Novidades do DataGrip 2025.2
Introspecção por níveis para MS SQL Server e PostgreSQL, a capacidade de anexar objetos de banco de dados para contexto de chat de IA, resultados de consulta SELECT editáveis e muito mais.
Recursos do AI Assistant
Para utilizar os recursos descritos nesta seção, pode ser necessário instalar o Plug-in do AI Assistant. Após a instalação do plug-in, os recursos serão ativados por padrão no seu IDE.
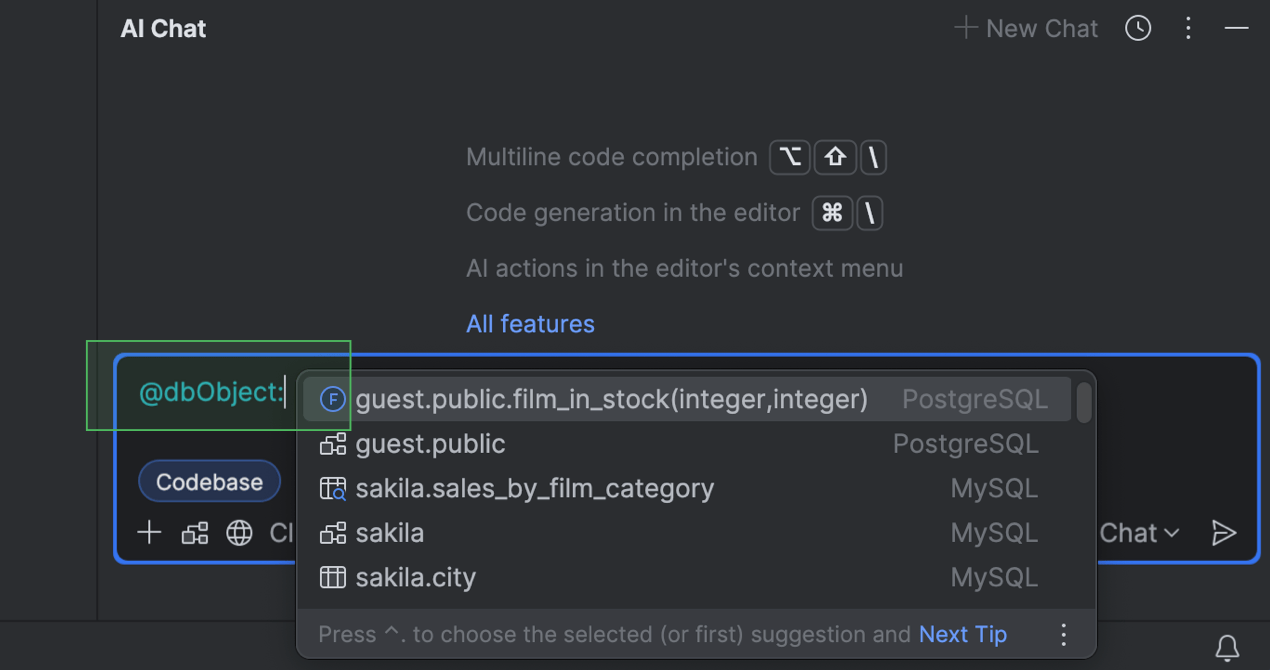
Possibilidade de anexar objetos de banco de dados ao chat por IA
O contexto do banco de dados que o usuário fornece ao chat por IA agora pode ser mais específico. Anteriormente, apenas o esquema completo podia ser anexado. Agora, é possível anexar o objeto do banco de dados necessário para o trabalho, como uma tabela ou uma exibição. Isso pode ser particularmente útil quando se trabalha com esquemas maiores.
Para anexar um objeto de banco de dados, digite @ ou # no campo de entrada, selecione ou digite dbObject: e, em seguida, selecione o objeto que deseja anexar na lista.
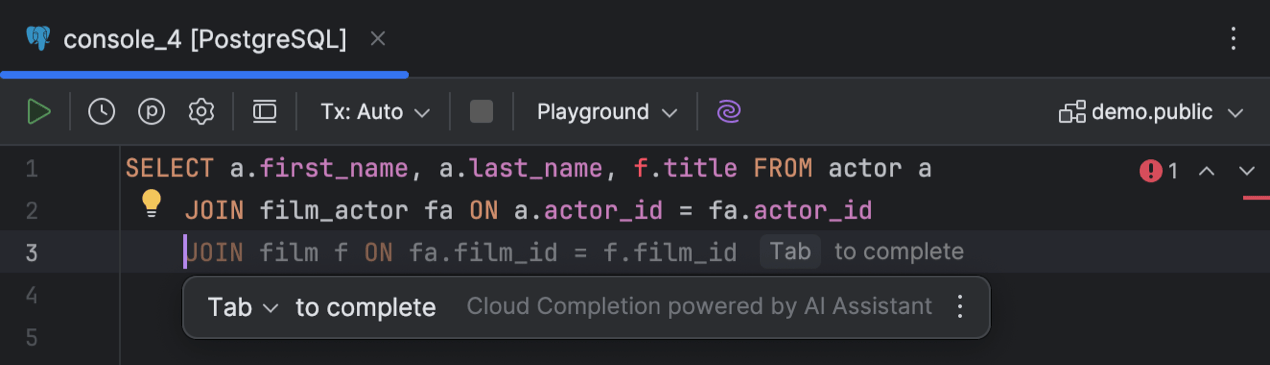
Complementação de código baseada na nuvem
O DataGrip agora oferece suporte à complementação de código baseada em nuvem. Ele utiliza recursos em nuvem para oferecer complementação de código mais precisa, aproveitando um poder computacional superior ao que os recursos locais podem oferecer. Esse recurso permite que o IDE complemente automaticamente linhas individuais, blocos de código e até scripts inteiros em tempo real, com base no contexto disponível. O SQL gerado é semelhante à forma como você escreveria suas instruções, correspondendo ao seu estilo e convenções de nomenclatura.
Com a complementação de código baseada em nuvem, o DataGrip exibe sugestões no editor enquanto você digita, e você também pode invocá-las pressionando Alt+Shift+\. Para desativar este recurso, acesse Settings | Editor | General | Inline Completion e desmarque a caixa de seleção Enable cloud completion suggestions.
