Messen der CI/CD-Performance mit DevOps-Kennzahlen
Ein CI-Server oder Buildserver koordiniert alle Schritte eines CI/CD-Prozesses, von der Überwachung Ihrer Versionsverwaltung auf Änderungen bis hin zum Bereitstellen neuer Builds.

Der Einsatz eines CI-Servers vereinfacht Ihre Continuous-Integration- und Continuous-Delivery/Deployment-Prozesse (CI/CD). Ein CI-Server überwacht Ihr Versionsverwaltungssystem (VCS), löst automatisierte Build-, Test- und Deployment-Aufgaben aus, sammelt die Ergebnisse und leitet die nächste Pipeline-Phase ein.
Zwar ist CI/CD auch ohne Buildserver möglich, aber viele Entwicklungsteams entscheiden sich für ein CI-Tool, um den Prozess zu koordinieren und die Ergebnisse der einzelnen Schritte zu kommunizieren. In diesem Leitfaden sehen wir uns an, was ein CI-Server tut und wie er Ihnen dabei helfen kann, CI/CD optimal umzusetzen.
Warum einen CI-Server verwenden?
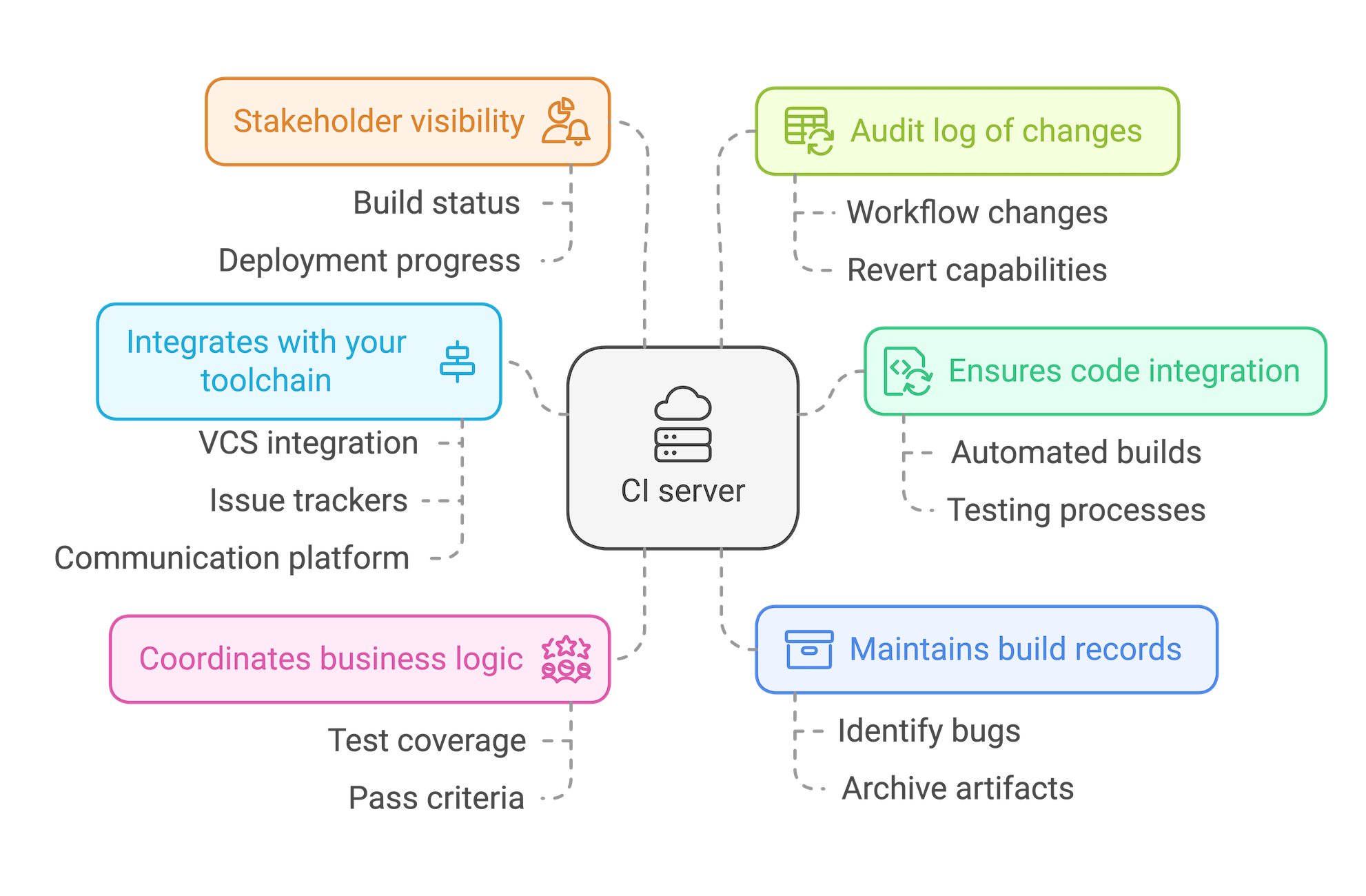
Ein CI-Server dient als zentraler Koordinationspunkt für alle Ihre CI/CD-Aktivitäten. Die Verwendung eines CI-Servers …
- … stellt sicher, dass jeder Commit den CI/CD-Prozess durchläuft: Durch die Integration mit Ihrer Versionsverwaltung stellt der CI-Server sicher, dass alle Codeänderungen Ihren automatisierten Build-, Test- und Deployment-Prozess durchlaufen – ohne Zusatzaufwand für die einzelnen Entwickler*innen.
