Что нового в DataGrip 2020.2
Редактор данных
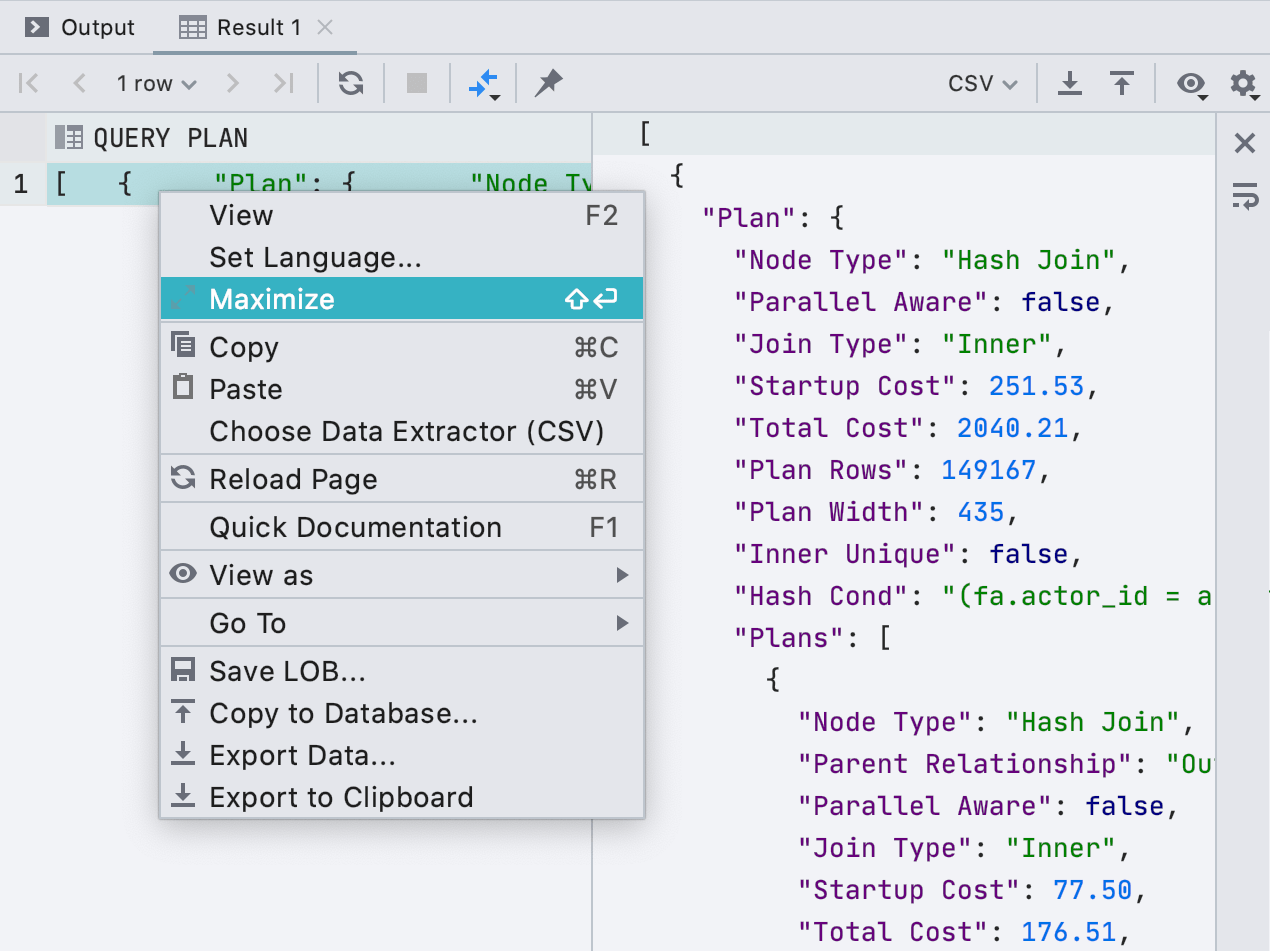
Редактор больших значений
Мы добавили полноценный редактор к ячейкам. Если в ячейке длинное значение, например XML или JSON, его удобно открыть в отдельной панели. Для этого нажмите Maximize в контекстном меню.
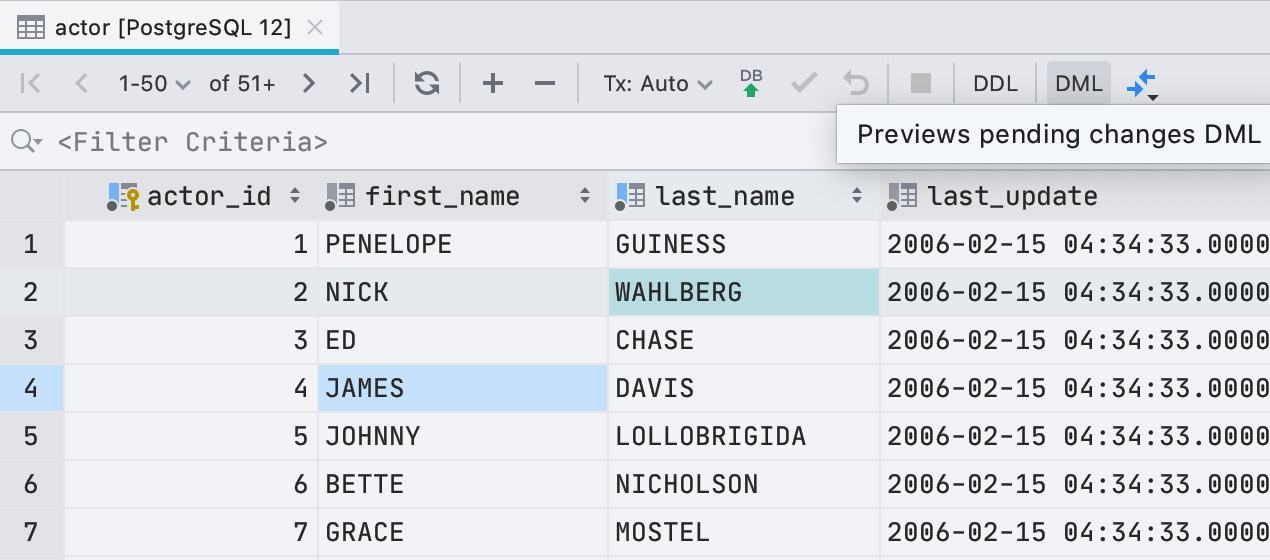
Предпросмотр запроса при редактировании
Теперь, прежде чем записать новые значения в редакторе данных, можно посмотреть, какой запрос будет выполнен. Для этого нажмите кнопку DML на панели инструментов.
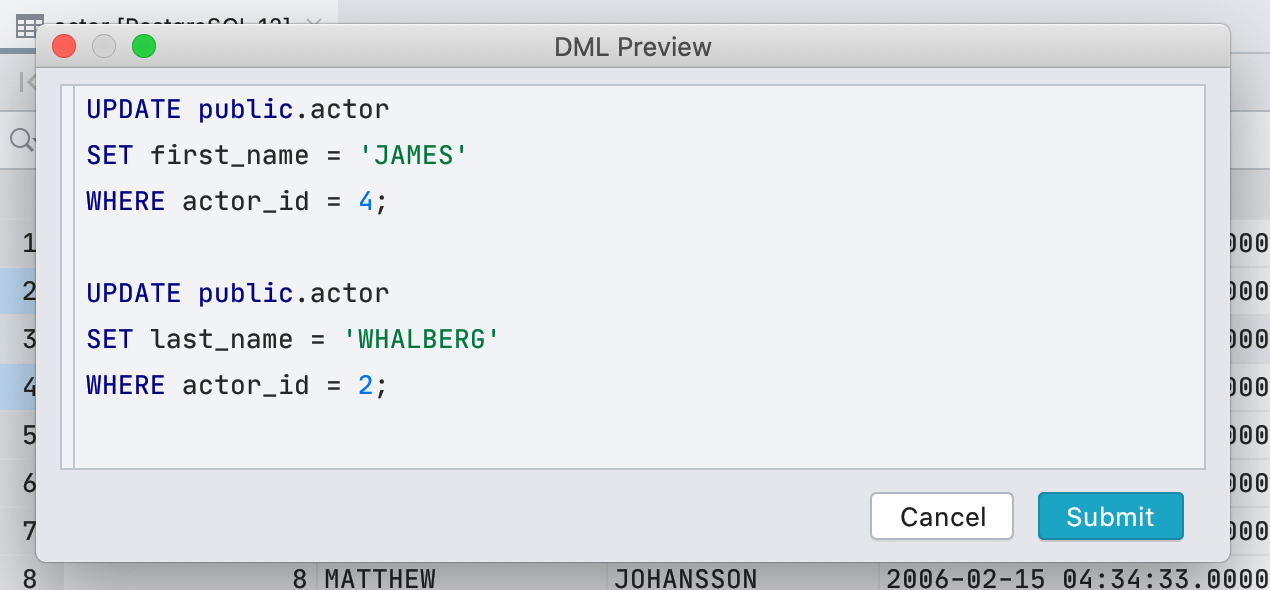
Это не именно тот запрос, который мы запустим, потому что для редактирования данных DataGrip использует JDBC-драйвер. Но в большинстве случаев то, что мы покажем, будет совпадать с тем, что реально запустится.
