Novedades de DataGrip 2021.3
¡DataGrip 2021.3 ya está aquí! Esta es la tercera actualización principal de 2021, y está cargada de mejoras diversas. ¡Echemos un vistazo a lo que nos ofrece!
Editor de datos
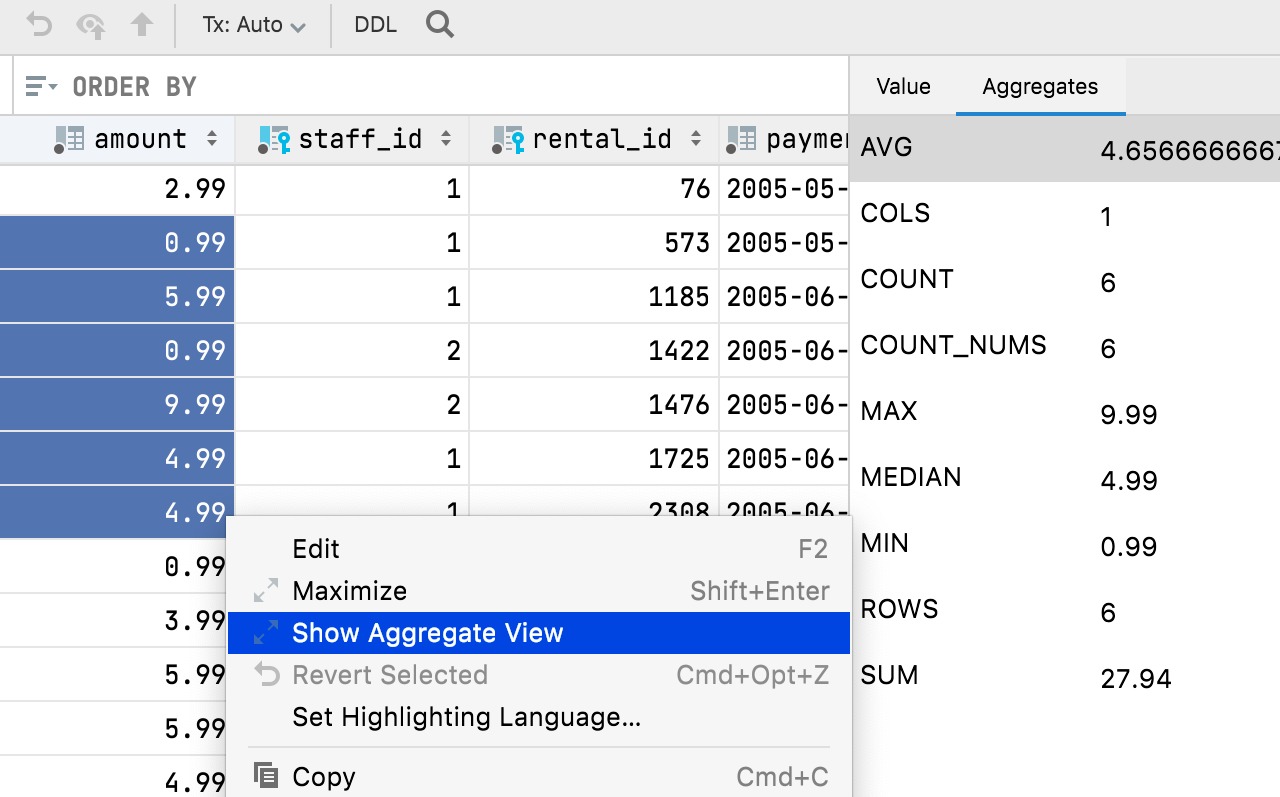
Aggregate
Hemos añadido la posibilidad de mostrar una vista Aggregate para un rango de celdas. Se trata de una función muy esperada que le ayudará a gestionar sus datos y le evitará tener que realizar consultas adicionales. Esto hace que el editor de datos sea más potente y fácil de usar, y lo hace más parecido a Excel y a las hojas de cálculo de Google.
Seleccione el rango de celdas que desea visualizar, haga clic con el botón derecho y seleccione Show Aggregate View.
Algunos datos importantes:
- Ahora, la vista Aggregate comparte el panel con la vista Value, cada una con su propia pestaña. Puede mover este panel a la parte inferior del editor de datos.
- Puede utilizar el icono de la rueda dentada para mostrar u ocultar cualquier agregado en esta vista.
- Al igual que los extractores, los agregados son scripts. Puede crear y compartir los suyos, además de los nueve scripts que hemos incluido de forma predeterminada.
- Los scripts de agregados y los extractores son intercambiables. Si ha utilizado un extractor para obtener un único valor, puede copiarlo en la carpeta Aggregators y utilizarlo para los agregados. Al igual que la carpeta Extractors, se encuentra en Scratches and consoles / Extensions / Database Tools and SQL.
En la barra de estado se muestra un valor de agregado, para el que puede elegir el tipo (suma, media, mediana, mínimo, máximo, etc.)
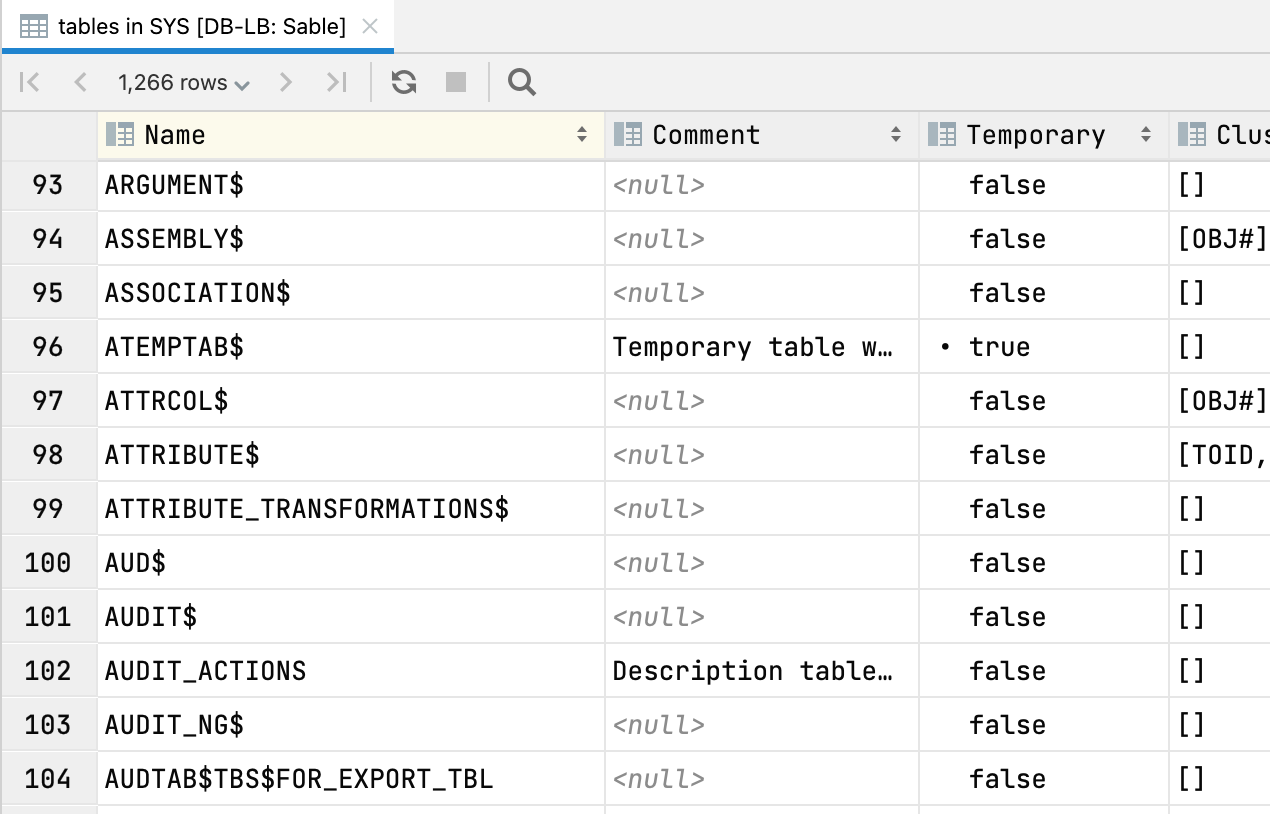
Vista de tabla para los nodos de árbol
Al pulsar F4 en cualquier nodo del esquema, se muestra una vista de tabla del contenido del nodo. Por ejemplo, puede obtener una vista de tabla con todas las tablas de su esquema:
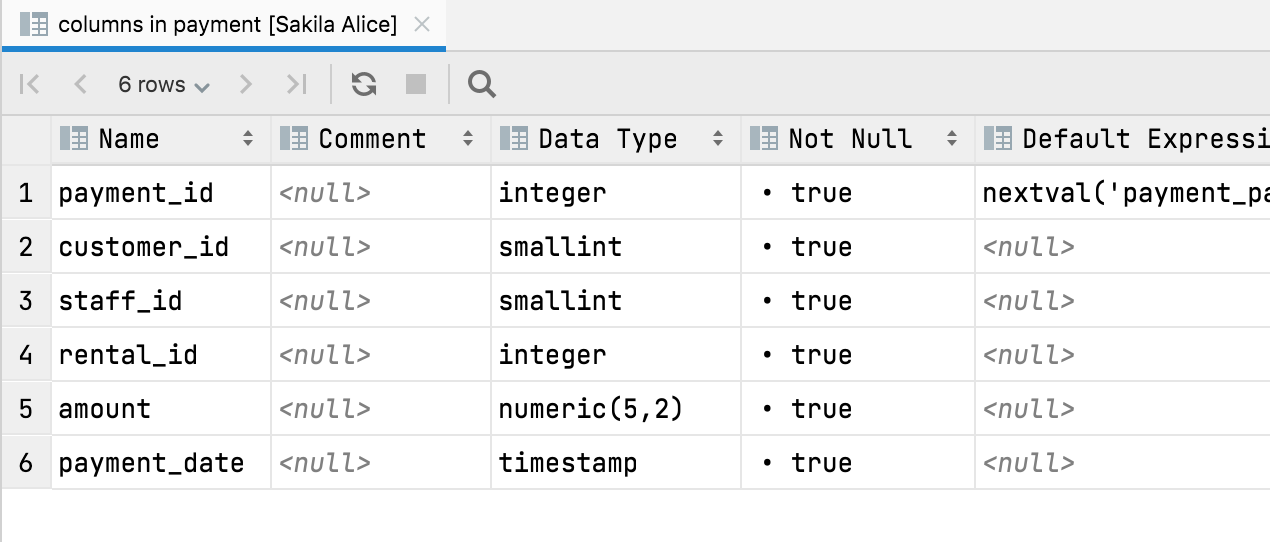
O puede obtener una vista de tabla con las columnas de una tabla:
Puede utilizar esta vista para ocultar o mostrar columnas, exportar los datos a muchos formatos y utilizar la búsqueda de texto, sin olvidar que aquí también funcionan las siguientes acciones de navegación:
- Ctrl+B muestra el DDL.
- F4 muestra los datos.
- Alt+Mayús+B resalta el objeto en el árbol de la base de datos.
División independiente
Ahora, si divide el editor y vuelve a abrir la misma tabla, las dos ventanas del editor de datos serán totalmente independientes. Además, puede establecer diferentes opciones de filtrado y ordenación para comparar y trabajar con los datos. Anteriormente, el filtrado y la ordenación estaban sincronizados, lo que no resultaba nada cómodo.
Fuente personalizada
Puede elegir la fuente con la que se mostrarán los datos desde Database | Data views | Use custom font.
Navegación por claves externas según varios valores
Ahora, desde el editor de datos, puede seleccionar varios valores y acceder a los datos relacionados.
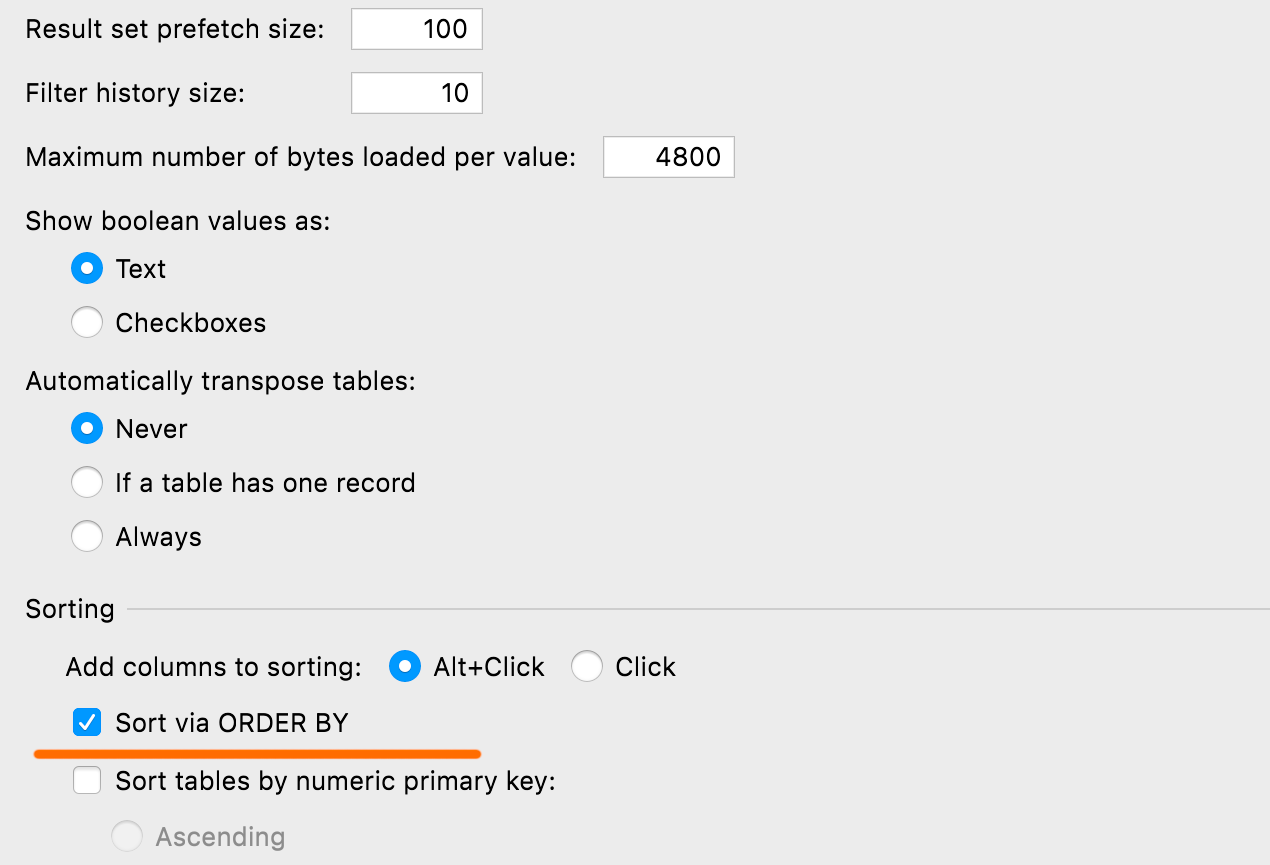
Configuración de la ordenación predeterminada
Puede definir el método de ordenación predeterminada de las tablas mediante ORDER BY o client-side: este último no ejecuta ninguna nueva consulta y solo ordena la página actual. La configuración se encuentra en Database | Data views | Sorting | Sort via ORDER BY.
