DataGrip 2021.3의 새로운 기능
DataGrip 2021.3이 출시되었습니다! 이번 버전은 2021년 세 번째 주요 업데이트이며 다양한 향상된 기능이 포함되어 있습니다. 지금부터 새 버전에서 제공하는 기능을 살펴보겠습니다!
데이터 에디터
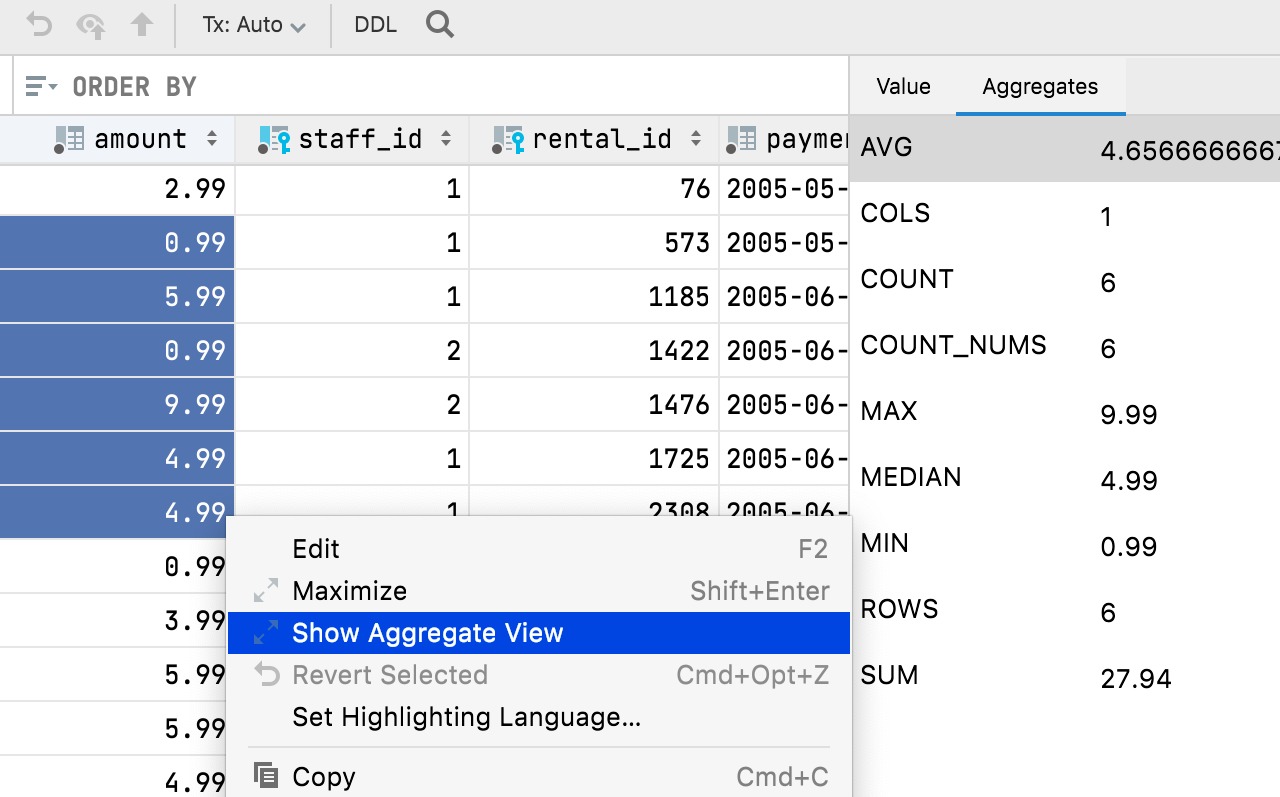
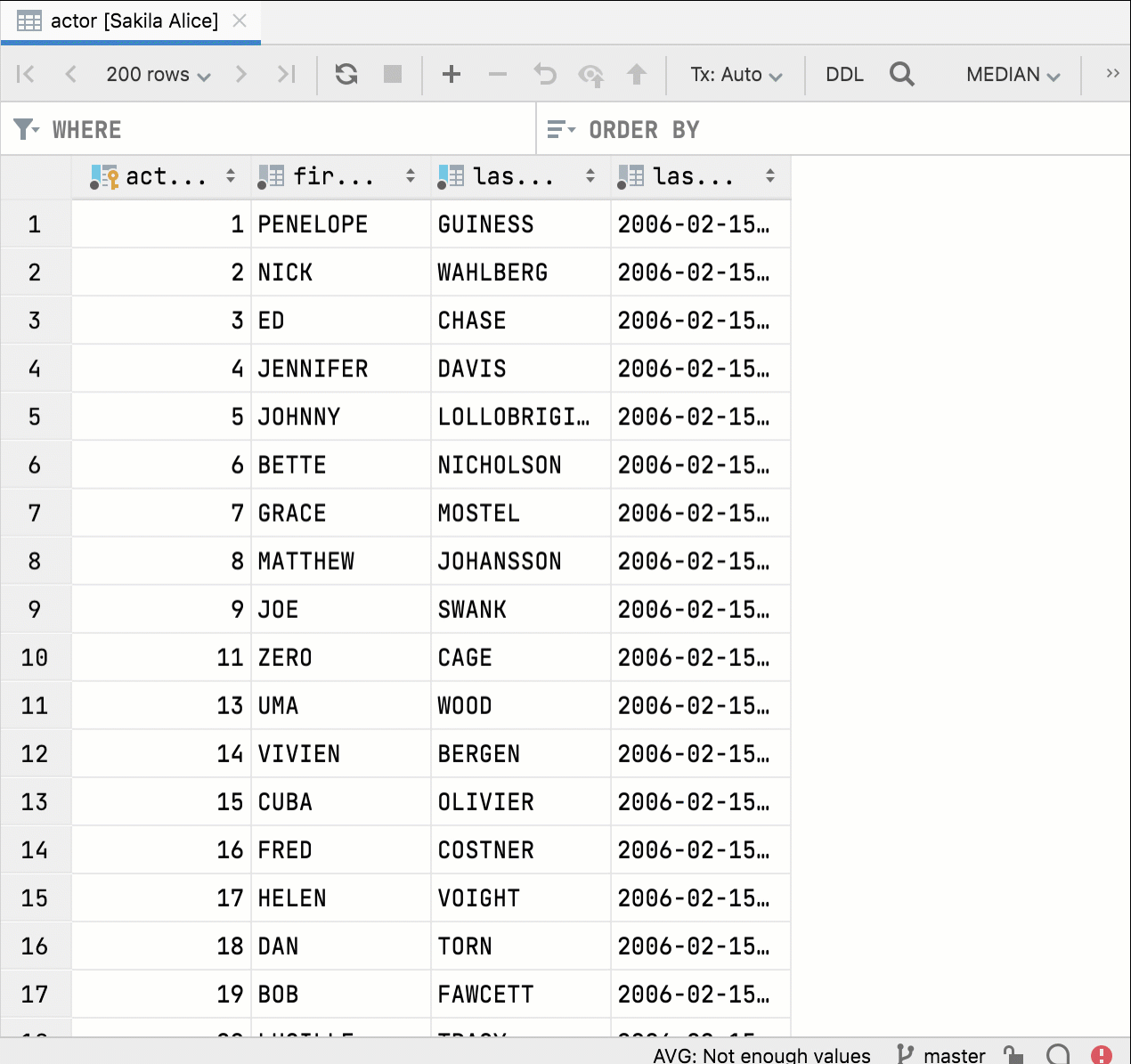
집계
일정 범위의 셀에 대해 Aggregate(집계) 뷰를 표시하는 기능을 추가했습니다. 오랫동안 기다려온 이 기능은 데이터 관리에 도움을 주고 추가 쿼리를 작성해야 하는 수고로움을 덜어줍니다. 이를 통해 데이터 에디터가 Excel 및 Google 스프레드시트와 더욱 유사해지고, 더 강력해지고 사용하기 쉬워졌습니다.
뷰를 보려는 셀 범위를 선택한 다음 마우스 오른쪽 버튼으로 클릭하고 Show Aggregate View(집계 뷰 표시)를 선택하면 됩니다.
빠른 요약:
- Aggregate(집계) 뷰는 Value(값) 뷰와 함께 같은 패널에 각각 별도의 탭으로 표시됩니다. 이 패널은 데이터 에디터의 맨 아래로 이동할 수 있습니다.
- 톱니바퀴 아이콘을 사용하여 이 뷰에서 집계를 표시하거나 숨길 수 있습니다.
- 추출기와 마찬가지로 집계는 스크립트입니다. 기본적으로 제공되는 9개의 스크립트 외에도 자신만의 스크립트를 만들고 공유할 수 있습니다.
- 집계 스크립트와 추출기는 서로 바꿔 사용할 수 있습니다. 이전에 추출기를 사용하여 값을 하나만 가져왔다면 이제 추출기를 Aggregators 폴더에 복사하여 집계에 사용할 수 있습니다. Extractors 폴더와 마찬가지로, 이 폴더는 Scratches and consoles(스크래치 및 콘솔) / Extensions(확장) / Database Tools and SQL(데이터베이스 도구 및 SQL)에 있습니다.
하나의 집계 값이 상태 표시줄에 표시되며 원하는 값(합계, 평균, 중앙값, 최솟값, 최댓값 등)을 선택할 수 있습니다.
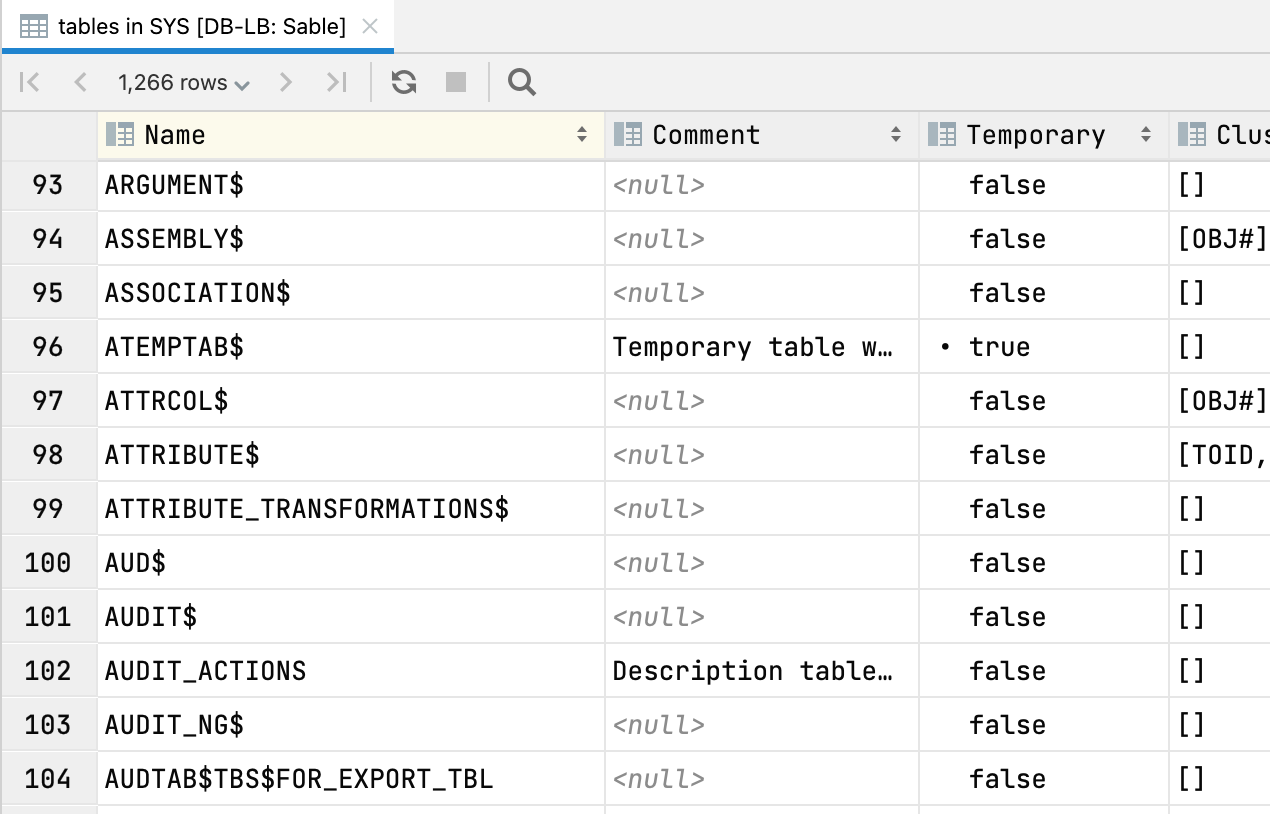
트리 노드의 테이블 뷰
스키마 노드에서 F4를 누르면 노드 내용이 테이블 뷰로 표시됩니다. 예를 들어, 스키마에서 모든 테이블의 테이블 뷰를 얻을 수 있습니다.
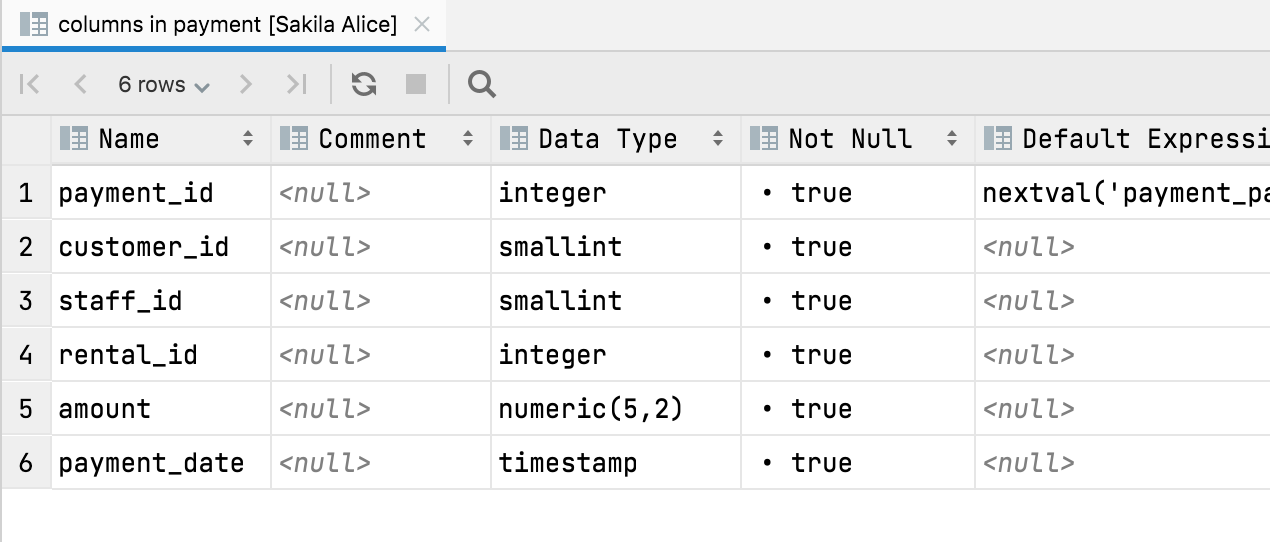
또는 테이블 열의 테이블 뷰를 볼 수 있습니다.
이 뷰를 사용하여 열을 표시하거나 숨기고, 데이터를 다양한 형식으로 내보내고, 텍스트 검색을 사용할 수 있습니다. 특히 다음 탐색 액션이 여기서도 작동합니다.
- Ctrl+B를 누르면 DDL이 표시됩니다.
- F4를 누르면 데이터가 표시됩니다.
- Alt+Shift+B를 누르면 데이터베이스 트리에서 해당 객체가 강조 표시됩니다.
독립 분할
에디터를 분할하고 동일한 테이블을 다시 열면 두 개의 데이터 에디터 창이 완전히 독립적으로 분리됩니다. 그러면 서로 다른 필터링 및 순서 지정 옵션을 설정하여 데이터를 비교하고 처리할 수 있습니다. 이전에는 필터링과 순서 지정이 동기화되어 완벽하지 않았습니다.
사용자 지정 글꼴
Database(데이터베이스) | Data views(데이터 뷰) | Use custom font(사용자 지정 글꼴 사용)에서 데이터 표시를 위한 전용 글꼴을 선택할 수 있습니다.
