Measure CI/CD Performance With DevOps Metrics
A CI server or “build server” coordinates all the steps in a CI/CD process, from monitoring your VCS for changes to deploying new builds.

Using a CI server can help you to streamline your continuous integration and delivery/deployment (CI/CD) processes. A CI server is responsible for monitoring your version control system (VCS), triggering automated build, test, and deployment tasks, collating the results, and initiating the next stage of the pipeline.
While it’s possible to practice CI/CD without a build server, many development teams choose to use a CI tool to coordinate the process and communicate the results of each step. In this guide, we’ll look at what a CI server does and how it can help you get the most out of CI/CD.
Why use a CI server?
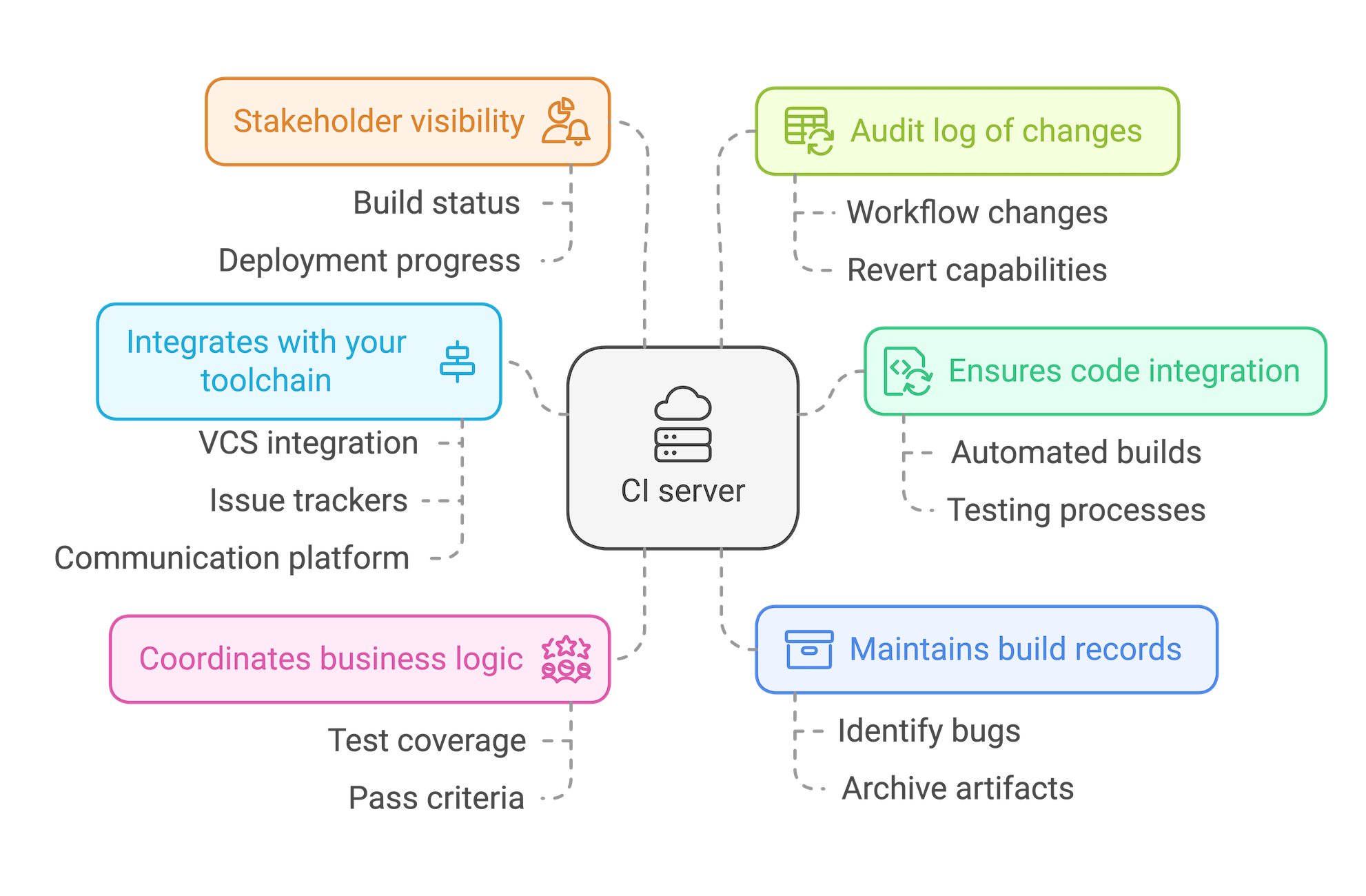
A CI server acts as a central point for coordinating all of your CI/CD activities. Using a CI server:
- Ensures every commit goes through CI/CD: By integrating with your VCS, a CI server ensures all code changes are put through your automated build, test, and deployment process – no additional effort is required by individual developers.
