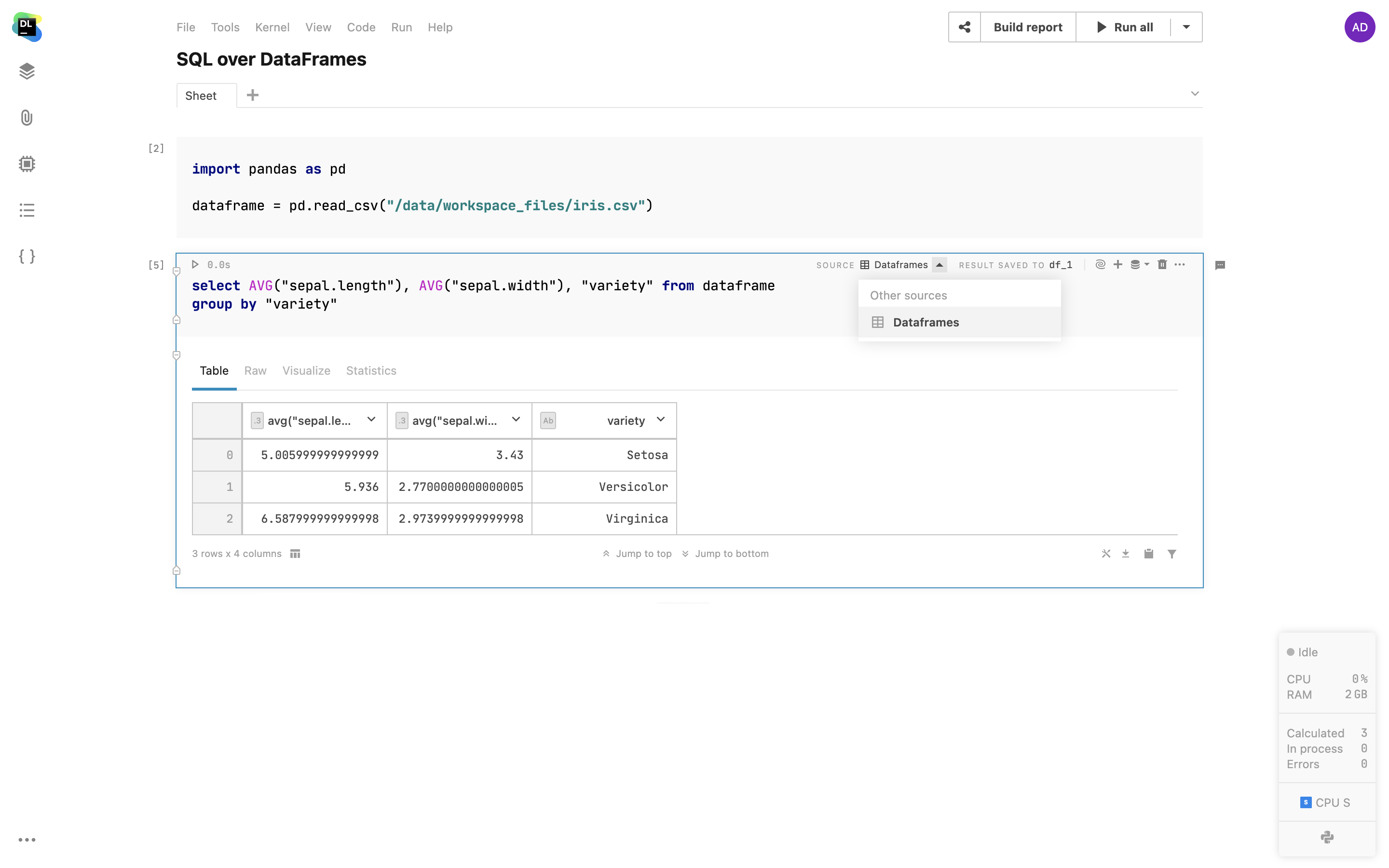
DataFrame-Abfragen über SQL-Zellen
Sie können SQL-Zellen verwenden, um 2D-DataFrames und CSV-Dateien aus angehängten Dokumenten genauso unkompliziert wie eine Datenbank abzufragen. Wählen Sie einfach einen DataFrame aus Ihrem Notebook aus und verwenden Sie ihn als Quelle für Ihre SQL-Zellen. Mit dieser Funktion können Sie per SQL die Daten verschiedener Quellen in einen einzigen DataFrame zusammenführen oder komplexe Abfragen in eine Abfolge von SQL-Zellen zerlegen.
