Connexions de données
Qu'il s'agisse de manipuler des fichiers CSV, des compartiments S3 ou des bases de données SQL, Datalore offre des solutions simples permettant d'accéder à vos données et d'exécuter des requêtes sur ces dernières à partir de plusieurs sources de données dans un seul notebook.
Dans la vidéo ci-dessous, vous trouverez un aperçu des connexions de données :
Stockage interne
Datalore est doté d'un stockage interne persistant pour un accès rapide à vos notebooks et autres artefacts de travail.

Fichiers de notebooks
Que vous mettiez en ligne des fichiers et des dossiers locaux, que vous importiez des données par lien ou que vous téléchargiez des fichiers à partir du code, toutes les données seront stockées dans les fichiers du notebook. Lorsque vous partagez un notebook à des collègues, les fichiers de ce notebook seront partagés automatiquement.
Fichiers d'espace de travail
Partagez des jeux de données entre plusieurs notebooks via les fichiers de l'espace de travail. Lorsque vous travaillez dans un espace de travail partagé, vous pouvez télécharger un jeu de données sur le serveur une seule fois ; il sera disponible pour chaque éditeur ou éditrice de l'espace de travail.
Connexions aux bases de données à partir de l'interface utilisateur
Connectez vos notebooks aux bases de données en quelques clics directement depuis l'éditeur, et interrogez vos données avec des cellules SQL natives sans transmettre vos informations d'identification à l'environnement.
Datalore prend en charge l'authentification des utilisateurs et des mots de passe pour Amazon Redshift, Azure SQL Database, MariaDB, MySQL, Oracle, PostgreSQL, Snowflake, etc. Veuillez nous contacter à l'adresse datalore-support@jetbrains.com si vous avez des questions spécifiques sur la connectivité des bases de données.
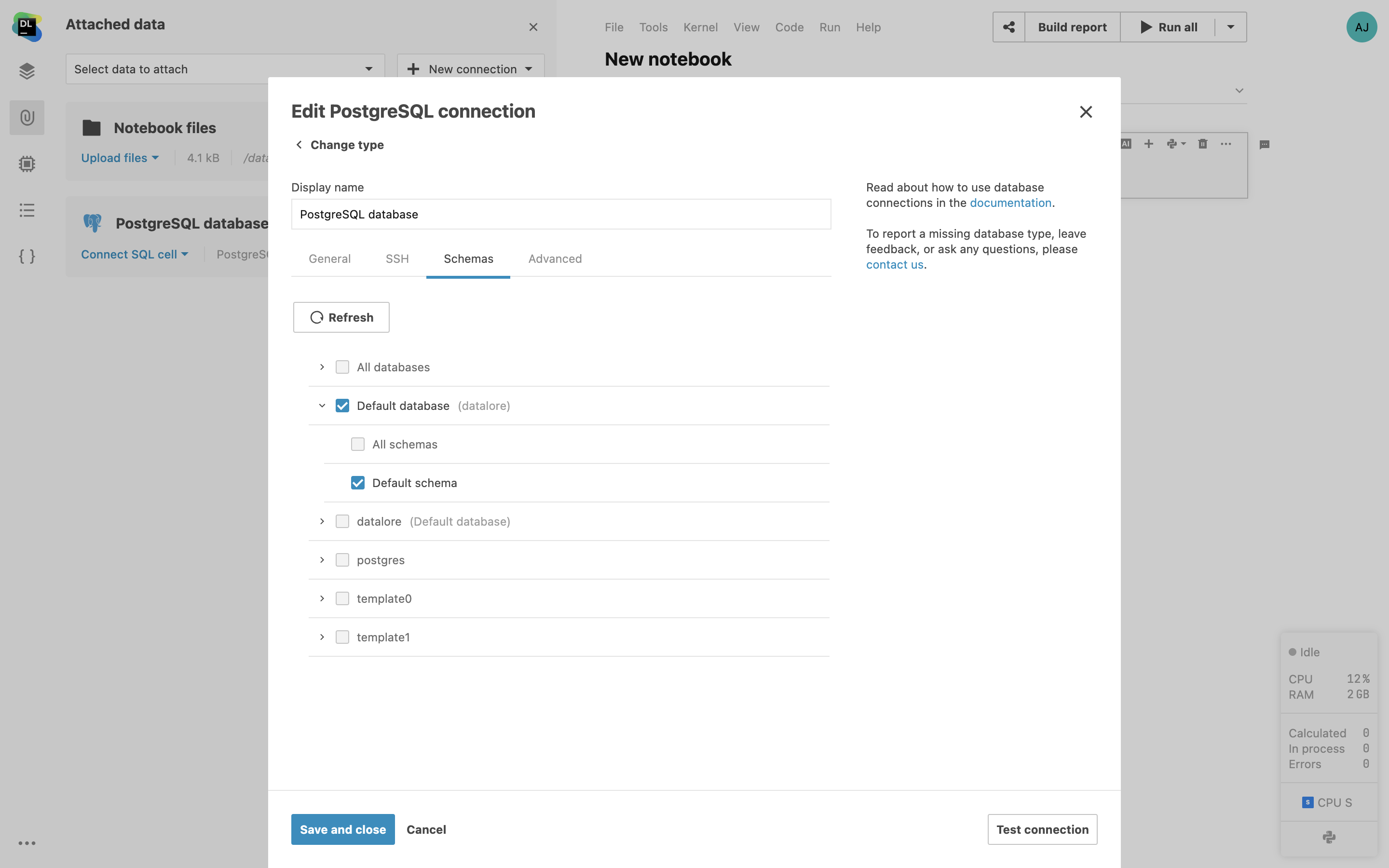
Limitation du schéma de base de données pour l'introspection
Choisissez des schémas de base de données et des tables spécifiques pour les introspections lors de la création d'une connexion de base de données dans Datalore. Cela permet d'accélérer l'introspection initiale et de faciliter la navigation dans les bases de données.