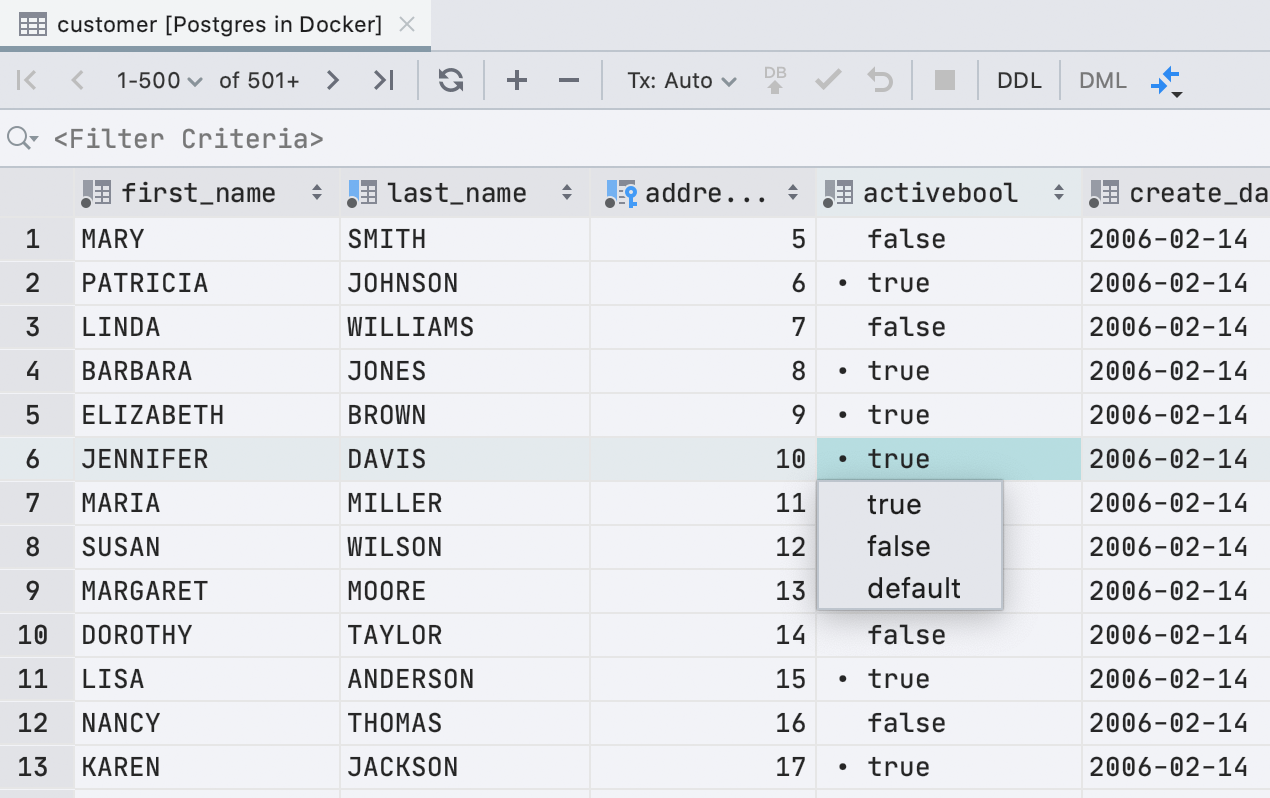
Новое отображение логических ячеек
Это действительно долгожданное улучшение. Просматривать и редактировать ячейки с типом boolean стало гораздо удобнее. Значения true помечены точкой, чтобы их можно было легко найти среди остальных.
Редактирование:
- Переключайтесь между доступными значениями, используя пробел.
- Для ввода нужного значения (
false,true,default,null,generatedилиcomputed) достаточно ввести первую букву:f,t,d,n,gилиc. Повезло, что все возможные значения —false,true,default,null,generatedиcomputed— начинаются с разных букв. - Если напечатать что-то другое, откроется выпадающий список.
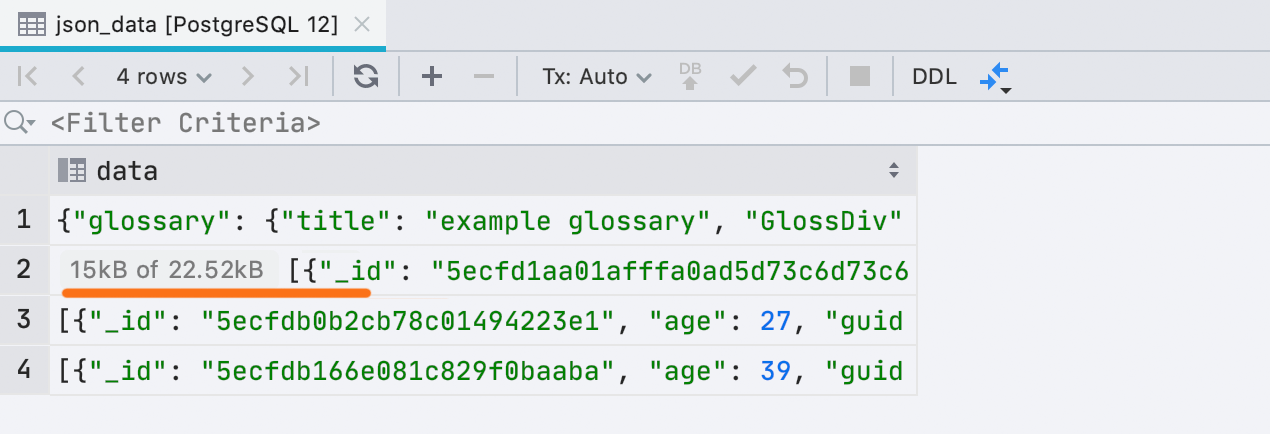
Новый интерфейс для недогруженных данных
Иногда DataGrip не может загрузить все данные в ячейку, если они занимают много памяти. Это определяется настройкой Database | Data views | Max LOB length. Раньше текст об этом вставлялся прямо в значение ячейки, и это неудобно. Сейчас это маленькая отдельная плашка:
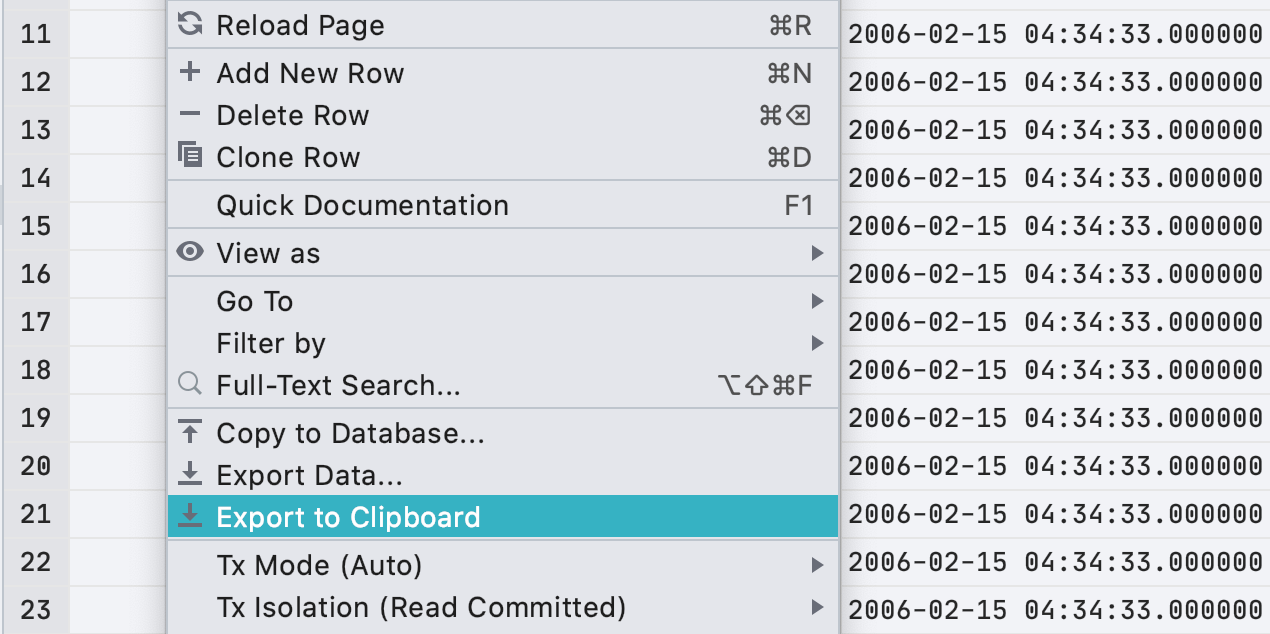
Экспорт в буфер обмена из контекстного меню
В прошлом релизе мы добавили диалоговое окно для экспорта, но не учли один случай: стало менее удобно копировать весь результат в буфер обмена мышкой. Теперь это можно сделать из контекстного меню.
Напомним, что действие Export to Clipboard копирует весь результат или таблицу, а Ctrl/Cmd+C или действие Copy – только выделенный фрагмент.
