DevOps メトリクスによる CI/CD パフォーマンスの測定
CI/CD のメリットがすべて活用されていることを調べるにはどうすればよいでしょうか? CI/CD パイプラインのパフォーマンスを測定することで、プロセスを最適化し、より幅広いビジネスにその価値を示すことができます。

継続的改善は、DevOps の哲学を支える礎の 1 つです。 大きな変化を持続的にもたらすのに役立つ手法でもあります。 この戦略は製品やサービスの作成方法だけでなく、ビルド対象の製品やサービス自体にも適用されます。
継続的改善とはその名前が示すとおり、以下を伴う継続的なプロセスです。
- ビルドしたものまたは作業方法に関するフィードバックの収集と分析。
- パフォーマンスに優れている点と改善可能な点の特定。
- これらのインサイトに基づいて最適化をさらに進めるための段階的な変更。
- その変更の有効性を確認できるフィードバックの継続的な収集。
CI/CD の重要なメリットの 1 つに、ソフトウェアの継続的な改善が容易になることが挙げられます。 CI/CD パイプラインを使用すると、リリース頻度を高め、ビルドの成果に対するフィードバックを定期的に得て、その情報に基づいて次の優先事項を決めることができます。
さらには自動ビルドとテストの各ステージから迅速にフィードバックを得られるため、ソフトウェアのバグの解決と品質の改善をより簡単に行えるようになります。
ただし、CI/CD における継続的改善はこれだけではありません。 DevOps メトリクスを収集することで、同じ手法を CI/CD プロセス自体にも適用できます。
DevOps メトリクスが重要な理由
自動テストの作成から本番前環境のリフレッシュの自動化まで、CI/CD パイプラインの構築に最初に着手する際にやるべきことは多数あります。 この段階でのプロセスの改善方法に関するアイデアをお探しの場合は、CI/CD のベストプラクティスガイドをご覧ください。
自動パイプラインが稼働したら、その効果をさらに高める方法を探りましょう。 この段階で CI/CD パイプラインのメトリクスを利用した継続的改善のサイクルが始まります。
Peter Druckerは、「測定できないものは管理できない」と述べています。 メトリクスは継続的改善に欠かせません。 このデータによって価値を付加できる箇所を特定し、変更の影響を測定するための基準を提供することができます。
重要な DevOps メトリクスを監視することにより、自動テストカバレッジの拡張、スループットの改善、または開発タスクの細分化が CI/CD パイプラインのパフォーマンスに大きな影響を与えるかどうかを判断できます。
CI/CD パイプラインのステージを最適化するたびに、このフィードバックループの効果はさらに強まります。 このような改良により、品質を維持して欠陥率を低く抑えながら、変更のリリース頻度を高められるようになります。
リリース頻度が高まるということは、主な機能を継続的に改善し、仮説を検証する実験を行い、迅速に問題を解決できるということです。 市場の発展と機能に対する需要の変化に素早く追従しながら、競争相手と同等またはそれ以上の優位性を維持できるということです。
さらに、CI/CD メトリクスの監視は、パイプラインの価値を関係者やその他の開発チームを含むより幅広いビジネスに示す手段としても優れています。
代表的な DevOps パフォーマンスメトリクス
Google の DevOps Research and Assessment(DORA)チームは、ソフトウェア開発チームのパフォーマンスを正確に示す以下の代表的な 4 つのメトリクスを明確にしました。
この選択の根拠となった研究の詳細については、Nicole Forsgren、Jez Humble、および Gene Kim による書籍『Accelerate』をご覧ください。
デプロイの頻度
