Nouveautés de DataGrip 2021.1
Aujourd'hui, nous vous présentons DataGrip 2021.1, notre première version majeure de l'année et probablement la plus remarquable de l'histoire de notre IDE. Nous espérons que cette v2021.1 résoudra au moins l'un de vos principaux problèmes, apporte une nouvelle fonctionnalité que vous allez adorer, ou les deux. Voyons cela !
Interface Utilisateur pour les autorisations
Ceci est disponible pour PostgreSQL, Redshift, Greenplum, MySQL, MariaDB, DB2, SQL Server et Sybase.
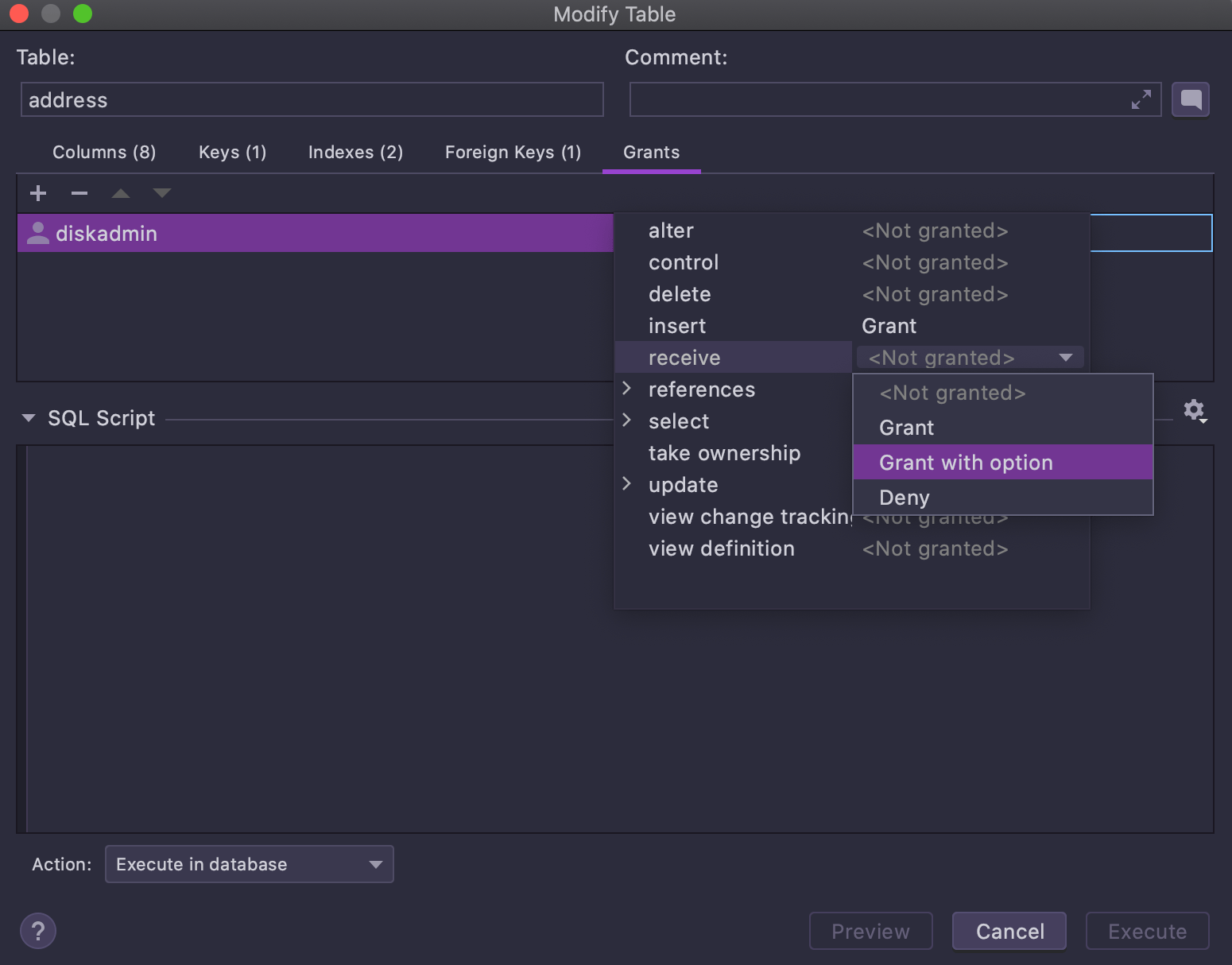
Nous avons ajouté une interface utilisateur pour l'édition des autorisations lors de la modification des objets.
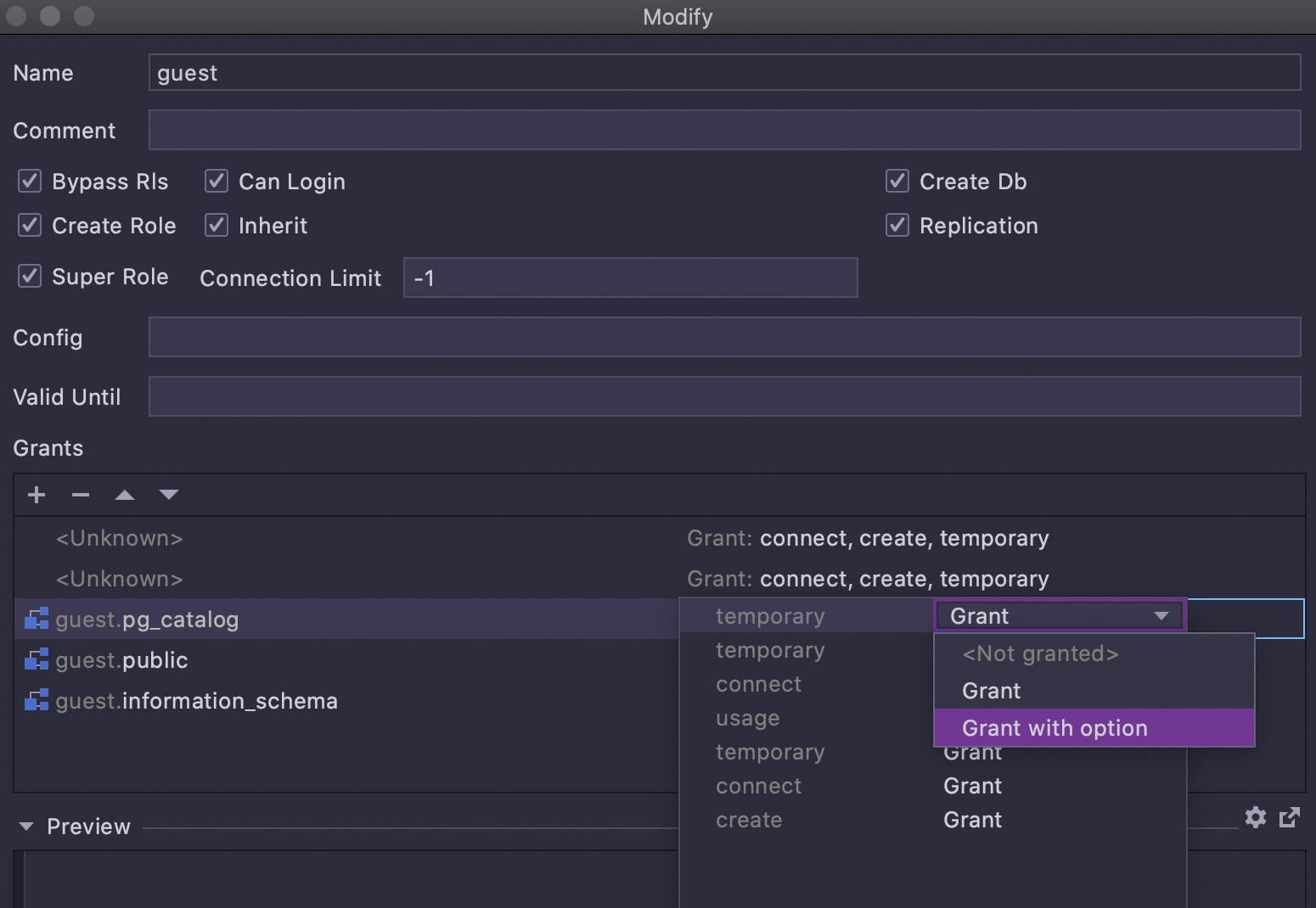
La fenêtre Modify user, que vous pouvez appeler sur un utilisateur dans l'explorateur de base de données avec Cmd/Ctrl+F6, dispose désormais d'une interface utilisateur pour ajouter des autorisations aux objets :
Modèles dynamiques contextuels
C'est la solution que nous proposons pour tous ceux qui souhaitent générer des instructions simples directement depuis l'explorateur de base de données. Les modèles dynamiques généraux couvrent de nombreux cas dans lesquels vous devez rédiger rapidement une requête simple. Mais nous comprenons aussi que lorsque vous êtes dans le contexte de l'explorateur de base de données et que vous vous concentrez déjà sur l'objet dont vous avez besoin, il peut y avoir une meilleure façon d'obtenir une requête simple utilisant cet objet.
Et beaucoup d'autres outils utilisent également ce mécanisme pour réduire les tâches répétitives, de nombreux utilisateurs y sont donc déjà habitués.
Voici une brève vidéo montrant comment cela fonctionne :
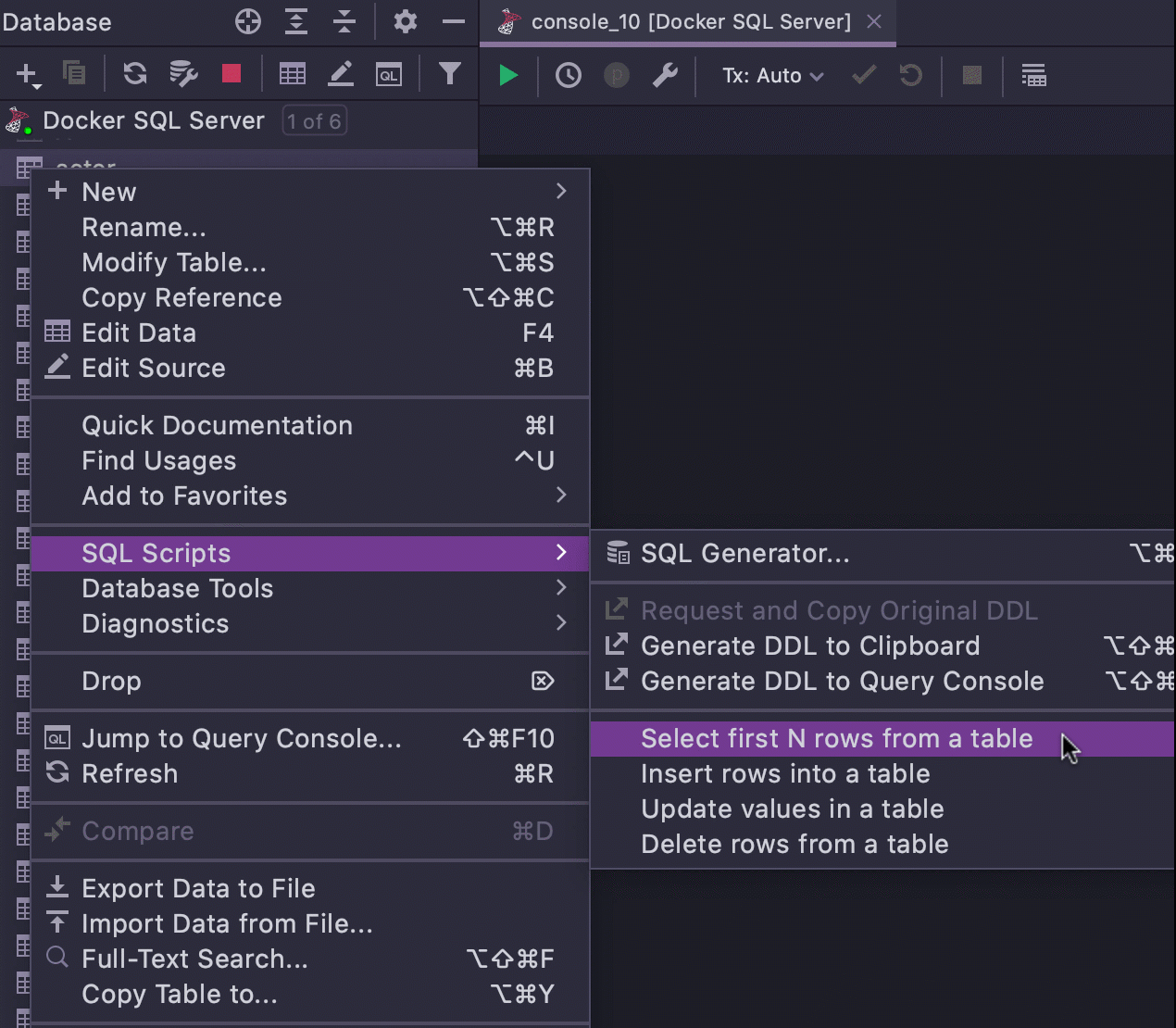
Chaque extrait de code de cette liste est en fait un modèle dynamique, mais ce sont tous des modèles spéciaux qui peuvent être générés dans le contexte de l'objet choisi. Par exemple, examinons le template Select first N rows from a table.
