Что нового в DataGrip 2026.1
Поддержка ИИ-агентов, новый сценарий создания файлов запросов, шаблоны источников данных и многое другое.
Представляем первое обновление DataGrip в 2026 году. В новой версии — практичные улучшения, которые делают работу с базами данных удобнее и быстрее. Главное в релизе — интеграция ИИ-агентов, обновленная логика работы с файлами запросов и консолями, а также простой способ синхронизации настроек источников данных между всеми вашими JetBrains IDE.
- ИИ:
- Файлы и консоли запросов:
- Подключение и источники данных:
- Другие улучшения:
Искусственный интеллект: агентный подход
JetBrains AI развивается и дает вам больше выбора, прозрачности и гибкости при работе с ИИ в DataGrip.
В этом релизе: умное создание SQL-файлов прямо в ИИ-чате, интеграция Claude Agent и Codex, а также специальные инструменты для баз данных в MCP-сервере для агентных сценариев.
Интеграция агентов в ИИ-чат
Claude Agent и Codex теперь нативно встроены в ИИ-чат. Так проще выбрать подходящего помощника для каждой задачи.
Для Codex сейчас требуется ручная настройка MCP-сервера. Подробные инструкции см. в документации.
Подробнее читайте в блоге JetBrains AI: о Claude Agent в JetBrains IDE, об интеграции Codex в JetBrains IDE.
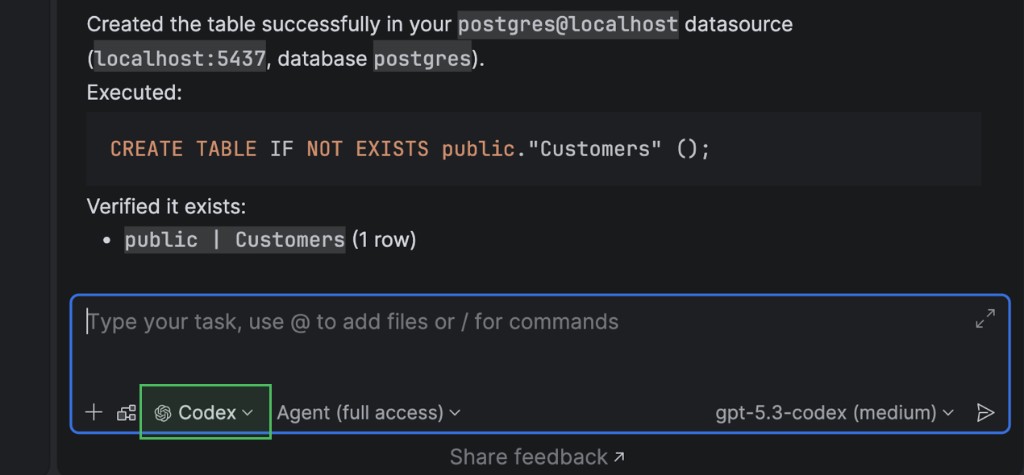
Возможности MCP-сервера для работы с базами данных
Мы расширили MCP-сервер, добавив специализированные инструменты для работы с базами данных. Благодаря этому встроенные ИИ-агенты и сторонние инструменты могут работать с базами данных более структурированно.
Новые возможности:
- получение настроек подключения и их тестирование;
- получение списка схем базы данных;
- получение списка поддерживаемых типов объектов схемы (например, таблиц и представлений) и просмотр объектов схемы;
- просмотр недавних и текущих SQL-запросов;
- выполнение и отмена текущих SQL-запросов;
- просмотр данных таблицы и получение результатов в формате CSV.
Для безопасности по умолчанию требуется согласие пользователя на четыре типа действий:
- запросы на доступ к схеме;
- запросы на доступ к данным;
- запросы на изменение схемы;
- запросы на изменение данных.
Когда потребуется разрешение, IDE запросит его автоматически.
Настройки согласия можно изменить в IDE: Tools | AI Assistant.
Создание файлов с учетом SQL-диалекта и подключенного источника данных
В окне AI Chat при работе с AI Assistant можно создать файл из фрагмента кода.
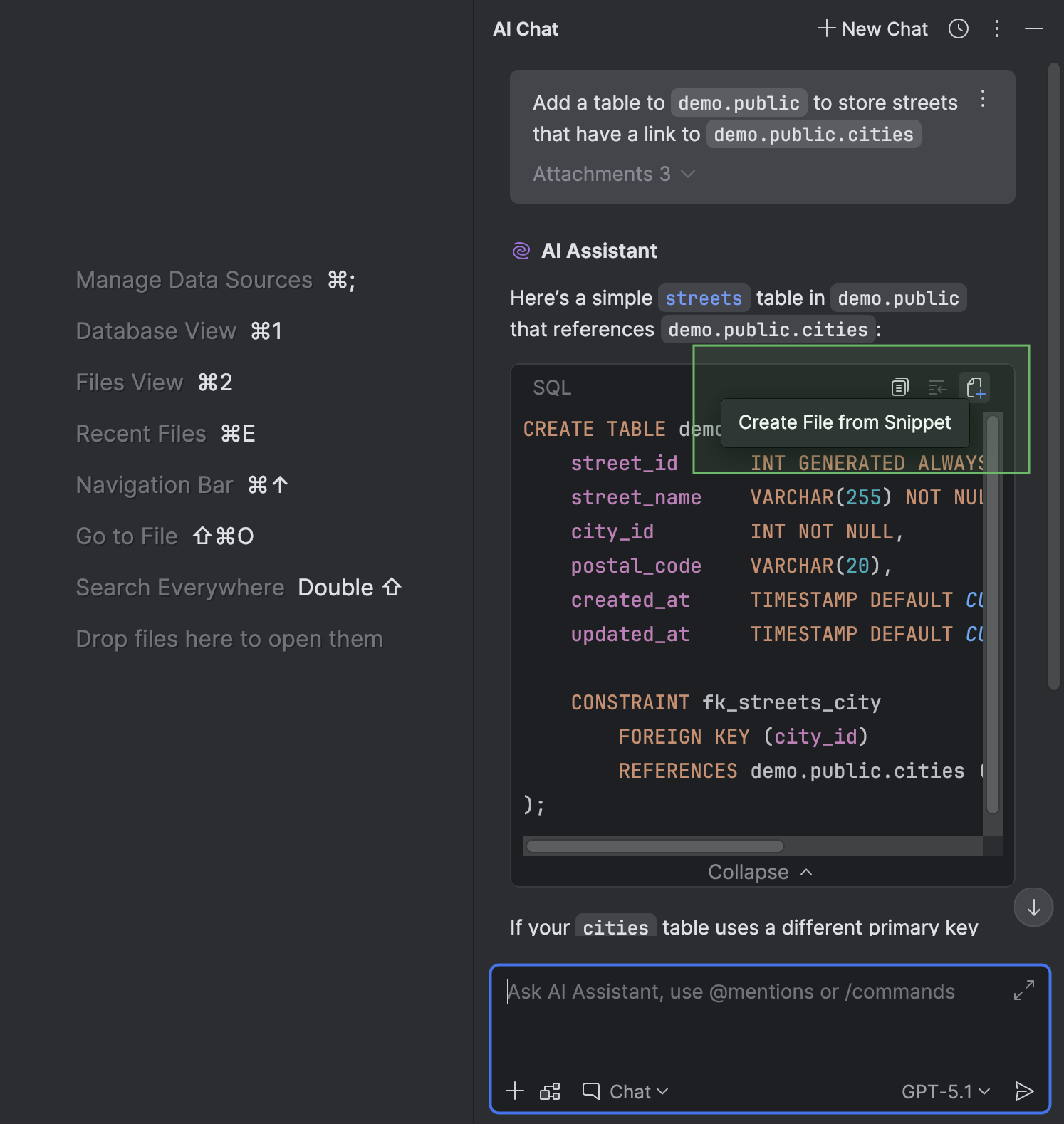
Если в чате уже указан SQL-диалект, источник данных или схема, ничего дополнительно прикреплять и настраивать не нужно — DataGrip сделает это автоматически. То же самое касается вопросов, которые вы задаете AI Assistant о файле с уже прикрепленным источником данных: DataGrip автоматически привяжет его к вновь созданному файлу.
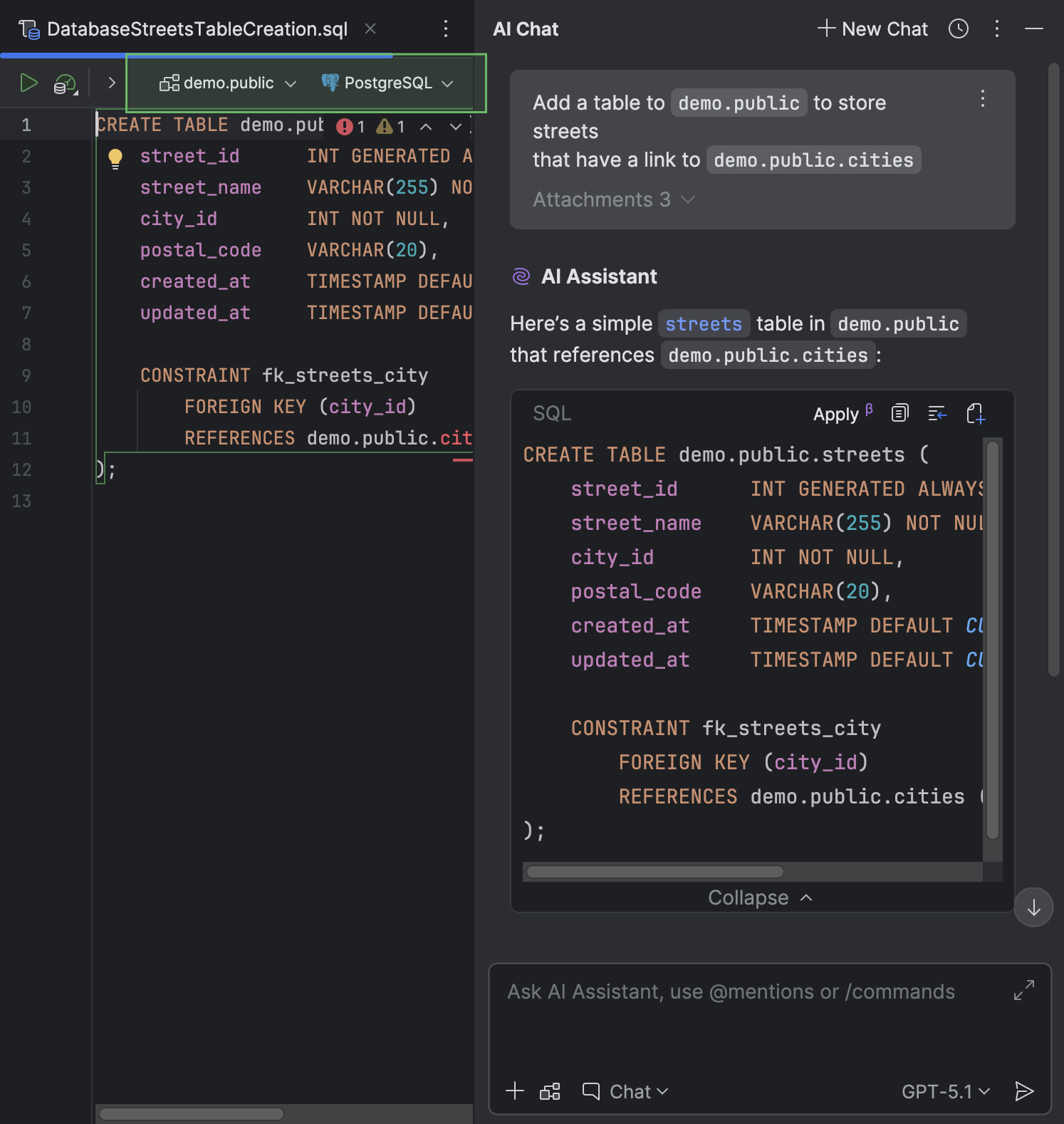
DataGrip сохранит созданный файл в директории текущего проекта.