Conectividade
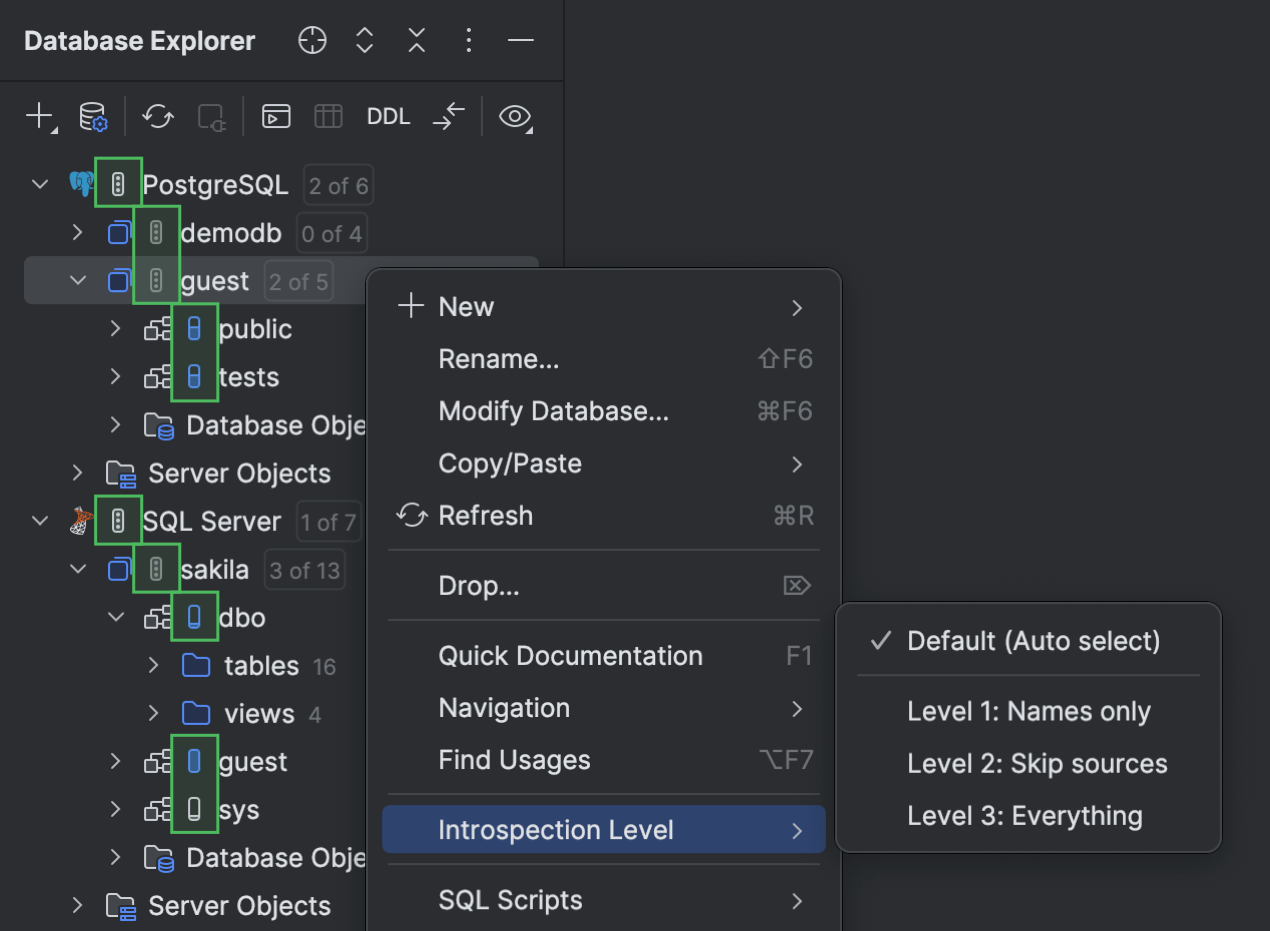
Introspecção por níveis PostgreSQL Microsoft SQL Server
Estamos ampliando a implementação da introspecção por níveis para mais bancos de dados – desta vez, PostgreSQL e Microsoft SQL Server! O DataGrip agora ajusta automaticamente a quantidade de metadados carregados para esses bancos de dados com base no tamanho do seu banco de dados. Isso significa que, para um banco de dados maior, não é necessário aguardar até que todos os metadados sejam carregados para começar a trabalhar com ele.
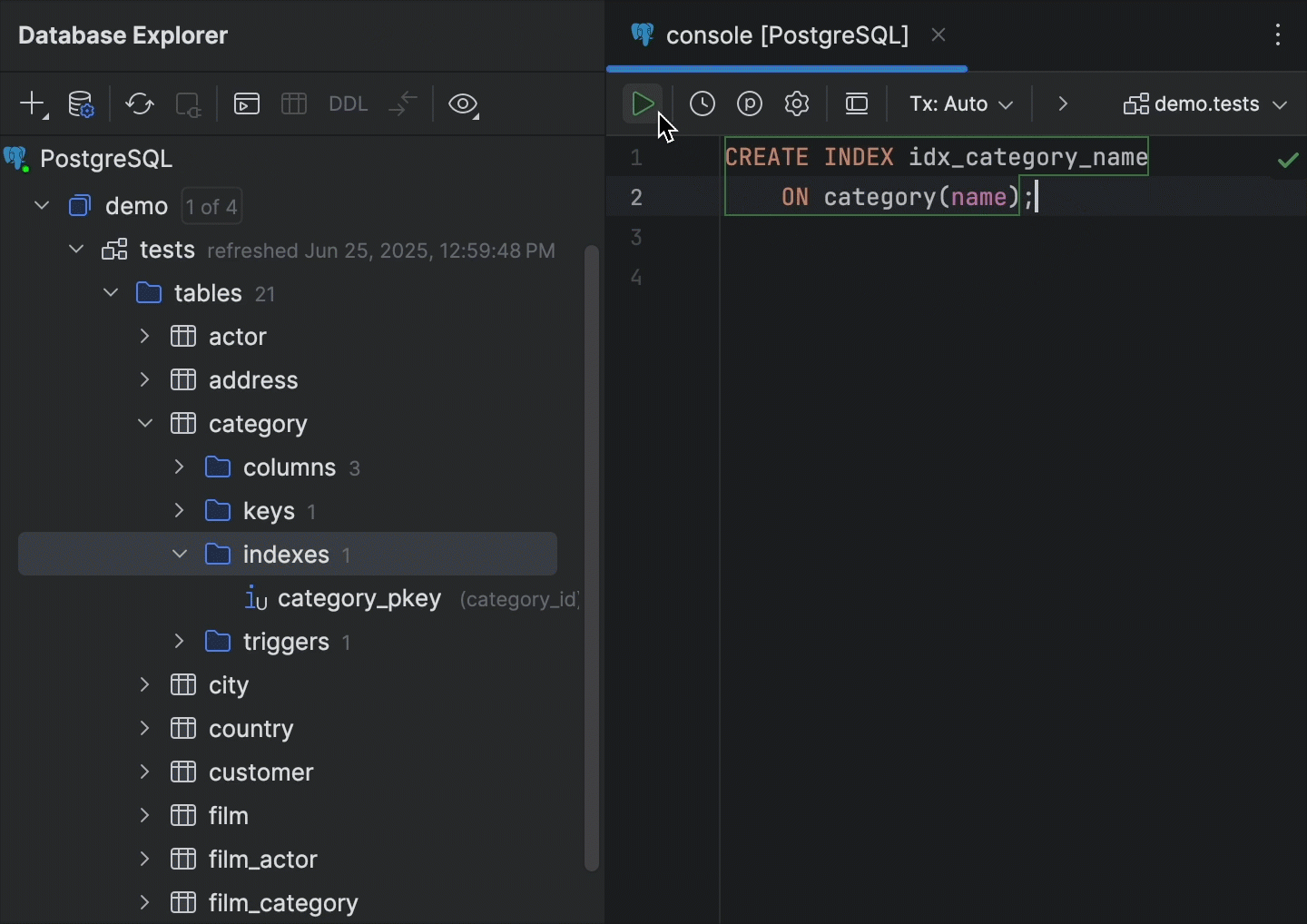
Atualização inteligente PostgreSQL
O DataGrip agora oferece suporte ao mecanismo de atualização inteligente para bancos de dados PostgreSQL. Anteriormente, o IDE atualizava automaticamente todo o esquema no explorador de banco de dados sempre que uma instrução DDL era executada. Com o mecanismo de atualização inteligente implementado, o DataGrip analisa quais objetos podem ser potencialmente modificados pela consulta e atualiza apenas esse conjunto específico de objetos.