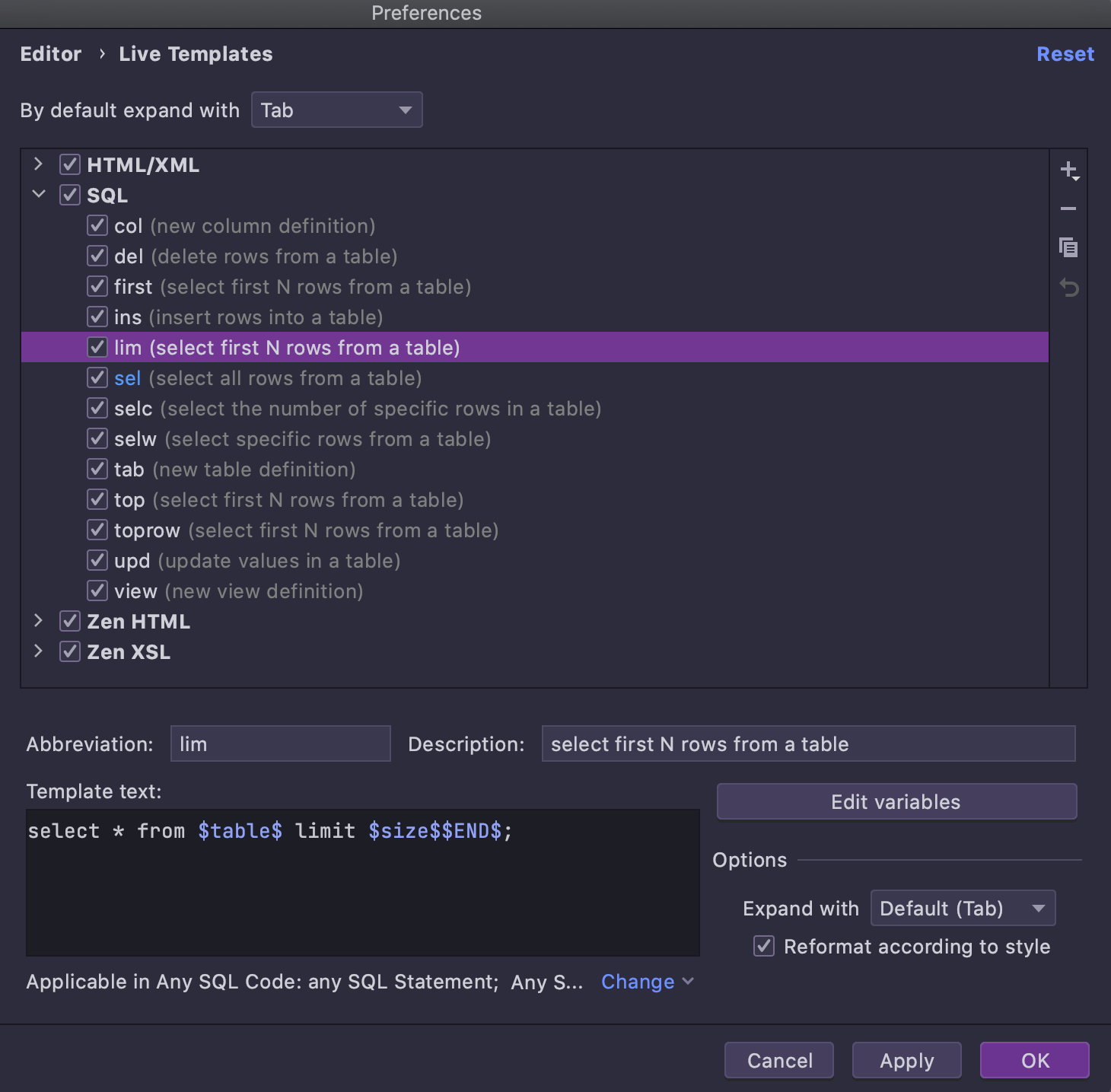
Ouvrez la page des paramètres des Modèles Dynamiques et localisez le modèle dont vous avez besoin :
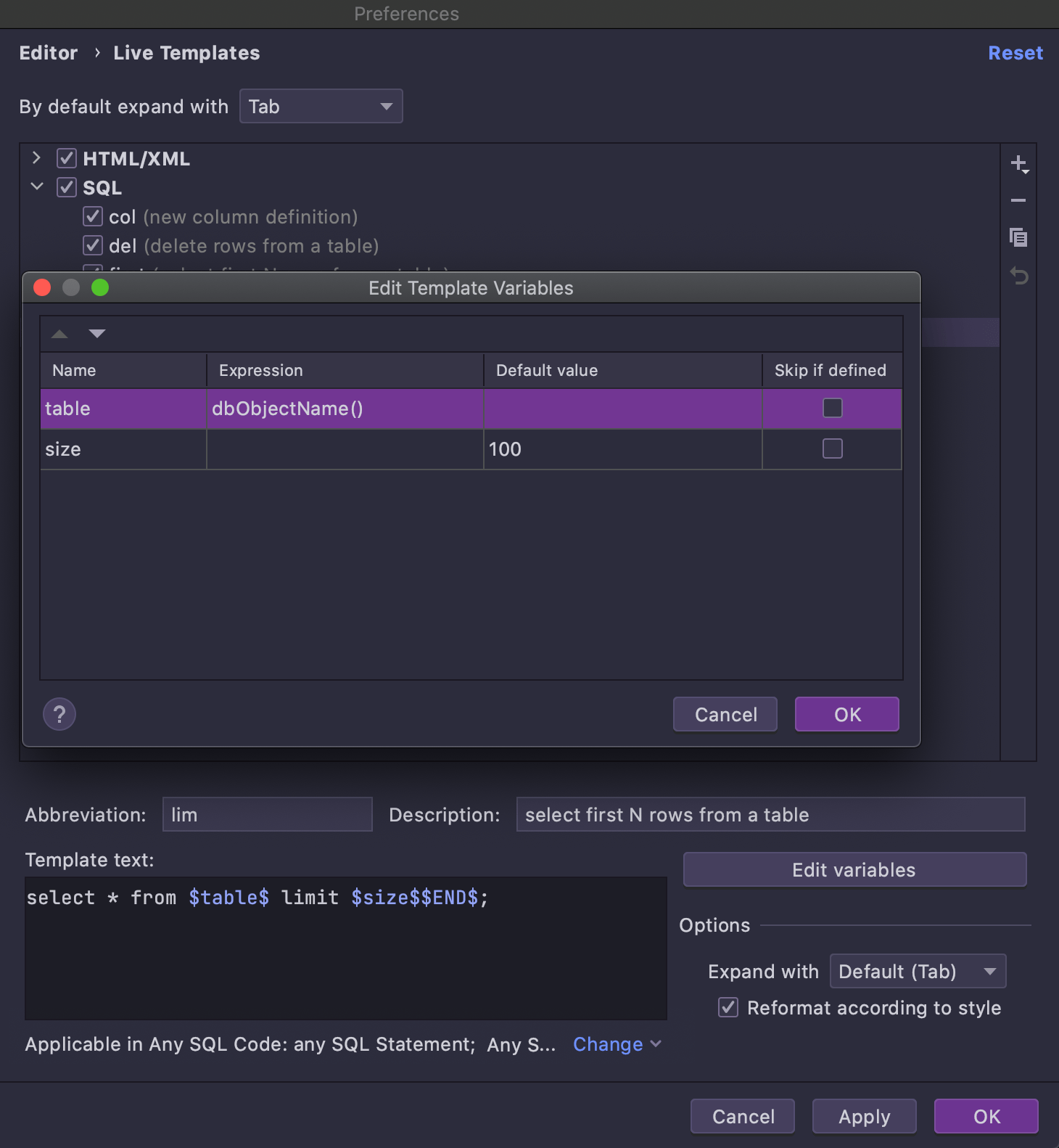
Select first N rows from a table ressemble à un template général (et peut être utilisé comme tel). Comme cette syntaxe spécifique ne peut pas être utilisée dans toutes les bases de données, les dialectes correspondants sont définis pour le template. La principale différence qui rend ce modèle applicable dans l'explorateur de base de données est l'expression spéciale dbObjectName, qui est utilisée pour la variable $table$ :
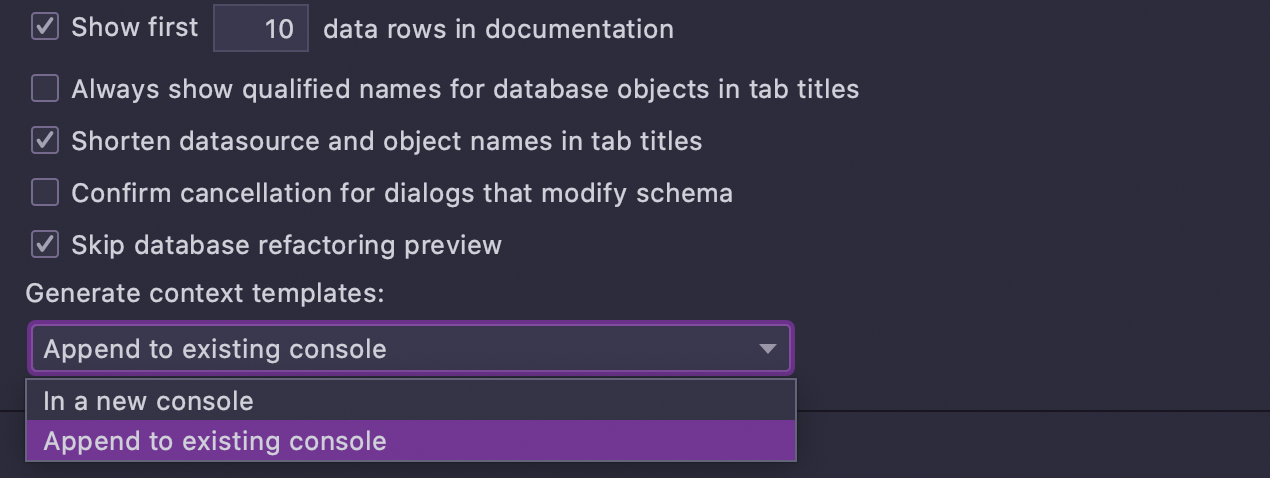
Vous pouvez bien sûr ajouter vos propres templates ou modifier les templates existants.
Dans Settings/Preferences | Database | General, choisissez si vous voulez que votre script soit généré sur la console actuelle ou sur une nouvelle console.
Éditeur de données
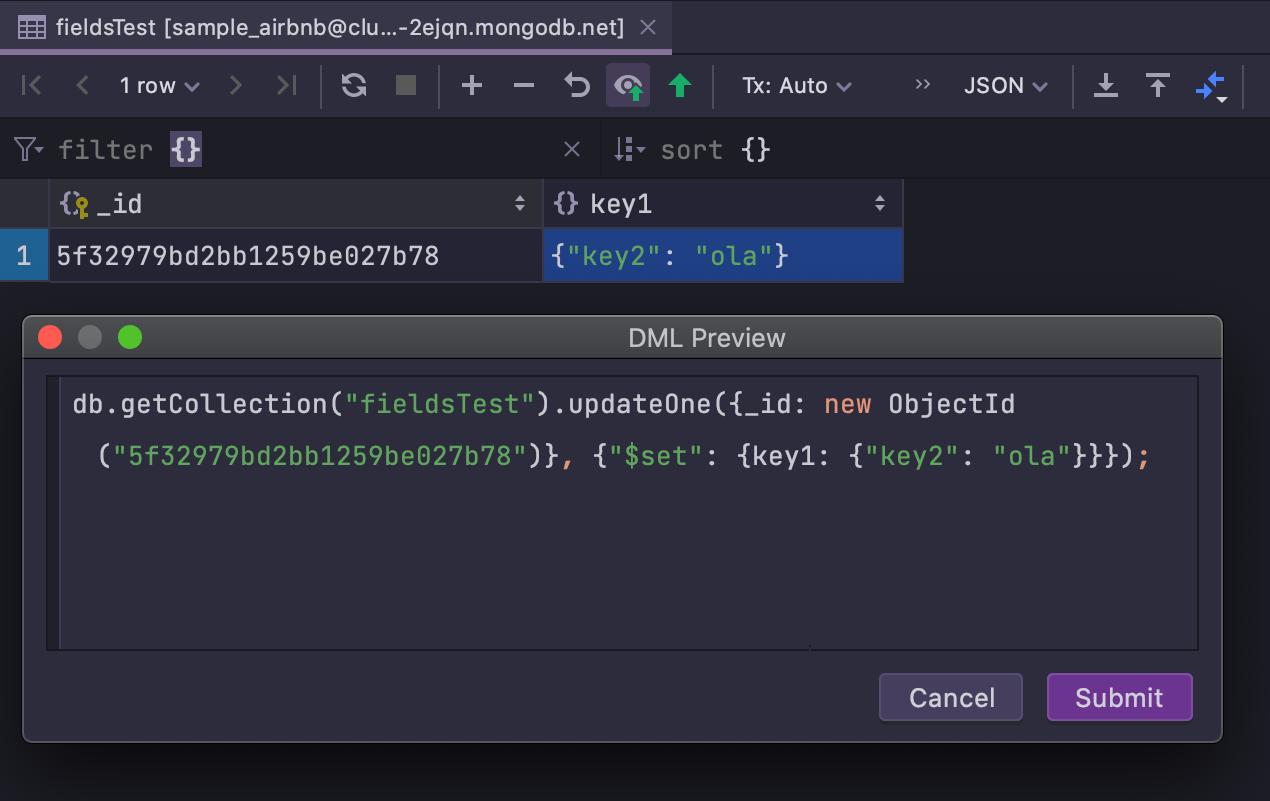
Édition des données dans MongoDB
Nous avons ajouté une fonctionnalité essentielle pour travailler avec MongoDB : à compter de cette version, vous pouvez modifier les données dans les collections MongoDB. Un aperçu de l'instruction est également disponible.
