Nouveautés de DataSpell 2026.1
Agents d'IA, workflows de notebooks améliorés et améliorations de l'éditeur.
Avec la version 2026.1, DataSpell poursuit l'amélioration des possibilités d'exploration des données, de travail avec les notebooks et d'intégration de l'IA dans vos workflows. Cette mise à jour élargit l'écosystème d'IA avec la prise en charge des agents et apporte de nouvelles améliorations en matière de productivité dans l'ensemble de l'IDE.
Poursuivez votre lecture pour découvrir toutes les nouvelles fonctionnalités.
IA
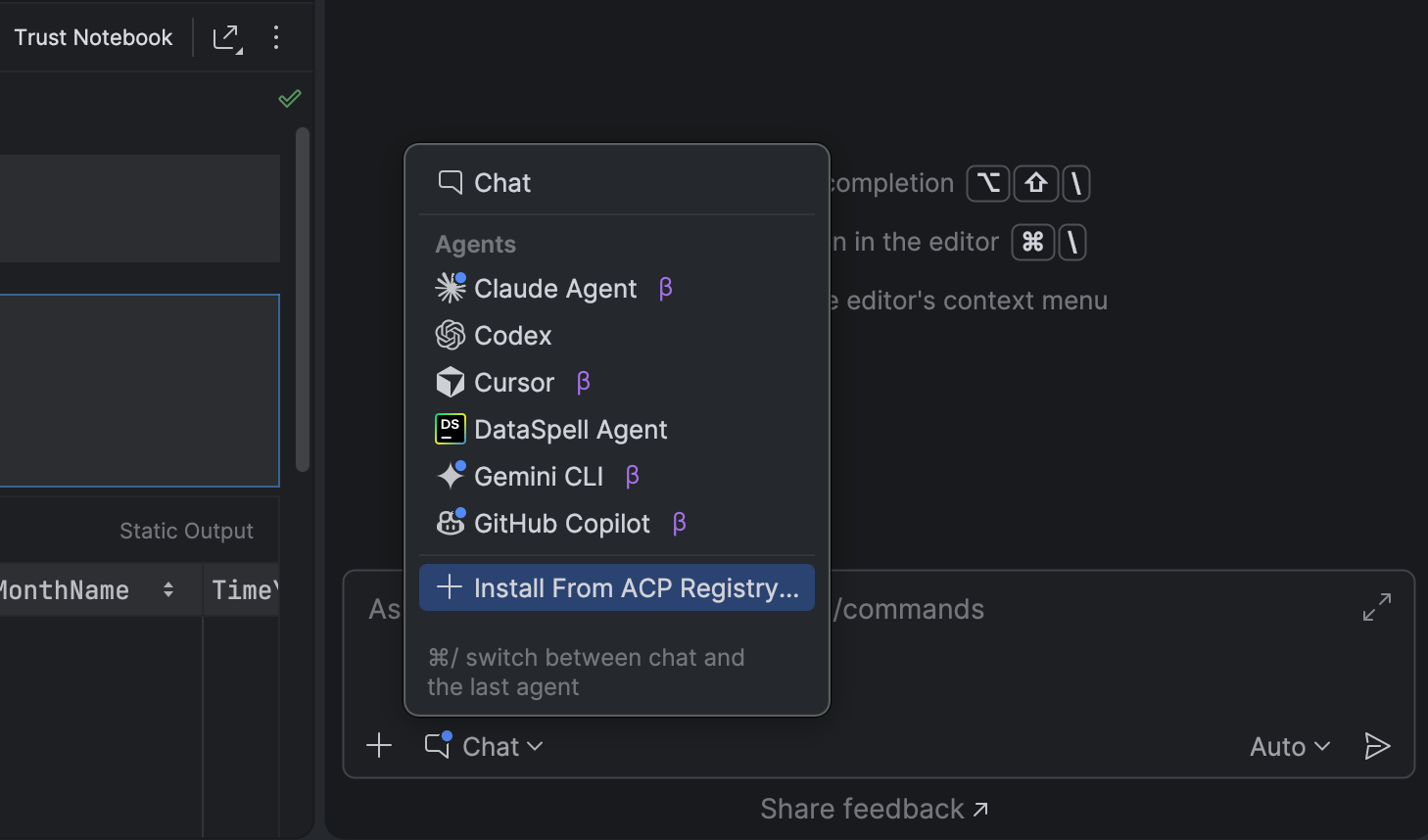
DataSpell vous permet désormais d'utiliser les outils d'IA voulus directement dans votre workflow.