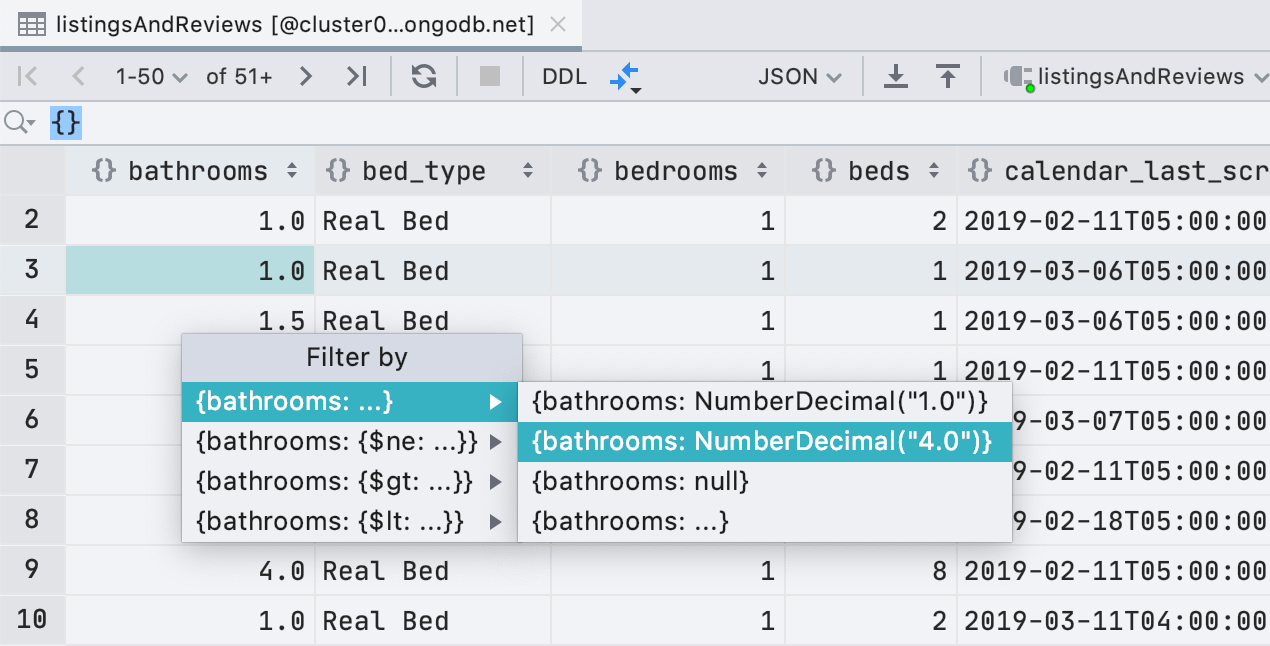
Улучшения фильтрации для MongoDB
Помимо ObjectId и ISODate, теперь можно фильтровать по UUID, NumberDecimal, NumberLong и BinData. Кроме того, если у вас в буфере обмена есть подходящее значение для UUID/ObjectId/ISODate, DataGrip предложит использовать его для фильтрации.
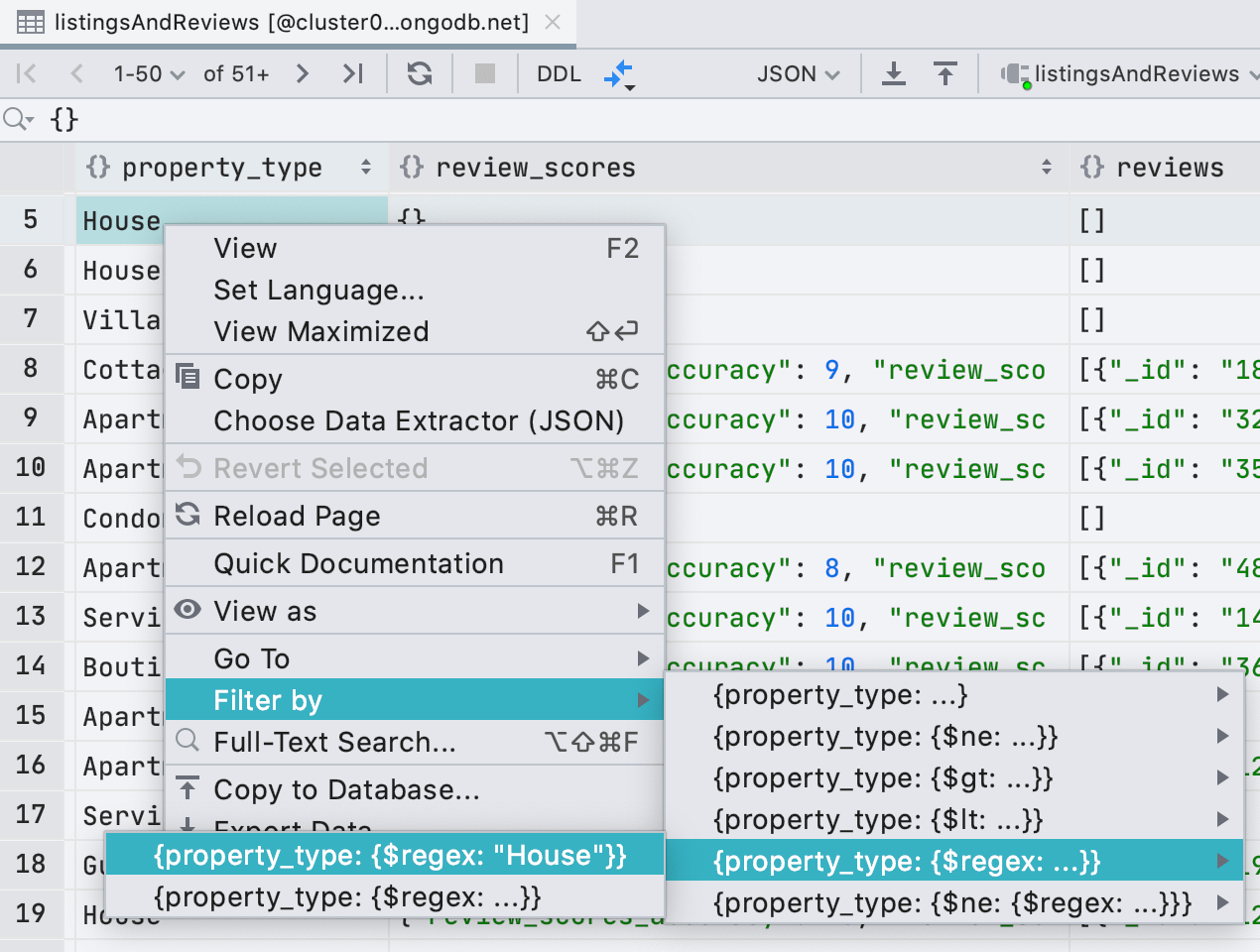
Кроме того, мы добавили в условия фильтра регулярные выражения, чтобы вы не слишком скучали по LIKE из фильтра в реляционных базах.
Редактор SQL
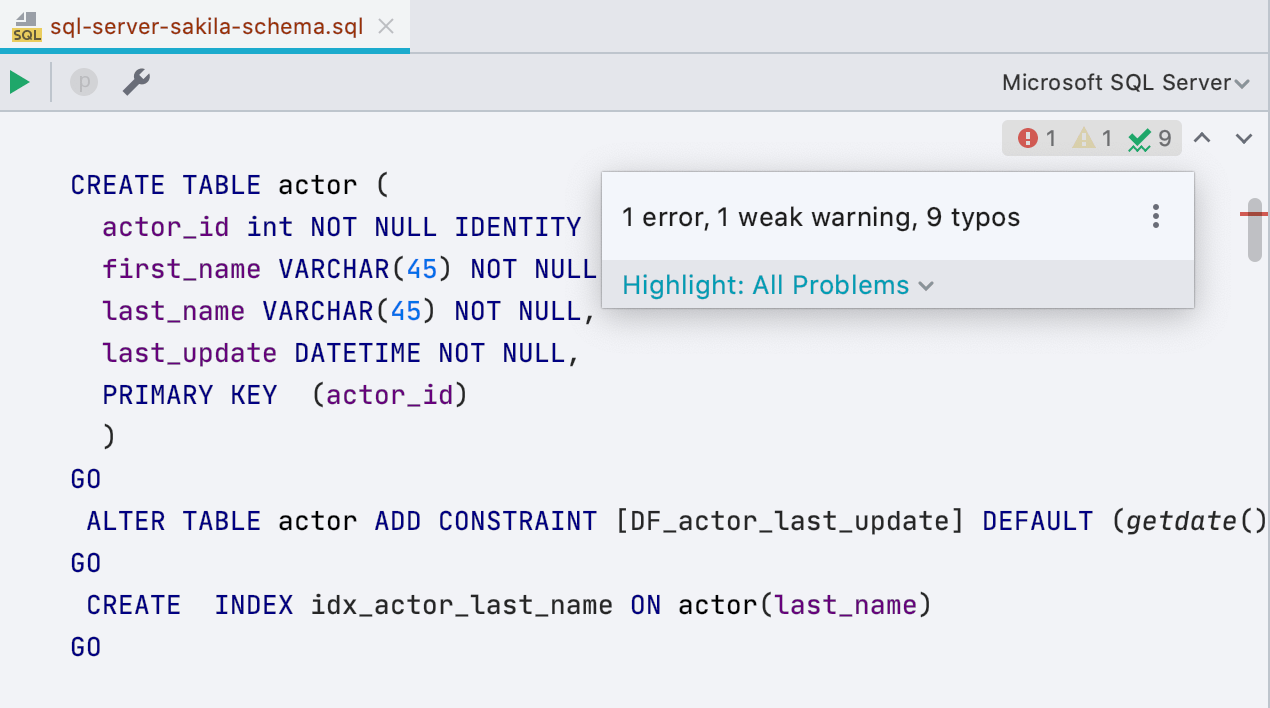
Новый виджет с инспекциями
Справа от редактора появилась маленькая панель — она расскажет, сколько в скрипте ошибок, а сколько мест вызывает подозрение. Оттуда можно навигироваться или выбирать, что подсвечивать, а что нет. Это все еще можно делать с помощью F2.