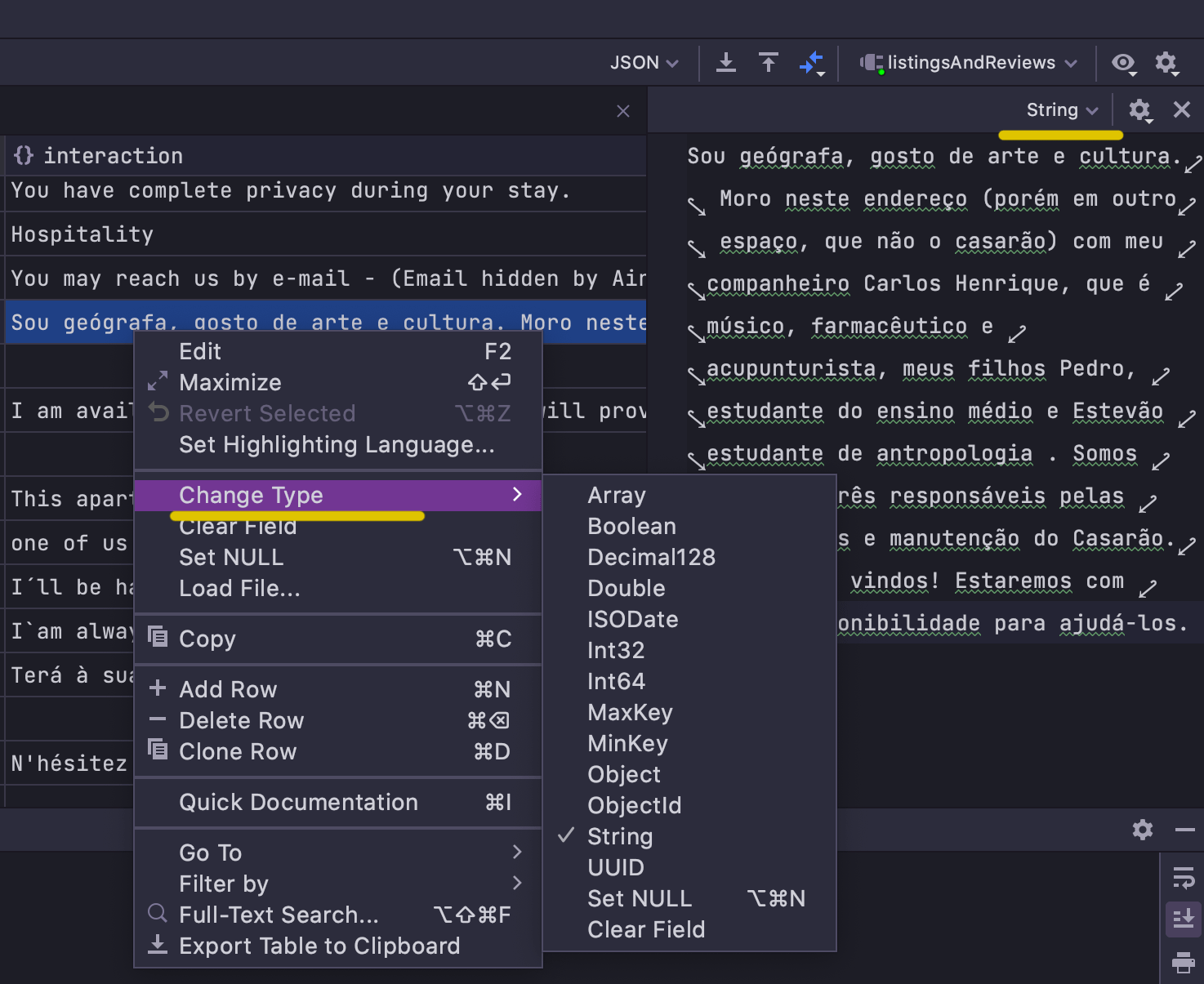
Pour rendre l'édition plus flexible, nous avons introduit la possibilité de changer le type d'un champ à partir de l'interface utilisateur. Cela peut se faire à partir du menu contextuel du champ ou dans l'éditeur de valeurs :
Amélioration du tri des données
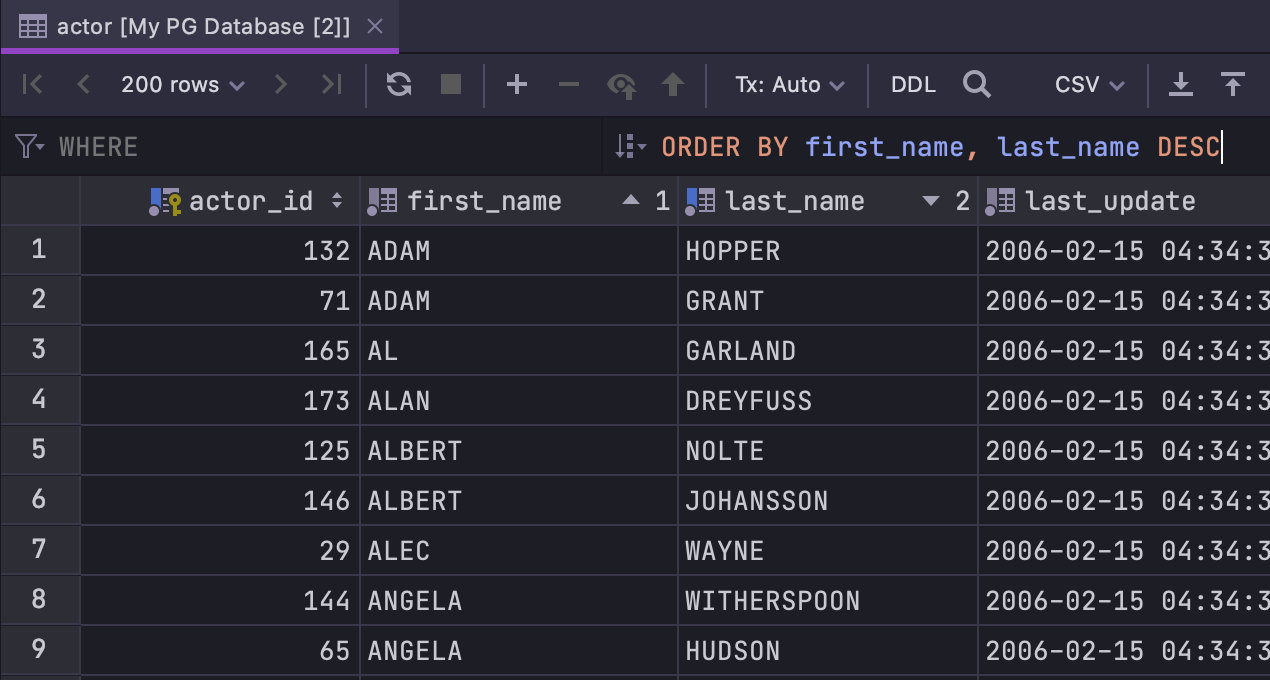
Nous avons amélioré le tri des données :
- Un nouveau champ
ORDER BYfonctionne de manière similaire au champWHERE(qui s'appelait Filter auparavant) : entrez une clause fonctionnelle afin qu'elle soit appliquée à la requête du tableau. - Le tri n'est pas "empilé" par défaut. Si vous cliquez sur le nom d'une colonne que vous voulez utiliser pour trier les données, le tri basé sur les autres colonnes sera supprimé. Si vous préférez utiliser le tri empilé, cliquez sur le nom d'une colonne tout en appuyant sur la touche Alt.
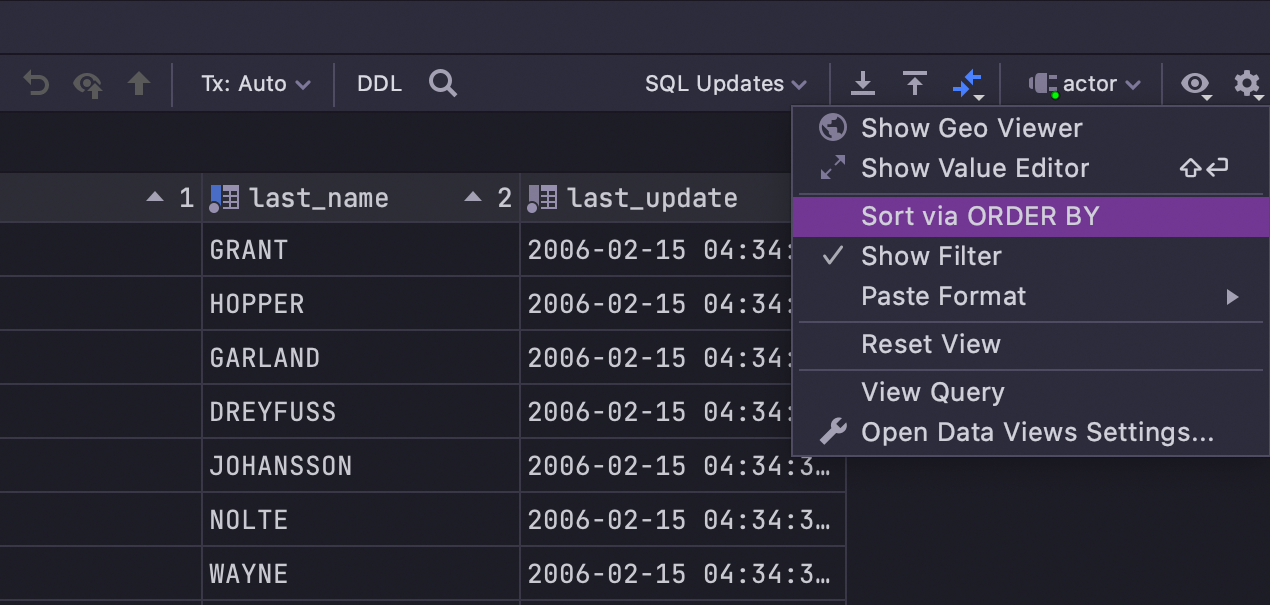
Si vous souhaitez utiliser le tri du côté client (ce qui implique que DataGrip ne réexécutera pas la requête mais triera les données au sein de la page actuelle), décochez Sort via ORDER BY :
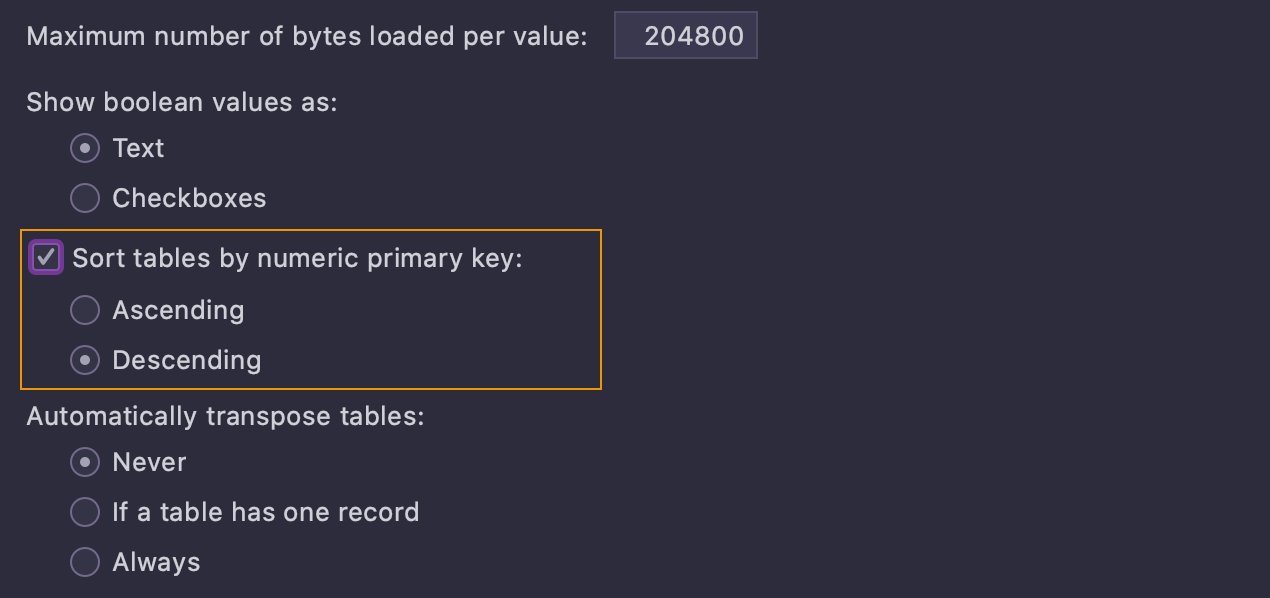
Il est également possible d'ouvrir les tables avec un tri prédéfini basé sur la clé primaire numérique. Ce paramètre se trouve dans Settings/Preferences | Database | Data Views.
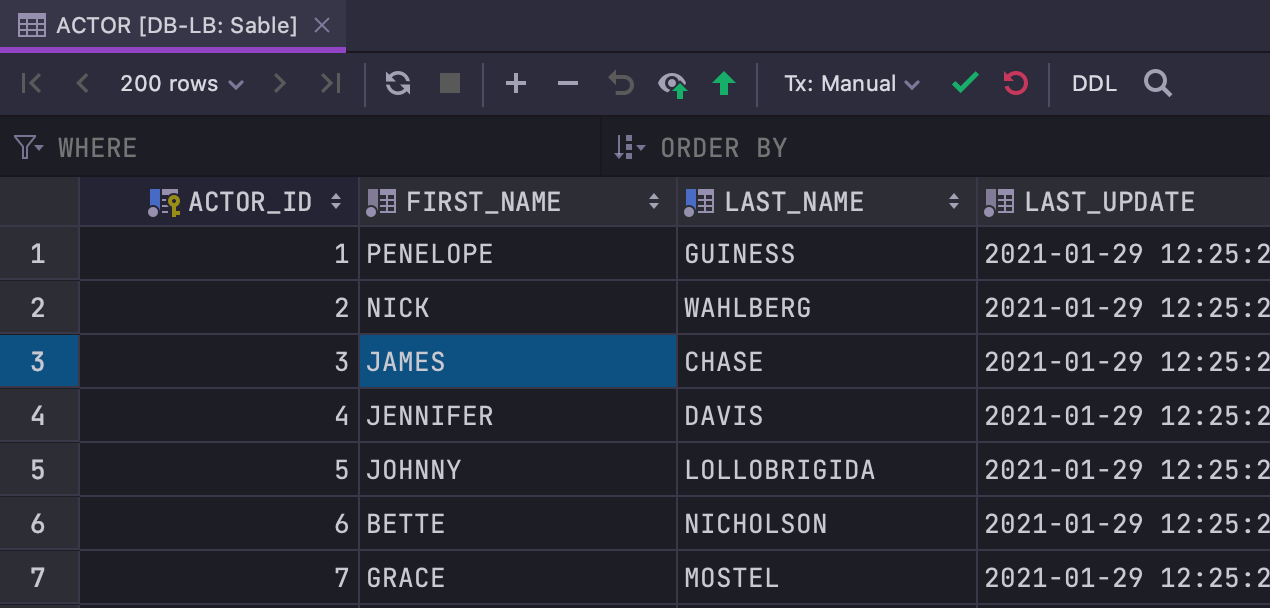
Nouvelle barre d'outils
Nous avons retravaillé la barre d'outils de l'éditeur de données. Les boutons Roll-back et Commit ne sont plus affichés en mode transaction automatique, et il y a deux nouveaux boutons, Revert changes et Find.
Transposition des résultats d'une seule ligne
Dans Settings/Preferences | Database | Data Views, il y a maintenant une option permettant de toujours transposer le résultat si il contient une seule ligne.
