What's New in DataGrip 2021.2
DataGrip 2021.2 is here! This is the second major update of 2021, and it’s packed with various enhancements. Let’s take a look at what it has to offer!
DDL data source
DDL data source generation is another step in our long-term development of seamless database versioning. With this feature, you can keep your DDL files under a VCS system and regenerate them every time your database structure is updated.
It is now possible to generate a DDL data source based on a real one. The DDL files are created locally and the new data source is based on them. This way you’ll always be able to regenerate these files and refresh the DDL data source.
Let’s take a look at how this works.
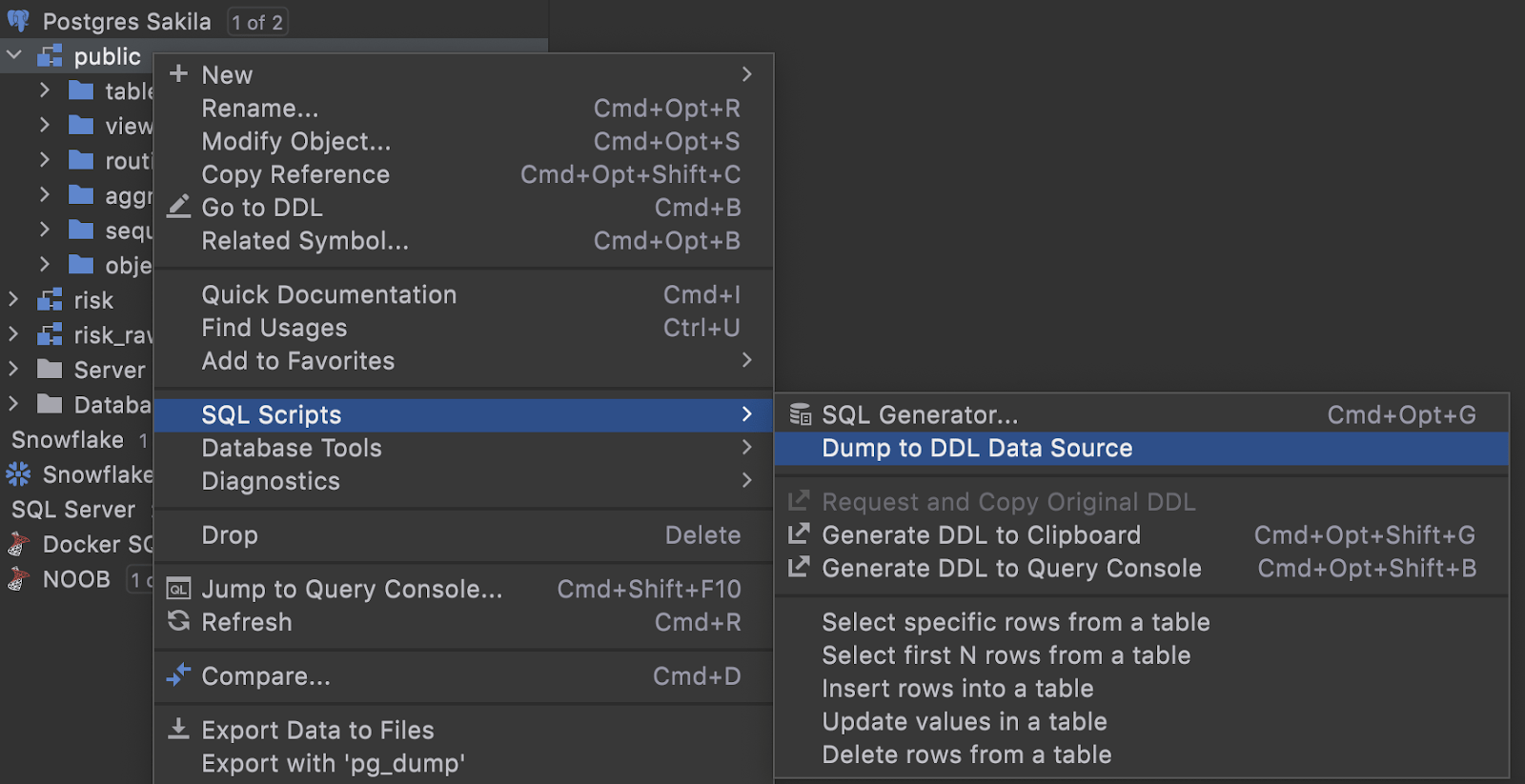
We’ve added a new menu item, Dump to DDL data source, to the SQL Scripts context menu.
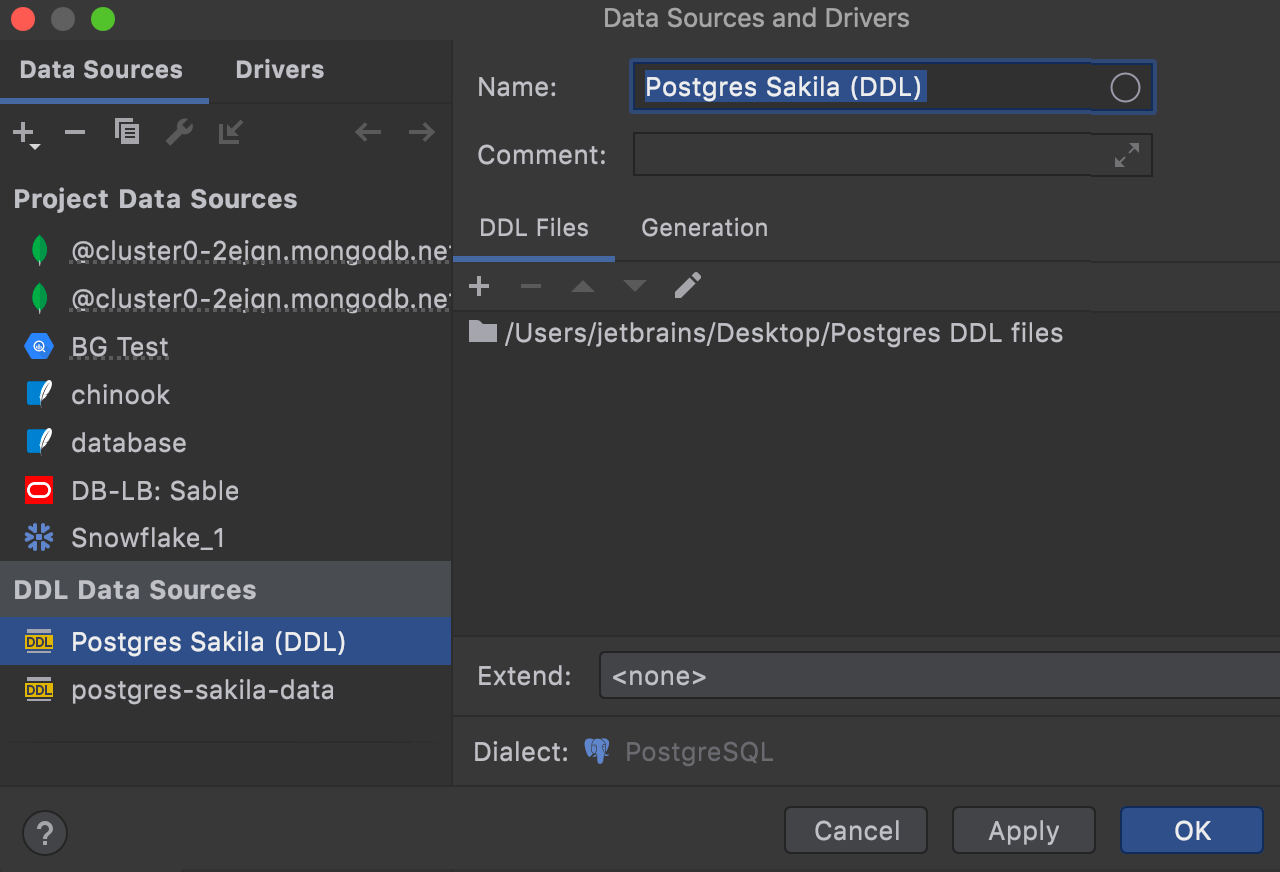
When the dialog opens, you need to specify the folder where the newly created files will be stored.
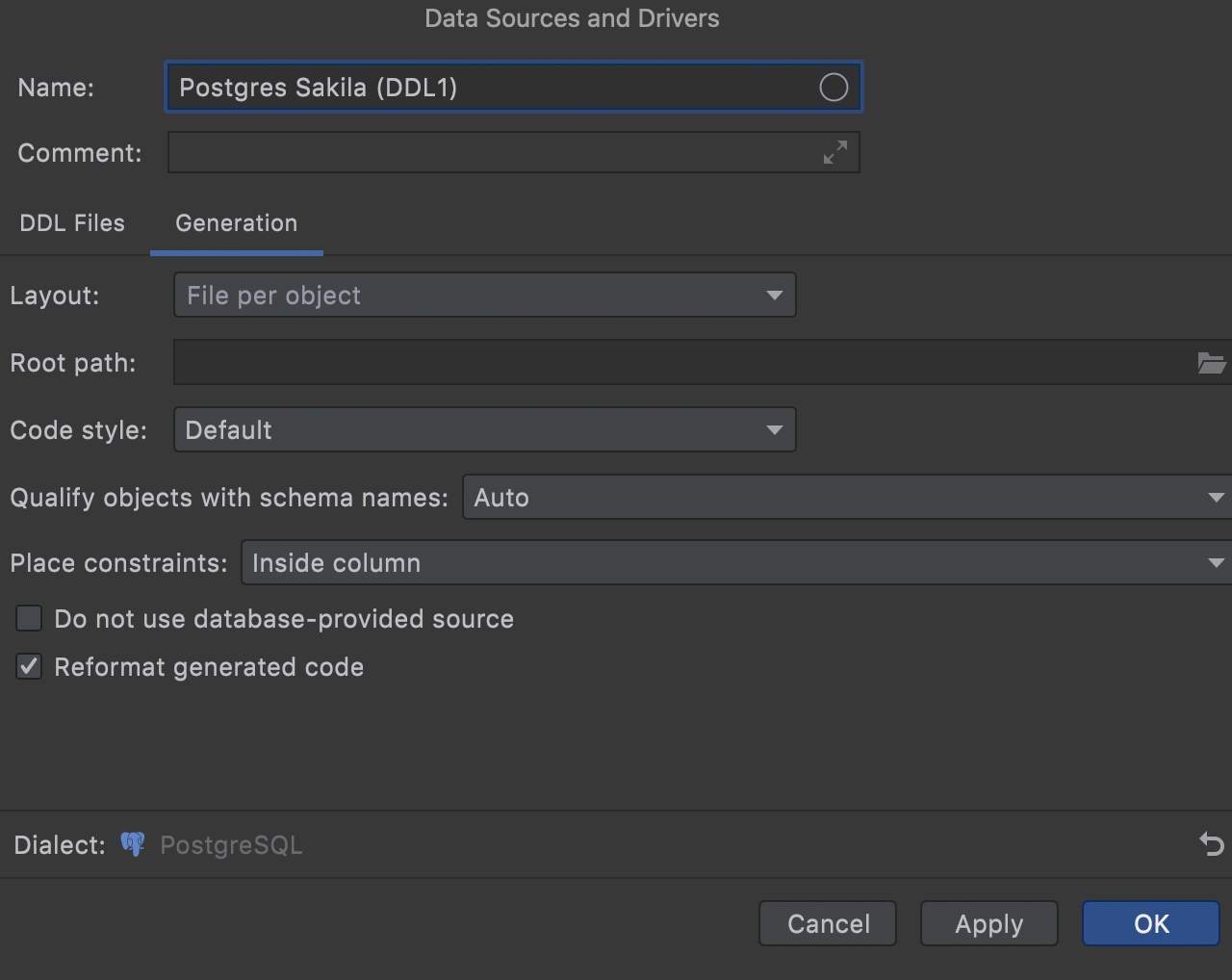
On the Generation tab, specify how these DDL files should be generated.
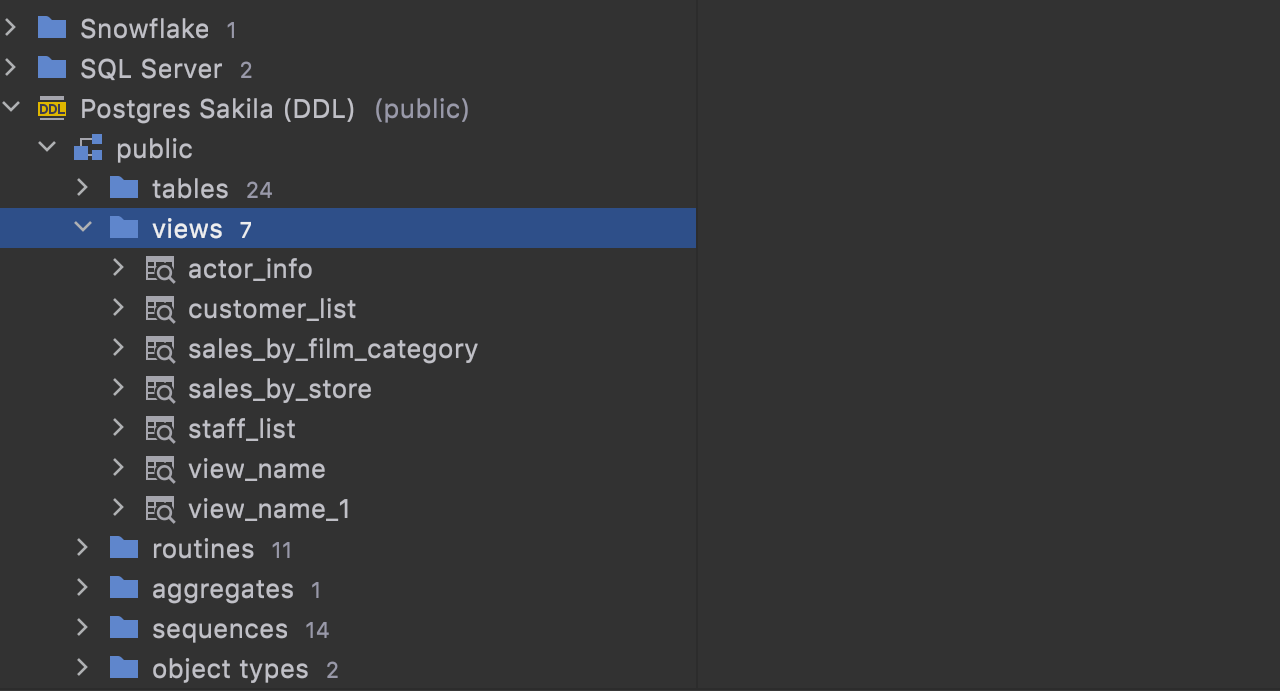
Finally, click OK to create the DDL data source.
