Novidades no DataGrip 2019.2
Janela de ferramentas Services
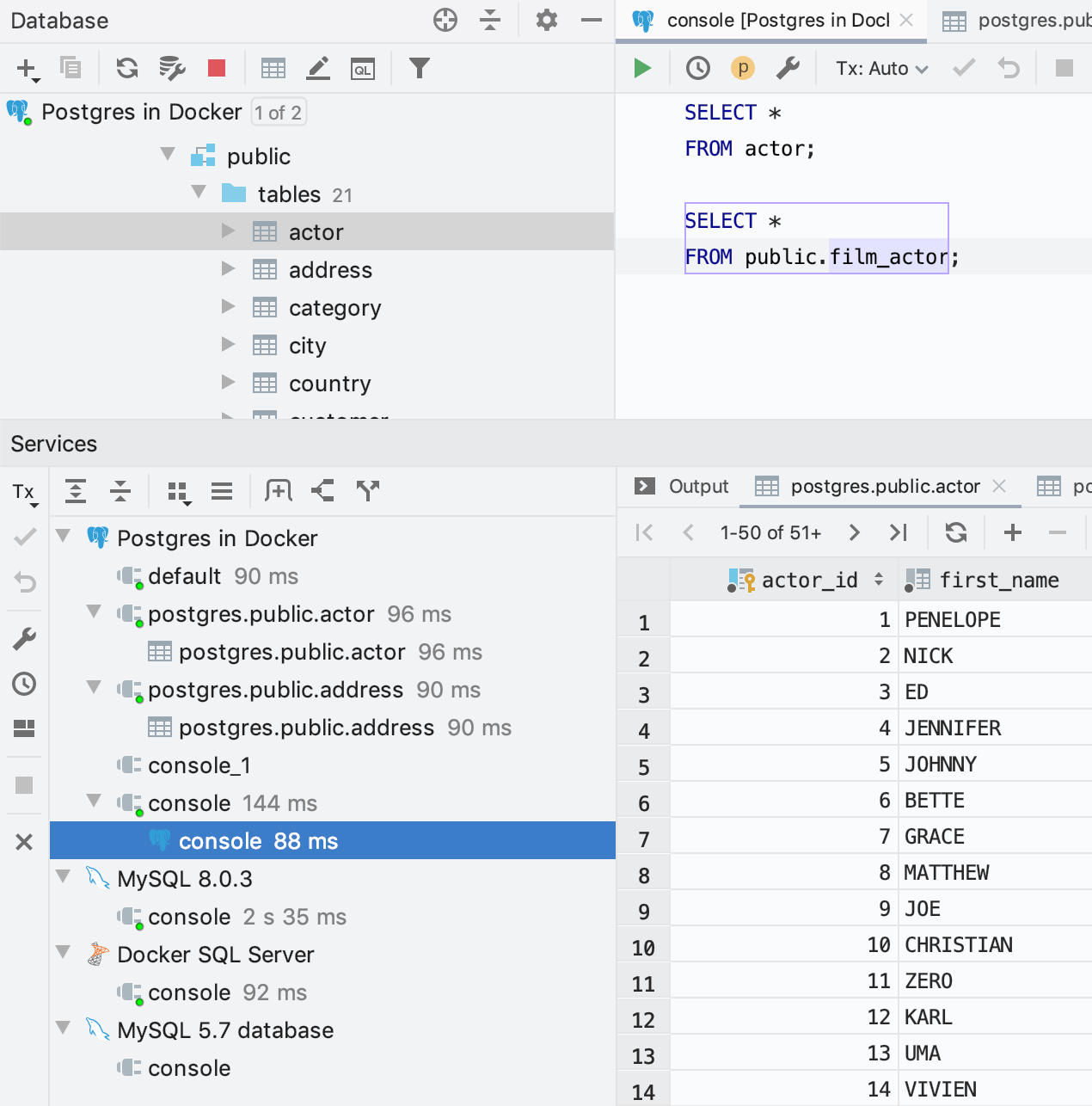
Todos os nossos IDEs agora têm uma nova janela de ferramentas chamada Services. No DataGrip, você pode observar e gerenciar todas as conexões nessa janela.
Toda conexão tem seu próprio nó na fonte de dados correspondente. Se a luz verde no ícone estiver acesa, significa que a conexão está ativa. Você pode facilmente fechar uma conexão usando o menu de contexto.
É possível visualizar todos os tipos de serviço como nós ou alterar a exibição para vê-los como guias. Use a ação Show in New Tab na barra de ferramentas ou simplesmente arraste o nó necessário até a barra de título da janela de ferramentas Services.
O resultado da consulta agora é anexado ao console específico sob sua conexão na exibição Services.
Importante! O atalho padrão para a janela de ferramentas Services é Alt+8.
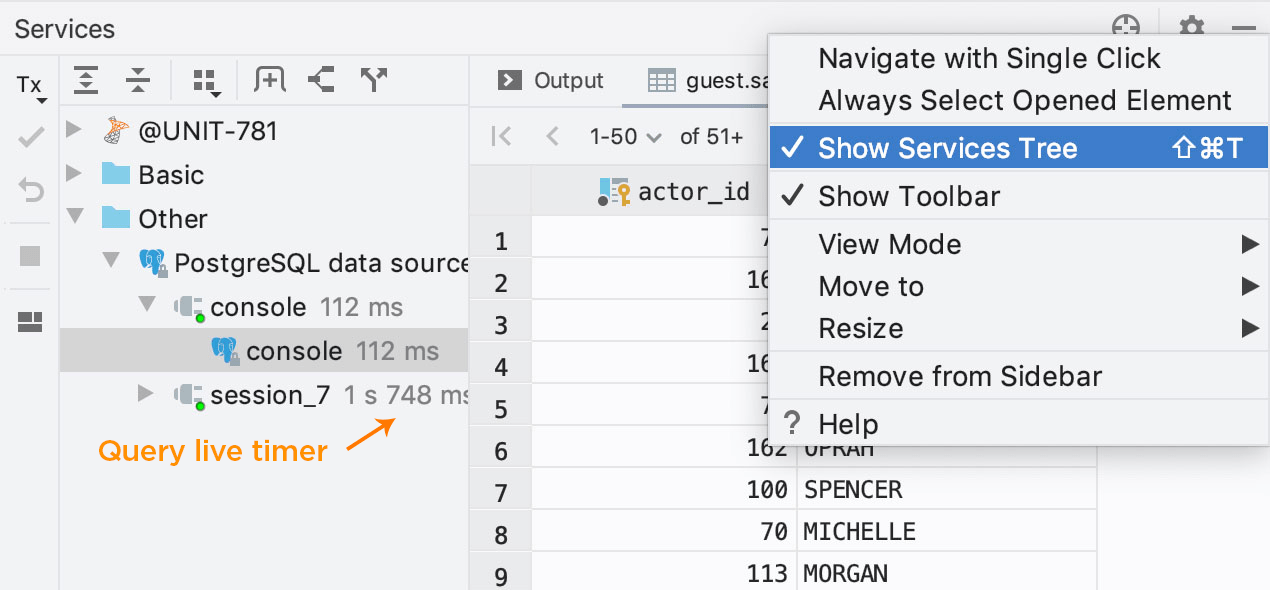
Ocultar a árvore
Se você não deseja ver a Árvore de serviços (ou seja, prefere as coisas como elas eram antes), clique no ícone de engrenagem para ocultar a árvore.
Timer dinâmico de consultas
A janela de ferramentas Services também fornece outro recurso bastante solicitado: um timer de consulta dinâmico. Para qualquer conexão que executa uma consulta, olhe à sua direita para ver quanto tempo ela demorou.
