Novidades no DataGrip 2026.1
Suporte a agentes de IA, um novo fluxo para criar arquivos de consulta, modelos para fontes de dados e muito mais!
Boas-vindas às primeiras Novidades do DataGrip de 2026. Esta nova versão traz melhorias práticas para aumentar a eficiência dos fluxos de trabalho com bancos de dados. As atualizações incluem a integração com agentes de IA, melhorias para arquivos de consulta e consoles e uma maneira mais fácil de reutilizar configurações de fontes de dados em todos os JetBrains IDEs.
- IA:
- Arquivos de consulta e consoles:
- Conectividade e fontes de dados:
- Outras melhorias:
Melhorias de IA: fluxo com agentes
O JetBrains AI está evoluindo para lhe dar mais opções, transparência e flexibilidade na forma de usar IA dentro do DataGrip.
Esta versão traz uma criação mais inteligente de arquivos SQL a partir do chat de IA, a integração do Claude Agent e do Codex à interface do chat e ferramentas específicas para bancos de dados no servidor MCP, para fluxos de trabalho com agentes.
Criação de arquivos com a fonte de dados e o dialeto de SQL anexados
Nos chats com o AI Assistant na janela de ferramentas AI Chat, você pode criar um arquivo a partir de um trecho de código.
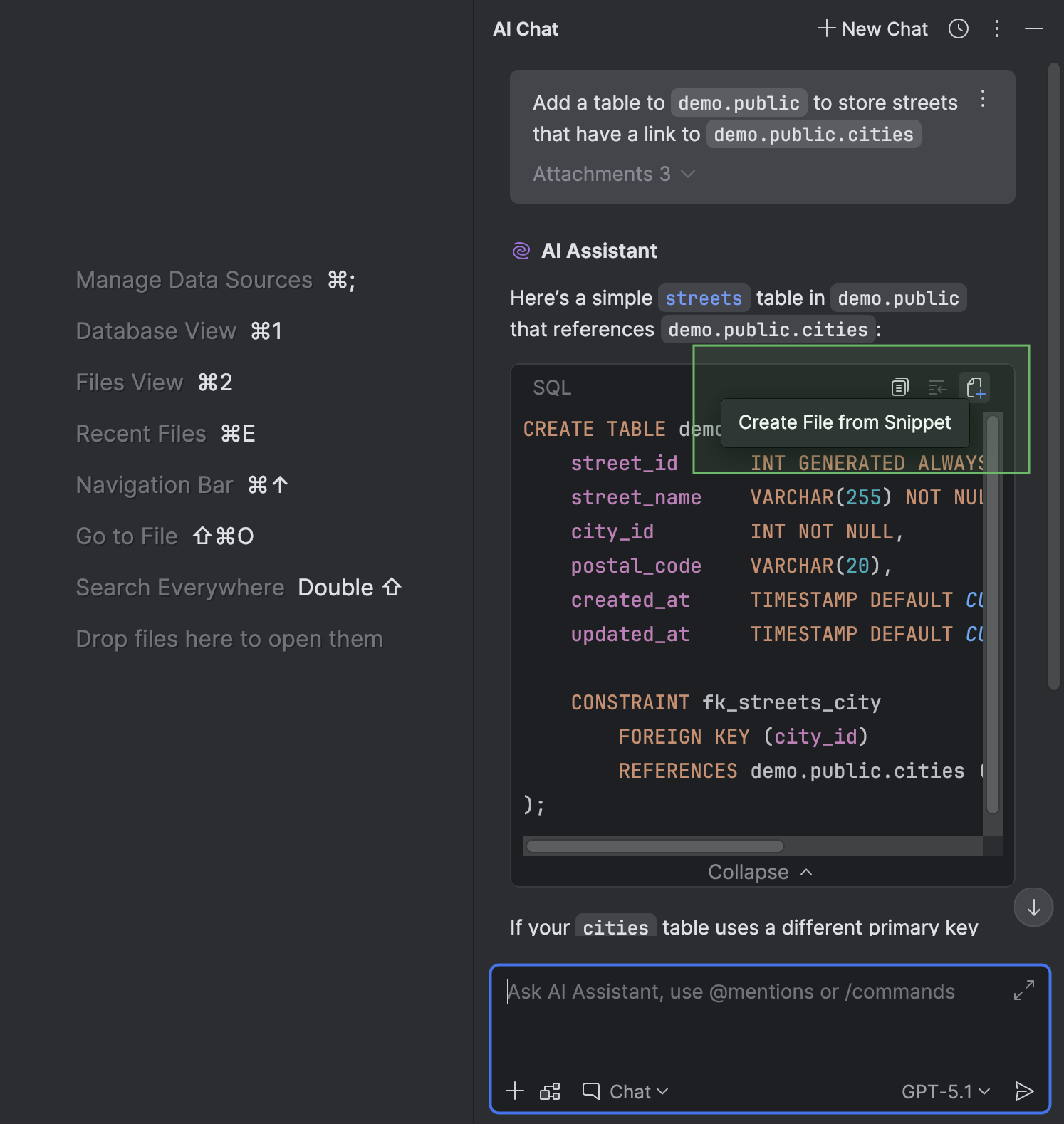
Se for fornecido no chat algum contexto referente ao dialeto de SQL, a uma fonte de dados ou a um esquema, você não tem que definir o dialeto ou anexar a fonte de dados ou o esquema, porque o DataGrip fará isso automaticamente. O mesmo vale para quando você faz perguntas ao AI Assistant sobre um arquivo SQL que já tenha uma fonte de dados associada: o DataGrip anexará essa mesma fonte de dados ao arquivo recém-criado.
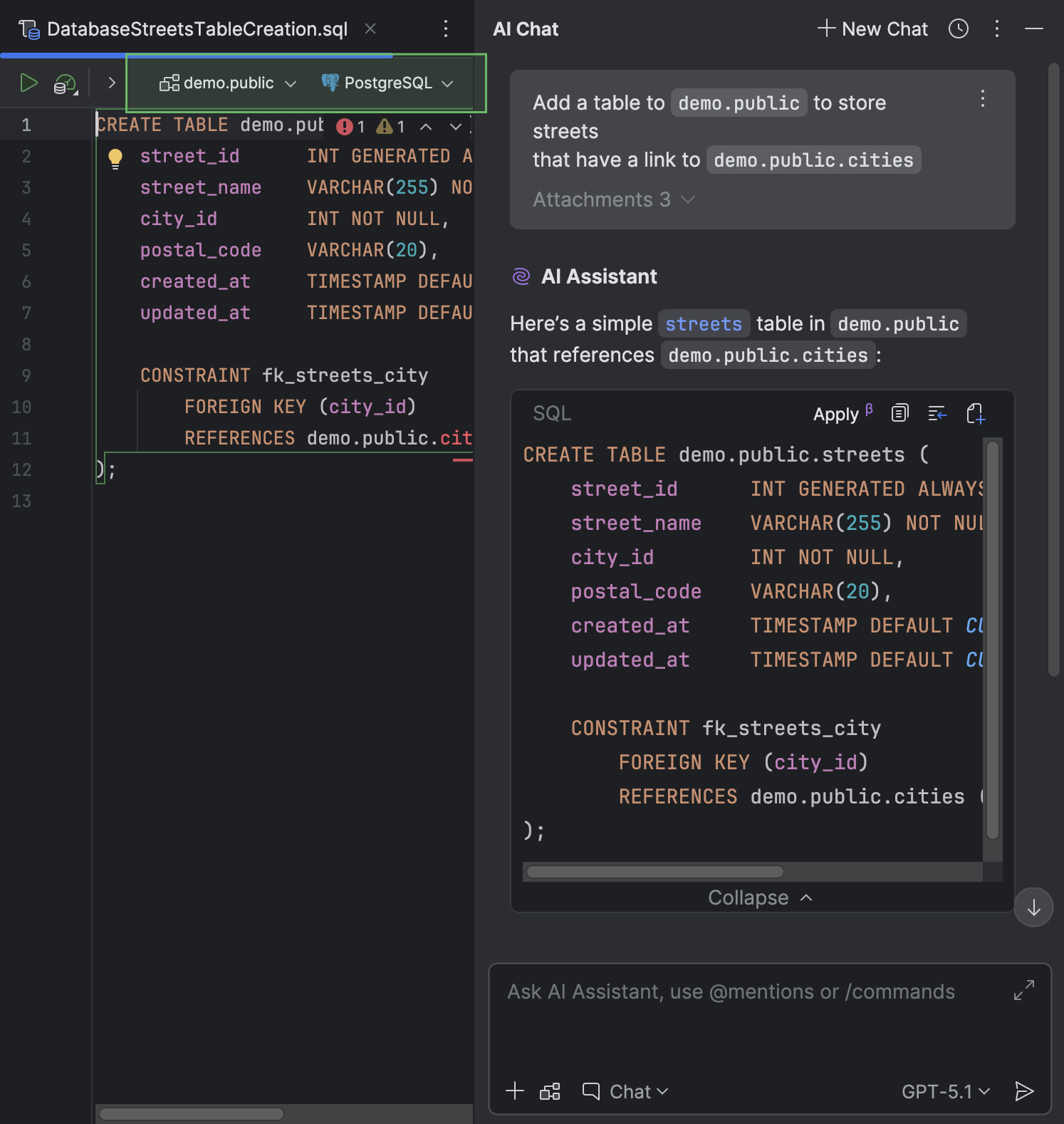
O DataGrip armazenará o arquivo criado no diretório atual do projeto.
Integração de agentes no chat de IA
Agora o Claude Agent e o Codex estão integrados nativamente na interface do chat de IA. Isso facilita obter o tipo certo de assistência para cada tarefa.
No momento, a integração com o Codex requer a configuração manual do servidor MCP. Para mais instruções, consulte a página correspondente da documentação para o Codex.
Você encontra mais informações sobre essas integrações nestas postagens no blog do JetBrains AI: Introduzindo o Claude Agent nos JetBrains IDEs e Codex agora integrado aos JetBrains IDEs.
