Novidades do DataGrip 2021.3
O DataGrip 2021.3 chegou! Esta é a terceira grande atualização de 2021 e vem com vários aprimoramentos. Vejamos o que ele tem a oferecer!
Editor de dados
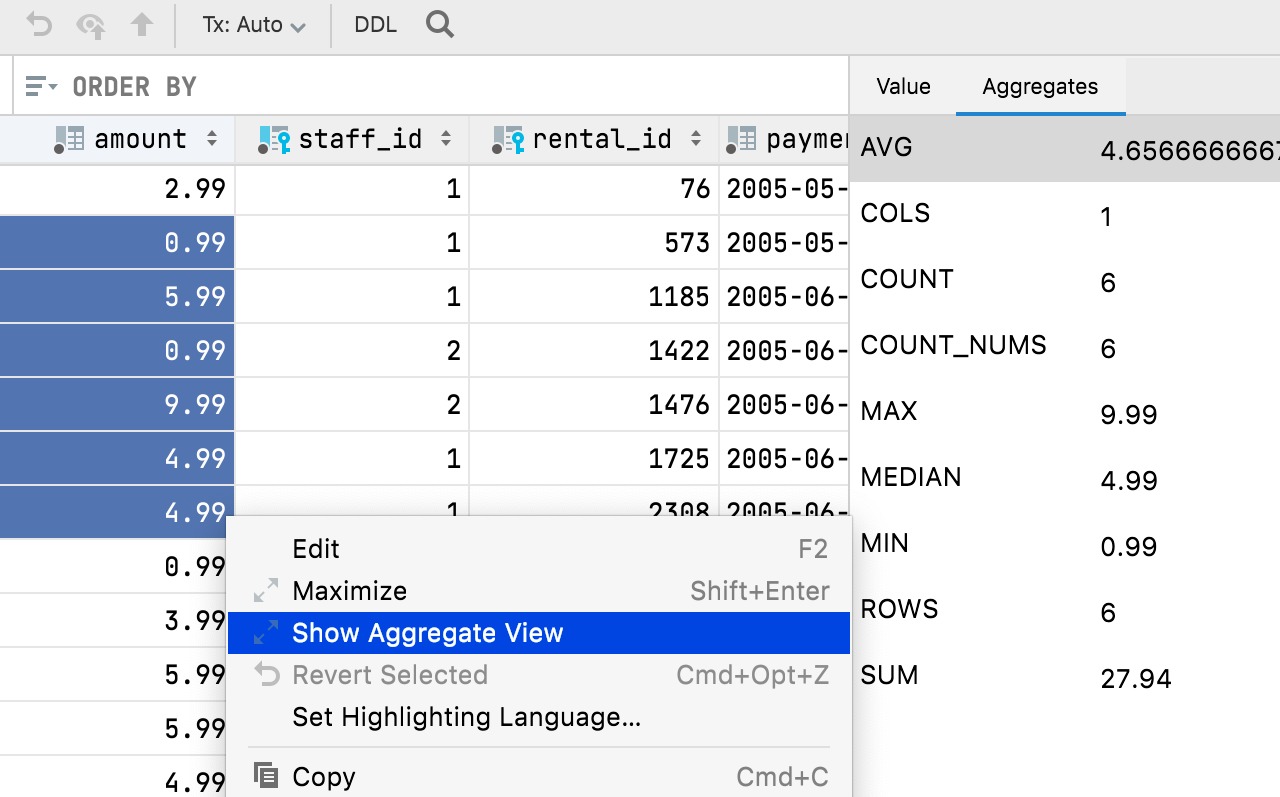
Aggregate
Adicionamos a capacidade de mostrar uma visualização agregada (Aggregate) para um intervalo de células. Este é um recurso aguardado há muito tempo que ajudará você a gerenciar os seus dados e evitará que você tenha que criar consultas adicionais! Isto torna o editor de dados mais poderoso e fácil de usar, deixando-o um passo mais próximo das planilhas do Excel e do Google.
Selecione o intervalo de células para o qual você deseja a visualização. Depois, clique com o botão direito e selecione Show Aggregate View.
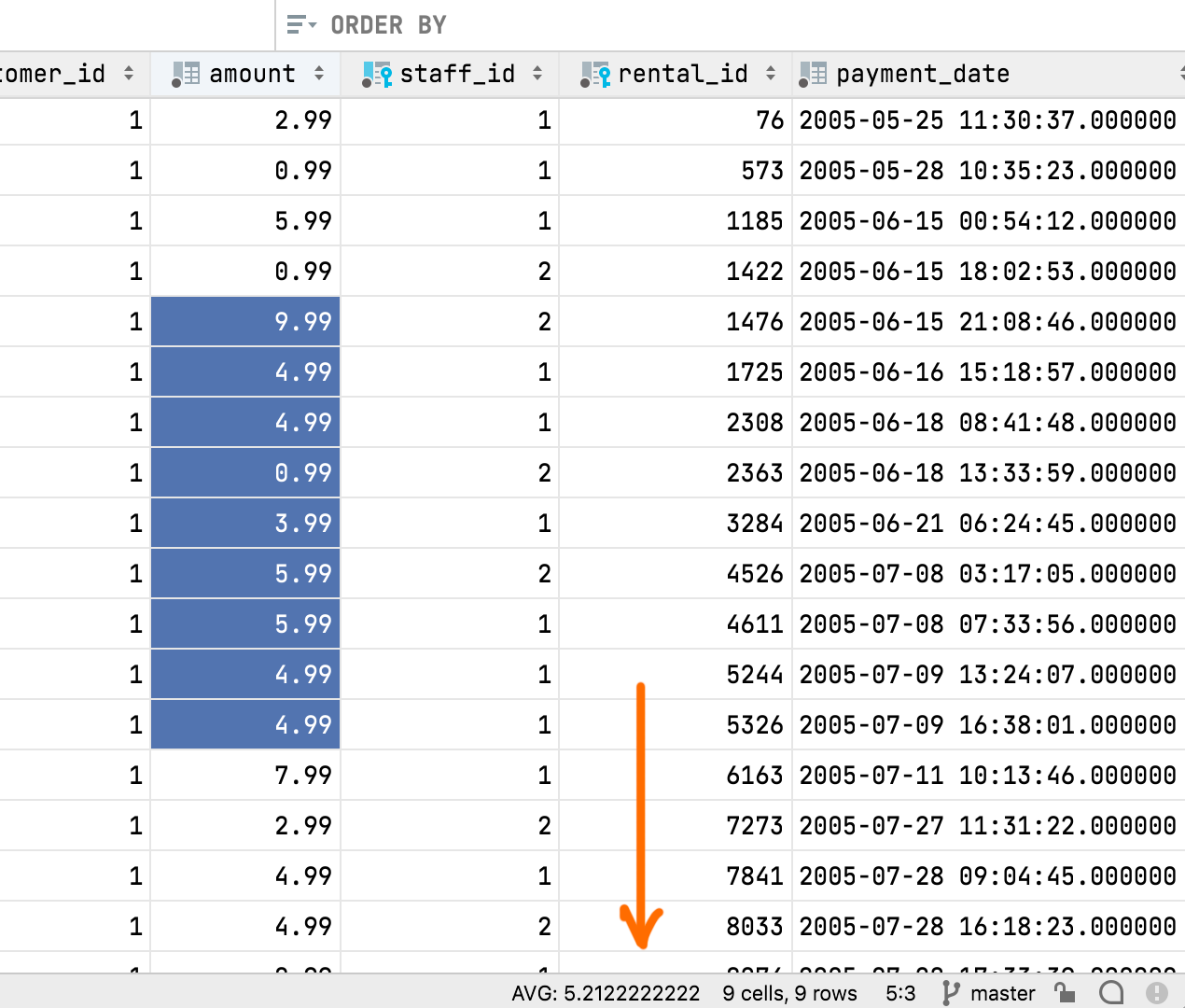
Algumas informações rápidas:
- A visualização Aggregate compartilha o painel com a visualização Value e agora cada uma tem sua aba. Você pode mover esse painel para o rodapé do editor de dados.
- Você pode usar o ícone da engrenagem para mostrar ou esconder qualquer aggregate desta visualização.
- Assim como os extratores, os aggregates são scripts. Você pode criar e compartilhar os seus próprios scripts, além dos nove que já vêm incluídos por default.
- Scripts de aggregates e extratores são intercambiáveis. Se você já tiver usado um extrator antes para obter só um valor, agora você poderá copiar esse valor para a pasta Aggregators e usar essa pasta para os aggregates. Assim como a pasta Extractors, essa pasta está localizada em Scratches and consoles / Extensions / Database Tools and SQL.
É mostrado um valor de aggregate na barra de status e você pode escolher qual valor (soma, média, mediana, mínimo, máximo, etc.) será mostrado ali.
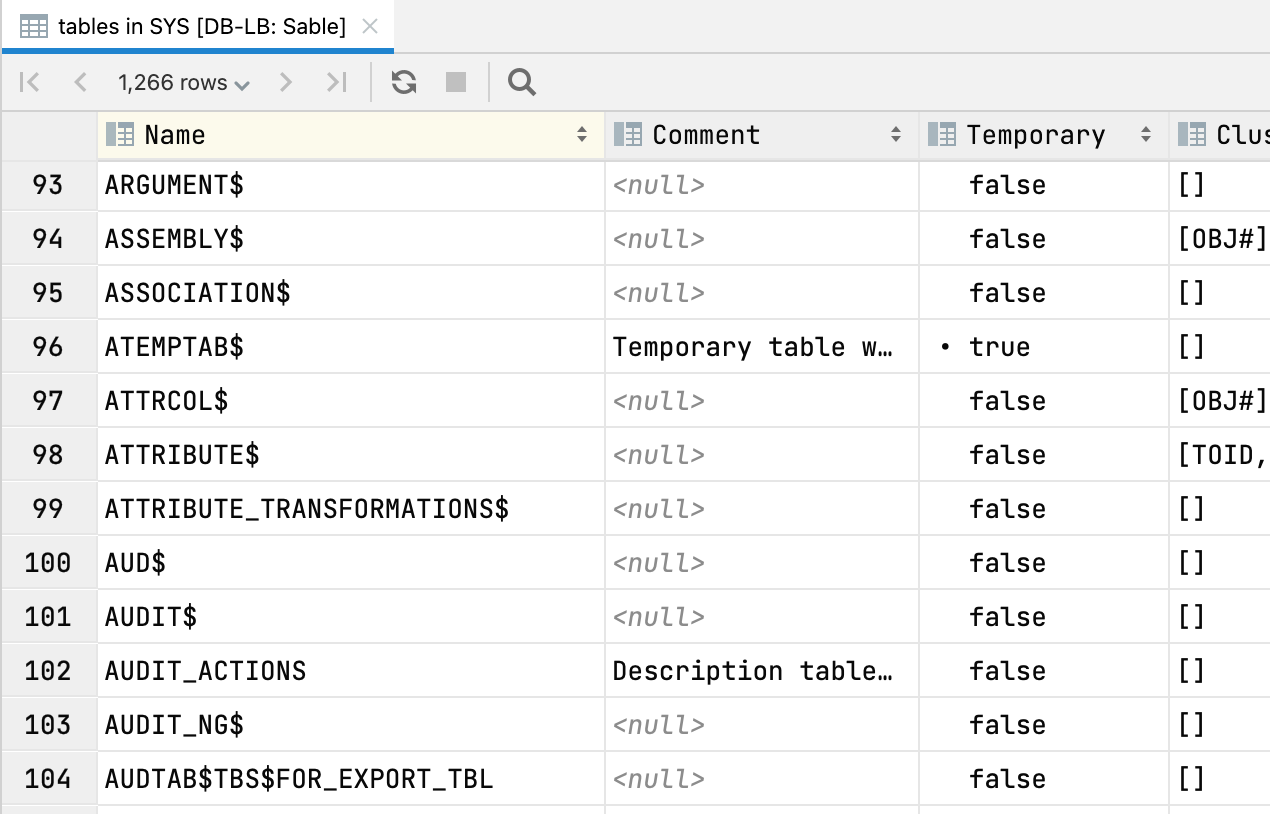
Visualização em tabela para nós de árvore
Teclar F4 em um nó de qualquer esquema mostra uma visualização em tabela do conteúdo daquele nó. Por exemplo, você pode obter uma visualização em tabela de todas as tabelas do seu esquema:
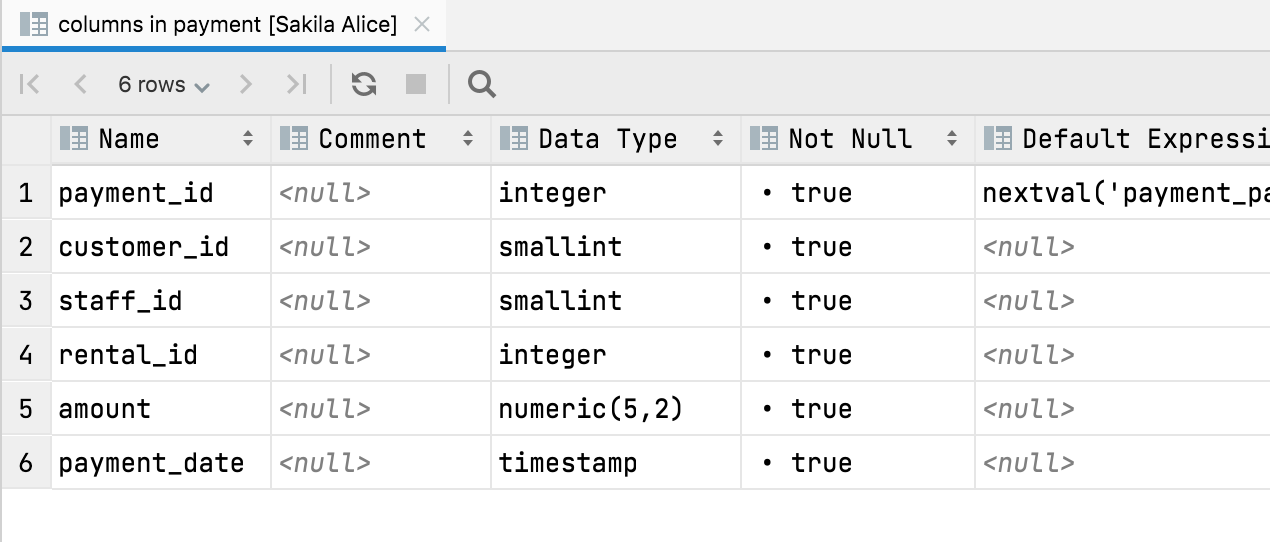
Ou você pode obter uma visualização em tabela das colunas de uma tabela:
Você pode usar essa visualização para ocultar ou mostrar colunas, exportar os dados para muitos formatos e fazer buscas de texto. Mais importante ainda, as ações de navegação a seguir também funcionam com esse recurso:
- Ctrl+B mostra a DDL.
- F4 mostra os dados.
- Alt+Shift+B destaca o objeto na árvore de bancos de dados.
Divisão independente das janelas
Se você dividir a janela do editor e abrir de novo a mesma tabela, as duas janelas do editor serão agora completamente independentes. Você poderá então configurar opções diferentes de filtros e ordenação para comparar e trabalhar com os dados. Antes, os filtros e a ordenação eram sincronizados, o que não era ideal.
Fonte personalizada
Você pode escolher uma fonte dedicada para exibir os dados em Database | Data views | Use custom font.
Navegação com chaves estrangeiras usando vários valores
No editor de dados, agora você pode selecionar vários valores ao mesmo tempo e navegar até os dados correspondentes.