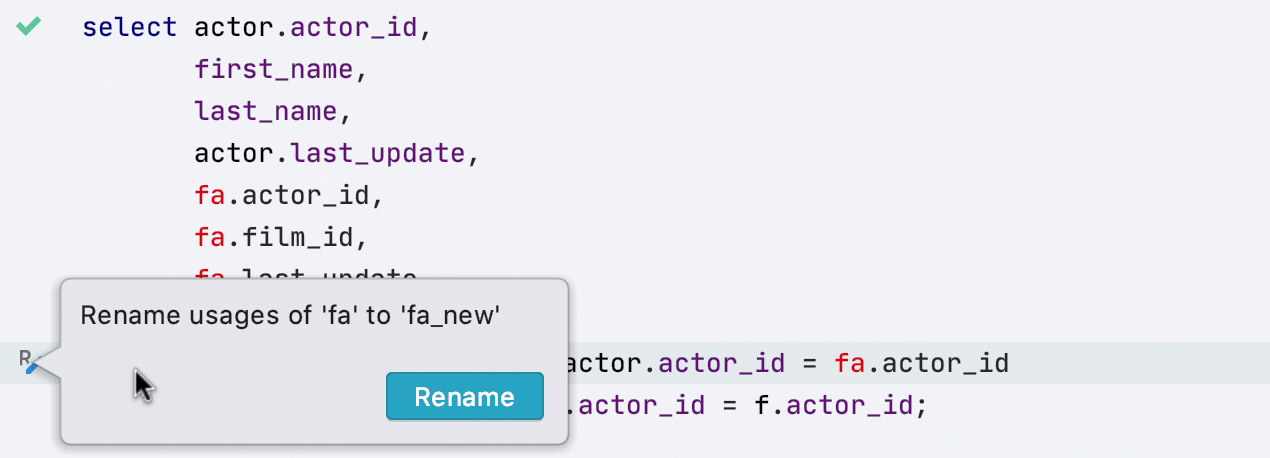
Предложение переименовать
Если вы переименовали что-нибудь не с помощью встроенного рефакторинга, а просто поменяли имя в коде, IDE предложит произвести рефакторинг и переименовать все соответствующие использования. Вот, например, как это работает с псевдонимами:
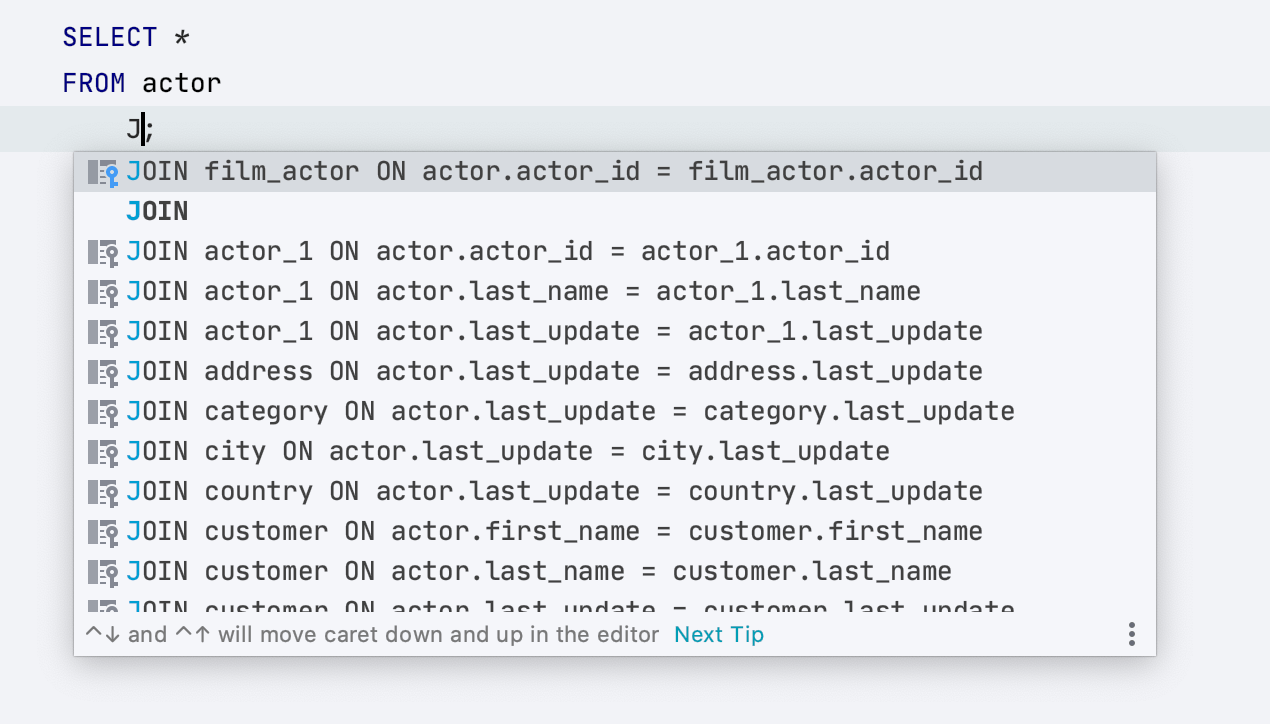
Автодополнение JOIN стало лучше
Раньше, чтобы IDE предложила условие для JOIN полностью, нужно было набрать это ключевое слово. Теперь достаточно ввести букву «J».

Кроме того, автодополнение теперь предлагает двойные условия, если так выставлены ключи таблиц.
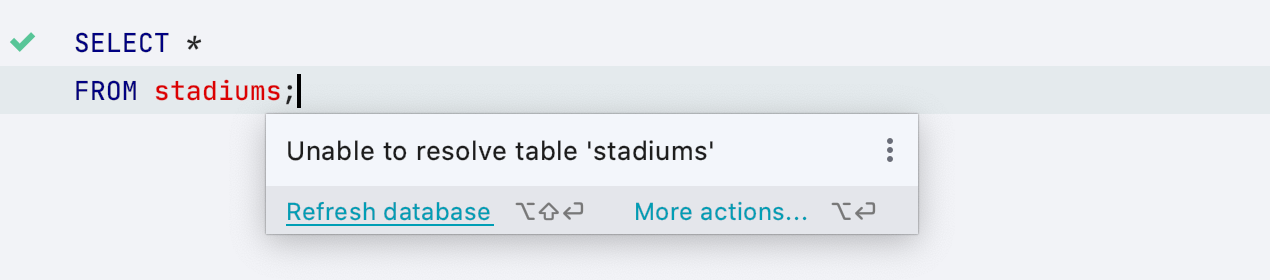
Обновить информацию о базе
Если DataGrip ничего не знает об объектах из ваших запросов, то сообщит вам об этом. Это происходит, если файл был ассоциирован не с тем источником данных. Еще одна причина такого события — объект уже появился, но IDE не получила информации о нем из базы.
Для этого мы добавили возможность запустить обновление структуры базы из редактора, если объект неизвестен.