Файлы и консоли запросов
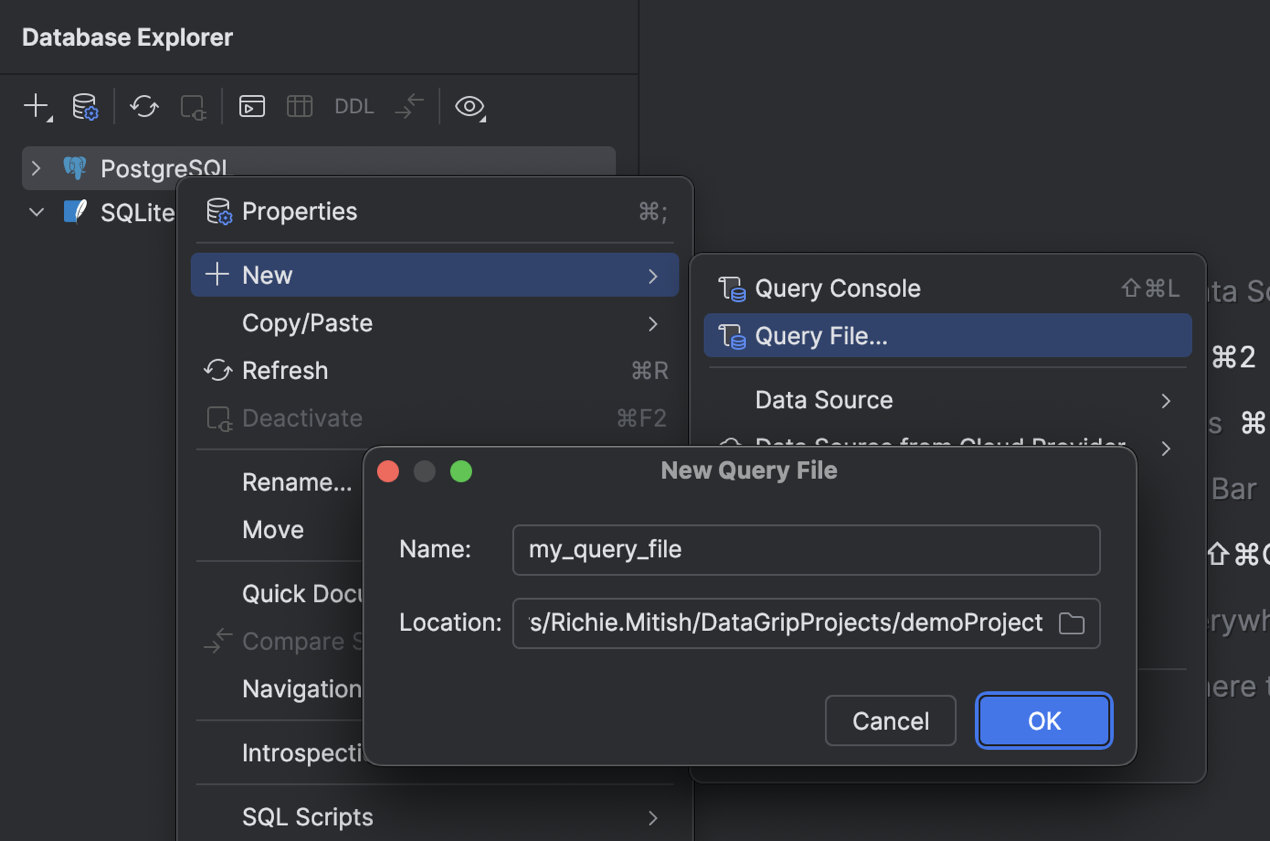
Новый сценарий создания файла запроса
Мы переработали сценарий работы с файлами запросов параллельно с консолями запросов. Теперь, в зависимости от задачи и привычного процесса работы, можно использовать только файлы, только консоли или и то и другое одновременно.
Чтобы создать новый файл запроса, нажмите правой кнопкой мыши на источнике данных и выберите New | Query File или нажмите Shift+Cmd+J (macOS) или Ctrl+Alt+Shift+Q (Windows/Linux). Затем в диалоге New Query File укажите имя файла и папку, в которой его нужно сохранить. Чтобы сохранить файл в текущем проекте и связать его с ним, укажите папку текущего проекта или одну из ее вложенных папок.
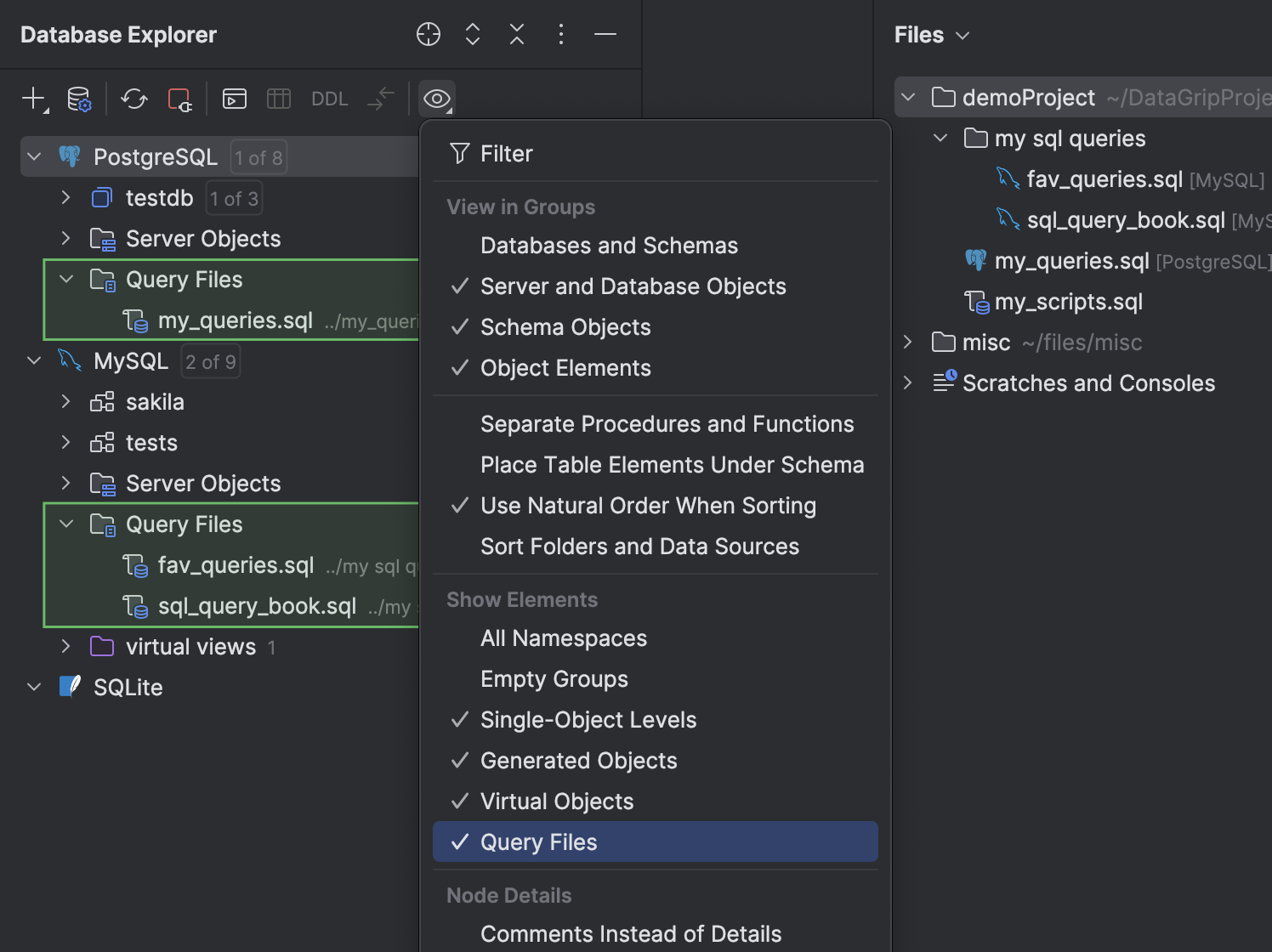
Папка Query Files в проводнике баз данных
Теперь файлы запросов доступны прямо в проводнике баз данных. Мы добавили папку Query Files, которая появляется у каждого источника данных. Чтобы показать или скрыть эту папку, нажмите View Options на панели инструментов окна и включите или отключите пункт Query Files.
