Nouveautés de DataGrip 2019.2
Fenêtre d'outils Services
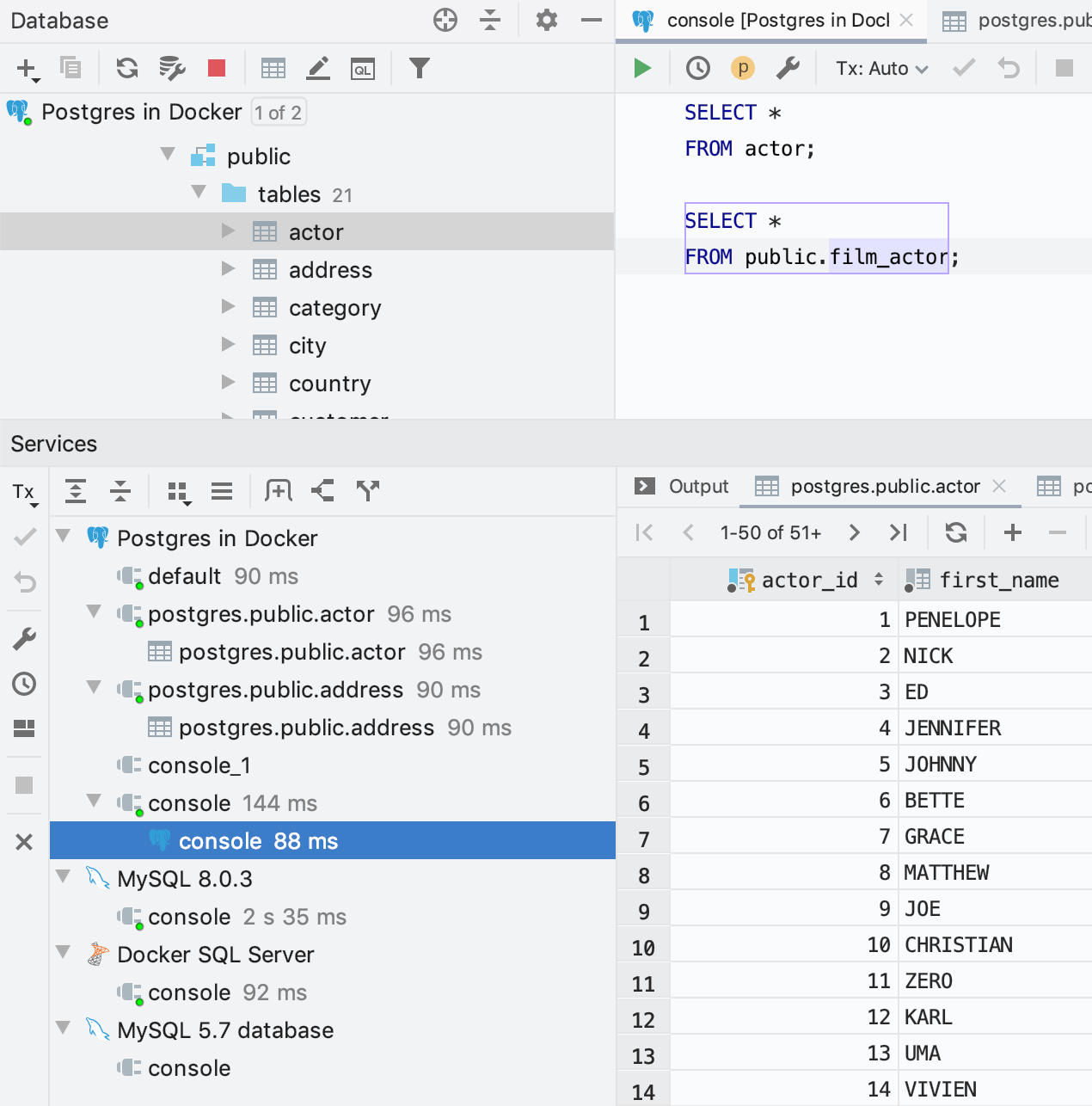
Tous nos IDE comportent désormais une nouvelle fenêtre d'outils appelée Services. Dans DataGrip, vous pouvez y observer et gérer toutes les connexions.
Toute connexion a son propre nœud dans la section de source de données correspondante. Si le petit voyant vert situé sur l'icône est allumé, cela signifie que la connexion est active. Vous pouvez facilement fermer une connexion en utilisant le menu contextuel.
Vous pouvez également afficher tous les types de services en tant que nœuds ou modifier la vue pour les afficher en tant qu'onglets. Utilisez l'action Show in New Tab de la barre d'outils ou faites simplement glisser le nœud voulu sur la barre de titre de la fenêtre d'outils Services.
Le résultat de la requête est désormais joint à la console sous sa connexion, dans la vue Services.
Important ! Le raccourci par défaut de la fenêtre Services est Alt+8.
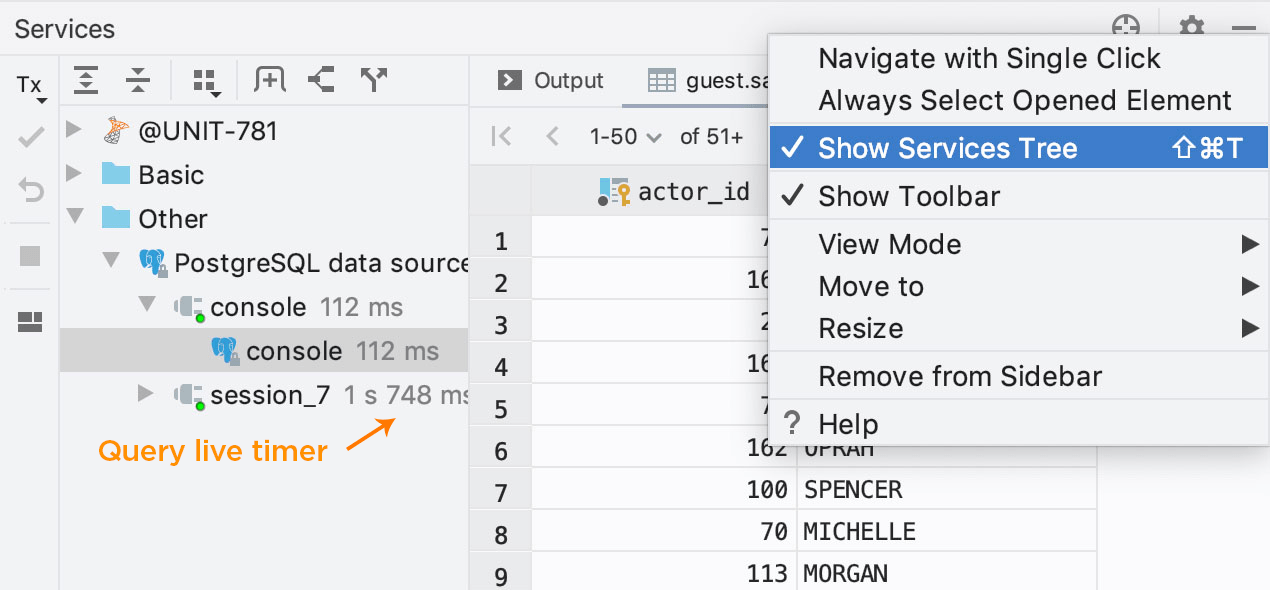
Masquage de l'arborescence
Si vous ne souhaitez pas afficher l'arborescence de services (c'est-à-dire que vous souhaitez rétablir l'état précédent), cliquez sur l'icône d'engrenage et masquez-la.
Minuteur de requête
La fenêtre d'outils Services contient également une autre fonctionnalité très demandée : un minuteur de requête. Pour toute connexion exécutant une requête, consultez sa partie droite pour voir combien de temps elle a pris.
