Messen der CI/CD-Performance mit DevOps-Kennzahlen
Wie können Sie sicherstellen, dass Sie alle Vorteile von CI/CD ausschöpfen? Indem Sie die Performance Ihrer CI/CD-Pipeline erfassen, können Sie Ihren Prozess optimieren und den für das Unternehmen geschaffenen Wert belegen.

Die kontinuierliche Verbesserung zählt zu den Grundpfeilern der DevOps-Philosophie. Dieser Ansatz unterstützt Sie dabei, signifikante Änderungen nachhaltig umzusetzen. Die Strategie gilt nicht nur für das Produkt oder den Service, den Sie entwickeln, sondern auch für die Art und Weise, wie diese Entwicklung abläuft.
Wie der Name schon sagt, ist kontinuierliche Verbesserung ein fortlaufender Prozess, der verschiedene Aspekte umfasst:
- Erfassung und Analyse von Rückmeldungen zum Arbeitsergebnis oder zur Arbeitsweise.
- Erkennung von gut laufenden und verbesserungswürdigen Teilaspekten.
- Schrittweise Änderungen auf Grundlage dieser Erkenntnisse, um den Prozess weiter zu optimieren.
- Weitere Feedback-Erfassung, um zu überprüfen, ob die umgesetzten Änderungen gewirkt haben.
Es gehört zu den zentralen Vorteilen von CI/CD, dass es die kontinuierliche Verbesserung Ihrer Software erleichtert. Eine CI/CD-Pipeline hilft Ihnen, Releases häufiger zu veröffentlichen und regelmäßiges Feedback zu Ihrer Arbeit zu erhalten, sodass Sie fundierte Entscheidungen über Ihre nächsten Prioritäten treffen können.
Außerdem erleichtert das schnelle Feedback aus jeder Phase Ihres automatisierten Build- und Testablaufs die Behebung von Fehlern und die Verbesserung der Softwarequalität.
Damit sind jedoch die Möglichkeiten für kontinuierliche Verbesserung im CI/CD-Kontext noch nicht ausgereizt. Wenn Sie DevOps-Kennzahlen erfassen, können Sie die gleichen Techniken auch auf den CI/CD-Prozess selbst anwenden.
Warum sind DevOps-Kennzahlen wichtig?
Beim Erstaufbau einer CI/CD-Pipeline gibt es eine Menge zu tun, vom Schreiben automatisierter Tests bis hin zum automatischen Zurücksetzen Ihrer Vorproduktionsumgebungen. Wenn Sie auf der Suche nach Ideen sind, wie Sie diese Prozessphase optimieren können, lesen Sie unseren Best-Practices-Leitfaden für CI/CD.
Sobald Ihre automatisierte Pipeline eingerichtet ist, können Sie erkunden, wie sich der Betrieb noch effektiver gestalten lässt. In dieser Phase beginnt der Zyklus der kontinuierlichen Verbesserung – mithilfe der Kennzahlen Ihrer CI/CD-Pipeline.
Peter Drucker sagte einmal: „Was wir nicht messen, können wir auch nicht managen“. Statistische Daten sind für einen kontinuierlichen Verbesserungsprozess unerlässlich. Die Daten helfen Ihnen zu erkennen, wo Sie Mehrwert schaffen können, und bieten eine Basis, um die Auswirkungen der vorgenommenen Änderungen zu messen.
Durch die Überwachung wichtiger DevOps-Kennzahlen können Sie feststellen, was den größten Effekt auf die Leistung Ihrer CI/CD-Pipeline haben würde: die Ausweitung Ihrer Test-Coverage, die Verbesserung des Durchsatzes oder die Aufteilung von Entwicklungsaufgaben in kleinere Schritte.
Jedes Mal, wenn Sie eine Phase Ihrer CI/CD-Pipeline optimieren, verstärken Sie die Wirkung dieser Feedbackschleife. Durch diese Optimierungen können Sie Releases häufiger veröffentlichen und gleichzeitig die Qualität gewährleisten und die Fehlerquote niedrig halten.
Häufigere Releases eröffnen Ihnen die Möglichkeit, wichtige Funktionen zu verbessern, Ihre Annahmen mit Experimenten zu validieren und jegliche Probleme sofort anzugehen. Bei Marktveränderungen und Nachfrageverschiebungen können Sie schnell reagieren und so mit der Konkurrenz mithalten oder ihr sogar enteilen.