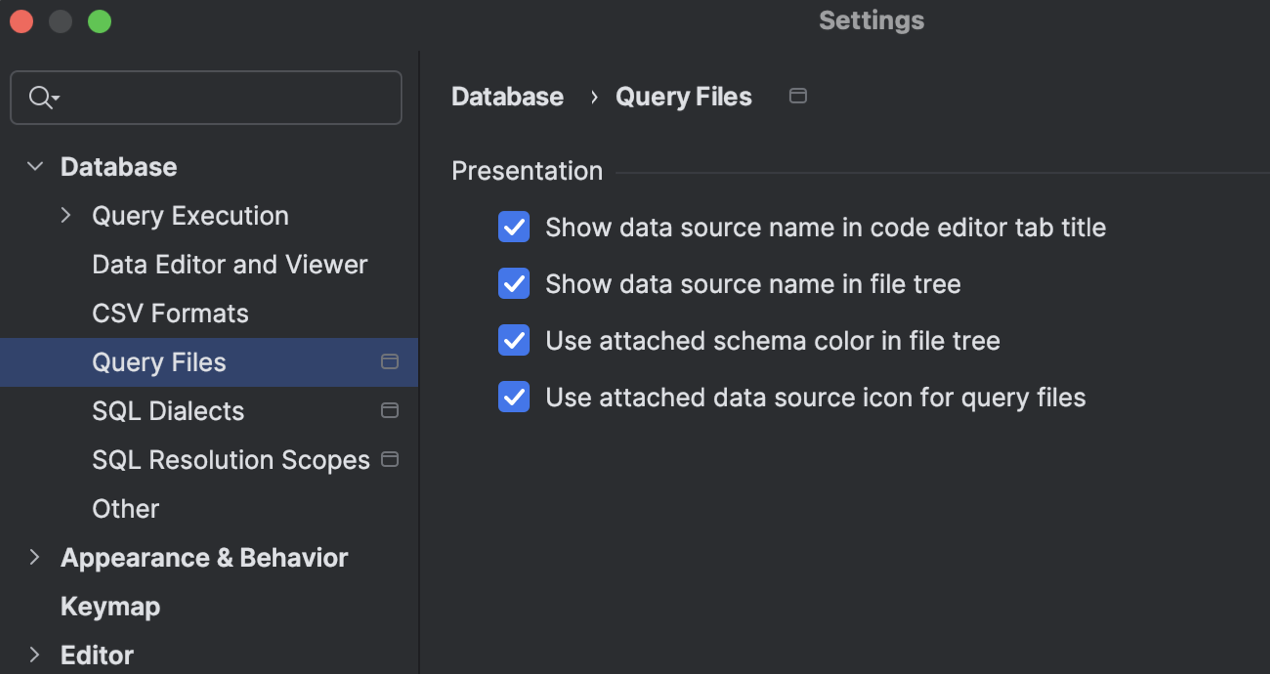
Новые настройки отображения файлов
Для разных задач нужна разная информация на экране. Мы добавили несколько настроек, чтобы представление файлов запросов лучше подходило под ваш сценарий работы. С их помощью можно показывать или скрывать имена источников данных, включать цвета схем и использовать для файлов запросов значок привязанного источника данных.
Подключение
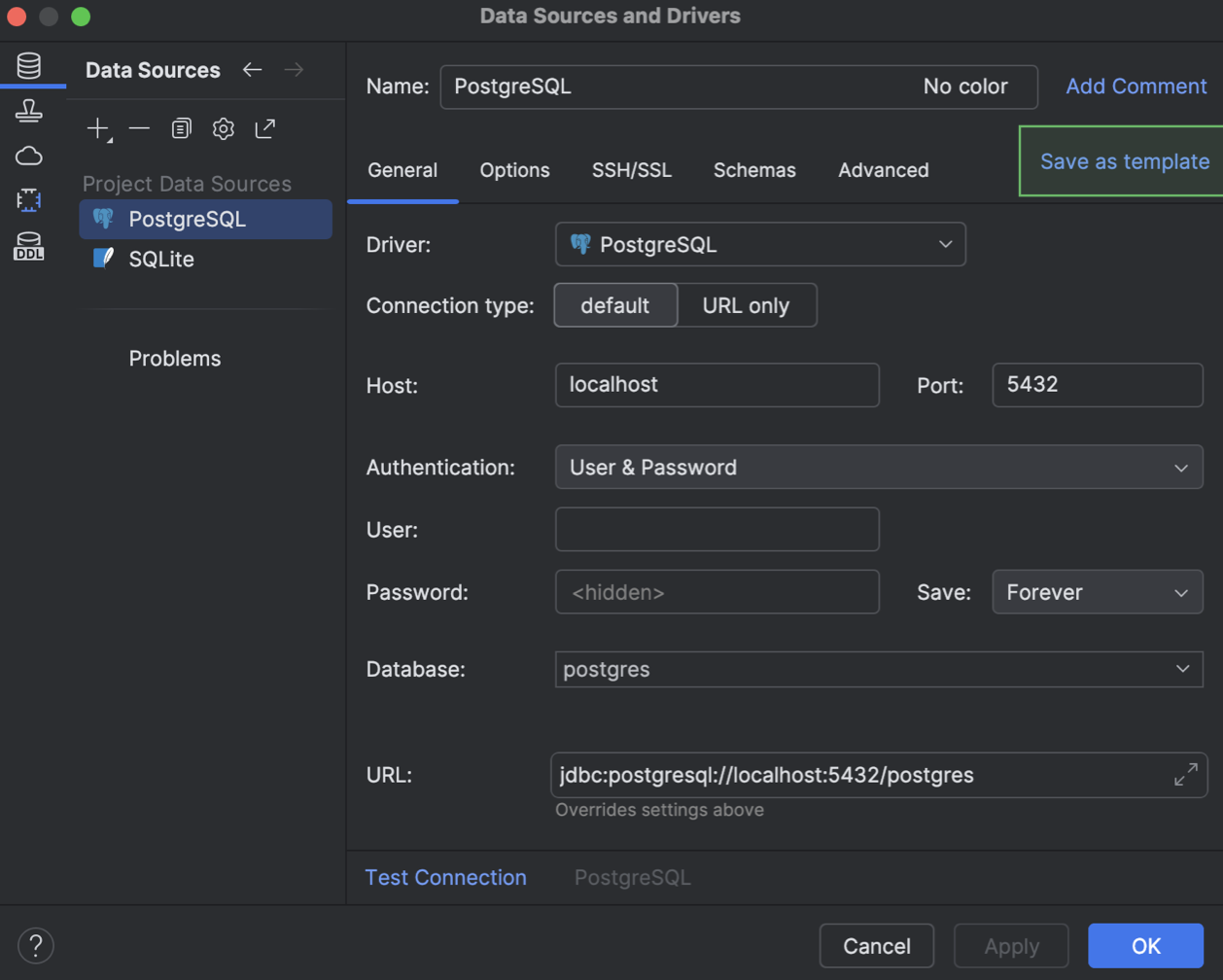
Шаблоны источников данных
Теперь настройки источников данных можно сохранять как шаблоны в вашем JetBrains-аккаунте. Такой шаблон будет доступен во всех JetBrains IDE с поддержкой баз данных, которые привязаны к вашему аккаунту. В таких шаблонах сохраняются параметры с вкладок General и Advanced из диалога Data Source and Drivers, при этом ваши данные для входа в базу не копируются.
Шаблон можно создать в диалоге Data Source and Drivers. На вкладке Data Sources выберите источник данных, из которого нужно создать шаблон, и нажмите Save as template.
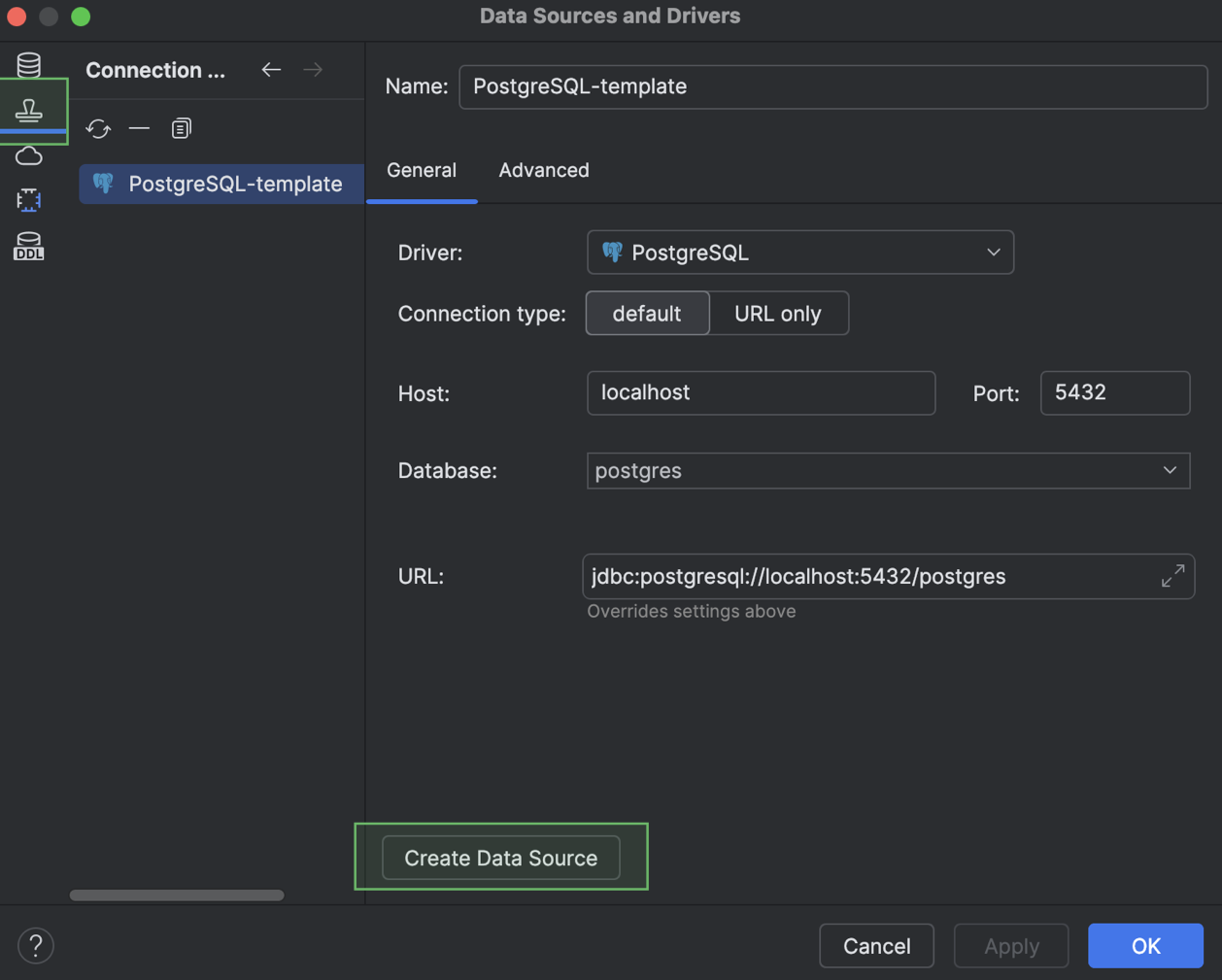
Новый шаблон появится на вкладке Data Source Templates. Создать новый источник данных на основе этого шаблона можно в любой момент кнопкой Create Data Source.