- … ermöglicht die Koordinierung Ihrer Geschäftslogik: Der CI-Server ist eine zentrale Informationsquelle (Single Source of Truth) für die Anforderungen Ihres Unternehmens, vom erwünschten Umfang der Test-Coverage bis hin zur Frage, wie Sie in den einzelnen Phasen der Testautomatisierung „Erfolg“ definieren wollen.
- … erlaubt die Integration in Ihre Toolchain: Ein CI-Server kann sich nicht nur in Ihre VCS- und Build-Tools integrieren, sondern auch in Issue-Tracker und Kommunikationsplattformen, um automatisierte Updates über die Build-, Test- und Deployment-Prozesse bereitzustellen.
- … bietet ein Archiv vergangener Builds: Ein Archiv der Build-Artefakte ist von unschätzbarem Wert, wenn Sie den Punkt identifizieren müssen, an dem sich ein besonders subtiler Fehler in Ihren Codebestand eingeschlichen hat.
- … informiert Stakeholder über den Release-Fortschritt: Als zentrale Informationsquelle für den Status von Builds und Deployments kann Ihr CI-Server die gesamte Organisation über Fortschritte informieren.
- … gewährleistet ein Audit-Protokoll der Änderungen: Workflows und Geschäftslogik entwickeln sich in der Regel mit der Zeit weiter. Ein CI-Server kann dafür sorgen, dass Sie nachvollziehen können, wie sich Ihr CI/CD-Prozess geändert hat, falls Sie jemals zu einer früheren Implementierung zurückkehren möchten.
Der Einsatz eines CI-Servers hilft Ihnen, die zahlreichen Vorteile von CI/CD zu nutzen, darunter schnelles Feedback zu Ihren Codeänderungen, frühzeitige Fehlererkennung und häufigere Releases.