Darüber hinaus bietet die Überwachung Ihrer CI/CD-Kennzahlen eine hervorragende Möglichkeit, den Wert Ihrer Pipeline für das gesamte Unternehmen – einschließlich Stakeholder und andere Entwicklungsteams – zu demonstrieren.
Allgemeine DevOps-Performancekennzahlen
Das DORA-Team von Google (das Kürzel steht für DevOps Research and Assessment) hat die folgenden vier allgemeinen Kennzahlen identifiziert, die die Performance von Software-Entwicklungsteams präzise abbilden.
Mehr über die Forschungsaktivitäten, die diesen Entscheidungen zugrunde liegen, erfahren Sie im Buch Accelerate von Nicole Forsgren, Jez Humble und Gene Kim.
Deployment-Häufigkeit
Die Deployment-Häufigkeit gibt an, wie oft Sie mithilfe Ihrer CI/CD-Pipeline Ihre Software für den Produktiveinsatz bereitstellen. Die Deployment-Häufigkeit wurde von DORA als Näherungsvariable für die Batchgröße ausgewählt, da eine hohe Deployment-Häufigkeit weniger Änderungen pro Deployment bedeutet.
Das Deployment einer geringeren Anzahl von Änderungen senkt das mit dem Release verknüpfte Risiko, da es weniger Variablen gibt, deren Zusammenwirken zu unerwarteten Ergebnissen führen kann. Häufigere Deployments geben außerdem ein direkteres Feedback zu Ihrer Arbeit.
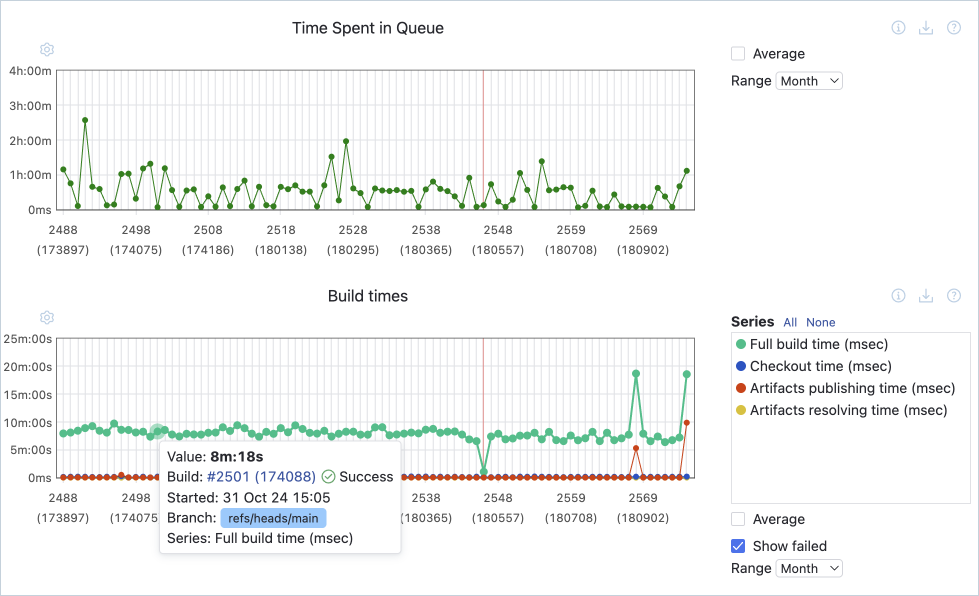
Eine niedrige Deployment-Häufigkeit kann ein Hinweis darauf sein, dass die Pipeline nicht mit regelmäßigen Commits gefüttert wird – vielleicht weil Sie die Aufgaben nicht in ausreichend kleine Stücke aufteilen. Der Aufbau einer DevOps-Kultur, in der die Vorteile von CI/CD allen Teammitgliedern bewusst sind, kann helfen, Ihr Team an die Arbeit in kleineren Schritten zu gewöhnen.
Manchmal resultiert eine niedrige Deployment-Häufigkeit auch aus der Bündelung von Änderungen in größere Releases im Rahmen einer Continuous-Deployment-Strategie. Wenn Sie Änderungen aus geschäftlichen Gründen (z. B. aufgrund der Benutzererwartungen) gebündelt vornehmen müssen, sollten Sie stattdessen die Häufigkeit von Staging-Deployments messen.