Поддержка PostgreSQL 18 PostgreSQL
DataGrip теперь поддерживает PostgreSQL 18, вышедший в прошлом году. Полная поддержка включает, помимо прочего, следующие ключевые слова и конструкции:
- разрешение
OLDиNEWв выраженияхRETURNING; WITHOUT OVERLAPSв ограничениях первичного ключа и уникальности;PERIODв ограничениях внешнего ключа;GENERATED ALWAYS AS (...) [STORED | VIRTUAL]для столбцов;- ограничения
NOT ENFORCEDиNOT VALID.
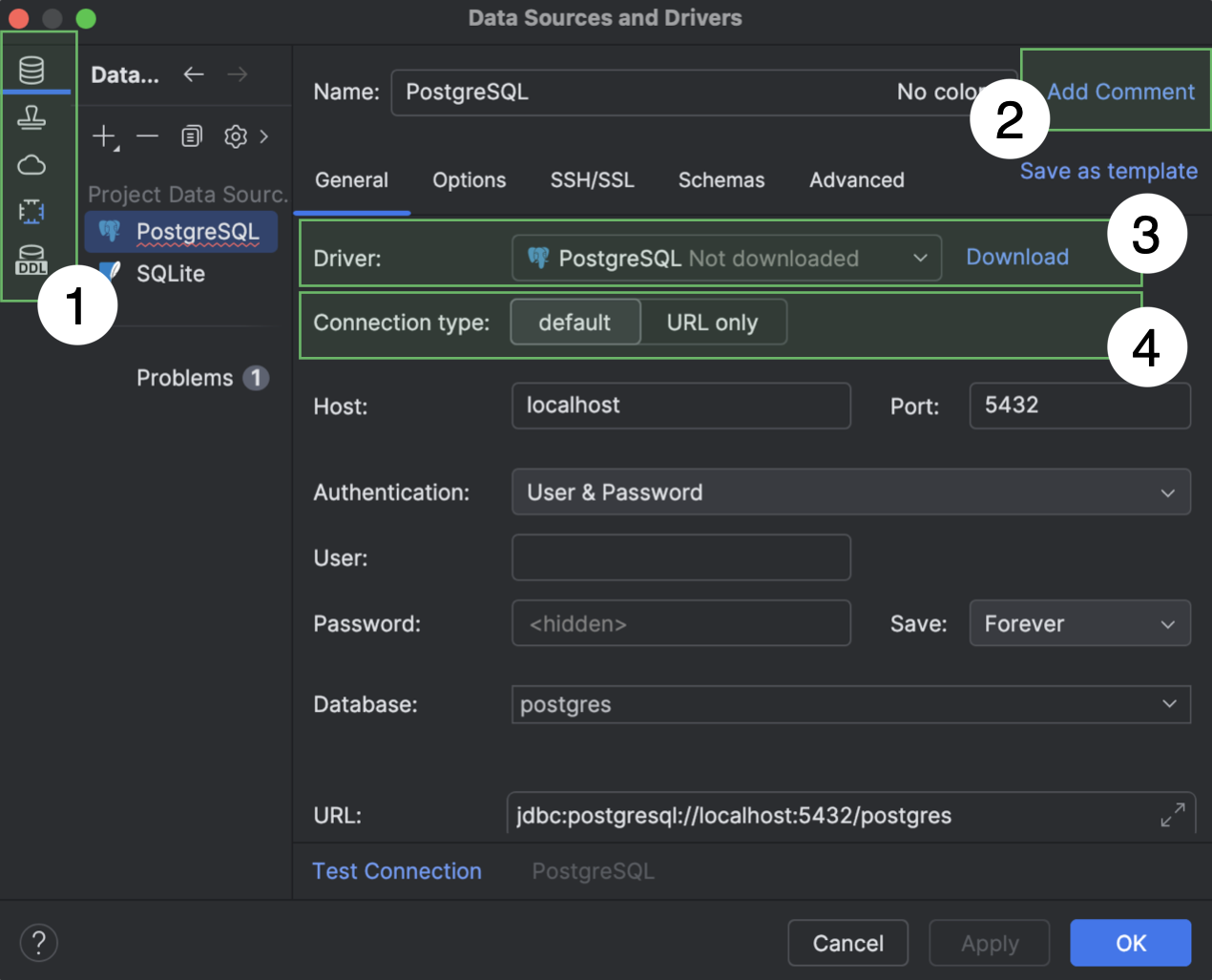
Улучшения в диалоге Data Sources and Drivers
Мы внесли несколько изменений в диалог Data Sources and Drivers.
- Разделы Data Sources, Clouds, Drivers и DDL Mappings стали основными вкладками в диалоге и расположены слева.
- Если поле Comment пустое, оно по умолчанию скрыто. Чтобы его отобразить, нажмите Add Comment рядом с полем Name.
- Если драйвер, выбранный в выпадающем списке Driver, еще не скачан, рядом с меню появится кнопка Download. Нажмите на нее, чтобы загрузить драйвер.
- Пункты выпадающего списка Connection type теперь отображаются как вкладки. Если у источника данных больше трех типов подключения, они по-прежнему показываются в выпадающем списке.
Кроме того, удалено действие Create DDL Mapping. Создать сопоставление DDL теперь можно на основной вкладке DDL Mappings.
Сценарий Explain Plan
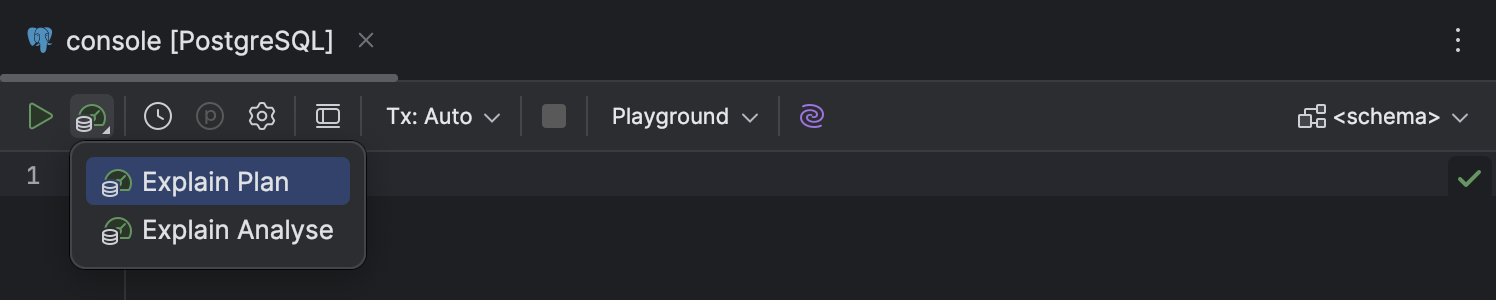
Улучшения в интерфейсе
Мы обновили раздел Explain Plan — теперь он нагляднее, удобнее, и его стало проще найти:
- Список в выпадающем меню Explain Plan на панели инструментов стал короче — теперь там всего два пункта: Explain Plan и Explain Analyse.
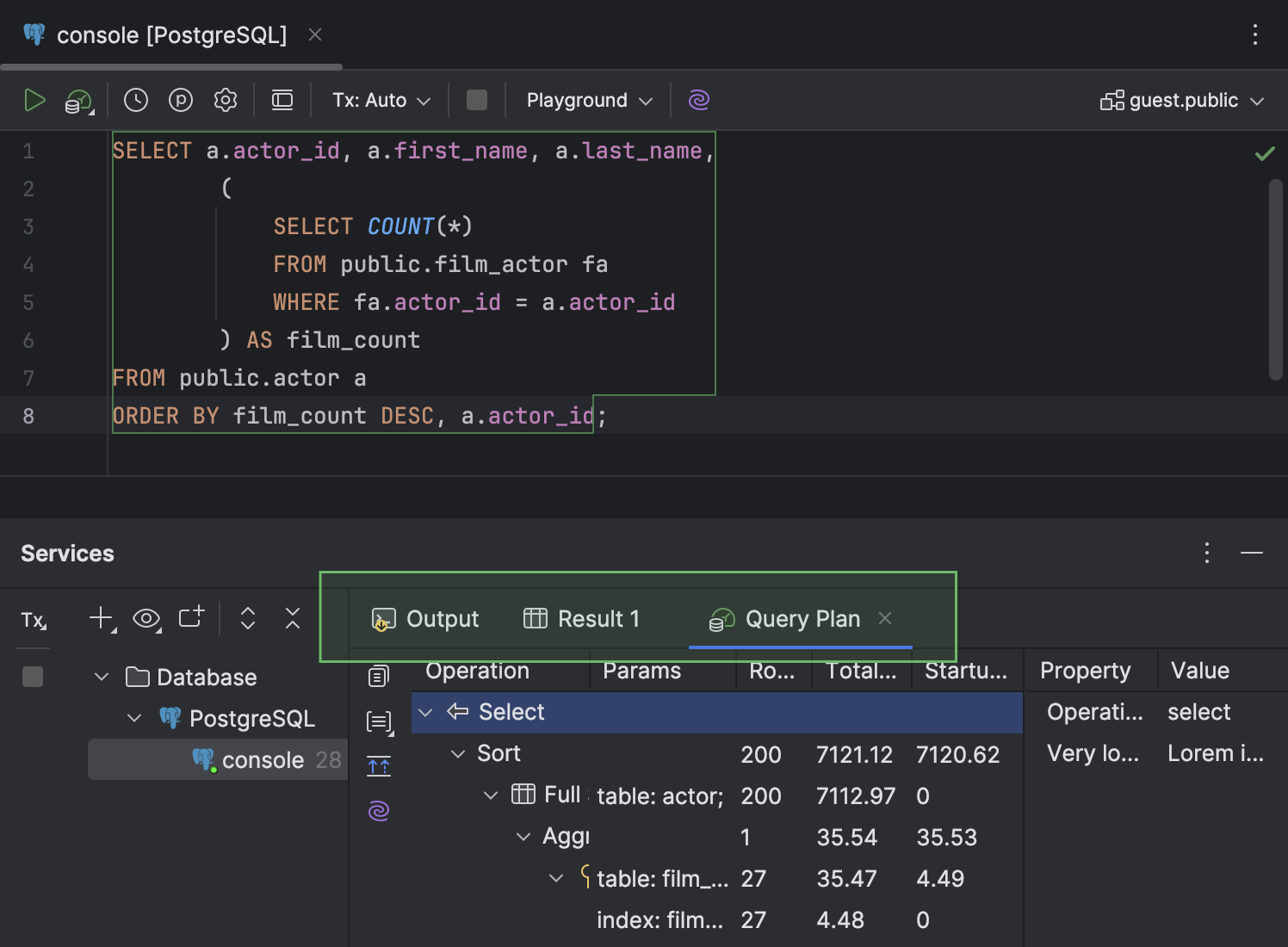
- В окне Services вкладка Query Plan, где отображается план, перенесена на тот же уровень, что и вкладки Output и Result. Кроме того, у нее новый значок.
