Conexões de dados
Quer você trabalhe com arquivos em CSV, buckets do S3 ou bancos de dados SQL, o Datalore lhe oferece maneiras fáceis de acessar e consultar seus dados a partir de diversas fontes em um só notebook.
Assista ao vídeo abaixo, com uma visão geral das conexões de dados:
Armazenamento interno
O Datalore vem com armazenamento interno persistente para acesso rápido aos seus notebooks e outros artefatos de trabalho.

Arquivos de notebooks
Quer você carregue arquivos e pastas locais ou importe dados por link ou baixe arquivos do código, todos os dados serão armazenados em arquivos de notebooks. Ao compartilhar um notebook com colaboradores, os arquivos desse notebook serão compartilhados automaticamente.
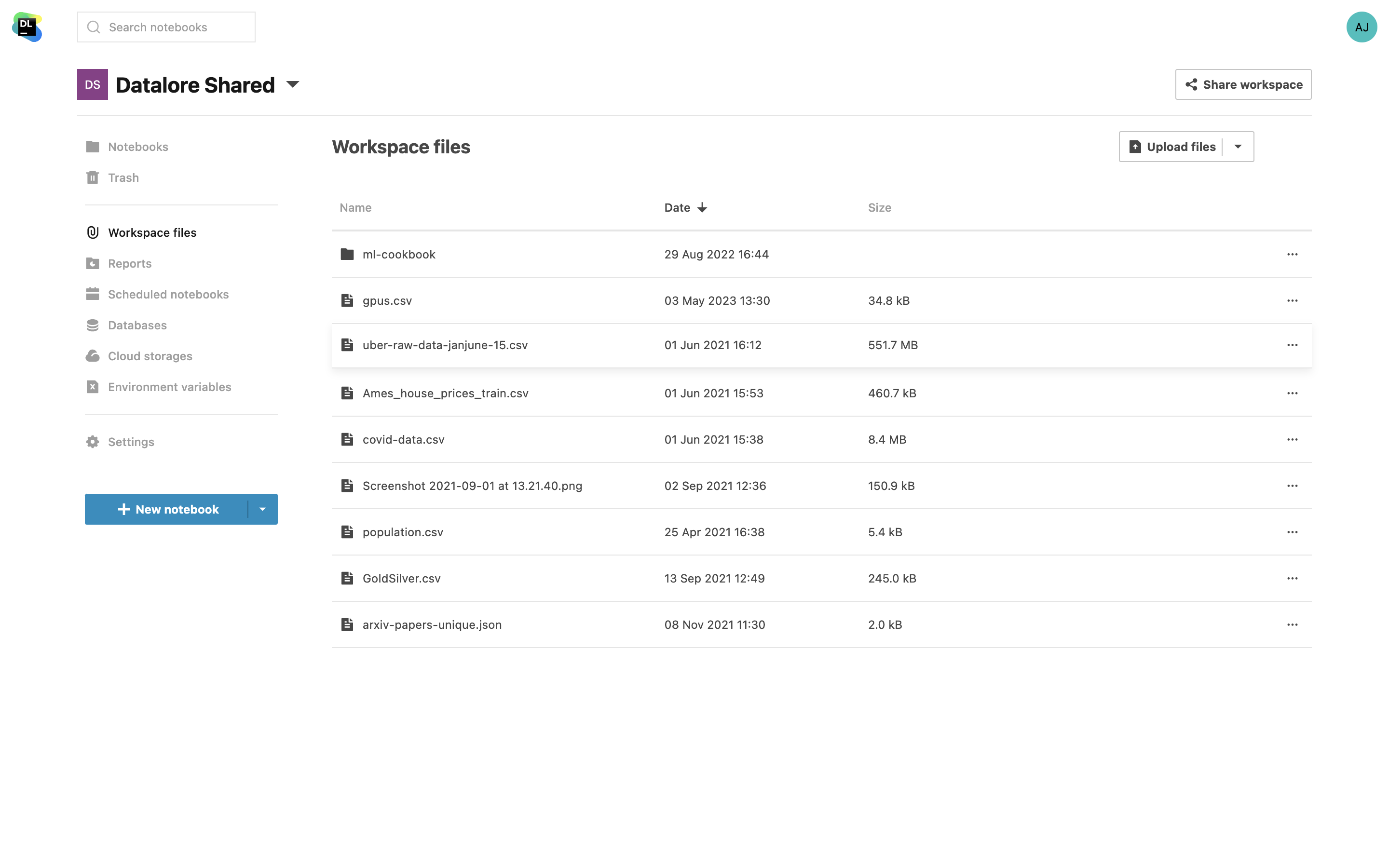
Arquivos de espaço de trabalho
Compartilhe conjuntos de dados entre vários notebooks por meio de arquivos do Workspace. Ao trabalhar em um espaço de trabalho compartilhado, você pode carregar um conjunto de dados uma única vez, e ele ficará disponível para todos os editores do espaço de trabalho.
