Novidades no DataGrip 2021.1
Hoje apresentamos o DataGrip 2021.1, nosso primeiro grande lançamento deste ano e possivelmente o lançamento mais notável da história do nosso IDE. Nós esperamos que você encontre na v2021.1 a solução para pelo menos um dos seus problemas, ou talvez você descubra um novo recurso favorito, ou as duas coisas. Vamos ver o que há de novo na nova versão!
Interface do usuário para permissões de acesso
Disponível para PostgreSQL, Redshift, Greenplum, MySQL, MariaDB, DB2, SQL Server e Sybase.
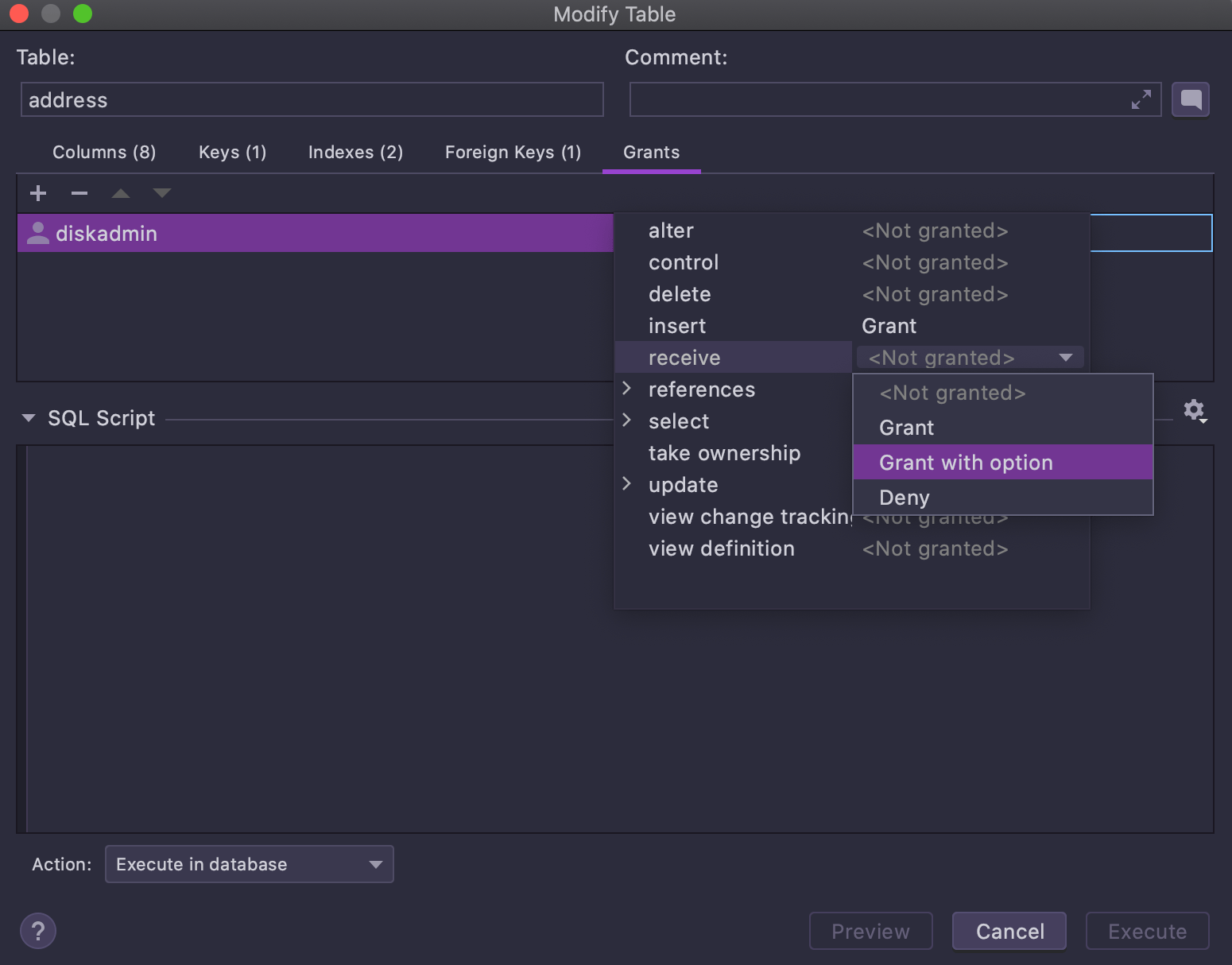
Adicionamos uma interface do usuário para editar permissões de acesso ao modificar objetos.
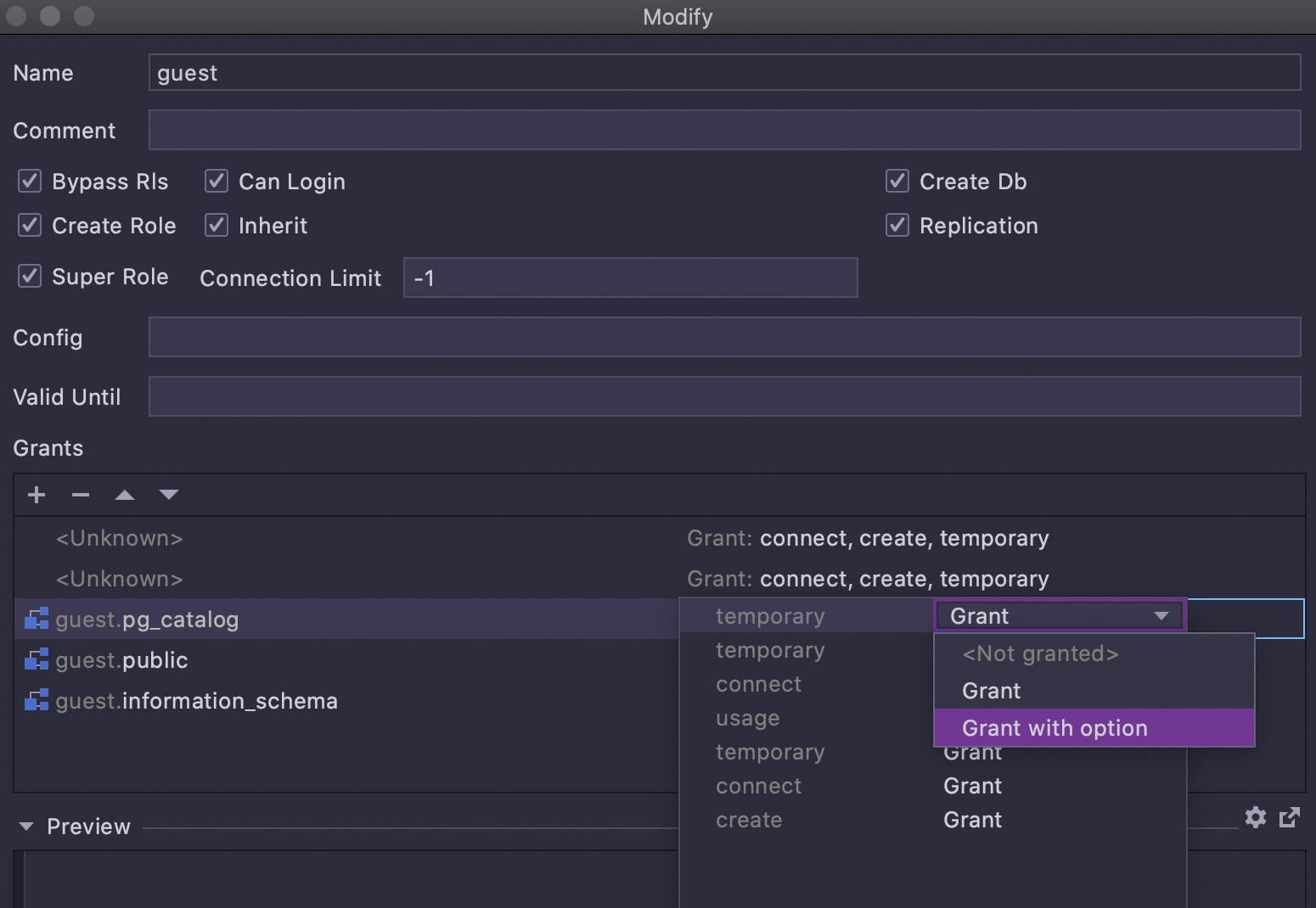
A janela Modify user, que você pode invocar em um usuário no Database Explorer com Cmd/Ctrl+F6, agora tem uma IU para adicionar concessões a objetos:
Modelos dinâmicos de contexto
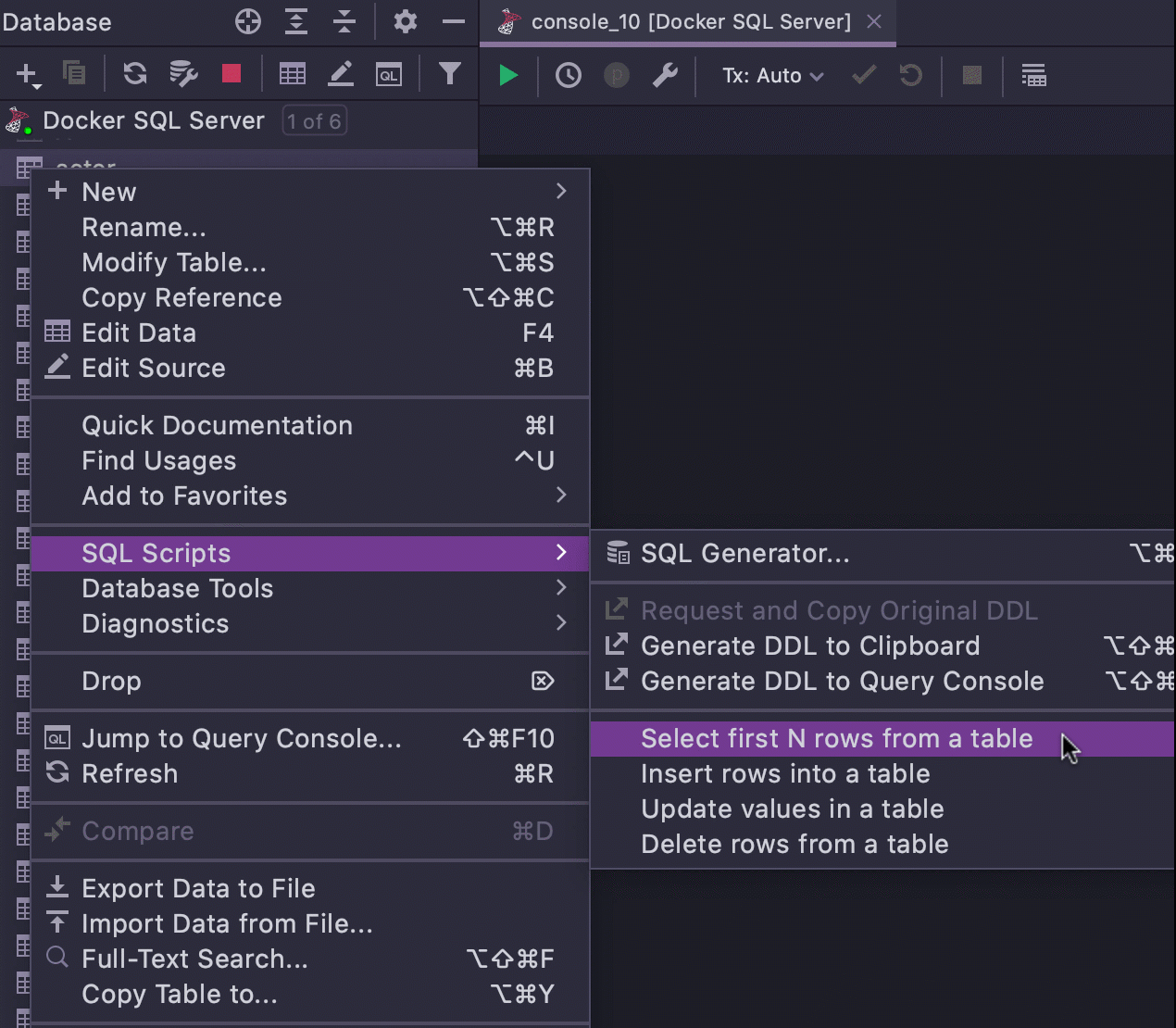
Esta é nossa solução para quem quiser gerar instruções simples diretamente a partir do navegador do banco de dados. Os modelos dinâmicos gerais abrangem muitas situações em que você precisa rapidamente escrever uma consulta simples. Mas também entendemos que às vezes, quando você está no contexto do navegador de banco de dados e já está focando no objeto que precisa, há uma maneira melhor de obter uma consulta simples usando esse objeto.
E, claro, muitas outras ferramentas também usam esse mecanismo para reduzir o trabalho repetitivo, portanto muitos usuários já estão acostumados com ele.