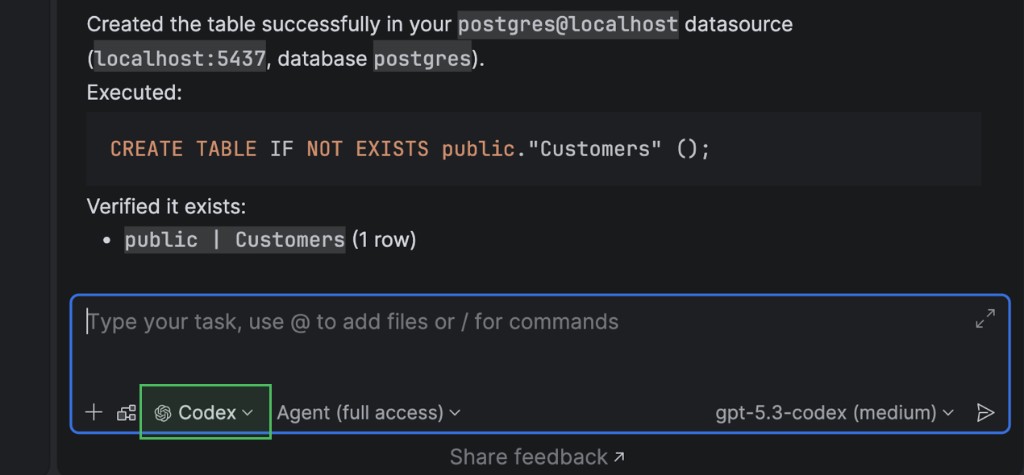
Recursos do servidor MCP específicos para bancos de dados
Ampliamos a funcionalidade do servidor MCP com recursos específicos para bancos de dados. Com essa melhoria, os agentes de IA integrados e as ferramentas de terceiros podem trabalhar com bancos de dados de maneira mais estruturada.
Os novos recursos incluem:
- Obter configurações de conexão e testá-las.
- Listar esquemas de bancos de dados.
- Obter tipos de objetos de esquemas com suporte (tais como tabelas e visualizações) e explorar esses objetos.
- Visualizar consultas de SQL recentes e em execução.
- Executar e cancelar a execução de consultas de SQL.
- Pré-visualizar dados de tabelas e obter conjuntos de resultados em formato CSV.
Por segurança e como padrão, são exigidos quatro tipos de consentimento do usuário:
- Solicitações de acesso a esquemas.
- Solicitações de acesso aos dados.
- Solicitações de modificação de esquemas.
- Solicitações de modificação de dados.
O IDE solicitará o seu consentimento, quando for necessária uma permissão.
Você pode mudar as suas preferências de consentimento nas configurações do IDE, em Tools | AI Assistant.
Arquivos de consulta e consoles
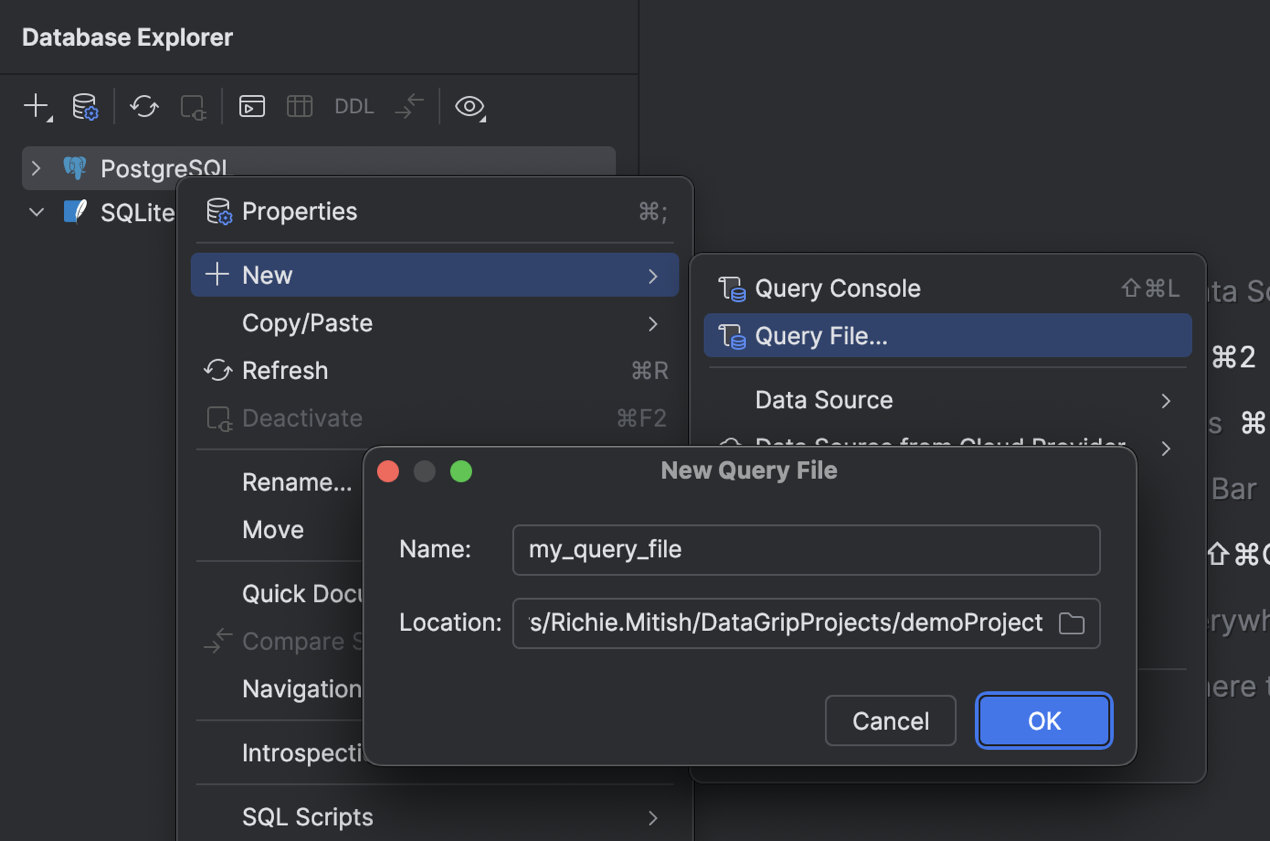
Novo fluxo para criar um arquivo de consulta
Reformulamos o fluxo de trabalho para trabalhar com arquivos de consulta lado a lado com consoles de consulta. Agora você pode usar apenas arquivos, apenas consoles ou os dois ao mesmo tempo, dependendo das suas tarefas e do seu fluxo de trabalho.
Para criar um novo arquivo de consulta, clique com o botão direito em uma fonte de dados e selecione New | Query File ou tecle Shift+Cmd+J (macOS) ou Ctrl+Alt+Shift+Q (Windows/Linux). Em seguida, no diálogo New Query File, especifique o nome do arquivo e o diretório onde você quer armazená-lo. Para armazenar o arquivo dentro do projeto atual e associá-lo com o projeto, especifique o diretório atual do projeto ou um de seus subdiretórios.
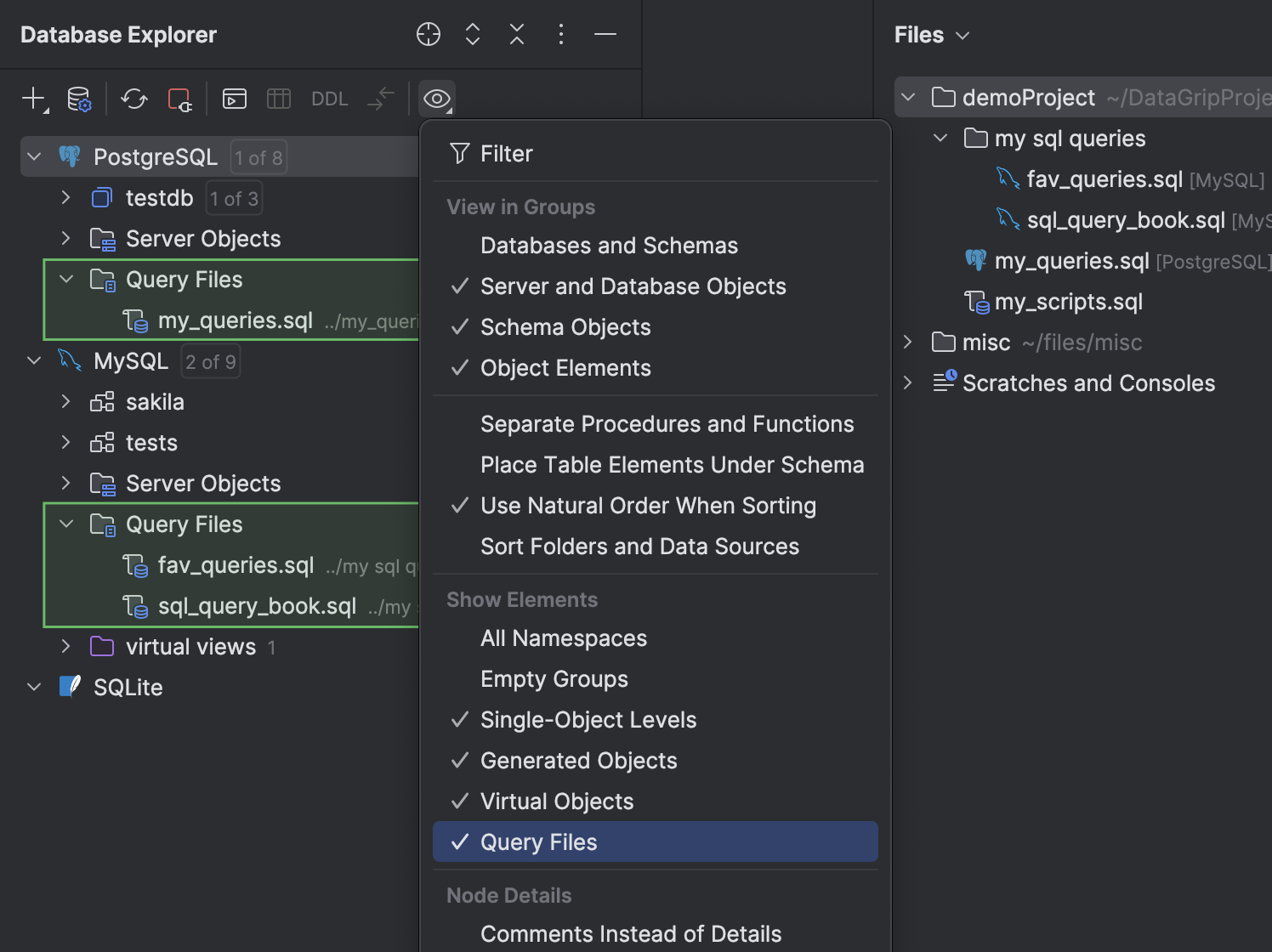
Pasta Query Files no explorador de bancos de dados
Agora você pode acessar os seus arquivos de consulta no explorador de bancos de dados. Adicionamos a pasta Query Files, que aparece abaixo de cada nó de fonte de dados. Para ativar ou desativar a visibilidade dessa pasta, clique em View Options na barra de ferramentas do explorador e marque ou desmarque a opção Query Files.