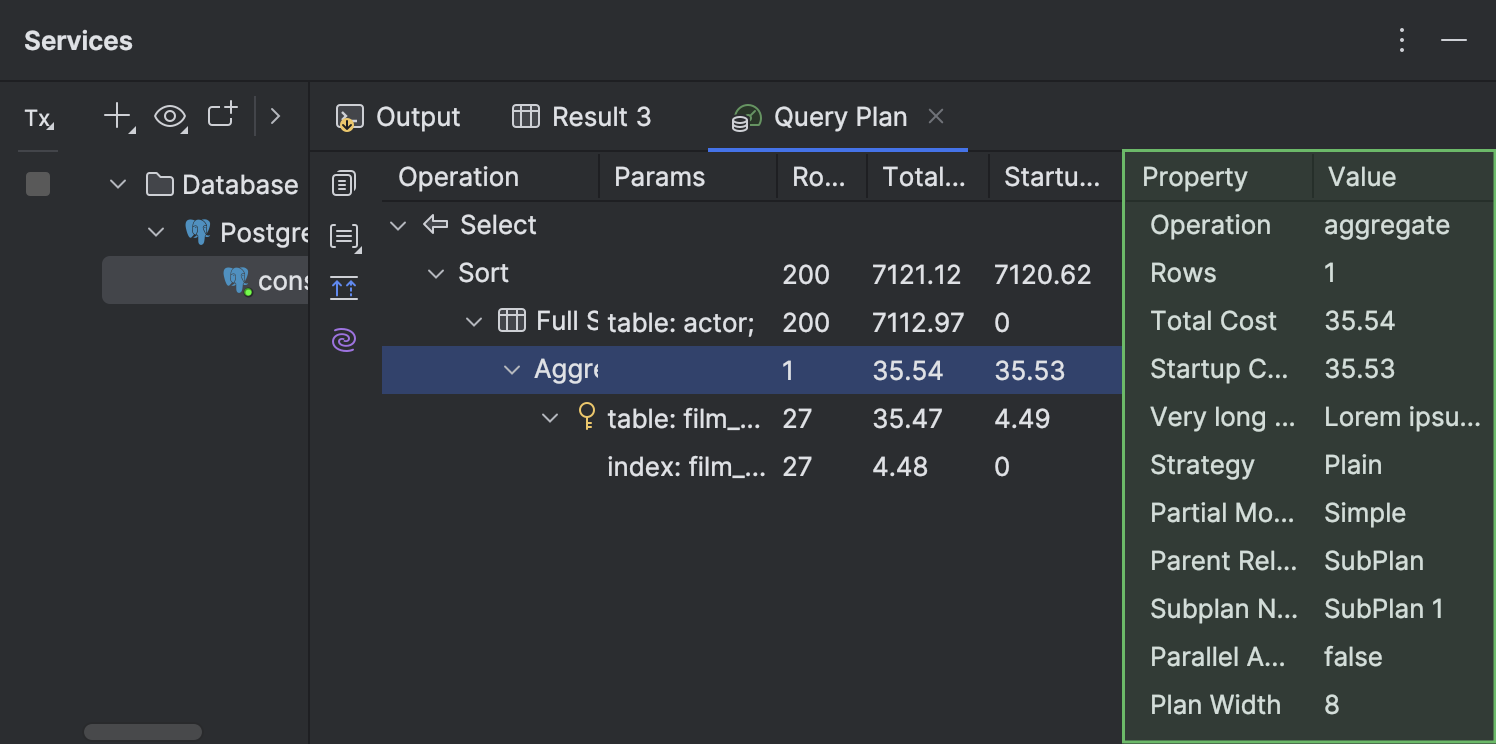
- На вкладке Query Plan теперь можно смотреть подробности по каждой строке плана на отдельной панели справа.
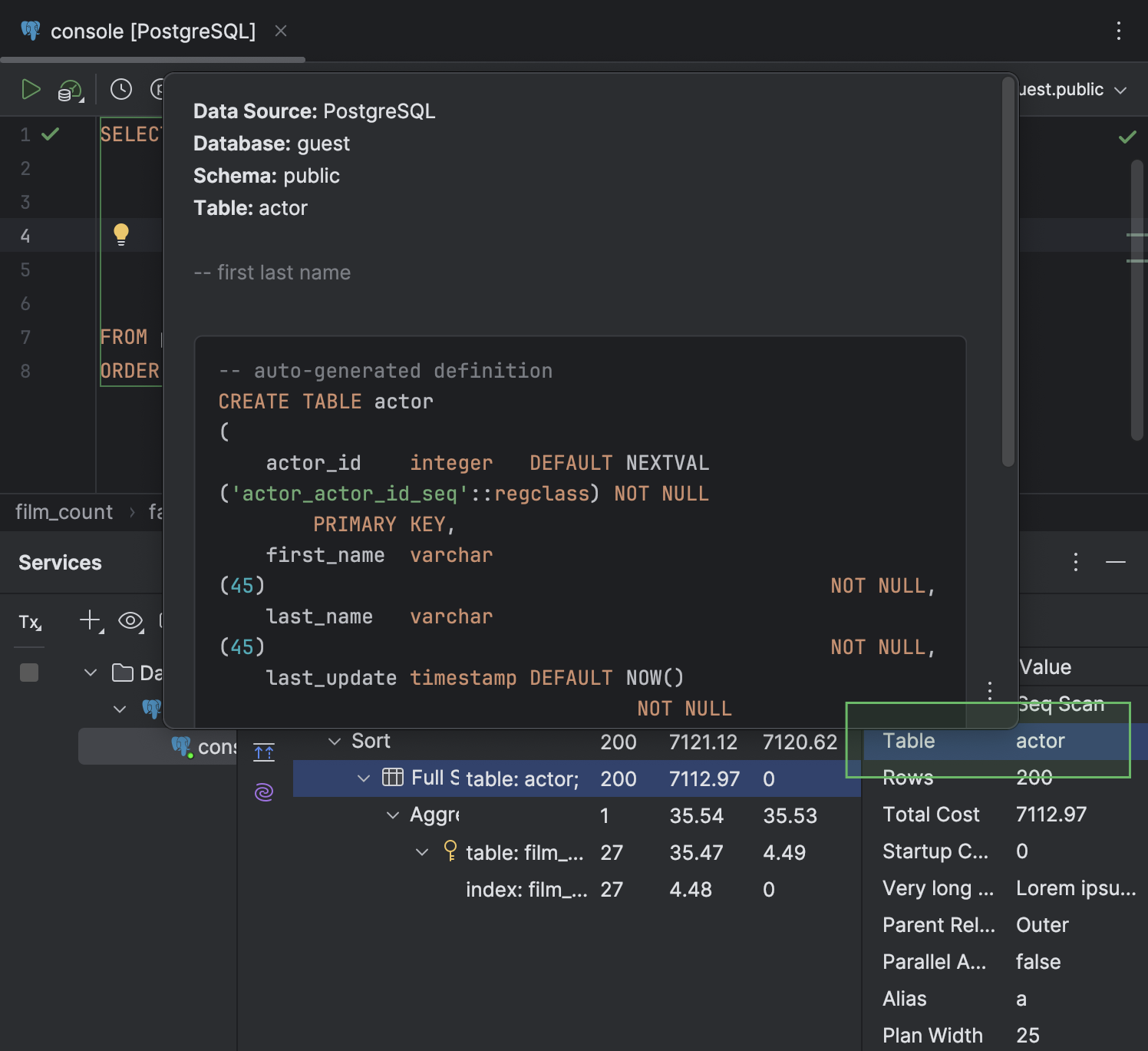
- Если ячейка содержит имя таблицы, при наведении на нее открывается всплывающее окно быстрой документации.