Navigation
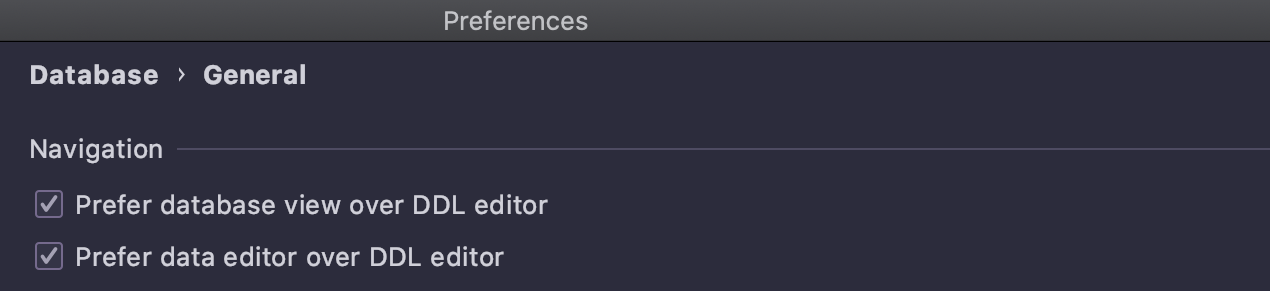
Simplification des actions
Nous avons simplifié la navigation et supprimé les paramètres suivants :
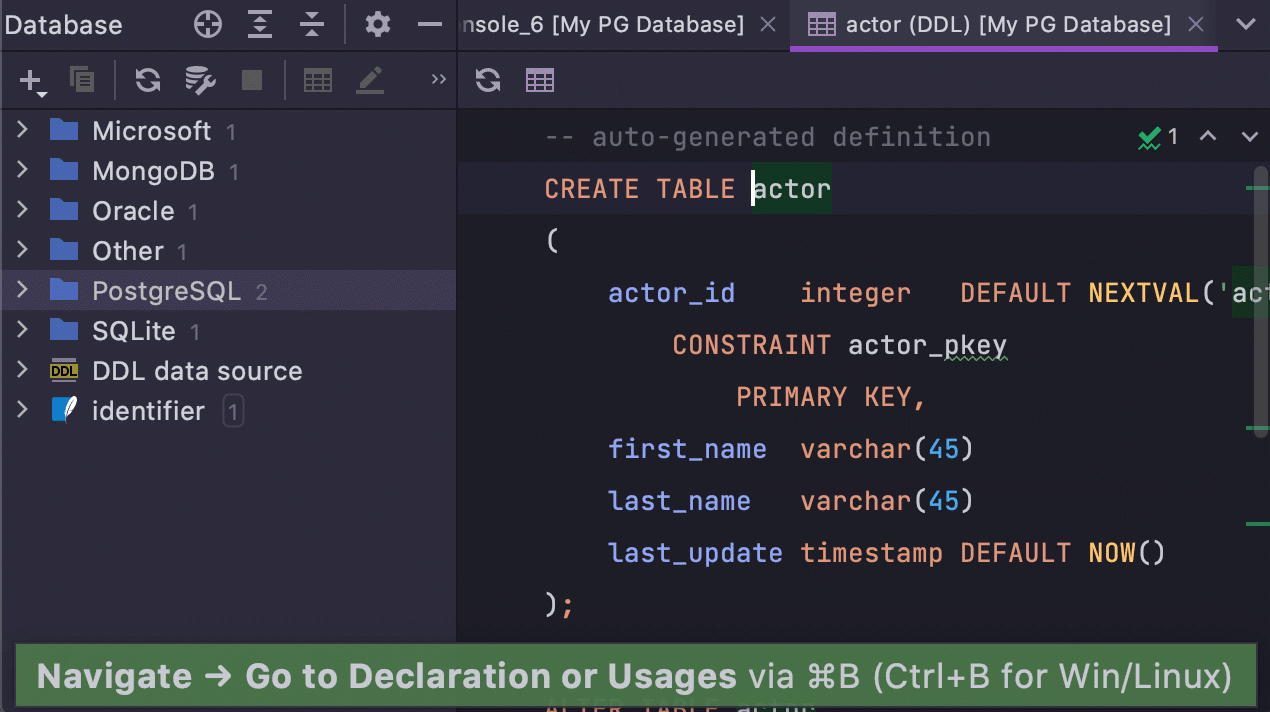
Si vous n'avez jamais modifié ces paramètres et que les cases à cocher étaient cochées par défaut, le principal changement de la version 2021.1 pour vous est le suivant : lorsque Go to declaration (Ctrl/Cmd+B) est appelé sur un objet dans SQL, il vous amène maintenant à la DDL, et non à l'arborescence de la base de données.
Nous avons également introduit un raccourci pour l'action Select in database tree : Alt+Maj+B pour Windows/Linux et Opt+Maj+B pour macOS.
Le principal objectif de ce changement est de simplifier la logique : chaque action doit vous conduire à l'endroit escompté.
Maintenant, si vous avez le curseur sur un objet :
- Ctrl/Cmd+B vous montre la DDL.
- F4 montre les données.
- Alt/Opt+Maj+B met en évidence l'objet dans l'arborescence de la base de données.
Nous comprenons que vos habitudes puissent être chamboulées par ces changements et nous sommes donc disposés à vous proposer des moyens pour conserver votre ancienne façon de procéder. Quelques conseils :
- Profitez de la puissance des raccourcis clavier. Si vous aimez utiliser Ctrl/Cmd+B pour ouvrir l'explorateur de base de données, il suffit de remapper le raccourci de l'action Select in database tree.
- Si vous aimez la façon dont Ctrl/Cmd+B ou Ctrl/Cmd+Clic ouvraient CREATE definition lorsque l'objet utilisé dans SQL n'a pas encore été créé, il suffit de ne pas supprimer ces raccourcis de Go to declaration après avoir fait le remappage de l'astuce précédente.
- Si vous utilisez le paramètre Prefer data editor over DDL editor et aimez que le double-clic ouvre la DDL, ce comportement peut être restauré en changeant la valeur de la clé de registre :
database.legacy.navigate.to.code.from.tree. D'après nos informations, très peu d'utilisateurs recouraient à ce procédé. Nous recommandons également d'utiliser les raccourcis pour ouvrir la DDL pour les objets.
Si certains de vos cas d'utilisation ne sont plus couverts par ce nouveau processus, veuillez nous le faire savoir.
Connectivité
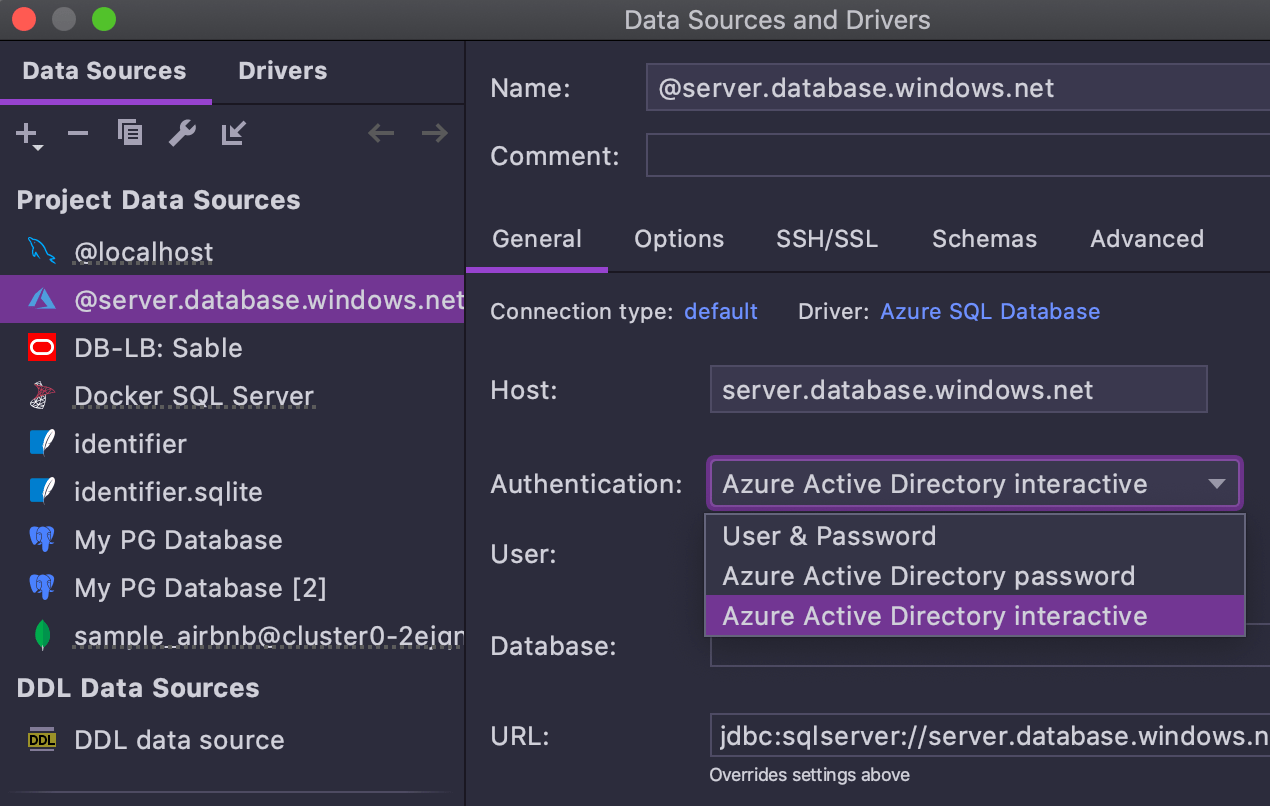
Prise en charge d'Azure MFA
L'authentification interactive Azure Active Directory est prise en charge. Lorsqu'elle est activée, le navigateur s'ouvre automatiquement et vous laisse vous connecter.
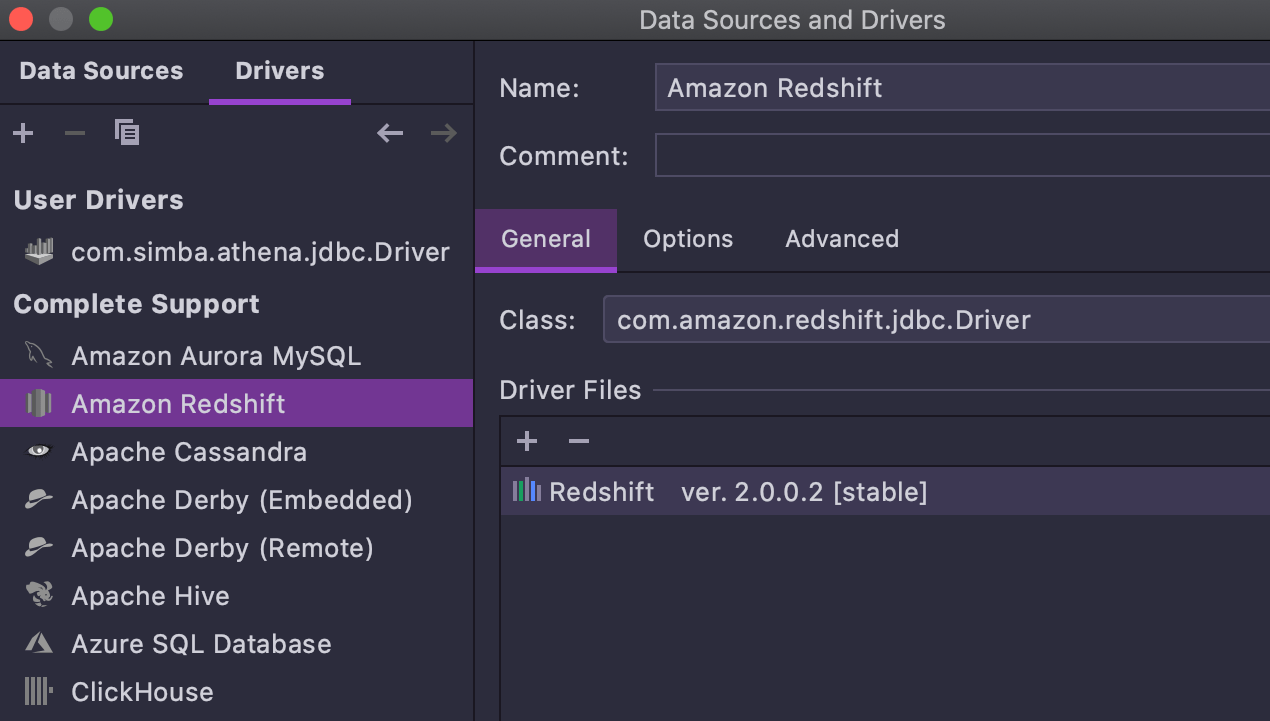
Pilote Redshift 2.x
Le pilote Redshift 2.x JDBC est disponible pour les utilisateurs de DataGrip à partir de cette version. L'amélioration majeure ici est la possibilité d'annuler des requêtes.
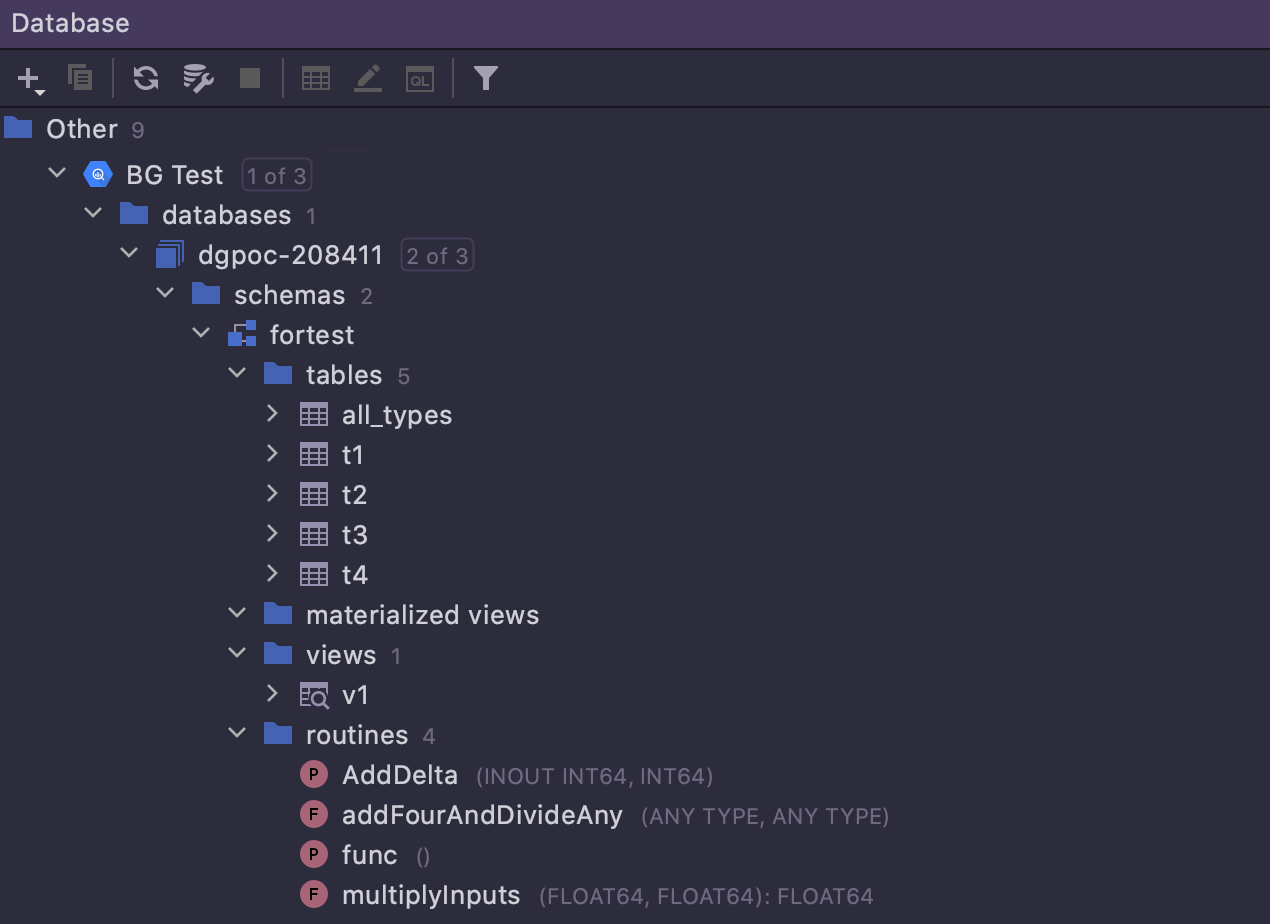
Prise en charge complète de Google BigQuery
La prise en charge du dialecte Google BigQuery a été ajoutée dans la version précédente. L'introspection de bases de données et la génération de code fonctionnent désormais correctement et ne dépendent plus de la fonctionnalité du pilote JDBC.