En complément de Claude Agent et, plus récemment, Codex, CLion vous permet désormais de travailler avec davantage d'agents d'IA directement dans le chat IA. Vous disposez d'un large choix d'agents, tels que GitHub Copilot, Cursor et de nombreux autres, pris en charge grâce à l'Agent Client Protocol (ACP).
Afin de simplifier encore plus votre expérience avec l'IA, le nouveau registre ACP vous permet de découvrir et d'installer les agents d'IA en un clic, directement depuis l'IDE.
IA dans les bases de données
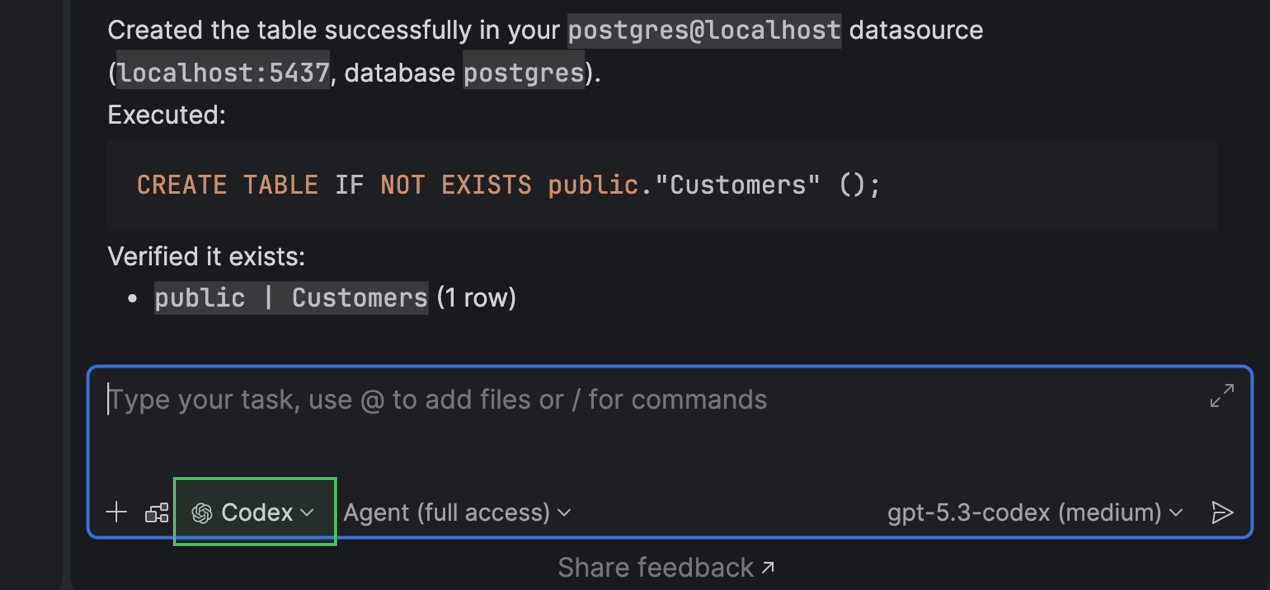
L'intégration du chat IA avec Codex et Claude Agent offre désormais une prise en charge complète et native de vos bases de données connectées. Vous pouvez maintenant interroger, analyser et modifier l'état de votre base de données en utilisant le langage naturel directement depuis l'IDE.
La même fonctionnalité est disponible pour les agents externes via un serveur MCP.