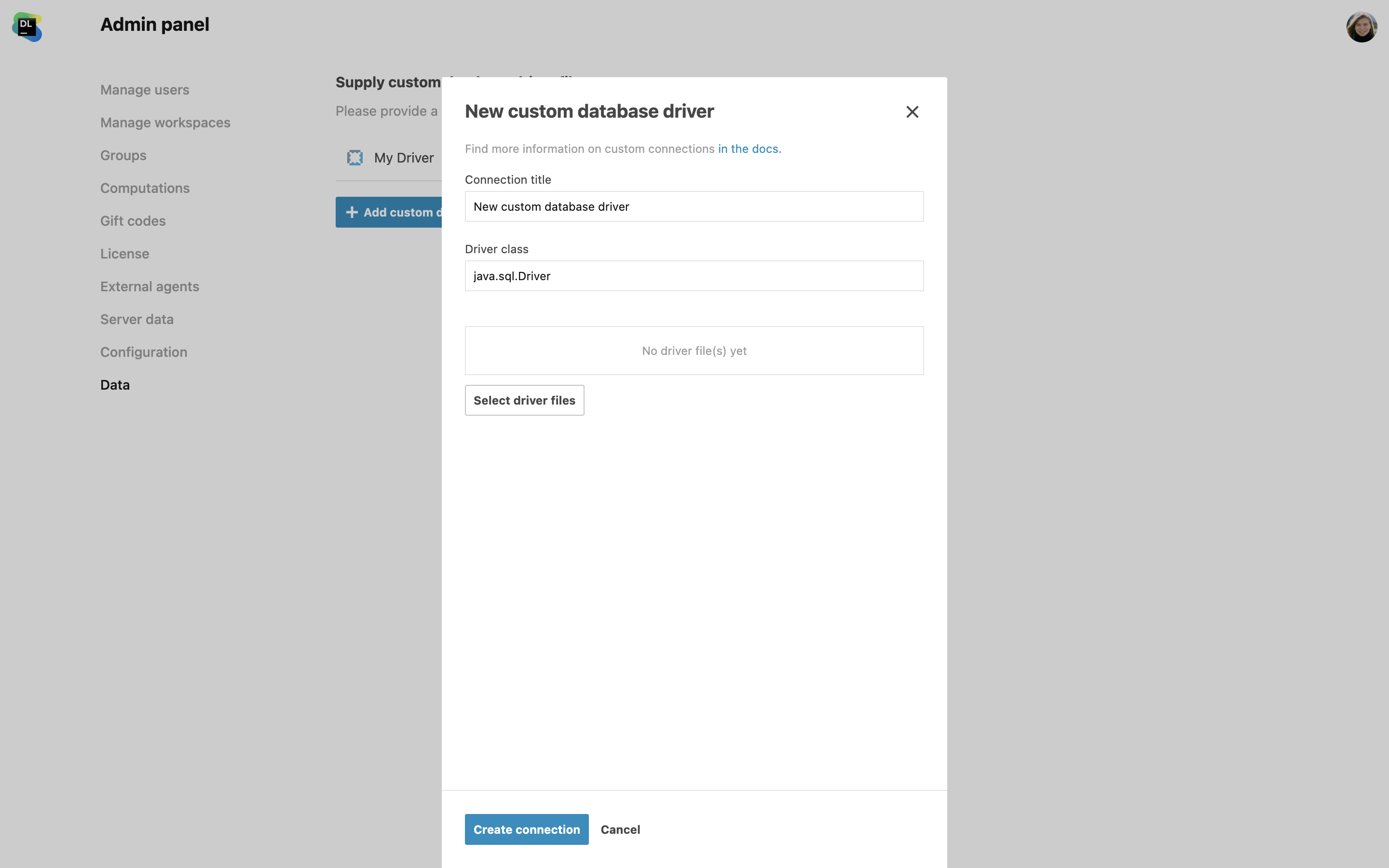
Prise en charge du pilote JDBC personnalisé
Les administrateurs peuvent désormais ajouter des pilotes JDBC personnalisés pour se connecter aux bases de données qui ne sont pas prises en charge nativement dans Datalore On-Premises. Accédez au volet Admin panel | Miscellaneous et utilisez la boite de dialogue New custom database driver pour sélectionner et télécharger les fichiers de pilote sur le serveur à partir de votre système local.