Isso significa que, se o seu banco de dados contém muitos objetos, não é necessário aguardar um longo período enquanto todo o esquema é atualizado cada vez que você executa uma instrução DDL. Como apenas um conjunto específico de objetos é sincronizado, é possível retornar ao trabalho com muito mais rapidez do que se todos os objetos precisassem ser atualizados, e ainda assim você continuará tendo tudo o que precisa diretamente no explorador de banco de dados.
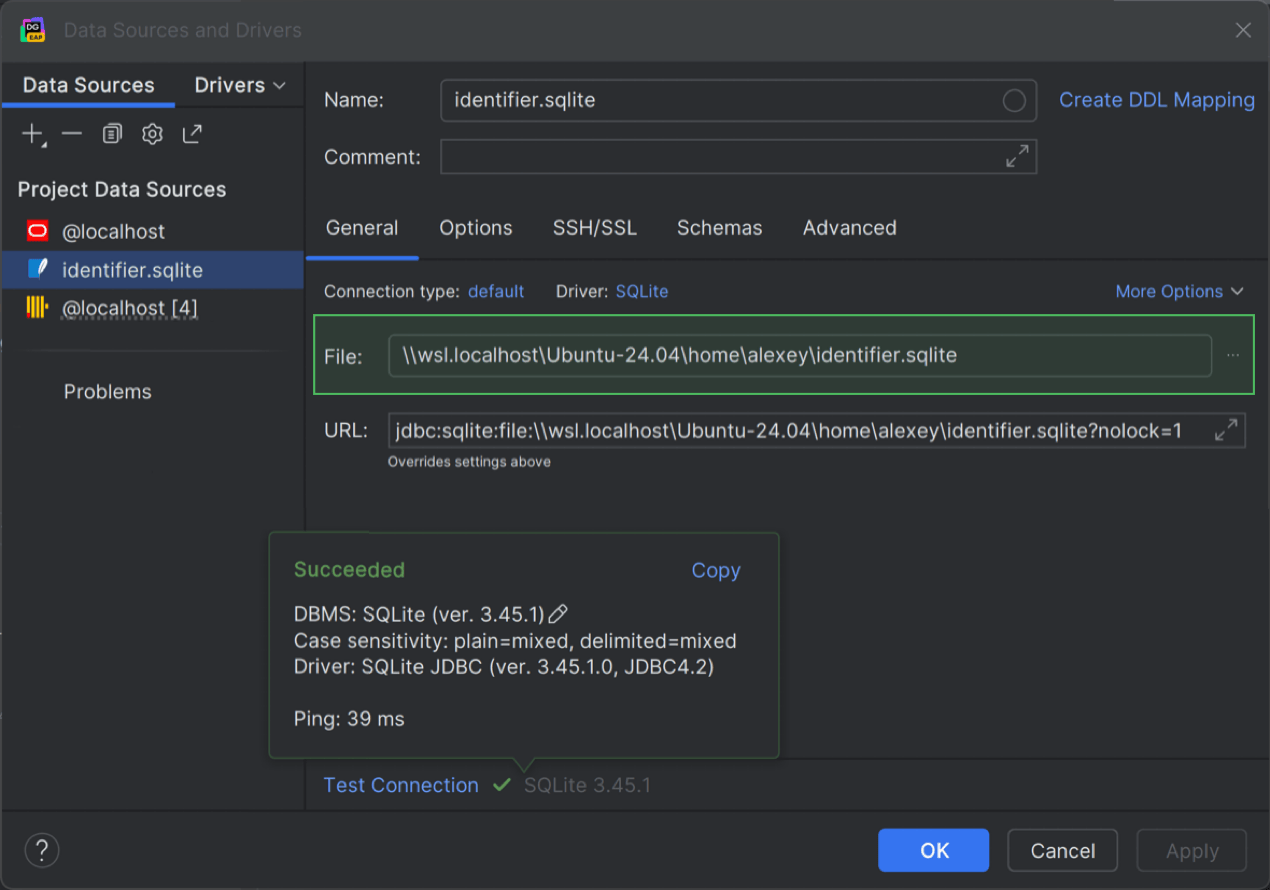
Caminho do arquivo de banco de dados WSL SQLite
Após muita expectativa, o DataGrip agora é compatível com caminhos de arquivos WSL para arquivos de banco de dados SQLite. Implementamos uma solução para resolver o problema de bloqueio de gravação no WSL em nosso sistema.
Isso significa que agora é possível acessar seu banco de dados SQLite no WSL e trabalhar com ele sem que o arquivo do banco de dados seja bloqueado. Para isso, acesse a caixa de diálogo Data Sources and Drivers e utilize o seguinte formato de caminho de arquivo: \\wsl$\<os>\home\<username>\<database_file_name>.sqlite. Por exemplo, \\wsl.localhost\Ubuntu-24.04\home\alexey\identifier.sqlite.