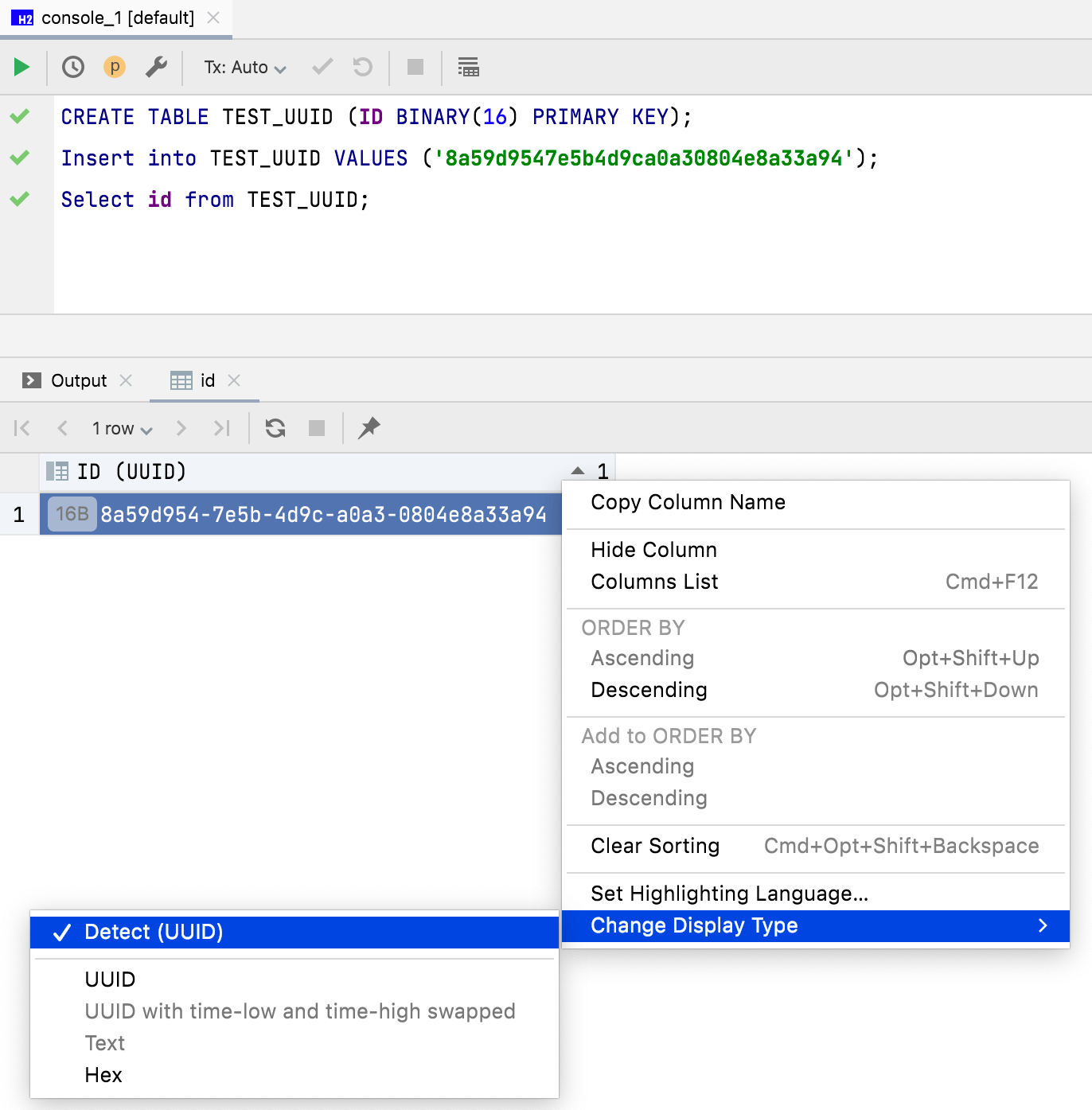
Modo de visualización de los datos binarios
Ahora, los datos de 16 bytes se muestran de forma predeterminada como UUID. También se puede personalizar el modo de visualización de los datos binarios en la columna del editor de datos.
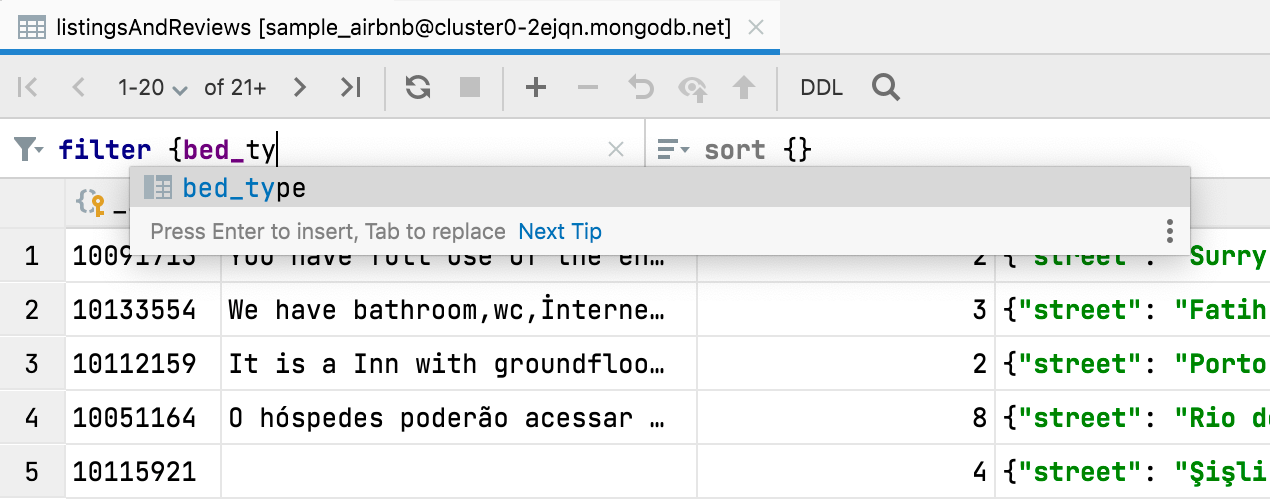
Finalización de filter {} y sort {} MongoDB
Ahora, la finalización de código está disponible al filtrar datos en las colecciones de MongoDB.
Conservación de la base de datos en el VCS
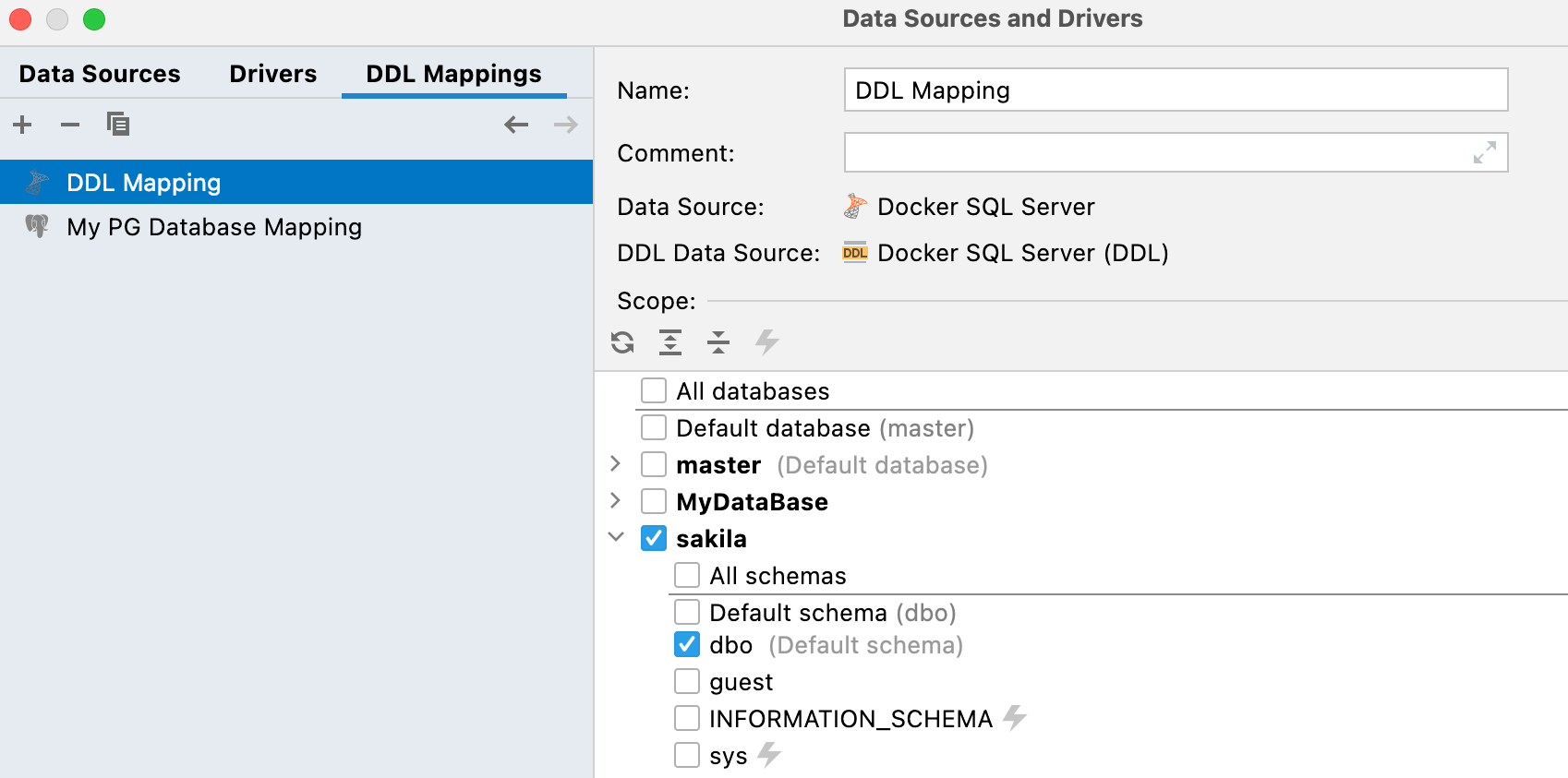
Asignación de la fuente de datos DDL y la fuente real
Esta versión es una continuación lógica de la anterior, que introdujo la posibilidad de generar una fuente de datos DDL basada en una real. Ahora, este flujo de trabajo es totalmente compatible. Puede:
- Generar una fuente de datos DDL a partir de una real: consulte el anuncio 2021.2.
- Asignar una fuente de datos DDL a una real.
- Compararlas y sincronizarlas en ambas direcciones.
Tenga en cuenta que una fuente de datos DDL es una fuente de datos virtual cuyo esquema se basa en un conjunto de scripts SQL. Almacenar dichos archivos en el sistema de control de versiones es una manera de conservar su base de datos dentro de este sistema.
Hay una nueva pestaña en las propiedades de configuración de datos, DDL mappings, donde se puede definir qué fuente de datos real se asigna a cada fuente de datos DDL.
Si quiere obtener más información sobre los beneficios de estas nuevas funcionalidades en su flujo diario de VCS, lea este artículo.
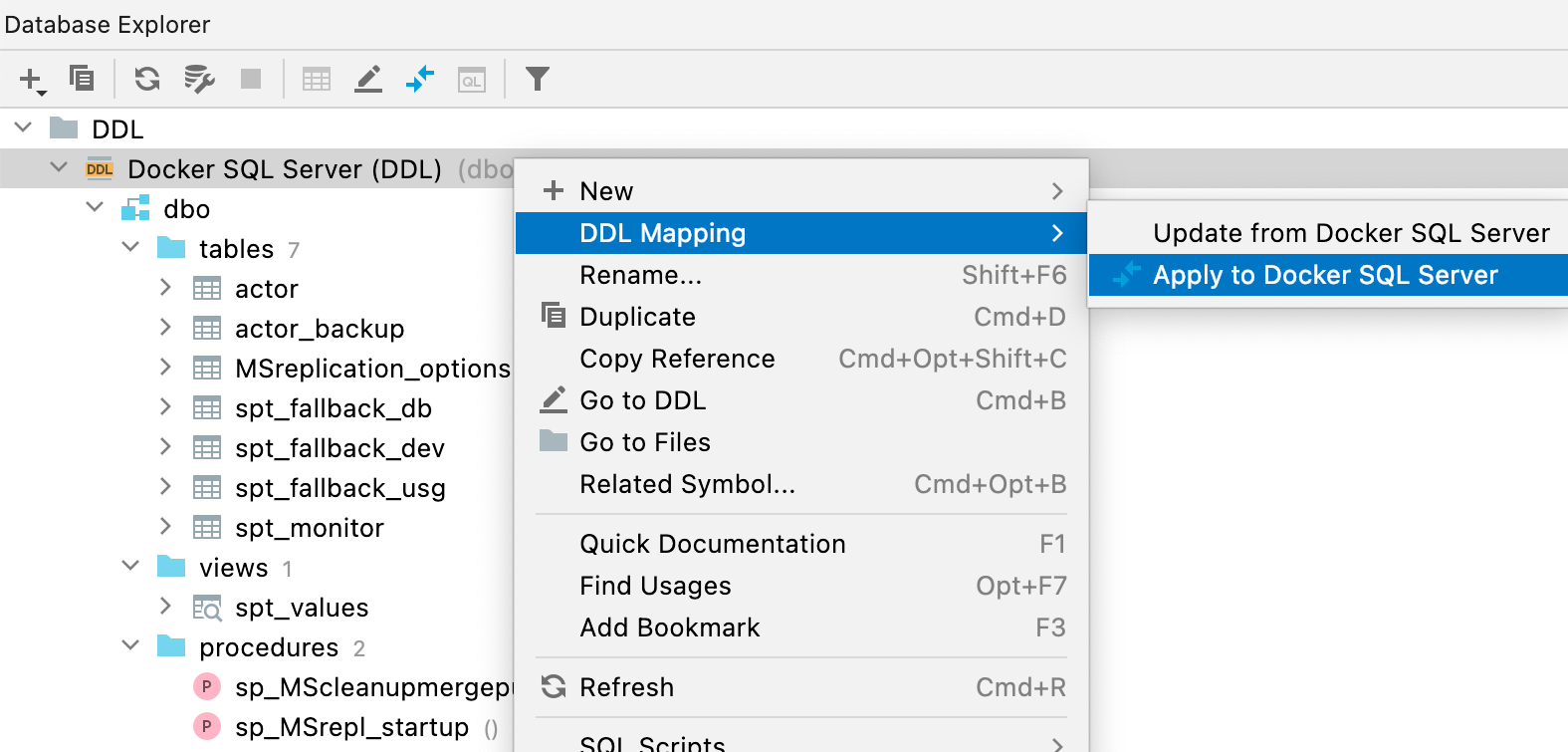
Nueva ventana de base de datos diff
Para comparar y sincronizar su fuente de datos DDL con la real, utilice el menú contextual y seleccione Apply from... o Dump to... desde el submenú DDL Mappings.
