Mida el rendimiento de CI/CD con métricas de DevOps
¿Cómo puede asegurarse de que está aprovechando todas las ventajas de CI/CD? Medir el rendimiento de su proceso de CI/CD le ayudará a optimizar sus procedimientos y a demostrar su valor para la empresa en general.

La mejora continua es una de las piedras angulares de la filosofía DevOps. Es un enfoque que puede ayudarle a realizar cambios significativos de forma sostenible. La estrategia se aplica tanto al producto o servicio que está creando como a la forma de crearlo.
Como su nombre lo indica, la mejora continua es un proceso continuo que implica:
- Recopilar y analizar los comentarios sobre lo que ha creado o cómo está trabajando.
- Identificar lo que funciona bien y lo que puede mejorarse.
- Realizar cambios graduales basados en esa información para intentar lograr una mayor optimización.
- Seguir recopilando información para confirmar si los cambios son útiles.
Una ventaja clave del CI/CD es que facilita la mejora continua del software. Un proceso de CI/CD le permite publicar con mayor frecuencia y obtener comentarios periódicos sobre lo que ha creado para que pueda tomar decisiones informadas sobre qué priorizar a continuación.
Del mismo modo, los comentarios rápidos que se obtienen de cada etapa de la compilación y las pruebas automatizadas facilitan la corrección de errores y la mejora de la calidad del software.
Sin embargo, la mejora continua en CI/CD no se detiene ahí. Al recopilar métricas de DevOps, puede aplicar las mismas técnicas al propio proceso de CI/CD.
¿Por qué son importantes las métricas de DevOps?
Cuando empieza a crear un proceso de CI/CD, hay muchas cosas que hacer, desde escribir pruebas automatizadas hasta hacer que sus entornos de preproducción se actualicen de forma automática. Si busca ideas sobre cómo mejorar el proceso en esta fase, consulte nuestra Guía de buenas prácticas de CI/CD.
Una vez que tenga un proceso automatizado en marcha, es hora de explorar cómo hacer que funcione de manera más eficaz. En esta etapa comienza el ciclo de mejora continua, con la ayuda de las métricas de su proceso de CI/CD.
Peter Drucker dijo una vez: «No se puede gestionar lo que no se mide». Las métricas son esenciales para la mejora continua. Los datos ayudan a identificar dónde puede añadir valor y ofrecen una base de referencia para medir la repercusión de los cambios que realiza.
Al supervisar las métricas importantes de DevOps, puede determinar si ampliar la cobertura de sus pruebas automatizadas, mejorar el rendimiento o dividir las tareas de desarrollo tendrá el mayor impacto en el rendimiento de su proceso de CI/CD.
Cada vez que optimiza una etapa de su proceso de CI/CD, amplifica el efecto de ese ciclo de retroalimentación. Este perfeccionamiento mejora su capacidad de publicar cambios con mayor frecuencia, manteniendo la calidad y una baja tasa de defectos.
Realizar lanzamientos más a menudo significa que puede seguir mejorando las principales funcionalidades, ejecutar experimentos para validar suposiciones y resolver rápidamente cualquier problema. A medida que evoluciona el mercado y cambia la demanda de funcionalidades, puede responder con rapidez y mantenerse a la par o incluso por delante de la competencia.
Además, la supervisión de sus métricas de CI/CD es una forma excelente de demostrar el valor de su proceso a la empresa en general, incluidas las partes interesadas y otros equipos de desarrollo.
Métricas de rendimiento de DevOps de alto nivel
El equipo DevOps Research and Assessment (DORA) de Google ha identificado las siguientes cuatro métricas de alto nivel que indican con precisión el rendimiento de los equipos de desarrollo de software.
Puede obtener más información acerca de la investigación en la que se basaron estas elecciones en el libro Accelerate, de Nicole Forsgren, Jez Humble y Gene Kim.
Frecuencia de implementación
La frecuencia de implementación registra la cantidad de veces que se utiliza el proceso de CI/CD para implementar a producción. DORA seleccionó la frecuencia de implementación como un proxy para el tamaño del lote, dado que una alta frecuencia de implementación implica menos cambios por implementación.
Implementar una cantidad menor de cambios reduce el riesgo asociado al lanzamiento, dado que menos variables pueden combinarse para producir resultados inesperados. Una implementación más frecuente también proporciona comentarios más inmediatos sobre su trabajo.