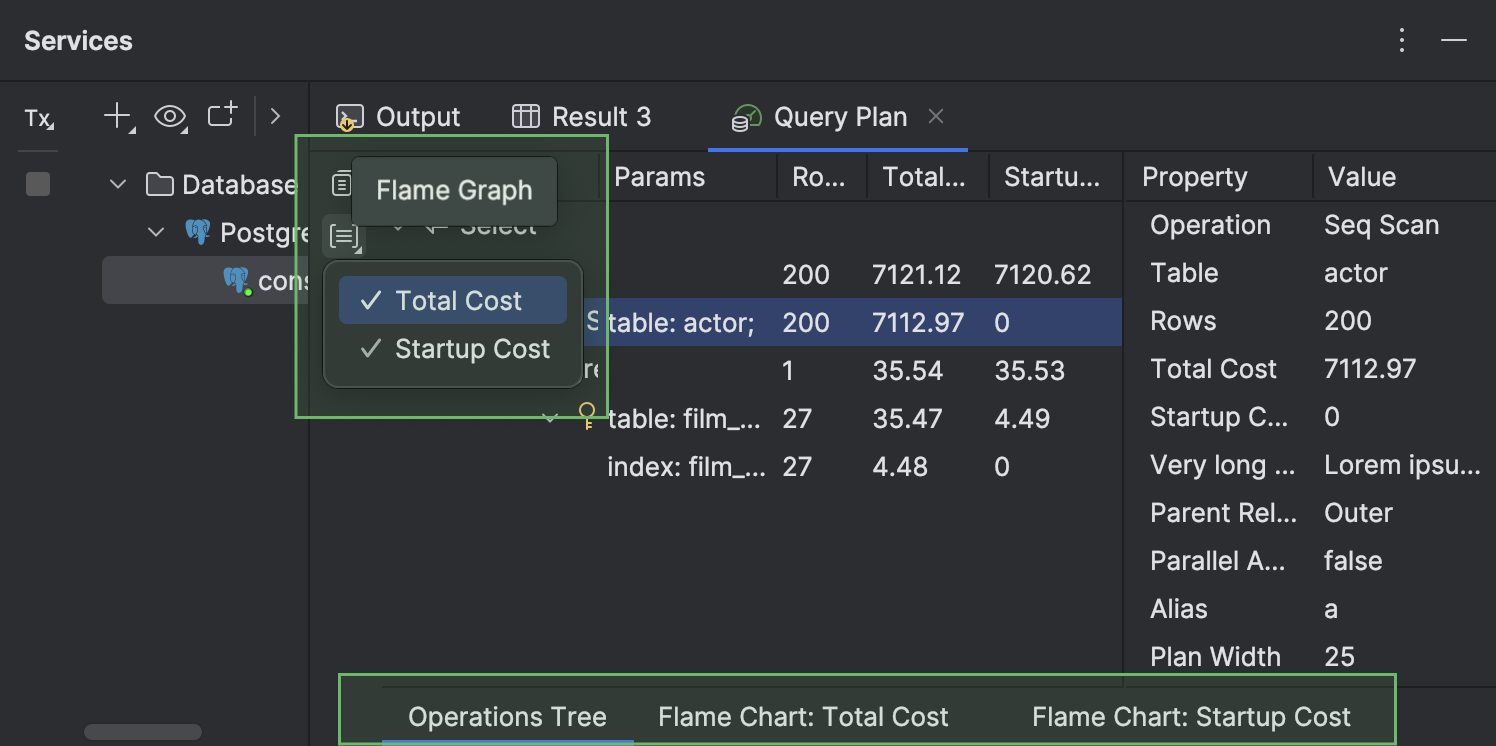
- Разные представления плана запроса теперь вынесены в отдельные вложенные вкладки. Эти вкладки находятся в нижней части вкладки Query Plan. По умолчанию они скрыты и появляются, только если открыто несколько вкладок. Чтобы открыть вкладку Total Cost или Startup Cost, нажмите Flame Graph на левой панели инструментов и выберите нужное представление.
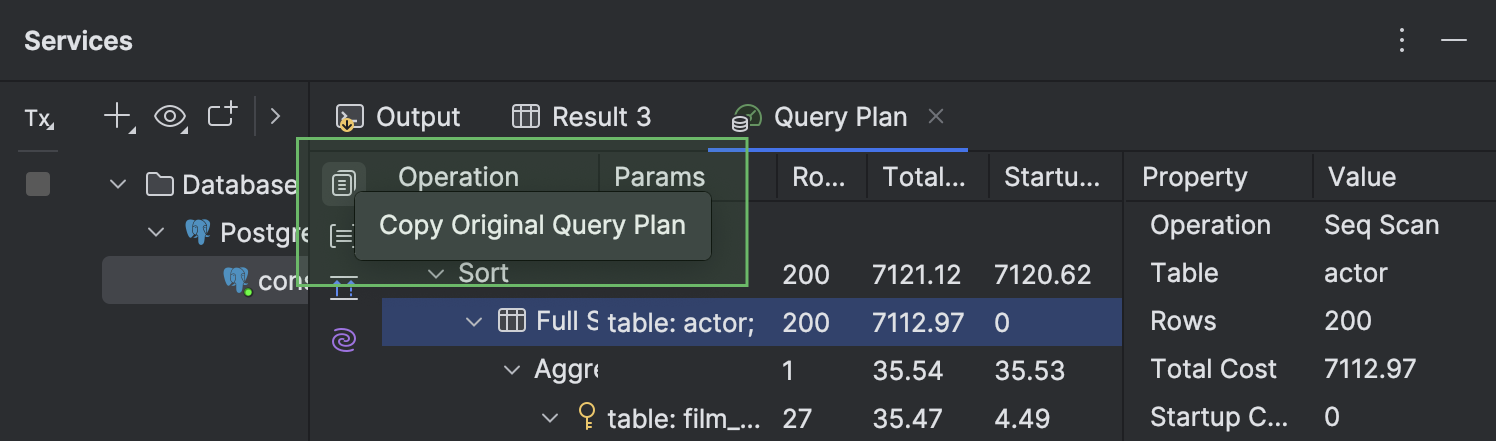
Возможность копировать план запроса в исходном формате
Теперь план запроса можно скопировать в исходном формате базы данных, например JSON или XML. Для этого нажмите кнопку Copy Original Query Plan на левой панели инструментов. Возможность поддерживается для PostgreSQL, Amazon Redshift, MySQL, MariaDB, Oracle, Microsoft SQL Server и Snowflake.
Редактор кода
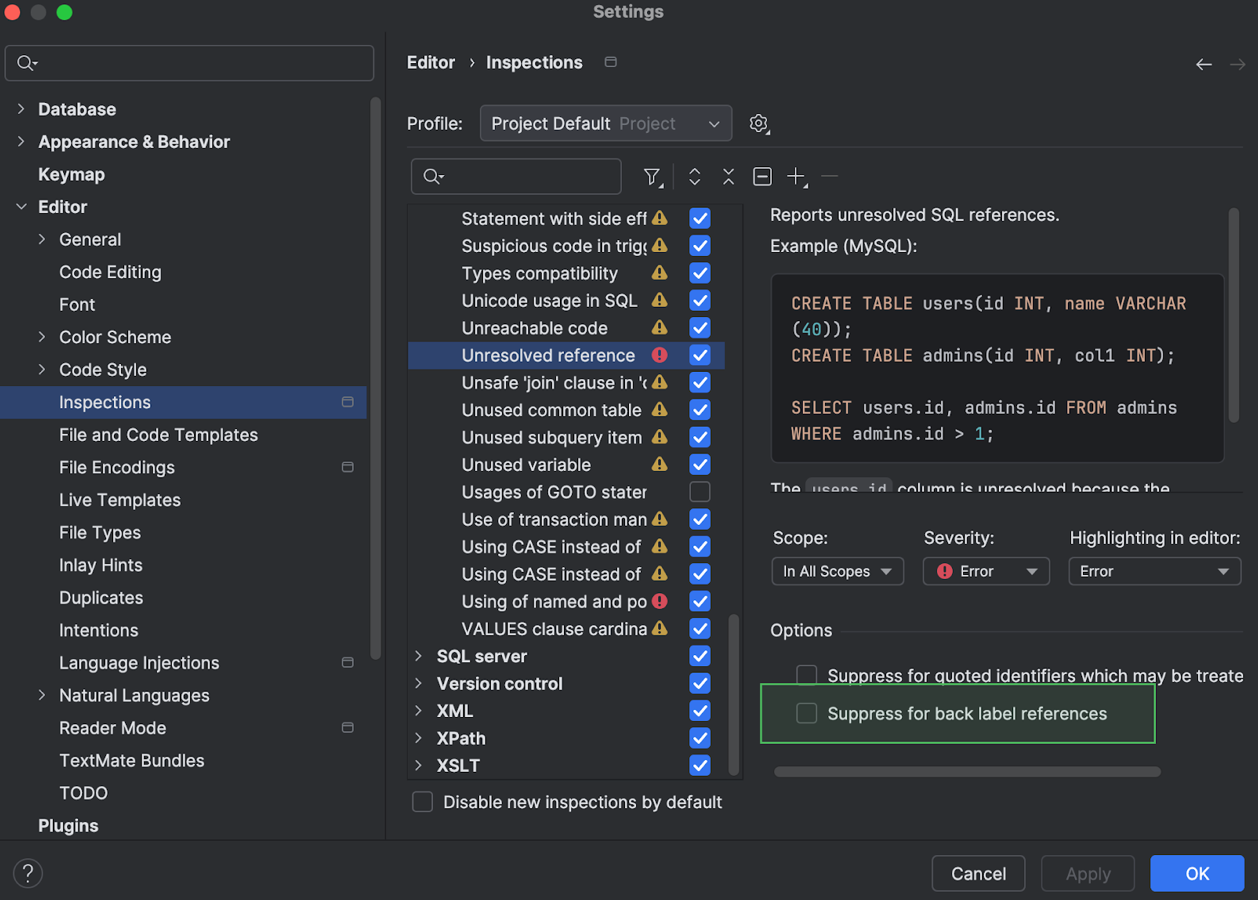
Контекстное действие для подавления проверки меток в конце цикла Oracle
Мы упростили доступ к опции Suppress for back label references. Раньше ее можно было найти только в диалоге Settings в разделе Editor | Inspections | SQL.