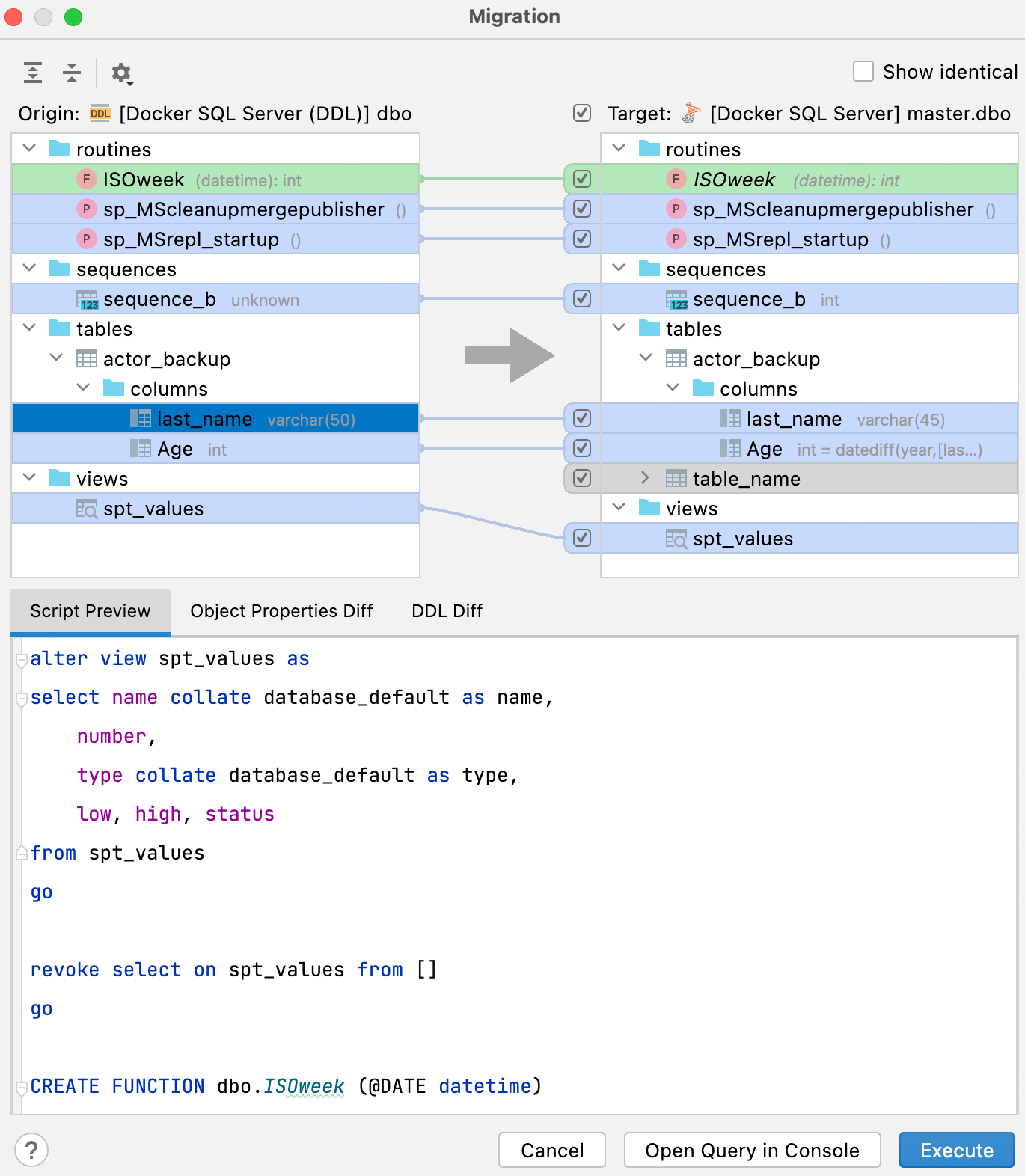
La interfaz de esta nueva ventana es mejor y muestra claramente en el panel derecho el resultado que obtendrá después de sincronizar.
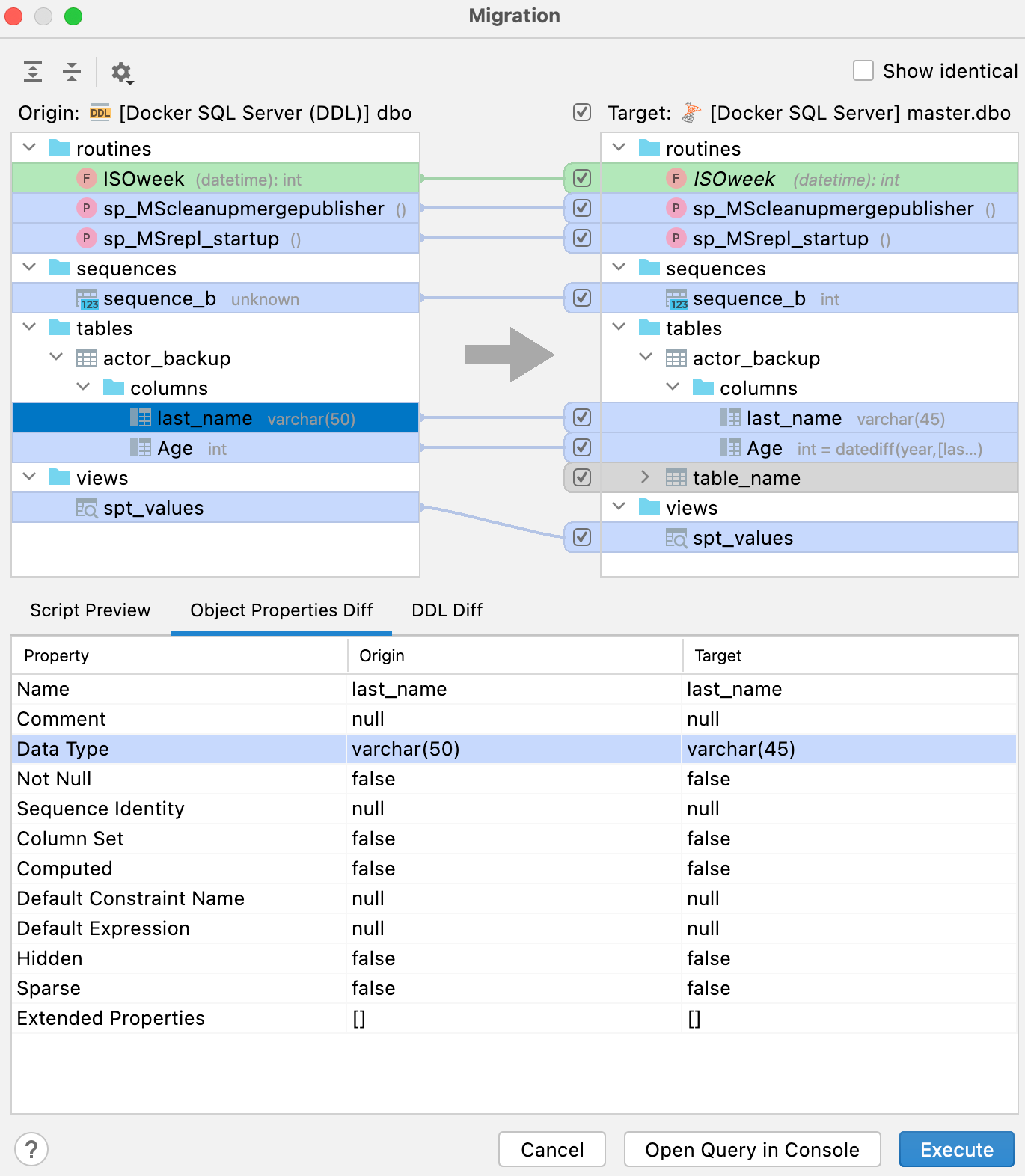
La leyenda del panel derecho muestra el significado de los colores que pueden aparecer en los resultados:
- Verde y cursiva: el objeto se creará.
- Gris: el objeto se eliminará.
- Azul: el objeto se modificará.
La pestaña Script preview muestra el script resultante, que puede abrirse en una nueva consola o ejecutarse desde este cuadro de diálogo. El resultado de este script es la aplicación de cambios para que la base de datos de la derecha (destino) sea una copia de la base de datos de la izquierda (origen).
Además de la pestaña Script preview, hay dos pestañas más en el panel inferior: Object Properties Diff y DDL Diff, que muestran la diferencia entre las versiones concretas del objeto en las bases de datos de origen y de destino.
Nota: si solo quiere comparar dos esquemas u objetos, selecciónelos y pulse Ctrl + D.
¡Importante! El visor Diff sigue en fase de desarrollo. Dado que cada base de datos tiene unas características específicas, es posible que algunos objetos se muestren diferentes, aunque sean idénticos, seguramente debido a los alias de tipo o a la omisión de las propiedades predeterminadas en la generación. Si se encuentra con este error, infórmenos de ello a través de nuestro sistema de seguimiento.
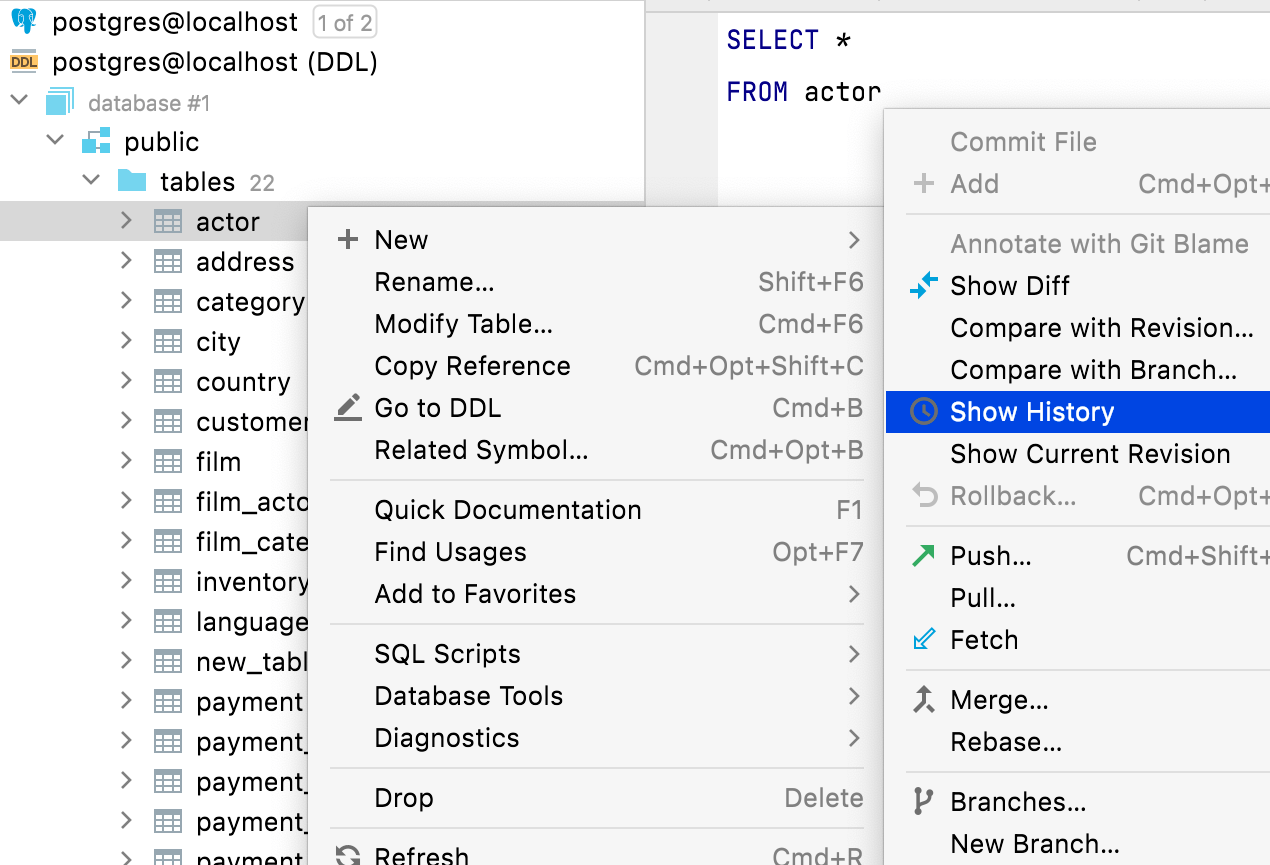
Acciones relacionadas con los archivos
Todas las acciones relacionadas con los archivos también están disponibles en los elementos de la fuente de datos DDL. Por ejemplo, puede eliminar, copiar o confirmar archivos relacionados con los elementos del esquema desde el explorador de la base de datos.
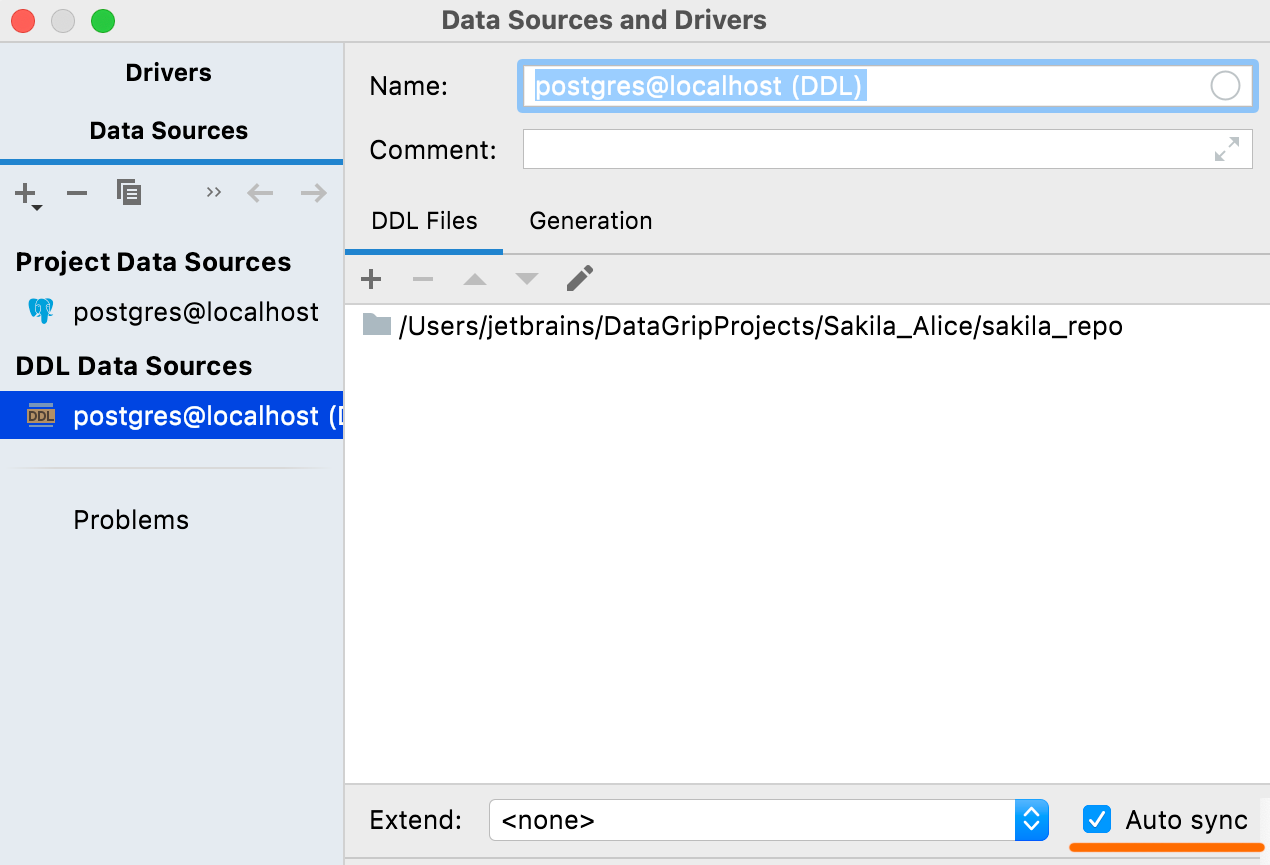
Sincronización automática
Si esta opción está activada, su fuente de datos DDL se actualizará de forma automática con los cambios en los archivos correspondientes. Este ya era el comportamiento predeterminado, pero ahora tiene la opción de desactivarlo.
Si lo desactiva, los cambios en los archivos fuente no se reflejarán de forma automática en la fuente de datos DDL, por lo que tendrá que hacer clic en Refresh para aplicarlos.