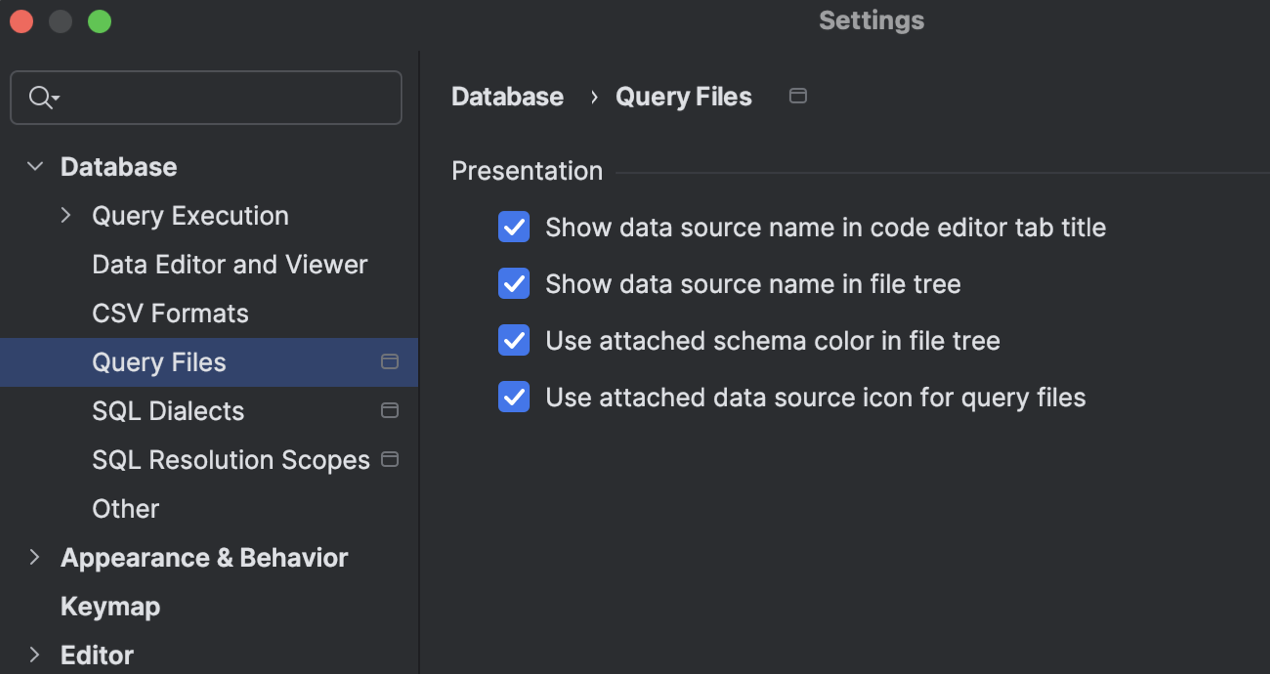
Novas opções para ajustar a forma de exibição dos arquivos
Tarefas diferentes precisam que informações diferentes estejam visíveis. Adicionamos algumas configurações para garantir que a apresentação dos arquivos de consulta lhe dê as informações certas para o seu caso específico de uso. Você pode usar essas informações para definir se os nomes das fontes de dados devem ou não ser exibidos, aplicar cores aos esquemas e usar ou não o ícone da fonte de dados anexada nos seus arquivos de consulta.
Conectividade
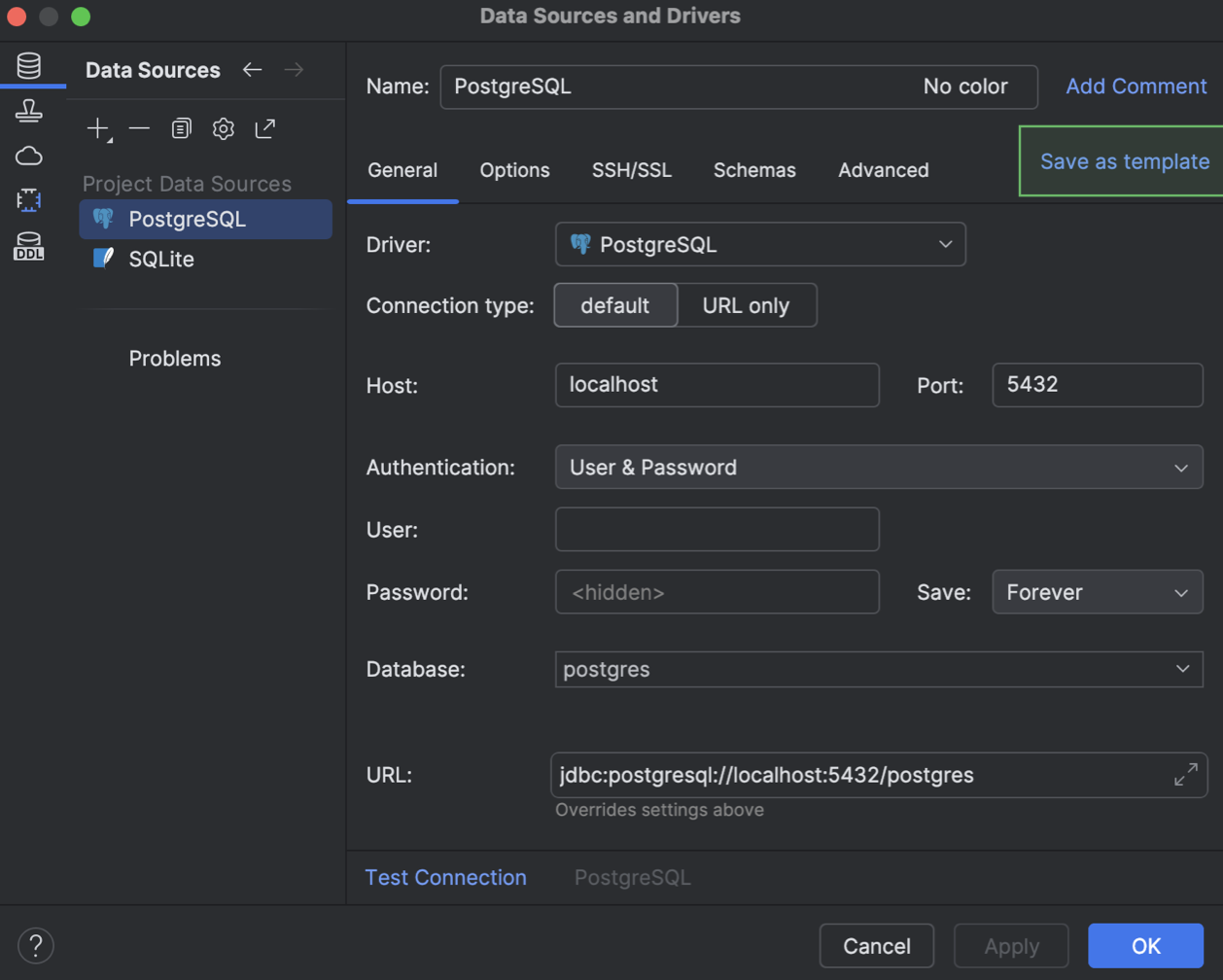
Modelos de fonte de dados
Implementamos uma maneira de armazenar configurações de fontes de dados como modelos na sua conta da JetBrains. Quando as configurações forem armazenadas dessa maneira, o modelo ficará disponível para todos os JetBrains IDEs com recursos de bancos de dados e será disponibilizado através da sua conta da JetBrains. Esses modelos armazenam as configurações das abas General e Advanced do diálogo Data Source and Drivers, mas excluem as suas credenciais para o banco de dados.
Você pode criar um modelo no diálogo Data Source and Drivers. Na aba Data Sources, selecione a fonte de dados a partir da qual você deseja criar um modelo e clique em Save as template.