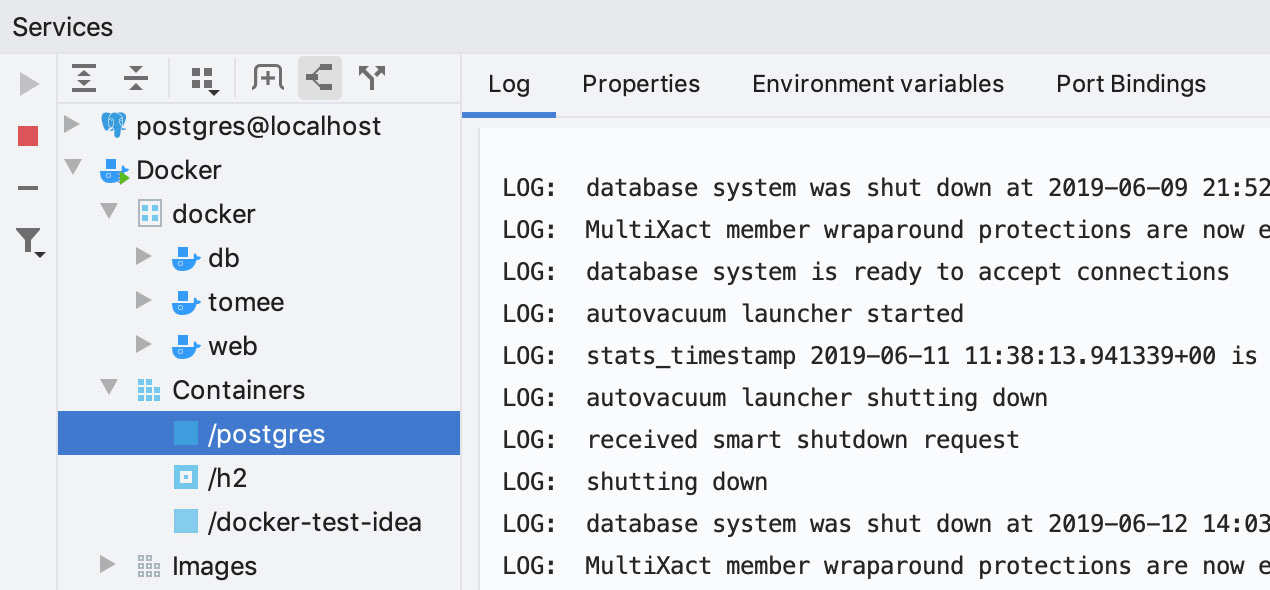
Docker
Si vous utilisez l'extension Docker, les services correspondants s'affichent également dans cette fenêtre d'outil.
Recherche en texte intégral
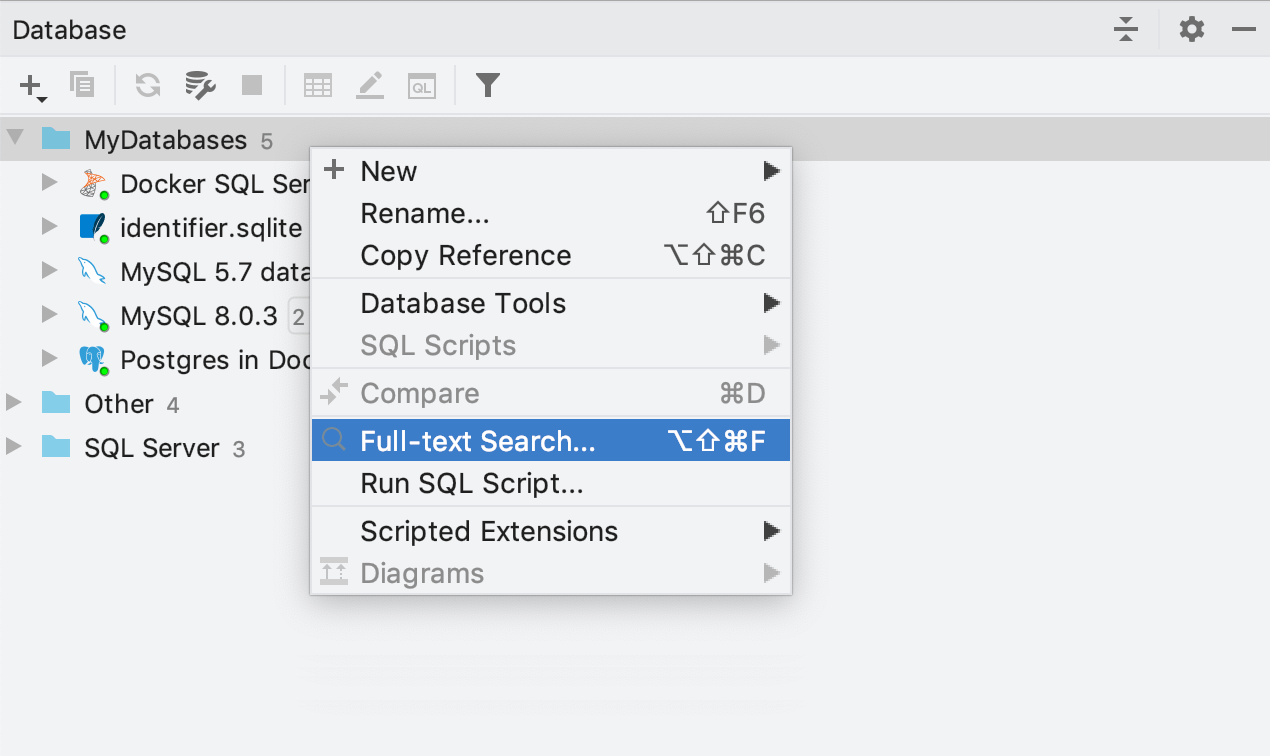
Vous pouvez désormais rechercher les données même si vous n'en connaissez pas l'emplacement. Pour ce faire, sélectionnez les sources de données, les groupes de sources de données voire les tables dans lesquelles vous souhaitez effectuer une recherche et appelez Full-text search dans le menu contextuel. Un raccourci a aussi été prévu pour cela : Ctrl+Alt+Maj+F.

Vous verrez s'afficher une boîte de dialogue permettant de saisir le texte. Vous verrez s'afficher la liste des sources de données dans lesquelles procéder à la recherche et vous pourrez définir certaines options pour votre recherche.
Vous pourrez également consulter les instructions que DataGrip doit exécuter pour procéder à la recherche de données.
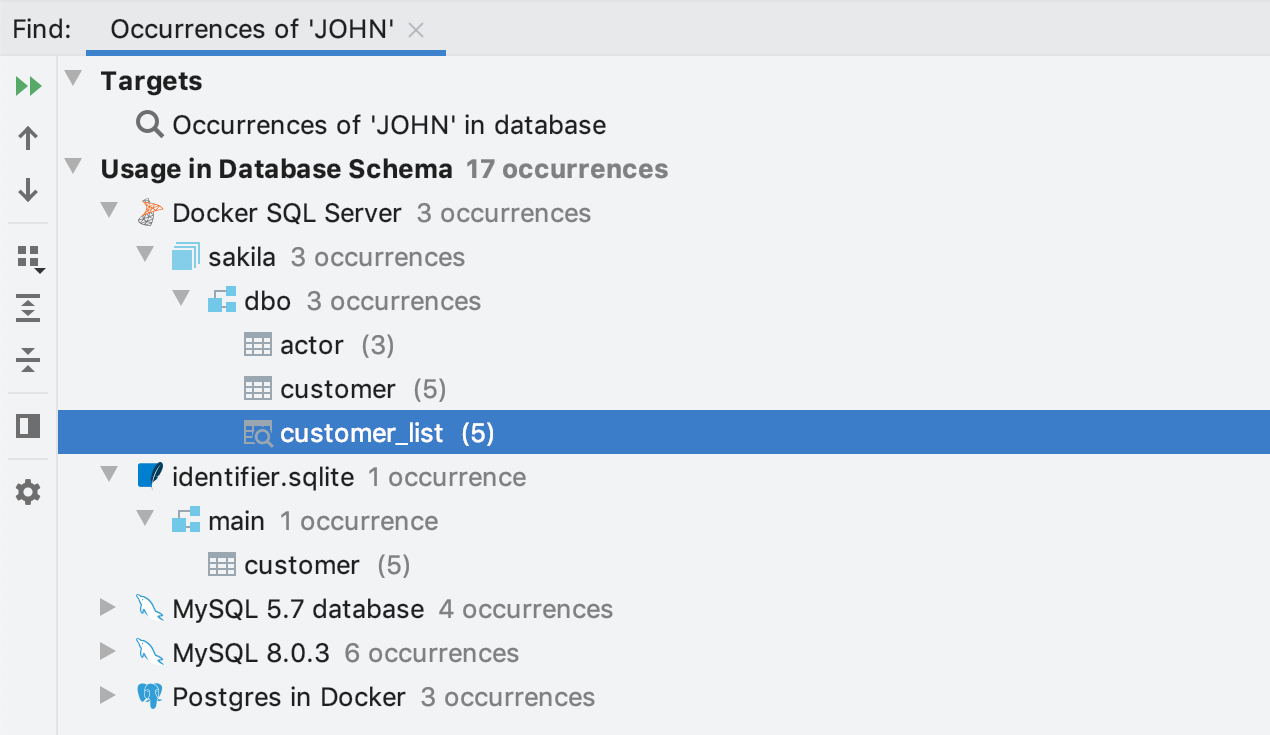
Une fois la recherche exécutée, vous verrez les résultats que vous pouvez ouvrir.