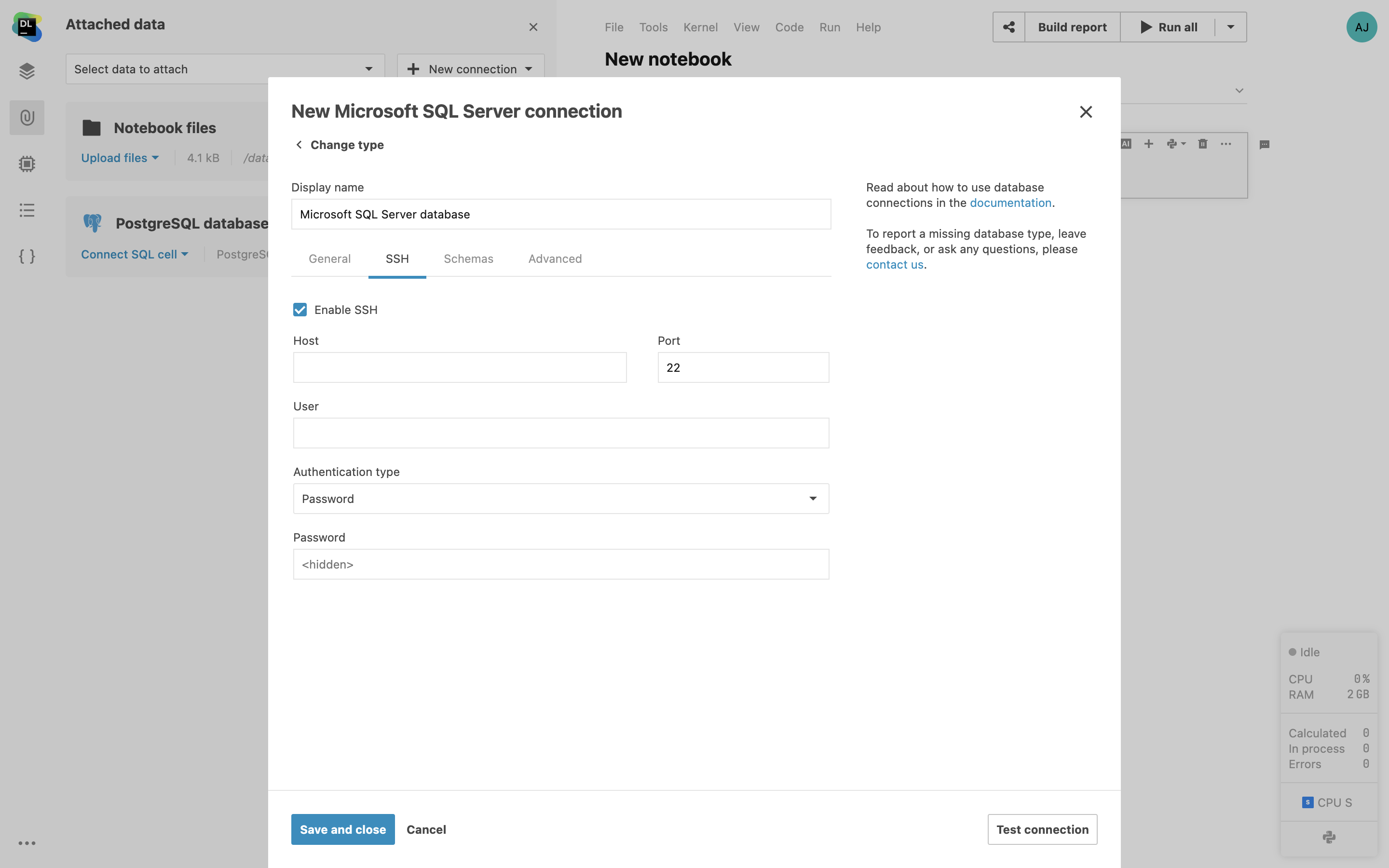
Prise en charge du tunneling SSH
Connectez-vous à vos bases de données distantes en utilisant le tunneling SSH dans Datalore. Cela crée une connexion SSH chiffrée entre Datalore et votre serveur de passerelle. La connexion via des tunnels SSH permet de se connecter à des bases de données qui ne sont pas exposées à un réseau public.
