Spark モニタリング
Spark(英語) プラグインを使用すると、 Spark(英語) クラスターと送信されたジョブを IDE で直接監視できます。
この章では:
Spark サーバーに接続する
「ビッグデータツール 」ウィンドウで「
 」をクリックし、「Spark 」を選択します。
」をクリックし、「Spark 」を選択します。開いた ビッグデータツール ダイアログで、接続パラメーターを指定します。

名前: 他の接続と区別するための接続の名前。
URL: Spark 履歴サーバーの URL (通常はポート 18080 で実行されます)。
オプションで、次を設定できます。
プロジェクト単位 ごと: これらの接続設定を現在のプロジェクトでのみ有効にするには、チェックボックスをオンにしてください。 この接続を他のプロジェクトでも表示したい場合は、チェックボックスをオフにしてください。
接続を有効にする: この接続を無効にする場合は、チェックボックスをオフにしてください。 デフォルトでは、新しく作成された接続は有効になっています。
トンネリングを有効にする: リモートホストへの SSH トンネルを作成します。 これは、ターゲットサーバーがプライベートネットワーク内にあるものの、ネットワーク内のホストへの SSH 接続が利用できる場合に便利です。
チェックボックスを選択し、SSH 接続の構成を指定します(... をクリックして新しい SSH 構成を作成します)。
HTTP 基本認証を使用可能にする: 指定されたユーザー名とパスワードを使用した HTTP 認証との接続。
プロキシ: IDE プロキシ設定を使用するか、カスタムプロキシ設定を指定するかを選択します。
設定を入力したら、 接続のテスト をクリックして、すべての構成パラメーターが正しいことを確認します。 次に OK をクリックします。
実行中のジョブを使用して Zeppelin から接続を確立する
Zeppelin(英語) プラグインをお持ちの場合は、Zeppelin ノートブックから Spark ジョブを開くことで、Spark サーバーにすぐに接続できます。
Spark を含む Zeppelin ノートブックで、段落を実行します。
オープンジョブ のリンクをクリックしてください。 開いた通知で、 リンクをクリックします。

ジョブが実行されている Spark 履歴サーバーにすでに接続している場合は、 接続の選択 をクリックしてリストから選択します。
開いた ビッグデータツール ダイアログで、接続設定を確認し、 接続のテスト をクリックします。 接続が正常に確立された場合は、「OK 」をクリックして構成を完了します。
Spark サーバーへの接続を確立すると、 Spark モニタリング ツールウィンドウが表示されます。