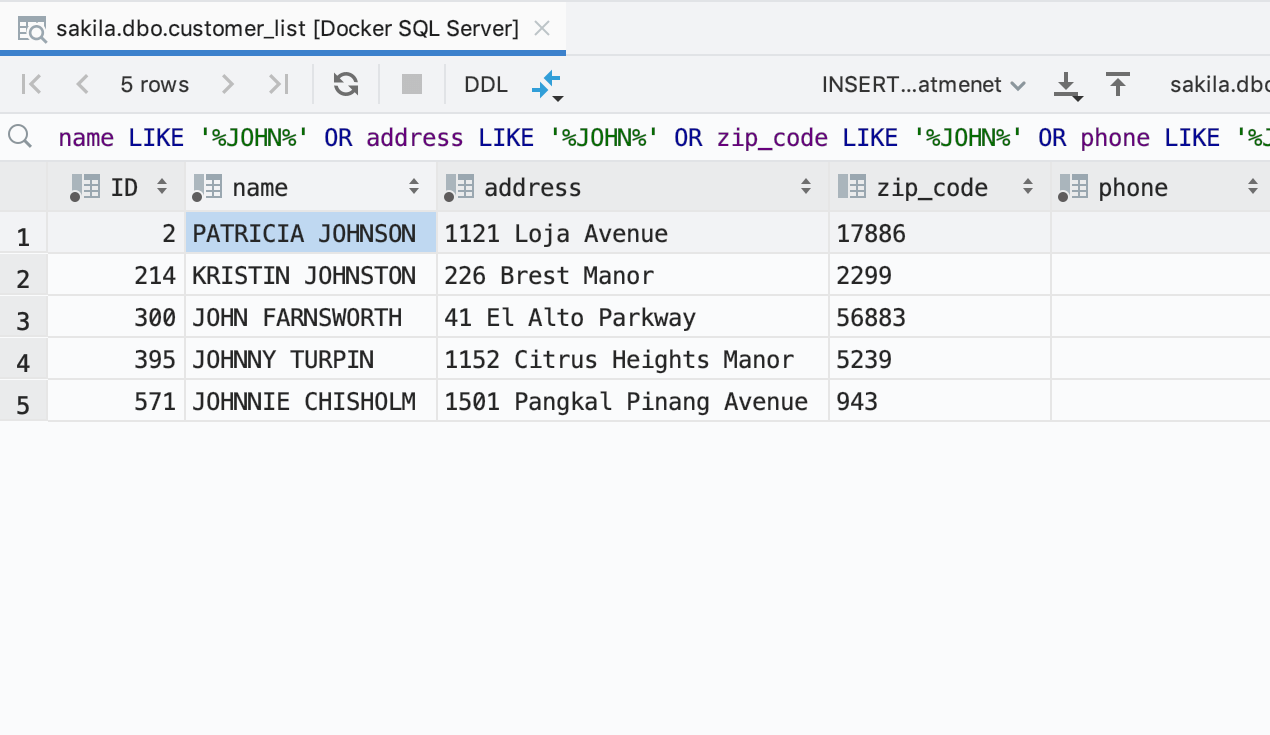
Cliquez sur un résultat pour ouvrir l'éditeur de données. Le filtre sera prédéfini afin de renvoyer uniquement les chaînes de caractères contenant les données recherchées. Si vous ne parvenez pas à trouver les données parce qu'il y a trop de colonnes, appelez la fonction de recherche de texte de l'éditeur de données en utilisant Ctrl+F.
Dans certaines bases de données, vous pouvez choisir de chercher uniquement dans les colonnes indexées. Pour utiliser ce mode, sélectionnez Only columns with full-text search indexes dans le menu déroulant Search in.
- Dans PostgreSQL, la requête sera :
where col @@ plainto_tsquery('text'). - Dans MySQL et MariaDB, la requête sera :
where match(col) against ('text' in natural language mode). - Dans Oracle, les index suivants sont utilisés, s'ils existent : context, ctxrule, ctxcat.
- Dans SQL Server, s'il existe des colonnes avec des index en texte intégral, DataGrip génère des requêtes avec
WHERE CONTAINS(col, N'text'). - Dans SQLite, DataGrip génère des requêtes avec
where col MATCH ‘text'.
Si le mode All columns est séléctionné, la recherche porte sur les colonnes qui ne prennent pas en charge l'opérateur LIKE. Par exemple, les colonnes du type JSON. Les valeurs de ces colonnes sont converties en chaînes au préalable.
Dans Cassandra, DataGrip crée plusieurs requêtes pour la même table, car la condition OR n'est pas prise en charge par la base de données.
Éditeur de données
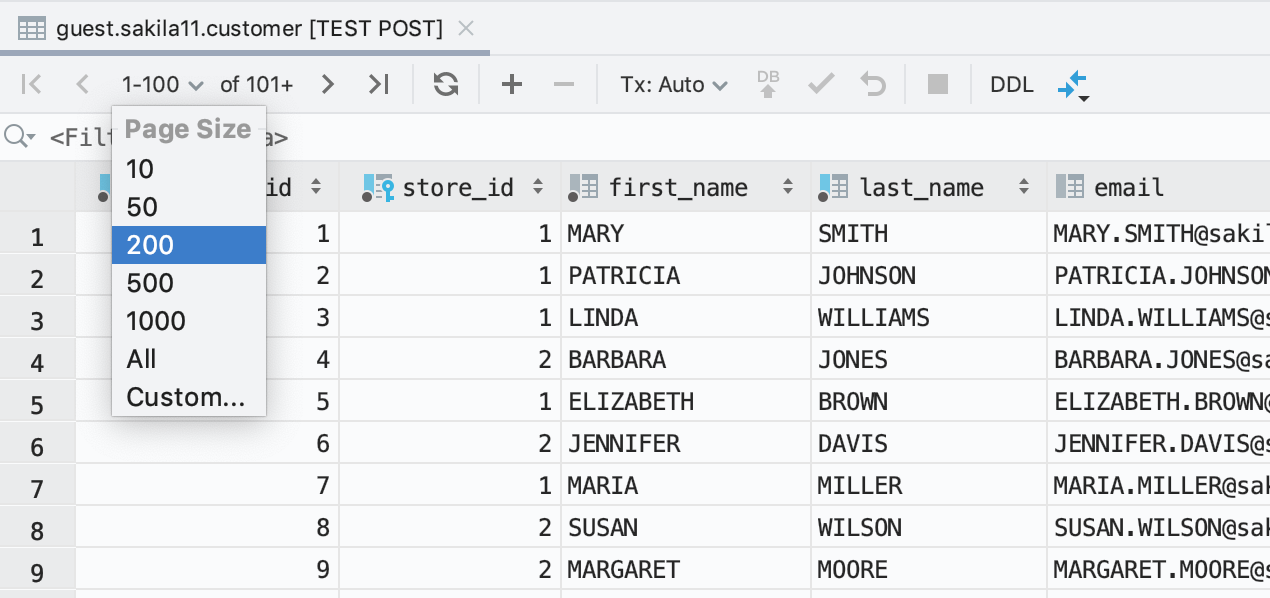
Il est facile de changer la taille de la page
À présent, pour définir le nombre de règles à extraire de la base de données, vous pouvez passer par la barre d'outils du jeu de résultats.