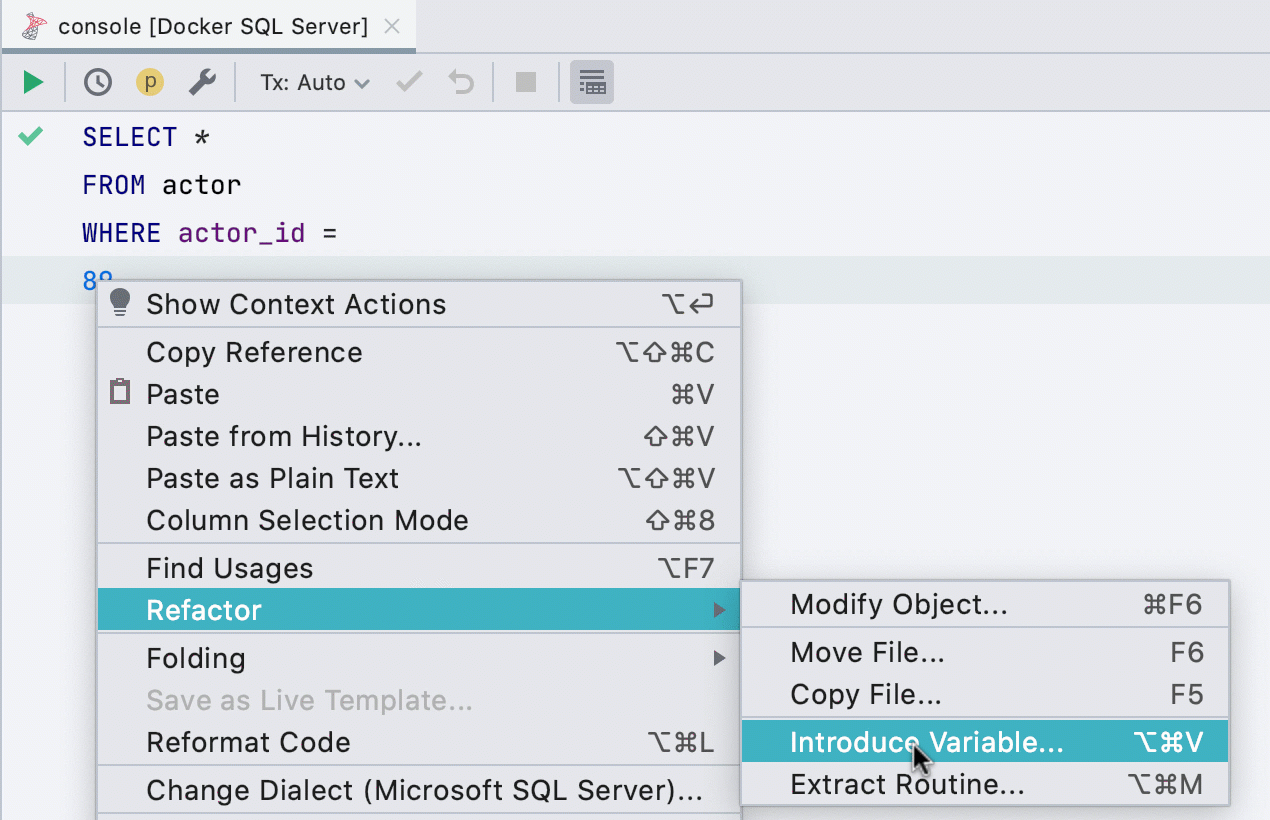
Выделить переменную
Этот рефакторинг раньше работал не для всех баз, а теперь работает в SQL Server, Db2, Exasol, HSQL, Redshift и Sybase. Вы можете выделить переменную из любого выражения, имеющего простой тип.
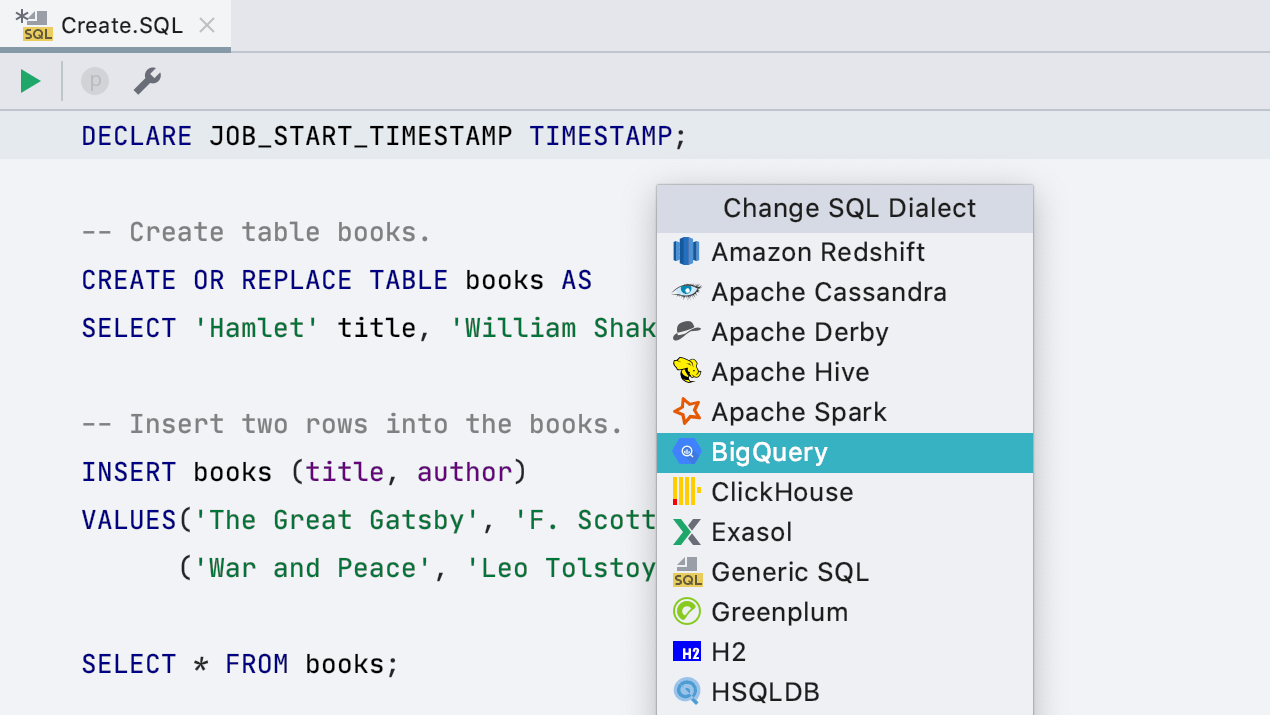
Подсветка Google BigQuery
В списке диалектов пополнение: Google BigQuery. Это пока еще не полноценная поддержка базы, а только правильная подсветка кода. Соответственно, для запуска запросов не надо выделять код, IDE сама определит, что нужно запустить.
Пакеты TextMate
Как и другие наши IDE, DataGrip теперь умеет подсвечивать код при помощи плагина TextMate.
Может пригодиться, если у вас есть скрипты на Python, JavaScript, Shell. Полный список языков вы найдете в Settings/Preferences | Editor | TextMate bundles.
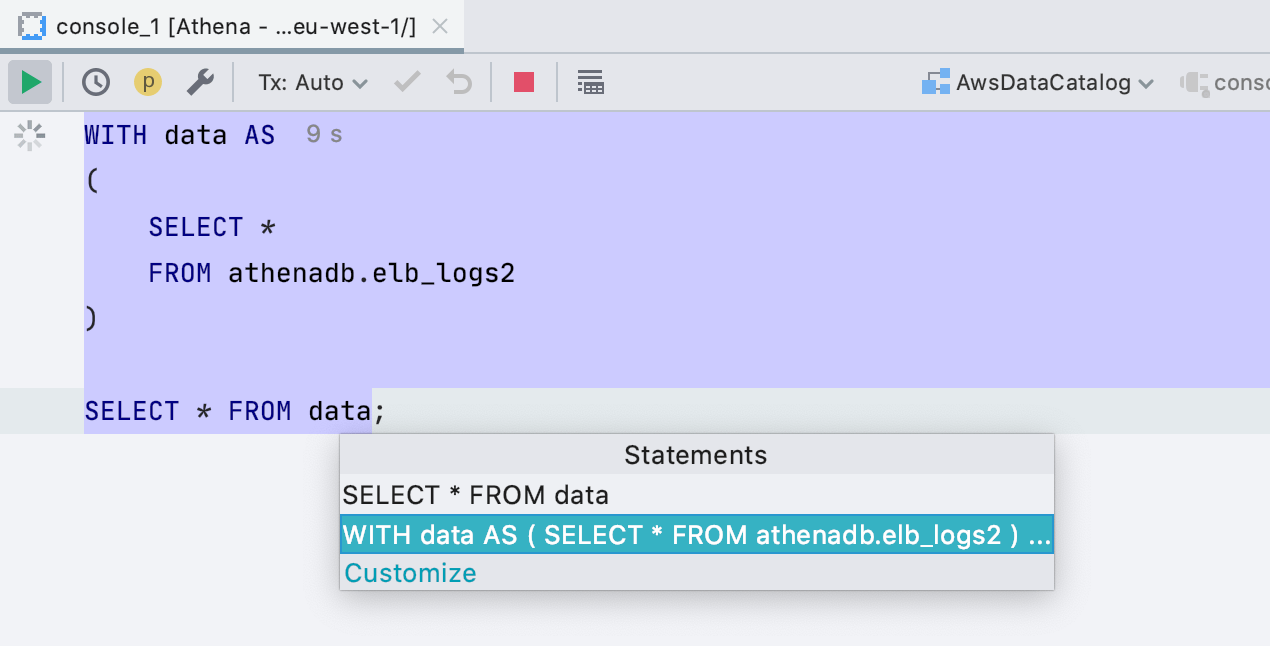
SQL 2016 в качестве диалекта Generic
Если вы работаете с базой, которую мы не поддерживаем, запросы подсвечиваются диалектом Generic. Раньше это был SQL 92, а теперь SQL 2016. А главное, DataGrip теперь корректно обрабатывает запросы с блоком WITH: они не только правильно подсвечены, но и запускать их можно без выделения кода.
