Nouveautés de DataGrip 2020.2
Éditeur de données
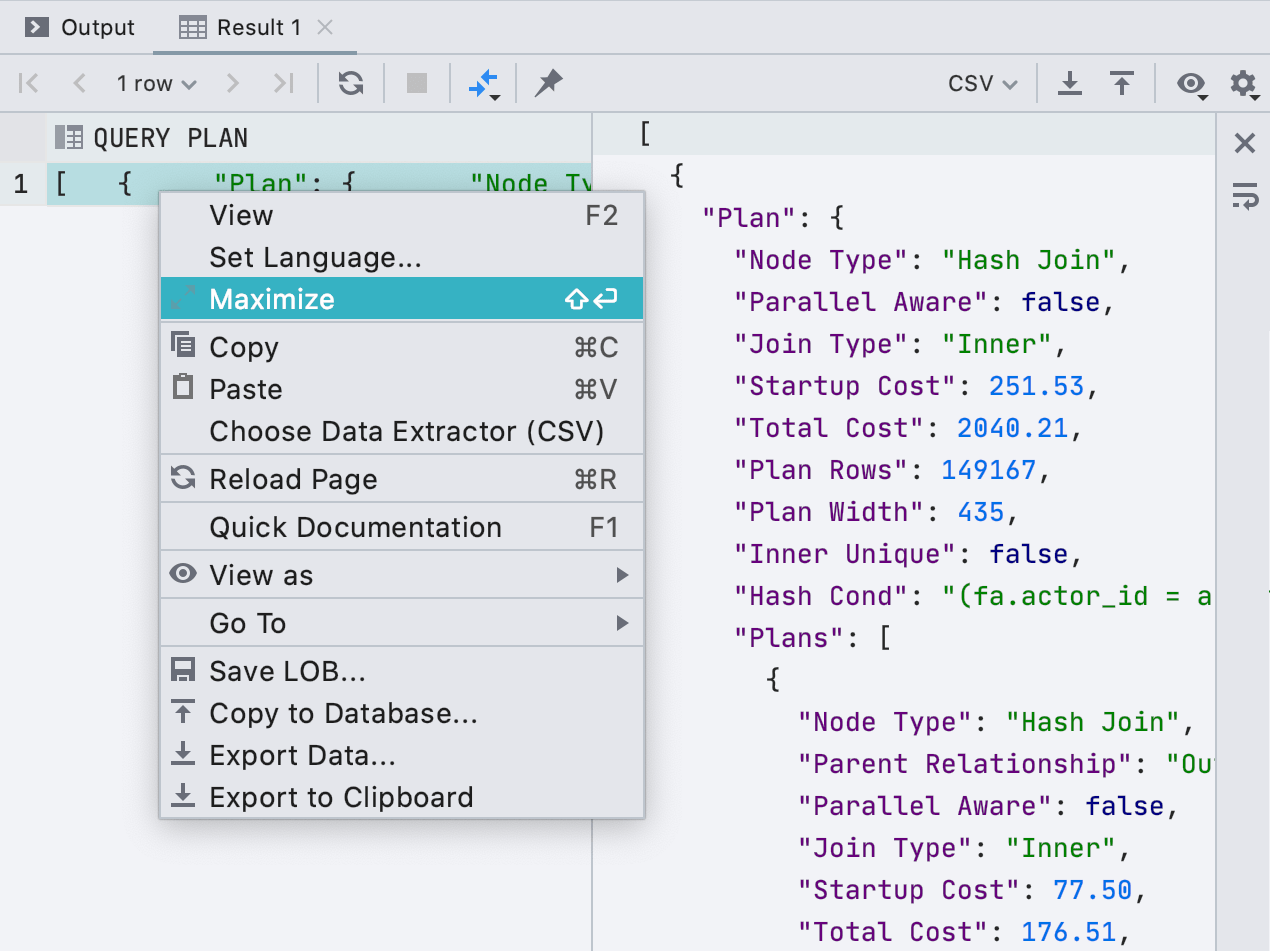
Éditeur séparé pour les valeurs de cellule
Désormais, si vous avez une valeur énorme dans votre cellule, vous pouvez l'afficher ou la modifier dans un volet séparé. Vous pouvez également passer au mode retour à la ligne (soft wrap) en utilisant la barre d'outils de droite. Utilisez toute la puissance de notre éditeur de code pour vos données !
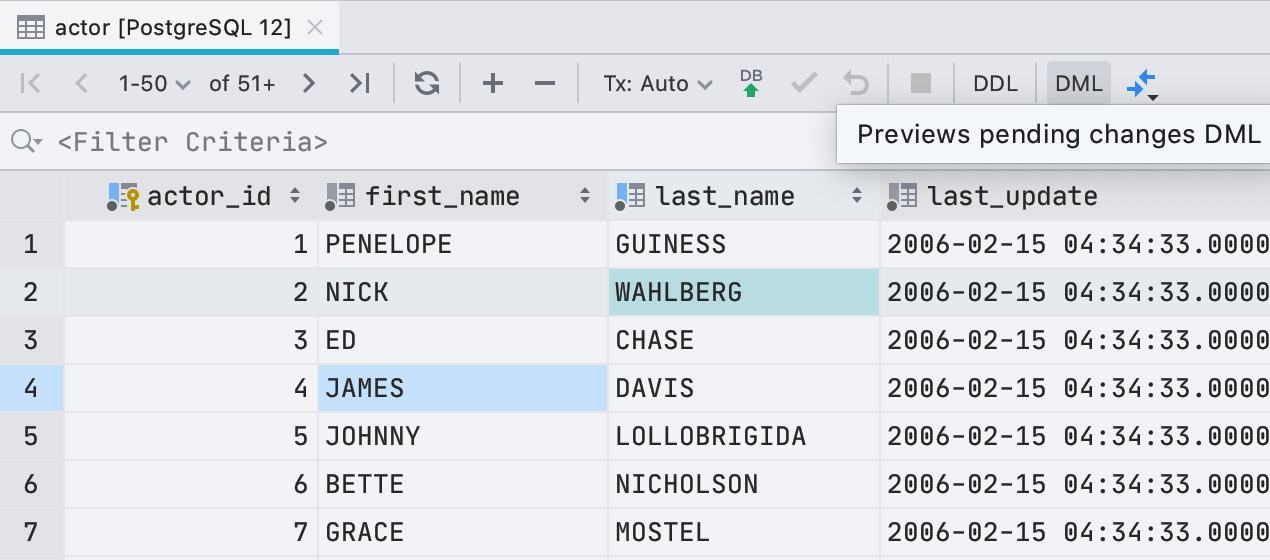
Aperçu DML dans l'éditeur de données
À partir de cette version, vous pouvez consulter la requête qui contient vos modifications dans l'éditeur de données. Il y a maintenant un bouton DML qui est actif s'il y a des modifications en attente :
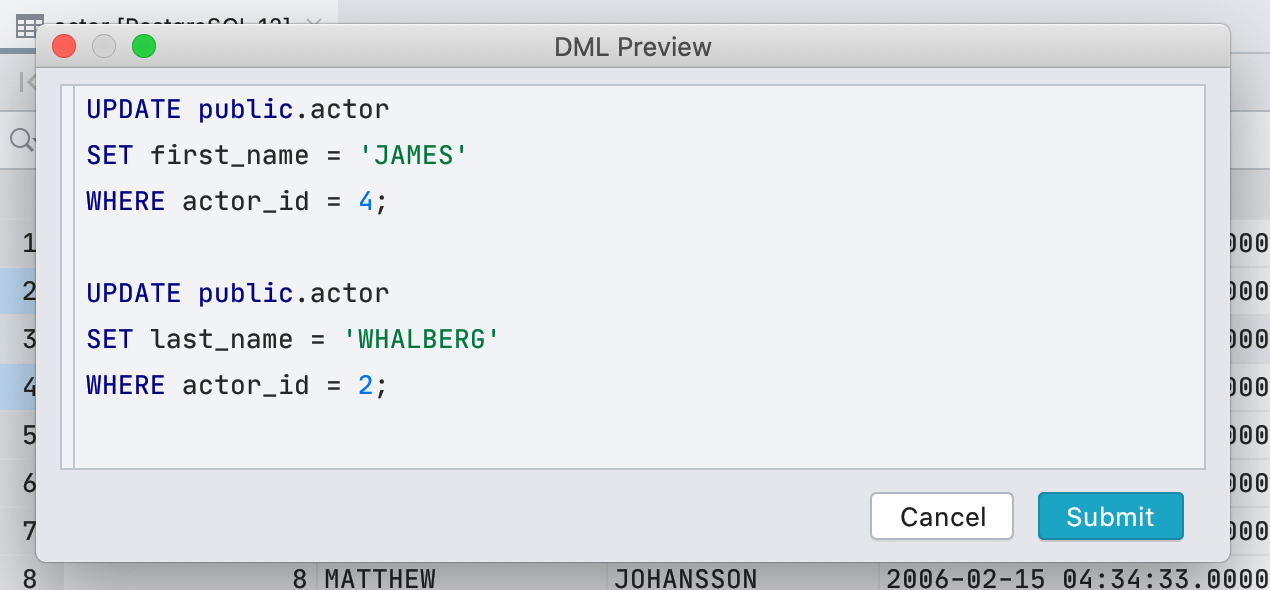
Et vous verrez une boîte de dialogue avec l'aperçu DML. Cette requête n'est pas le SQL exact qui sera exécuté pour modifier vos données car DataGrip utilise un pilote JDBC pour mettre à jour les tables, mais la plupart du temps cela sera le même.