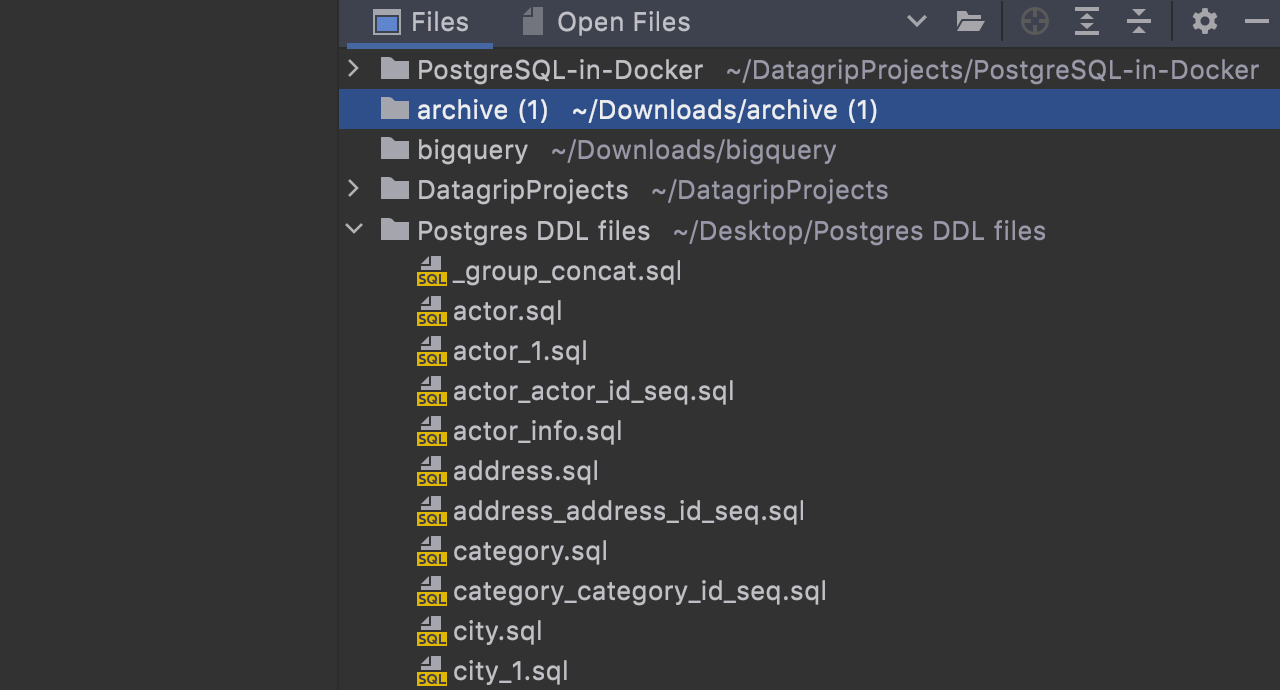
The folder with the new files is automatically attached to your project.
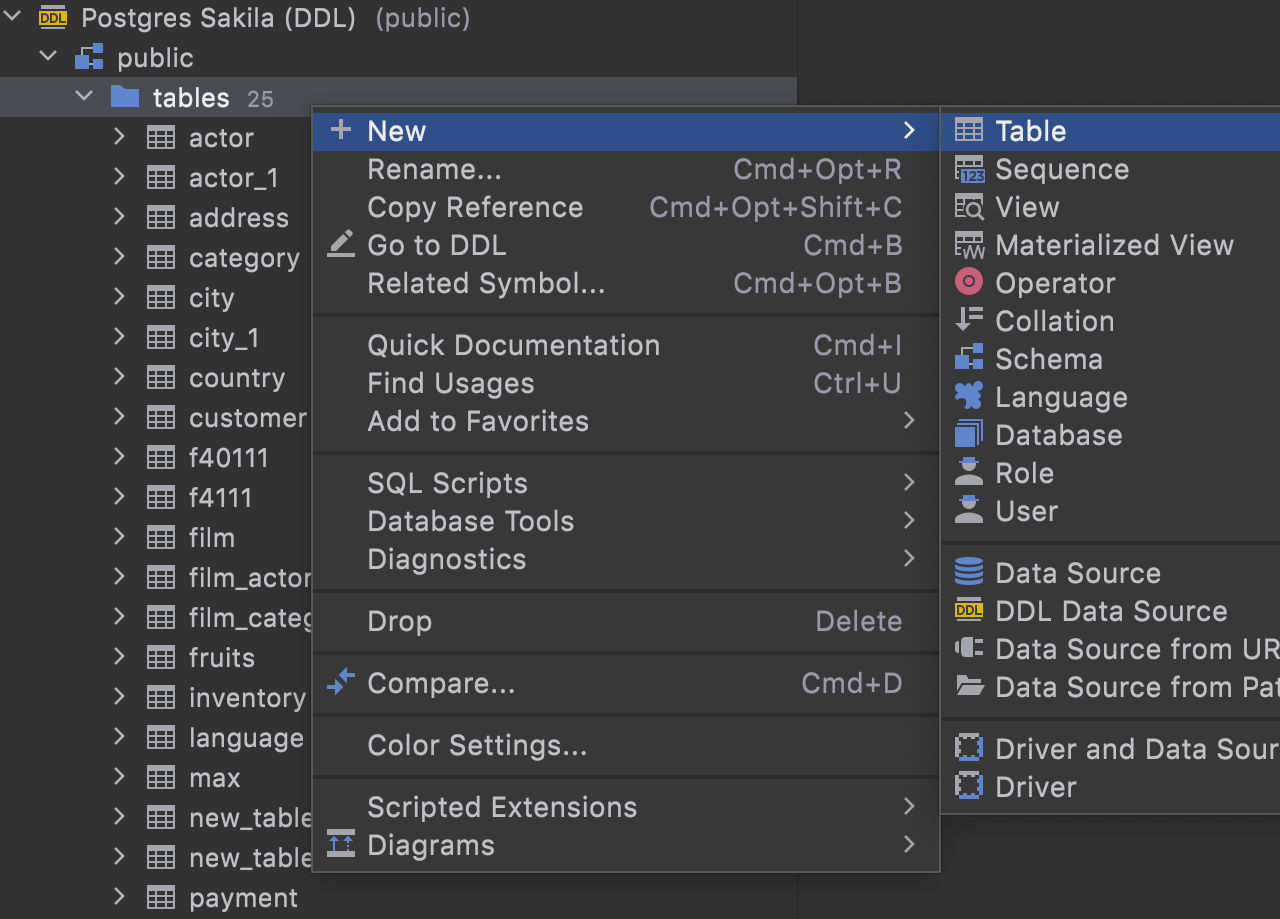
Creating objects
In v2021.2, you can create objects in a DDL data source via the UI. The corresponding files will be created locally.
Diagrams
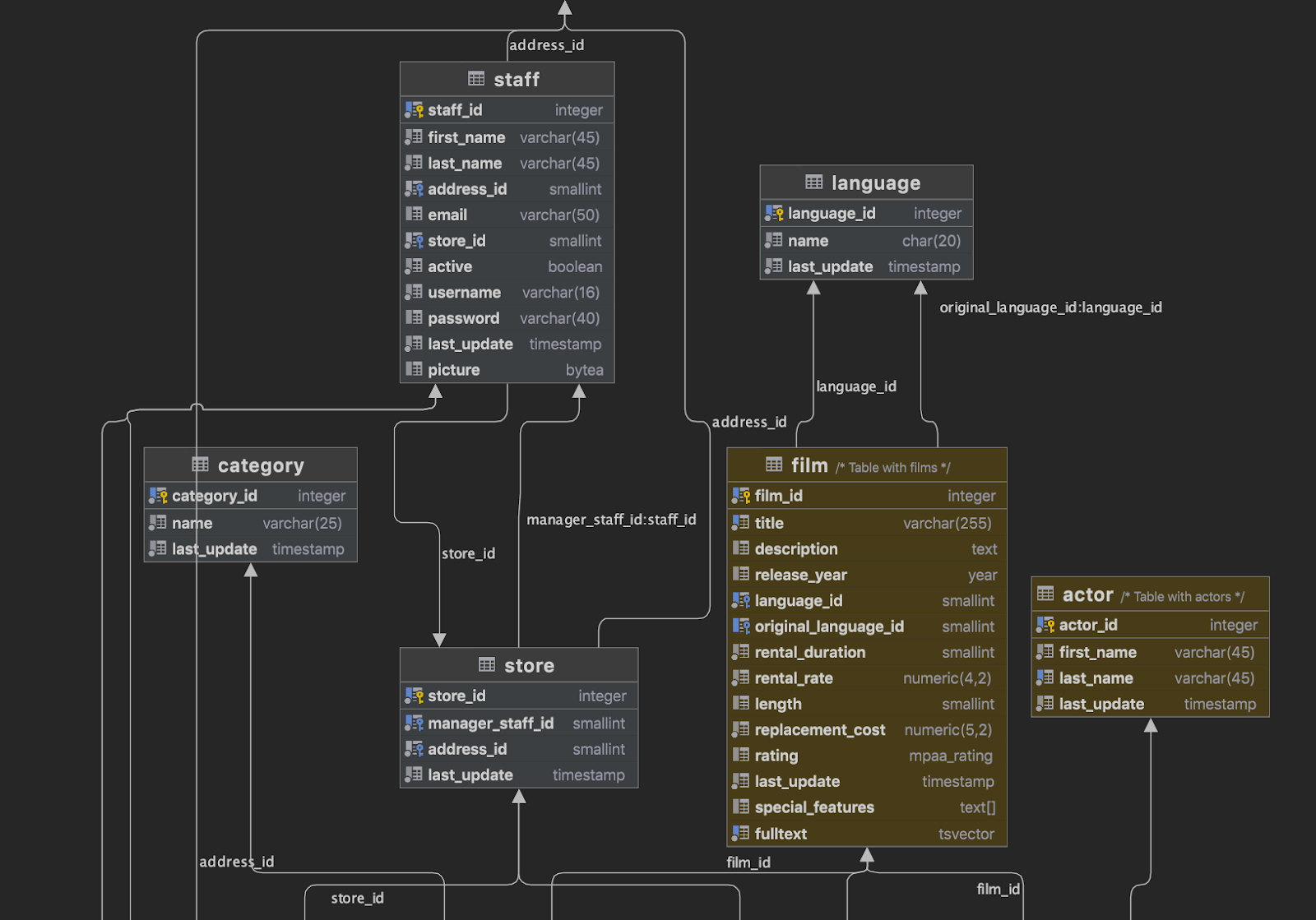
The following important features have been added to diagrams:
- Table comments are now visible
- Table colors are displayed on the diagram
- You can turn off edge merges
Code editor
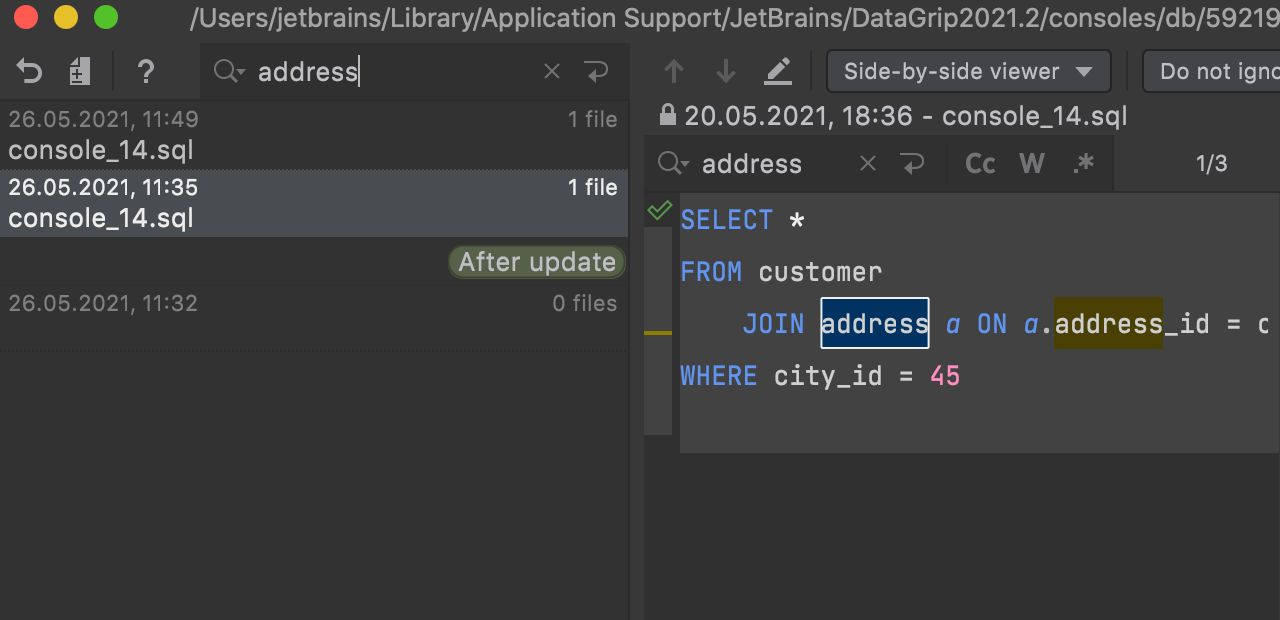
Search in Local History
If you are looking for a particular revision in Local History, you can use text search for help!
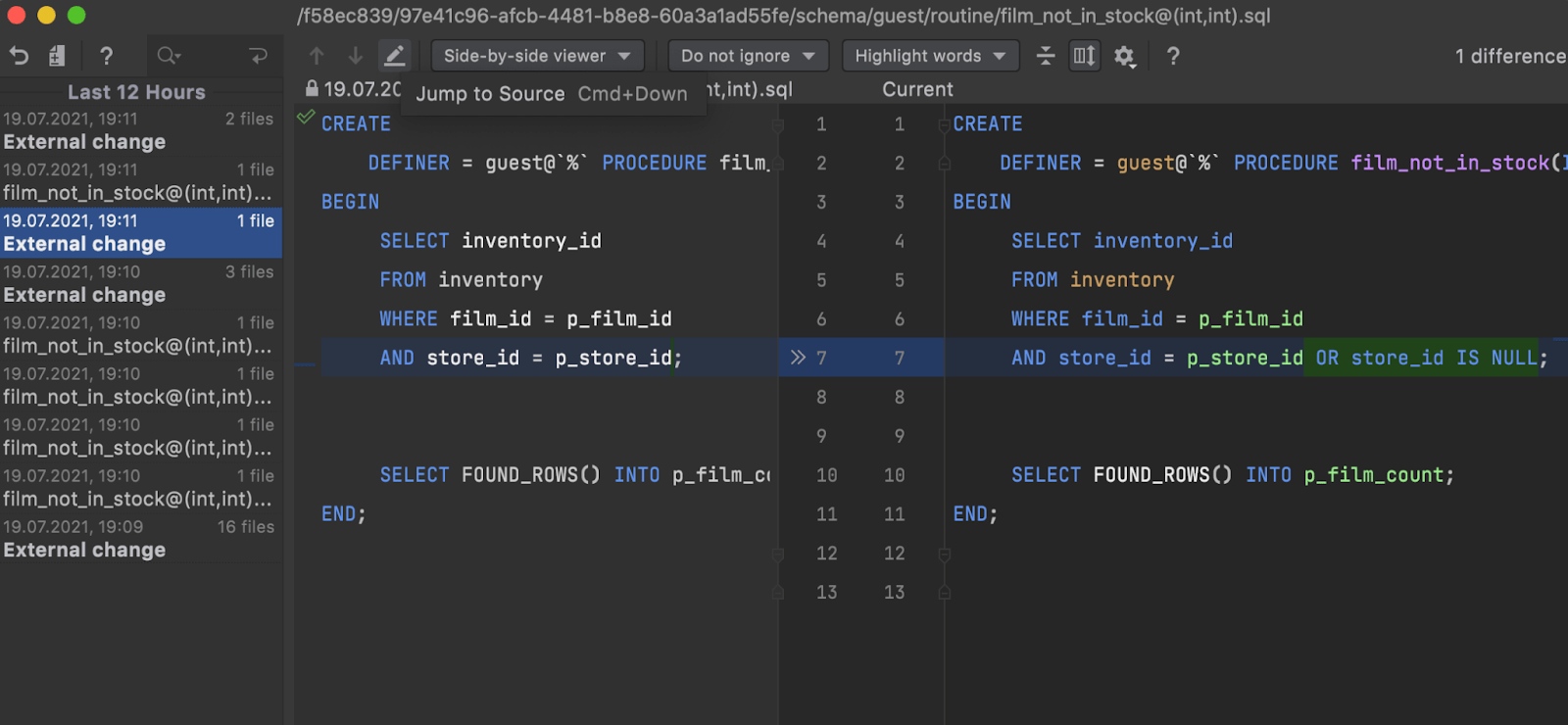
Local History for sources
DataGrip now tracks local changes for object source codes. It can be especially useful when working with procedures and functions.