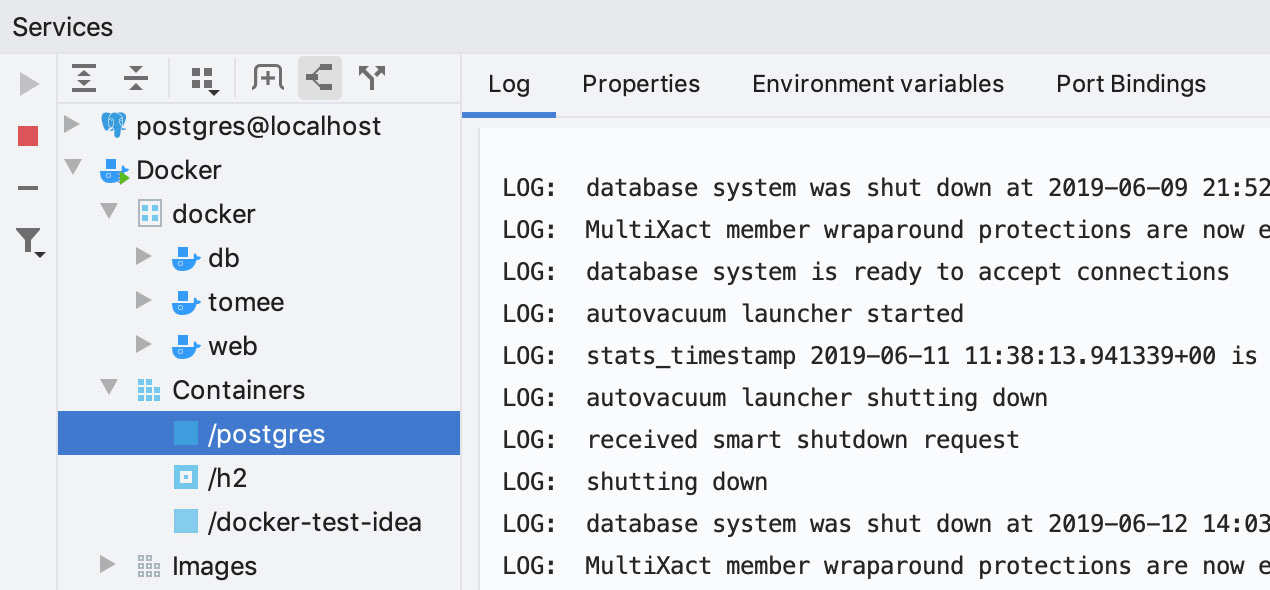
Docker
Se você usar o plug-in Docker, os serviços correspondentes também aparecerão nessa janela de ferramentas.
Pesquisa de texto completo
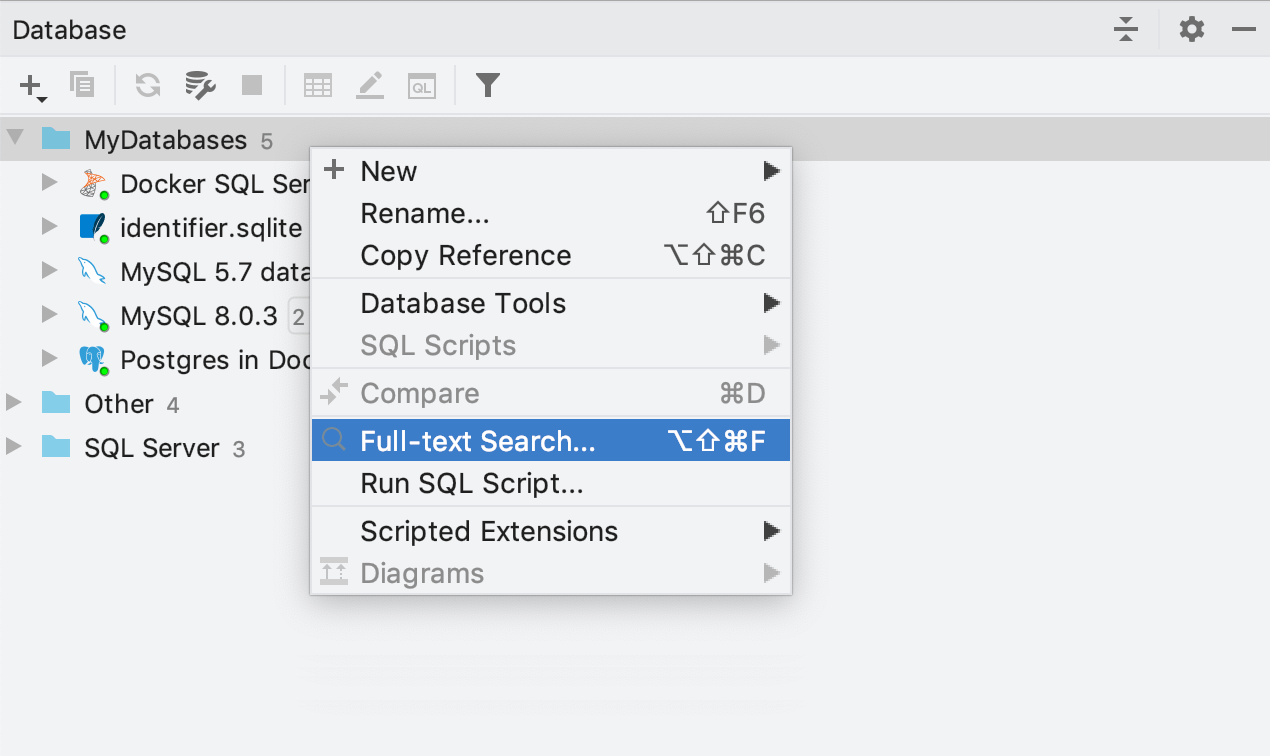
Agora, você pode procurar dados mesmo não sabendo onde eles estão localizados. Para fazer isso, selecione fontes de dados, grupos de fontes de dados ou até mesmo tabelas separadas que você deseja pesquisar e invoque Full-text search no menu de contexto. Naturalmente, há também um atalho para isso: Ctrl+Alt+Shift+F.

Você verá uma caixa de diálogo para inserir a string. Você verá a lista de fontes de dados para pesquisar e poderá definir algumas opções para a sua pesquisa.
Além disso, é possível ver quais instruções específicas o DataGrip executará para realizar a pesquisa de dados.
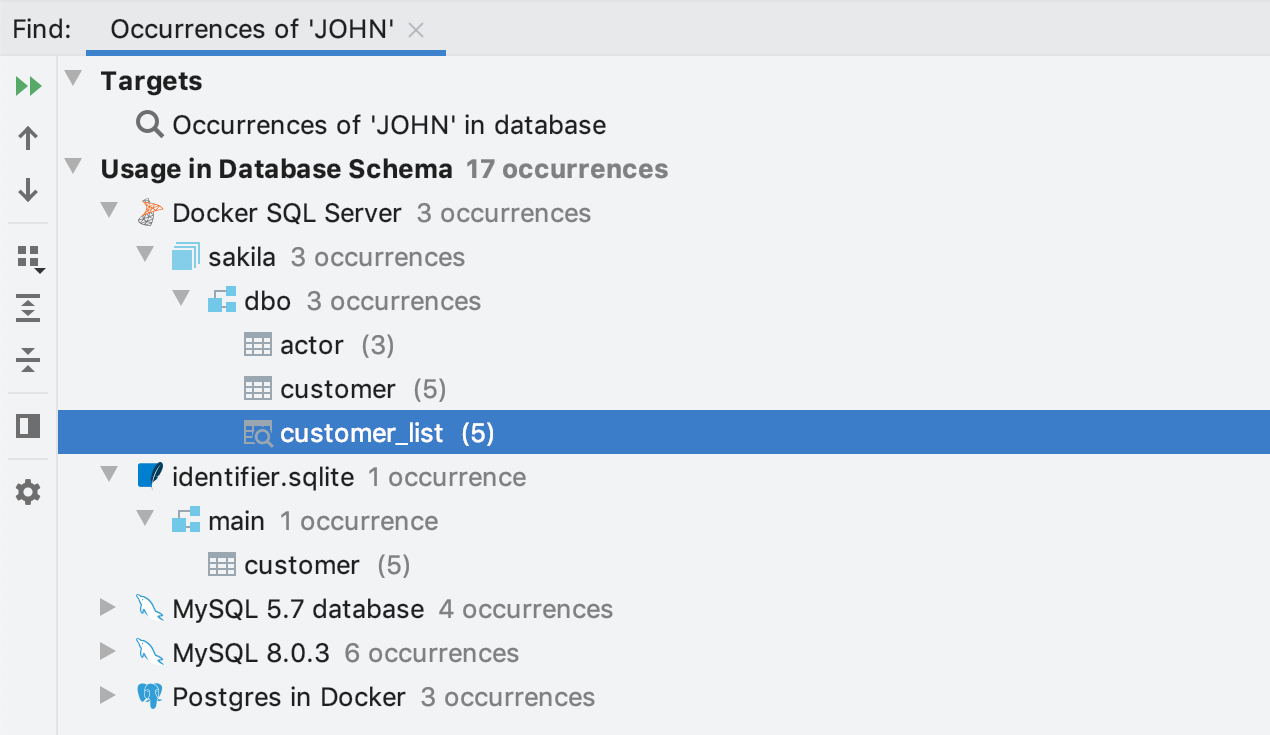
Depois de executar a pesquisa, você verá os resultados, que podem ser abertos.