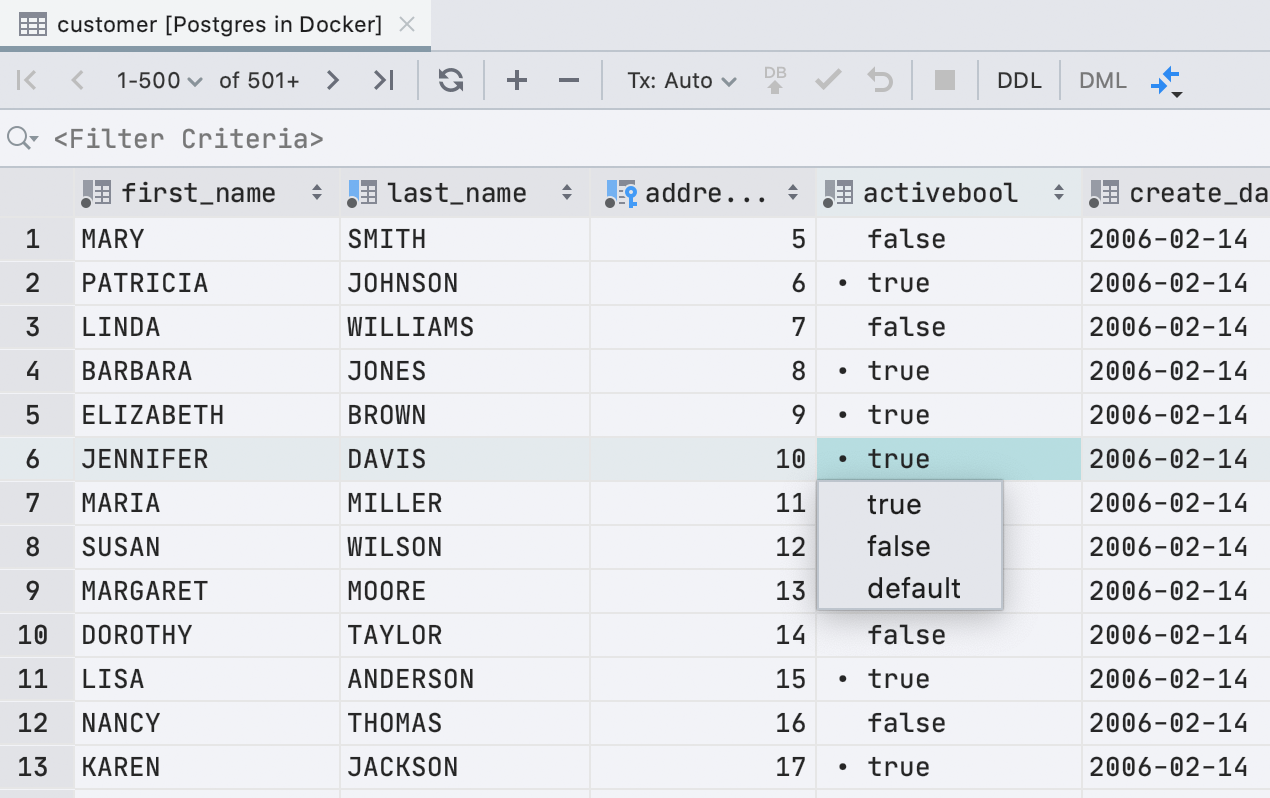
Nouvelle interface utilisateur pour les valeurs booléennes
Eh bien, c'est un développement plutôt bienvenu ! Il existe désormais un moyen plus intuitif d'afficher et de modifier les valeurs booléennes. Les valeurs true sont maintenant marquées avec une puce afin de les distinguer des autres.
Édition :
- La touche espace permet d'alterner entre les valeurs comme c'était le cas auparavant.
- La saisie de
f,t,d,n,goucintroduira les valeurs correspondantes :false,true,default,null,generatedetcomputed. Nous avons de la chance que toutes ces valeurs commencent par des lettres différentes ! - Saisir quoi que ce soit d'autre ouvrira la liste déroulante avec toutes les valeurs possibles.
Nouvelle interface utilisateur pour les données tronquées
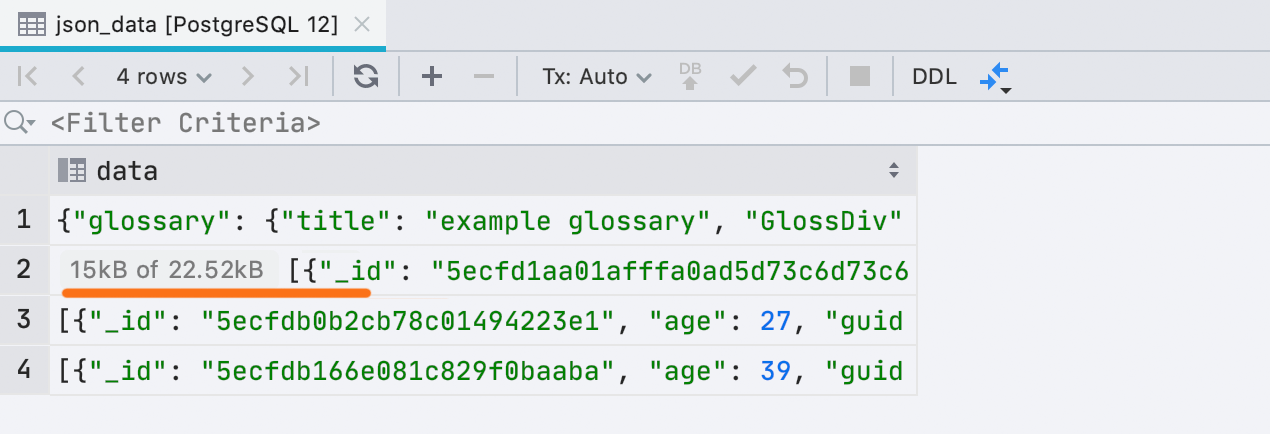
Parfois, DataGrip ne peut pas charger toutes les données d'une cellule. Cela arrive si la taille des données dans ladite cellule est supérieure à celle autorisée par le paramètre Database | Data views | Max LOB length. Auparavant, dans ce cas, nous ajoutions généralement un petit morceau de texte, par exemple “10 KB of 50 KB loaded”. Désormais, nous affichons simplement un conseil au lieu de modifier la valeur.
Exporter vers le presse-papiers dans le menu contextuel de l'éditeur de données
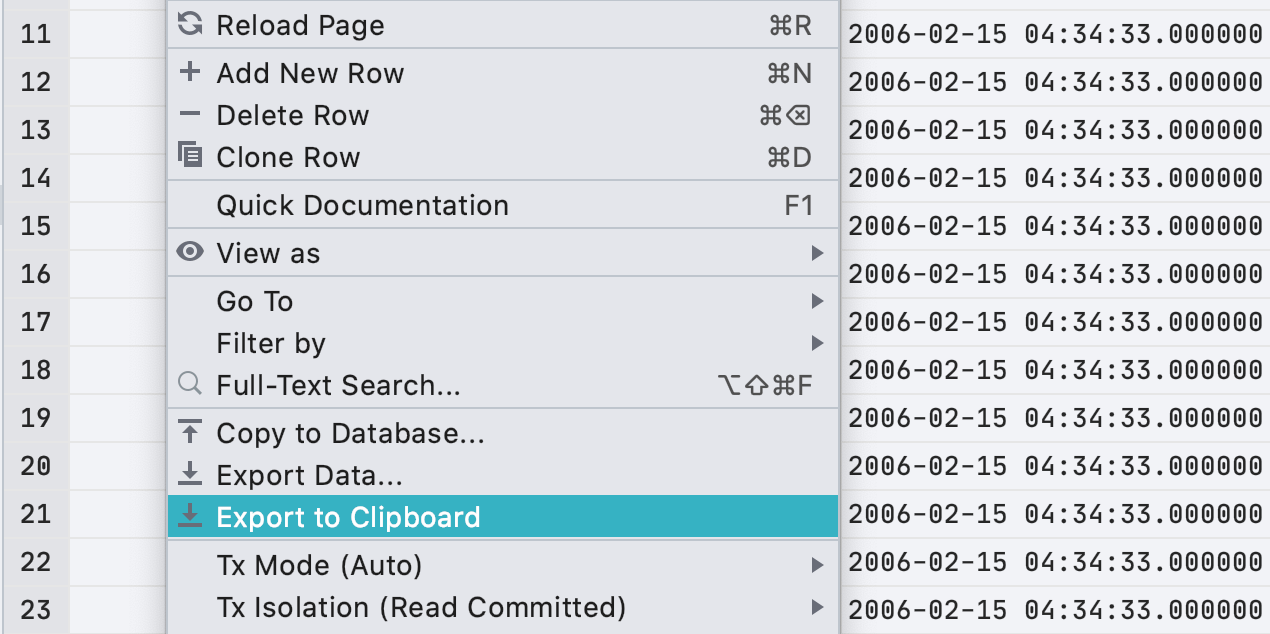
Désormais pour l'exportation des données, une boîte de dialogue s'ouvre avant de pouvoir exporter le résultat entier ou la table complète vers le presse-papiers. Nous avons donc ajouté l'élément suivant au menu contextuel :
Notez que Copy copie la sélection, tandis que Export to Clipboard copie l'ensemble des données.