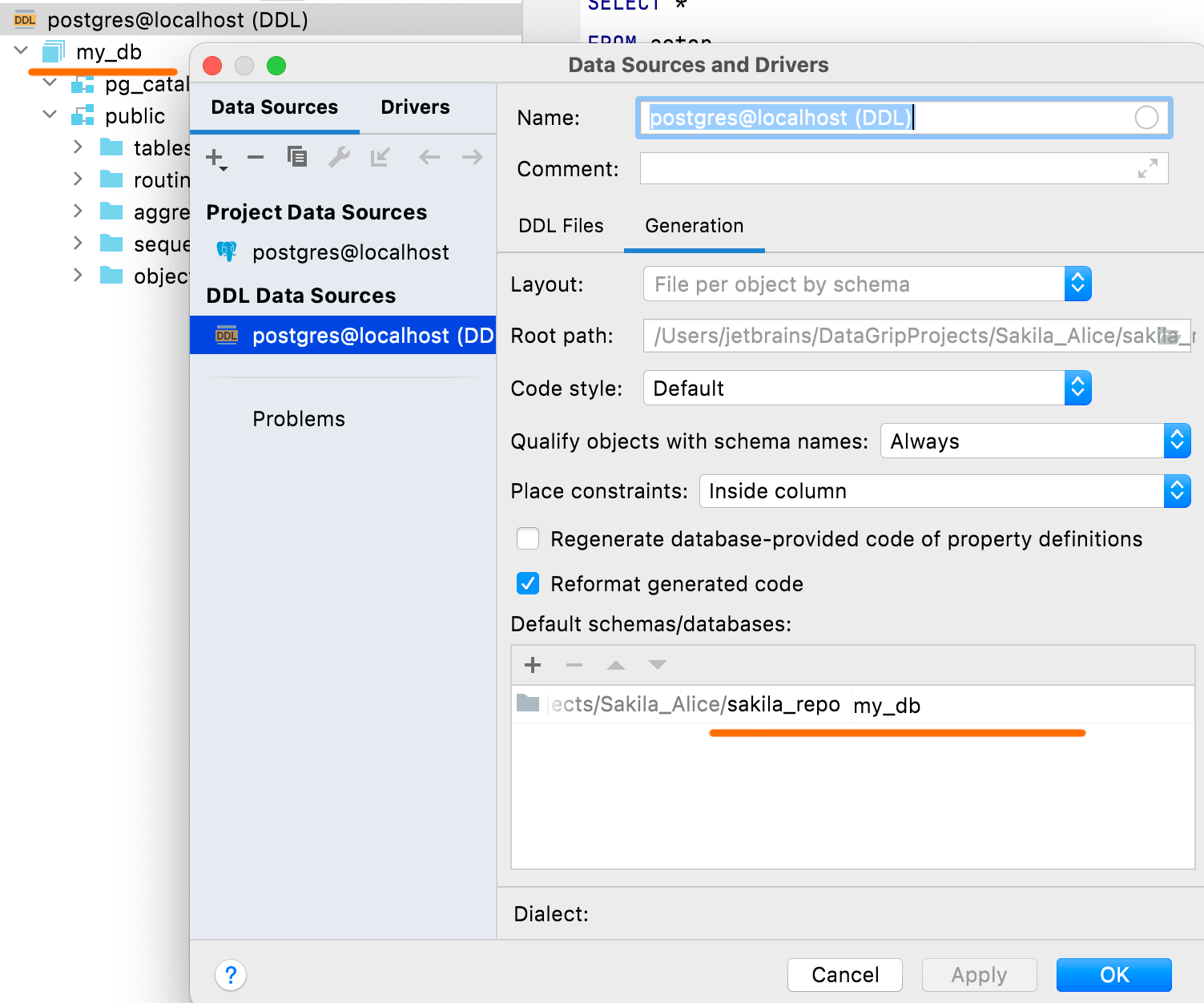
Configuración de los esquemas y bases de datos predeterminados
En el panel Default schemas/databases, puede definir los nombres de sus bases de datos y esquemas, que se mostrarán en el origen de datos DDL. Los scripts DDL no suelen contener nombres, y en estos casos verá que se asignan nombres ficticios a las bases de datos y a los esquemas de forma predeterminada.
Conectividad
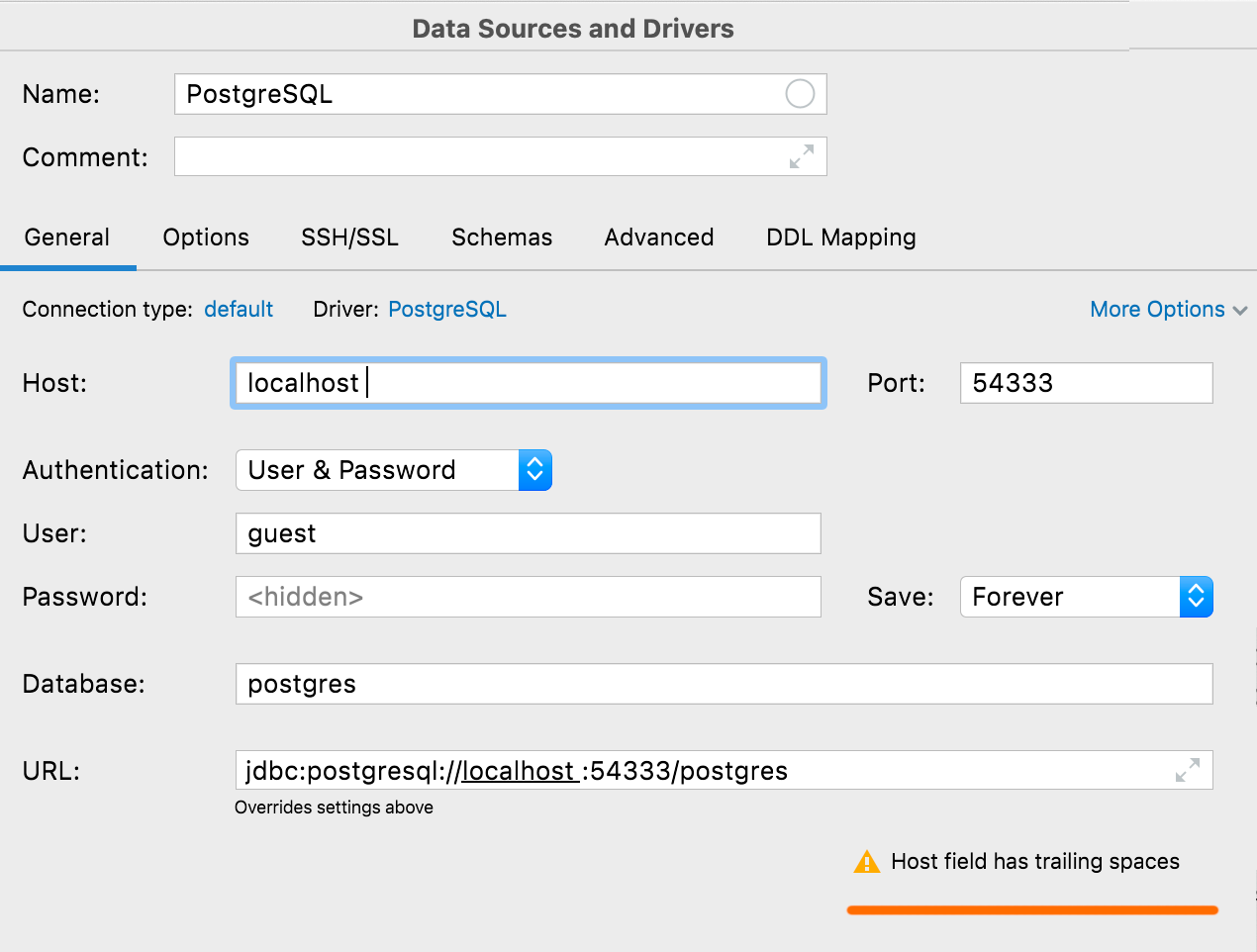
Aviso de espacios no intencionados
Si algún valor, excepto User o Password, tiene espacios iniciales o finales, DataGrip le mostrará una advertencia cuando haga clic en Test Connection.
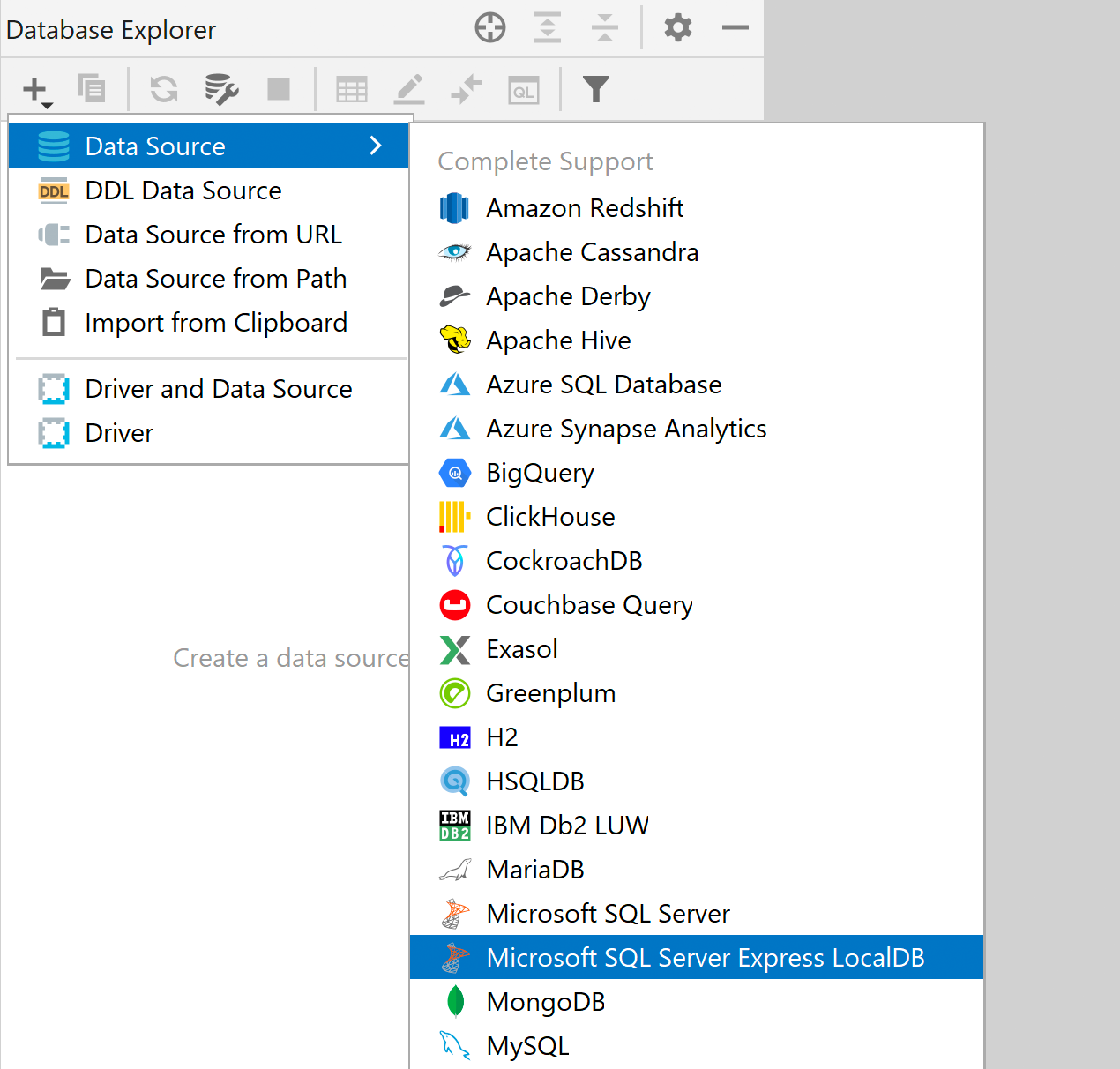
LocalDB como fuente de datos específica SQL Server
SQL Server LocalDB tiene un controlador específico en la lista de controladores, lo cual significa que tiene otro tipo de fuente de datos que debe utilizarse para LocalDB, y cuyas ventajas son:
- La conexión LocalDB es más fácil de encontrar.
- Solo tiene que establecer la ruta del ejecutable una vez, en las opciones del controlador, y se aplicará a todas las fuentes de datos.
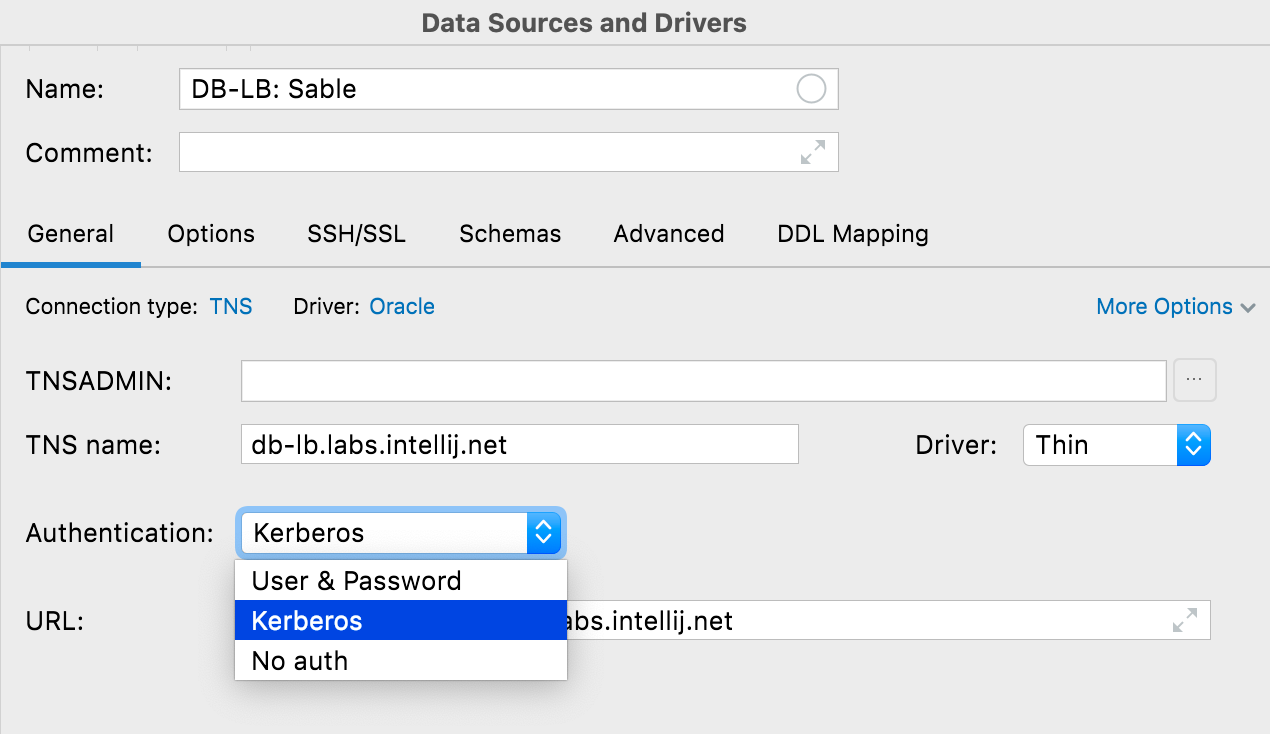
Autenticación Kerberos Oracle, SQL Server
Ahora, es posible utilizar la autenticación Kerberos en Oracle y SQL Server. Es necesario obtener un ticket TGT (ticket-granting ticket) para la principal mediante el comando kinit, que DataGrip utilizará cuando elija la opción Kerberos.