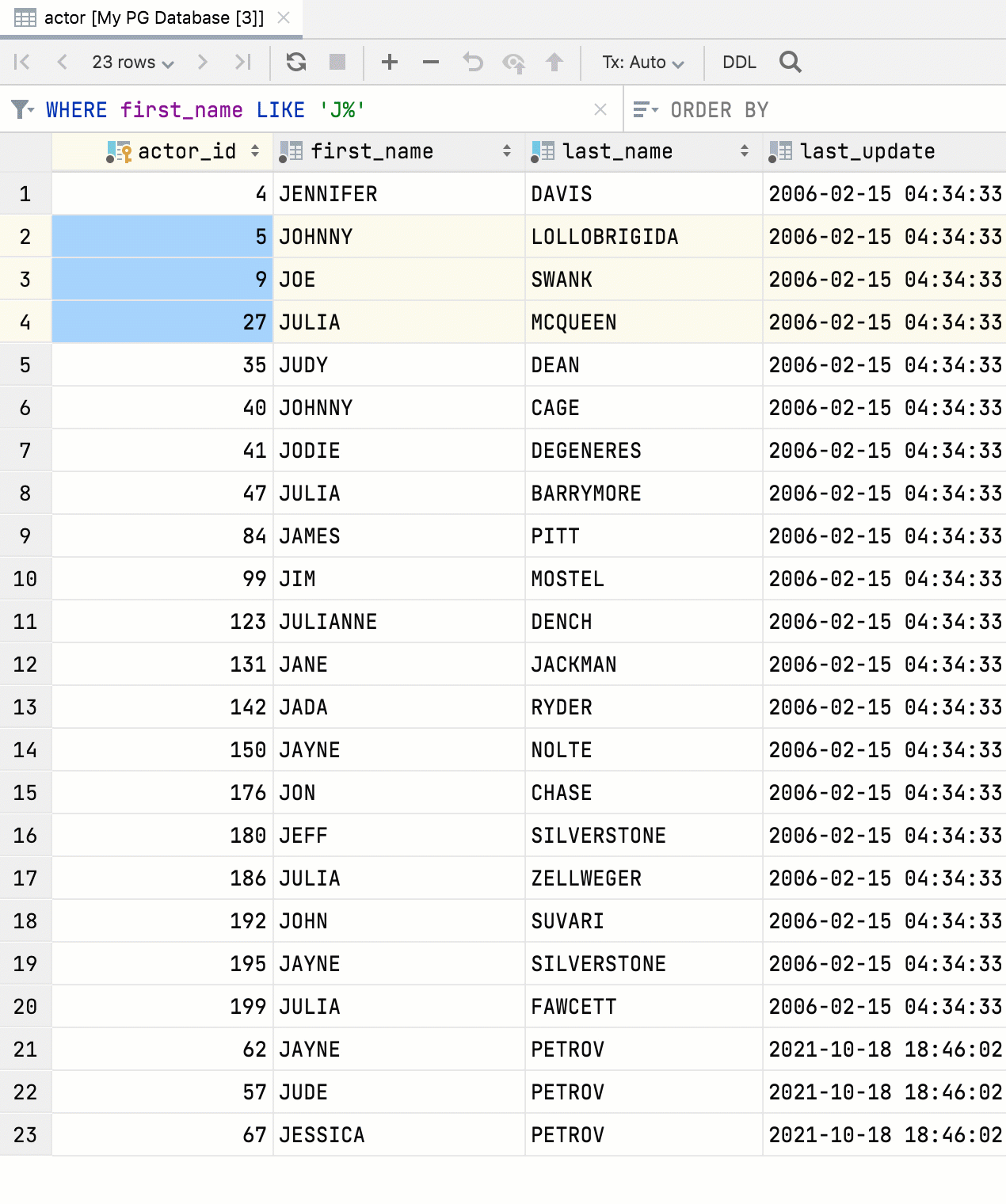
여러 값을 사용한 외래 키 탐색
이제 데이터 에디터에서 여러 값을 선택하고 관련 데이터로 이동할 수 있습니다.
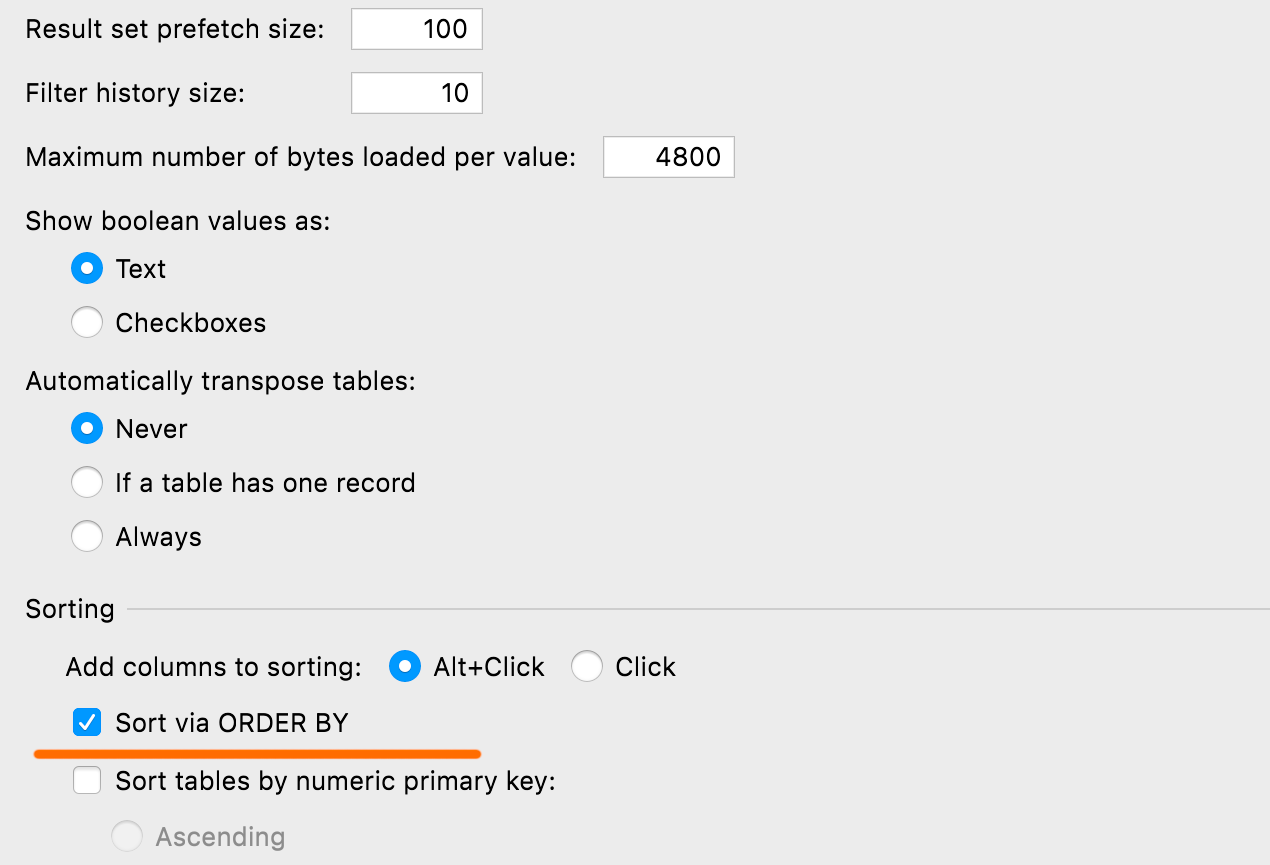
디폴트 정렬 설정
ORDER BY 또는 client-side를 통해 테이블을 정렬하는 디폴트 방법을 정의할 수 있습니다. 후자는 새 쿼리를 실행하지 않고 현재 페이지만 정렬합니다. 이 설정은 Database(데이터베이스) | Data views(데이터 뷰) | Sorting(정렬) | Sort via ORDER BY(ORDER BY를 통한 정렬)에서 찾을 수 있습니다.
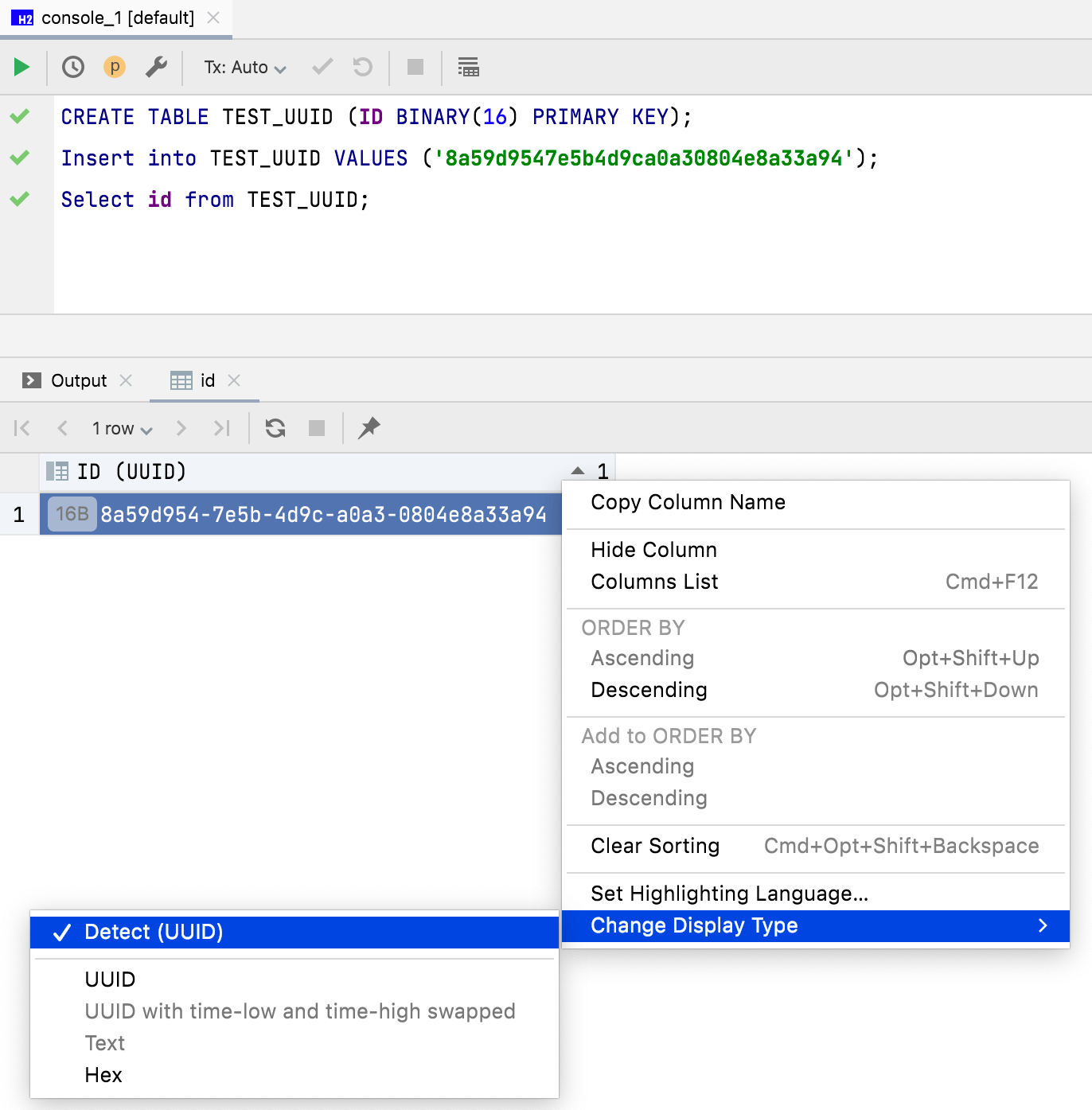
바이너리 데이터의 표시 모드
이제 16바이트 데이터가 기본적으로 UUID로 표시됩니다. 데이터 에디터 열에 바이너리 데이터가 표시되는 방식을 사용자 지정할 수도 있습니다.
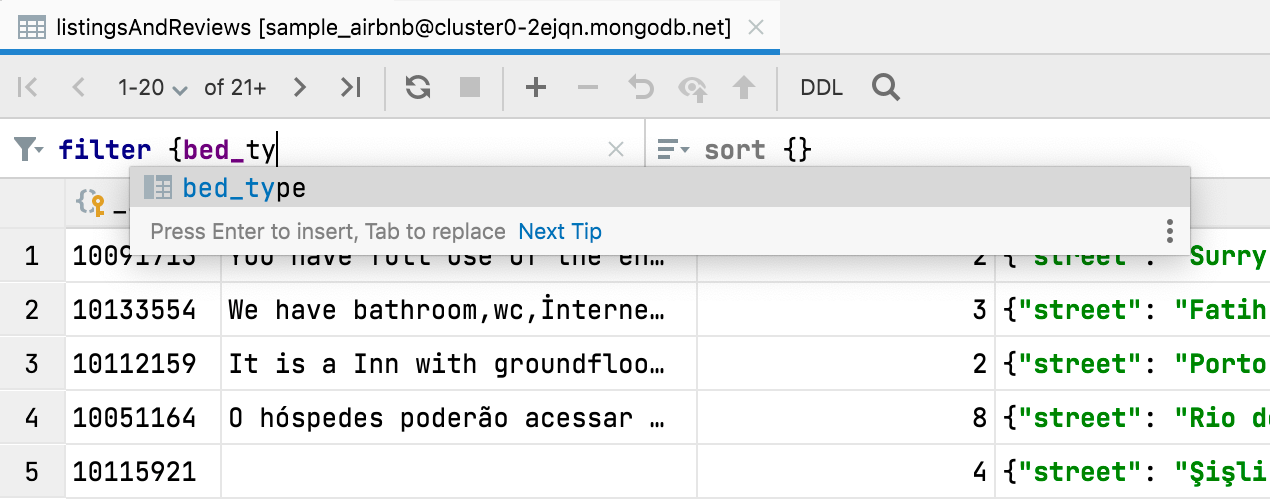
filter {} 및 sort {} 코드 완성 MongoDB
이제 MongoDB 컬렉션에서 데이터를 필터링할 때 코드 완성을 사용할 수 있습니다.
VCS에 데이터베이스 유지
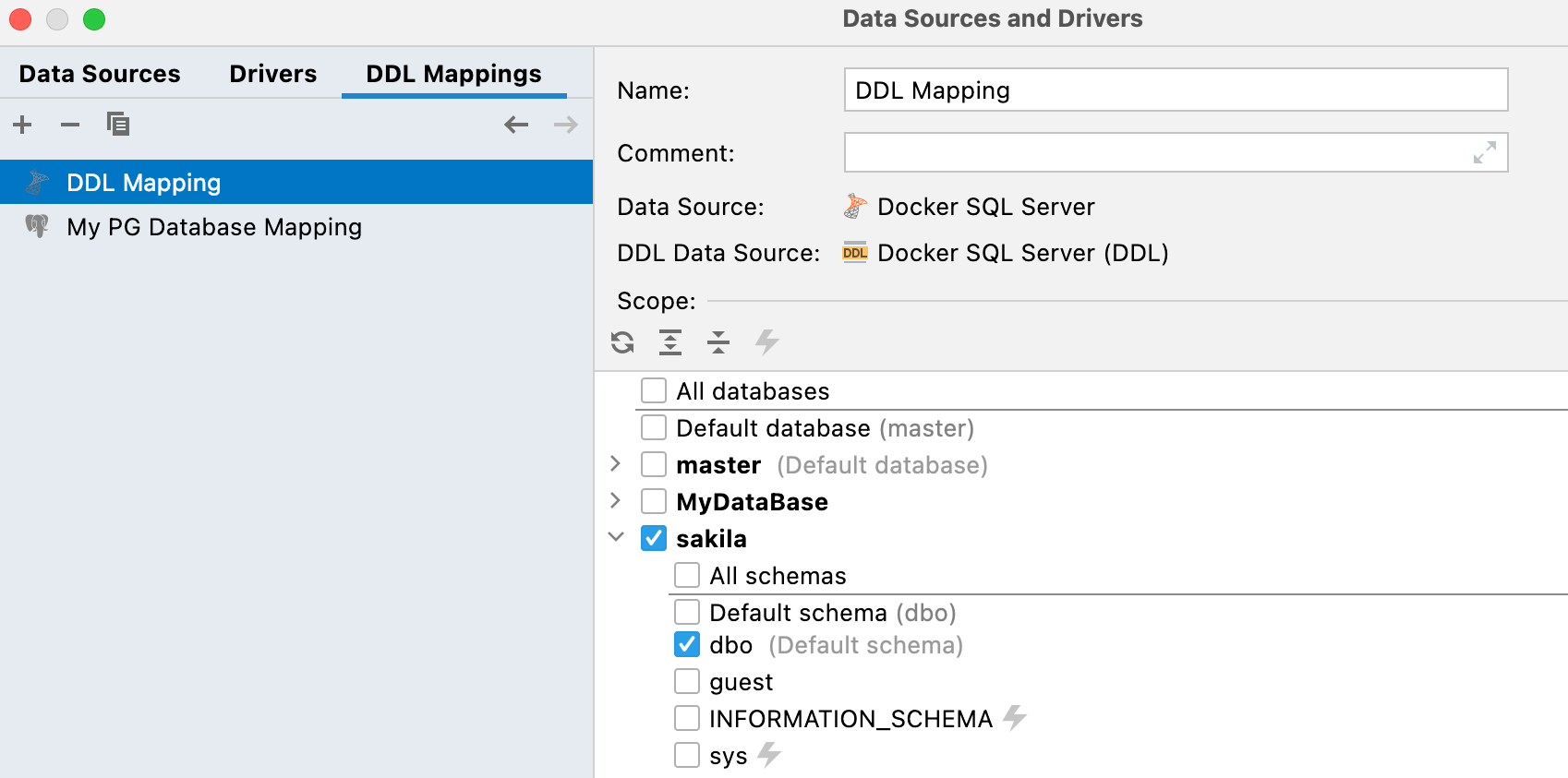
DDL 데이터 소스와 실제 데이터 소스 매핑
이번 릴리스는 이전 릴리스의 자연스러운 연장으로, 실제 데이터 소스를 기반으로 DDL 데이터 소스를 생성하는 기능이 도입되었습니다. 이제 이 워크플로가 완전히 지원됩니다. 사용자는 다음 작업을 수행할 수 있습니다.
- 실제 데이터 소스에서 DDL 데이터 소스를 생성합니다(2021.2 발표 참조).
- DDL 데이터 소스를 사용하여 실제 데이터 소스를 매핑합니다.
- 이러한 데이터 소스를 양방향으로 비교하고 동기화합니다.