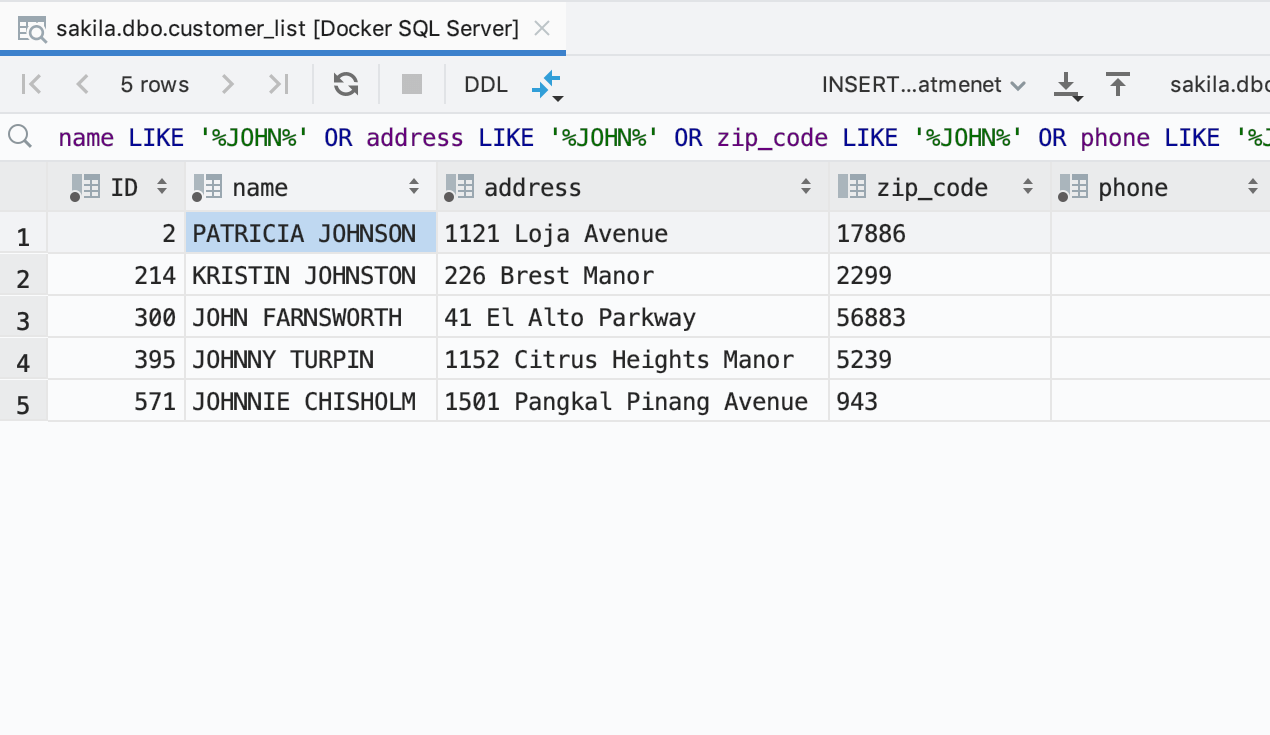
Clique em um resultado para abrir o editor de dados. O filtro será predefinido para mostrar apenas as strings nas quais os dados foram encontrados. Se você não conseguir localizar os dados porque há muitas colunas, use a pesquisa de texto no editor de dados com Ctrl+F.
Em alguns bancos de dados, existe a opção de pesquisar apenas nas colunas indexadas. Para usar esse modo, selecione Only columns with full-text search indexes no menu suspenso Search in.
- No PostgreSQL, a consulta será:
where col @@ plainto_tsquery('text'). - No MySQL e no MariaDB, a consulta será:
where match(col) against ('text' in natural language mode). - No Oracle, os seguintes índices são usados, se existirem: context, ctxrule, ctxcat.
- No SQL Server, se houver colunas com índices fulltext, o DataGrip gerará consultas com
WHERE CONTAINS(col, N'text'). - No SQLite, o DataGrip gera consultas com
where col MATCH ‘text’.
Se o modo All columns estiver selecionado, a pesquisa procurará colunas que não oferecem suporte ao operador LIKE, por exemplo, colunas do tipo JSON. Os valores nessas colunas serão convertidos em string antecipadamente.
No Cassandra, o DataGrip cria várias consultas para uma tabela, porque a condição OR não tem suporte pelo banco de dados.
Editor de dados
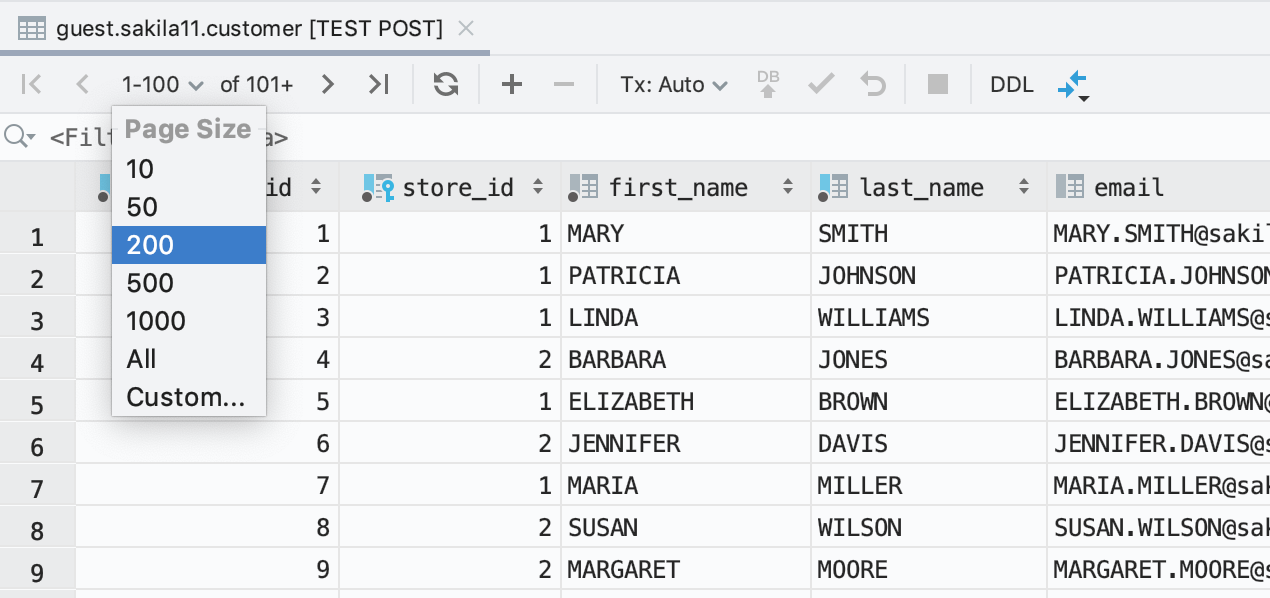
É fácil mudar o tamanho da página
Agora, para definir quantas linhas você deseja recuperar do banco de dados, use a barra de ferramentas do conjunto de resultados.
