Notebooks
Un notebook Jupyter est au cœur de tout projet de science des données. Datalore vous fournit des outils intelligents permettant de travailler avec les notebooks Jupyter. Appuyez-vous sur son assistance intelligente au codage pour Python, SQL, R, Scala et Kotlin pour aller plus vite et écrire du code de meilleure qualité avec moins d'efforts. L'éditeur de Datalore permet d'accéder rapidement à tous les outils essentiels, dont les sources de données jointes, les visualisations automatiques, les statistiques sur les jeux de données, le générateur de rapports, le gestionnaire d'environnement, le contrôle des versions et bien plus encore.
Regardez la vidéo ci-dessous pour découvrir la facilité de création de notebooks Jupyter dans Datalore :
Compatibles avec Jupyter
Les notebooks dans Datalore sont compatibles avec Jupyter, ce qui signifie que vous pouvez télécharger vos fichiers IPYNB existants et continuer à travailler dessus dans Datalore. Vous pouvez également exporter les notebooks au format IPYNB. Notez que les connexions de données et les contrôles interactifs ne seront pas exportés.
Notebooks Python
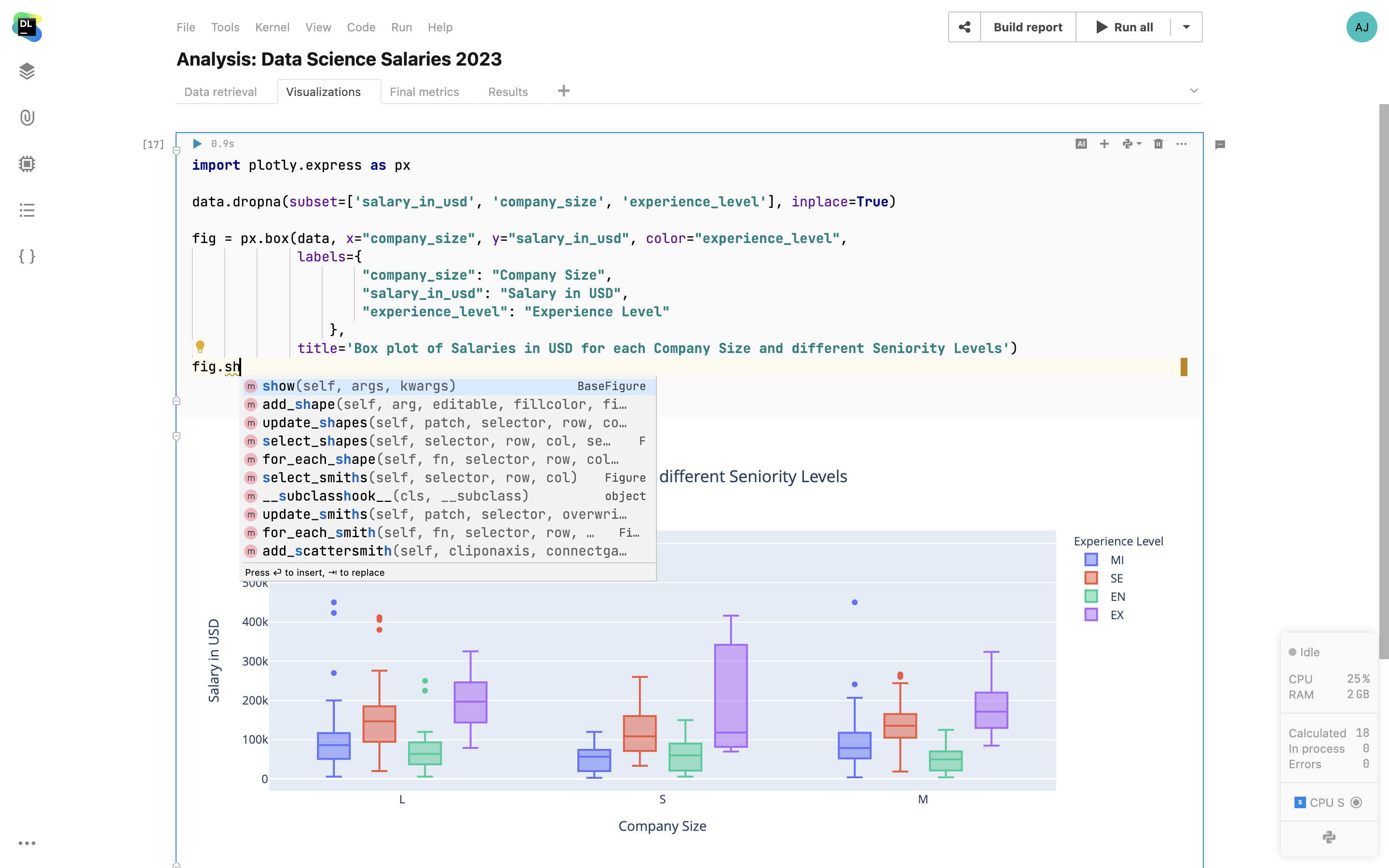
Une assistance intelligente au codage grâce à PyCharm
Datalore intègre les fonctions d'analyse du code de PyCharm. Pour les notebooks Python, vous disposez d'une saisie semi-automatique du code de première classe, d'informations sur les paramètres, d'inspections, de correctifs rapides et de refactorisations qui vous aident à écrire un code de meilleure qualité avec moins d'efforts.
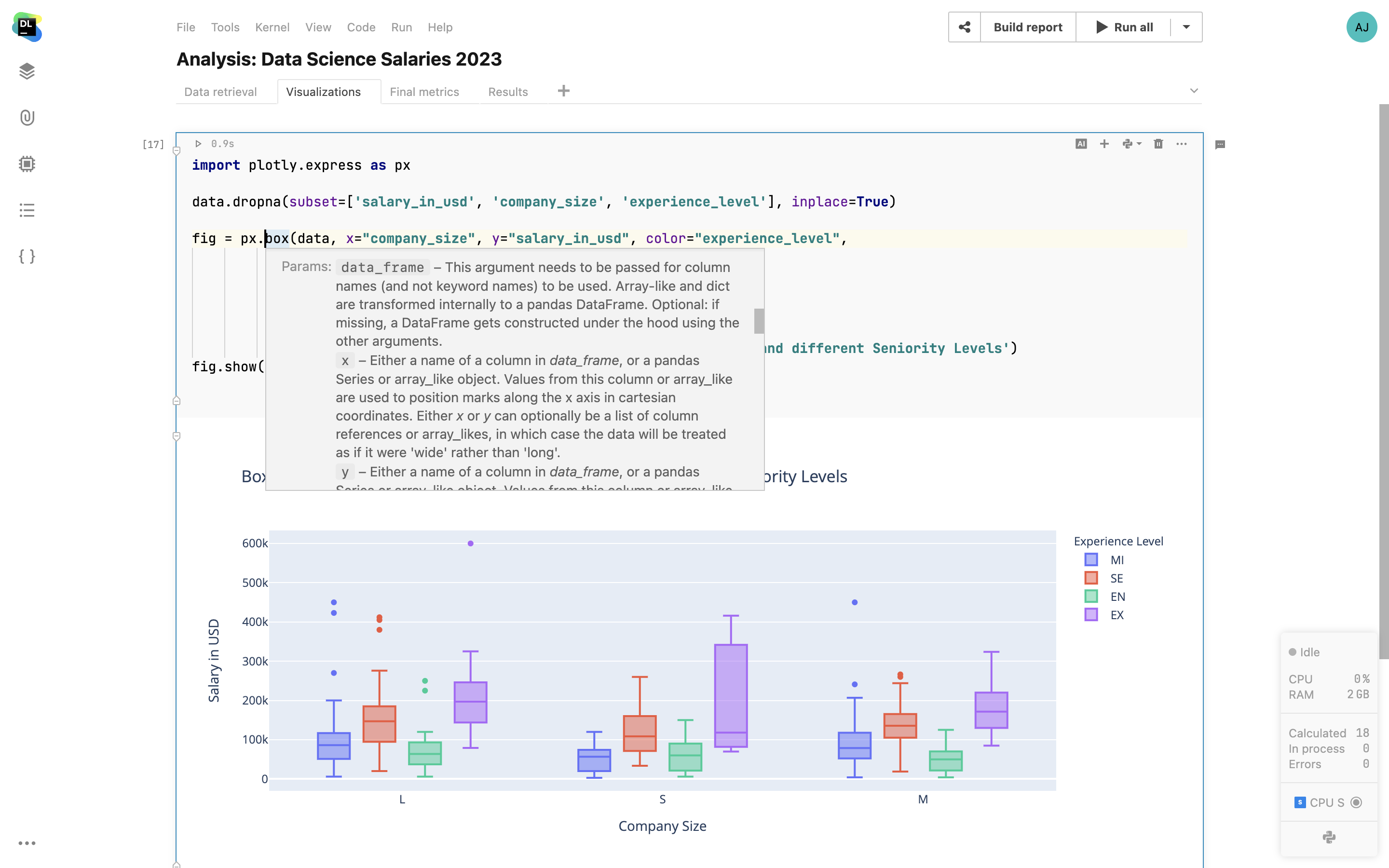
Documentation intégrée à l'application
Accédez à des fenêtres contextuelles de documentation pour les méthodes, fonctions, paquets ou classes. Datalore affiche la documentation là où vous en avez besoin.
Prise en charge de conda et pip
Datalore prend en charge pip et conda. Pip est rapide et gratuit pour tous, tandis que conda n'est gratuit que pour une utilisation non commerciale.