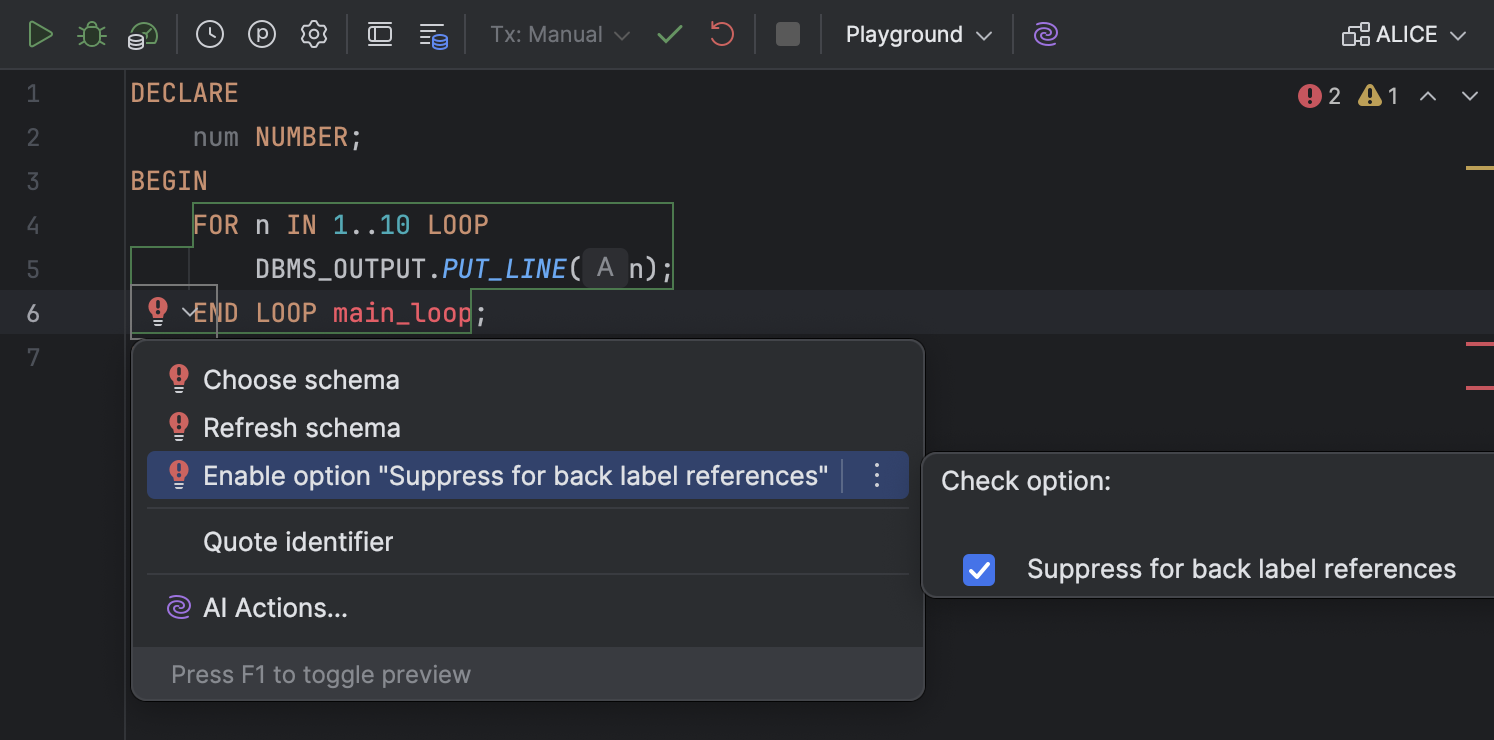
Теперь ее можно переключить прямо в меню контекстных действий. Чтобы включить или выключить ее, откройте список действий нажатием Alt+Enter (Windows/Linux) или Option+Enter (macOS), перейдите к пункту Enable option "Suppress for back label references" и установите либо снимите флажок.
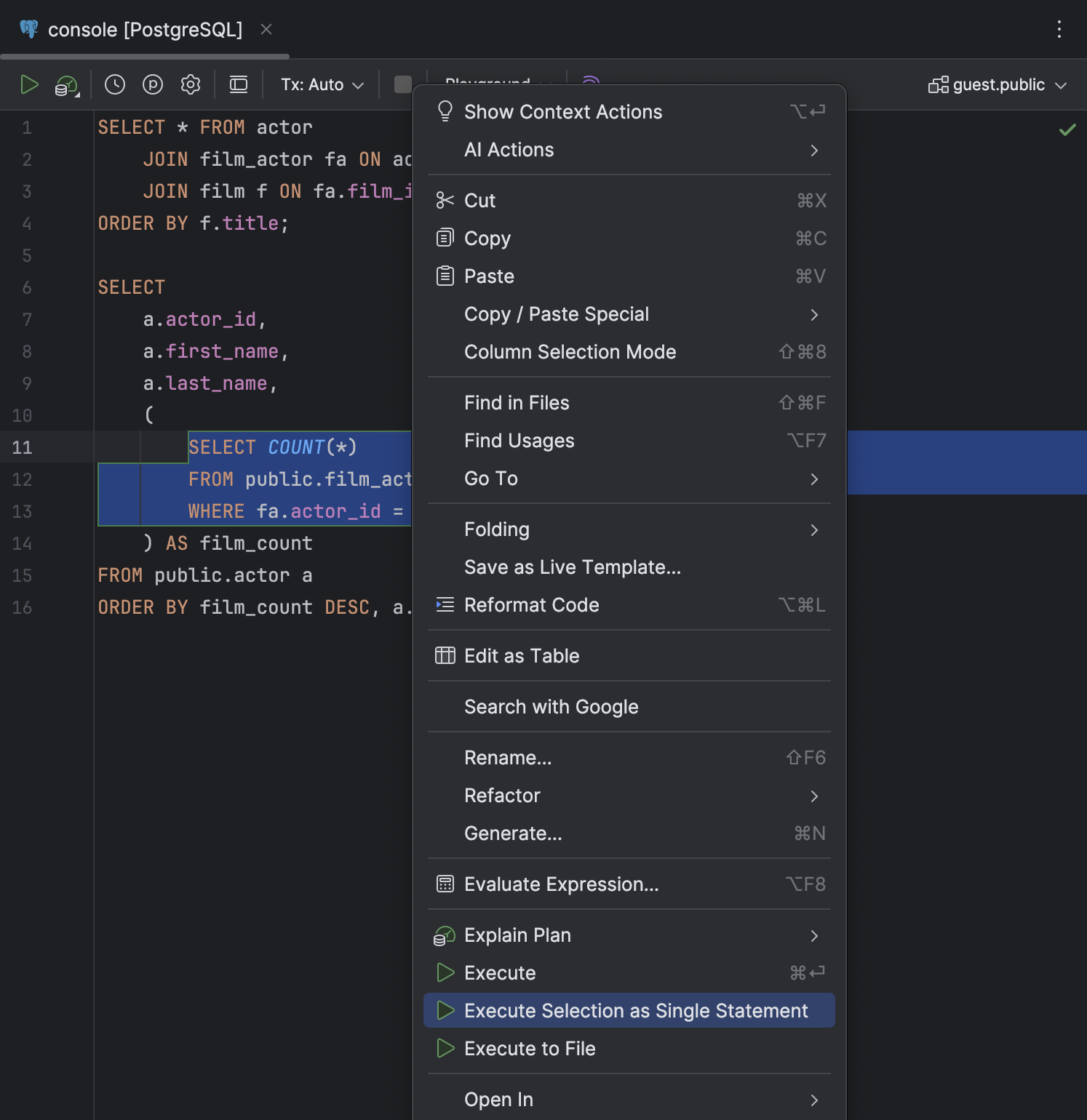
Действие Execute Selection as Single Statement в контекстном меню
Мы добавили действие Execute Selection as Single Statement в контекстное меню выделения кода. Это пригодится, если DataGrip некорректно распознает структуру кода, а вам нужно выполнить именно этот конкретный фрагмент.
Анимация движения курсора в редакторе
У курсора в редакторе кода появились два новых режима анимации, которые делают набор текста комфортнее.
Мы понимаем, что предпочтения у всех разные. Поэтому мы разработали собственный режим движения курсора — Snappy. Он дет плавную анимацию без ощущения медлительности, задержек и лишней визуальной нагрузки. В этом режиме курсор сначала быстро перемещается в новую позицию, затем немного замедляется и встает на место. В результате движение выглядит быстрым, но при этом плавным.
Во втором режиме, Gliding, курсор движется плавно, и за его перемещениями легко следить взглядом. Этот режим похож на то, что можно видеть в других популярных текстовых редакторах.
Чтобы попробовать новую анимацию, откройте окно Settings, перейдите в Editor | General | Appearance, включите опцию Use smooth caret movement и выберите нужный режим.
Работа с данными
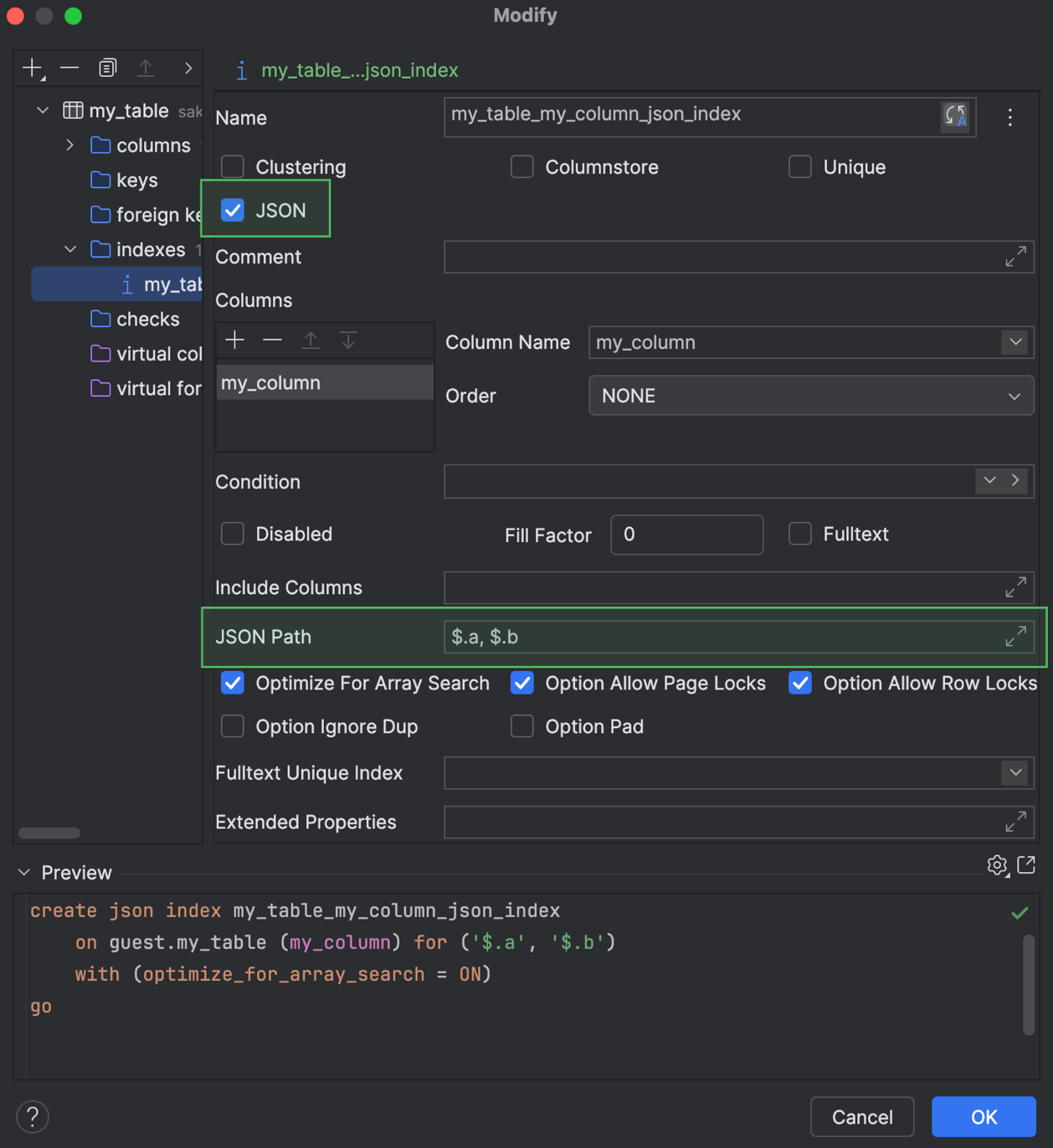
Поддержка индексов JSON Microsoft SQL Server
DataGrip теперь поддерживает создание и изменение JSON-индексов в Microsoft SQL Server. С ними можно работать при генерации кода, а также в диалогах Create и Modify.