참고로, DDL 데이터 소스는 스크립트가 일련의 SQL 스크립트에 기반을 둔 가상 데이터 소스입니다. 버전 관리 시스템에 이러한 파일을 저장하는 것은 VCS에서 데이터베이스를 관리하는 한 가지 방법입니다.
데이터 구성 프로퍼티의 새 탭인 DDL mappings(DDL 매핑)에서 각 DDL 데이터 소스에 매핑되는 실제 데이터 소스를 정의할 수 있습니다.
이러한 새로운 기능이 일상적인 VCS 흐름에 정확히 어떤 도움을 주는지 자세히 알고 싶다면 이 문서를 읽어보세요.
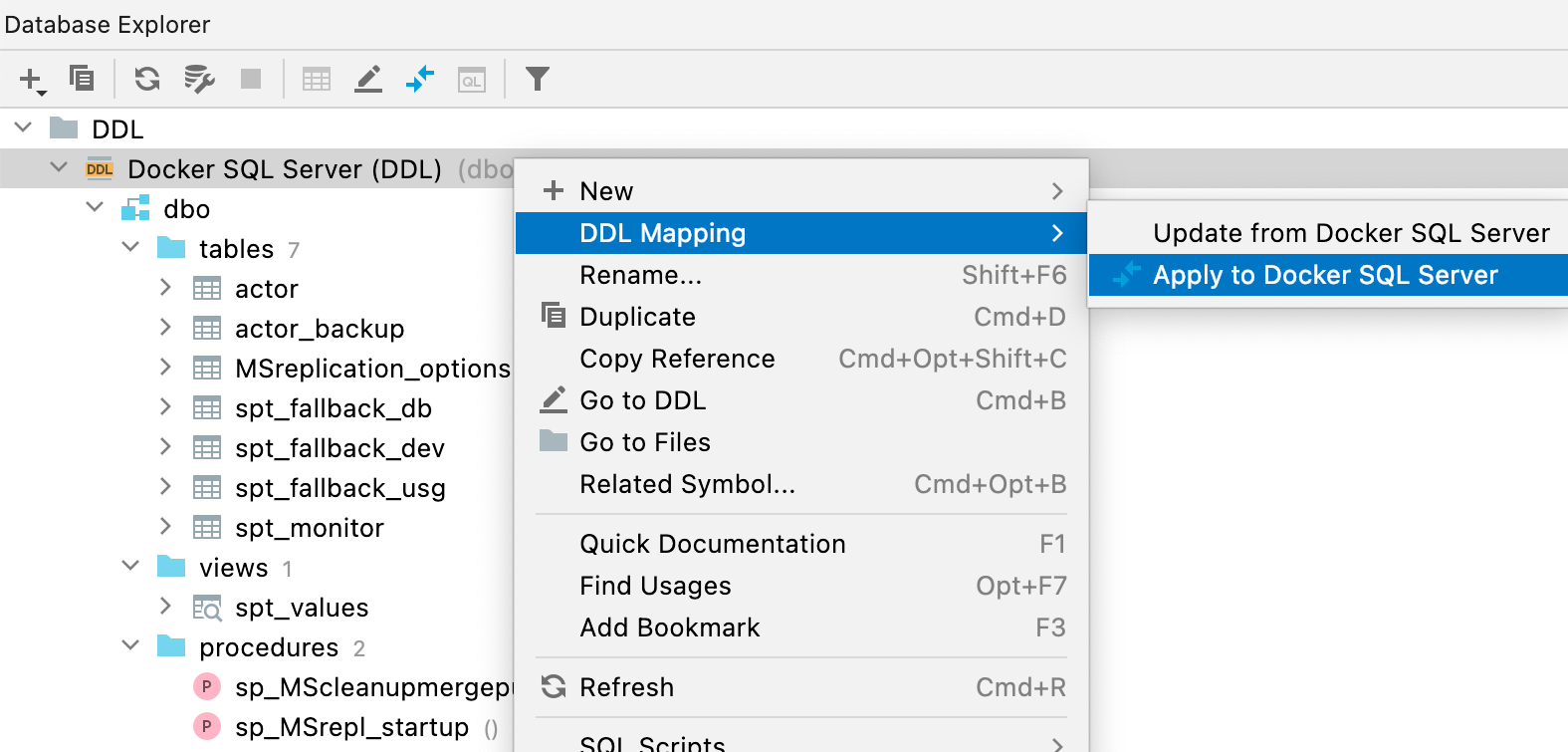
새 데이터베이스 Diff 창
DDL 데이터 소스를 실제 데이터 소스와 비교하고 동기화하려면 컨텍스트 메뉴를 선택한 후 DDL Mappings(DDL 매핑) 하위 메뉴에서 Apply from...(다음에서 적용) 또는 Dump to...(다음으로 덤프)를 선택하세요.
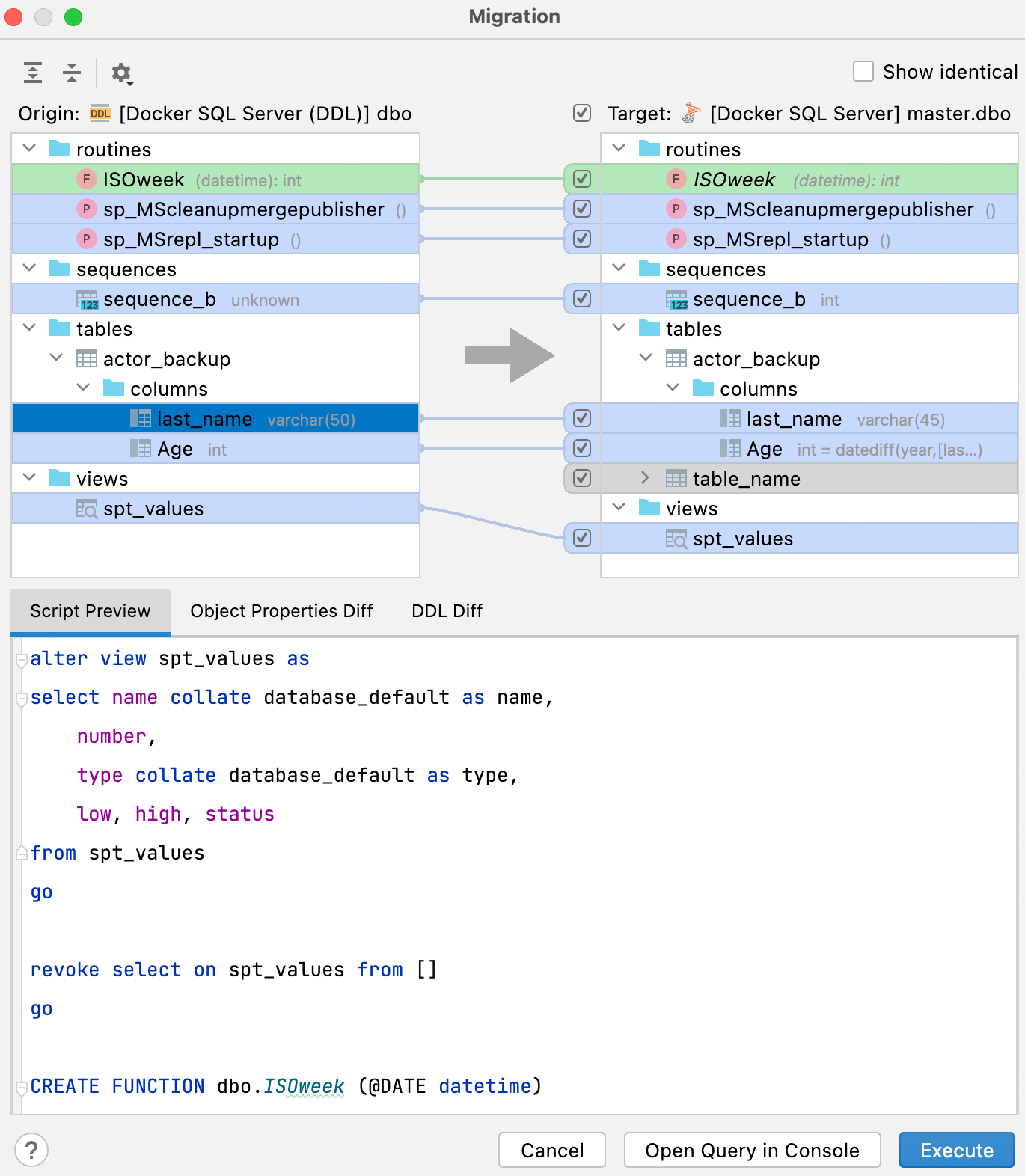
이 새로운 창은 UI가 향상되어 동기화를 수행한 후 얻을 수 있는 결과가 오른쪽 패널에 더 명확하게 표시됩니다.
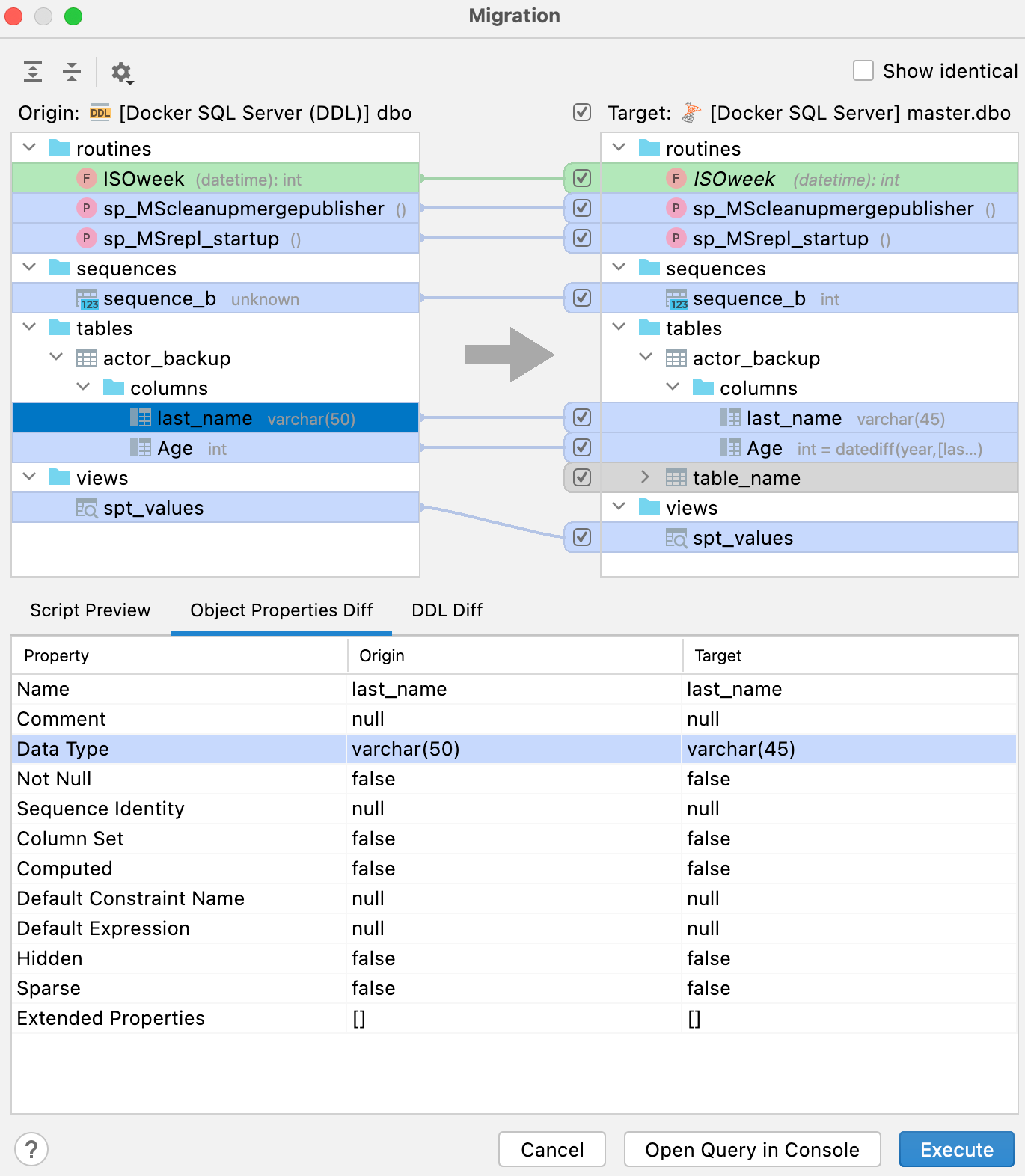
오른쪽 패널의 범례는 잠재적 결과에 대한 색상의 의미를 보여줍니다.
- 녹색 및 기울임꼴: 객체가 생성됩니다.
- 회색: 객체가 삭제됩니다.
- 파란색: 객체가 변경됩니다.
Script preview(스크립트 미리보기) 탭에는 새 콘솔에서 열거나 이 대화상자에서 실행할 수 있는 결과 스크립트가 표시됩니다. 이 스크립트의 결과는 변경 사항을 적용하여 오른쪽에 있는 데이터베이스(대상)를 왼쪽 데이터베이스(원본)의 복사본으로 만듭니다.
Script preview(스크립트 미리보기) 탭 외에도 하단 패널에는 Object Properties Diff(객체 프로퍼티 Diff) 및 DDL Diff의 두 가지 탭이 더 있습니다. 여기에는 원본과 대상 데이터베이스에 있는 객체의 특정 버전 간 차이가 표시됩니다.
참고 사항: 단순히 두 스키마 또는 객체를 비교하려는 경우라면 해당 스키마 또는 객체를 선택하고 Ctrl + D를 누르세요.
중요! Diff 뷰어는 아직 개발 중입니다. 각 데이터베이스에는 고유한 특정 기능이 있기 때문에 일부 객체는 실제로는 동일하지만 다르게 표시될 수 있습니다. 이러한 상황은 타입 별칭, 또는 생성 시 디폴트 프로퍼티의 누락으로 인해 발생할 수 있습니다. 이 버그를 발견하면 트래커에 보고해 주세요.
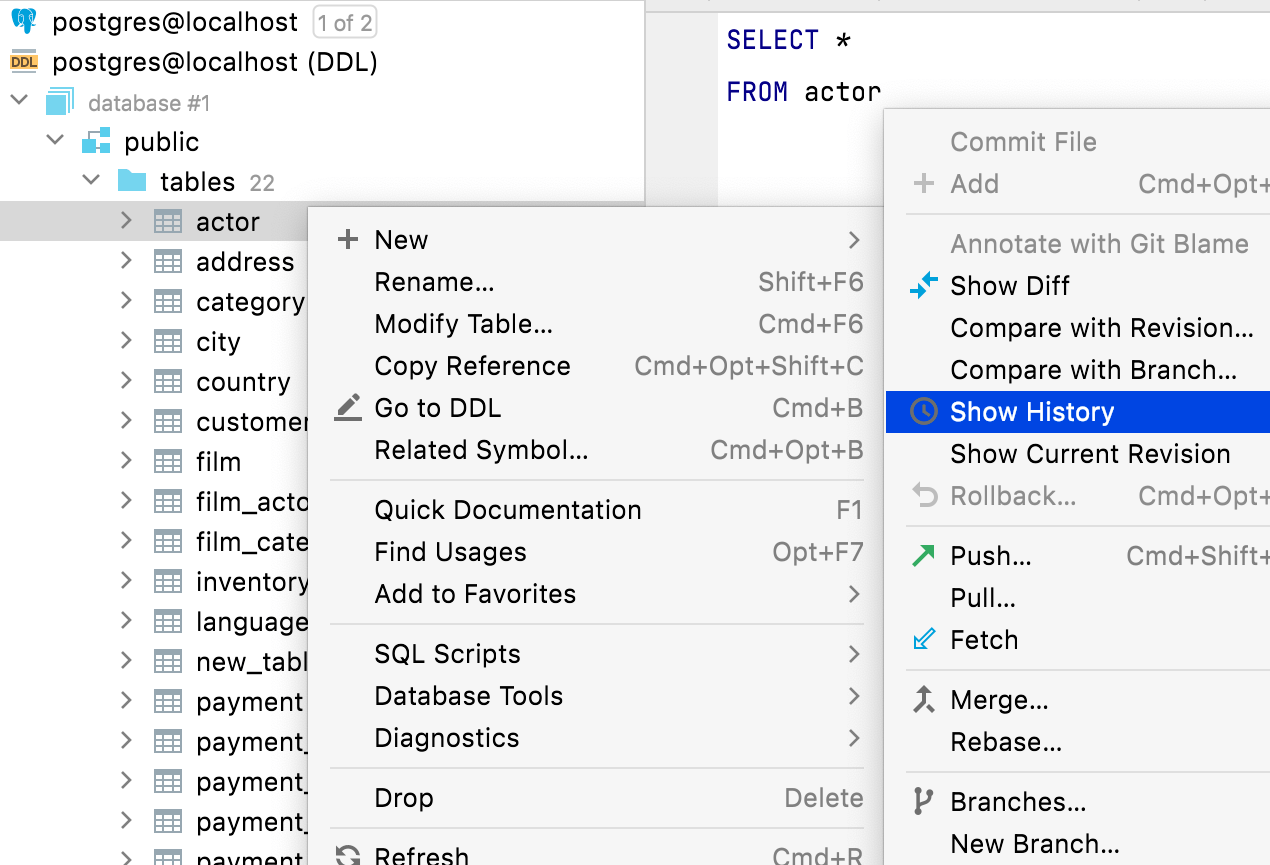
파일 관련 액션
모든 파일 관련 액션은 DDL 데이터 소스 요소에서도 사용할 수 있습니다. 예를 들어, 데이터베이스 탐색기에서 스키마 요소와 관련된 파일을 삭제, 복사 또는 커밋할 수 있습니다.