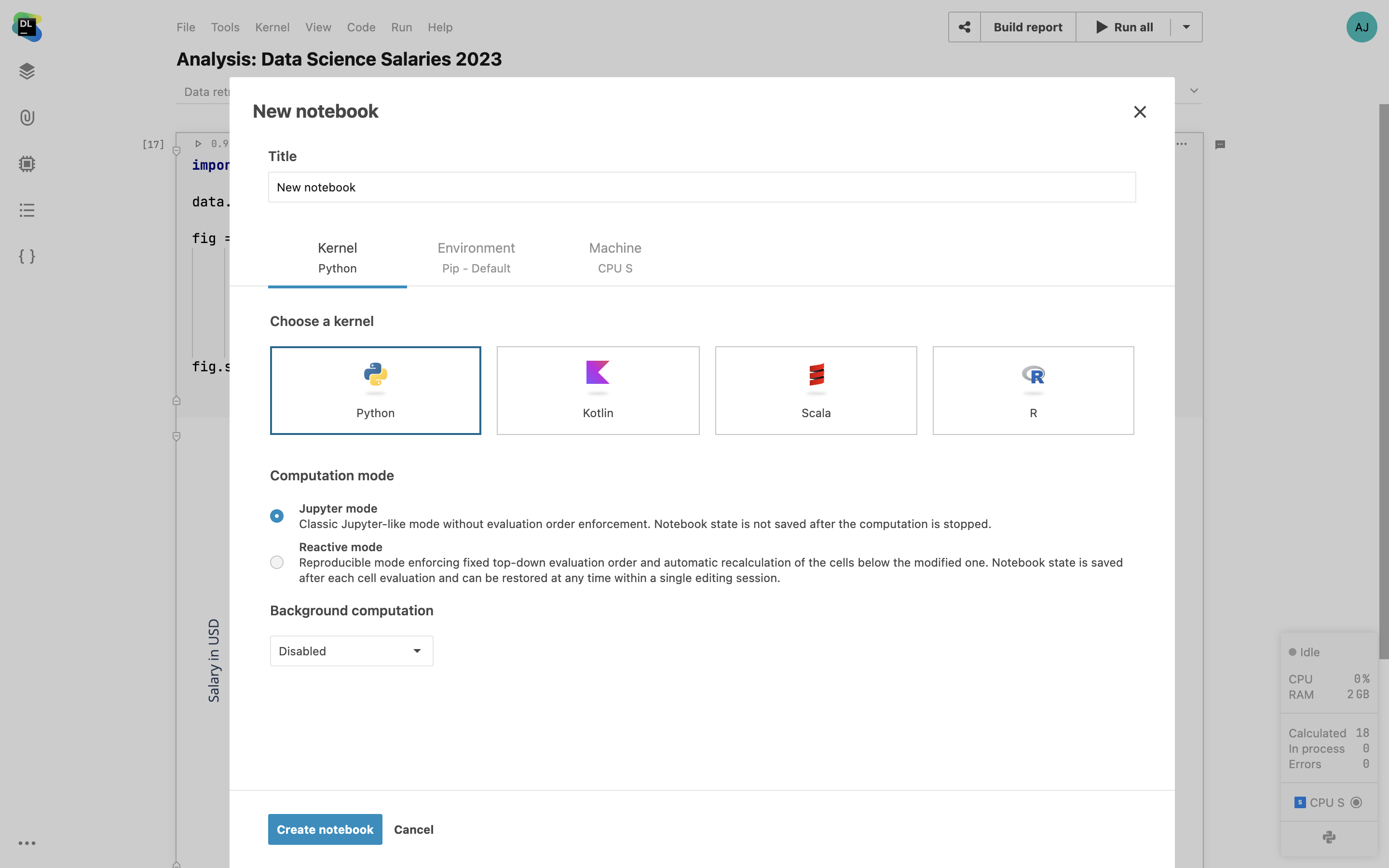
Notebooks Kotlin, Scala et R
Dans Datalore, vous pouvez créer des notebooks Kotlin, Scala et R. Vous pouvez utiliser les commandes magiques pour installer des paquets et bénéficier de la saisie semi-automatique lorsque vous écrivez du code.
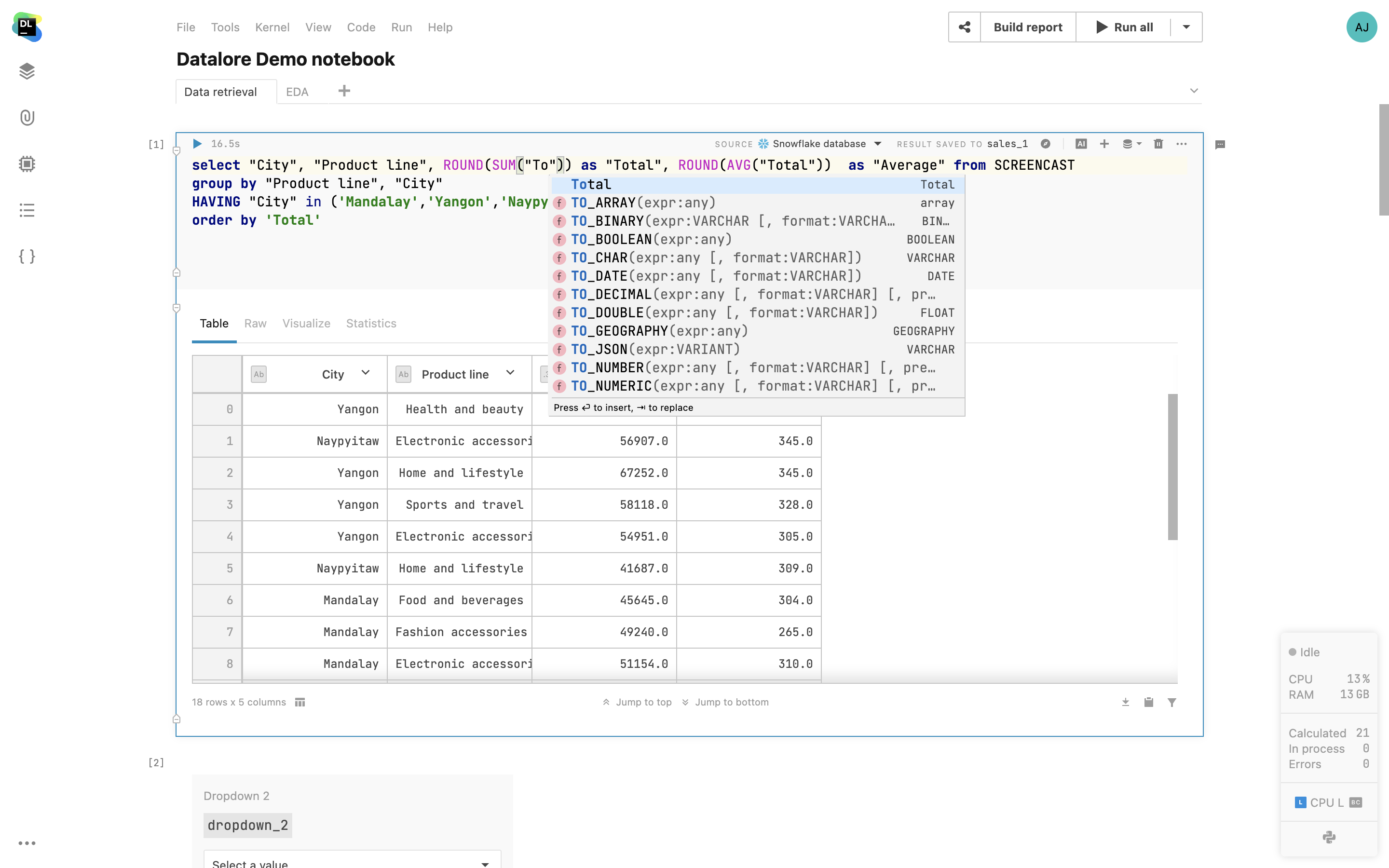
Cellules SQL
Les cellules SQL natives vous permettent d'interroger les connexions de votre base de données. En plus de la mise en évidence de la syntaxe SQL, vous bénéficiez également de la saisie semi-automatique de code basée sur les tables de la base de données introspectée. Le résultat de la requête est automatiquement transféré dans un DataFrame pandas et vous pouvez poursuivre votre travail sur le jeu de données en Python.
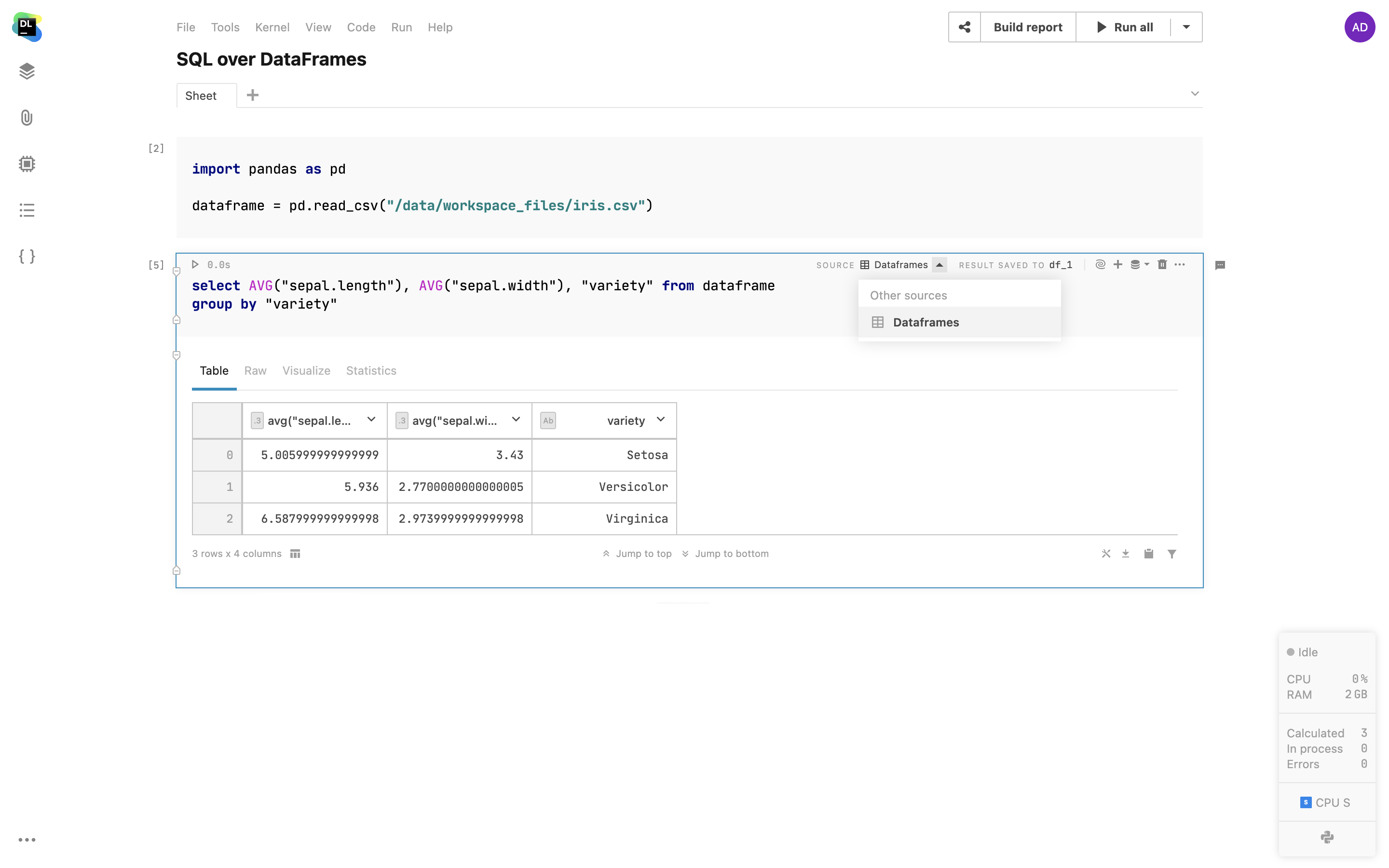
Requêtes de dataframes via des cellules SQL
Utilisez des cellules SQL pour créer facilement des requêtes sur les dataframes 2D et les fichiers CSV à partir des documents attachés, comme cela serait le cas avec les bases de données. Parcourez simplement les dataframes de votre notebook, choisissez-en un et utilisez-le comme source pour les cellules SQL. Avec cette fonctionnalité, vous pouvez fusionner les données provenant de différentes sources dans un seul dataframe en utilisant du code SQL ou simplifier des requêtes complexes en les répartissant dans une séquence de cellules SQL.