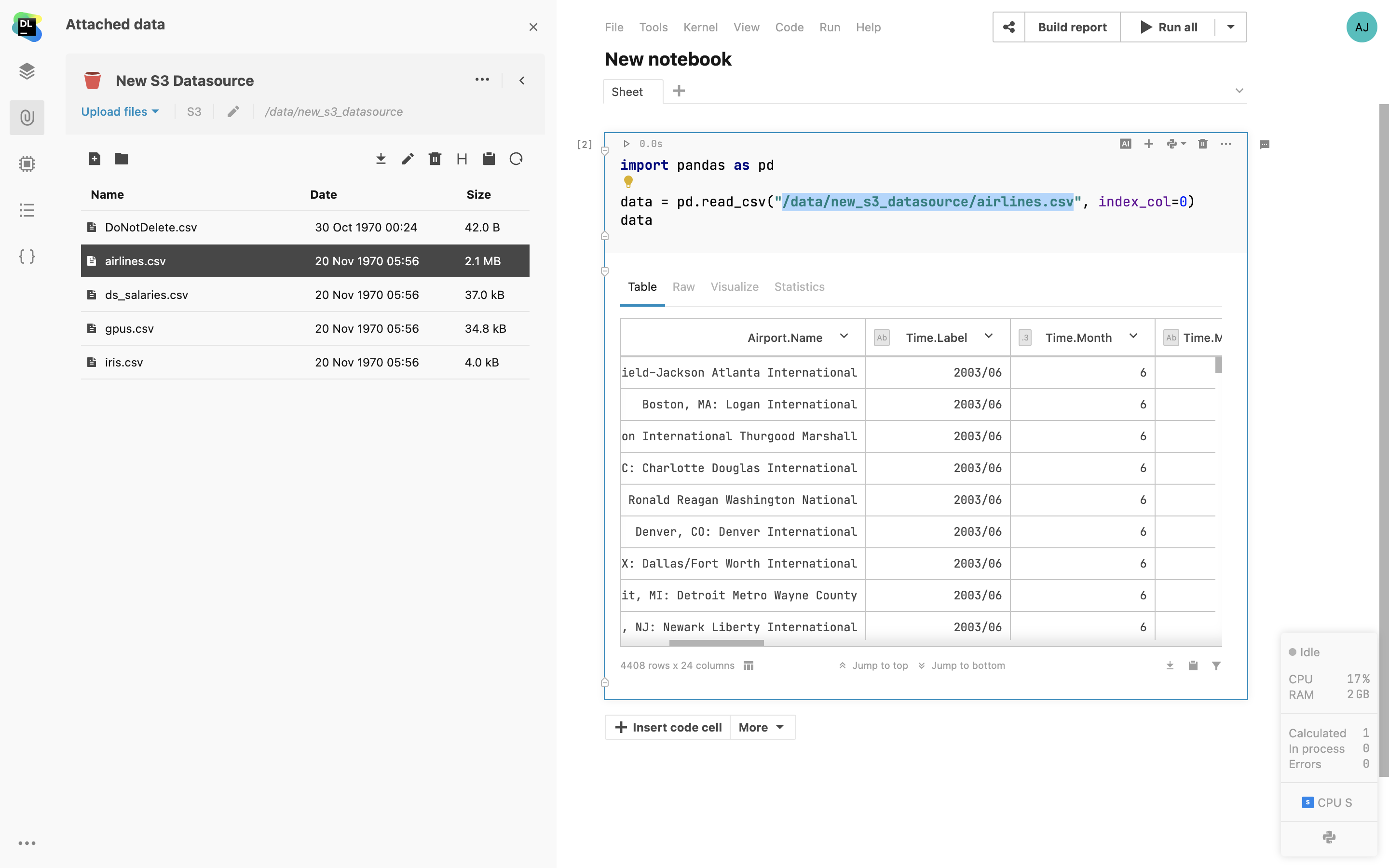
Montage d'un compartiment S3
Montez les compartiments AWS S3 et les buckets GCS en tant que dossiers directement sur le notebook sans transmettre vos informations d'identification à l'environnement.