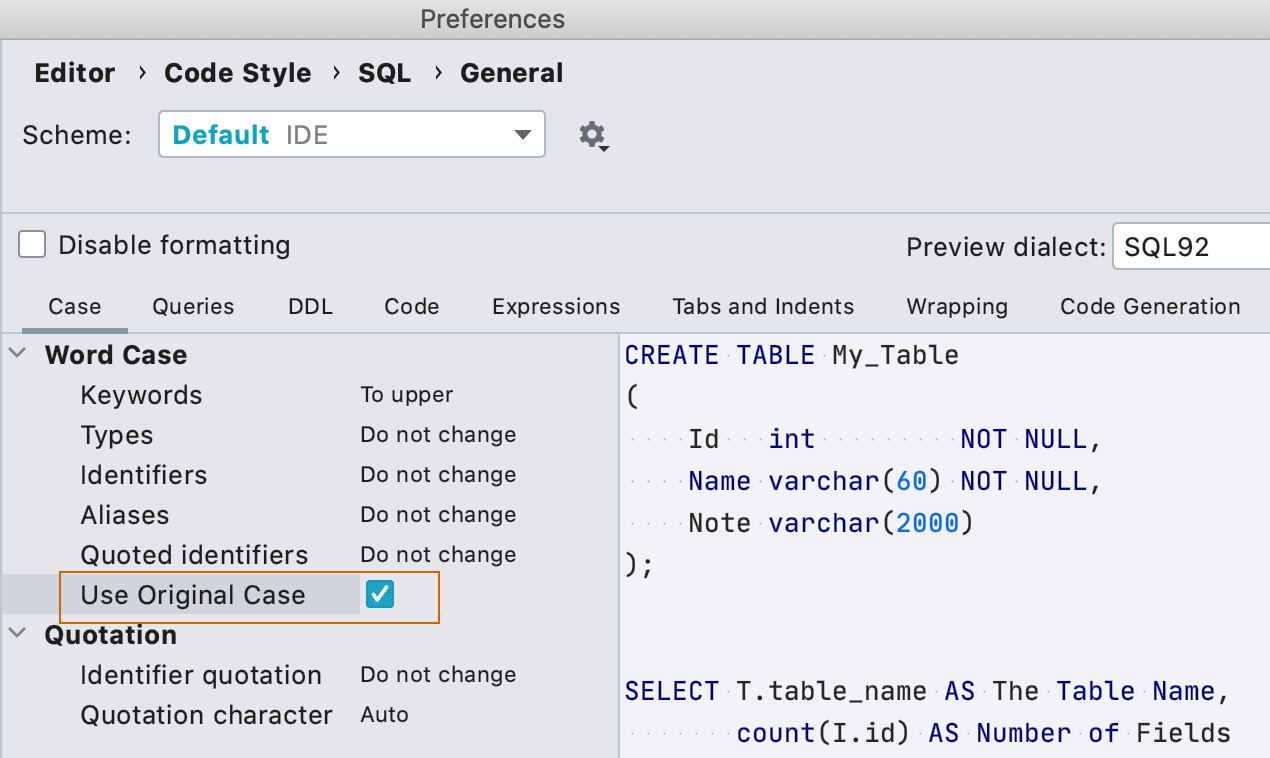
Регистр имен объектов в форматировании
В настройках форматирования было три настройки для имен объектов базы данных: прописными, строчными или не менять. Оказалось, есть и четвертый случай: пользователи хотят использовать тот регистр, который был использован при создании объекта в скрипте. Мы это поддержали.
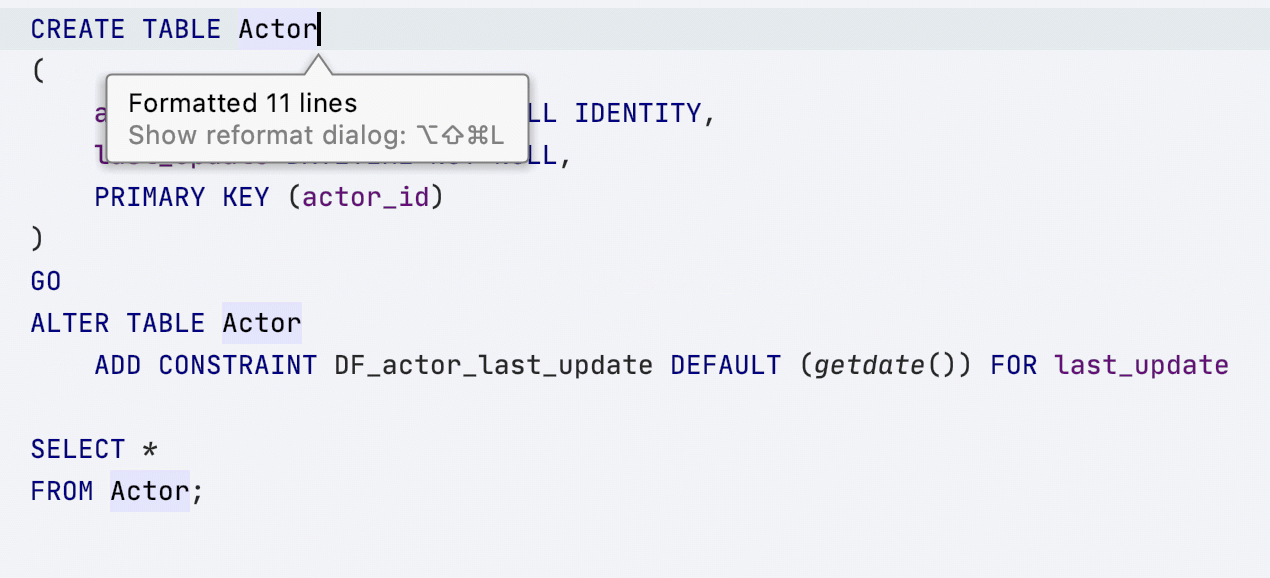
Вот как это работает: в примере таблица Actor создана с первой заглавной, и в использовании имя таблицы теперь приведено к такому же регистру.
DataGrip ищет скрипты создания только внутри того же файла, где происходит форматирование. Если же вы хотите, чтобы форматтер нашел объявление объекта в соседнем файле, создайте из своих файлов источник данных на основе DDL.
Несколько кареток в выделенном фрагменте
Теперь вы можете выделить фрагмент кода и поставить каретку на каждую строчку. Используйте для этого действие Add Carets to Ends of Selected Lines или сочетание клавиш Shift+Alt+G.
Проводник базы данных
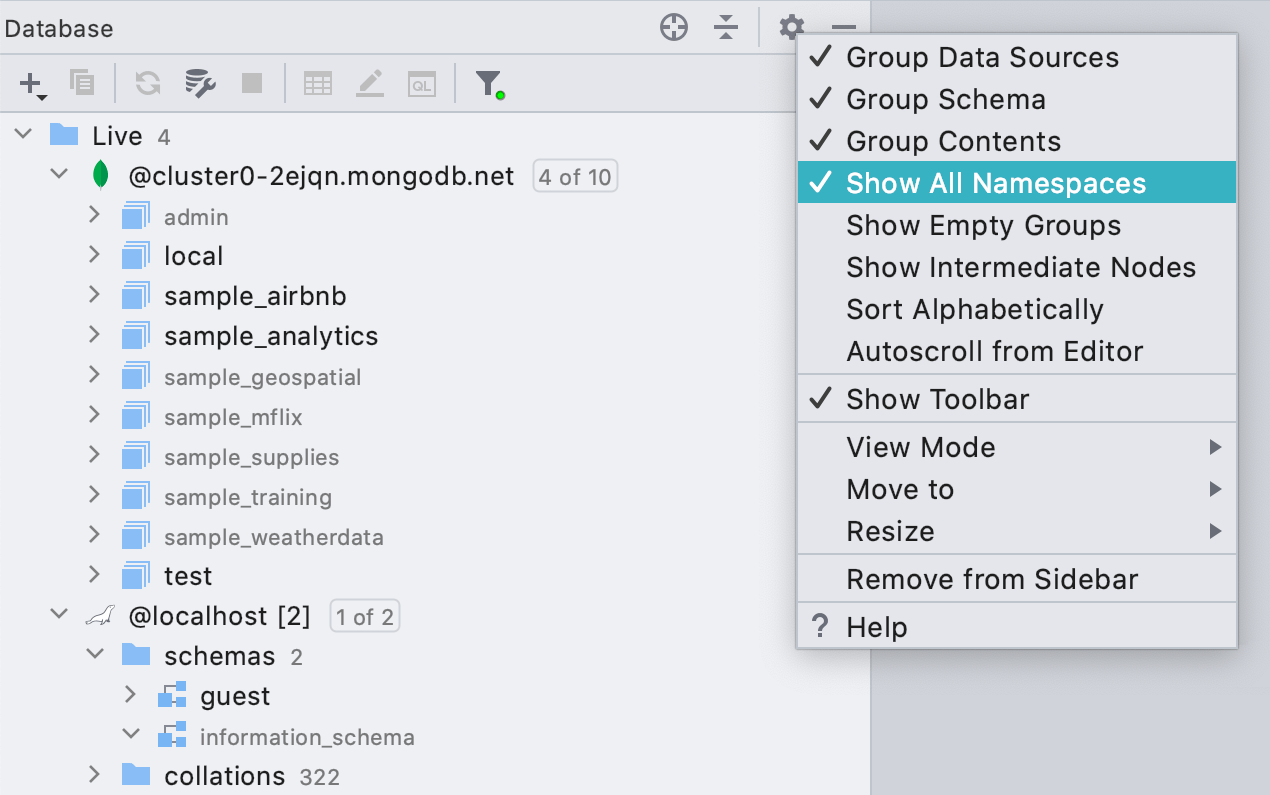
Все базы и схемы в дереве
По умолчанию DataGrip показывает в дереве только те базы и схемы, которые вы выбрали сами. Это удобно, если у вас много баз данных и схем. Однако вся метаинформация об объектах используется для дальнейшей работы IDE, и DataGrip загружает только то, что нужно, чтобы случайно не повиснуть на гигантской базе.
