Nouveautés de DataGrip 2026.1
Prise en charge des agents d'IA, nouveau flux pour la création de fichiers de requêtes, modèles de sources de données et bien plus encore !
Bienvenue dans la première édition des Nouveautés de DataGrip pour 2026. La nouvelle version apporte des améliorations pratiques permettant de rendre les workflows de base de données plus efficace. Citons parmi ces mises à jour l'intégration d'agents d'IA, des améliorations apportées aux fichiers de requêtes et aux consoles, ainsi qu'un moyen plus simple de réutiliser les paramètres de source de données dans vos JetBrains IDEs.
- IA:
- Fichiers et consoles de requête:
- Connectivité et sources de données :
- Autres améliorations :
Améliorations de l'IA : flux agentique
JetBrains AI évolue pour vous offrir encore plus de choix, de transparence et de flexibilité concernant l'utilisation de l'intelligence artificielle dans DataGrip.
Cette version apporte une création de fichiers SQL plus intelligente à partir du chat avec l'IA, l'intégration de Claude Agent et de Codex dans l'interface de chat, ainsi que des outils spécifiques à la base de données dans le serveur MCP pour les workflows agentiques.
Création de fichier avec le dialecte SQL et la source de données jointe
Pendant que vous discutez avec l'AI Assistant dans la fenêtre d'outils AI Chat, vous pouvez créer un fichier à partir d'un extrait de code.
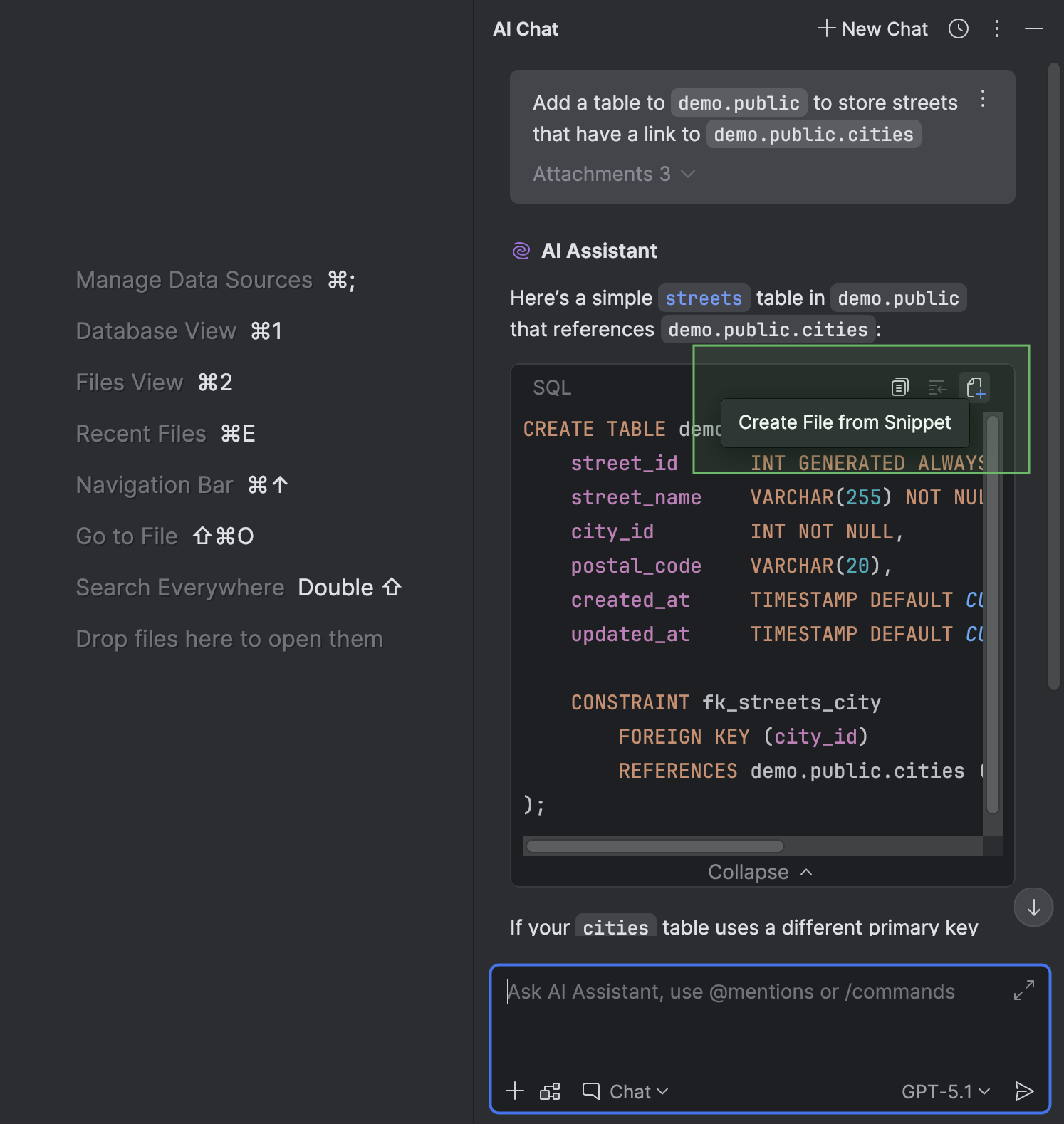
Si un contexte se rapportant au dialecte SQL, une source de données ou un schéma est fourni dans le chat, il est inutile de joindre la source de données ou le schéma, ni de définir le dialecte, car DataGrip s'en charge automatiquement. Cela s'applique également aux questions que vous posez à l'AI Assistant sur un fichier qui dispose déjà d'une source de données jointe : DataGrip joint cette source de données au fichier qui vient d'être créé.
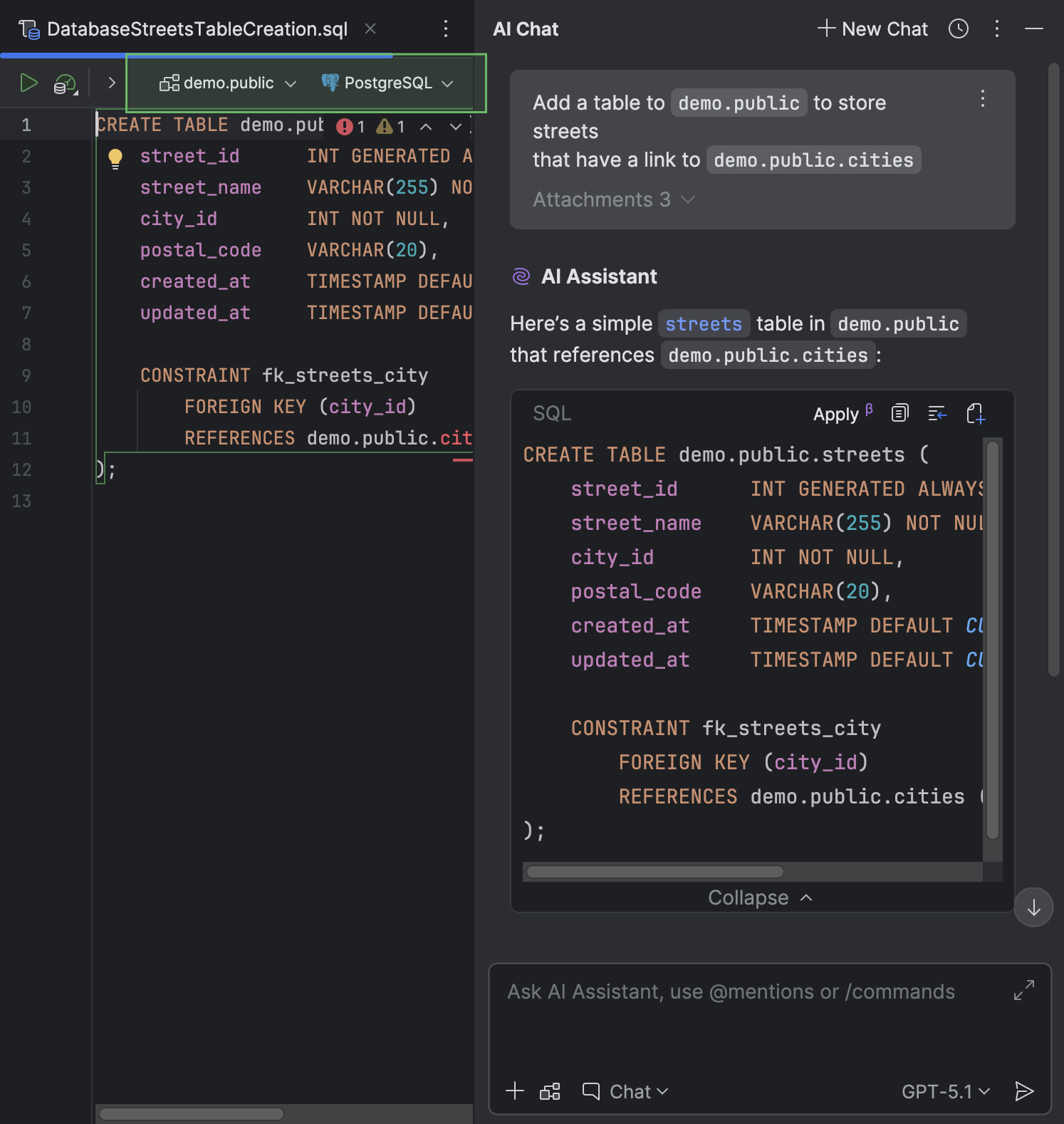
DataGrip stocke le fichier créé dans le répertoire de projet actif.
Intégration des agents d'IA dans le chat avec l'IA
Claude Agent et Codex sont désormais intégrés de façon native dans l'interface de chat par IA. Il est ainsi plus facile d'obtenir de l'assistance pour votre tâche, quelle qu'en soit la nature.
Actuellement, l'intégration de Codex impose la configuration manuelle du serveur MCP. Pour de plus amples instructions, reportez-vous à la page de documentation correspondante pour Codex.
Vous trouverez plus d'informations sur l'intégration dans les articles de blog consacrés à JetBrains AI : Présentation de Claude Agent dans les JetBrains IDEs (en anglais), Codex est désormais intégré aux JetBrains IDEs.
