Nouveautés de DataGrip 2025.2
Introspection par niveaux pour MS SQL Server et PostgreSQL, possibilité d'attacher des objets de base de données au contexte du chat IA, résultats de requête SELECT modifiables et bien plus.
Fonctionnalités de l'AI Assistant
Pour utiliser les fonctionnalités décrites dans cette section, il peut être nécessaire d'installer le plugin AI Assistant. Une fois ce plugin installé, les fonctionnalités seront activées par défaut dans votre IDE.
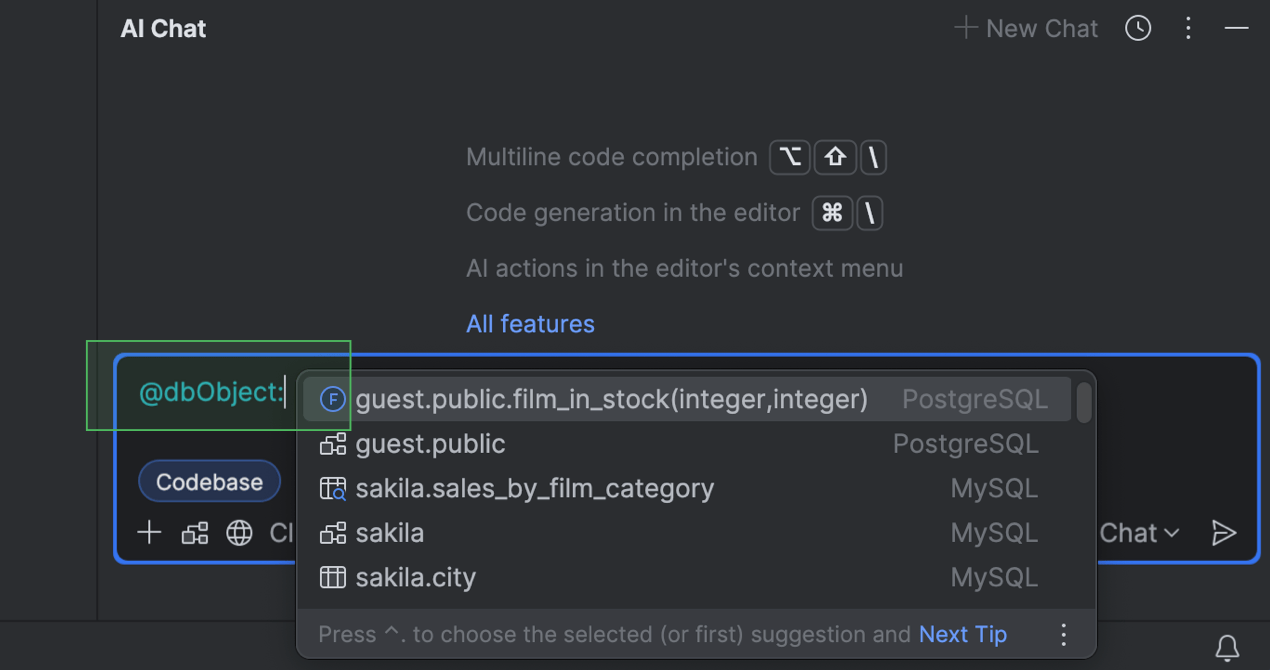
Possibilité de joindre des objets de base de données au chat IA
Le contexte de base de données que vous fournissez au chat IA peut désormais être plus précis. Précédemment, il était uniquement possible de joindre l'ensemble du schéma. Désormais, vous pouvez joindre l'objet de base de données avec lequel vous souhaitez travailler, par exemple une table ou une vue. Cela peut être particulièrement utile lorsque vous travaillez avec des schémas plus volumineux.
Pour attacher un objet de base de données, tapez @ ou # dans le champ d'entrée, sélectionnez ou saisissez dbObject:, puis sélectionnez l'objet à joindre dans la liste.
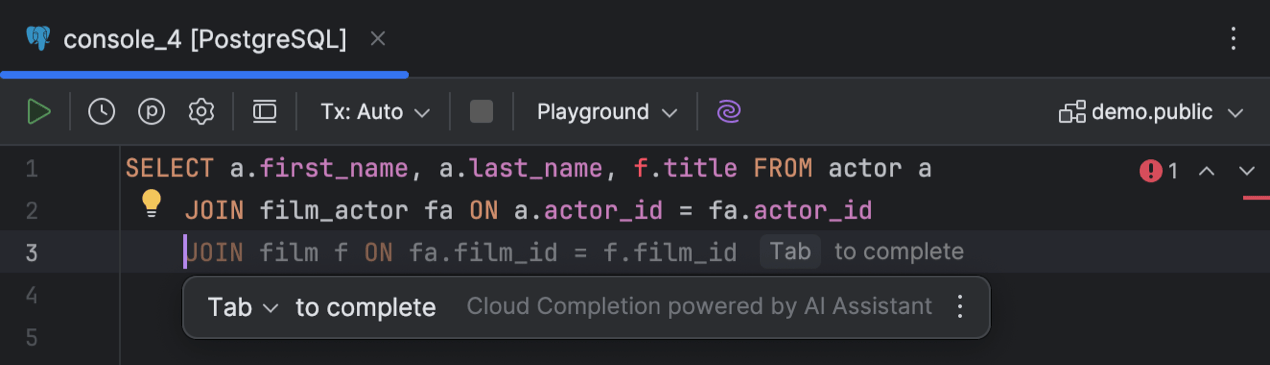
Saisie semi-automatique du code basée sur le cloud
DataGrip prend désormais en charge la saisie semi-automatique de code basée sur le cloud. Cette fonctionnalité utilise les ressources cloud pour fournir des suggestions plus précises en utilisant une puissance de calcul supérieure à celle des ressources locales. Elle permet à l'IDE de proposer des lignes entières ou des blocs de code, voire des scripts complets en temps réel, sur la base du contexte disponible. Le code SQL ainsi généré est similaire à la manière dont vous écririez vos instructions, et respecte votre style et vos conventions de nommage.
Avec la saisie semi-automatique de code basée sur le cloud, DataGrip présente des suggestions dans l'éditeur au cours de la saisie. Vous pouvez également y accéder en appuyant sur Alt+Maj+\. Pour désactiver cette fonctionnalité, allez dans Settings | Editor | General | Inline Completion, puis désactivez la case Enable cloud completion suggestions.