Eis um vídeo curto que mostra como funciona:
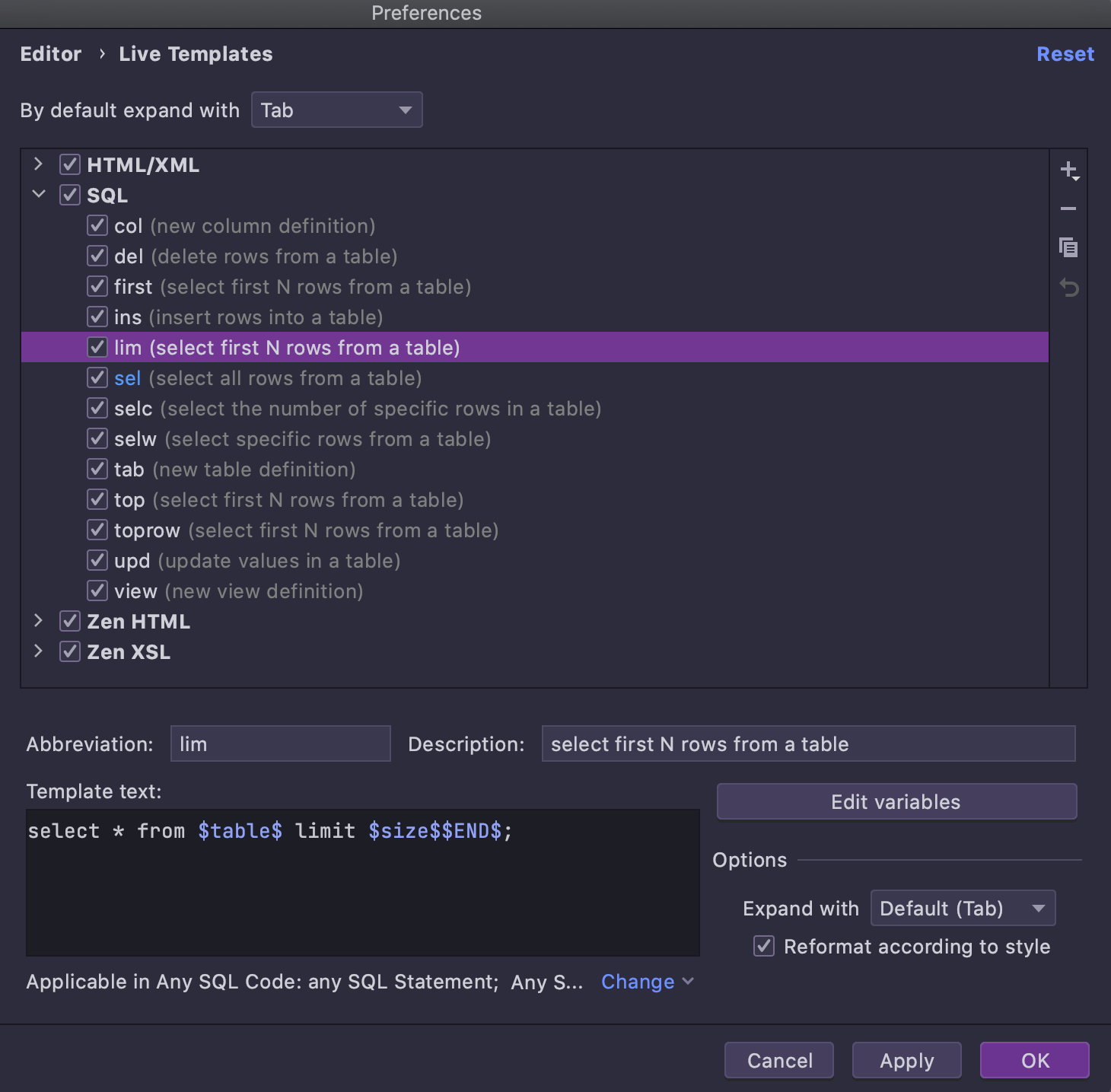
Cada fragmento de código nesta lista é, na verdade, um modelo dinâmico, mas são todos modelos especiais que podem ser gerados no contexto do objeto escolhido. Por exemplo, vejamos o modelo Select first N rows from a table.
Abra a página de configurações de modelos dinâmicos e localize o modelo que você precisa:
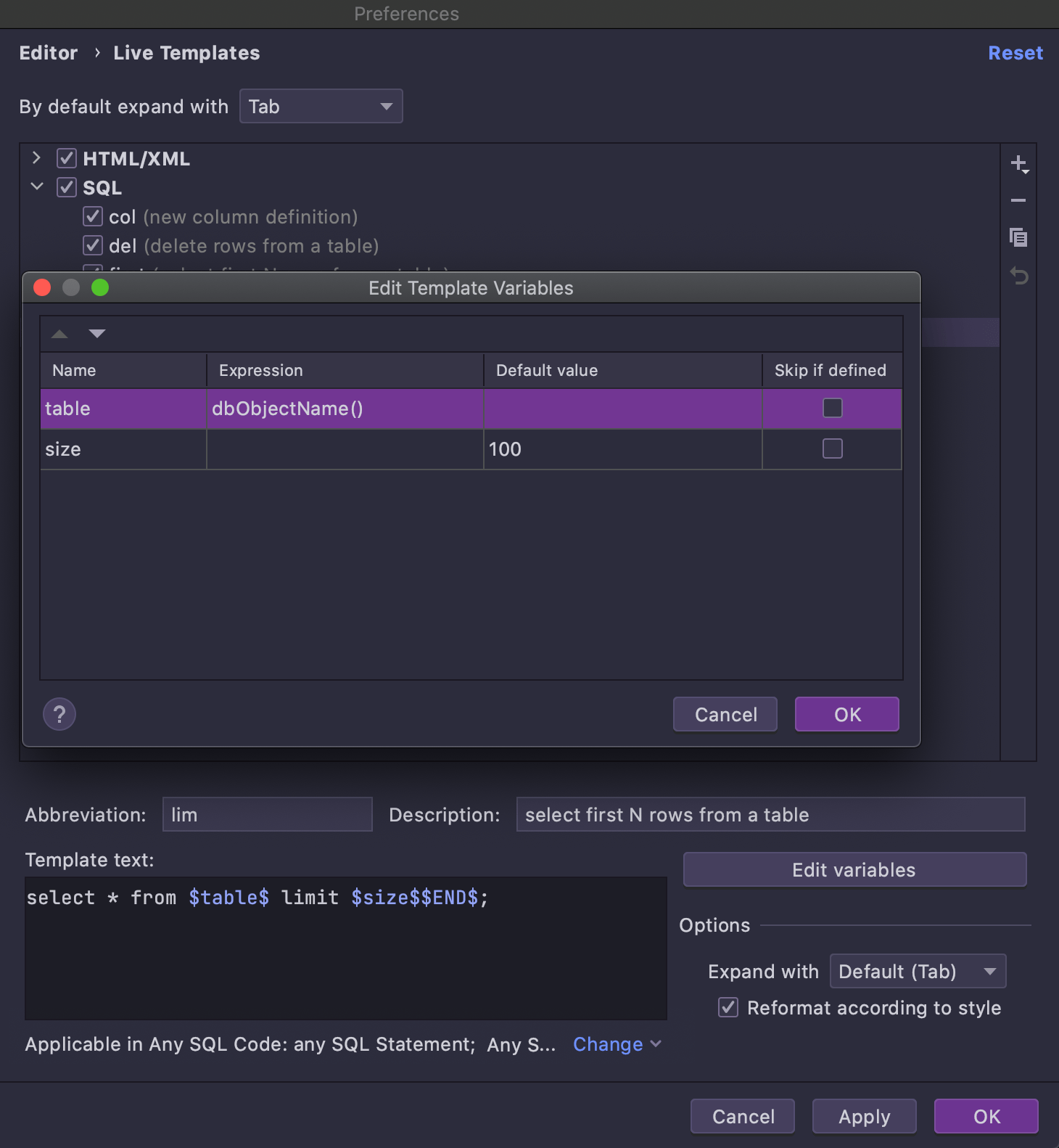
Select first N rows from a table parece um modelo geral (e pode ser usado como tal). Já que esta sintaxe específica não pode ser usada em qualquer banco de dados, os dialetos correspondentes são configurados para o modelo. A principal diferença que torna este modelo aplicável no navegador do banco de dados é a expressão especial dbObjectName, que é usada para a variável $table$:
Você pode, claro, adicionar seus próprios modelos ou editar os existentes.
Em Settings/Preferences | Database | General escolha se prefere que seu script seja gerado no console atual ou em um novo.
Editor de dados
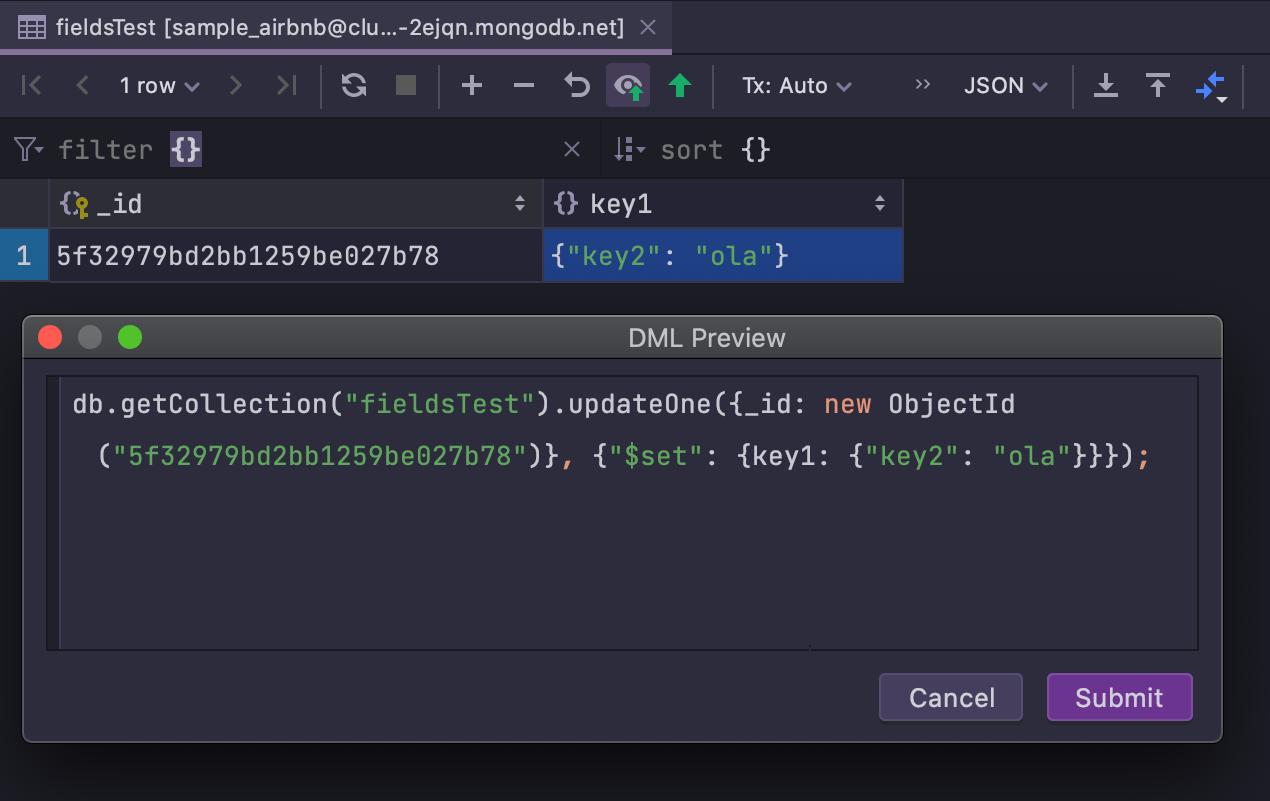
Edição de dados no MongoDB
Adicionamos um recurso essencial para trabalhar com o MongoDB; a partir desta versão, você pode editar dados em coleções MongoDB. Uma pré-visualização da declaração também está disponível.
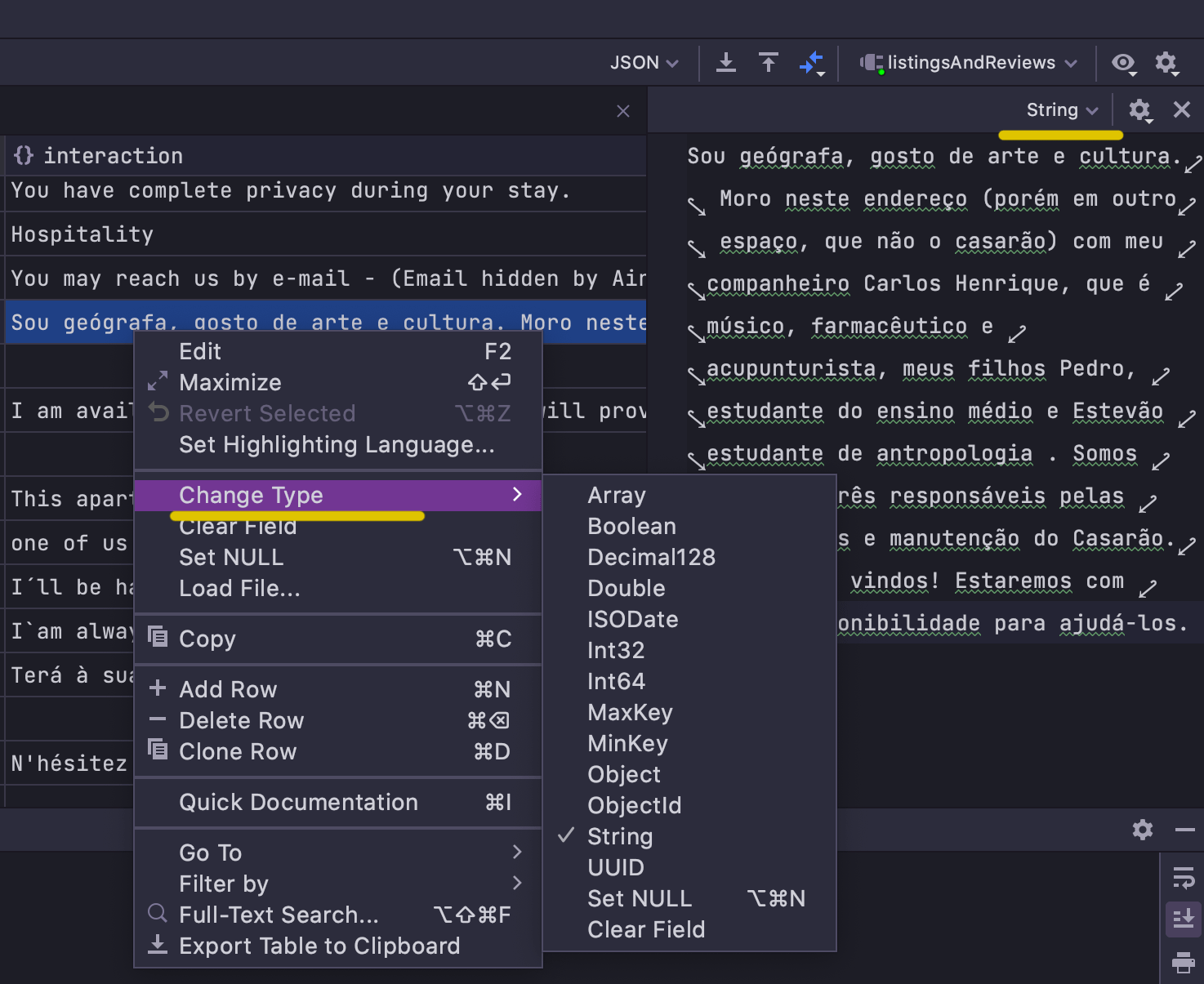
Para deixar a edição mais flexível, incluímos a capacidade de alterar o tipo de campo a partir da interface do usuário. Isto pode ser feito ou a partir do menu de contexto do campo ou através do editor de valor:
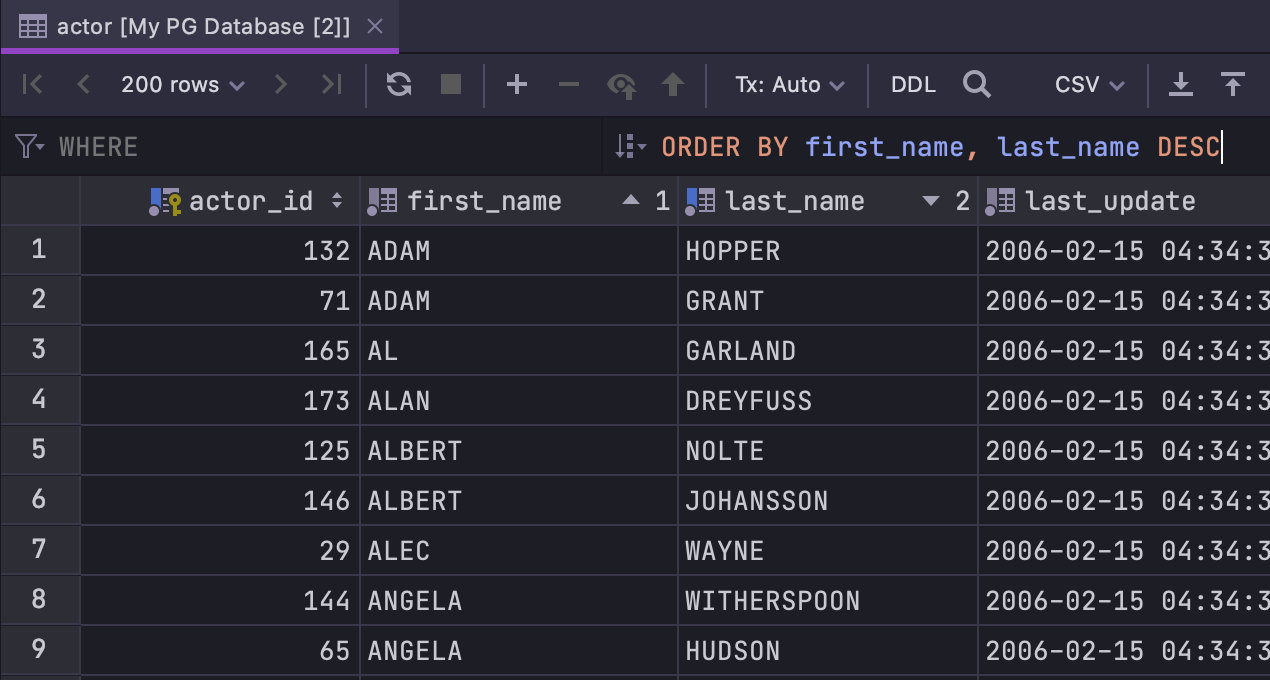
Melhor ordenação
Melhoramos o processo de ordenar dados:
- Um novo campo
ORDER BYfunciona de forma semelhante ao campoWHERE(que antes era chamado Filter): insira uma cláusula funcional para aplicá-la à consulta da tabela. - A ordenação não é 'empilhada' por default. Se você clicar no nome de uma coluna que deseja usar para ordenar os dados, a ordenação baseada nas outras colunas será ignorada. Se você preferir usar ordenação empilhada, clique no nome da coluna enquanto pressiona a tecla Alt.