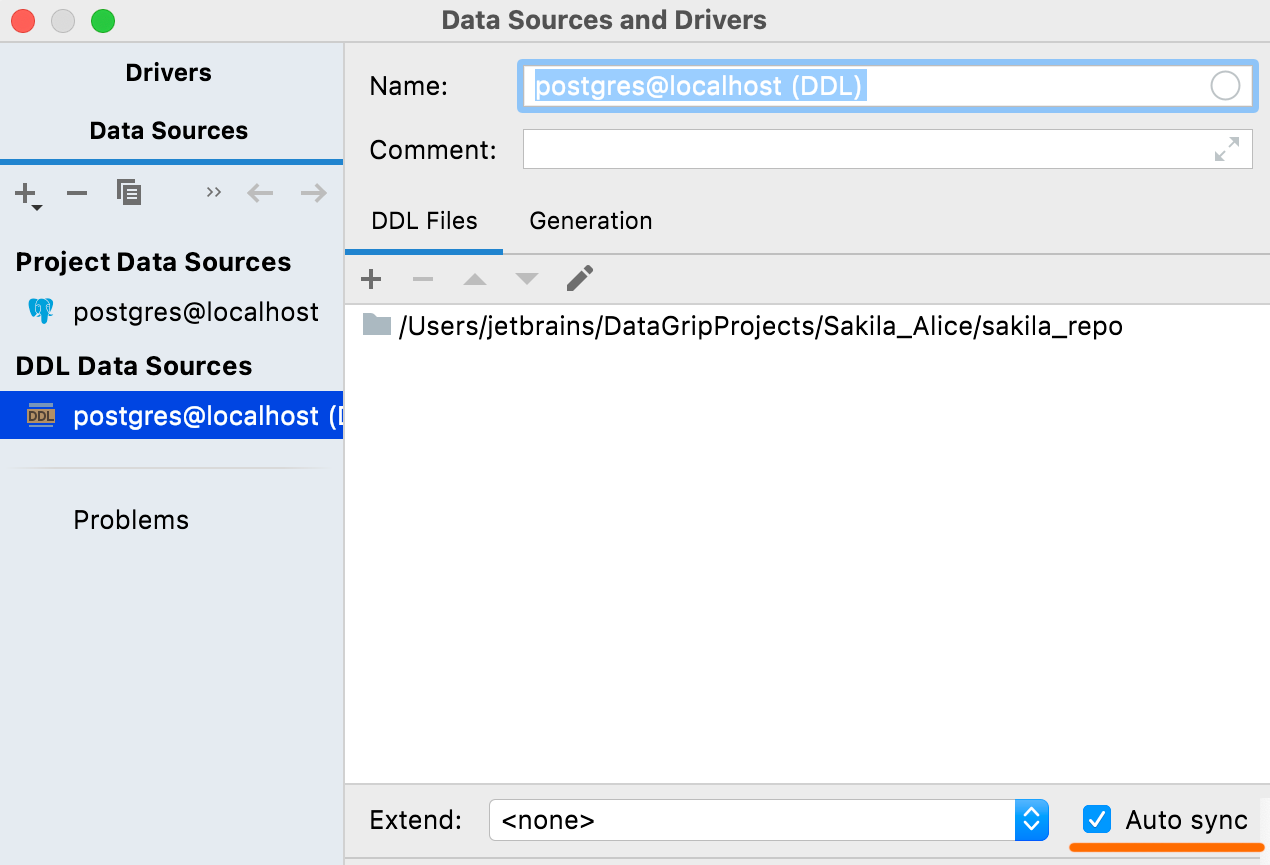
자동 동기화
이 옵션이 켜져 있으면 해당 파일에 대한 변경 내용이 적용되어 DDL 데이터 소스가 자동으로 새로 고쳐집니다. 디폴트였던 이 동작을 이제 비활성화할 수 있는 옵션이 추가되었습니다.
비활성화하면 소스 파일의 변경 내용이 DDL 데이터 소스에 자동으로 반영되지 않으므로 적용하려면 Refresh(새로고침)를 클릭해야 합니다.
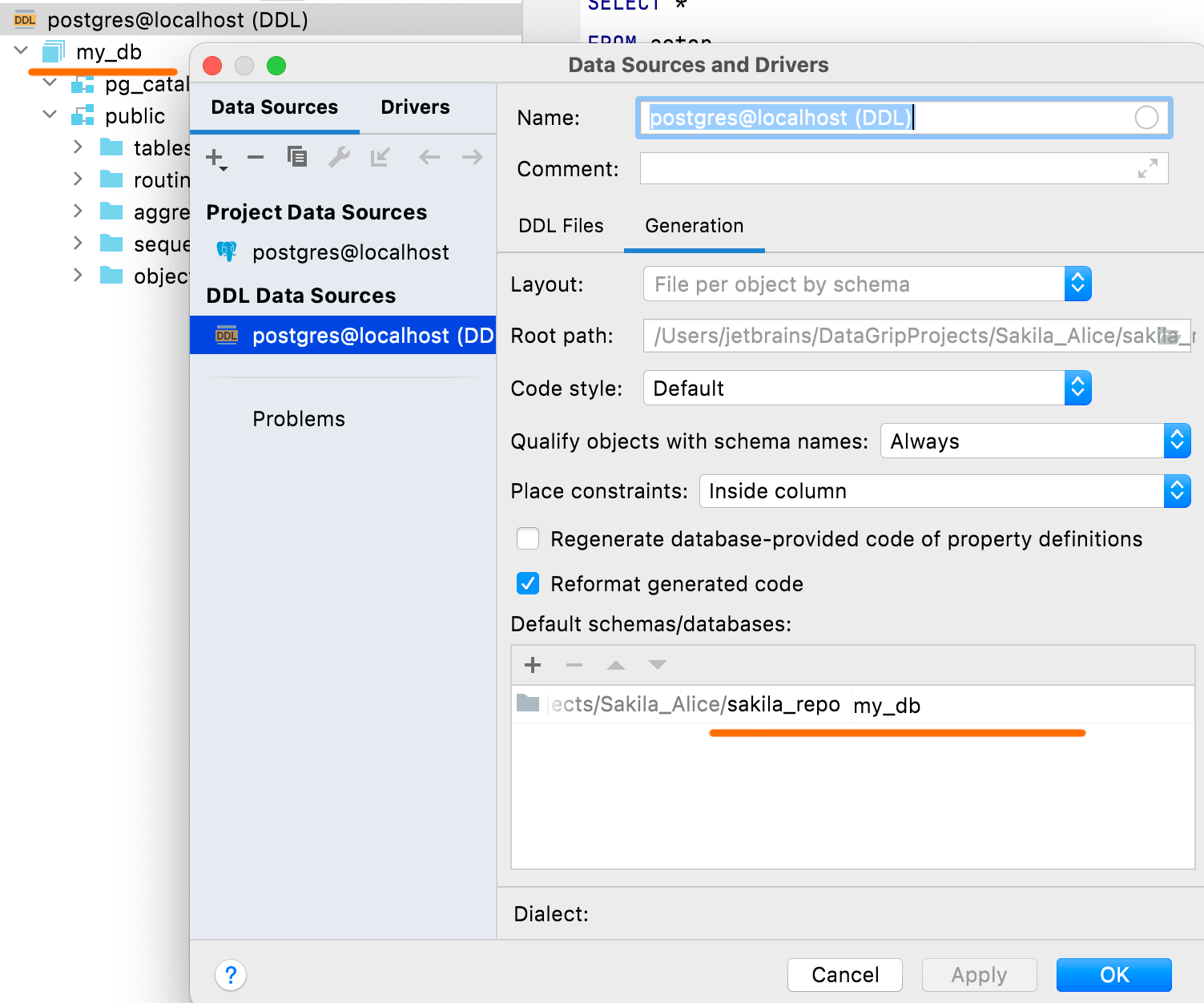
디폴트 스키마 및 데이터베이스 설정
Default schemas/databases(디폴트 스키마/데이터베이스) 패널에서 DDL 데이터 소스에 표시될 데이터베이스 및 스키마의 이름을 정의할 수 있습니다. DDL 스크립트에는 일반적으로 이름이 포함되지 않으며, 이러한 경우 기본적으로 데이터베이스 및 스키마에 대한 더미 이름이 있습니다.
연결성
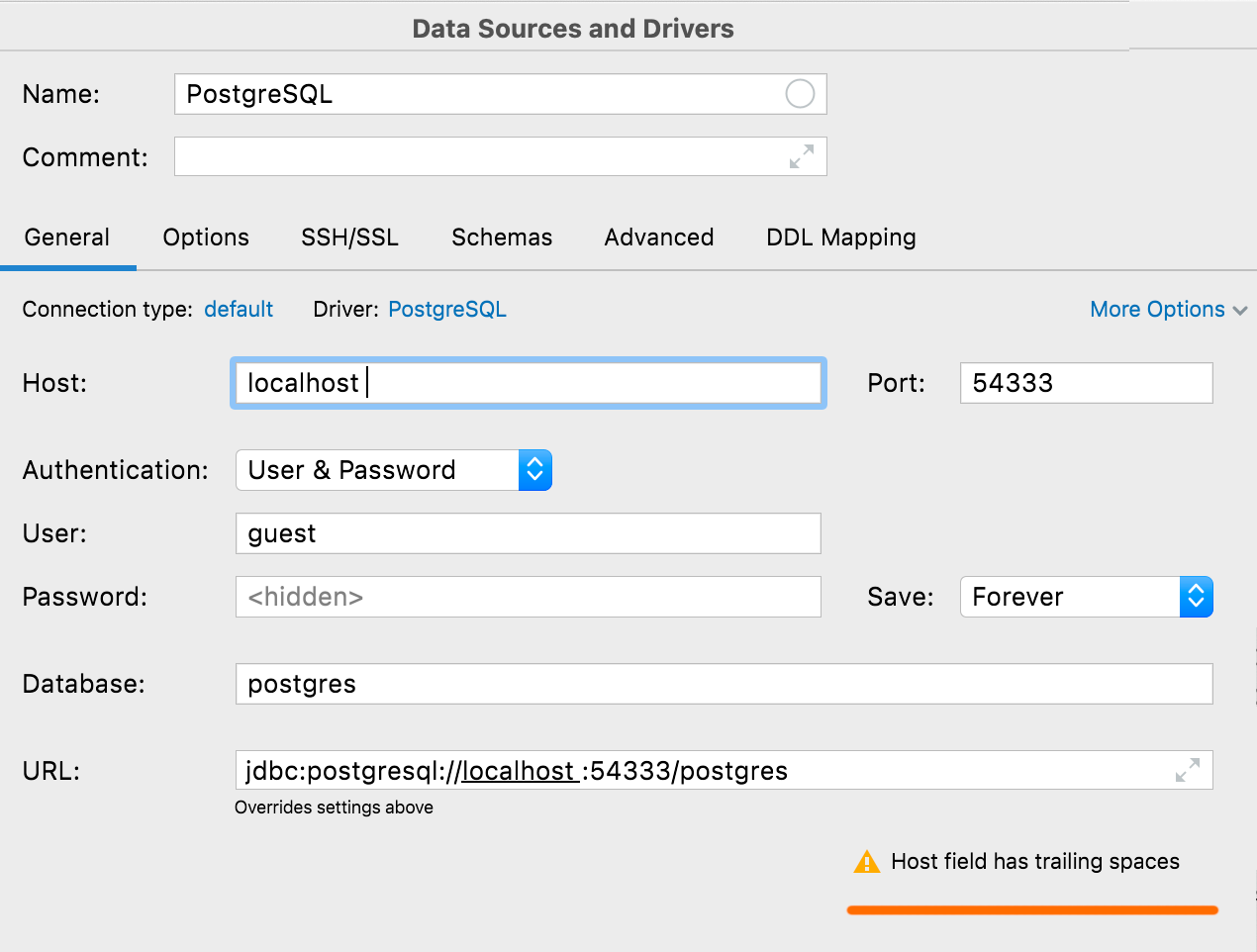
실수로 포함된 공백 경고
User 또는 Password를 제외한 값에 선행 또는 후행 공백이 있는 경우, Test Connection(연결 테스트)을 클릭하면 DataGrip에서 이에 대한 경고를 표시합니다.
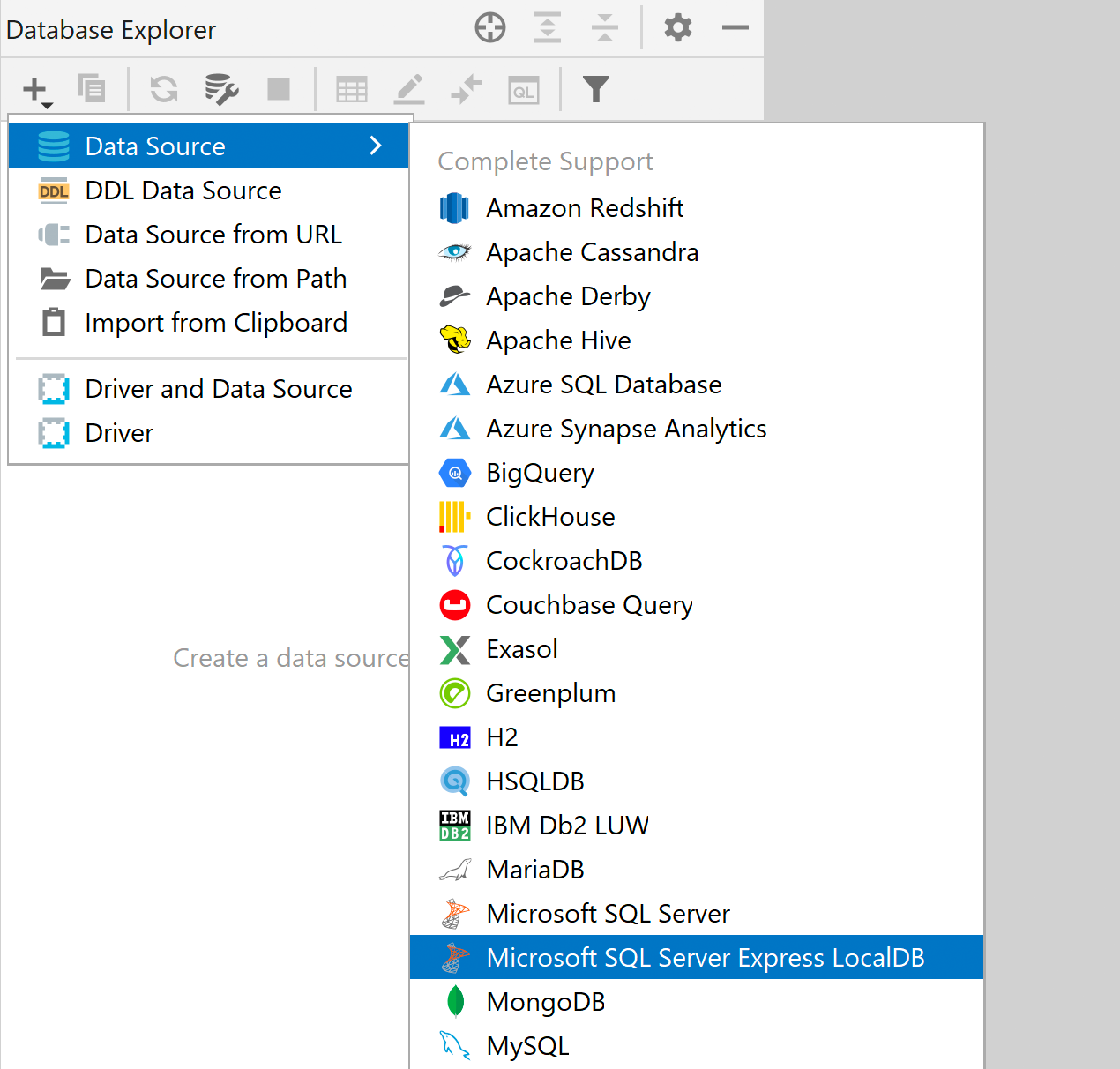
전용 데이터 소스 역할을 하는 LocalDB SQL Server
SQL Server LocalDB에는 드라이버 목록에 전용 드라이버가 있습니다. 즉, LocalDB에 사용해야 하는 별도의 데이터 소스 유형이 있습니다. 주요 이점은 다음과 같습니다.
- LocalDB 연결을 탐색하기가 더욱 쉽습니다.
- 드라이버 옵션에서 실행 파일의 경로를 한 번만 설정하면 모든 데이터 소스에 적용됩니다.
