Avalie o desempenho de CI/CD com métricas de DevOps
Como você pode garantir que está colhendo todos os benefícios da CI/CD? Medir o desempenho do seu pipeline de CI/CD ajudará você a otimizar o processo e a demonstrar seu valor para a empresa como um todo.

A melhoria contínua é um dos pilares da filosofia DevOps. É uma abordagem que pode ajudar você a realizar alterações significativas de maneira sustentável. A estratégia se aplica tanto ao produto ou serviço que você está criando quanto à maneira de criá-lo.
Como o nome sugere, a melhoria contínua é um processo contínuo que envolve:
- Coletar e analisar feedback sobre o que você criou ou como está trabalhando.
- Identificar o que está funcionando bem e o que pode ser melhorado.
- Fazer alterações incrementais com base nesses insights para tentar otimizar ainda mais as coisas.
- Continuar a coletar feedback para poder confirmar se essas alterações estão ajudando.
Um dos principais benefícios da CI/CD é que ela facilita a melhoria contínua do seu software. Um pipeline de CI/CD permite que você faça lançamentos com mais frequência e obtenha feedback regular sobre o que foi criado, para que possa tomar decisões embasadas sobre o que priorizar em seguida.
Da mesma maneira, o feedback rápido que você obtém com cada estágio da criação e dos testes automatizados facilita a correção de bugs e o aprimoramento da qualidade do software.
No entanto, a melhoria contínua em CI/CD não para por aí. Ao coletar métricas de DevOps, você pode aplicar as mesmas técnicas ao próprio processo de CI/CD.
Por que as métricas de DevOps são importantes?
Quando você começa a criar um pipeline de CI/CD, há muitas coisas a fazer, desde escrever testes automatizados até atualizar automaticamente seus ambientes de pré-produção. Se estiver procurando ideias sobre como melhorar o processo nesse estágio, consulte nosso Guia de práticas recomendadas de CI/CD.
Depois de ter um pipeline automatizado em funcionamento, é hora de explorar como fazer com que ele funcione de maneira mais eficaz. É nesse estágio que o ciclo de melhoria contínua começa, com a ajuda das métricas do seu pipeline de CI/CD.
Peter Drucker disse certa vez: "Não se pode gerenciar o que não se mede". Métricas são essenciais para a melhoria contínua. Os dados ajudam a identificar onde você pode agregar valor e oferecem uma referência para medir o impacto das alterações que você faz.
Ao monitorar métricas importantes de DevOps, você pode determinar se ampliar a cobertura de testes automatizados, melhorar o rendimento ou dividir as tarefas de desenvolvimento vão garantir o maior impacto no desempenho do pipeline de CI/CD.
Cada vez que você otimiza um estágio do seu pipeline de CI/CD, você amplia o efeito desse ciclo de feedback. Esse refinamento melhora sua capacidade de lançar alterações com mais frequência, mantendo a qualidade e a taxa de defeitos baixa.
Fazer lançamentos com mais frequência significa que você pode continuar aprimorando os principais recursos, rodar experimentos para validar suposições e resolver prontamente quaisquer problemas. Conforme o mercado evolui e a demanda por recursos muda, você pode responder rapidamente, mantendo-se no mesmo nível ou até mesmo à frente da concorrência.
Além disso, monitorar as métricas de CI/CD é uma ótima maneira de demonstrar o valor do seu pipeline para a empresa como um todo, incluindo as partes interessadas e outras equipes de desenvolvimento.
Métricas de desempenho de DevOps de nível superior
A equipe de Pesquisa e Avaliação de DevOps (DORA) do Google identificou as quatro métricas de alto nível a seguir que indicam com precisão o desempenho das equipes de desenvolvimento de software.
Você pode saber mais sobre a pesquisa que embasou essas escolhas no livro Accelerate, de Nicole Forsgren, Jez Humble e Gene Kim.
Frequência de implantação
A frequência de implantação registra o número de vezes que você usa o pipeline de CI/CD para implantar em produção. O DORA selecionou a frequência de implementação como um indicador do tamanho do lote, pois uma alta frequência de implementação implica menos alterações por implementação.
A implementação de um número menor de alterações reduz o risco associado a lançamentos, pois menos variáveis podem se combinar para produzir resultados inesperados. A implantação mais frequente também garante um feedback mais imediato sobre seu trabalho.