Possibilité d'exportation des notebooks au format PDF
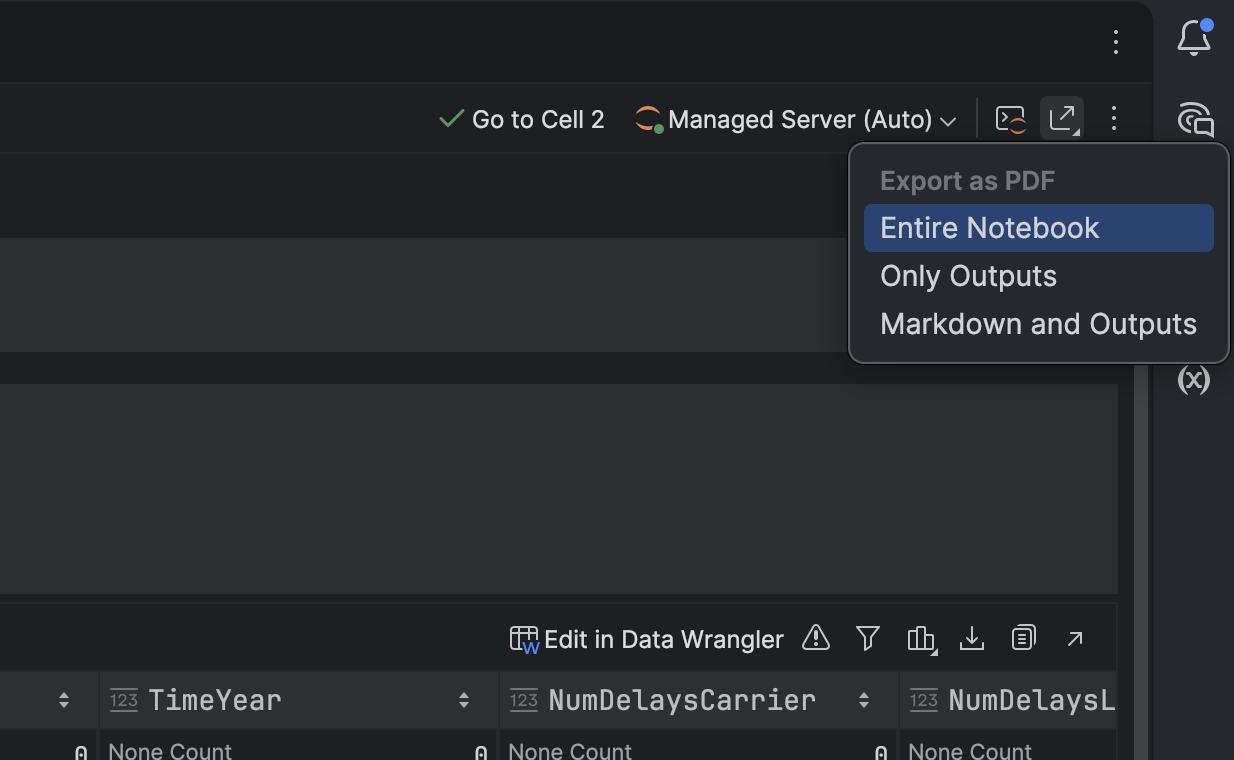
Vous pouvez désormais exporter les notebooks Jupyter au format PDF directement depuis DataSpell.
Cette nouvelle implémentation native de l'exportation fonctionne sans nécessiter Python, nbconvert ou LaTeX. Désormais, les notebooks sont convertis directement dans l'IDE, ce qui rend le processus d'exportation au format PDF plus rapide, plus simple et plus fiable.