Since every object's sources are stored in a file, all external changes are also considered as local changes. When you introspect your database, this file is refreshed.
You can use the Local History popup to keep track of any changes to a function or procedure. Note that all external changes are considered as one change if they happened within two runs of the introspection.
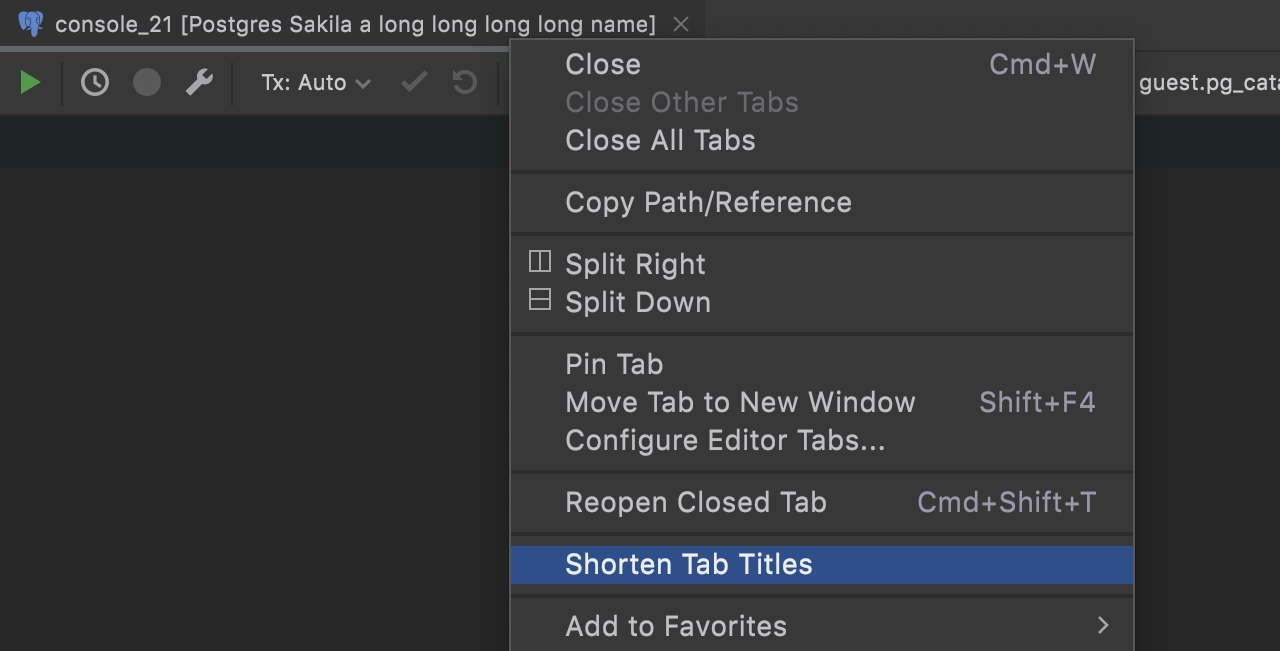
Long tab names are back
After receiving some feedback from users who didn’t like the shortened tab names, we introduced the option to change them back. If you prefer long tab names, uncheck the Shorten Tab Titles option.
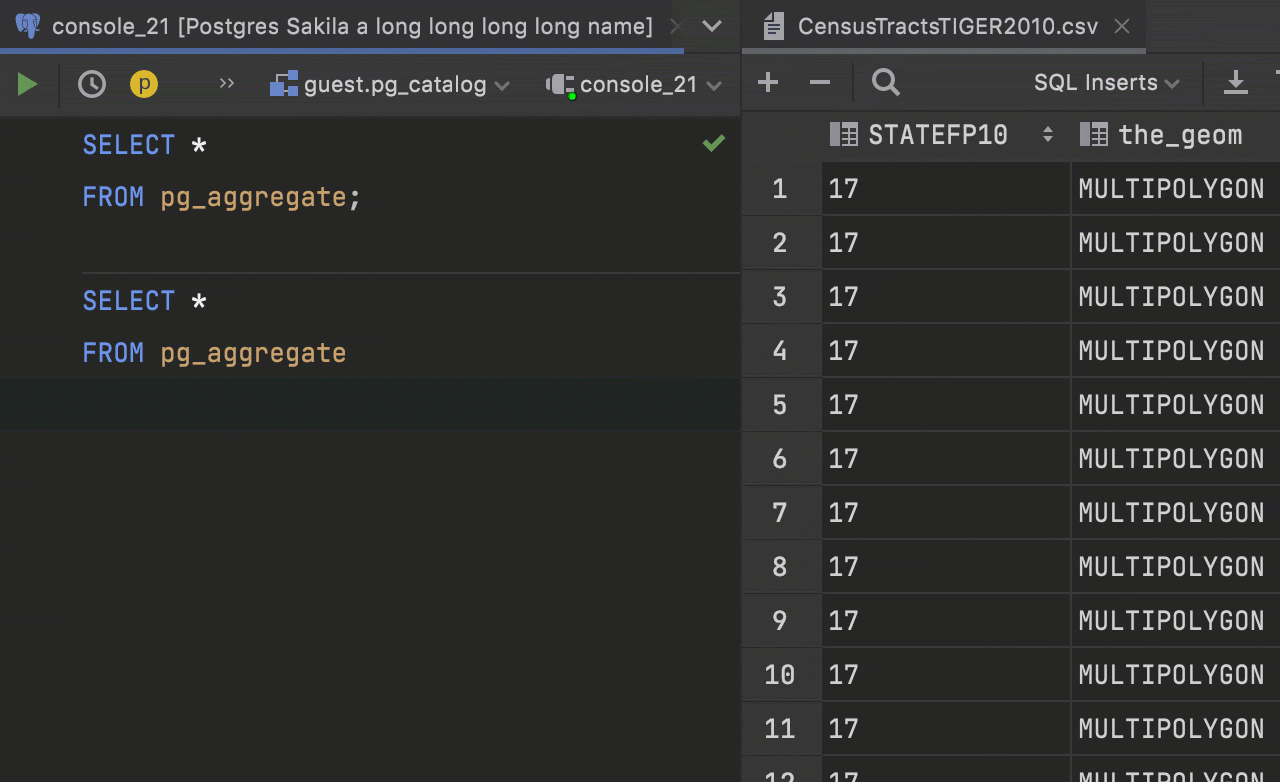
Maximize Editor / Normalize Splits action
For a long time we had the Hide All Tool Windows action, which could be called by double clicking on a tab or pressing Shift+Ctrl+F12. Many users treated it as a Maximize Editor action and it worked as such!
After we introduced the split mechanism, the situation became more complicated. Should this action hide the split tabs or not? So we did the following:
- The Hide All Tool Windows action no longer hides the split tabs.
- The new Maximize Editor / Normalize Splits action maximizes the current tab, but doesn’t hide the tool windows.
Code completion
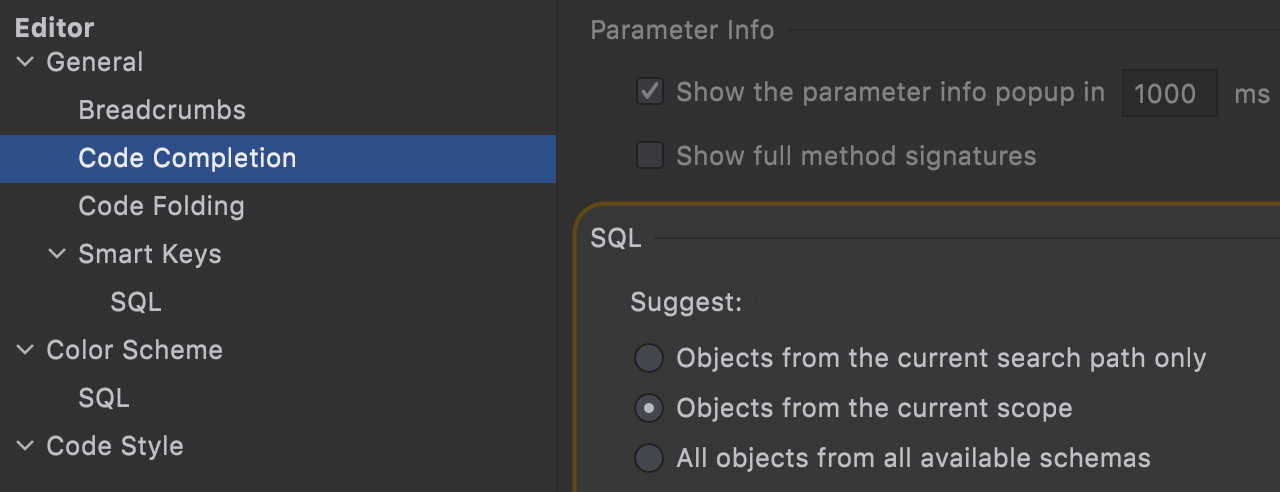
Completion scope
Now it's possible to define which objects should be presented in the code completion list: objects only from the schema switcher (or the search path), from the current scope, or from all schemas.
- Suggest only search path objects: only objects from the schemas chosen in the schema switcher are suggested.
- Suggest objects from current scope (default setting): the list will be populated with the objects DataGrip can correctly resolve without qualification – the set of objects from the schema switcher, USE statements, and the default schema.
- Suggest objects from all available schemas: the list will contain all objects from all available schemas.
This can be also managed by smart completion. Smart completion is invoked when you press the completion hotkey (usually Ctrl+Space) several times.
- Pressed once or invoked automatically: as described above.
- Pressed twice: all schemas except those turned off for the introspection.
- Pressed three times: objects from all available schemas and databases.
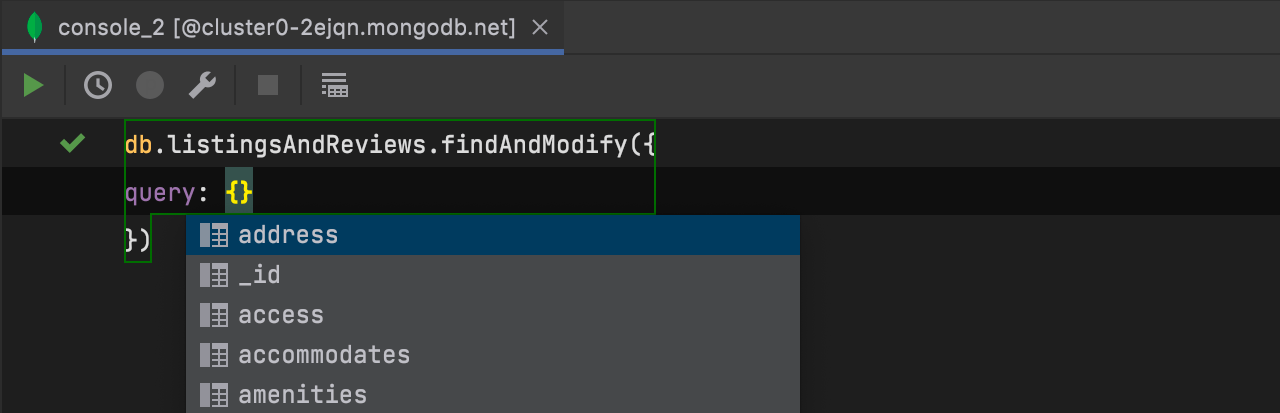
Completion of fields and operators MongoDB
Fields and operators are now available in code completion for MongoDB. Read this post for more details.
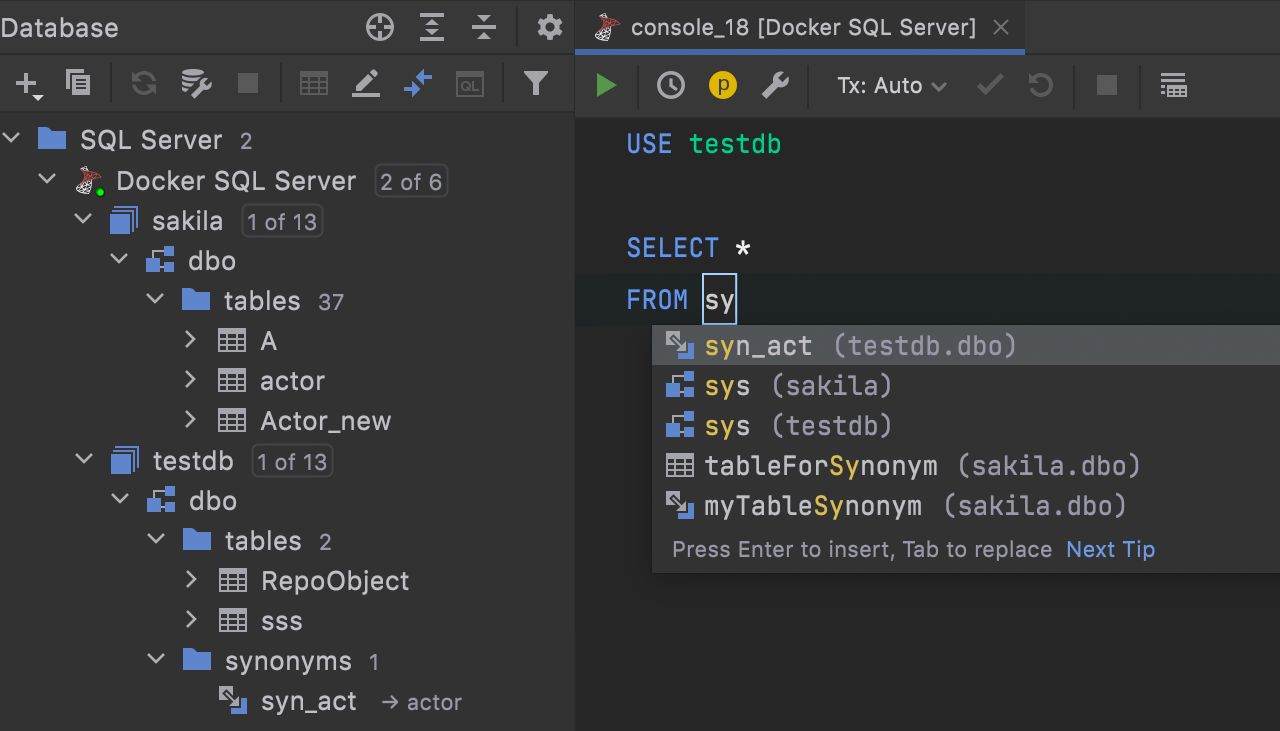
Completion for cross-database synonyms SQL Server
Code completion for cross-database synonyms is now available.