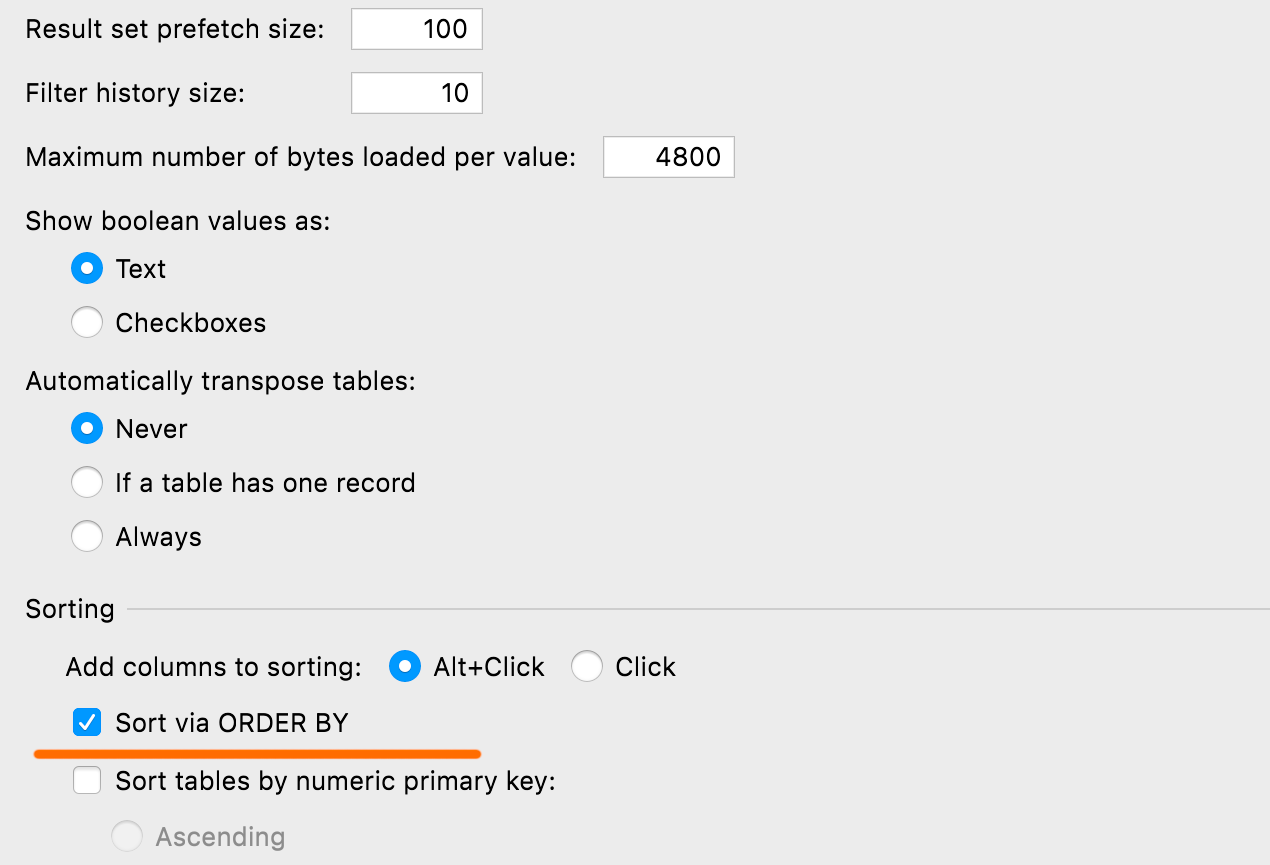
Configuração para ordenação default
Você pode definir o método-padrão para ordenar tabelas via ORDER BY ou client-side. Este último não executa nenhuma nova consulta e ordena apenas a página atual. Essa configuração pode ser encontrada em Database | Data views | Sorting | Sort via ORDER BY.
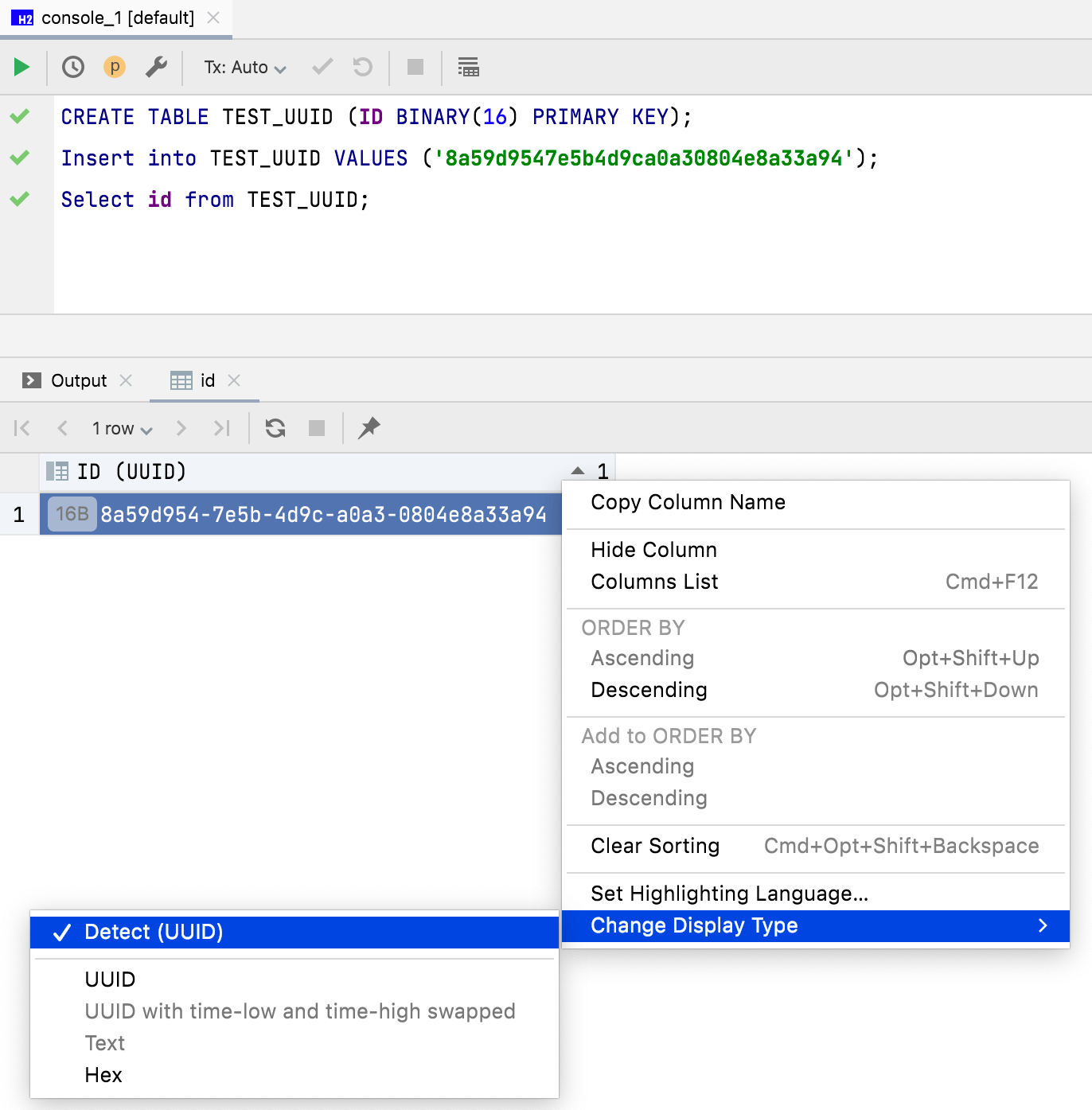
Modo de exibição para dados binários
Dados de 16 bytes agora são exibidos como UUID por default. Você também pode personalizar como dados binários são exibidos na coluna do editor de dados.
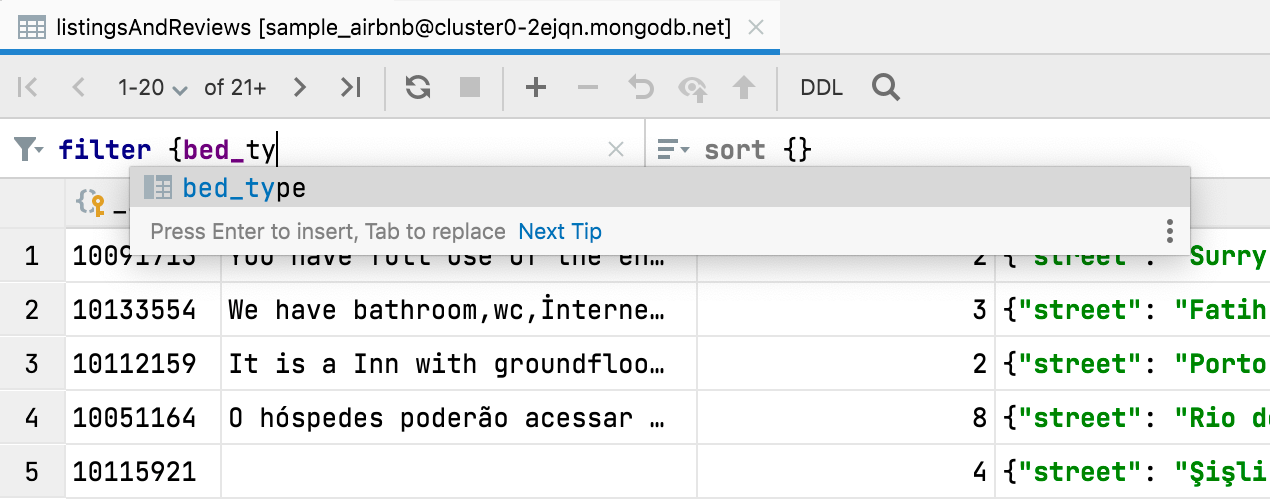
Complementação para filter {} e sort {} no MongoDB
A complementação de código agora está disponível ao filtrar dados em coleções do MongoDB.
Mantendo seu banco de dados no VCS
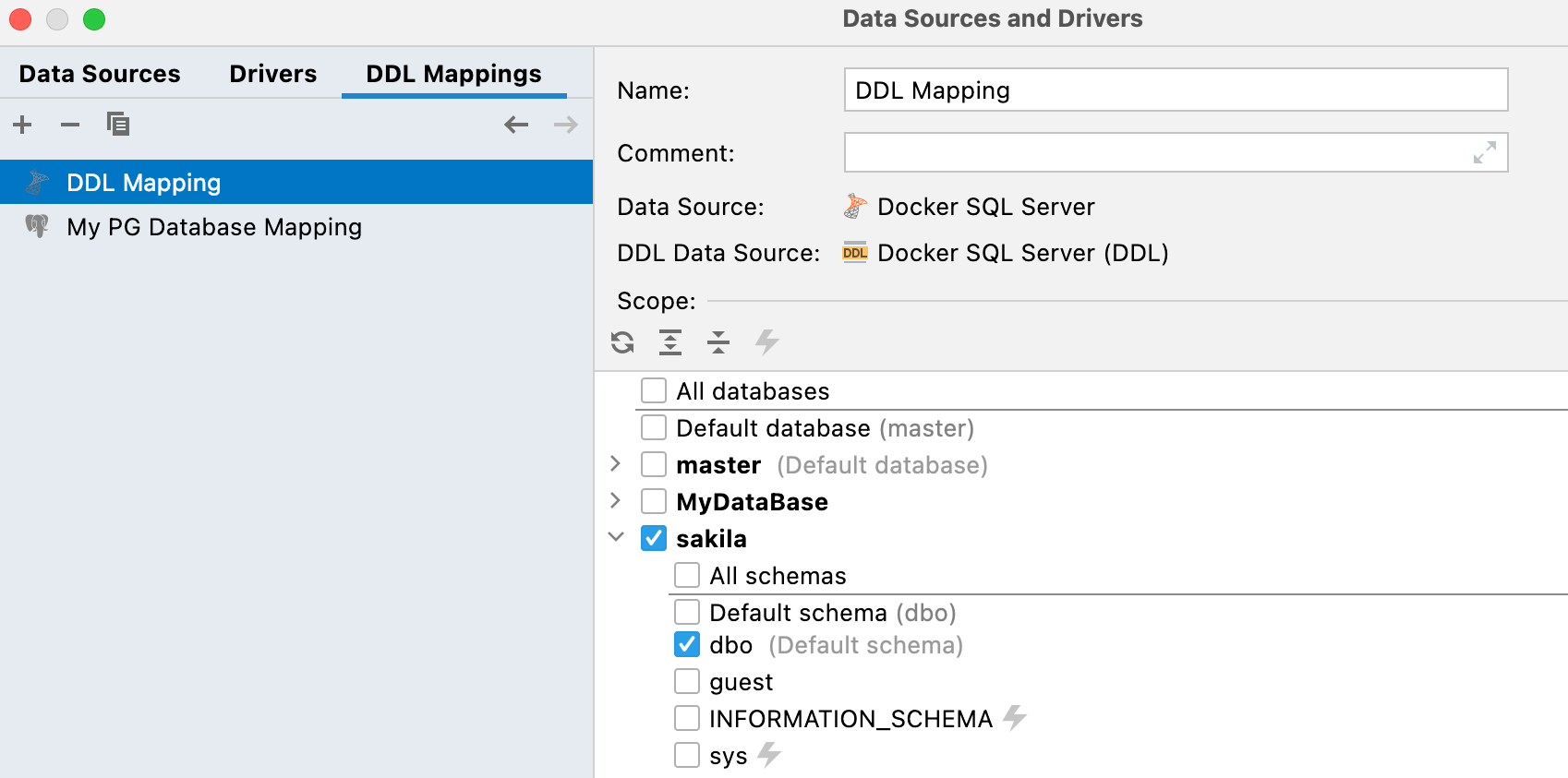
Mapeando a fonte de dados DDL e a real
Esta versão é uma continuação lógica da anterior, que introduziu a capacidade de gerar uma fonte de dados DDL com base numa fonte de dados real. Agora, esse workflow tem suporte total. Você pode:
- Gerar uma fonte de dados DDL a partir de uma fonte de dados real: veja o anúncio da versão 2021.2.
- Usar a fonte de dados DDL para mapear a fonte de dados real.
- Comparar e sincronizar as duas fontes em ambas as direções.
Apenas como lembrete, uma fonte de dados DDL é uma fonte de dados virtual cujo esquema é baseado num conjunto de scripts de SQL. Armazenar esses arquivos no Sistema de Controle de Versões (VCS) é uma maneira de manter o seu banco de dados sob o VCS.
Há uma nova aba DDL mappings nas propriedades de configuração dos dados. Nessa aba, você pode definir qual fonte de dados real será mapeada para cada fonte de dados DDL.
Se você quiser saber mais sobre como esses novos recursos podem ajudar você no seu fluxo diário de VCS, leia este artigo.
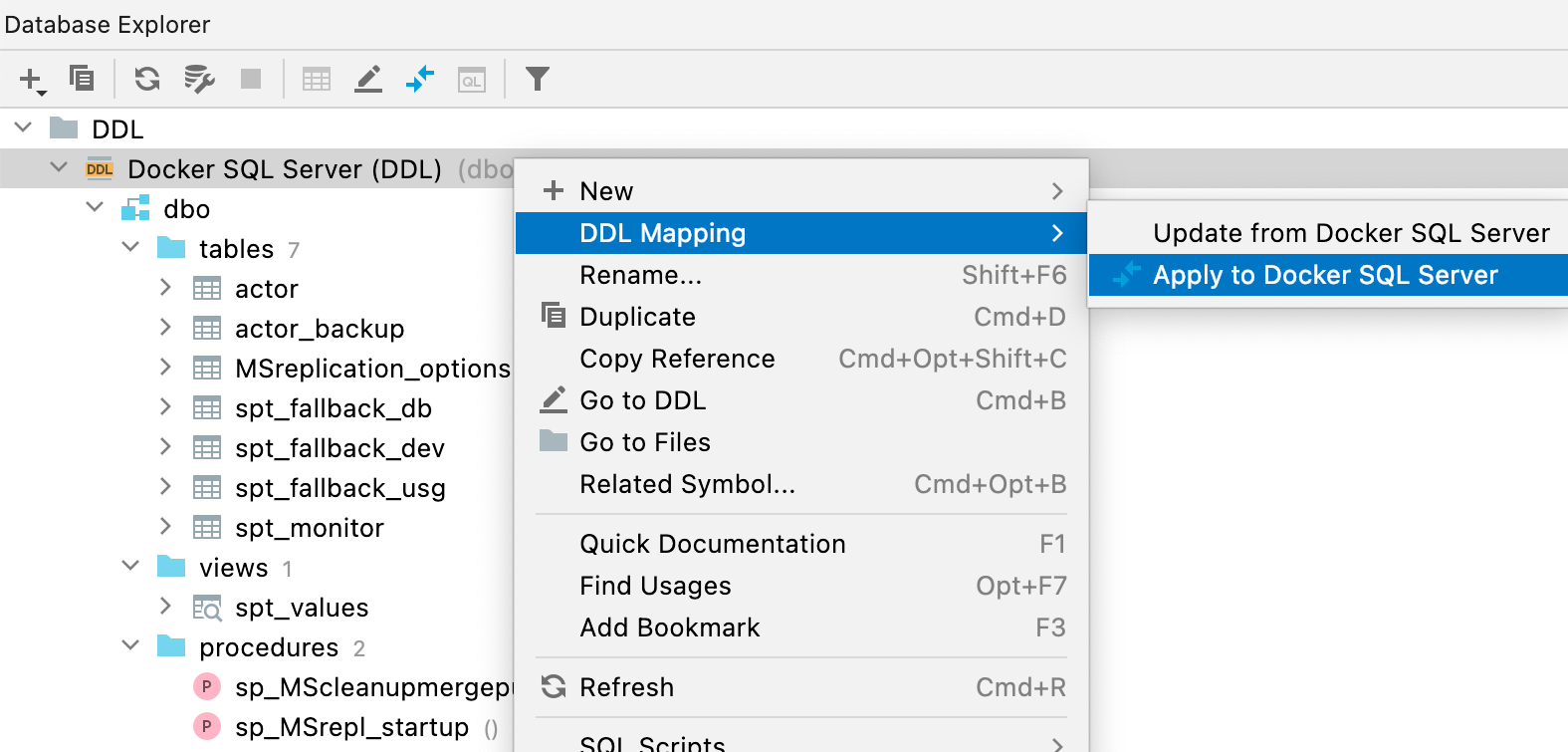
Nova janela database diff
Para comparar e sincronizar sua fonte de dados de DDL com a fonte de dados real, use o menu de contexto e selecione Apply from... ou Dump to... no submenu DDL Mappings.