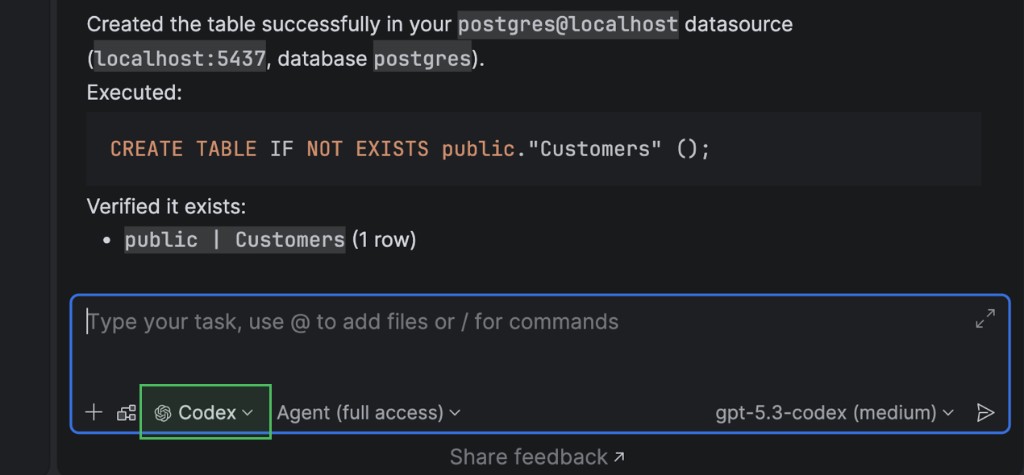
Fonctionnalités propres aux bases de données du serveur MCP
Nous avons étendu le serveur MCP avec des fonctionnalités propres aux bases de données. Grâce à cette amélioration, les agents d'IA intégrés et les outils tiers peuvent fonctionner avec les bases de données de façon plus structurée.
Ces nouvelles fonctionnalités incluent :
- Obtention et test des configurations de connexion.
- Liste des schémas de base de données.
- Extraction des types d'objets de schéma pris en charge (tels que les tables et les vues) et navigation des objets de schéma.
- Affichage des requêtes SQL récentes et en cours d'exécution.
- Exécution et annulation des requêtes SQL en cours d'exécution.
- Aperçu des données tabulaires et obtention de jeux de résultats au format CSV.
Pour la sécurité, quatre types de consentement utilisateur sont requis par défaut :
- Requêtes d'accès au schéma.
- Requêtes d'accès aux données.
- Requêtes de modification des schémas.
- Requêtes de modification des données.
L'IDE demande votre consentement si une autorisation est requise.
Vous pouvez modifier vos préférences de consentement dans les paramètres de l'IDE, dans la section Tools | AI Assistant.
Fichiers et consoles de requête
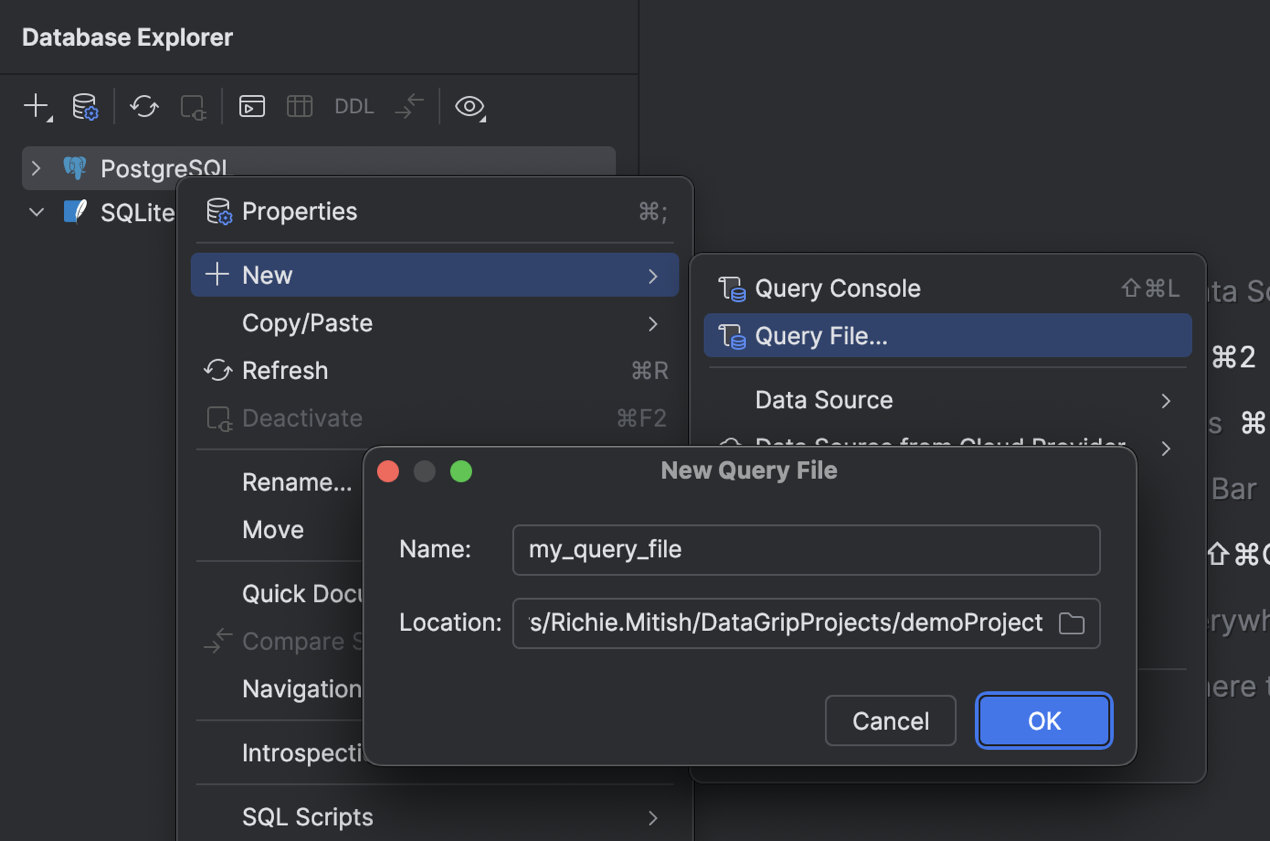
Nouveau flux de création de fichier de requête
L’interface a été repensée pour faciliter le travail impliquant à la fois des fichiers de requêtes et des consoles de requêtes. Vous pouvez désormais utiliser uniquement les fichiers ou les consoles, ou les deux en même temps, selon vos tâches et votre workflow.
Pour créer un fichier de requête, faites un clic droit sur une source de données et sélectionnez New | Query File ou appuyez sur Maj+Cmd+J (macOS) ou Ctrl+Alt+Maj+Q (Windows/Linux). Ensuite, dans la boîte de dialogue New Query File, spécifiez le nom de fichier et le répertoire où vous souhaitez le stocker. Pour le stocker dans le projet actif et lui associer le fichier, spécifiez le répertoire de projet actif ou l'un de ses sous-répertoires.
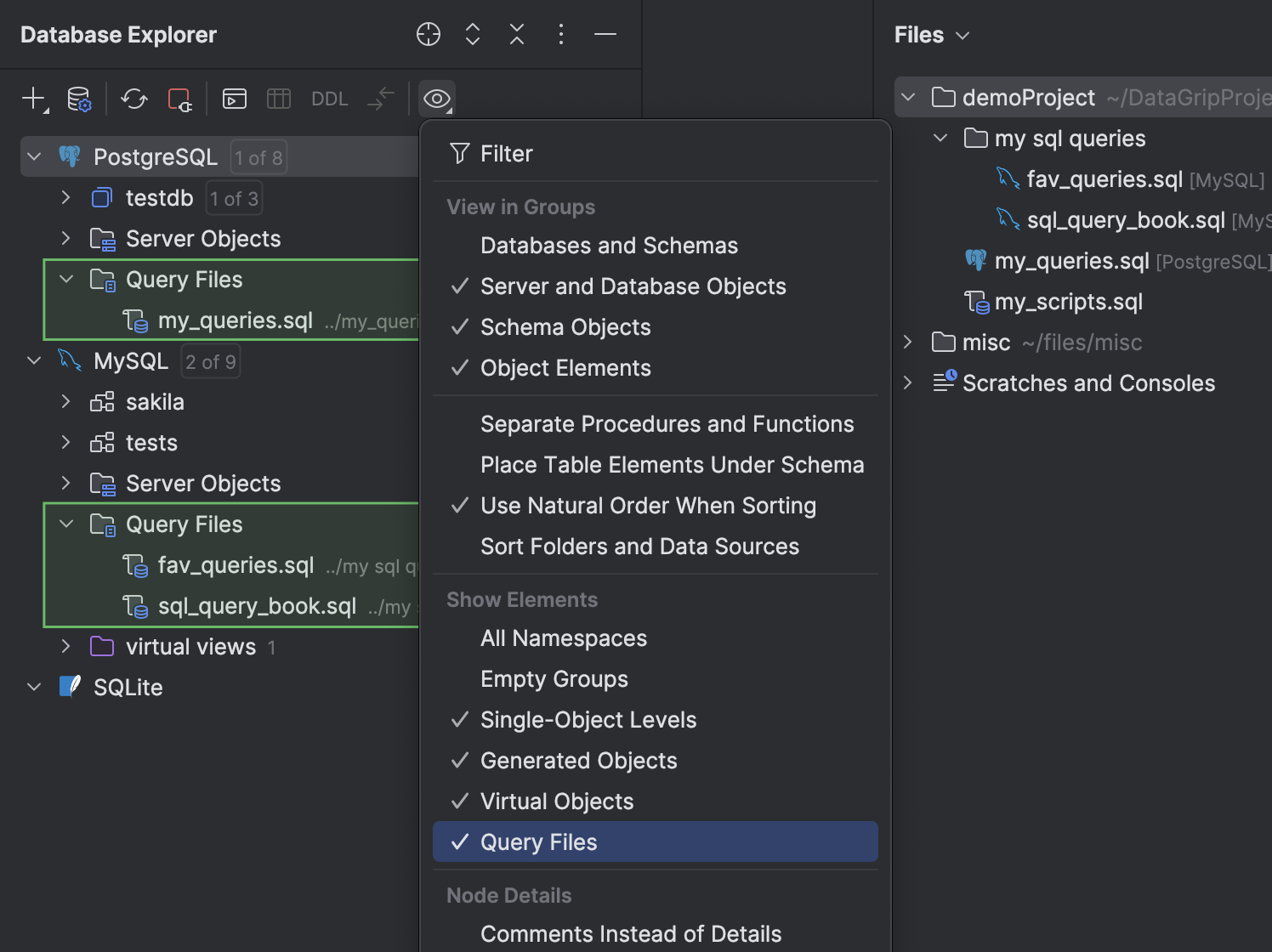
Dossier Query Files dans l'explorateur de bases de données
Il est désormais possible d'accéder à vos fichiers de requête dans l'explorateur de bases de données. Nous avons ajouté le dossier Query Files, qui apparaît sous chaque nœud de source de données. Pour afficher ou masquer ce dossier, cliquez sur View Options sur la barre d'outils de la fenêtre d'outils, puis activez ou désactivez l'option Query Files.