Vorlaufzeit
Die Vorlaufzeit (auch Bereitstellungszeit, Markteinführungszeit, Time to Delivery oder Time to Market genannt) ist die Zeit vom Beginn der Arbeit an einer Funktion bis zu ihrer Bereitstellung an die Benutzer*innen. Der Zeitaufwand für Ideenfindung, Benutzerforschung und Prototyping kann jedoch enorm variieren.
Aus diesem Grund misst DORA die Zeit vom letzten Code-Commit bis zum Deployment. Dieser Zeitrahmen ermöglicht es Ihnen, sich auf die Phasen Ihrer CI/CD-Pipeline zu konzentrieren.
Eine lange Vorlaufzeit bedeutet, dass Sie Ihre Benutzer*innen nicht regelmäßig mit Codeänderungen versorgen können. Daher stehen Ihnen Nutzungsstatistiken und andere Feedback-Arten nicht für die Produktoptimierung zur Verfügung.
Längere Vorlaufzeiten treten vor allem bei Pipelines mit vielen manuellen Schritten auf. Dabei kann es sich um eine große Anzahl von manuellen Tests oder um einen Deployment-Prozess handeln, bei dem die Umgebungen manuell zurückgesetzt werden müssen.
Durch Investitionen in automatisierte Tests und einen CI-Server zur Koordinierung von Build-, Test- und Deployment-Aufgaben kann die Bereitstellungszeit von Software verkürzt werden. Gleichzeitig können Sie mit einem CI-Server Kennzahlen erfassen, die die Rendite Ihrer Investitionen belegen.
Angenommen, Sie haben bereits mit der Automatisierung Ihres CI/CD-Prozesses begonnen, aber die einzelnen Schritte sind langsam oder unzuverlässig. In diesem Fall können Sie anhand der Kennzahlen zur Builddauer die vorhandenen Engpässe ermitteln.
Wenn Ihre Unternehmensrichtlinien vor jedem Release Risikobewertungen oder Change-Review-Boards vorschreiben, kann dies jedes Deployment um Tage oder Wochen verzögern. Wenn Sie die Zuverlässigkeit des Prozesses durch Kennzahlen nachweisen, kann dies das Vertrauen der Stakeholder stärken und sie dazu bewegen, auf solche manuelle Genehmigungsschritte zu verzichten.
Ausfallrate von Änderungen
Die Änderungsausfallrate bezeichnet den Anteil der in die Produktion übernommenen Änderungen, die zu Ausfällen oder Fehlern führen und entweder ein Rollback oder einen Hotfix erfordern. Probleme, die vor der Übernahme von Codeänderungen in die Produktion entdeckt werden, sind darin nicht enthalten.
Der Vorteil dieser Kennzahl besteht darin, dass fehlgeschlagene Bereitstellungen in den Kontext des Änderungsumfangs gestellt werden. Eine niedrige Änderungsausfallrate gibt Ihnen Vertrauen in Ihre Pipeline. Sie ist ein Hinweis darauf, dass die vorgeschalteten Phasen wie vorgesehen funktionieren und die meisten Fehler abfangen, bevor Ihr Code veröffentlicht wird.
Wenn Ihre Änderungsausfallrate hoch ist, ist es an der Zeit, die Coverage Ihrer automatisierten Tests zu überprüfen. Decken Ihre Tests die häufigsten Anwendungsfälle ab? Sind Ihre Tests zuverlässig? Können Sie Ihr Testprogramm durch automatisierte Performance- oder Sicherheitstests erweitern?
Mittlere Wiederherstellungszeit
Die mittlere Wiederherstellungszeit (mean time to recovery/resolution, MTTR) gibt die Zeit an, die benötigt wird, um einen Ausfall in der Produktion zu beheben. Mit dieser Maßzahl erkennen wir an, dass in einem komplexen System mit vielen Variablen gelegentliche Ausfälle in der Produktion unvermeidlich sind. Anstatt nach Perfektion zu streben (und auf die Vorteile häufiger Releases zu verzichten), legen Sie den Schwerpunkt darauf, wie Sie schnell auf Probleme reagieren können.
Um die MTTR niedrig zu halten, ist eine proaktive Produktionsüberwachung erforderlich, die Alarm schlägt, sobald ein Problem auftritt. Außerdem müssen Sie in der Lage sein, Änderungen zurückzunehmen oder Hotfixes über die Pipeline zu verteilen.
Eine verwandte Kennzahl ist die mittlere Erkennungszeit (mean time to detection, MTTD). Sie misst die Zeit zwischen der Bereitstellung einer Änderung und der Erkennung eines durch diese Änderung verursachten Problems durch Ihr Überwachungssystem. Indem Sie MTTD und Builddauer vergleichen, können Sie ermitteln, ob Investitionen zur Reduzierung der MTTR einem der beiden Bereiche zugutekommen könnten.