При этом многие привыкли к инструментам, которые всегда показывают все объекты, и те, кто не знаком с нашей концепцией, могут терять из виду базы и схемы.
Поэтому мы добавили настройку Show All Namespaces. Когда она включена, в дереве будут показаны все базы и схемы, даже если информация об их объектах не загружена. Такие схемы и базы отмечены серым шрифтом.
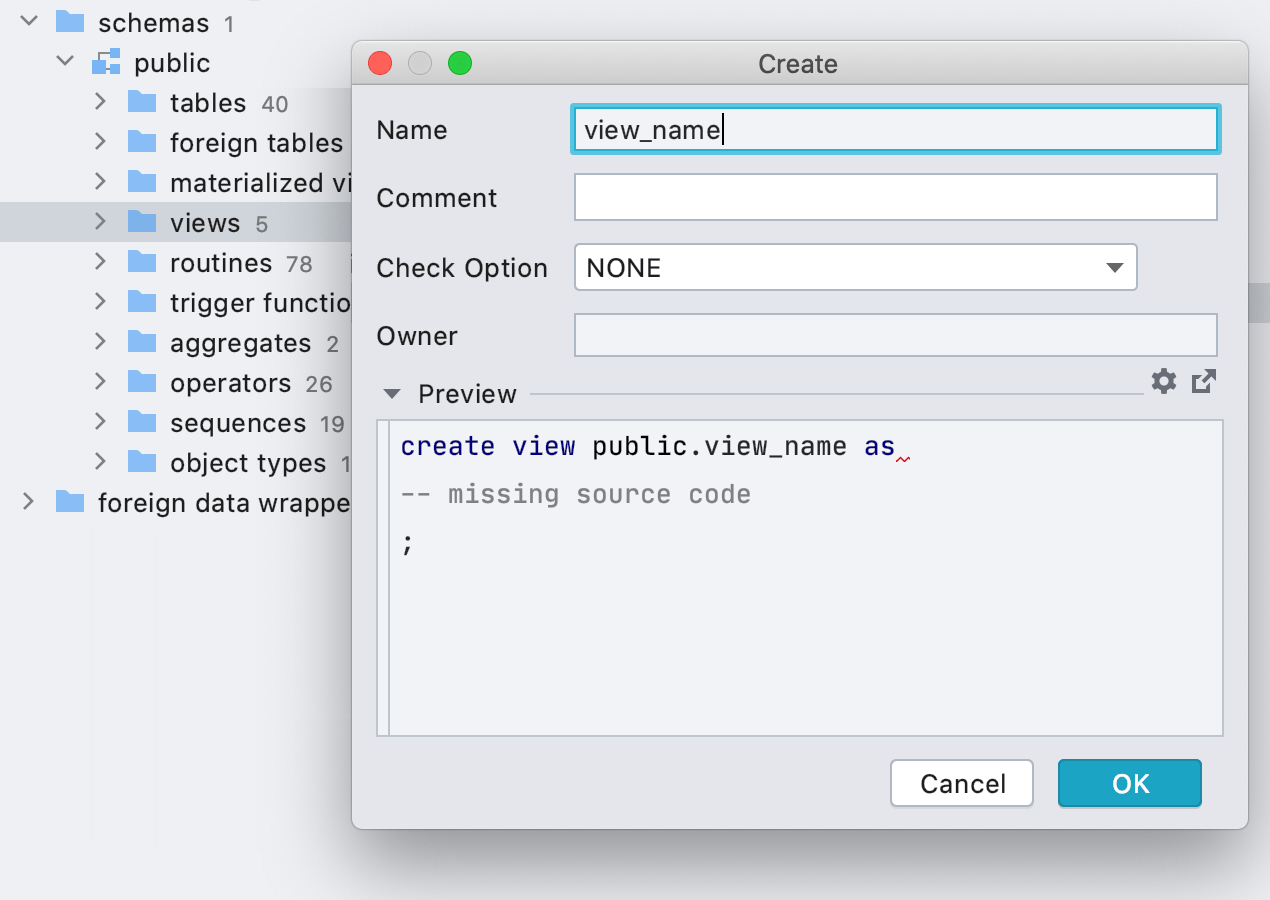
Интерфейс для создания представлений
Для создания объектов мы обычно рекомендуем использовать функцию генерации кода (Alt+Ins), но в некоторых случаях это все же менее удобно. Поэтому мы начали добавлять интерфейсы: в новой версии можно создавать представления.
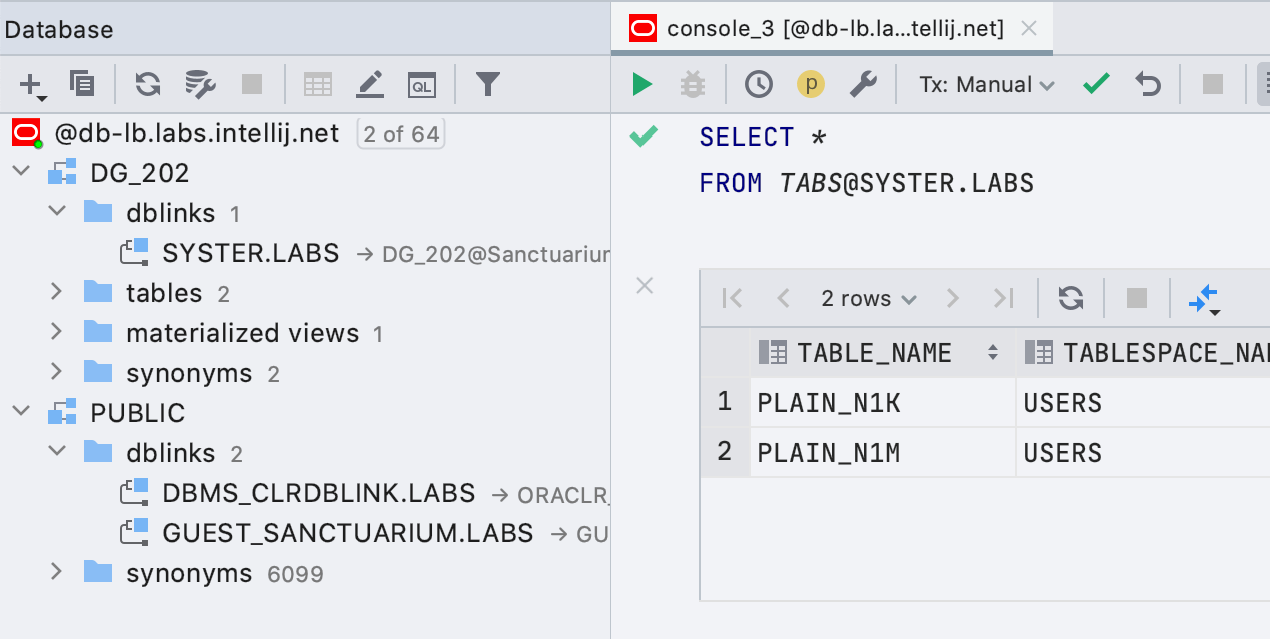
Простая поддержка ссылок на базы данных в Oracle
Ссылки на базы данных теперь показываются в проводнике, а запросы, которые их используют, подсвечены правильно.
Вкладка General
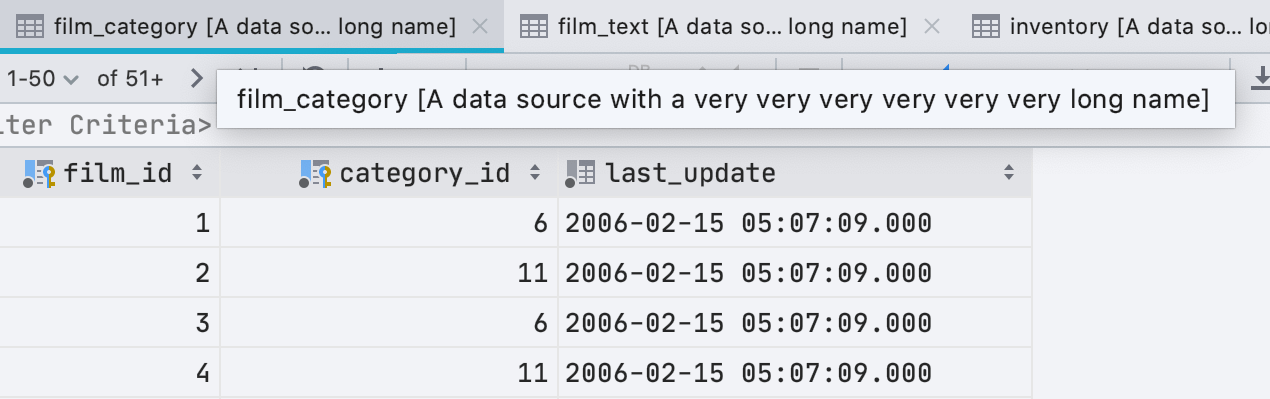
Больше никаких длинных имен вкладок
В DataGrip 2020.2 мы избавились от чрезмерно длинных имен вкладок.