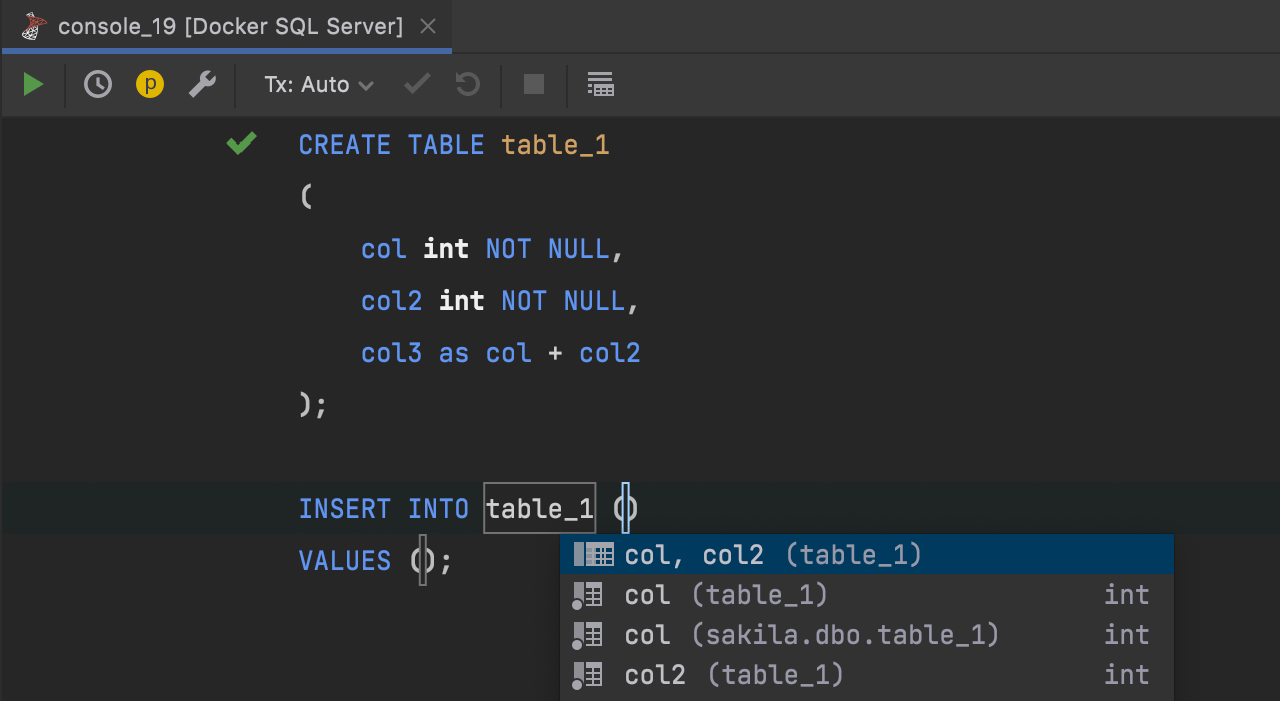
INSERT completion and computed columns
Computed columns are taken into account when completing INSERT
statements – they are not included in the suggested item.
Quality improvements
DBE-10515, DBE-2212: Objects from the schema of the current context have higher priority in the code completion list.
DBE-7781, DBE-10650: The automatic alias appears only when needed.
DBE-12018:
Table qualification in JOIN completion works as expected.
DBE-12479:
The priority of ASC/DESC inside an ORDER BY clause has
been increased.
DBE-13341:
PostgreSQL
Completion in GRANT/REVOKE statements works as expected.
Code highlighting
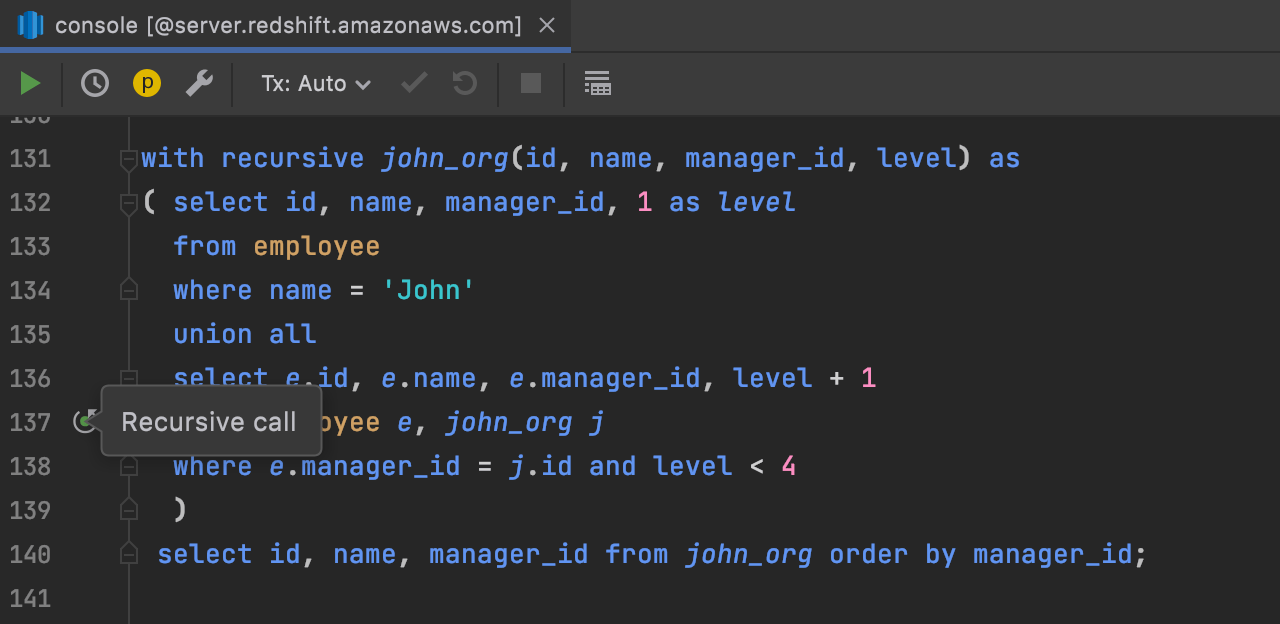
Support for recursive CTE Redshift
Queries that use recursive common table expressions are now properly highlighted and can be run without being selected.
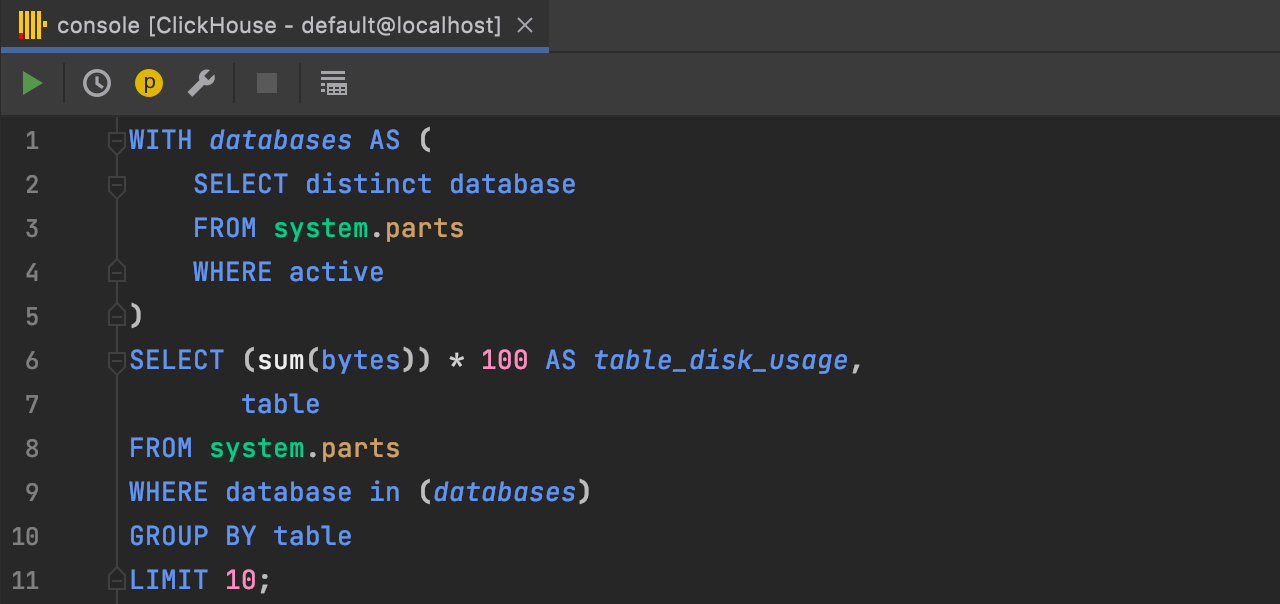
Better CTE support ClickHouse
The common table expressions syntax, when the CTE name goes before the AS
keyword, is now supported.
Quality improvements
DBE-3759, DBE-13364, DBE-13365: Inspections for aggregates work more precisely.
DBE-10782:
ClickHouse
No more false-positive alerts from the inspection that reports not-null arguments
in COALESCE.
DBE-13188: Oracle PL/SQL record type fields are resolved correctly.
DBE-10550: DB2 Table aliases are resolved correctly.
Database explorer
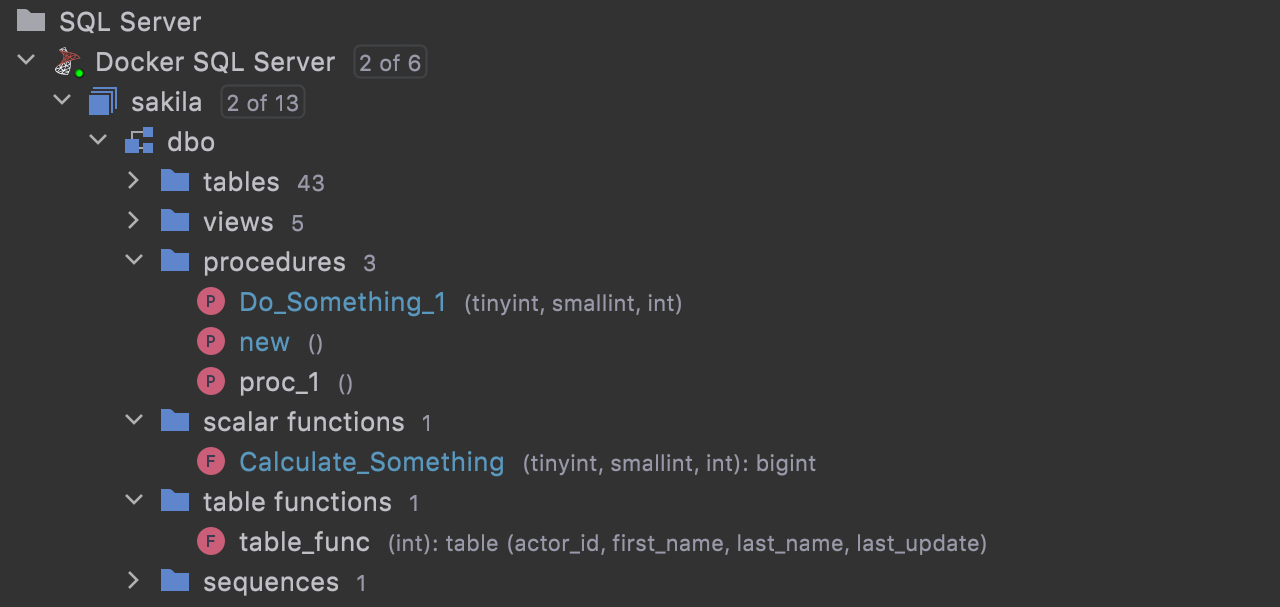
Separate folders for functions and procedures
If you turn on the Separate Procedures and Function option in the database explorer settings (the gear icon), it will immediately take effect.
For SQL Server there are dedicated nodes for scalar and table functions. For PostgreSQL there is a node for trigger functions.
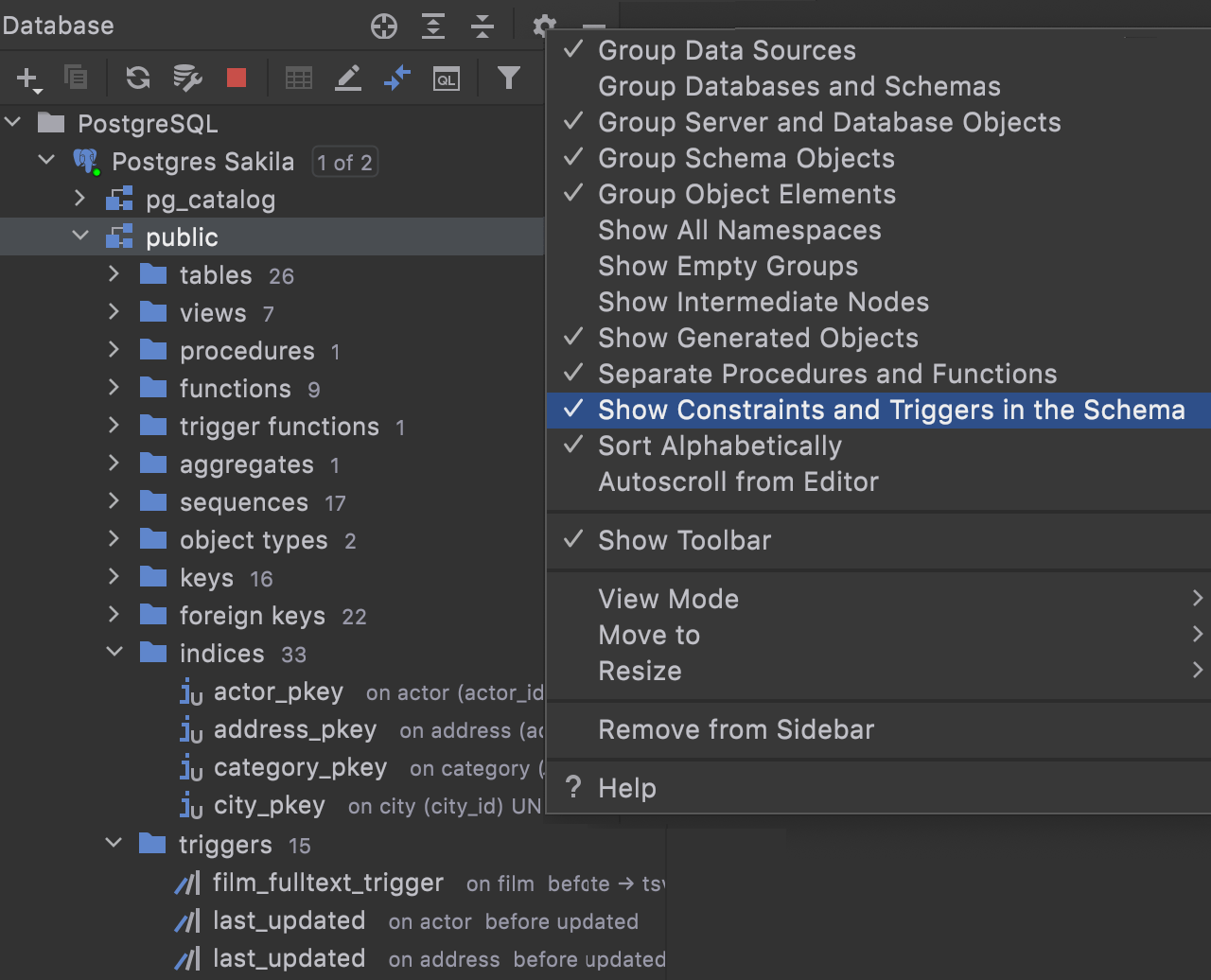
Separate nodes for triggers, keys, and indices
A new database tree option, Show Constraints and Triggers in the Schema, assigns triggers, keys, and indices their own individual nodes in the database explorer.
