Mesure des performances de CI/CD grâce aux métriques DevOps
Un serveur de CI ou « serveur de build » coordonne toutes les étapes d'un processus de CI/CD, de la détection des changements dans votre système de contrôle de version au déploiement de nouveaux builds.

L'utilisation d'un serveur de CI peut vous aider à simplifier vos processus d'intégration et de livraison/déploiement continus (CI/CD). Un serveur de CI surveille votre système de contrôle de version, déclenche automatiquement les tâches de build, de test et de déploiement, collecte les résultats et lance la phase suivante du pipeline.
S'il est possible d'exécuter un processus de CI/CD sans serveur de build, de nombreuses équipes de développement optent pour un outil de CI pour coordonner le processus et communiquer les résultats de chaque étape. Dans ce guide, nous allons examiner le rôle d'un serveur de CI et la manière dont il peut vous aider à tirer pleinement partie du processus de CI/CD.
Pourquoi utiliser un serveur de CI ?
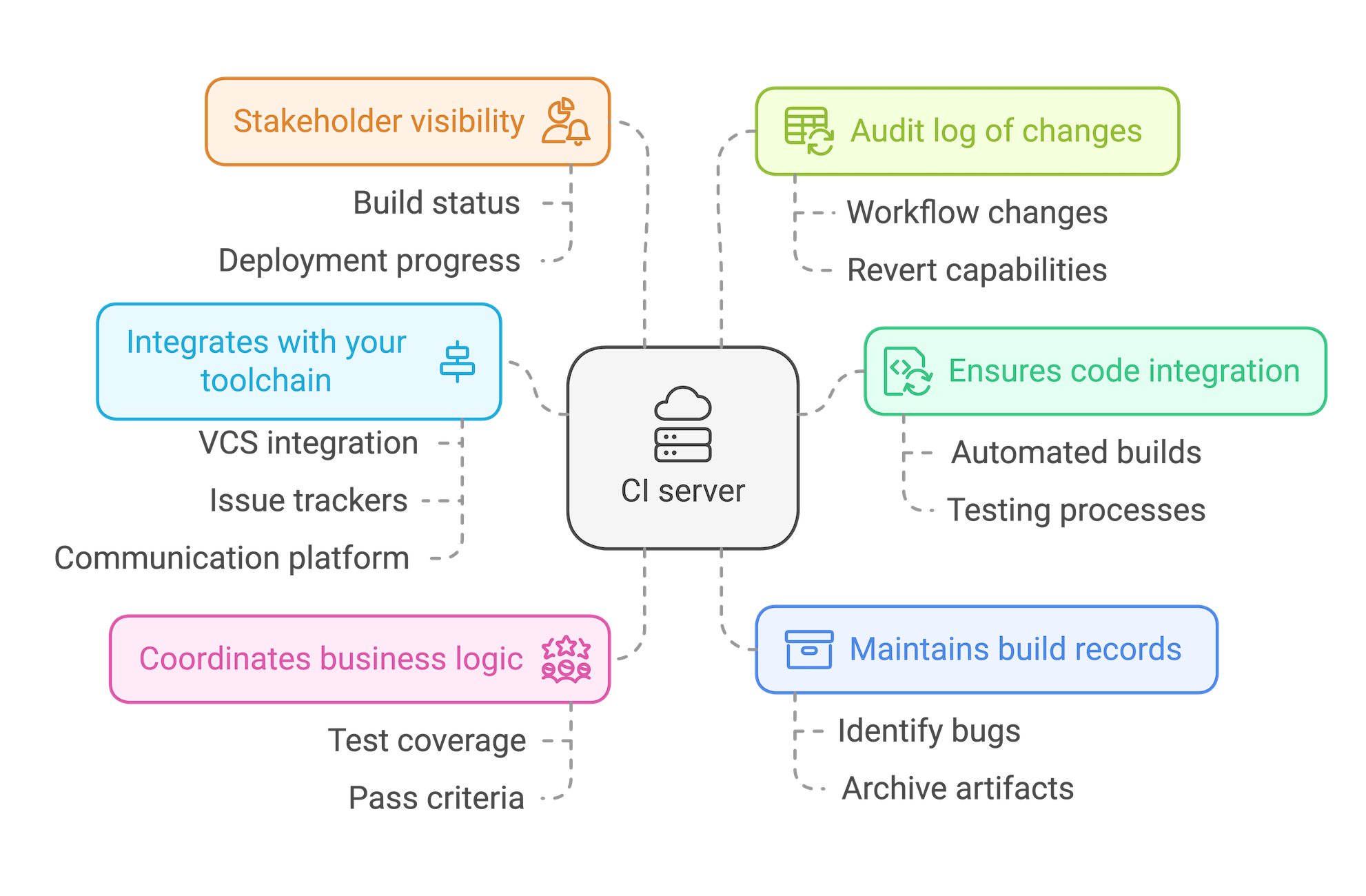
Le serveur de CI est le point central qui coordonne l'ensemble de vos activités de CI/CD. L'utilisation d'un serveur de CI :
- Assure que chaque commit passe par le processus de CI/CD : en s'intégrant avec votre système de contrôle de version, un serveur de CI garantit que toutes les modifications de code transitent par votre processus automatisé de build, de test et de déploiement, sans effort supplémentaire de la part des développeurs.