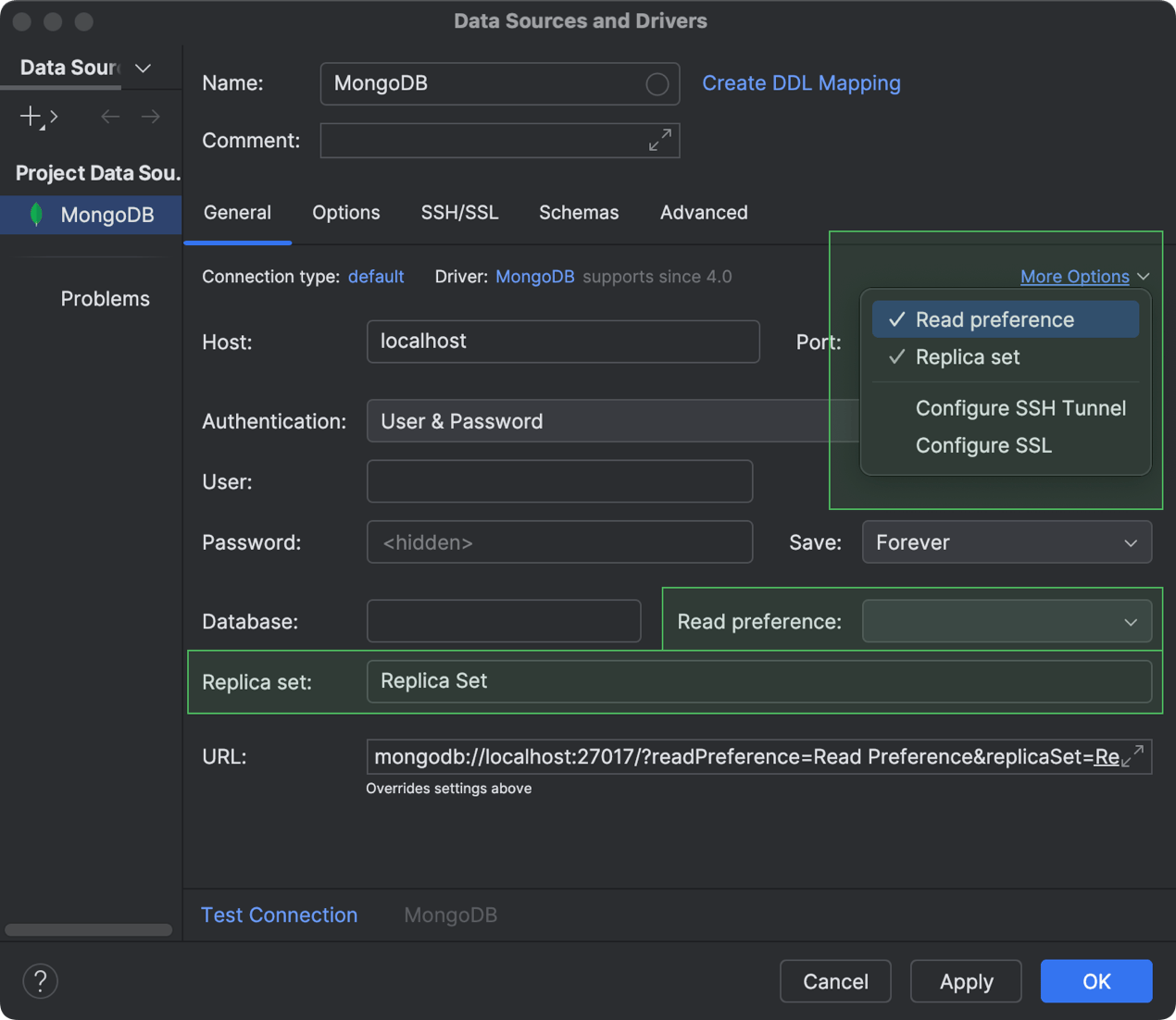
Suporte para as configurações de conectividade Read preference e Replica set MongoDB
Agora é possível configurar a forma como as operações de leitura são encaminhadas para os membros de um conjunto de réplicas do MongoDB e até mesmo definir qual conjunto de réplicas deve ser utilizado. Para isso, enquanto estiver configurando a conexão com o banco de dados MongoDB, acesse More Options e habilite a opção correspondente na caixa de diálogo Data Sources and Drivers. Após selecionar uma das opções da lista, aparecerá um novo campo onde você poderá especificar a configuração. Para especificar sua preferência de leitura, selecione a opção desejada no campo Read preference. Para definir seu conjunto de réplicas, basta digitar o nome dele no campo Replica set.
Trabalhando com dados
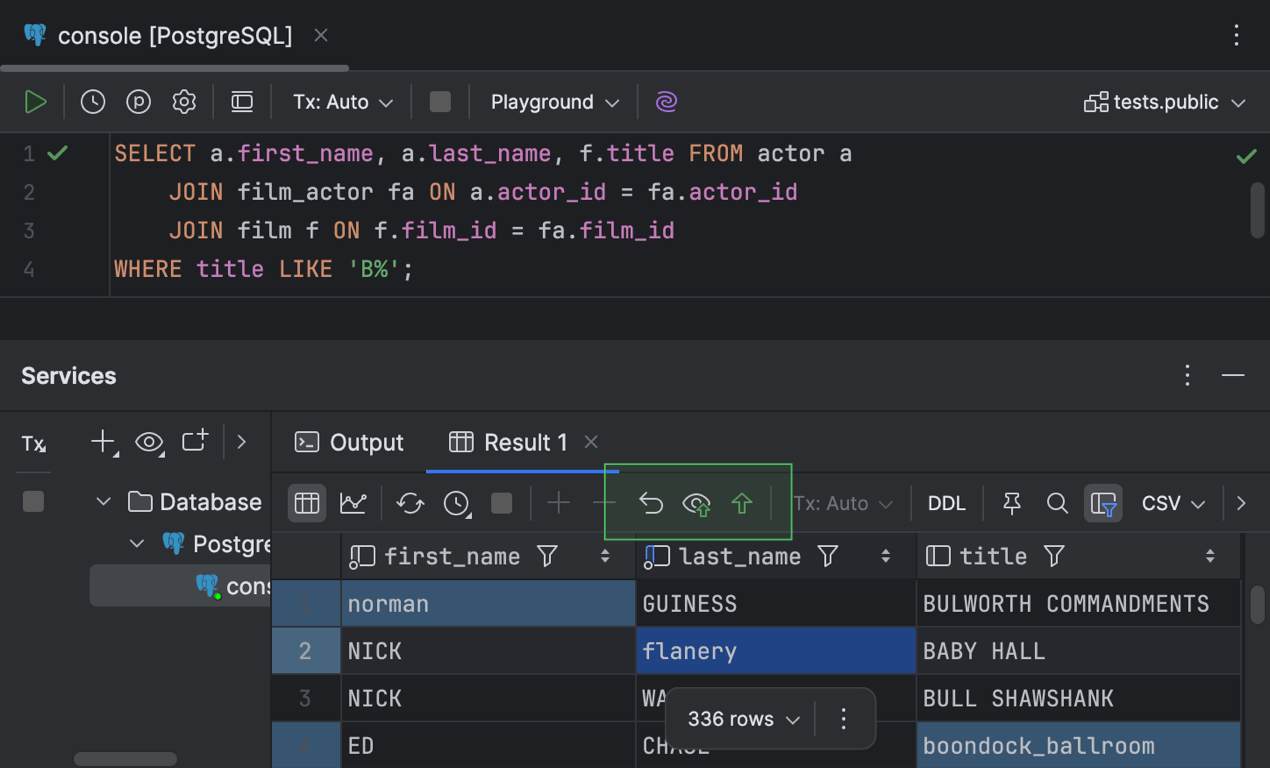
Resultados editáveis para consultas SELECT com cláusulas JOIN
Após uma década de trabalho, este tão aguardado recurso agora está disponível! Anteriormente, a grade de resultados para consultas SELECT com cláusulas JOIN era somente leitura. Agora, é possível executar essas consultas, visualizar o conjunto de resultados e, em seguida, editar os valores das células diretamente na grade de resultados da consulta. Para fazer isso, basta clicar duas vezes em uma célula ou selecioná-la e pressionar Enter. Além disso, assim como em qualquer outra grade, é possível clicar com o botão direito do mouse na célula e selecionarOpen in Value Editor para editar o valor em um painel separado que se abre à direita.