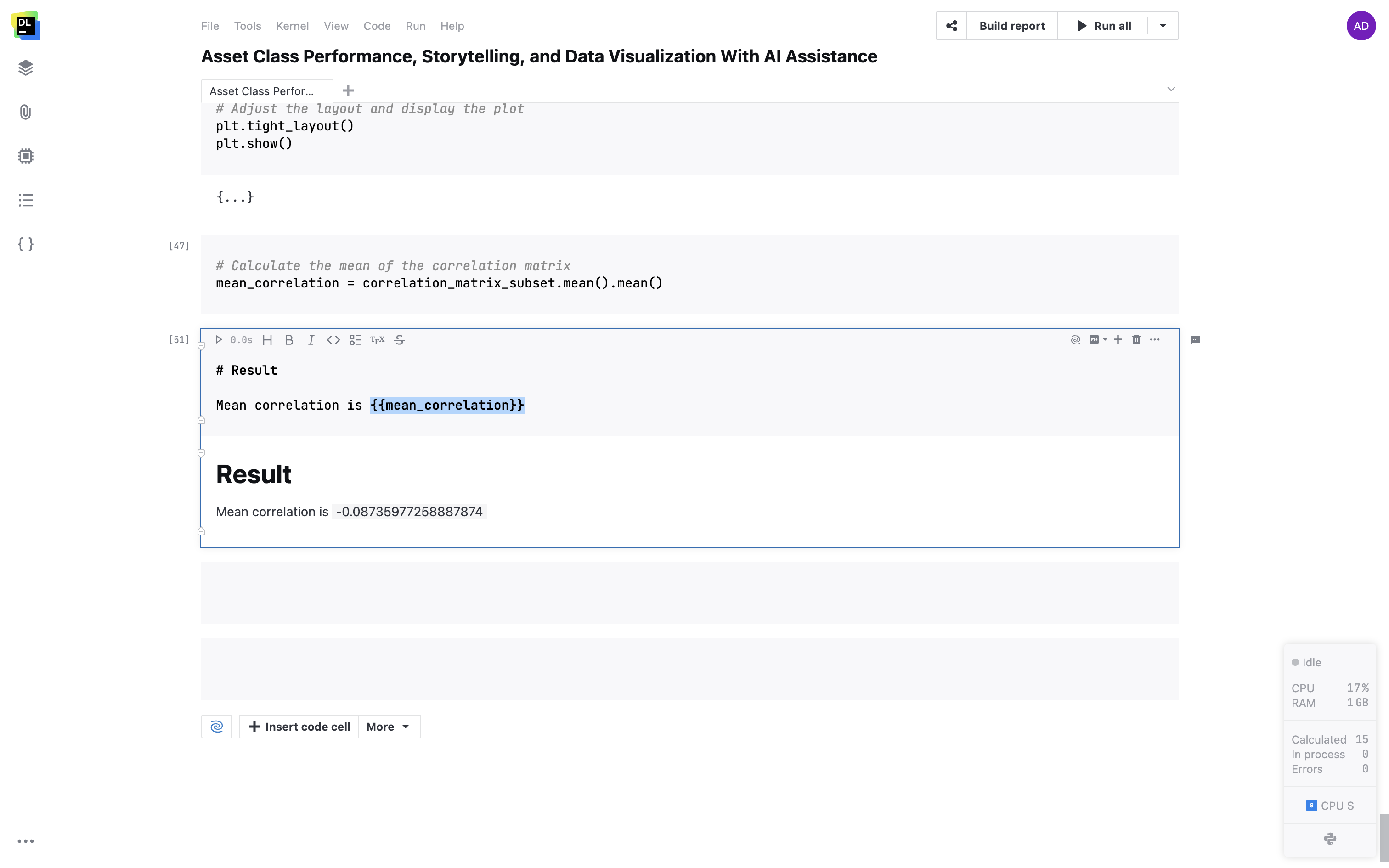
Prise en charge des variables dans les cellules Markdown
Intégrez vos variables dans des cellules Markdown avec des accolades doubles. Les variables seront converties de façon dynamique en leurs valeurs réelles dans votre texte.
Environnement
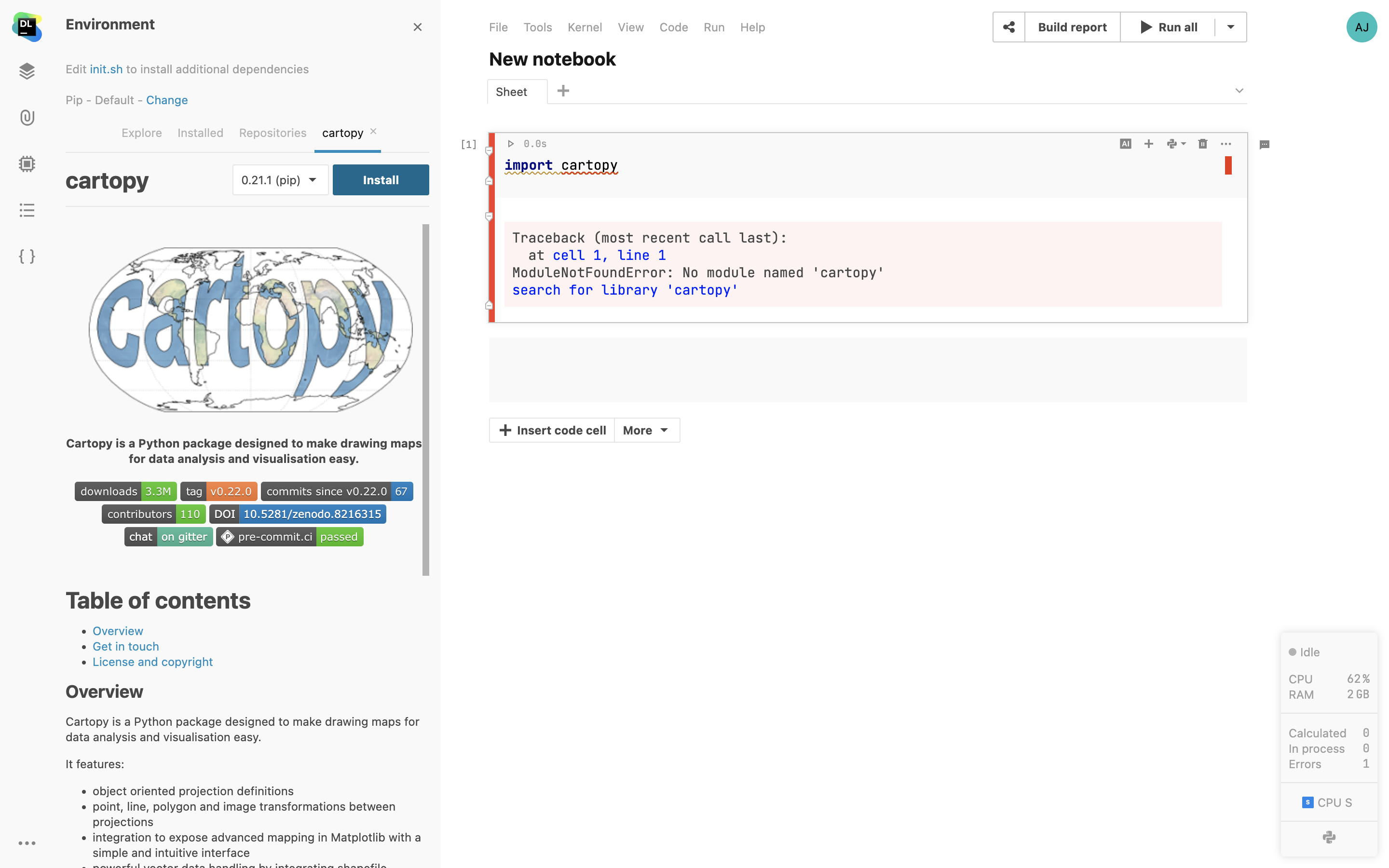
Gestionnaire de paquets
Datalore est livré avec un gestionnaire de paquets intégré qui permet de reproduire votre environnement. Le gestionnaire de paquets vous permet d'installer et de gérer de nouveaux paquets et s'assure qu'ils soient toujours disponibles lors des prochaines ouvertures du notebook.
Environnements de base personnalisés
Créez plusieurs environnements de base à partir d'images Docker personnalisées. Vous pouvez préconfigurer toutes les dépendances, les versions des paquets et les configurations des outils de build afin que votre équipe ne perde pas de temps à installer manuellement les éléments et à synchroniser les versions des paquets.
Paquets provenant de référentiels Git
Installez un paquet personnalisé compatible avec pip à partir d'un référentiel Git en joignant une branche Git à votre notebook.
Scripts d'initialisation
Configurez un script à exécuter avant le démarrage du notebook. Vous pouvez y spécifier tous les outils de build nécessaires et les dépendances requises.
Visualisations
Onglet Visualize
Obtenez des options de visualisation automatique dans l'onglet Visualize pour tout DataFrame pandas. Les diagrammes de points, de lignes, de barres, de surfaces et de corrélation vous aideront à comprendre rapidement le contenu de vos données. Un jeu de données de grande taille sera automatiquement échantillonné. Tous les graphiques peuvent ensuite être extraits vers des cellules de code ou de graphique pour une personnalisation plus poussée.
Prise en charge de tous les paquets de visualisation Python
Créez des visualisations avec le paquet de votre choix. Matplotlib, plotly, altair, seaborn, lets-plot et de nombreux autres paquets sont pris en charge dans les notebooks Datalore.