Why is this useful?
- You can find an object inside one schema by using quick search.
- You can see the columns just under the table node. To do this, make sure the Show Empty Groups option is turned off.
Natural sort order for database objects
If you turn off the Sort Alphabetically option in the database explorer settings, natural sorting for objects will be applied.
Here’s what it looks like when Sort Alphabetically is off:
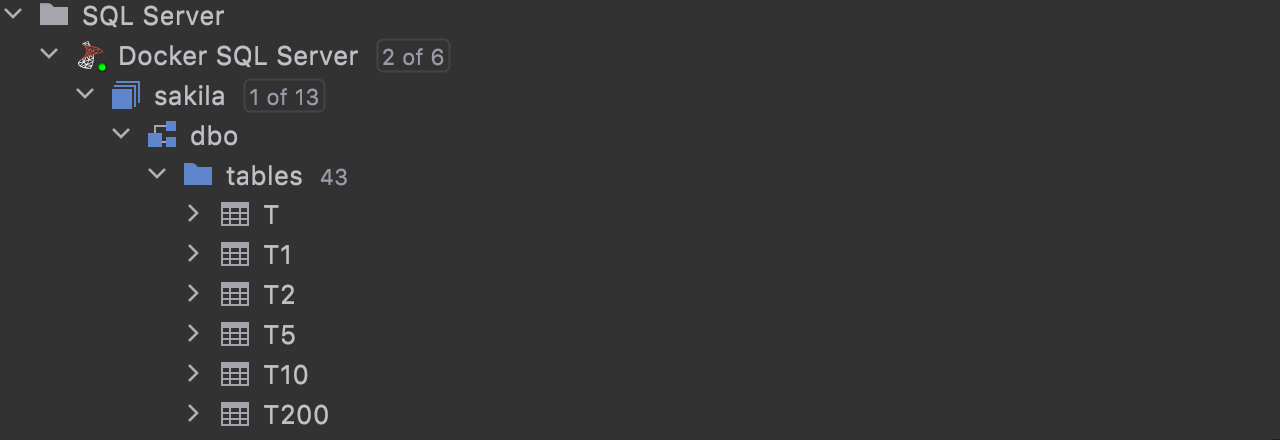
Here’s what it looks like when Sort Alphabetically is off:
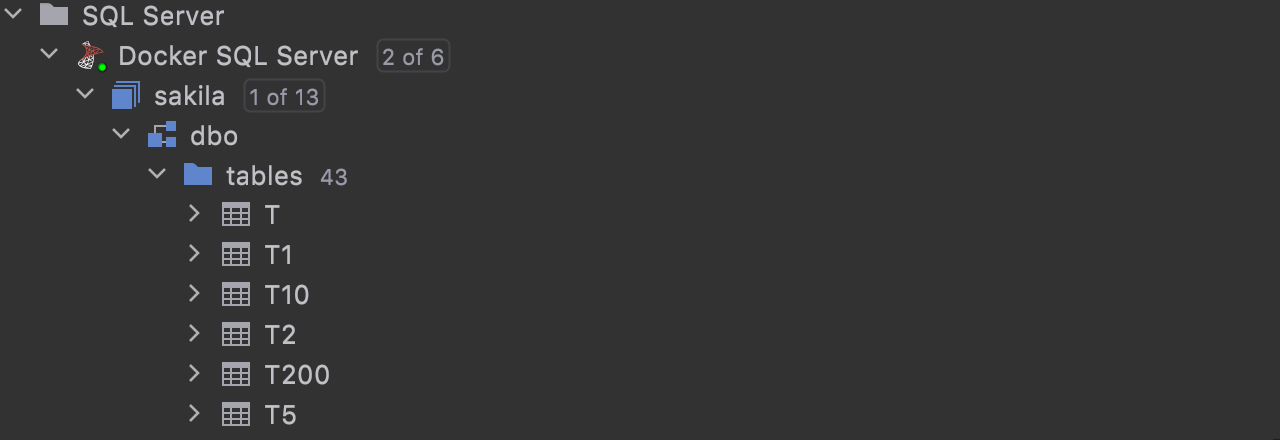
...and when Sort Alphabetically is on:
Introspection
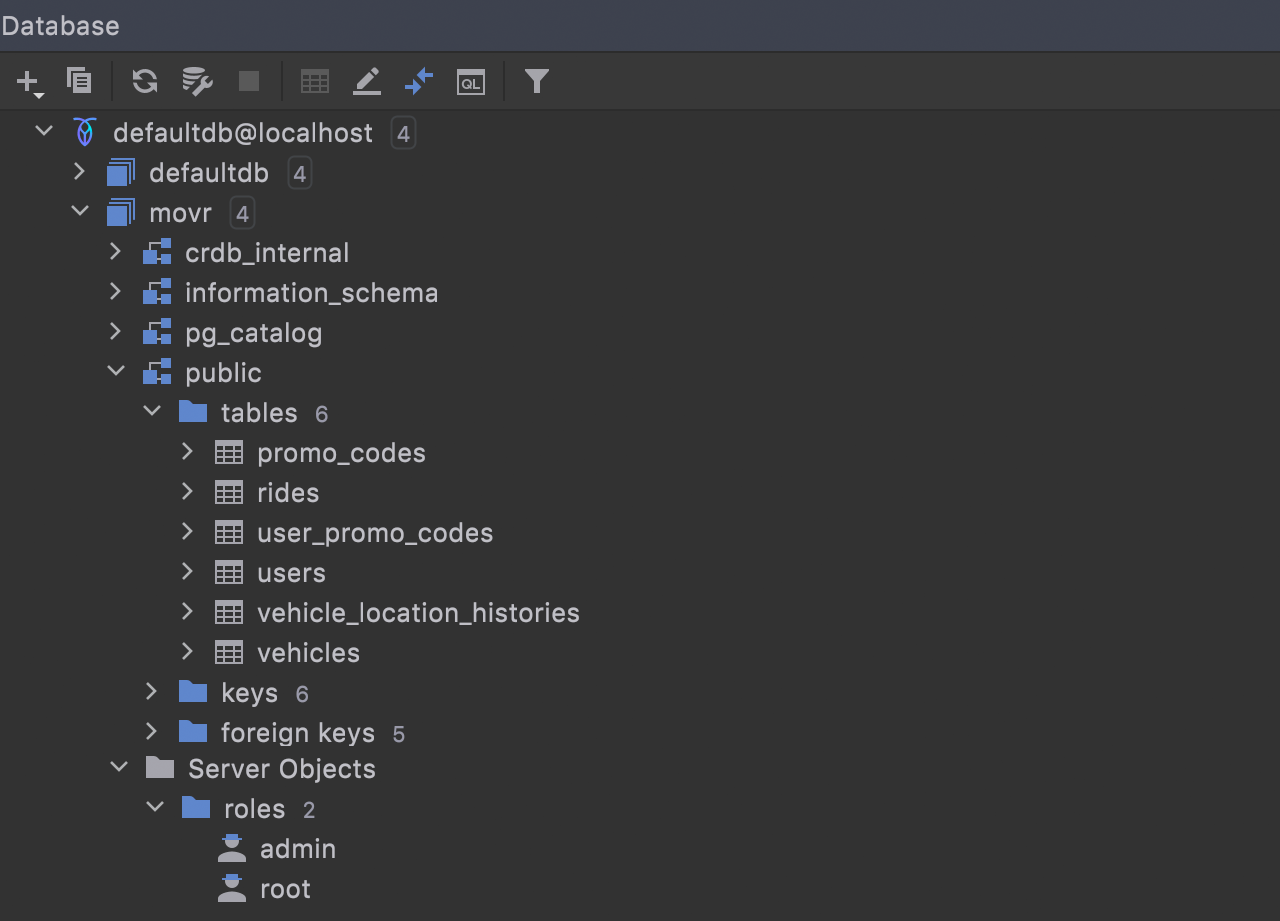
Native introspection CockroachDB
CockroachDB will be fully supported in this release. DataGrip will no longer rely on JDBC-based introspection, but use the native one instead.
This is much faster than JDBC-based introspection. Also, role, deftype, and check constraint could not be introspected at all in the previous version. The full list of objects that are now introspected includes database, role, privilege, schema, sequence, deftype, table, view, mat view, index, column, and constraints. That partitions are not introspected yet is a known issue.
Virtual foreign keys for pg_catalog PostgreSQL
Some time ago, we announced a mechanism for creating virtual foreign keys. Now we’ve used this mechanism to cover pg_catalog with virtual foreign keys. This brings a couple of improvements.