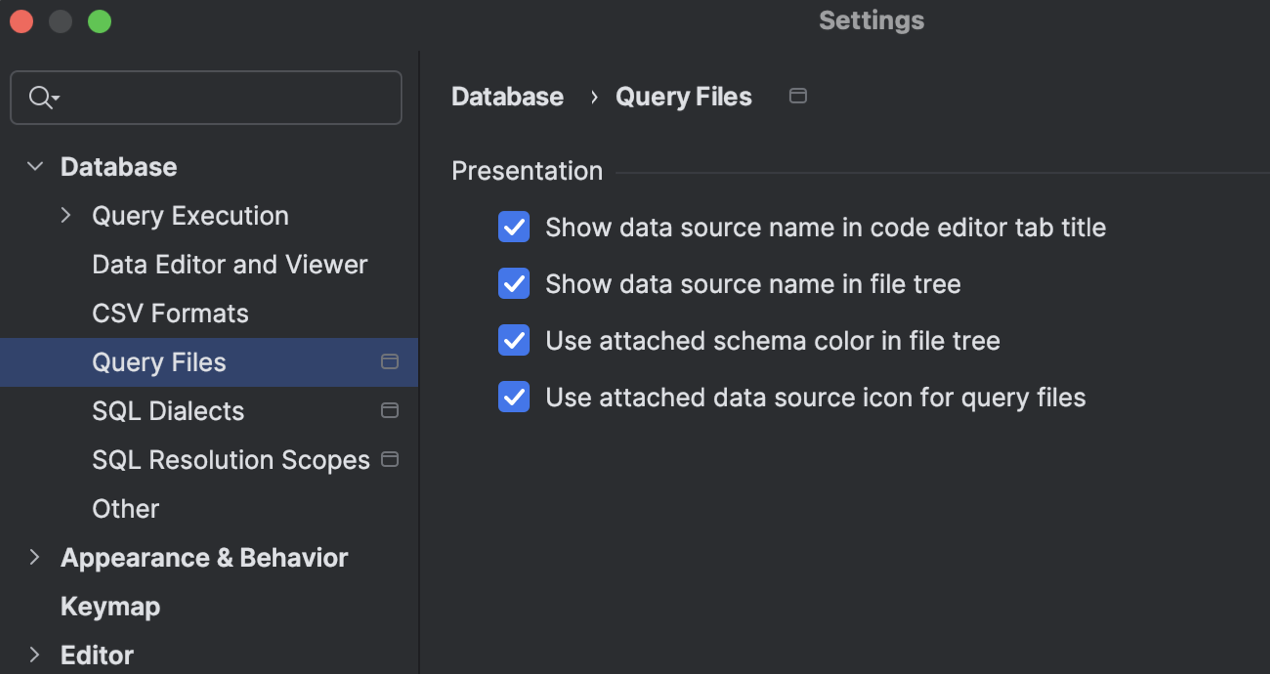
Nouvelles options d'adaptation de l'affichage des fichiers
Différentes tâches nécessitent différentes informations pour être visibles. Nous avons ajouté certains paramètres pour nous assurer que la présentation des fichiers de requête vous donne les bonnes informations pour votre propre cas d'usage. Vous pouvez utiliser ces paramètres pour afficher ou masquer les noms de sources de données, appliquer des couleurs de schéma et utiliser l'icône de la source de données jointe à vos fichiers de requête.
Connectivité
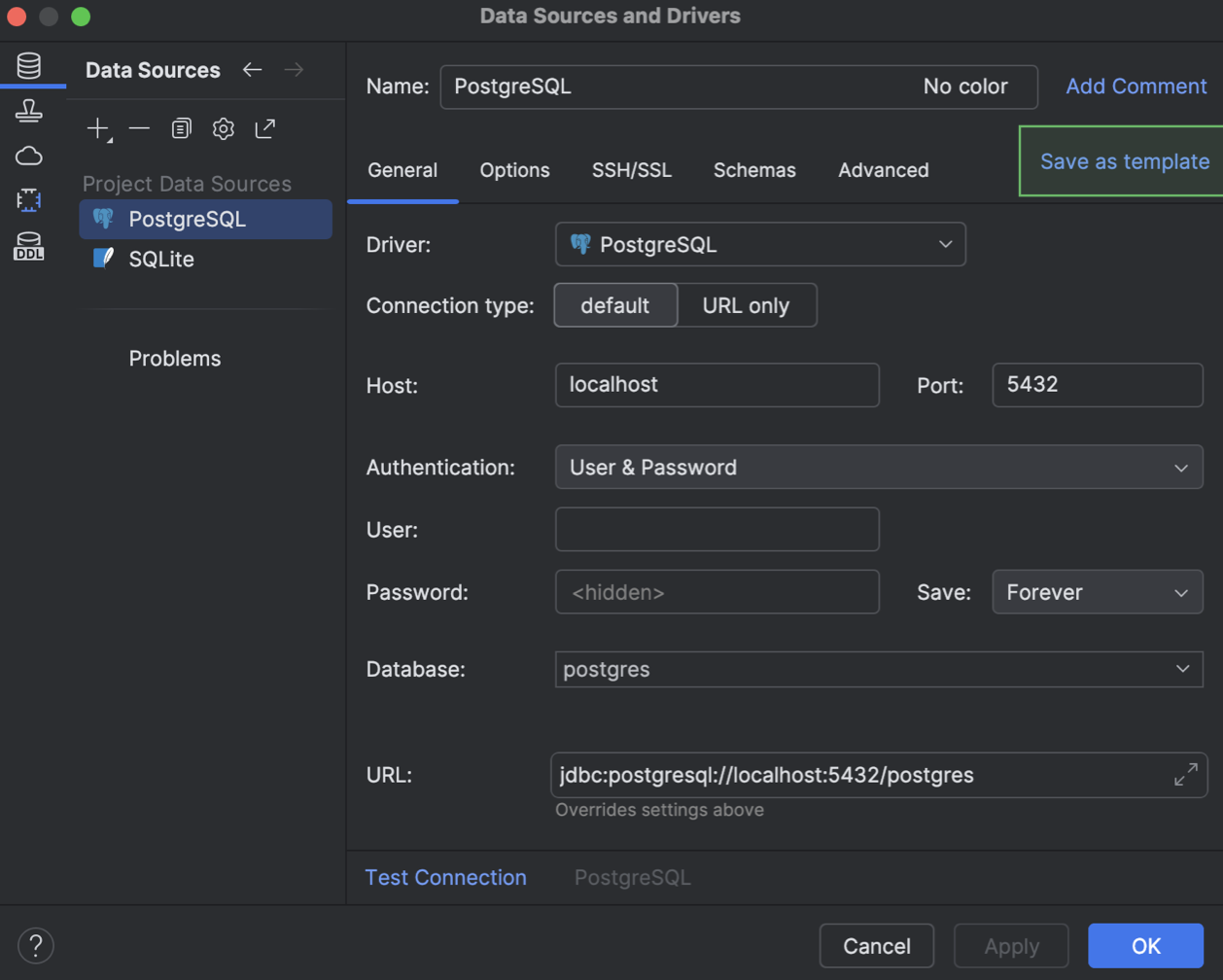
Modèles de sources de données
Nous avons implémenté une solution permettant de stocker les paramètres de source de données sous forme de modèle dans votre compte JetBrains. Lorsqu'il est stocké de cette façon, le modèle devient disponible dans tous les JetBrains IDE disposant d'une fonctionnalité de base de données fournie via votre compte JetBrains. Ces modèles stockent les paramètres des onglets General et Advanced de la boîte de dialogue Data Source and Drivers, mais excluent vos identifiants de base de données.
Vous pouvez créer un modèle dans la boîte de dialogue Data Source and Drivers. Dans l'onglet Data Sources, sélectionnez la source de données devant servir à créer un modèle et cliquez sur Save as template.