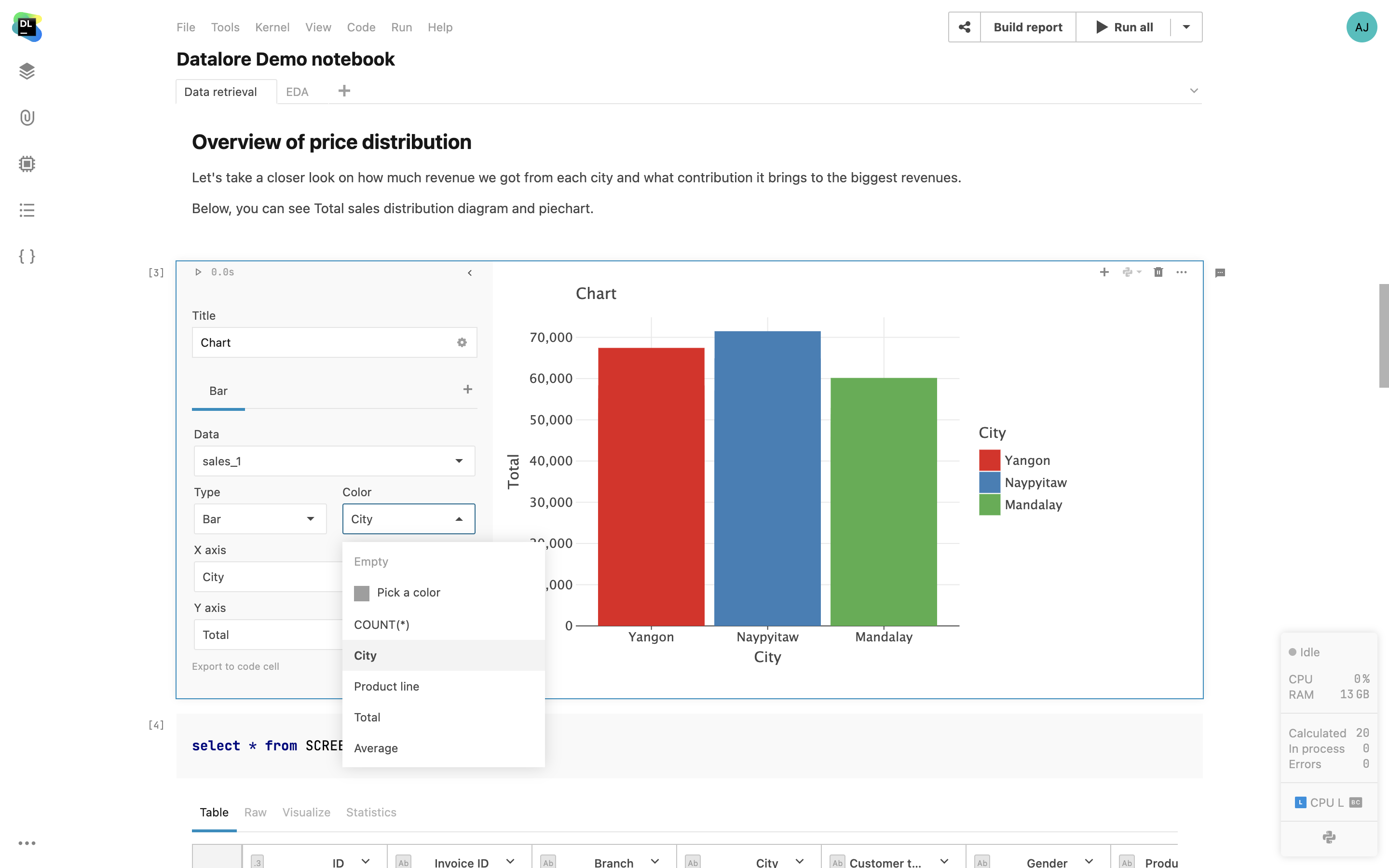
Cellules de graphiques
Créez des visualisations prêtes pour la production en quelques clics seulement. L'état des cellules est partagé avec vos collègues pour vous permettre de travailler ensemble sur la visualisation.
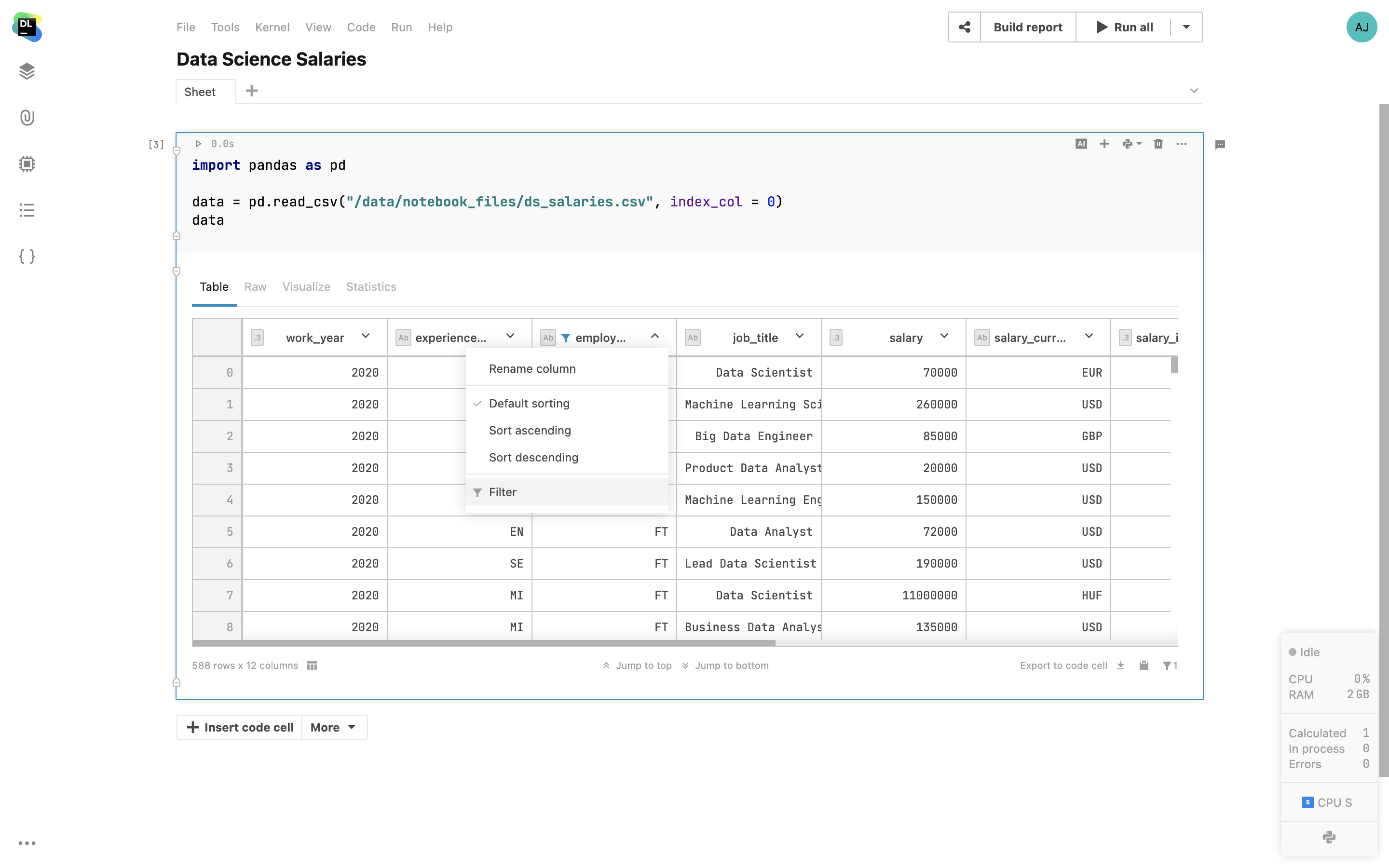
Sortie de table interactive
Filtrez et triez les Pandas DataFrames et les résultats des requêtes SQL directement dans la sortie des cellules. Sélectionnez les colonnes à afficher, triez les ensembles de données en fonction d'une colonne spécifique, filtrez les données en fonction d'expressions « equals » et « contains », et passez facilement au début ou à la fin de l'ensemble de données. Une fois les données triées et filtrées, utilisez l'option Export to code cell pour générer l'extrait de code Pandas et permettre de reproduire la vue de la table.
Modification des cellules DataFrame dans les tables interactives
Vous n'avez plus à télécharger des fichiers CSV pour réaliser plusieurs modifications dans un DataFrame. Il suffit de modifier le contenu des cellules dans des tables interactives et de cliquer sur Export to code pour reproduire le résultat dans un notebook.
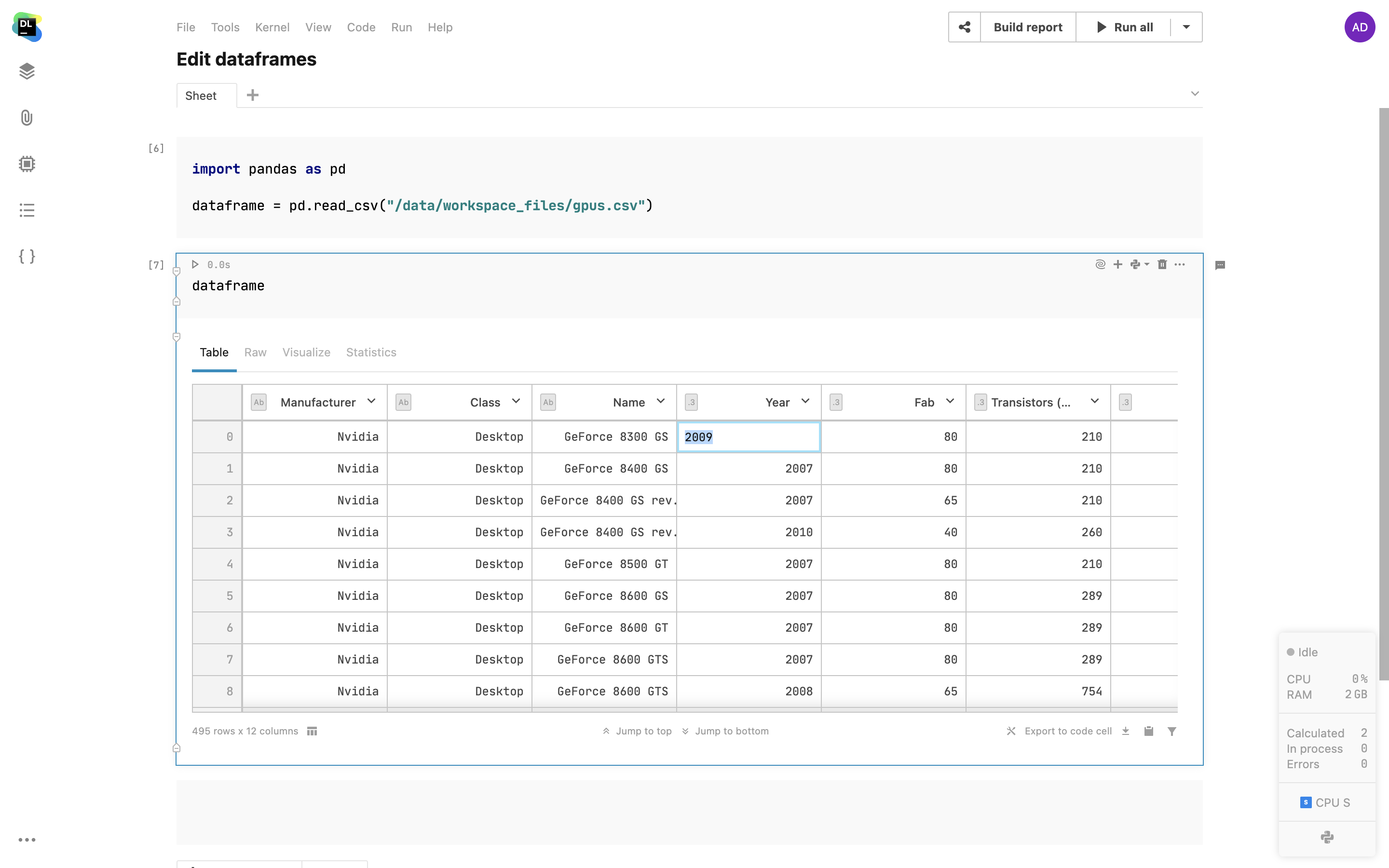
Statistiques pour DataFrame