デプロイの頻度は、CI/CD パイプラインを使用して本番環境にデプロイしている頻度を示します。 デプロイの頻度が高いことは各デプロイにおける変更内容が少ないことを意味するため、DORA はこのメトリクスをバッチサイズの代わりに選択しました。
デプロイする変更の数を少なくすると、リリースに関連するリスクが軽減されます。不確実要素の数が少なくなり、それらが組み合わさることによって予期しない結果をもたらす可能性も下がるためです。 デプロイの頻度を高めることで、作業に対するフィードバックをより迅速に得られるようになります。
デプロイの頻度が低い場合はタスクが十分に細分化されていないため、パイプラインに定期的なコミットが行われていない可能性があります。 チームメンバー全員が CI/CD のメリットを理解している DevOps カルチャーを築くことで、チームを比較的小さな増分で作業することに慣れさせることができます。
継続的デリバリー戦略の一環で変更を比較的大規模なリリースにまとめて実行することにより、デプロイ頻度が低くなることもあります。 業務上の理由(ユーザーの期待など)で変更をまとめる必要がある場合は、ステージングサイトへのデプロイの頻度を代わりに測定することを検討しましょう。
リードタイム
リードタイム(デリバリー時間または市場投入時間としても知られる)とは、機能への取り組みを始めた時点からそれがユーザーにリリースされるまでの時間を指します。 ただし、アイデアの創出、ユーザー調査、およびプロトタイピングにかかる時間はかなり大きく変化する可能性があります。
このため、DORA は最後のコードコミットからデプロイまでの時間を計測しています。 この期間では、CI/CD パイプラインの範囲内のステージに専念することができます。
リードタイムが長いということは、ユーザーに定期的にコードの変更を提供していないということです。 その結果、使用状況統計やその他のフィードバックを利用してビルド対象物を改良できなくなっています。
複数の手動ステップが含まれるパイプラインでは、リードタイムが長くなるのが一般的です。 このようなステージには、大量の手動テストや環境を手動でリフレッシュする必要のあるデプロイプロセスが含まれる可能性があります。
自動テストと CI サーバーに投資してビルド、テスト、およデプロイタスクを調整すると、ソフトウェアのリリースにかかる時間が短縮されます。 それと同時に CI サーバーを使用することで、投資収益率を示すメトリクスを収集することができます。
すでに継続的インテグレーションとデプロイプロセスを自動化したにもかかわらず、ステップに時間がかかっているか、その信頼性に問題がある場合、 ビルド期間のメトリクスを使用することで、ボトルネックを特定できます。
組織によってリリース前のリスク評価や変更内容の審査が要求されている場合は、デプロイごとに数日または数週間が追加でかかる可能性があります。 プロセスの信頼性を示すメトリクスを使用することで、関係者が確証を持てるようになり、このような手動による承認ステップの必要性を排除することができます。
変更の失敗率
変更の失敗率とは、本番環境にデプロイされる変更内容のうち、ロールバックやホットフィックスが必要なサービスの停止やバグになるものの割合を指します。 コードの変更を本番環境にデプロイする前に検出された問題は対象外です。
このメトリクスには、失敗したデプロイを加えられた変更の量に関連付けて考慮できるというメリットがあります。 変更の失敗率が低いと、その時点までの各ステージがそれぞれの役割を果たし、コードがリリースされる前にほとんどの不具合を発見できていることを意味するため、パイプラインに自信を持てるでしょう。
変更の失敗率が高い場合は、自動テストカバレッジを調べることができます。 テストはほとんどの一般的なユースケースをカバーしていますか? テストに信頼性はありますか? パフォーマンスまたはセキュリティテストを自動化することで、テストの仕組みを強化できますか?