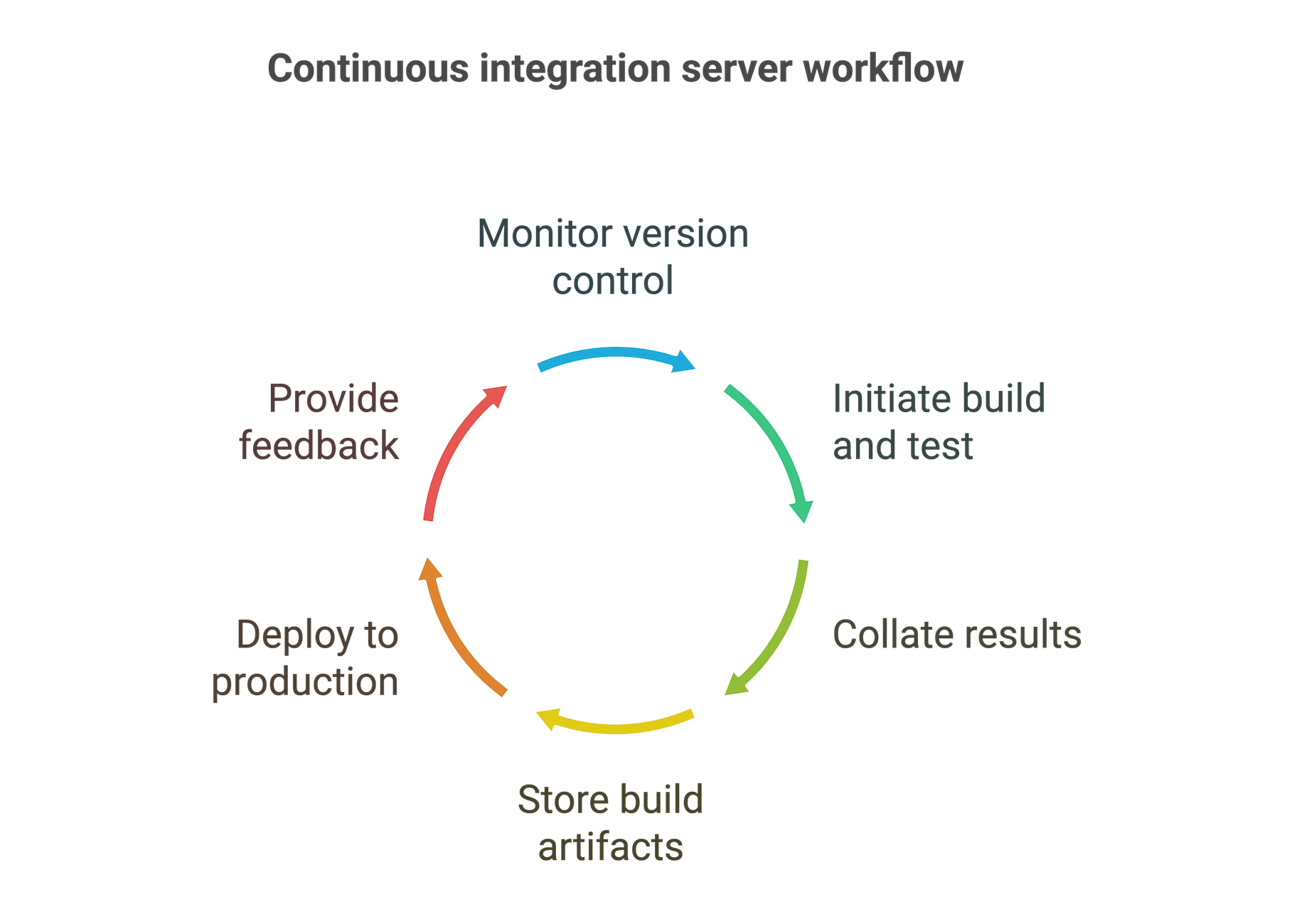
Wie funktioniert ein CI-Server?
Der genaue Prozess kann zwar je nach Team und organisatorischen Anforderungen variieren, aber ein CI-Server führt in der Regel die folgenden Schritte aus:
- Integration in Ihre Versionsverwaltung und Überwachung der Versionsverwaltung auf Commits in den entsprechenden Branches.
- Auslösen einer Reihe von Build- und Testaufgaben bei jedem Commit. Diese werden entweder auf andere Systeme in Ihrer Buildfarm verteilt oder auf dem CI-Server selbst ausgeführt.
- Sammeln der Ergebnisse dieser Aufgaben und Einleiten der nächsten Prozessphase in Abhängigkeit von dieser Daten.