Meilleur filtrage pour MongoDB
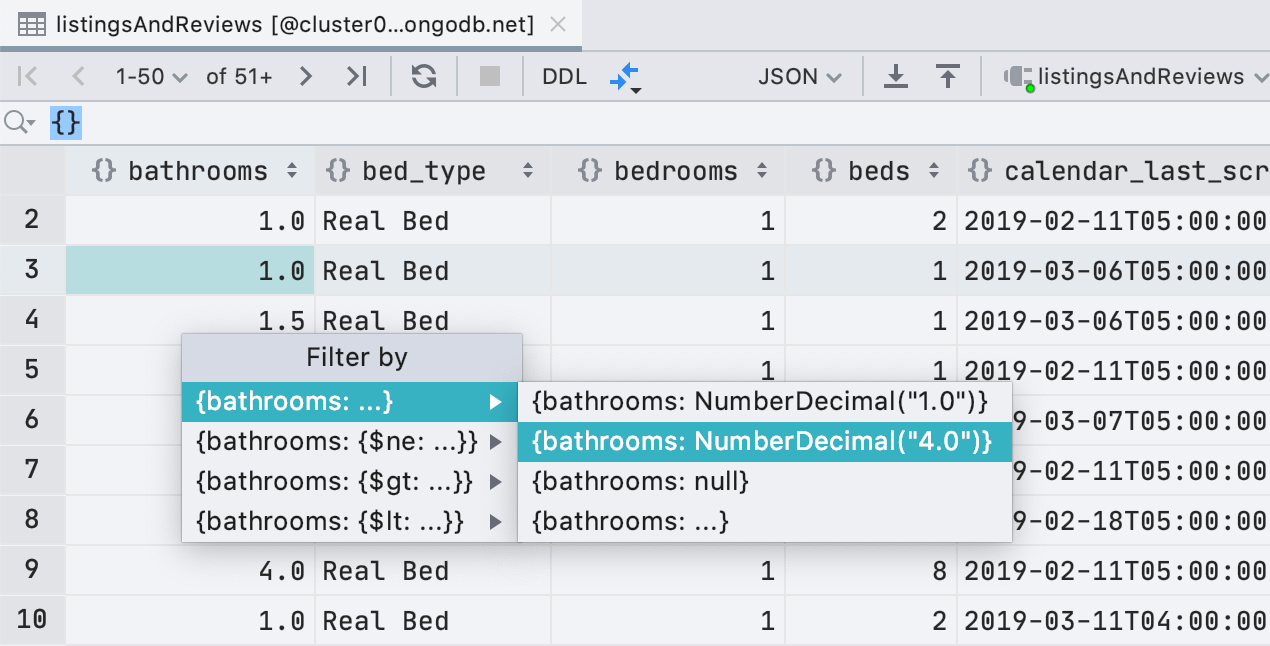
Outre ObjectId et ISODate, le filtrage prend désormais en charge UUID, NumberDecimal, NumberLong et BinData. De plus, si vous avez un UUID/ObjectId/ISODate valide dans votre presse-papiers, vous verrez cette valeur dans la liste des filtres suggérés.
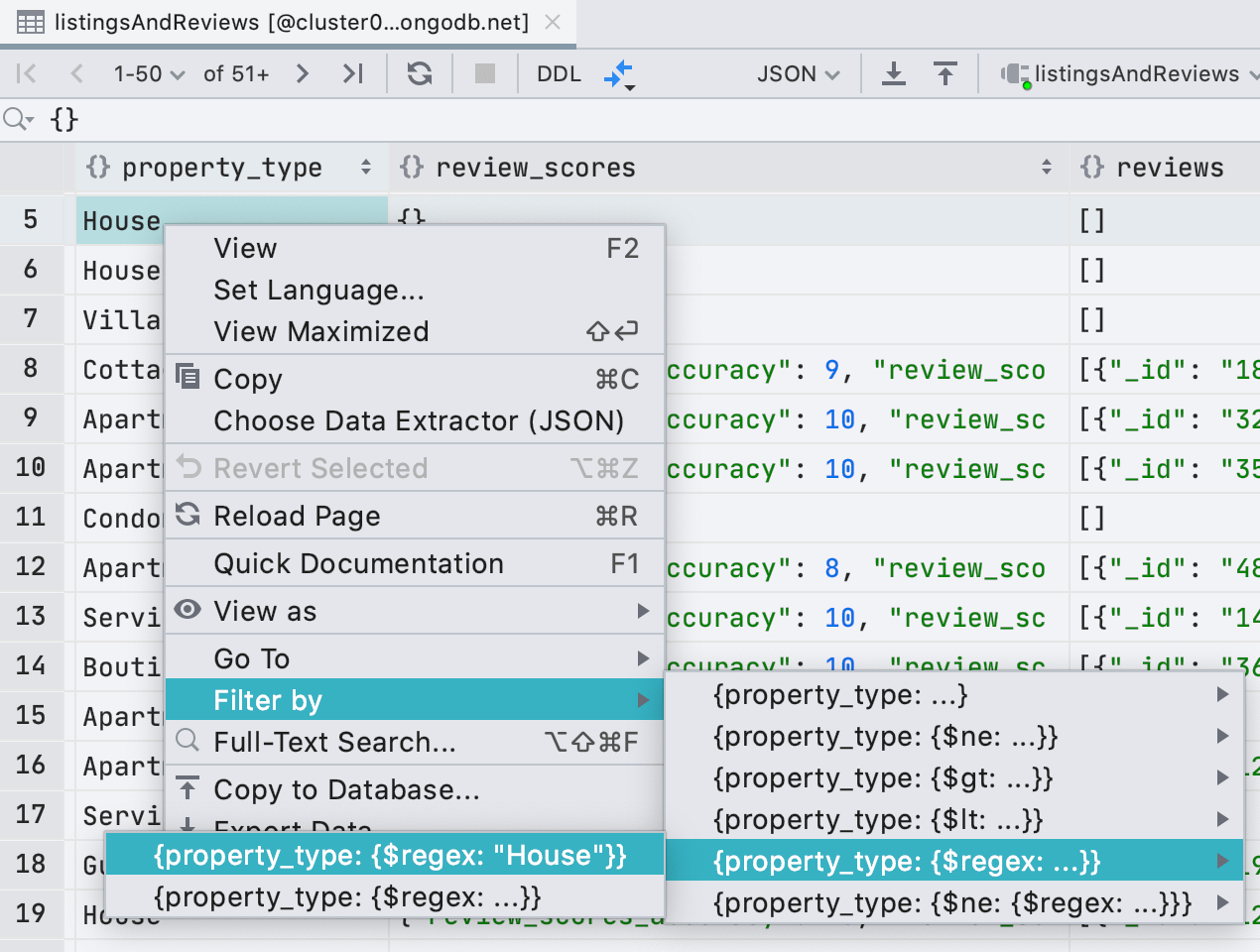
Nous avons également ajouté les expressions régulières au filtrage, au cas où le filtre LIKE de MongoDB vous manquerait.
Éditeur SQL
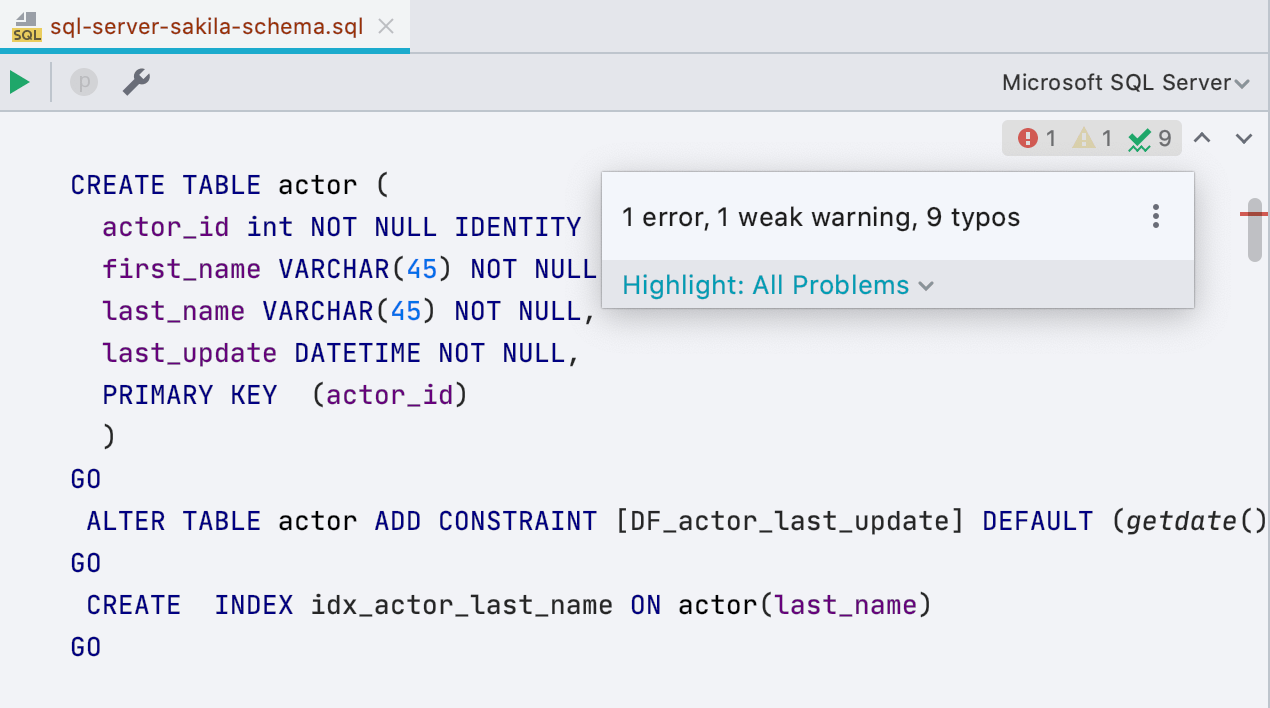
Nouveau widget d'inspections
Le nouveau widget d'inspections vous permet de visualiser tous les problèmes de votre script et de naviguer entre eux plus facilement. Il fournit des informations détaillées sur le nombre d'avertissements, d'erreurs et autres problèmes dans le fichier actuel. Vous pouvez utiliser les icônes flèches pour parcourir les erreurs dans les fichiers, et bien sûr, il est aussi toujours possible d'utiliser le raccourci F2.