Conexões com bancos de dados a partir da UI
Conecte seus notebooks a bancos de dados diretamente do editor com alguns cliques e consulte seus dados com células SQL nativas sem passar suas credenciais para o ambiente.
O Datalore oferece suporte à autenticação com usuário e senha para Amazon Redshift, Azure SQL Database, MariaDB, MySQL, Oracle, PostgreSQL, Snowflake e muito mais. Entre em contato conosco via datalore-support@jetbrains.com se tiver perguntas específicas sobre conectividade com bancos de dados.
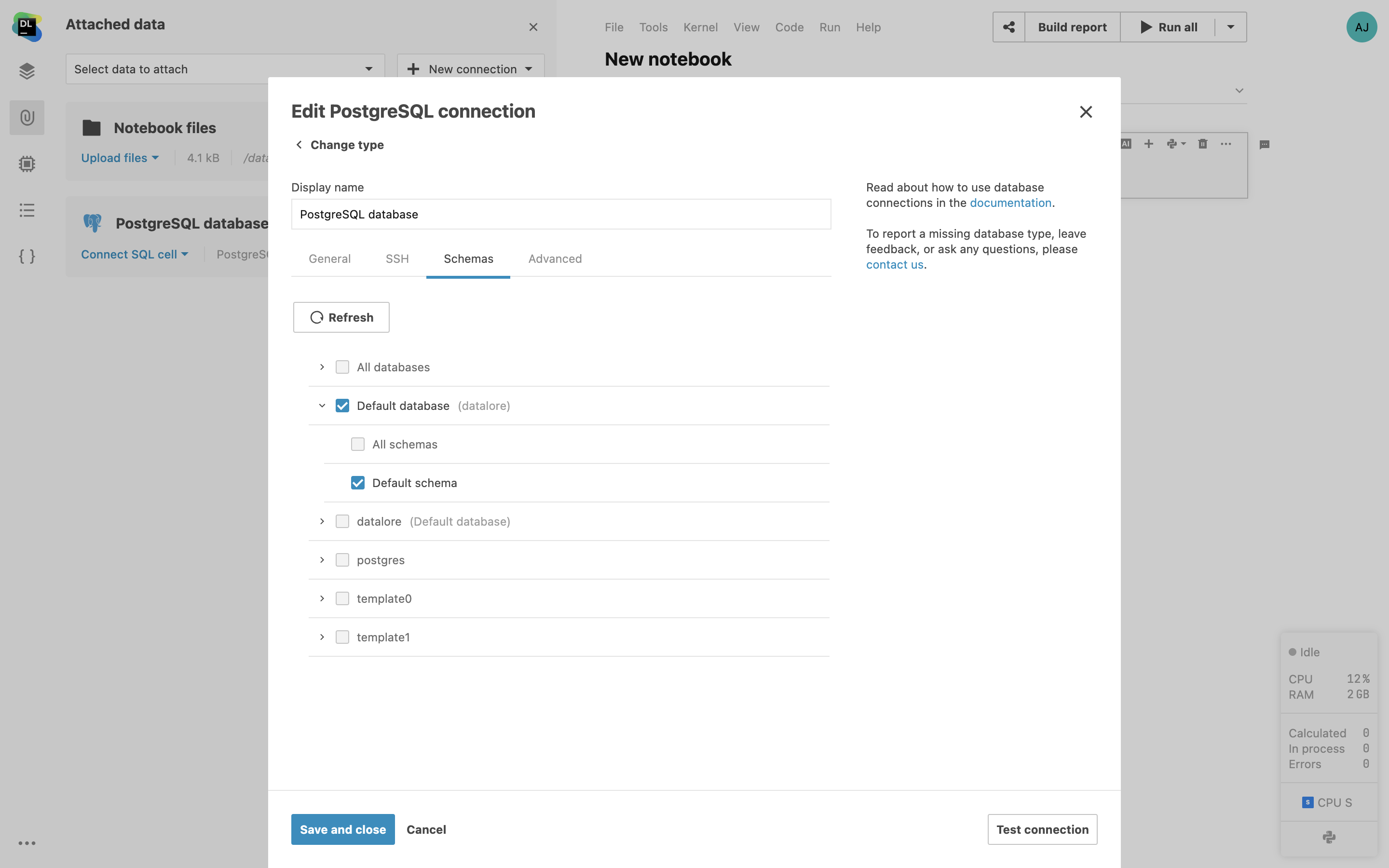
Limitando o esquema do banco de dados para introspecção
Escolha esquemas e tabelas de banco de dados específicos para introspecções ao criar uma conexão de banco de dados no Datalore. Isso ajudará a acelerar a introspecção inicial e facilitará a navegação do esquema.