Как это работает:
- Настройка
Database | General | Always show qualified names for database objectsвыключена по умолчанию, то есть имена объектов будут квалифицированы схемой, только если открыто два объекта с одним именем из разных схем. Например, если у вас открыты две таблицы акторов из разных схем, имя схемы будет указано в заголовке вкладки. В противном случае — нет. - Если имя источника данных больше 20 символов, мы его подрежем.
- Если у вас только один источник данных, DataGrip не будет показывать его во вкладках.
- Если имя объекта со всеми классификаторами превышает 36 символов, его мы тоже подрежем.
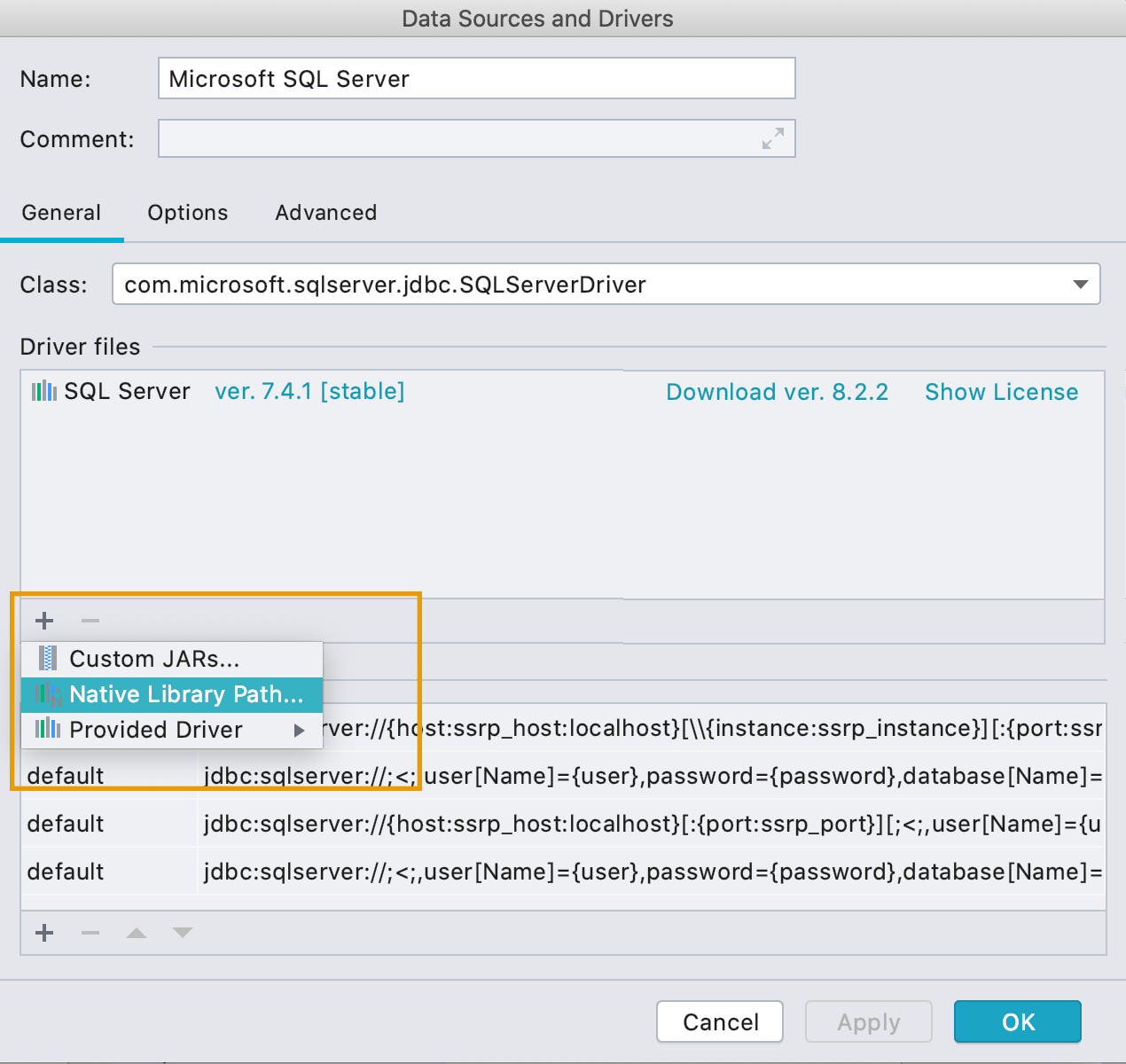
Нативные библиотеки в настройках драйвера
Теперь можно указать путь к нативной библиотеке, которая нужна драйверу. Вот несколько случаев, когда это может понадобиться:
- В SQL Server вы можете указать путь к mssql-jdbc_auth-‹version›-‹arch›.dll для аутентификации по SSO, если настраиваете драйвер вручную. По умолчанию аутентификация по SSO работает из коробки.
- В базе данных Oracle вы можете указать библиотеку ocijdbc, чтобы использовать OCI-драйвер.
- В SQLite, можно указать расширения, загружаемые в рантайме, чтобы потом было легко использовать их при написании запросов, не указывая каждый раз полный путь.
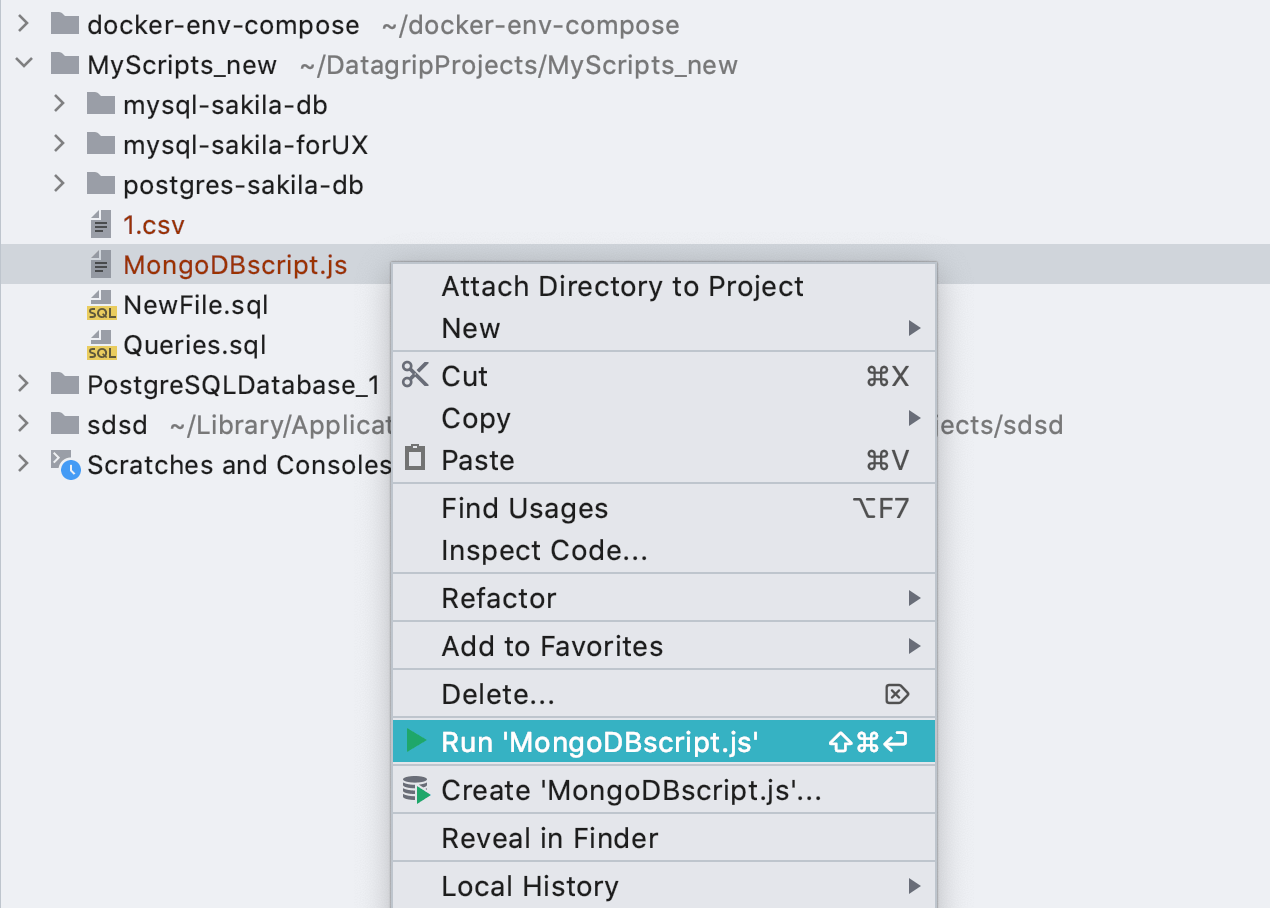
Конфигурации запуска для файлов *.js
Теперь конфигурации запуска работают и для скриптов базы MongoDB.
Интеграция с Git и GitHub работает из коробки
Наконец, плагины Git и GitHub теперь встроены в DataGrip — вам не нужно устанавливать их из Plugin Marketplace.