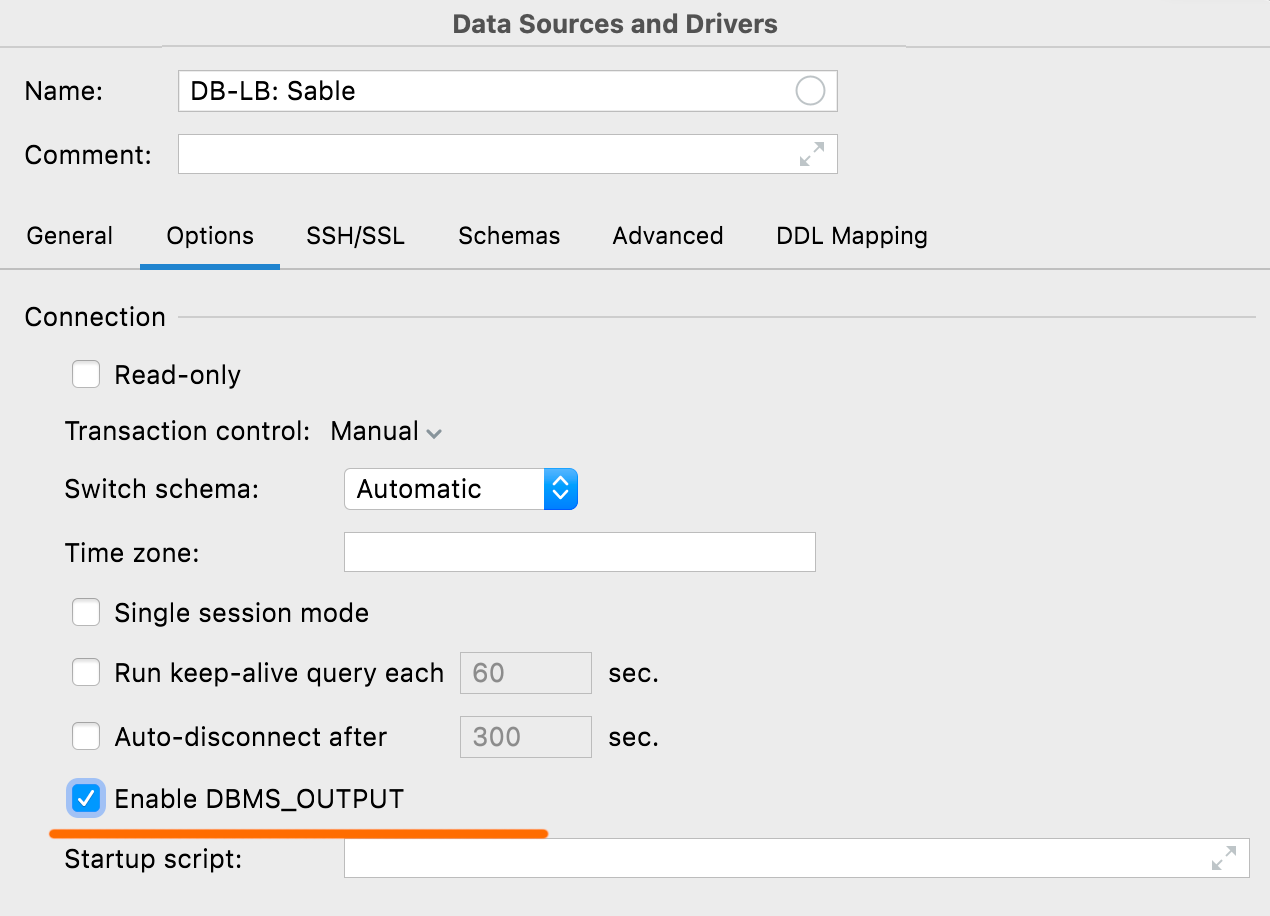
Habilitar DBMS_OUTPUT Oracle, IBM Db2
Esta nueva opción de la pestaña Options le permite habilitar DBMS_OUTPUT de forma predeterminada para las nuevas sesiones.
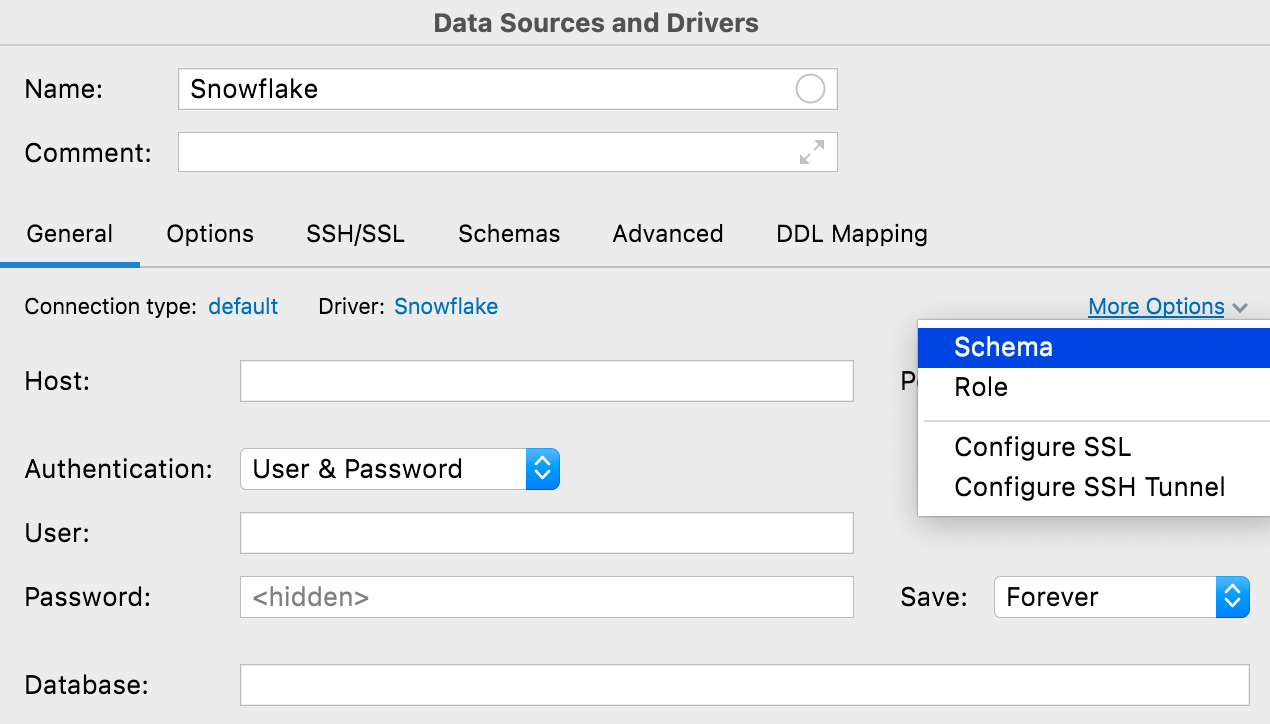
Botón More options
Hemos añadido el botón More Options para que pueda configurar mejor las opciones menos habituales de una conexión. Con las opciones disponibles actualmente, es posible añadir los campos Schema y Role para las conexiones Snowflake, y dos elementos de menú para configurar SSH y SSL, con el objetivo de aumentar su detectabilidad.
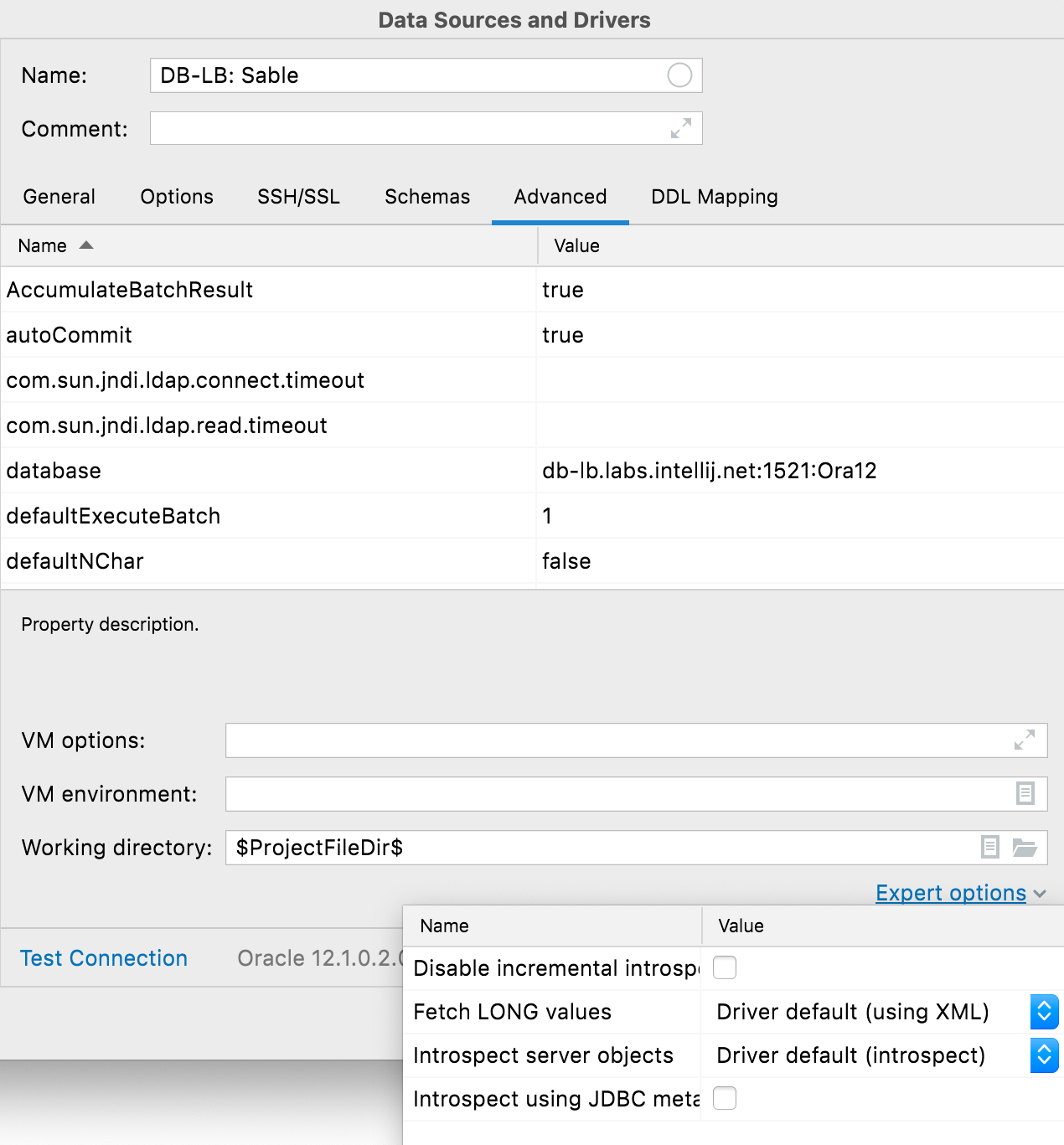
Lista Expert Options
Ahora, la pestaña Advanced incluye la lista Expert options. Además de la opción de activar el introspector JDBC (póngase en contacto con nuestro equipo de asistencia antes de utilizarla), están disponibles las siguientes opciones específicas de las bases de datos:
- Oracle: deshabilitar la introspección incremental, recuperar valores LONG y hacer introspección de objetos del servidor
- SQL Server: deshabilitar la introspección incremental
- PostgreSQL (y similares): deshabilitar la introspección incremental y no utilizar xmin en las consultas en pgdatabase
- SQLite: registrar la función REGEXP
- MYSQL: Utilizar SHOW/CREATE para código fuente
- ClickHouse: asignar sessionid de forma automática
Introspección
Niveles de introspección Oracle
Los usuarios de Oracle han estado teniendo problemas con la introspección de DataGrip, que se ralentizaba si tenían muchas bases de datos y esquemas. La introspección es el proceso de obtención de los metadatos de la base de datos, como nombres de los objetos y código fuente. DataGrip la necesita para proporcionar una asistencia rápida a la codificación, la navegación y la búsqueda.
Los catálogos del sistema Oracle son bastante lentos y la introspección se ralentizaba todavía más si el usuario no tenía derechos de administrador. Hicimos todo lo posible por optimizar las consultas para obtener los metadatos, pero todo tiene sus limitaciones.
Nos dimos cuenta de que para la mayor parte del trabajo diario, e incluso para una asistencia a la codificación eficaz, no hace falta cargar las fuentes de objetos. En muchos casos, basta con tener los nombres de los objetos de la base de datos para proporcionar una finalización de código y una navegación adecuadas, de modo que hemos introducido tres niveles de introspección para las bases de datos de Oracle:
- Nivel 1: nombres de todos los objetos compatibles y sus firmas, excepto los nombres de las columnas del índice y las variables de paquetes privados
- Nivel 2: todo, excepto el código fuente
- Nivel 3: todo
La introspección es más rápida en el nivel 1 y más lenta en el nivel 3.
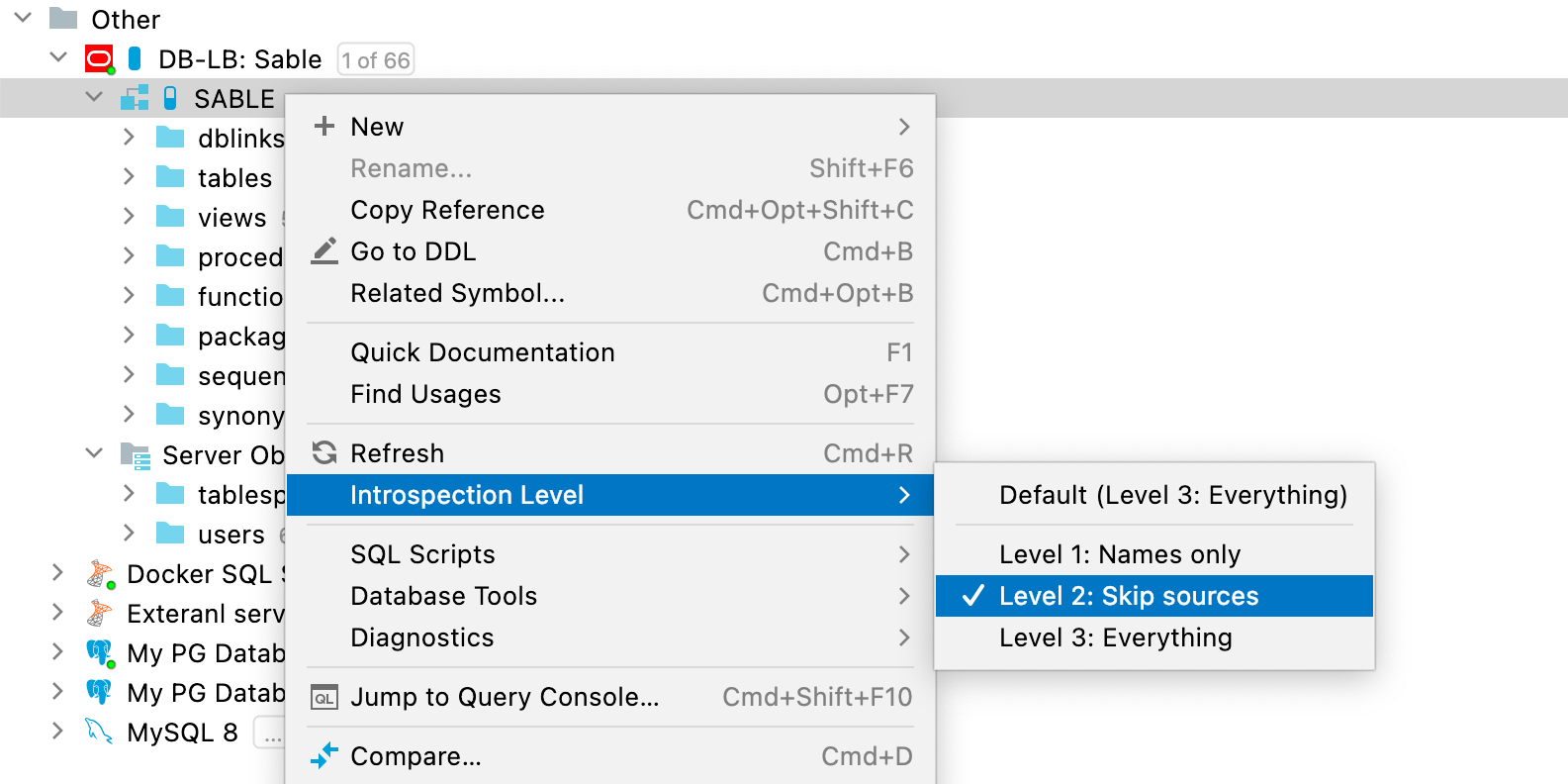
Utilice el menú contextual para cambiar el nivel de introspección según convenga:

El nivel de introspección puede establecerse para un esquema o para toda la base de datos. Los esquemas heredan el nivel de introspección de la base de datos, pero este también se puede establecer de forma independiente.
El nivel de introspección está representado por los iconos con forma de píldora situados junto al icono de la fuente de datos. Cuanto más llena esté la píldora, mayor será el nivel. El icono azul indica que el nivel de introspección se establece directamente, mientras que el gris indica que este se hereda.