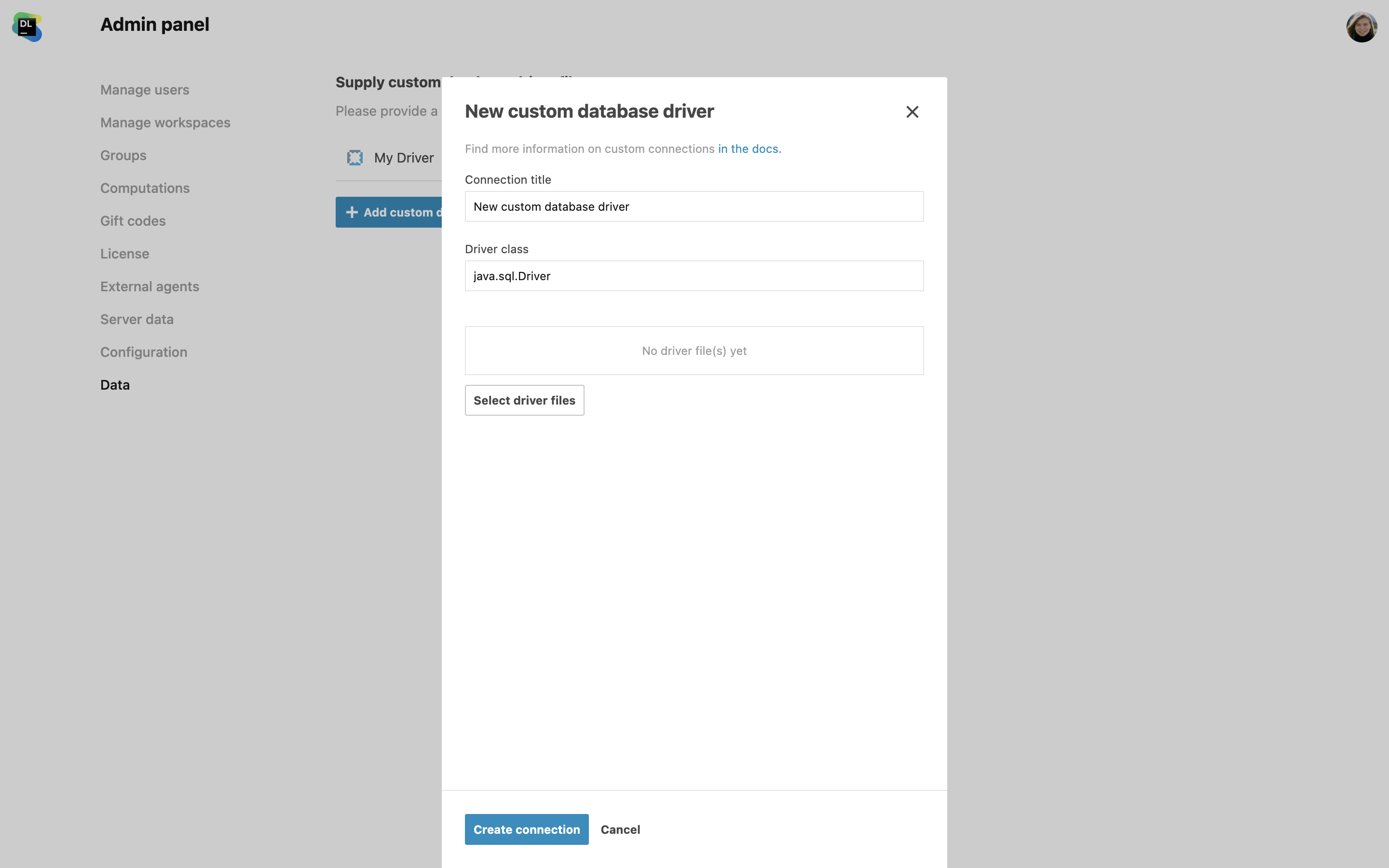
Suporte personalizado para drivers JDBC
Agora, os administradores podem adicionar drivers JDBC personalizados para se conectarem a bancos de dados que não têm suporte nativo no Datalore On-Premises. Acesse Admin panel | Miscellaneous e use a caixa de diálogo New custom database driver para selecionar e carregar arquivos de driver do sistema local.