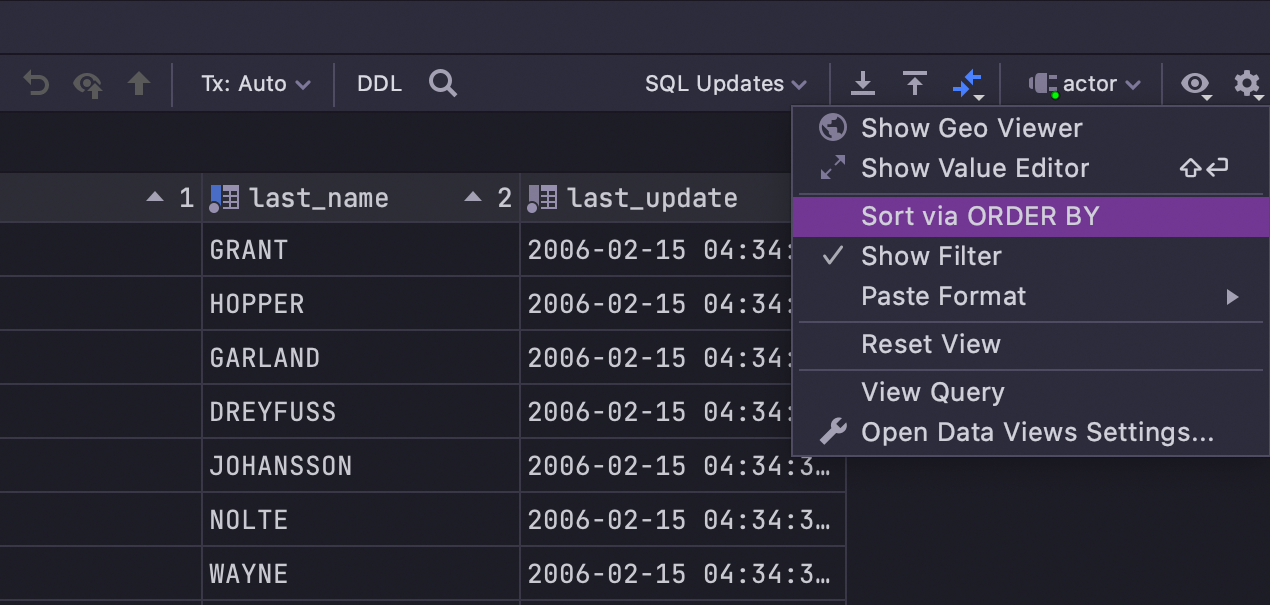
Se você quiser usar classificação no lado do cliente (o DataGrip não irá executar novamente a consulta, mas classificará os dados dentro da página atual), desmarque Sort via ORDER BY:
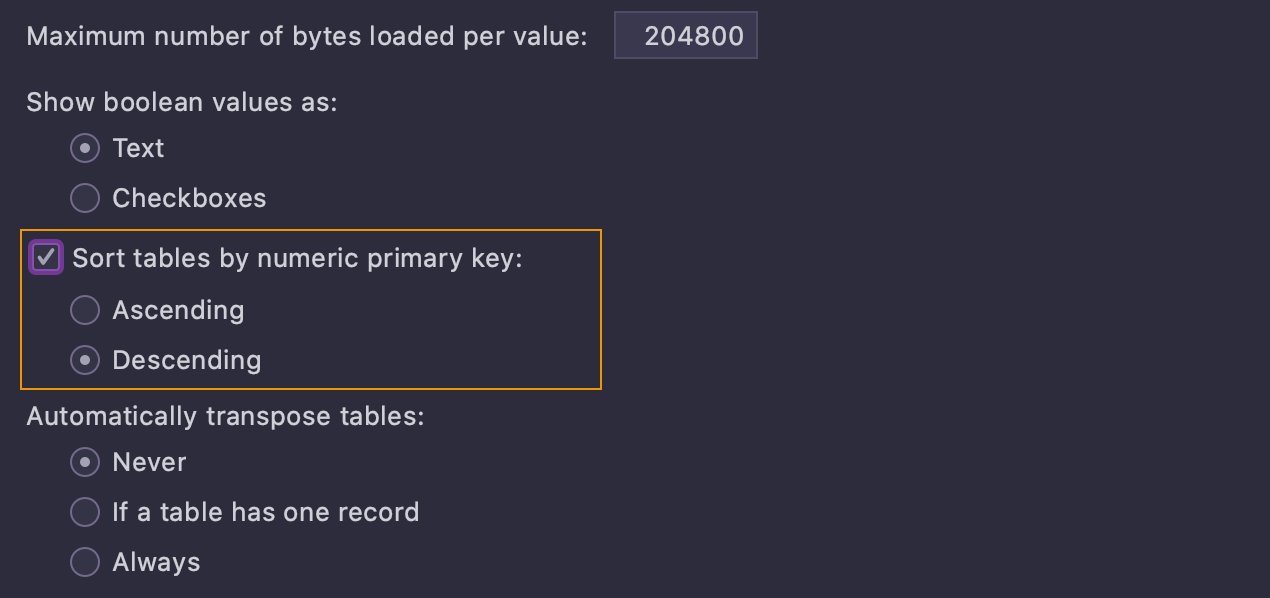
Também é possível abrir tabelas com ordenação predefinida com base na chave primária numérica. Esta configuração está em Settings/Preferences | Database | Data Views.
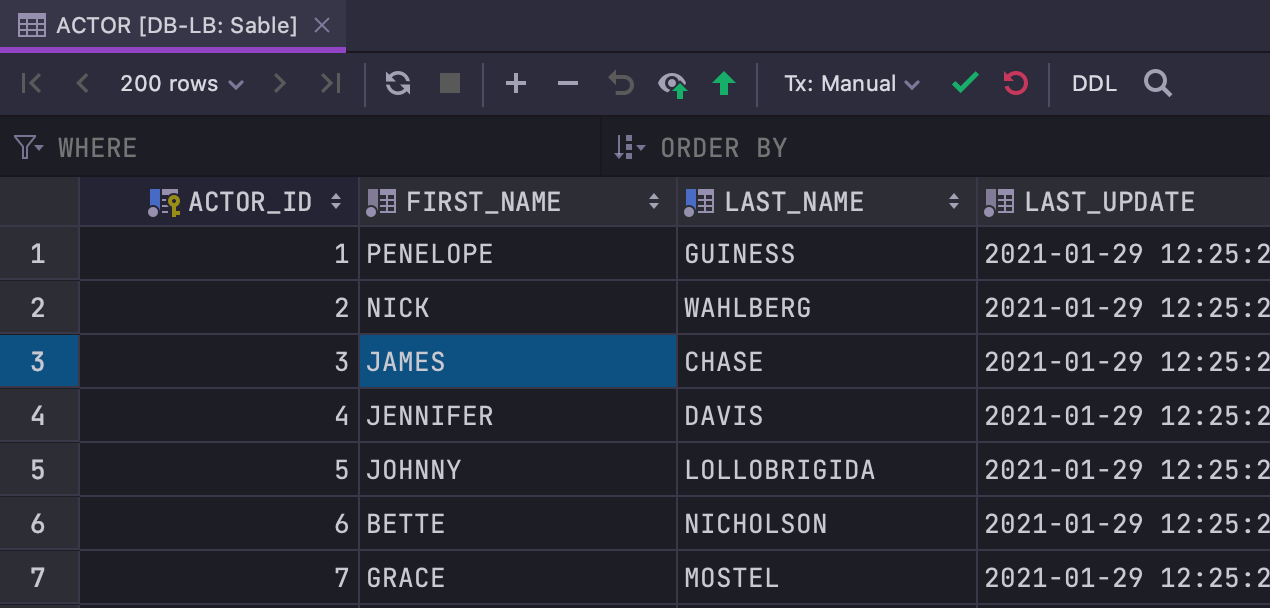
Nova barra de ferramentas
Nós redesenhamos a barra de ferramentas no editor de dados. Os botões Roll-back e Commit não são mais exibidos no modo de transação automática. Há dois novos botões Revert changes e Find.
Transposição de resultados de uma linha
Agora existe uma opção em Settings/Preferences | Database | Data Views para sempre transpor o resultado se ele tiver uma única linha.
Navegação
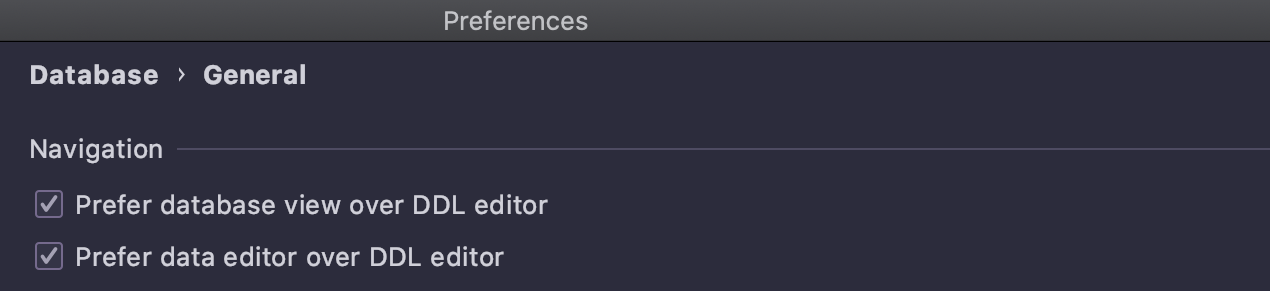
Ações diretas
Simplificamos a navegação e eliminamos as seguintes configurações:
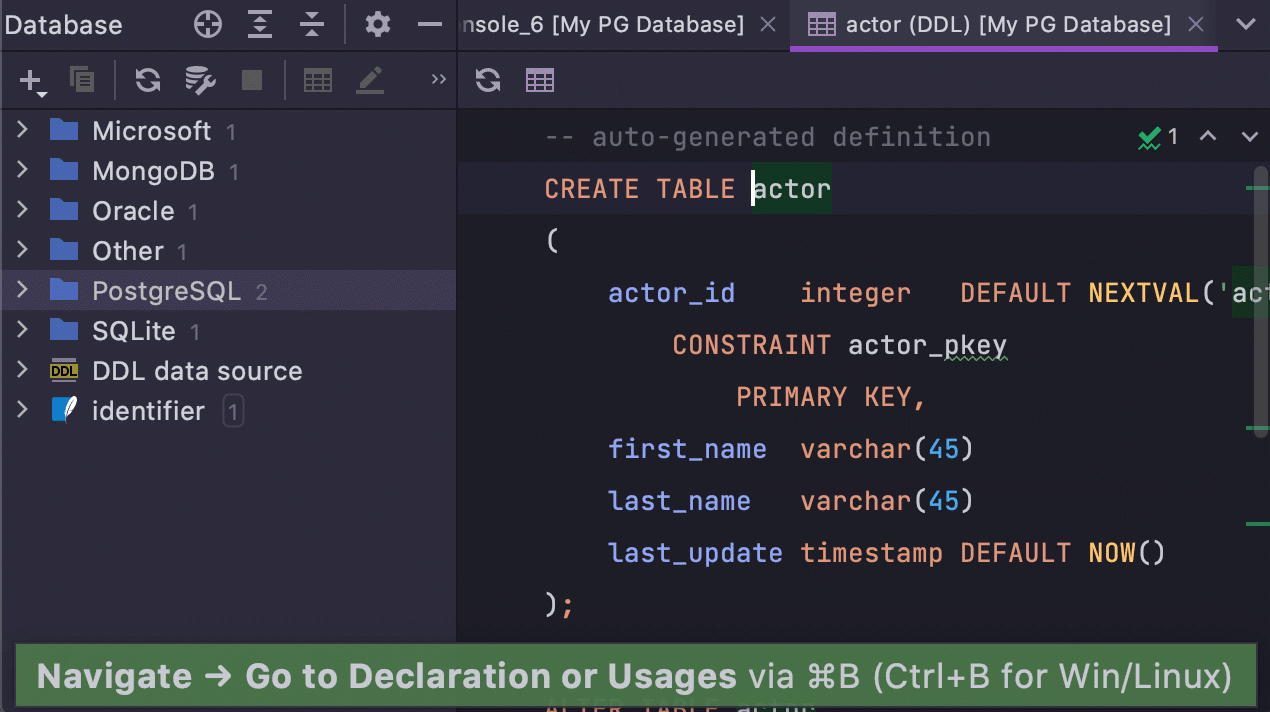
Se você nunca alterou essas configurações e tinha as caixas de seleção marcadas por default, a principal diferença para você na versão 2021.1 será a seguinte: Go to declaration (Ctrl/Cmd+B) chamada num SQL DDL agora leva você para o objeto e não mais para a árvore do banco de dados.