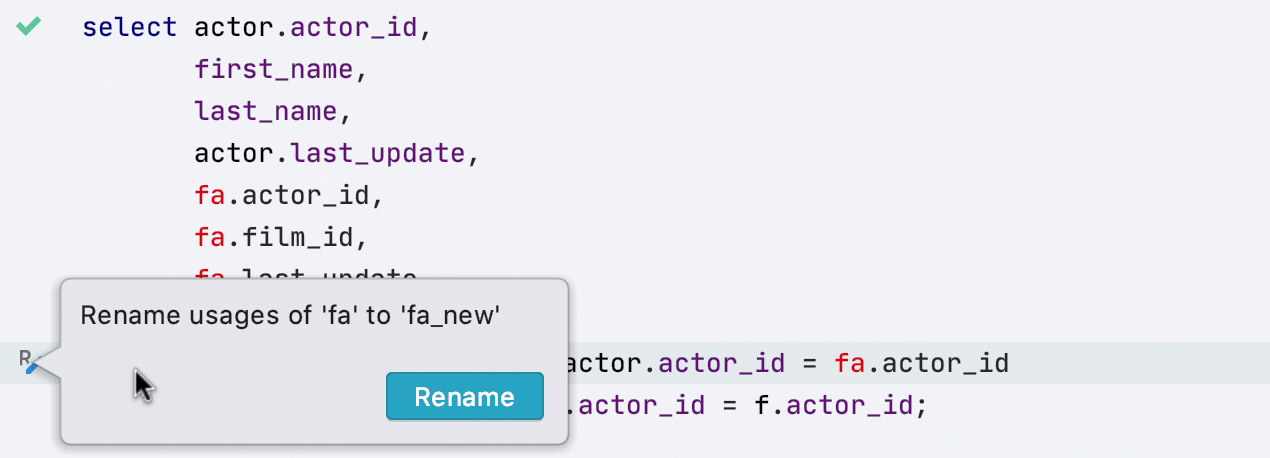
Suggestion de renommage
Si vous changez le nom d'un objet dans le code, ce petit bouton de la barre d'outils vous permettra d'effectuer une refactorisation ! Voici comment cela fonctionne pour les alias par exemple :
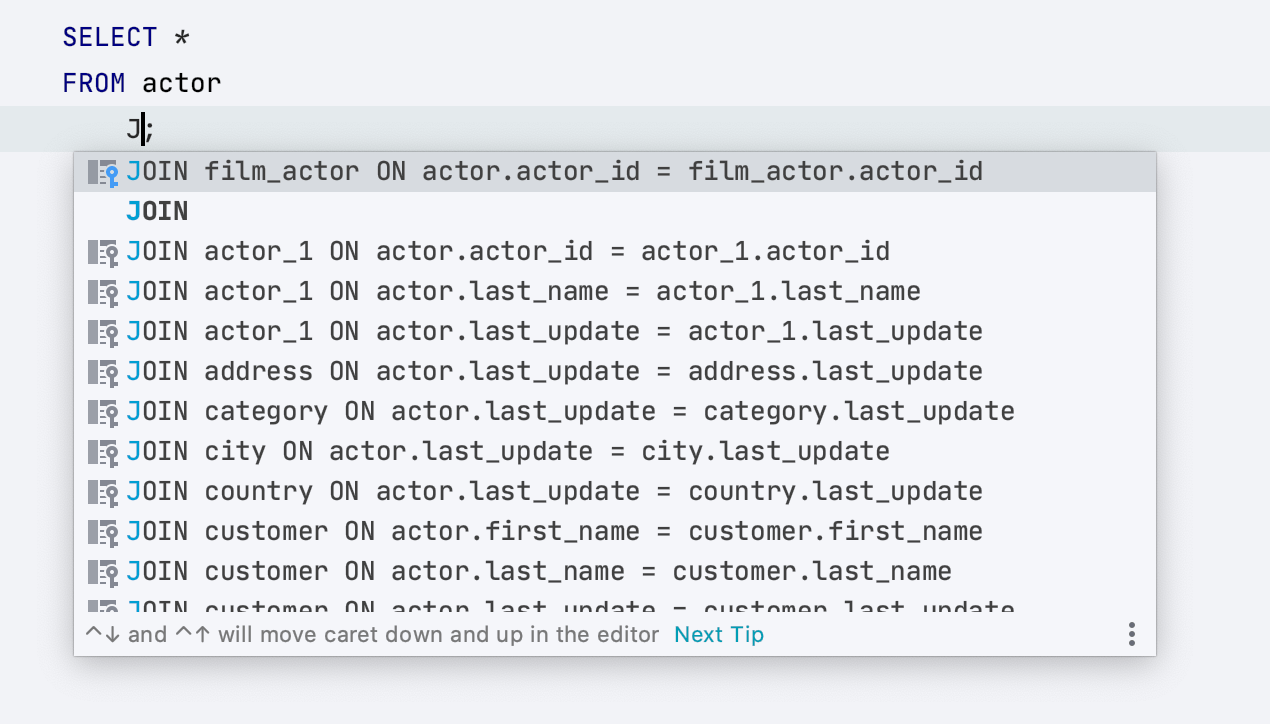
Nouvelles améliorations de la saisie semi-automatique JOIN
Il y a une étape de moins pour terminer les clauses JOIN : nous proposons maintenant la clause entière lorsque vous commencez à taper 'JOIN' :

En outre, la saisie semi-automatique offre un moyen de joindre par deux colonnes, le cas échéant :
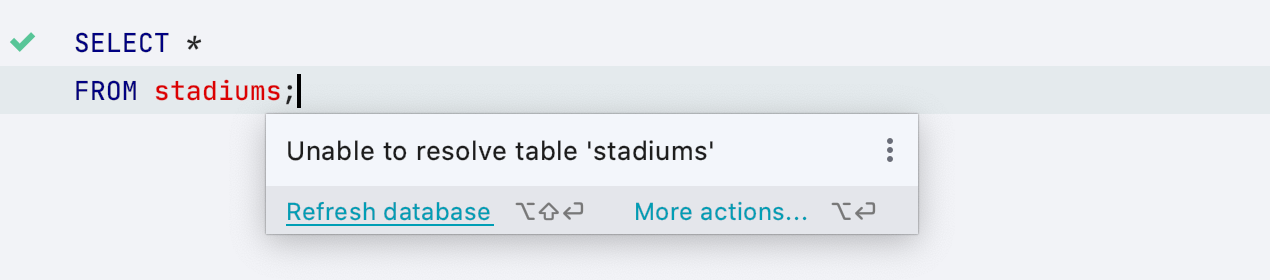
Correctif rapide Refresh database
Vous avez parfois des objets non résolus dans votre script. Lorsque c'est le cas, DataGrip ne comprend pas où se trouvent ces objets et suppose qu'ils n'existent pas du tout. Bien que cela soit vrai dans de nombreux cas, il arrive que les objets ne soient pas résolus car il faut modifier le contexte sur lequel vous travaillez.
Nous avons ajouté le correctif rapide Refresh database pour actualiser la base de données, ce qui vous aidera si un objet a été ajouté de l'extérieur à la base de données depuis la dernière fois que vous l'avez actualisée.
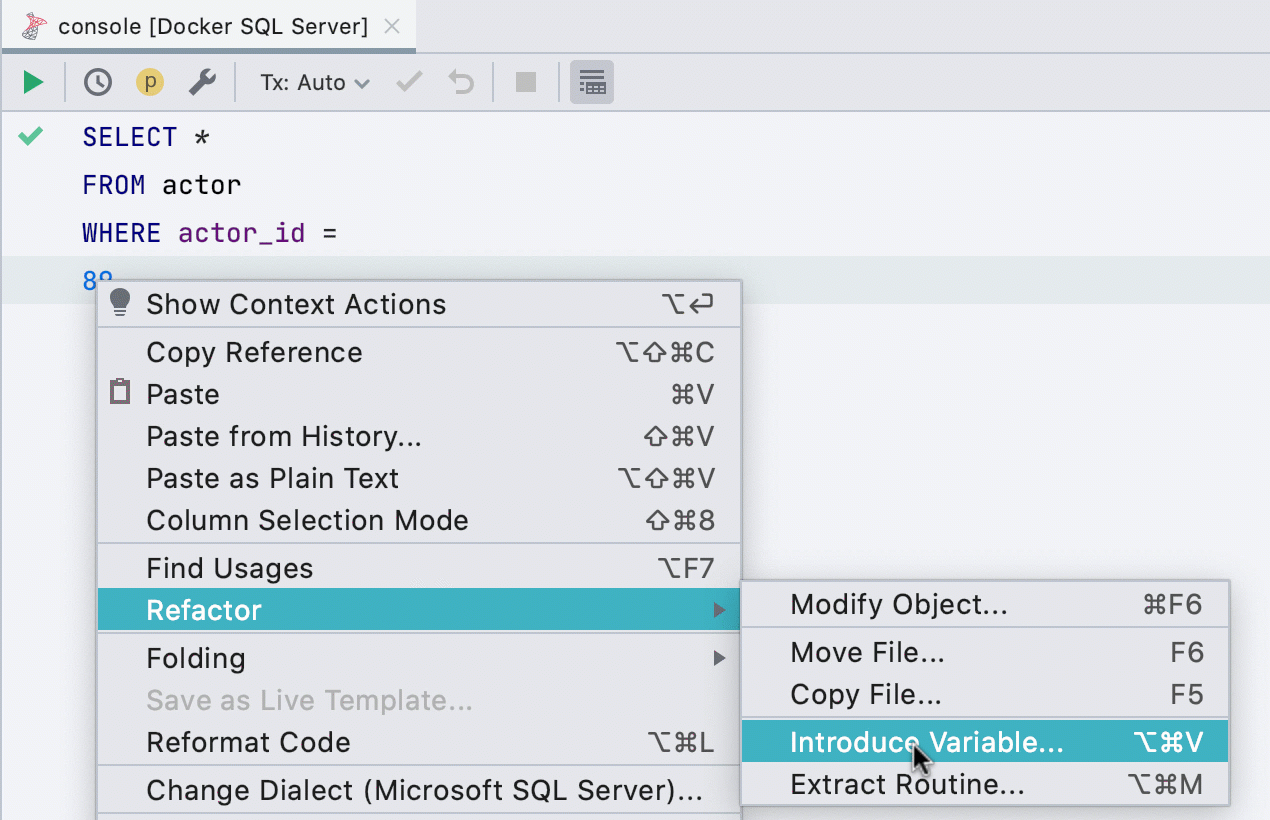
Introduire une variable
Cette refactorisation est désormais prise en charge dans un plus grand nombre de dialectes : SQL Server, Db2, Exasol, HSQL, Redshift, et Sybase. Vous pouvez introduire des variables à partir de toute expression de type simple.
