Release notes
This section lists functionality added to product in the current release. To view Release notes for other DataGrip versions, click the version switcher on the help site and select the version that you need.

Data editor: automatic table transposing
Configure when you want to transpose tables and views when you open them in the data editor. In a transposed view, columns and rows are interchanged.

Data editor: change field type in MongoDB
In MongoDB, you can change the type of a field in the maximized view or by right-clicking the cell.

Data editor: edit data in MongoDB collections
In MongoDB, you can now double-click a cell and modify a value.
When you finished editing, click the Preview pending changes icon (![]() ) to preview your changes.
) to preview your changes.
Data editor: one navigation shortcut per action
Now DataGrip has separate shortcuts for different navigation actions.
Press Ctrl+B to open the DDL of the selected object. For example, if you press this shortcut on a table's name in the SELECT statement, you will see the DDL of this table (the CREATE TABLE statement).

Press F4 to open the object data. For example, if you press this shortcut on a table's name in the SELECT statement, you will see the contents of the table.
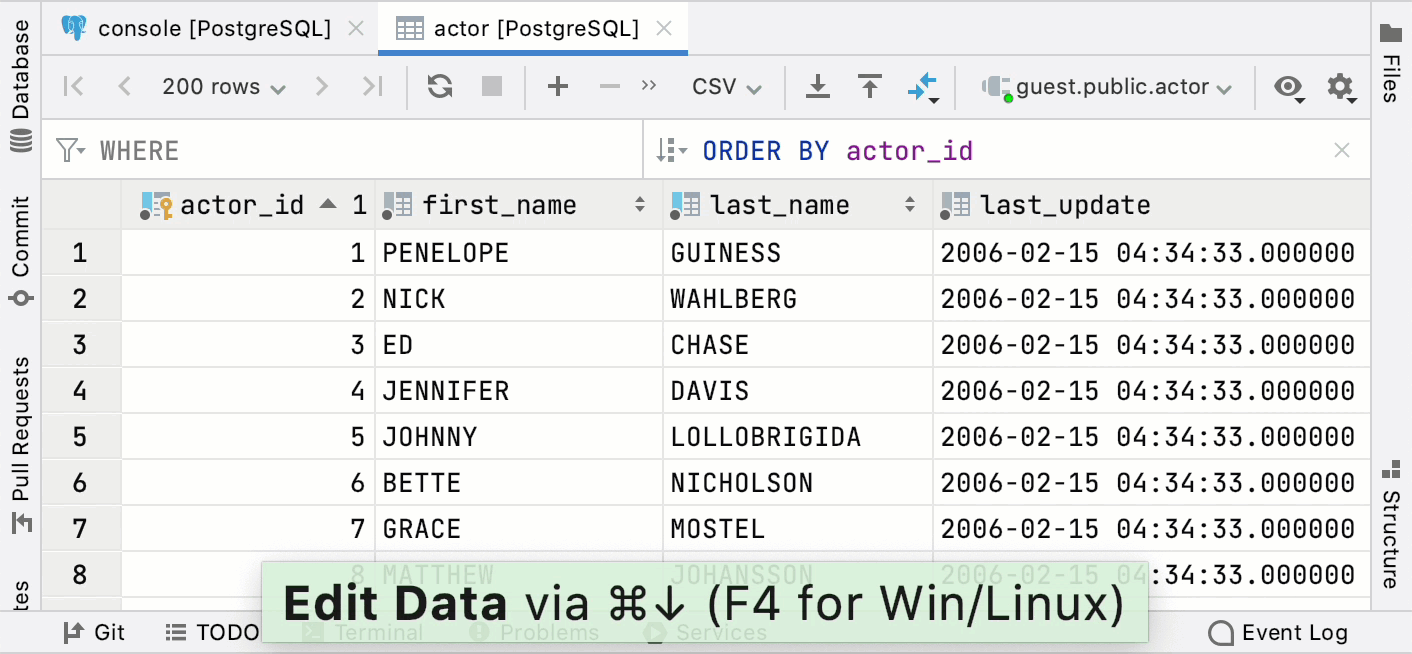
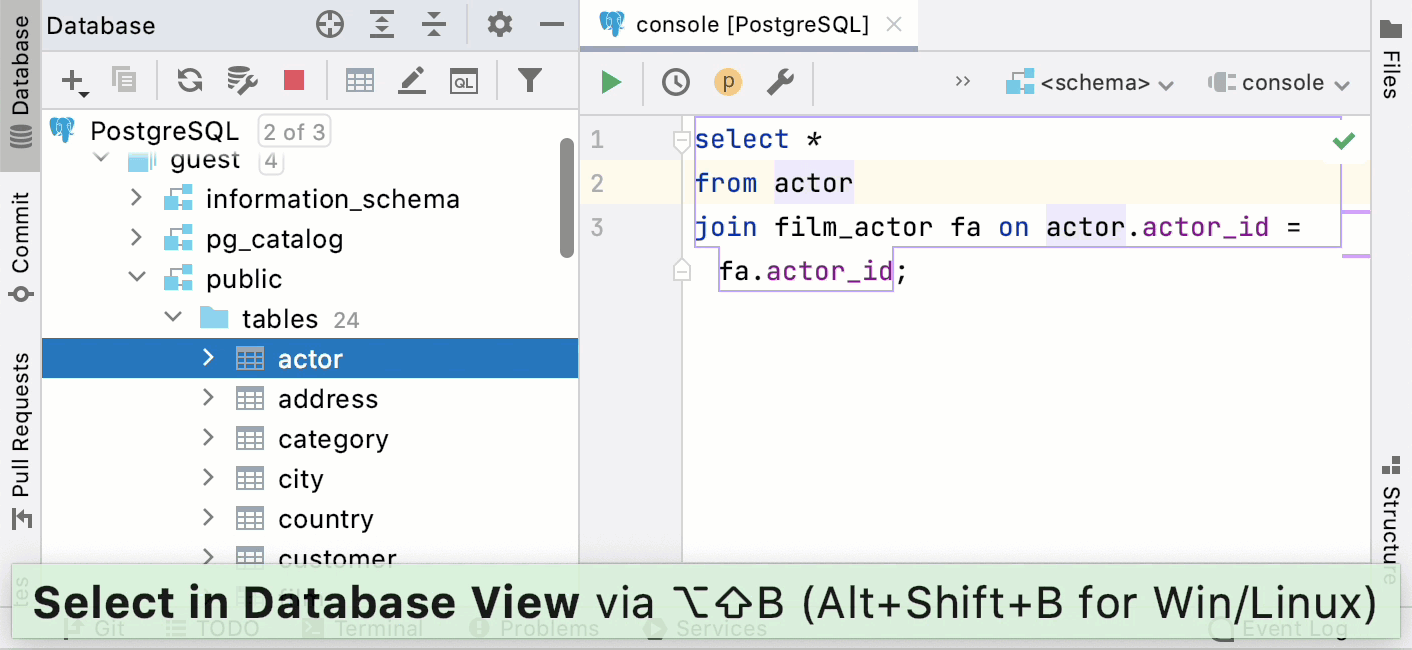
Press Alt+Shift+B to navigate to the object in the Database tool window.
Data editor: predefined sorting based on the numeric primary key
To configure predefined sorting based on the numeric primary key, open settings by pressing Ctrl+Alt+S and navigate to . Select the Sort tables by numeric primary key and configure the type of sorting you want: Ascending or Descending.