Uma baixa frequência de implantação pode significar que o pipeline não é alimentado com commits regulares, talvez porque você não divide as tarefas o suficiente. Criar uma cultura de DevOps na qual todos os membros da equipe entendam os benefícios da CI/CD pode ajudar sua equipe a se adaptar ao trabalho em incrementos menores.
Às vezes, uma baixa frequência de implantação resulta do agrupamento de alterações em versões maiores como parte de uma estratégia de entrega contínua. Se for necessário fazer alterações em lote por motivos comerciais (como expectativas do usuário), considere medir a frequência de implantações nos ambientes de preparação.
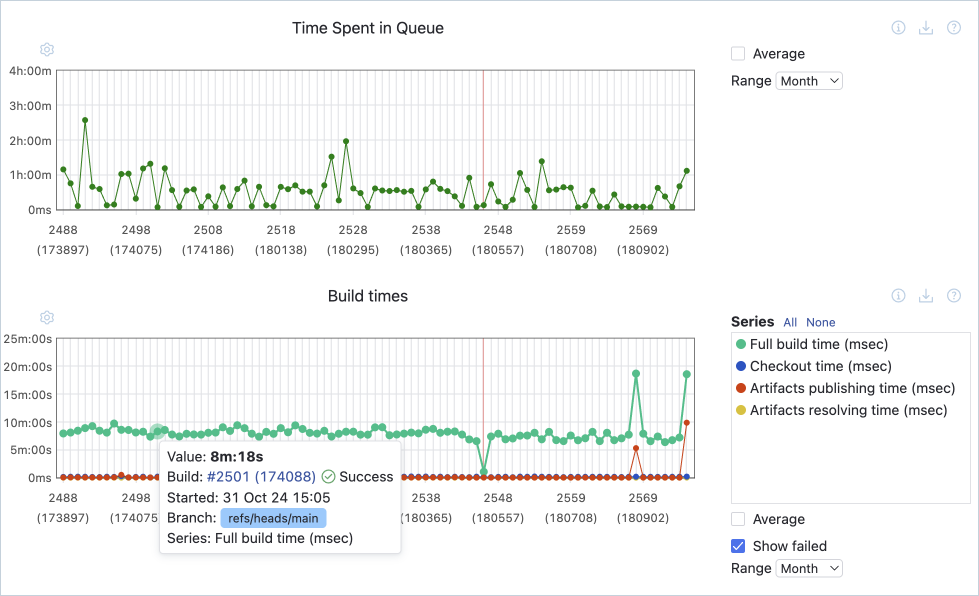
Lead time
O lead time (também conhecido como tempo até a entrega ou "time to market") é o tempo entre o início do trabalho em um recurso e seu lançamento para os usuários. No entanto, o tempo envolvido em ideação, pesquisa de usuário e prototipagem pode variar muito.
Por esse motivo, o DORA mede o tempo desde o último commit de código até a implantação. Esse período permite que você se concentre nos estágios dentro do escopo do seu pipeline de CI/CD.
Um longo tempo de espera significa que você não apresenta regularmente as alterações de código aos usuários. Como resultado, você não pode tirar proveito das estatísticas de uso e de outros comentários para refinar o que está criando.
Prazos de entrega estendidos são comuns em pipelines com várias etapas manuais. Esses estágios podem incluir um grande número de testes manuais ou um processo de implantação que exige que os ambientes sejam atualizados manualmente.
Investir em testes automatizados e em um servidor de CI para coordenar as tarefas de build, teste e implantação reduzirá o tempo necessário para a entrega de software. Ao mesmo tempo, você pode usar um servidor de CI para coletar métricas que demonstrem o retorno do seu investimento.
Suponha que você já tenha começado a automatizar seu processo de integração e implantação contínuas, mas as etapas são lentas ou não confiáveis. Nesse caso, é possível usar métricas de duração da build para identificar os gargalos.
Se a sua organização requer avaliações de risco ou conselhos de revisão de alterações antes de cada lançamento, isso pode adicionar dias ou semanas a cada implantação. O uso de métricas para demonstrar a confiabilidade do processo pode ajudar a aumentar a confiança das partes interessadas e eliminar a necessidade dessas etapas de aprovação manual.