Connectivité
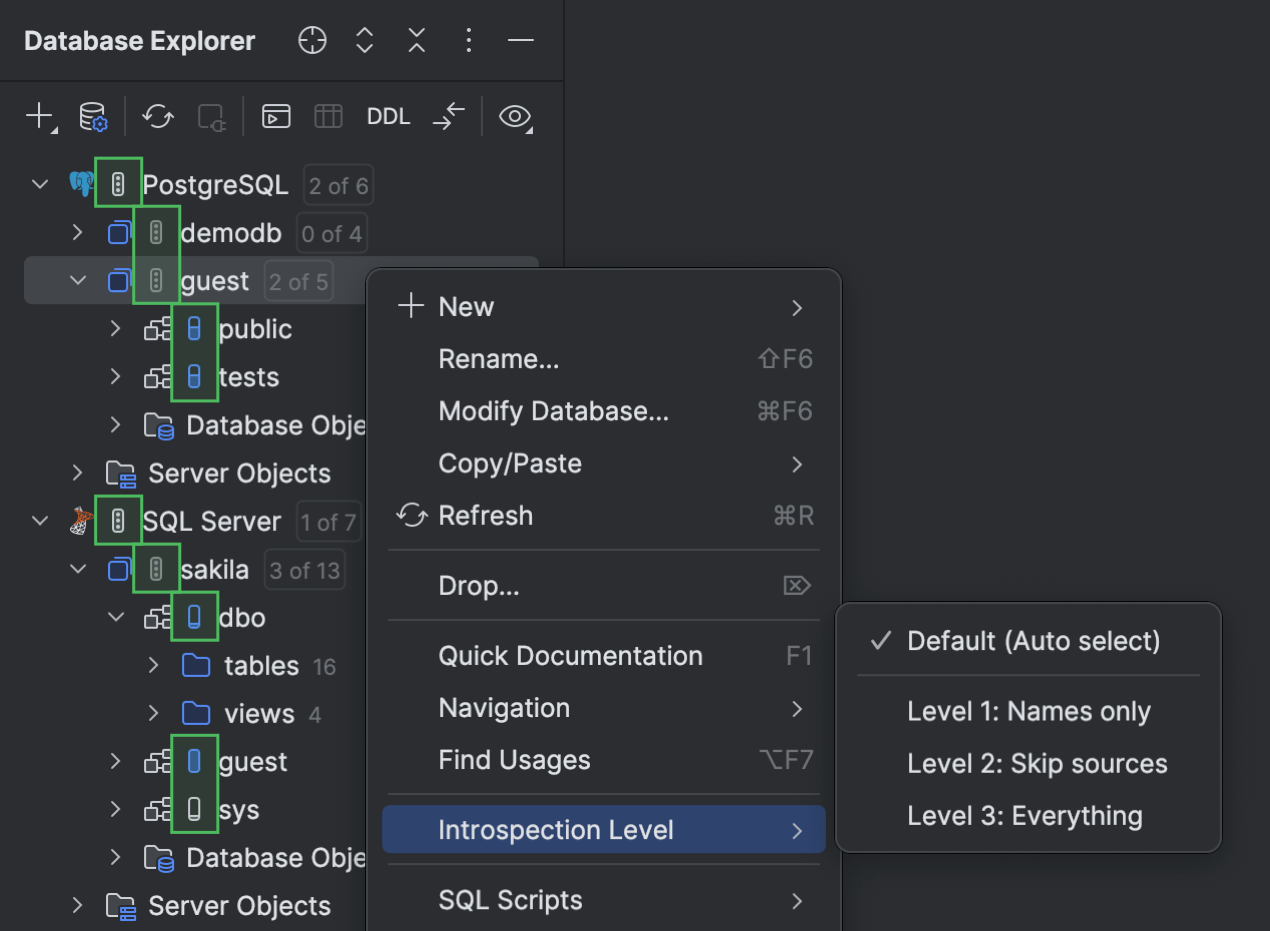
Introspection par niveaux PostgreSQL Microsoft SQL Server
Nous avons étendu l'implémentation de l'introspection par niveaux à davantage de bases de données, cette fois-ci PostgreSQL et Microsoft SQL Server ! DataGrip ajuste désormais automatiquement la quantité de métadonnées chargées pour ces bases de données en fonction de la taille de votre bases de données. Cela signifie que pour une bases de données de grande taille, vous n'aurez pas à attendre que toutes les métadonnées soient chargées pour travailler dessus.
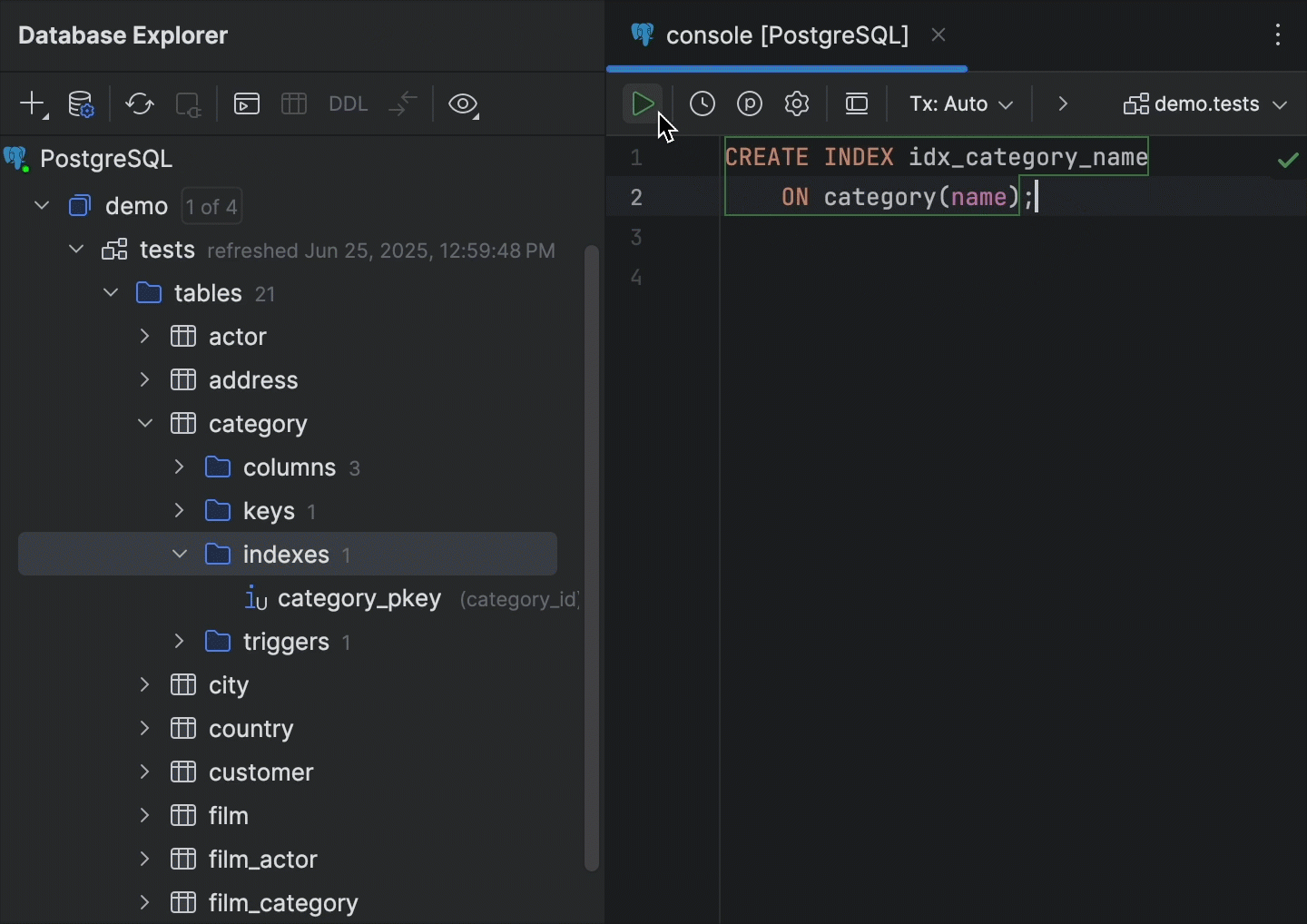
Actualisation intelligente PostgreSQL
DataGrip prend maintenant en charge le mécanisme d'actualisation intelligente pour les bases de données PostgreSQL. Précédemment, l'IDE actualisait automatiquement l'intégralité du schéma dans l'explorateur de base de données dès qu'une instruction DDL était exécutée. Une fois le mécanisme d'actualisation intelligente implémenté, DataGrip recherche les objets susceptibles d'être modifiés par la requête et actualise uniquement cet ensemble d'objets.