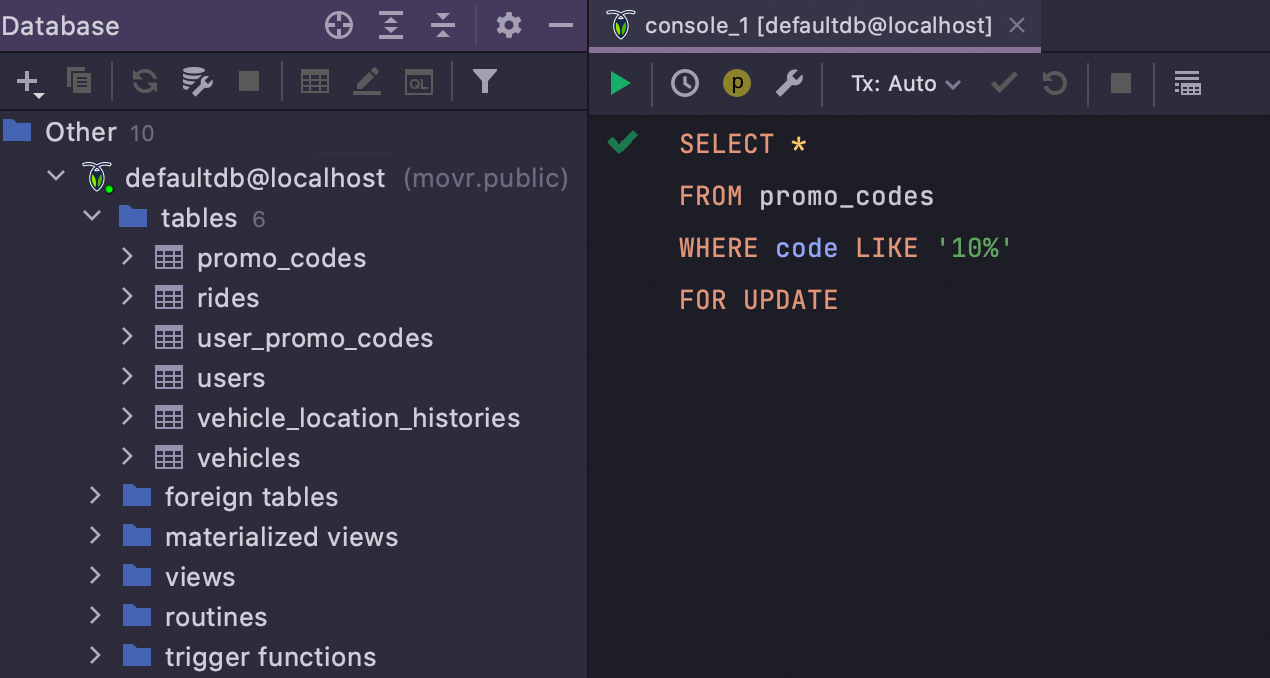
Prise en charge du dialecte CockroachDB
Si vous travaillez avec les scripts CockroachDB ou si vous écrivez du SQL pour interroger cette base de données, votre code sera désormais correctement mis en évidence et toutes les erreurs seront affichées avant que vous n'exécutiez la requête. Il s'agit de la première étape vers la prise en charge complète de CockroachDB, qui sera disponible dans l'une des prochaines versions.
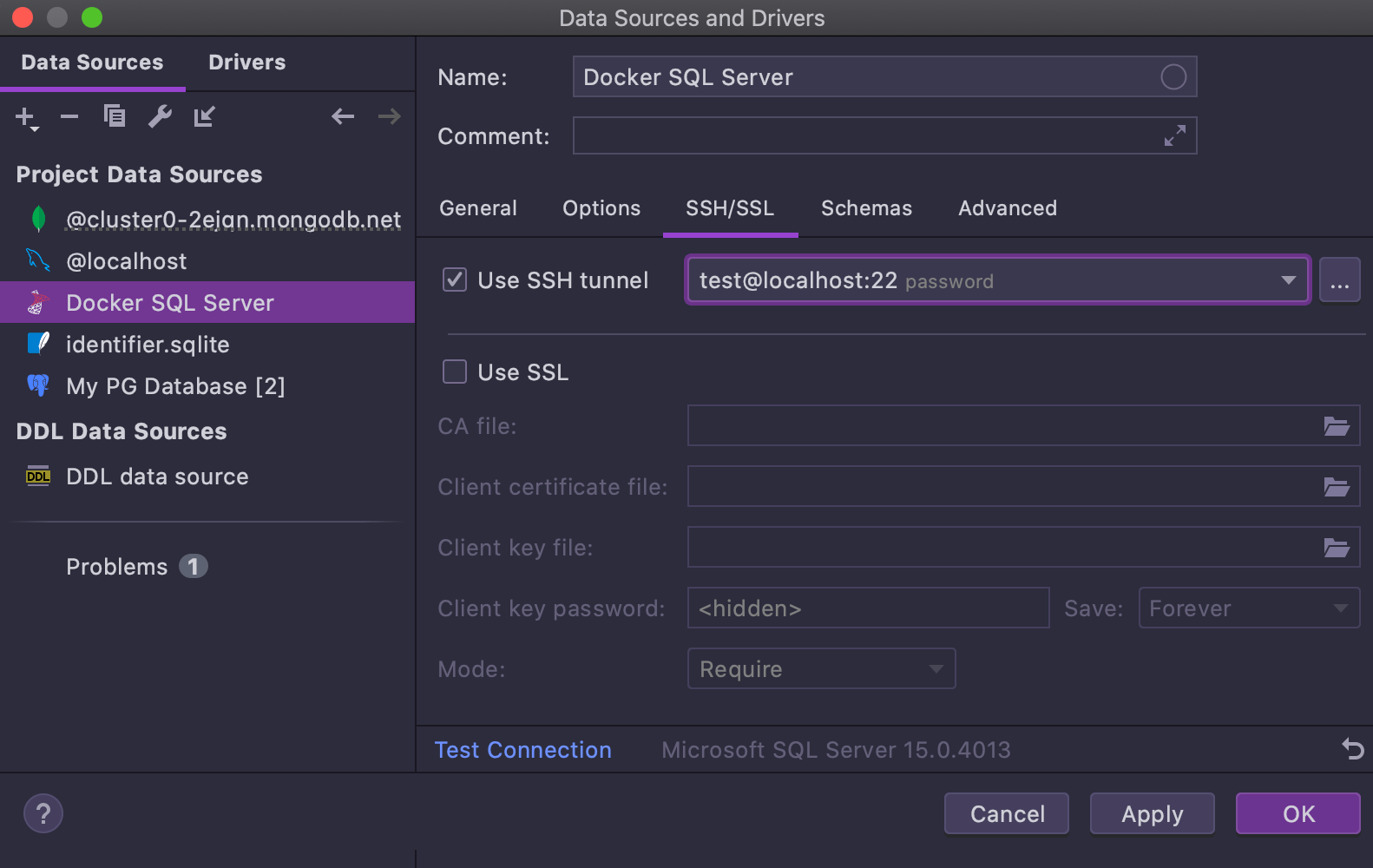
Améliorations dans la fenêtre de connexion
Nous avons retravaillé la fenêtre de connexion pour la rendre plus conviviale.
- Les pilotes et les sources de données sont désormais listés dans deux onglets différents. La liste des pilotes devraient aider les nouveaux utilisateurs à ne pas les confondre avec les sources de données, sans pour autant être une gêne pour le utilisateurs lus expérimentés.
- Chaque page de pilote comprend un bouton Create data source.
- Le bouton Test Connection a été déplacé vers le pied de page afin que vous puissiez l'utiliser à partir de n'importe quel onglet des propriétés de la source de données, et pas seulement l'onglet General and SSH/SSL comme auparavant.
- La page des propriétés de la source de données DDL comporte une liste déroulante permettant de choisir le dialecte.
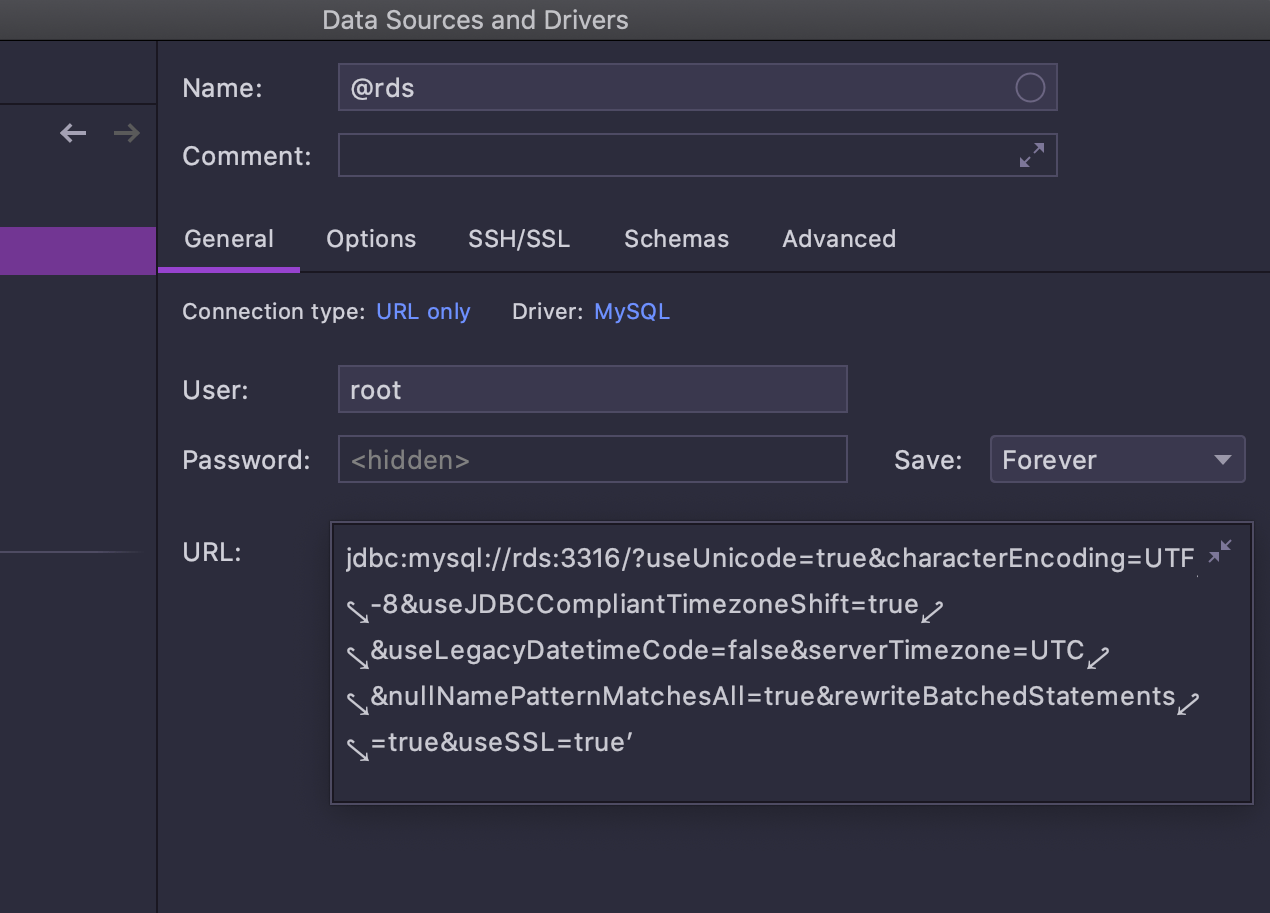
Le champ URL est désormais extensible, ce qui facilite la gestion des URL longues.
Explorateur de bases de données
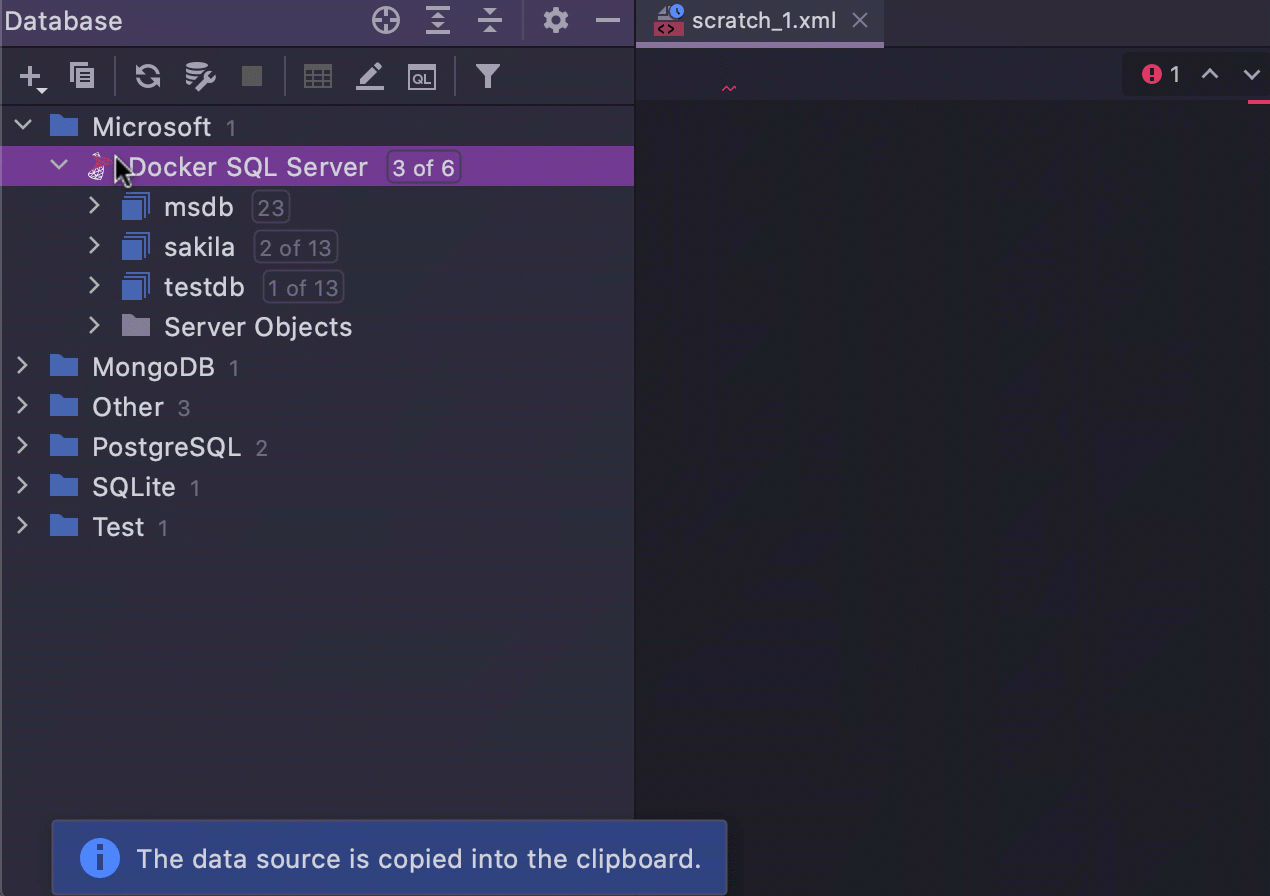
Copier-coller facile des sources de données
La possibilité de copier-coller des sources de données a été introduite il y a longtemps. Mais à partir de la version 2021.1, vous pouvez copier, couper et coller des sources de données en utilisant certains des raccourcis les plus célèbres au monde : Ctrl/Cmd+C/V/X.