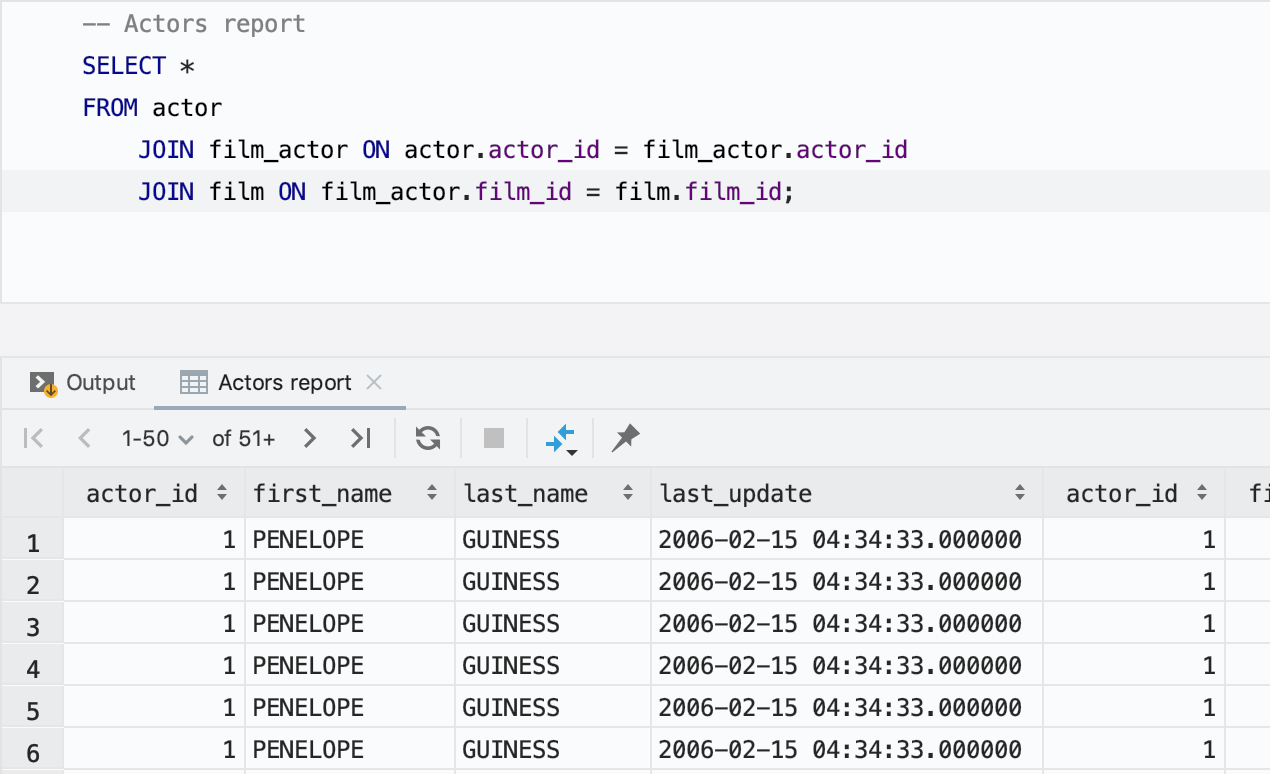
É possível nomear as guias de resultados
Outra melhoria super bacana em resultados: a definição de nomes para guias! Basta usar o comentário antes da consulta.
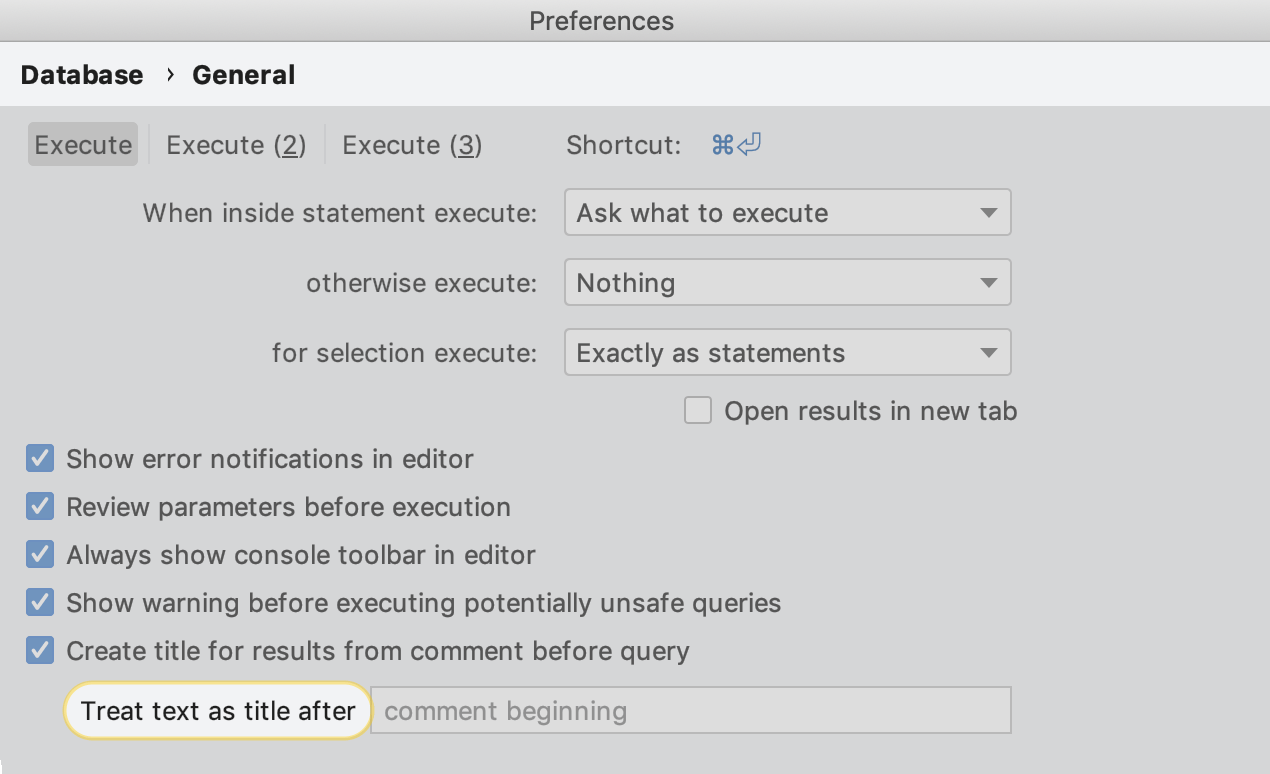
Se quiser que apenas alguns comentários se tornem nomes de guias, use o campo Treat text as title after nas configurações para especificar a palavra de prefixo. Dessa forma, somente as palavras que vierem após essa palavra serão usadas como títulos.
Exibição em árvore do banco de dados
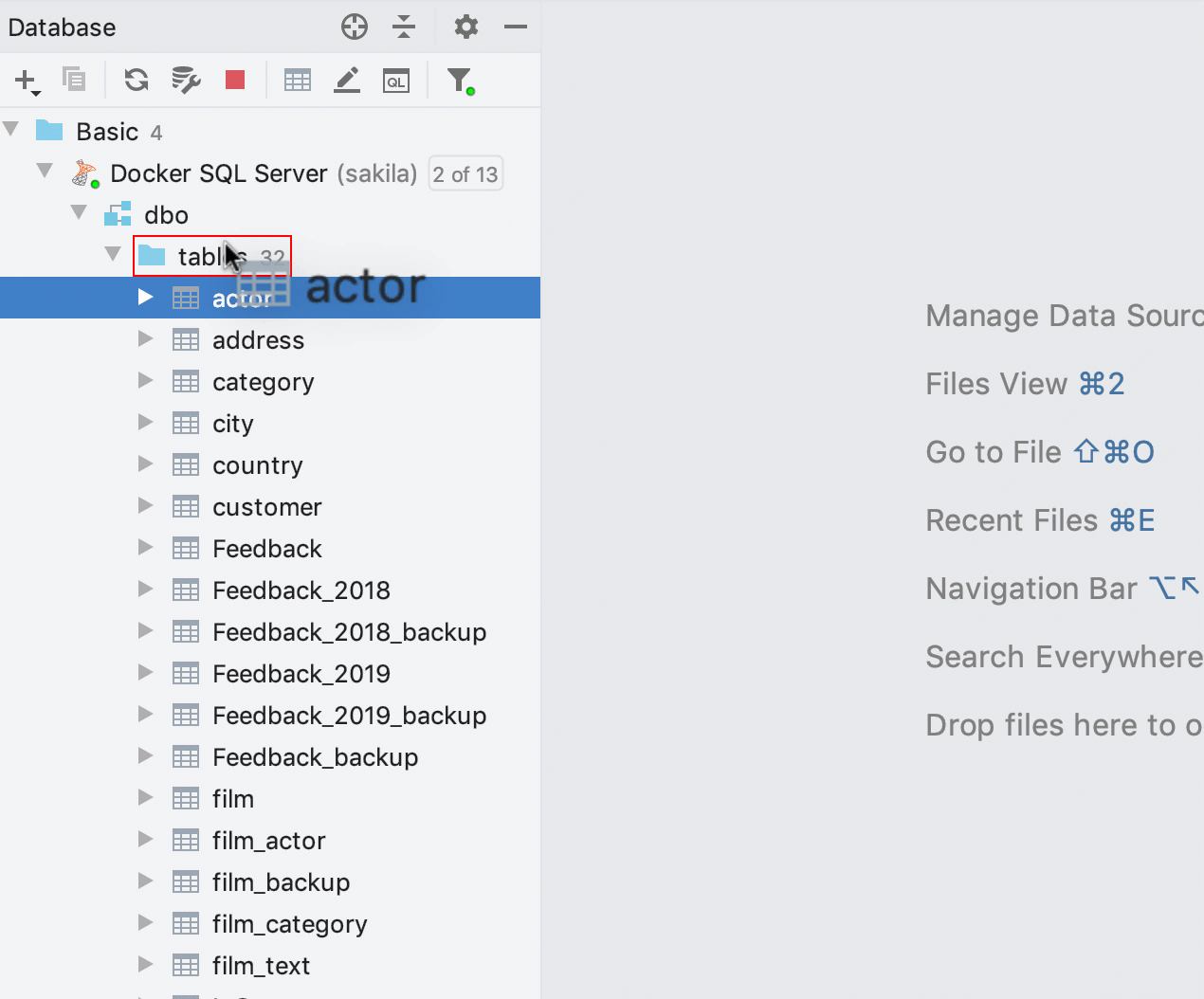
Backup rápido de tabelas
Era possível copiar tabelas via arrastar e soltar, mas isso não funcionava ao copiar para o mesmo esquema. Na verdade, isso pode ser muito útil se você precisa criar um backup rápido da tabela antes de qualquer manipulação de dados crucial. Então, agora fizemos funcionar!