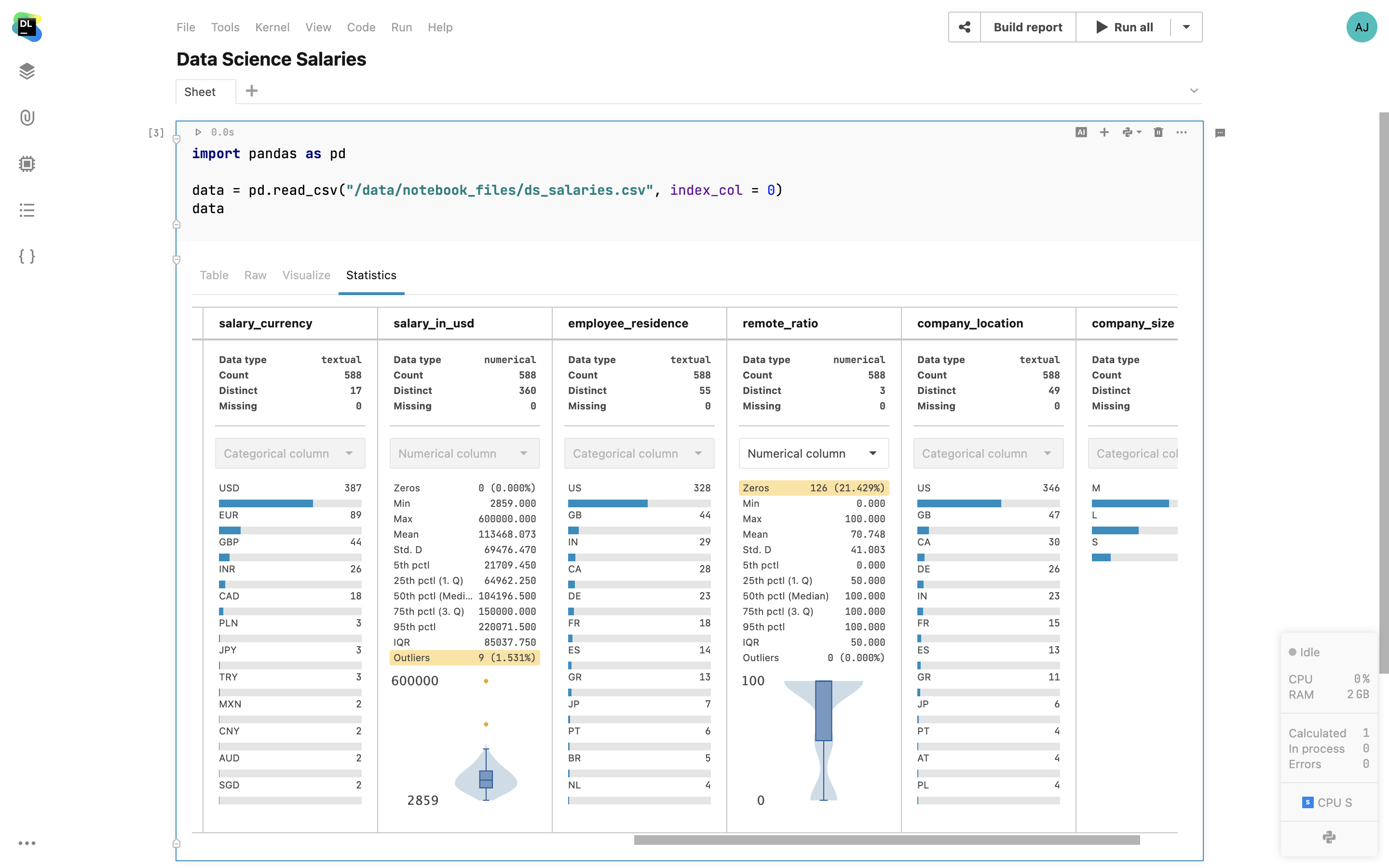
En un simple clic, vous pouvez obtenir des statistiques descriptives pour un DataFrame dans un onglet Statistics distinct. Les colonnes de catégories affichent la distribution des valeurs, tandis que dans les colonnes numériques, Datalore calcule les valeurs minimales, maximales, médianes, la déviation standard, les percentiles et surligne également le pourcentage de valeurs nulles et les exceptions.
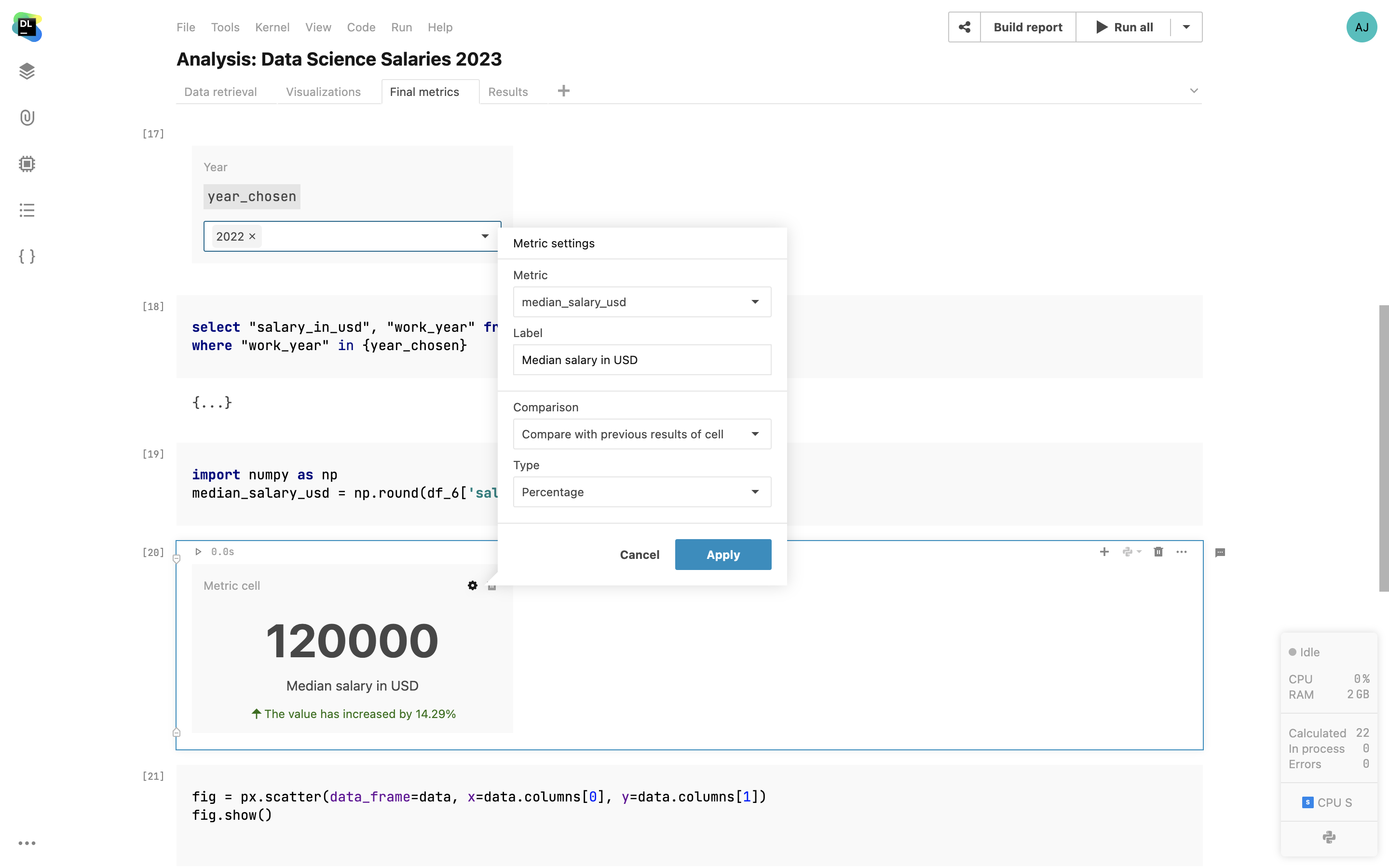
Contrôles interactifs
Ajoutez des entrées interactives, telles que des listes déroulantes, des curseurs, des entrées de texte et des cellules de dates dans vos notebooks et utilisez les valeurs d'entrée comme variables dans votre code. Présentez les visualisations avec des cellules de graphique et mettez en évidence des chiffres spécifiques dans les cellules numériques.
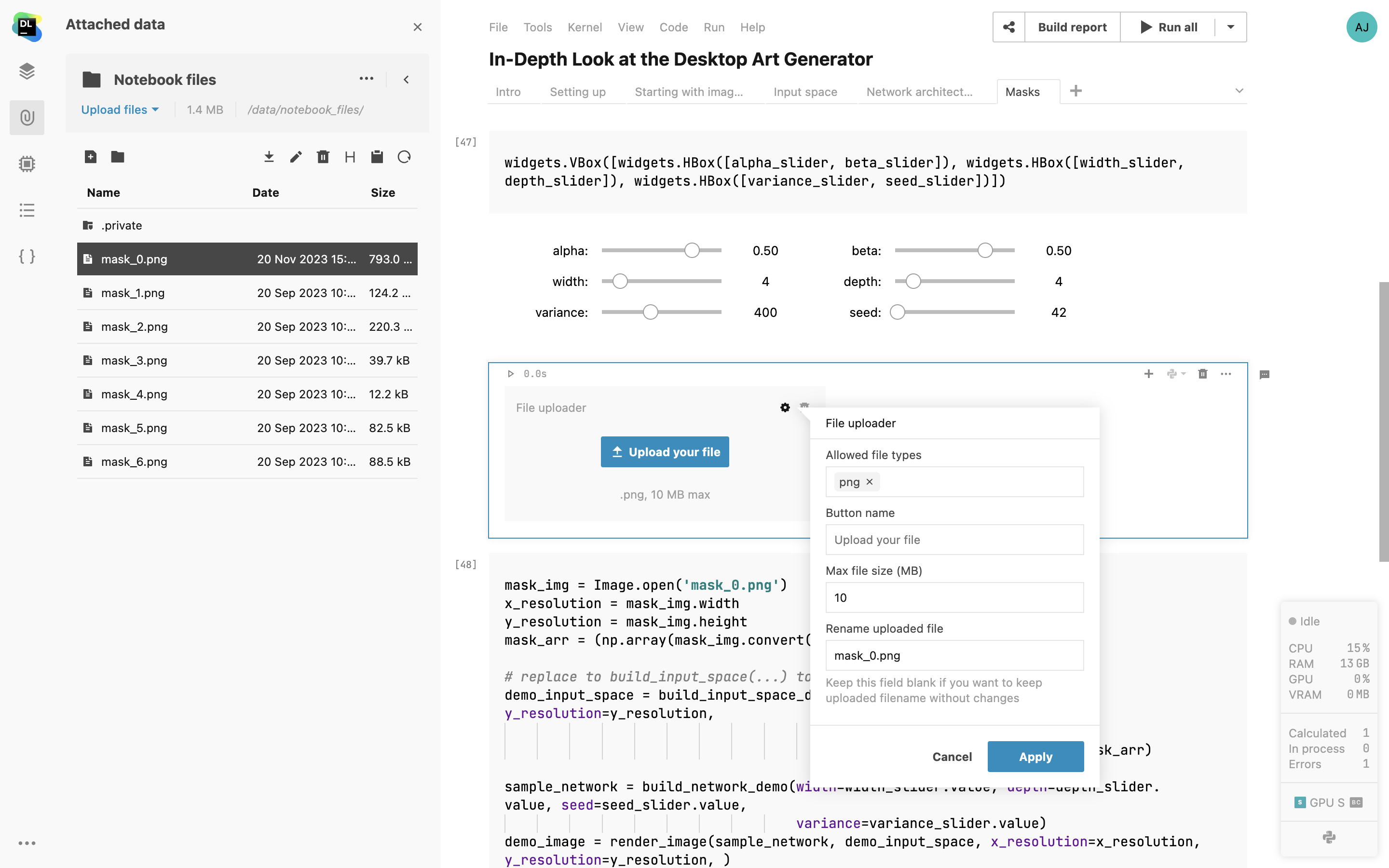
Contrôle interactif du chargeur de fichiers
Les responsables des rapports et des notebooks permet désormais aux collaborateurs de charger des fichiers CSV, TXT ou d'image depuis leurs machines locales. Définissez des types de fichiers et des limites de taille pour incorporer le chargement des fichiers dans votre workflow.