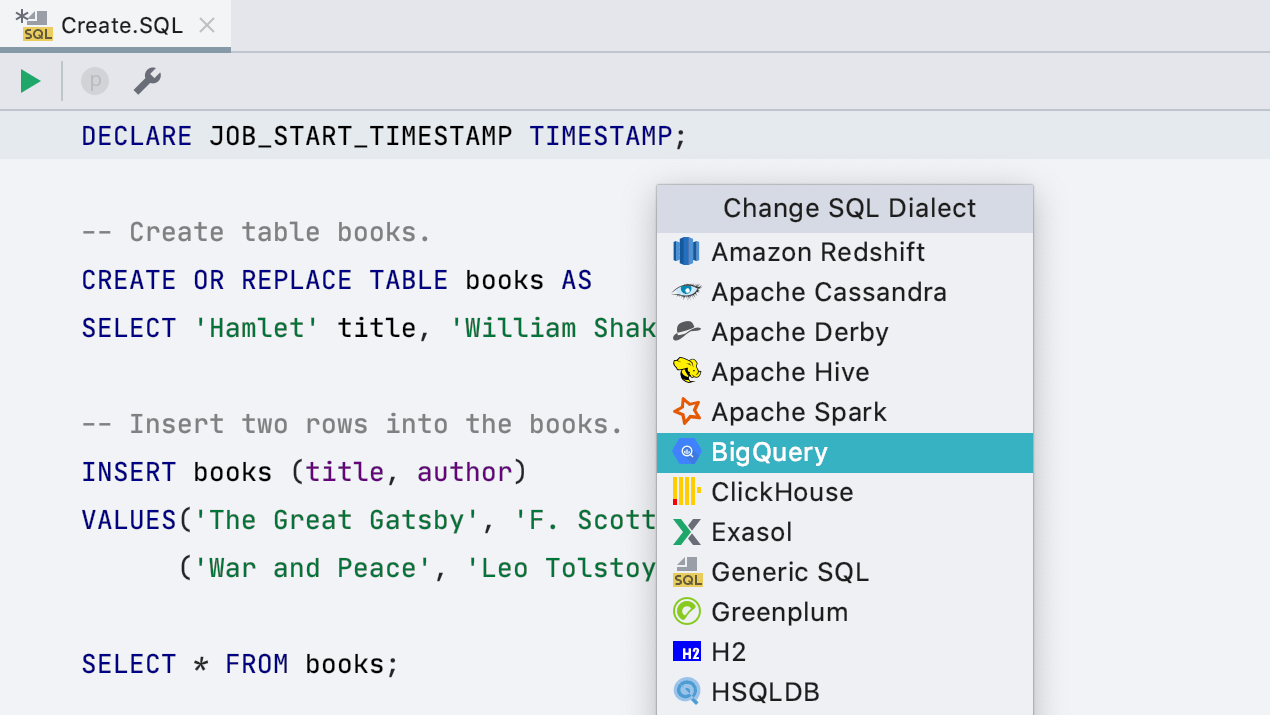
Dialecte Google BigQuery
Nous avons ajouté un nouveau dialecte SQL : Google BigQuery. La prise en charge complète de BigQuery n'est pas encore disponible, mais il faut bien commencer quelque part. Pour le moment, DataGrip peut correctement mettre en évidence le code et fournir une assistance au codage pour vos requêtes si vous utilisez Google BigQuery.
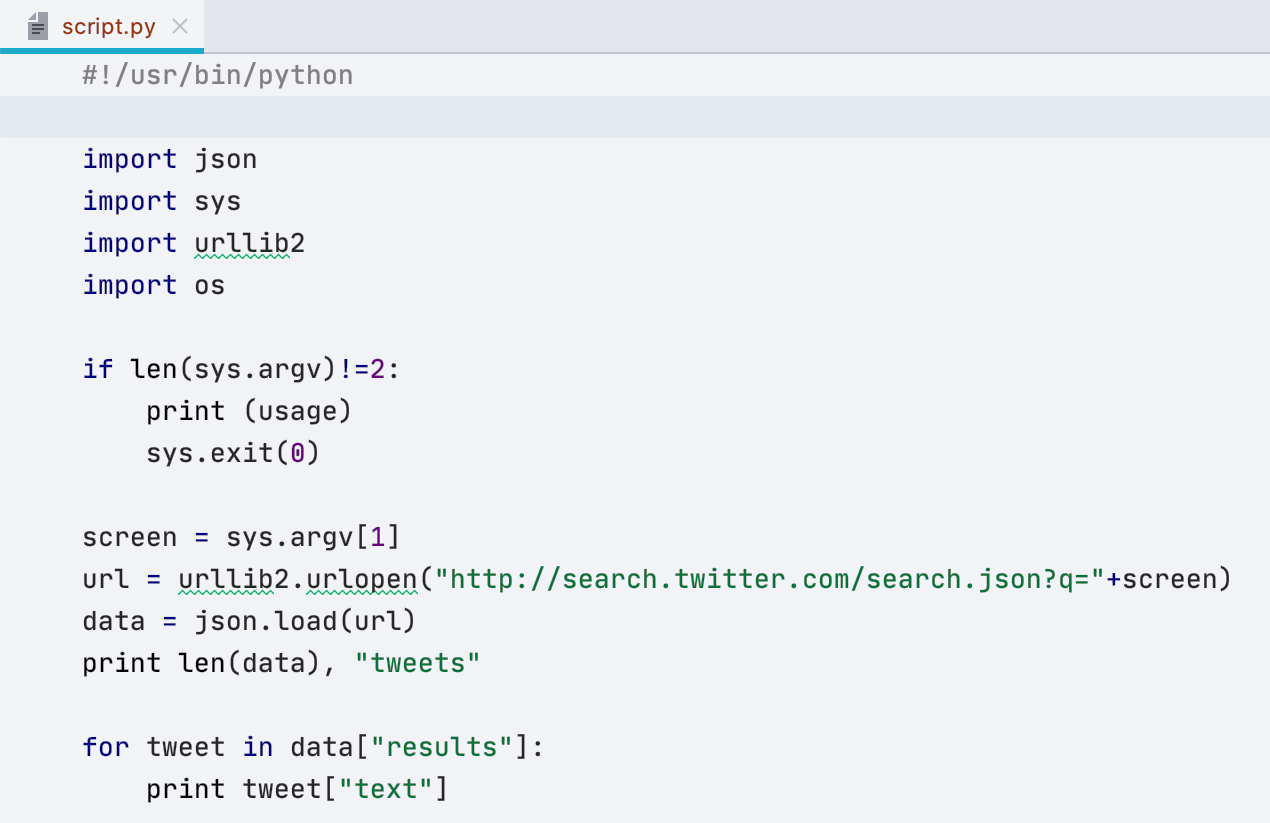
Bundles TextMate
TextMate, un éditeur de texte pour Mac, propose des bundles de surlignage syntaxique pour de nombreux langages. Nous pouvons les importer et les utiliser dans DataGrip. À partir de cette version, l'IDE fournira un surlignage syntaxique pour les types de fichiers enregistrés avec le bundle.
Désormais, la syntaxe de vos fichiers Python, JavaScript, Shell et de nombreux autres types de fichiers, sera surlignée par défaut. Pour voir tous les types de fichiers auxquels cela s'applique, allez dans Settings/Preferences | Editor | TextMate bundles.
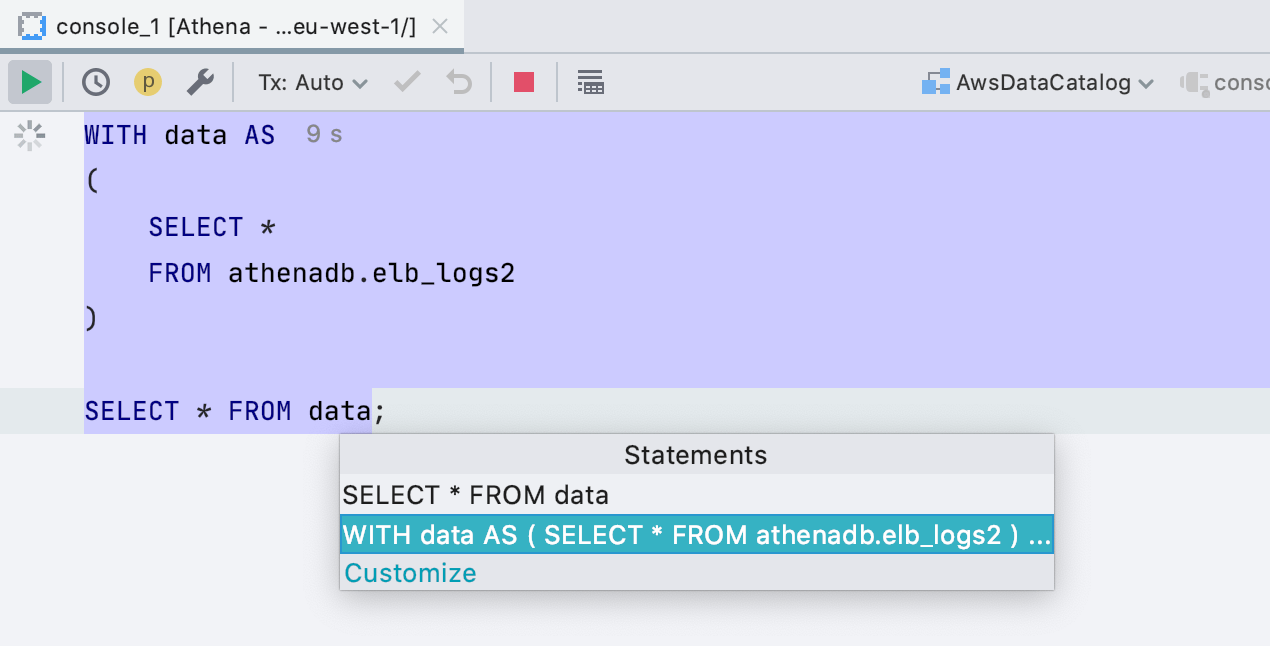
SQL 2016 pour le dialecte Generic
Désormais, les fichiers et les consoles qui sont mis en surbrillance avec le dialecte Générique le sont avec SQL 2016. Auparavant, c'est SQL 92 qui était utilisé. La principale amélioration découlant de ce changement est la possibilité d'exécuter des expressions de table communes sans sélectionner de code.