- Allows you to coordinate your business logic: From the level of test coverage you want to enforce to what constitutes a “pass” for each stage of the automated testing process, a CI server provides a single source of truth for your organization’s requirements.
- Integrates with your toolchain: As well as your VCS and build tools, a CI server can integrate with issue trackers and communications platforms to provide automated updates from the build, test, and deployment process.
- Maintains a record of past builds: Having an archive of build artifacts is invaluable when you need to identify the point at which a particularly subtle bug made it into your codebase.
- Gives stakeholders visibility of release progress: As a central source of truth for the status of builds and deployments, you can use your CI server to keep the wider organization informed on progress.
- Provides an audit log of changes: It’s likely your workflow and business logic will evolve over time. Using a CI server can provide you with a record of how your CI/CD process has changed, just in case you ever want to revert to an earlier implementation.
In turn, using a CI server will help you leverage the many benefits of CI/CD, including rapid feedback on your code changes, early bug identification, and more frequent releases.
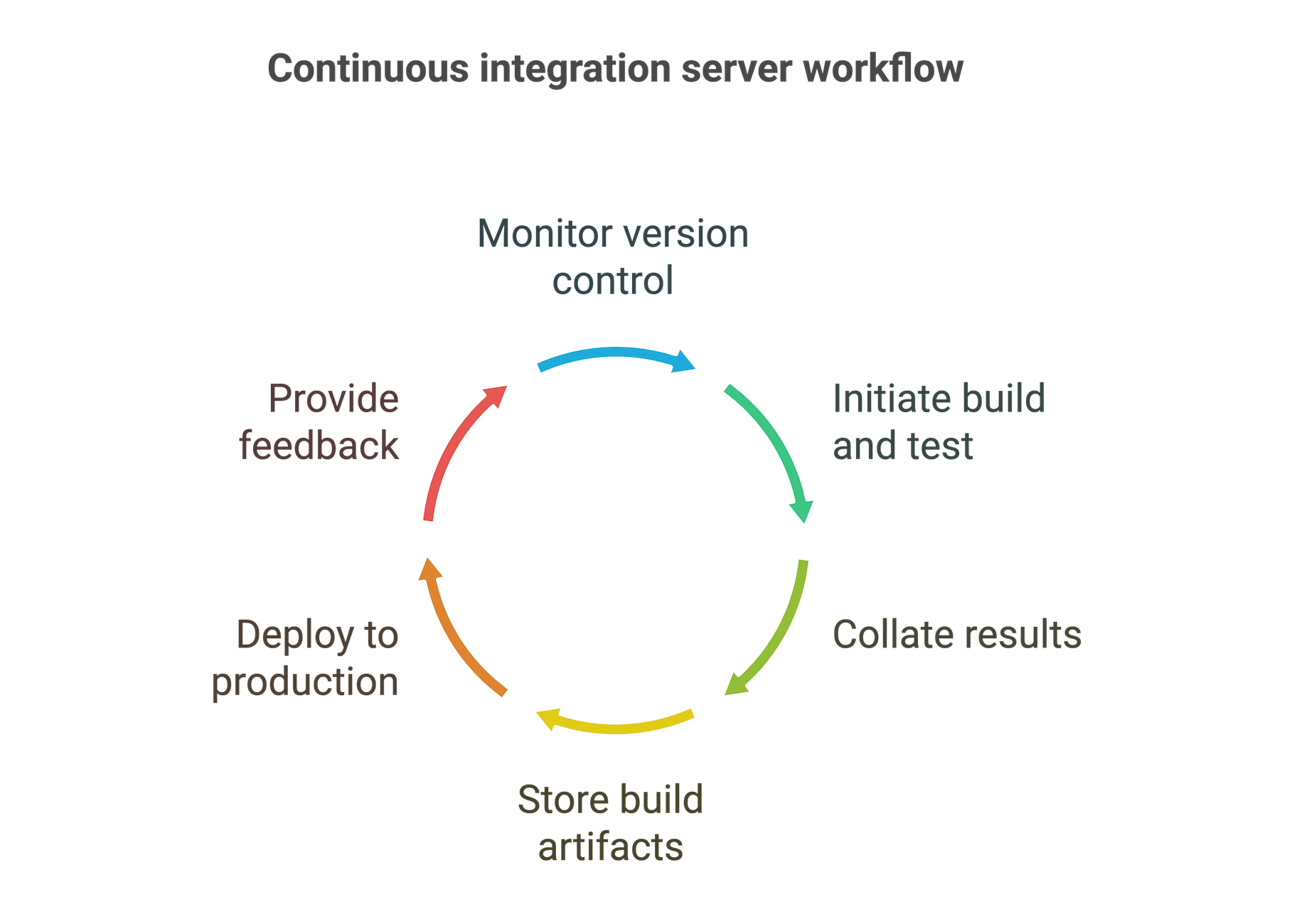
How does a CI server work?
Although the exact process will vary according to your team and organizational requirements, a CI server typically performs the following steps:
- Integrates with your version control system and monitors it for commits to the relevant branches.
- Initiates a series of build and test tasks each time a change is committed. These are either distributed to other machines in your build farm or run on the CI server itself.
- Collates the results of those tasks and uses that data to determine whether to proceed to the next stage of the process.
- Stores the build artifacts in a central archive.
- Deploys the new version to production.
- Provides feedback throughout the process.
Monitor version control
At the start of any CI/CD pipeline, you’ll find an integration with a version or source control system.
Typically, a CI server is configured to listen for commits on a particular branch and trigger a new run of the pipeline each time a change is made. This ensures that each time a developer shares their changes, it is built and tested to ensure the codebase as a whole still functions correctly.