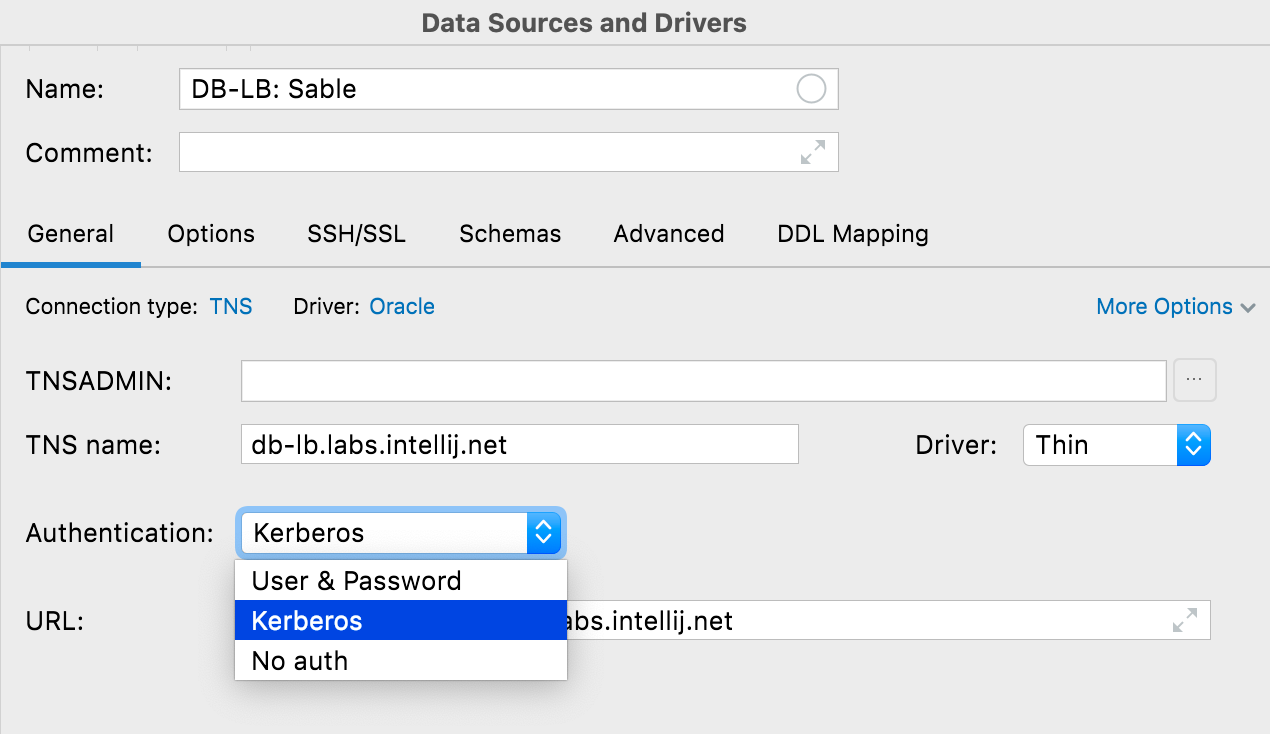
Kerberos 인증 Oracle, SQL Server
이제 Oracle 및 SQL Server에서 Kerberos 인증을 사용할 수 있습니다. Kerberos 옵션을 선택하면, DataGrip이 사용할 기본 요소의 초기 티켓 부여 티켓을 kinit 명령어를 사용하여 얻어야 합니다.
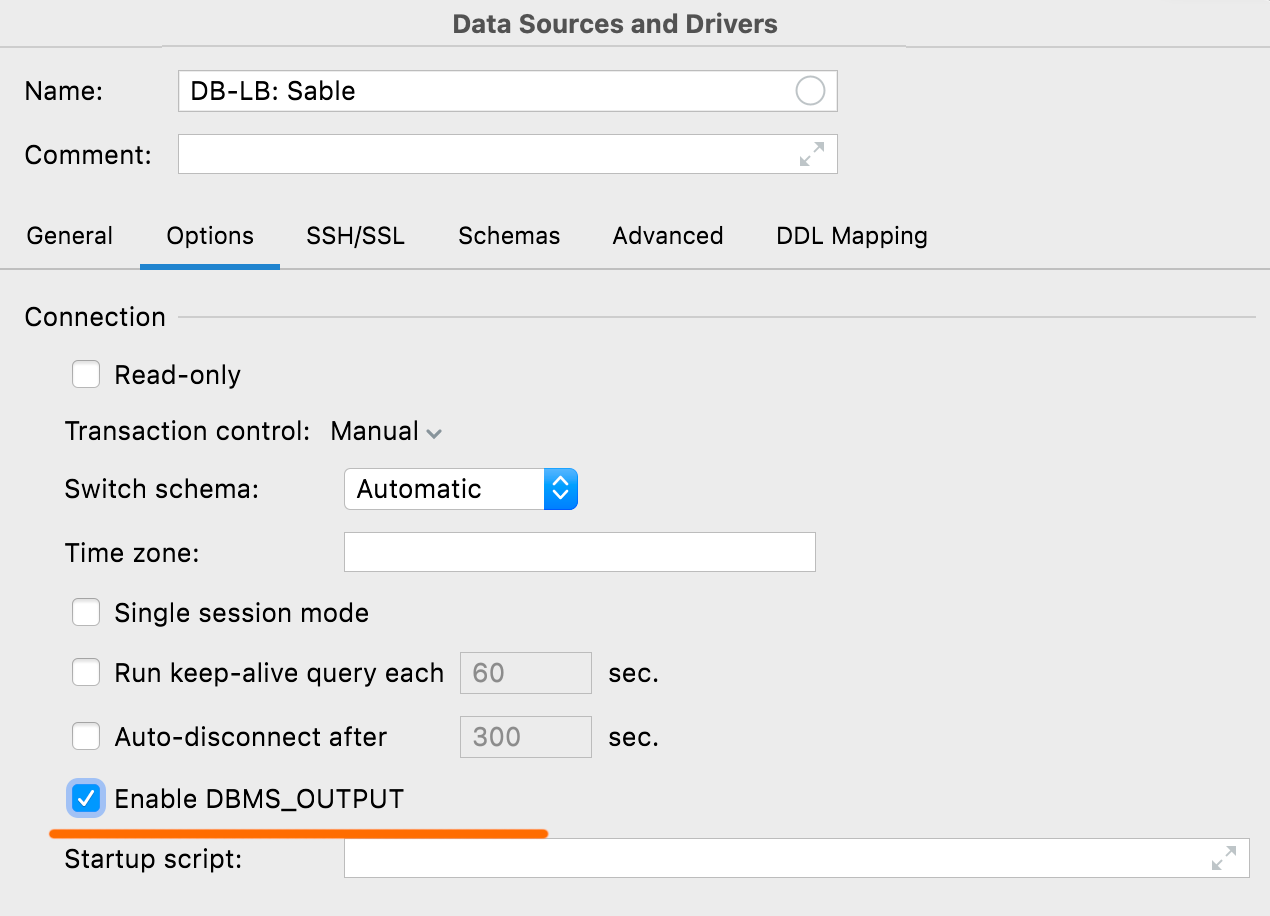
DBMS_OUTPUT 활성화 Oracle, IBM Db2
Options(옵션) 탭의 이 새 옵션을 사용하면 새 세션에 대해 기본적으로 DBMS_OUTPUT을 활성화할 수 있습니다.
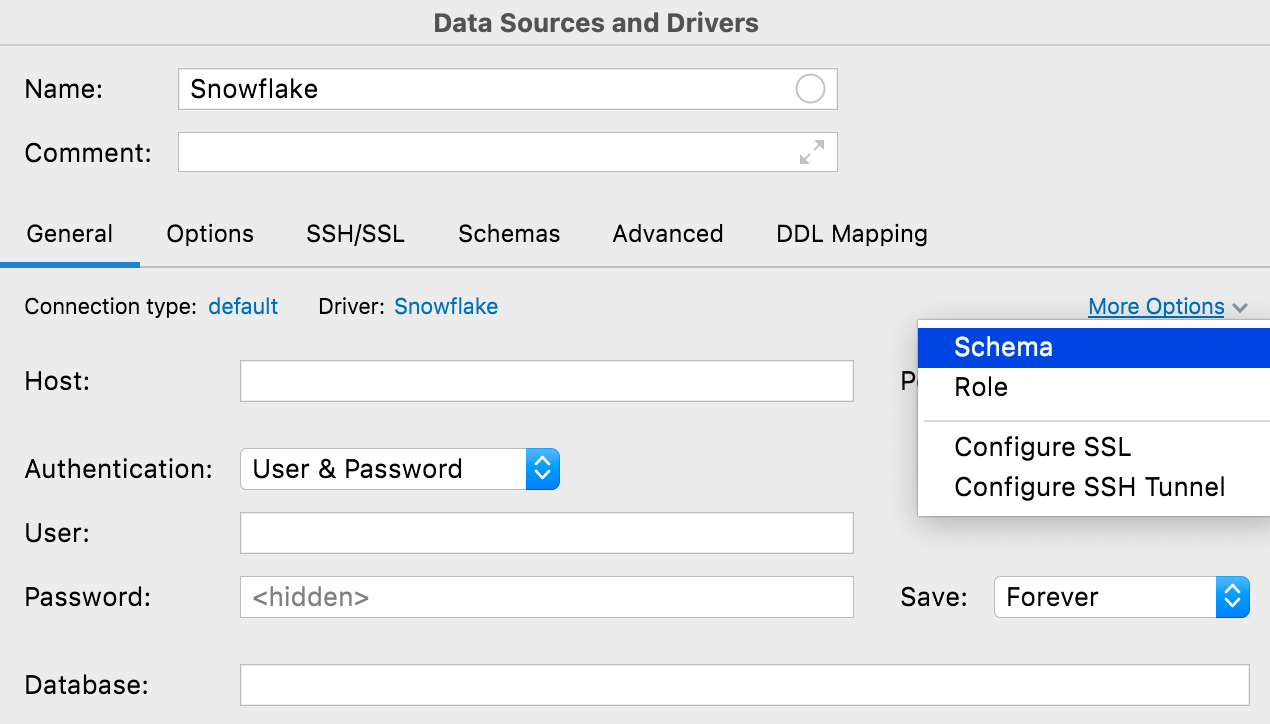
기타 옵션 버튼
연결을 위해 이례적인 구성이 필요한 경우를 위해 More Options(기타 옵션) 버튼을 추가했습니다. 현재 사용 가능한 옵션에는 Snowflake 연결을 위해 Schema(스키마) 및 Role(역할) 필드를 추가하는 기능과 검색 가능성을 높이기 위해 SSH 및 SSL을 구성하기 위한 두 가지 메뉴 항목이 포함됩니다.
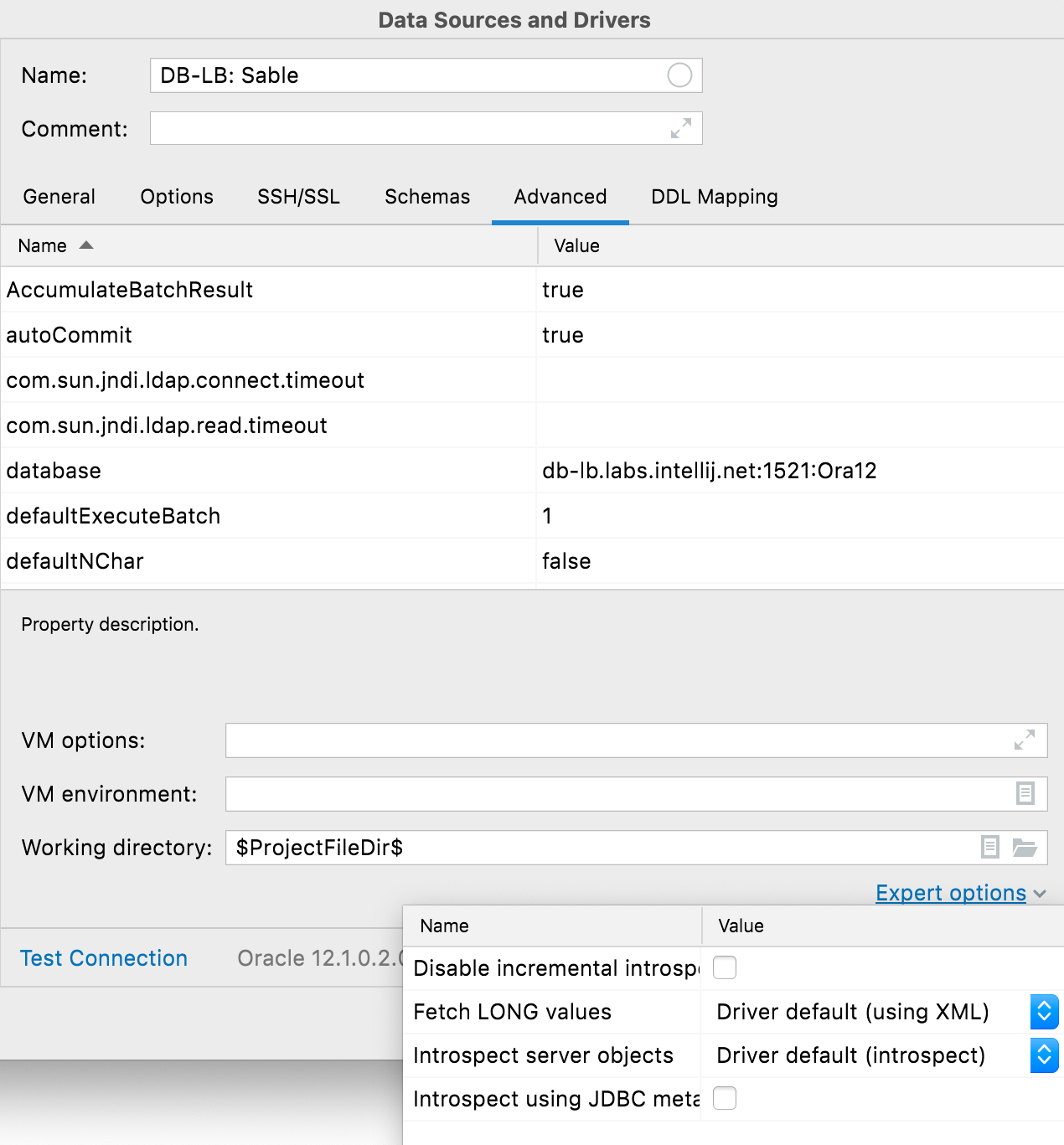
전문가 옵션
Advanced(고급) 탭에 이제 Expert options(전문가 옵션) 목록이 포함됩니다. JDBC 내부 검사기를 켜는 옵션(사용하기 전에 지원 팀에 문의해주세요!) 외에도 다음과 같은 데이터베이스별 옵션을 사용할 수 있습니다.
- Oracle: 증분 내부 검사, Fetch LONG 값 및 내부 검사 서버 객체 비활성화
- SQL Server: 증분 내부 검사 비활성화
- PostgreSQL(및 유사): 증분 내부 검사 비활성화 및 pgdatabase에 대한 쿼리에 xmin 사용 안 함
- SQLite: REGEXP 함수 등록
- MYSQL: 소스 코드에 SHOW/CREATE 사용
- ClickHouse: sessionid 자동 할당
내부 검사
내부 검사 수준 Oracle
데이터베이스와 스키마가 많은 경우에 Oracle 사용자는 DataGrip 내부 검사가 오래 걸리는 불편을 겪었습니다. 내부 검사는 데이터베이스의 메타데이터(예: 객체 이름 및 소스 코드)를 가져오는 프로세스입니다. 내부 검사는 DataGrip에서 신속한 코딩 지원, 탐색 및 검색을 제공하는 데 필요합니다.
Oracle 시스템 카탈로그는 다소 느리며, 사용자에게 관리자 권한이 없는 경우 내부 검사는 더욱 느려집니다. 메타데이터 가져오기 쿼리를 최적화하기 위해 최선을 다했지만 모든 것에는 한계가 있습니다.
그런데 생각해보니 대부분의 일상적인 작업 측면이나 효과적인 코딩 지원 측면에서도 객체 소스를 로드할 필요가 없었습니다. 보통 적절한 코드 완성 및 탐색을 제공하는 데에는 데이터베이스 객체 이름만 있으면 충분합니다. 그래서 Oracle 데이터베이스에 대한 세 가지 내부 검사 수준을 도입했습니다.
- 수준 1: 색인 열 및 private 패키지 변수의 이름을 제외한 지원되는 모든 객체 및 해당 시그니처의 이름
- 수준 2: 소스 코드를 제외한 모두
- 수준 3: 모두
내부 검사는 수준 1에서 가장 빠르고 수준 3에서 가장 느립니다.