- Speichern der Build-Artefakte in einem zentralen Archiv.
- Deployment der neuen Version in die Produktion.
- Bereitstellen von Feedback während des gesamten Prozesses.
Überwachung der Versionsverwaltung
Am Anfang jeder CI/CD-Pipeline steht die Integration in eine Versions- bzw. Quellcodeverwaltung.
Normalerweise wird ein CI-Server so konfiguriert, dass er auf Commits in einem bestimmten Branch wartet und bei jeder Änderung einen neuen Pipeline-Lauf auslöst. Dadurch wird sichergestellt, dass jedes Mal, wenn Entwickler*innen ihre Änderungen committen, diese kompiliert und getestet werden, um zu gewährleisten, dass der Codebestand als Ganzes weiterhin korrekt funktioniert.
Bei einigen CI-Servern können Sie noch einen Schritt weiter gehen und einen lokalen Build- und Testvorgang vorschreiben, bevor Entwickler*innen ihre Änderungen in einen CI-Branch hochladen können. Dies ist zwar keine Garantie dafür, dass der nächste Schritt erfolgreich durchlaufen wird, aber es hilft, die Anzahl der fehlerhaften Builds und die damit verbundenen Verzögerungen zu reduzieren. Eine weitere Möglichkeit besteht darin, Ihren CI-Server in Ihr Code-Review-Tool zu integrieren, sodass jeder Commit eine Code-Review-Phase durchlaufen muss, bevor er freigegeben wird.
Diese zusätzlichen Schichten von Geschäftslogik zu Beginn des Prozesses tragen dazu bei, dass Ihr Codebestand sauber bleibt und stets releasefähig ist. Gleichzeitig werden Unterbrechungen und Verzögerungen in der Pipeline minimiert.
Verwaltung von Builds und Tests
Jedes Mal, wenn eine Änderung erkannt und ein Pipeline-Lauf ausgelöst wird, koordiniert der CI-Server die Build- und Testaufgaben. Diese werden im Normalfall dedizierten Systemen – sogenannten „Agents“ – zugewiesen. Die eigentliche Arbeit beim Buildvorgang und bei der Testausführung wird dann – gemäß den Anweisungen des CI-Servers – von den Build-Agents übernommen.
Alternativ können Build- und Testaufgaben auch auf dem CI-Server selbst ausgeführt werden. Dies kann jedoch bei einem intensiv bearbeiteten Codebestand zu Ressourcenengpässen und Leistungseinbußen führen.
Wenn Sie auf Ihrem CI-Server die Logik für eine Pipeline-Phase konfigurieren, können Sie eine Reihe von Details und Regeln festlegen. Dabei haben Sie unter anderem folgende Möglichkeiten:
- Bei Commits im Hauptbranch alle automatisierten Tests ausführen, in Feature-Branches jedoch nur einen reduzierten Testumfang verwenden.
- Festlegen, wie viele Builds gleichzeitig auf eine Testdatenbank zugreifen können.
- Das Deployment in eine Staging-Umgebung nur einmal pro Woche ausführen, um umfassendere manuelle Tests zu ermöglichen.
Durch die gleichzeitige Ausführung bestimmter Aufgaben mithilfe von Build-Agents können Sie die Effizienz Ihrer Pipeline erhöhen. Dies ist hilfreich, wenn Sie Tests auf verschiedenen Betriebssystemen ausführen müssen oder wenn Sie mit einer riesigen Codebasis mit Hunderttausenden Tests arbeiten, sodass die Parallelisierung die einzige praktische Option darstellt. Im letzteren Fall können Sie durch Einrichten eines Composite-Builds die Ergebnisse aggregieren, um die Aufgaben als einen einzelnen Build-Schritt handhaben zu können.
Wenn der Build-Server eine Integration mit Cloud-Infrastrukturen wie AWS bietet, können Sie elastische, skalierbare Ressourcen nutzen, um Ihre Builds und Tests auszuführen. Unterstützung für containerisierte Build-Agents und die Integration mit Kubernetes können bei erheblichem Infrastrukturbedarf hilfreich sein, um Build-Ressourcen – egal ob lokal oder Cloud-basiert – effizient zu verwalten.