Data editor: the stacked sorting for columns is disabled by default
The sorting is not stacked by default. It means that if you click a column name to sort data by, the sorting based on other columns will be cleared. If you prefer to use the stacked sorting, click a column name while pressing Alt.
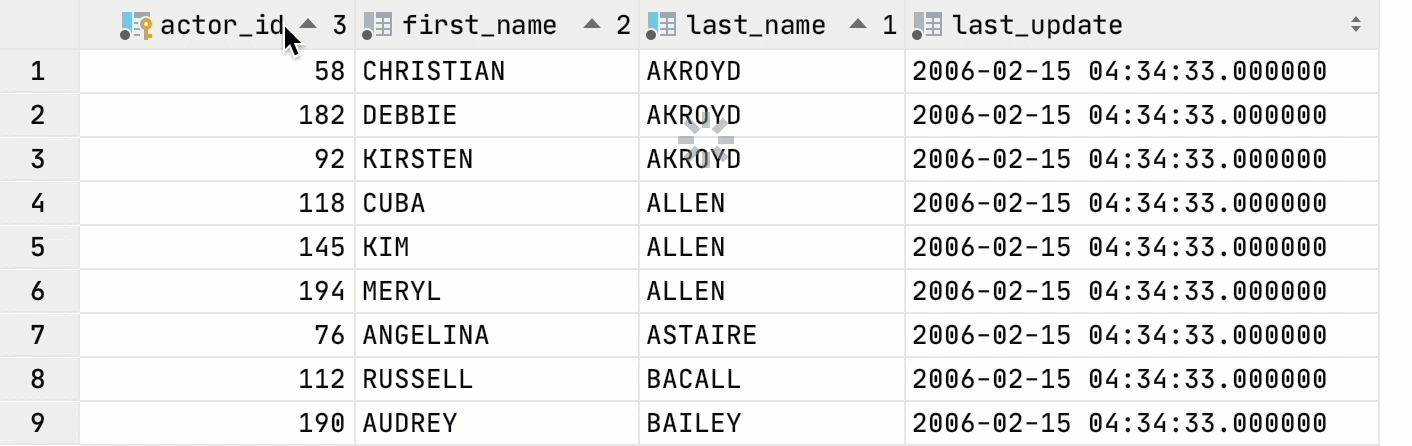
Data editor: WHERE and ORDER BY fields for sorting
The Filter Criteria field was replaced by WHERE and ORDER BY fields.