Taxa de falha de alterações
A taxa de falhas de alteração refere-se à proporção de alterações implantadas em produção que resultam em interrupções ou bugs e que exigem reversões ou hotfixes. Ela não inclui problemas descobertos antes de você implantar as alterações do código em produção.
A vantagem dessa métrica é que ela coloca as implantações com falha no contexto do volume de alterações feitas. Uma baixa taxa de falhas de alteração deve lhe dar confiança em seu pipeline: indica que os estágios anteriores estão fazendo seu trabalho e detectando a maioria dos defeitos antes que seu código seja lançado.
Se sua taxa de falhas de alteração for alta, é hora de examinar sua cobertura de testes automatizados. Seus testes abrangem os casos de uso mais comuns? Seus testes são confiáveis? Você pode aprimorar seu regime de testes com testes automatizados de desempenho ou segurança?
Tempo médio de recuperação
O tempo médio de recuperação ou resolução (MTTR) mede o tempo que leva para resolver uma falha de produção. O destaque ao MTTR reconhece que, em um sistema complexo com muitas variáveis, algumas falhas na produção são inevitáveis. Em vez de buscar a perfeição (e perder os benefícios de lançamentos frequentes), o foco está em saber se você pode responder aos problemas rapidamente.
Para manter o MTTR baixo, é necessário um monitoramento proativo da produção para alertar você sobre os problemas à medida que eles surgem, juntamente com a capacidade de reverter as alterações ou implementar hotfixes por meio do pipeline.
Uma métrica relacionada, o tempo médio de detecção (MTTD), mede o tempo entre a implantação de uma alteração e o sistema de monitoramento que detecta um problema introduzido por essa alteração. Ao comparar o MTTD e a duração da build, você pode determinar se alguma das áreas se beneficiaria de um investimento para reduzir o MTTR.