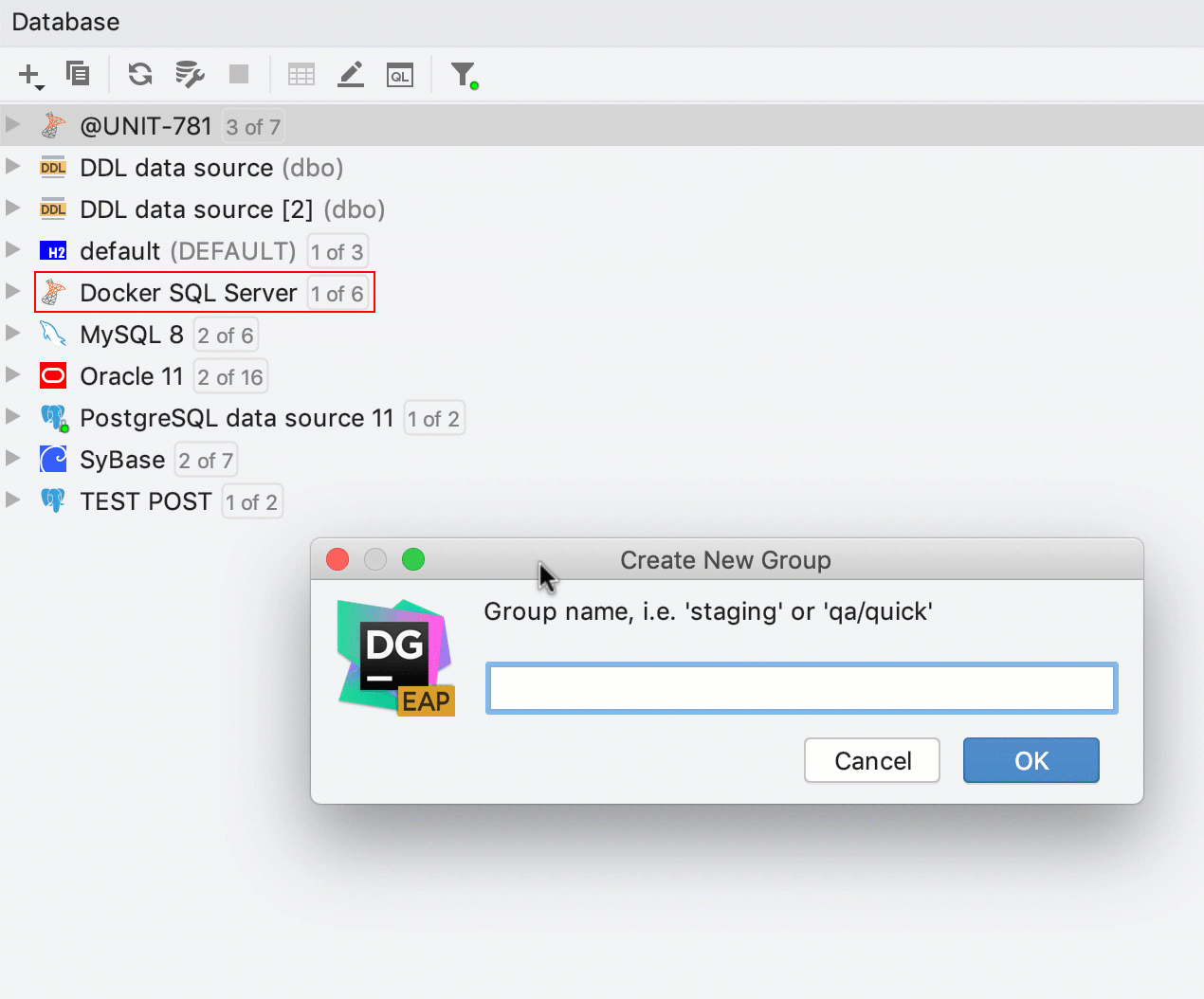
Criação rápida de grupos
Agora, arrastar e soltar também funciona para criar grupos no explorador de banco de dados.
Para criar um novo grupo, basta arrastar uma fonte de dados até a outra.
Para colocar a fonte de dados em um grupo existente, arraste-a e solte-a lá.
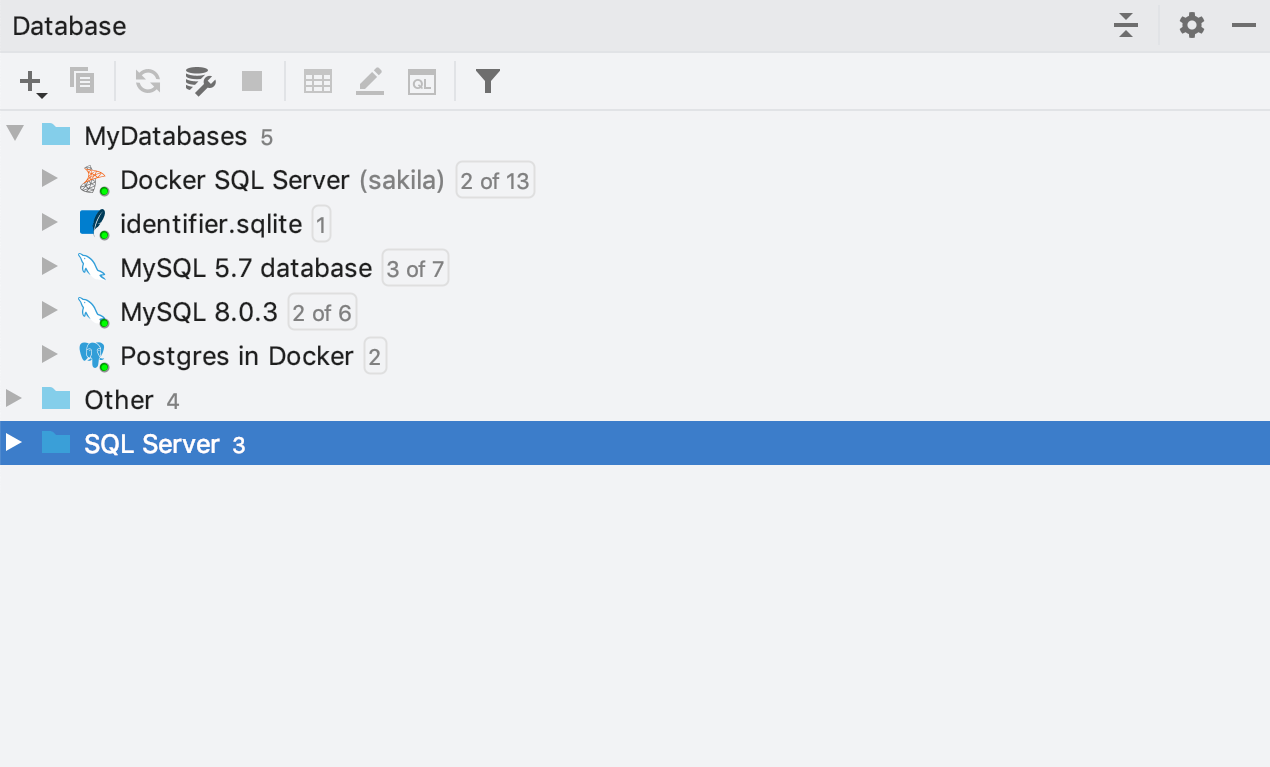
Conexões dinâmicas
A partir da versão 2019.2, a luz verde indica se há uma conexão ativa com a fonte de dados.