いつでも、次のいずれかの方法で接続設定を開くことができます。
ツール | ビッグデータツールの設定 設定ページ Ctrl+Alt+S に移動します。
ビッグデータツール ツールウィンドウ () を開き、Spark 接続を選択して、
 をクリックします。
をクリックします。Spark モニタリング ツールウィンドウの任意のタブで
 をクリックします。
をクリックします。
Spark モニタリング ツールウィンドウでアプリケーションを選択すると、次のタブを使用してデータを監視できます。
情報: アプリ ID や試行 ID など、送信されたアプリケーションに関する高レベルの情報。
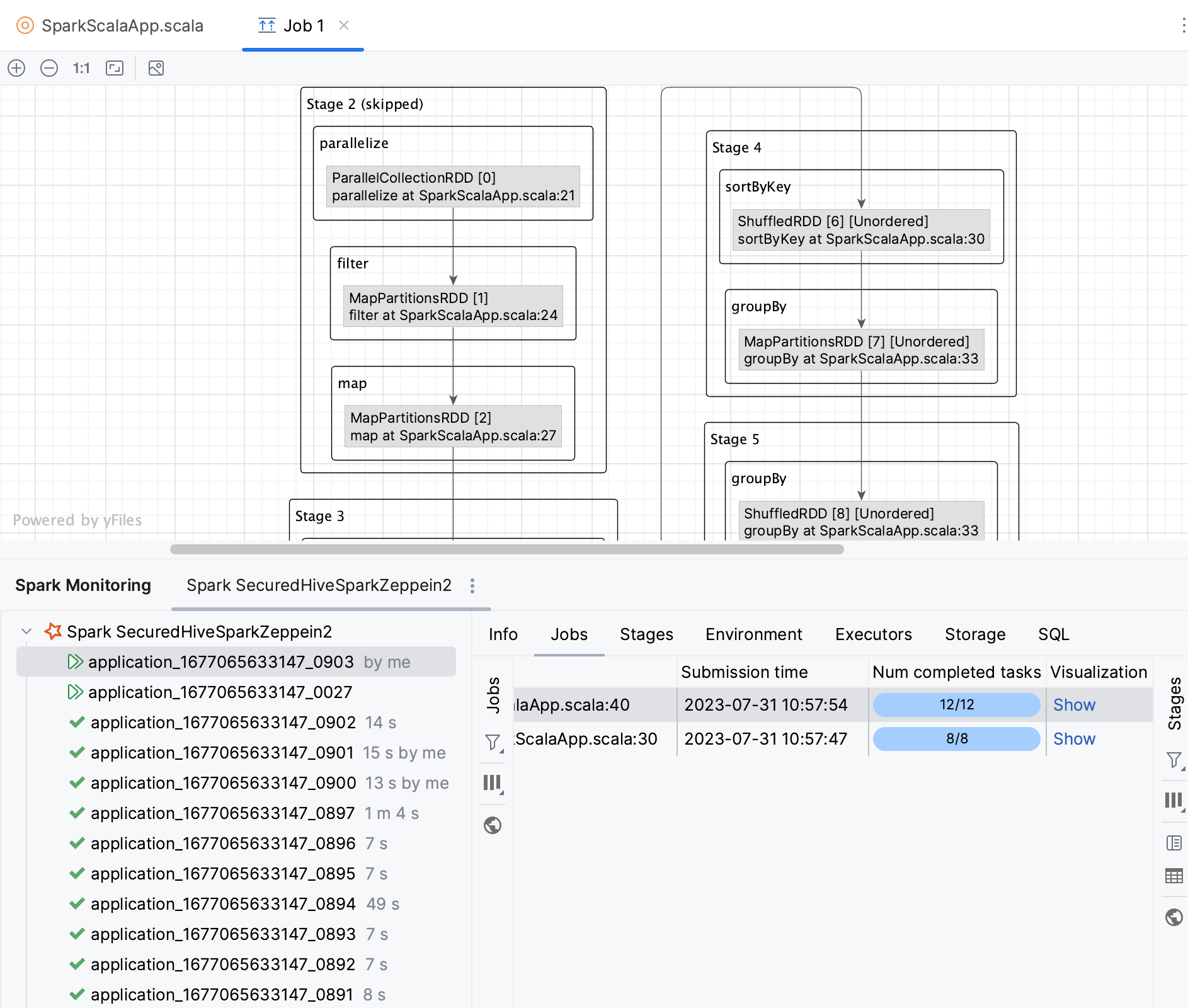
ジョブ: アプリケーションジョブの概要。 ジョブをクリックすると、詳細が表示されます。 「可視化 」タブを使用して、 ジョブ DAG を表示します。
ステージ: 各ステージの詳細。
環境: 環境変数と構成変数の値。
実行プログラム: タスクを実行し、タスク全体のメモリまたはディスクストレージにデータを保持するアプリケーション用に起動されるプロセス。 「ログ 」タブを使用して、executor stdout および stderr ログを表示します。
ストレージ: 永続化された RDD と DataFrame。
SQL: SQL クエリの実行に関する詳細 (アプリケーションで使用される場合)。
また、1 つのエグゼキューターに送信された作業単位 タスク の情報をプレビューすることもできます。
データの種類の詳細については、「Spark のドキュメント(英語) 」を参照してください。
DAG グラフからソースコードに移動する
DAG (有向非巡回グラフ) は、Spark ジョブの論理実行プランを表します。 Spark UI と同様に、Spark ジョブの DAG を視覚化できます。 IntelliJ IDEA を使用すると、DAG からソースファイル内の対応するコード部分にすばやく移動することもできます。
Spark モニタリング ツールウィンドウを開きます: 。
アプリケーションを選択し、 ジョブ タブを開きます。
可視化 列で、 表示 をクリックします。
これにより、新しいエディタータブでジョブの視覚化が開きます。
グラフ内で任意の操作をダブルクリックします。
ソースコードファイル、対応する操作にリダイレクトされます。
監視データを除外する
Spark モニタリング ツールウィンドウで、次のフィルターを使用してアプリケーションをフィルターします。
フィルター: アプリケーション名または ID を入力します。
制限: 表示されるアプリケーションの制限を変更するか、 すべて を選択してすべてのアプリケーションを表示します。
起動済み :アプリケーションを開始時間でフィルタリングするか、 任意 を選択します。
終了 :完了時間でアプリケーションをフィルタリングするか、 任意 を選択します。
 : 実行中または完了したアプリケーションのみを表示します。
: 実行中または完了したアプリケーションのみを表示します。

「ジョブ」、「ステージ」、「SQL 」タブでは、
を使用してステータス別にデータをフィルターすることもできます。
いつでも、 Spark モニタリング ツールウィンドウで ![]() をクリックして、監視データを手動でリフレッシュできます。 または、 更新 ボタンの横にあるリストを使用して、特定の時間間隔内の自動リフレッシュを構成できます。
をクリックして、監視データを手動でリフレッシュできます。 または、 更新 ボタンの横にあるリストを使用して、特定の時間間隔内の自動リフレッシュを構成できます。