Métricas operacionais e de CI
Além das medições de alto nível, você pode usar uma série de métricas operacionais e de integração contínua para entender melhor o desempenho do seu pipeline e identificar oportunidades de melhoria.
Cobertura de código
Os testes automatizados em um pipeline de CI/CD devem fornecer a maior parte de sua cobertura de testes. A primeira camada de testes automatizados deve ser a de testes de unidade, que são mais rápidos de executar e fornecem o feedback mais imediato.
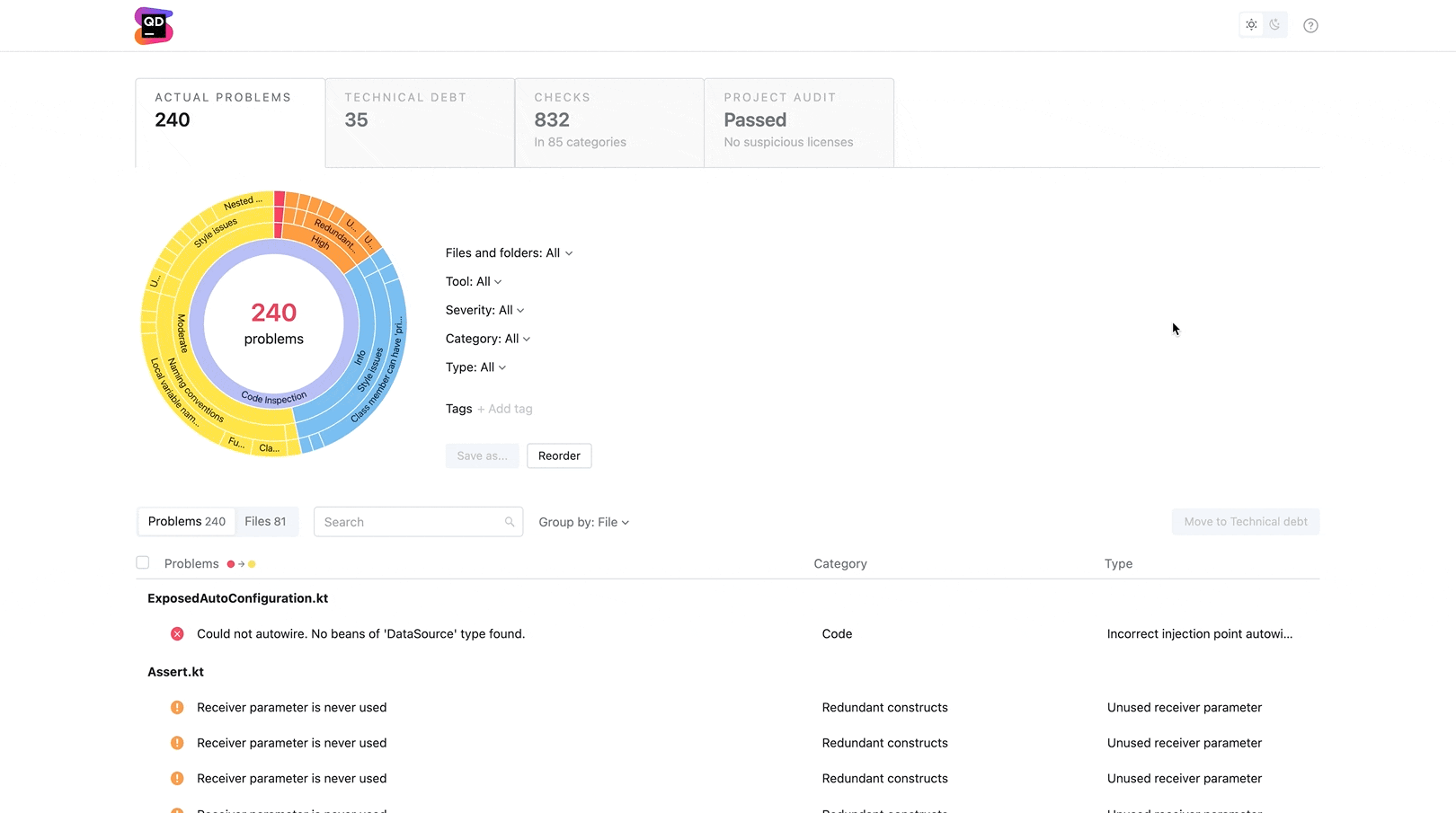
A cobertura de código é uma métrica fornecida pela maioria dos servidores de CI que calcula a proporção de seu código coberto por testes de unidade. Vale a pena monitorar essa métrica para garantir que você mantenha uma cobertura de testes adequada à medida que escreve mais código. Se a sua cobertura de código começar a apresentar tendências de queda, é hora de investir algum esforço nessa primeira linha de feedback.
Duração do build
A duração ou tempo de build mede o tempo necessário para concluir as várias etapas do pipeline automatizado. Analisar o tempo gasto em cada estágio do processo ajuda a identificar pontos problemáticos ou gargalos que podem aumentar o tempo necessário para obter resultados de testes ou implantar em produção.
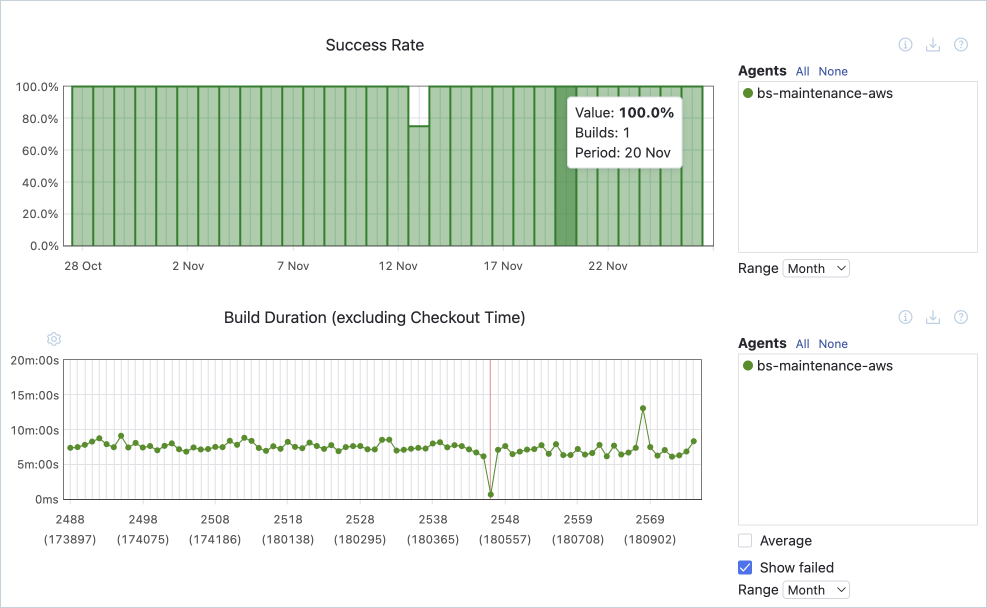
Taxa de sucesso de testes
A taxa de sucesso dos testes é a porcentagem de casos de teste bem-sucedidos numa determinada build. Desde que você tenha um nível razoável de testes automatizados, a métrica indica a qualidade de cada build. Você pode usar os dados para entender a frequência com que alterações no código introduzem novos bugs.