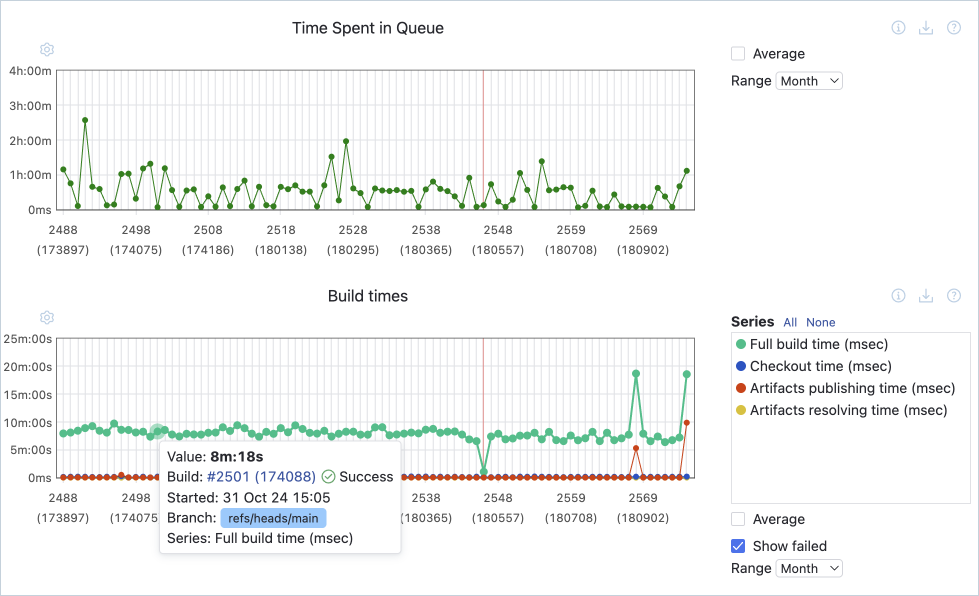
Una baja frecuencia de implementación puede significar que el proceso no se alimenta con confirmaciones periódicas, quizás porque no se dividen las tareas lo suficiente. Crear una cultura de DevOps en la que todos los miembros del equipo comprendan las ventajas del CI/CD puede ayudar a su equipo a adaptarse a trabajar en incrementos más pequeños.
En ocasiones, una baja frecuencia de implementación se debe a la agrupación de cambios en versiones más grandes como parte de una estrategia de entrega continua. Si necesita agrupar los cambios en lotes por motivos comerciales (como las expectativas de los usuarios), considere la posibilidad de medir la frecuencia de las implementaciones en los sitios de almacenamiento provisional.
Plazo de entrega
El plazo de entrega (también conocido como tiempo para la entrega o plazo de comercialización) es el tiempo que transcurre desde que se empieza a trabajar en una funcionalidad hasta que se pone a disposición de los usuarios. Sin embargo, el tiempo dedicado a la conceptualización, el estudio de usuarios y la creación de prototipos puede variar enormemente.
Por este motivo, DORA mide el tiempo transcurrido desde la última confirmación de código hasta la implementación. Este plazo le permite centrarse en las etapas dentro del ámbito de su proceso de CI/CD.
Un plazo de entrega largo significa que los cambios de código no se ponen a disposición de los usuarios de forma periódica. Como consecuencia, no puede aprovechar las estadísticas de uso y otros comentarios para perfeccionar lo que está creando.
Los plazos de entrega prolongados son comunes en procesos con varias etapas manuales. Estas etapas podrían incluir una gran cantidad de pruebas manuales o un proceso de implementación que requiere que los entornos se actualicen manualmente.
Invertir en pruebas automatizadas y un servidor de integración continua para coordinar las tareas de compilación, prueba e implementación reducirá el tiempo que se tarda en entregar el software. Al mismo tiempo, puede utilizar un servidor de integración continua para recopilar métricas que demuestren la rentabilidad de su inversión.
Supongamos que ya ha empezado a automatizar su proceso de integración e implementación continuos, pero los pasos son lentos o poco fiables. En ese caso, puede utilizar métricas de duración de la compilación para identificar los cuellos de botella.
Si su organización requiere evaluaciones de riesgos o juntas de revisión de cambios antes de cada lanzamiento, esto puede añadir días o semanas a cada implementación. El uso de métricas para demostrar la fiabilidad del proceso puede ayudar a generar confianza entre las partes interesadas y eliminar la necesidad de estos pasos de aprobación manual.
Tasa de fallos por cambios
La tasa de fallos por cambios se refiere a la proporción de los cambios implementados en producción que provocan interrupciones o errores y requieren una reversión o un hotfix. No incluye los problemas descubiertos antes de implementar los cambios de código en producción.