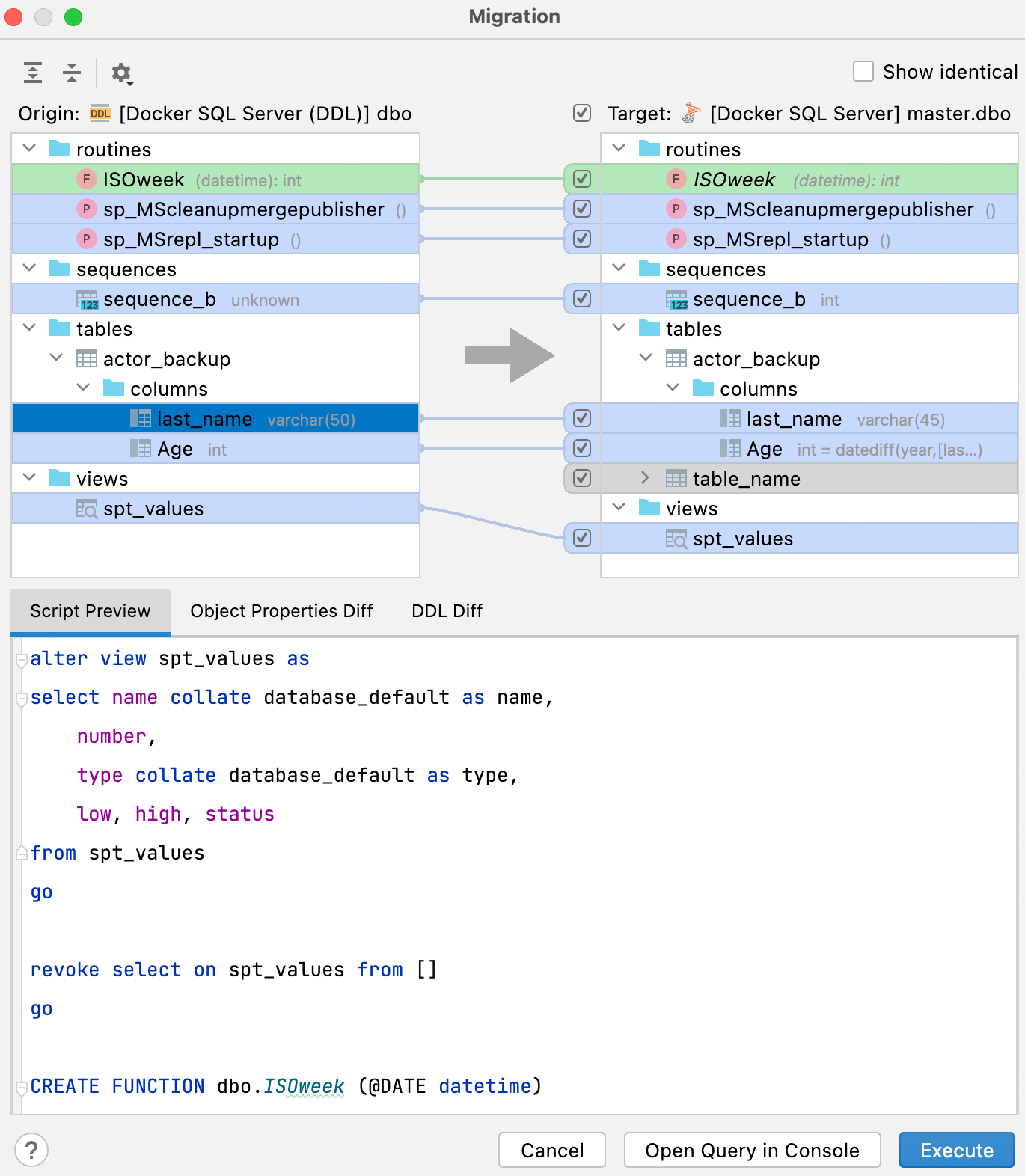
Essa novíssima janela tem uma interface de usuário melhor e mostra claramente no painel direito qual resultado você obterá depois de realizar a sincronização.
A legenda do painel direito mostra o que significam as cores em relação ao resultado em potencial:
- Verde e itálico: o objeto será criado.
- Cinza: o objeto será excluído.
- Azul: o objeto será alterado.
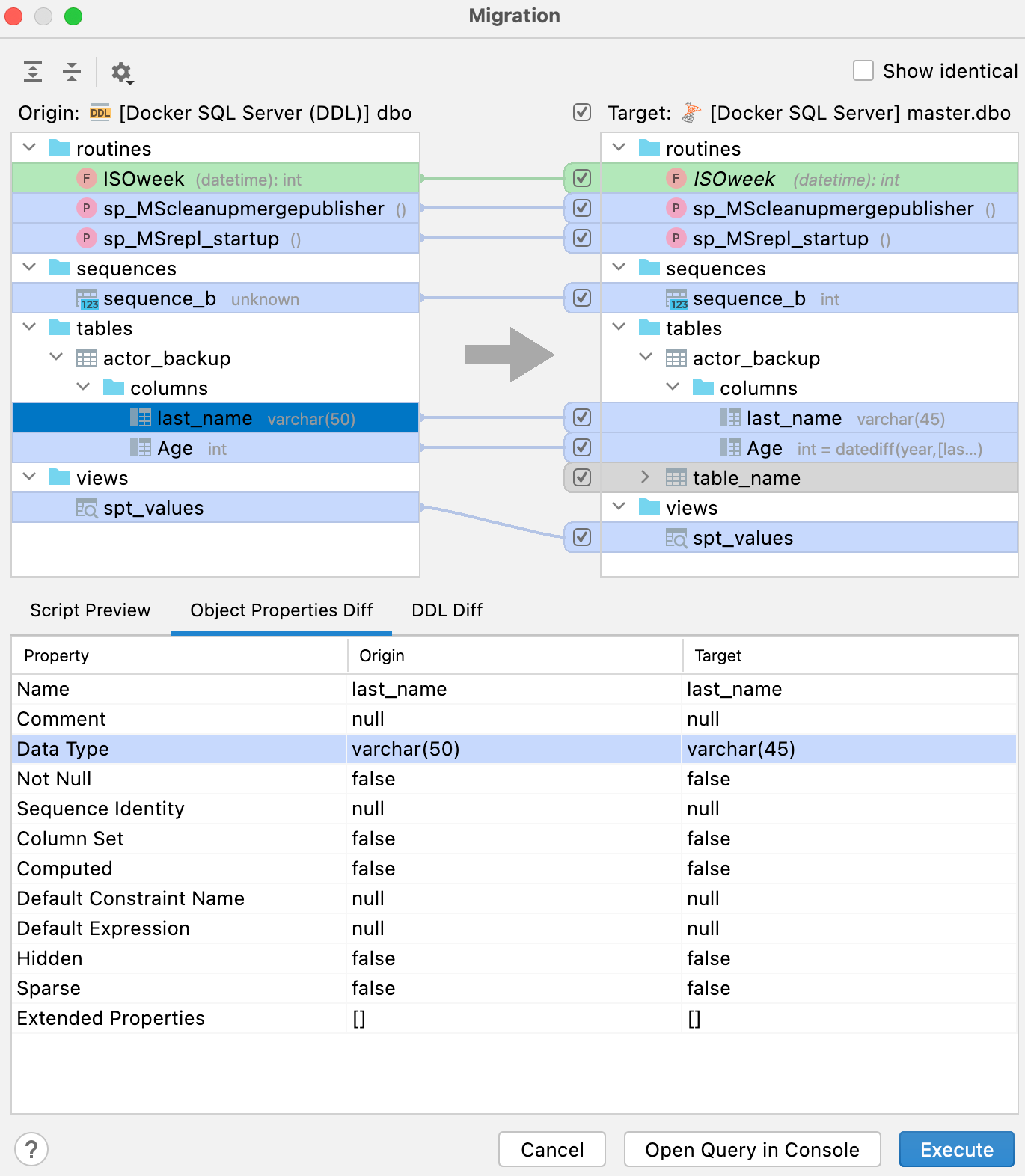
A aba Script preview mostra o script de resultado, que pode ser aberto num novo console ou executado a partir deste diálogo. O resultado desse script é aplicar alterações para fazer com que o banco de dados à direita (o destino) seja uma cópia do banco de dados à esquerda (a origem).
Além da aba Script preview, há mais duas abas no painel inferior: Object Properties Diff e DDL Diff. Elas mostram as diferenças entre as versões específicas do objeto nos bancos de dados de origem e de destino.
Só um lembrete: se você quiser apenas comparar dois esquemas ou objetos, selecione-os e tecle Ctrl + D.
Importante! O visualizador de diff ainda está em desenvolvimento. Como cada banco de dados tem seus próprios recursos específicos, alguns objetos podem ser exibidos como diferentes quando, na verdade, são idênticos. Isto pode acontecer por causa de type aliases ou por omitir as propriedades default durante a geração. Se você encontrar esse bug, por favor relate-o no nosso rastreador.
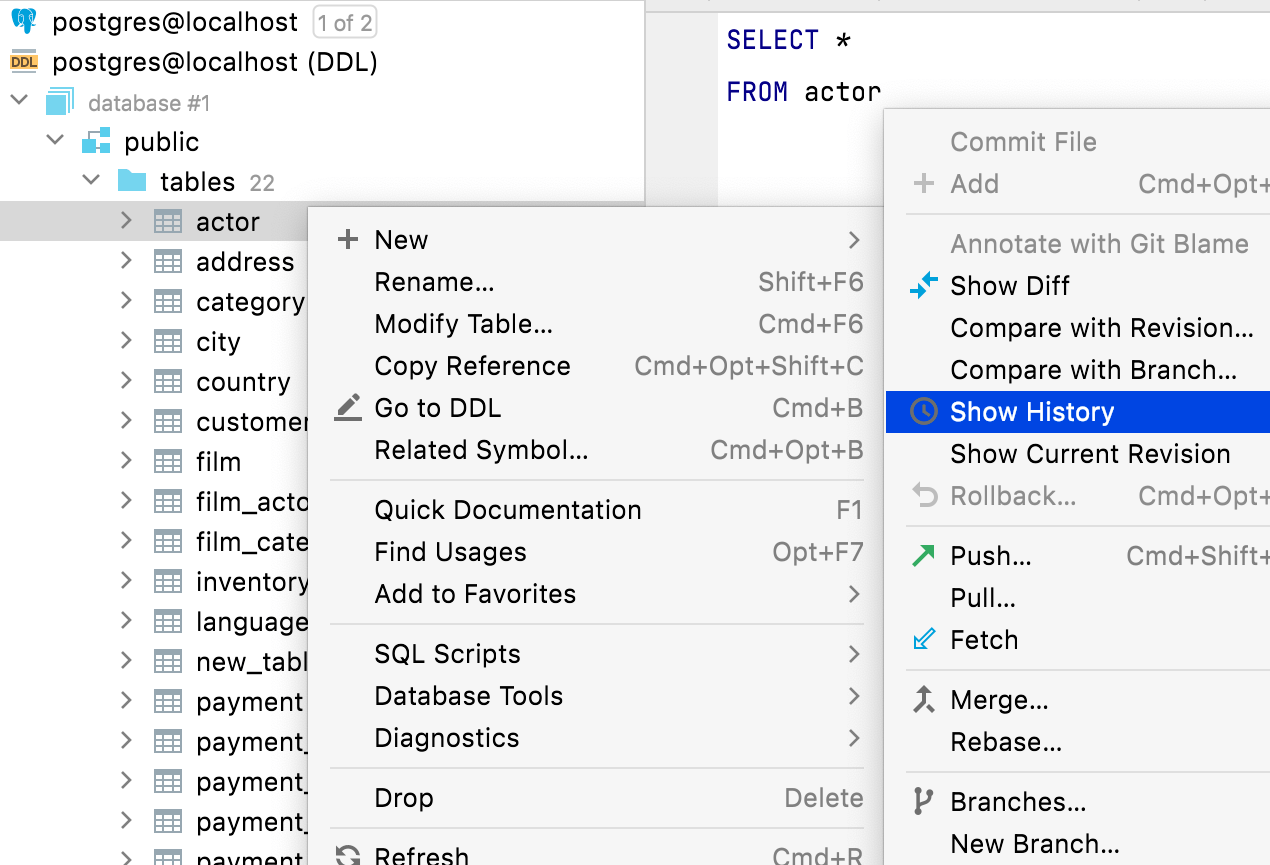
Ações relacionadas a arquivos
Todas as ações em arquivos também estão disponíveis nos elementos da fonte de dados DDL. Por exemplo, você pode excluir, copiar ou submeter versões de arquivos relacionados aos elementos do esquema a partir do explorador de banco de dados.
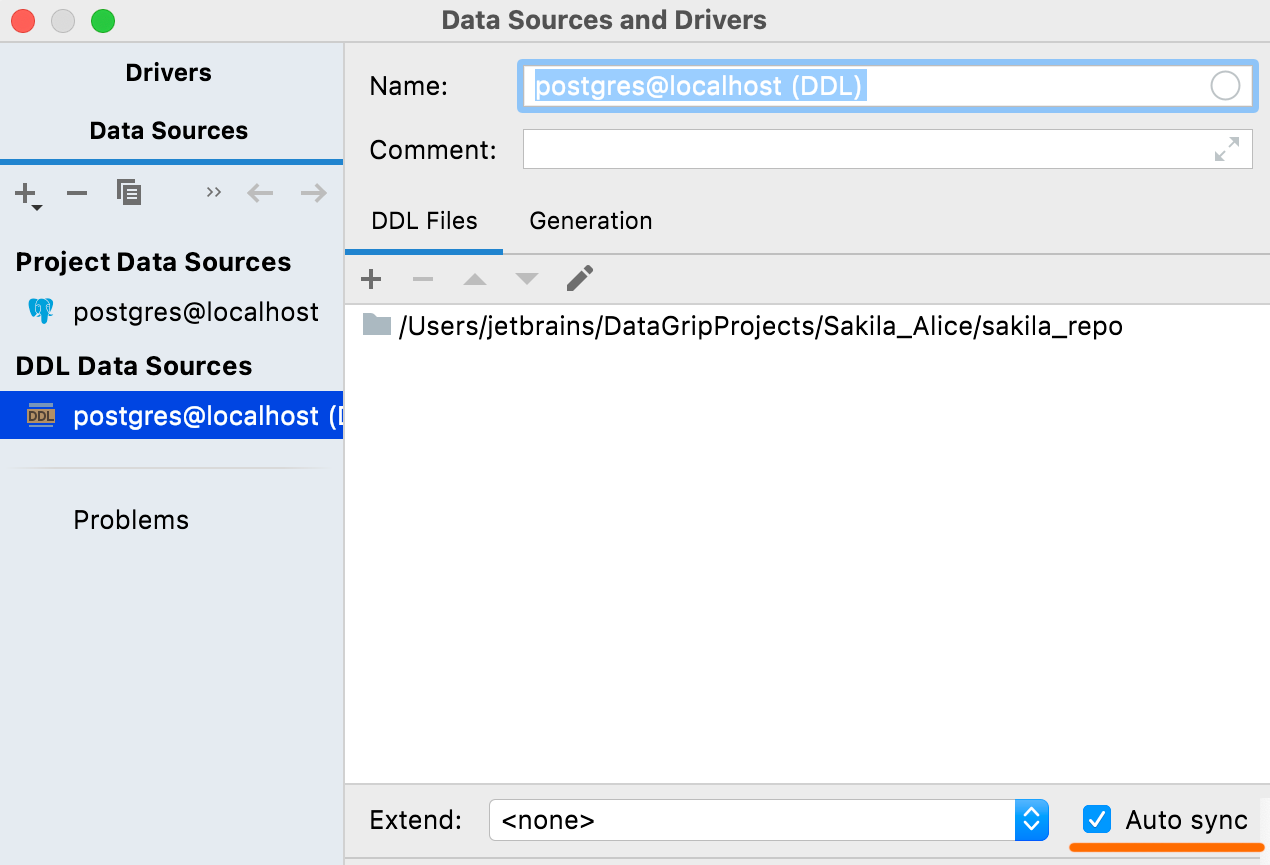
Sincronização automática
Se esta opção estiver ativa, sua fonte de dados DDL será automaticamente atualizada com quaisquer alterações nos arquivos correspondentes. Este já era o comportamento default, mas agora você tem a opção de desativá-lo.