- Permet de coordonner votre logique métier : du niveau de couverture des tests aux critères de validation de chaque phase du processus de test automatisé, un serveur de CI offre une source unique de référence pour les exigences de votre organisation.
- S'intègre avec votre chaîne d'outils : comme votre système de contrôle de version et vos outils de build, un serveur de CI peut s'intégrer avec les outils de suivi des tickets et les plateformes de communication pour transférer les informations les plus récentes en provenance du processus de build, de tests et de déploiement.
- Conserve une trace des anciens builds : disposer d'une archive des artefacts de build est précieux lorsque vous devez identifier à quel endroit un bug particulièrement complexe s'est introduit dans votre base de code.
- Offre aux parties prenantes une visibilité sur l'avancement des versions : le serveur de CI étant votre source de référence sur l'état des builds et des déploiements, vous pouvez l'utiliser pour tenir l'ensemble de l'organisation informée de l'avancement.
- Fournit un journal d'audit des modifications : votre workflow et la logique métier évoluent généralement dans le temps. L'utilisation d'un serveur de CI permet de conserver une trace de l'évolution de votre processus de CI/CD, au cas où vous souhaiteriez revenir à une implémentation précédente.
Au fil du temps, un serveur de CI permet d'exploiter les nombreux avantages du CI/CD, tels que des retours rapides sur vos modifications de code, une détection précoce des bugs et des publications de versions plus fréquentes.
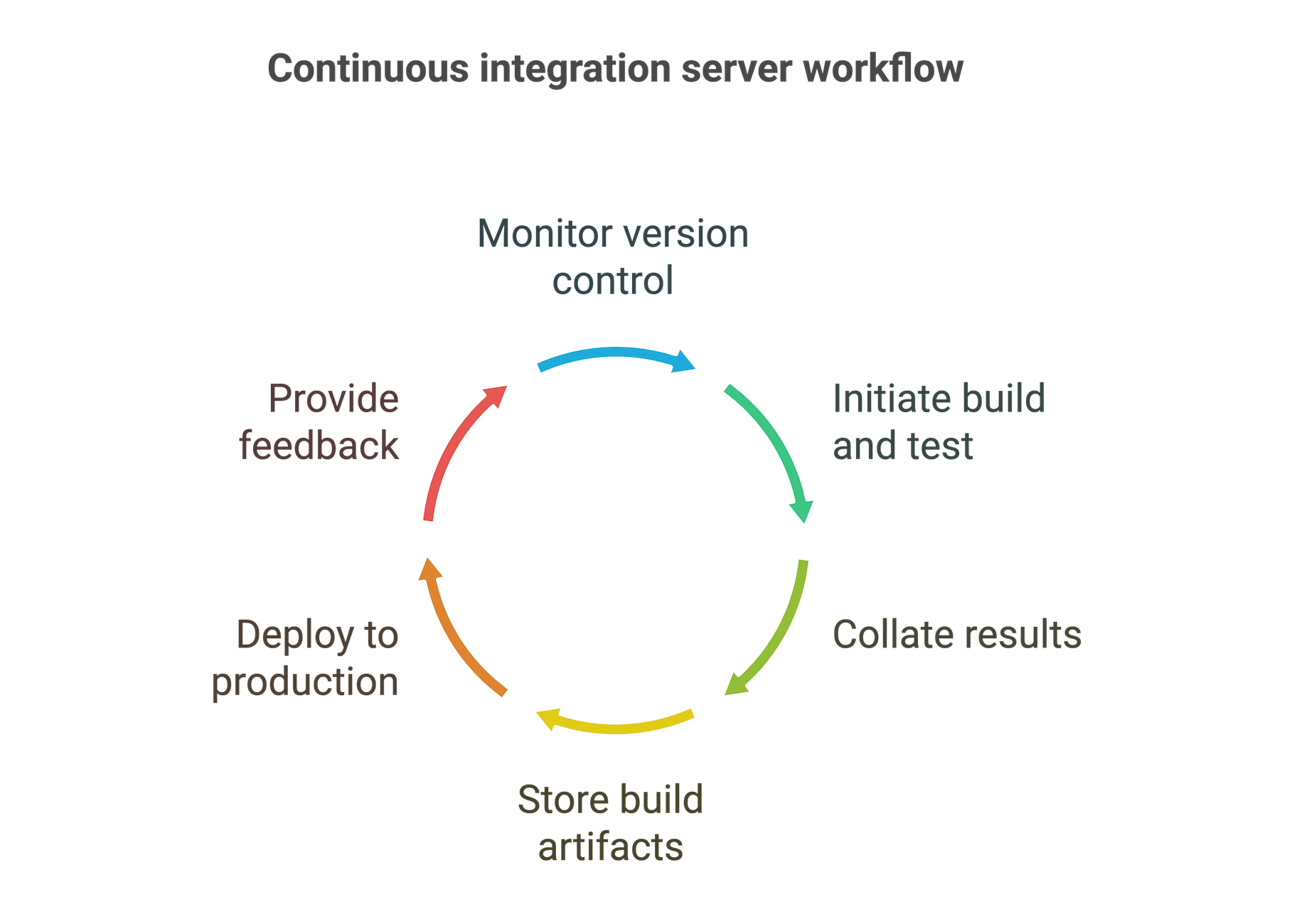
Comment fonctionne un serveur de CI ?
Le processus exact peut varier selon les besoins de votre équipe et de l'organisation, mais un serveur de CI fonctionne généralement de la façon suivante :