- Lorsque vous copiez une source de données, le XML est copié dans le presse-papiers, que vous pouvez ensuite partager via un messenger. Vous pouvez également utiliser l'action Coller pour coller un extrait de XML provenant d'un autre endroit.
- Si vous coupez et collez une source de données à l'intérieur d'un projet, elle sera simplement déplacée, pas besoin de mot de passe. Mais le mot de passe est requis dans tous les autres cas.
- Un Couper peut être annulé avec Ctrl/Cmd+Z.
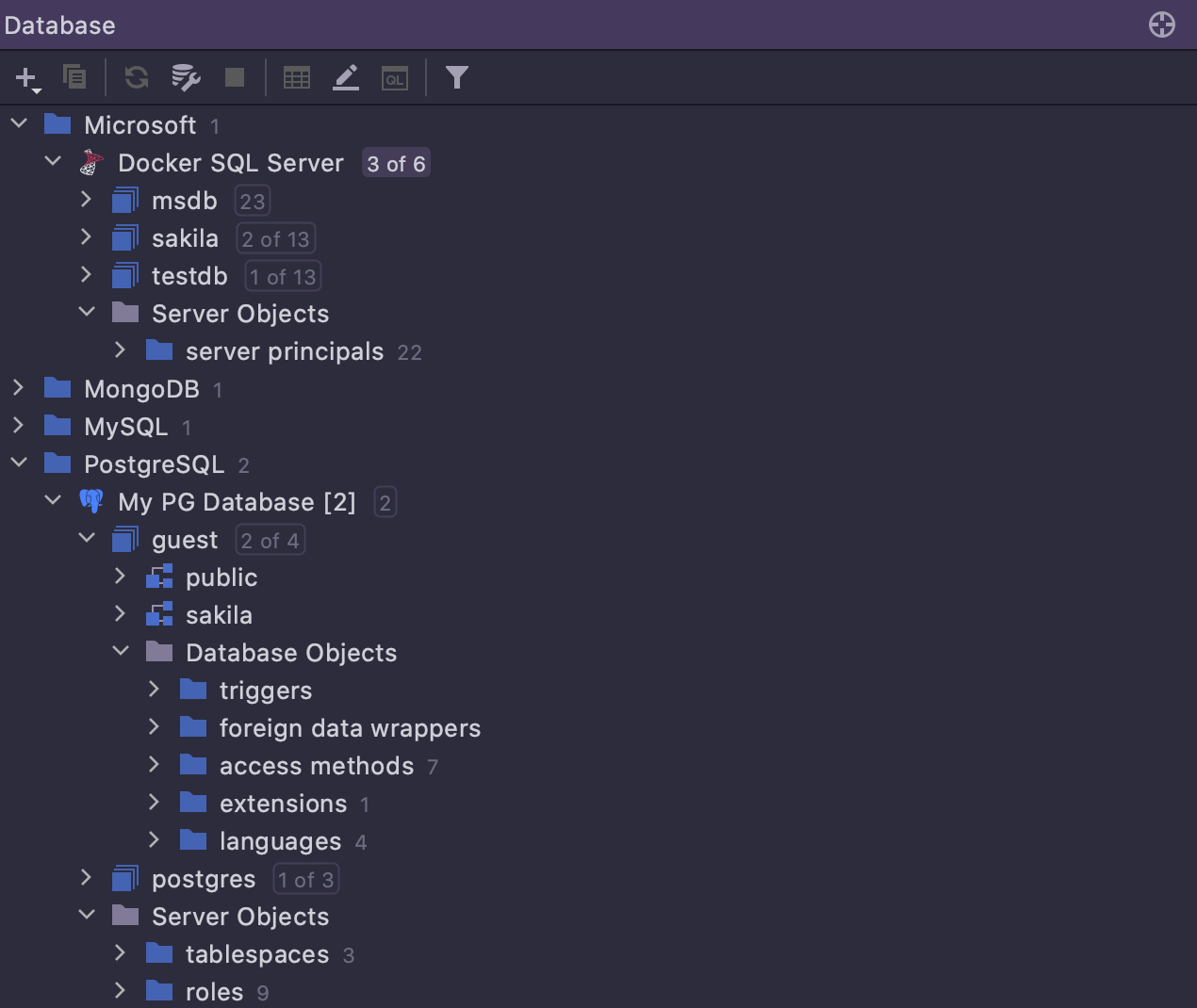
Nouvel agencement
L'agencement par défaut de l'explorateur de base de données a été modifié, les objets non majeurs figurant désormais sous un nœud dédié. La plupart du temps, les gens travaillent avec des tables, des vues et des routines, et voir les utilisateurs, rôles, tablespaces, wrappers de données externes et autres types d'objets n'est pas une priorité. C'est pourquoi ces objets secondaires sont maintenant cachés sous deux nœuds : Server Objects et Database Objects.
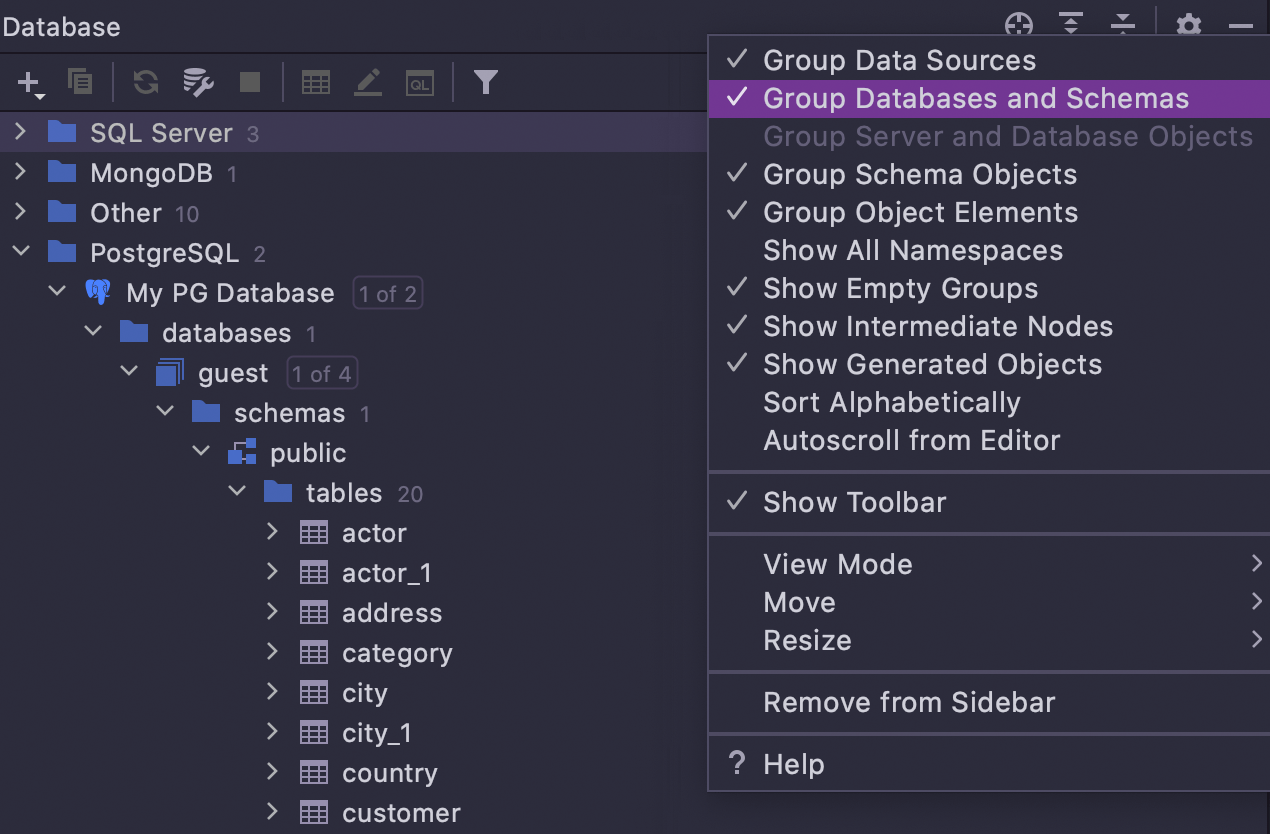
Si vous voulez retrouver l'ancien agencement, il suffit de sélectionner Group Database and Schemas dans les paramètres sous l'icône d'engrenage.
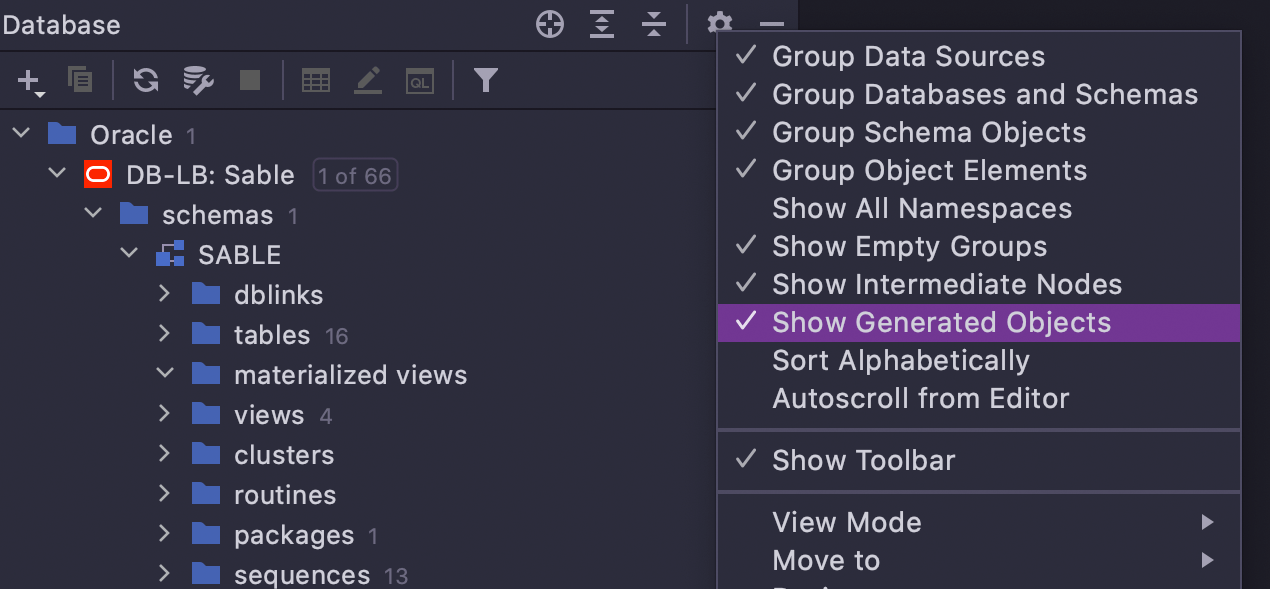
Masquer les objets générés automatiquement Oracle
Si vous utilisez Oracle, il existe une option permettant d'afficher ou de masquer les objets générés automatiquement dans l'arborescence, parmi lesquels :
- Journaux de vues matérialisées
- Les tables sous-jacentes pour les vues matérialisées
- Les tables secondaires
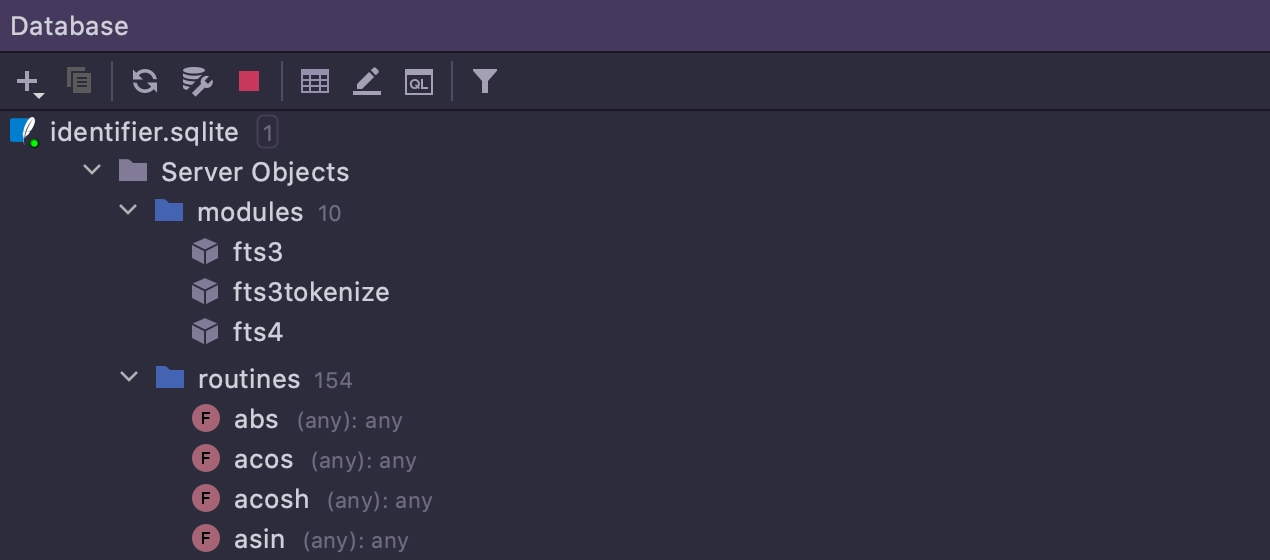
Nouveaux types d'objets SQLite
Les fonctions, les modules et les colonnes virtuelles sont introspectés pour SQLite.
Améliorations pour les bases de données non prises en charge
Modèles de sources de données
À partir de la version 2021.1, il est plus facile d'ajouter des sources de données pour les bases de données non prises en charge. Nous fournissons désormais des pilotes JDBC pour AWS Athena, Informix, Presto, SAP HANA, Google Cloud Spanner et bien d'autres. Vous pouvez trouver ces bases de données dans la liste des bases de données dans la section Other.