O editor de dados permite editar os valores tanto nos resultados no editor quanto na janela de ferramentas Services. Após editar o valor de uma célula, os seguintes botões ficam ativos na barra de ferramentas da aba Result da janela de ferramentas Services: Revert Selected, Preview Pending Changes, Submit.
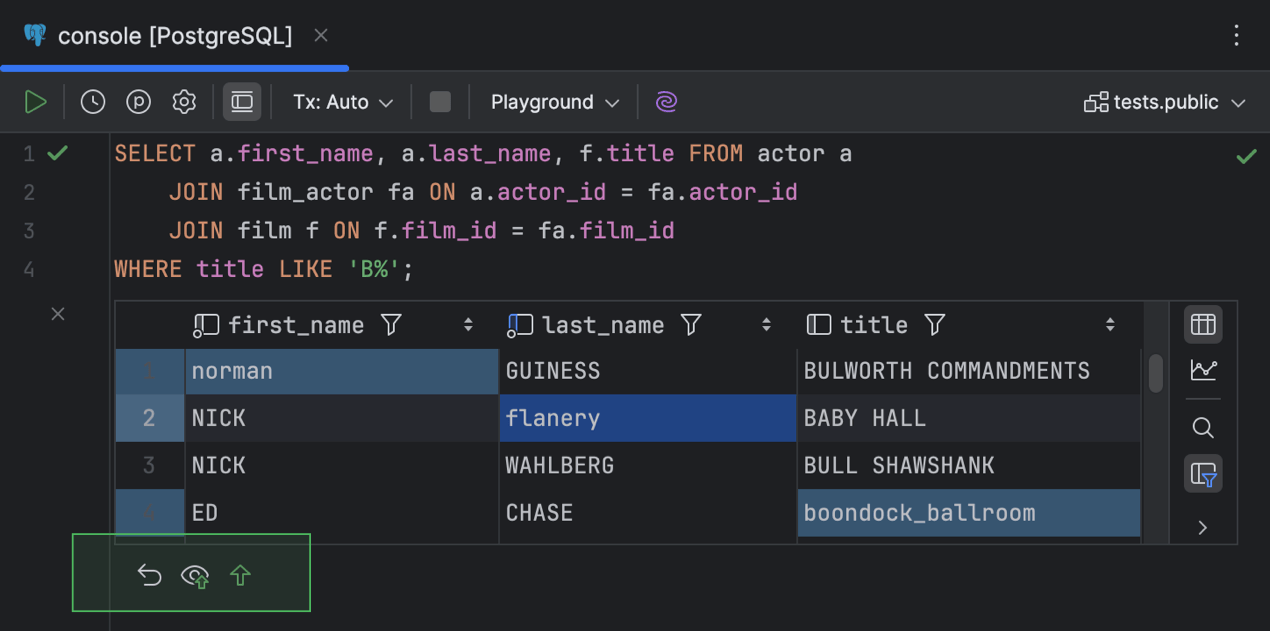
Uma barra de ferramentas adicional com esses botões também aparece na parte inferior do painel de resultados do editor.
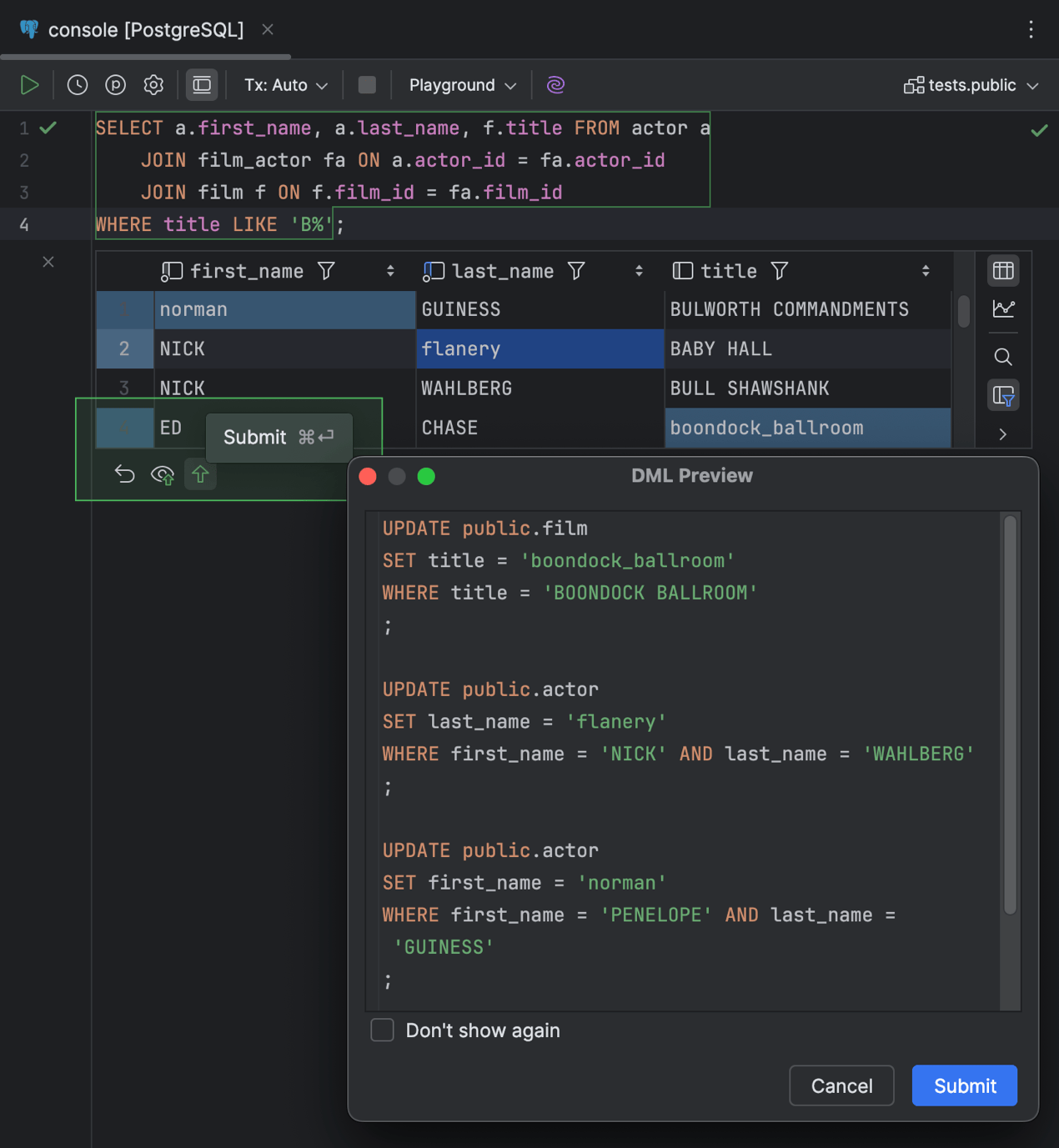
Ao enviar as alterações para o banco de dados, o DataGrip exibe a caixa de diálogo DML Preview para que você verifique primeiro as instruções geradas. Para editar suas alterações, clique em Cancel e prossiga com a edição. Para enviar as alterações, clique em Submit.