Cela signifie que si votre base de données comporte de nombreux objets, vous n'avez plus à attendre la fin de l'actualisation du schéma à chaque fois que vous exécutez une instruction DDL. Dans la mesure où un seul ensemble d'objets est synchronisé, vous pouvez reprendre votre travail bien plus rapidement que si tous les objets devaient être actualisés, et vous aurez toujours tout ce dont vous avez besoin dans votre explorateur de bases de données.
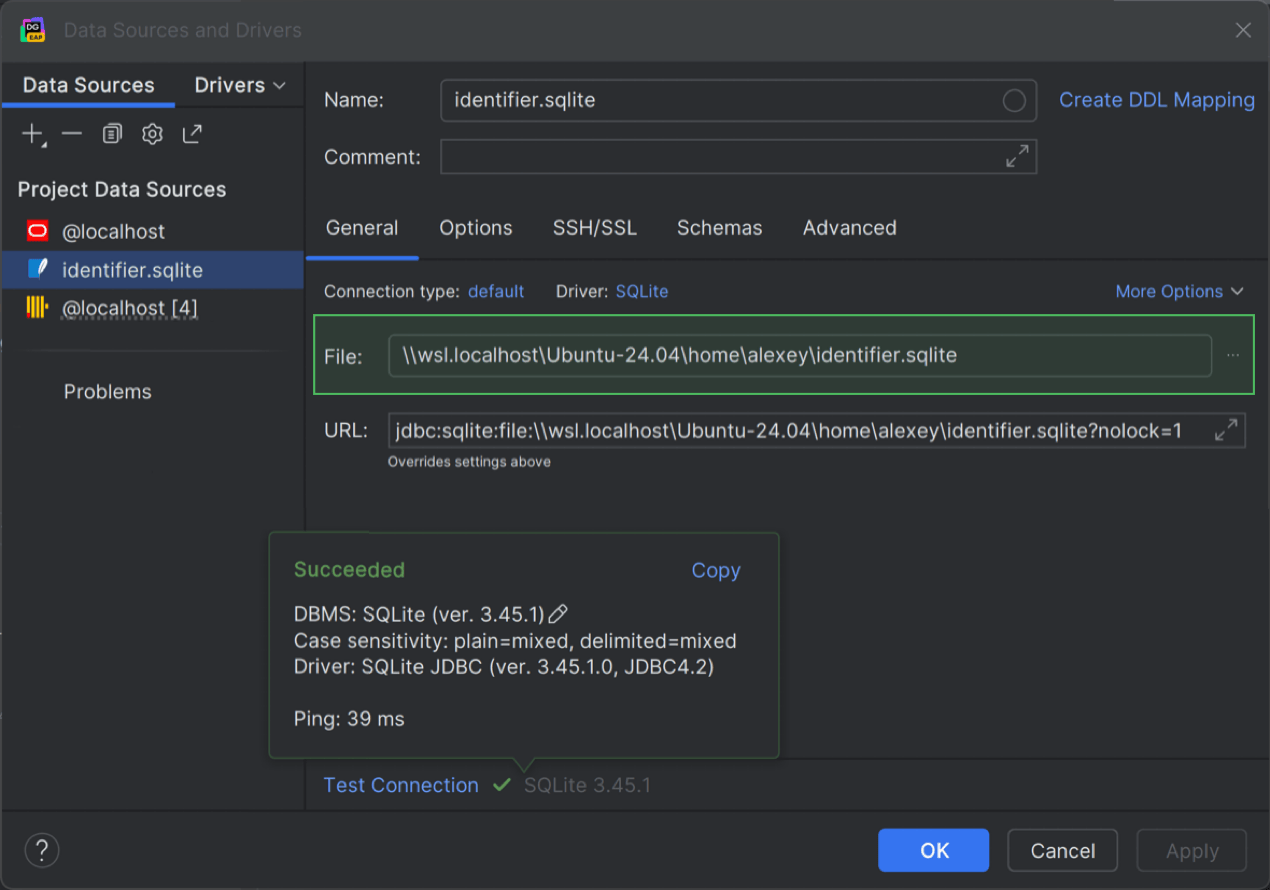
Chemin de fichier de base de données WSL SQLite
DataGrip prend désormais en charge les chemins WSL pour les fichiers de bases de données SQLite, une fonctionnalité qui était très attendue. Nous avons implémenté une solution pour gérer le problème de verrouillage en écriture dans WSL de notre côté.
Cela signifie que vous pouvez désormais accéder à votre base de données SQLite dans WSL et l'utiliser sans que le fichier ne soit verrouillé. Pour ce faire, ouvrez la boîte de dialogue Data Sources and Drivers et utilisez le format de chemin de fichier suivant : \\wsl$\<os>\home\<username>\<database_file_name>.sqlite. Par exemple, \\wsl.localhost\Ubuntu-24.04\home\alexey\identifier.sqlite.