Some CI servers allow you to take this a step further and require developers to build and test changes locally before they can share their changes to a CI branch. While this doesn’t guarantee that the next step will pass successfully, it helps reduce the number of broken builds and the delays they can cause. Another option is to integrate your CI server with your code review tool so that each commit must pass a code review stage before it can be shared.
Enforcing these extra layers of business logic at the start of the process helps to keep your codebase clean and ready for release while minimizing interruptions and delays in the pipeline.
Manage builds and tests
Each time a change is detected, and a pipeline run is triggered, the CI server coordinates the build and test tasks. Typically, these are allocated to dedicated build machines or “agents”. Your build agents then do the heavy lifting of running builds and executing tests according to instructions received from the CI server.
Another option is to run build and test tasks on the CI server itself. However, this can result in contention for resources and reduced performance on busy codebases.
When you use your CI server to configure the logic for a stage of your pipeline, you can specify a range of details and rules. For example, you may want to:
- Run all your automated tests on commits to the main branch, but run a reduced set of checks on feature branches.
- Control how many builds can call a test database at the same time.
- Limit deployments to a staging environment to once a week to allow for more involved manual testing.
Being able to run certain tasks at the same time using different build agents can make your pipeline more efficient. This is useful if you need to run tests on different operating systems or if you’re working on a huge codebase with tests numbering in the hundreds of thousands where the only practical option is to parallelize. In the latter case, setting up a composite build will aggregate the results so you can treat the tasks as a single build step.
A build server that integrates with cloud-hosted infrastructure, such as AWS, will allow you to benefit from elastic, scalable resources in which to run your builds and tests. If your infrastructure needs are considerable, support for containerized build agents and integration with Kubernetes will allow you to manage your build resources efficiently, whether they are in the cloud or on-premises.