Também incluímos um atalho para a ação Select in database tree: Alt+Shift+B para Windows/Linux e Opt+Shift+B para macOS.
O principal motivo dessa mudança é deixar a lógica mais direta: cada ação deve levá-lo ao lugar que você espera.
Agora, se você estiver com o cursor sobre um objeto:
- Ctrl/Cmd+B mostra o DDL.
- F4 mostra os dados.
- Alt/Opt+Shift+B destaca o objeto na árvore de bancos de dados.
Entendemos que alguns hábitos podem ser quebrados por causa dessas alterações e estamos prontos a fornecer maneiras de preservar sua experiência anterior. Algumas dicas:
- Conheça o poder do mapa de teclas. Se você gosta de usar Ctrl/Cmd+B para abrir o navegador do banco de dados, basta remapear o atalho para Select in database tree.
- Se você prefere comoCtrl/Cmd+B ou Ctrl/Cmd+Click abre a CREATE definition quando o objeto usado no SQL ainda não foi criado, simplesmente não remova esses atalhos de Go to declaration depois que fizer o remapeamento sugerido acima.
- Se você mantém desmarcada a configuração Prefer data editor over DDL editor mas prefere a forma como o clique duplo abre o DDL, esse comportamento pode ser recuperado alterando o valor da chave de registro:
database.legacy.navigate.to.code.from.tree. De acordo com nossos dados, pouquíssimos usuários usaram esse fluxo. Também recomendamos o uso de atalhos para abrir o DDL em objetos.
Se algum caso de uso não for mais coberto por esse novo fluxo, por favor nos avise.
Conectividade
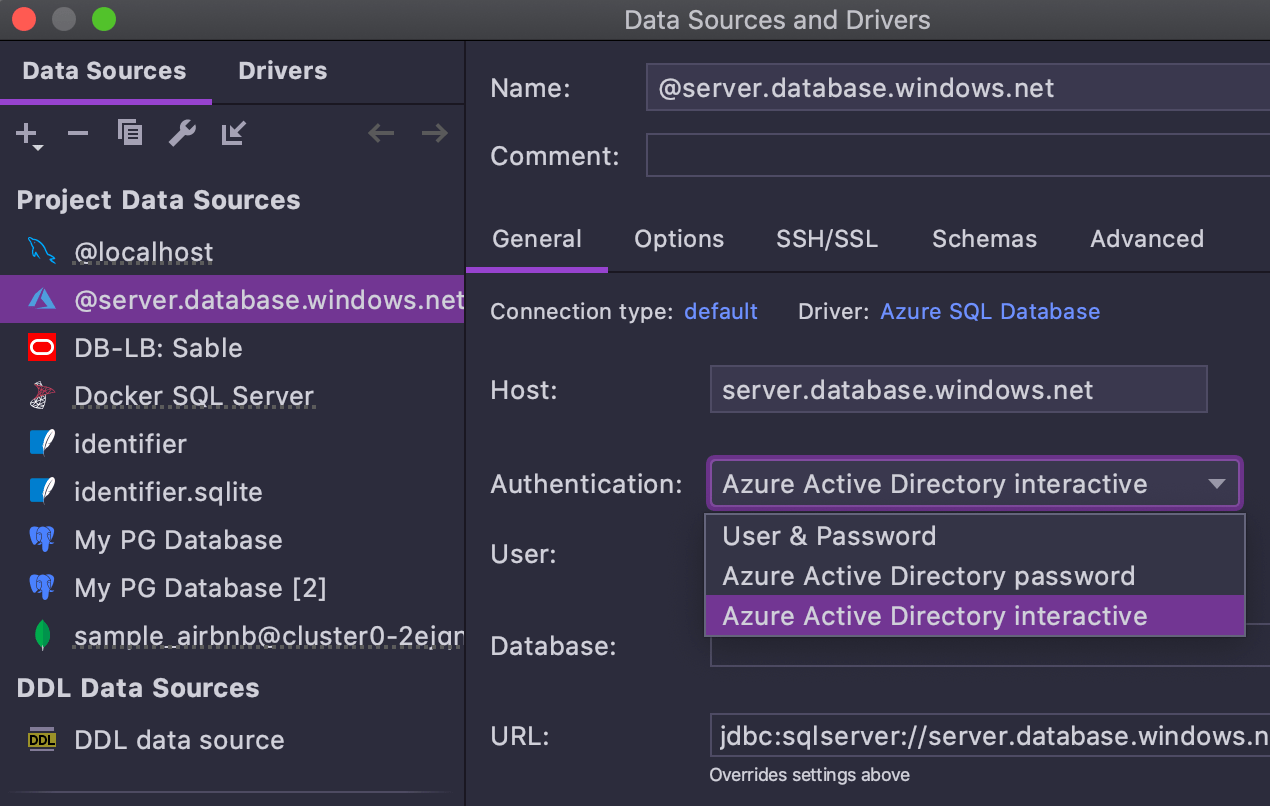
Suporte Azure MFA
A autenticação interativa do Azure Active Directory é suportada. Quando esta opção estiver ativada, o navegador abrirá automaticamente e permitirá que você faça login.
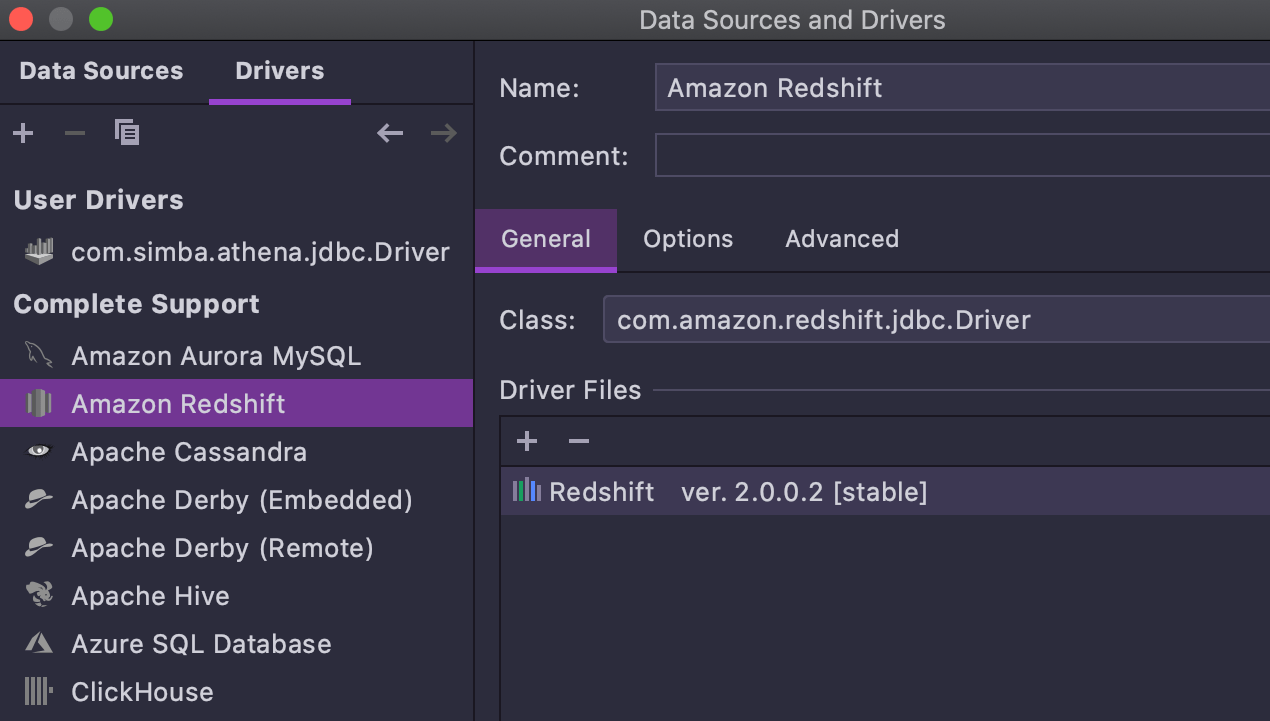
Driver Redshift 2.x
O driver JDBC Redshift 2.x está disponível para usuários DataGrip a partir desta versão. Aqui, a principal melhoria é a capacidade de cancelar consultas.
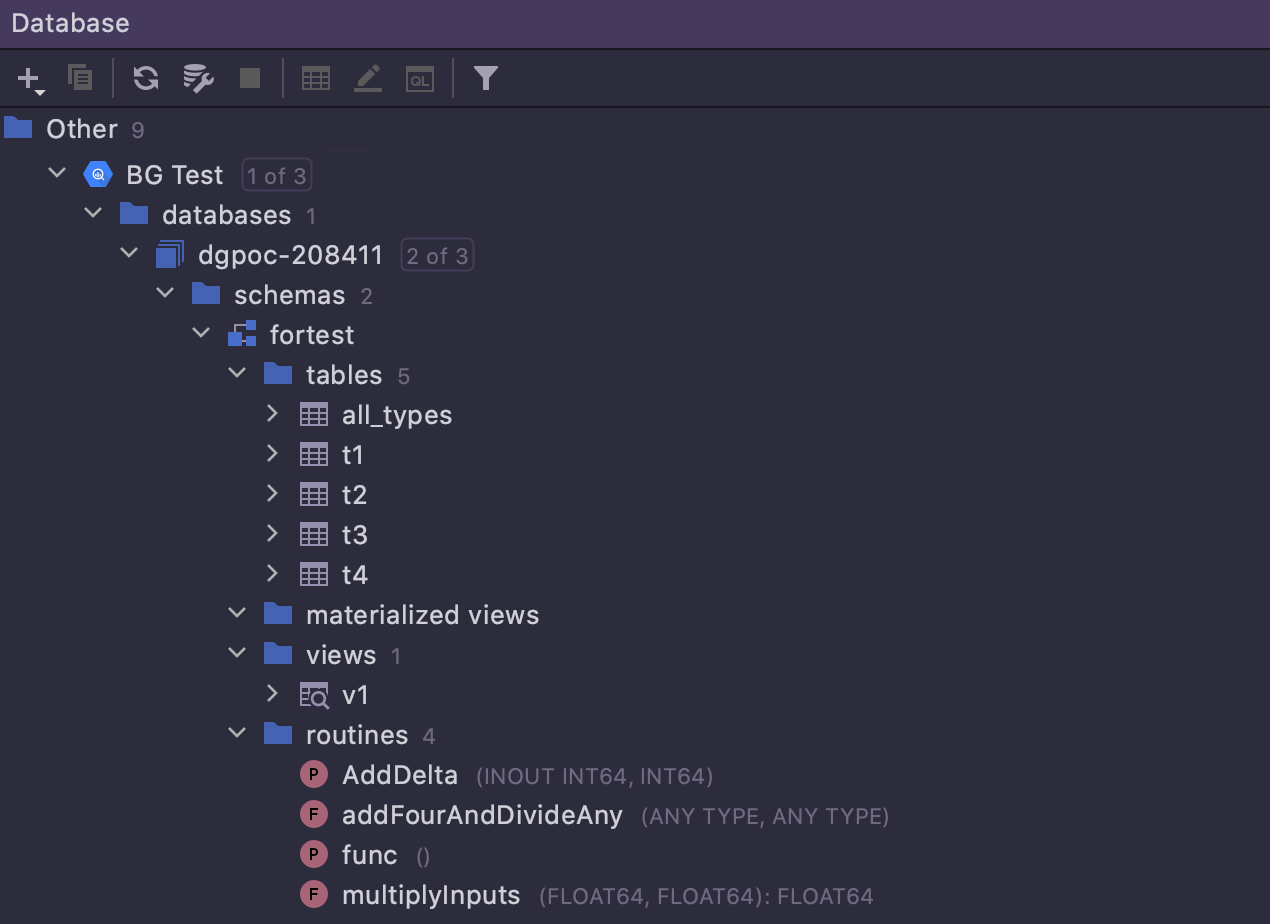
Suporte total ao Google BigQuery
O suporte ao dialeto do Google BigQuery foi incluído na versão anterior. Nesta versão ele foi expandido para que a introspecção do banco de dados e a geração de código agora funcionem corretamente e não dependam mais da funcionalidade do driver JDBC.