- Intégration avec votre système de contrôle de version et détection des commits dans les branches voulues.
- Lancement d'une série de tâches de build et de test à chaque commit. Ces tâches peuvent être distribuées sur d'autres machines de votre ferme de build ou s'exécuter directement sur le serveur de CI.
- Collecte des résultats de ces tâches et utilisation de ces données pour déterminer s'il faut passer à la phase suivante du processus.
- Stockage des artefacts de build dans une archive centrale.
- Déploiement en production de la nouvelle version.
- Retour d'informations tout au long du processus.
Suivi du contrôle de version
Au début de tout pipeline de CI/CD se trouve une intégration avec un système de contrôle de version ou de code source.
En général, un serveur de CI est configuré pour surveiller une branche donnée et déclencher une nouvelle exécution du pipeline à chaque commit. Cela permet de s'assurer que chaque fois qu'un développeur partage ses modifications, elles sont intégrées dans le build et testées afin de s'assurer que l'ensemble de la base de code fonctionne correctement.
Certains serveurs de CI permettent d'aller plus loin et de demander aux développeurs de créer un build et de tester les modifications localement avant de les partager sur une branche de CI. Bien que cela ne garantisse pas le succès de l'étape suivante, cela permet de réduire le nombre de builds défaillants et les retards qu'ils peuvent engendrer. Une autre option consiste à intégrer votre serveur de CI avec vos outils de révision de code afin que chaque commit passe par une phase de révision de code avant d'être partagé.
Appliquer ces couches supplémentaires de logique métier au début du processus permet de garder votre base de code propre et prête à être publiée en production, tout en minimisant les interruptions et les retards dans le pipeline.