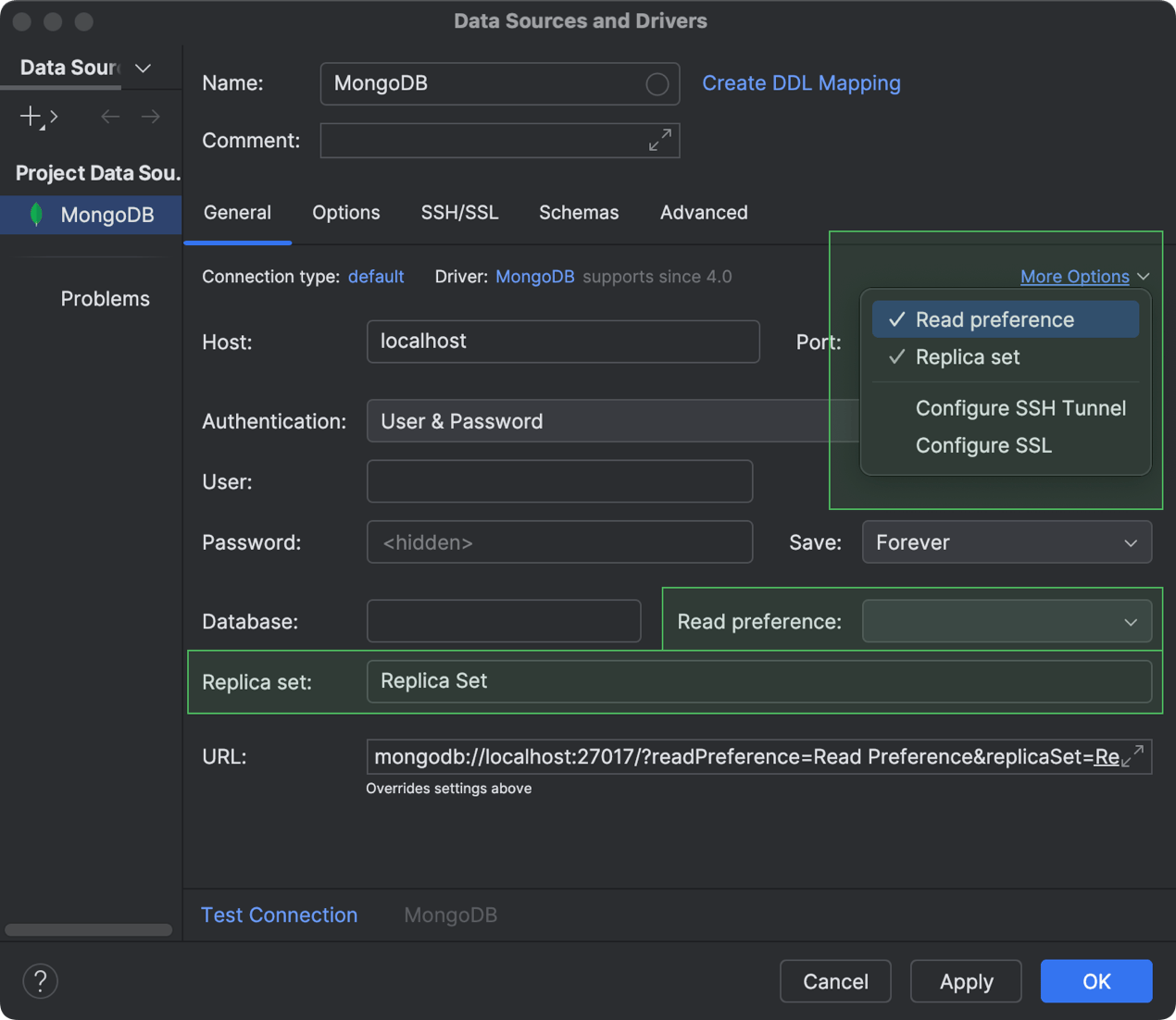
Prise en charge des paramètres de connectivité Read preference et Replica set MongoDB
Vous pouvez désormais configurer la façon dont les opérations de lecture sont acheminées aux membres d'un ensemble de réplicas MongoDB et même définir quel ensemble de réplicas doit être utilisé. Pour ce faire, pendant la configuration de la connexion à votre base de données MongoDB, allez dans la section More Options et activez l'option correspondante dans la boîte de dialogue Data Sources and Drivers. Une fois que vous avez sélectionné l'un des deux dans la liste, un nouveau champ s'affiche pour vous permettre de spécifier le paramètre. Pour spécifier vos préférences de lecture, sélectionnez celle qui vous convient dans le champ Read preference. Pour définir votre ensemble de réplicas, saisissez simplement son nom dans le champ Replica set.
Travailler avec les données
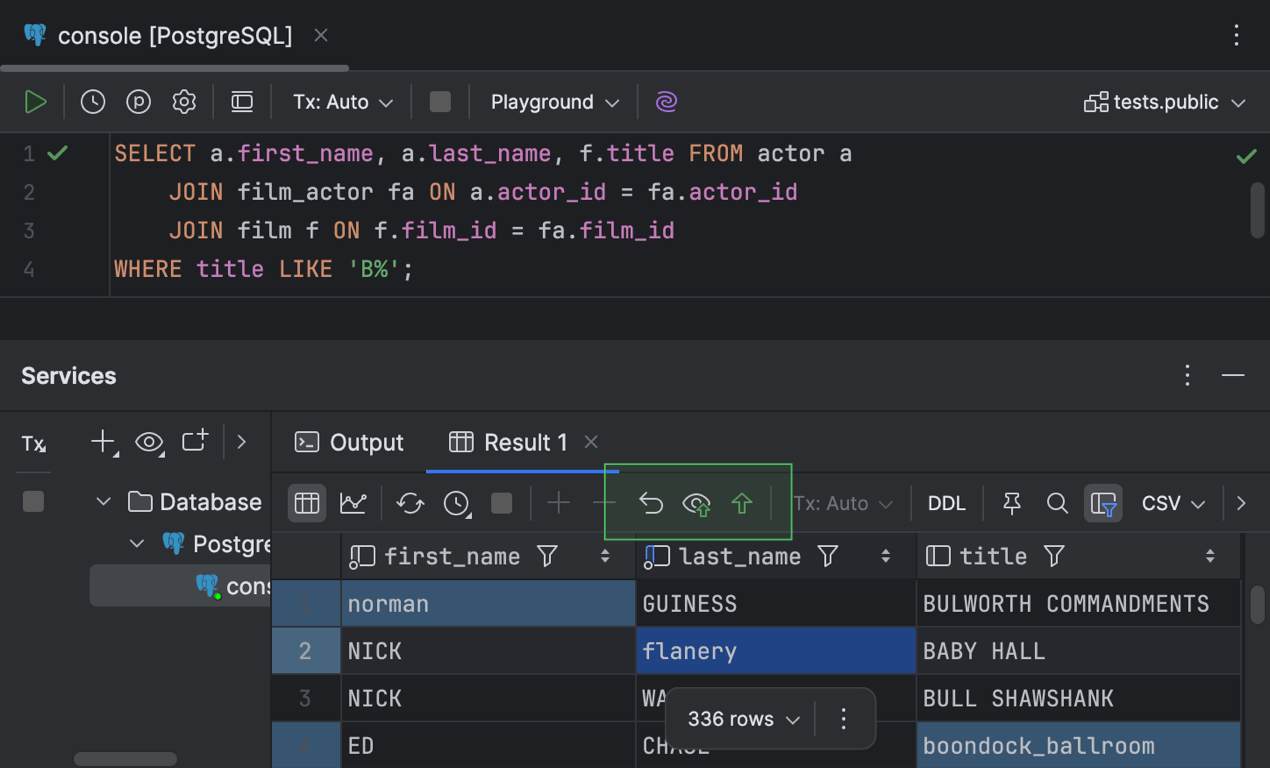
Résultats modifiables pour les requêtes SELECT avec des clauses JOIN
Fruit d'une décennie de travail, cette fonctionnalité tant attendue est maintenant disponible ! Auparavant, la grille des résultats des requêtes SELECT avec des clauses JOIN était en lecture seule. Désormais, vous pouvez exécuter ces requêtes, afficher leurs résultats et modifier les valeurs de cellules directement dans la grille des résultats de la requête. Pour ce faire, double-cliquez simplement sur une cellule ou sélectionnez-la et appuyez sur Entrée. Comme dans toute autre grille, vous pouvez également faire un clic droit sur la cellule et sélectionner Open in Value Editor pour modifier la valeur dans un autre volet qui s'ouvre à droite.