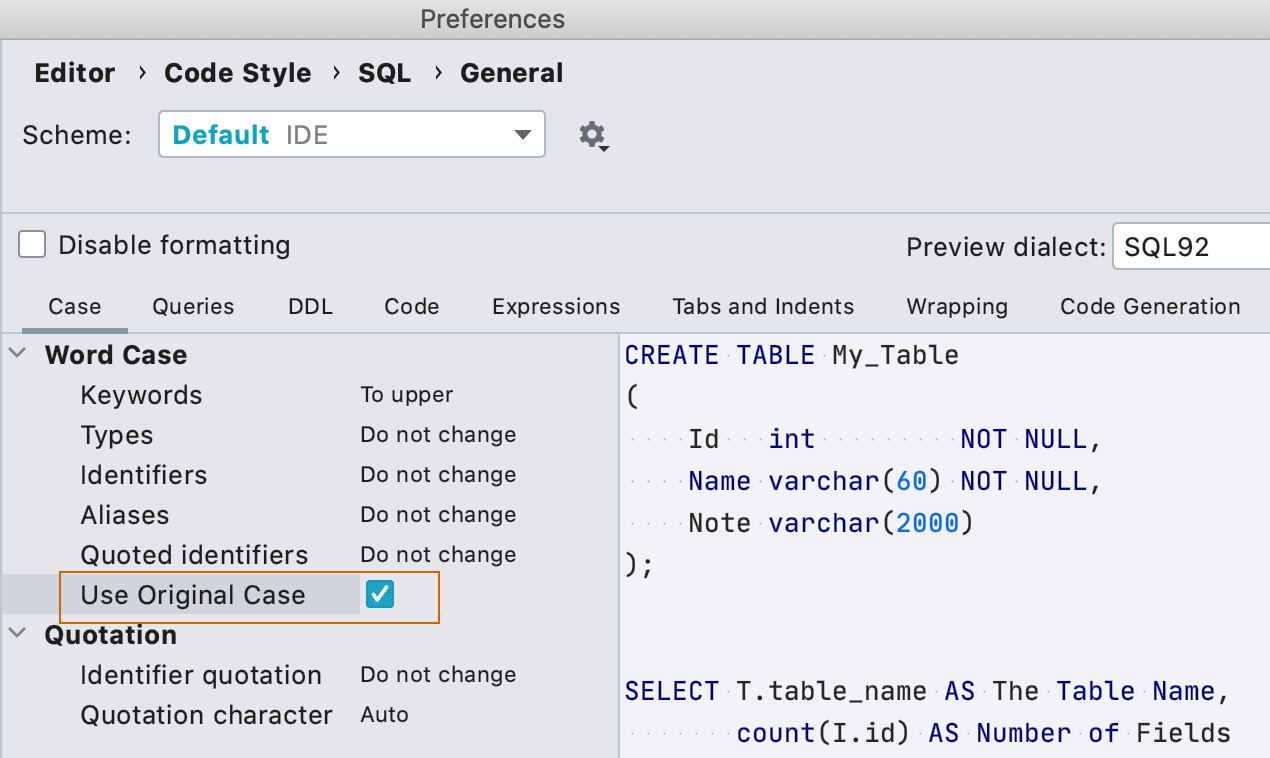
Casse d'origine des objets pour l'outil de mise en forme SQL
Auparavant, l'outil de formatage SQL avait trois options pour modifier les noms d'objet dans votre code : to upper case, to lower case ou don't change. Mais cela s'est avéré insuffisant – certain·e·s ont besoin que les noms des objets soient modifiés en fonction de la casse utilisée dans la déclaration. Nous proposons désormais cette option.
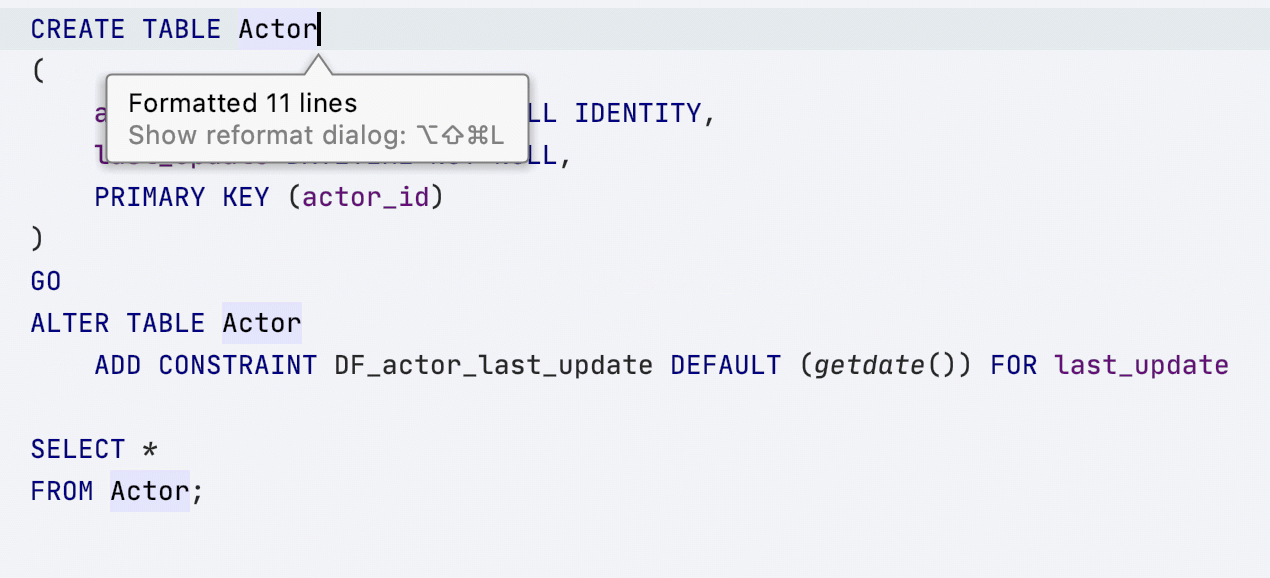
Voici ce qu'il se passe : la table Acteur a été déclarée avec la première lettre en majuscule et l'outil de formatage ne la modifie pas.
Un conseil : si la déclaration est dans un autre fichier SQL, créez une source de données DDL basée sur votre fichier SQL afin que l'outil de formatage utilise la casse adéquate.
Plusieurs carets pour chaque ligne de la sélection
Cette nouvelle action offre un autre moyen pratique de placer plusieurs carets ! Sélectionnez simplement le code et appelez plusieurs carets via Find Action ou le raccourci dédié : Maj+Alt+G
Vue arborescente de la base de données
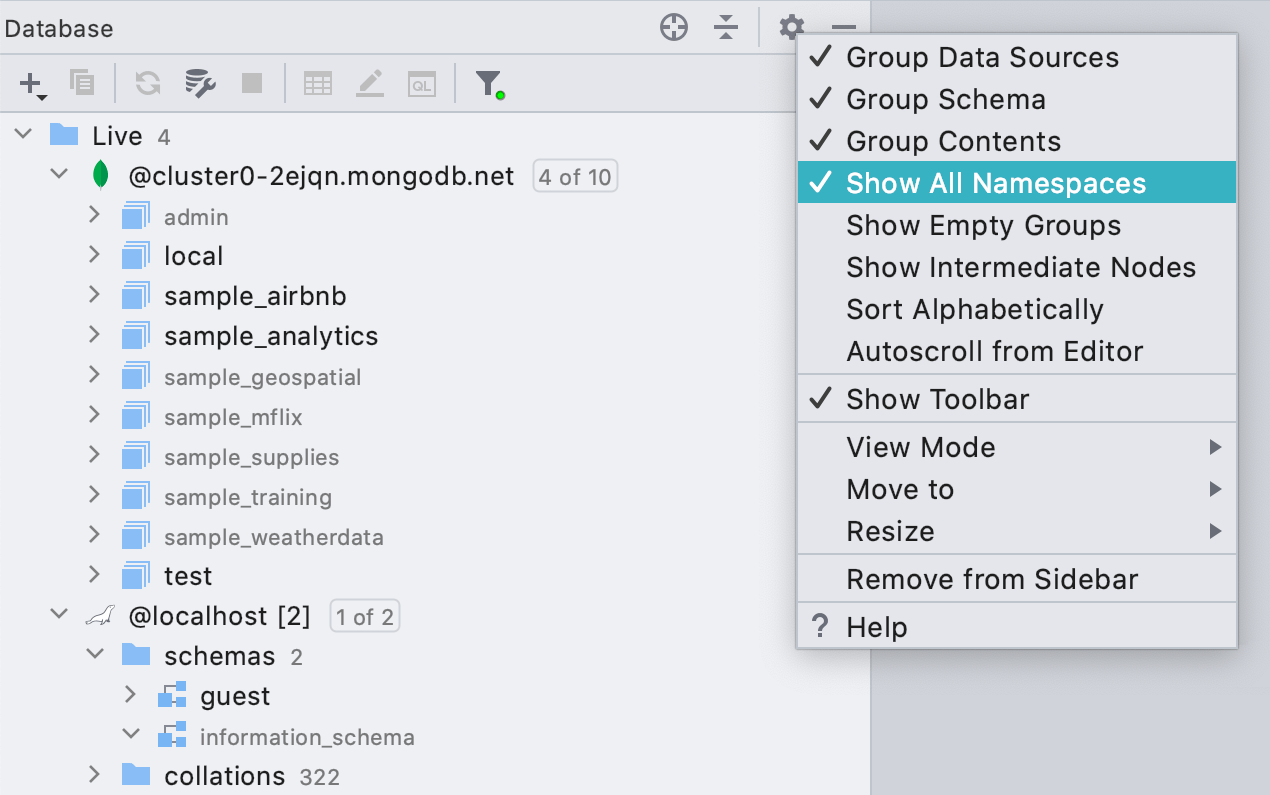
Tous les schémas et bases de données dans l'arborescence de la base de données
DataGrip ne montrera que les bases de données et les schémas que vous avez choisi d'afficher. Cela peut être utile si vous avez de nombreuses bases de données et schémas, mais cela définit également les schémas qu'il faut examiner car DataGrip charge les métadonnées de la base de données et les utilise plus tard.