Se você o desativar, as alterações nos arquivos de origem não serão refletidas automaticamente na fonte de dados DDL. Nesse caso, você precisará clicar em Refresh para aplicar essas alterações.
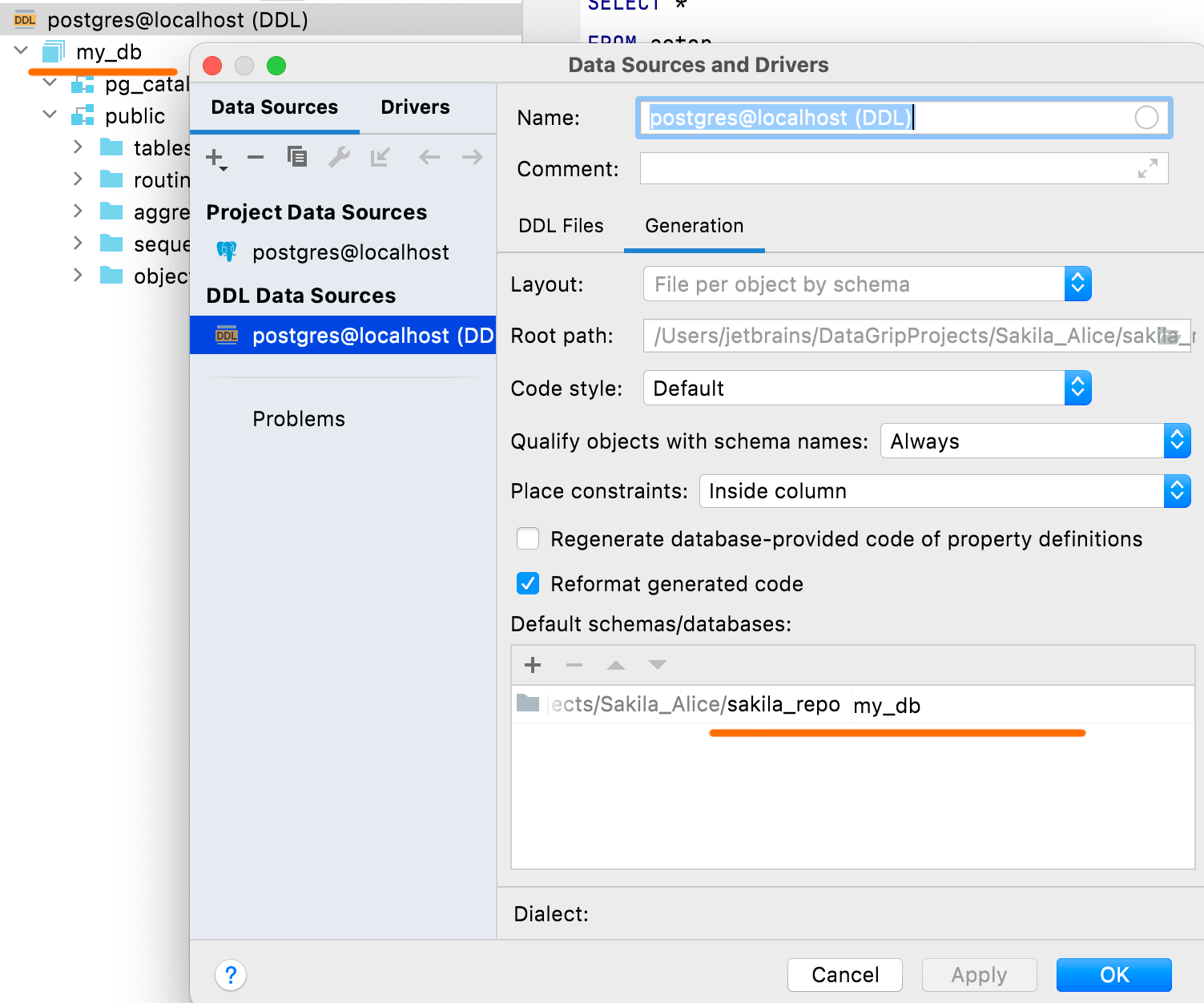
Configuração dos esquemas e bancos de dados default
No painel Default schemas/databases, você pode definir os nomes do banco de dados e dos esquemas que serão exibidos na fonte de dados DDL. Os scripts DDL geralmente não contêm nomes. Nesses casos, serão usados nomes temporários por default para os bancos de dados e esquemas.
Conectividade
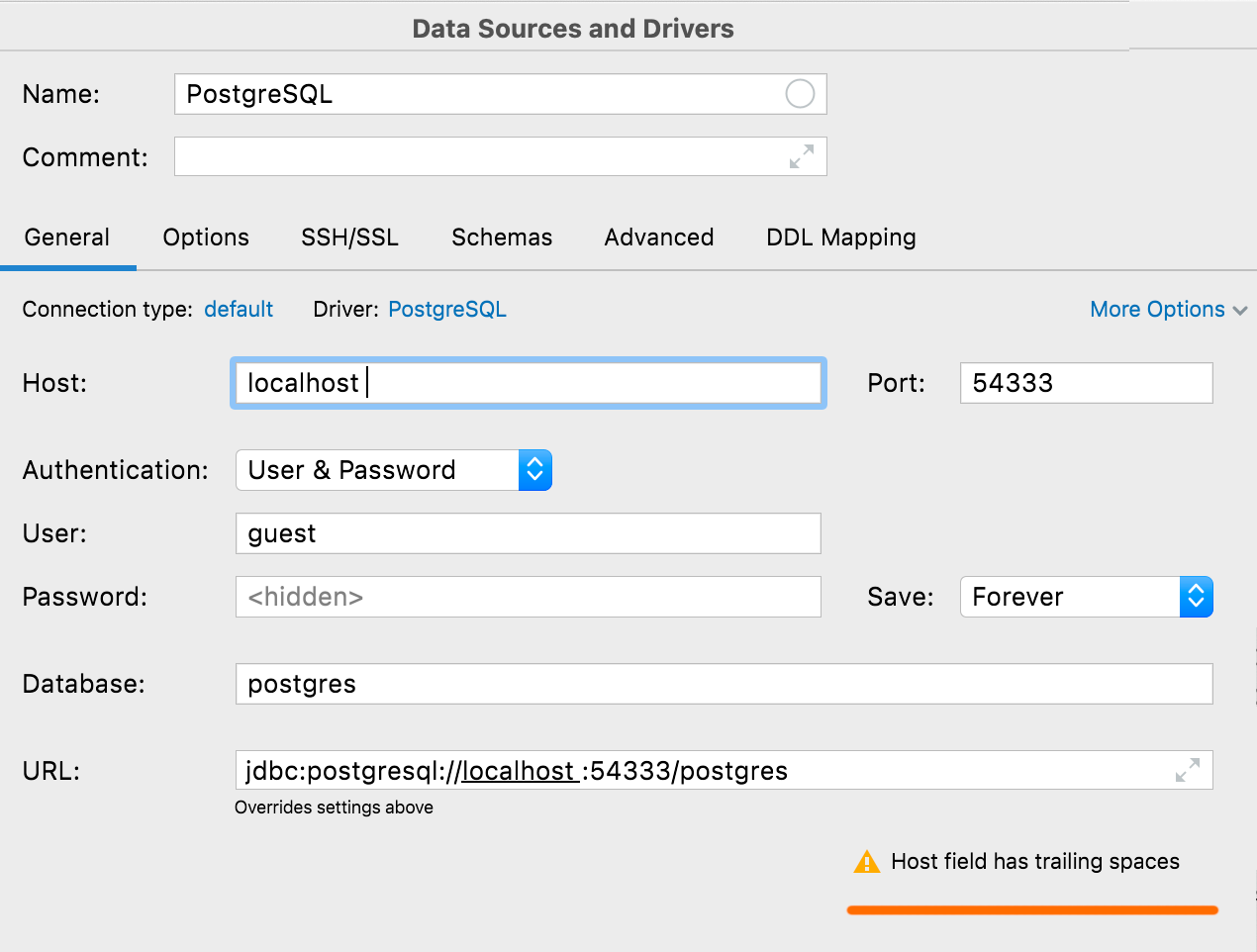
Aviso sobre espaços acidentais
Se qualquer valor, com exceção de User e Password, começar ou terminar com um espaço, o DataGrip alertará você sobre isso quando você clicar em Test Connection.
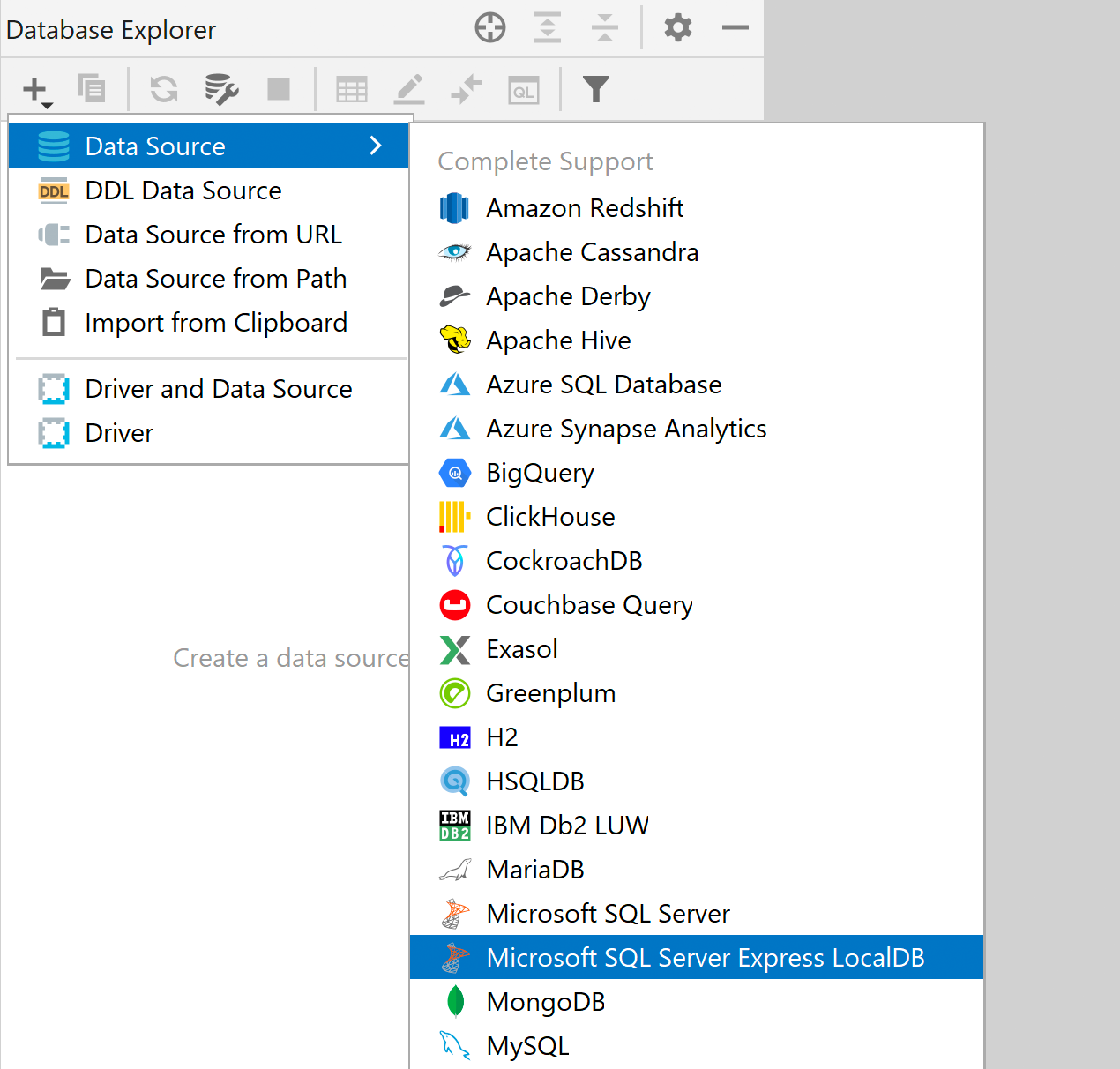
LocalDB como uma fonte de dados dedicada do SQL Server
O LocalDB do SQL Server tem o seu próprio driver dedicado na lista de drivers. Isto significa que ele tem um tipo separado de fonte de dados que deve ser usado para o LocalDB. Isto traz os seguintes benefícios:
- A conexão do LocalDB é mais fácil de ser explorada.
- Você só precisa configurar o caminho do programa executável uma vez, nas opções do driver, e esse caminho será aplicado a todas as fontes de dados.
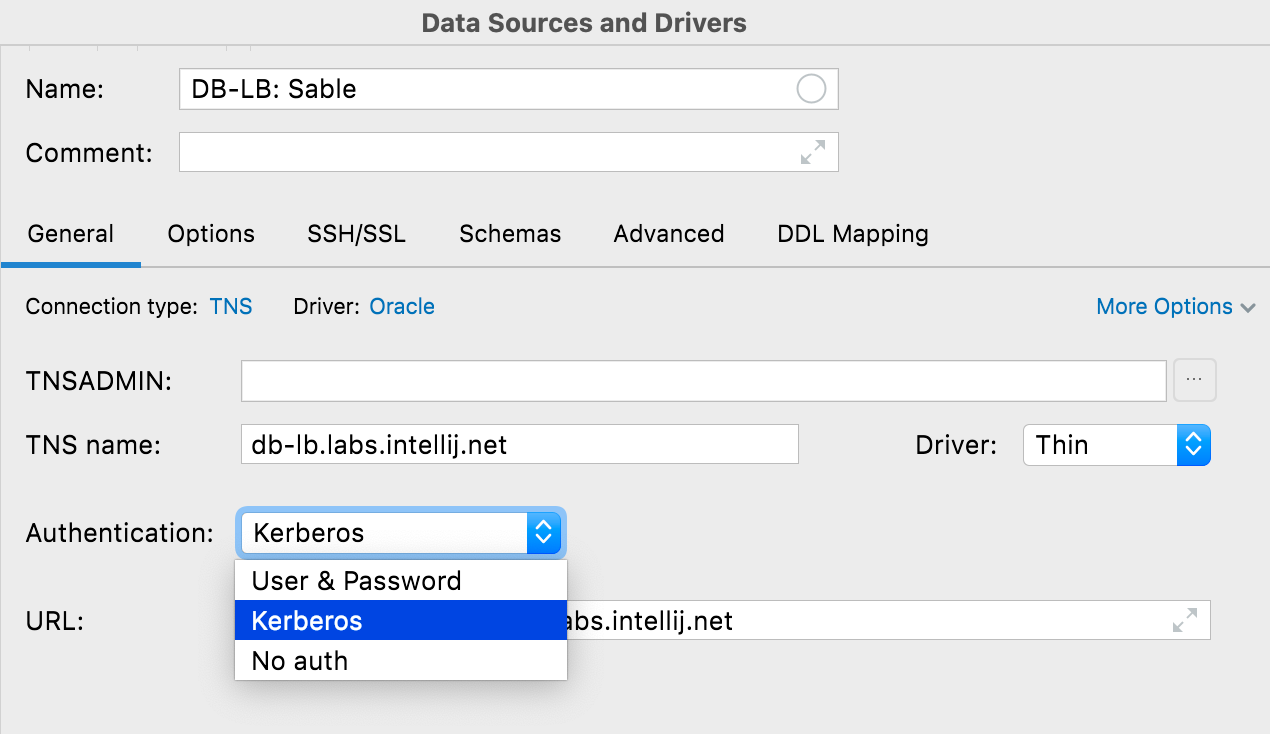
Autenticação Kerberos no Oracle e SQL Server
Agora é possível usar autenticação Kerberos no Oracle e no SQL Server. Você precisa obter um ticket inicial de concessão de outros tickets para o principal, usando o comando kinit, que o DataGrip usará quando você selecionar a opção Kerberos.