L'éditeur de données permet de modifier les données, que ce soit dans les résultats affichés dans l'éditeur ou dans la fenêtre d'outils Services. Une fois que vous modifiez une valeur de cellule, les boutons suivants deviennent actifs dans la barre d'outils de l'onglet Result de la fenêtre d'outils Services : Revert Selected, Preview Pending Changes, Submit.
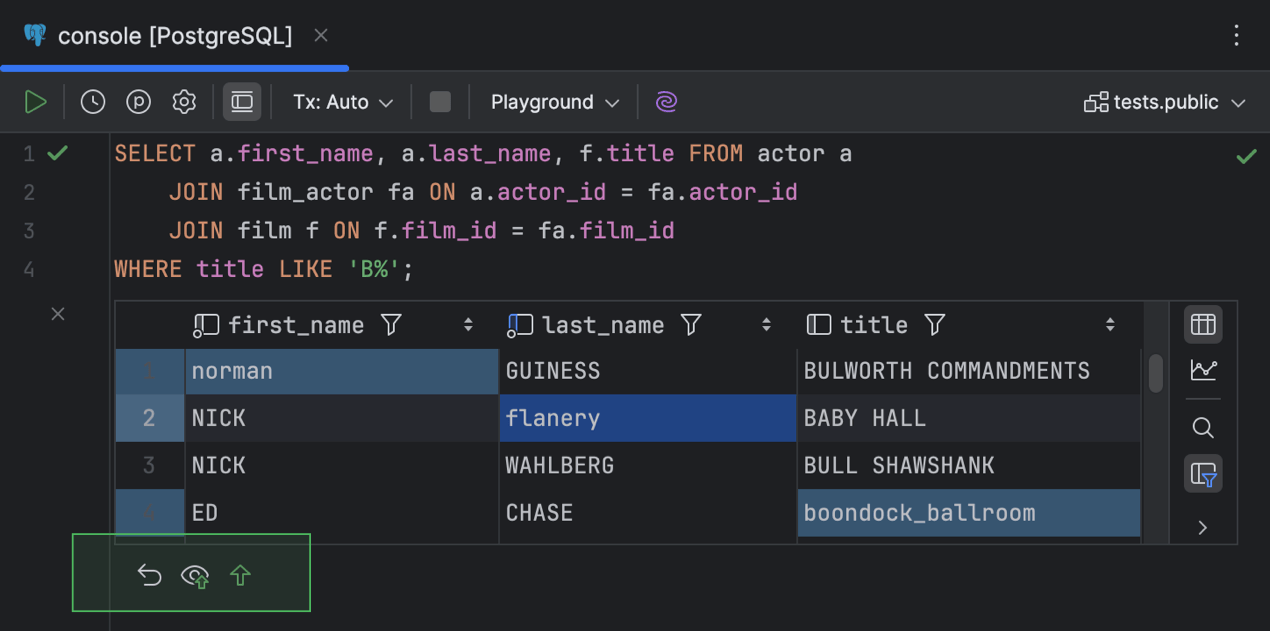
Une barre d'outils supplémentaire regroupant tous ces boutons s'affiche également en bas de la fenêtre de résultats de l'éditeur.
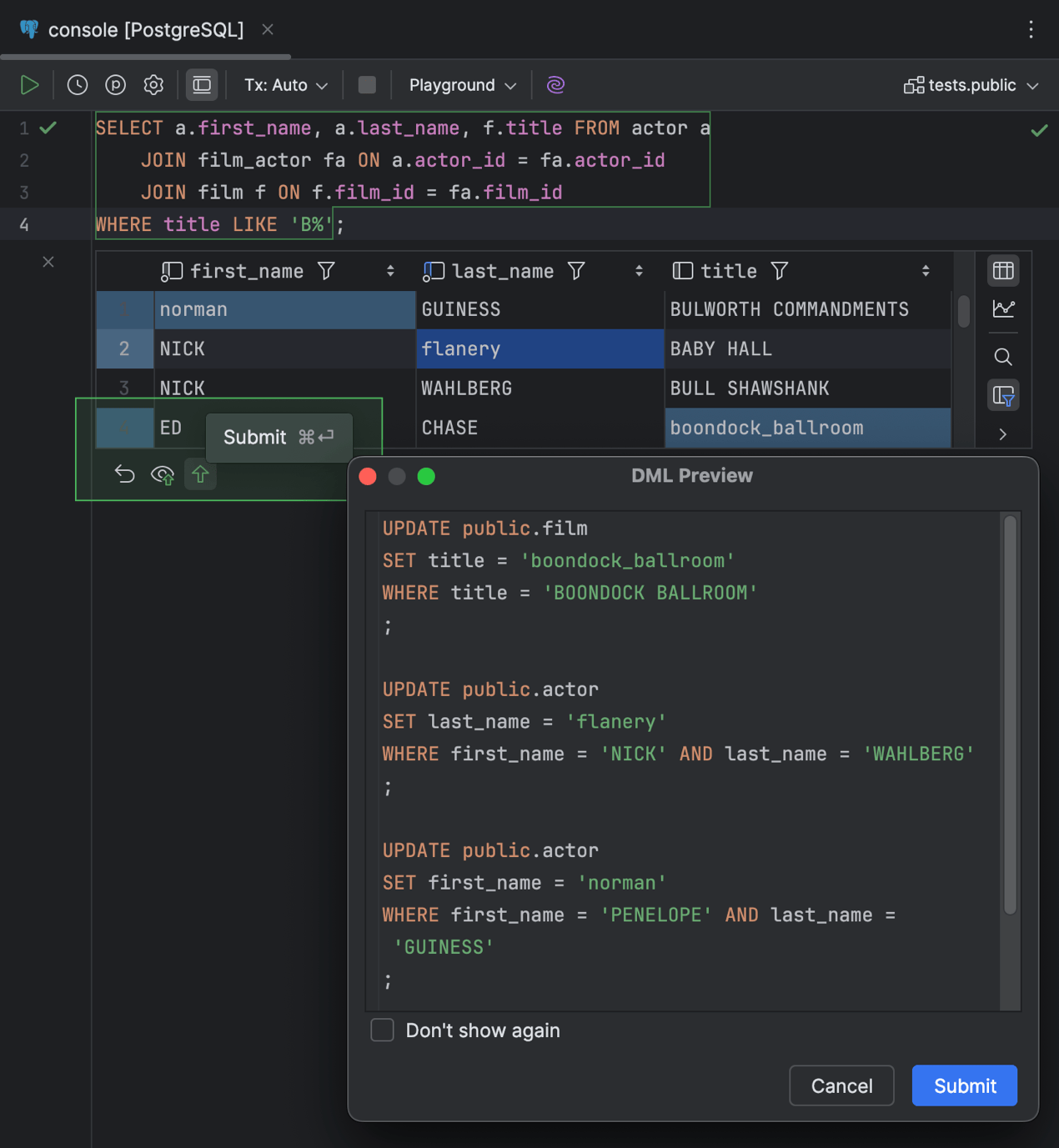
Lorsque vous transférez vos modifications dans la base de données, DataGrip affiche la boîte de dialogue DML Preview pour vous permettre de vérifier les instructions générées en premier lieu. Pour éditer vos modifications, cliquez sur Cancel et apportez les ajustements souhaités. Pour confirmer vos modifications, cliquez sur Submit.