Esse recurso não é compatível com o operador SQL UNION, resultados de operações de auto-junção de tabelas, conjuntos de resultados com colunas de resultados de cálculos (por exemplo, CONCAT) ou bancos de dados NoSQL. Para garantir que este recurso funcione corretamente, cada linha deve possuir um campo ou conjunto de campos que a identifique de forma exclusiva.
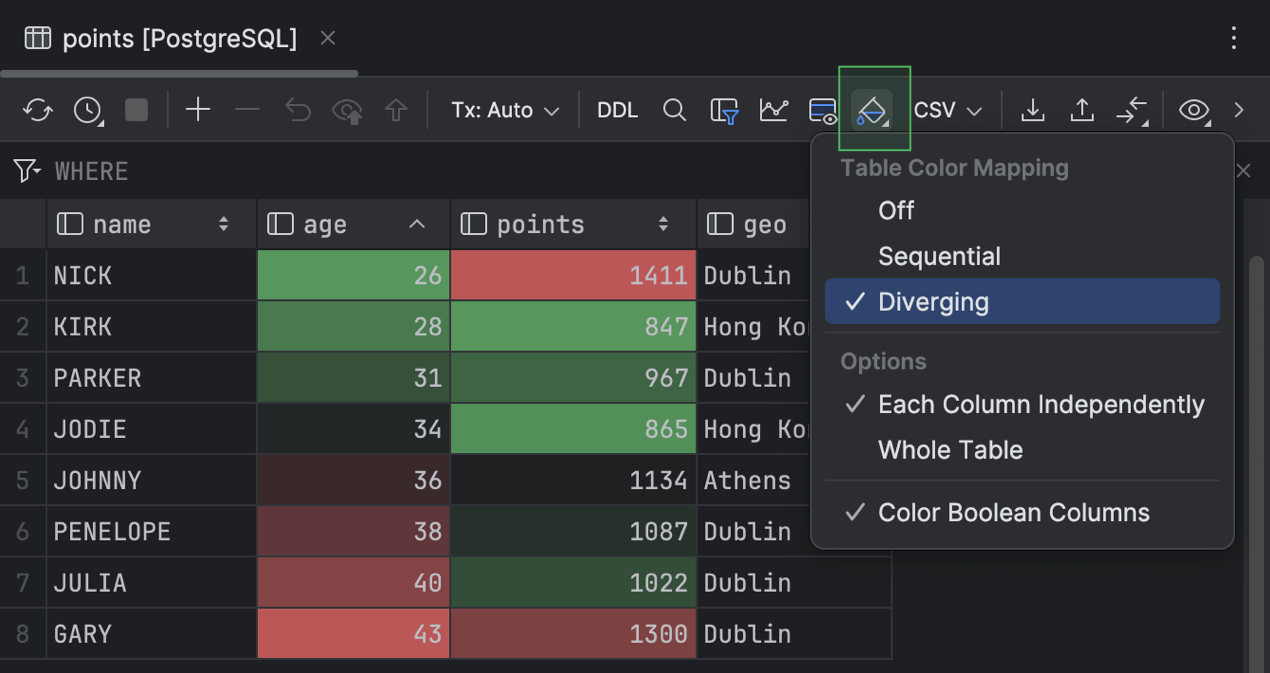
Mapa de calor em grade
No editor de dados, o DataGrip agora fornece mapas de calor em grade com duas opções de esquema de cores: Diverging e Sequential. Para ativar o mapa de calor para sua grade, clique em Table Coloring Options na barra de ferramentas e selecione um dos esquemas.
O esquema de cores Diverging enfatiza a variação em relação a uma norma. Ele consiste em duas cores contrastantes que desviam de um valor central em duas direções opostas.
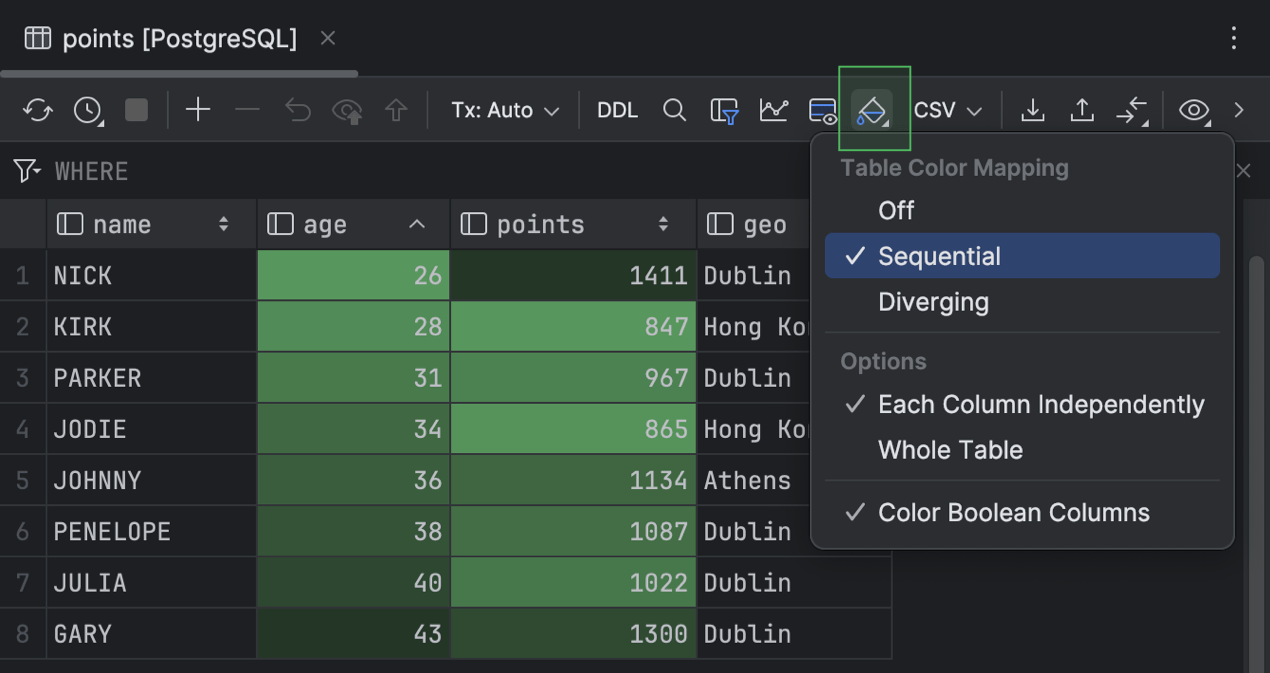
Já o esquema de cores Sequential consiste em uma única cor ou faixa de cores próximas que variam de intensidade.
Você pode aplicar os esquemas de cores de mapa de calor a toda a tabela, separadamente a cada coluna ou apenas a valores booleanos.