Operative und CI-Kennzahlen
Neben der Erfassung allgemeiner Kennzahlen können Sie eine Reihe von operativen und CI-bezogenen Kennzahlen verwenden, um die Leistung Ihrer Pipeline zu verbessern und Verbesserungsmöglichkeiten zu erkennen.
Code-Coverage
Automatisierte Tests in einer CI/CD-Pipeline sollten den größten Teil Ihrer Test-Coverage ausmachen. Die erste automatisierte Testebene sollte Unit-Tests enthalten, da diese am schnellsten ausgeführt werden und unmittelbares Feedback bieten.
Die Code-Coverage ist eine Kennzahl, die von den meisten CI-Servern berechnet wird und den Anteil des Codes angibt, der von Ihren Unit-Tests abgedeckt wird. Es lohnt sich, diesen Wert zu beobachten, um sicherzustellen, dass Sie beim Schreiben von neuem Code eine angemessene Testabdeckung aufrechterhalten. Wenn Ihre Code-Coverage im Laufe der Zeit nach unten tendiert, ist es an der Zeit, etwas Arbeit in diese erste Feedback-Schleife zu investieren.
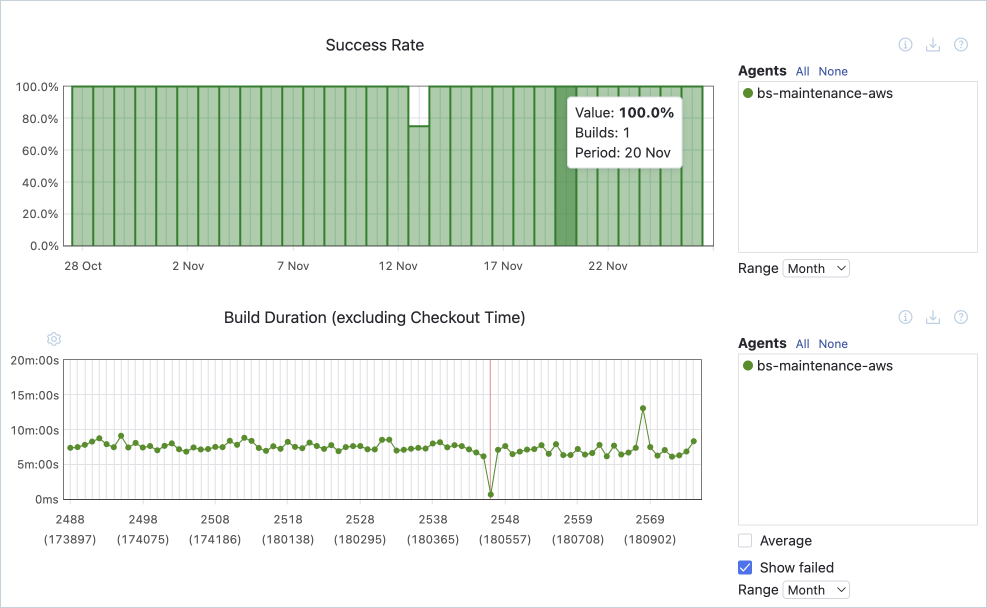
Builddauer
Die Builddauer gibt die Zeit an, die benötigt wird, um die verschiedenen Phasen der automatisierten Pipeline zu durchlaufen. Die Analyse des Zeitaufwands in jeder Prozessphase hilft dabei, Problempunkte oder Engpässe zu erkennen, die dazu führen können, dass es länger dauert, Testergebnisse zu erhalten oder Updates für die Produktion freizugeben.
Erfolgsrate von Tests
Die Testerfolgsrate ist der Prozentsatz der Testfälle, die bei einem bestimmten Build erfolgreich bestanden wurden. Ein angemessenes Maß an Testautomatisierung vorausgesetzt, zeigt dieser Wert die Qualität jedes Builds an. Anhand der Daten können Sie nachvollziehen, wie oft Codeänderungen neue Fehler verursachen.
Auch wenn das Erkennen von Fehlern mittels automatisierter Tests manuellen Tests oder Fehlern in der Produktion vorzuziehen ist, sollten Sie Ursachenforschung betreiben, wenn ein bestimmter automatisierter Test regelmäßig fehlschlägt.