Cette fonctionnalité n'est pas prise en charge pour l'opérateur SQL UNION, les résultats de l'opération d'auto-jointure de la table, les résultats avec des colonnes de résultat de calcul (par exemple, CONCAT), ou des bases de données NoSQL. Pour s'assurer que cette fonctionnalité s'exécute correctement, chaque ligne doit comporter un champ ou un ensemble de champs pour l'identifier de façon unique.
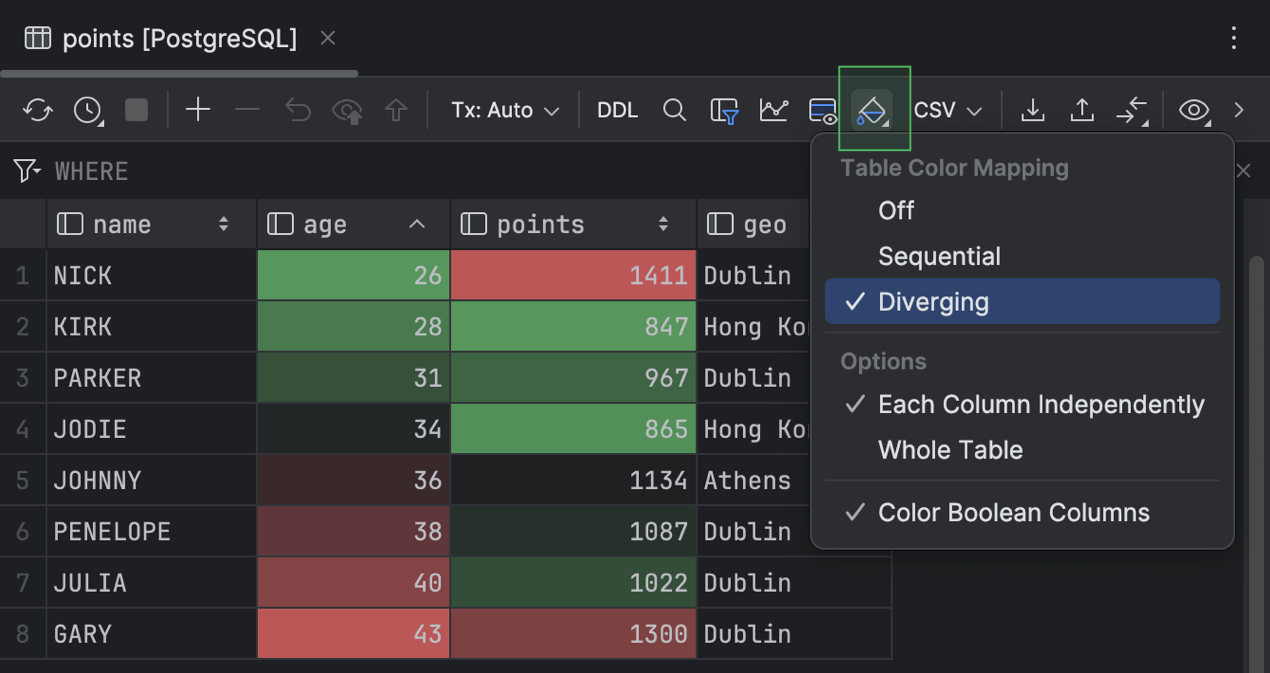
Carte thermique de grille
Dans l'éditeur de données, DataGrip fournit désormais des cartes thermiques de grilles pour lesquelles deux profils de couleurs sont possibles, Diverging et Sequential. Pour activer la carte thermique de votre grille, cliquez sur Table Coloring Options sur la barre d'outils et sélectionnez l'un des profils.
La palette de couleurs Diverging met l'accent sur la variation par rapport à une norme. Elle se compose de deux couleurs contrastées qui s'écartent d'une valeur centrale dans deux directions opposées.
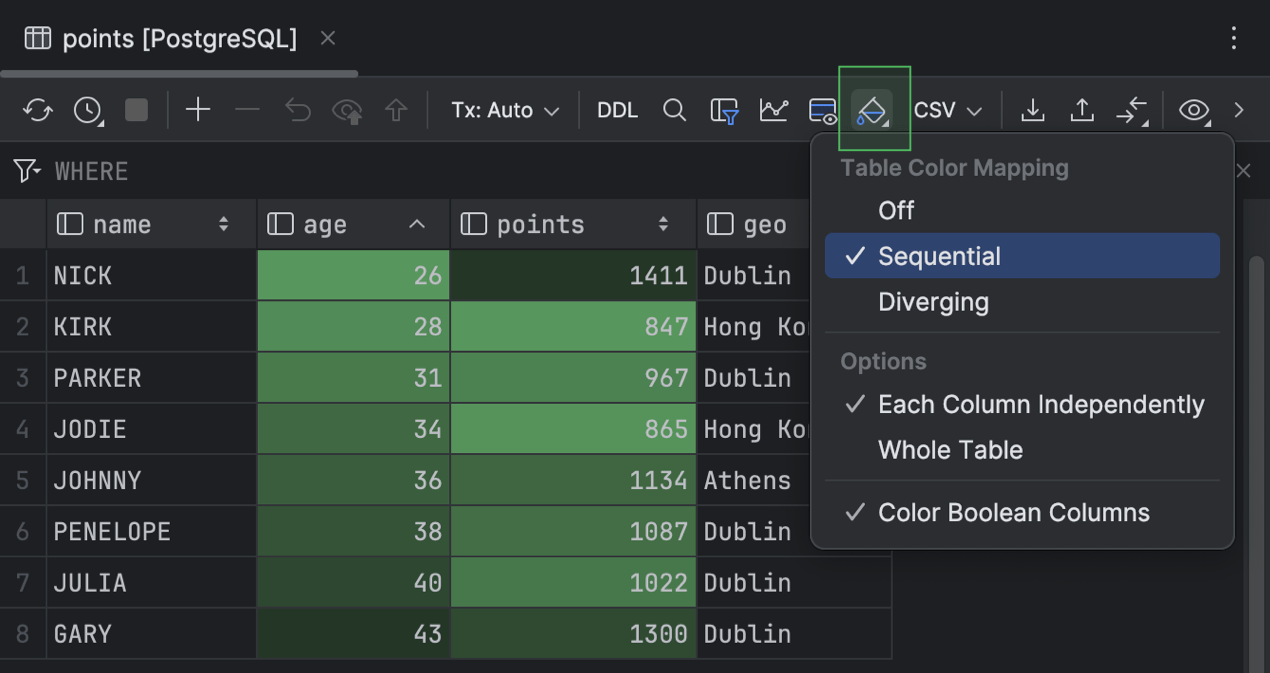
La palette de couleurs Sequential consiste en une seule couleur ou en une gamme de couleurs proches dont l'intensité varie.