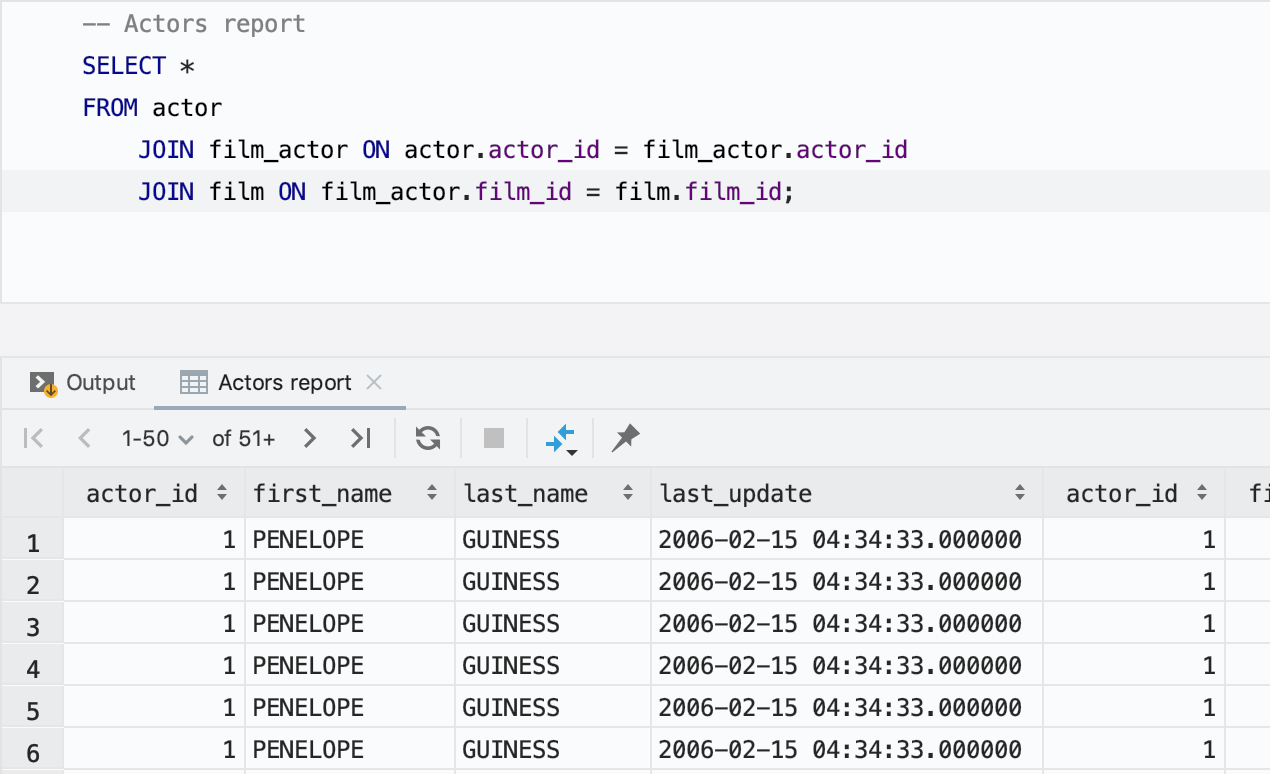
Les onglets de résultats peuvent être nommés
Encore une amélioration très intéressante pour les résultats : le nommage de l'onglet ! Utilisez simplement le commentaire avant la requête.
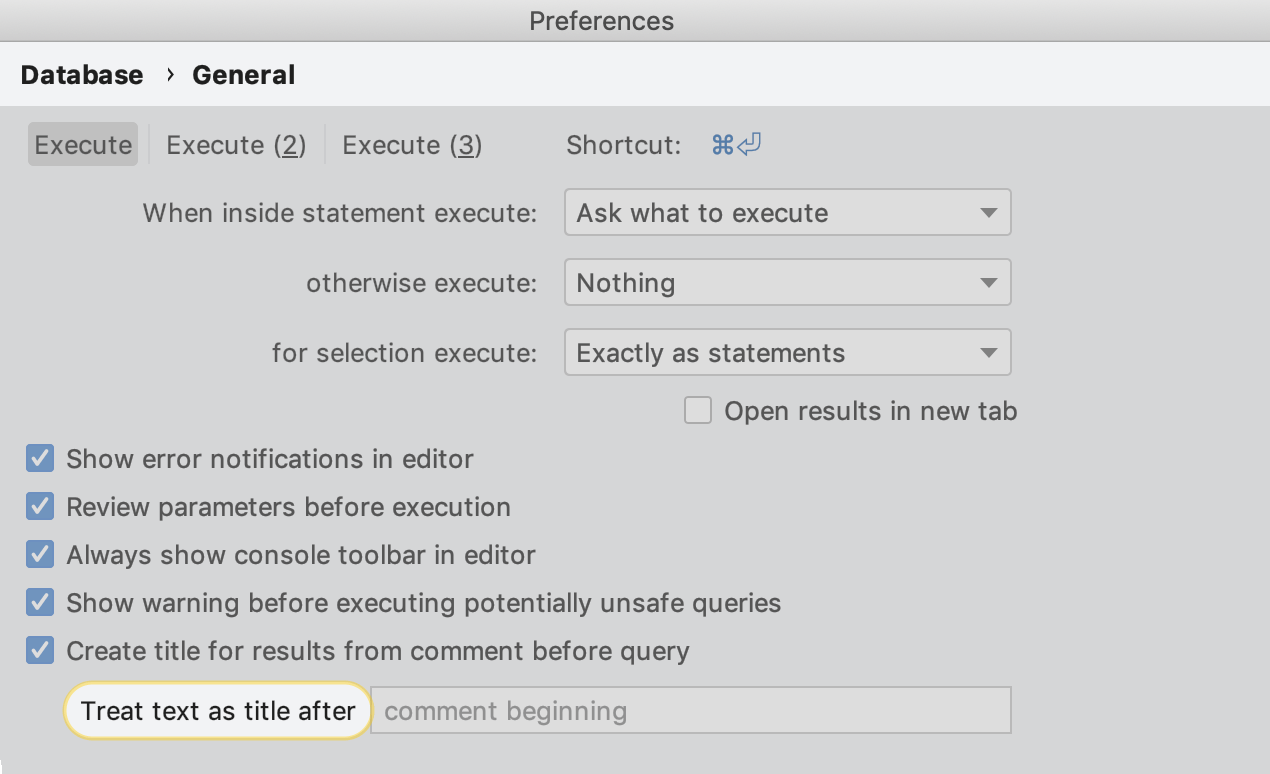
Si vous voulez convertir seulement certains commentaires en noms d'onglets, utilisez le champ Treat text as title after dans les paramètres pour spécifier le mot du préfixe. Ensuite, seuls les mots venant après ce mot seront utilisés en tant que titres.
Vue arborescente de la base de données
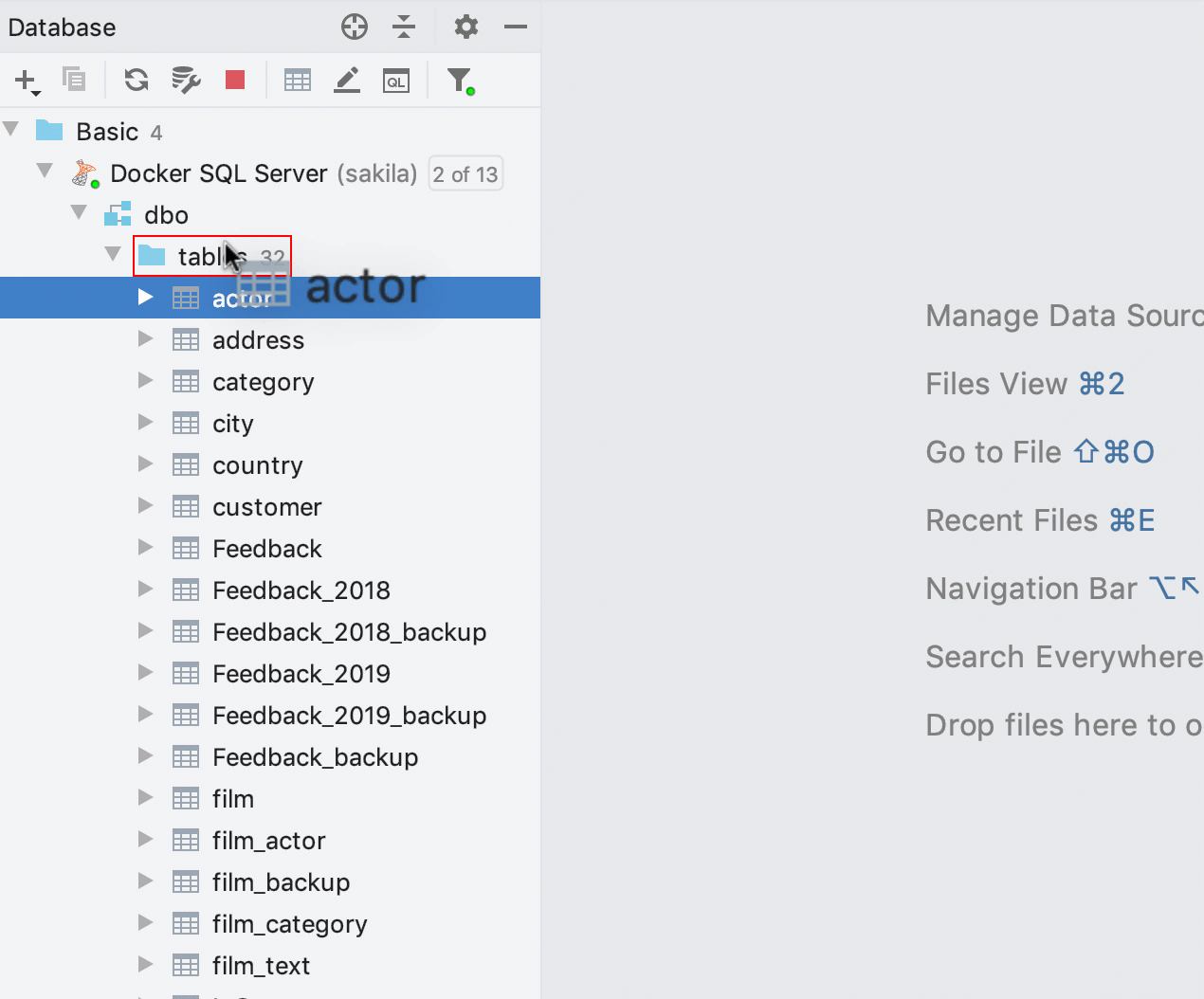
Sauvegarde rapide des tables
Il était possible de copier les tables par glisser/déposer, mais cela ne fonctionnait pas lors de la copie vers le même schéma. En pratique, c'est une option très utile pour réaliser une sauvegarde rapide de la table avant des manipulations de données cruciales. Par conséquent, nous l'avons mise en place !