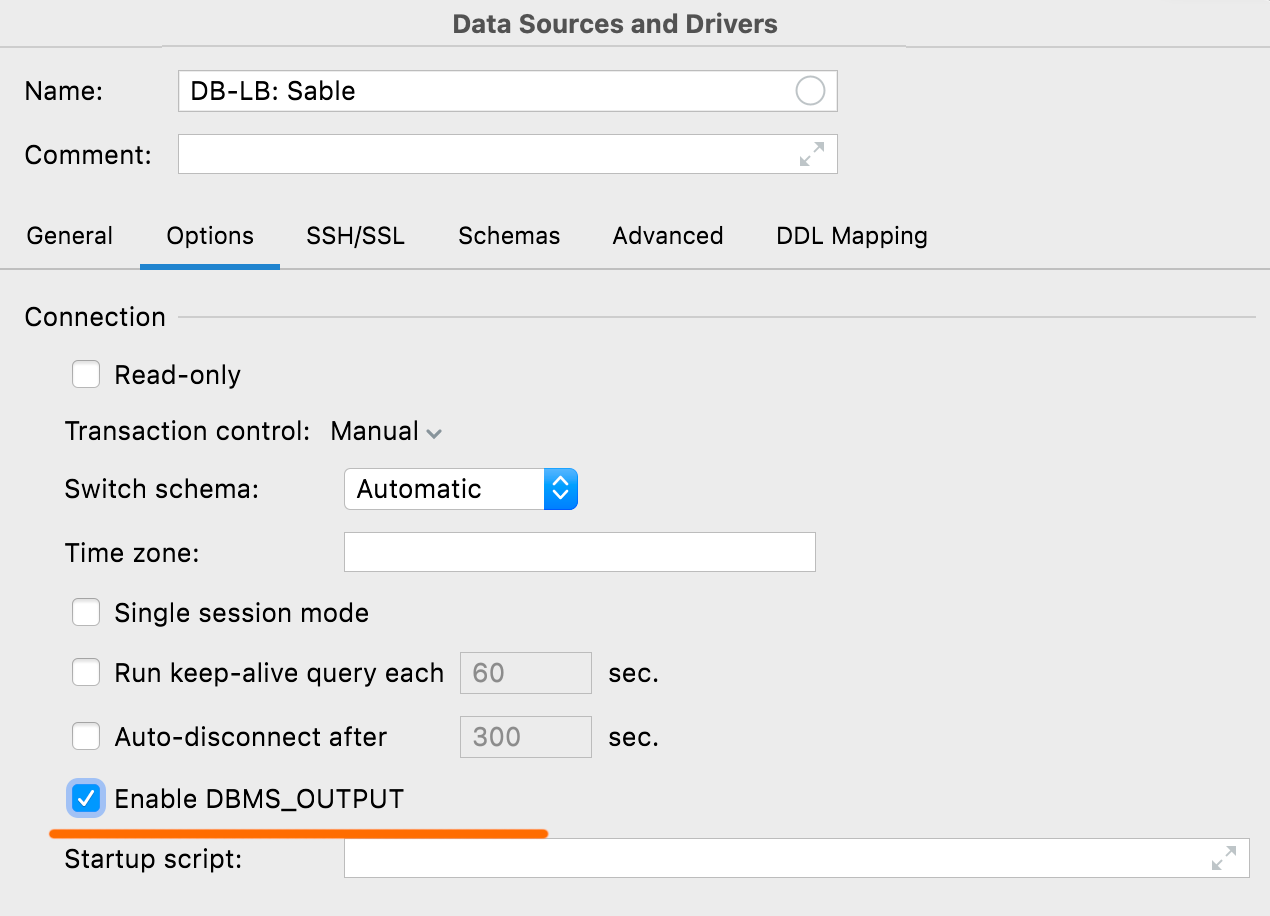
Ativar DBMS_OUTPUT no Oracle e IBM Db2
Esta nova opção na aba Options permite que você ative o DBMS_OUTPUT como default para novas sessões.
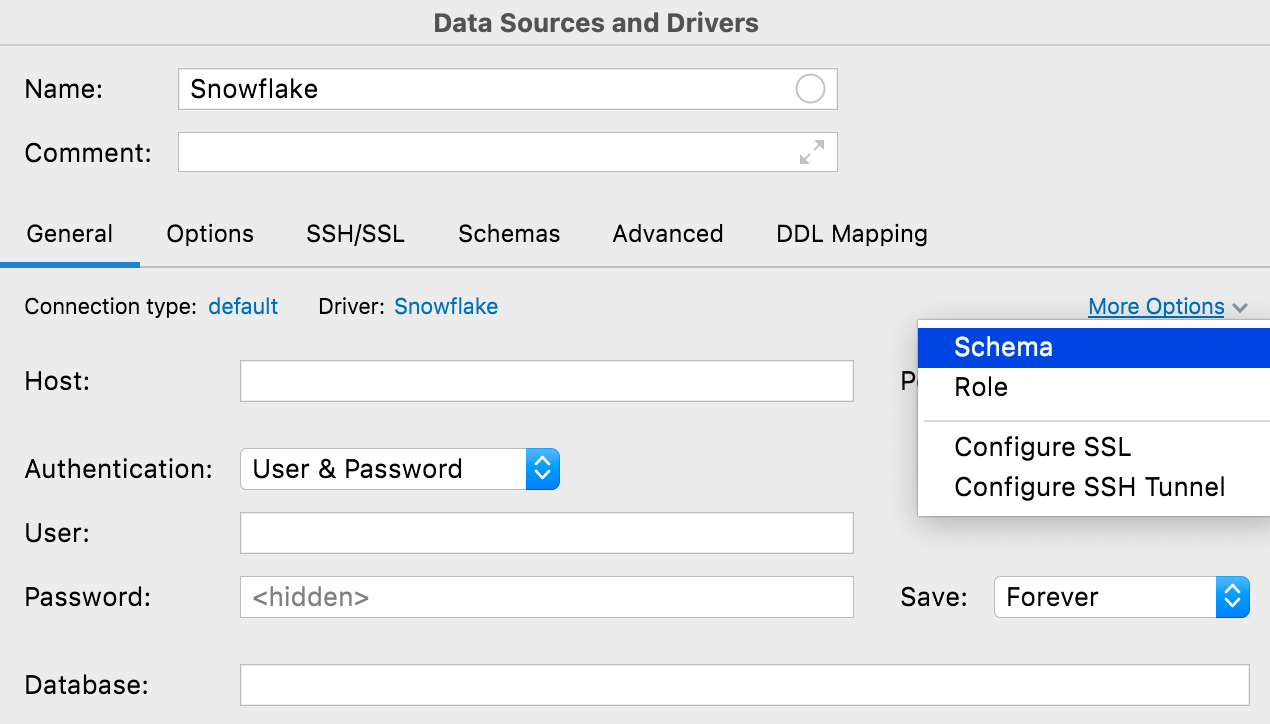
Botão More options
Adicionamos um botão More Options, para quando você precisar configurar algo incomum em uma conexão. As opções atualmente disponíveis incluem a capacidade de adicionar campos Schema e Role em conexões Snowflake e dois itens de menu para configurar o SSH e o SSL de modo a tornar mais fácil a descoberta desses protocolos.
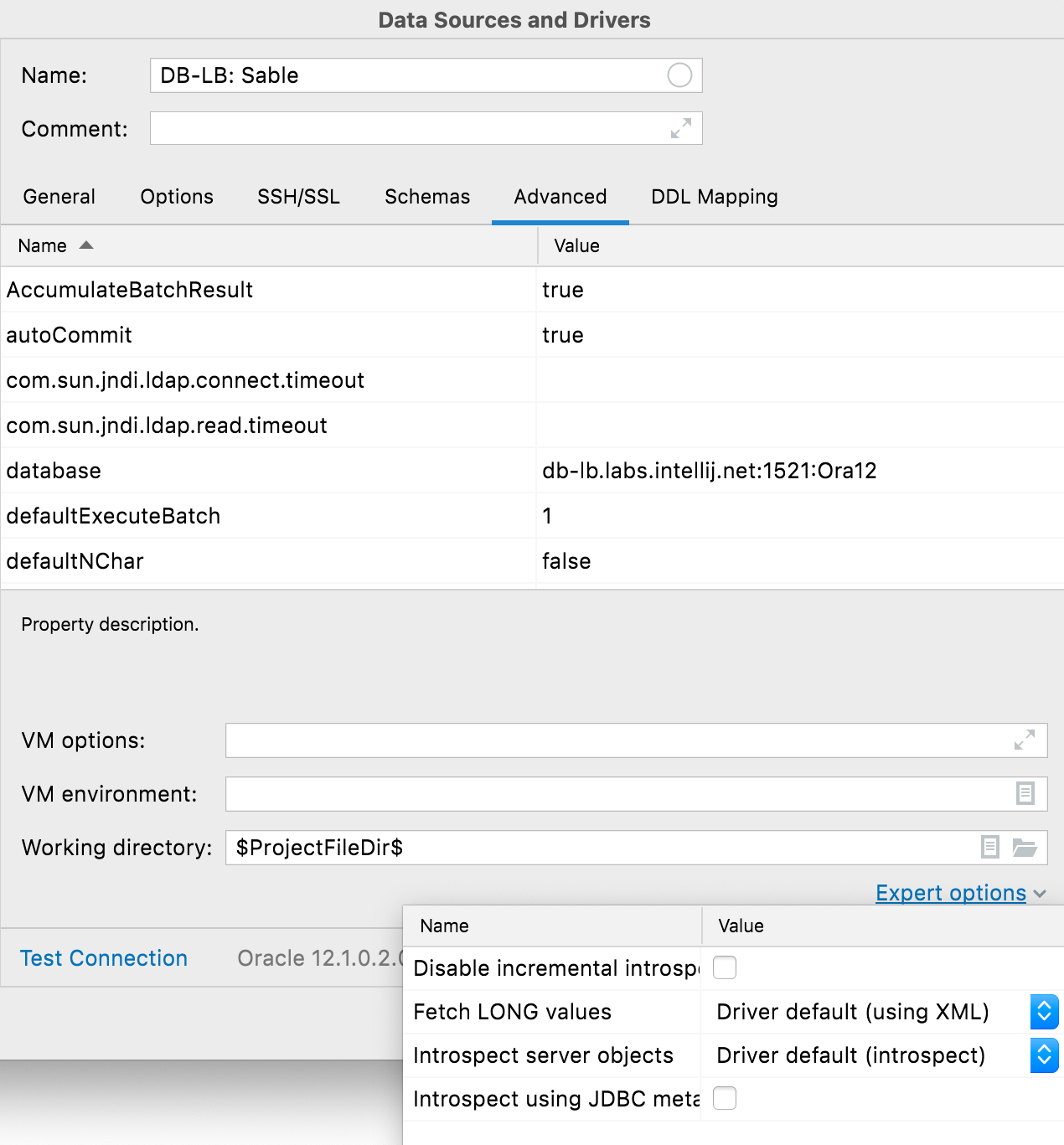
Lista "Expert Options"
A aba Advanced agora inclui uma lista Expert options. Além da opção de ativar a introspecção com o JDBC (por favor, contate o nosso suporte antes de usar isso!), estão disponíveis as seguintes opções específicas de banco de dados:
- Oracle: Desativar a introspecção incremental, buscar valores LONG e fazer a introspecção de objetos do servidor
- SQL Server: Desativar a introspecção incremental
- PostgreSQL (e similares): Desativar a introspecção incremental e não usar (Do not use) xmin em buscas no pgdatabase
- SQLite: Registrar a função REGEXP
- MYSQL: Usar SHOW/CREATE para o código-fonte
- ClickHouse: Atribuir a sessionid automaticamente
Introspecção
Níveis de introspecção no Oracle
Alguns usuários do Oracle têm tido um problema com a introspecção no DataGrip, que demorava demais se houvesse muitos bancos de dados e esquemas. "Introspecção" é o processo de obter os metadados do banco de dados, tais como os nomes dos objetos e o código-fonte. O DataGrip precisa da introspecção para fornecer rapidamente assistência à codificação, navegação e buscas.
O acesso aos catálogos de sistema da Oracle é bastante lento e a introspecção era ainda mais demorada se o usuário não tivesse privilégios de administrador. Fizemos o possível para otimizar as buscas para obter os metadados, mas tudo tem limitações.
Percebemos que para a maior parte do trabalho diário, e mesmo para que a assistência à codificação seja eficaz, não é preciso carregar fontes de objetos. Em muitos casos, basta conhecer os nomes dos objetos do banco de dados para proporcionar um bom desempenho na complementação de código e na navegação. Então, introduzimos três níveis de introspecção em bancos de dados Oracle:
- Nível 1: os nomes de todos os objetos com suporte, bem como suas assinaturas, exceto nomes de colunas de índice e variáveis de pacote privativas
- Nível 2: tudo, menos o código-fonte
- Nível 3: tudo
A introspecção é mais rápida no nível 1 e mais demorada no nível 3.
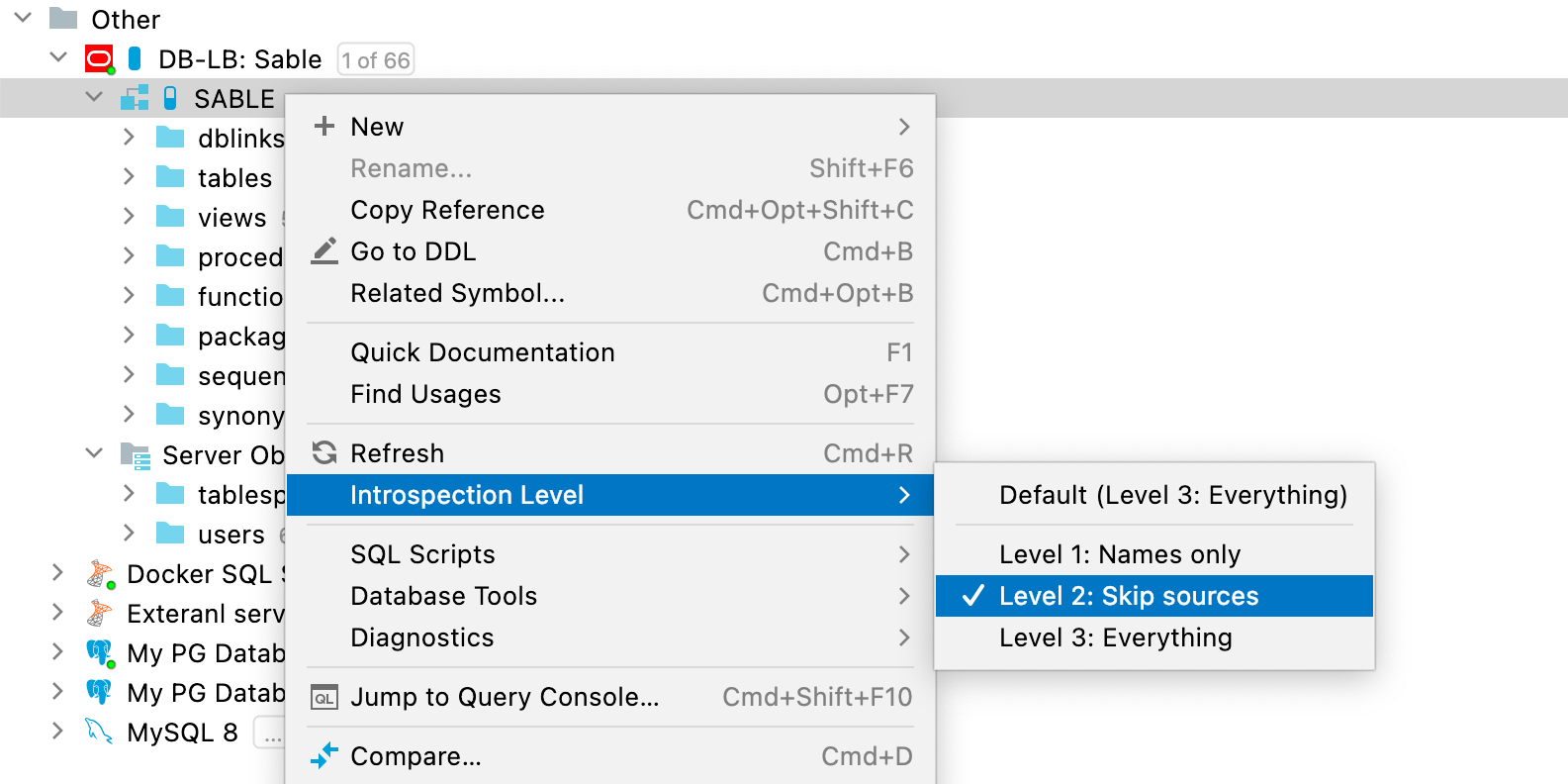
Use o menu de contexto para mudar o nível de introspecção conforme for apropriado.