Vous pouvez appliquer les palettes de couleurs de la carte thermique à l'ensemble de la table, à chaque colonne séparément ou aux valeurs booléennes uniquement.
Une seule action pour effacer tous les filtres locaux d'une grille
Désormais, vous pouvez effacer le filtre local pour toutes les colonnes de votre grille en une seule action. Pour ce faire, ouvrez la fenêtre contextuelle Find Action en appuyant sur Ctrl+Maj+A, commencez à taper Clear Local Filter For All Columns, puis sélectionnez l'action dans la liste.
Éditeur de code
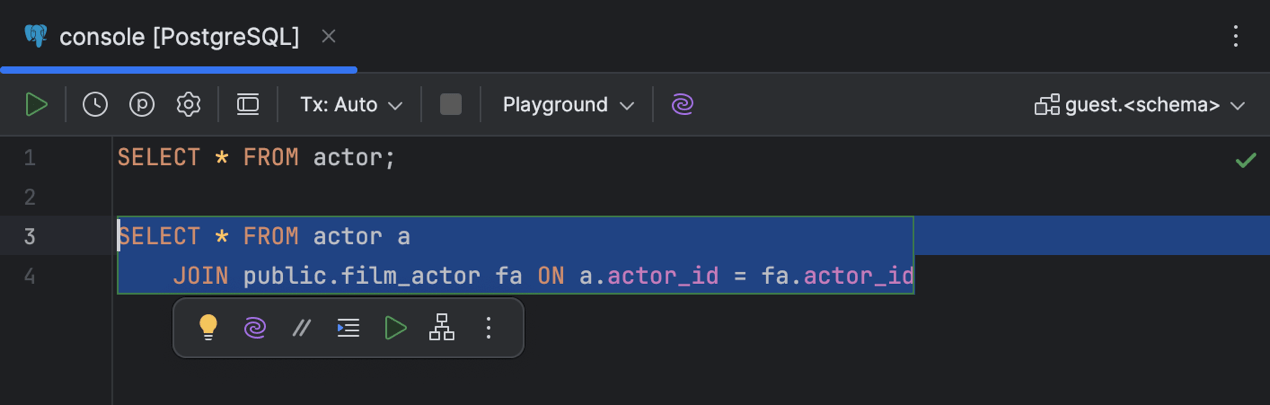
Barre d'outils flottante
DataGrip affiche désormais un ensemble d'actions basées sur le contexte et sur l'IA disponibles pour un élément de code donné dans la barre d'outils flottante. Sélectionnez du code dans votre éditeur de code pour afficher la barre d'outils.
Pour personnaliser la barre d'outils flottante, utilisez le menu kebab (trois points verticaux). Pour la masquer, utilisez le même menu ou allez dans Settings | Advanced Settings | Editor et cochez l'option Hide floating toolbar for code editing.
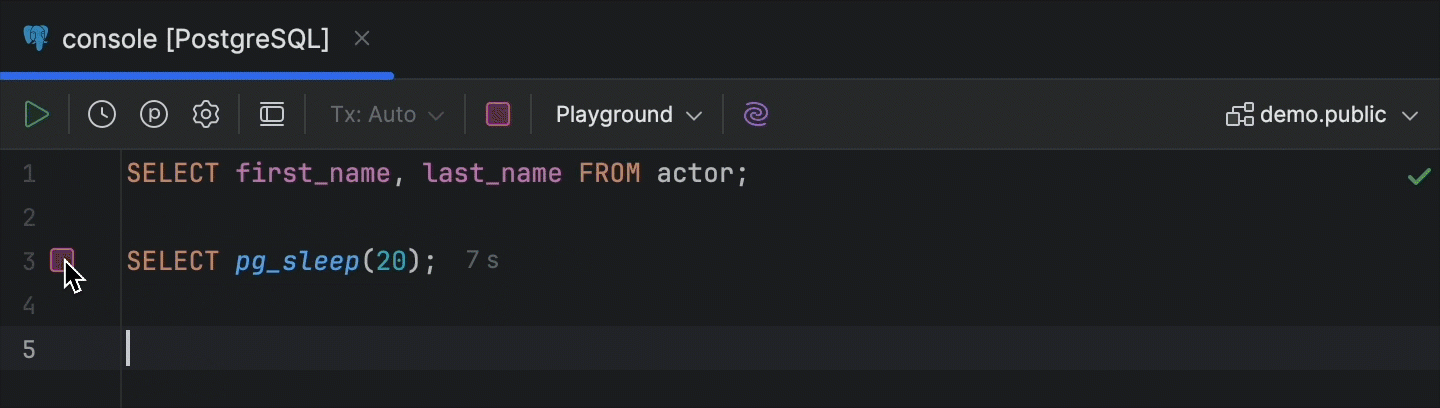
Bouton Cancel Running Statements dans la gouttière
Le survol de l'icône de progression dans la gouttière d'une instruction en cours d'exécution la transforme désormais en bouton Cancel Running Statements.
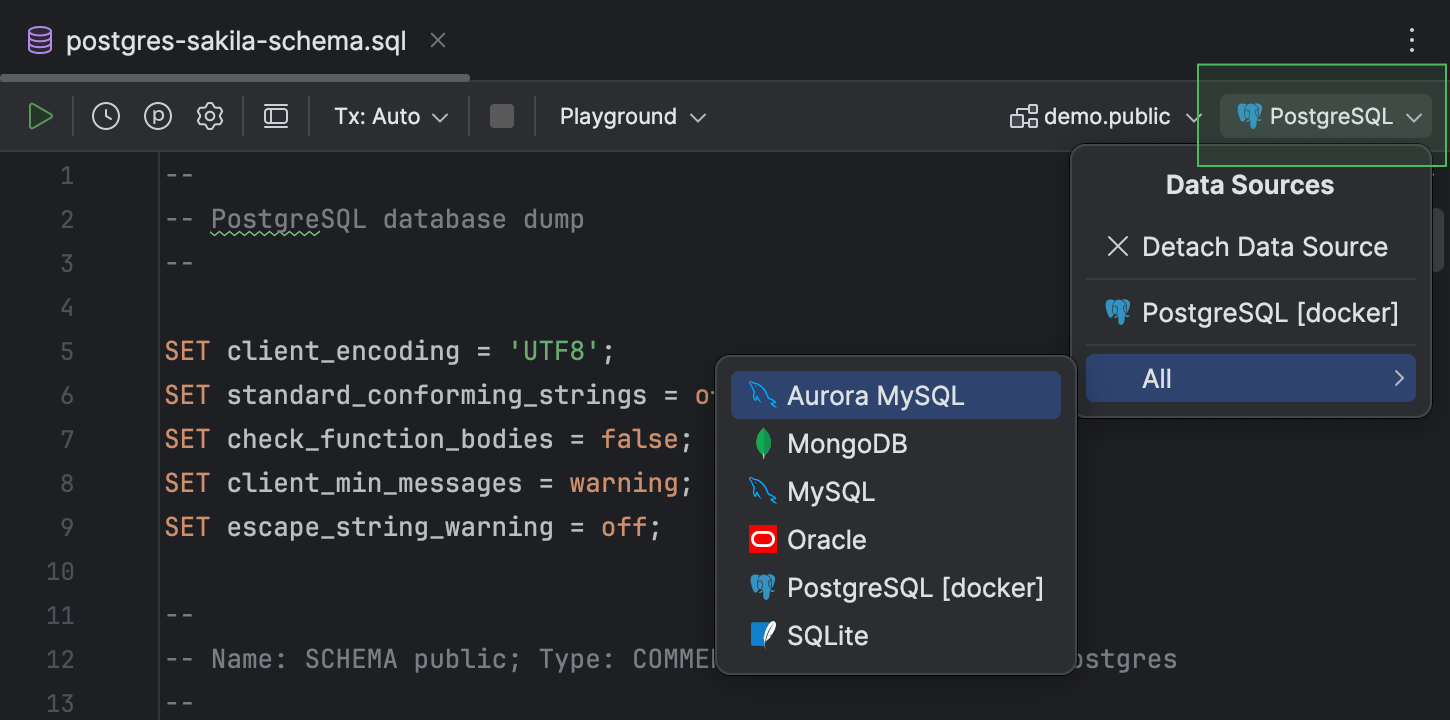
Sources de données jointes qui persistent après le redémarrage
Précédemment, vous deviez joindre les sources de données aux fichiers à chaque redémarrage de l'IDE. C'était particulièrement pénible, donc nous l'avons corrigé !