Definieren von Erfolgs- und Fehlerbedingungen
Ein wichtiger Aspekt Ihrer Geschäftslogik besteht darin, für jede Phase der CI/CD-Pipeline zu definieren, was als Fehler gelten soll.
Ihr CI-Server sollte Ihnen die Möglichkeit bieten, verschiedene Fehlerbedingungen zu konfigurieren. Diese Kriterien werden dann geprüft, um den Status eines bestimmten Schritts zu bestimmen und zu entscheiden, ob die nächste Pipeline-Phase eingeleitet werden soll.
Neben offensichtlichen Fehlern – etwa wenn der Buildvorgang einen Fehlercode zurückgibt oder wenn ein Test nicht ausgeführt werden kann – können Sie anhand der vom CI-Server gesammelten Daten weitere Fehlerbedingungen definieren.
Beispiele hierfür wären ein Rückgang der Test-Coverage-Rate im Vergleich zum Vorgängerbuild (dies würde bedeuten, dass keine Tests für die neuesten Codeänderungen hinzugefügt wurden) oder eine höhere Anzahl von ignorierten Tests im Vergleich zum letzten erfolgreichen Build.
Diese Zahlen dienen auch als Warnsignale, die auf eine Verschlechterung der Codequalität hindeuten können. Indem Sie diese Fälle als Fehler definieren und nicht allen Benutzer*innen das Ignorieren dieser Fehler erlauben, können Sie positives Verhalten fördern.
Speichern von Build-Artefakten
Wenn eine Änderung erfolgreich ist, speichert der CI-Server die Artefakte aus dem Buildprozess. Hierzu können Binärdateien, Installationsprogramme, Container-Images und andere Ressourcen gehören, die für das Deployment Ihrer Software erforderlich sind.
Anschließend können Sie dieselben Artefakte weiteren Tests in Vorproduktionsumgebungen unterziehen, um sie schließlich in die Produktion zu übernehmen. Dadurch wird sichergestellt, dass in jeder Phase derselbe Output getestet wird – dies ist viel zuverlässiger als ein Neukompilieren des Quellcodes vor jedem Deployment. Insbesondere vermeiden Sie dadurch die Gefahr, dass Sie Abhängigkeiten übersehen oder Inkonsistenzen einführen.
Das Pflegen eines Artefakt-Repositorys mit erfolgreichen Builds ist auch dann nützlich, wenn Sie zu einer früheren Version Ihrer Software zurückkehren möchten oder herausfinden müssen, wann ein bestimmtes Problem eingeführt wurde.
Bereitstellen von Builds
Obwohl die Bezeichnung „CI-Server“ eine Beschränkung auf Continuous Integration andeutet, unterstützen die meisten CI-Server auch Continuous Delivery und Continuous Deployment.
Nachdem Sie in der CI-Phase Ihre Build-Artefakte erstellt und einige erste Tests durchgeführt haben, besteht der nächste Schritt darin, diese Artefakte für weitere Tests in speziellen QA-Umgebungen bereitzustellen. Danach folgt das Staging, bei dem Ihre Stakeholder die Möglichkeit erhalten, den neuen Build auszuprobieren. Wenn alles einwandfrei funktioniert, folgt im Normalfall die Produktionseinführung.
Sie können einen CI-Server verwenden, um die Parameter für jede Umgebung in Ihrer Pipeline zu speichern und zu verwalten. Dadurch können Sie entscheiden, ob Ihre Deployment-Skripte entsprechend dem Ergebnis der vorherigen Phase automatisch ausgelöst werden sollen.
Feedback geben
Eine zentrale Funktion eines CI-Servers ist die Bereitstellung von schnellem Feedback zu jeder Build- und Testphase. Wenn Ihr CI-Server in Ihre IDE oder Ihre Kommunikationsplattform integriert ist, können Sie benachrichtigt werden, wenn eine Ihrer Änderungen einen Fehler in der Pipeline verursacht hat, sodass Sie den Fortschritt nicht ständig aktiv überwachen müssen.