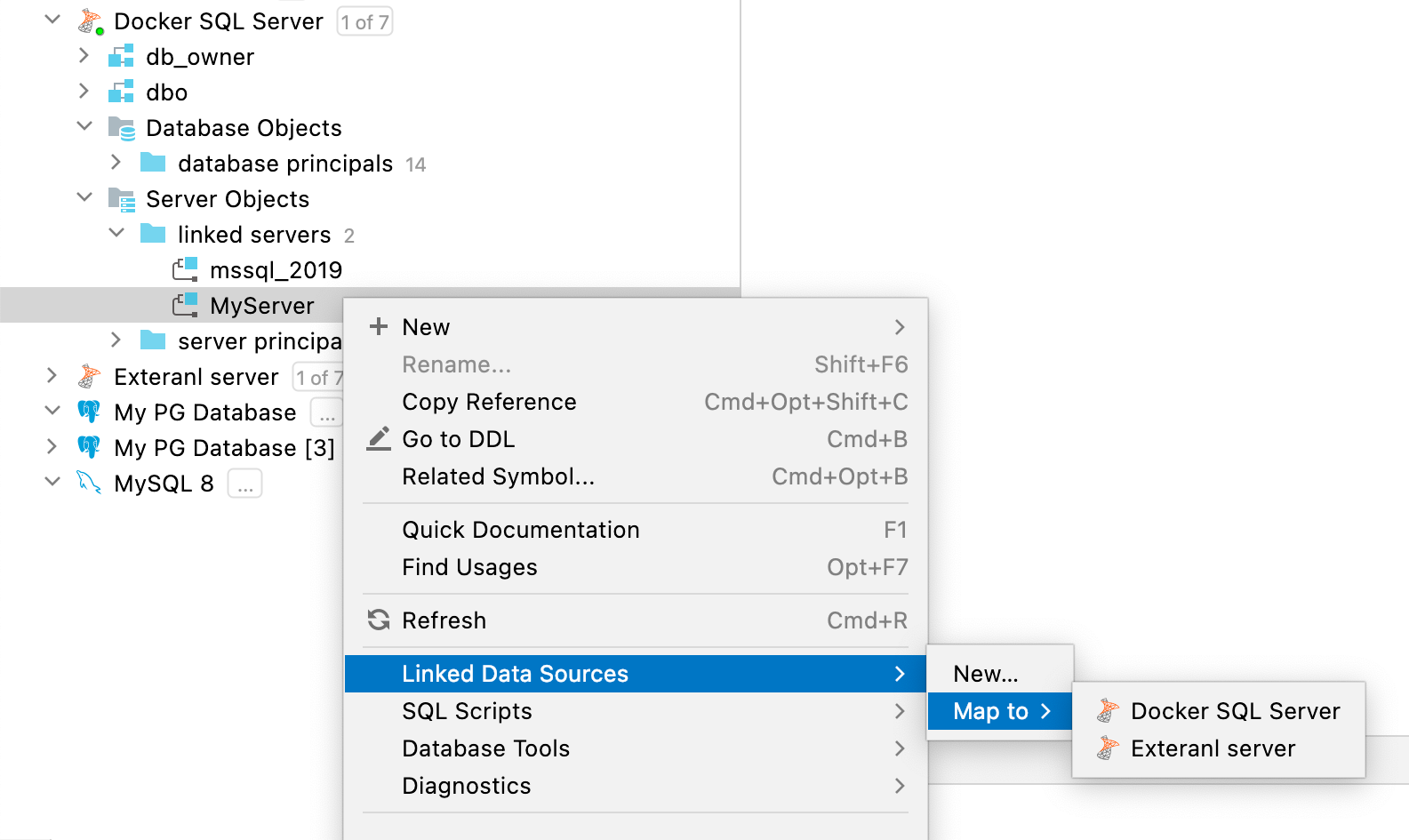
Asignación de servidores vinculados y enlaces de bases de datos a fuentes de datos SQL Server, Oracle
Puede asignar el servidor vinculado en SQL Server o el enlace de base de datos en Oracle a cualquier fuente de datos existente.
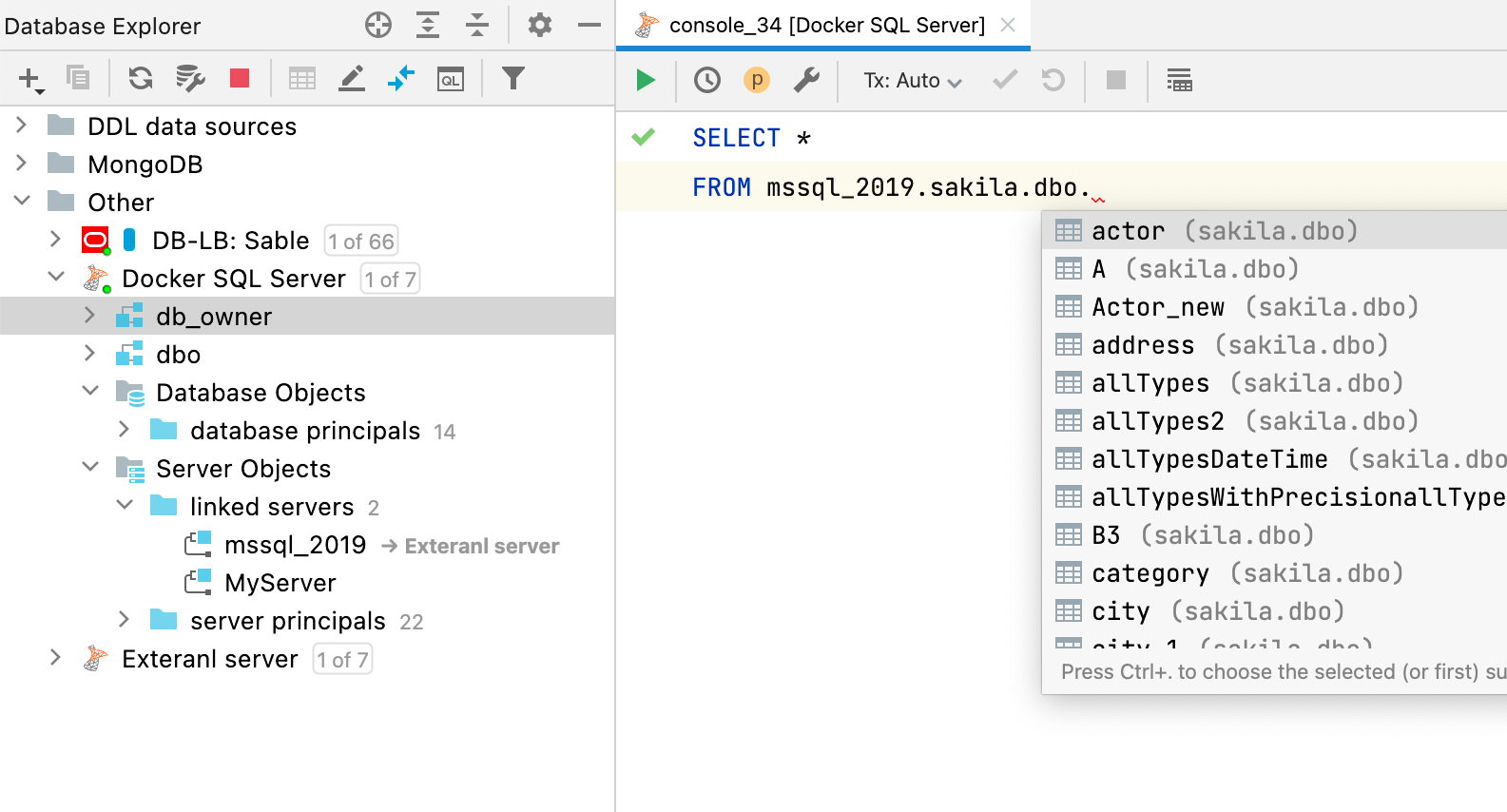
Cuando se asignan objetos externos a la fuente de datos, la finalización de código y la resolución estarán disponibles para las consultas que utilicen esos objetos externos.
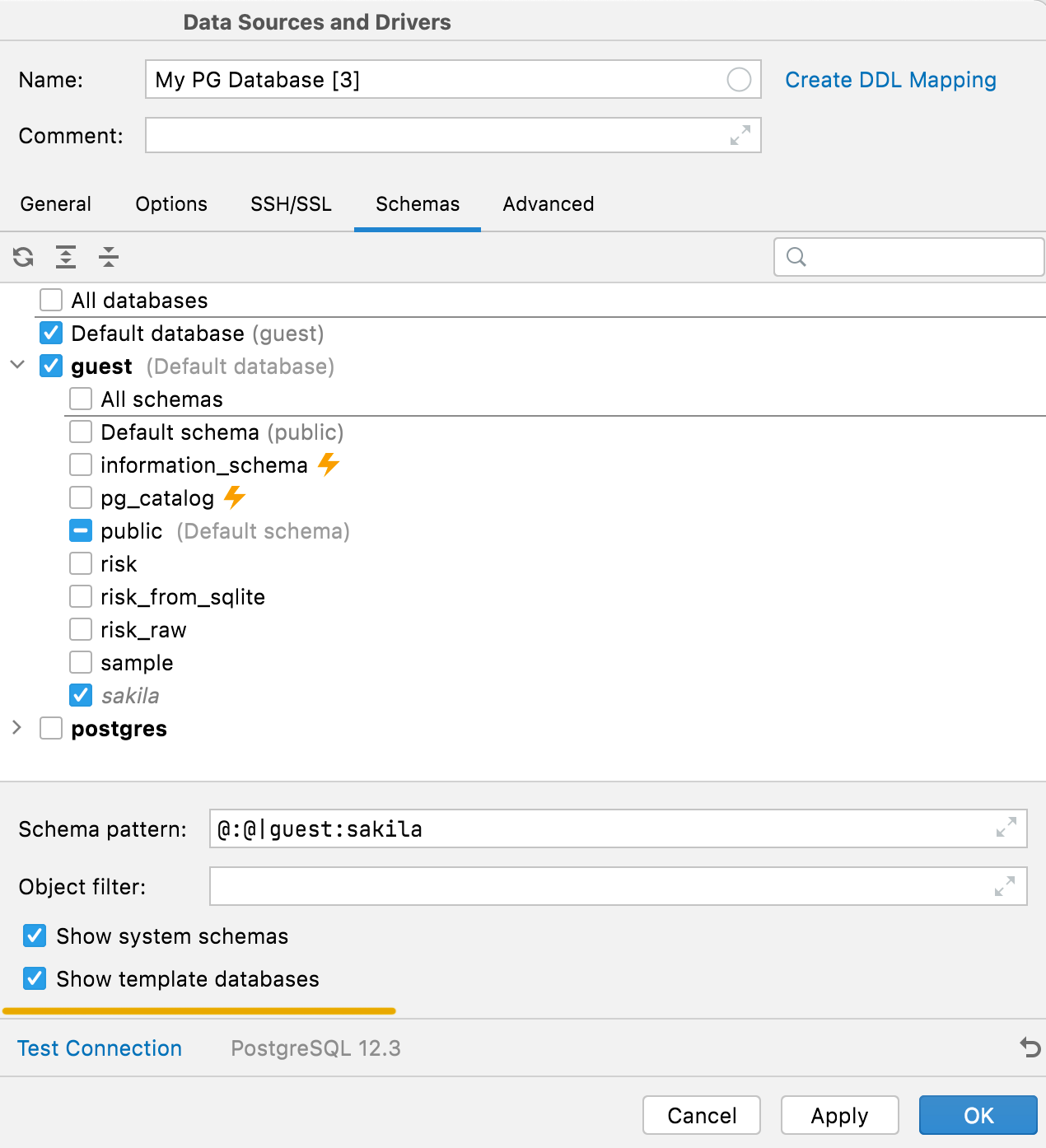
Ocultación de los esquemas del sistema y las bases de datos de plantilla PostgreSQL
Los esquemas internos del sistema (como pg_toast o pg_temp) y las bases de datos de plantillas solían estar ocultos en la lista de esquemas. Ahora es posible mostrarlos usando las opciones correspondientes en la pestaña Schemas.
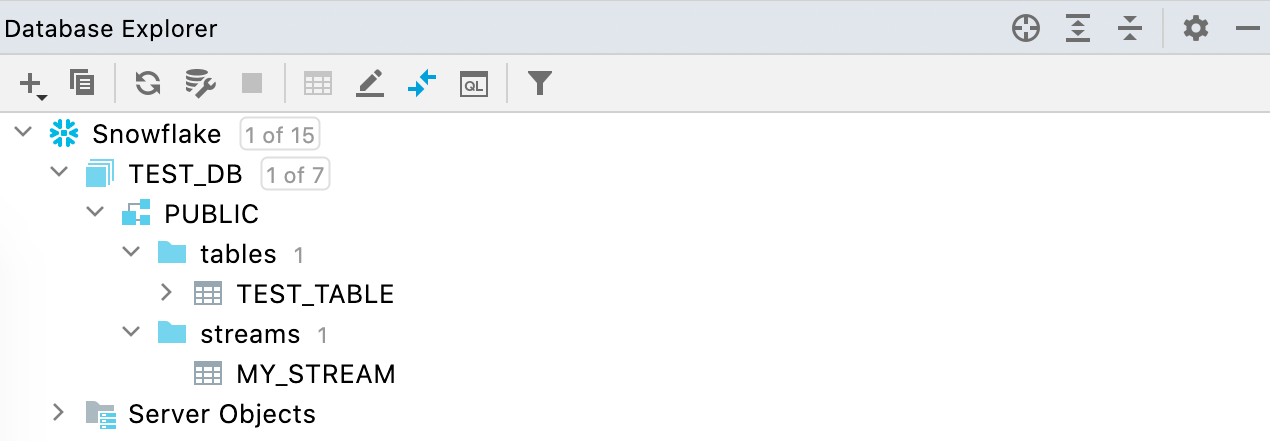
Compatibilidad con las secuencias Snowflake
Ahora, las secuencias se muestran en la vista de la base de datos junto con las tablas y las vistas.
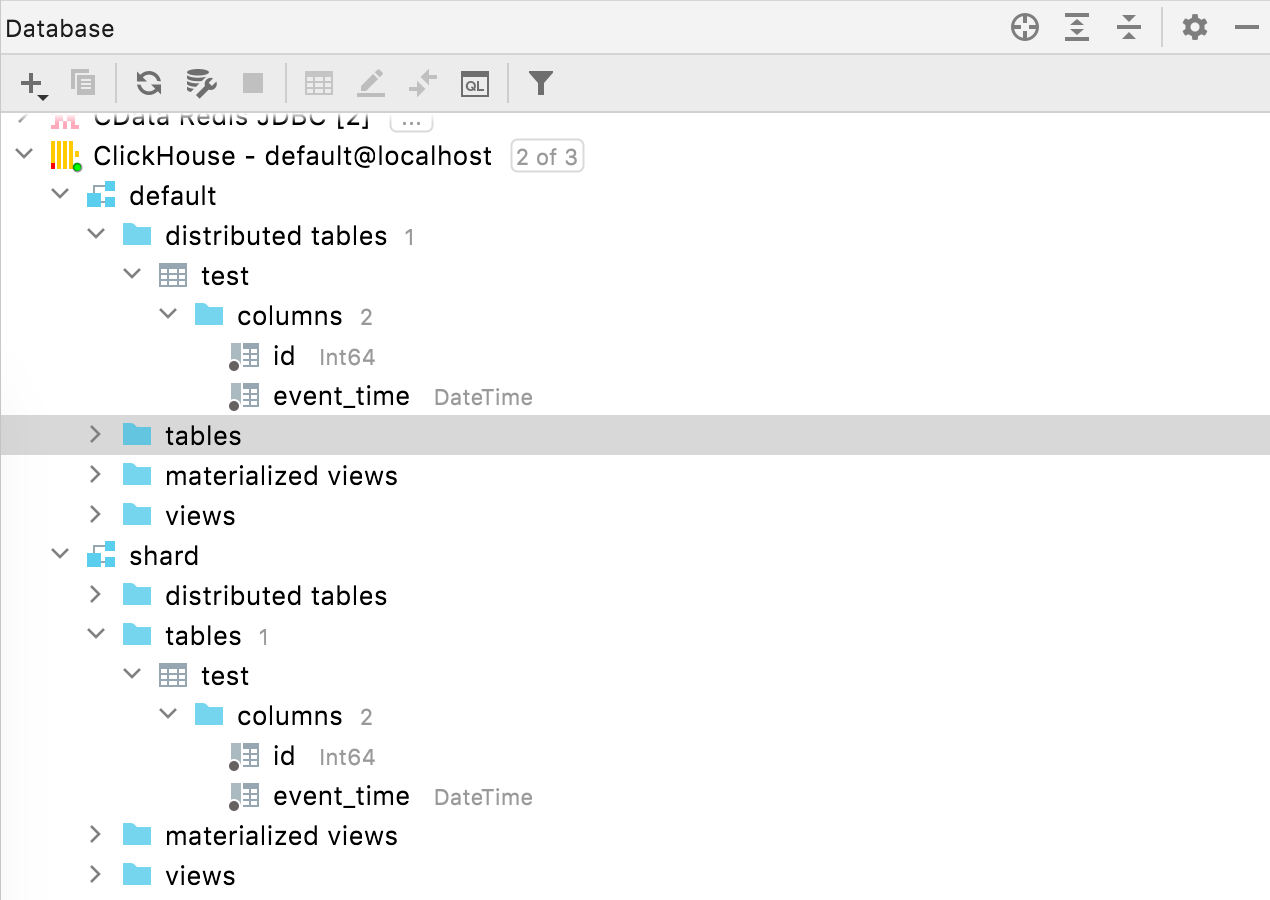
Tablas distribuidas ClickHouse
Ahora, las tablas distribuidas se encuentran en un nodo exclusivo en el explorador de bases de datos.