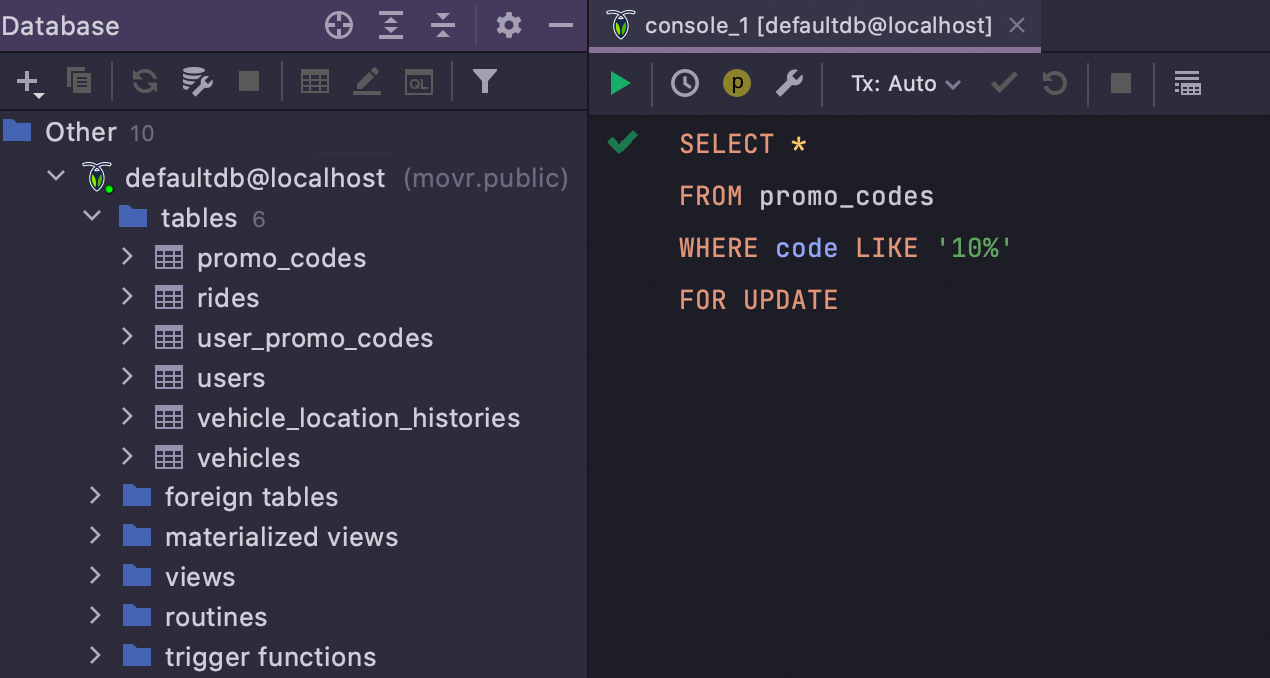
Suporte ao dialeto CockroachDB
Agora, se você trabalha com scripts CockroachDB ou escreve SQL para consultas neste banco de dados, seu código será destacado corretamente e todos os erros serão mostrados antes da consulta ser executada. Esta é a primeira etapa para o suporte total ao CockroachDB, que chegará numa versão futura.
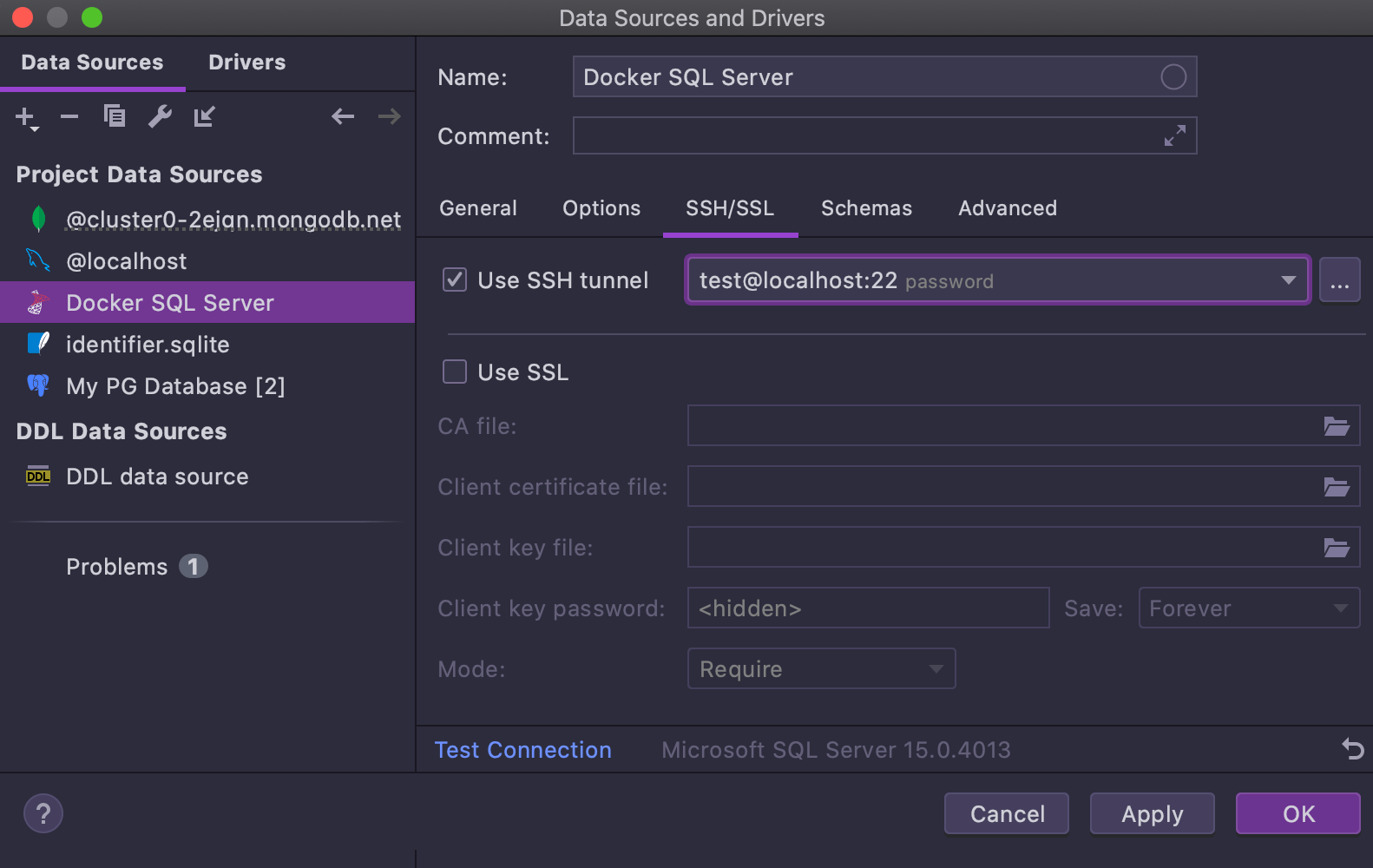
Melhorias na janela de conexão
Nós redesenhamos a janela de conexão para deixá-la mais amigável.
- Drivers e fontes de dados agora aparecem listados em duas abas diferentes. A lista de drivers não deve incomodar usuários experientes, enquanto que deve ajudar os novatos a não confundi-los com fontes de dados.
- Cada página de driver inclui um botão Create data source.
- O botão Test Connection foi movido para o rodapé para que você possa usá-lo em qualquer aba das propriedades da fonte de dados, não apenas na aba General and SSH/SSL como era antes.
- A página de propriedades da fonte de dados DDL contém uma lista drop-down para a escolha do dialeto.
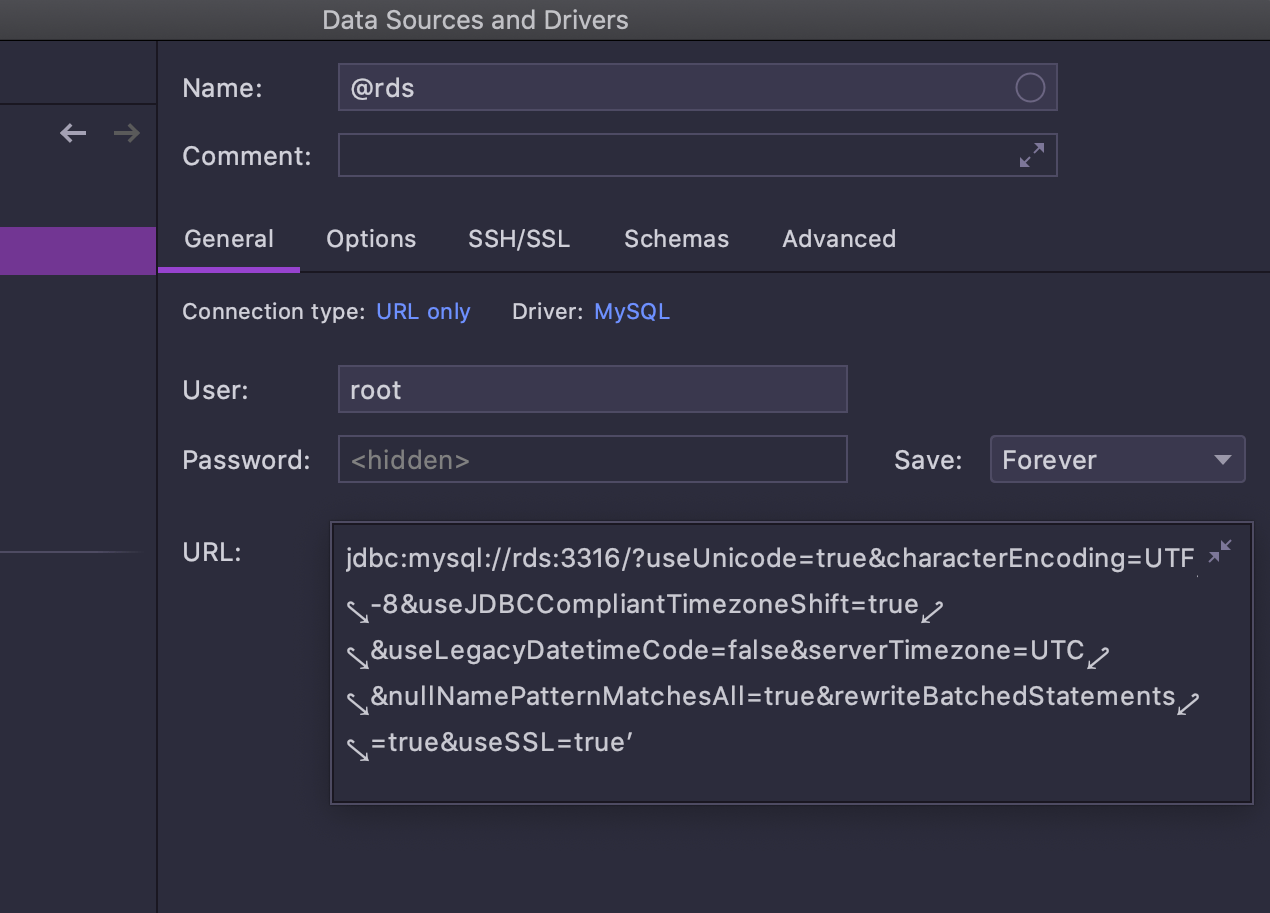
O campo URL agora pode aumentar, o que facilita trabalhar com URLs longas.
Navegador de banco de dados
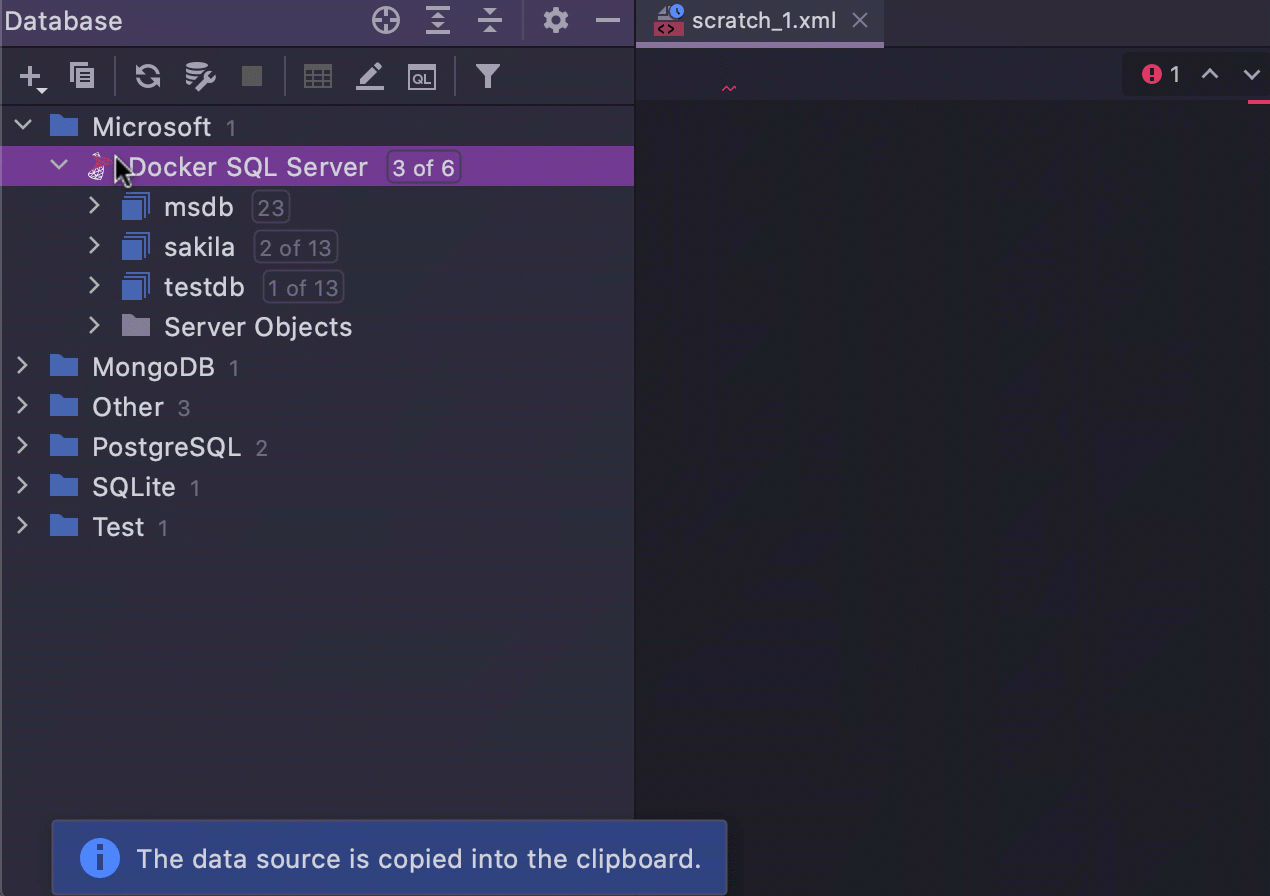
Facilidade para copiar e colar fontes de dados
A capacidade de copiar e colar fontes de dados foi introduzida há muito tempo. Mas a partir da versão 2021.1, você pode copiar, cortar e colar fontes de dados usando os atalhos mais populares do mundo: Ctrl/Cmd+C/V/X.