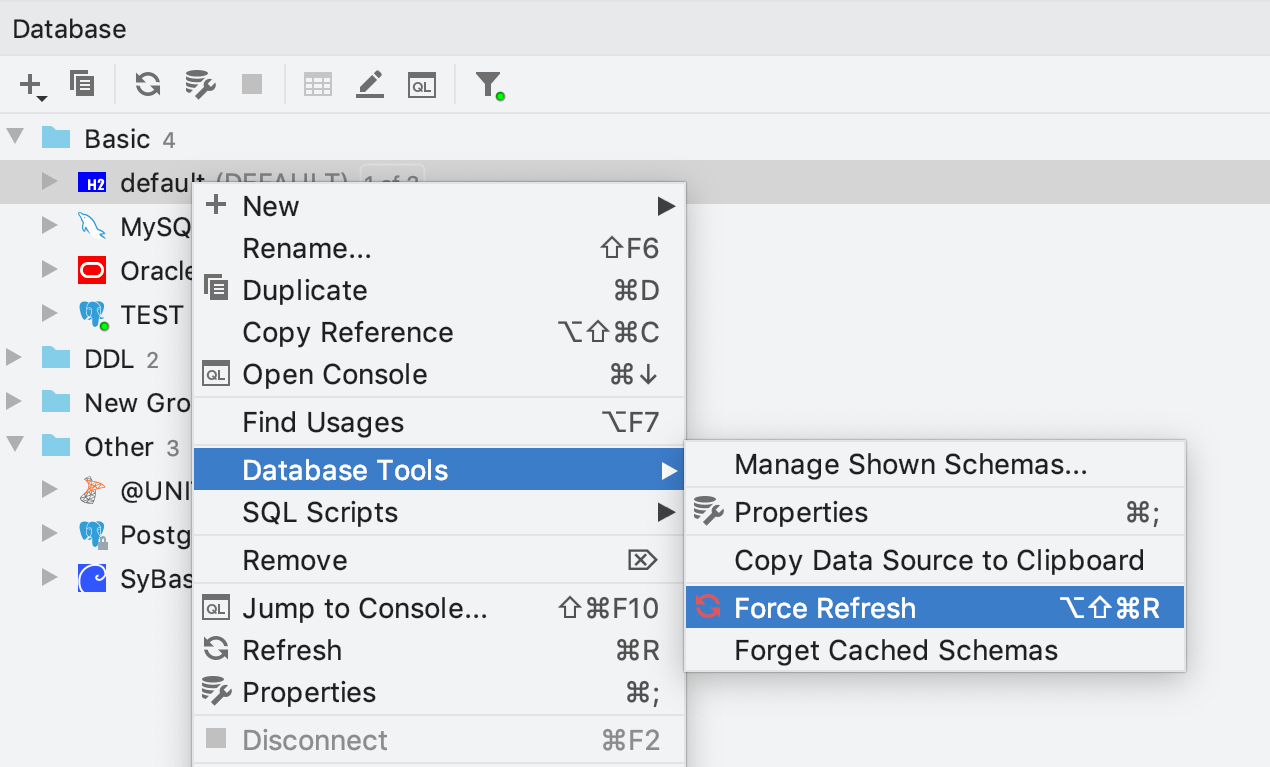
Forçar atualização
Uma nova ação está disponível para a fonte de dados ou o esquema, chamada Force Refresh. Ela limpa as informações de fonte de dados que o DataGrip armazena em cache e as atualiza do zero.
Filtragem por uma fonte de dados em pesquisa e navegação
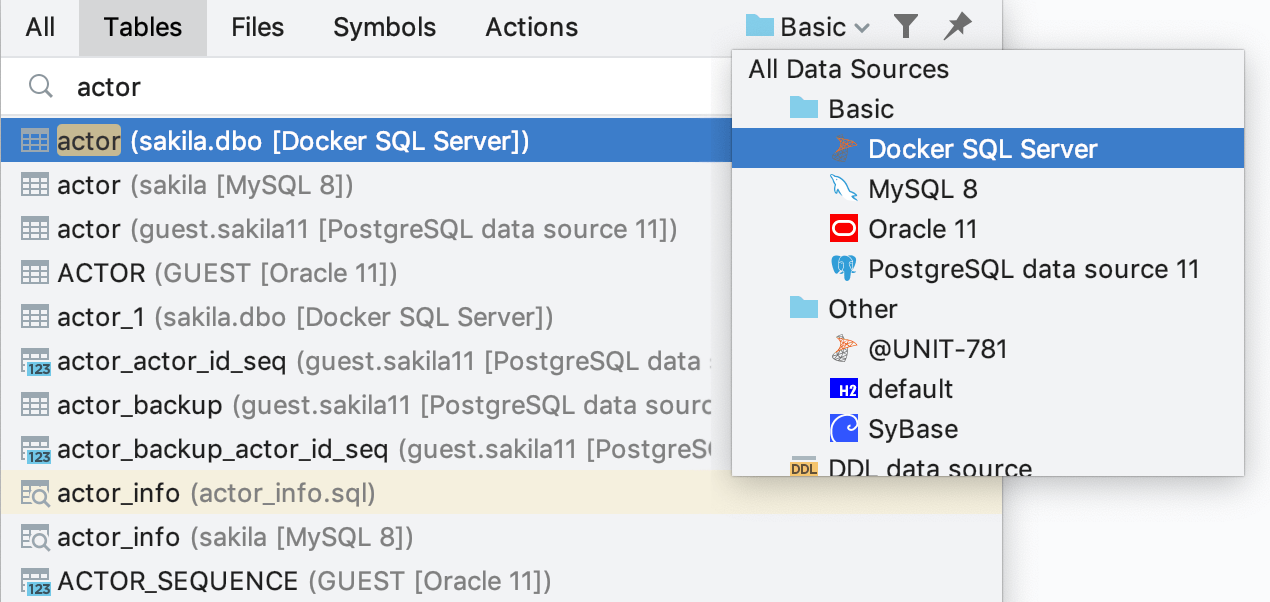
Ao localizar um objeto no pop-up GoTo, às vezes muitos objetos semelhantes estão presentes na lista. Isso acontece frequentemente quando existem muitos espelhos, como produção, preparo, teste, e assim por diante.
No DataGrip 2019.2, você pode escolher onde procurar: em uma fonte de dados específica ou em um grupo delas.
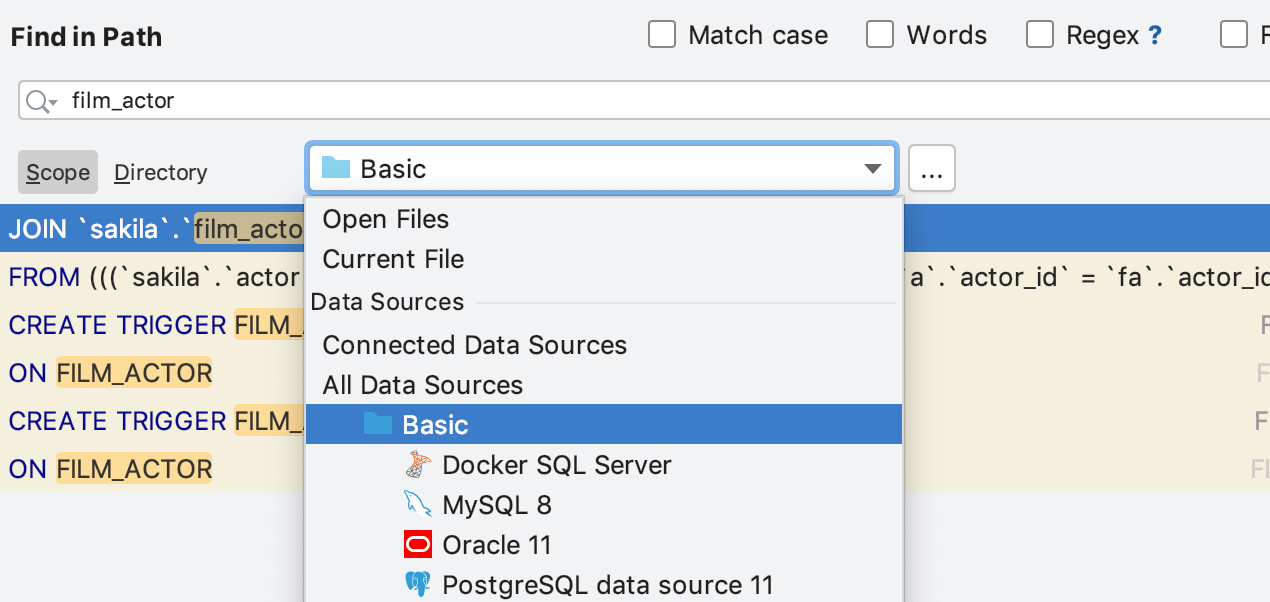
O mesmo funciona para Find In Path, que é extremamente útil ao procurar o código-fonte dentro das DDLs de outros objetos.