Connexions aux données à partir du code
Outre les connexions de sources de données prises en charge via l'interface utilisateur, vous pouvez connecter n'importe quel bucket, base de données ou stockage de données depuis le code, comme vous le feriez normalement avec un notebook Jupyter.
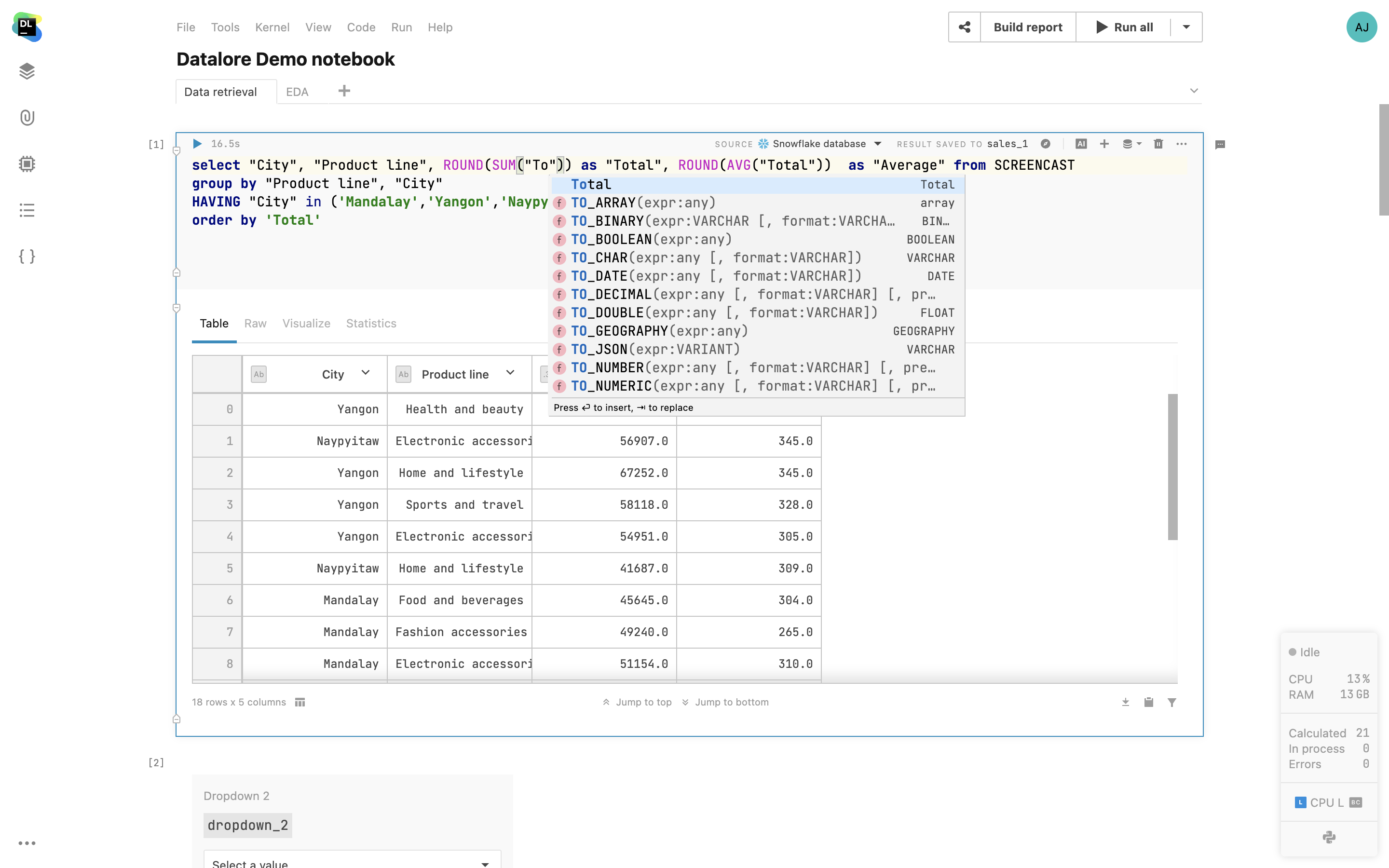
Cellules SQL
Les cellules SQL natives vous permettent d'interroger les connexions de votre base de données. En plus de la mise en évidence de la syntaxe SQL, vous bénéficiez également de la saisie semi-automatique de code basée sur les tables de la base de données introspectée. Le résultat de la requête est automatiquement transféré dans un DataFrame pandas et vous pouvez poursuivre votre travail sur le jeu de données en Python.