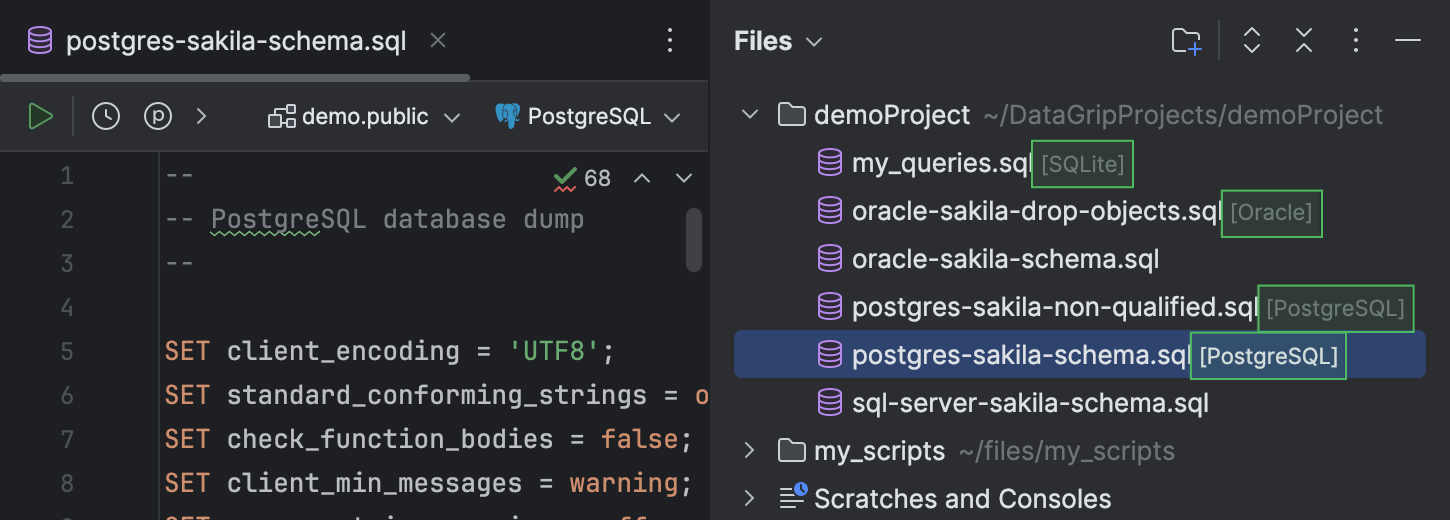
De plus, vous pouvez voir la source de données jointe à chaque fichier dans la fenêtre d'outils Files.
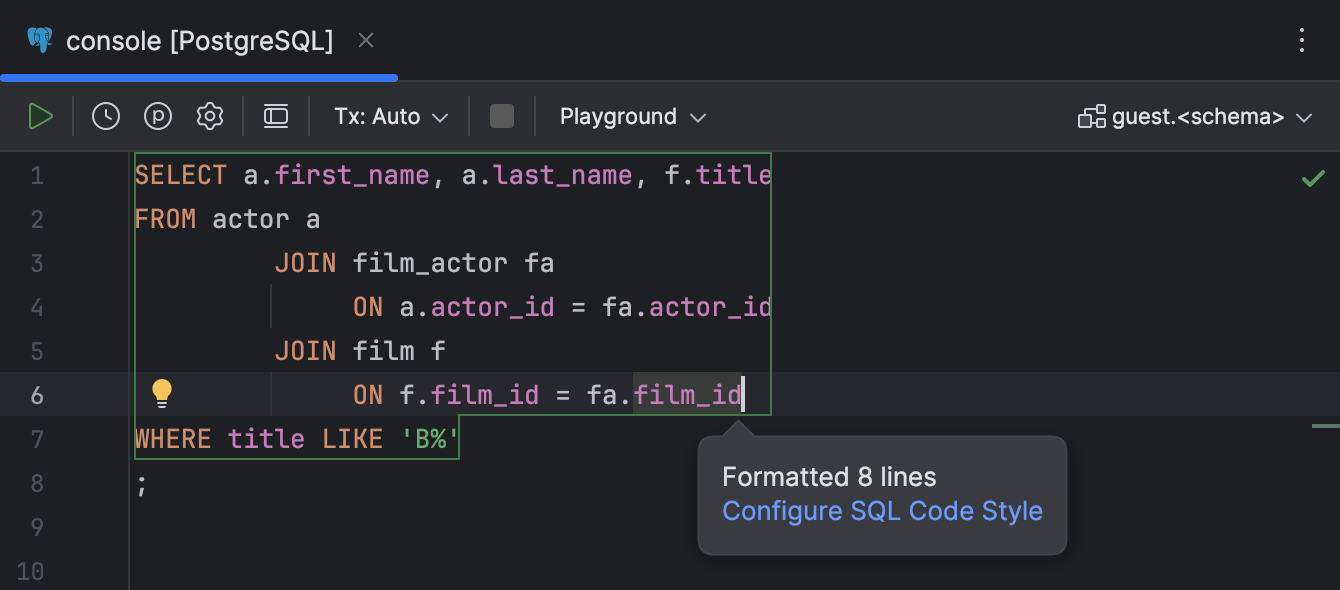
Accès rapide aux paramètres de style du code
Il est désormais plus simple d'accéder aux paramètres de style du code directement depuis la fenêtre contextuelle qui s'affiche à chaque reformatage du code.
Nous espérons que vous apprécierez ces nouveautés ! Si vous rencontrez un bug ou souhaitez nous suggérer des fonctionnalités, indiquez-le dans notre outil de suivi des tickets.
Vous souhaitez vous tenir au courant des dernières fonctionnalités et savoir comment travailler avec les bases de données de façon plus productive ? Abonnez-vous à notre blog et suivez-nous sur X !