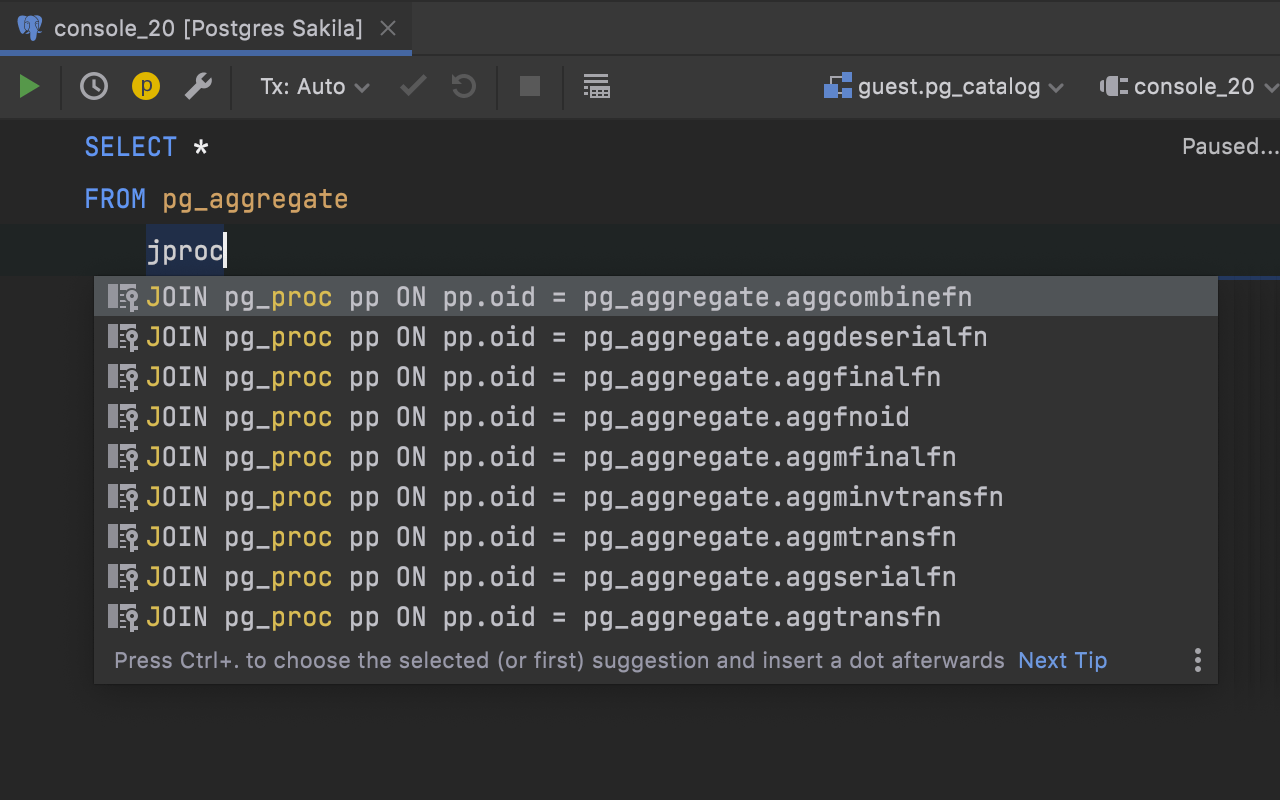
First, JOIN completion helps you when querying system tables:
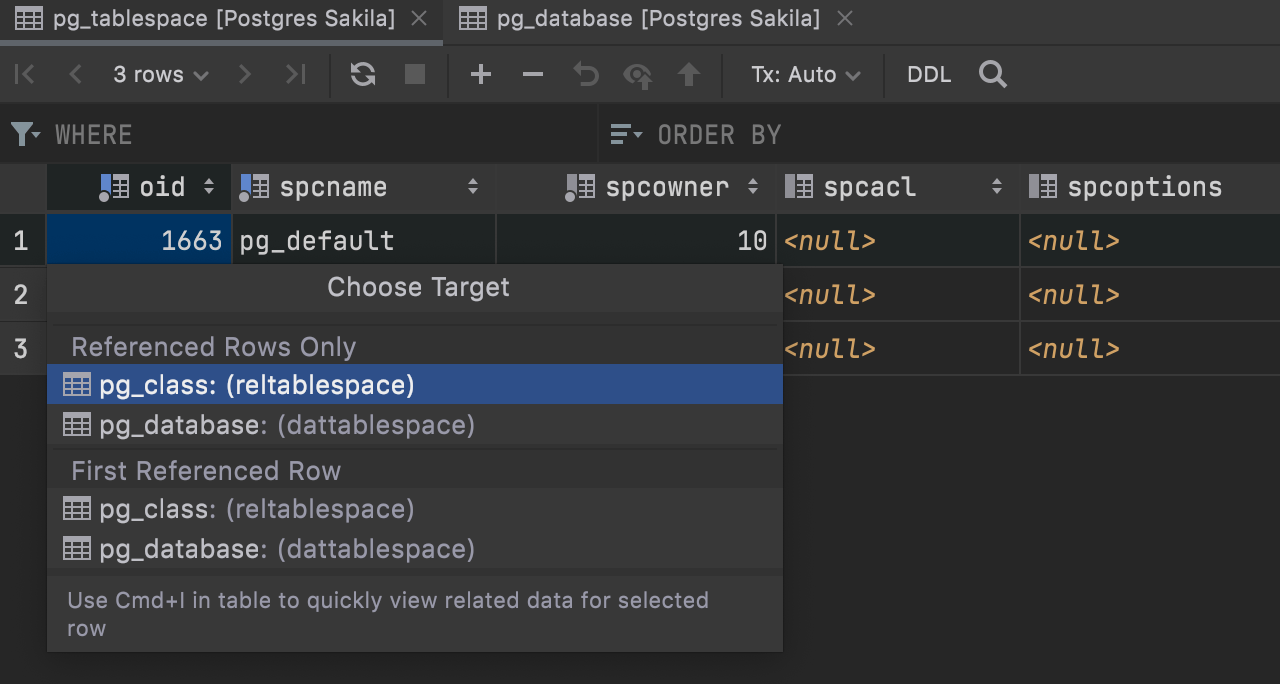
Second, you can navigate by data in system tables:
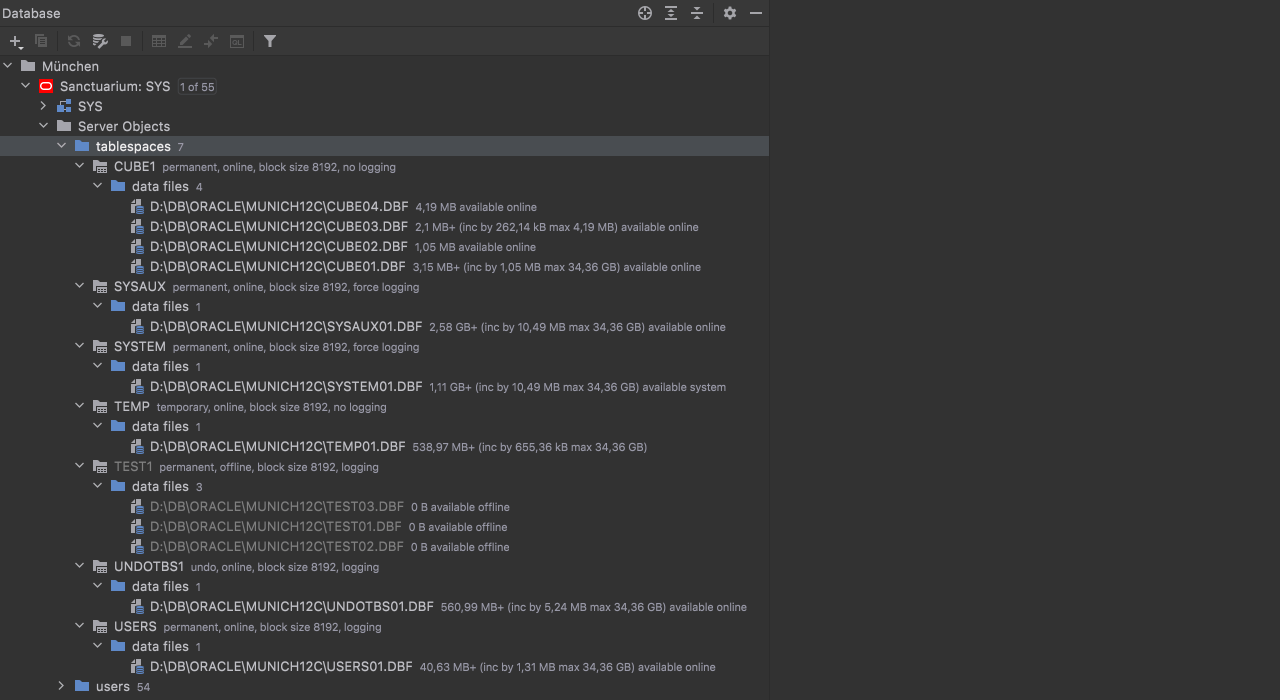
Tablespaces Oracle
We added support for tablespaces, data files, and temporary files. They are now introspected:
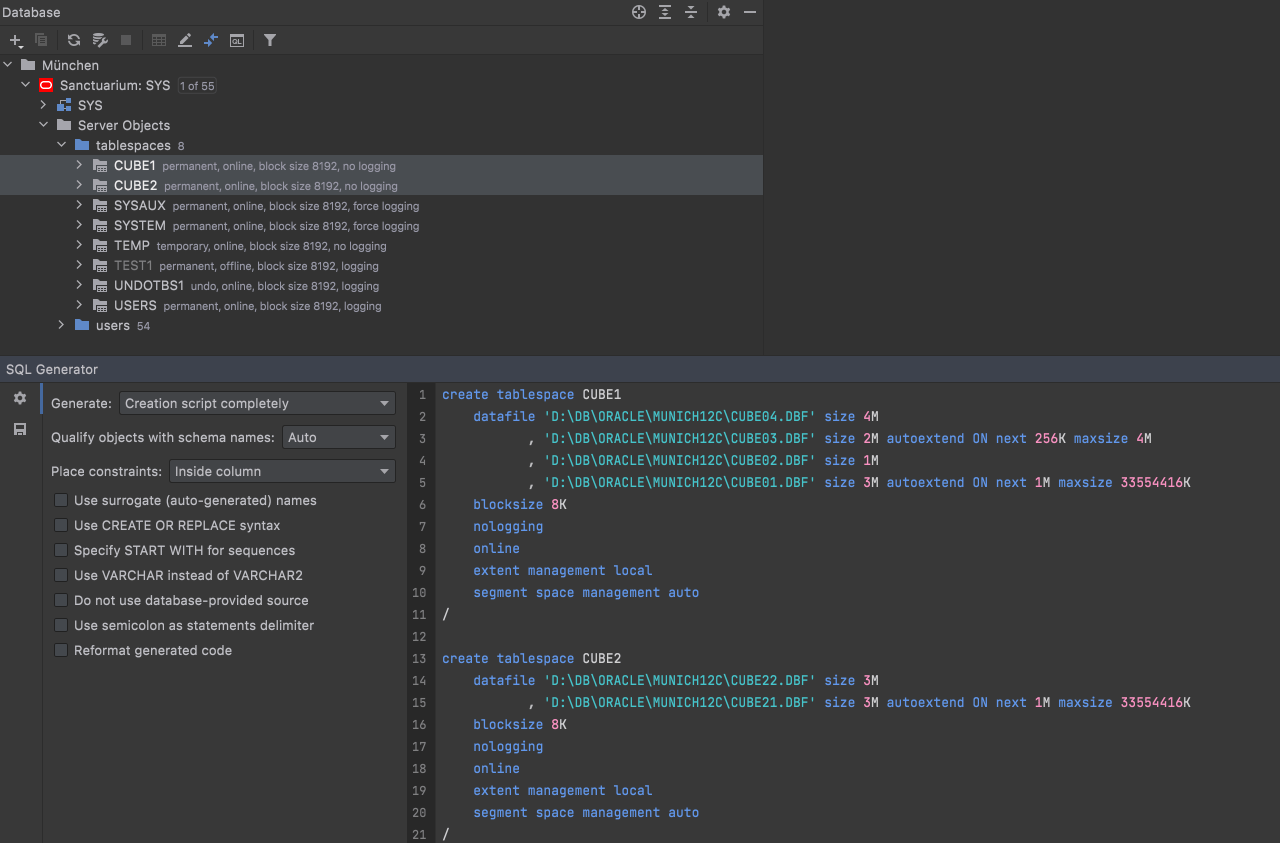
They are also included in DDL generation:

Linked Servers SQL Server
This isn’t full support yet, because metadata is not available for objects in linked servers. Linked servers are shown in the database explorer, and the DDL for their creation can be generated.
Data editor
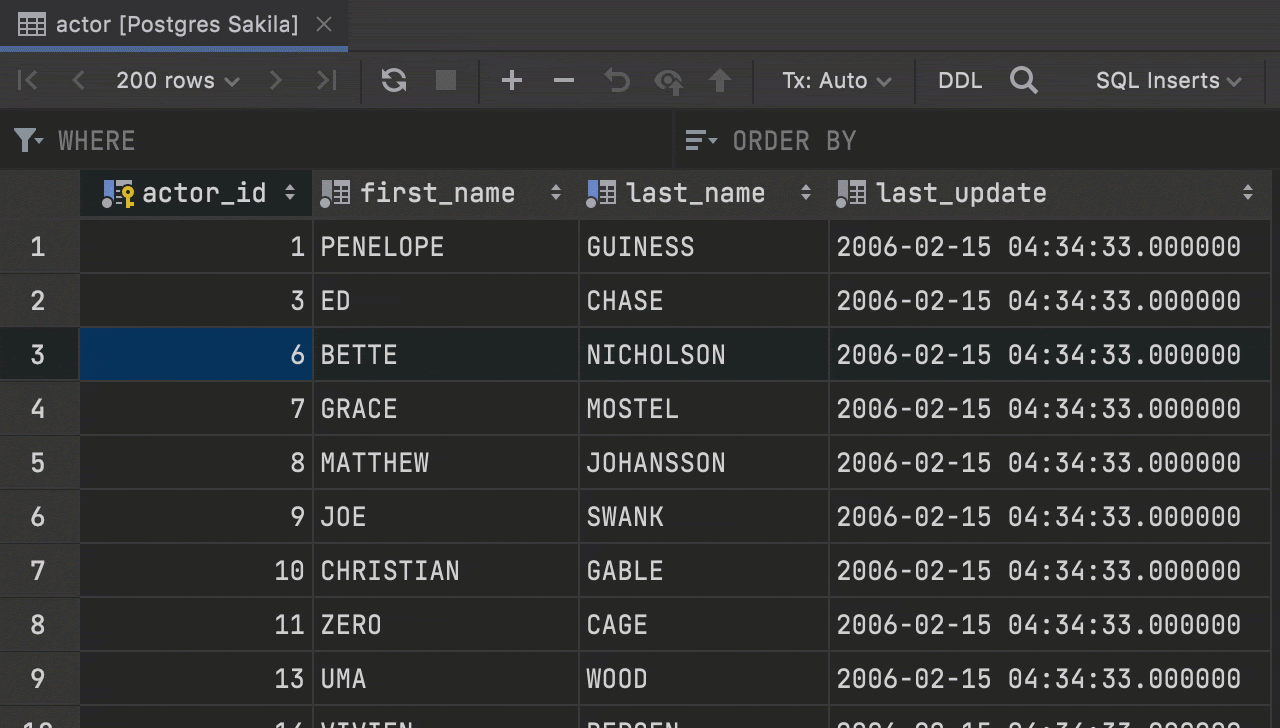
Context live templates from the data editor
Introduced in the previous release, context live templates now work from the data editor. If you’re working with a table and you wish to query it, you can easily do so with the help of the SQL Scripts action.
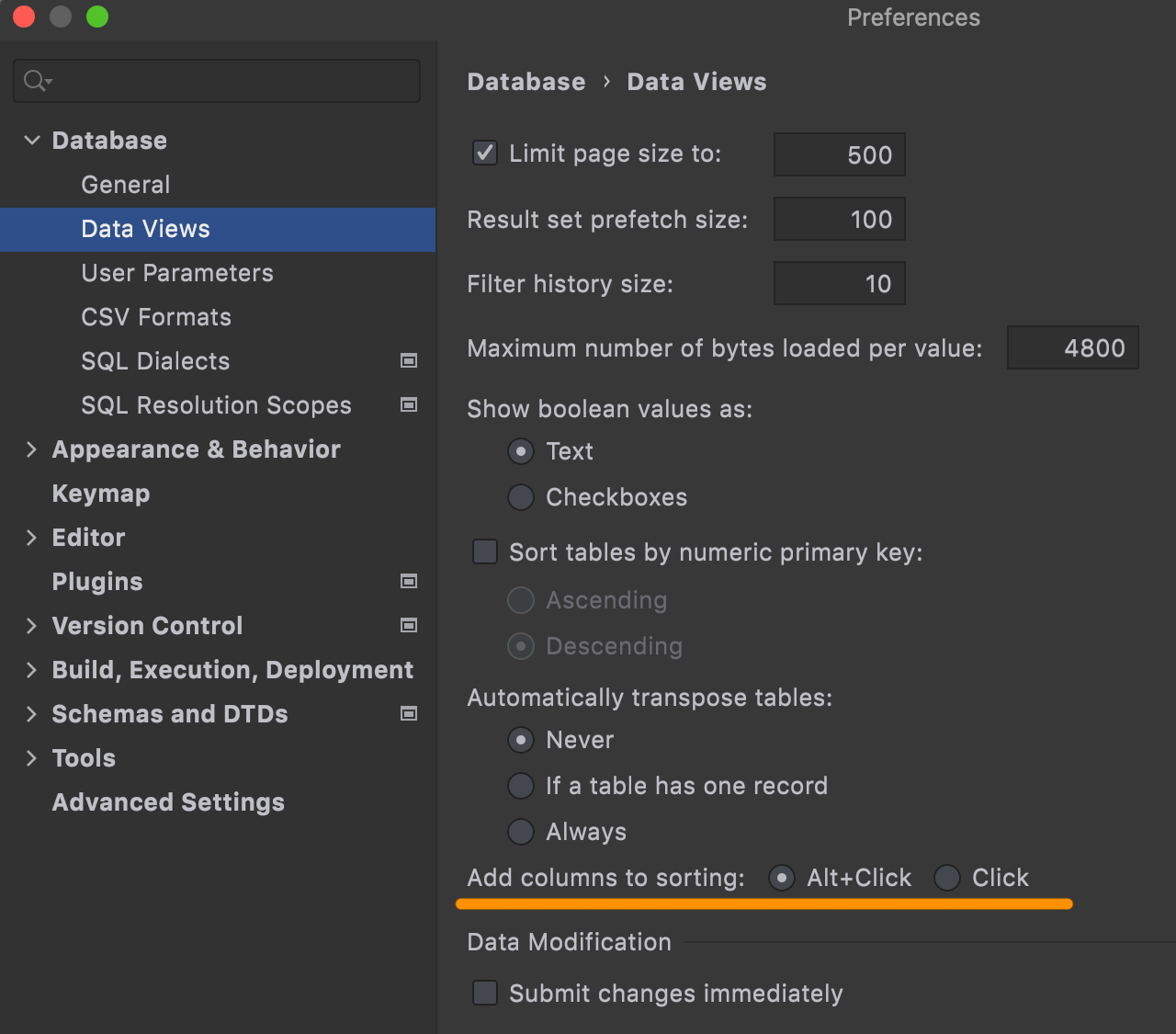
Option for additive sorting
We recently introduced Alt+Click for additive sorting. But if you prefer using Click, you can customize this behavior:
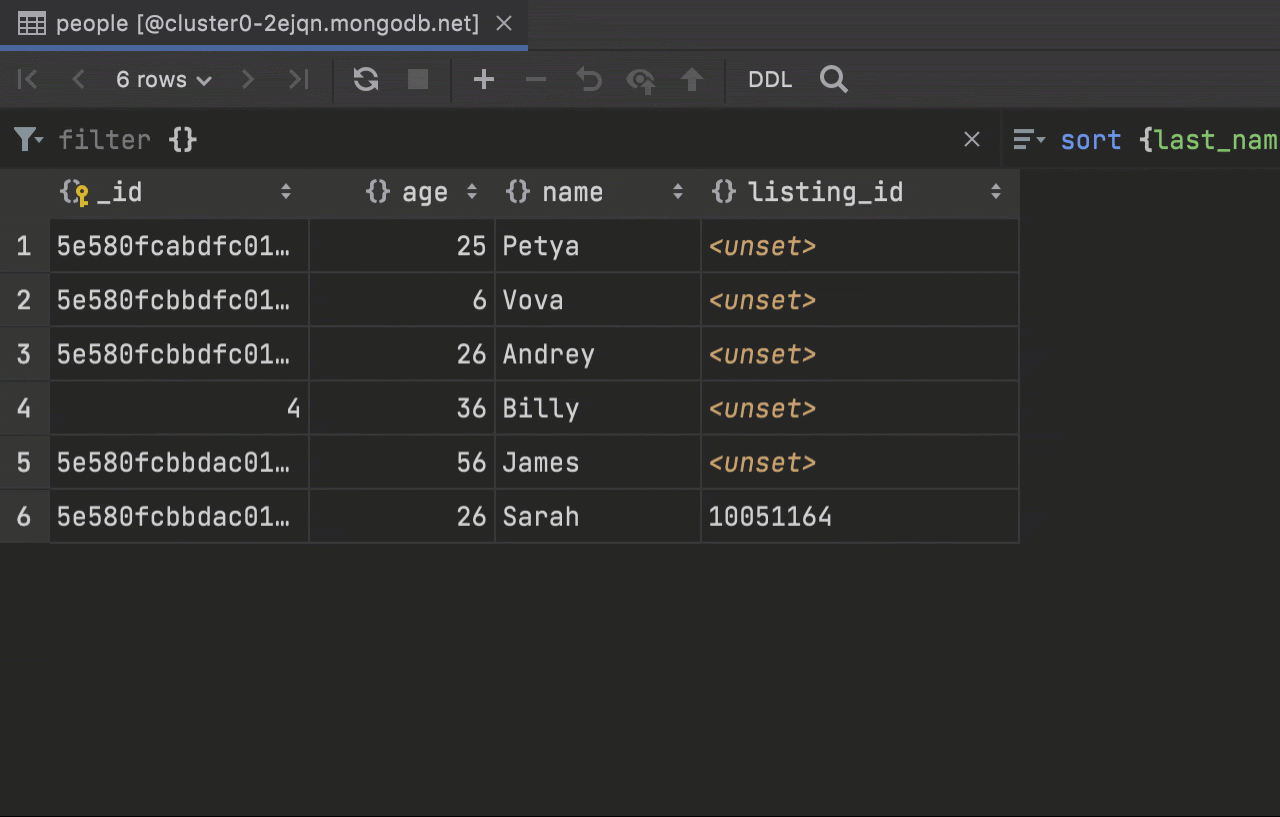
Add/delete column MongoDB
You can now add columns to MongoDB collections. This action lets you add a new field to any document of a collection.