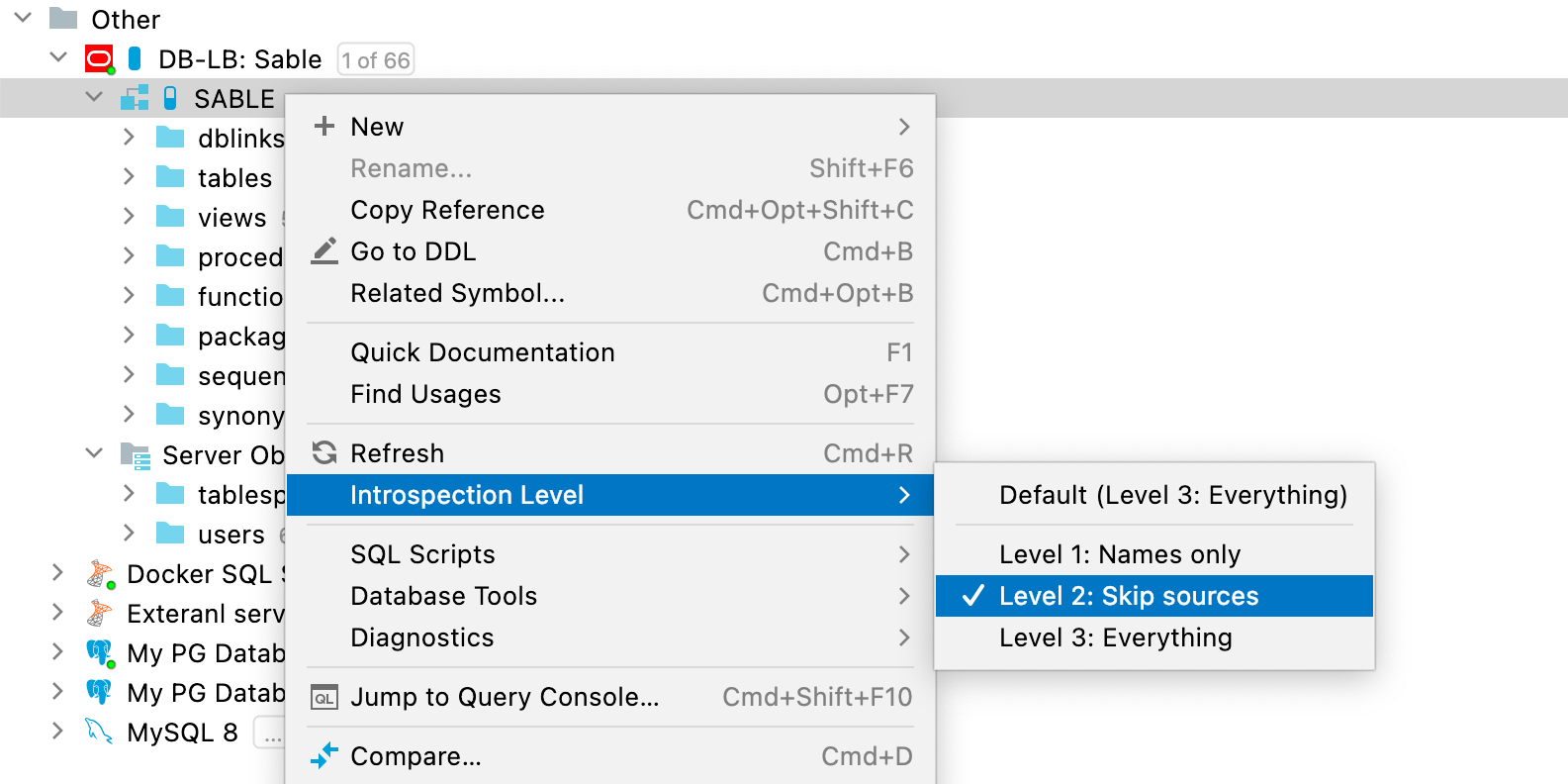
컨텍스트 메뉴를 사용하여 내부 검사 수준을 적절하게 전환하세요.

내부 검사 수준은 스키마 또는 전체 데이터베이스에 대해 설정할 수 있습니다. 스키마는 데이터베이스에서 내부 검사 수준을 상속하지만 독립적으로 설정할 수도 있습니다.
내부 검사 수준은 데이터 소스 아이콘 옆에 있는 알약 모양의 아이콘으로 표시됩니다. 알약이 더 많이 채워질수록 수준이 높습니다. 파란색 아이콘은 내부 검사 수준이 직접 설정되었음을 의미하고, 회색 아이콘은 상속되었음을 의미합니다.
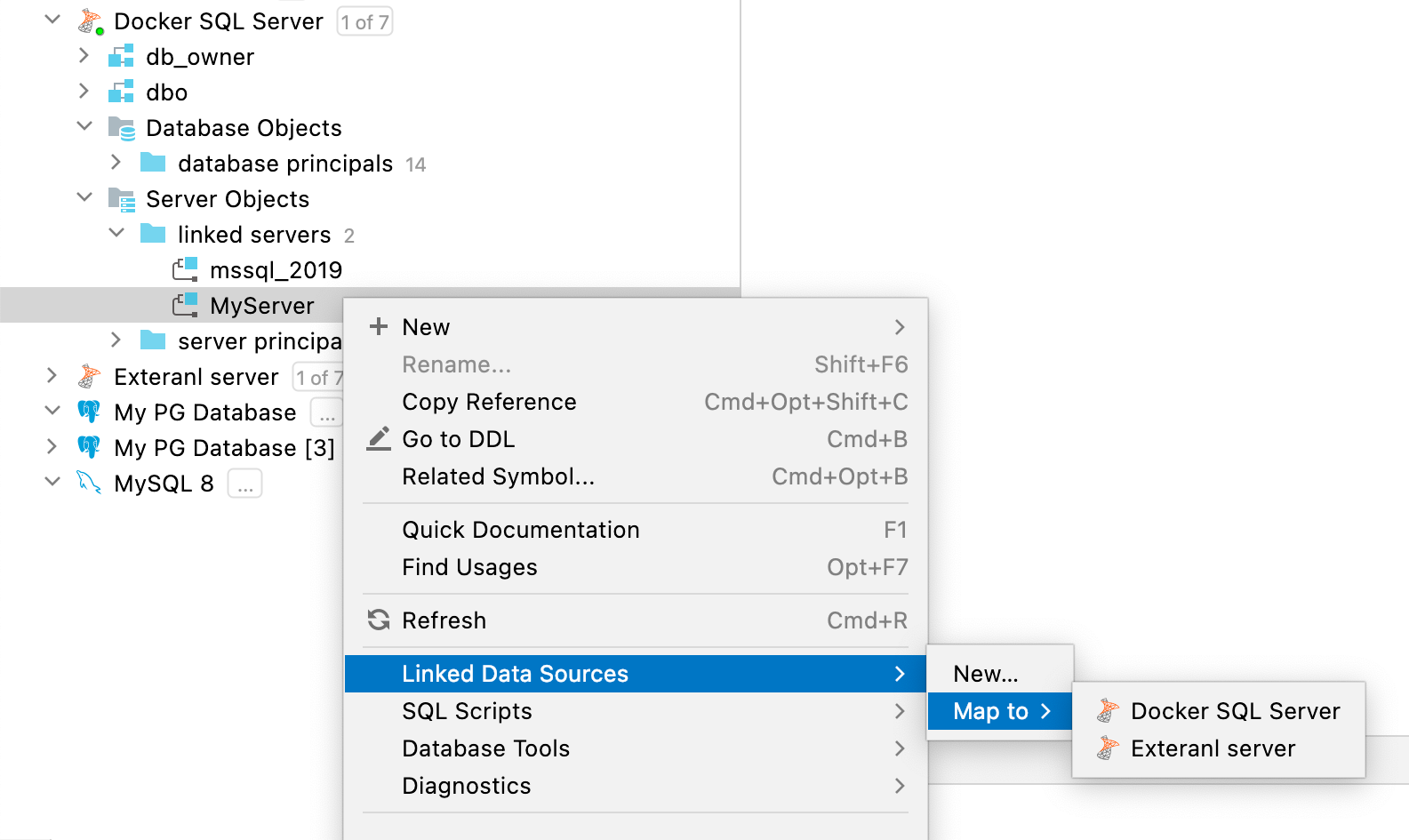
연결된 서버 및 데이터베이스 링크를 데이터 소스에 매핑 SQL Server, Oracle
SQL Server의 연결된 서버 또는 Oracle의 데이터베이스 링크를 기존 데이터 소스에 매핑할 수 있습니다.
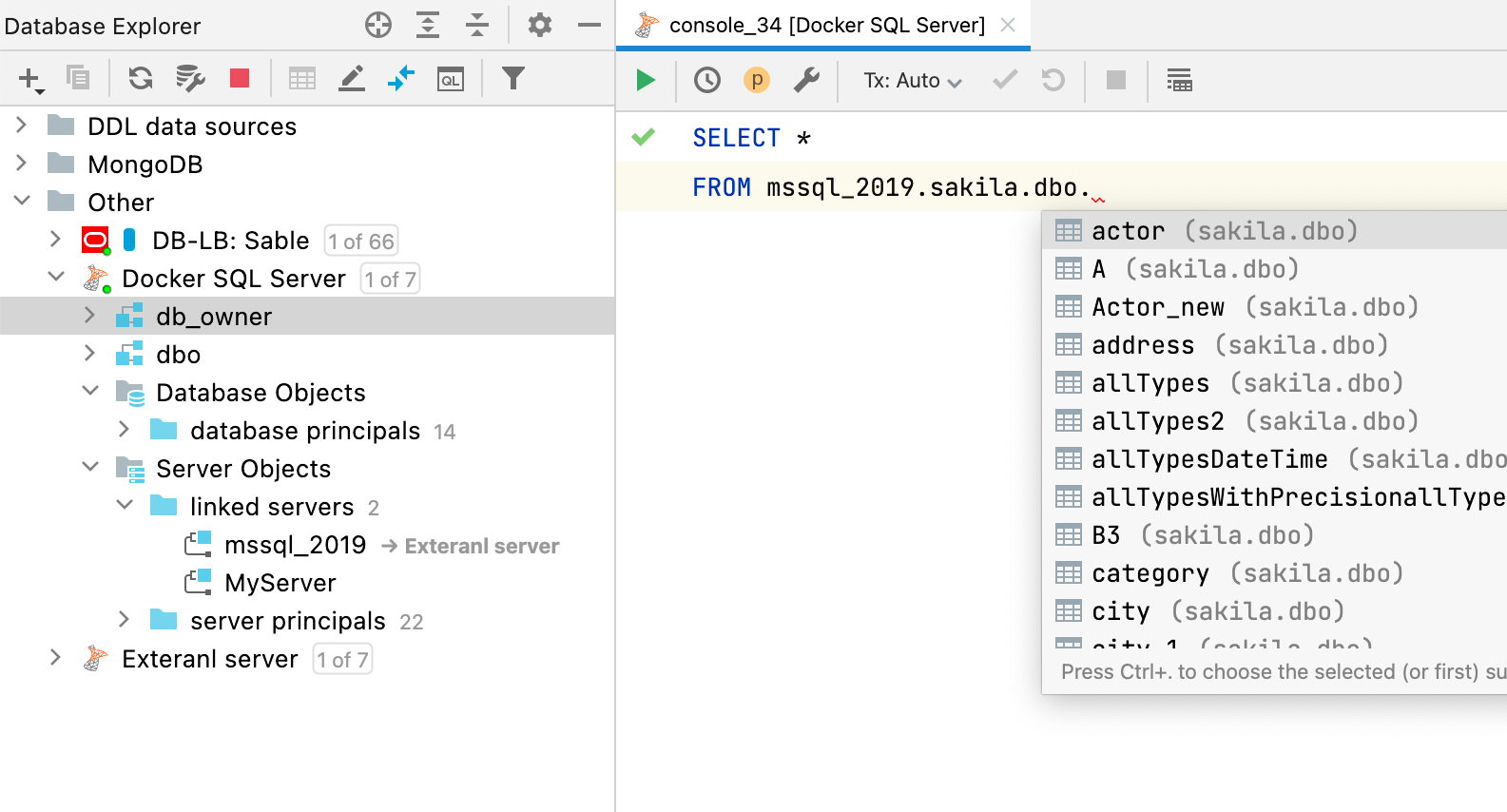
외부 객체가 데이터 소스에 매핑되면 해당 외부 객체를 사용하는 쿼리에 대해 코드 완성과 해결이 작동합니다.
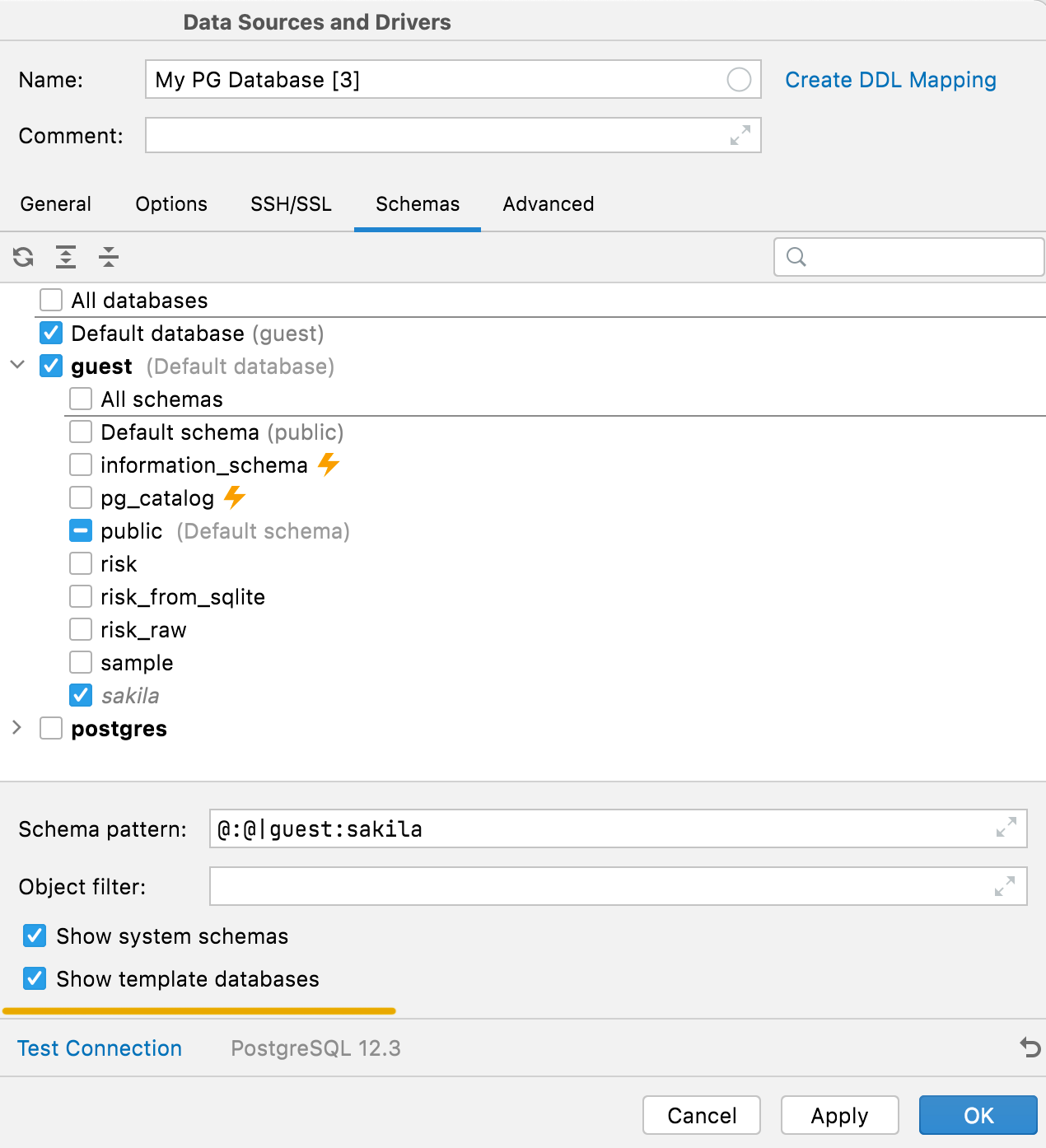
시스템 스키마 및 템플릿 데이터베이스 숨기기 PostgreSQL
이전에는 내부 시스템 스키마(예: pg_toast 또는 pg_temp) 및 템플릿 데이터베이스가 스키마 목록에서 숨겨지고는 했습니다. 이제 Schemas(스키마) 탭에서 해당 옵션을 사용하여 이를 표시할 수 있습니다.
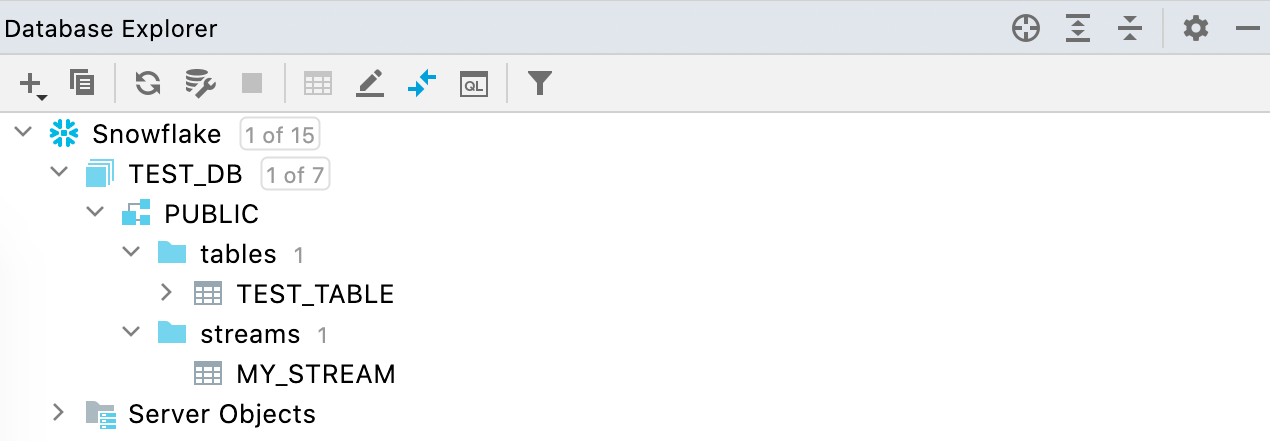
스트림 지원 Snowflake
테이블 및 뷰뿐만 아니라 데이터베이스 뷰에도 스트림이 표시됩니다.