Toutefois, certaines personnes sont plus habituées à des outils qui affichent toujours tous les schémas et bases de données disponibles. Elles préfèrent également que les schémas ajoutés en externe s'affichent dans l'explorateur de base de données après une actualisation.
C'est pourquoi nous avons ajouté une nouvelle option à l'explorateur de base de données : Show All Namespaces. Dans ce mode, les bases de données et les schémas qui ne sont pas inspectés sont grisés.
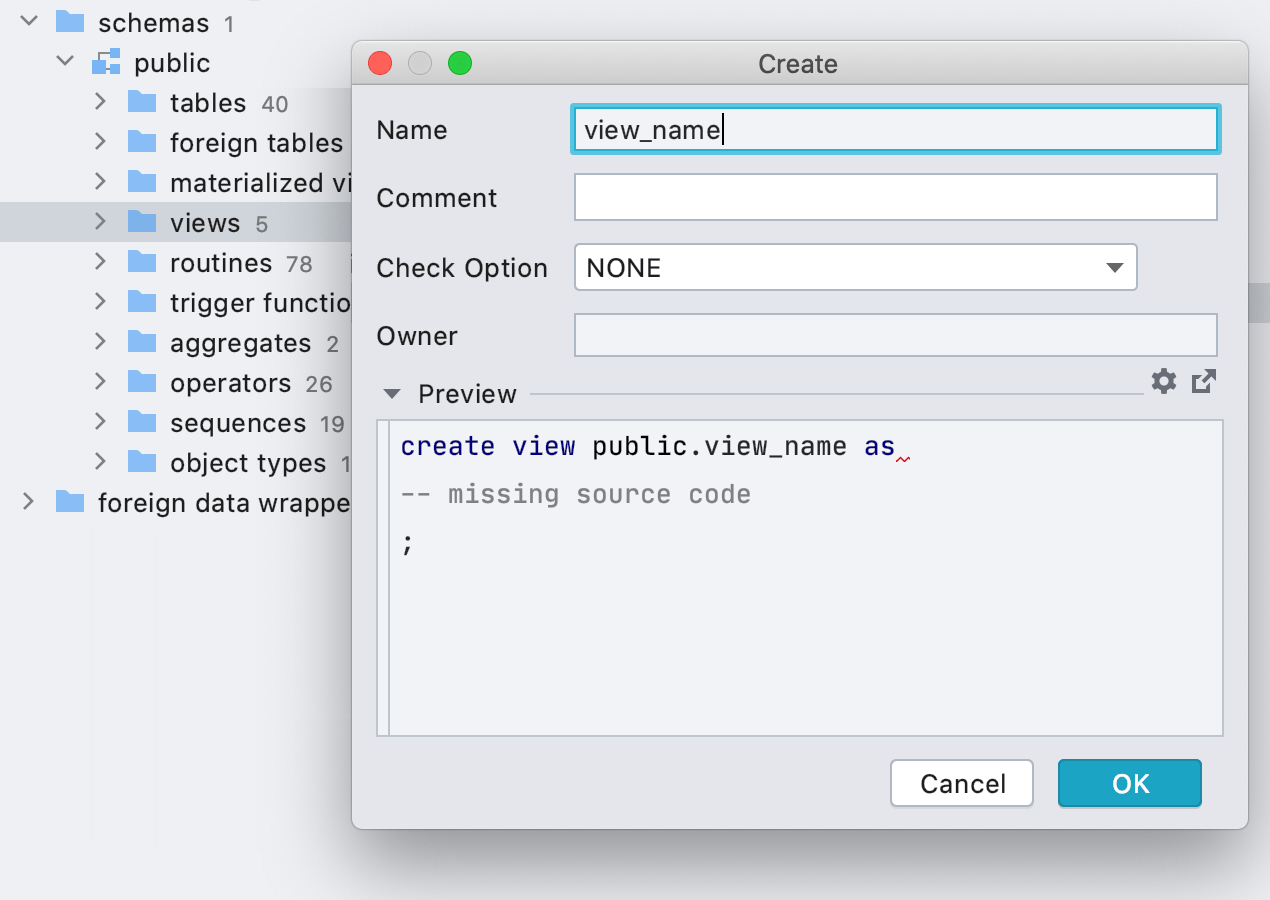
Interface utilisateur pour la création de vues
Nous vous encourageons toujours à utiliser la fonctionnalité Generate (Alt+Ins dans l'éditeur SQL) pour créer une vue, mais beaucoup de personnes préfèrent passer par l'interface utilisateur. Nous avons donc ajouté à l'interface utilisateur une option permettant la création de vues.
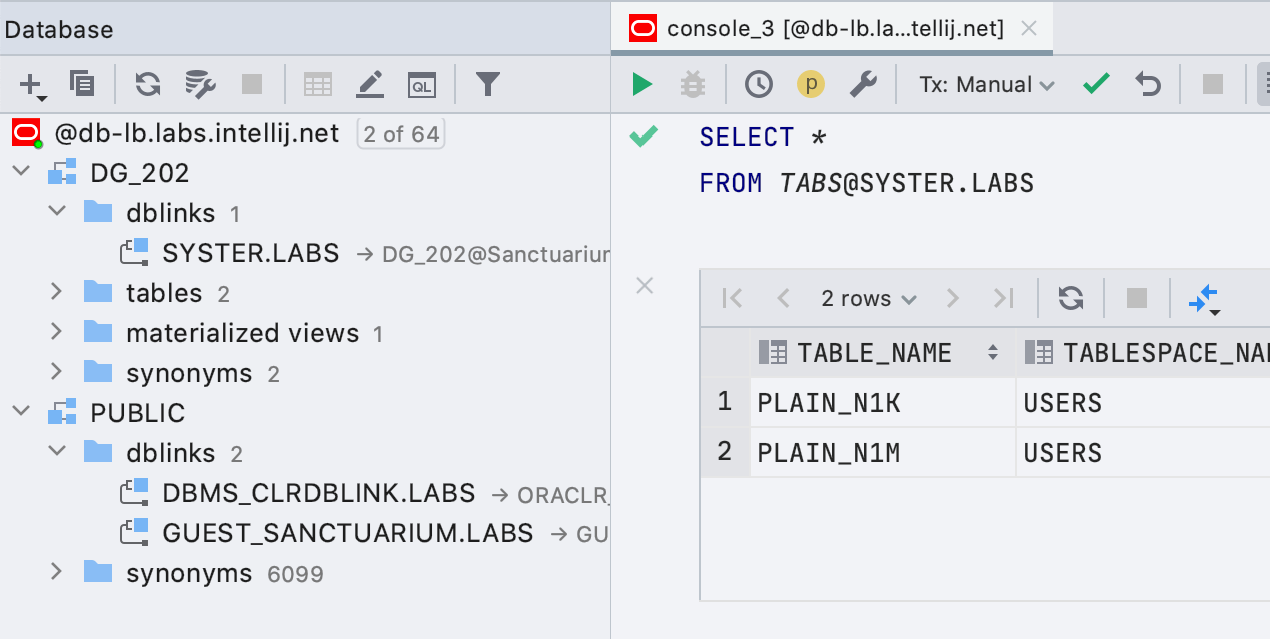
Prise en charge des liens Oracle DB
Les liens Oracle DB s'affichent désormais dans l'explorateur de bases de données et le code qui les utilise est correctement mis en évidence.
Général
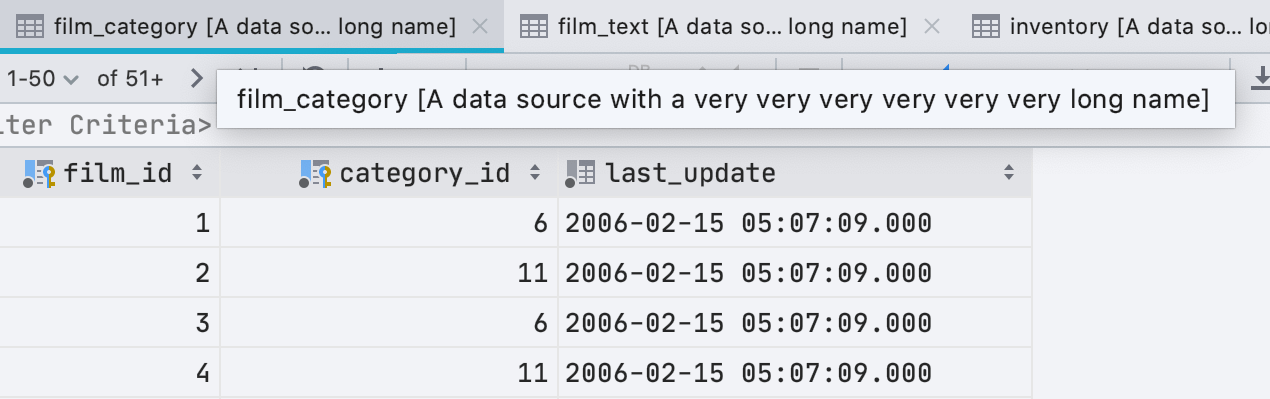
Fini les onglets longs !