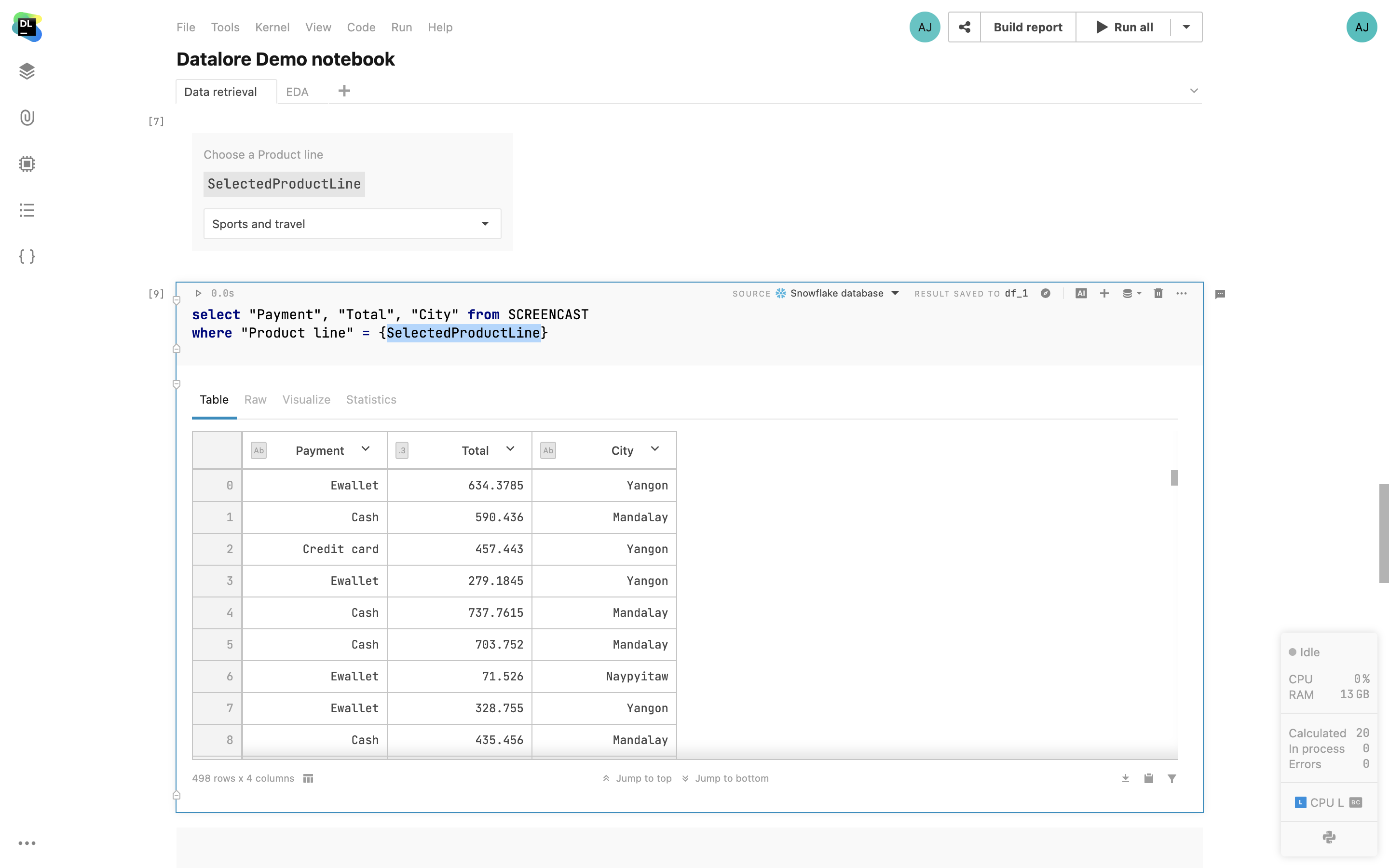
Parametrisierte SQL-Abfragen
In Datalore können Sie jetzt in Python-Code definierte Variablen (Zeichenfolgen, Zahlen, Boolesche Werte, Listen) in Ihren SQL-Zellen verwenden. Dadurch können Sie interaktive Berichte mit parametrisierten Abfragen erstellen, das Schreiben von SQL-Code minimieren und den Benutzer*innen der Berichte eine bessere Bedienoberfläche bieten.
Verwendung von Datenbanken in isolierten Umgebungen
Diese Funktion ermöglicht Ihnen das Arbeiten mit Datenbanken auch in isolierten Umgebungen. Sie können Ihren SQL-Code ohne Internetverbindung ausführen und dadurch sicherstellen, dass die zwischen Ihrem Notebook und der Datenbank ausgetauschten Informationen korrekt und konsistent sind und das Risiko von Datenkorruption oder -verlust minimiert wird.