Consola de consultas
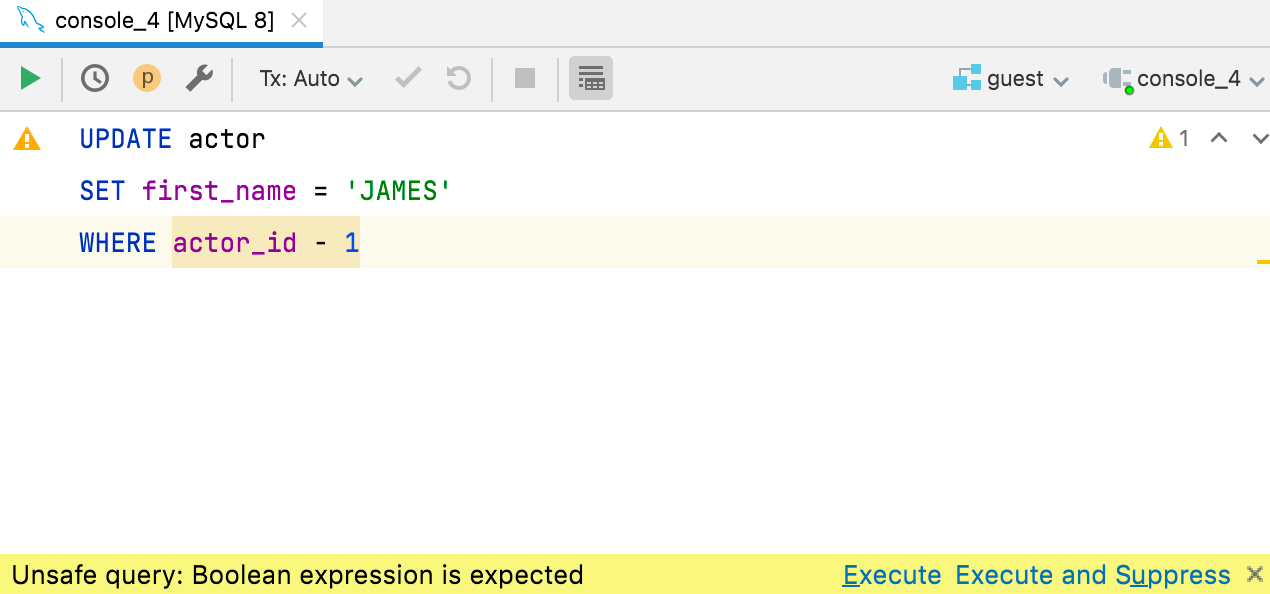
Comprobación de expresiones booleanas
One of our users posted about an unfortunate situation: he executed the UPDATE query on a production database with the condition WHERE id - 3727 (instead of =) and had millions of records updated!
Nos sorprendió que MySQL se lo permitiera, pero así es la vida. Sin embargo, no seríamos el equipo de DataGrip si no añadiéramos una inspección para eso, de modo que tenemos el placer de presentarles la comprobación de las expresiones booleanas en las cláusulas WHERE y HAVING.
Aunque la expresión no parece ser explícitamente booleana, DataGrip la resaltará en amarillo y le avisará antes de que ejecute la consulta. Funciona con ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite y Vertica. En todas las demás bases de datos, se resaltará como un error.
Extracción de función para las consultas
Ahora, las consultas pueden extraerse como una función de tabla. Para ello, seleccione la consulta, invoque el menú Refactor y utilice Extract Routine.
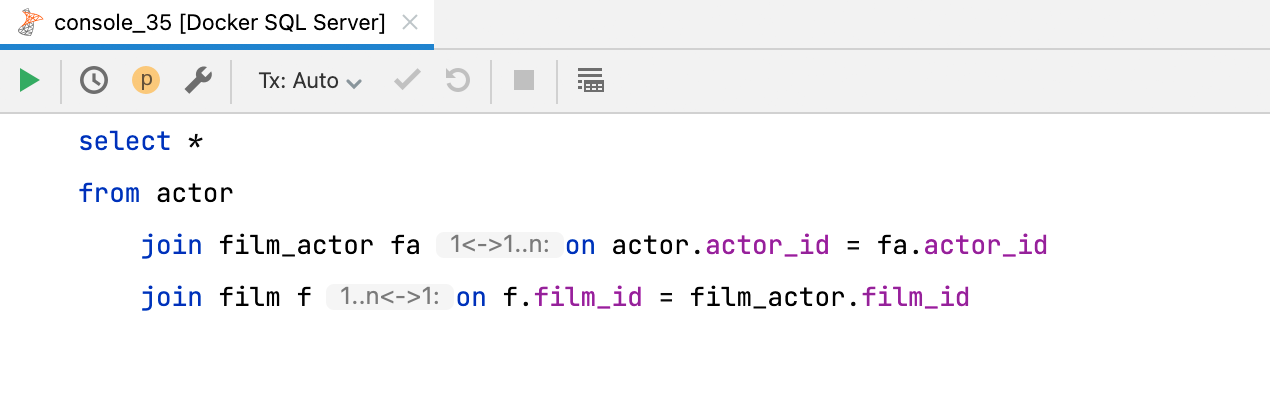
Sugerencia de incrustación de cardinalidad JOIN
La nueva sugerencia de incrustación le indicará la cardinalidad de una cláusula JOIN. Hay tres posibilidades: de uno a uno, de uno a muchos y de muchos a muchos. Si quiere desactivarla, puede ajustar la configuración en Preferences | Editor | Inlay Hints | Join cardinality.
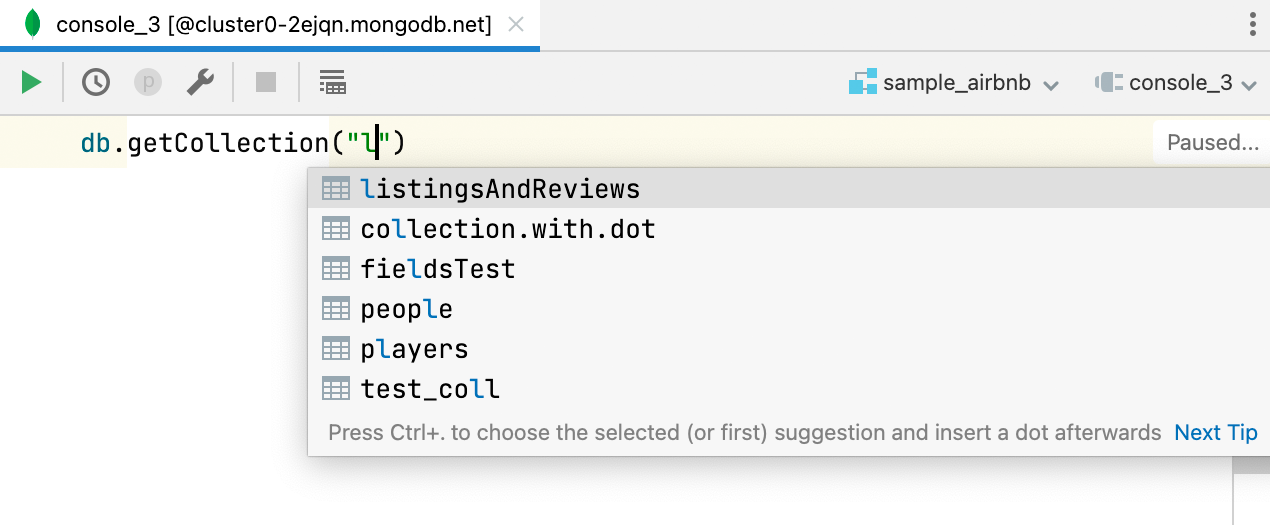
Finalización de código para los nombres de las bases de datos MongoDB
Los nombres de las bases de datos se completan de forma automática si utiliza getSiblingDB, y los nombres de las colecciones lo hacen si utiliza getCollection.
Además, los nombres de los campos se completan y resuelven si se utilizan desde una colección definida con getCollection.
Ventana de herramientas Services
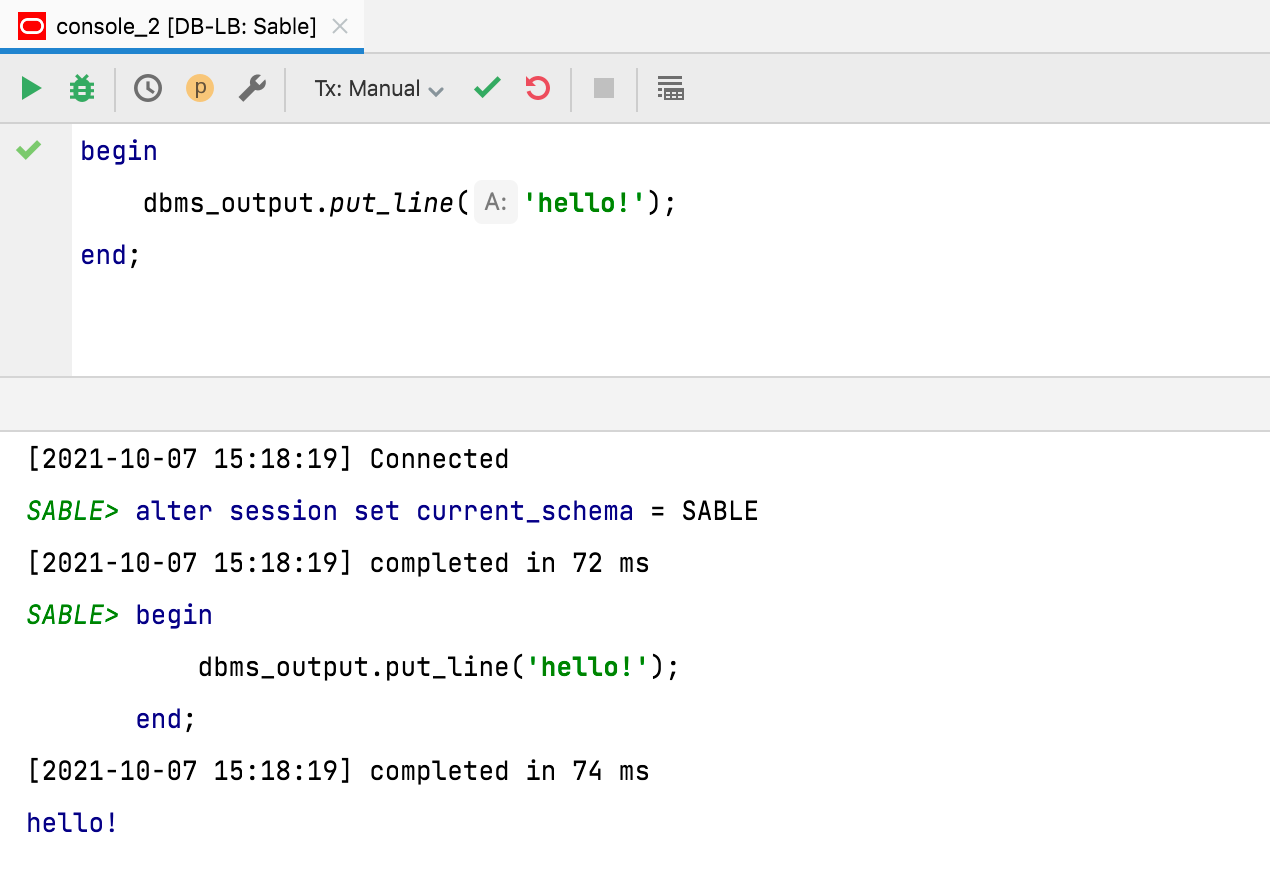
Marcas de tiempo ocultas en el resultado de forma predeterminada
Gracias a esta solicitud, las marcas de tiempo ya no se muestran de forma predeterminada en el resultado de las consultas. Si desea restablecer el comportamiento anterior, puede modificar la configuración desde Database | General | Show timestamp for query output.
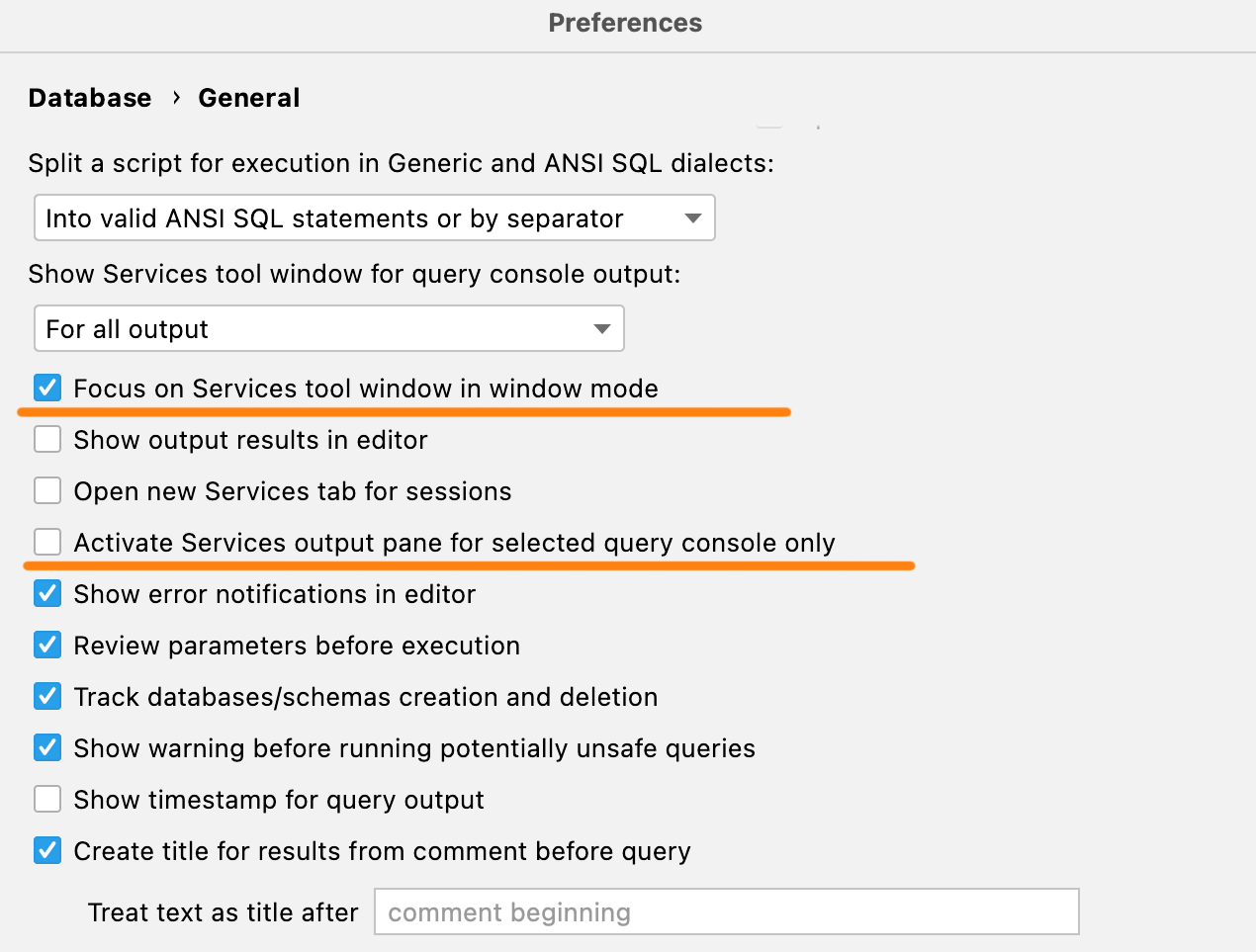
Nuevas opciones de activación
Si utiliza la ventana de herramientas Services en modo ventana, quedará oculta detrás del IDE de forma predeterminada. Con la nueva configuración, puede ponerla en primer plano cada vez que ejecute una consulta, por lo que aparecerá cuando la consulta haya terminado.