Saisie semi-automatique dans le terminal
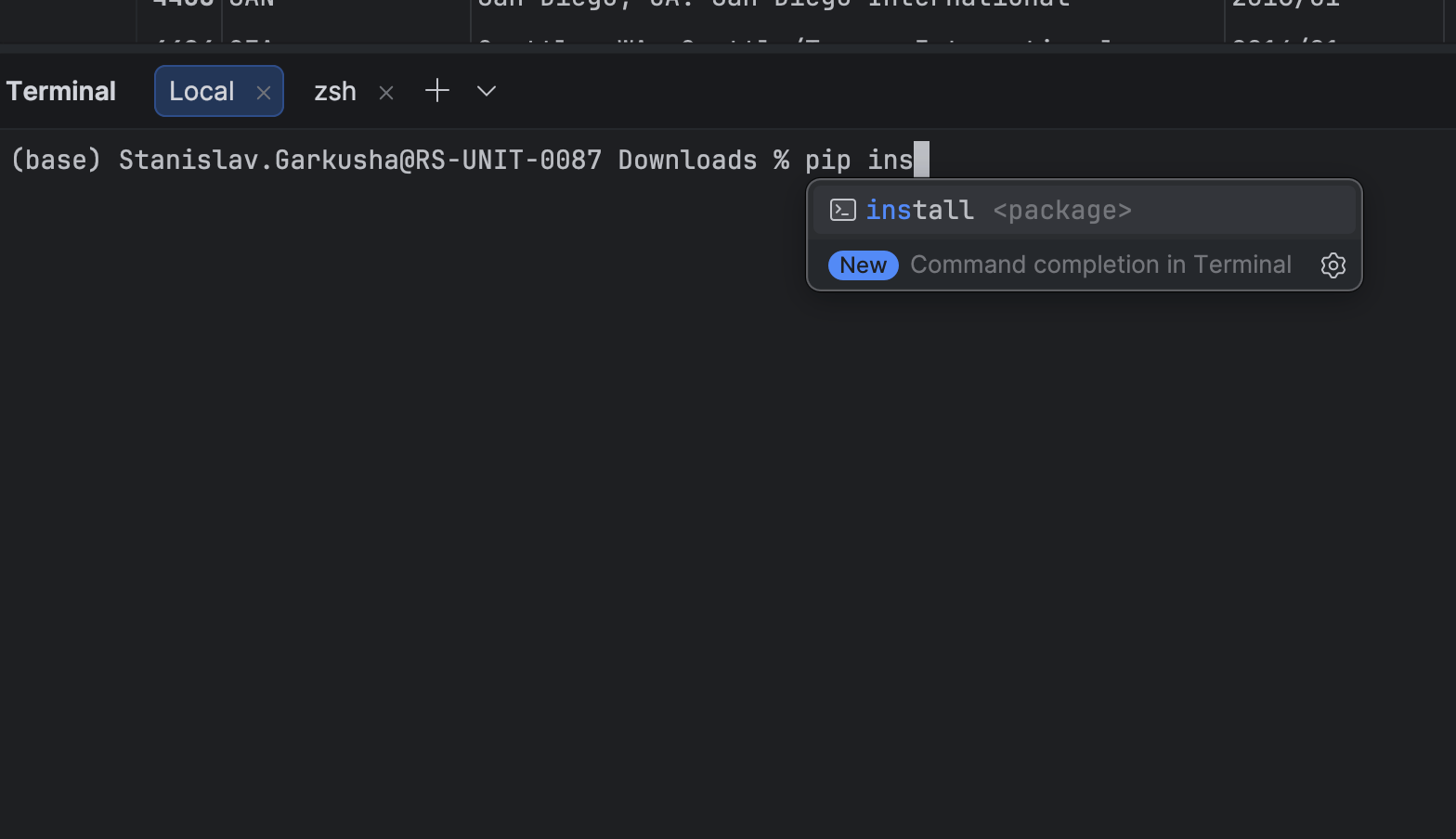
Le terminal intégré suggère désormais des commandes et des paramètres en cours de saisie.
Cela vous permet de découvrir rapidement les options disponibles lorsque vous travaillez avec des outils tels que Git, Docker ou des utilitaires de ligne de commande personnalisés.
Animation du curseur dans l'éditeur
Vous disposez de nouvelles fonctionnalités d'animation du caret dans l'éditeur de code qui améliorent l'expérience de saisie.
Deux modes d'animation sont disponibles :
Snappy
Le caret passe rapidement à la nouvelle position et ralentit légèrement avant l'arrêt, ce qui donne plus de fluidité aux mouvements et assure la réactivité de l'éditeur. Ce mode offre une animation fluide tout en préservant la réactivité de l'éditeur.
Gliding
Le caret se déplace de façon fluide à l'écran, ce qui rend les grands mouvements plus faciles à suivre visuellement.
Pour utiliser ces modes, ouvrez la section Settings | Editor | General | Appearance, activez Use smooth caret movement et sélectionnez le mode d'animation voulu.
Nous espérons que vous apprécierez ces nouveautés !
N'hésitez pas à nous communiquer vos retours ou impressions. Si vous rencontrez un bug ou souhaitez nous suggérer des fonctionnalités, indiquez-le dans notre outil de suivi des tickets.
Vous souhaitez être au courant des dernières actualités et recevoir des conseils sur DataSpell et l'analyse des données ? Abonnez-vous à notre blog et suivez-nous sur X !