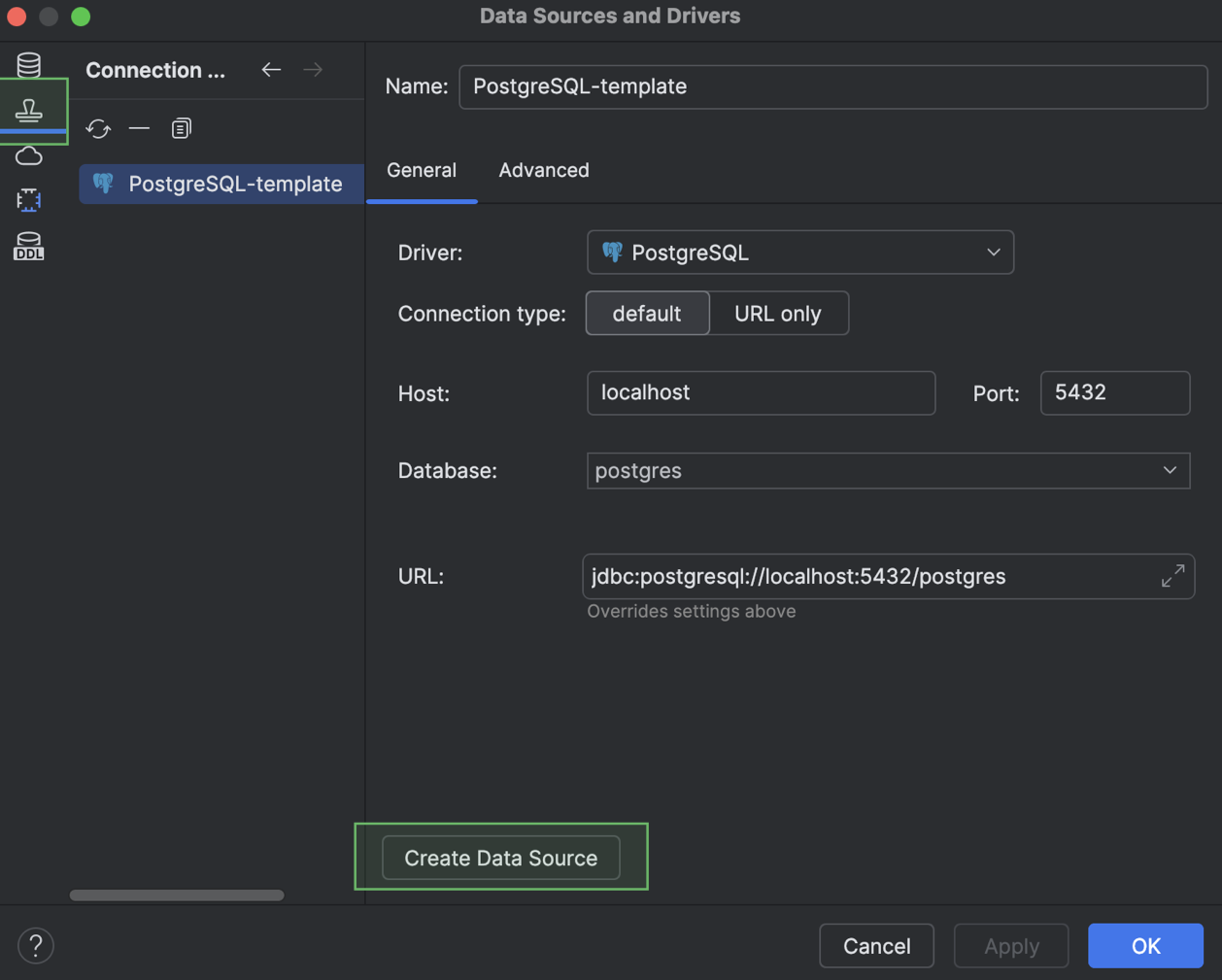
Le nouveau modèle va s'afficher sur l'onglet Data Source Templates. Vous pouvez créer une source de données utilisant le modèle à tout moment avec le bouton Create Data Source.
PostgreSQL 18 prend en charge PostgreSQL
DataGrip prend désormais en charge PostgreSQL 18, qui a été publié l'année dernière. La prise en charge complète inclut notamment les mots-clés et commandes suivants :
- Résolution de
OLDetNEWdans les clausesRETURNING. WITHOUT OVERLAPSdans les contraintes primaires et uniques.PERIODdans les contraintes de clé étrangère.GENERATED ALWAYS AS (...) [STORED | VIRTUAL]pour les colonnes.- Contraintes
NOT ENFORCEDetNOT VALID.
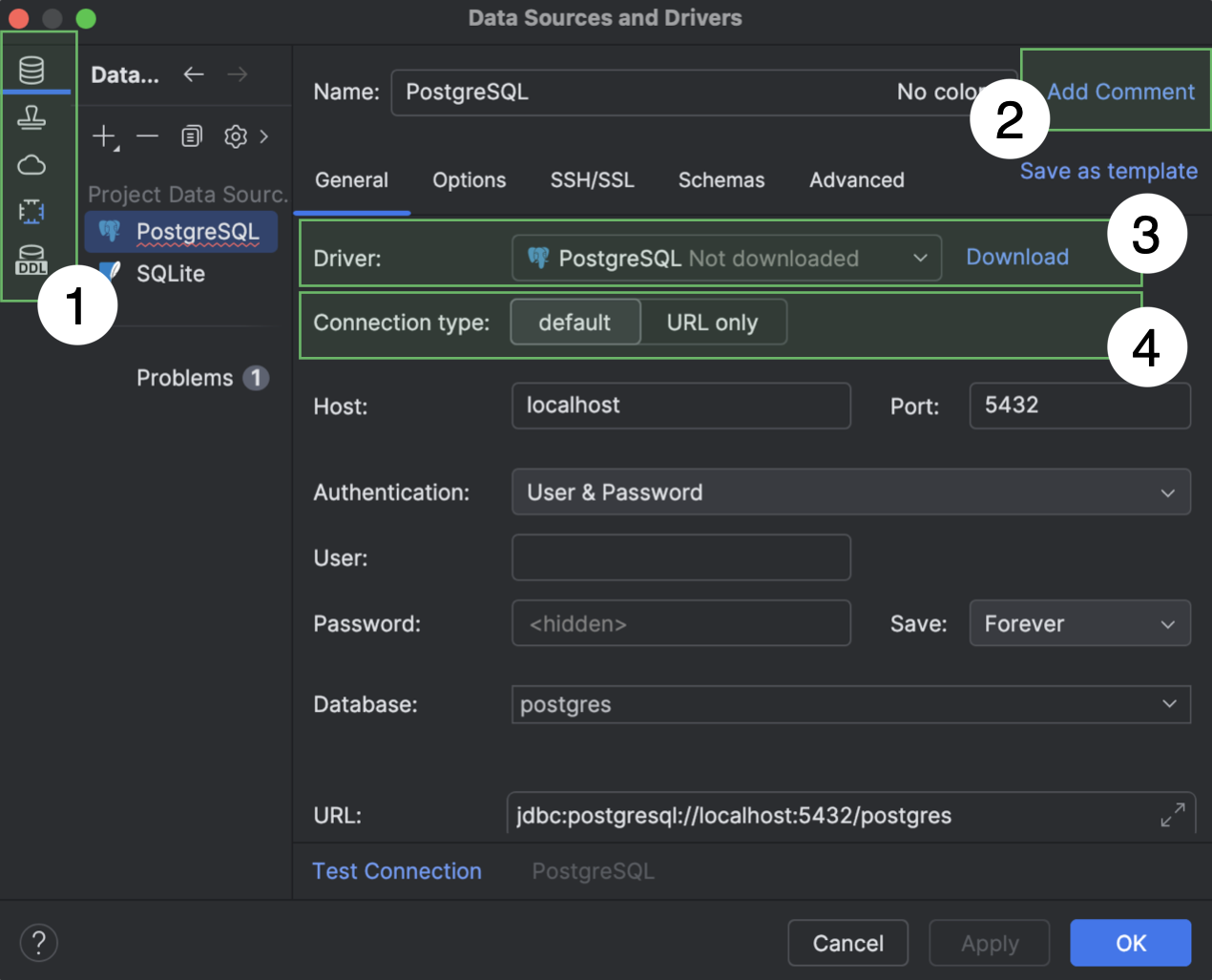
Améliorations de la boîte de dialogue Data Sources and Drivers
Nous avons apporté plusieurs modifications à la boîte de dialogue Data Sources and Drivers.
- Les sections Data Sources, Clouds, Drivers et DDL Mappings constituent désormais les onglets principaux de la boîte de dialogue, dans sa partie gauche.
- Lorsque le champ Comment est vide, il est masqué par défaut. Pour l'afficher, cliquez sur Add Comment près du champ Name.
- Si le pilote sélectionné dans le menu déroulant Driver n'a pas encore été téléchargé, l'option Download s'affiche près du menu. Cliquez dessus pour télécharger le pilote.
- Les options de la liste déroulante Connection type sont devenues des onglets. Si une source de données comporte plus de trois types de connexion, ils s'affichent dans une liste déroulante.
De plus, l'action Create DDL Mapping a été supprimée. Vous pouvez créer un mappage DDL sur l'onglet principal DDL Mappings.
Workflow Explain Plan
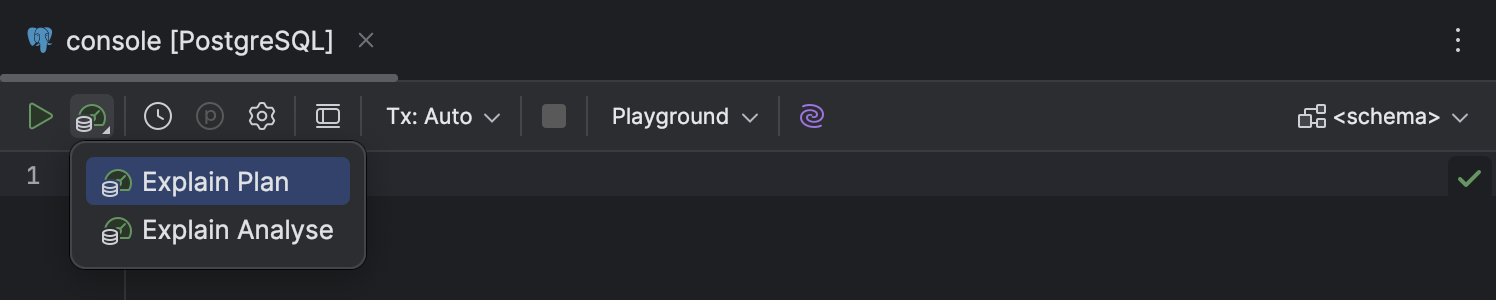
Améliorations de l'interface et de l'expérience utilisateur
Nous avons retouché en partie le workflow Explain Plan pour le rendre plus facile à découvrir, plus informatif et simple à utiliser :
- La liste d'options de la liste déroulante Explain Plan de la barre d'outils de l'éditeur de code a été limitée à deux possibilités : Explain Plan et Explain Analyse.