Además, si al finalizar una consulta larga, le molesta que en alguna otra consola se active la pestaña correspondiente en la ventana de herramientas Services, marque la casilla Activate Services output pane for selected query console only.
Importar/Exportar
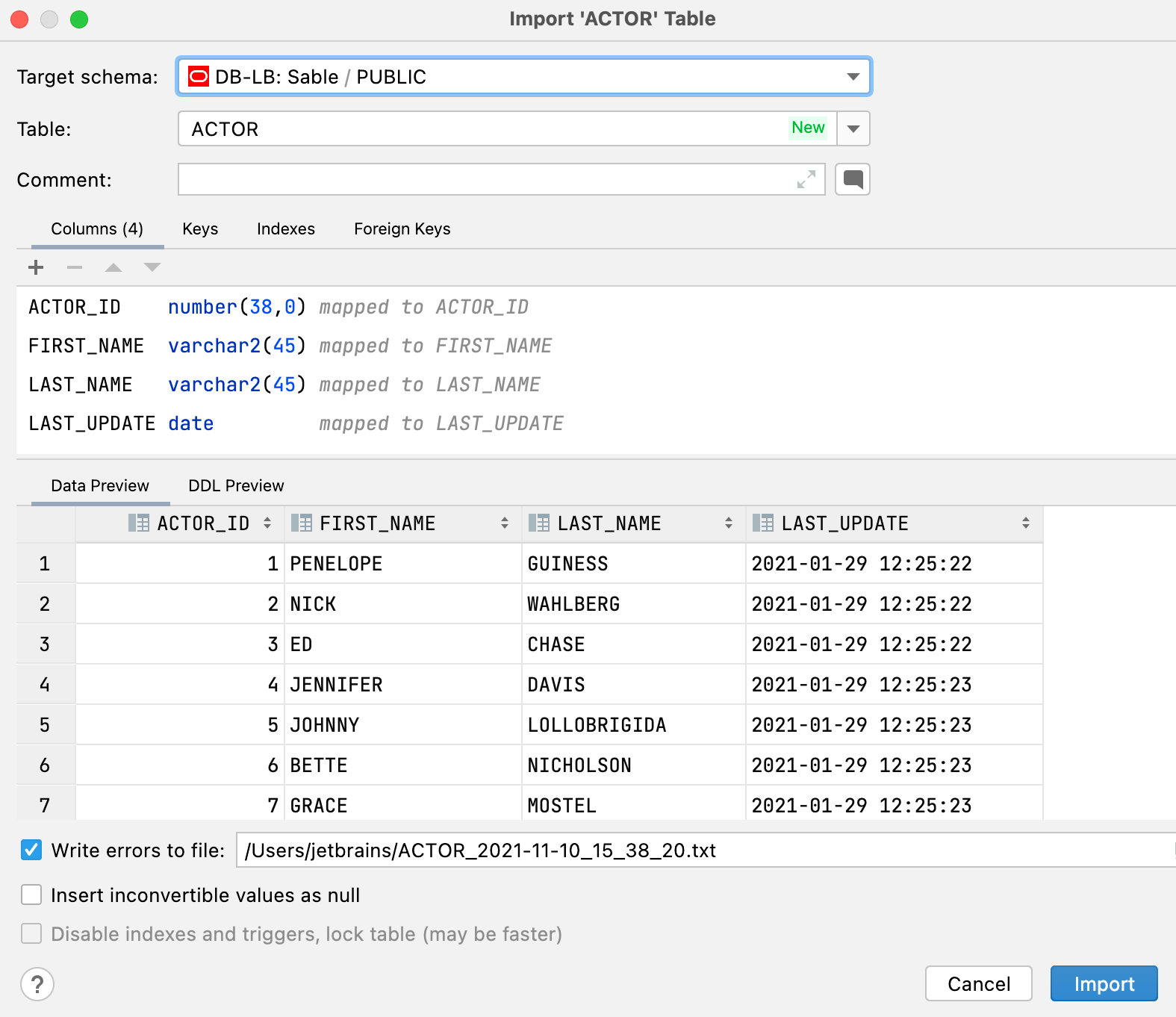
Nueva interfaz para la importación de datos
Al importar archivos .csv o copiar tablas o conjuntos de resultados, observará las siguientes mejoras:
- Puede elegir una tabla existente o crear una nueva.
- Puede cambiar el esquema de destino en el cuadro de diálogo de importación. El cuadro de diálogo específico del destino no aparecerá si copia una tabla o un conjunto de resultados.
- El destino se guarda como valor predeterminado por esquema. Por lo tanto, si suele copiar de un esquema en concreto a otro, ya no tendrá que elegir el objetivo cada vez que lo haga.
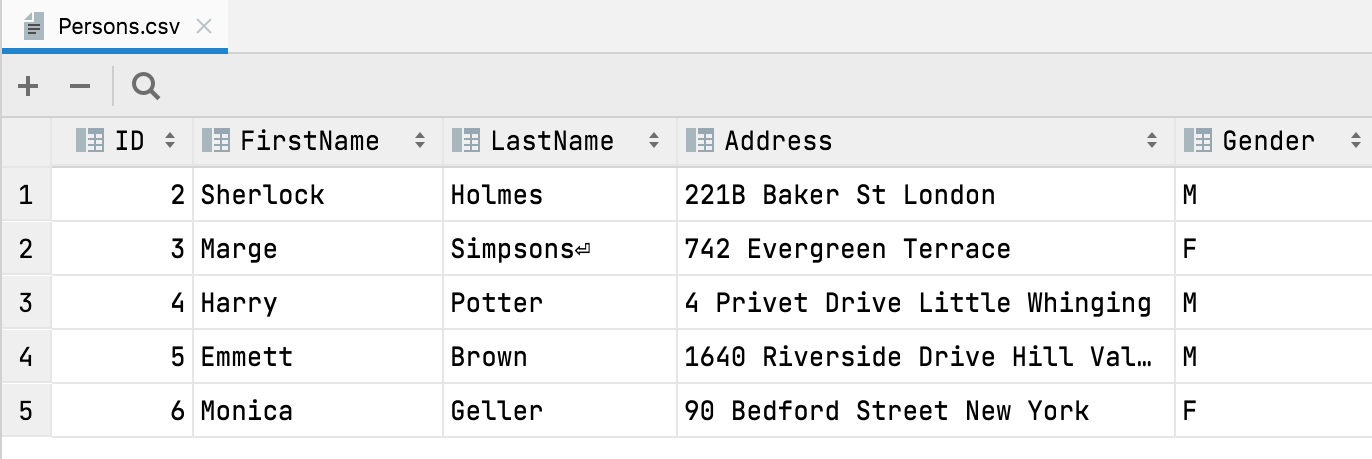
Detección automática para First row is header
Ahora, al abrir o importar un archivo CSV, DataGrip detectará de forma automática que la primera fila es el encabezado y contiene los nombres de las columnas.
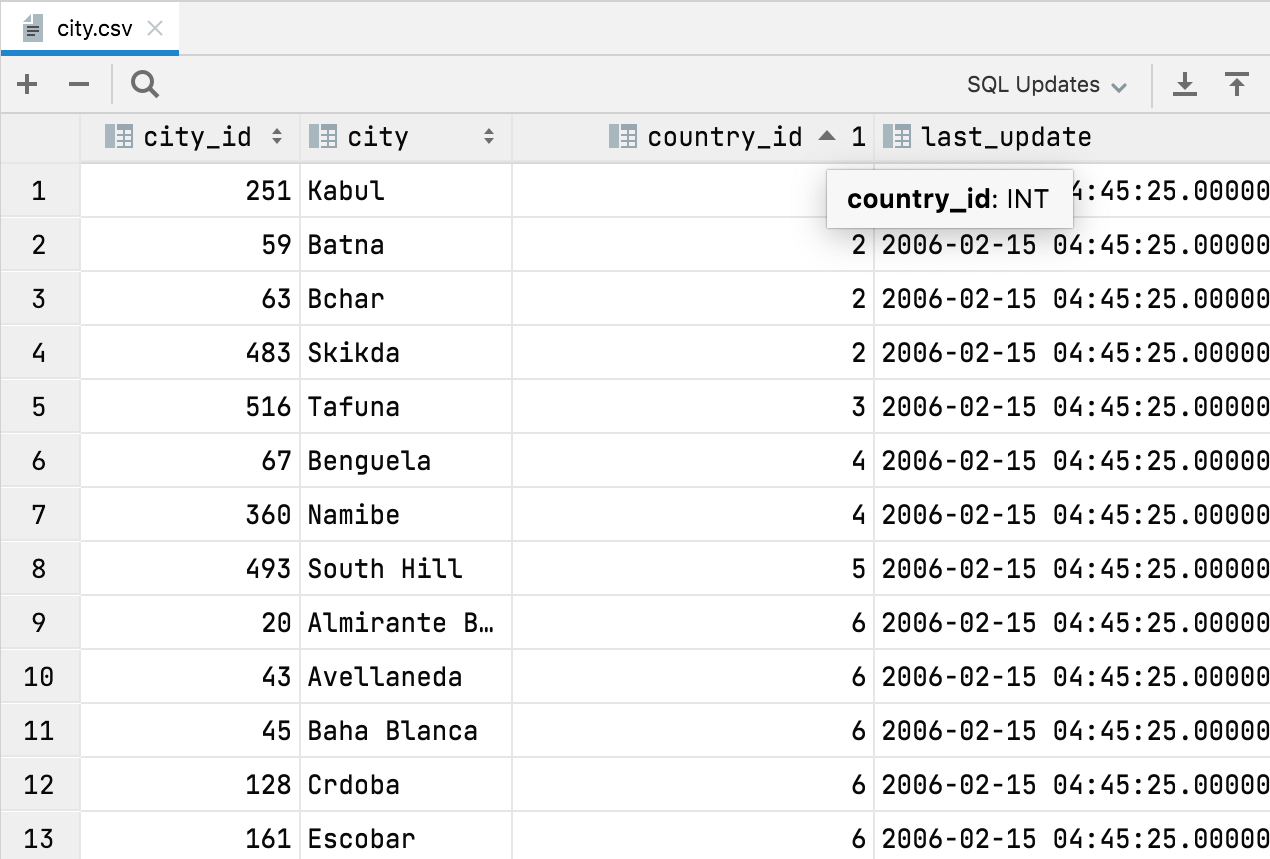
Tipos de columna automáticos en archivos CSV
Ahora, DataGrip puede detectar los tipos de columna en los archivos CSV. La principal ventaja que supone esto es que puede ordenar los datos por valores numéricos, ya que antes se trataban como texto y la ordenación no era intuitiva.
Miscelánea
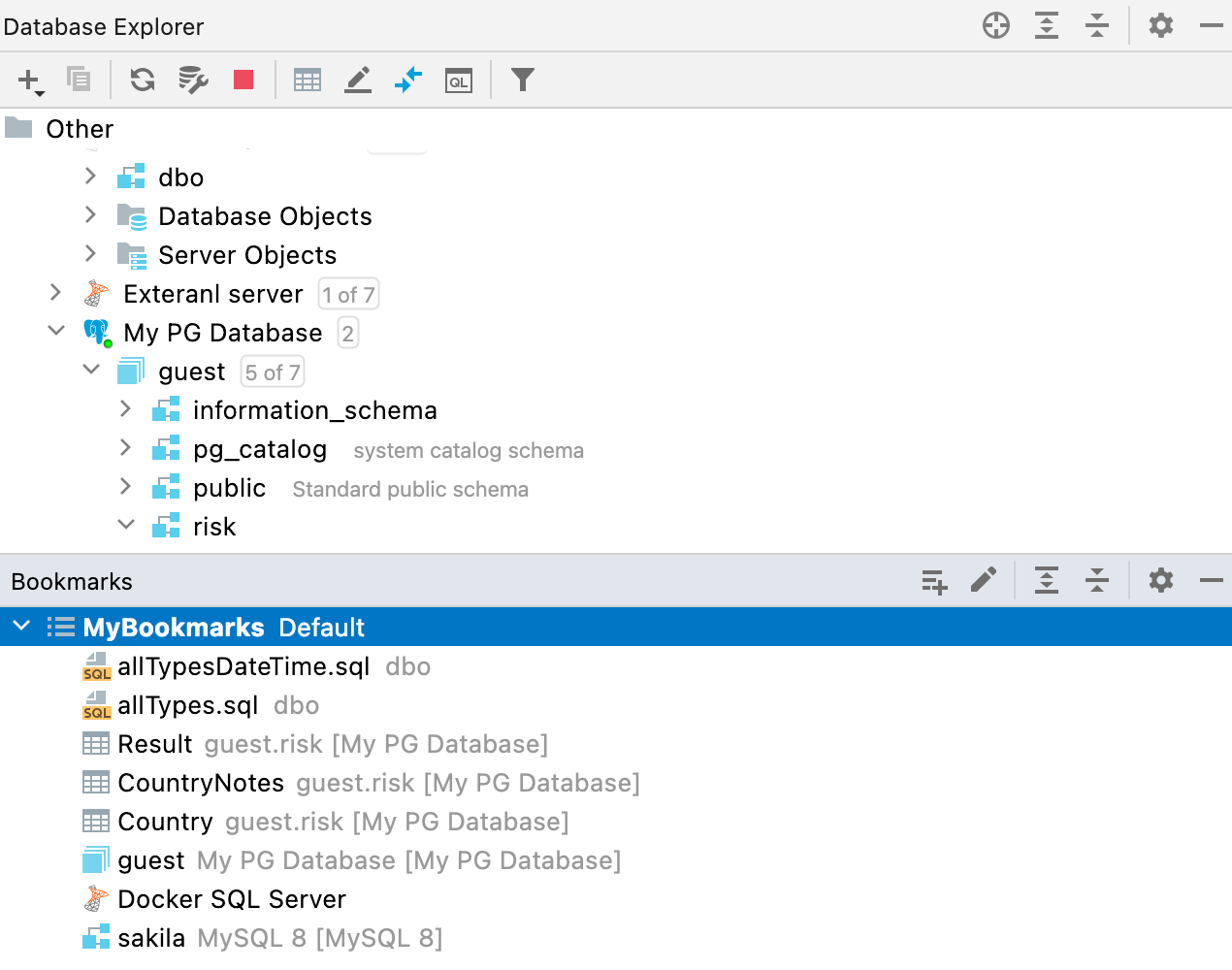
Nueva ventana de herramientas Bookmarks
Antes teníamos dos instancias muy similares: Favorites y Bookmarks. Como la diferencia entre ambas no estaba clara, hemos decidido quedarnos solamente con una de ellas: Bookmarks. Hemos rediseñado el flujo de trabajo de esta funcionalidad y hemos creado una nueva ventana de herramientas para ella.
A partir de ahora, todos los objetos o archivos que marque como importantes (con la tecla F3 en macOS o F11 en Windows y Linux) se almacenarán en la nueva ventana de herramientas Bookmarks.