Delete column will delete data not only on the page that is being displayed, but also throughout the whole collection.
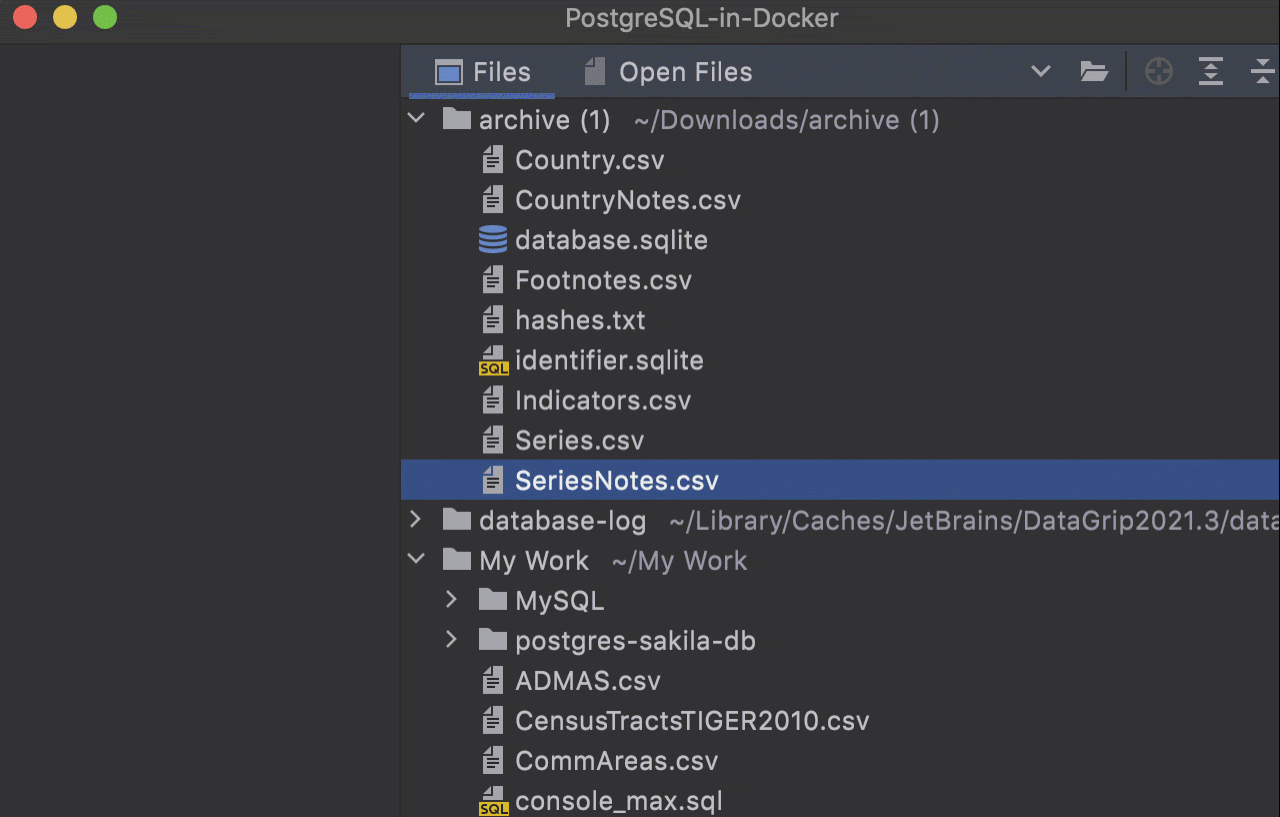
Adding/renaming columns in CSV files
With the help of the UI data editor, you can now add and remove columns in CSV files.
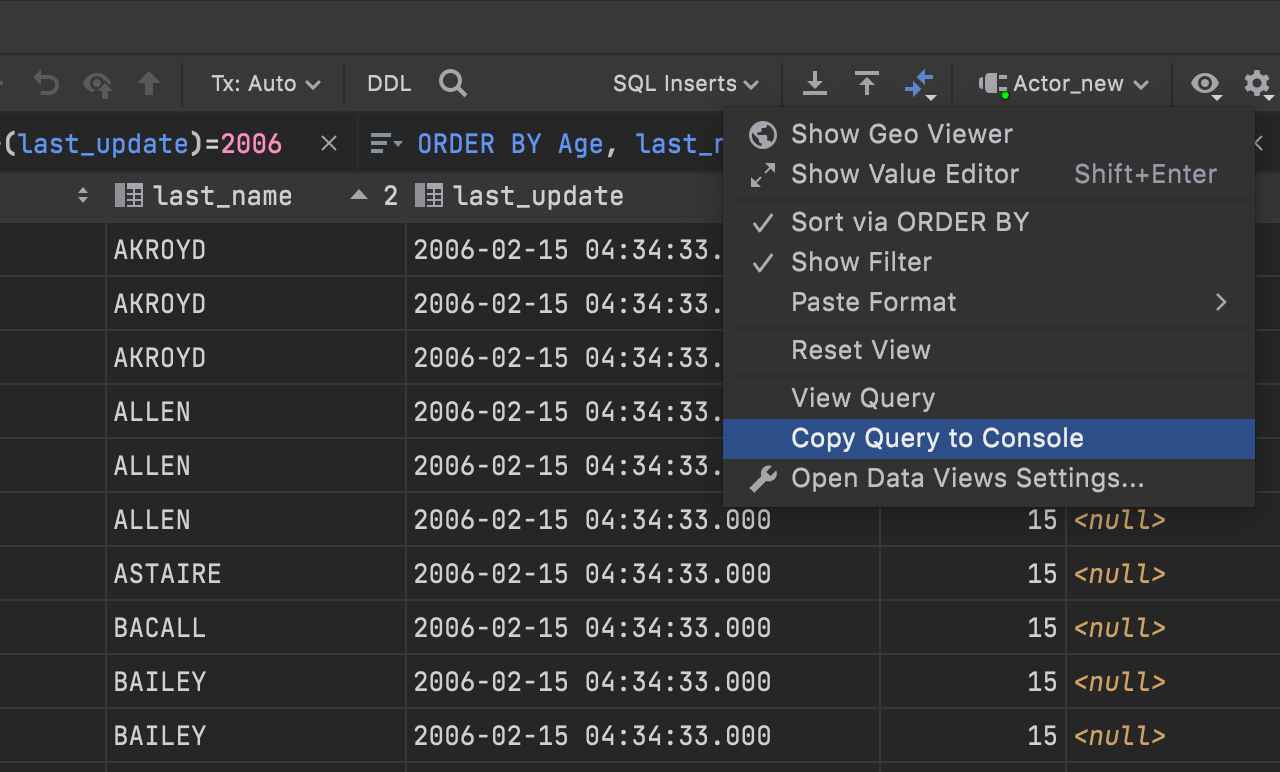
Copy query to console
When working in a data editor, you might sometimes use complicated clauses in
WHERE and ORDER BY fields. If you want to continue
working with the resulting query, use a new action, Copy Query to Console,
under the gear icon. It opens the query in the default console.
No more First row option in navigation by foreign keys
To make the navigation faster, we’ve removed the First row option. No popup will be displayed, and you will be navigated to the table that shows all referencing or referenced rows.
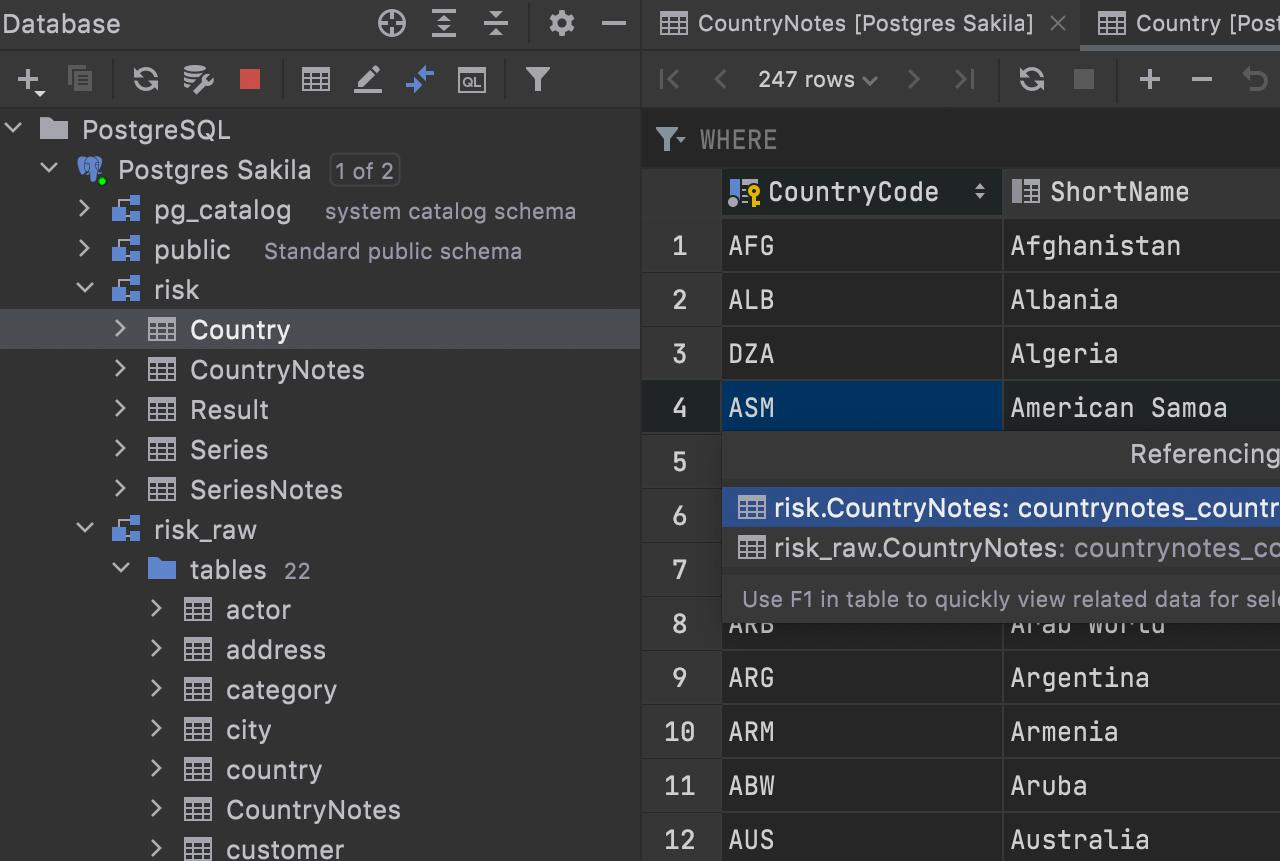
Qualification in navigation by foreign keys
If you have foreign keys pointing to objects in another schema and these objects have the same names, they will be displayed as qualified in the foreign keys navigation UI.
Quality improvements
DBE-12545:
The size of the ORDER BY field is saved.
DBE-13055: The time zone is always shown for values with a time zone.
DBE-9814:
Oracle
DATE type values don’t display time if no time is set.
DBE-12679:
Oracle
Filtering by the DATE field is possible.
DBE-12716: DB2 Filtering by binary, blob, char for bit data, and varchar for bit data fields is possible.
Import/Export
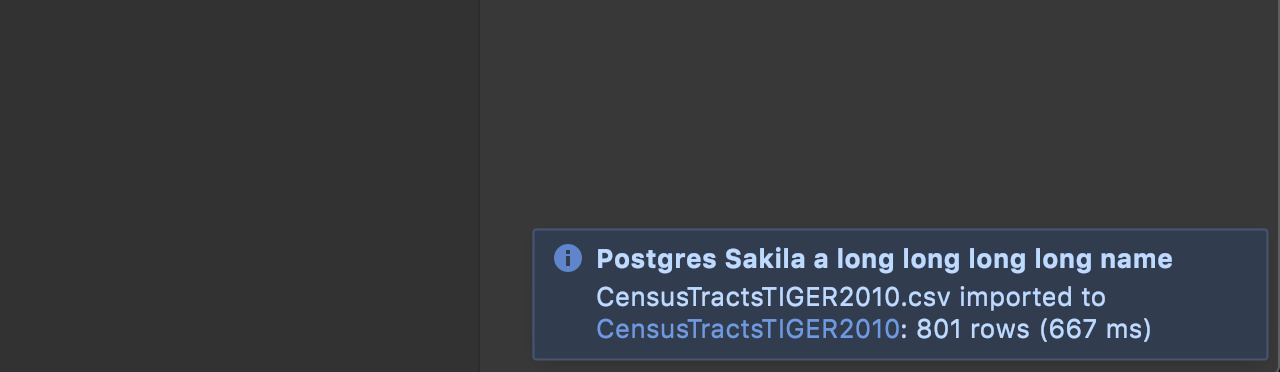
Table link after import
When you finish an import, a link to the new table appears in the notifications.