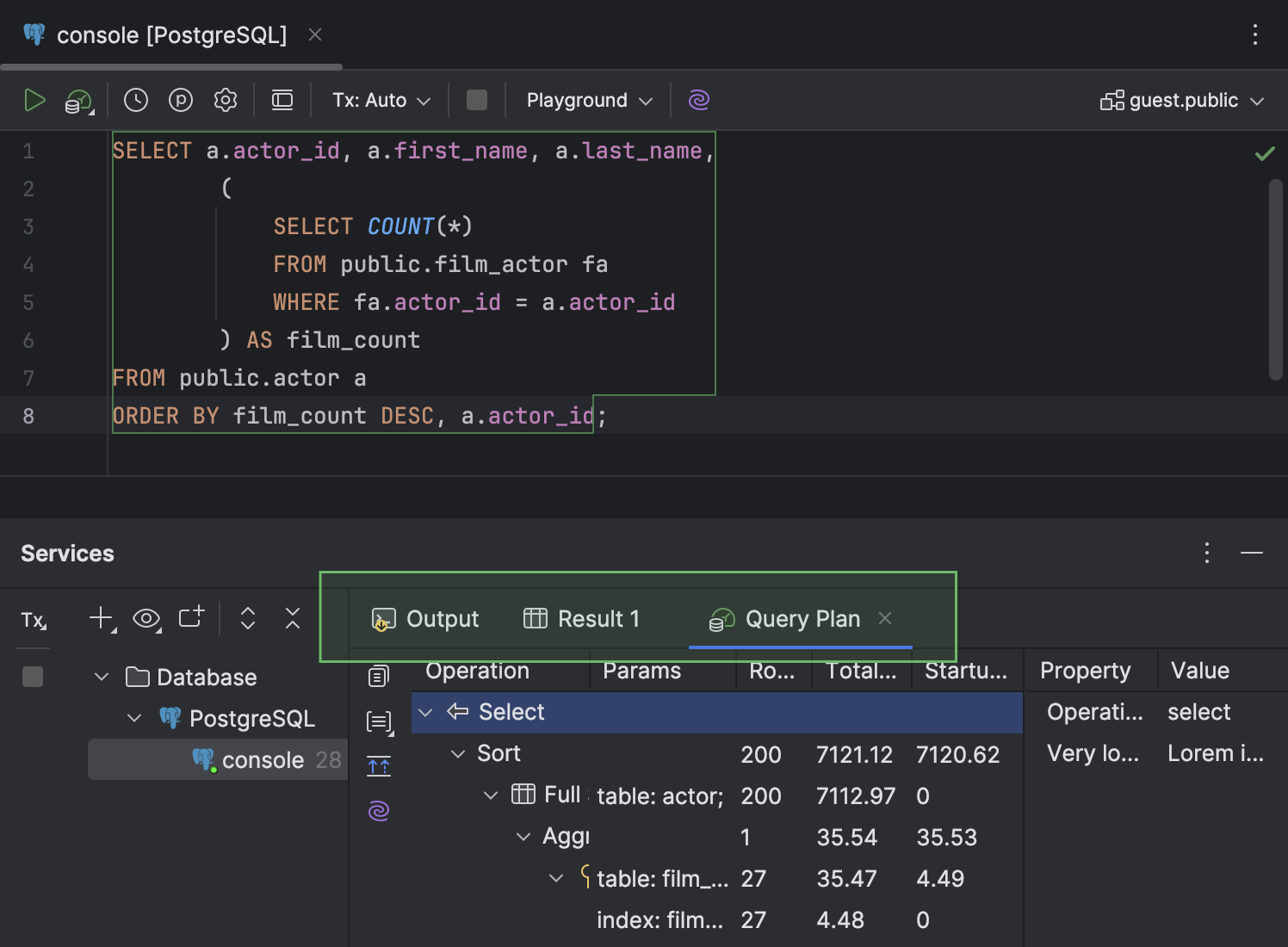
- Dans la fenêtre d'outils Services, l'onglet Query Plan qui sert à afficher le plan a été déplacé au même niveau que les onglets Output et Result. Il comporte également une nouvelle icône.
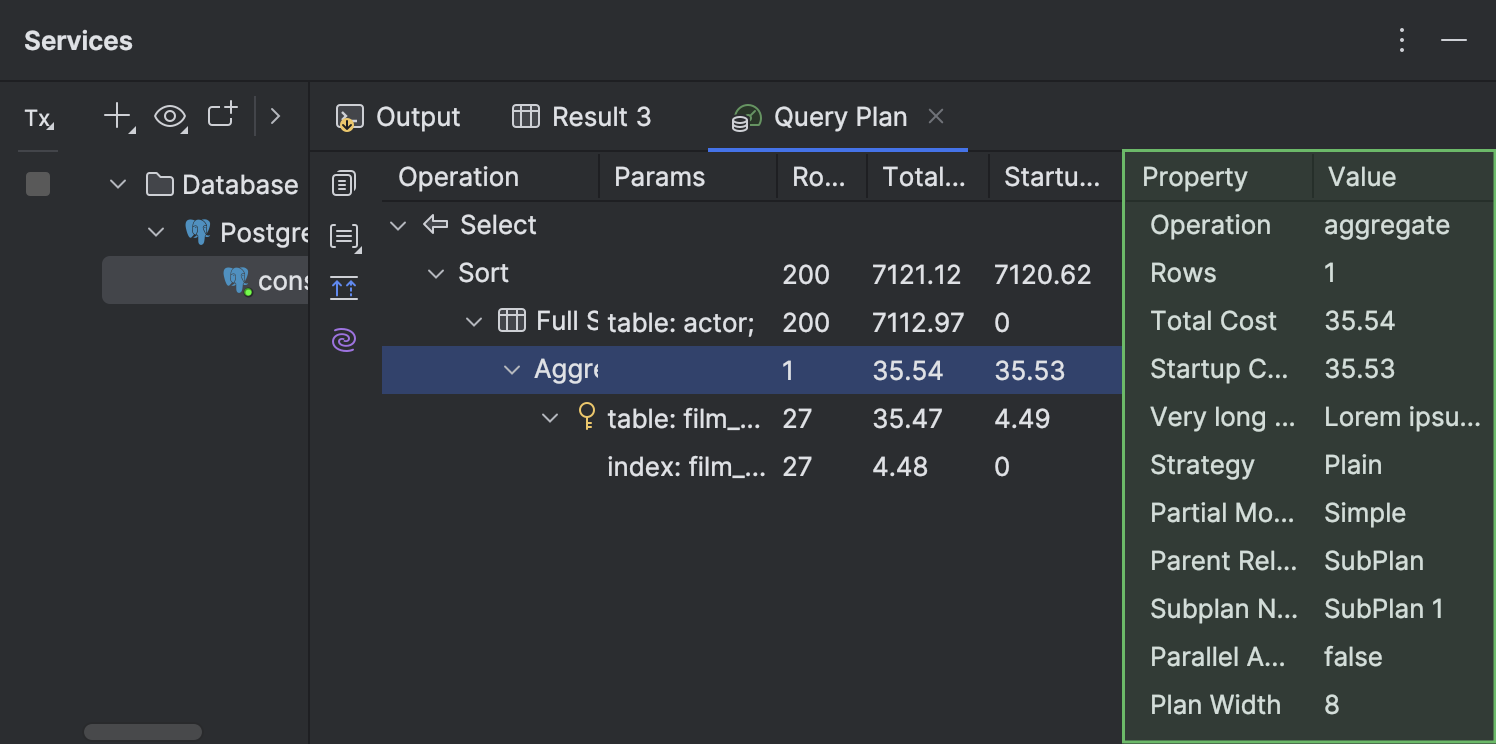
- Dans l'onglet Query Plan, vous pouvez désormais afficher les détails de chaque ligne de plan dans un panneau différent, situé dans la partie droite de l'onglet.
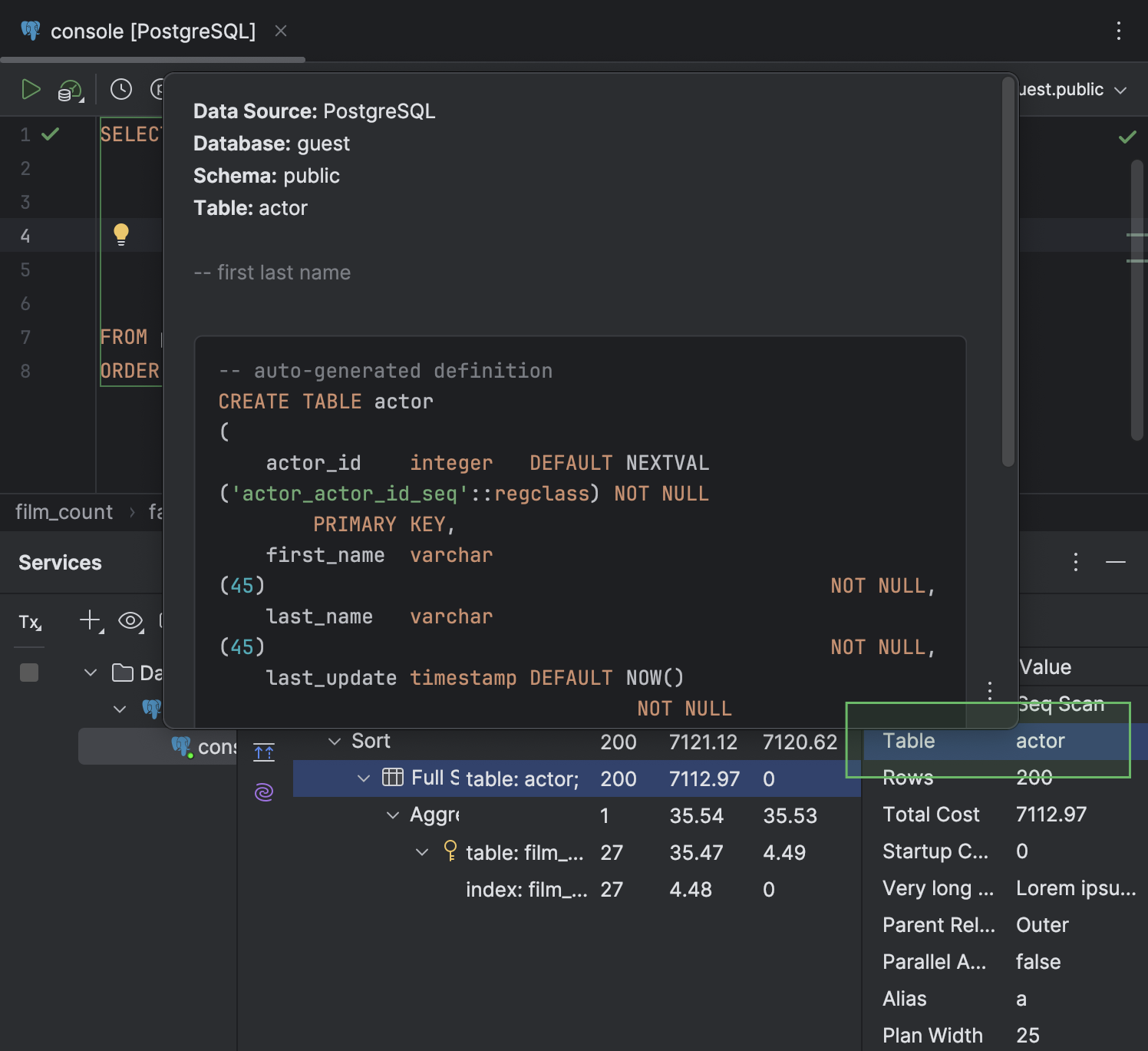
- Pour les cellules contenant un nom de table, une documentation rapide s'affiche dans une fenêtre contextuelle lorsque vous survolez la table avec le curseur.