Requêtes de dataframes via des cellules SQL
Utilisez des cellules SQL pour créer facilement des requêtes sur les dataframes 2D et les fichiers CSV à partir des documents attachés, comme cela serait le cas avec les bases de données. Parcourez simplement les dataframes de votre notebook, choisissez-en un et utilisez-le comme source pour les cellules SQL. Avec cette fonctionnalité, vous pouvez fusionner les données provenant de différentes sources dans un seul dataframe en utilisant du code SQL ou simplifier des requêtes complexes en les répartissant dans une séquence de cellules SQL.
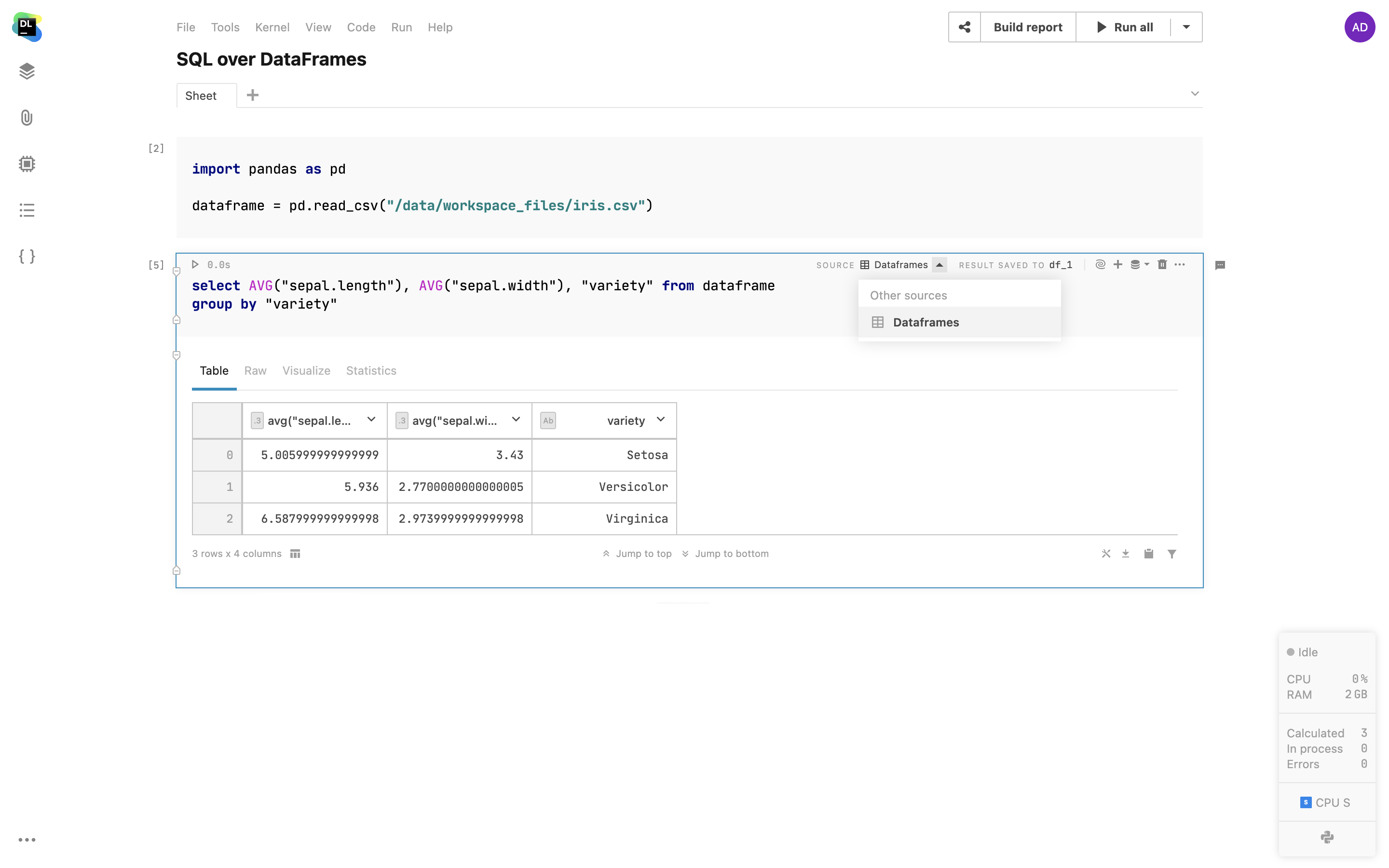
Requêtes SQL paramétrées
Il est maintenant possible d'utiliser des variables (chaînes de caractères, nombres, booléens, listes) définies dans du code Python à l'intérieur des cellules SQL. Cela permet de pouvoir créer des rapports interactifs avec des requêtes paramétrées, d'avoir moins de code SQL à écrire et de proposer une meilleure interface aux utilisateurs des rapports.