Assistência para codificação
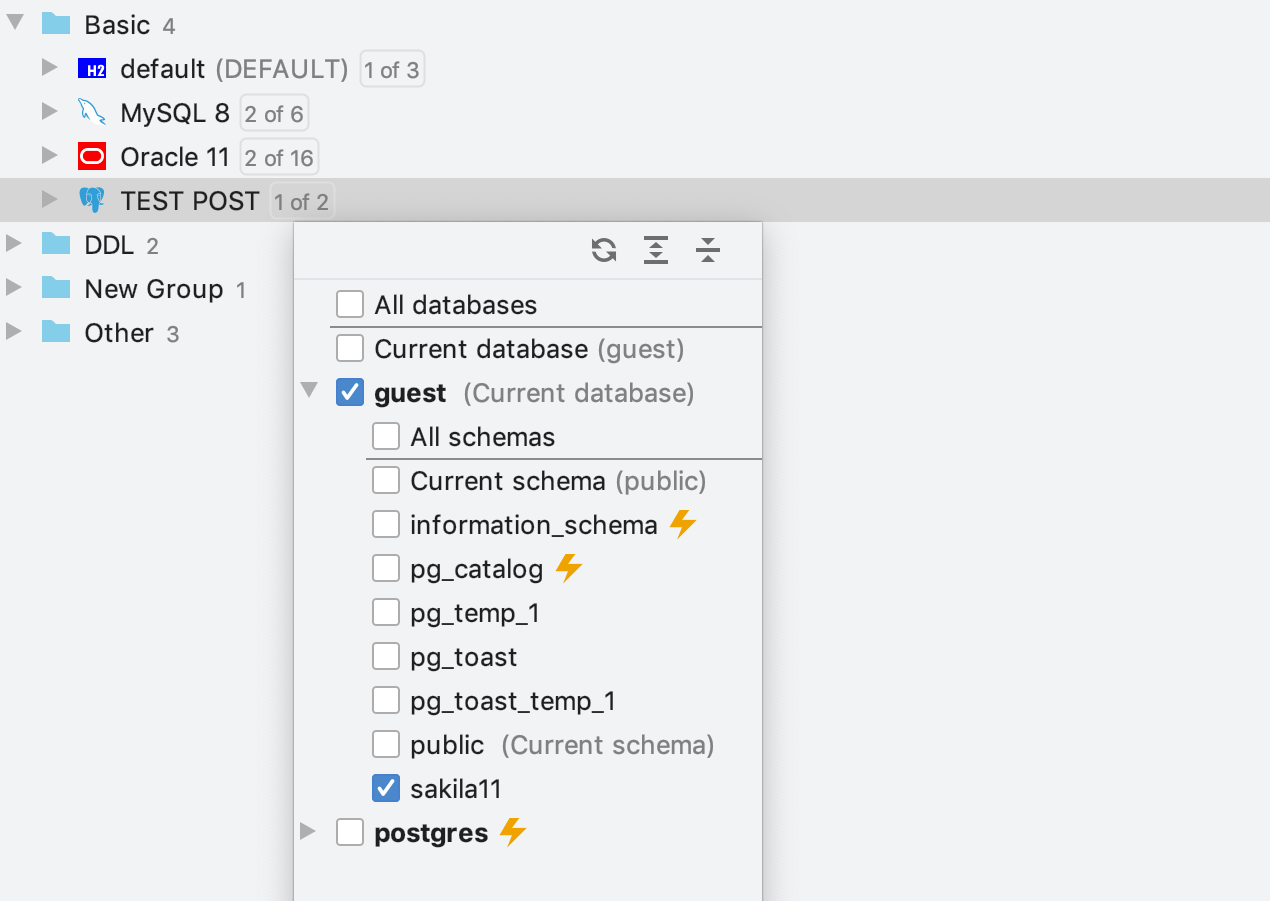
Objetos de catálogos de sistema
Em quase todos os bancos de dados, existe um catálogo do sistema – o local em que um sistema de gerenciamento de banco de dados relacional armazena metadados de esquema, como informações sobre tabelas e colunas, funções incorporadas, etc.
Os objetos desses catálogos são necessários para fornecer assistência de codificação. É bom tê-los no preenchimento de código, e o código que os utiliza não deve ser vermelho.
Antes, a única maneira de ter catálogos do sistema na assistência de codificação era adicioná-los ao explorador de banco de dados. Na verdade, o DataGrip recuperava informações sobre eles do banco de dados (sempre o mesmo, a propósito), o que exigia tempo. Além disso, eles ficavam visíveis no explorador de banco de dados, o que nem sempre era necessário.
Esse tipo de esquema possui um ícone de raio no seletor de esquema. Agora, se você não os marcar, o DataGrip não fará a introspecção e não os mostrará, mas usará as informações sobre seus objetos na assistência de codificação. Para tornar isso possível, o DataGrip usa seus dados internos sobre catálogos do sistema para cada banco de dados.
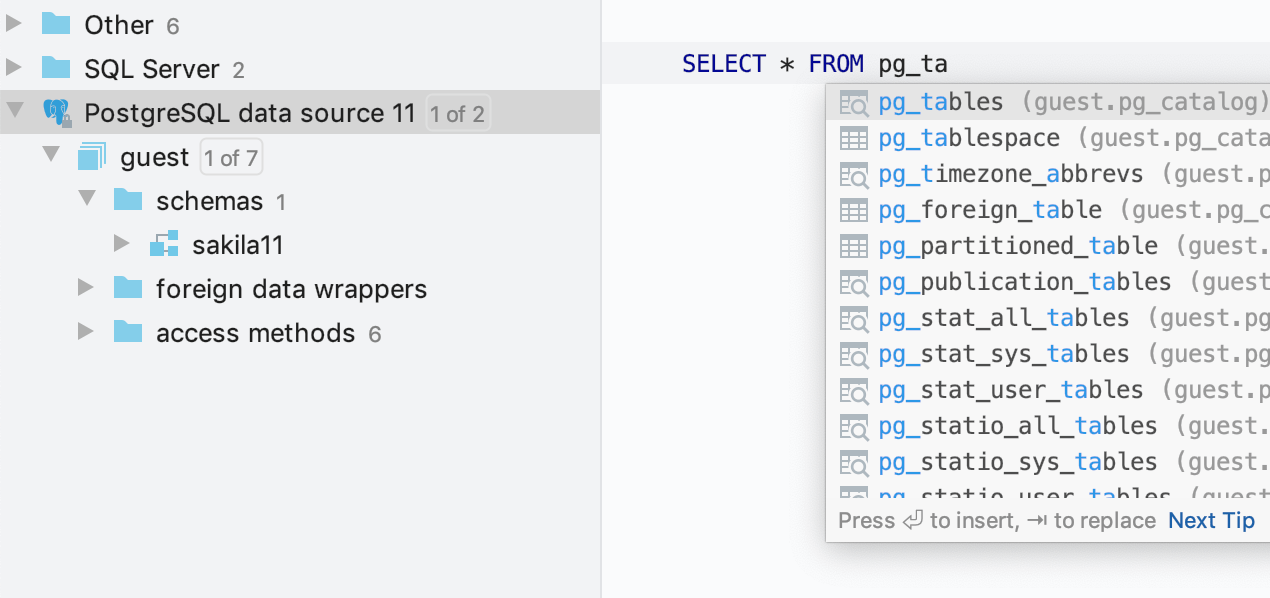
Alguns exemplos de catálogos de sistema para vários bancos de dados:
- PostgreSQL: pg_catalog, information_schema
- SQL Server: INFORMATION_SCHEMA
- Oracle: SYS, SYSTEM
- MySQL: information_schema
- DB2: SYSCAT, SYSFUN, SYSIBM, SYSIBMADM, SYSPROC, SYSPUBLIC, SYSSTAT, SYSTOOLS
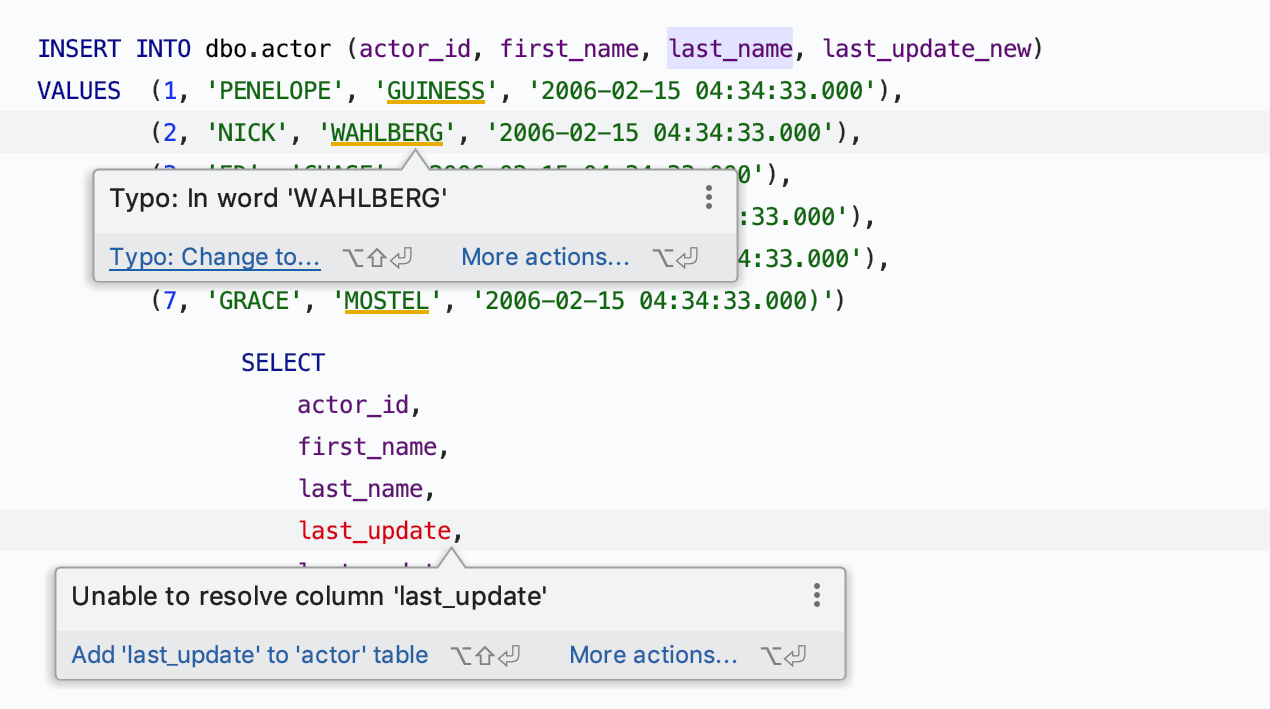
Ações de intenção e correções rápidas
Primeiro, integramos uma correção rápida na dica de ferramenta de inspeção. Se o DataGrip souber como corrigir o problema, você apenas saberá isso passando o mouse sobre o aviso. Para corrigir o problema, basta clicar no link no canto inferior esquerdo da dica de ferramenta ou pressionar Alt+Shift+Enter.
Alt+Enter ainda funciona para obter a lista de todas as possíveis correções rápidas.
Também introduzimos várias novas inspeções.

Uso desnecessário de CASE
Quando você usa construções CASE, o DataGrip analisa se elas podem ser transformadas em algo mais legível.
Para um IF:

Para um COALESCE:

Conversão GROUP BY em DISTINCT