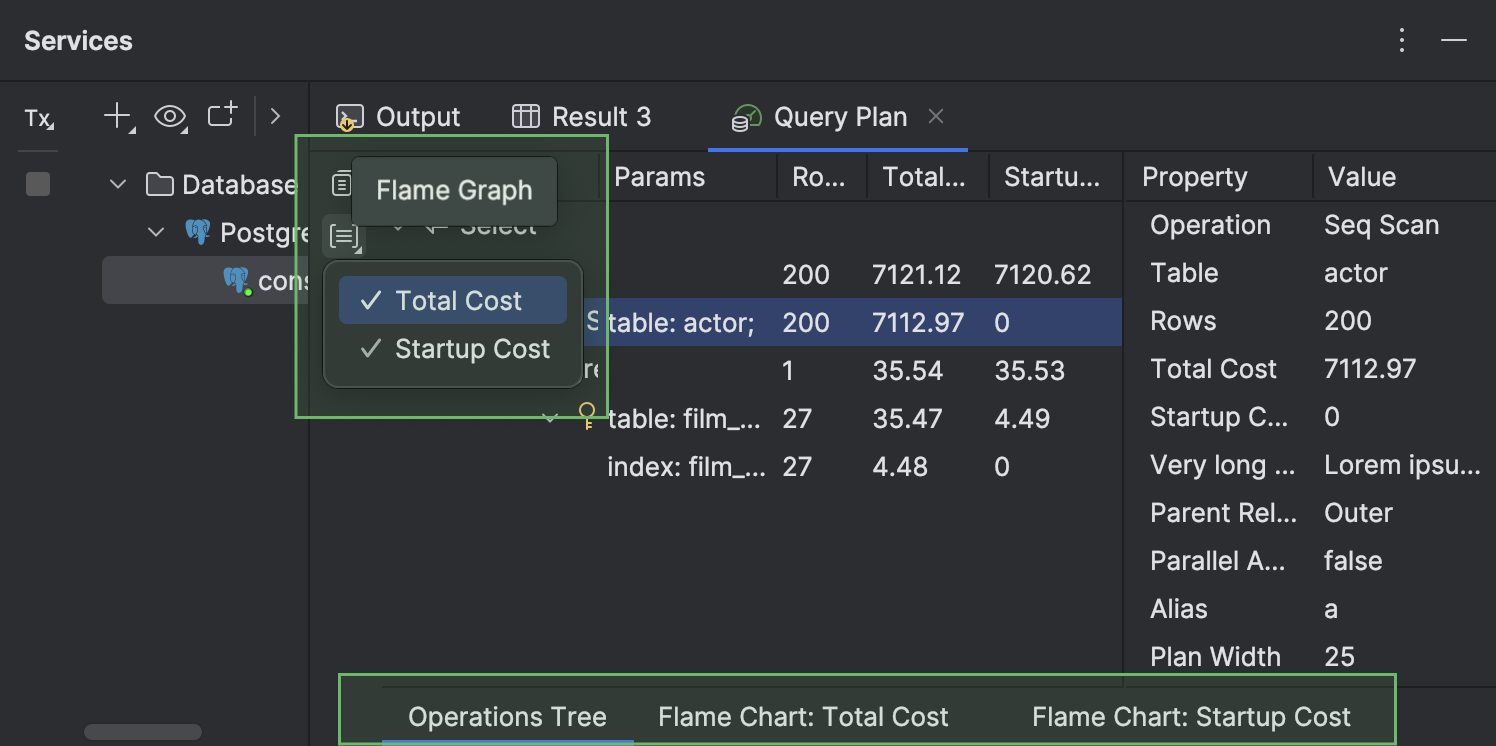
- Les différentes vues disponibles pour un plan de requête s'affichent dans des sous-onglets distincts. Ces onglets internes peuvent s'afficher en bas de l'onglet Query Plan. Ils sont masqués par défaut et s'affichent uniquement si au moins un onglet est ouvert. Pour ouvrir l'onglet Total Cost ou Startup Cost, cliquez sur Flame Graph dans la barre d'outils de gauche et sélectionnez la vue voulue.
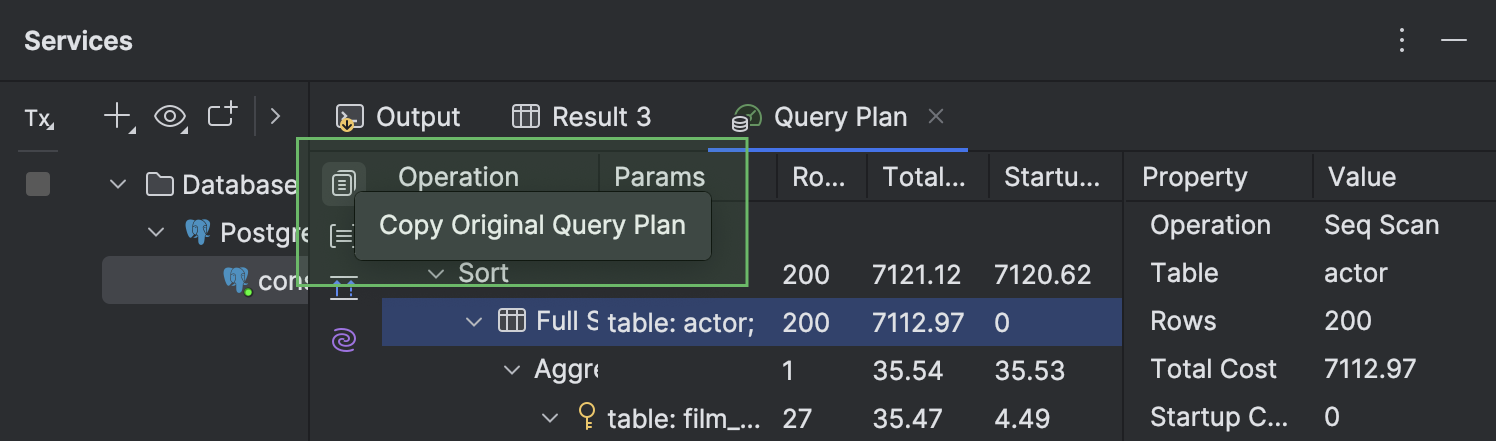
Possibilité de copie d'un plan de requête à son format natif
Vous pouvez désormais copier un plan de requête au format natif de la base de données, par exemple, JSON ou XML. Pour ce faire, cliquez sur le bouton Copy Original Query Plan en haut de la barre d'outils de gauche. Cela est pris en charge pour PostgreSQL, Amazon Redshift, MySQL, MariaDB, Oracle, Microsoft SQL Server et Snowflake.