La ventaja de esta métrica es que sitúa las implementaciones fallidas en el contexto del volumen de cambios realizados. Una baja tasa de fallos por cambios debería darle confianza en su proceso; indica que las primeras etapas están haciendo su trabajo y detectando la mayoría de los defectos antes de que su código se publique.
Si su tasa de fallos por cambios es alta, es hora de examinar su cobertura de pruebas automatizadas. ¿Cubren sus pruebas los casos de uso más comunes? ¿Sus pruebas son fiables? ¿Puede mejorar su régimen de pruebas con pruebas automatizadas de rendimiento o seguridad?
Tiempo medio de recuperación
El tiempo medio de recuperación o resolución (MTTR) mide el tiempo que se tarda en solucionar un fallo de producción. Al destacar el MTTR se reconoce que, en un sistema complejo con muchas variables, algunos fallos en la producción son inevitables. En lugar de buscar la perfección (y renunciar a las ventajas de los lanzamientos frecuentes), hay que centrarse en si se puede responder a los problemas con rapidez.
Mantener un MTTR bajo requiere una supervisión proactiva de la producción para alertar de los problemas a medida que surgen, junto con la capacidad de revertir los cambios o implementar hotfixes a través del proceso.
Una métrica relacionada, el tiempo medio de detección (MTTD), mide el tiempo que transcurre entre la implementación de un cambio y la detección por parte de su sistema de supervisión de un problema introducido por ese cambio. Al comparar el MTTD y la duración de la compilación, puede determinar si a alguna de las dos áreas le vendría bien una inversión para reducir el MTTR.
Métricas operativas y de CI
Además de las mediciones de alto nivel, puede utilizar una serie de métricas operativas y de integración continua para comprender mejor el rendimiento de su proceso e identificar oportunidades de mejora.
Cobertura de código
Las pruebas automatizadas en un proceso de CI/CD deben proporcionar la mayor parte de la cobertura de las pruebas. La primera capa de pruebas automatizadas debe ser la de las pruebas de unidad, que son las más rápidas de ejecutar y proporcionan la información más inmediata.
La cobertura de código es una métrica proporcionada por la mayoría de los servidores de CI que calcula la proporción de su código que cubren las pruebas de unidad. Merece la pena controlar esta métrica para asegurarse de que mantiene una cobertura de pruebas adecuada a medida que escribe más código. Si su cobertura de código tiende a disminuir, es hora de invertir algún esfuerzo en esta primera línea de comentarios.
Duración de la compilación
La duración de la compilación o el tiempo de compilación mide el tiempo que se tarda en completar las distintas etapas del proceso automatizado. Analizar el tiempo empleado en cada fase del proceso ayuda a detectar puntos conflictivos o cuellos de botella que podrían aumentar el tiempo que se tarda en obtener resultados de las pruebas o en implementar en la producción.
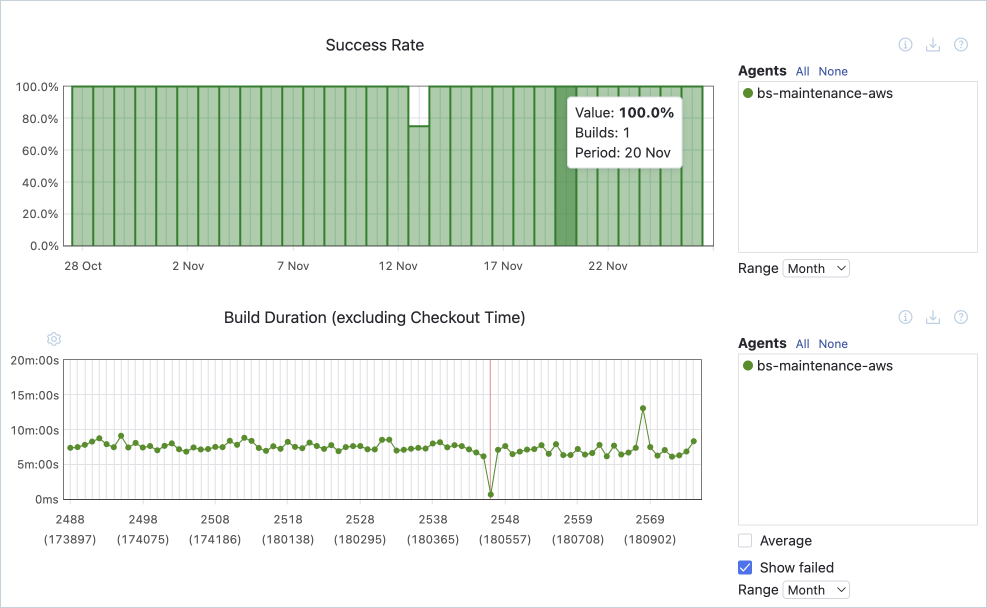
Tasa de superación de pruebas
La tasa de superación de pruebas es el porcentaje de casos que se han superado con éxito en una compilación determinada. Mientras tenga un nivel razonable de pruebas automatizadas, la métrica indica la calidad de cada compilación. Puede utilizar los datos para comprender con qué frecuencia los cambios de código introducen nuevos errores.