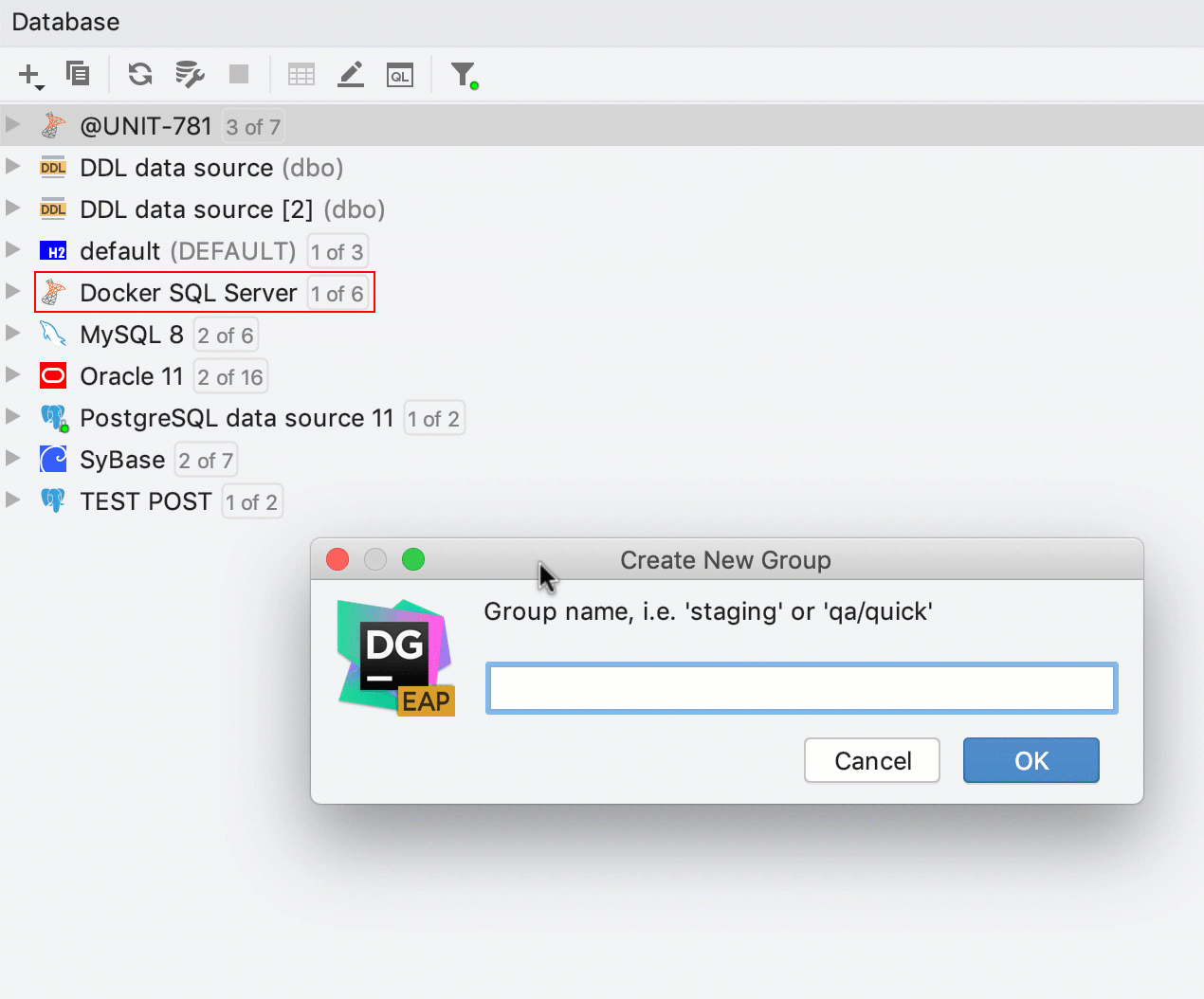
Création de groupe rapide
Désormais, le glisser/déposer fonctionne également pour la création de groupes dans l'explorateur de bases de données.
Pour créer un groupe, faites simplement glisser une source de données sur l'autre.
Pour placer une source de données dans un groupe existant, faites-la glisser à cet endroit.
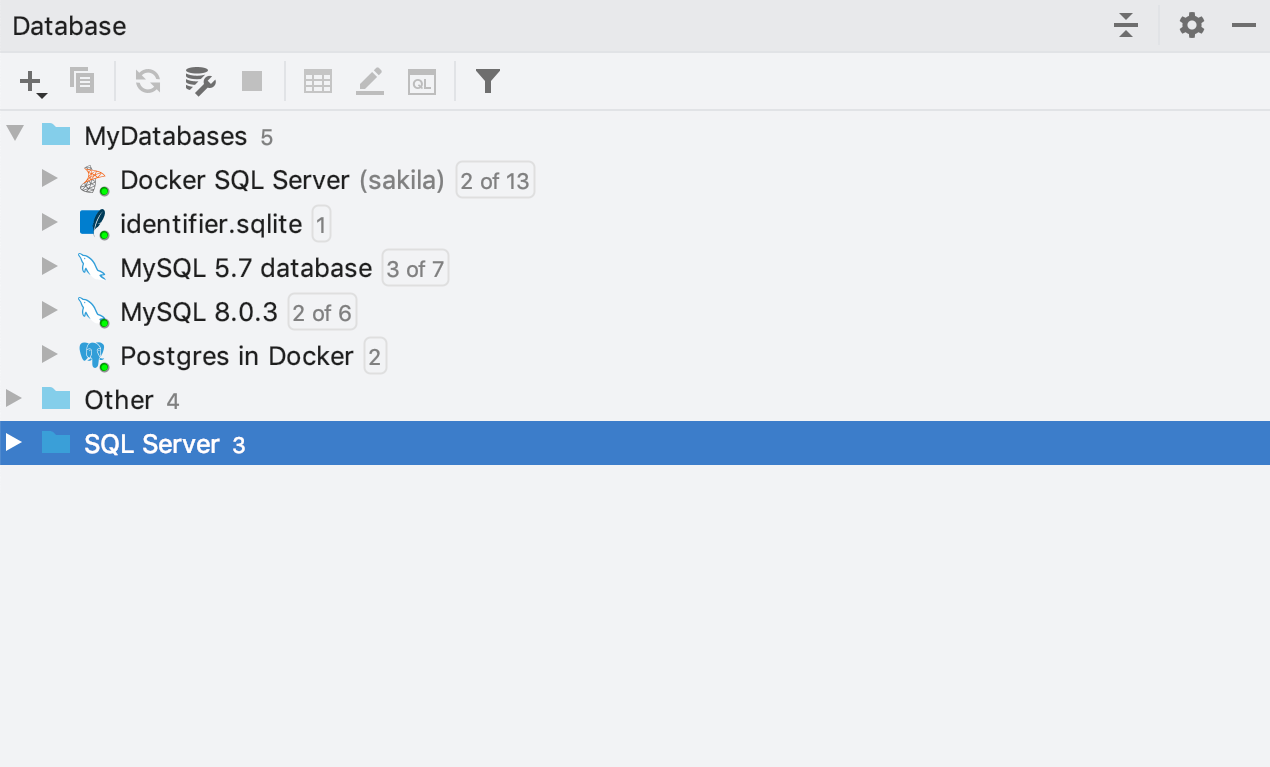
Connexions actives
À compter de la version 2019.2, le petit voyant vert indique si la connexion de la source de données est active.