Nous avons résolu un autre problème d'ergonomie dans la version 2020.2 : les onglets longs.
Nouveau fonctionnement :
- L'option
Database | General | Always show qualified names for database objectsest maintenant désactivée par défaut. Les objets seront qualifiés dans les noms d'onglets seulement si il y a deux objets avec le même nom ouverts. Par exemple, si vous ouvrez deux tables d'acteurs à partir de schémas différents, le nom du schéma sera affiché dans le nom de l'onglet. Sinon, cela ne sera pas le cas. - Si le nom de la source de données comporte plus de 20 caractères, il sera tronqué.
- Si vous n'avez qu'une seule source de données, DataGrip ne l'affichera pas dans le nom de l'onglet.
- Si un nom d'objet qualifié comporte plus de 36 caractères, il sera tronqué.
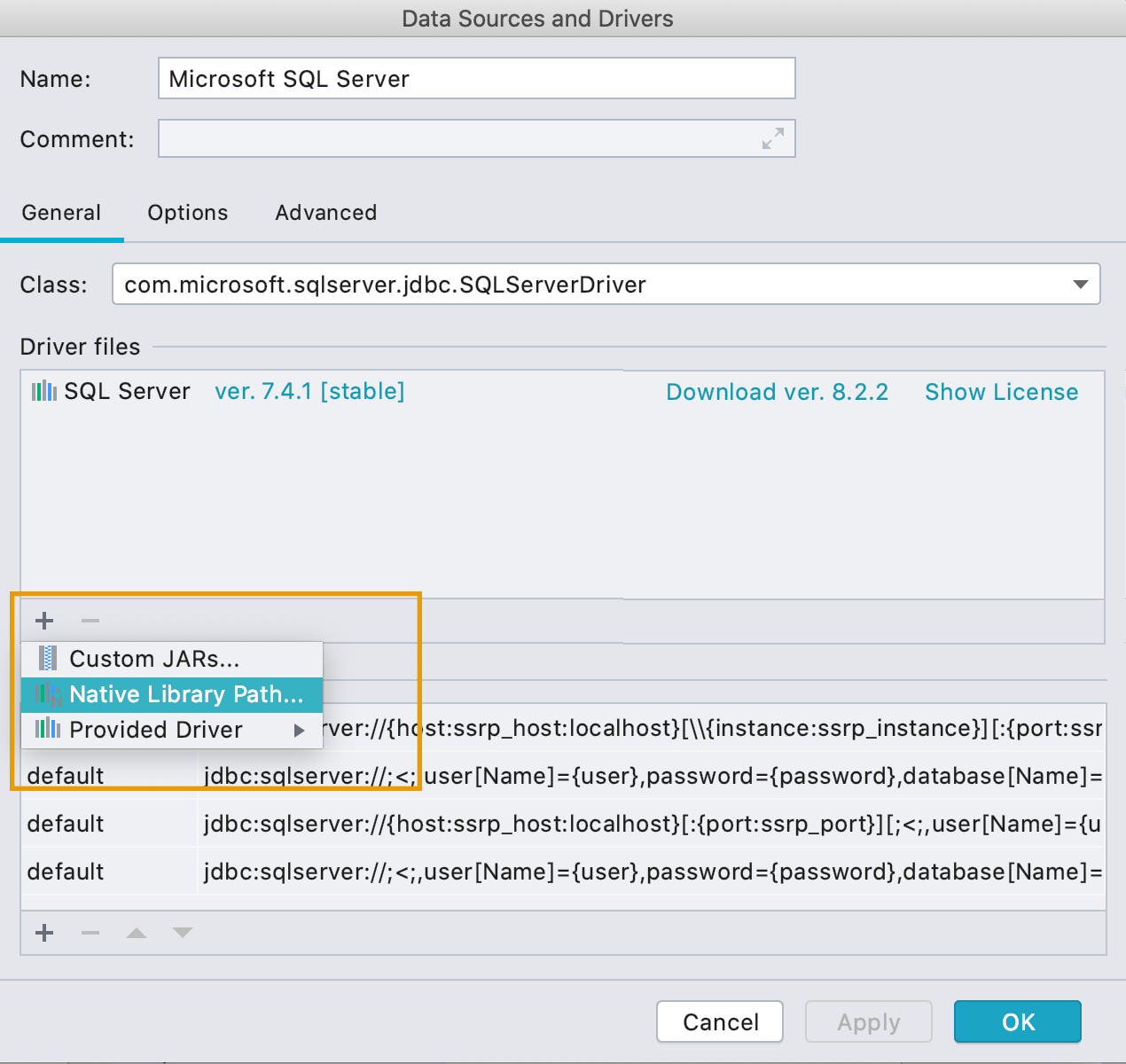
Bibliothèques natives dans les paramètres du pilote
Vous pouvez maintenant spécifier le chemin vers n'importe quelle bibliothèque native pour le pilote. Voici quelques situations dans lesquelles cela peut être particulièrement utile :
- Dans SQL Server, vous pouvez spécifier le mssql-jdbc_auth-‹version›-‹arch›.dll pour l'authentification unique si vous configurez manuellement le pilote. Par défaut, l'authentification unique (SSO) est prête à l'emploi.
- Dans une base de données Oracle, vous pouvez spécifier la bibliothèque ocijdbc pour utiliser le pilote OCI.
- Dans SQLite, vous pouvez spécifier les extensions chargeables à l'exécution pour faciliter leur utilisation à partir de la console de requête. Inutile de spécifier le chemin d'accès complet.
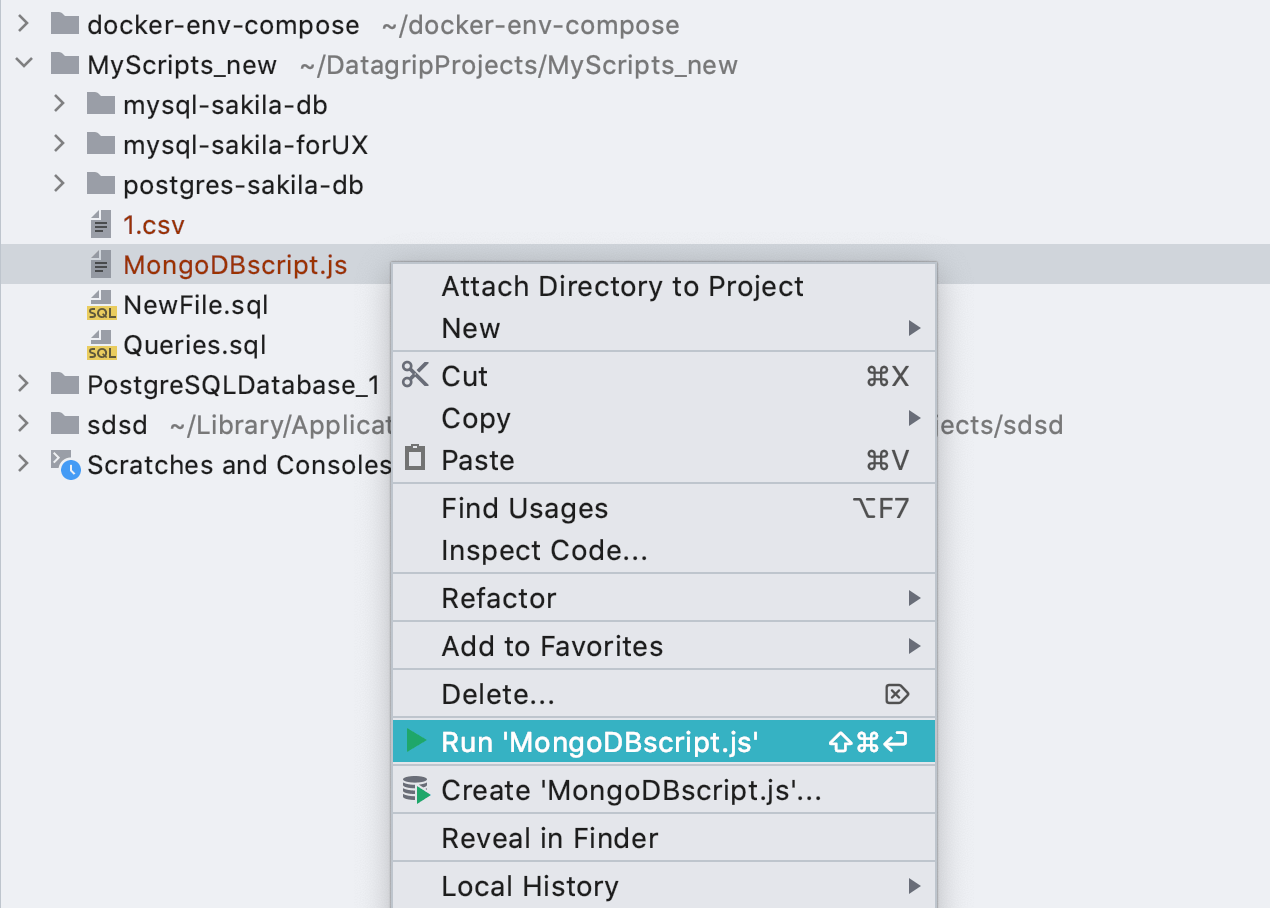
Configurations d'exécution pour les fichiers *.js
Si vous avez des scripts MongoDB, vous pouvez créer des configurations Run à partir de ceux-ci.
Plugins Git et Github intégrés
Enfin, les plugins Git et Github fonctionnent maintenant directement dans DataGrip, vous n'avez donc plus à les installer à partir de la Marketplace.