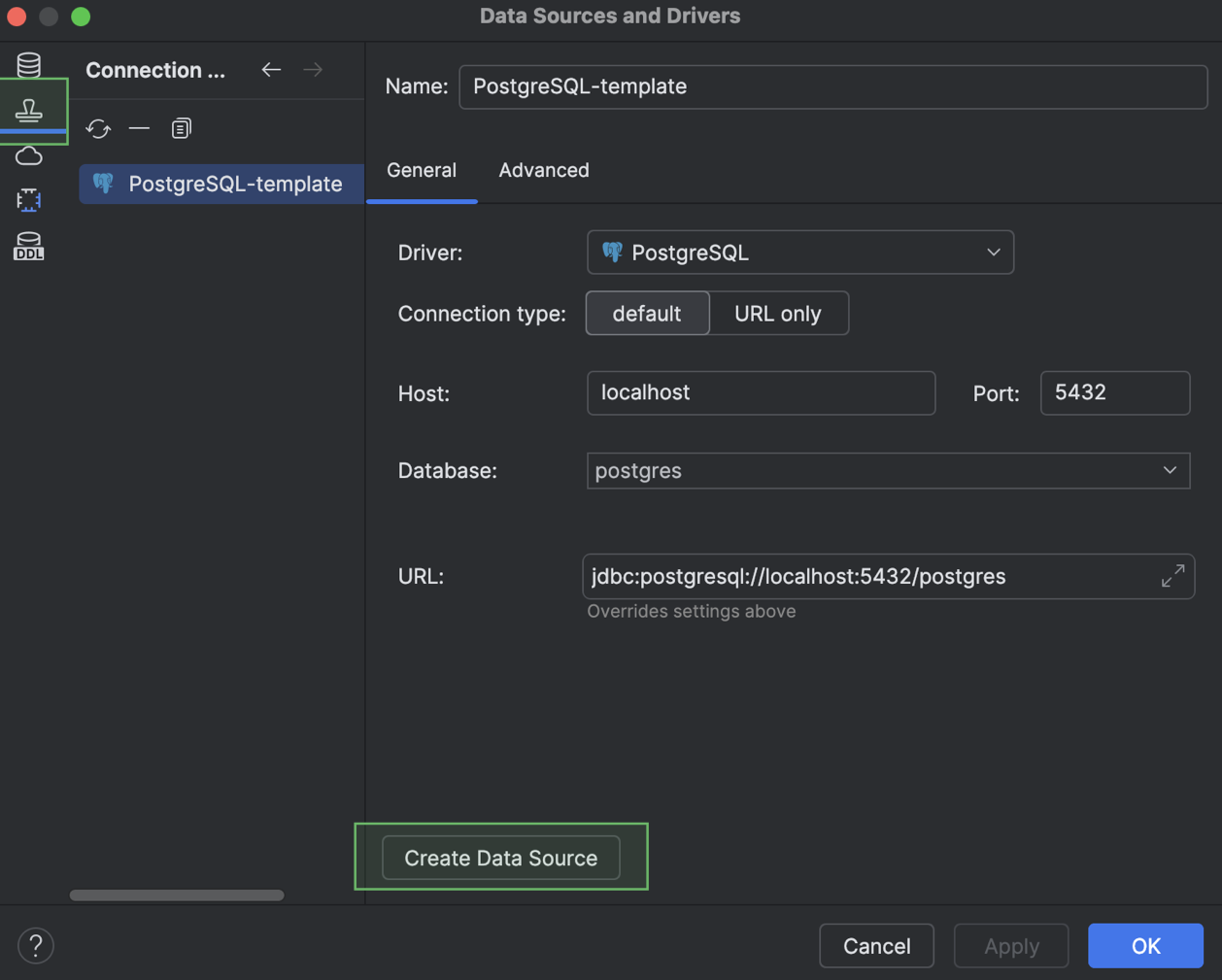
O novo modelo aparecerá na aba Data Source Templates. A qualquer momento, você pode criar uma nova fonte de dados que use esse modelo, através do botão Create Data Source.
Suporte ao PostgreSQL 18 PostgreSQL
Agora o DataGrip tem suporte ao PostgreSQL 18, lançado no ano passado. Esse suporte inclui os seguintes comandos e palavras-chave, dentre outros:
- Resolução de
OLDeNEWem cláusulasRETURNING. WITHOUT OVERLAPSem restrições primárias ou exclusivas.PERIODem restrições de chave estrangeira.GENERATED ALWAYS AS (...) [STORED | VIRTUAL]para colunas.- Restrições
NOT ENFORCEDeNOT VALID.
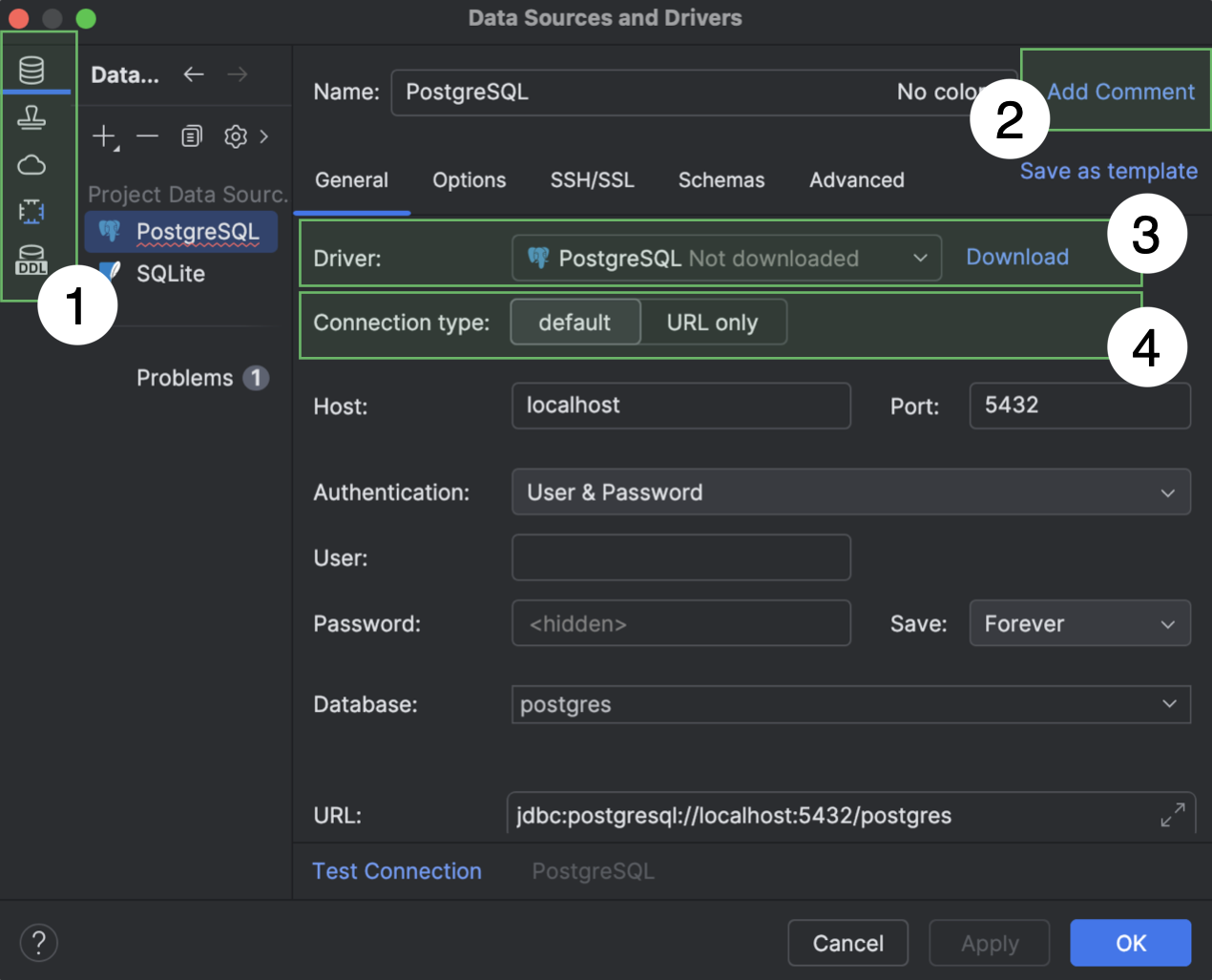
Melhorias no diálogo Data Sources and Drivers
Fizemos algumas mudanças no diálogo Data Sources and Drivers.
- Agora as seções Data Sources, Clouds, Drivers e DDL Mappings são as abas principais do diálogo e estão localizadas no lado esquerdo.
- Se o campo Comment estiver vazio, ficará oculto como padrão. Para mostrá-lo, clique em Add Comment, junto ao campo Name.
- Se o driver selecionado no menu suspenso Driver ainda precisar ser baixado, aparecerá a opção Download junto ao menu. Clique nessa opção para baixar o driver.
- As opções do menu suspenso Connection type foram convertidas em abas. Se uma fonte de dados tiver mais de três tipos de conexões, estes serão exibidos na forma de um menu suspenso.
Além disso, removemos a ação Create DDL Mapping. Você pode criar um mapeamento de DDL na aba principal DDL Mappings.
Fluxo de trabalho Explain Plan
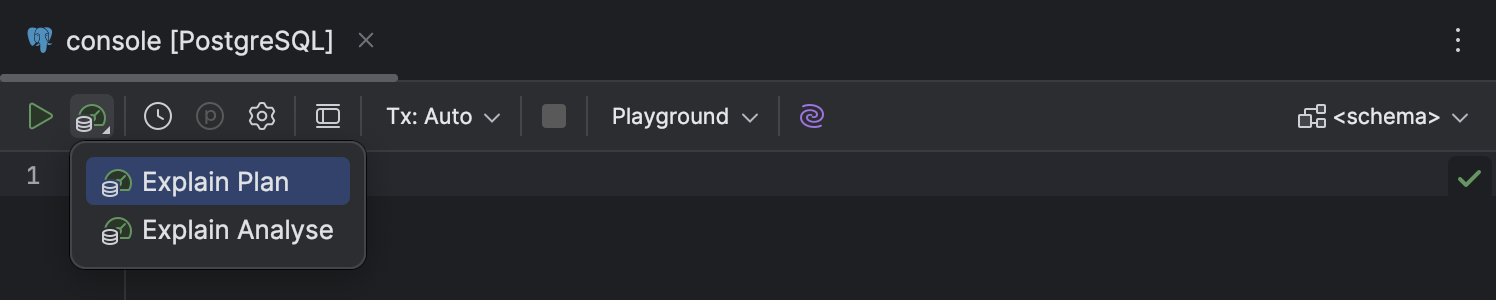
Melhorias na interface e na experiência do usuário
Fizemos algumas mudanças no fluxo de trabalho Explain Plan, para torná-lo mais informativo e mais fácil de descobrir e usar:
- O menu suspenso Explain Plan, na barra de ferramentas do editor de código, foi reduzido a apenas duas opções: Explain Plan e Explain Analyse.