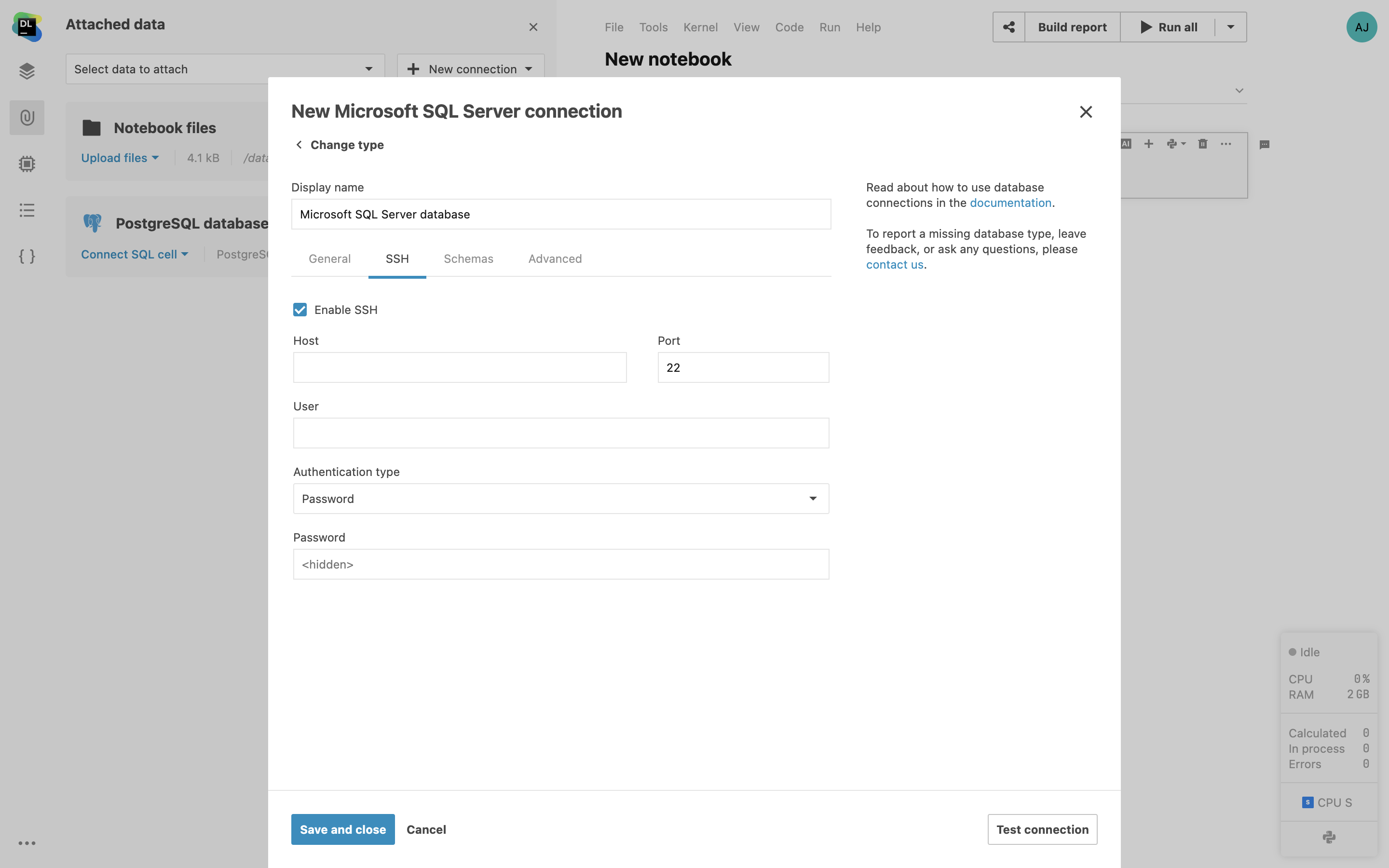
Suporte ao tunelamento com SSH
Conecte-se aos seus bancos de dados remotos usando tunelamento com SSH no Datalore. Isto cria uma conexão SSH criptografada entre o Datalore e o seu servidor de gateway. Conexões através de túneis de SSH tornam possível o acesso a bancos de dados que não estão expostos à rede pública.
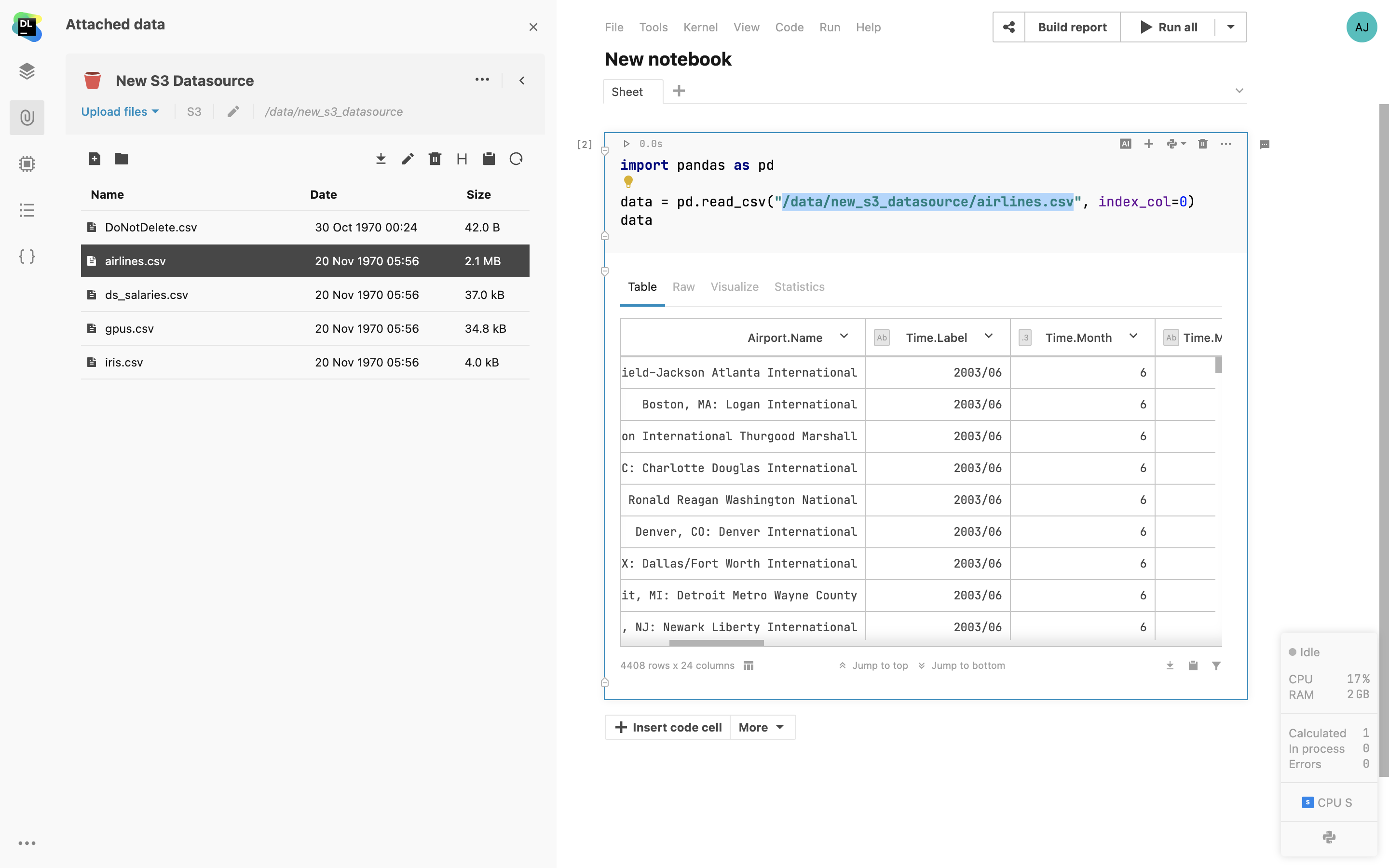
Montagem de buckets do S3
Monte buckets do AWS S3 e GCS como pastas diretamente no notebook, sem passar suas credenciais para o ambiente.
Conexões de dados a partir do código