Buildserver bieten außerdem folgende Möglichkeiten:
- Echtzeitberichte über laufende Builds und Tests bereitstellen und über den Status abgeschlossener Build-Schritte informieren.
- Durch die Integration in Issue-Tracking-Tools Details zu den in einem Commit enthaltenen Änderungen bereitstellen und dadurch zur schnellen Eingrenzung von Fehlern beitragen.
- Statistiken – Deployment-Häufigkeit, Zeit bis zum nächsten Fehler, durchschnittliche Fehlerbehebungszeit usw. – bereitstellen, damit Sie Ihren Entwicklungsprozess evaluieren und verbessern können.
- Informationen über die Auslastung und Leistung Ihres CI-Servers und Ihrer Build-Systeme bereitstellen, die Sie zur Optimierung Ihrer Pipelines nutzen können.

Sollten Sie Ihren eigenen CI-Server aufbauen?
Die Einrichtung eines eigenen CI-Servers erscheint oft als eine attraktive Option. Wenn Sie Ihre eigene Lösung gestalten, können Sie sie auf Ihre Bedürfnisse zuschneiden, und gleichzeitig vermeiden Sie Lizenzkosten.
Die Erstellung eines eigenen Tools ist jedoch nur der Anfang des Prozesses. Auch nach der Ersteinrichtung müssen Sie Zeit investieren, um die Lösung auf dem aktuellen Stand zu halten – einschließlich der Behebung von Fehlern und der Entwicklung neuer Funktionen, wenn sich die Anforderungen ändern.
Zu bedenken ist auch der Aufwand für die Integration eines CI-Servers in Ihre Toolchain. Ihr anfängliches Setup mag zwar mit Ihrer aktuellen Kombination aus Versionsverwaltung, Issue-Tracker, Build-Tools und Testframeworks funktionieren – aber was passiert, wenn Sie auf ein neues Produkt oder eine neue Technologie umsteigen?
Der Aufbau eines eigenen CI-Servers bietet zwar die Flexibilität eines auf Ihren Anwendungsfall zugeschnittenen Tools, aber die Ersteinrichtung und die laufende Wartung erfordern einen erheblichen und kontinuierlichen Arbeitseinsatz.
Fazit
Ein Continuous-Integration-Server spielt eine tragende Rolle bei der Umsetzung Ihrer CI/CD-Pipeline, der Koordination und Auslösung der verschiedenen Prozessschritte sowie der Erfassung und Bereitstellung von Daten aus den einzelnen Phasen. In unserem Leitfaden für CI/CD-Tools finden Sie Tipps zur Auswahl des richtigen CI-Servers für Ihre Organisation.
So kann TeamCity helfen
TeamCity ist ein CI-Server, der Integrationen für alle führenden Versionsverwaltungssysteme – darunter Git, Perforce, Mercurial und Subversion – sowie verschiedene Hosting-Dienste bietet. Außerdem erhalten Sie umfangreiche Unterstützung für eine Vielzahl von Build-Tools und Testframeworks sowie Integrationen mit IDEs, Issue-Trackern, Messaging-Plattformen und Container-Managern.
Mit TeamCity Professional oder Enterprise können Sie Ihren CI-Server lokal oder in einer Cloud Ihrer Wahl hosten, und wenn Sie sich für TeamCity Cloud entscheiden, erhalten Sie eine vollständig verwaltete Lösung. Mit einer Vielzahl von flexiblen Pipeline-Triggern können Sie Ihre CI/CD-Prozesse nach Ihren Bedürfnissen konfigurieren, einschließlich Vorab-Tests für Commits, Unterstützung von Feature-Branches und regelmäßiger Buildvorgänge. Sobald Sie Ihre Pipeline-Logik über die Bedienoberfläche konfiguriert haben, können Sie Ihre Konfiguration als Code speichern, um einen vollständig versionierten CI/CD-Prozess zu gewährleisten.