Uma ação para limpar todos os filtros locais em uma grade
Agora, é possível limpar o filtro local para todas as colunas da sua grade usando apenas uma ação. Para realizar essa ação, acione o menu pop-up Find Action pressionando Ctrl+Shift+A, comece a digitar Clear Local Filter For All Columns e, em seguida, selecione a ação na lista.
Editor de código
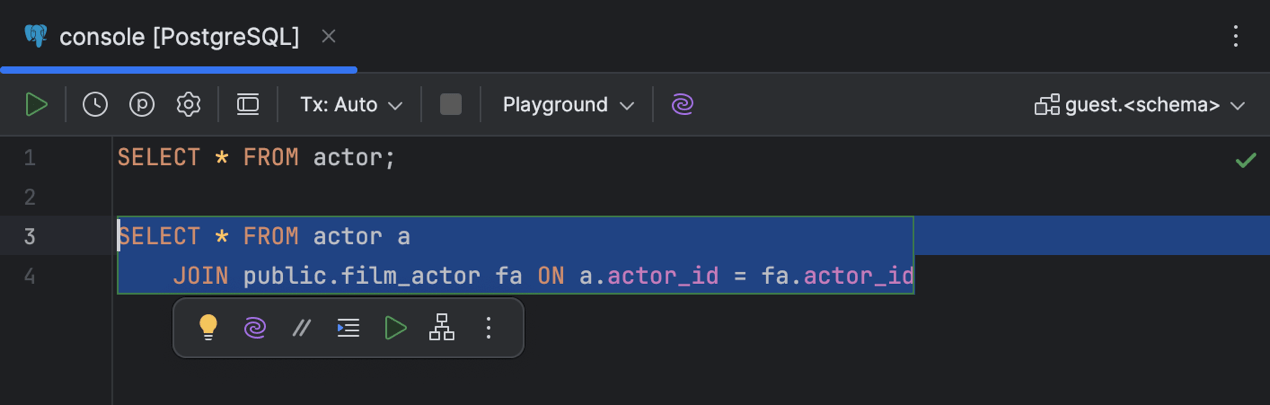
Barra de ferramentas flutuante
O DataGrip agora exibe um conjunto de ações baseadas no contexto e orientadas por IA disponíveis para um determinado trecho de código em uma barra de ferramentas flutuante. Selecione qualquer código no seu editor de código para exibir a barra de ferramentas.
Para personalizar a barra de ferramentas flutuante, utilize o menu de três pontos verticais. Para ocultá-lo, é possível usar o mesmo menu ou acessar Settings | Advanced Settings | Editor e marcar a opção Hide floating toolbar for code editing.
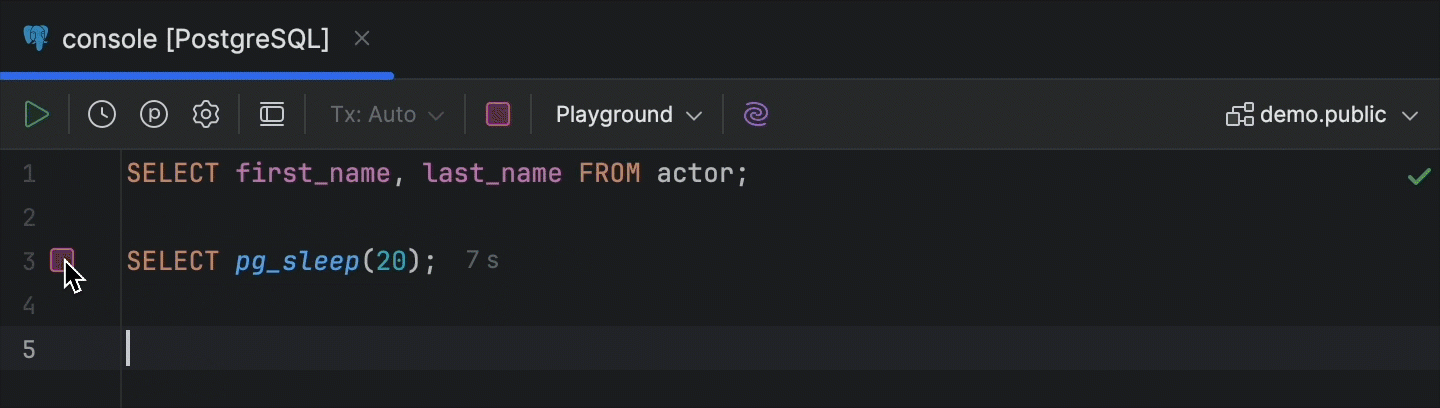
Botão Cancel Running Statements na margem
Para uma instrução em execução, o ícone de progresso na margem agora se transforma no botão Cancel Running Statements ao passar o mouse sobre ele.
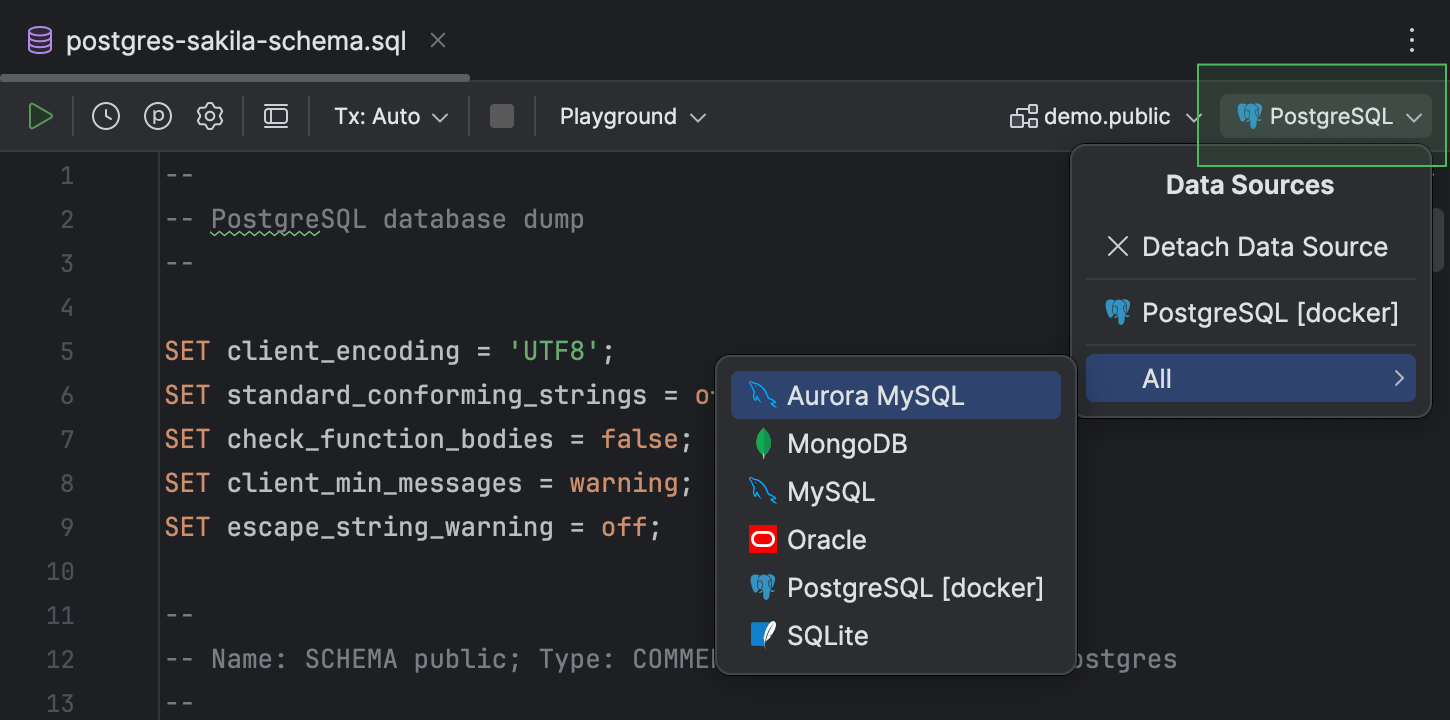
Fontes de dados anexadas que persistem após a reinicialização
Anteriormente, era necessário anexar fontes de dados aos arquivos sempre que reiniciava o IDE. Isso era um verdadeiro incômodo, então nós o corrigimos!