- Quando você copia uma fonte de dados, seu XML é copiado para a área de transferência que você pode compartilhar através de aplicativos de mensagens. Você também pode usar a ação Paste para colar um pedaço de XML de outro lugar.
- Se você recortar e colar uma fonte de dados dentro de um projeto, ela será apenas movida. Não há necessidade de senha. Mas a senha é necessária em todos as outras situações.
- Um Cut pode ser desfeito com Ctrl/Cmd+Z.
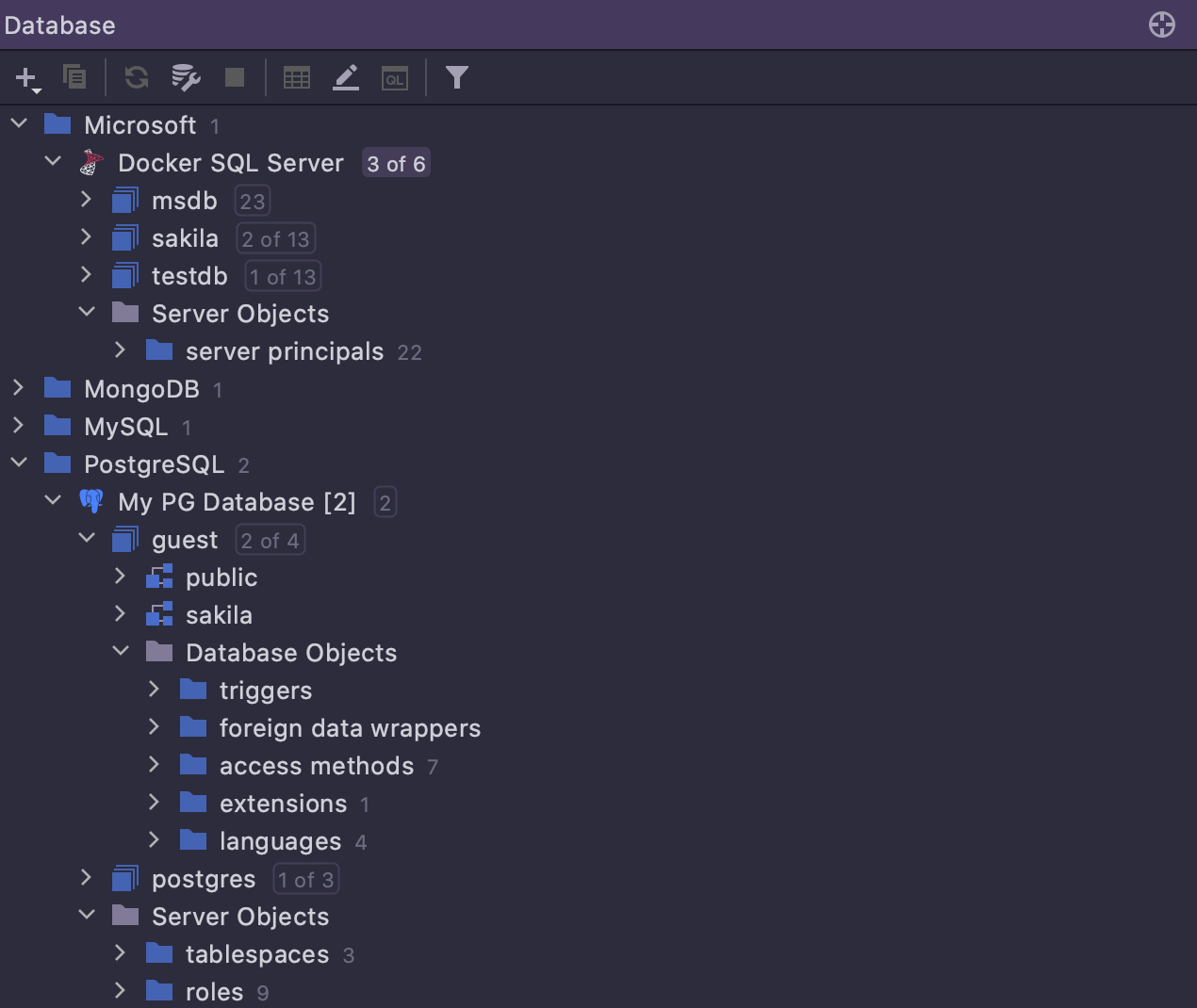
Novo layout
O layout default do navegador de banco de dados foi alterado, fazendo com que objetos secundários estejam agora disponíveis sob um nó dedicado. As pessoas geralmente costumam trabalhar com tabelas, visualizações e rotinas, enquanto que usuários, funções, tablespaces, wrappers de dados externos e diversos outros tipos de objetos não figura no topo de sua lista de prioridades. Portanto, agora esses objetos secundários ficam ocultos debaixo de dois nós: Server Objects e Database Objects.
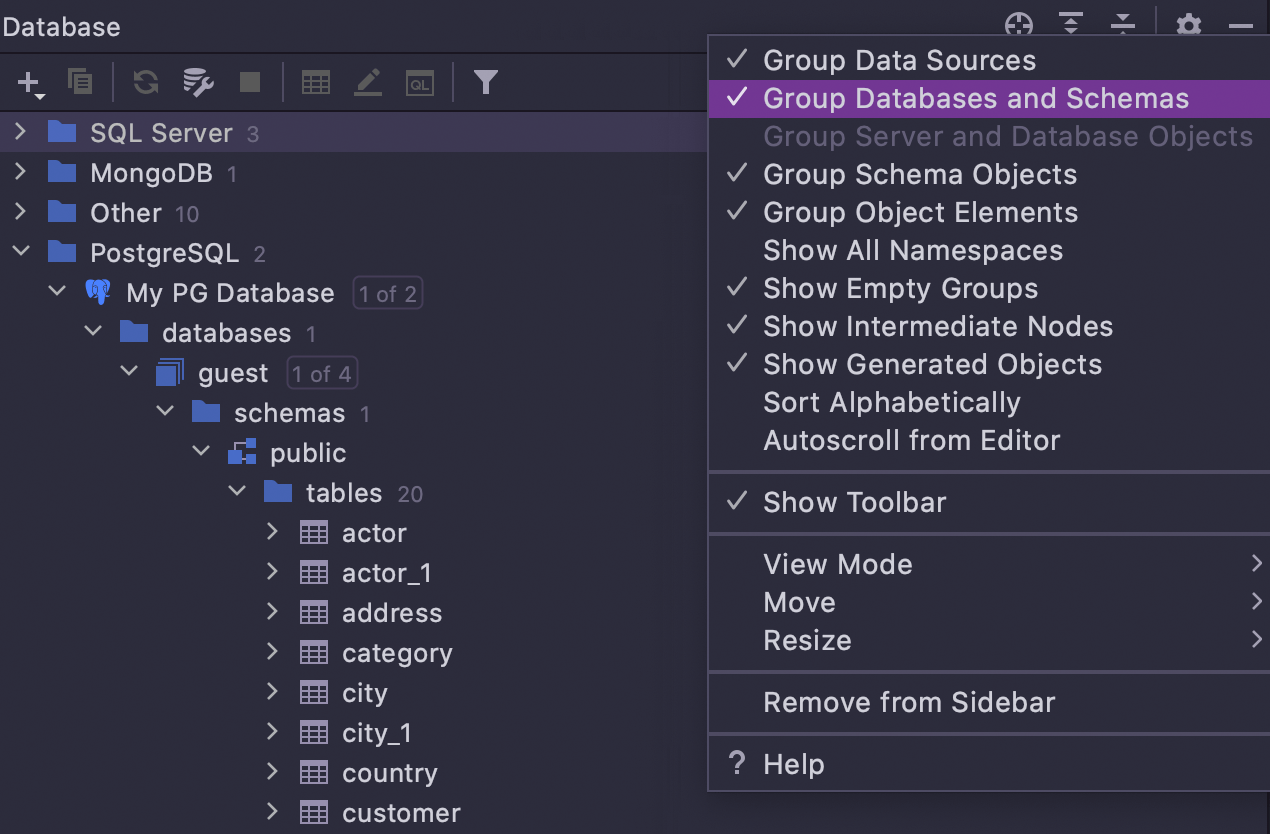
Se você preferir o layout antigo, basta selecionar Group Database and Schemas nas configurações sob o ícone de engrenagem.
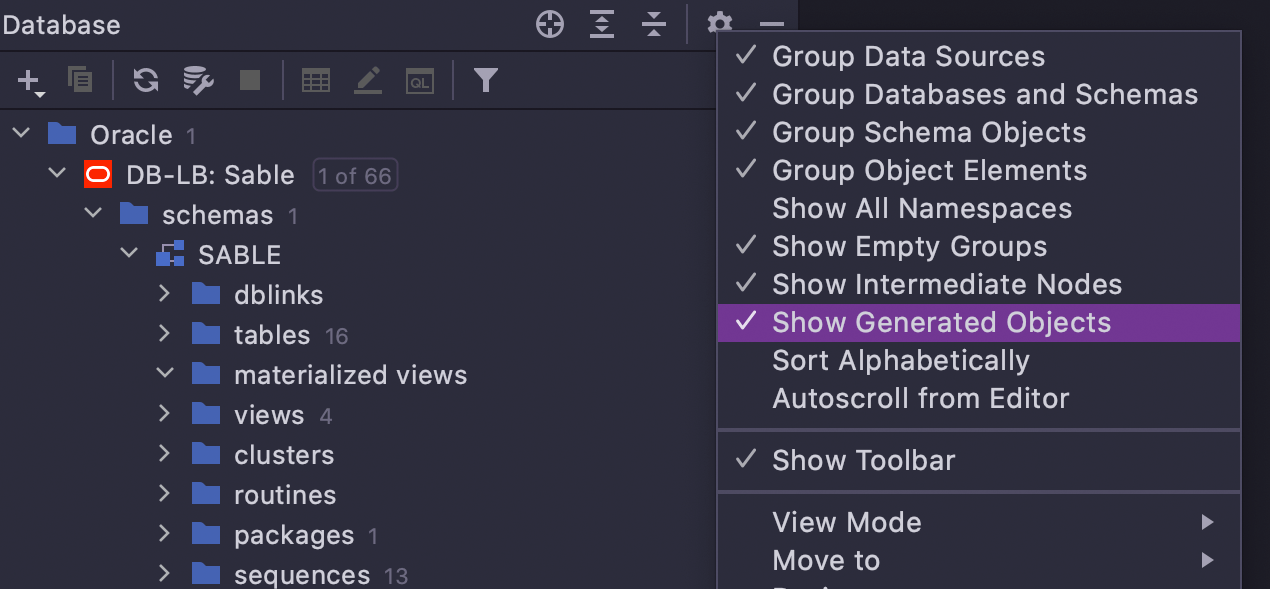
Ocultar objetos Oracle gerados automaticamente
Se você usa Oracle, há uma opção para mostrar ou ocultar objetos gerados automaticamente na árvore, que inclui:
- Registros de views materializados
- As tabelas subjacentes para views materializados
- Tabelas secundárias
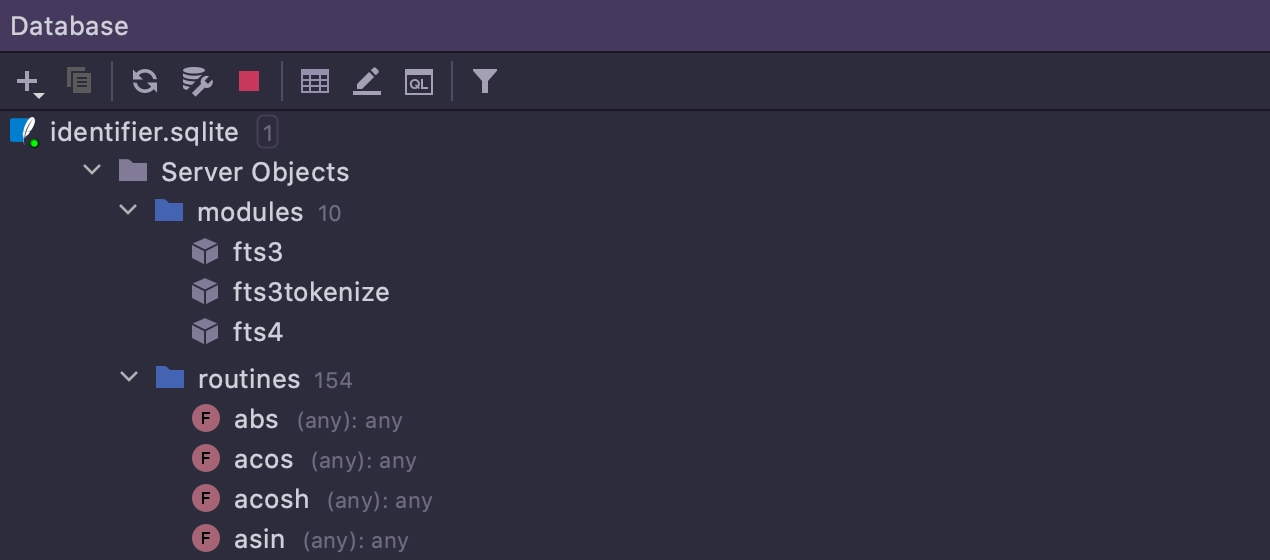
Novos tipos de objetos SQLite
É realizada uma introspecção para o SQLite nas funções, módulos e colunas virtuais.
Melhorias para bancos de dados não suportados
Modelos de fonte de dados
A partir da versão 2021.1, será mais fácil adicionar a fonte de dados para bancos de dados que não suportamos. Agora fornecemos drivers JDBC para AWS Athena, Informix, Presto, SAP HANA, Google Cloud Spanner e muitos outros. Procure por esses bancos de dados na seção Other da lista de bancos de dados.
Fizemos algumas melhorias adicionais:
- Você não precisa mais baixar o driver nem criar manualmente uma fonte de dados com base nele.
- Novas versões do driver serão fornecidas pelo DataGrip.
- Alguns novos bancos de dados têm seus próprios ícones dedicados.
Observe que o suporte para esses bancos de dados é limitado. Depende principalmente das capacidades do driver JDBC e do suporte ao dialeto SQL:2016 pelo editor SQL do DataGrip.