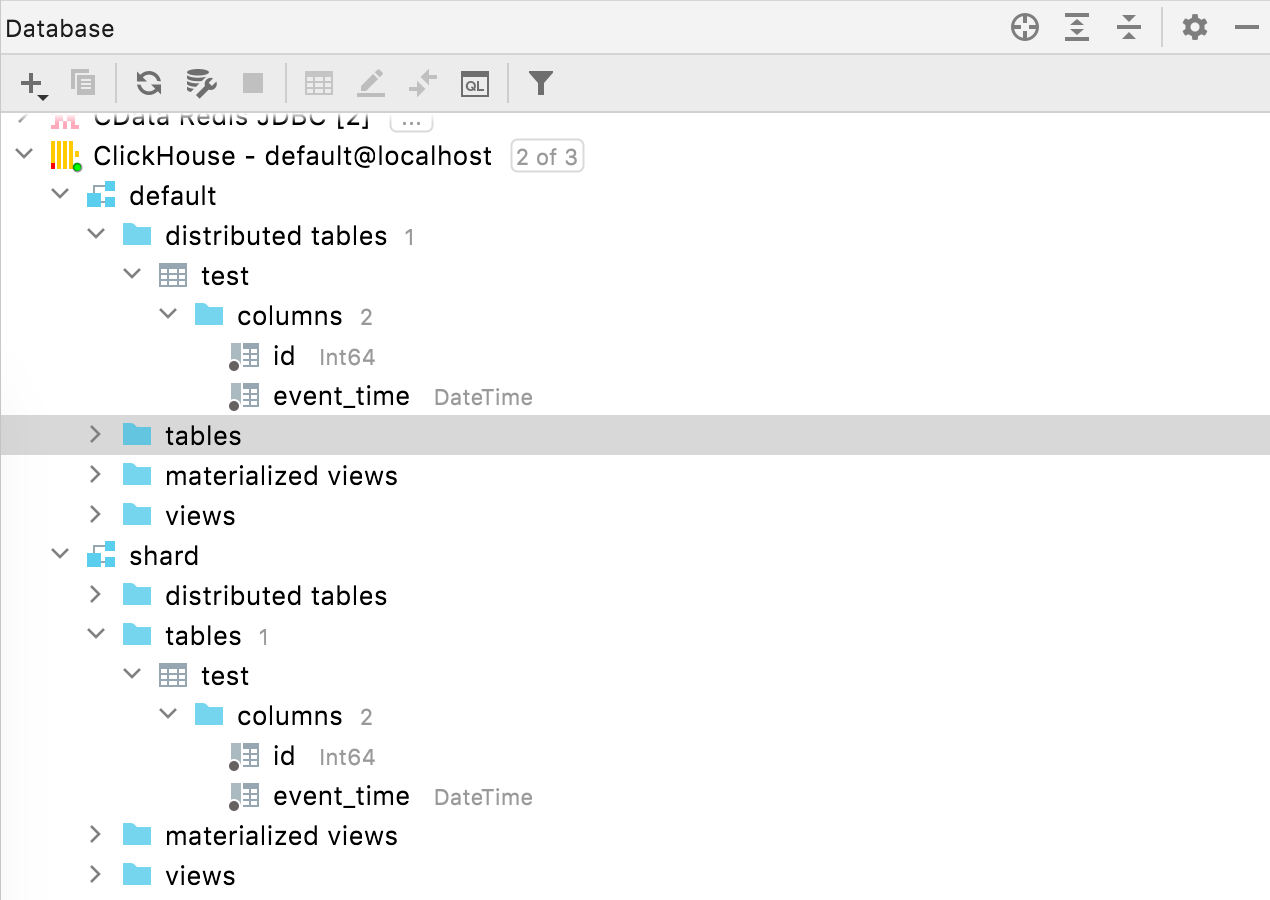
분산 테이블 ClickHouse
이제 분산 테이블이 데이터베이스 탐색기의 전용 노드 아래에 배치됩니다.
쿼리 콘솔
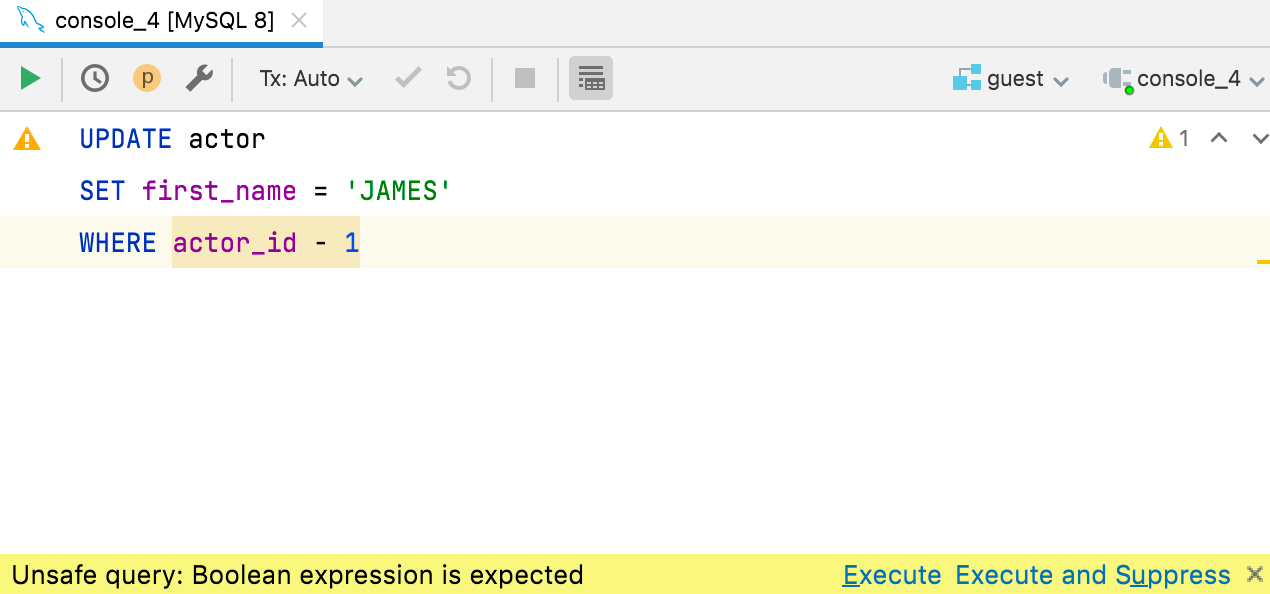
bool 표현식 검사
One of our users posted about an unfortunate situation: he executed the UPDATE query on a production database with the condition WHERE id - 3727 (instead of =) and had millions of records updated!
놀랍게도 MySQL에서도 이 쿼리를 허용했다고 합니다. 불행은 함께 온다고 하죠. 그리고 DataGrip 팀에서는 언제나 그랬듯이 이 상황에 대처할 검사를 추가했습니다. WHERE 및 HAVING 절 내 bool 표현식에 대한 검사를 반가이 맞아주세요.
표현식이 명시적으로 부울 값이 아닌 것 같으면 DataGrip에서 해당 표현식을 노란색으로 강조 표시하고 이러한 쿼리를 실행하기 전에 사용자에게 경고를 표시합니다. 이 기능은 ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite 및 Vertica에서 작동합니다. 다른 모든 데이터베이스에서는 이 표현식이 오류로 강조 표시됩니다.
쿼리 추출 함수
이제 쿼리를 테이블 함수로 추출할 수 있습니다. 이를 수행하려면 쿼리를 선택하고 Refactor(리팩터링) 메뉴를 호출한 다음 Extract Routine(루틴 추출)을 사용하세요.
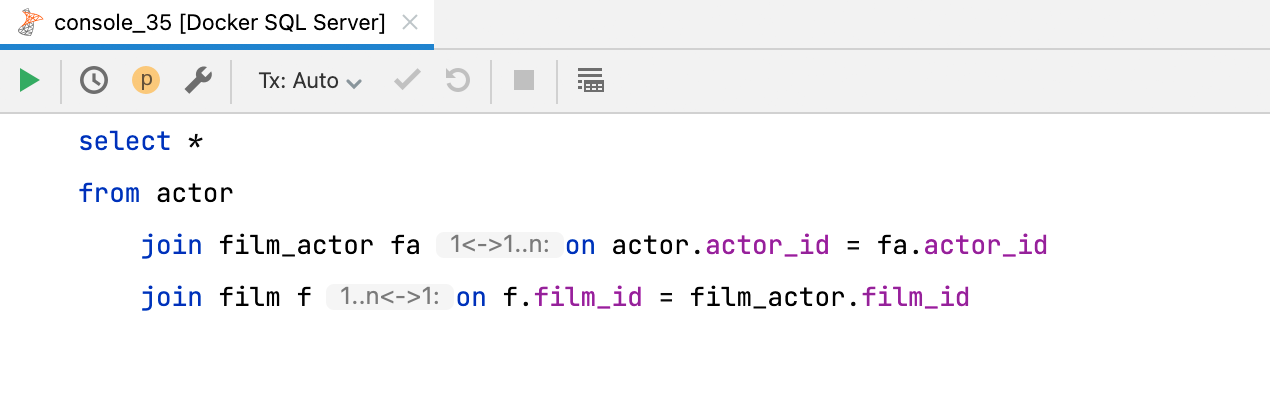
JOIN 기수 인레이 힌트
새 인레이 힌트가 JOIN 절의 기수를 알려줍니다. 일대일, 일대다 및 다대다의 세 가지 가능한 옵션이 있습니다. 해당 기능을 비활성화하려면 Preferences(환경 설정) | Editor(에디터) | Inlay Hints(인레이 힌트) | Join cardinality(기수 결합)의 설정을 변경할 수 있습니다.
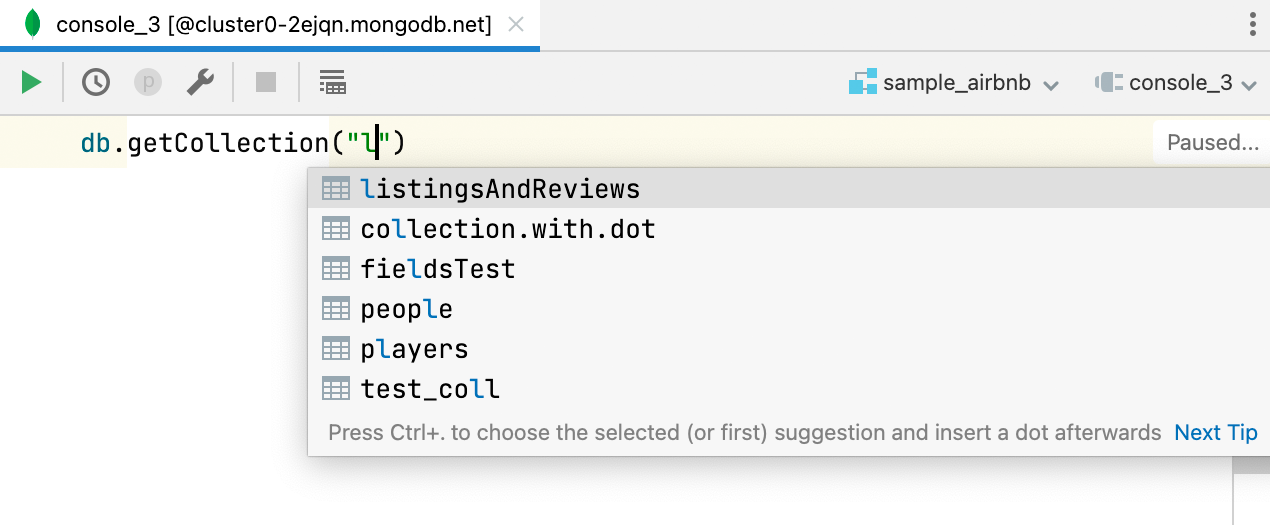
데이터베이스 이름에 대한 코드 완성 MongoDB
getSiblingDB를 사용하면 데이터베이스 이름이 완성되고, getCollection을 사용하면 컬렉션 이름이 완성됩니다.
또한 getCollection으로 정의된 컬렉션에서 사용하는 경우 필드 이름이 완성 및 해결됩니다.
서비스 도구 창
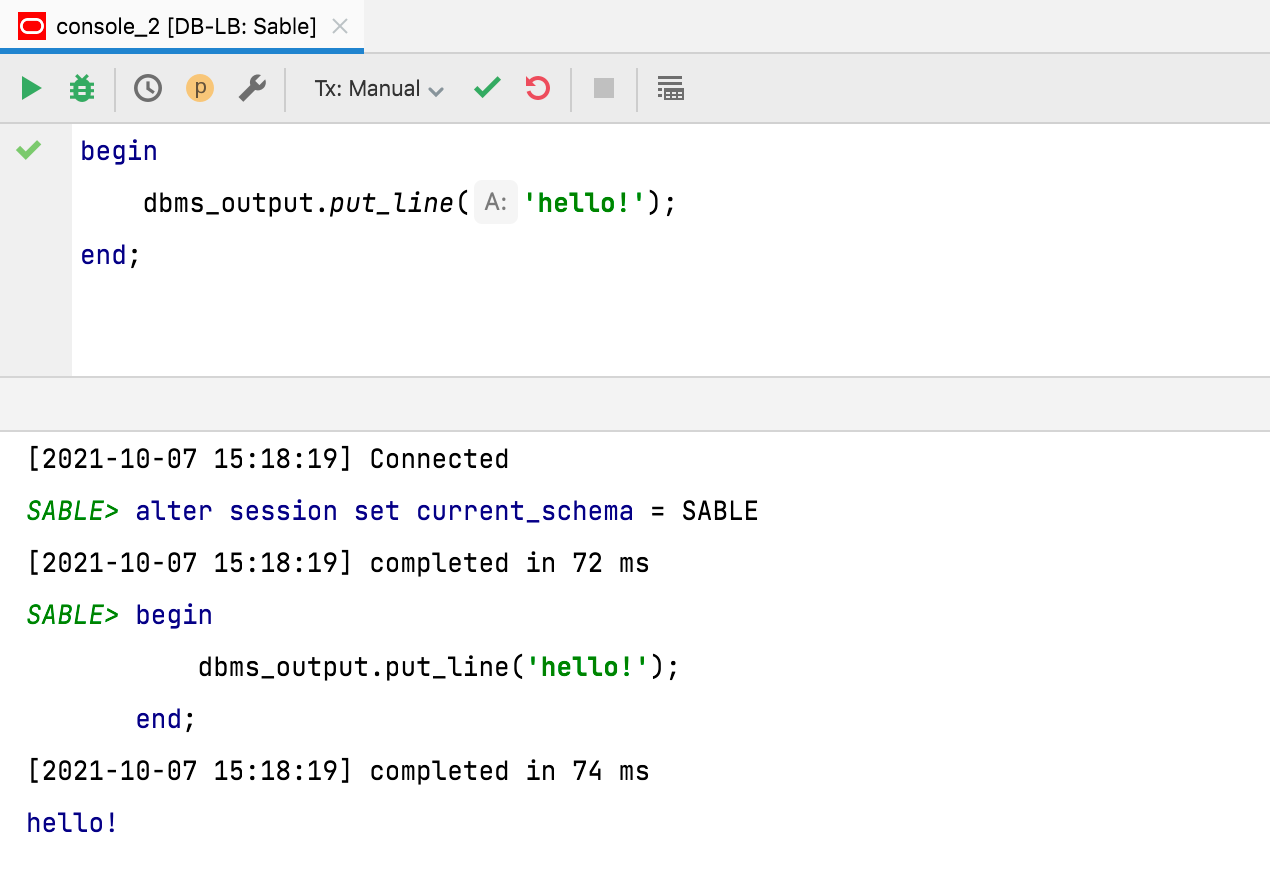
출력에서 타임스탬프를 기본적으로 숨김 처리
이 요청에 따라, 기본적으로 쿼리 출력에 타임스탬프가 더 이상 표시되지 않습니다. 이전 동작으로 돌아가려면 Database(데이터베이스) | General(일반) | Show timestamp for query output(쿼리 출력에 타임스탬프 표시)에서 설정을 조정할 수 있습니다.