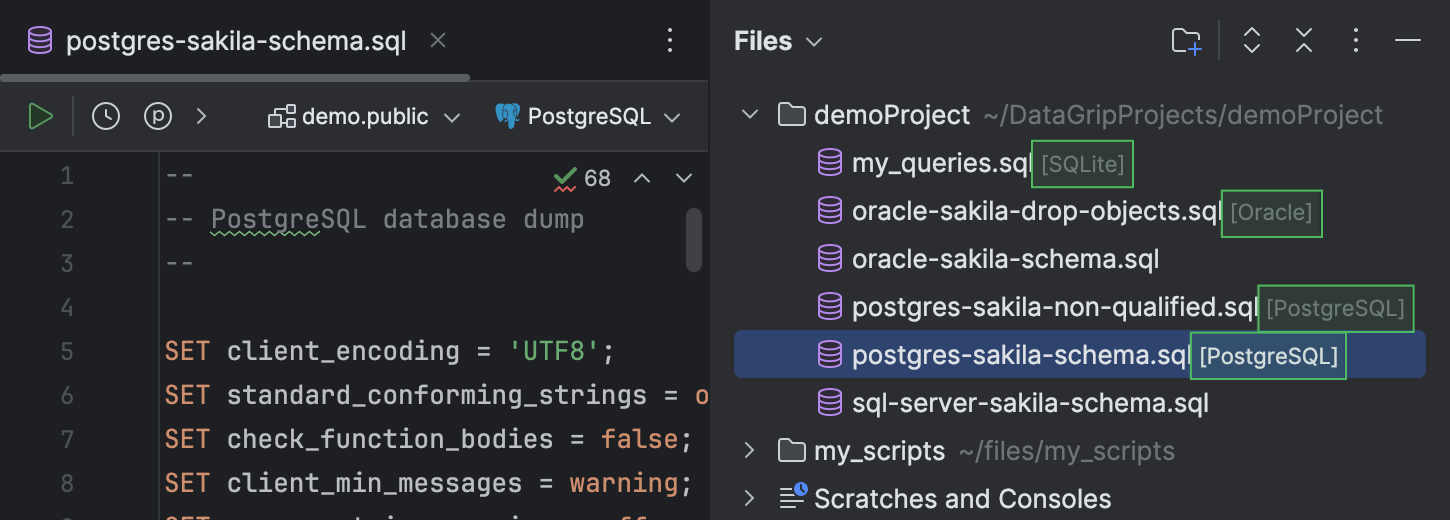
Além disso, é possível visualizar a fonte de dados anexada a cada arquivo na janela de ferramentas Files.
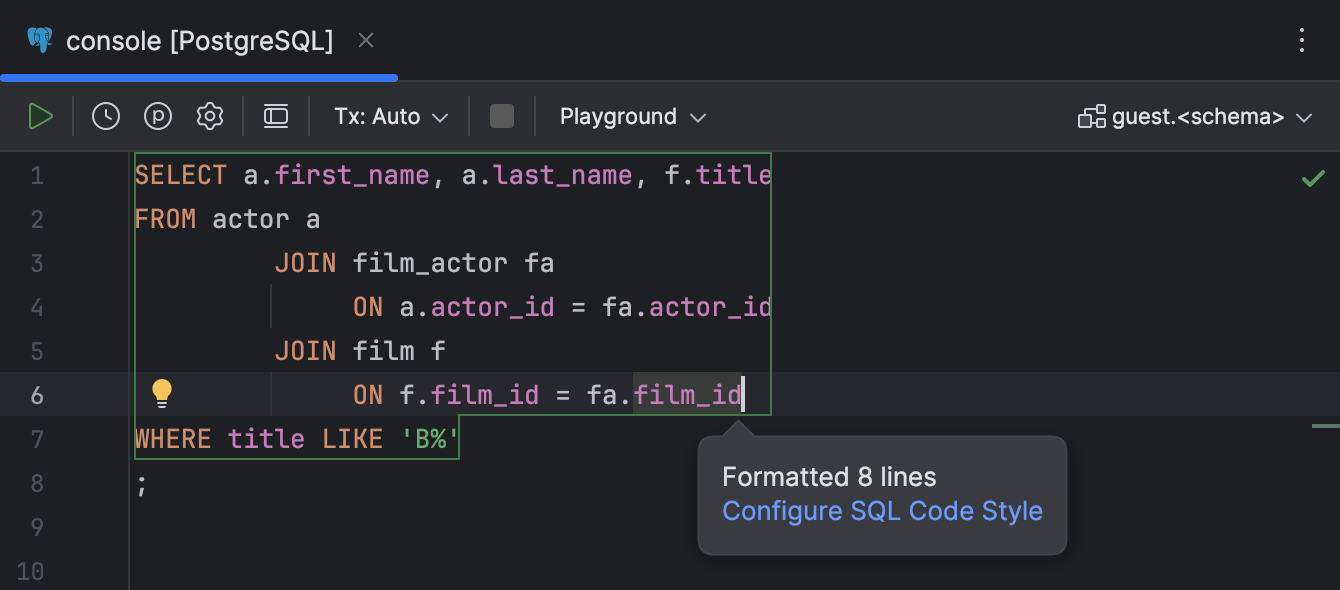
Acesso rápido às configurações de estilo de código
Agora é fácil navegar até as configurações de estilo de código diretamente da janela pop-up exibida sempre que o código é reformatado.
Esperamos que você aproveite ao máximo essas novidades! Se você se deparar com um bug ou tiver uma sugestão de recurso, compartilhe em nosso rastreador de issues.
Quer ficar por dentro das últimas novidades e receber dicas sobre como trabalhar com bancos de dados de maneira mais produtiva? Inscreva-se no nosso blog e siga-nos no X!