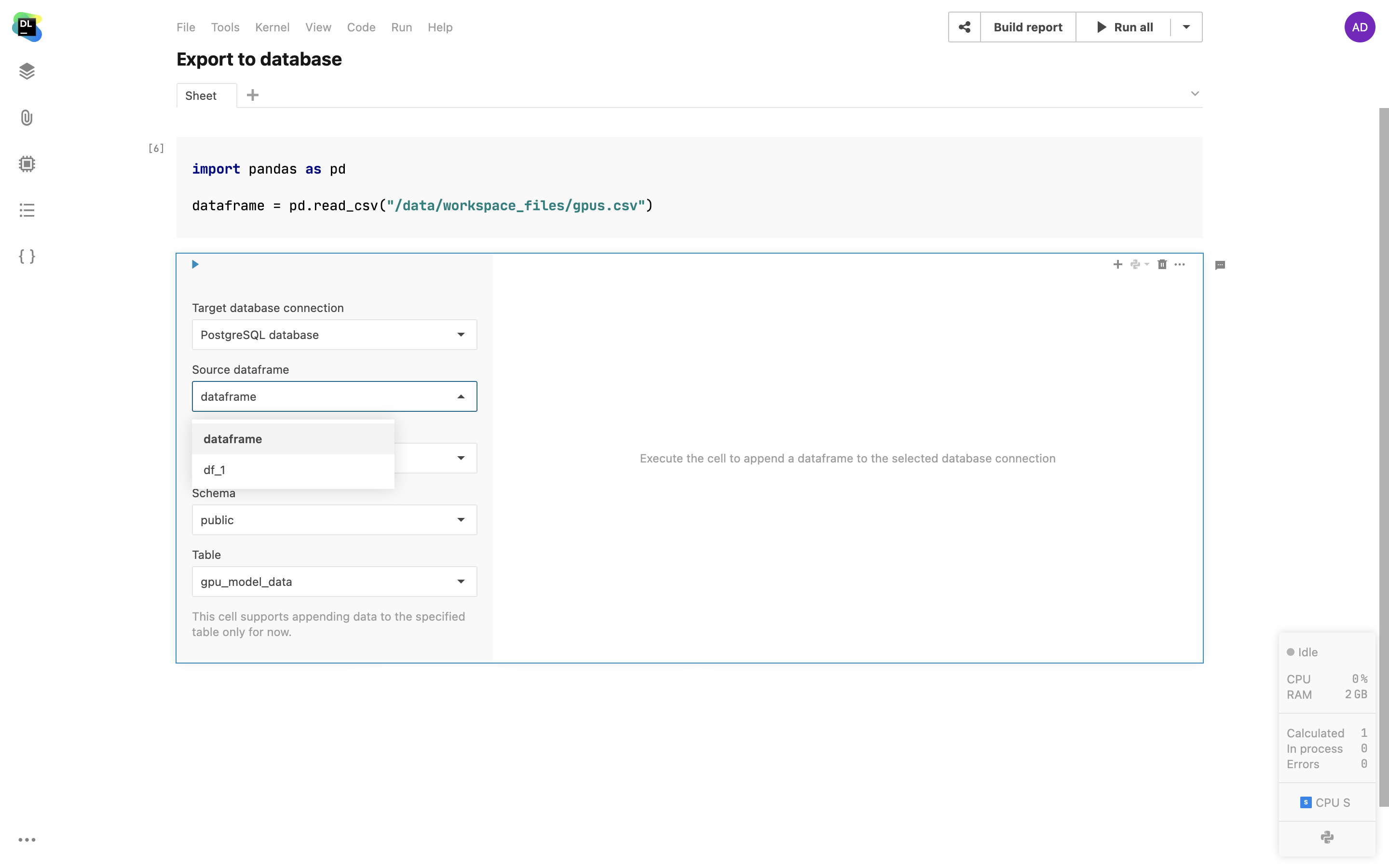
Cellule Export to database
Vous pouvez exporter des dataframes vers les tables existantes d'une base de données directement depuis votre notebook. Pour personnaliser l'exportation, sélectionnez le dataframe, la base de données cible, le schéma et la table. La fonctionnalité de planification vous permet également d'automatiser les exportations.
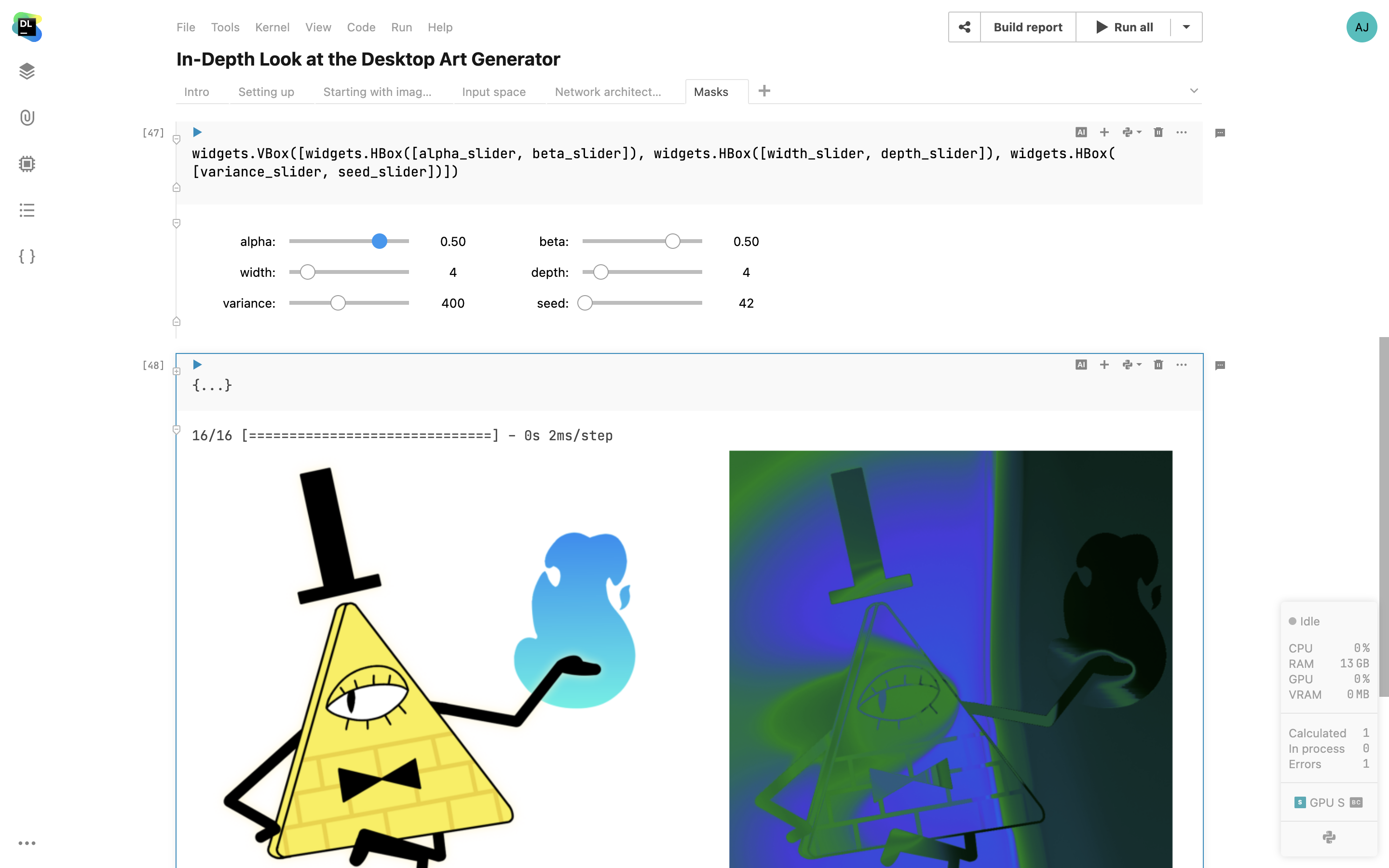
Prise en charge d'IPyWidgets
Datalore prend en charge IPyWidgets, le framework classique pour les widgets Jupyter. Ajoutez des contrôles interactifs avec votre code Python, combinez plusieurs widgets dans une sortie de cellule et utilisez la sélection en tant que variable dans les parties suivantes de votre notebook.