O nível de introspecção pode ser configurado só para um esquema ou para todo o banco de dados. Os esquemas herdam seu nível de introspecção do banco de dados, mas o nível também pode ser configurado de forma independente.
O nível de introspecção é representado pelos ícones em forma de pílula encontrados junto ao ícone da fonte de dados. Quanto mais a "pílula" estiver preenchida, maior o nível. Um ícone azul significa que o nível de introspecção foi configurado diretamente, enquanto um ícone cinza significa que o nível foi herdado.
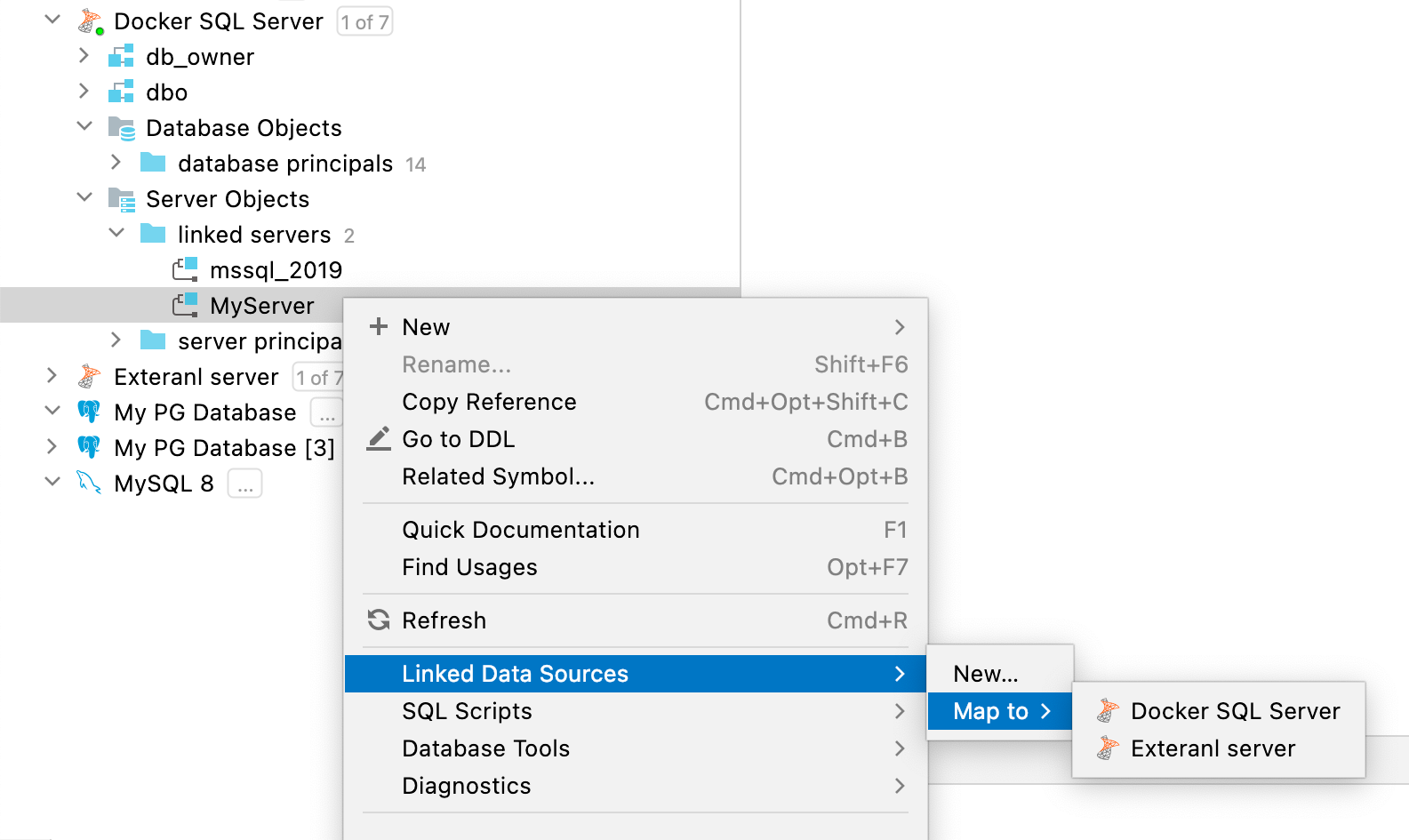
Mapeamento de servidores vinculados e links de bancos de dados a fontes de dados no SQL Server e Oracle
Você pode mapear seu servidor vinculado no SQL Server ou link de banco de dados no Oracle a qualquer fonte de dados existente.
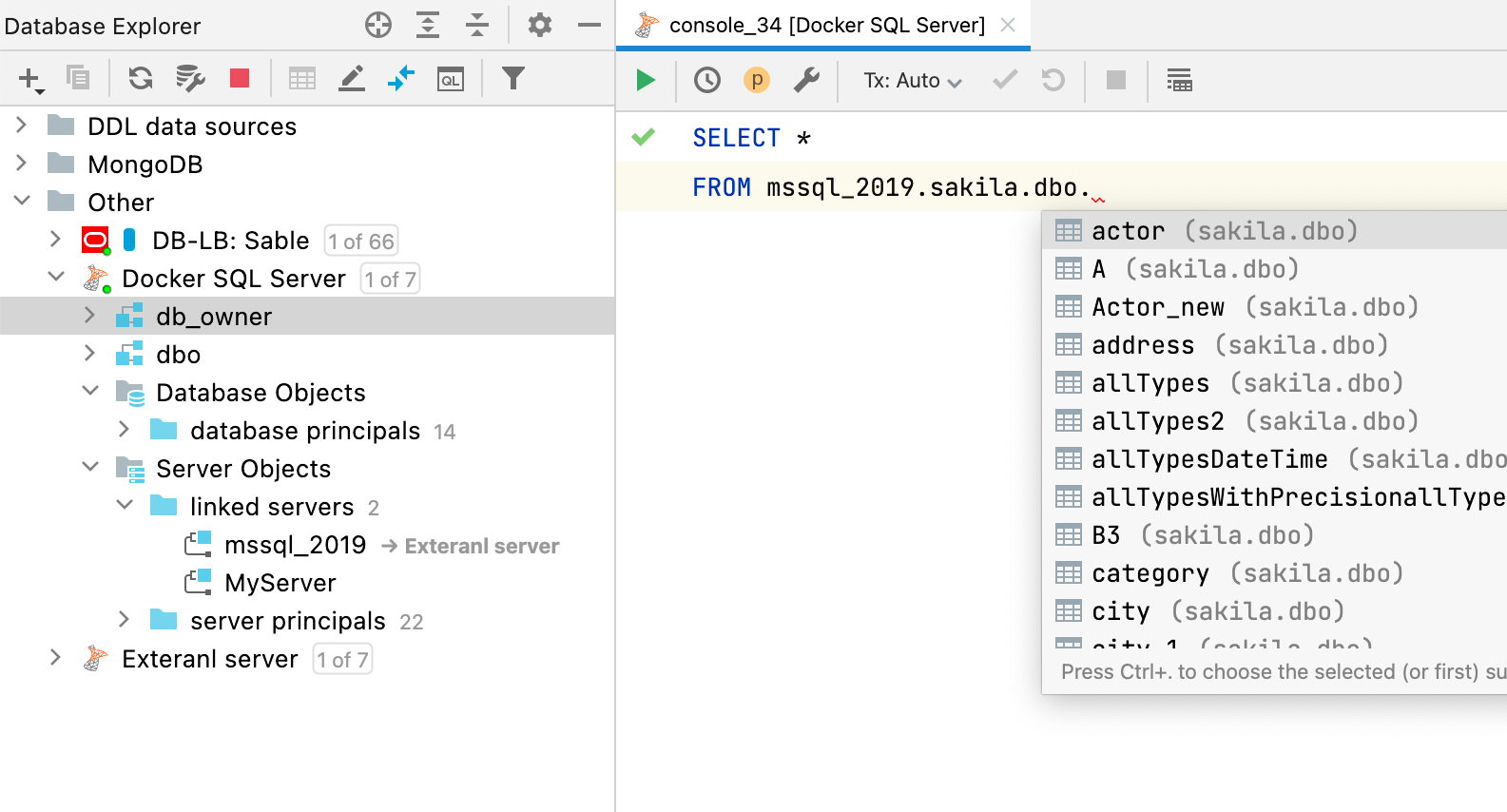
Quando objetos externos forem mapeados à fonte de dados, o preenchimento e a resolução de código funcionarão nas consultas que utilizarem esses objetos externos.
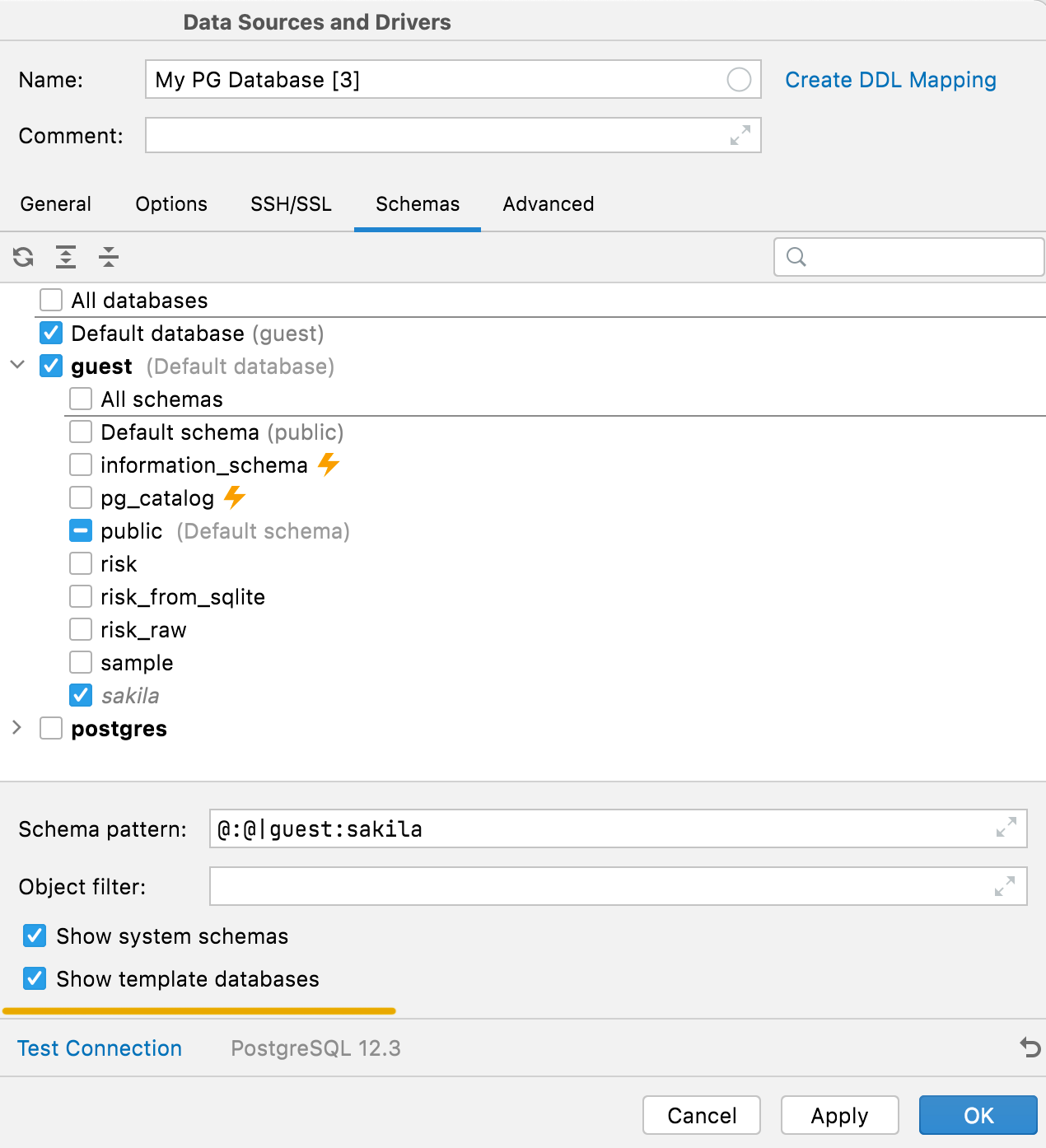
Esconder esquemas de sistema e bancos de dados de modelo no PostgreSQL
Anteriormente, esquemas internos de sistema (tais como pg_toast ou pg_temp) e bancos de dados de modelo (template databases) não apareciam na lista de esquemas. Agora é possível mostrá-los, usando as opções correspondentes na aba Schemas.
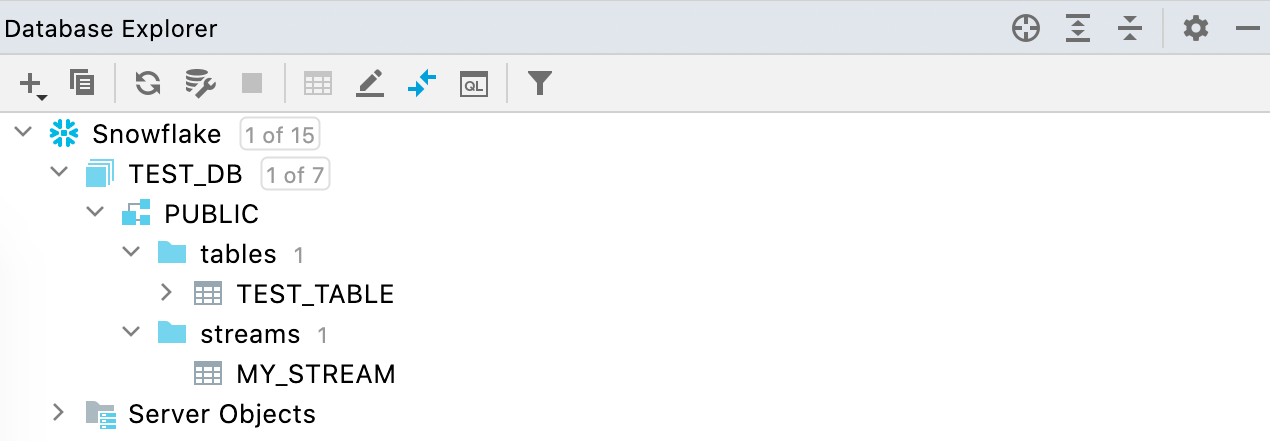
Suporte a fluxos do Snowflake
Agora os fluxos são mostrados na visualização de banco de dados, além das tabelas e visualizações.