平均修復時間
平均修復時間または平均解決時間 (MTTR) は、実稼働の失敗に対処するまでに要する時間を計測するものです。 MTTR に注目すると、多くの不確定要素を伴う複雑な環境では何らかの失敗が発生することは避けられないことを認識できます。 完璧を求める(それによって頻繫なリリースのメリットを失う)のではなく、問題に迅速に対応できるかどうかが焦点です。
MTTR を低く保つには、プロアクティブな本番環境システムの監視を通じて問題発生時に警戒することに加えて、変更内容をロールバックしたり、パイプラインを通じてホットフィックスをデプロイしたりできる能力が必要です。
関連するメトリクスに平均検出時間(MTTD)がありますが、それは変更がデプロイされた後、その変更が原因で発生する問題を監視システムが検出するまでの時間を計測するものです。 MTTD とビルド所要時間を比較することで、どちらの領域で MTTR を短縮するための投資による恩恵を受けられるかどうかを判断できます。
運用および CI メトリクス
代表的な測定だけでなく、運用および継続的インテグレーションの多様なメトリクスを使用することで、パイプラインの有効性を把握し、改善の機会を発見することができます。
コードカバレッジ
CI/CD パイプラインでテストを自動化することで、ほとんどのテストをカバーできるはずです。 自動テストの最初のレイヤーは、最速で実行してフィードバックをすぐに得られるユニットテストにする必要があります。
コードカバレッジは、ほとんどの CI サーバーが提供しているメトリクスであり、ユニットテストでカバーされるコードの割合を割り出す指標です。 十分なテストカバレッジが維持されていることを確認しながらコードを書けるようになるため、このメトリクスは監視する価値があります。 コードカバレッジが減少傾向にある場合は、この最も重要なメトリクスに労力をかけるべきです。
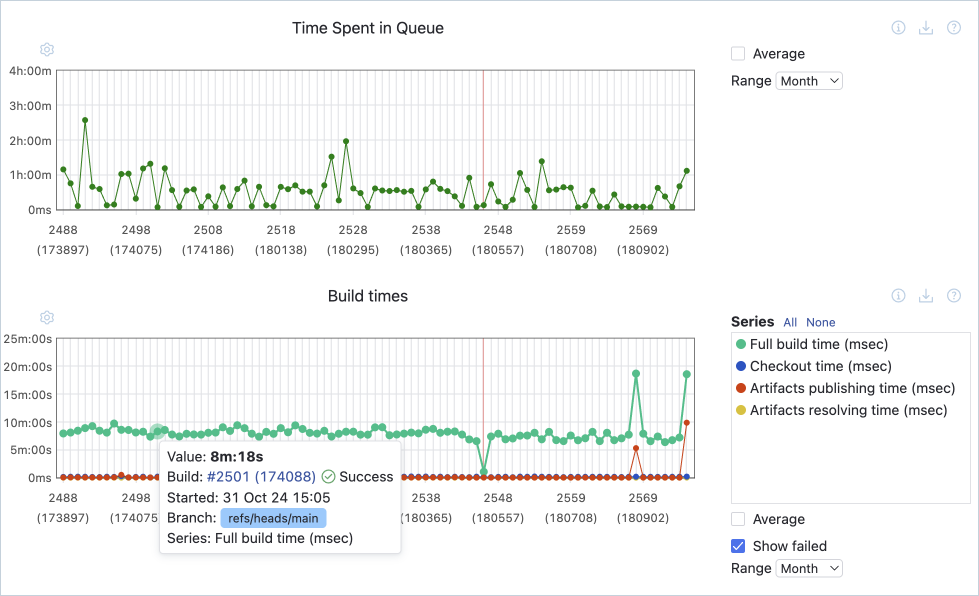
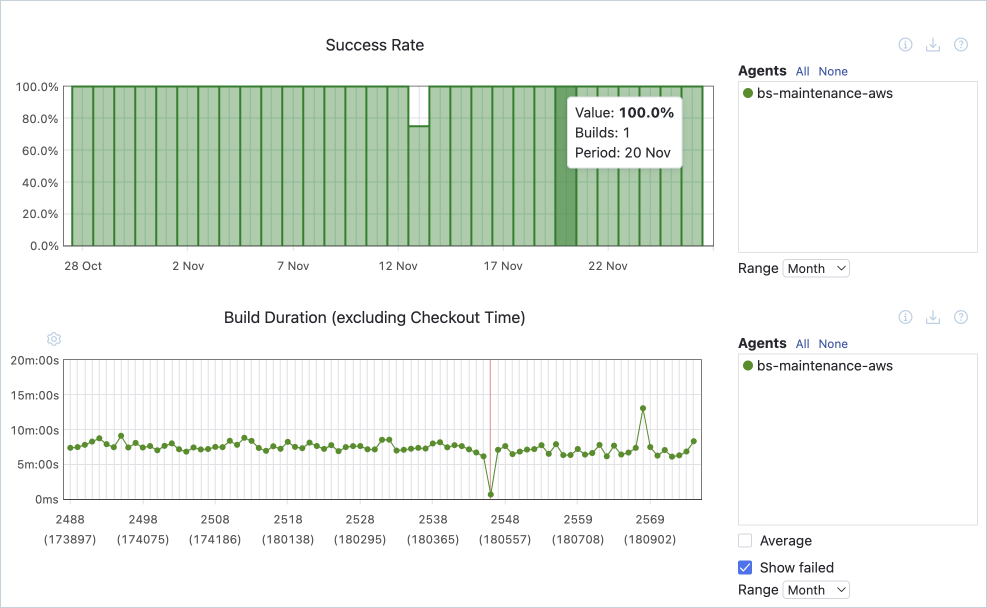
ビルド所要時間
ビルド所要時間またはビルド時間は、自動化されたパイプラインの様々なステージを完了するのにかかる時間を計測します。 プロセスの各ステージにおける経過時間を分析することで、テスト結果の取得や本番環境へのデプロイに時間がかかっている原因となっている問題箇所やボトルネックを特定することができます。
テスト合格率
テスト合格率は、特定のビルドで正常に合格したケースの割合です。 自動テストが合理的なレベルで行われる場合、これは各ビルドの品質を示す目安となります。 このデータを使用することで、コード変更によってどれくらいの頻度で新しいバグが導入されているかを把握できます。
自動テストで失敗を発見するほうが手動テストに頼ったり、本番環境で問題が発覚するよりは望ましいですが、特定の自動テスト一式が頻繁に失敗している場合は、そのような失敗の根本的な原因を探るべきです。
テスト修正の所要時間
テスト修正の所要時間は、テストの失敗がビルドによって報告されてから、同じテストがその後のテストを合格するまでに要する時間です。 このメトリクスは、パイプラインで特定された問題に対応できる速度の目安です。