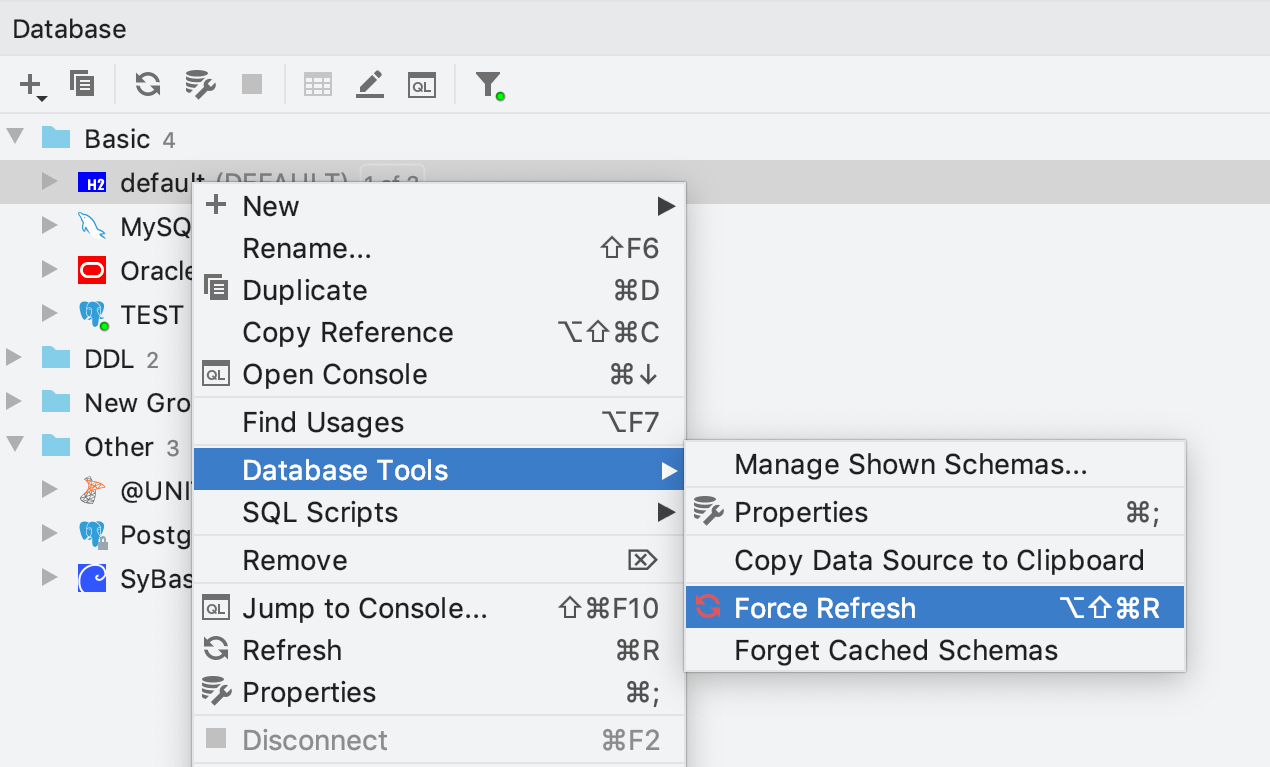
Actualisation forcée
Une nouvelle action est disponible pour la source de données ou le schéma : Force Refresh. Elle efface les informations de la source de données que DataGrip place en mémoire cache et l'actualise totalement.
Filtrage en fonction d'une source de données dans la recherche et la navigation
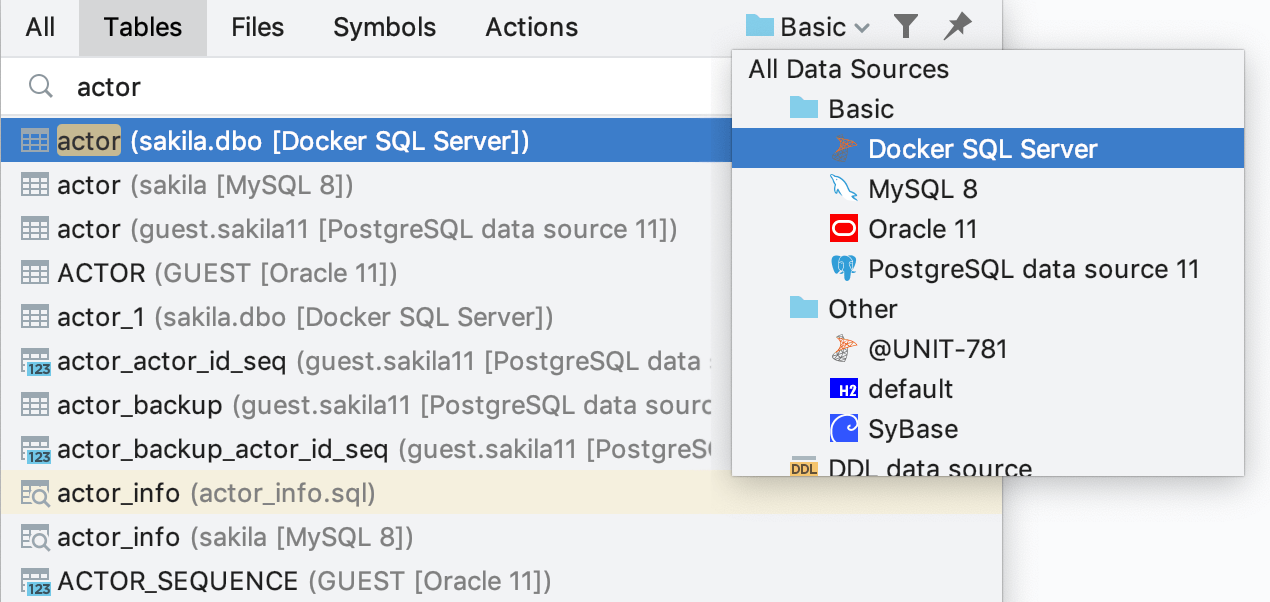
Lorsque vous consultez un objet dans la fenêtre contextuelle GoTo, il arrive parfois que la liste contienne de nombreux éléments similaires. Cela se produit fréquemment en présence de nombreux miroirs, telles que la production, le staging, les tests, etc.
Avec DataGrip 2019.2, vous pouvez choisir le périmètre de recherche, que ce soit dans une source de données spécifique ou dans un groupe de sources.
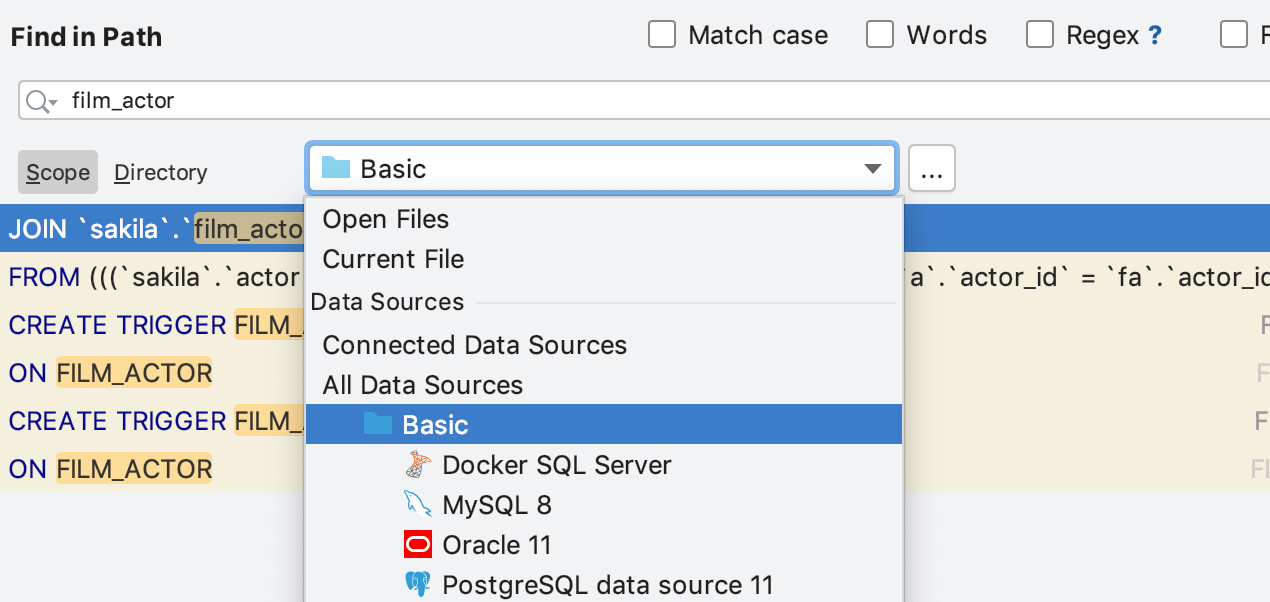
C'est également valable pour Find In Path, ce qui est extrêmement utile pour rechercher du code source dans les DDL d'autres objets.