Database connections: data sources and drivers are separated
Data sources and drivers are separated into different tabs.

Database connections: set a dialect for the DDL data source
When creating a DDL data source, you can select a dialect that you want to use for this data source.

Database connections: the Drivers tab has a link to create data sources
To create a data source from the Drivers tab, click the Create Data Source link.

Database connections: the JDBC URL field can be expanded
Click the Expand icon (![]() ) if the JDBC URL is too long.
) if the JDBC URL is too long.

Database connections: the Test connection link is available on all the tabs of the data source window
In the Data Sources and Drivers dialog, you can use the Test Connection link on all the available tabs, not only on General and SSH/SSL tabs.

Database support: Azure MFA support
Azure Active Directory interactive authentication is supported. When it is used, the browser will automatically open and let you log in. For more information about connecting to Azure, see Azure SQL Database.

Database support: data source templates for unsupported databases
DataGrip includes JDBC drivers for AWS Athena, Informix, MemSQL, Presto, SAP HANA, Google Cloud Spanner, and others. You can find these databases in the Other section of the database list.
For more information about the Other menu, see Creating data sources by using the Other submenu.

Database support: the Amazon Redshift driver 2.0.0.2
With the Amazon Redshift driver 2.0.0.2 and later, you can cancel running queries.
Database view: configure GRANT privileges for objects
In the Database tool window (), right-click an object and select Modify Object.
Add a user and click the grant field. From the drop-down near each privilege, select Grant or Grant with option. The Grant with option privilege means that a user can grant to or revoke from other users those privileges.
You can autocomplete user names by pressing Ctrl+Space.

Export: a notification if binary data was not completely loaded
When you copy binary data that has not been completely loaded yet, the Data was copied partially notification is shown.

Export: a query on a separate sheet
When you export to Excel, the resulting file will contain the query on a separate sheet.
Import: the First Row is Header option
When you import a CSV file, the option to clarify that the first row is a header is now available upon the right-click on a header row.

Inspections: ambiguous column name when using CTE
The inspection that reports about ambiguous column names also takes into account columns inside common table expressions.

Query consoles: query parsing for unsupported databases
You can customize the query parsing for unsupported databases that use SQL:2016 or Generic dialects. The Generic dialect differs from SQL:2016 in error highlighting. In the Generic dialect, all found errors are not highlighted.
To customize the setting, open settings by pressing Ctrl+Alt+S and navigate to . Find the Split a script for execution in Generic and ANSI SQL dialects option and select the necessary value.
On valid ANSI SQL statements or by separator: DataGrip analyzes a script and splits it on valid statements or by separators. This setting is default.
On ANSI SQL statements: split scripts according to the SQL:2016 grammar.
By statement separator: extract and run statements by separators. For the Generic dialect, the separator is a semicolon.

Search: the Database tab
The Tables tab is renamed to Database.