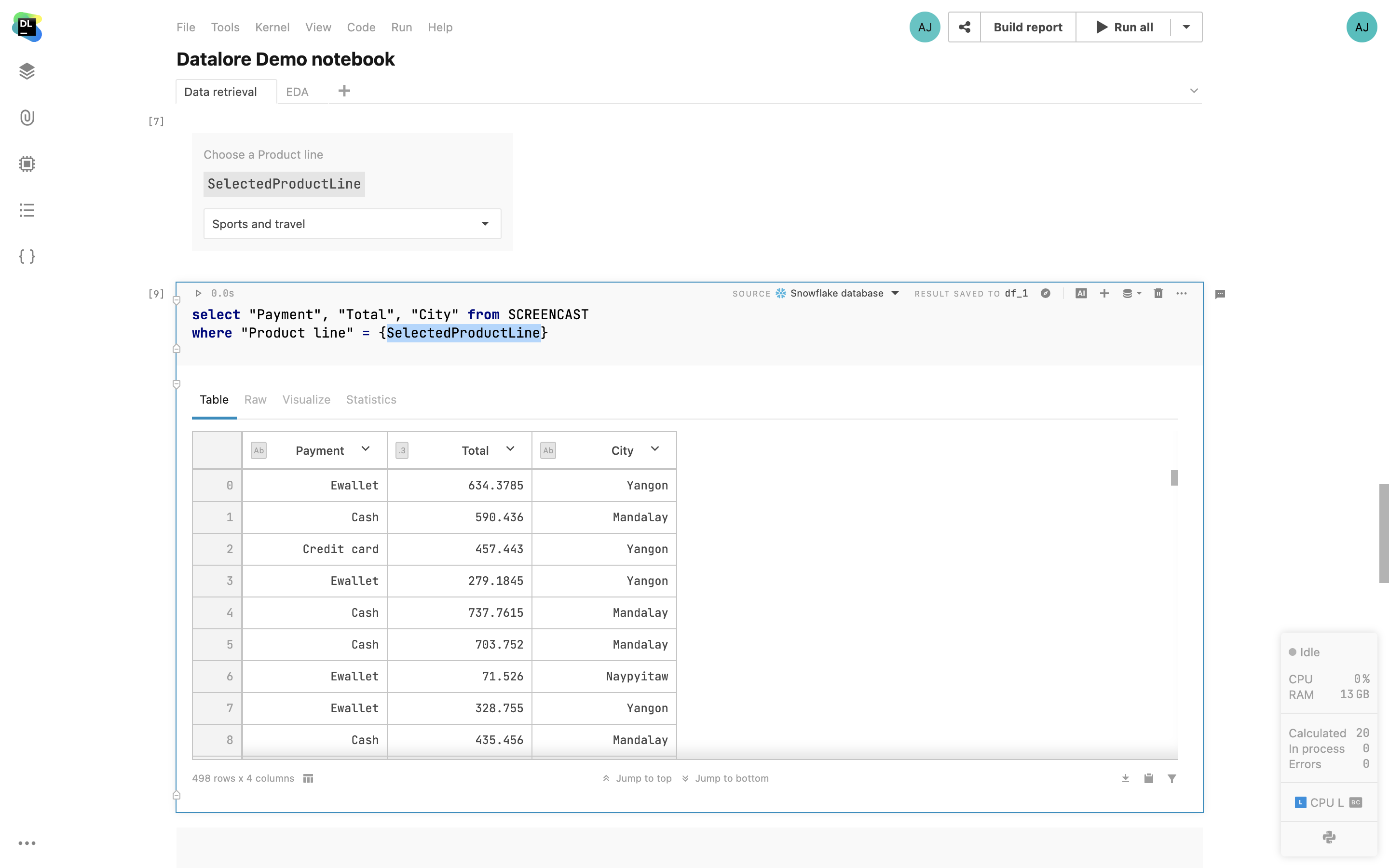
Manipulation des bases de données dans les environnements isolés
Cette fonctionnalité permet de travailler avec les bases de données, y compris dans les environnements isolés. Exécutez le code SQL sans connexion Internet, afin de garantir que les informations échangées entre votre notebook et la base de données restent exactes et cohérentes et de minimiser les risques de corruption ou de perte de données.