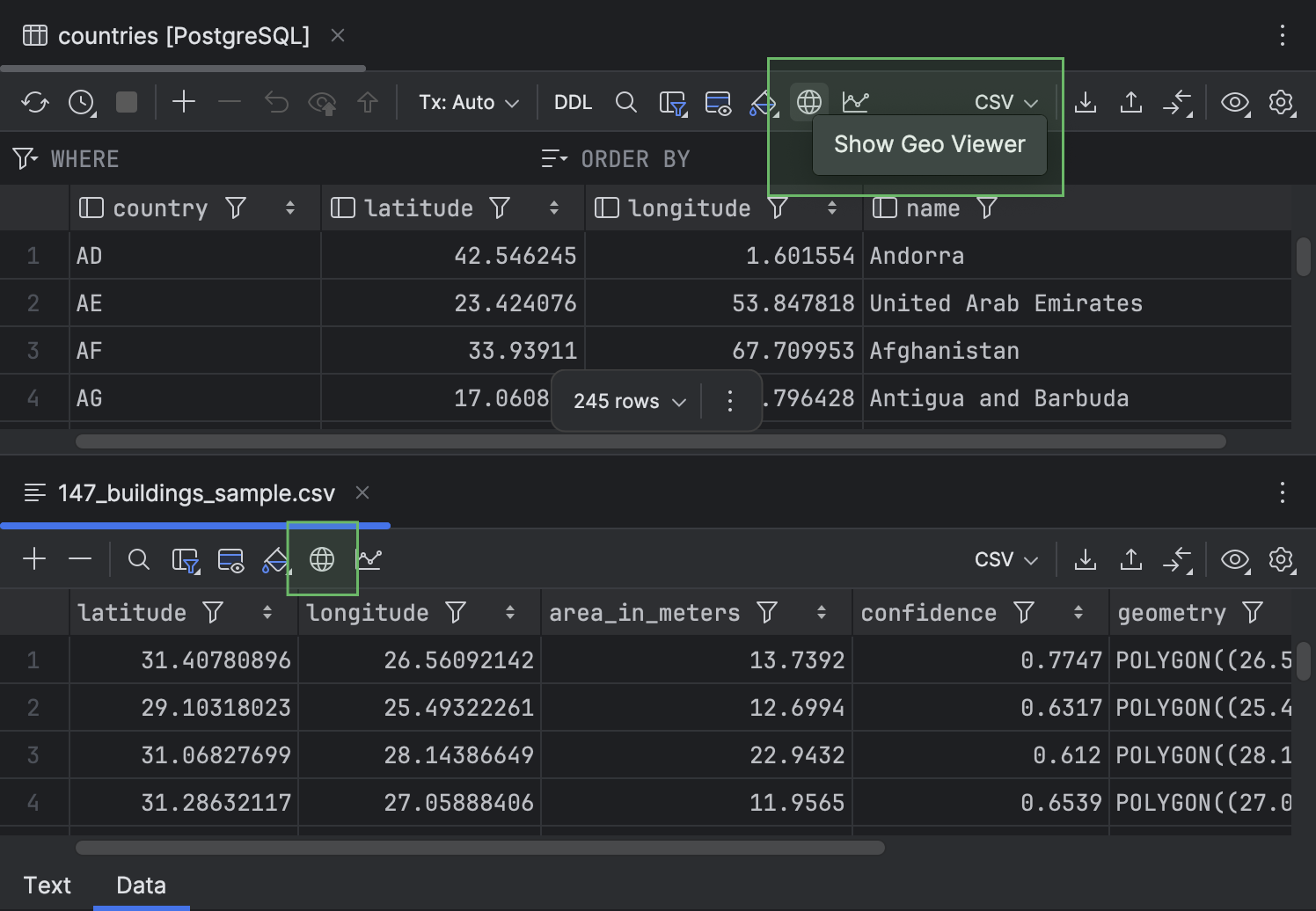
Кнопка Show Geo Viewer на панели инструментов
Чтобы кнопку Show Geo Viewer было проще найти, мы перенесли ее на панель инструментов редактора данных.
Работа с файлами
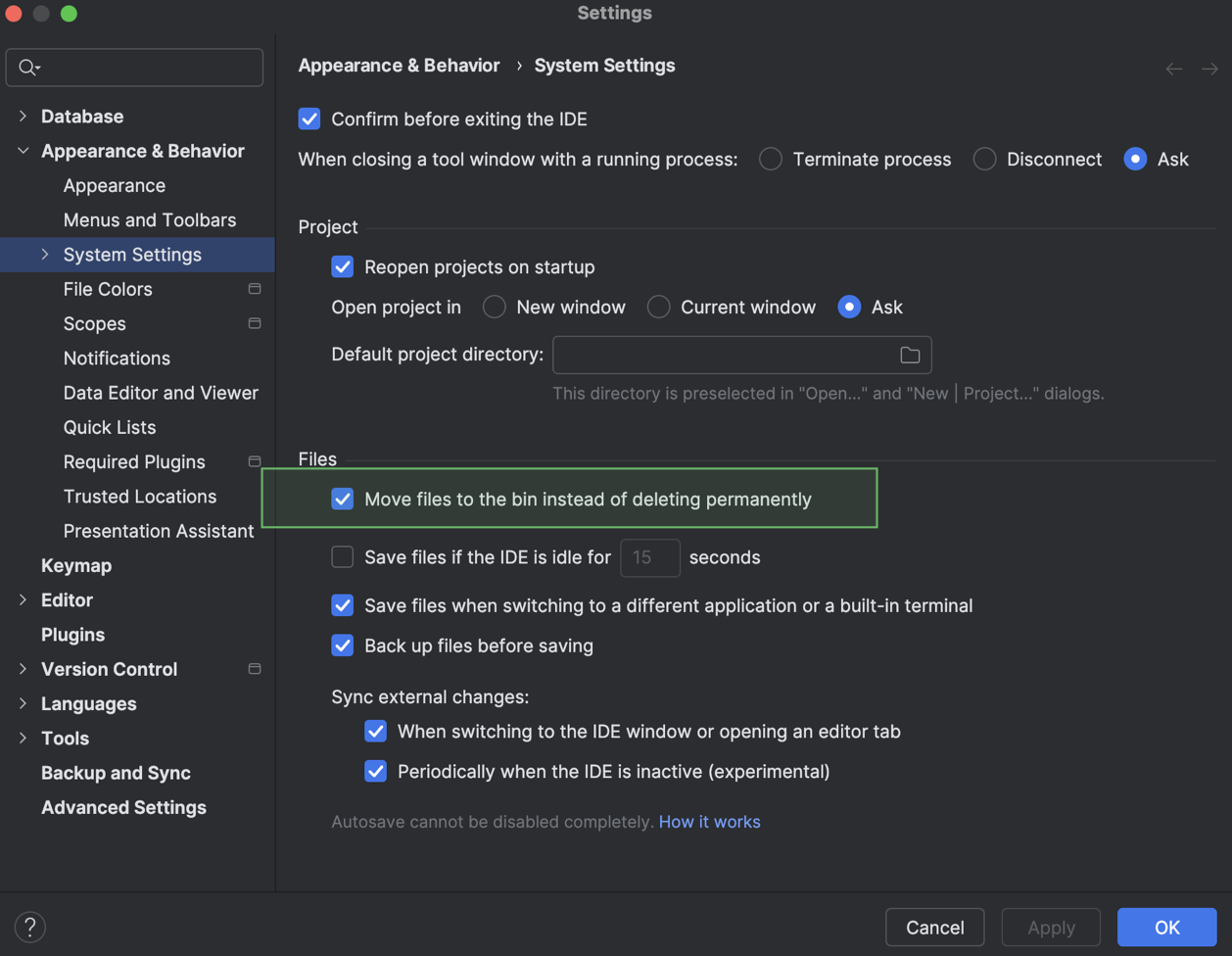
Удаленные файлы по умолчанию отправляются в корзину
Раньше действие Delete удаляло файлы безвозвратно вместо того, чтобы перемещать их в корзину. Теперь появилась настройка, которая отправляет файлы в корзину. Она называется Move files to the bin instead of deleting permanently и по умолчанию включена.
Изменить настройку можно в меню Settings | Appearance & Behavior | System Settings.
Надеемся, эти нововведения вам понравятся. Если вы нашли ошибку или хотите предложить улучшение, напишите в наш баг-трекер.
Хотите быть в курсе новых возможностей и получать советы, которые помогут продуктивнее работать с базами данных? Подписывайтесь на блог DataGrip и следите за нами в X!