Além das conexões de fonte de dados com suporte por meio da interface do usuário, você pode conectar qualquer bucket, banco de dados ou armazenamento de dados do código como faria normalmente com um notebook Jupyter.
Células SQL
Adicione células SQL nativas para fazer consultas nas suas conexões de banco de dados. Além do realce da sintaxe SQL, você obtém complementação de código com base nas tabelas de banco de dados examinadas. O resultado da consulta é automaticamente transferido a um DataFrame pandas e você pode continuar trabalhando no conjunto de dados em Python.
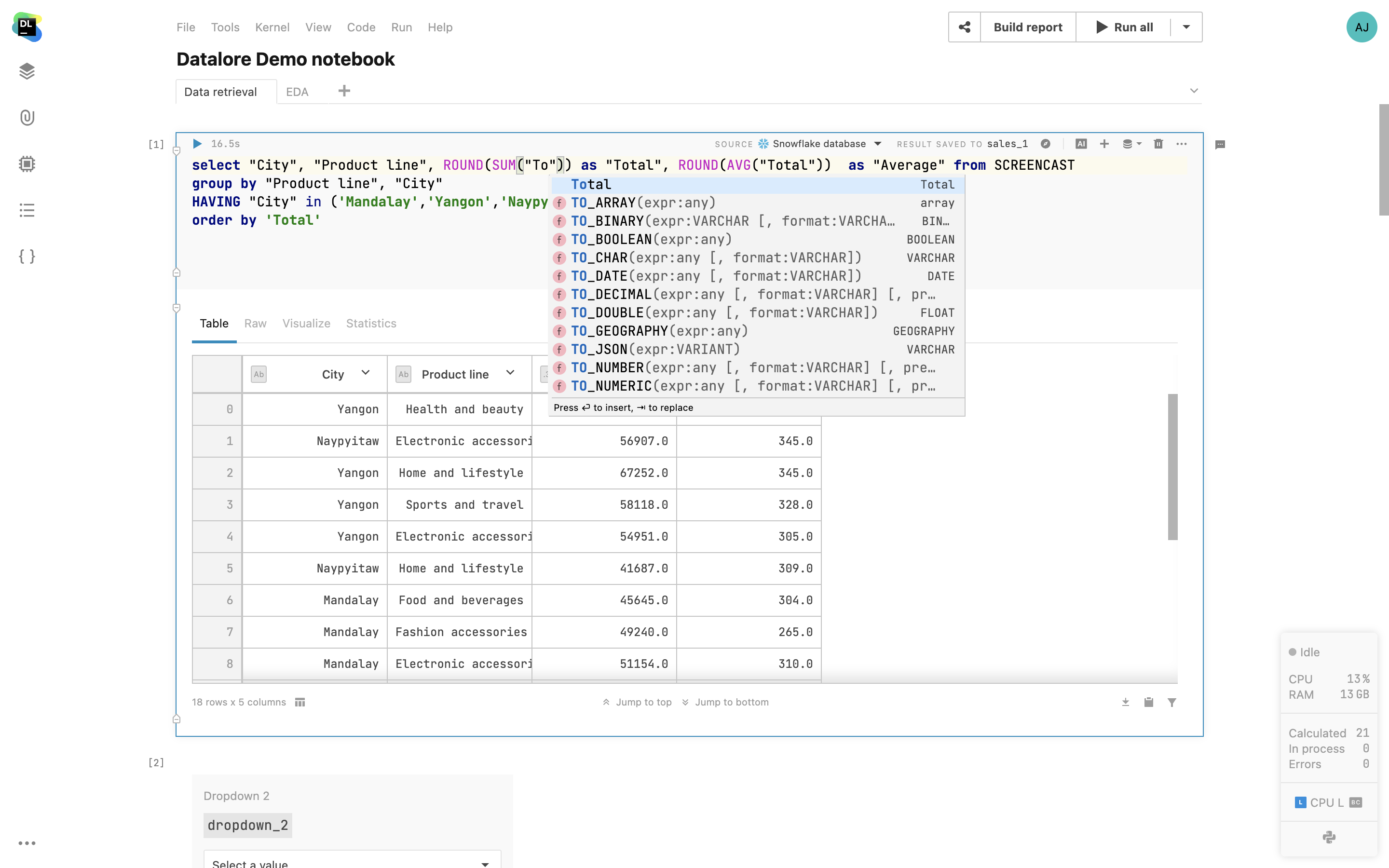
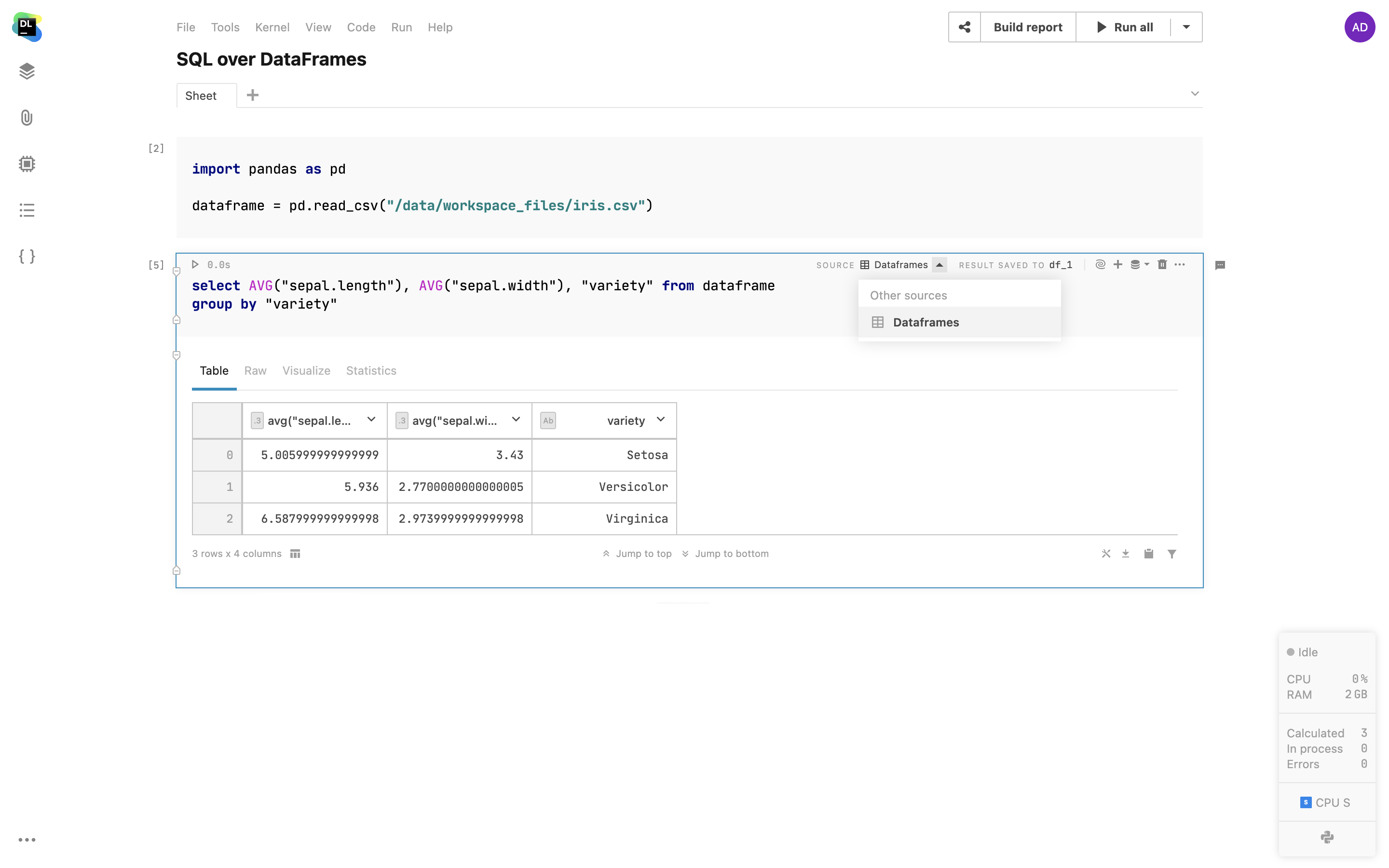
Faça consultas em DataFrames via células SQL
Use células SQL para fazer consultas com facilidade em DataFrames 2D e arquivos CSV de documentos anexados, como você faria com bancos de dados. Basta navegar pelos DataFrames do seu notebook, escolher um e usá-lo como fonte para células SQL. Com esse recurso, você pode mesclar dados de várias fontes em um único DataFrame usando SQL ou dividir consultas complexas em uma sequência de células SQL.