Assistance au codage
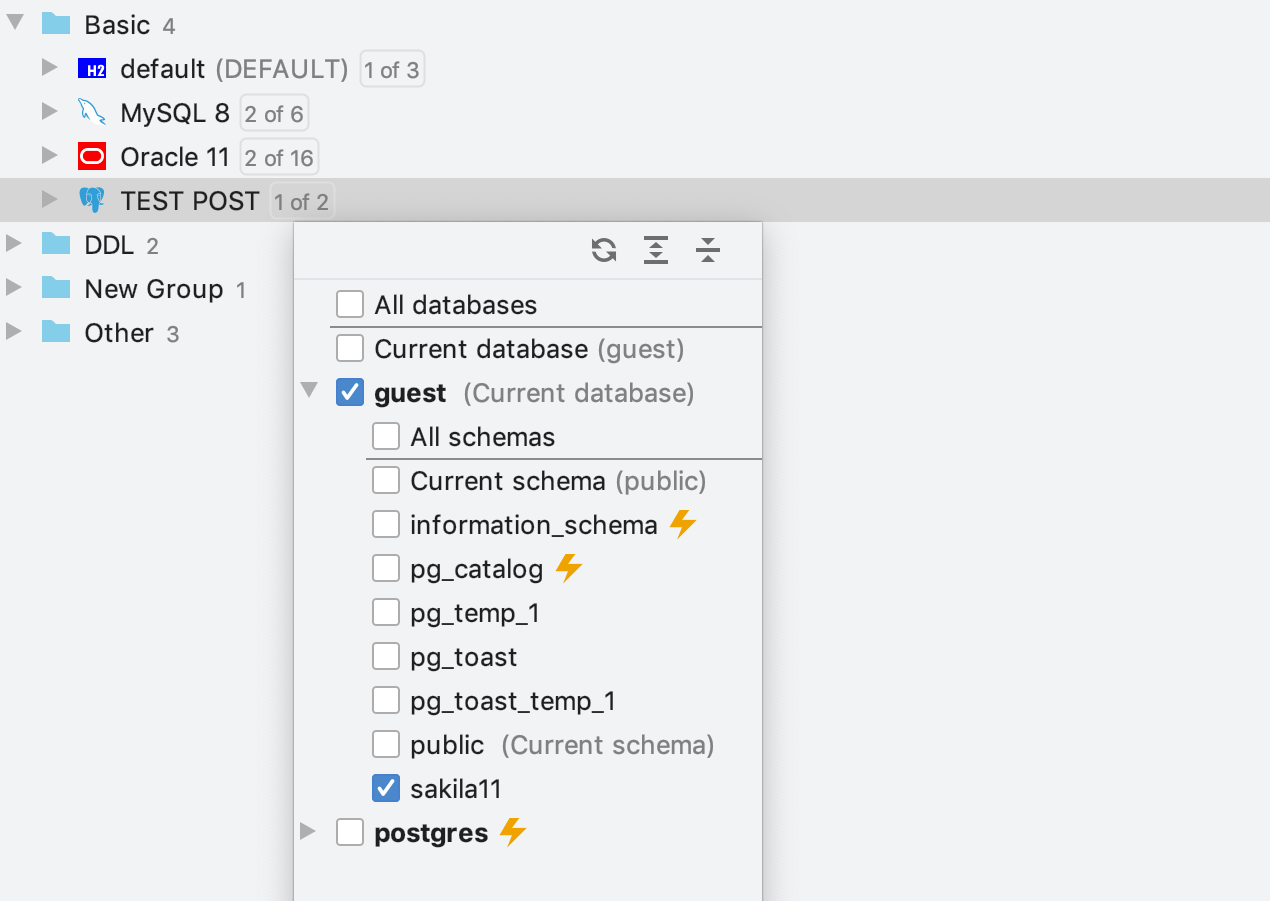
Objets provenant de catalogues système
Quasiment toutes les bases de données contiennent un catalogue système, un endroit où le système de gestion de bases de données relationnelles stocke les métadonnées de schéma, telles que les informations sur les tables et les colonnes, les fonctions intégrées, etc.
Les objets de ces catalogues sont nécessaires pour assurer l'assistance au codage. Il est intéressant de pouvoir y accéder depuis la saisie semi-automatique du code, et le code qui les utilise ne doit pas être en rouge.
Avant, la seule façon d'intégrer des catalogues système à l'assistance au codage impliquait de les ajouter à l'explorateur de bases de données. DataGrip extrayait les informations sur ces dernières depuis la base de données (toujours la même, d'ailleurs !), ce qui prenait du temps. Ces informations étaient également visibles dans l'explorateur de bases de données, ce qui n'est pas toujours nécessaire.
Ce type de schéma comporte une icône en forme d'éclair dans le sélecteur de schémas. À présent, si vous ne les vérifiez pas, DataGrip n'applique pas d'introspection et ne les affiche pas, mais utilisera les informations sur leurs objets dans l'assistance au codage. Pour rendre cela possible, DataGrip utilise ses données internes concernant les catalogues système de chaque base de données.
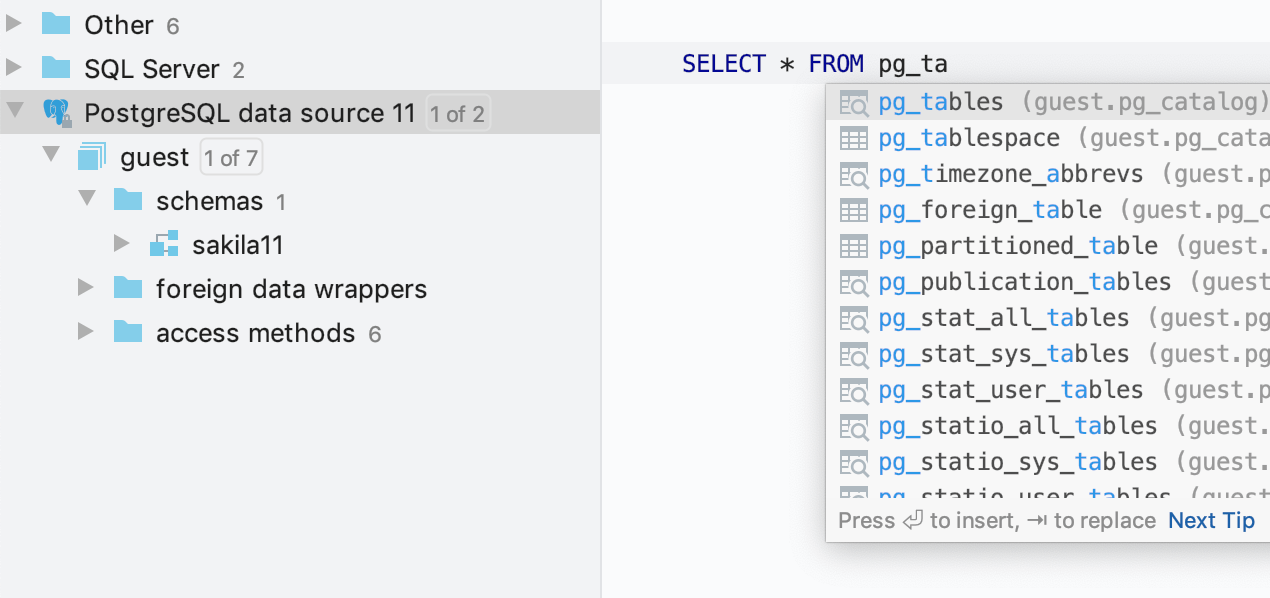
Quelques exemples de catalogues système pour plusieurs bases de données :
- PostgreSQL : pg_catalog, information_schema
- SQL Server : INFORMATION_SCHEMA
- Oracle : SYS, SYSTEM
- MySQL : information_schema
- DB2 : SYSCAT, SYSFUN, SYSIBM, SYSIBMADM, SYSPROC, SYSPUBLIC, SYSSTAT, SYSTOOLS
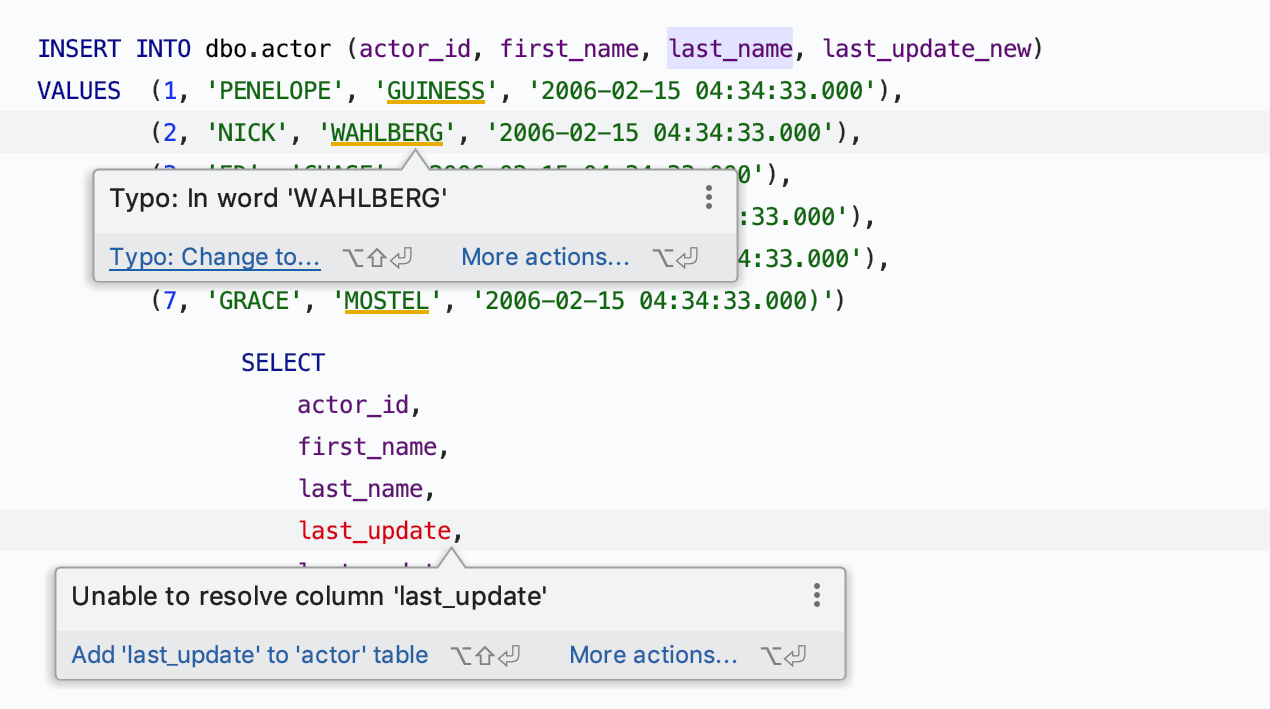
Actions d'intention et correctifs rapides
Tout d'abord, nous avons intégré un correctif rapide dans l'infobulle d'inspection. Si DataGrip sait comment corriger le problème, vous pouvez en prendre connaissance en survolant l'avertissement avec le curseur de la souris. Pour résoudre le problème, cliquez simplement sur le lien dans le coin inférieur gauche de l'infobulle ou appuyez sur Alt+Maj+Entrée.
Alt+Entrée fonctionne toujours pour obtenir la liste des correctifs rapides.
Nous avons introduit plusieurs nouvelles inspections.

Utilisation superflue de CASE
Lorsque vous utilisez des constructions CASE, DataGrip analyse les possibilités d'amélioration de leur lisibilité.
Pour IF :

Pour COALESCE:

Conversion de GROUP BY vers DISTINCT