Parsing de consultas
Introduzimos uma nova configuração para o uso de bancos de dados não suportados. Quando você estiver trabalhando com esses bancos de dados no DataGrip, você deverá ou usar o dialeto SQL:2016 ou o dialeto Generic. Generic é quase igual a SQL:2016, com apenas uma diferença: o DataGrip não coloca em destaque os erros que encontrar.
Para acessar essa configuração, vá para Settings/Preferences | Database | General | Split a script for execution in Generic and ANSI SQL dialects. Você poderá escolher dentre os seguintes valores:
- On valid ANSI SQL statements or by separator: esta é a configuração padrão adequada para a maioria dos casos. Em outras palavras, faremos o melhor para entender o que você deseja executar.
- On ANSI SQL Statements: instruções divididas como antes. A lógica é baseada apenas no que o DataGrip considera válido com base na gramática SQL:2016.
- By statement separator: extrai e executa instruções por separadores. Use-a se a primeira opção não funcionar. Para GenericSQL, o separador é um ponto-e-vírgula. Observe que não é mais possível definir um separador personalizado.
Aqui estão alguns dos problemas que resolvemos:
- Muitos usuários relataram um problema com a execução de CTEs. Ele deveria ter sido parcialmente atenuado quando a gramática Generic foi atualizada de SQL:92 para SQL:2016, mas a opção On valid ANSI SQL statements or by separator ainda ajuda com CTEs complexos. Outro exemplo de uma instrução que funcionará com essa opção é a incomum instrução MERGE.
- A opção On valid ANSI SQL statements or by separator também ajuda a executar coisas que não sejam instruções na gramática SQL:2016, como show databases.
Assistência para codificação
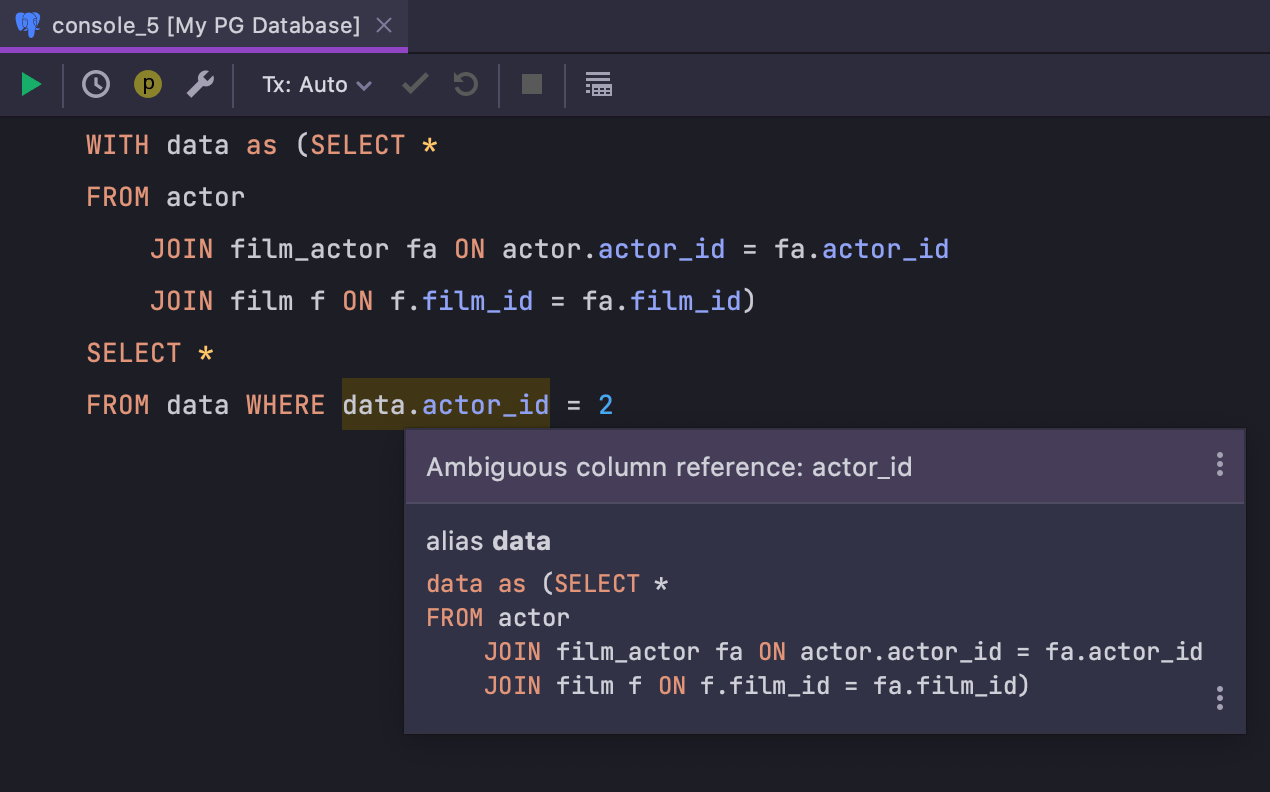
Nome de coluna ambíguo ao usar CTE
A inspeção que relata nomes de coluna ambíguos ficou mais inteligente e agora leva em consideração quaisquer colunas dentro de expressões de tabela comuns:
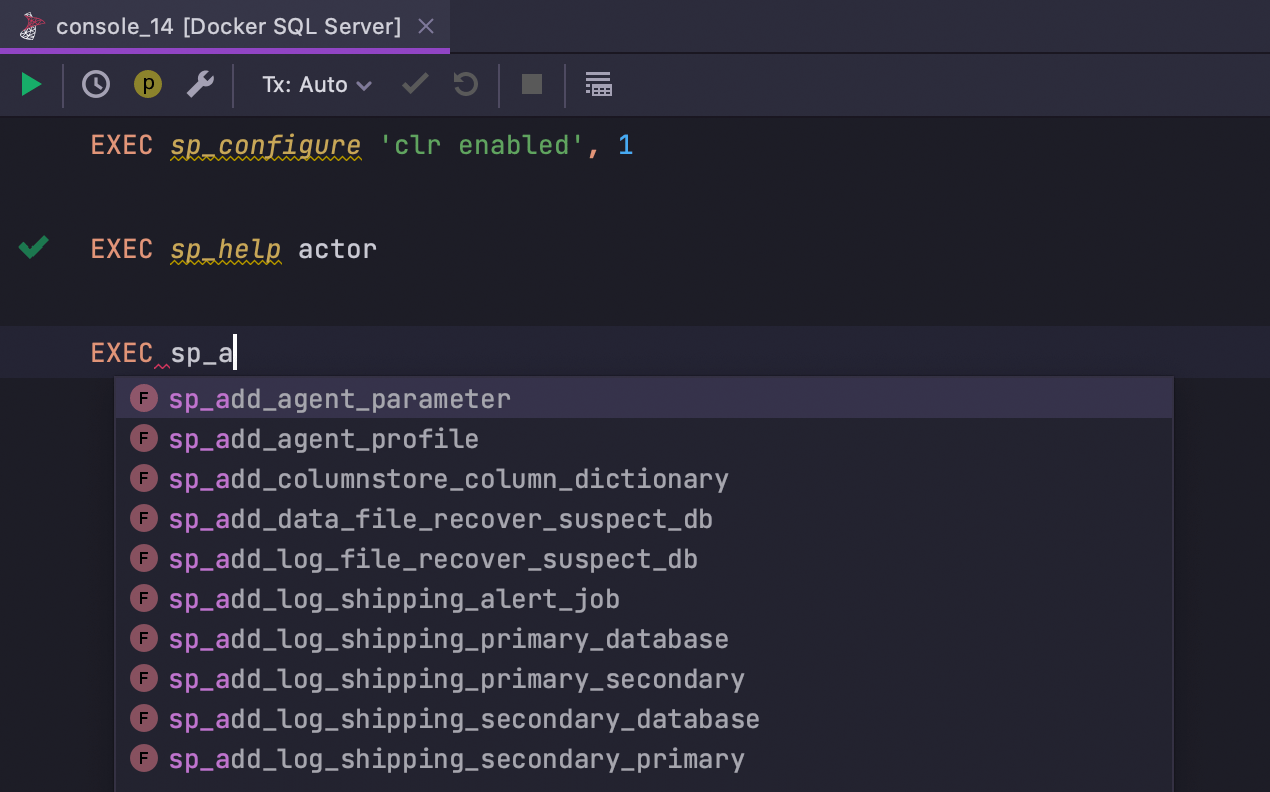
As funções do sistema podem ser usadas sem qualificação SQL Server
Funções e procedimentos do sistema não aparecem mais em destaque como erros quando usados sem qualificação. Agora eles também suportam navegação e complementação.
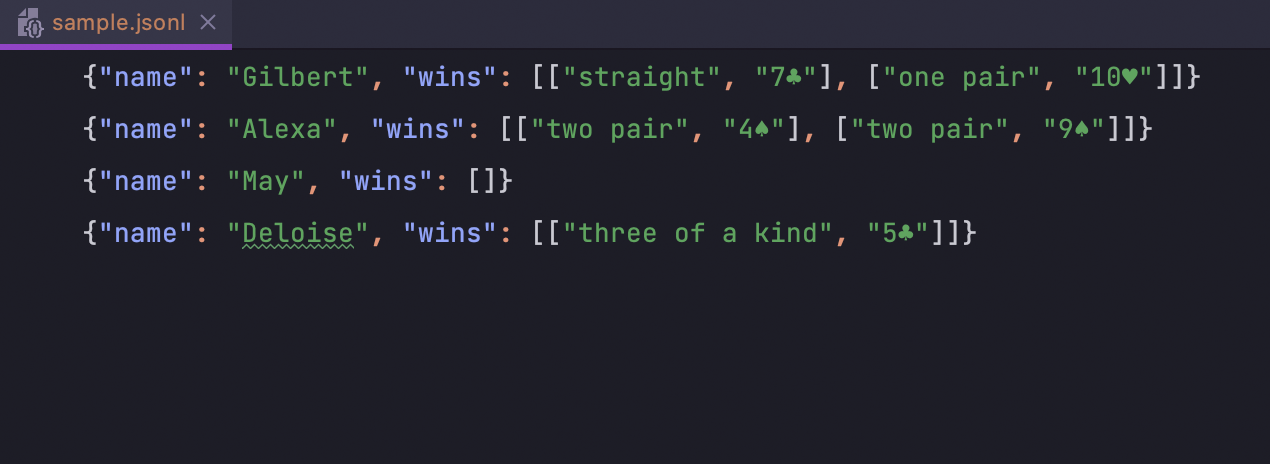
Suporte a JSON Lines
Thanks to the IntelliJ Platform, DataGrip now has support for the newline-delimited JSON Lines format used for working with structured data and logs. O IDE reconhece os tipos de arquivo .jsonl, .jslines, .ldjson e .ndjson.
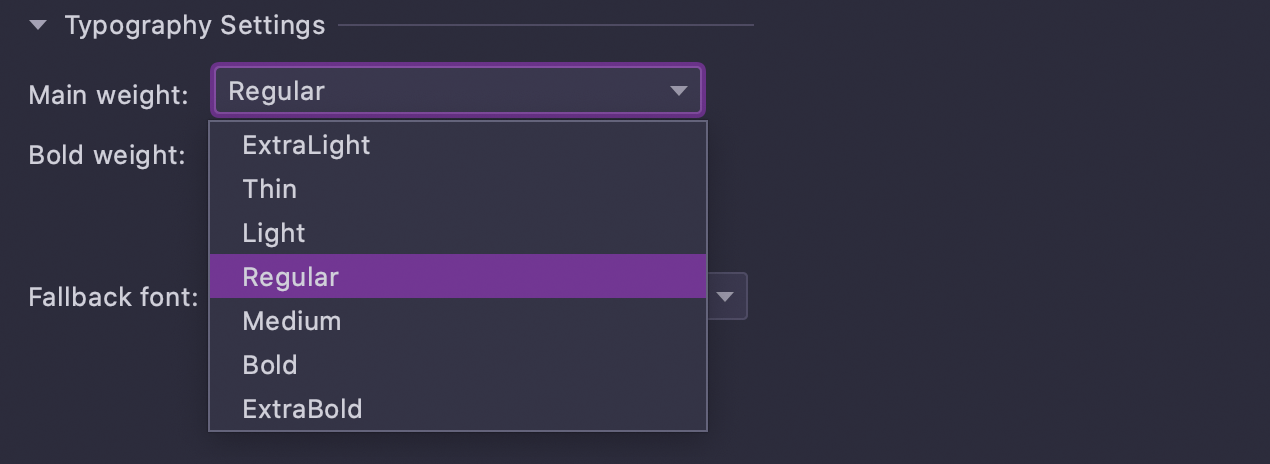
Espessura da fonte ajustável
Novas configurações de tipografia permitem ajustar o estilo da fonte. Na versão v2021.1, você pode definir a espessura das fontes principal e negrito em Settings/Preferences | Editor | Fonts.
Importação / Exportação
Aviso sobre dados não carregados
Quando você copia dados binários que ainda não foram completamente carregados, o seguinte aviso será mostrado:
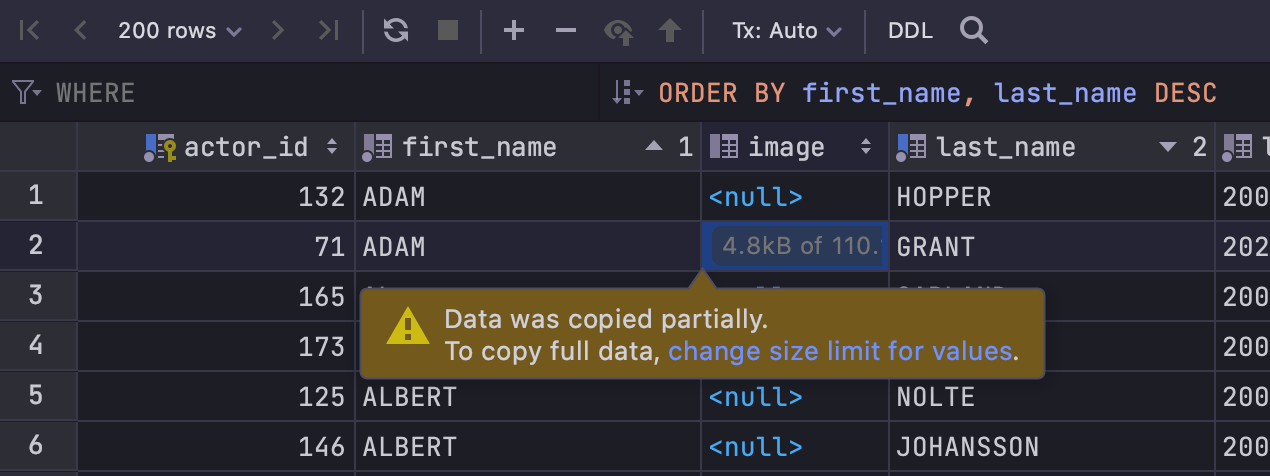
Se você não quiser que os dados sejam truncados, aumente o valor em Settings/Preferences | Database | Data Views | Maximum number of bytes loaded per value.