Define pass and failure conditions
A key part of your business logic involves defining what constitutes a failure at each stage of your CI/CD pipeline.
Your CI server should allow you to configure various failure conditions. It then checks to see if these criteria have been met in order to determine the status of a particular step and decide whether to proceed to the next stage of the pipeline.
In addition to self-evident failures, such as a build returning an error code or tests failing to execute, you can define other failure conditions based on data collected by your build server.
Examples include test coverage decreasing relative to the previous build (indicating that tests have not been added for the latest code changes) or the number of ignored tests increasing compared to the last successful build.
These metrics also serve as a useful warning when code quality may be deteriorating. By triggering a failure for these reasons and limiting which users have permission to override these failures, you can drive desirable behavior.
Store build artifacts
When a change is successful, the CI server stores the artifacts of the build process. These might include binaries, installers, container images, and any other resources required to deploy your software.
You can then deploy the same artifacts to pre-production environments for further testing before finally deploying to production. This ensures that the same output is tested at every stage and is much more reliable than rebuilding from source code before each deployment. In particular, it avoids the risk of missing dependencies and introducing other inconsistencies.
Maintaining an artifact repository of successful builds is also useful when you need to revert to a previous version of your software or when trying to identify when a particular issue was introduced.
Deploy builds
Although the name “CI server” suggests their use is limited to continuous integration, most CI servers also provide support for continuous delivery and deployment.
Having produced your build artifacts and run an initial set of tests during the continuous integration phase, the next step is to deploy those artifacts to QA environments for further testing. This is followed by staging, which gives your stakeholders a chance to try out the new build. Then, if everything seems to work properly, you would typically go ahead and release it to live.
You can use a CI server to store and manage parameters for each environment in your pipeline. This enables you to specify whether your deployment scripts are triggered automatically based on the outcome of the previous stage.
Provide feedback
A central function of a CI server is providing rapid feedback on each stage of building and testing. CI servers that integrate with your IDE or communications platform can notify you whenever one of your changes has caused the pipeline to fail, without requiring you to constantly monitor its progress.
Build servers can also:
- Offer real-time reporting on builds and tests that are underway and notify you of the status of completed build steps.
- Integrate with issue tracking tools so you can see details of the fixes that were included in a commit and quickly investigate the cause of a failure.
- Collate statistics on deployment frequency, time to next failure, and mean time to resolution, to help you measure and improve your development process.
- Provide insights into the usage and performance of your CI server and build machines, that you can use to optimize your pipelines.

Should you build your own CI server?
Building your own CI server can sound like an attractive option. By designing your own solution, you can tailor it to your needs while avoiding any license costs.
However, building a custom tool is just the start of the process. Once in place, you’ll need to invest time to keep it up to date – including addressing any bugs that arise and developing new features as requirements evolve.
It’s also worth considering the effort involved in integrating a CI server with your toolchain. While your initial design will work with the version control system, issue tracker, build tools, and test frameworks you currently use, what happens when you switch to a new product or technology?
While building your own CI server gives you the flexibility to create a tool tailored to your use case, the initial effort and ongoing maintenance require a significant and ongoing commitment.
Wrapping up
A continuous integration server plays a vital role in implementing your CI/CD pipeline, coordinating and triggering the various steps in your process, and collating and delivering data from each stage. Have a look at our guide to CI/CD tools for tips on how to choose the right CI server for your organization.
How TeamCity can help
TeamCity is a CI server offering integrations with all leading version control systems – including Git, Perforce, Mercurial, and Subversion – as well as various hosting services. You’ll also find extensive support for a wide range of build tools and testing frameworks, as well as integrations with IDEs, issue trackers, messaging platforms, and container managers.
You can host your CI server on-premises or in a cloud of your choice with TeamCity Professional or Enterprise, or go with TeamCity Cloud for a fully managed solution. A flexible set of pipeline triggers allows you to configure CI/CD processes to suit your needs, including pre-tested commits, feature branch support, and scheduled builds. Once you’ve configured your pipeline logic via the UI, you can store your configuration as code for a fully version-controlled CI/CD process.