解決時間が短いということは、パイプラインを効果的に使用しているということです。 問題を発見した場合は、変更内容がまだ記憶に残っているうちに早く修正するほうが効率的です。 問題を素早く修正することで、不安定なコードに機能を追加することを確実に防げます。
失敗したデプロイ
失敗したデプロイによって想定外のダウンタイムが生じると、デプロイのロールバックや緊急の修正が必要になります。 失敗したデプロイの回数は、変更の失敗率を計算するのに使用されます。
デプロイの合計数のうち、失敗する割合をモニタリングすると、SLA に対するパフォーマンスを評価しやすくなります。
ただし、失敗したデプロイをゼロにする(または非常に少なくする)ことを目標とすることは必ずしも現実的ではありません。高品質な製品を安定して出荷することではなく、確実性を優先する要因になりかねません。 このような考え方では複数の変更がまとめにされ、それによってリード時間が長引いたり、デプロイの規模が大きくなったりする可能性があります。 デプロイの規模が大きいほど不確実要素が増えるため、本番環境で失敗する確率が高まり、修正がより困難になります(より多くの変更を検討する必要があるため)。
欠陥数
失敗したデプロイメトリクスとは逆に、欠陥数はバックログでバグとして分類されているオープンチケットの数を指します。 この CI メトリクスは、テスト、ステージング、および本番環境内で検出された問題にさらに分けられます。
欠陥数を監視することで、全体的に欠陥の数が上昇傾向にあり、バグが手に負えなくなっている可能性があることを警戒できます。 ただし、このメトリクスを目標にすると、チームはチケットの修正よりもチケットの分類に集中してしまう可能性があるので注意が必要です。
デプロイのサイズ
デプロイの頻度によって決まるデプロイのサイズ(ビルドまたはリリースに含まれるストーリーポイントの数によって計測される)を使用することで、特定のチーム内のバッチサイズを監視できます。
デプロイを小規模に維持していることは、チームが定期的に変更をコミットしていること、そしてそれに伴うすべてのメリットを確保できていることを示します。 ただし、ストーリーの見積りは開発チーム全体で比較できるものではないため、デブロイの全体的なサイズを計測するためにこの指標を使用することはお勧めしません。
まとめ
これらの DevOps メトリクスにより、デプロイの速度やソフトウェアの品質の観点から見た CI/CD パイプラインの有効性をよりよく理解することができます。
これらのメトリクスを追跡することにより、最も注意が必要なプロセスの部分を特定できます。 変更を加えた後は継続的に関連するメトリクスを監視し、意図した効果が得られたのかどうかを確認してください。
ただし、メトリクスは便利なパフォーマンス指標になりますが、コンテキストに合わせて数値を読み取り、特定のメトリクスがどのような動作を促す可能性があるかを検討することが重要です。
目指すのは数字そのものではなく、パイプラインの速度と信頼性を維持することによってユーザーに価値を提供し続け、その結果として組織の目標を支援することです。