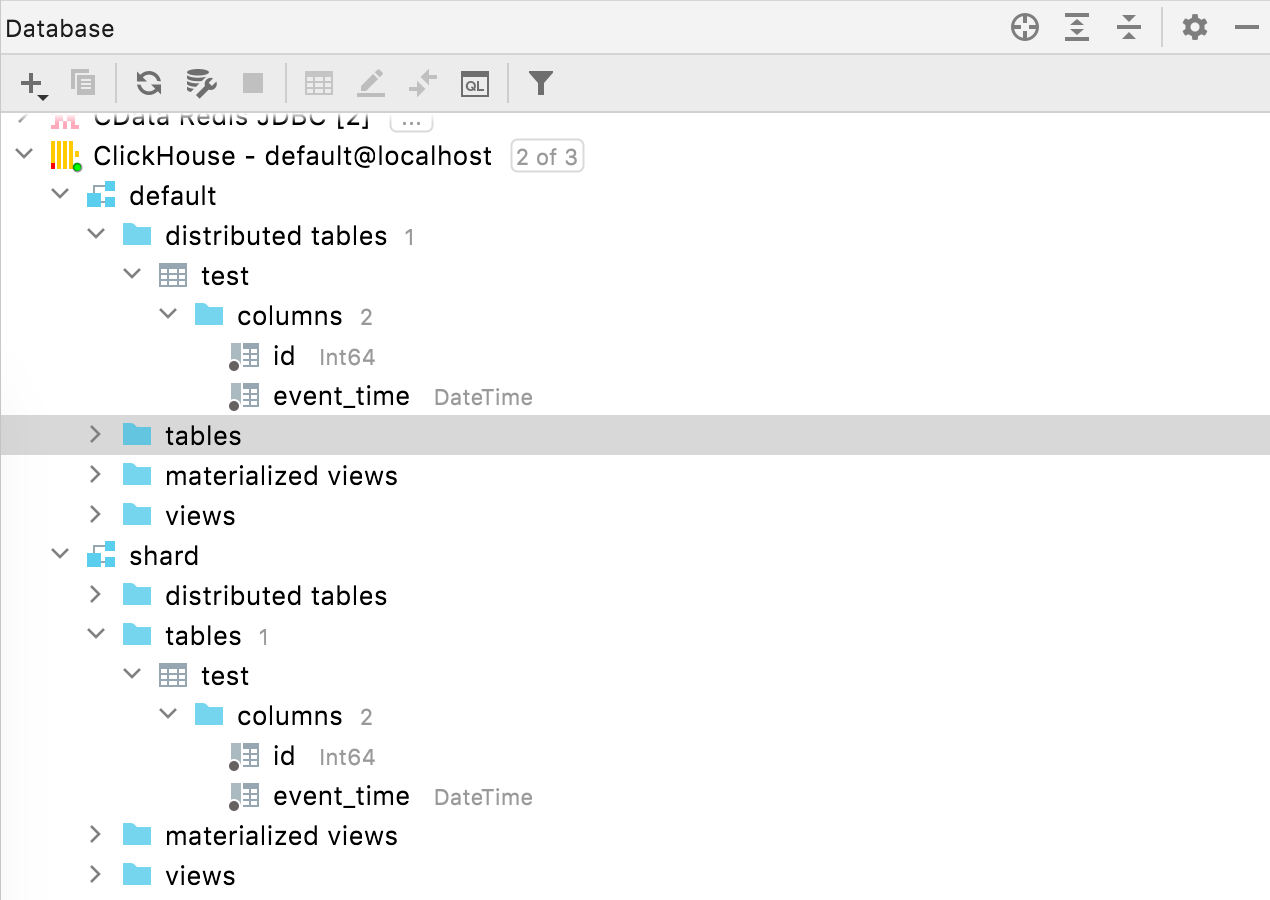
Tabelas distribuídas no ClickHouse
As tabelas distribuídas agora são colocadas sob um nó dedicado no explorador de banco de dados.
Console de consulta
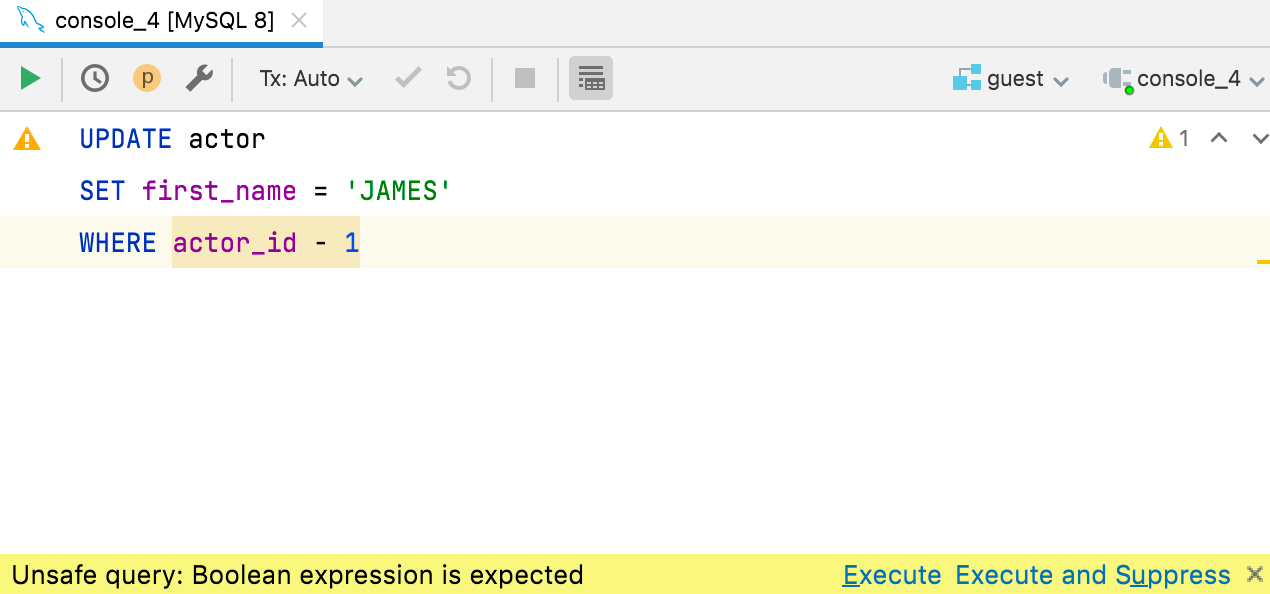
Verificação de expressões booleanas
One of our users posted about an unfortunate situation: he executed the UPDATE query on a production database with the condition WHERE id - 3727 (instead of =) and had millions of records updated!
Também ficamos surpresos de o MySQL permitir isso, mas é a vida. Porém, nós não seríamos a equipe do DataGrip se não adicionássemos uma inspeção para isso! Deem as boas-vindas à verificação de expressões booleanas em condições WHERE e HAVING.
Se a expressão não parecer ser explicitamente booleana, o DataGrip a realçará em amarelo e avisará a você antes de executá-la. Isso funciona no ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite e Vertica. Em todos os outros gerenciadores de bancos de dados, isso será realçado como um erro.
Função Extract para consultas
Agora as consultas podem ser extraídas como funções de tabela. Para isto, acione o menu Refactor e clique em Extract Routine.
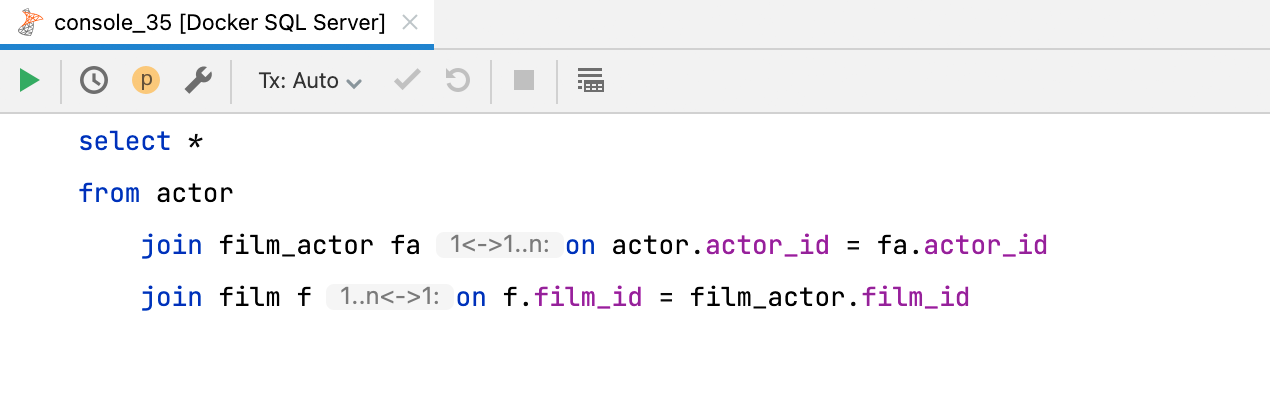
Cardinalidade em dicas de inserção para cláusulas JOIN
A nova dica de inserção informa a cardinalidade de uma cláusula JOIN. Há três opções possíveis: um para um; um para muitos; e muitos para muitos. Se você quiser desativá-la, poderá ajustar a configuração em Preferences | Editor | Inlay Hints | Join cardinality.
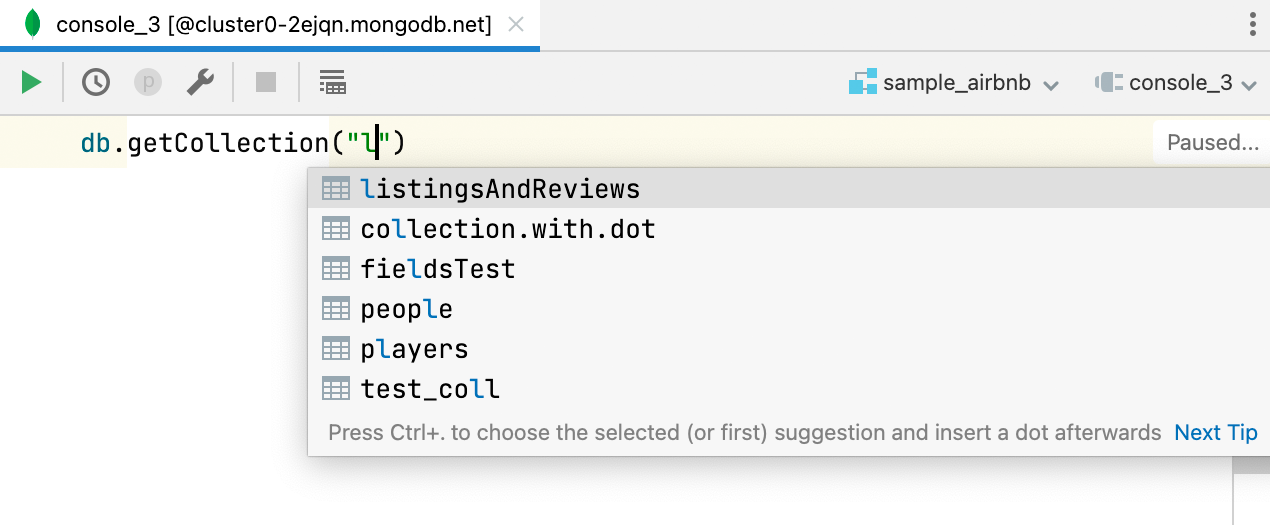
Complementação de código para nomes de bancos de dados no MongoDB
Os nomes dos bancos de dados agora são complementados quando se usa getSiblingDB. Da mesma forma, nomes de coleções agora são complementados quando se usa getCollection.
Além disso, nomes de campos agora também são complementados e resolvidos quando utilizados a partir de uma coleção definida por getCollection.
Janela de ferramentas Services
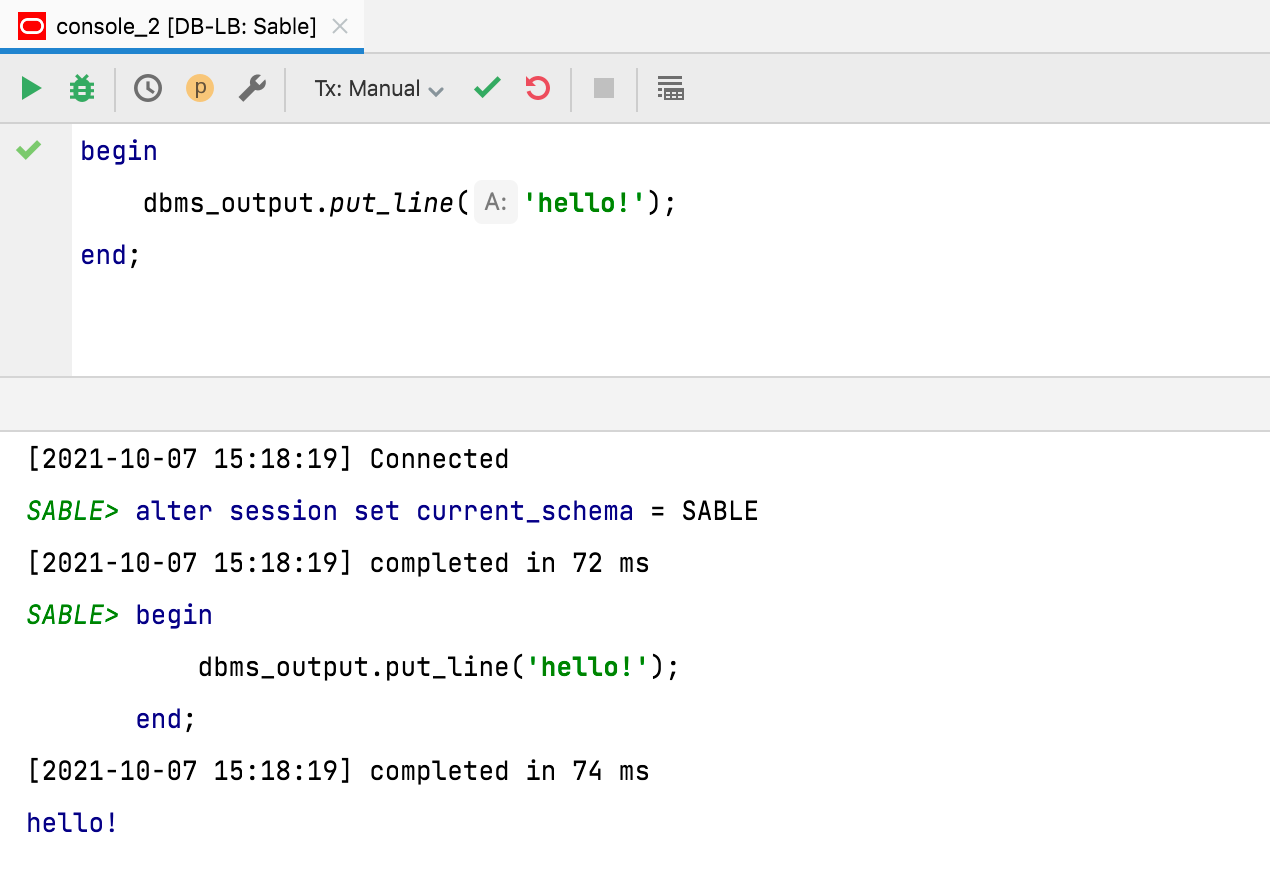
Timestamps na saída escondidos por default
Atendendo a este pedido, não são mais mostrados timestamps na saída das consultas, por default. Se você desejar voltar ao comportamento anterior, pode ajustar essa configuração em Database | General | Show timestamp for query output.
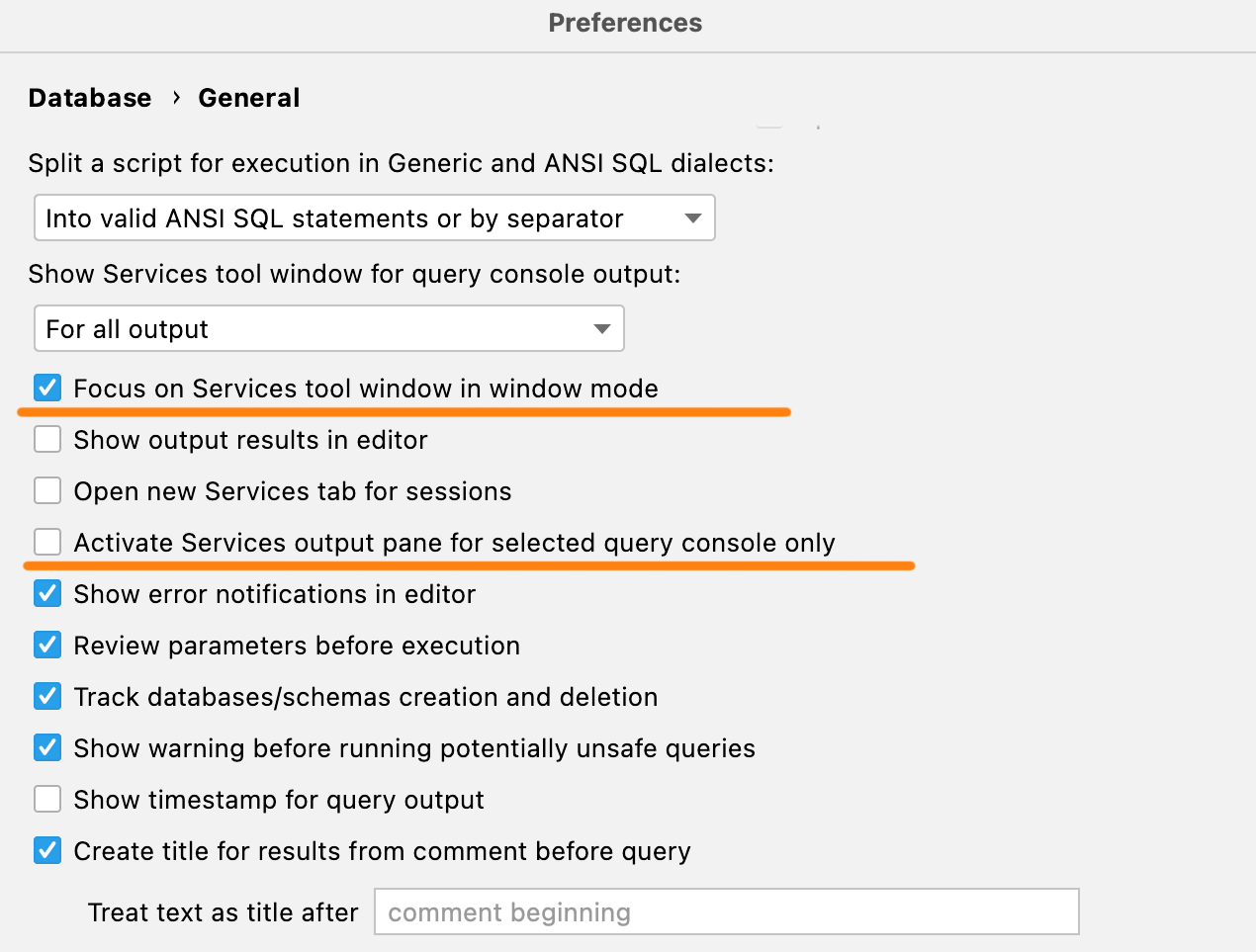
Novas configurações de ativação
Se você utilizar a janela de ferramentas Services no modo janela, ela estará oculta atrás do IDE por default. Com esta nova configuração, você pode alternar o foco para a janela toda vez que executar uma consulta, de modo que ela apareça depois que a consulta tiver terminado.