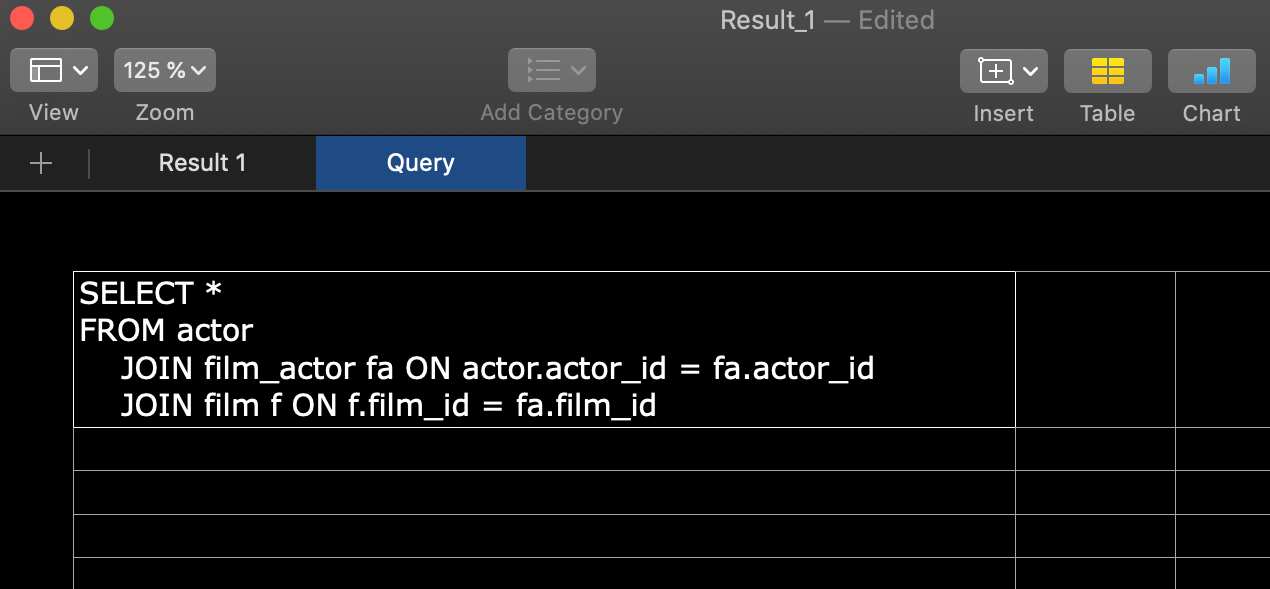
Consultas em arquivo Excel
Ao exportar para o Excel, o arquivo resultante conterá a consulta numa planilha separada.
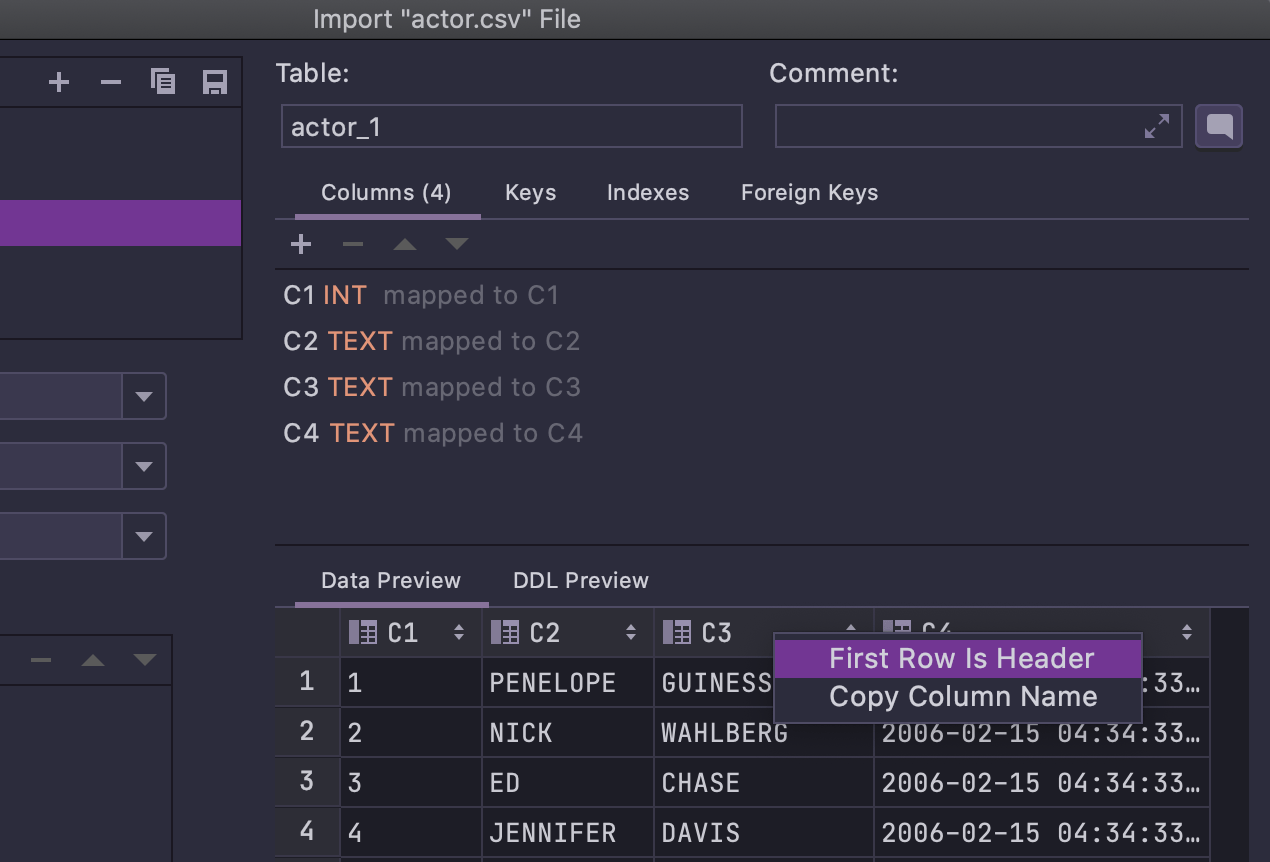
First row is header no menu de contexto
Ao importar um arquivo CSV, a opção de informar que a primeira linha é um cabeçalho agora aparece no menu de contexto, conforme mostrado abaixo:
Interface do usuário
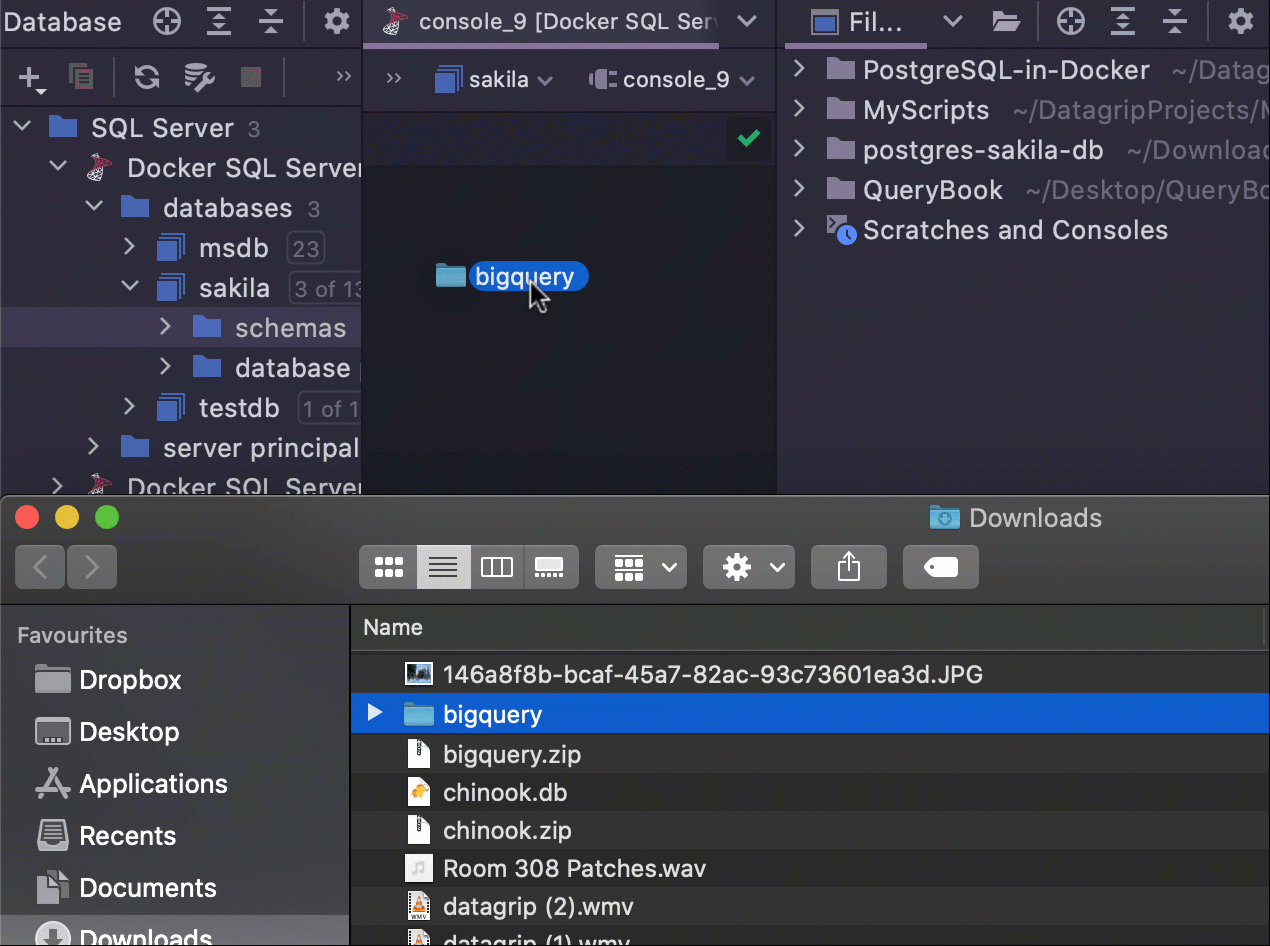
Anexar pasta através de arrastar e soltar
Agora é possível anexar uma pasta arrastando e soltando-a no seu projeto.
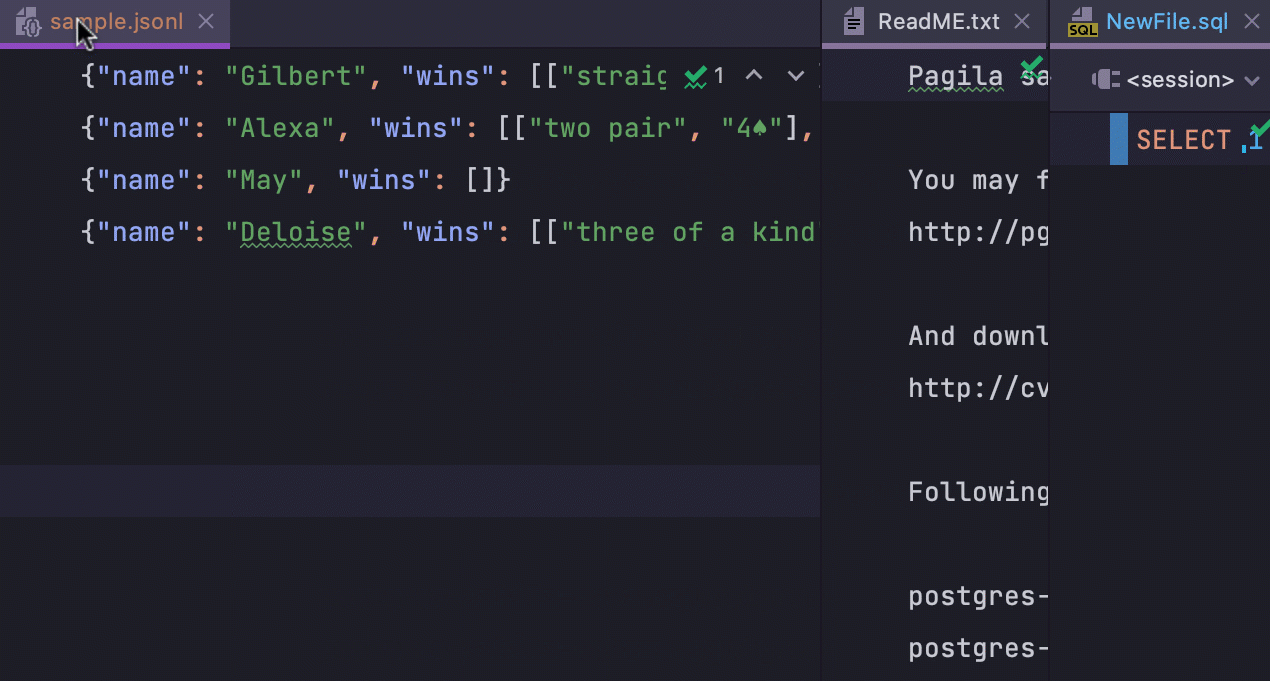
Maximize as abas na view repartida
Sempre que várias abas que dividem o editor verticalmente estiverem abertas, você poderá clicar duas vezes nelas para maximizar a janela do editor para cada uma. Para trazer a janela de volta ao tamanho original, basta clicar nela duas vezes novamente.

Nomes longos em títulos de abas
Algum tempo atrás, fizemos com que os nomes de abas fossem abreviados. Nem todo mundo gostou, então eis uma configuração para permitir que você escolha como quer que eles sejam exibidos.