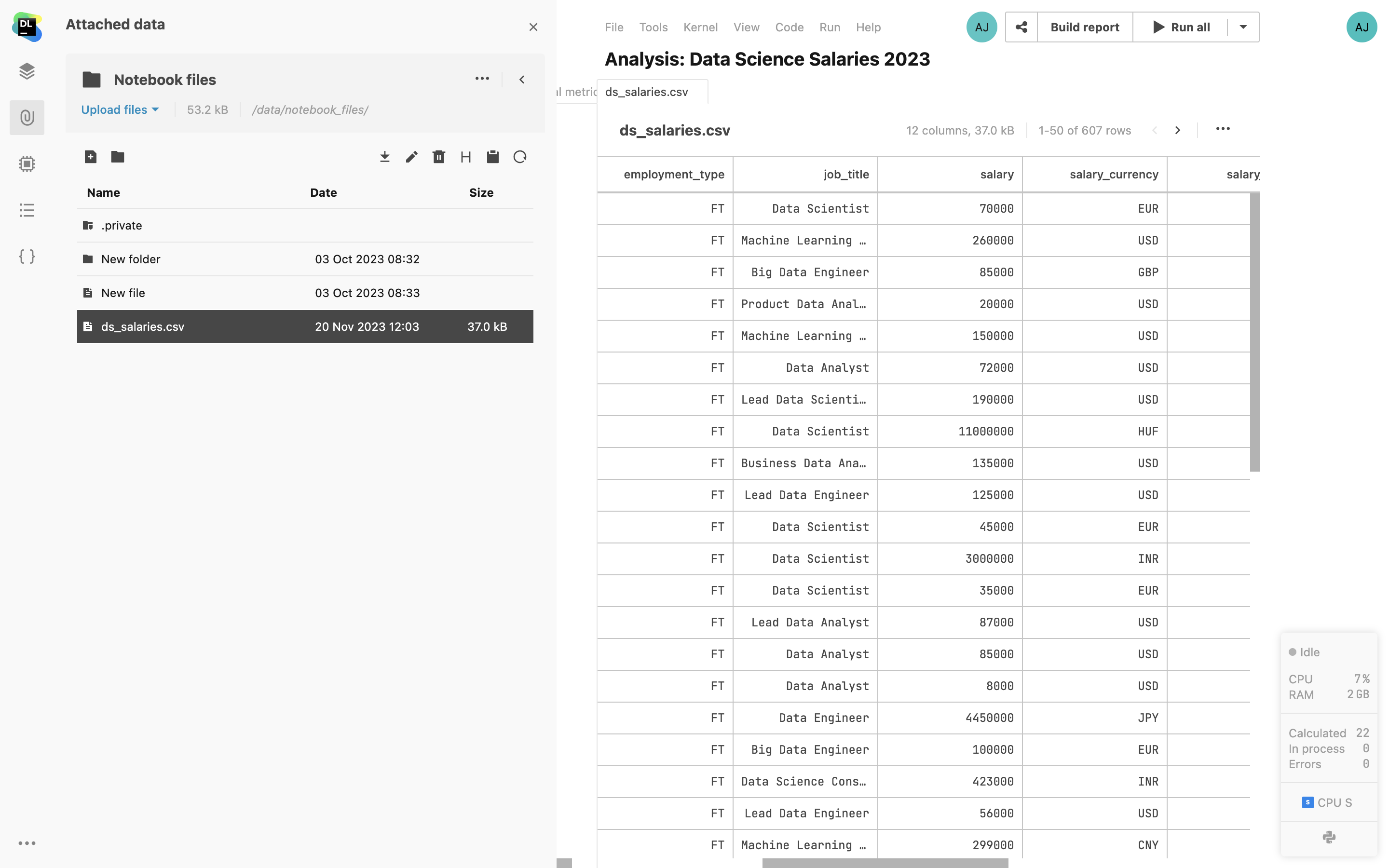
Aperçus de fichiers CSV
Ouvrez les fichiers CSV et TSV depuis l'onglet de données Attached dans un autre onglet de l'éditeur de Datalore. Triez les valeurs des colonnes et paginez le contenu du fichier.
Modification de fichier CSV
Créez et modifiez les fichiers CSV et TSV directement dans l'éditeur de Datalore. Vous pouvez créer un tout nouveau fichier ou modifier le contenu d'un fichier existant.
Terminal
Ouvrez des fenêtres de terminal dans l'éditeur, exécutez des scripts .py et accédez à l'agent, à l'environnement et au système de fichiers à l'aide de commandes bash standard.
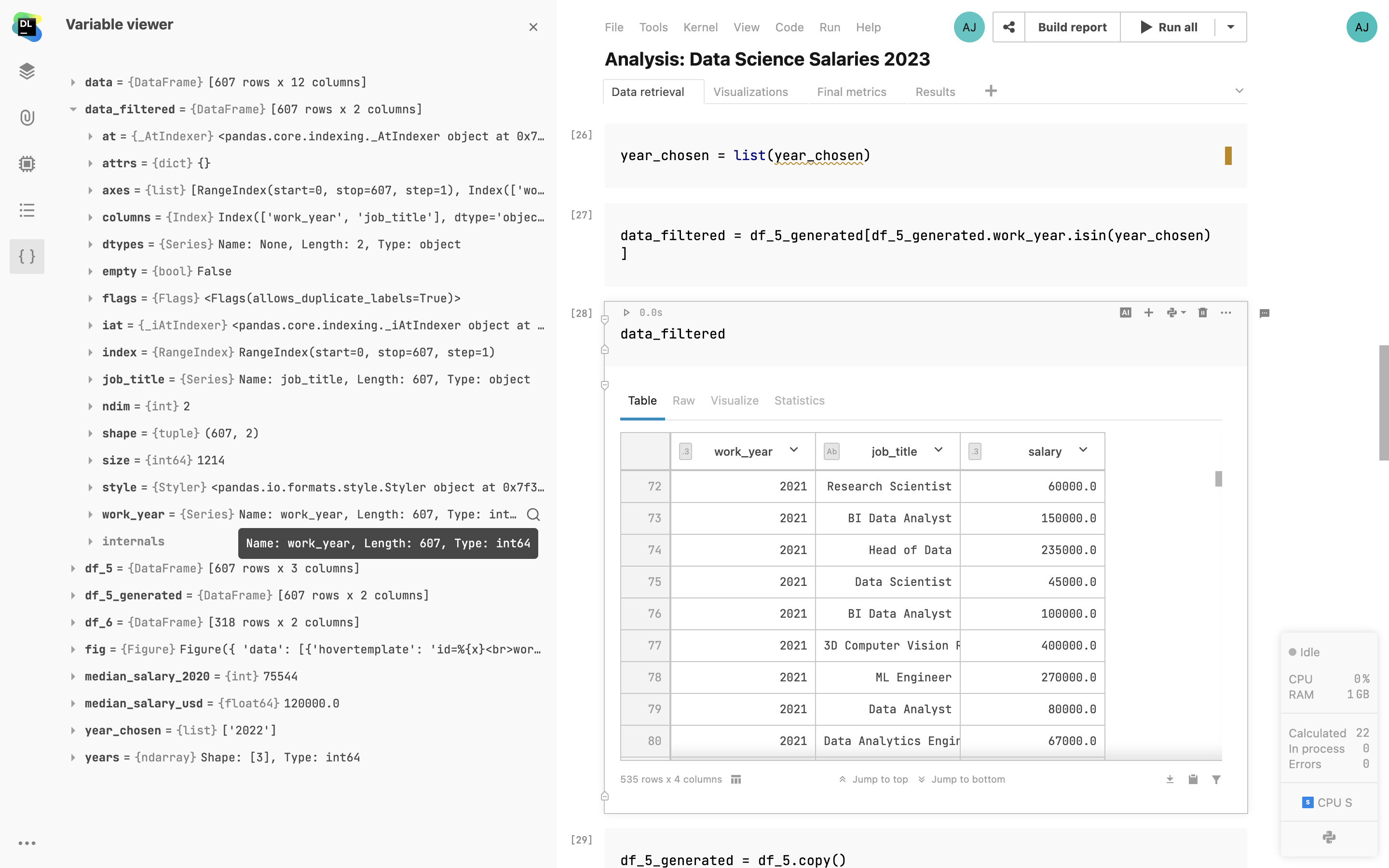
Visionneuse des variables
Parcourez les variables des notebooks et les valeurs des paramètres intégrés depuis le même emplacement.
Gestion des versions interne
Créez des points de contrôle d'historique personnalisés pour revenir sur les modifications à tout moment à l'aide de l'outil d'historique. Lorsque vous parcourez un point de contrôle, la différence entre la version actuelle du notebook et celle qui est sélectionnée s'affiche.

Calculs
Exécutez des notebooks sur des CPU et des GPU
Dans Datalore, vous pouvez exécuter vos notebooks sur des CPU et des GPU. Vous pouvez choisir la machine dont vous avez besoin à partir de l'interface utilisateur. Le type et la quantité de ressources dont vous bénéficiez dépendent de votre forfait. Vous trouverez plus d'informations ici.

Cloud privé et machines sur site
Vous pouvez connecter tout type de matériel serveur que vous utilisez déjà à Datalore pour permettre à vos utilisateurs d'y accéder depuis l'interface de Datalore.
Mode réactif pour une recherche reproductible
Le mode réactif applique un ordre d'évaluation descendant et recalcule automatiquement les cellules situées sous la cellule modifiée. L'état du notebook sera sauvegardé après chaque évaluation de cellule et pourra être restauré à tout moment.
Calculs en arrière-plan
Activez les calculs en arrière-plan pour que l'exécution de votre notebook se poursuive même si vous fermez l'onglet du navigateur. Vous garderez accès à votre liste de calculs en cours à partir du menu User ou du panneau d'administration.
Rapports d'utilisation des machines
Téléchargez des rapports CSV indiquant le temps passé à exécuter chaque machine. Ces rapports peuvent vous aider à déterminer à quels projets vous avez accordé le plus d'attention.
Planification des notebooks
Utilisez la planification pour exécuter vos notebooks selon un calendrier : toutes les heures, tous les jours, toutes les semaines ou tous les mois. Ainsi, les rapports publiés seront mis à jour régulièrement. Choisissez les paramètres de planification à partir de l'interface utilisateur ou utilisez la chaîne CRON. Notifiez les collaborateurs du notebook par e-mail en cas de réussite ou d'échec.