Gestion des builds et des tests
Dès qu'un changement est détecté et qu'une exécution de pipeline est déclenchée, le serveur de CI coordonne les tâches de build et de test. En général, cela est affecté à des machines de build dédiées ou à des « agents ». Vos agents de build se chargent ensuite des tâches les plus importantes, à savoir l'exécution des builds et des tests en fonction des instructions reçues du serveur de CI.
Une autre option consiste à exécuter les tâches de build et de test directement sur le serveur de CI. Cependant, cela risque de créer des conflits d'accès aux ressources et de réduire les performances sur les bases de code sollicitées.
Lorsque vous utilisez votre serveur de CI pour configurer la logique d'une étape de votre pipeline, vous pouvez spécifier un ensemble de détails et de règles. Par exemple, vous pouvez :
- Exécuter tous vos tests automatisés de commits sur la branche principale, mais exécuter un ensemble réduit de vérifications sur les branches de fonctionnalités.
- Contrôler le nombre de builds pouvant appeler une base de données de test en même temps.
- Limiter les déploiements dans un environnement de préproduction à une fois par semaine afin de permettre des tests manuels plus approfondis.
Exécuter certaines tâches en même temps, en utilisant différents agents de build, peut rendre votre pipeline plus efficace. Cette méthode est utile si vous devez exécuter des tests sur différents systèmes d'exploitation ou si vous travaillez sur une base de code très volumineuse avec des centaines de milliers de tests, pour laquelle la seule option envisageable est la parallélisation. Dans ce dernier cas, la définition d'un build composite regroupe les résultats, ce qui permet de traiter les tâches comme une étape de build unique.
Un serveur de build qui s'intègre à une infrastructure hébergée dans le cloud, comme AWS, vous permet de bénéficier de ressources flexibles et évolutives pour exécuter vos builds et vos tests. Si vos besoins en infrastructure sont considérables, la prise en charge des agents de build conteneurisés et l'intégration avec Kubernetes vous permettront de gérer efficacement vos ressources de build, qu'elles soient dans le cloud ou sur site.
Définition des conditions de réussite ou d'échec
Une partie essentielle de votre logique métier consiste à définir ce qui constitue un échec à chaque étape de votre pipeline de CI/CD.
Votre serveur de CI doit vous permettre de configurer différentes conditions d'échec. Il détermine ensuite si ces conditions sont réunies, de façon à déterminer le statut d'une étape donnée et de décider s'il faut passer à l'étape suivante du pipeline.
En plus des échecs évidents, tels que le retour d'un code d'erreur ou l'échec de l'exécution des tests, vous pouvez définir d'autres conditions d'échec basées sur les données collectées par votre serveur de build.
Par exemple, la couverture de test diminue par rapport au build précédent (ce qui indique que les tests n'ont pas été ajoutés pour les dernières modifications du code) ou le nombre de tests ignorés augmente par rapport au dernier build réussi.
Ces métriques constituent également un avertissement utile en cas de détérioration de la qualité du code. En déclenchant un échec pour ces raisons et en limitant les utilisateurs autorisés à passer outre ces échecs, vous pouvez favoriser un comportement optimal.
Stockage des artefacts de build
Lorsqu'une modification réussit, le serveur de CI stocke les artefacts du processus de build. Cela peut inclure les fichiers binaires, les fichiers d'installation, les images de conteneurs et toute autre forme de ressources nécessaires pour déployer votre logiciel.
Vous pouvez ensuite déployer les mêmes artefacts dans les environnements de préproduction pour exécuter d'autres tests avant le déploiement final en production. Cela permet de s'assurer que la même sortie est testée à tous les stades et est bien plus fiable que de devoir regénérer le build à partir du code source avant chaque déploiement. En particulier, cela évite d'ignorer des dépendances et d'introduire de nouvelles incohérences.
L'utilisation d'un référentiel d'artefacts pour les builds réussies est également utile lorsqu'il faut revenir à une version précédente de votre logiciel ou lorsque vous tentez d'identifier si un problème spécifique a été introduit.
Déploiement des builds
Même si le nom laisse à penser que leur utilisation est limitée à l'intégration continue, la plupart des serveurs de CI peuvent également contribuer à la livraison et au déploiement continus.