Nous avons apporté quelques améliorations supplémentaires :
- Vous n'avez plus besoin de télécharger le pilote vous-même et de créer manuellement une source de données basée sur la base du pilote.
- Les nouvelles versions du pilote seront fournies par DataGrip.
- Certaines nouvelles bases de données ont leurs propres icônes dédiées.
Veuillez noter que la prise en charge de ces bases de données est limitée. Elle dépend principalement des capacités du pilote JDBC et de la prise en charge du dialecte SQL:2016 par l'éditeur SQL de DataGrip.
Analyse des requêtes
Nous avons ajouté un nouveau paramètre permettant d'utiliser les bases de données non prises en charge. Lorsque vous travaillez avec ces bases de données dans DataGrip, vous devez utiliser le dialecte SQL:2016 ou Generic. Generic est quasiment identique à SQL:2016 mais DataGrip ne met pas en évidence les erreurs qu'il trouve.
Pour accéder à ce paramètre, allez dans Settings/Preferences | Database | General | Split a script for execution in Generic and ANSI SQL dialects. Vous pouvez choisir parmi les valeurs suivantes :
- On valid ANSI SQL statements or by separator – le paramètre par défaut qui convient à la majorité des cas. Autrement dit, nous ferons de notre mieux pour comprendre ce que vous voulez exécuter.
- On ANSI SQL Statements – fractionne les instructions comme avant. La logique est basée uniquement sur ce que DataGrip considère comme valide selon la grammaire SQL:2016.
- By statement separator – les instructions sont extraites et exécutées par des séparateurs. Utilisez cette option si la première n'a pas fait l'affaire. Pour GenericSQL, le séparateur est un point-virgule. Veuillez noter qu'il n'est plus possible de définir un séparateur personnalisé.
Voici quelques-uns des problèmes que nous avons résolus :
- De nombreux utilisateurs ont signalé un problème avec l'exécution des CTE. Cela a été partiellement corrigé quand la grammaire Generic est passée de SQL:92 à SQL:2016, mais l'option On valid ANSI SQL statements or by separator aide toujours avec les CTE complexes. Un autre exemple d'une instruction qui fonctionnera avec cette option est l'instruction peu commune MERGE.
- L'option On valid ANSI SQL statements or by separator aide également à exécuter des choses qui ne sont pas du tout des instructions dans la grammaire SQL:2016, telles que show databases.
Assistance au codage
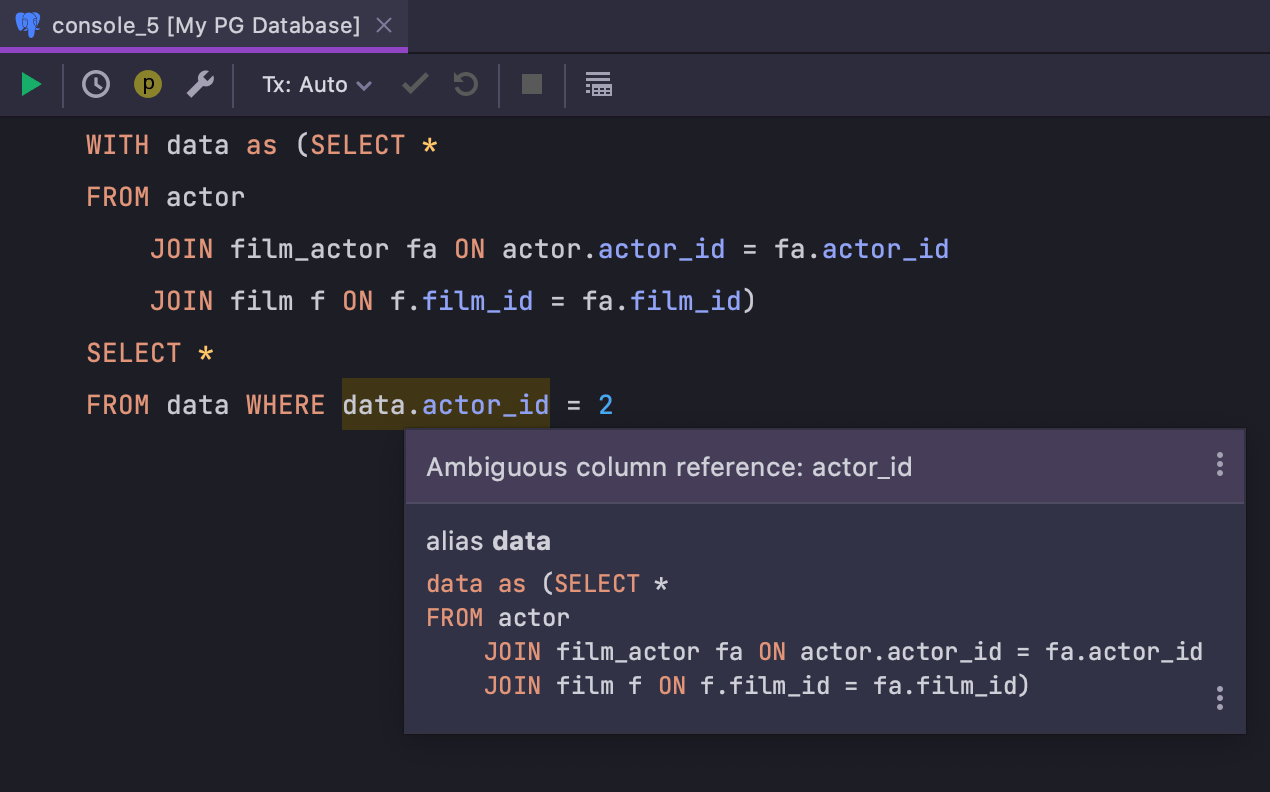
Nom de colonne ambigu lors de l'utilisation du CTE
L'inspection qui signale les noms de colonne ambigus est maintenant plus intelligente et prend en compte toutes les colonnes situées dans des expressions de table communes :
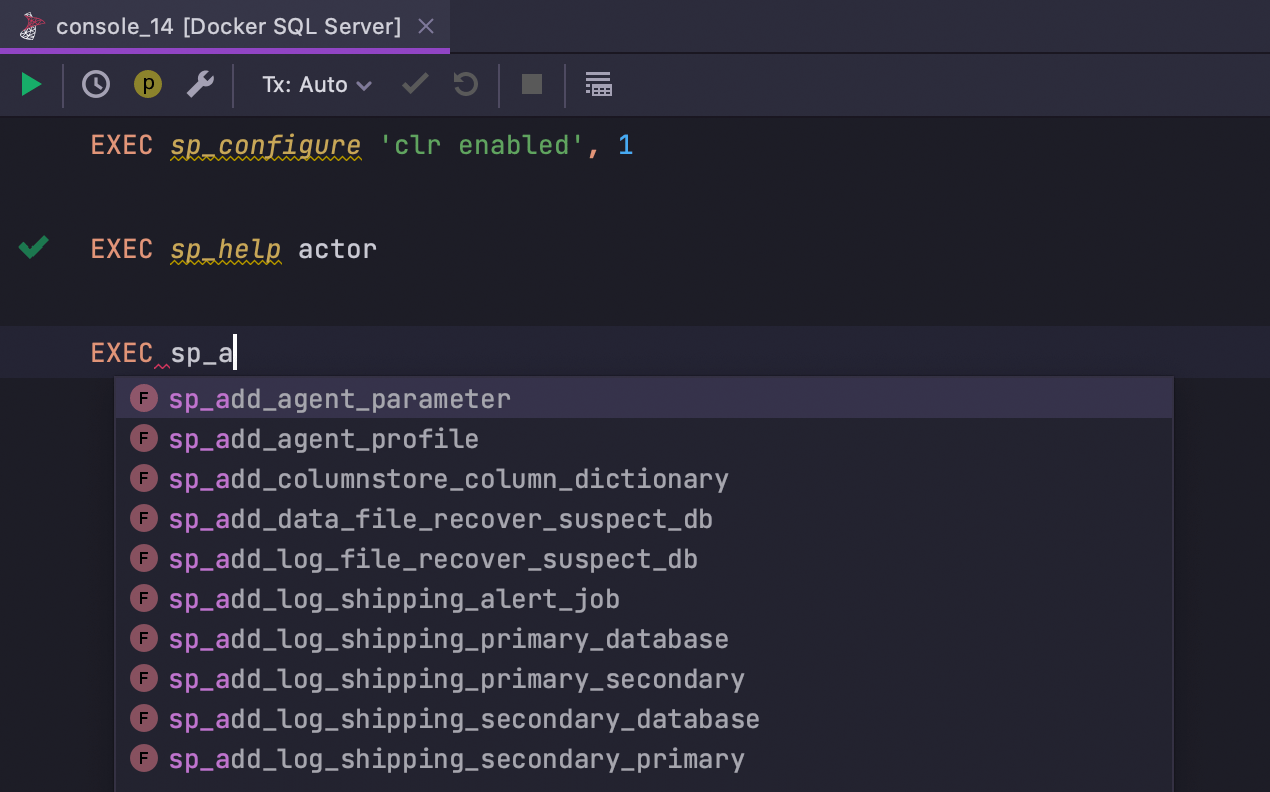
Les fonctions du système peuvent être utilisées sans qualification SQL Server
Les fonctions et procédures du système ne sont plus mises en évidence comme des erreurs lorsqu'elles sont utilisées sans qualification. La navigation et la saisie semi-automatique fonctionnent maintenant pour les fonctions et procédures du système.
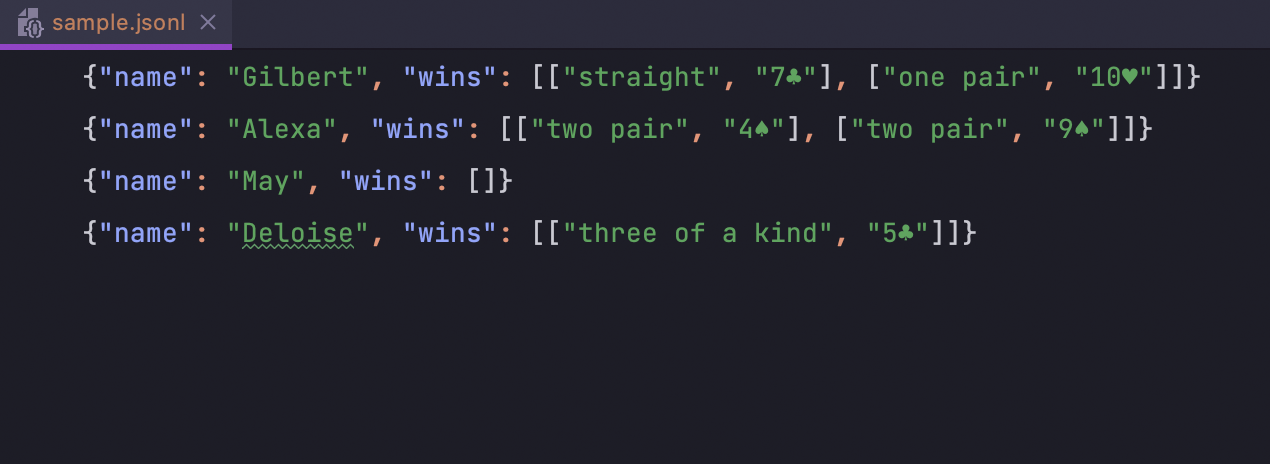
Prise en charge du format JSON Lines
Thanks to the IntelliJ Platform, DataGrip now has support for the newline-delimited JSON Lines format used for working with structured data and logs. L'IDE reconnaît les types de fichiers .jsonl, .jslines, .ldjson et .ndjson.
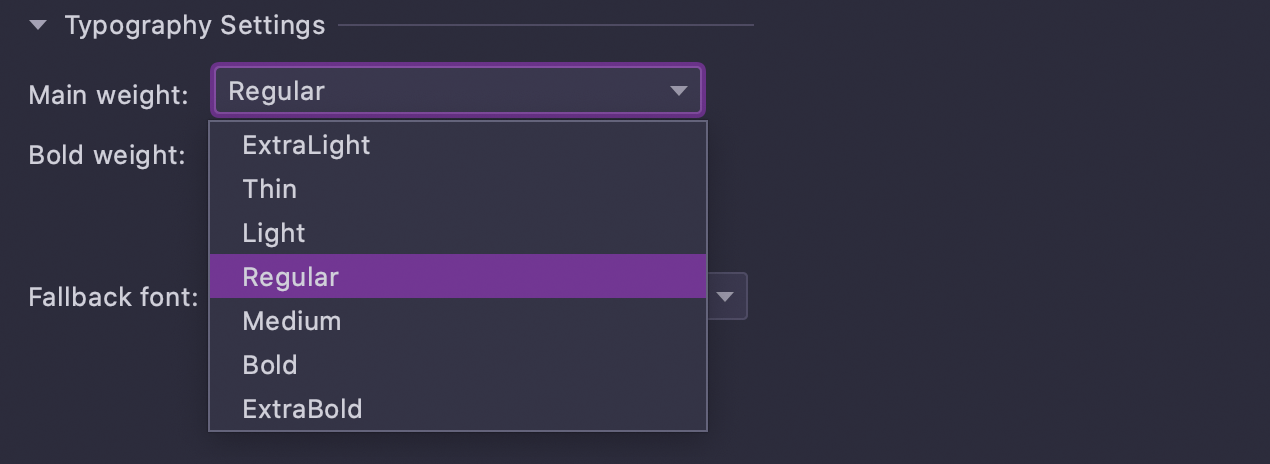
Poids de police ajustable
Les nouveaux paramètres de typographie vous permettent d'ajuster le style de votre police. Dans la v2021.1, vous pouvez choisir le poids de la police par défaut et de la police grasse dans Preferences / Settings | Editor | Fonts.
Importation / Exportation
Avertissement sur les données non chargées
Lorsque vous copiez des données binaires qui n'ont pas encore été complètement chargées, la notification suivante s'affiche :
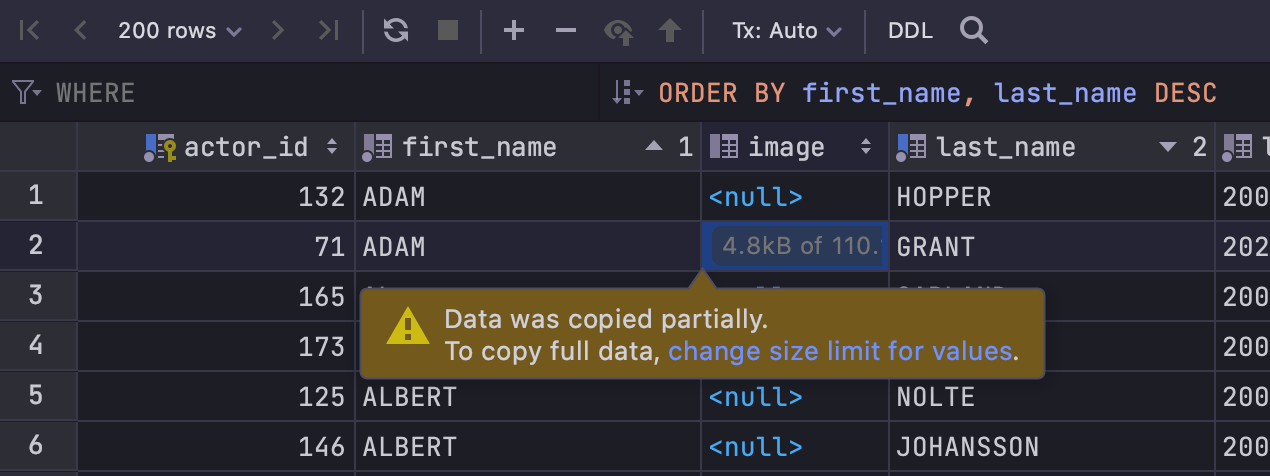
Pour éviter que les données ne soient tronquées, augmentez la valeur dans Settings/Preferences | Database | Data Views | Maximum number of bytes loaded per value.