Aunque es preferible detectar los fallos con las pruebas automatizadas que depender de las pruebas manuales o descubrir los problemas en producción, si un conjunto concreto de pruebas automatizadas falla con regularidad, es hora de investigar la causa originaria de esos fallos.
Tiempo de resolución de pruebas
El tiempo de resolución de pruebas es el tiempo que transcurre entre que una compilación informa de que una prueba ha fallado y la misma prueba se supera en una compilación posterior. Esta métrica le indica la rapidez con la que es capaz de responder a los problemas identificados en el proceso.
Un tiempo de resolución bajo indica que está utilizando su proceso de forma eficaz. Resolver los problemas en cuanto se detectan es más eficaz, dado que los cambios aún están frescos en la mente. Al corregir los problemas rápidamente, también garantiza que usted y sus compañeros de equipo evitan compilar más funcionalidad sobre un código inestable.
Implementaciones fallidas
Las implementaciones fallidas provocan tiempos de inactividad involuntarios, obligan a revertir las implementaciones o requieren correcciones urgentes. El recuento de implementaciones fallidas se utiliza para calcular la tasa de fallos por cambios.
La supervisión de la proporción de fallos sobre el número total de implementaciones ayuda a medir su rendimiento con respecto a los acuerdos de nivel de servicio.
Sin embargo, recuerde que un objetivo de cero (o muy pocos) implementaciones fallidas no es necesariamente realista y puede animar a los equipos a dar prioridad a la certidumbre en lugar de entregar sistemáticamente un producto de calidad. Esta mentalidad puede dar lugar a plazos de entrega más largos e implementaciones más grandes, dado que los cambios se agrupan. Dado que las implementaciones más grandes contienen una mayor cantidad de variables, existe una mayor probabilidad de fallos en producción que son más difíciles de solucionar (debido a que hay más cambios que revisar).
Recuento de defectos
A diferencia de la métrica de fallos en la implementación, el recuento de defectos se refiere al número de tickets abiertos en su backlog clasificados como errores. Esta métrica de Integración continua puede dividirse a su vez en problemas detectados en pruebas, almacenamiento provisional y producción.
Controlar el número de defectos ayuda a alertarle si se desarrolla una tendencia general al alza, lo que indica que los errores pueden estar saliéndose de control. Sin embargo, tenga en cuenta que convertir esta métrica en un objetivo puede hacer que su equipo se centre más en clasificar los tickets que en solucionarlos.
Tamaño de la implementación
Como consecuencia de la frecuencia de implementación, el tamaño de la implementación ―medido por el número de puntos de historia incluidos en una compilación o lanzamiento― puede utilizarse para controlar el tamaño de los lotes dentro de un equipo concreto.
Mantener las implementaciones reducidas muestra que su equipo confirma los cambios con frecuencia, con todos los beneficios que ello conlleva. Sin embargo, como las estimaciones de las historias no son comparables entre los equipos de desarrollo, esta métrica no debería utilizarse para medir el tamaño total de la implementación.
Conclusión
Estas métricas de DevOps le permiten comprender mejor el rendimiento de su proceso de CI/CD en términos de velocidad de implementación y calidad del software.
Mediante el seguimiento de estas métricas, puede identificar las áreas de su proceso que más atención necesitan. Una vez que haya realizado cambios, siga supervisando las métricas pertinentes para verificar si han surtido el efecto deseado.
Sin embargo, aunque las métricas pueden servir como indicadores útiles de rendimiento, es importante leer las cifras en su contexto y considerar qué comportamientos puede incentivar una métrica concreta.
Tenga en cuenta que el objetivo no son los números en sí, sino mantener su proceso rápido y fiable para poder seguir ofreciendo valor a los usuarios y, a su vez, apoyar los objetivos de su organización.