Adicionamos mais uma ação de intenção: agora você pode converter GROUP BY em DISTINCTse todas as colunas de uma cláusula SELECT forem apresentadas em uma cláusula GROUP BY.
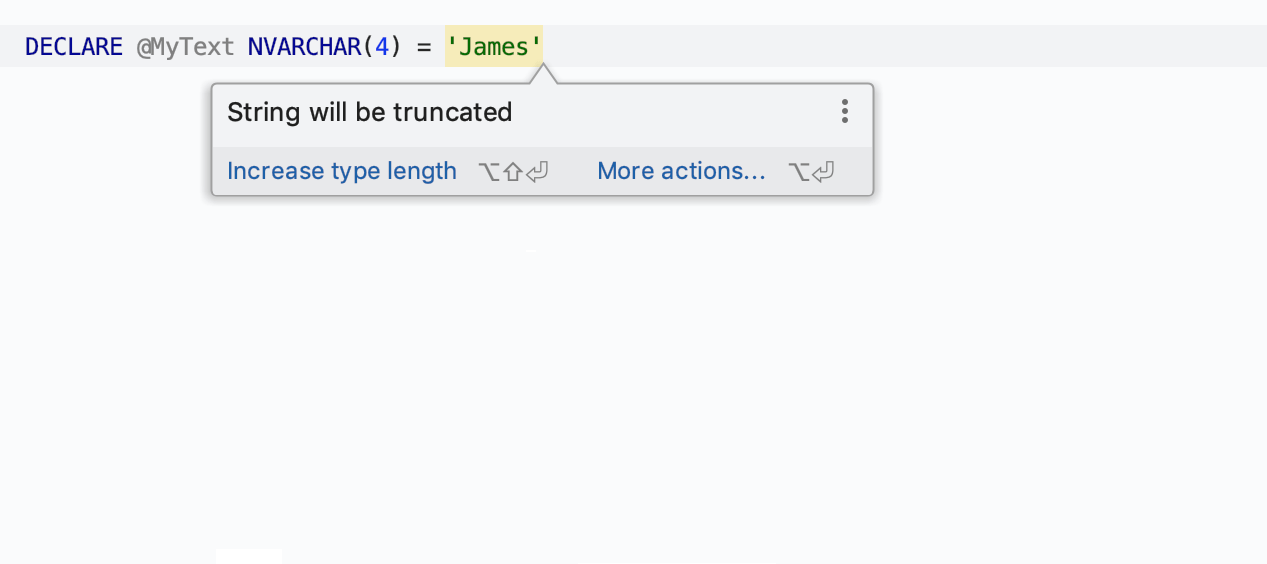
Possível truncamento da string
O IDE detecta o comprimento da string ao atribuir um valor à variável e avisa se será truncado.
Editor SQL
Nova opção para controlar o comportamento de Move Caret to Next Word
O comportamento padrão da ação Move Caret to Next Word mudou: o DataGrip moverá o sinal de intercalação para o final da palavra atual.
Para alterar o comportamento das ações de movimento de sinal de intercalação, vá para Preferences/Settings | Editor | General.
As pessoas geralmente executam essa ação pressionando Ctrl+setas no Windows e Linux no Opt+setas no Mac. Ela tem um comportamento padrão diferente em diferentes sistemas operacionais. No DataGrip, alteramos o comportamento ao estilo Windows para o comportamento ao estilo Mac.
Antes era assim:
E agora é assim:

Opção Select current statement
Uma nova ação, "Select current statement", está disponível. Você pode acessá-lo em "Find Action" Ctrl+Shift+A ou atribuir a ele um atalho próprio.

Desdobramento de números grandes
Se você deseja melhorar a legibilidade de números grandes, desdobre-os com o atalho Ctrl+Menos.
Outras alterações
- O DataGrip 2019.2 é executado no JetBrains Runtime 11, a bifurcação não certificada do OpenJDK 11, por padrão.
- Se você deseja ver comentários para tabelas na exibição em árvore, vá para View | Appearance e alterne a opção Descriptions in Tree Views.
- [Cassandra] Agora, você pode editar esses tipos de colunas: conjunto, lista, mapa, tupla, udt, inet, uuid e timeuuid.
- Novos itens combinados agora estão incluídos no preenchimento de código: IS NULL e IS NOT NULL.
- A opção Jump outside closing bracket/quote with Tab está habilitada por padrão.
- A opção Surround a selection with a quote or brace está habilitada por padrão.
- A opção Introduce alias foi adicionada ao menu de refatoração.
- O DataGrip funciona com o PostgreSQL 12: DBE-8384.
- Havia uma certa inconsistência ao trabalhar no modo somente leitura: se você quisesse executar uma consulta de atualização no modo de somente leitura, o IDE desativada apenas o modo de nível de IDE, mas não o do JDBC: DBE-8145. Agora, porém, desativamos os dois para que você possa executar a consulta, se realmente precisar.