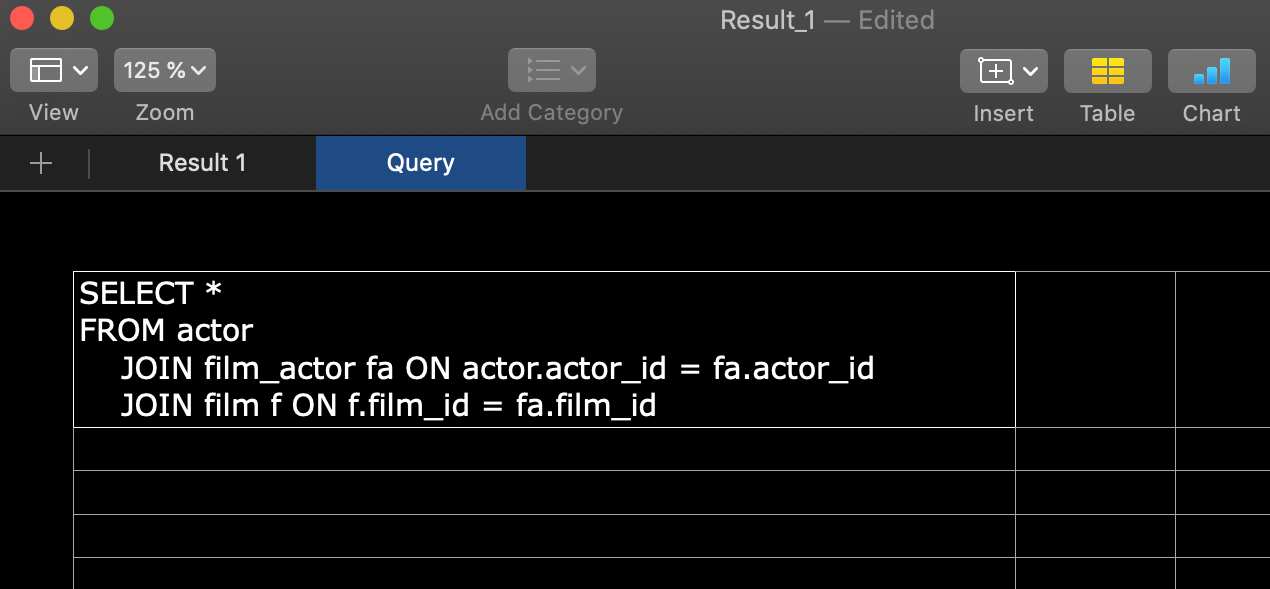
Requête dans le fichier Excel
Lorsque vous exportez vers Excel, le fichier résultant contiendra la requête sur une feuille séparée.
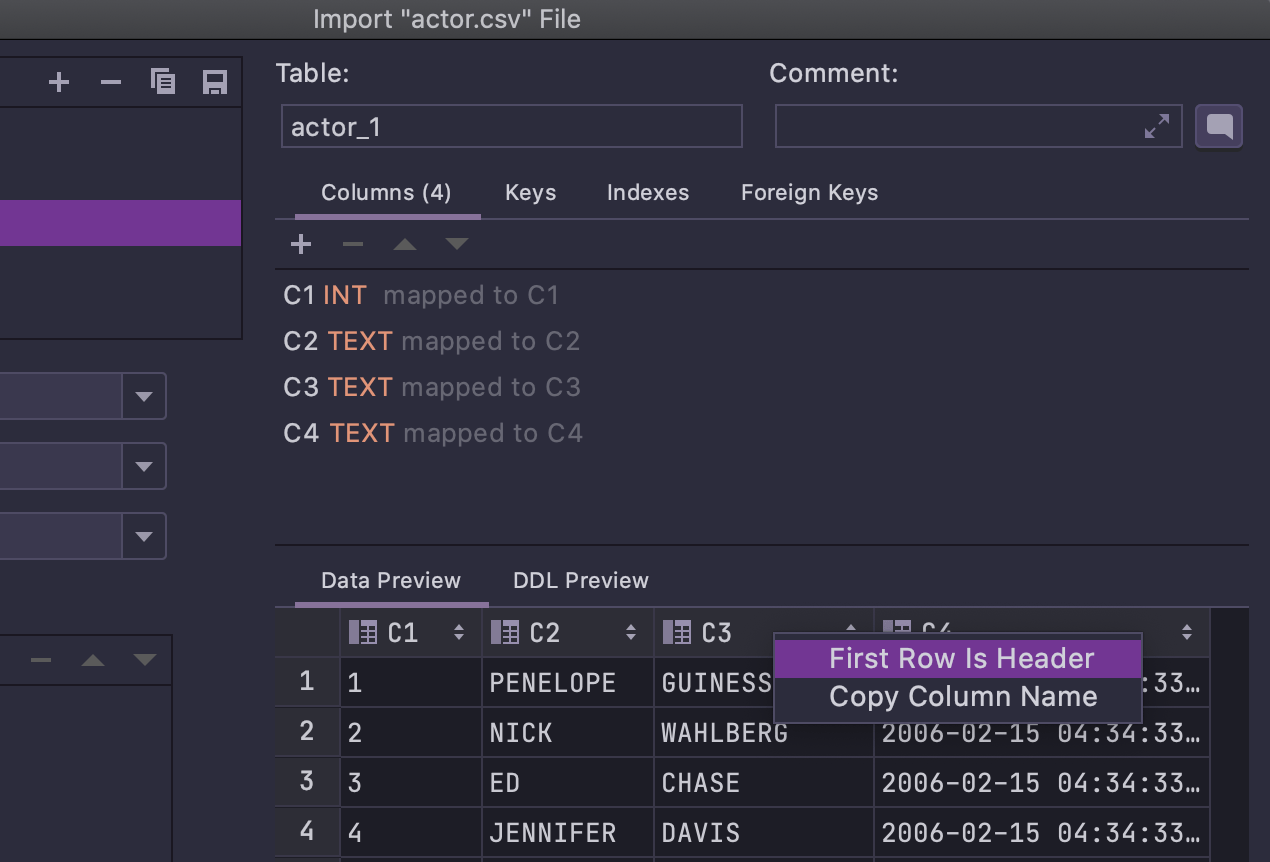
First row is header dans le menu contextuel
Lorsque vous importez un fichier CSV, l'option permettant de préciser que la première ligne est un en-tête est désormais disponible dans le menu contextuel, comme indiqué ci-dessous :
Interface utilisateur
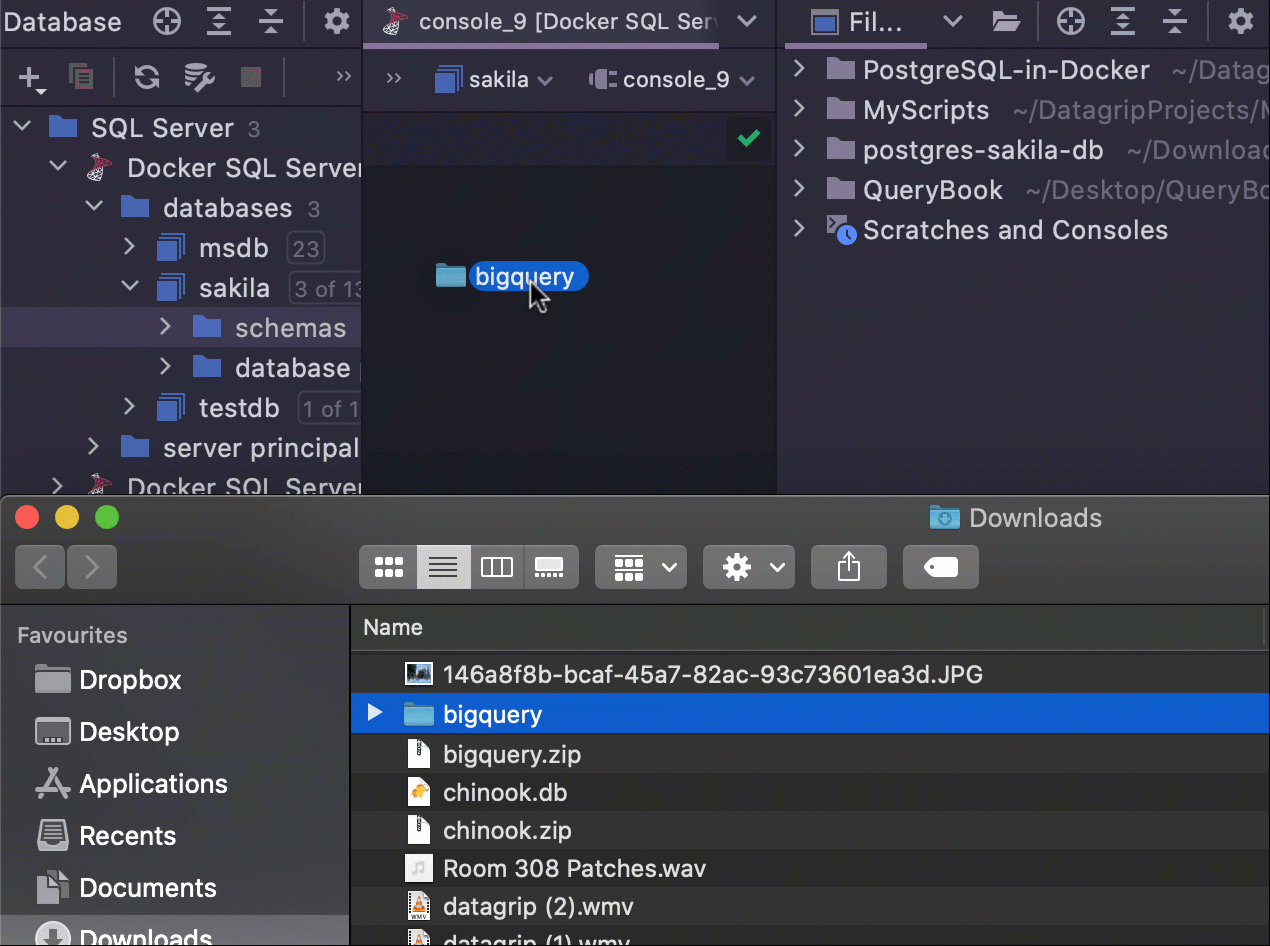
Joindre un dossier par glisser-déplacer
Il est désormais possible de joindre un dossier à votre projet grâce à une simple action de glisser-déposer.
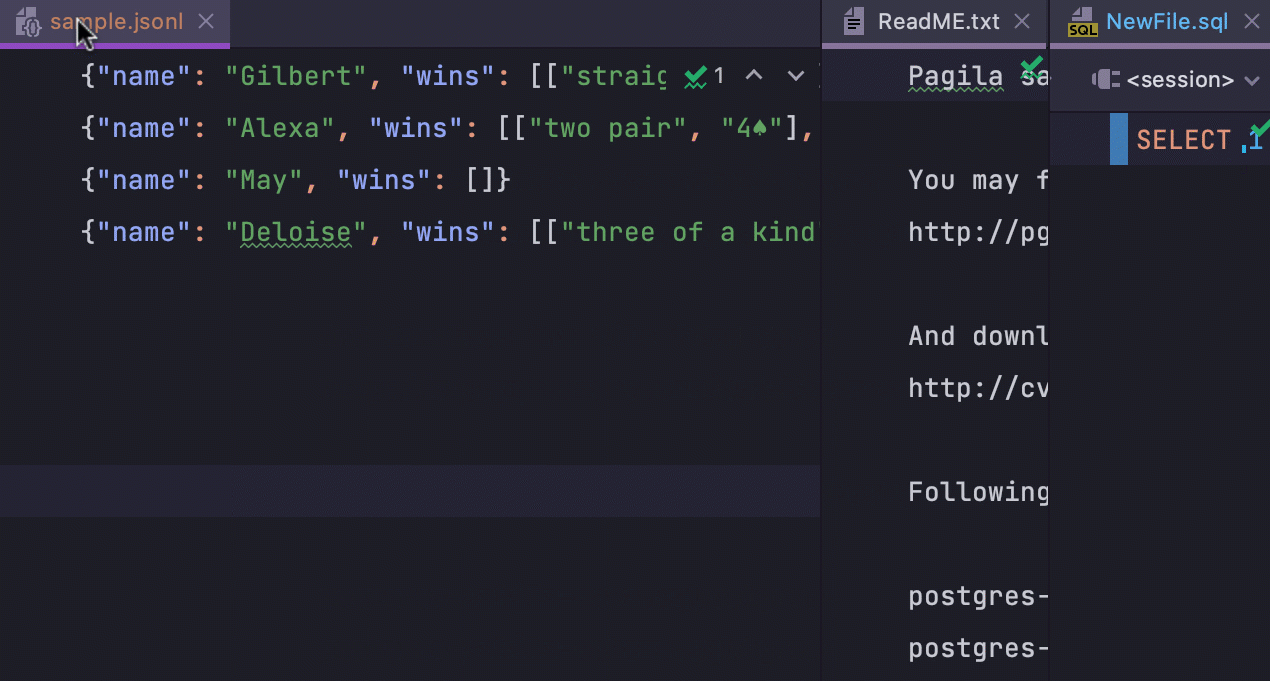
Maximiser la taille des onglets dans la vue fractionnée
Lorsque plusieurs onglets qui divisent l'éditeur verticalement sont ouverts, vous pouvez les double-cliquer et agrandir la fenêtre de l'éditeur pour chacun d'eux. Pour ramener la fenêtre à sa taille initiale, il suffit de double-cliquer à nouveau sur celle-ci.

Noms longs dans les titres d'onglets
Il y a quelque temps, nous avons introduit des noms d'onglets raccourcis. Cette fonctionnalité ne convenant pas à tout le monde, nous avons ajouté la possibilité de la personnaliser à votre convenance.