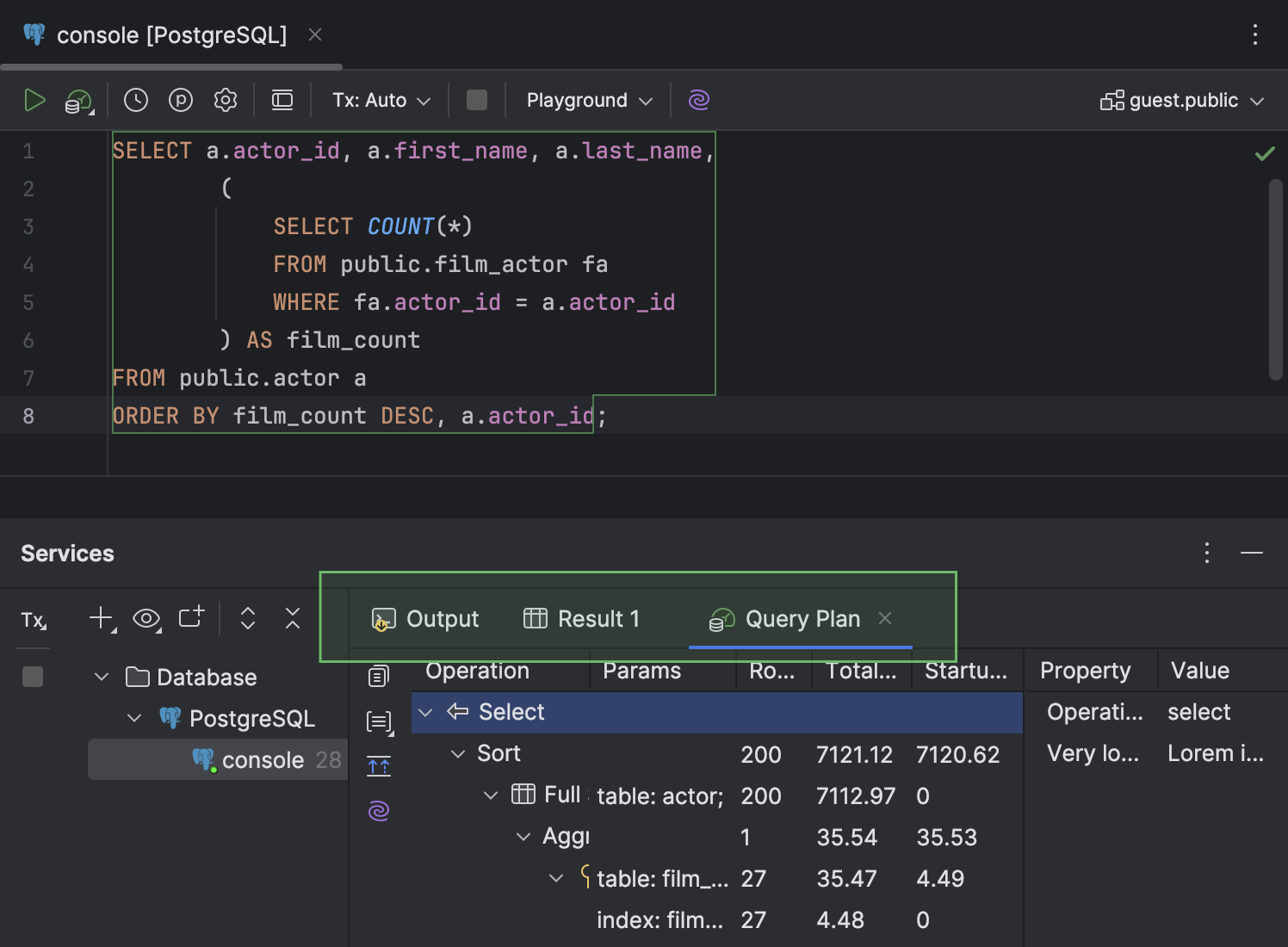
- Na janela de ferramentas Services, a aba Query Plan, que mostra o plano, foi movida para o mesmo nível das abas Output e Result. Essa aba também tem um novo ícone.
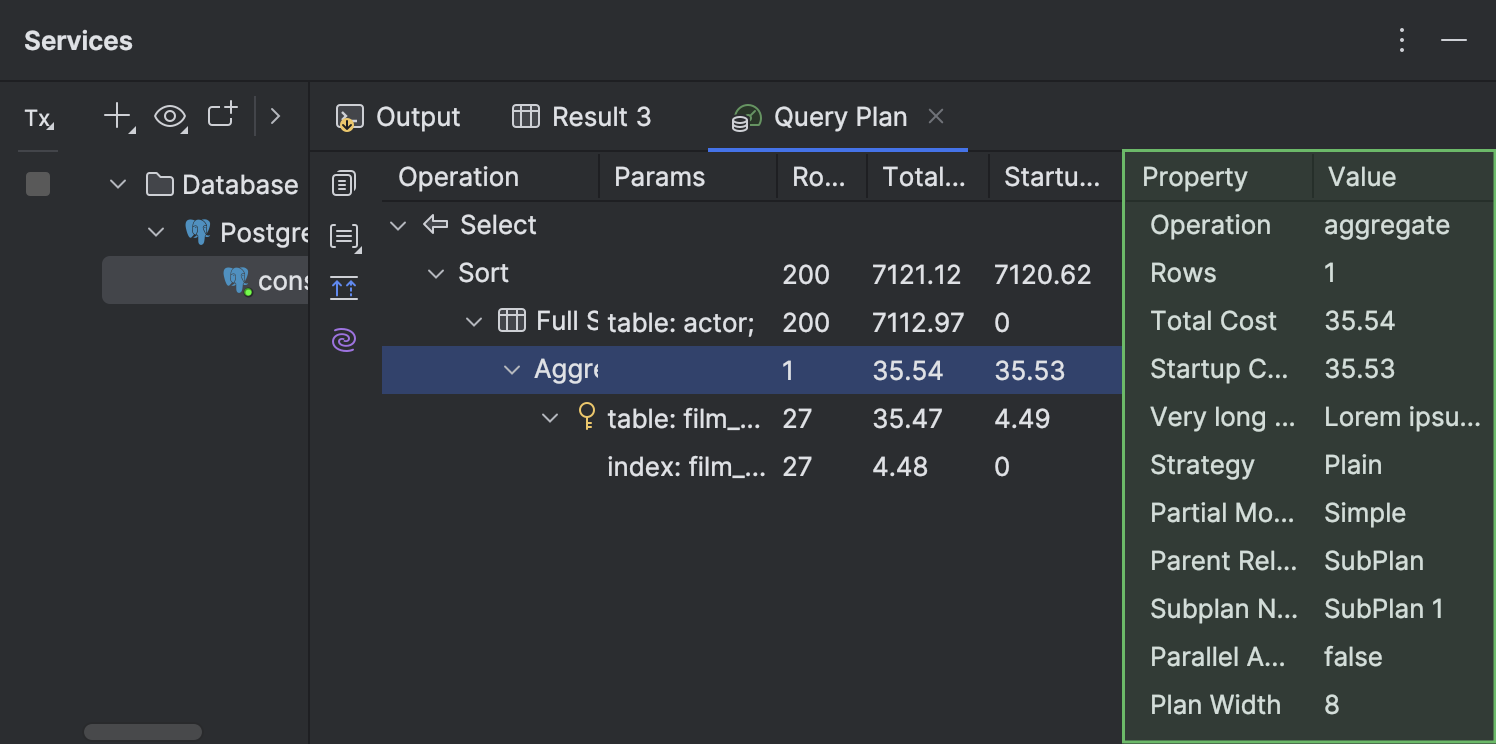
- Na aba Query Plan, agora você pode visualizar os dados de cada linha do plano em um painel separado, no lado direito da aba.
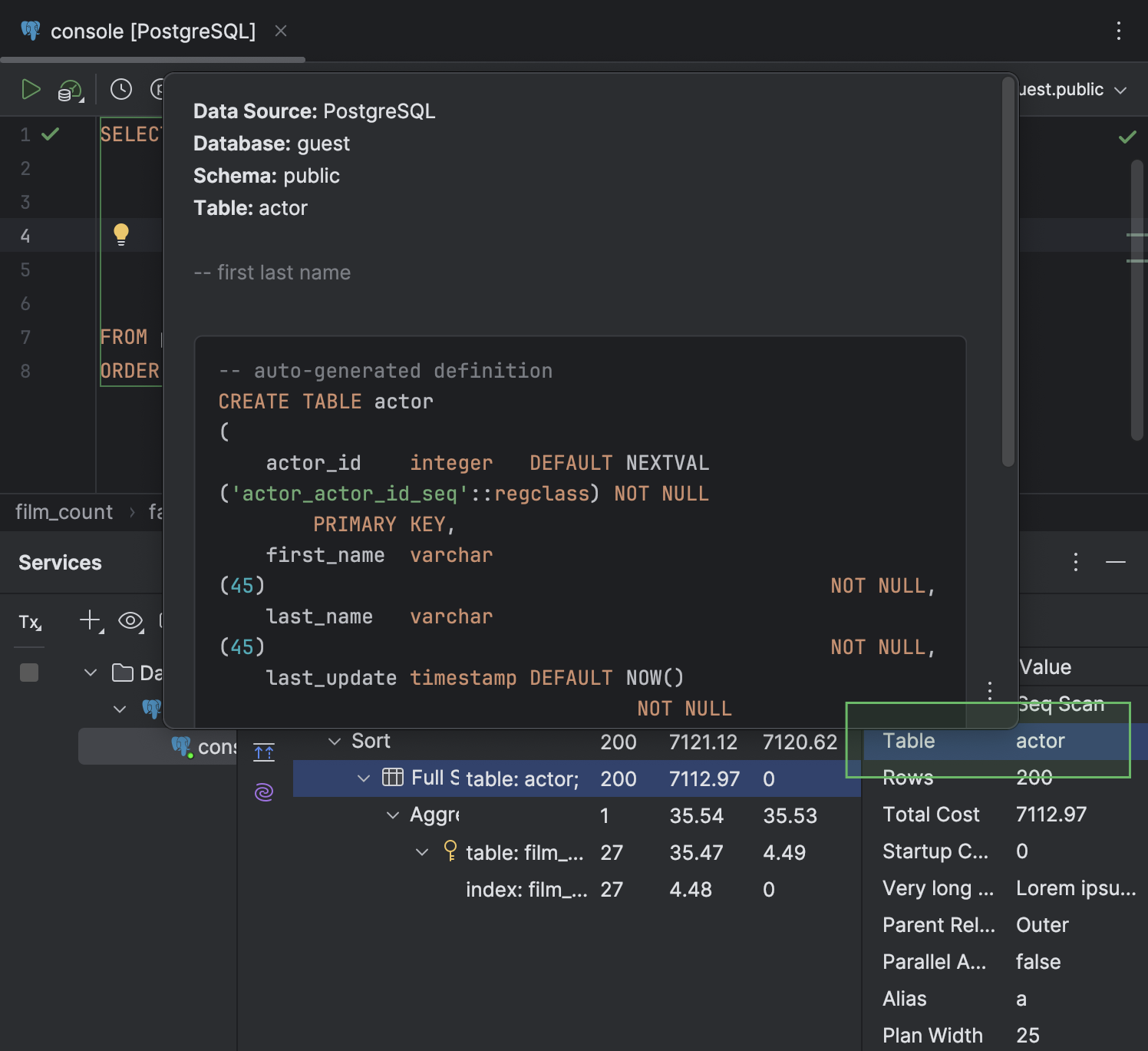
- Nas células que contiverem um nome de tabela, ao passar o cursor do mouse sobre a tabela, a documentação rápida fica disponível em um pop-up.