Éditeur de code
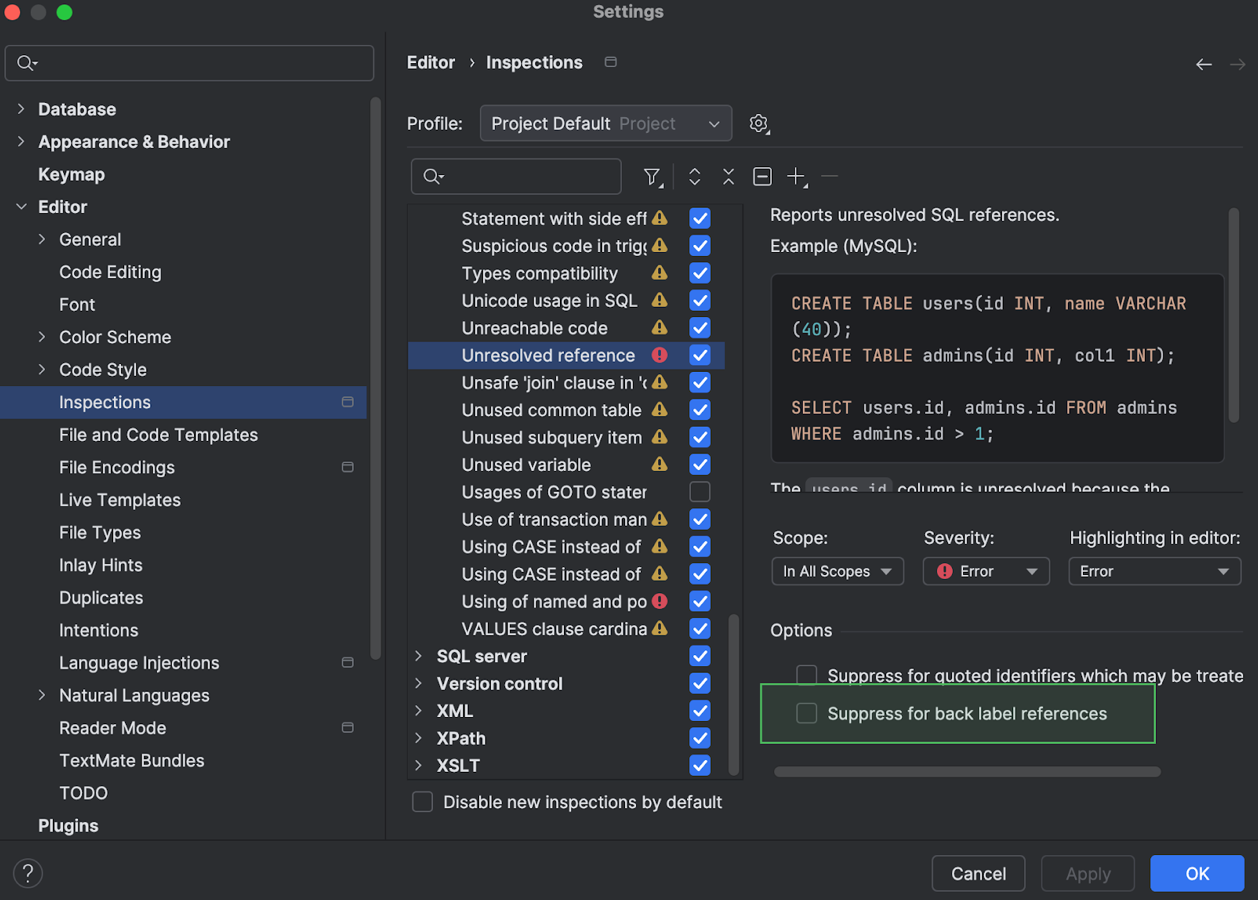
Accès simplifié à l'action d'intention Suppress for back label references Oracle
Nous avons rendu l'option Suppress for back label references plus simple à trouver et utiliser. Précédemment, elle était uniquement disponible dans la boîte de dialogue Settings, dans la section Editor | Inspections | SQL.
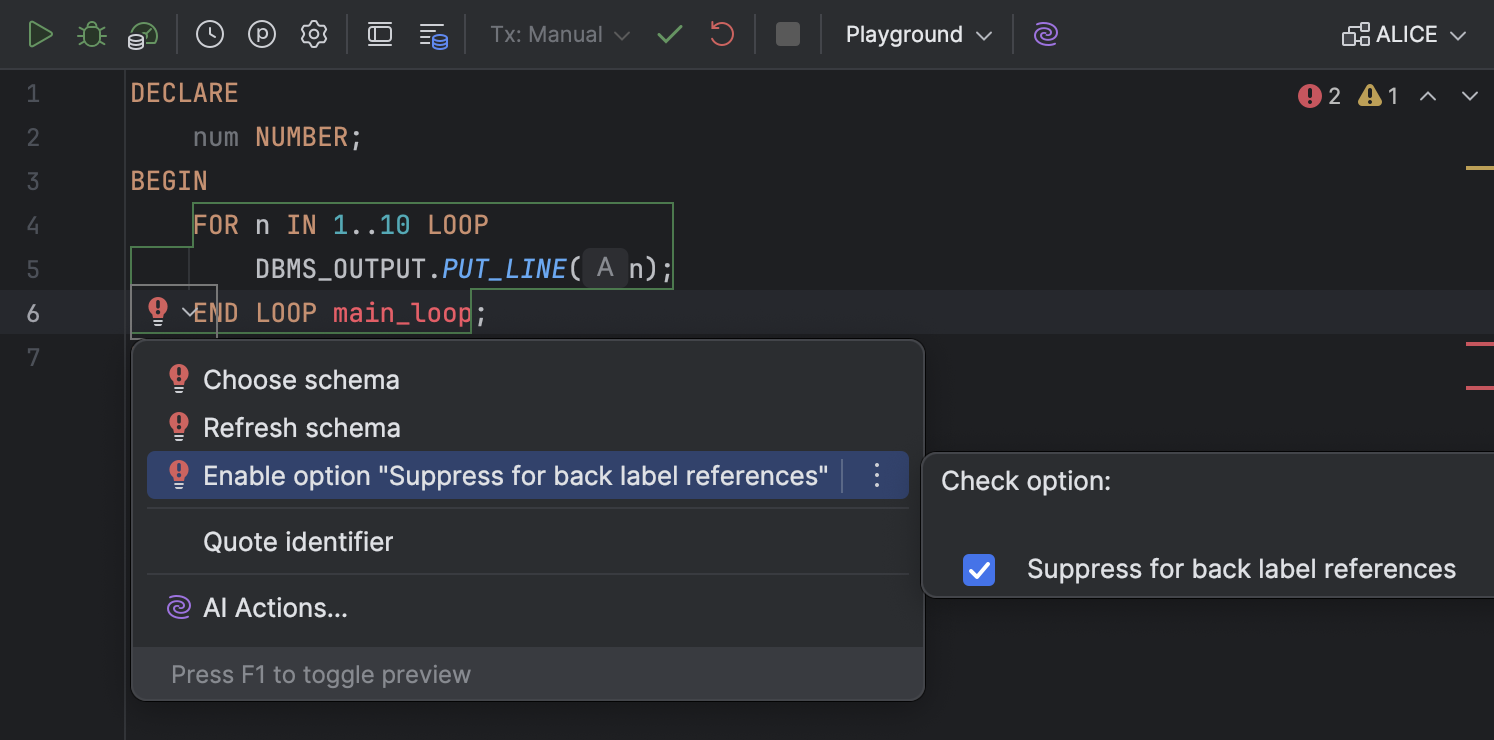
Désormais, il est possible de l'activer ou de la désactiver depuis les actions d'intention. Pour l'activer ou la désactiver, ouvrez la liste des actions d'intention en appuyant sur Alt+Entrée (Windows/Linux) ou Option+Entrée (macOS), allez dans Enable option "Suppress for back label references" et cochez ou désactivez la case Suppress for back label references.
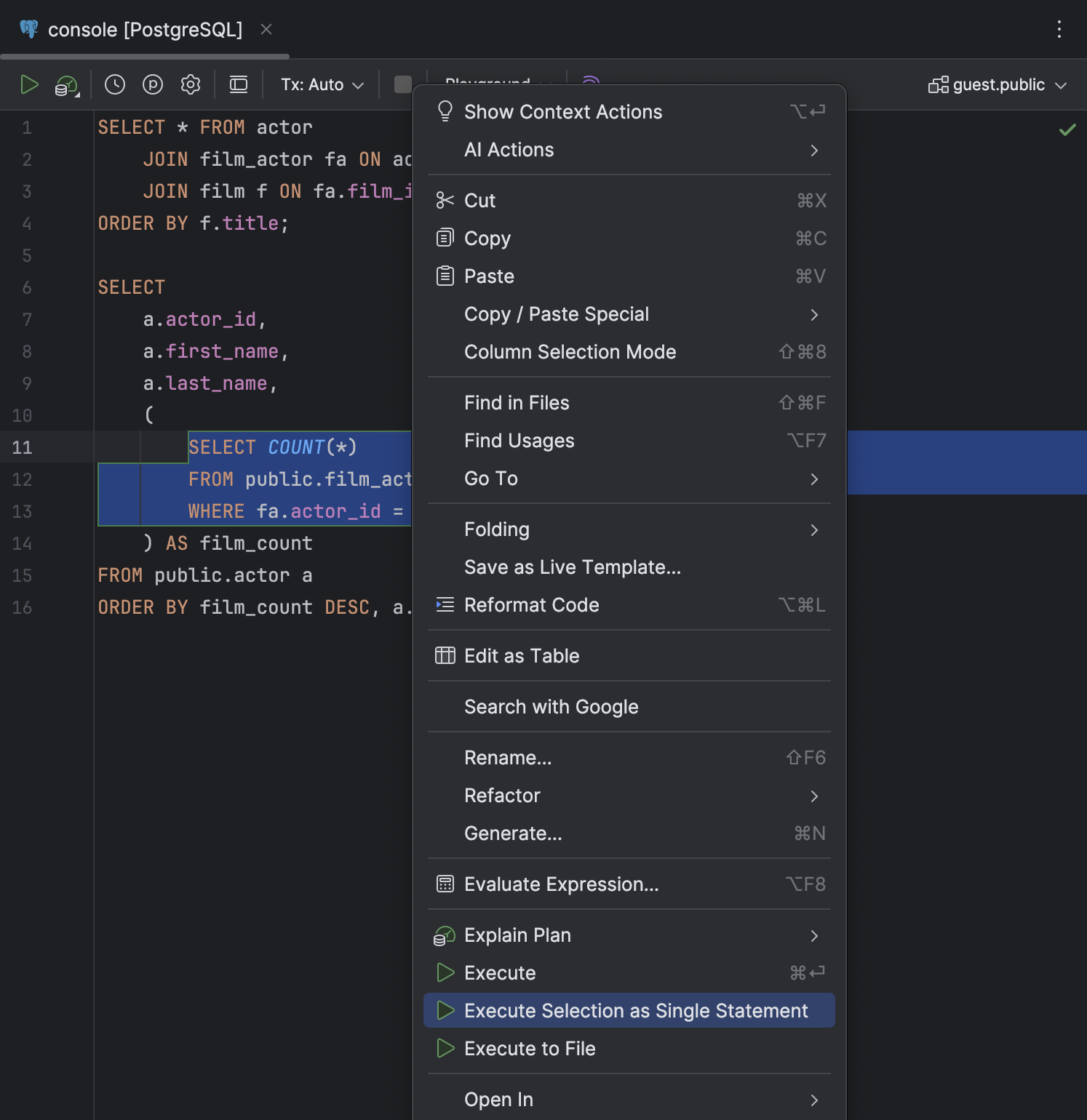
Action Execute Selection as Single Statement dans le menu contextuel
Nous avons ajouté l'action Execute Selection as Single Statement au menu contextuel d'une sélection de code. Utilisez-la lorsque vous devez exécuter un bloc de code spécifique alors que DataGrip ne l'analyse pas correctement.