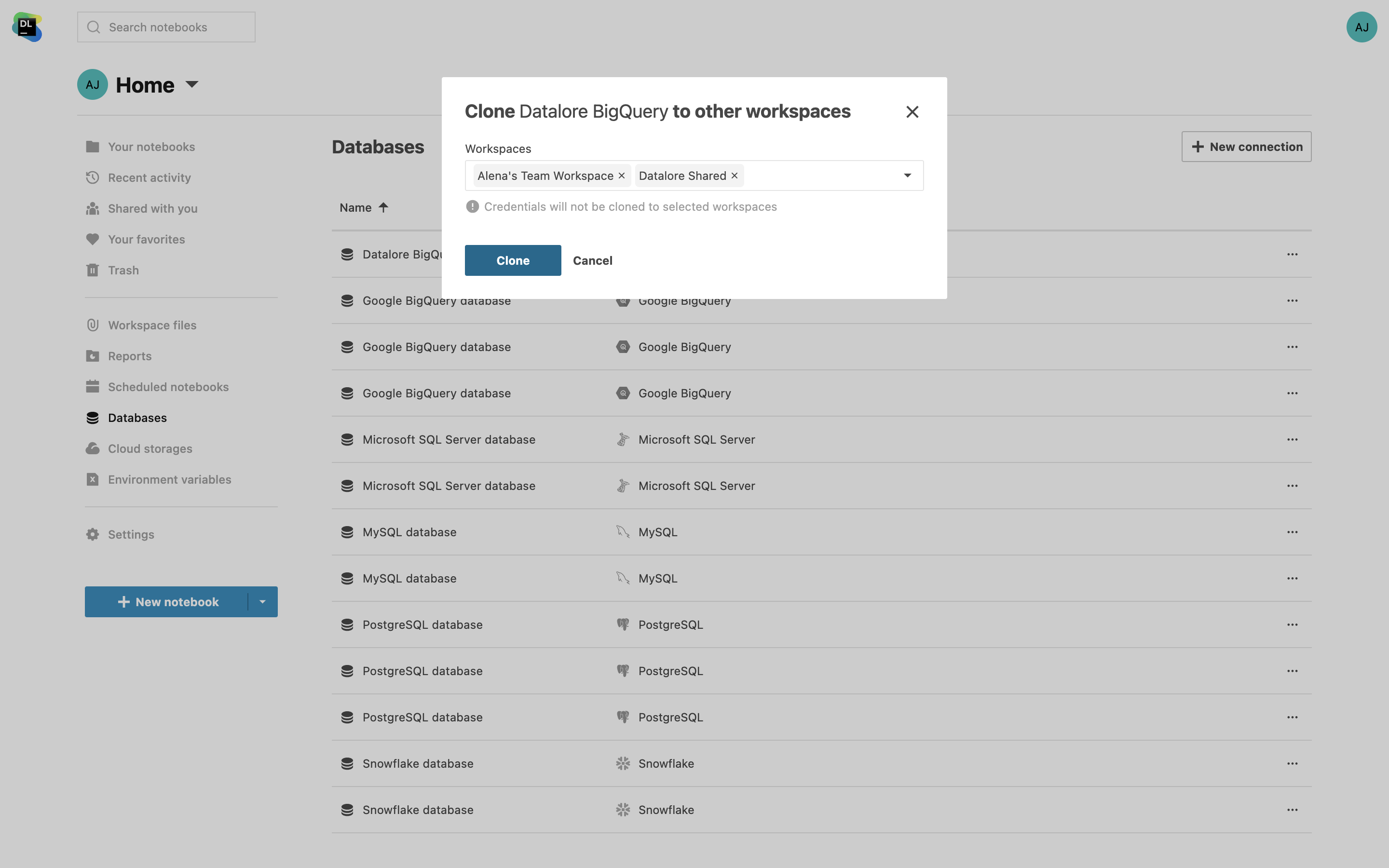
Klonen von Datenverbindungen über Workspaces hinweg
Sie haben jetzt die Möglichkeit, Datenbankverbindungen über Workspaces hinweg zu klonen und sich dadurch viel Einrichtungsarbeit zu ersparen. Sparen Sie Zeit, indem Sie die Einstellungen einfach kopieren – Zugangsdaten bleiben davon ausgenommen. Sie können auch mehrere Workspaces gleichzeitig auswählen.
SMB/CIFS-Speicher
Sie können über die Dateisystem-Ansicht oder direkt über die Notebook-Oberfläche SMB/CIFS-Speicher zu Ihrem Workspace hinzufügen. Auf diese Weise können Sie die Inhalte in SMB-Ordnern nutzen und bearbeiten, ohne die Notebook-Umgebung zu verlassen.