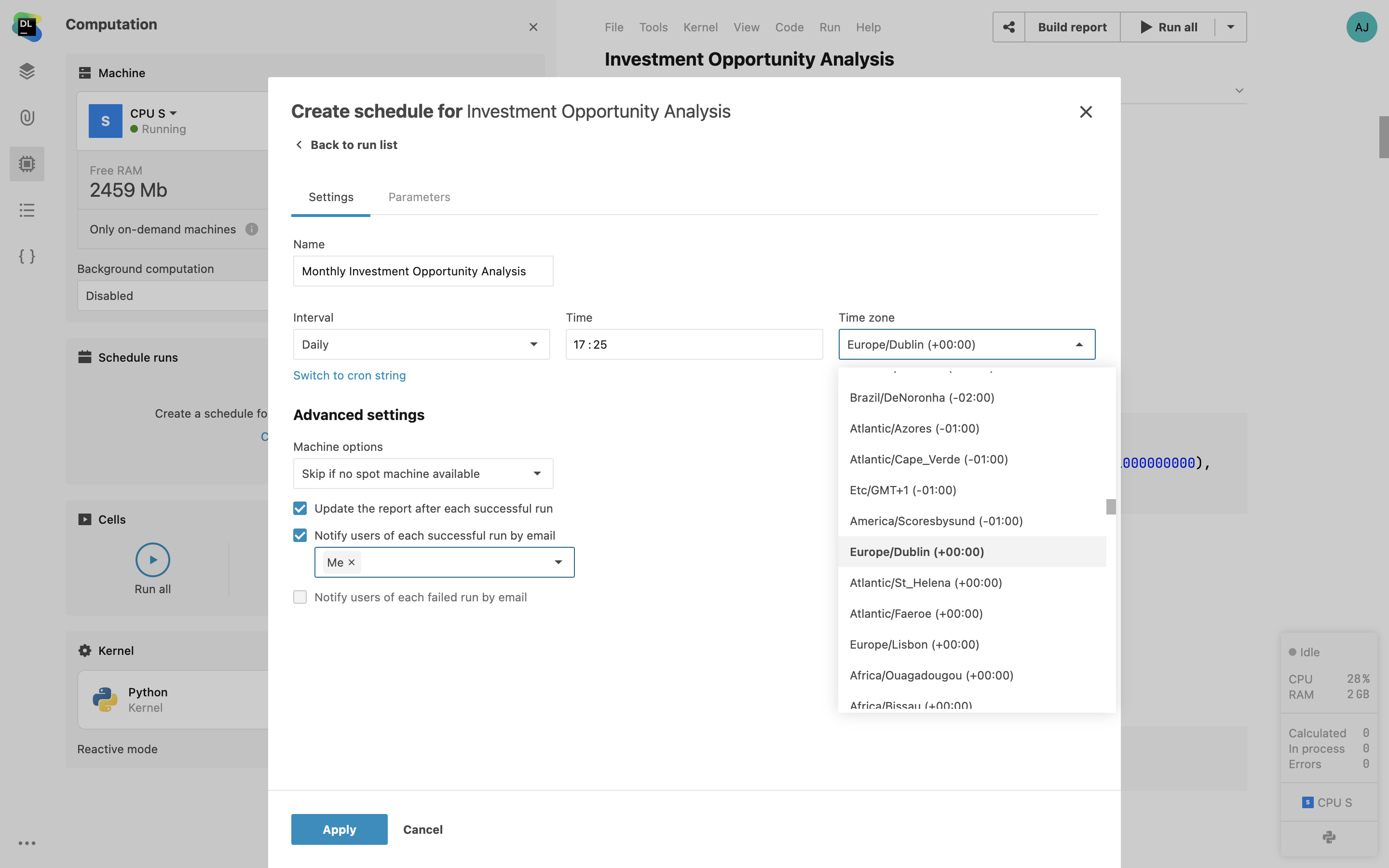
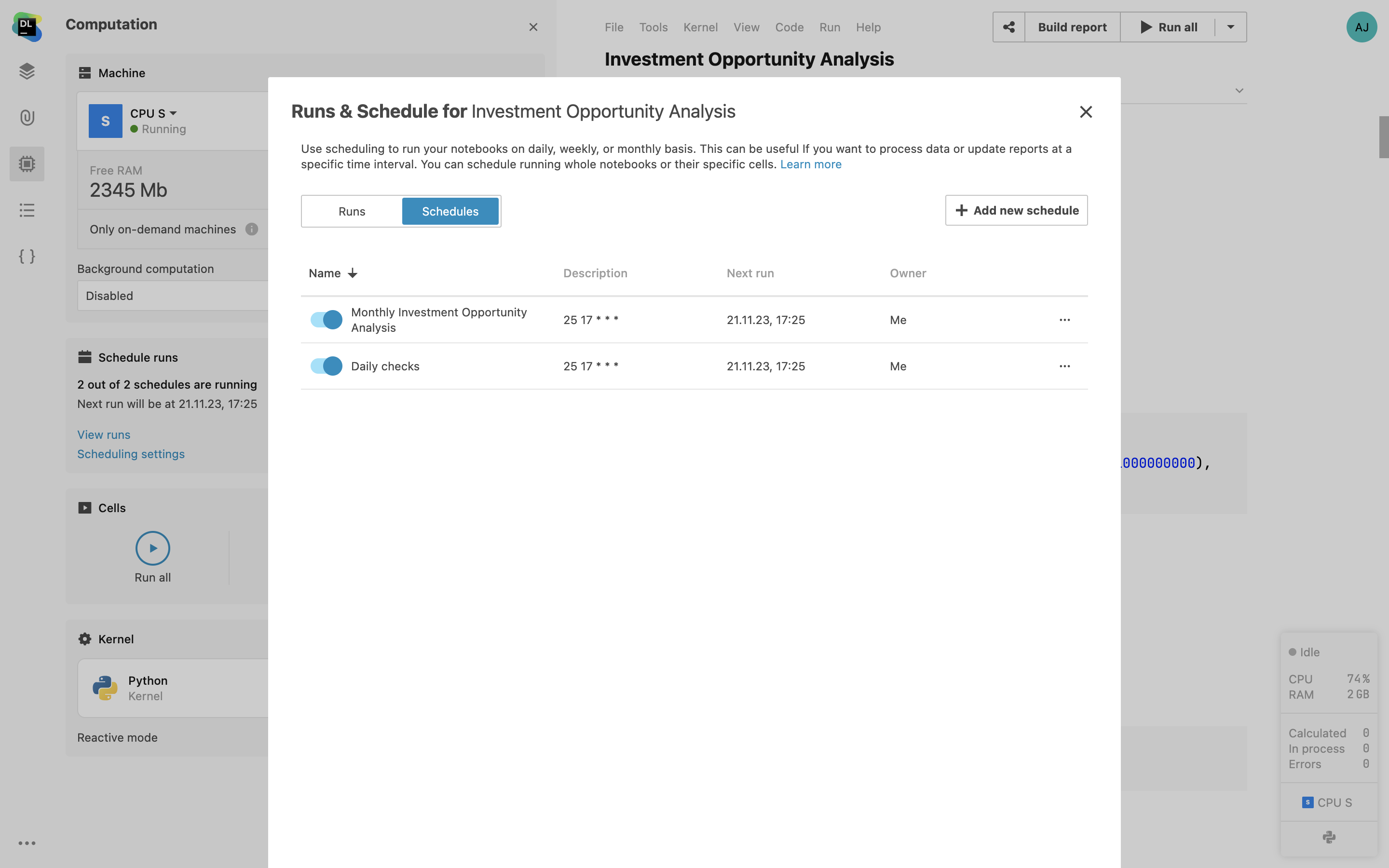
Planifications multiples de notebook
Spécifiez et gérez plusieurs planifications portant sur le même notebook depuis l'interface utilisateur. Cette fonctionnalité permet de créer des planifications personnalisées et d'exécuter le notebook toutes les heures, chaque jour ou semaine, ou encore à des dates spécifiques. Vous pouvez désormais planifier vos tâches en fonction de vos besoins, ce qui permet d'allouer les ressources plus efficacement et de choisir quand exécuter le code en fonction des contraintes de votre projet.
API Datalore Run
Vous pouvez à présent déclencher l'exécution d'un notebook Datalore ou republier un rapport à l'aide d'un appel API. Cette fonctionnalité est un complément des exécutions planifiées pour vous permettre de déclencher la réexécution d'un notebook à la demande à partir d'applications externes et de notebooks Datalore internes. Vous pouvez également visualiser les résultats de l'exécution à partir du menu Scheduled run. Vous pouvez trouver plus d'informations sur l'utilisation de l'API ici.

Prise en charge native des paquets R
Pour les notebooks R, vous pouvez désormais installer des paquets depuis des dépôts de paquets R, publics et privés, pris en charge par install.packages dans l'onglet Environment manager. L'utilisation d'Environment manager permet de conserver une configuration d'environnement persistante tout au long de l'exécution du notebook. Il est possible de configurer un dépôt personnalisé en créant un fichier .Rprofile dans init.sh ou une image d'agent personnalisé.
Si l'installation conda reste l'installation par défaut dans la version cloud, les clients Enterprise peuvent configurer un environnement de base personnalisé autre que conda avec le noyau R. Cela débouche sur l'absence de paquets conda dans les résultats de recherche de l'Environment manager. Vous pouvez trouver un exemple de cette installation ici.

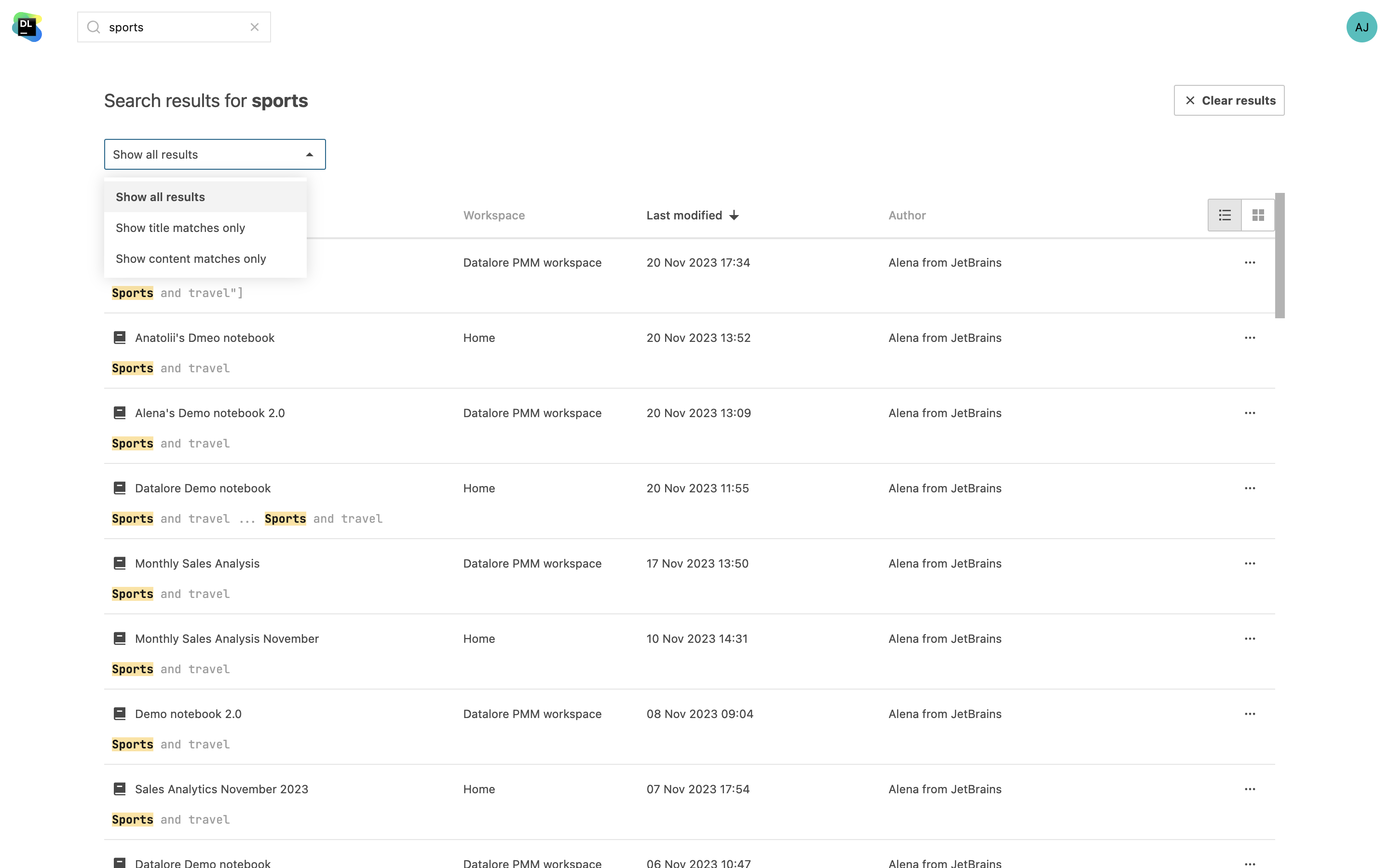
Recherche dans le contenu des notebooks
Recherchez des sections spécifiques du code ou les informations nécessaires dans tous les notebooks de l'ensemble de vos espaces de travail. En complément de la recherche sur le nom des notebooks, il est désormais possible de rechercher des noms de variables et du contenu. Votre requête est sélectionnée dans les résultats de la recherche.