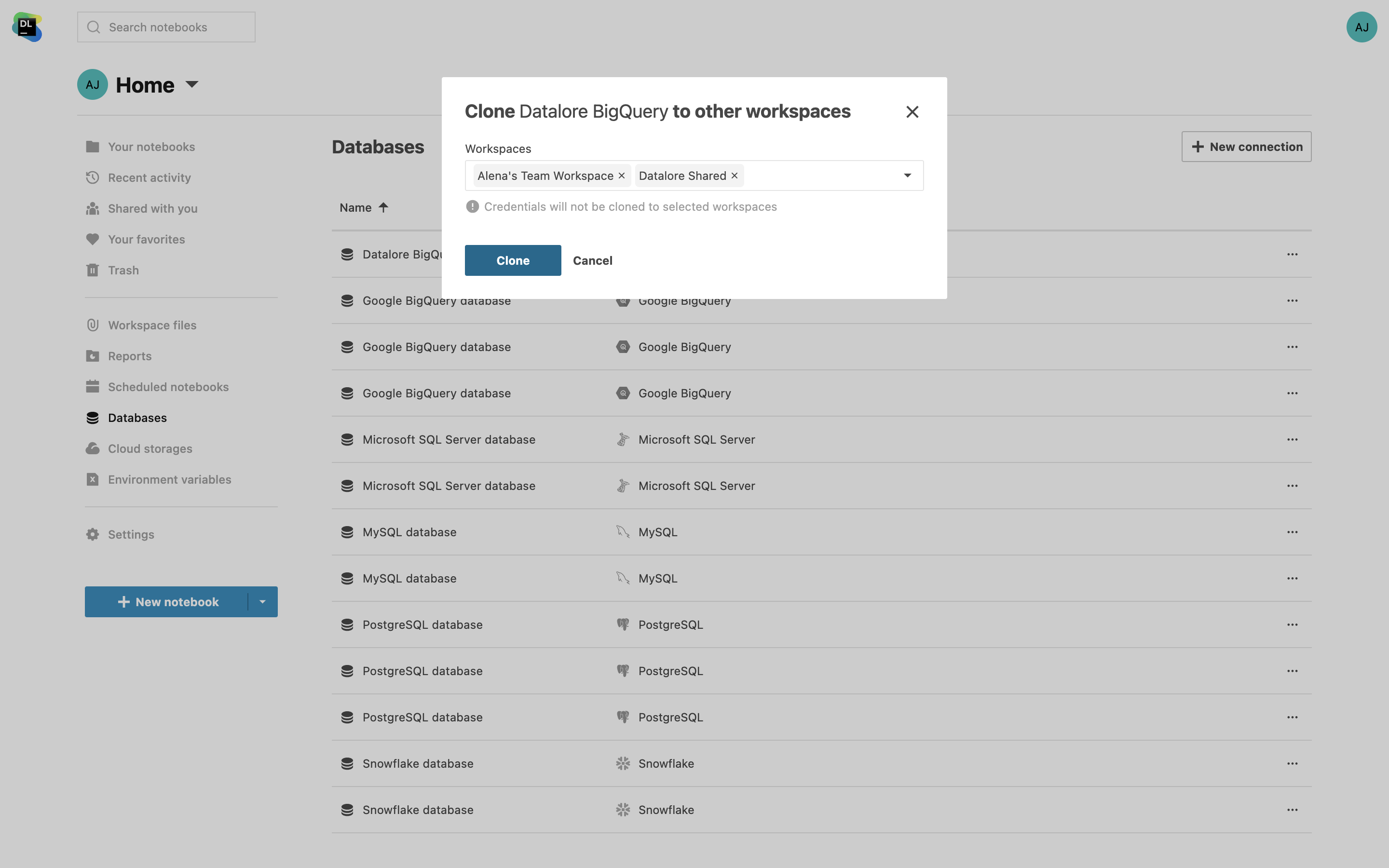
Clonage des connexions de données dans plusieurs espaces de travail
Il est désormais possible de cloner les connexions de bases de données d'un espace de travail à l'autre, afin d'éviter les configurations répétitives. Gagnez du temps en copiant simplement les paramètres sans les informations d'authentification. Vous avez également la possibilité de sélectionner plusieurs espaces de travail à la fois.
Stockage SMB/CIFS
Ajoutez le stockage SMB/CIFS à votre espace de travail à partir de la vue File system ou directement depuis l'interface du notebook. Vous pouvez accéder au dossier SMB et apporter des modifications à son contenu sans quitter l'environnement du notebook.