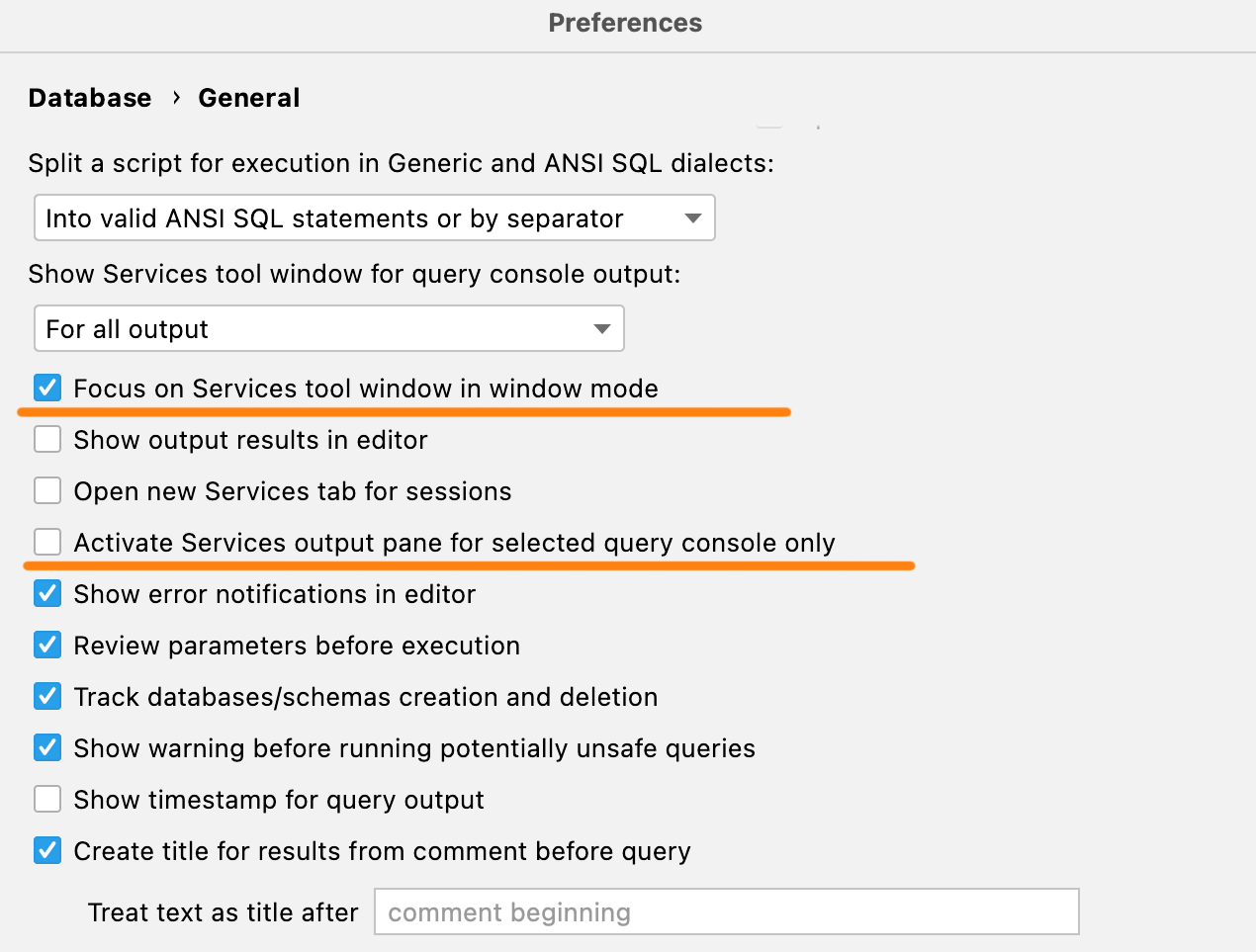
새로운 활성화 설정
창 모드에서 Services(서비스) 도구 창을 사용하는 경우, 기본적으로 이 창이 IDE 뒤에 숨겨집니다. 새로운 설정을 사용하면 쿼리를 실행할 때마다 여기에 포커스를 전달할 수 있으므로 쿼리가 완료된 후에 표시됩니다.
또한 다른 콘솔에서 긴 쿼리를 완성할 때 Services 도구 창에서 해당 탭이 활성화되는 것이 불편하다면 Activate Services output pane for selected query console only(선택한 쿼리 콘솔에 대해서만 서비스 출력 창 활성화) 체크박스를 선택하세요.
가져오기/내보내기
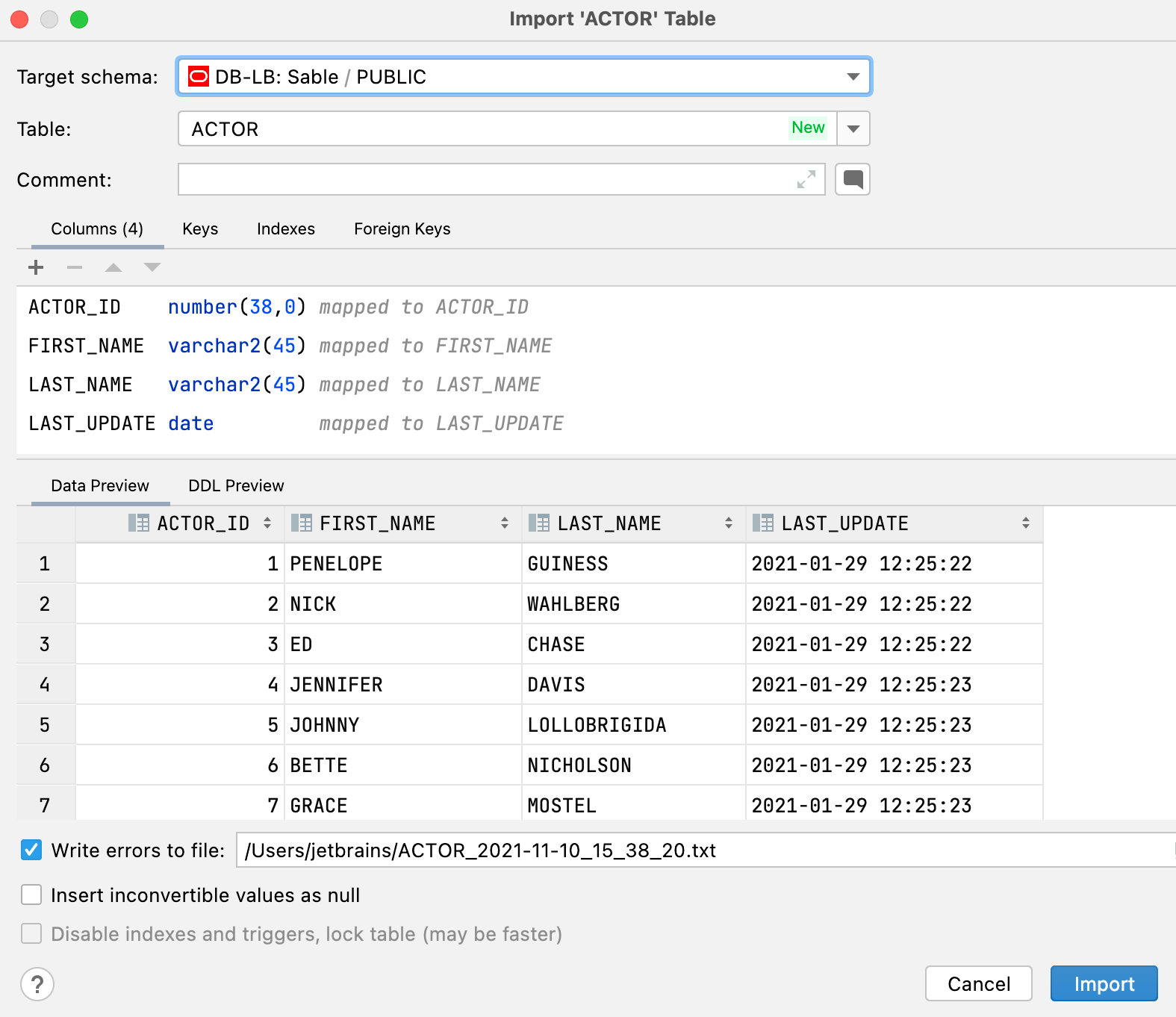
데이터 가져오기를 위한 새로운 UI
.csv 파일을 가져오거나 테이블/결과 세트를 복사할 때 다음과 같은 개선 사항을 확인할 수 있습니다.
- 기존 테이블을 선택하거나 새 테이블을 생성할 수 있습니다.
- 가져오기 대화상자에서 대상 스키마를 변경할 수 있습니다. 테이블 또는 결과 세트를 복사하는 경우, 대상에 대한 전용 대화상자가 나타나지 않습니다.
- 대상은 스키마별로 디폴트로 저장됩니다. 따라서 하나의 특정 스키마에서 다른 스키마로 지속적으로 복사하는 경우, 매번 대상을 선택할 필요가 없습니다.
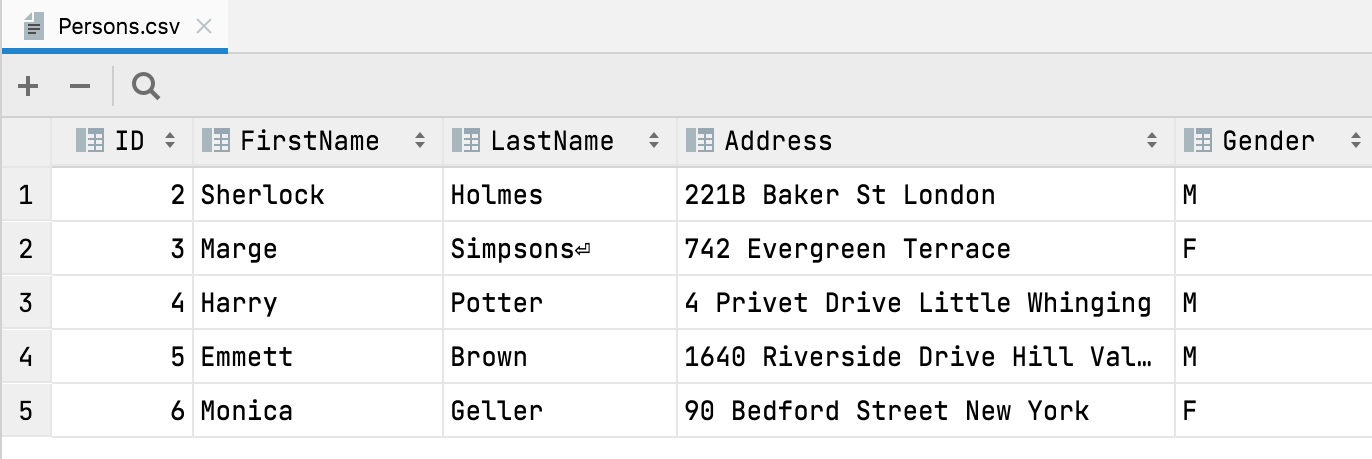
첫 번째 행은 헤더 자동 탐지
CSV 파일을 열거나 가져올 때 DataGrip은 이제 첫 번째 행이 헤더이고 열 이름을 포함하고 있음을 자동으로 탐지합니다.
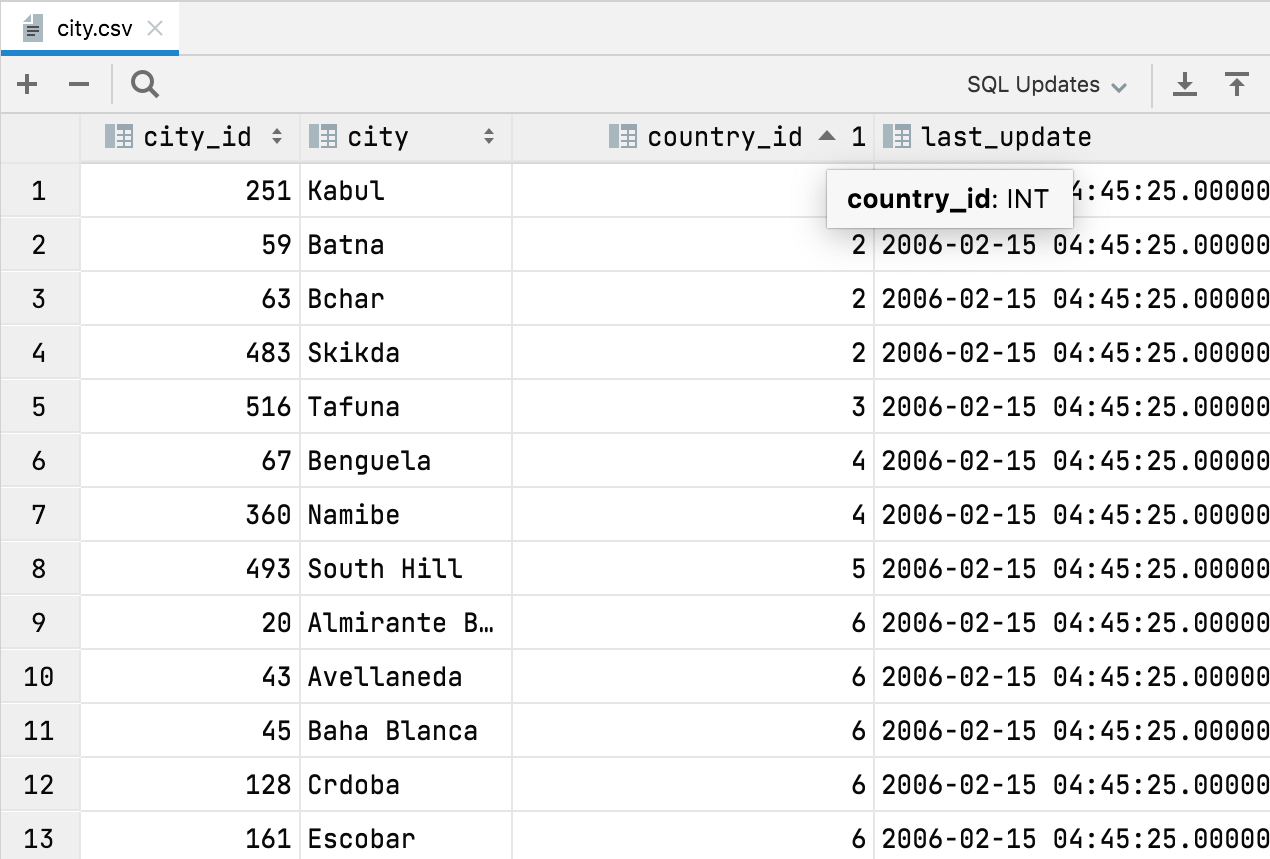
CSV 파일의 자동 열 유형
DataGrip이 이제 CSV 파일에서 열 유형을 탐지할 수 있습니다. 이러한 탐지의 가장 큰 장점은 숫자 값을 기준으로 데이터를 정렬할 수 있다는 것입니다. 이전에는 열 내용이 텍스트로 처리되어 정렬이 직관적이지 않았습니다.
기타
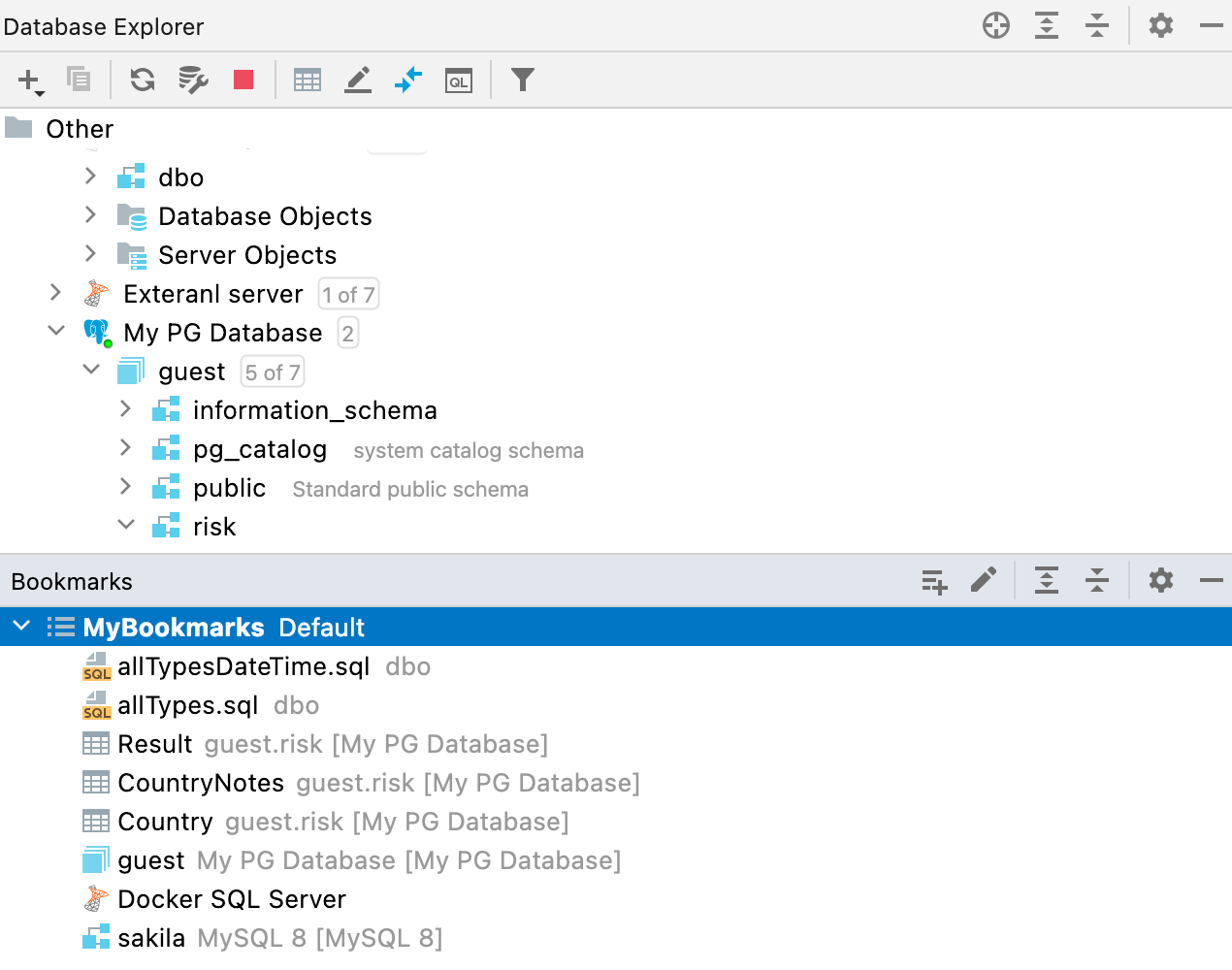
새 북마크 도구 창
이전에는 즐겨찾기와 북마크라는 매우 유사한 두 가지 기능이 있었습니다. 하지만 이 둘의 차이가 혼동되기 쉬워, 북마크 하나만 사용하기로 결정했습니다. 이 기능에 대한 워크플로를 새롭게 정비하고 새 도구 창으로 만들었습니다.
이제부터 중요한 것으로 표시된 모든 객체 또는 파일(macOS의 경우 F3 또는 Windows/Linux의 경우 F11 단축키 사용)은 새 Bookmarks(북마크) 도구 창에 배치됩니다.