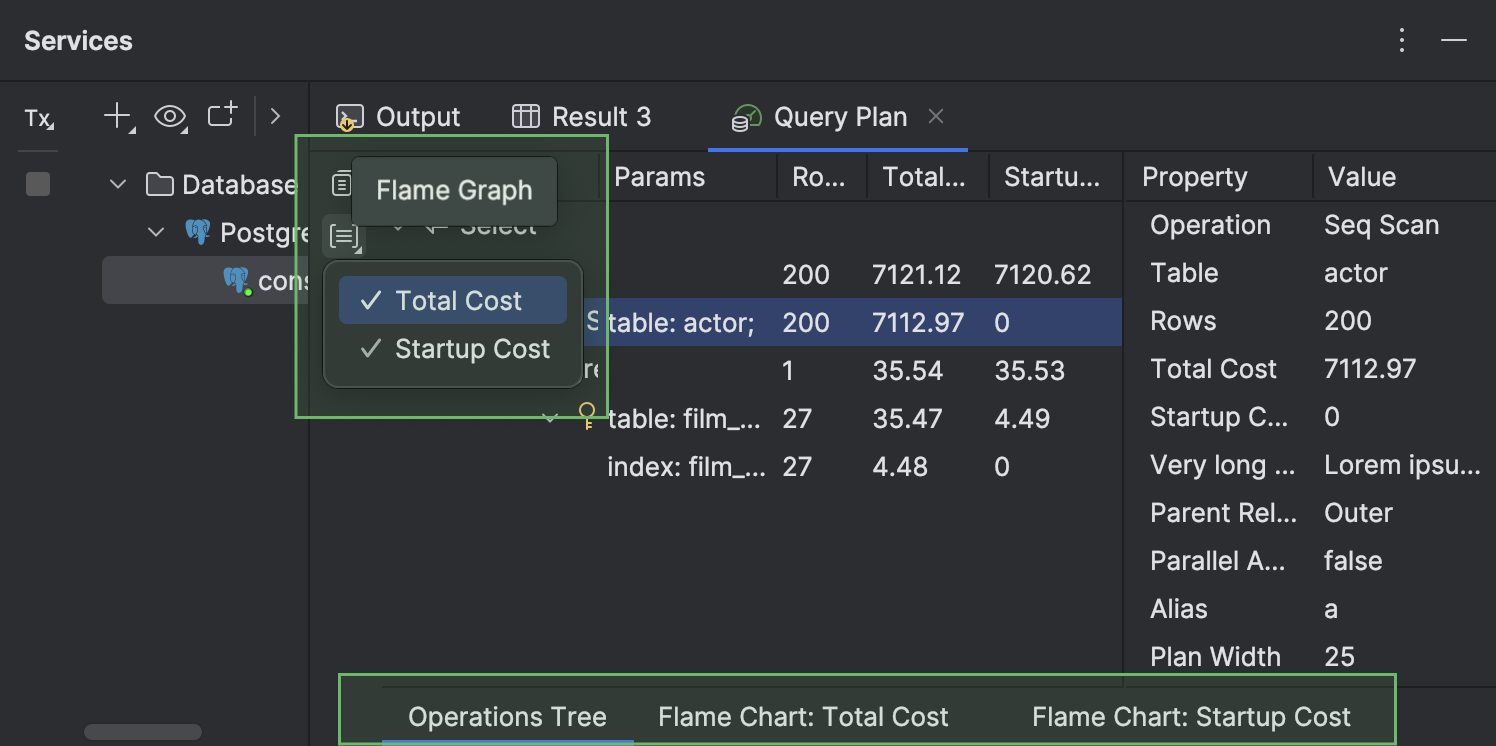
- As várias visualizações disponíveis para um plano de consulta são exibidas em abas internas separadas. Essas abas internas são encontradas no rodapé da aba Query Plan. Elas ficam ocultas como padrão e aparecem apenas quando mais de uma aba estiver aberta. Para abrir a aba Total Cost ou Startup Cost, clique em Flame Graph na barra de ferramentas da esquerda e selecione a visualização necessária.
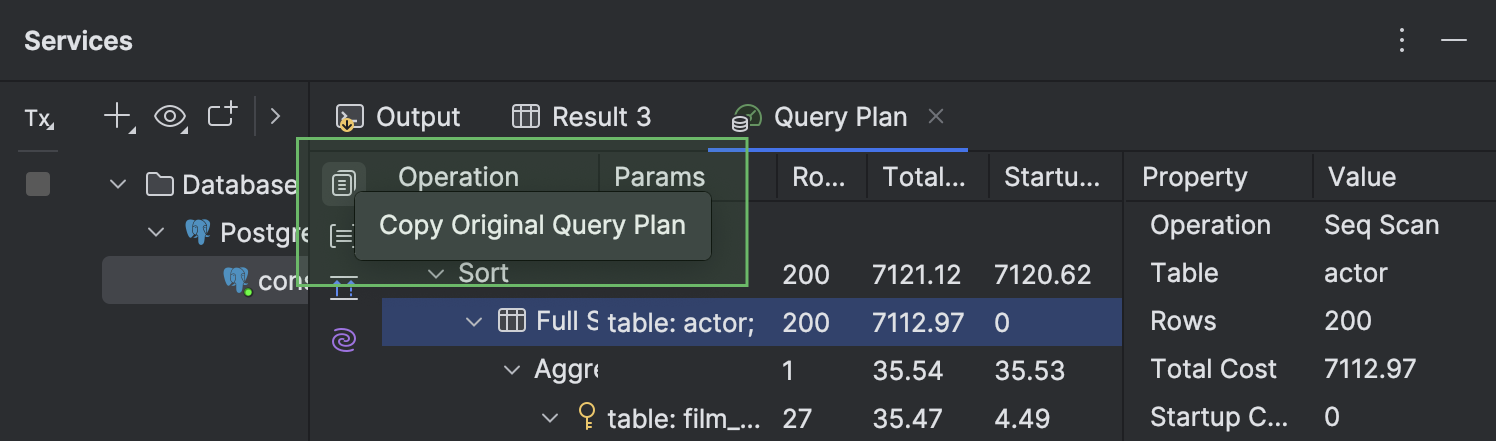
Opção para copiar um plano de consulta em seu formato nativo
Agora você pode copiar um plano de consulta no formato nativo do banco de dados, como JSON ou XML. Para isso, clique no botão Copy Original Query Plan, no alto da barra de ferramentas da esquerda. Este recurso tem suporte para PostgreSQL, Amazon Redshift, MySQL, MariaDB, Oracle, Microsoft SQL Server e Snowflake.