Embora a detecção de falhas com testes automatizados seja preferível a depender de testes manuais ou descobrir problemas na produção, se um determinado conjunto de testes automatizados falha regularmente, é hora de investigar a causa raiz dessas falhas.
Tempo para corrigir os testes
O tempo para corrigir os testes é o tempo entre o instante que um build relata um teste com falha e o mesmo teste passando com sucesso num build subsequente. Essa métrica dá uma indicação da rapidez com que você pode responder aos problemas identificados no pipeline.
Um tempo de resolução baixo mostra que você está usando seu pipeline de maneira eficaz. A correção de problemas assim que você os encontra é mais eficiente, pois as alterações ainda estão frescas na sua mente. Ao corrigir os problemas rapidamente, você também garante que você e seus colegas de equipe evitem criar mais funcionalidades sobre um código instável.
Implantações com falha
Implantações com falha resultam em tempo de inatividade não intencional, requerem a reversão das implantações ou correções urgentes. A contagem de implantações com falha é usada para calcular a taxa de falhas de alteração.
O monitoramento da proporção de falhas em relação ao número total de implantações ajuda a medir seu desempenho em relação aos SLAs.
No entanto, lembre-se de que uma meta de zero (ou pouquíssimas) implantações com falha não é necessariamente realista e pode incentivar as equipes a priorizar a certeza em vez de entregar um produto de qualidade de maneira consistente. Essa mentalidade pode resultar em prazos de entrega mais longos e implantações maiores, à medida em que várias alterações são agrupadas. Como as implantações maiores contêm um número maior de variáveis, há uma probabilidade maior de falhas na produção que são mais difíceis de corrigir (devido ao fato de haver mais alterações a serem analisadas).
Contagem de defeitos
Em contraste com a métrica de implantação com falha, a contagem de defeitos refere-se ao número de tickets abertos no seu backlog classificados como bugs. Essa métrica de CI pode ser ainda dividida em problemas encontrados em testes, preparação e produção.
O monitoramento do número de defeitos ajuda a alertar você se houver uma tendência geral de aumento, indicando que os bugs podem estar ficando fora de controle. No entanto, lembre-se de que tornar essa métrica uma meta pode levar sua equipe a se concentrar mais na classificação dos tickets do que na correção deles.
Tamanho da implantação
Como resultado da frequência de implantação, o tamanho da implantação (medido pelo número de pontos de história incluídos em uma build ou versão) pode ser usado para monitorar o tamanho do lote em uma determinada equipe.
Manter as implantações pequenas mostra que sua equipe está fazendo alterações regularmente, com todos os benefícios que isso traz. No entanto, como as estimativas de histórias não são comparáveis entre equipes de desenvolvimento, essa métrica não deve ser usada para medir o tamanho geral da implantação.
Conclusão
Essas métricas de DevOps permitem que você entenda melhor o desempenho do seu pipeline de CI/CD em termos de velocidade de implantação e qualidade do software.
Ao acompanhar essas métricas, você pode identificar as áreas do seu processo que mais precisam de atenção. Depois de fazer as alterações, continue monitorando as métricas relevantes para verificar se elas tiveram o efeito desejado.
No entanto, embora as métricas possam servir como indicadores de desempenho úteis, é importante considerar os números em contexto e decidir quais comportamentos uma determinada métrica pode incentivar.
Lembre-se de que o objetivo não são os números propriamente ditos, mas manter o pipeline rápido e confiável, para que você possa continuar fornecendo valor aos usuários e, por sua vez, apoiar as metas da sua organização.