The Database tool window: context live templates
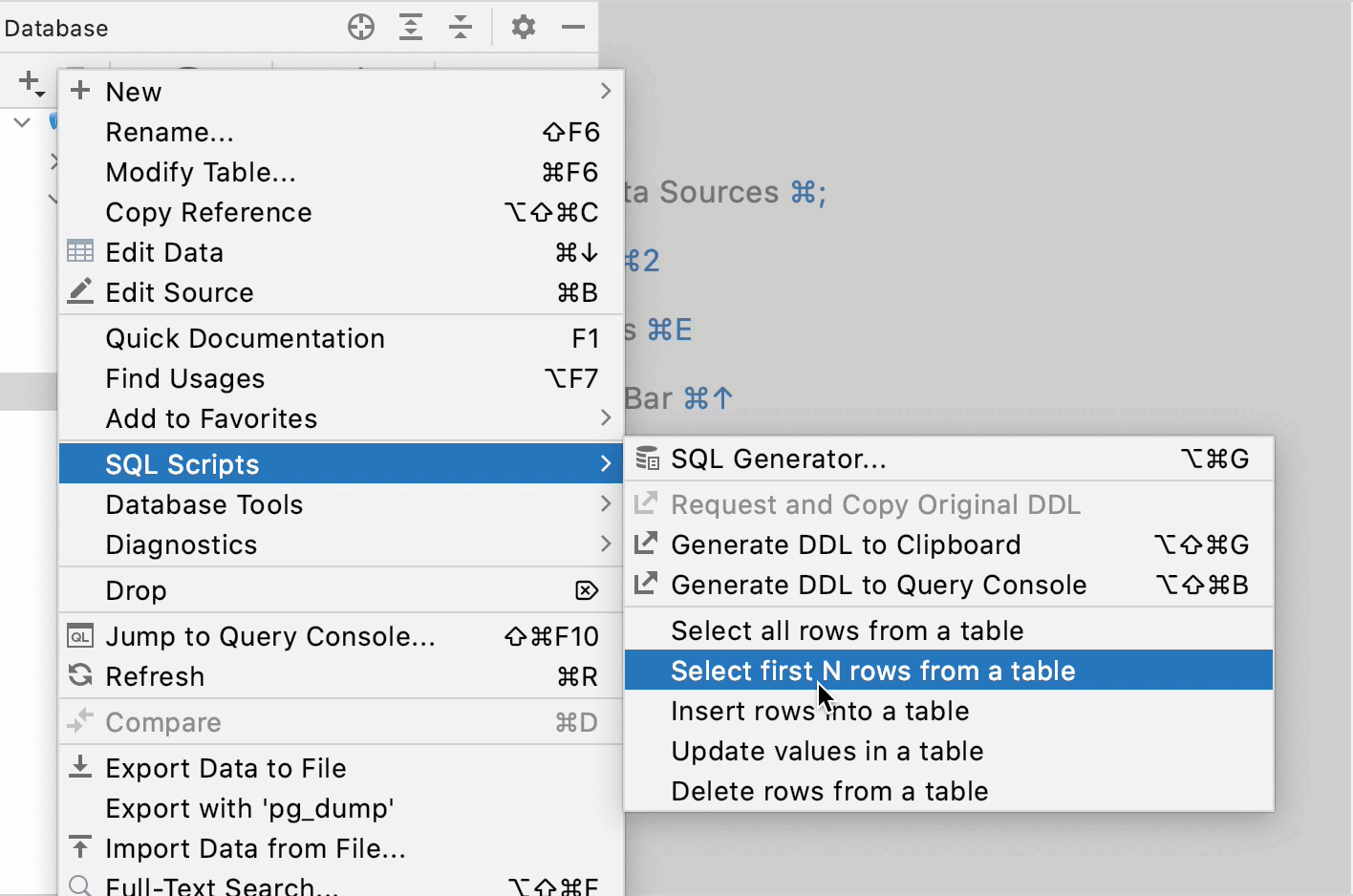
Context live templates is a solution for anyone who wants to generate simple statements straight from the Database tool window. While live templates cover many cases where you need to write a simple query, context live templates take into account the context of the database explorer and the data source that you are using.
In the following animation, we use the Select first N rows from a table context live template for PostgreSQL, Microsoft SQL Server, and MySQL. Depending on a table of a data source, DataGrip generates different queries.
The Database tool window: copying and pasting data sources with shortcuts
You can use Ctrl+C, Ctrl+V, and Ctrl+X to copy, paste, and cut your data sources.
When you copy a data source, the XML is copied into the clipboard. You can share it in a messenger or paste in another JetBrains IDE.
If you cut and paste a data source inside one project, it will be just moved, no password is required. But the password is required in all the other cases.
Cut can be undone via Ctrl+Z.
The Database tool window: groups for server and database objects in the Database tool window
The default layout of the database tree has been changed. Non-major objects are available under a dedicated node. Most of the time users work with tables, views, and routines. Other types of objects like users, roles, tablespaces, foreign data wrappers are not that high on their list of priorities. So, these secondary objects are now hidden under two nodes, Server Objects and Database Objects.

UI and UX: a new toolbar of the data editor
Rollback and Submit and Commit buttons are no longer displayed in automatic transaction mode, and there are two new buttons: Revert Selected and Find on Current Page.
The Revert Selected button reverts changes that you made to a cell value. The Find on Current Page button activates the search field for the current page of results in the data editor.

User management: GRANT permissions for users
In the Modify dialog, you can add GRANT permissions to users. To call the Modify dialog, right-click a user and select Modify Object or press Ctrl+F6.