Navigation
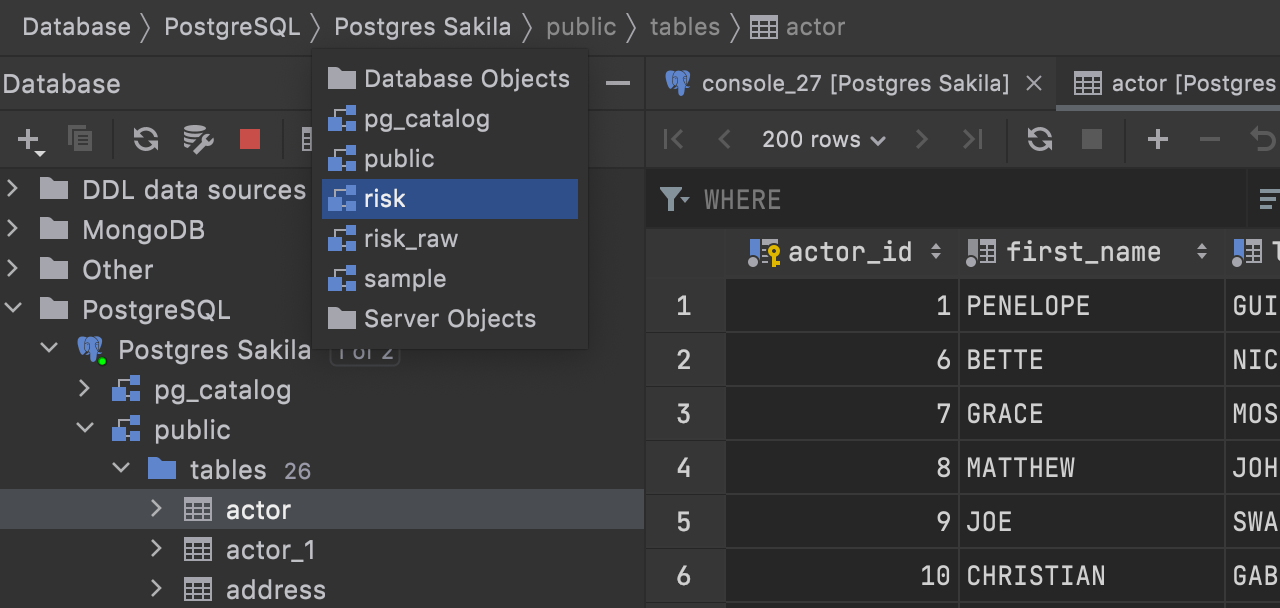
Behavior of the Enter key in the navigation bar
The behavior of the navigation bar is now more straightforward – the Enter key always expands the node.
Before, the Enter key opened data for tables and opened consoles for data sources.
If you want to navigate from the object in the navigation bar rather than opening its node, you can use these navigation shortcuts:
- Open DDL: Ctrl+B
- Open data: F4
- Select in the database tree: Alt+Shift+B
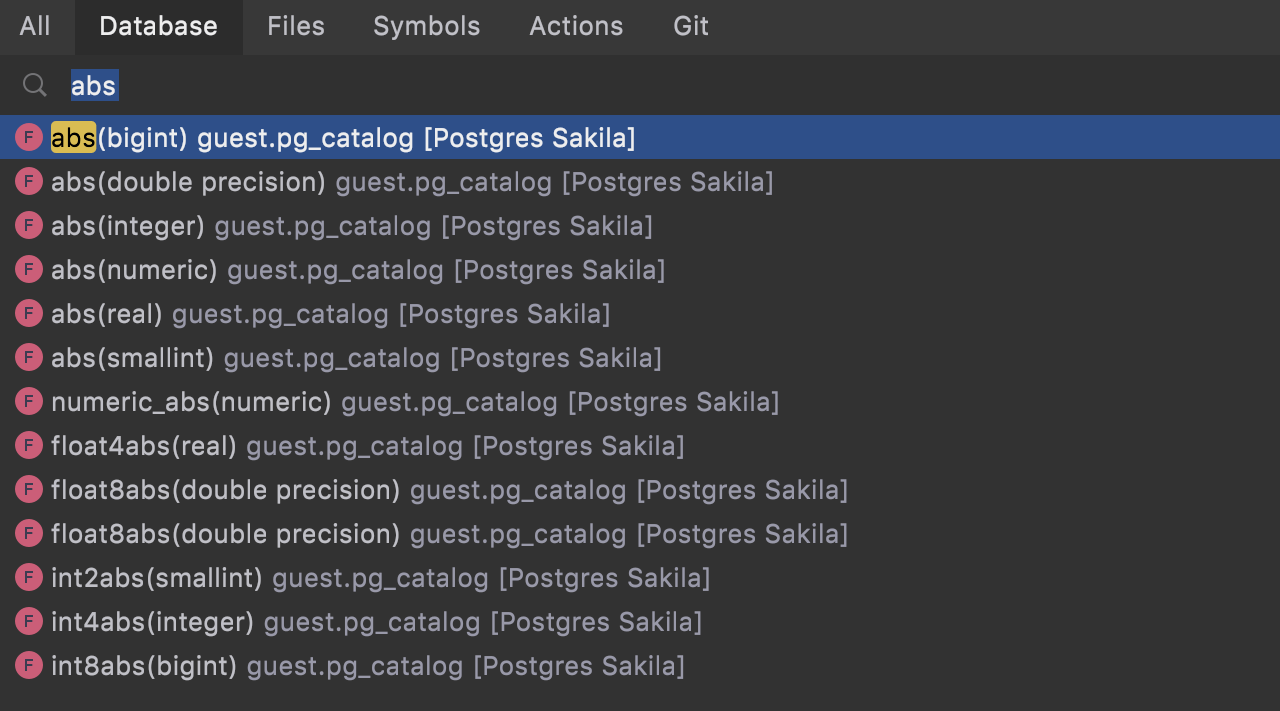
Signatures in the Go To popup
Now, when you are searching for a function, procedure, or operator, DataGrip shows the signature in the Go To window. This helps when you use overloading heavily.
General
Localized UI
Starting from this version, you can enjoy the fully localized UI of DataGrip in Chinese, Korean and Japanese. Localization is available as non-bundled language pack plugins, which can be easily installed to DataGrip. More than 1.5 mln users started using the partially localized EAP version of our language packs. Now you can enjoy the full localization experience!
New location for projects
In DataGrip, projects are now located by default in the same place as they are in all other IntelliJ-based IDEs – in the user’s home folder, inside the DataGripProjects subfolder.
Your project in DataGrip is a complex of your data sources, console and scratch files, and attached folders. They were previously stored in the configuration folder, meaning that each time you updated your IDE, the projects were copied, along with IDE settings.
This sometimes caused the data source list to become empty. This problem has been solved, and now DataGrip behaves consistently with other IDEs.
Because of errors in project migration, those who used the first EAP build might have lost their Favorites, Bookmarks, Run Configurations, or data about virtual foreign keys. To restore them, please migrate from the previous version again. The details are described here: DBE-13410.
Settings
Back and forward buttons
These buttons make it easier to navigate in the Settings window and not get lost there.
Advanced Settings
We’ve added Advanced Settings as a new node in Preferences/Settings. It contains some use-case-specific options conveniently grouped by IDE tool. Most of the settings have been transferred from the Registry, though some of them are new.
A couple of notable settings:
- Left-hand margin in Distraction-free mode.
- Ability to set the caret to move down after you use the Comment with Line Comment action.
- Customizing the behavior of double-clicking on a tab.
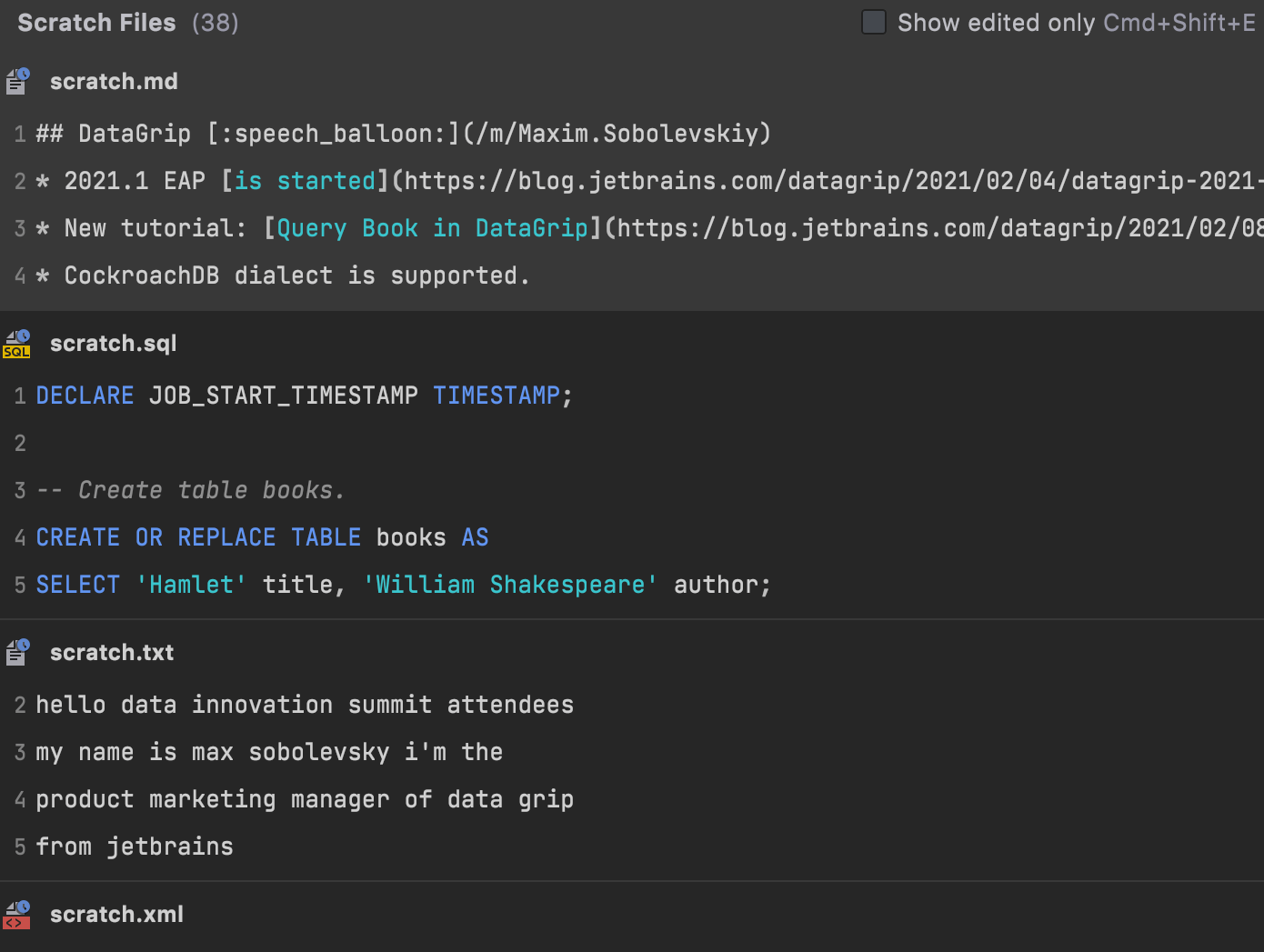
Show scratch files action
A new Show Scratch Files action (found via Find Action: Cmd+Shift+A) shows a list of scratches with snippets in a popup. It has the same UI as the Recent Locations popup with speed-search and deletion.
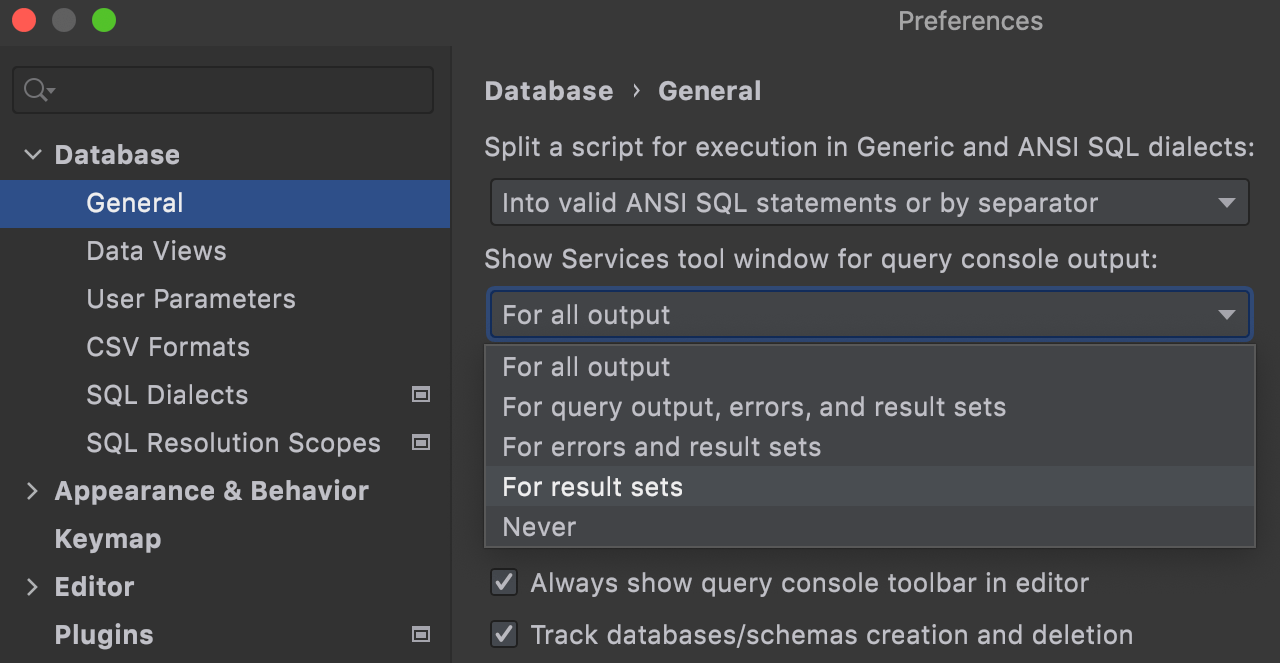
Managing the Services tool window popups
When a query returns no data, there’s no need for the Services tool window to appear if it was hidden already. Now you can define which operations make the Services tool window appear on your own.
Quality improvements
DBE-12079: PostgreSQL We’ve reworked the introspector. For you, the main effect of the new introspector is – no more object duplicates!
DBE-13164:
No more freezing when typing JOIN statements along with using virtual
foreign keys.
DBE-194931: Empty scratch files are now automatically removed.