Além disso, se você fica irritado quando uma longa consulta termina ativando a aba correspondente a essa consulta na janela de ferramentas Services, marque a opção Activate Services output pane for selected query console only.
Importação/exportação
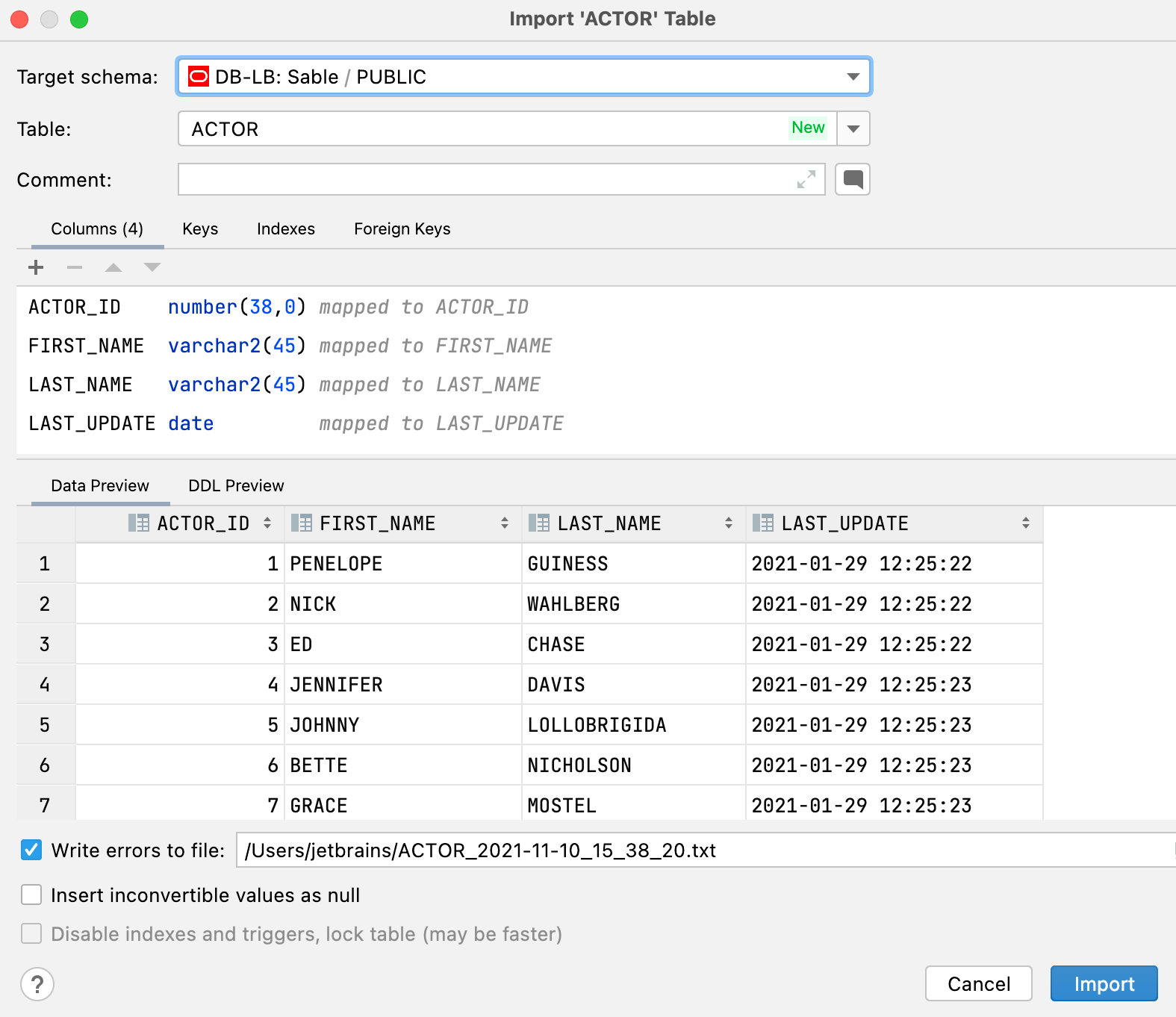
Nova interface de usuário para a importação de dados
Você notará as seguintes melhorias ao importar arquivos .csv ou copiar tabelas ou conjuntos de resultados:
- Você pode escolher uma tabela já existente ou criar uma nova.
- Você pode alterar o esquema de destino no diálogo de importação. O diálogo referente ao destino não aparecerá se você copiar uma tabela ou conjunto de resultados.
- O destino agora é salvo como default para cada esquema. Então, se você estiver sempre fazendo cópias de um esquema em especial para outro, não será mais preciso escolher o destino todas as vezes.
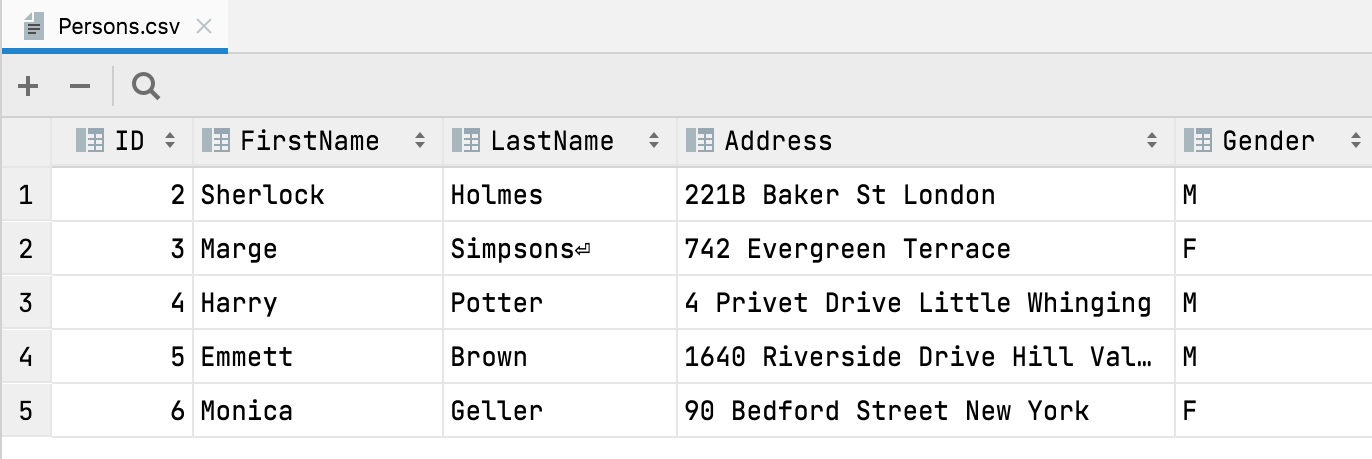
Detecção automática para First row is header
Quando um arquivo CSV for aberto ou importado, agora o DataGrip detectará automaticamente se a primeira linha for o cabeçalho e, portanto, contiver os nomes das colunas.
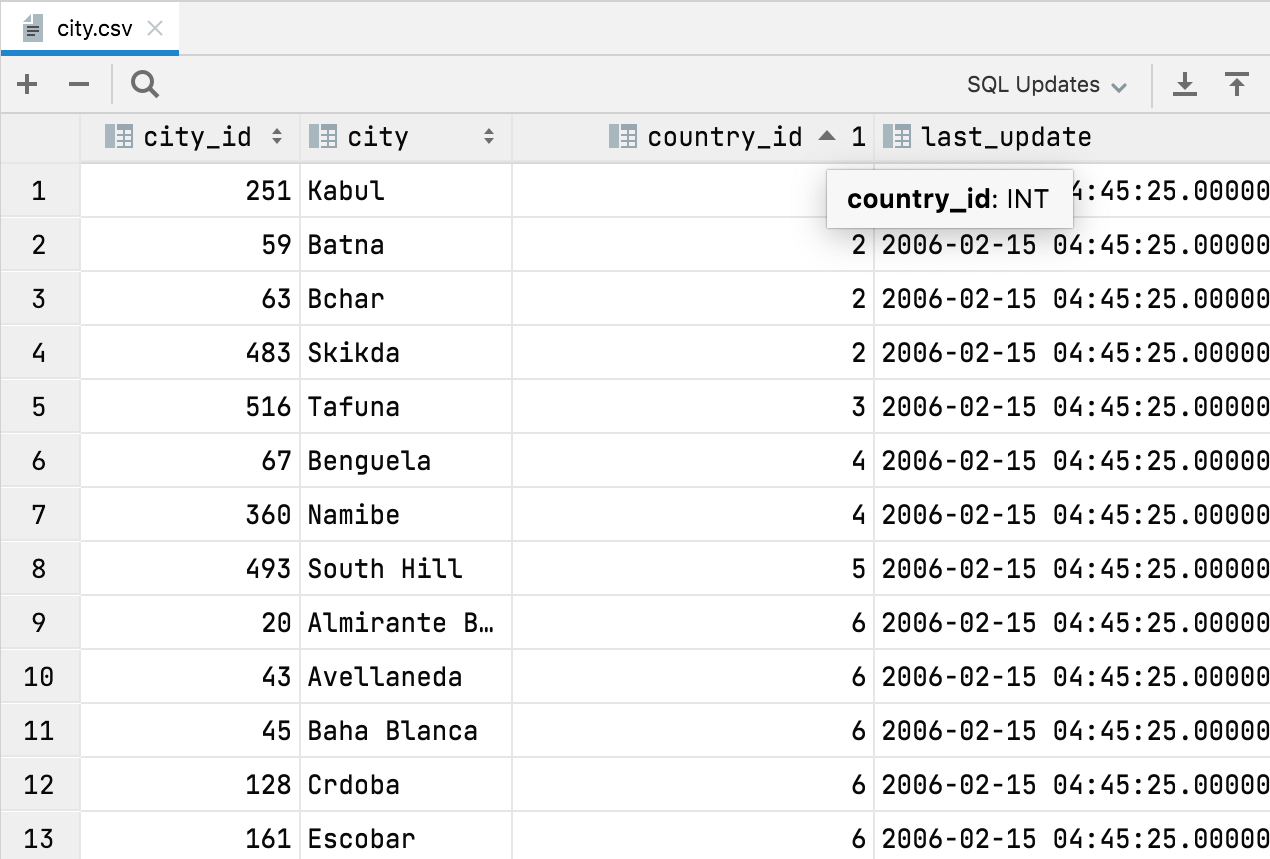
Tipos de colunas automáticos em arquivos CSV
O DataGrip agora detecta os tipos das colunas em arquivos CSV. O maior benefício disso poder ordenar os dados por valores numéricos. Anteriormente, dados numéricos eram tratados como texto e a ordenação não era intuitiva.
Diversos
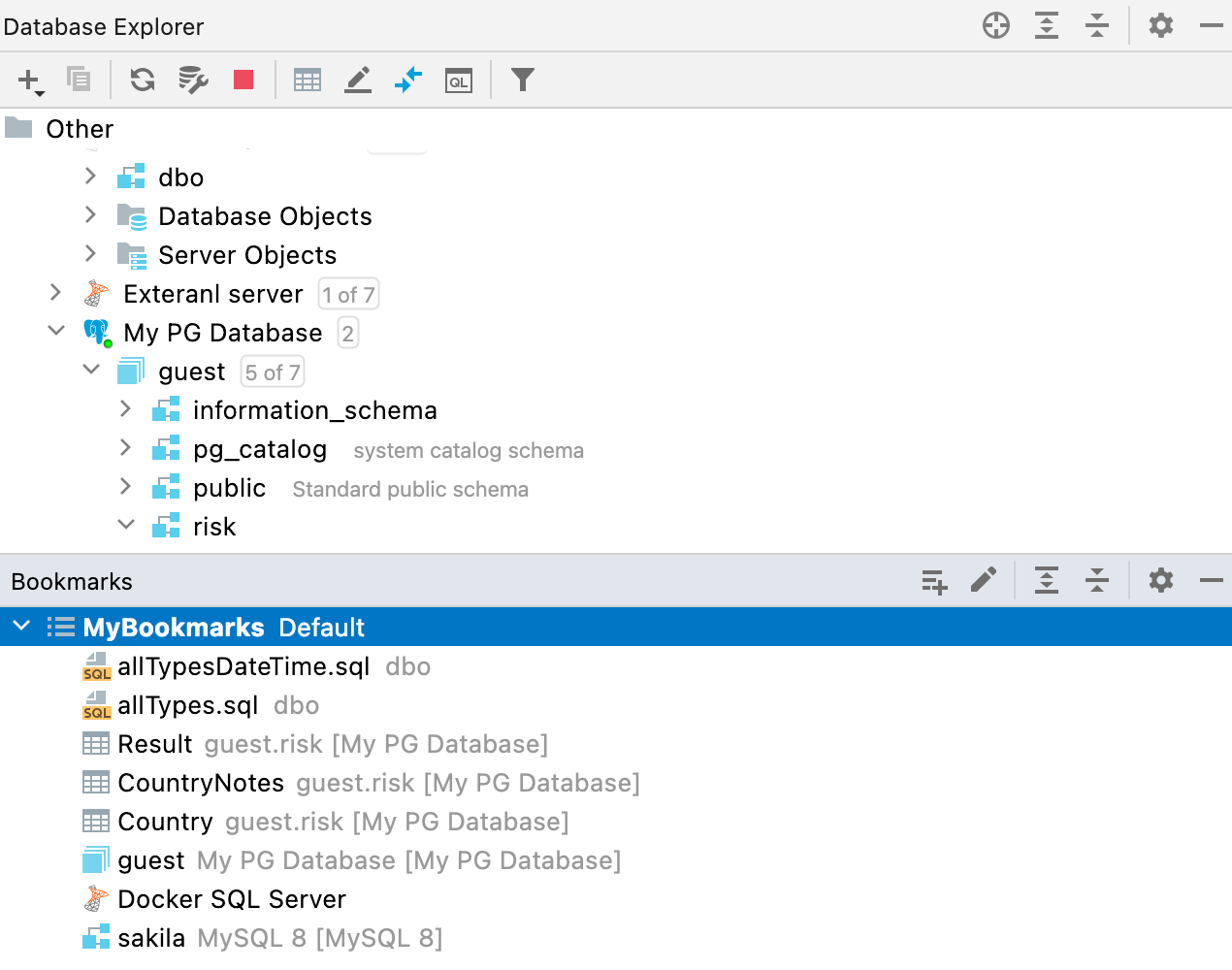
Nova janela de ferramentas Bookmarks
Anteriormente, havia dois recursos muito semelhantes – Favorites e Bookmarks, mas a diferença entre os dois podia ser confusa às vezes. Por isso, decidimos ficar com um só – Bookmarks. Reformulamos o workflow desta funcionalidade e criamos uma nova janela de ferramentas para ela.
De agora em diante, todos os objetos ou arquivos que você marcar como sendo importantes (através do atalho F3 no macOS ou F11 no Windows e no Linux) estarão na nova janela de ferramentas Bookmarks.