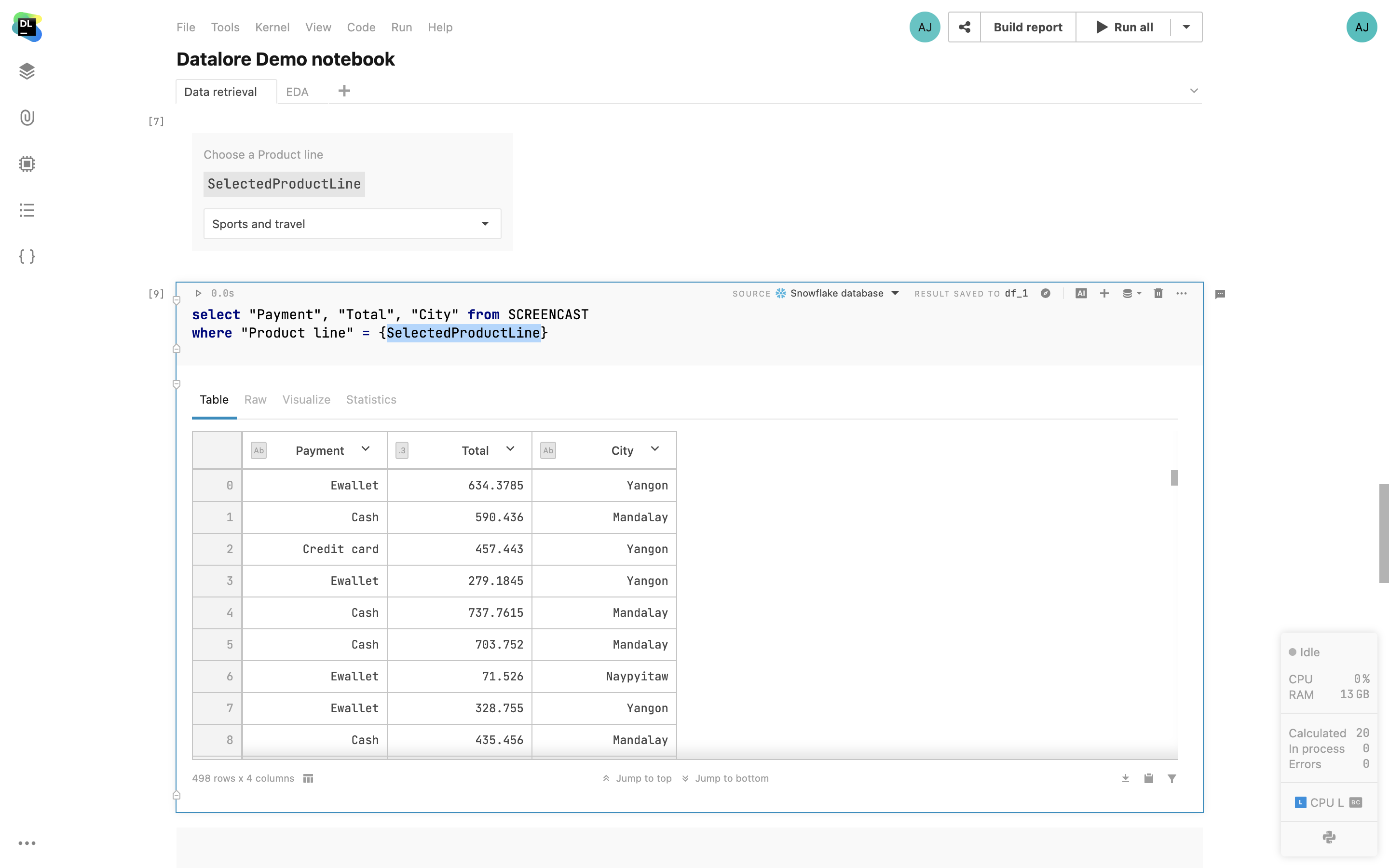
Consultas SQL parametrizadas
No Datalore, agora é possível usar variáveis (strings, números, booleanos, listas) definidas em código Python dentro de células SQL. Isto permite que você crie relatórios interativos com consultas parametrizadas, ajuda a minimizar o código SQL escrito e apresenta uma interface de usuário melhor para usuários de relatórios.