Nous avons ajouté une action d'intention supplémentaire : vous pouvez désormais convertir GROUP BY vers DISTINCT si toutes les colonnes d'une clause SELECT sont présentées dans une clause GROUP BY.
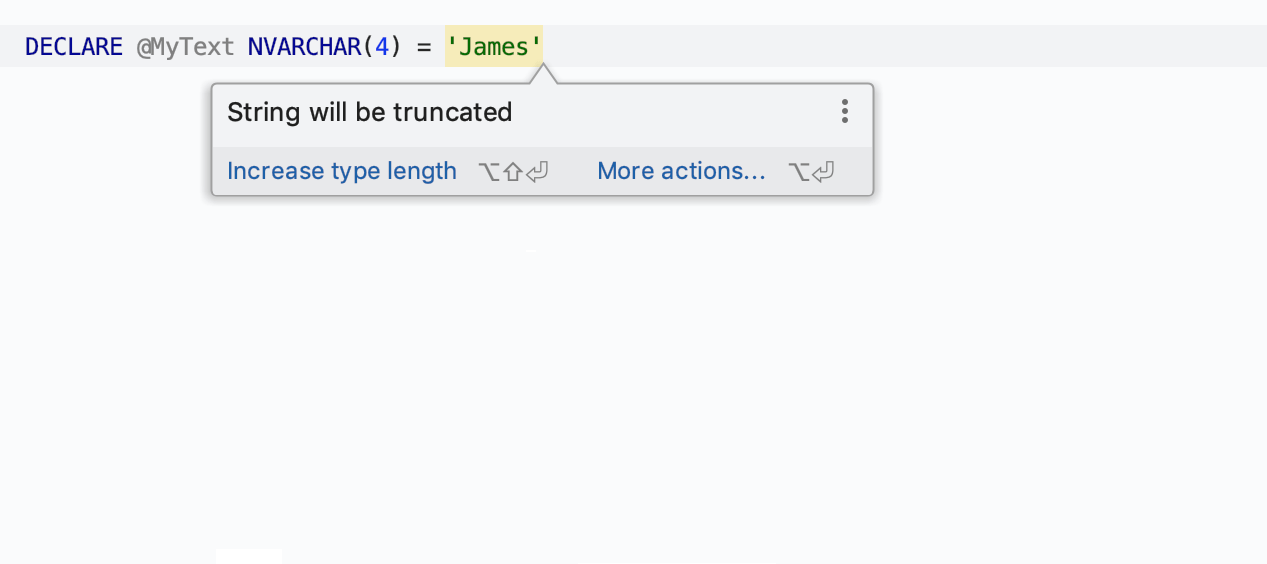
Troncation potentielle de la chaîne
L'IDE détecte la longueur de la chaîne lors de l'affectation d'une valeur à la variable et vous informe si elle doit être tronquée.
Éditeur SQL
Nouvelle option de contrôle du comportement de Move Caret to Next Word
Le comportement par défaut de l'action Move Caret to Next Word a changé : DataGrip déplace désormais le caret vers la fin du mot actuel.
Pour modifier le comportement des actions de déplacement du caret, allez dans Preferences/Settings | Editor | General.
Les gens appellent généralement cette action en appuyant sur Ctrl+Flèches sous Windows et Linux, et Option+Flèches sur le Mac. Le comportement par défaut varie en fonction du système d'exploitation. Dans Datagrip, nous avons calqué le comportement de Windows sur le Mac.
Voici comment cela fonctionnait avant :
Et voici la situation actuelle :

Sélection de la déclaration active
Une nouvelle action, Select current statement, est disponible. Vous la trouverez dans la section Find Action Ctrl+Maj+A ou vous pouvez lui affecter un raccourci personnalisé.

Pliage des grands nombres
Si vous souhaitez améliorer la lisibilité des grands nombres, pliez-les avec le raccourci Ctrl+Moins.
Autres évolutions
- DataGrip 2019.2 s'exécute par défaut sous JetBrains Runtime 11, la version non certifiée d'OpenJDK 11.
- Si vous souhaitez afficher les commentaires des tables dans l'arborescence, allez dans la section View | Appearance et activez l'option Descriptions in Tree Views.
- [Cassandra] Vous pouvez à présent modifier ces types de colonnes : set, list, map, tuple, udt, inet, uuid et timeuuid.
- Les nouveaux éléments combinés sont désormais inclus dans la saisie semi-automatique du code : IS NULL et IS NOT NULL.
- L'option Jump outside closing bracket/quote with Tab est activée par défaut.
- L'option Surround a selection with a quote or brace est activée par défaut.
- Introduce alias a été ajouté au menu de refactorisation.
- DataGrip fonctionne avec PostgreSQL 12 : DBE-8384.
- L'utilisation du mode lecture créait quelques incohérences : si vous deviez exécuter une requête de mise à jour en mode lecture seule, l'IDE désactivait uniquement son propre niveau, mais pas le niveau JDBC : DBE-8145. Désormais, ces deux niveaux sont désactivés et vous pouvez exécuter cette requête si cela est indispensable.