Editor de código
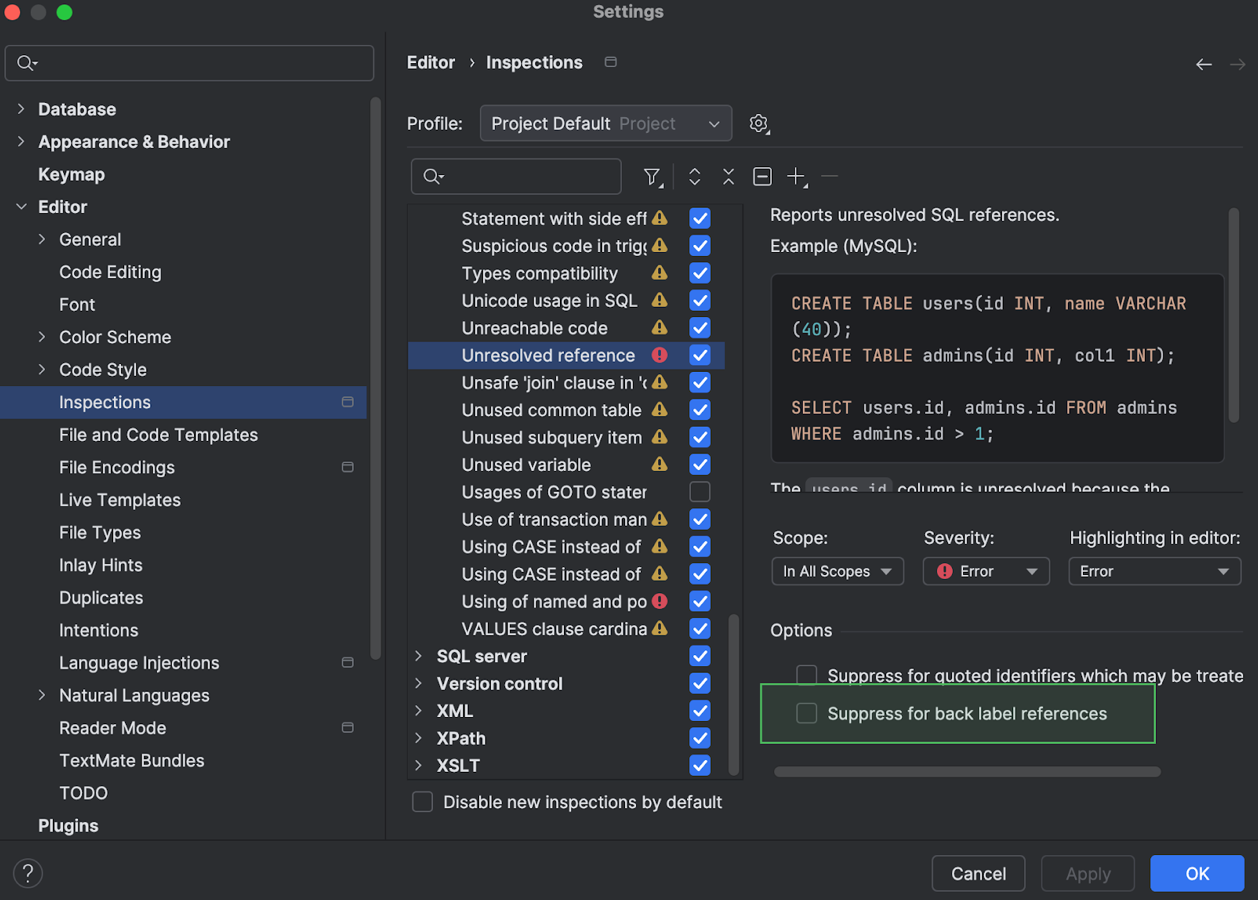
Opção "Suppress for back label references" em ações de intenção Oracle
Tornamos a opção Suppress for back label references mais fácil de encontrar e usar. Anteriormente, ela só estava disponível no diálogo Settings, sob Editor | Inspections | SQL.
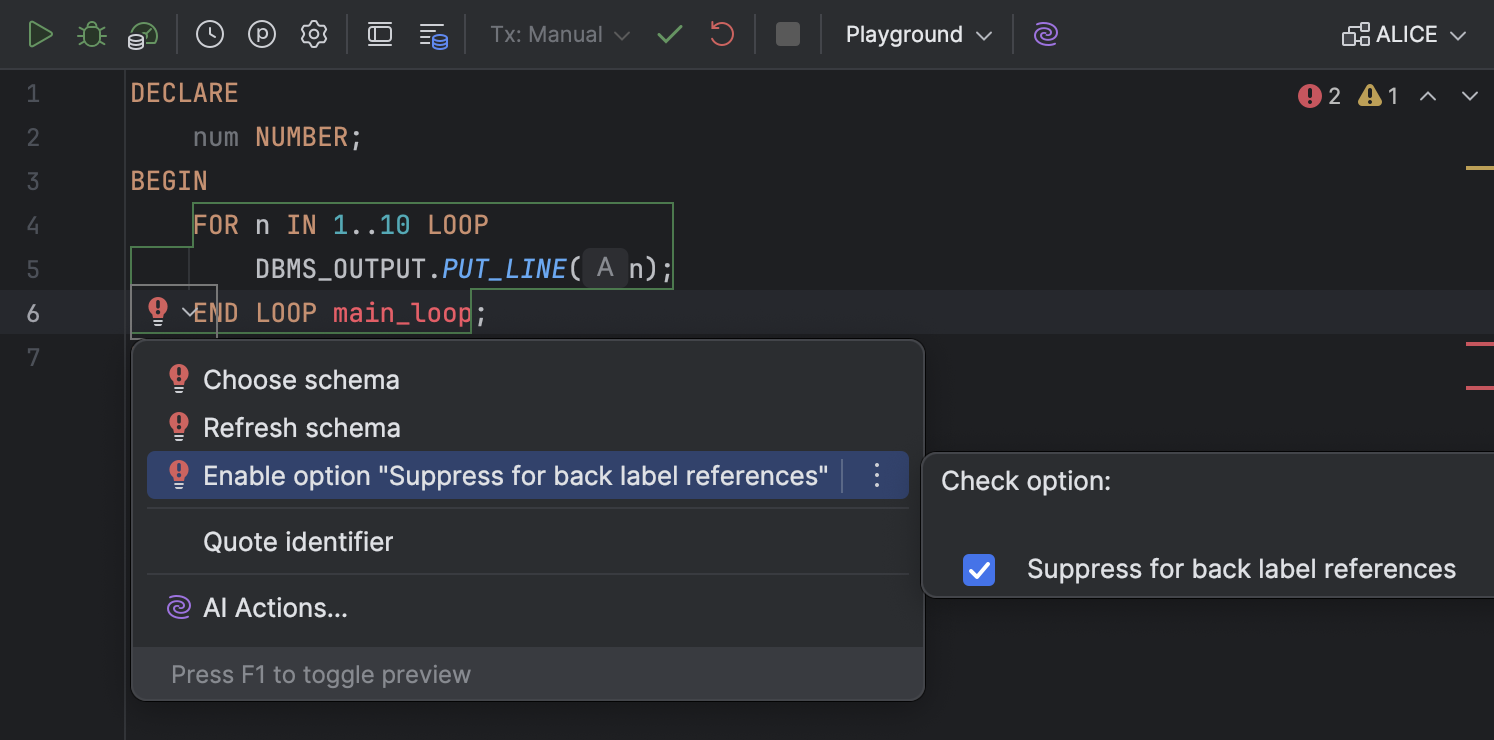
Agora ela pode ser ativada ou desativada em ações de intenção. Para isso, abra a lista de ações de intenção, teclando Alt+Enter (Windows/Linux) ou Option+Enter (macOS). Depois, navegue até Enable option "Suppress for back label references" e marque ou desmarque a caixa de opção Suppress for back label references.
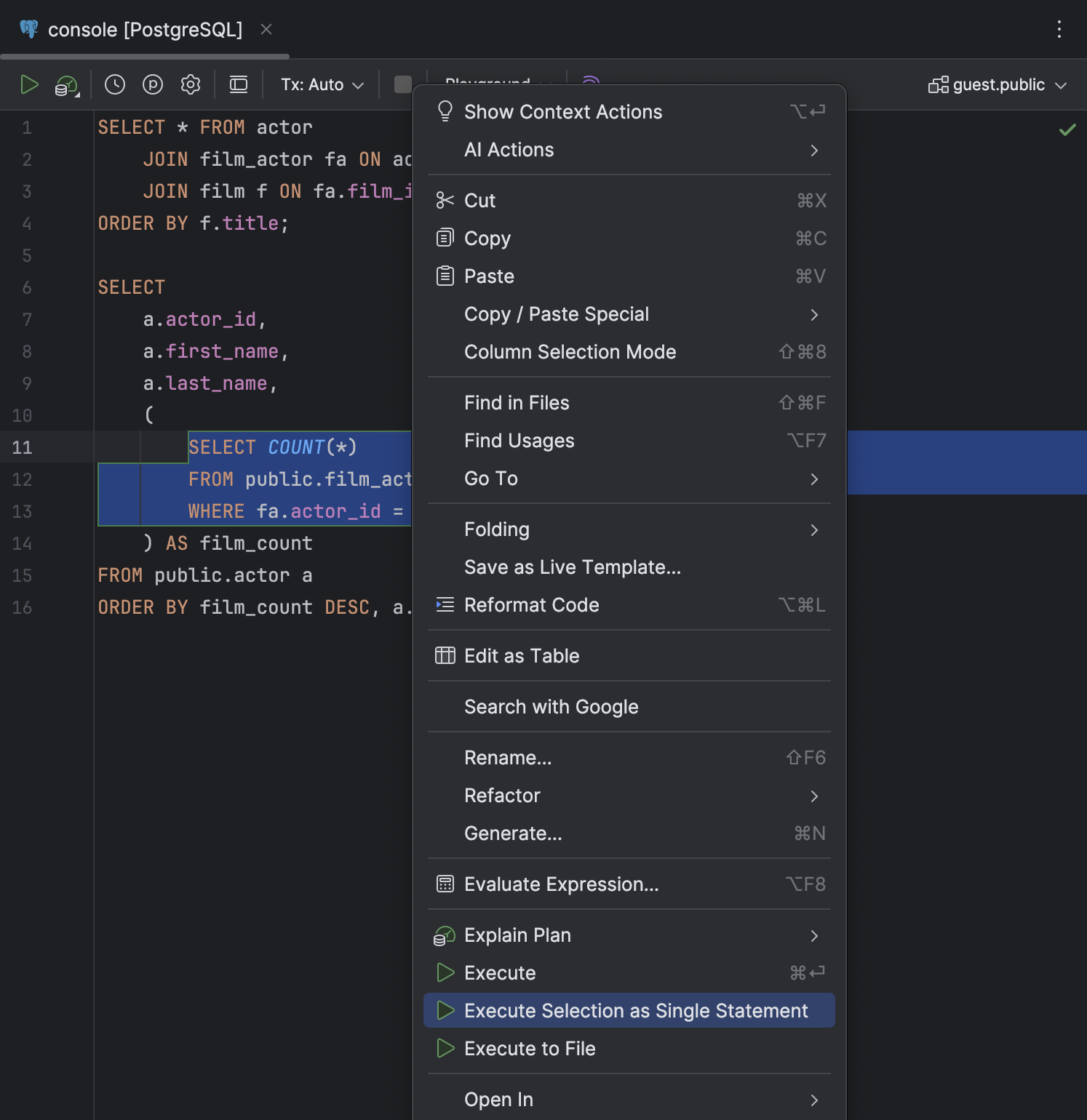
Ação Execute Selection as Single Statement no menu de contexto
Adicionamos a ação Execute Selection as Single Statement ao menu de contexto da seleção de código. Use-a quando você precisar executar um determinado bloco de código e o DataGrip não estiver analisando-o adequadamente.