Behebungszeit von Testfehlern
Die Testfehler-Behebungszeit ist die Zeit zwischen dem Auftreten eines Testfehlers bei einem Buildvorgang und dem Bestehen desselben Tests durch einen nachfolgenden Build. Diese Kennzahl ist ein Hinweis darauf, wie schnell Sie auf Probleme reagieren können, die in der Pipeline identifiziert wurden.
Eine kurze Behebungszeit zeigt, dass Sie Ihre Pipeline effektiv nutzen. Es ist effizienter, Probleme sofort nach ihrer Erkennung zu beheben, da die Änderungen noch frisch in Ihrem Gedächtnis sind. Indem Sie Probleme schnell beheben, stellen Sie auch sicher, dass Sie und andere Teammitglieder nicht weitere Funktionen auf instabilen Code aufbauen.
Fehlgeschlagene Deployments
Fehlgeschlagene Deployments führen zu ungeplanten Ausfallzeiten und erfordern ein Rollback des Deployments oder die Installation von Hotfixes. Die Anzahl der fehlgeschlagenen Bereitstellungen wird zur Berechnung der Änderungsausfallrate verwendet.
Die Überwachung des Ausfallanteils an der Gesamtzahl der Bereitstellungen hilft dabei, Ihre Leistung zu SLAs in Bezug zu setzen.
Denken Sie jedoch daran, dass ein Ziel von null (oder nahezu null) fehlgeschlagenen Deployments nicht unbedingt realistisch ist und Teams dazu verleiten kann, absolute Sicherheit zu priorisieren, statt konsequent ein Qualitätsprodukt zu liefern. Diese Denkweise kann zu längeren Vorlaufzeiten und größeren Deployments führen, da Änderungen gebündelt werden. Da größere Deployments eine größere Anzahl von Variablen enthalten, steigt die Wahrscheinlichkeit von Fehlern in der Produktion, die schwieriger zu beheben sind (da mehr Änderungen zu überprüfen sind).
Defektanzahl
Im Gegensatz zur Anzahl fehlgeschlagener Deployments bezieht sich die Defektanzahl auf die Anzahl der offenen Tickets in Ihrem Backlog, die als Fehler klassifiziert sind. Diese CI-Kennzahl kann weiter unterteilt werden, je nachdem, ob ein Problem beim Testen, beim Staging oder in der Produktion aufgetreten ist.
Wenn Sie die Defektanzahl überwachen, können Sie einen allgemeinen Aufwärtstrend erkennen, der darauf hindeutet, dass die Bugs außer Kontrolle geraten könnten. Zu bedenken ist dabei jedoch, dass diese Kennzahl Teams dazu verleiten kann, sich mehr um die Klassifizierung von Tickets zu kümmern als um deren Behebung.
Deployment-Größe
Als Pendant zur Deployment-Häufigkeit kann die Deployment-Größe – angegeben durch die Anzahl der Story Points, die in einem Build oder Release enthalten sind – verwendet werden, um die Batchgröße innerhalb eines Teams im Auge zu behalten.
Kleine Deployments zeigen, dass Ihr Team regelmäßige Commits vornimmt – mit allen damit verbundenen Vorteilen. Da jedoch Story-Schätzungen unterschiedlicher Entwicklungsteams nicht miteinander vergleichbar sind, sollte dieser Wert nicht verwendet werden, um die Gesamtgröße von Deployments zu messen.
Fazit
Diese DevOps-Kennzahlen helfen Ihnen zu verstehen, wie gut Ihre CI/CD-Pipeline in Bezug auf die Deployment-Geschwindigkeit und die Softwarequalität funktioniert.
Indem Sie diese Kennzahlen beobachten, können Sie die Prozessbereiche identifizieren, die Ihre Aufmerksamkeit am dringendsten benötigen. Überwachen Sie nach Änderungen die entsprechenden Kennzahlen weiter, um zu überprüfen, ob die Änderungen die beabsichtigte Wirkung entfalten.
Kennzahlen sind zwar nützliche Leistungsindikatoren, aber es ist wichtig, die Zahlen im Kontext zu lesen und auch mal zu überlegen, welche Verhaltensweisen durch eine bestimmte Kennzahl gefördert werden.
Denken Sie daran: Das Ziel sind nicht die Zahlen selbst, sondern eine schnelle und zuverlässige Pipeline, die Ihnen hilft, Ihrer Benutzergemeinde einen kontinuierlichen Mehrwert zu bieten und damit zum Erreichen der Unternehmensziele beizutragen.