Animation du mouvement du caret de l'éditeur
L'éditeur de code comporte deux nouvelles options d'animation du mouvement du caret pour améliorer votre expérience de saisie.
Nous savons que les préférences d'animation varient considérablement. Par conséquent, nous avons développé soigneusement notre propre mode de déplacement du caret : Snappy. Cela garantit une animation fluide sans que le caret ne paraisse lent ou peu réactif, et sans saturer l’interface avec des actions excessives. Dans ce mode, le caret passe rapidement à sa nouvelle position, puis ralentit légèrement et se « stabilise » à sa position finale. Le résultat donne une sensation de rapidité et de fluidité.
Quant à l'autre mode d'animation du caret, Gliding, le caret se déplace de façon fluide, ce qui permet de suivre les transitions plus facilement avec les yeux. Ce mode est similaire à ceux que vous voyez dans d'autres éditeurs de texte populaires.
Pour essayer ces nouveaux modes d'animation, ouvrez la boîte de dialogue Settings, allez dans Settings | Editor | General | Appearance, activez l'option Use smooth caret movement et sélectionnez le mode que vous souhaitez utiliser.
Travailler avec les données
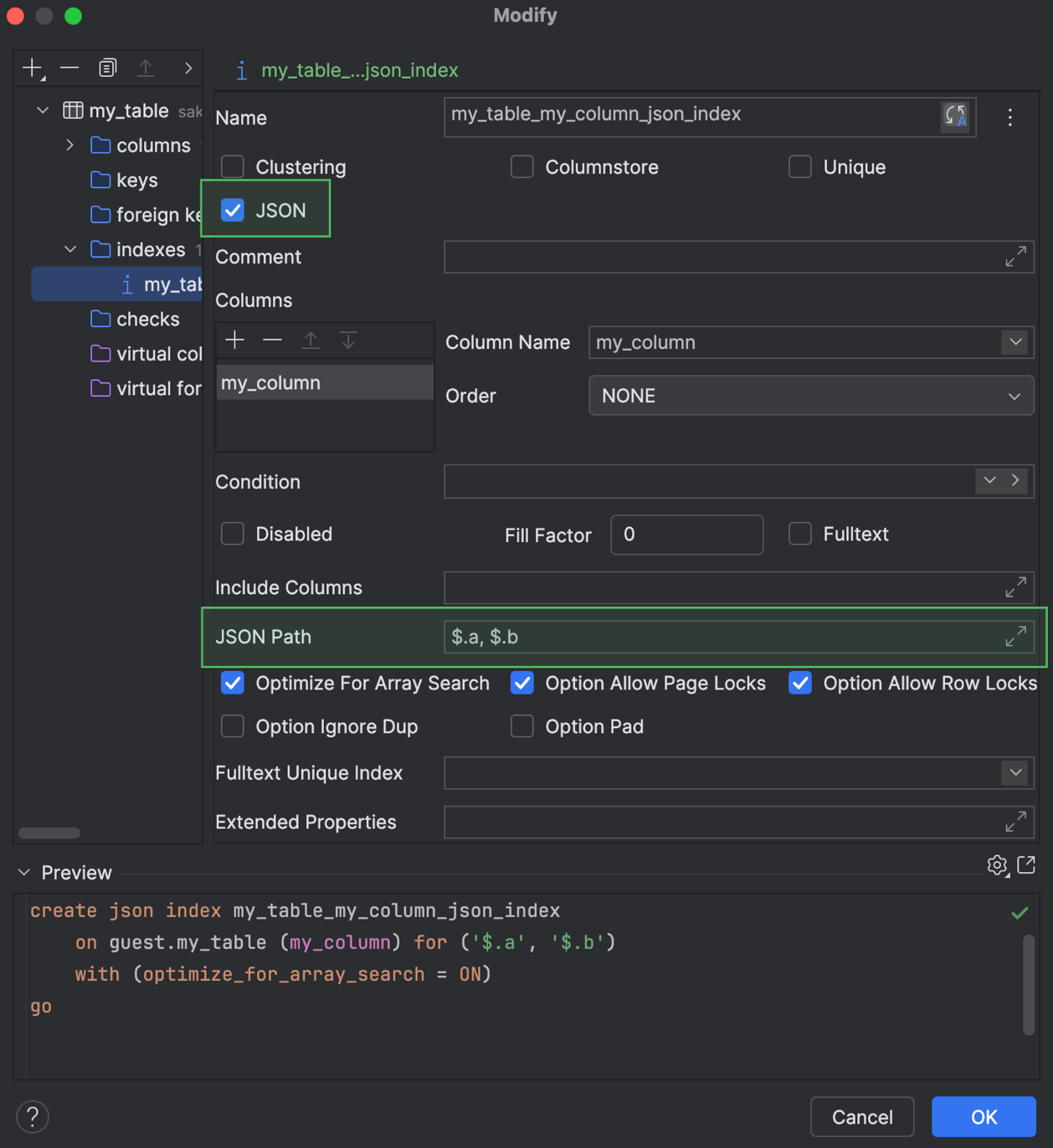
Prise en charge des index JSON Microsoft SQL Server
DataGrip prend désormais en charge la création et la modification des index JSON pour Microsoft SQL Server. Vous pouvez travailler avec eux pour la génération de code et également utiliser les index dans les boîtes de dialogue Create et Modify.
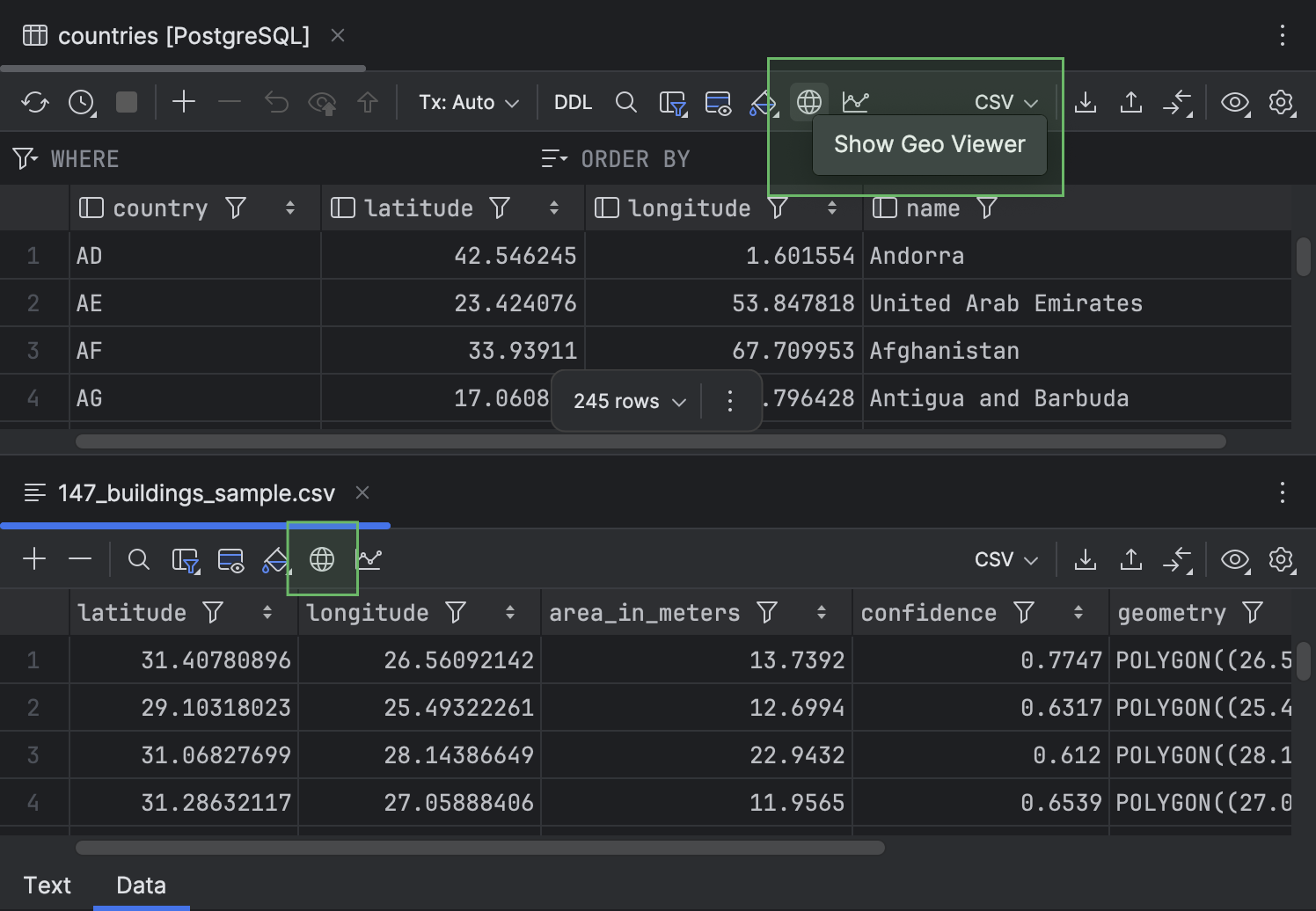
Bouton Show Geo Viewer de la barre d'outils
Pour une meilleure accessibilité, nous avons déplacé le bouton Show Geo Viewer vers la barre d'outils de l'éditeur de données.
Travail avec des fichiers
Les fichiers supprimés sont placés dans la corbeille par défaut
Auparavant, lorsque les actions Delete étaient appelées, DataGrip supprimait directement les fichiers, sans les placer dans la corbeille. Nous avons ajouté un paramètre pour remédier à cela : Move files to the bin instead of deleting permanently. Il est activé par défaut.
Vous pouvez modifier ce paramètre dans la section Settings | Appearance & Behavior | System Settings.
Nous espérons que vous apprécierez ces nouveautés ! Si vous rencontrez un bug ou souhaitez nous suggérer des fonctionnalités, indiquez-le dans l'outil de suivi des tickets de DataGrip.
Vous souhaitez vous tenir au courant des dernières fonctionnalités et savoir comment travailler avec les bases de données de façon plus productive ? Abonnez-vous au blog de DataGrip et suivez-nous sur X !