Animação do movimento do cursor do editor
O cursor do editor de código ganhou duas novas opções de animações de movimento, para melhorar a sua experiência de digitação.
Entendemos que as preferências de animação variam muito. Pensando nisso, desenvolvemos cuidadosamente nosso próprio modo de movimento do cursor: o Snappy. Ele garante animações suaves, sem que o cursor pareça estar lento ou respondendo mal e sem sobrecarregar a interface com um excesso de ações. Neste modo, o cursor começa saltando rapidamente para sua nova posição, mas depois desacelera um pouco e "se ajusta" à posição. O resultado fica rápido, mas suave.
No outro modo de animação, Gliding, o cursor move-se suavemente, facilitando seguir visualmente os saltos. Este modo é semelhante aos que você encontra em outros editores de texto populares.
Para experimentar estes novos modos de animação, abra o diálogo Settings, navegue até Settings | Editor | General | Appearance, ative a opção Use smooth caret movement e selecione o modo que você deseja usar.
Trabalhando com dados
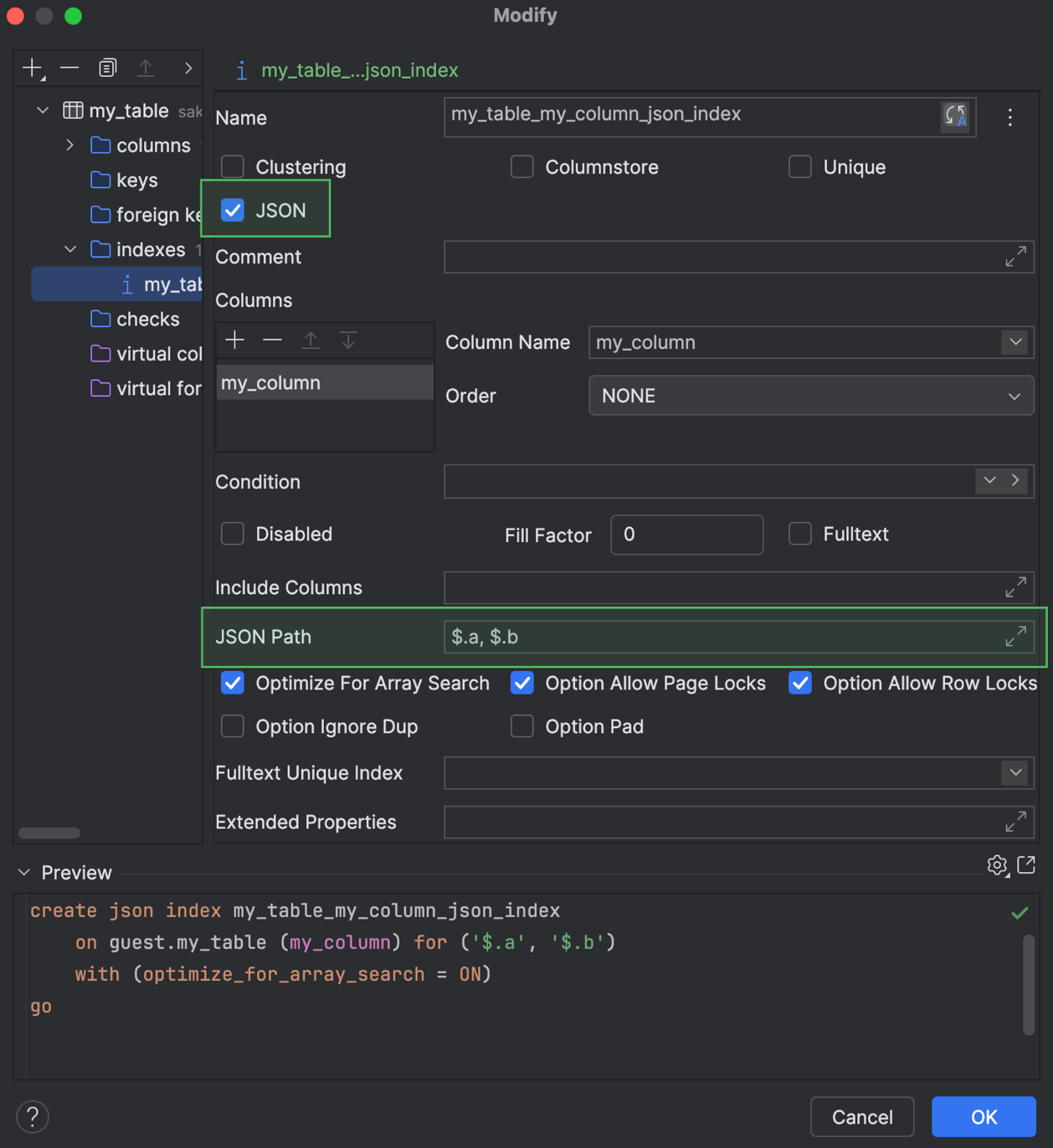
Suporte a índices JSON Microsoft SQL Server
Agora o DataGrip tem suporte à criação e modificação de índices JSON para o Microsoft SQL Server. Você pode trabalhar com eles na geração de código e também usá-los nos diálogos Create e Modify.
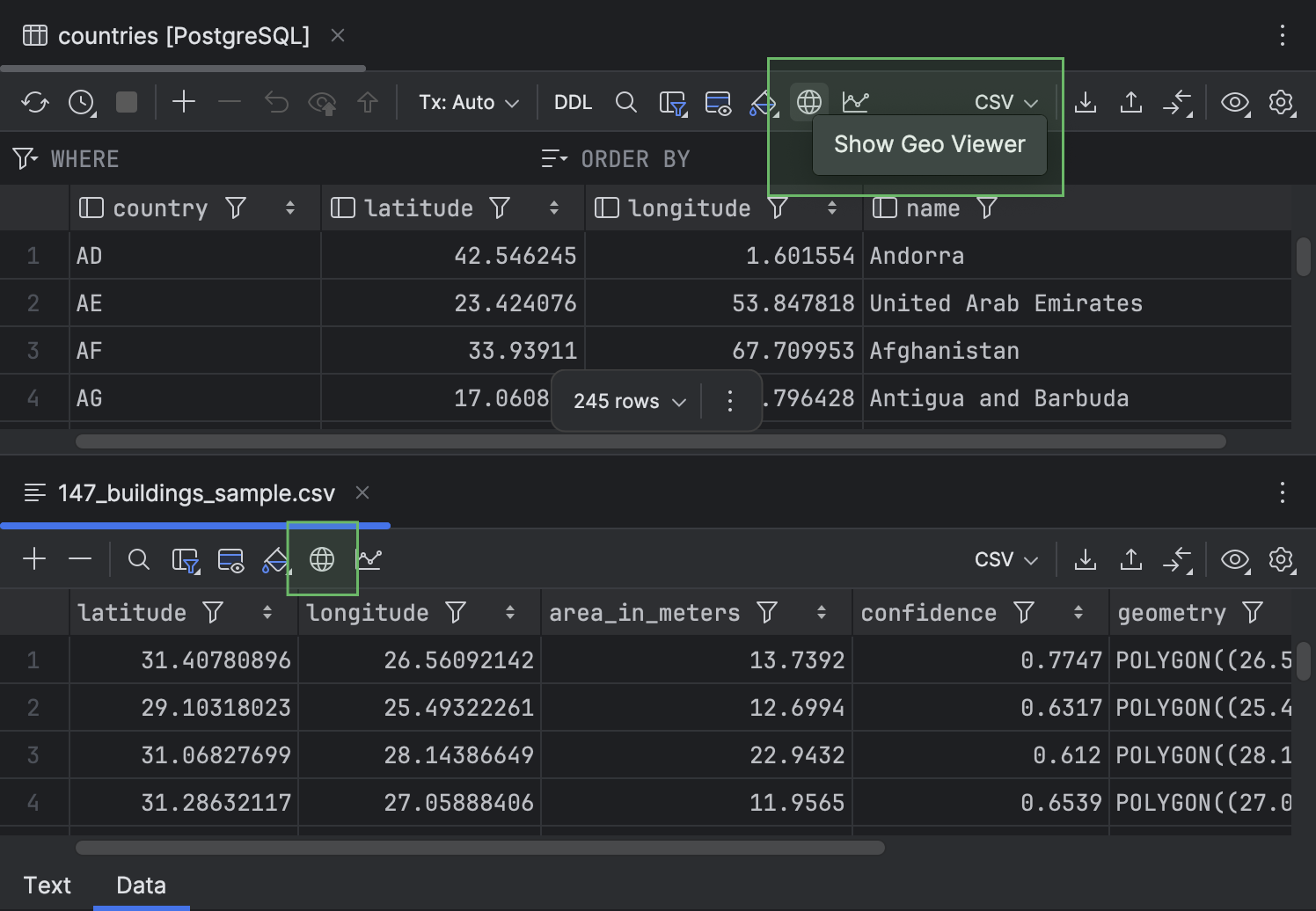
Botão Show Geo Viewer na barra de ferramentas
Para tornar o botão Show Geo Viewer mais fácil de ser descoberto, nós o movemos para a barra de ferramentas do editor de dados.
Trabalhar com arquivos
Arquivos excluídos vão para a lixeira como padrão
Anteriormente, quando ações Delete eram executadas, o DataGrip excluía os arquivos permanentemente, em vez de movê-los para a lixeira. Adicionamos uma configuração que, em vez disso, envia os arquivos para a lixeira. É a opção Move files to the bin instead of deleting permanently, que fica ativa como padrão.
Você pode mudar esta configuração em Settings | Appearance & Behavior | System Settings.
Esperamos que você aproveite ao máximo essas novidades! Se você encontrar um bug ou quiser enviar uma sugestão de recurso, use a funcionalidade de rastreador de issues do DataGrip.
Quer ficar por dentro das últimas novidades e receber dicas sobre como trabalhar com bancos de dados de maneira mais produtiva? Assine o blog do DataGrip e siga-nos no X!