Après avoir produit vos artefacts de build et exécuté une première série de tests au cours de la phase d'intégration continue, l'étape suivante consiste à déployer ces artefacts dans des environnements d'assurance qualité pour des tests complémentaires. Puis vient la mise en préproduction pour que vos partenaires puissent essayer le nouveau build. Et enfin, si tout semble correct, vous pouvez le déployer en production.
Vous pouvez utiliser un serveur de CI pour stocker et gérer les paramètres de chaque environnement dans votre pipeline. Cela permet de définir si vos scripts de déploiement sont déclenchés automatiquement en fonction du résultat de l'étape précédente.
Retour d'informations
L'une des principales fonctions d'un serveur de CI est de fournir des retours rapides à chaque étape du processus de build et de test. Les serveurs de CI qui s'intègrent avec votre IDE ou plateforme de communication peuvent vous prévenir à chaque fois que l'une de vos modifications entraîne l'échec du pipeline, sans avoir à suivre constamment sa progression.
Les serveurs de build peuvent également :
- Créer en temps réel des rapports sur des builds ou des tests en cours et vous indiquer l'état des différentes étapes terminées.
- S'intégrer avec les outils de suivi de tickets afin de voir les détails des correctifs inclus dans un commit et d'analyser rapidement la cause d'un échec.
- Collecter des statistiques sur la fréquence de déploiement, l'intervalle des pannes et le temps moyen de résolution, afin de vous aider à mesurer et améliorer votre processus de développement.
- Fournir des informations sur l'utilisation et les performances de votre serveur de CI et vos machines de build, que vous pouvez utiliser pour optimiser vos pipelines.

Faut-il créer son propre serveur de CI ?
Créer son propre serveur de CI peut paraître intéressant a priori. En concevant votre propre solution, vous pouvez l'adapter à vos besoins tout en évitant les frais de licence.
Cependant, la création d'un outil personnalisé n'est que le début d'un processus. Une fois ce nouvel outil en place, vous devez en assurer la mise à jour, notamment en corrigeant les bugs et développant de nouvelles fonctionnalités au fur et à mesure que les besoins évoluent.
Il faut également tenir compte du travail nécessaire pour intégrer le serveur de CI dans votre chaîne d'outils. La forme initiale de votre serveur peut fonctionner avec le système de contrôle de version, l'outil de suivi des bugs, les outils de build et les frameworks de test que vous utilisez actuellement, mais que se passera-t-il si vous basculez vers un autre produit ou une autre technologie ?
Bien que créer votre propre serveur de CI vous offre la flexibilité de concevoir un outil adapté à votre cas d'utilisation, les efforts initiaux et la maintenance continue nécessitent un engagement significatif sur le long terme.
Conclusion
Un serveur d'intégration continue joue un rôle essentiel dans l'implémentation de votre pipeline de CI/CD, en coordonnant et en déclenchant les différentes étapes de votre processus, et en collectant et en fournissant les données de chaque étape. Consultez notre Guide pour les outils de CI/CD pour obtenir des conseils sur la manière de choisir le serveur de CI adapté à votre organisation.
Comment TeamCity peut vous aider
TeamCity est un serveur de CI qui peut être intégré avec les principaux systèmes de contrôle de version, tels que Git, Perforce, Mercurial et Subversion, ainsi que différents services d'hébergement. Il prend également en charge une large gamme d'outils de build et de frameworks de test, ainsi que des intégrations avec les IDE, les outils de suivi des tickets, les plateformes de messagerie et les gestionnaires de conteneurs.
Vous pouvez héberger votre serveur de CI sur site ou dans l'environnement cloud de votre choix avec TeamCity Professional ou Enterprise, ou opter pour TeamCity Cloud pour une solution entièrement gérée. Un ensemble flexible de déclencheurs de pipeline vous permet de configurer les processus de CI/CD en fonction de vos besoins, avec notamment les commits pré-testés, la prise en charge des branches de fonctionnalités et les builds planifiés. Une fois la logique de pipeline configurée depuis l'interface utilisateur, vous pouvez stocker votre configuration en tant que code pour obtenir un processus de CI/CD avec un contrôle de version complet.