Trabalhe com bancos de dados em ambientes isolados
Com esse recurso, você pode trabalhar com bancos de dados mesmo em ambientes isolados. Execute o código SQL sem conexão com a Internet, garantindo que as informações trocadas entre seu notebook e o banco de dados permaneçam precisas e consistentes e minimizando as chances de corrupção ou perda de dados.
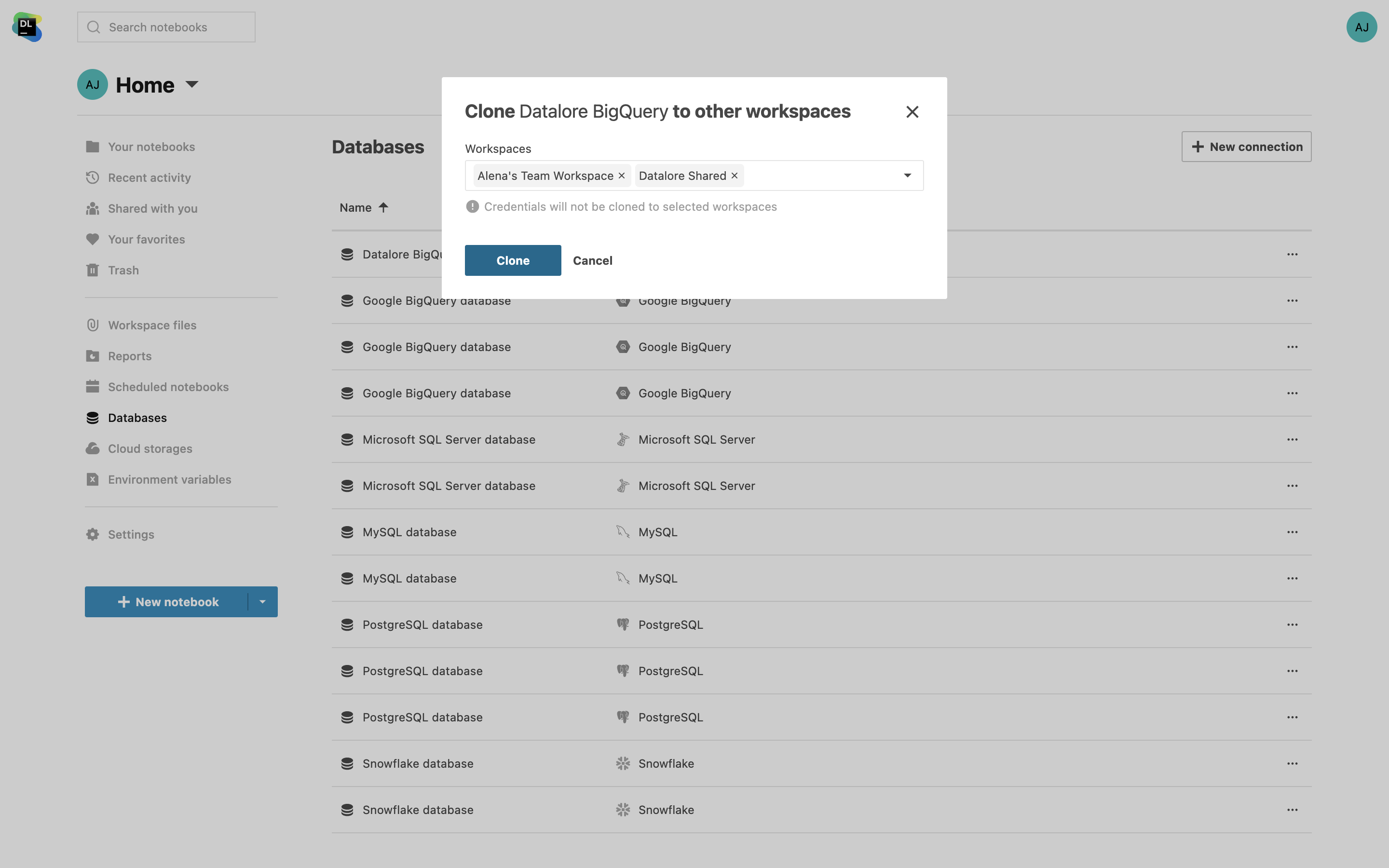
Clonagem de conexões de bancos de dados entre espaços de trabalho
Agora você pode clonar conexões de bancos de dados de um espaço de trabalho para outro, eliminando a necessidade de configurações repetitivas. Poupe tempo ao simplesmente copiar as configurações, menos as credenciais. Você também tem a opção de selecionar vários espaços de trabalho de uma vez.
Armazenamento SMB/CIFS
Adicione o armazenamento SMB/CIFS ao seu espaço de trabalho através da visualização File system ou diretamente a partir da interface do notebook. Acesse e modifique o conteúdo de pastas SMB sem sair do ambiente do notebook.